Keywords
Red Blood Cell, Thalassemia, Image processing, Image Segmentation, Morphological Operations, Feature Extraction, Data Resampling, Machine Learning
This article is included in the Research Synergy Foundation gateway.
This article is included in the Sickle Cell Disease collection.
Red Blood Cell, Thalassemia, Image processing, Image Segmentation, Morphological Operations, Feature Extraction, Data Resampling, Machine Learning
Sickle cell disease is a hereditary disease that disrupts the efficiency of RBCs to carry sufficient oxygen to the body. Traditional methods to detect this disease relied on hematologists manually counting RBCs and classifying them based on their topologies. This has motivated us to explore and develop an automated process to detect the presence of the disease. However, this field poses a lot of challenges such as insufficient medical data, poor extraction methods, and the tedious pipeline-related issues.
This paper aims to solve some of the aforementioned problems. Firstly, a hybrid segmentation method is presented to accurately segment the RBCs. Next, the data imbalance treatment is used to solve the imbalance cell type class in a distribution manner. The pipeline of the paper includes the comparison between the conventional methods in the image segmentation layer, data resampling layer and the classification layer. The proposed method involves the image acquisition, image pre-processing, image segmentation, morphological operations, image cropping and manual classification, feature extraction, data resampling, and classification. The aim is to create a workflow that is able to detect the presence of thalassemia by recognizing the types of RBCs.
In image pre-processing, Rashid et al.1 and Das et al.2 employed a mixture of global contrast techniques, median blurring and color space conversion to increase the contrast. Color channel conversion is used to filter the unwanted cells in the image.
In image segmentation layer, an inter-combination of the thresholding, edge-based, region-based, clustering-based and artificial neural network (ANN) is used to perform the segmentation. Sharma et al.3 compared different techniques of thresholding; their findings showed that Otsu’s thresholding performed the best among other thresholding methods. This concurred with the observation done by Das et al.2 Marked water controlled segmentation was used to solve the segmentation of cells in.2,4 Tyagi et al.5 indicated that the Canny Edge technique was better at filtering noise presented in the image. Achargee et al.6 used Hough transformation (HT) to detect cells with varying diameter, while Seth and Palodhi7 proposed a modified version of the HT to detect white blood cells (WBC).
Feature extraction in cell morphology are classified into boundary and region descriptors. Some of the features may overlap, but generally, boundary descriptors deal with the morphology of the RBCs and region descriptors extract the geometric and texture properties. Lotfi et al.4 used Fourier descriptors to represent cell morphology. Tyagi et al.5 used shape features such as area, perimeter solidity, eccentricity to describe the cells. Other features involved extracting the moment invariant such as invariant to scaling, translation and rotation were proposed by Lofti et al.4 Since the introduction of deep learning, many skipped this layer due to the models can automatically extract the features. Fadhel et al.8 proposed extracting features from the last fully connected layers and subsequently fed the features into the support vector machine (SVM) classifier. Purwar et al.9 proposed a hybrid method of features extracted from the convolutional neural network (CNN) models15-17 and hand clinical features extracted from a CBC test.
Hortinela et al.10 and Safca et al.11 used SVM to classify cells based on features extracted from different layers. In multiclass classification, Lotfi et al.4 compared the K-nearest neighbors and SVM method using the one versus all approach and found that SVM performed better. In a seperate study, Dalvi et al.12 showed that an ANN with ten hidden nodes and five output nodes performed better than decision tree. Tyas et al.13 used ANN with momentum backpropagation and produced the best results among the classifiers.
Ethical approval number: EA1542021
Ethical approval body: Research Ethic Committee 2021, Multimedia University
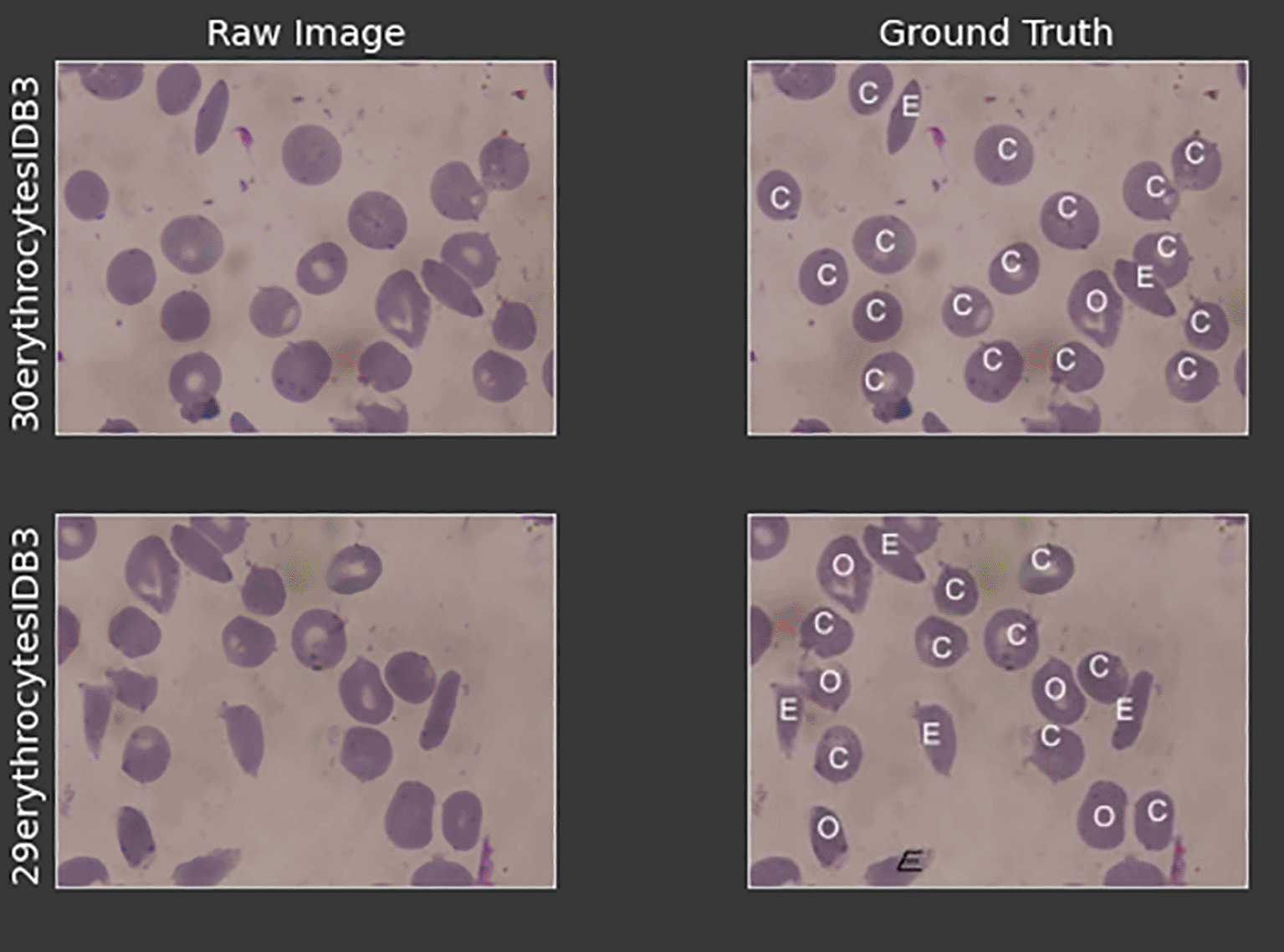
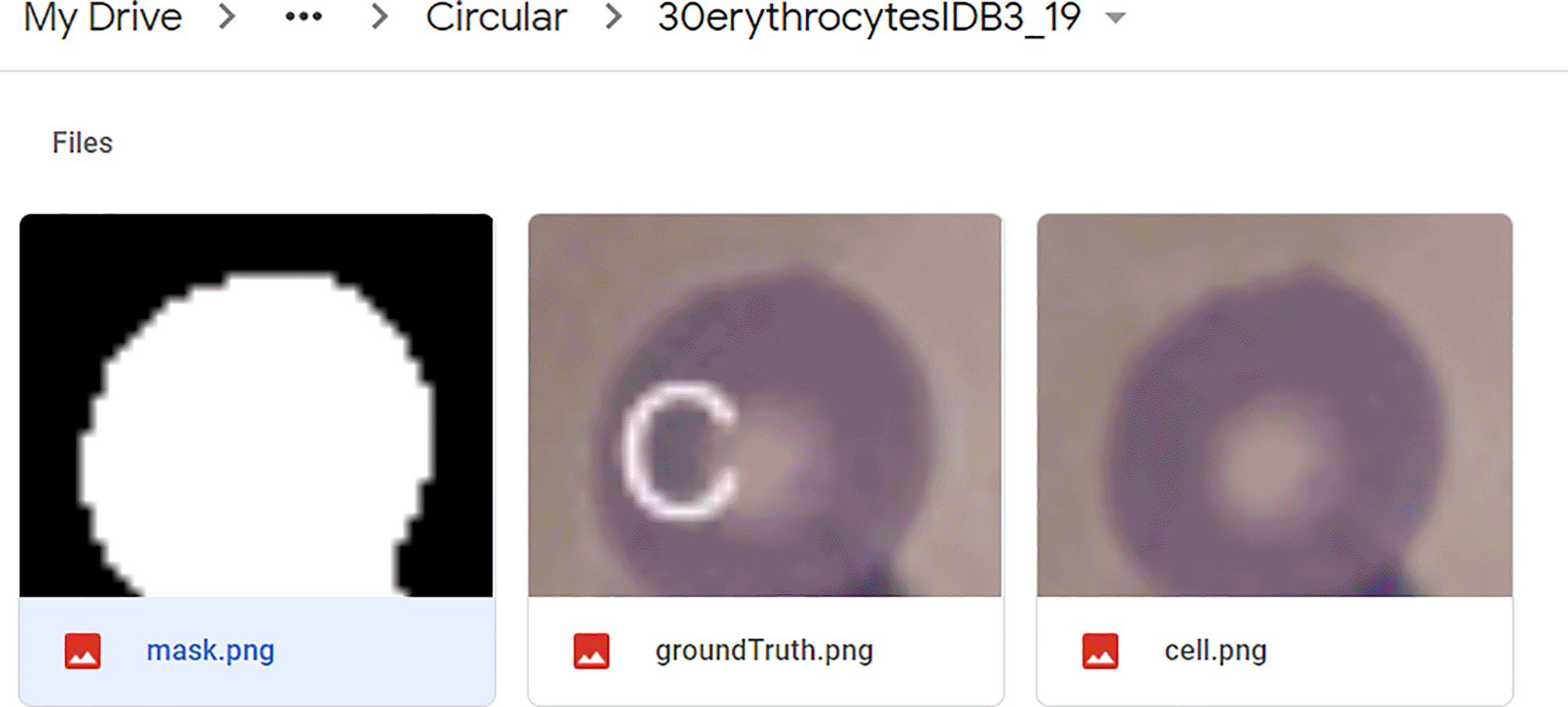
The dataset used in this project was obtained from the erythrocytesIDB by Pedro et al.14 It is selected because of the image clarity and optimal cell size. Each subdirectory contains the raw image, ground truth labels, and binary segmented masks. Figure 1 shows the raw blood smear images and its ground truth label for two images.
As many of the images are extracted using different extraction techniques, to increase the quality of the images while standardizing all of the images, firstly, the images are contrastly increased by using the contrast limited adaptive histogram equalization (CLAHE) method. The image is primarily converted to L.A.B. color space. The L, which refers to the luminance channel is operated by CLAHE and is then merged back with the other two channels.
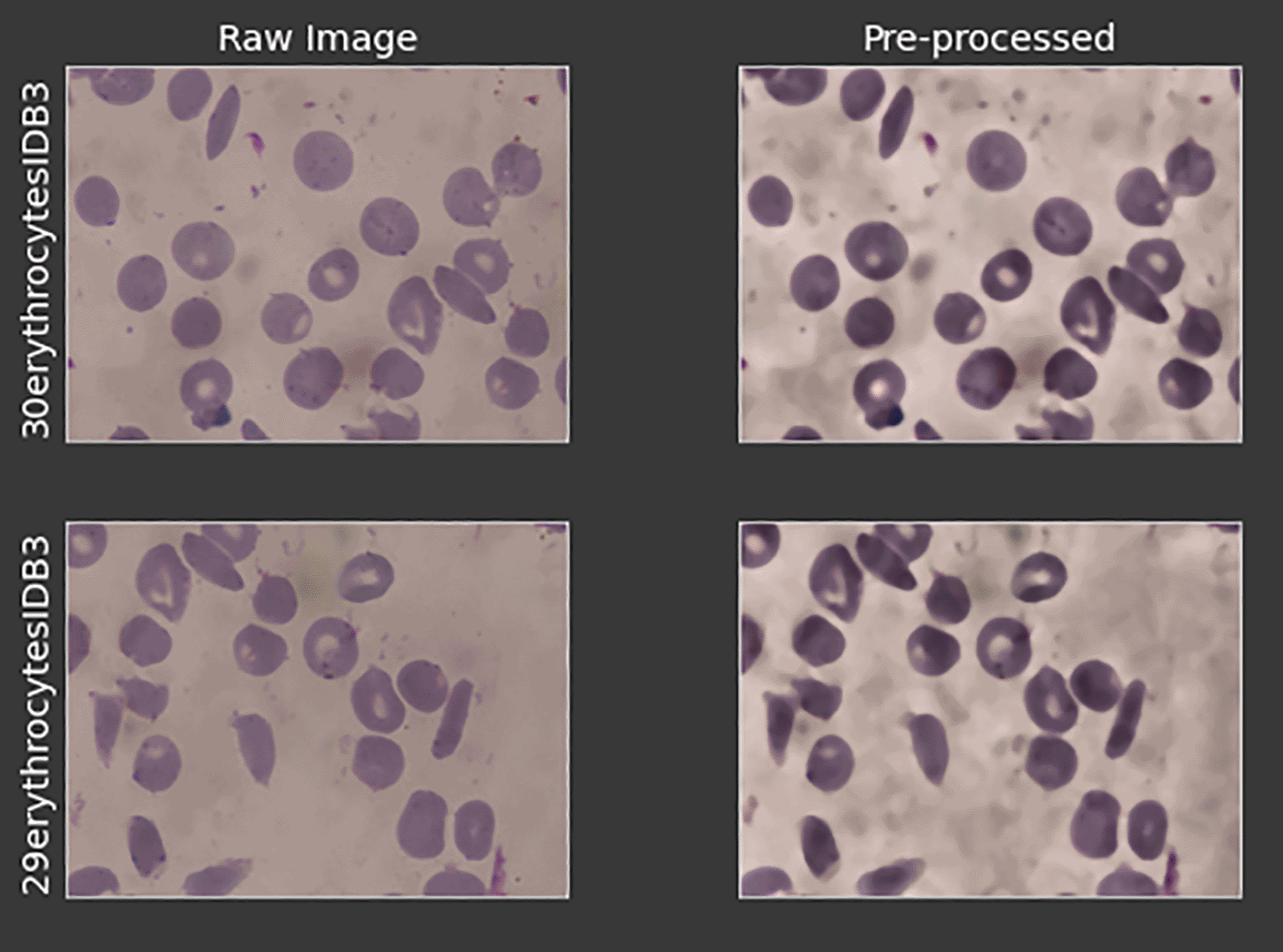
Next, median filtering is applied to remove noise in the image. An unsharped mask operation is applied to sharpen the edges of the cells which are previously lost during the median filtering process. Image subtraction is then constructed from the original image to obtain the details and the edges. Figure 2 depicts the result after the pre-processed layer of the two images.
A hybrid technique is proposed by merging the adaptive thresholding and the canny edge detection method. Gaussian adaptive thresholding is employed to segment the color images with varying intensities. However, this method unable to capture the edges of the cells. An additional of the canny edge detection method with the parameter of μ to be set to a lower value is applied. This allows the cell edges to be captured precisely and subsequently to be added to the threshold binary image later.
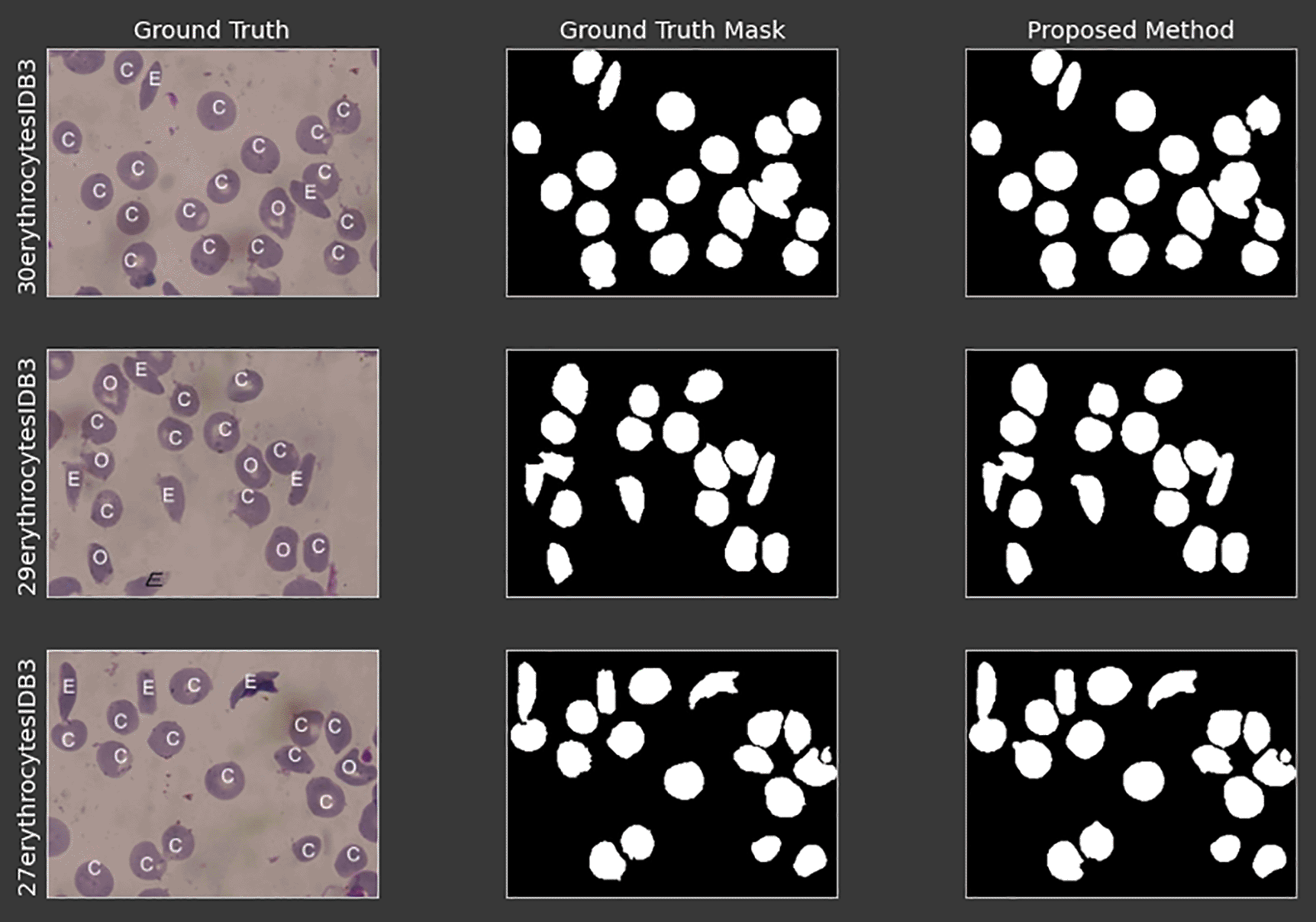
Lastly, the leftover edges that are protruding out are removed to show a clean finish. Figure 3 shows the result of the segmentation layer compared to the ground truth given from the dataset. The evaluation of this layer is performed by calculating the SSIM index of the binary segmented image with the ground truth binary given in the dataset.
Morphological operations are performed on binary images to clean up the leftover noises from the previous layers. A hole-filling operation is performed to close up the holes that are created using the canny edge detection method. Next, binary opening is used to remove the small particles that are presented in the image. Finally, cells that are located at the border are removed because they do not accurately provide the full feature description of the cell. Figure 4 depicts the result of the morphological operations.

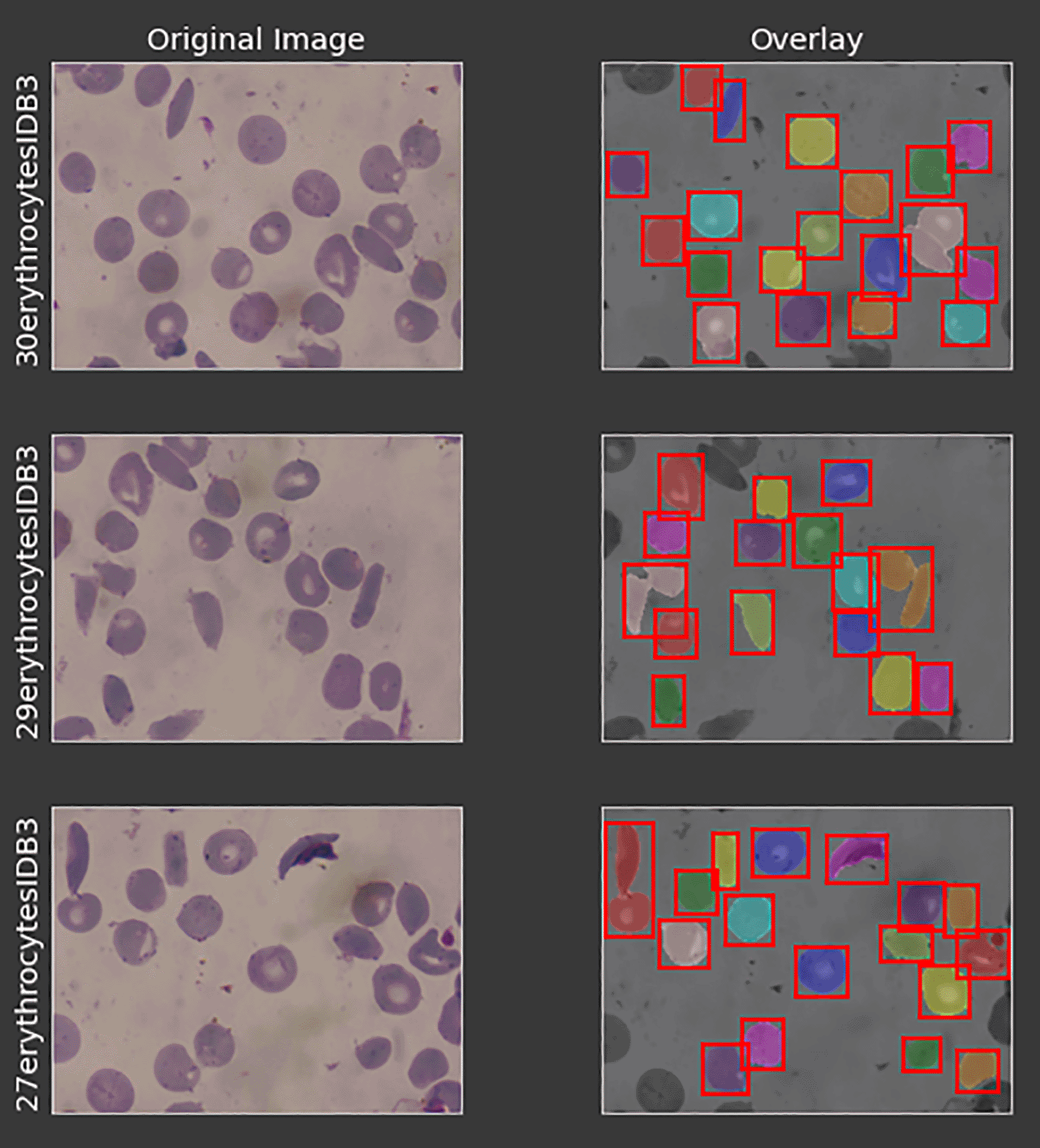
Each of the cells in the microscopic blood sample images are cropped using the masks that are segmented from the previous layers. Figure 5 shows the individual cells that are being cropped, while Figure 6 depicts the sub-category of one particular cell. Each of the cropped cells has their own directory which is named based on their origin and cell number as depicted in Figure 7. The cells are manually classified into their own class which is based on the classification given by Pedro et al.14
Two types of features are extracted: shape features and texture features.
The shape features are extracted from the individually cropped masks and then to be combined into a data frame. The features extracted include the area, perimeter, major axis length, minor axis length, eccentricity, and the seven moment invariants immune to the scaling, translation, and rotation. Additional shape features which are circulatory factor and elliptical factor are calculated.
Next, texture features are extracted using the gray level co-occurrence matrix (GLCM). The features extracted from the textures are the contrast, dissimilarity, homogeneity, ASM, energy and correlation.
Finally, the two features are merged into a data frame with its correct label of either one of the three classes: circular, elongated, or other cells.
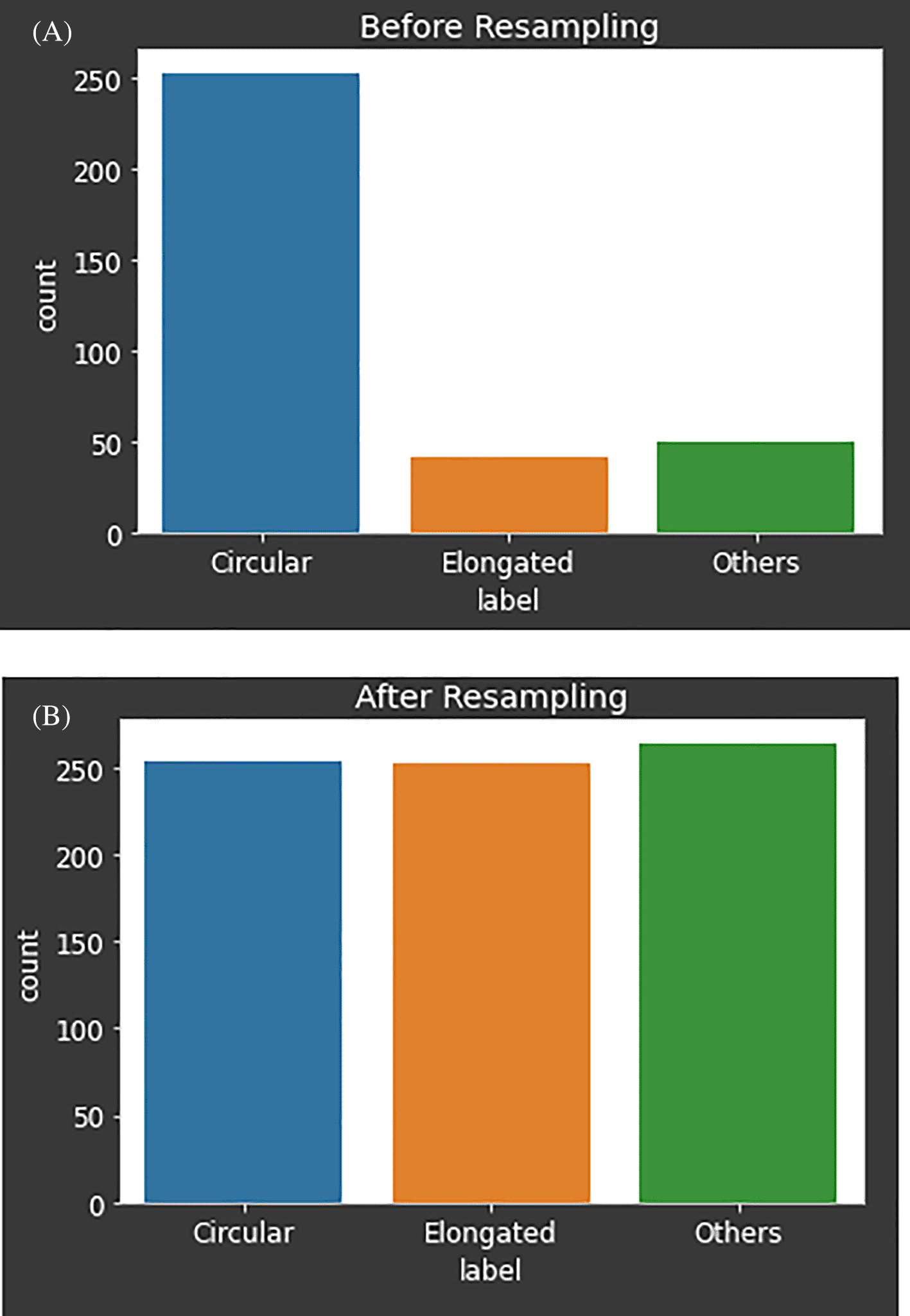
The number of circulars, elongated and other types of cells total up to 316, 53 and 59 respectively. This dataset is imbalanced and may result the classifier to be overfit or bias to certain category of data.
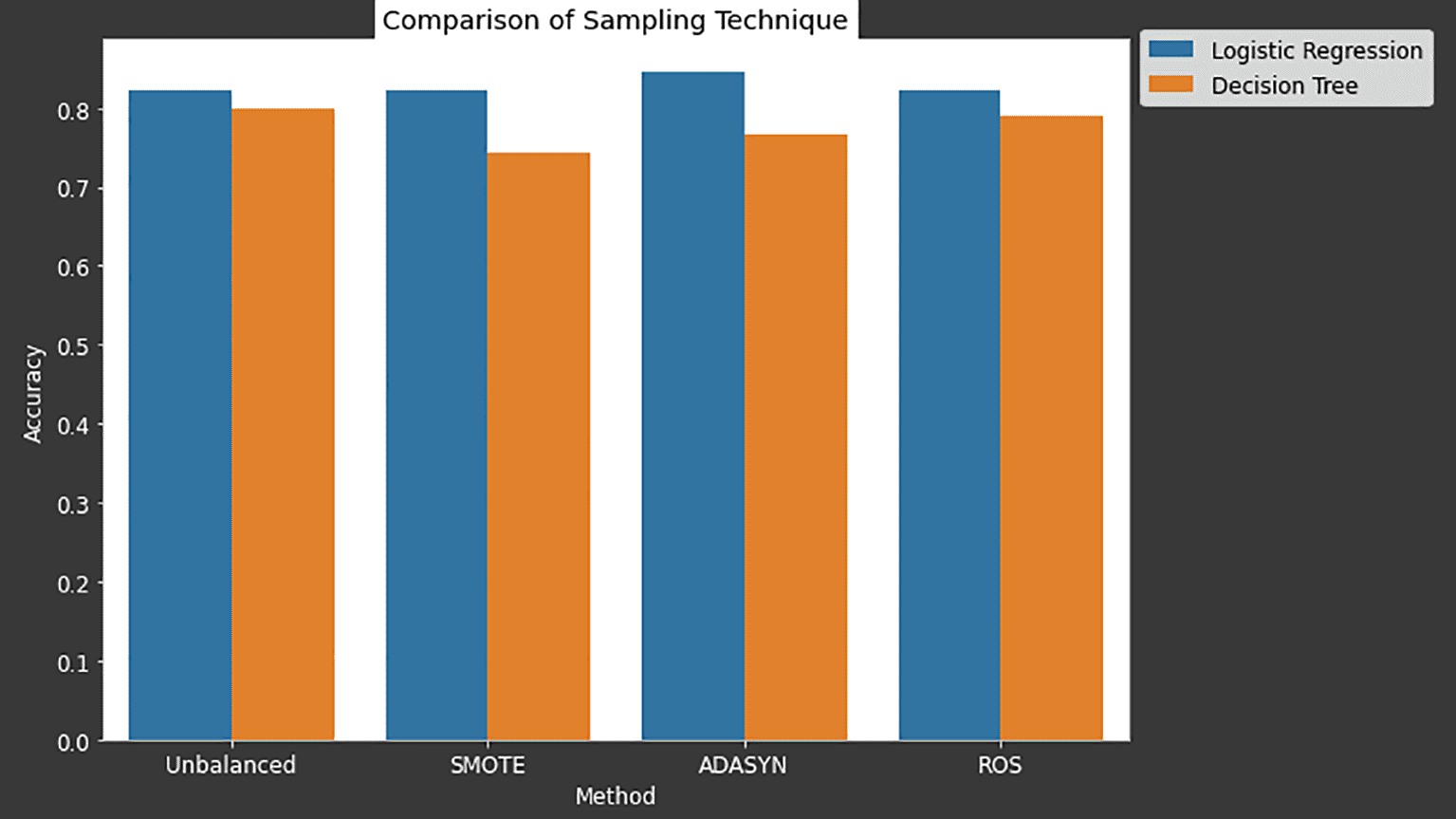
The synthetic minority oversampling technique (SMOTE), adaptive synthetic sampling (ADASYN) and random over sampling (ROS) are evaluated by using two classifiers, which are logistic regression and decision tree. Figure 8 shows the number of classes prior and after the resampling process. The bottom graph of Figure 8 demonstrations the best result for solving the imbalanced problem using ADASYN resampling technique.
In classification, a total of three classifiers are trained and compared. The chosen classifiers are the decision tree, random forest and the support vector machine.
The models are evaluated using the classification report which contains the information of accuracy, precision, recall f1-score and support.
For each classifier, the receiver operating characteristic (ROC) curve is plotted to observe the results. The images that are excluded before the sampling process are tested individually for their accuracy and reliability of the model chosen.
The ground truth masks are provided in the dataset. The evaluation are calculated based on the structural similarity index (SSIM) between the ground truth masks and the segmentation of the proposed method.
The average of the computed SSIM index from each image is 89.88%. However, it is worth noting that the value only estimates how well the segmentation is. In Figure 9, observing the ground truth mask, some cells are not presented in the ground truth mask (middle image), while it is presented in the proposed segmented image (right most image).

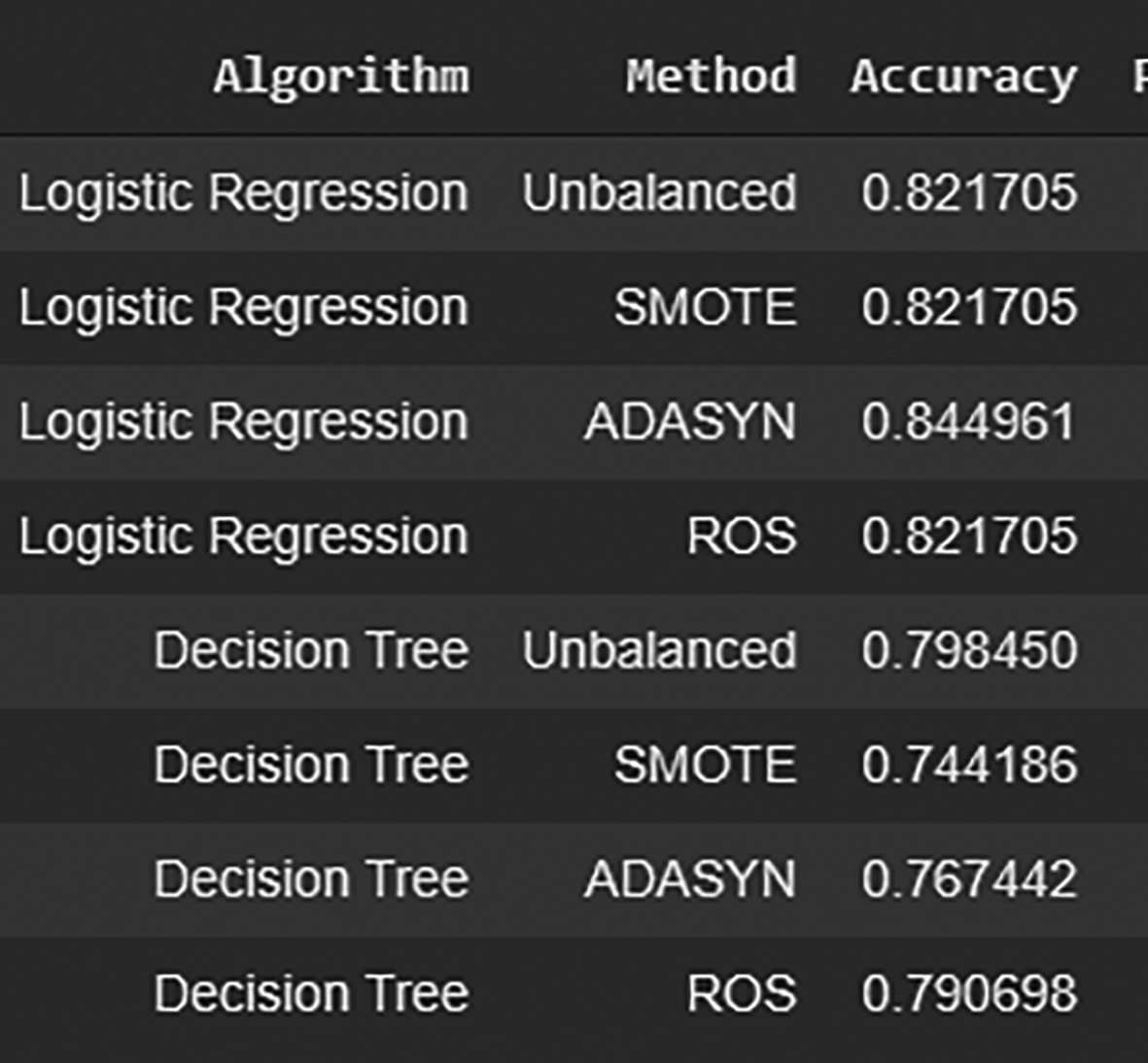
Figure 10 shows the comparison of the resampling techniques between the SMOTE, ADASYN and ROS. Based on the result, logistic regression handles the unbalanced data-sets well as compared with the decision tree. ADASYN outperforms the rest at 84.49% of its accuracy through the logistic regression classifier. Also worth noting is that, even with the unbalanced dataset, its accuracy sits highly at 82.17%, which indicates that the features extracted optimally best describe the types of cells (Figure 11).
The classification layer is evaluated based on the accuracy of the classification report and the ROC curve of each classifier. Figures 12 to 14 depict the model evaluation summary for each of the classifiers.
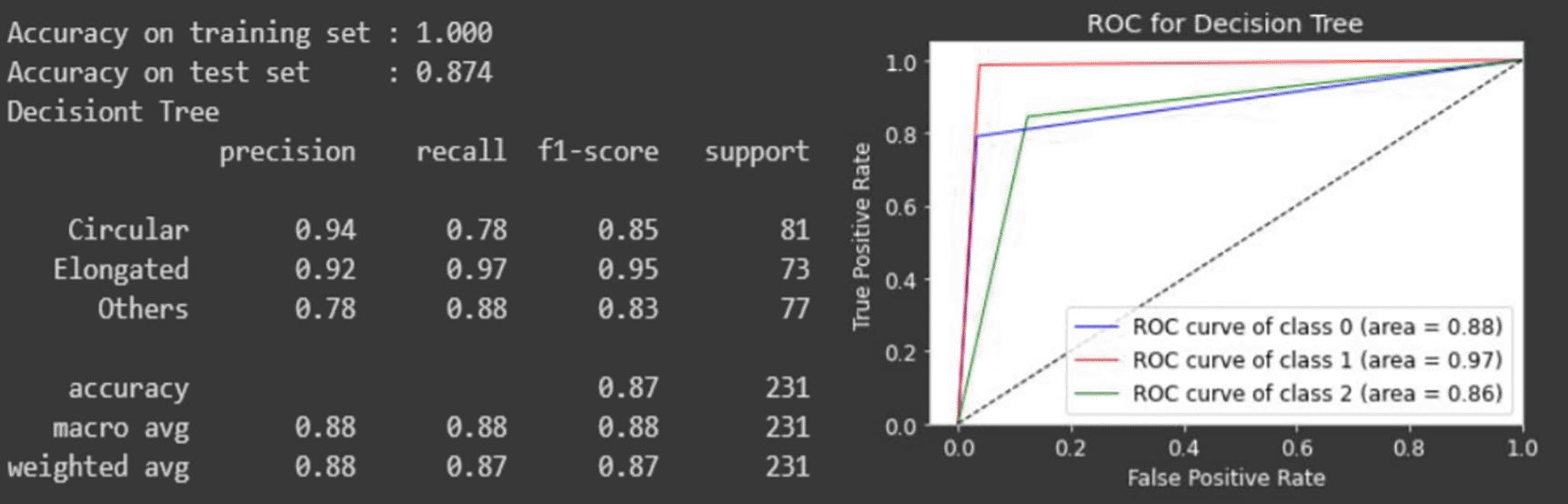
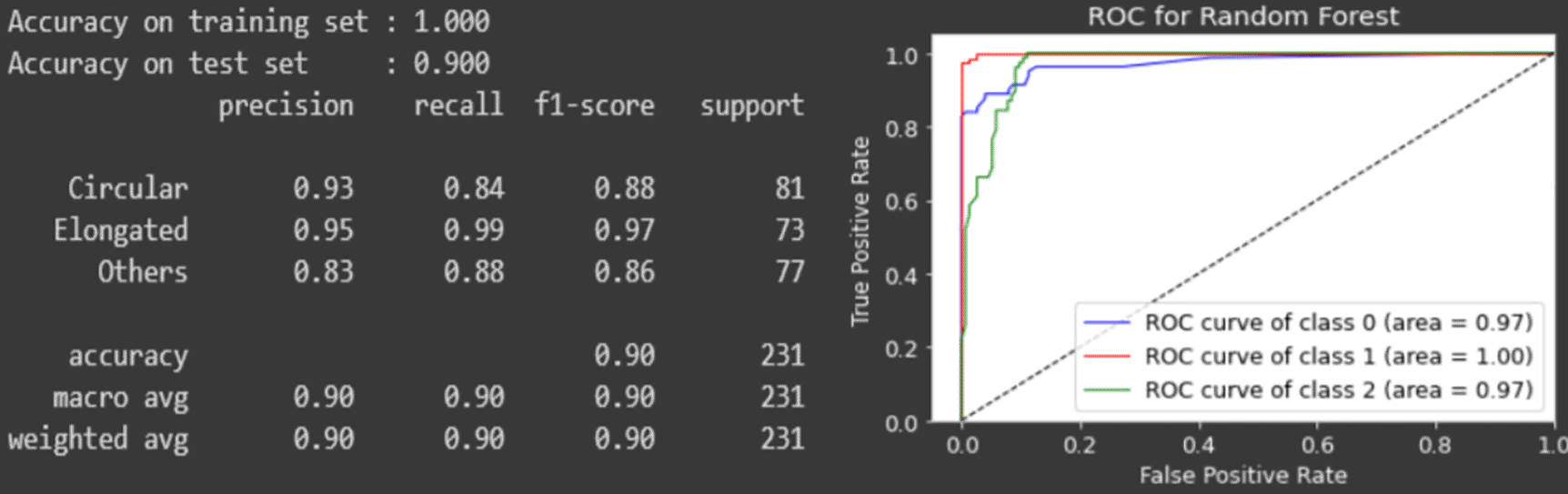
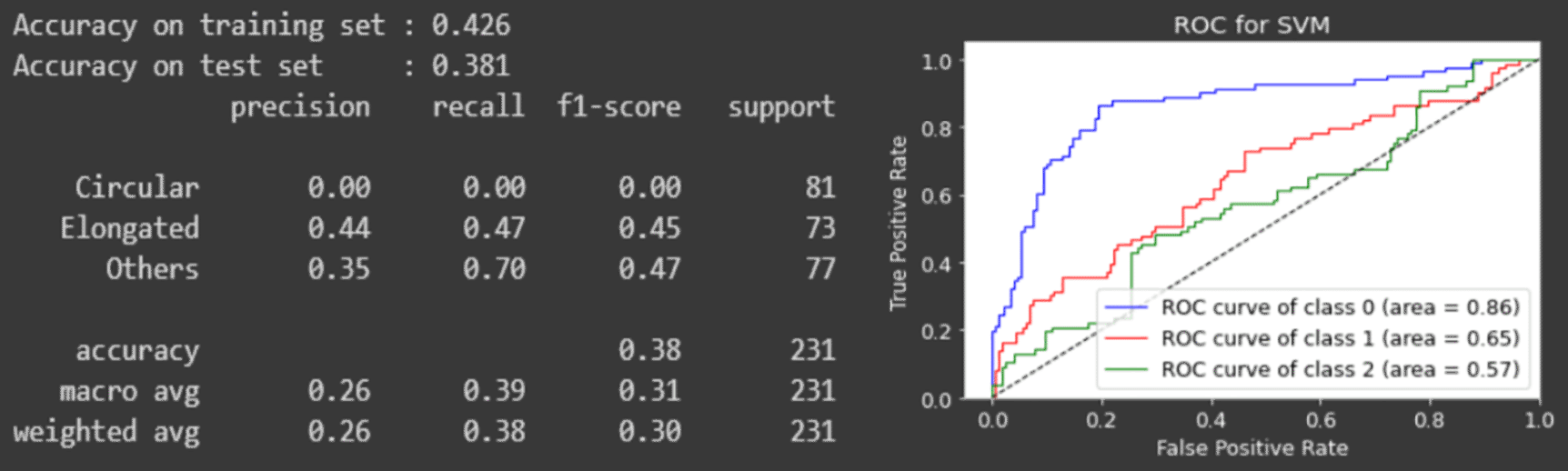
From the results, the random forest classifier performs the best with the accuracy of 90% while the others are below 90%.
The ROC curve for the SVM dips below the threshold where the number of incorrectly classified classes are more than the correctly classified classes, which indicates a bad classifier.
Comparing the area under curve (AUC) of the ROC curve, the random forest classifier covers the most area for all the three cell classes of the circular, elongated and other types of cell, which demonstrates a superior classifier.
We performed several comparisons and the implementation between different techniques in the segmentation layer, data resampling layer and the classification layer. These provide a good working pipeline for a complete aiding diagnosis for the sickle cell disease detection. The whole pipeline provides a precise classification for each of the cells in microscopic blood smeared images with a 90–95% of accuracy on average.
In addition, we present a strong baseline in the segmentation layer, which is able to detect some of the missing cells that were not presented in the previous work. At the same time, the data resampling layers are added to observe the effect of an unbalanced medical dataset. The combination of different models exhibits the performance of the best classification model.
Leow YS, Ng KW, Yoong YJ and Ng SB conceived the presented idea. Leow YS carried out the experiment and wrote the manuscript. Ng KW, Yoong YJ and Ng SB supervised the project and provided feedback.
Data were obtained by permission from http://erythrocytesidb.uib.es/.
Data samples were obtained from volunteer patients. This dataset was not generated nor is it owned by the authors of this article; the listed owners are Universidad de Oriente, Cuba, and Universitat de les Illes Balears, Spain. Therefore, neither the authors nor F1000Research are responsible for the content of this dataset and cannot provide information about data collection.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)