Keywords
Customer Churn, Net Promoter Score (NPS), Data Mining Techniques, Classification and Regression Trees (CART)
This article is included in the Research Synergy Foundation gateway.
Customer Churn, Net Promoter Score (NPS), Data Mining Techniques, Classification and Regression Trees (CART)
Customer retention and customer satisfaction are essential for a business to succeed.1 Customer satisfaction is improved by repeating businesses, brand loyalty, and positive word of mouth.2 Consumers prefer to stay with their current providers due to quality and price. Therefore, new anti-churn strategies must be constantly developed.3 Data processing automates analytical model building. Machine learning algorithms improve the dataset iteratively to find hidden patterns.4 Several studies show that machine learning can predict churn and severe problems in competitive service sectors. Predicting churning customers early on can be a valuable revenue source.5 The results of the mediating effects of a customer's partial defection on the relationship between churn determinants and total defection show that some churn determinants influence customer churn, either directly or indirectly through a customer's status change, or both; thus, a customer's status change explains the relationship between churn determinants and the probability of churn.6 This study hypothesised that changes in Net Promoter Score (NPS) can indicate whether churn determinants directly or indirectly influence churn.
Figure 1 presents the revenue generated by telecommunications in Malaysia. Telekom Malaysia (TM) has made RM11.43 million in 2019 and ranked top.7

Malaysia's mobile, fixed broadband, and household penetration are expected to grow further between 2019 and 2025, providing 30 to 500 Mbps fibre internet for cities, with gigabit connections for industries.8 As a result, customers expect the same or better service from providers. This statistic is also used to compare a company's performance to competitors.9
Total customer turnover is the number of customers leaving the provider.10 In the telecommunications industry, market competitiveness is measured by churn rate. Telephone, internet, and mobile services are all part of telecommunications. For example, one of the Internet Service Provider (ISP) from 20 subscribers will cancel, reducing annual revenue by 5%.11 Every day, the telecom industry loses 20%-40% of its customers.12 Without pricing and subscription plans, 83% of Malaysians would switch telecom providers. On the other hand, 66% had no problem cancelling their existing service provider subscription.13 Customer satisfaction metrics would help providers to sustain their customers.
Net Promoter Score (NPS) measures customer satisfaction and loyalty using a 10-point Likert scale.14 Consistency in purchases shows commitment regardless of performance and fulfilment.15 Risk scores are used to predict customer churn. Churn is predicted using customer profiles and transaction patterns—predictive analytics use demographic, transactional data and NPS.16 The NPS outperforms customer satisfaction.17 A high NPS indicates that word of mouth can help businesses thrive. Customers are classified as promoters, detractors, or passives after receiving assistance from the helpdesk (Table 1).
Customer satisfaction
Customer satisfaction is defined as customers being happy with a company's products, services, and capabilities.18 Customers' satisfaction is influenced by buyer experience.19 Satisfied customers lead to more sales and referrals. Proactive personal helpdesk and staff assistance require a company's ability to anticipate customer needs. Most businesses benefit from happy customers. In this study, the NPS measures customer satisfaction.
An excellent service exceeds consumer expectations and satisfaction by providing high-quality services. Those are ability, attitude, appearance, attention, action, and accountability.20 A customer-centric approach benefits both private and public companies. Using this mindset also helps providers win customers and save money. In addition, customers will stay loyal regardless of market choice if companies treat them well.
Transparent subscriptions
In 2019, accountability was the key to sustaining a profitable company. Authenticity trumps traditional priorities like price and brand recognition.21 In addition, transparency promotes trust, peace of mind and openness. Happy customers are more pleasant than dissatisfied customers, As such, individual customers feedback counts.
Companies can classify potential customers who leave the services using advanced machine learning (ML) technology. Then, using existing data, the company can identify potential churn customers. This knowledge would allow the company to target those customers and recover them. Table 2 and Table 3 summarise the most recent churn prediction and framework studies.
| Author (Year) | Techniques and method | The disadvantage of the prediction studies & proposed enhancement |
|---|---|---|
| Ahmad et al. (2019) | Techniques: Decision Tree, Random Forest, Gradient Boost Machine Tree, and XGBoost. Method: Churn predictive system using Hortonworks Data Platform (HDP) categorised under specific specialisation like Data Management, Data Access, Security, Operations and Governance Integration.22 | Disadvantage: Only about 5% of the dataset entries represent customer's churn. Proposed enhancement: The dataset entries can be solved using under-sampling or trees algorithms. |
| Höppner et al. (2020) | Techniques: Decision Tree Method: ProfTree learns profit-driven decision trees using an evolutionary algorithm. ProfTree outperforms traditional accuracy-driven tree-based methods in a benchmark study using real-life data from various telecommunication service providers.23 | Disadvantage: The evolutionary algorithm (EA) training times are relatively slower than other classification algorithms. Proposed enhancement: Combining the ProfTree algorithm with random forests further optimises property by creating profit-driven trees and aggregating them. |
| Yang (2019) | Techniques: Random Forest Method: A new T+2 churn customer prediction model was proposed, in which churn customers are identified in two months, and a one-month window T+1 is set aside for implementing churn management strategies.24 | Disadvantage: In the T+2 churn prediction, a precision ratio of about 50% was achieved, with a recall ratio of about 50%. Proposed enhancement: Proposed to use more than one algorithm technique to compare the outcome result. |
| Ahmed and Maheswari (2017) | Techniques: Firefly Method: Simulated Annealing modifies the actual firefly algorithm comparison to provide faster and more accurate churn predictions.25 | Disadvantage: The proposed algorithm's accuracy is comparable to that of the average firefly algorithm. Proposed enhancement: Incorporation of schemes or modifications to reduce False Positive rates. |
| Eria and Marikannan (2018) | Techniques: Support Vector Machines, Naïve Bayes, Decision Trees, and Neural Networks. Method: This study looks at 30 CCP studies from 2014-2017. Some data preparation and churn prediction issues arose.26 | Disadvantage: Telecom datasets should be handled cautiously due to their unbalanced nature, large volume, and complex structure. Proposed enhancement: It is necessary to investigate a gap in real-time churn prediction using big data technologies. More adaptable approaches that consider changing national or regional economic conditions are required. Customer churn could also be identified using word and voice recognition. |
| Author (Year) | |||
|---|---|---|---|
| Ahn et al. (2006) | Clemes et al. (2010) | Geetha and Abitha Kumari (2012) | Kim et al. (2017) |
| Propose | |||
| Describes a customer's status transition from active to non-user or suspended as a partial defection and from functional to absolute defective defection from active to churn.27 | Identifies and analyses factors influencing bank customers' switching behaviour in the Chinese retail banking industry.28 | Provides a brief overview of the trend of non-revenue earning customers (NRECs) that trigger revenue churn and are likely to churn soon.29 | Analyses the factors that are affecting IPTV service providers' behaviour regarding switching barriers, VOCs, and content consumption.30 |
| Dataset and techniques | |||
| Dataset: 10,000 random samples from leading providers of mobile telecommunications services in South Korea Technique: Logistic regression | Dataset: 437/700 questionnaires Technique: Logistic regression | Dataset: 37,388 datasets from a leading telecom service Provider Technique: Linear modelling | Dataset: 5000 datasets from IPTV users in South Korea/ Technique: Logistic regression |
| Variables | |||
| Dependent variables Customer churn Independent variables Customer Dissatisfaction Call drop rate Call failure rate Number of complaints Switching costs Loyalty points Membership card Service usage Billed amounts Unpaid balances Number of unpaid monthly bills Customer status Customer-related variables | Dependent variables Switching Behaviour Independent variables Price Reputation Service Quality Effective Advertising by The Competition Involuntary Switching Distance Switching Costs Demographic Characteristic | Dependent variables Susceptibility to Churn Independent variables The extent of Local Calls and STD Calls to Other Networks Multiple directory numbers Rate plan Tariff Admin fee Count of recharge Sum of recharge VAS Usage Total minutes of usage VAS Overall usage revenue per minute slab Total usage revenue | Dependent variables Customer Behaviours Customer defection Independent variables Switch Barrier Service bundling Remaining contract months Membership points VOC (Voice of Customer) Total VOC Membership Period Membership years Degree of Content Usage Channel views VOD views TVOD views PPV Monthly subscriptions |
| Hypotheses | |||
| H1 Customer Dissatisfaction à Customer churn H2 Switching costs à Customer churn H3 Service usage à Customer churn H4 Customer status à Customer churn Mediation effects H1' Customer Dissatisfaction à Customer Status H2' Switching costs à Customer Status H3' Service usage à Customer Status | H1 price à customers switching banks H2 reputation à customers switching banks H3 service quality à customers switching banks H4 Effective advertising by the competition à customers switching banks H5 Involuntary switching à customers switching banks H6 distance à customers switching banks H7 switching costs à customers switching banks H8 –H15 Demographic Characteristic à customers switching banks | H1 Proportion of local calls to other networks à susceptibility to churn H2 Proportion of STD calls to other networks à susceptibility to churn H3 Usage of VASs à susceptibility to churn H4 Overall usage RPM à susceptibility to churn | H1 Service bundling à Degree of contents usage H2 Remaining contract months à Degree of contents usage H3 Membership points à Degree of contents usage H4 Total VOC à Degree of contents usage H5 Membership years à Degree of contents usage H6 Service bundling à Customer defection H7 Remaining contract months à Customer defection H8 Membership points à Customer defection H9 Total VOC à Customer defection H10 Membership years à Customer defection H11 Channel views à Customer defection H12 VOD views à Customer defection H13 TVOD views à Customer defection H14 PPV à Customer defection H15 Monthly subscriptions à Customer defection |
| Results | |||
| H1a, H1c, H2a, H3a, H4, H1c′, H2a′ and H3a′ = Supported H1b, H2b, H3b, H3c, H1a′, H1b′, H2b′, H3b′ and H3c′ = Rejected | H1 to H15 = Supported | H1 to H4 = Supported | H1, H2, H3, H4, H5, H6, H9, H14 and H15 = Supported H7, H8, H10, H11, H12 and H13 = Rejected |
Machine learning can predict customer churn by identifying at-risk clients, pain points and interpreting data. Table 3 identifies dependent and independent variables in prior research on customer churn prediction. The cause is an independent variable, and the effect is a dependent variable. As such, the factors included in this study are customer churn, defection, demographics, and the voice of the customer (NPS rating).
The traditional statistics approaches are used to solve problems involving less linear and repeatable data. They work well in environments with stable data and relationships. This is still widely used for medium- to long-term sales forecasting, where a reasonable forecast can be made with a few hundred or even fewer data points. Machine learning and statistics differ significantly. Machine learning models are created to make the most precise predictions possible. The purpose of statistical models is to make inferences about the relationships between variables.31 Machine Learning is a data-driven algorithm that does not rely on rules-based programming. Statistical modelling is the use of mathematical equations to formalise relationships between variables.32 This study applied machine learning and statistical approaches to analyse the potential churn and the mediation relationship between variables.
Machine Learning (ML) is a branch of artificial intelligence. ML uses existing algorithms and data sets to classify patterns.33 This study adopts six widely used churn prediction techniques. All these algorithms were evaluated based on the performance accuracy when applied to the same data for a fair comparison. Table 4 describes the well-known churn prediction techniques.
| Algorithms | Description |
|---|---|
| Logistic Regression (LR) | Logistic regression is a practical regression analysis where the dependent variable is dichotomous; (binary). Logistic regression is used to characterise data and explain the relationship between one dependent binary variable and one or more nominal, ordinal, interval, or ratio-level independent variables. The odds ratio of multiple explanatory variables is calculated by logistic regression. Except that the response variable is binomial, the method is like multiple linear regressions. The result is the impact of each variable on the odds ratio of the event of interest.34 |
| Linear Discriminant Analysis (LDA) | Linear Discriminant Analysis, or LDA, is a technique used to minimise dimensionality. It is used as a pre-processing stage in applications for ML and pattern classification. The LDA aims to project the functions into a lower-dimensional space in a higher-dimensional space to avoid the curse of dimensionality and minimise energy and dimensional costs.35 |
| K-Nearest Neighbours Classifier (KNN) | The Nearest Neighbour Classifier is a classification accomplished by defining the nearest neighbours as an example of a query and using those neighbours to evaluate the query's class. This classification approach is of particular interest since common run-time efficiency concerns are not the available computing resources these days.36 |
| Classification and Regression Trees (CART) | Classification of and Regression Trees is a classification scheme that uses historical data to construct so-called decision trees. Decision trees can then be used in the form of new outcomes. First, the CART algorithm will search for all possible variables and all possible values to find the best partition—a query that divides the data into two parts with the highest homogeneity. Then, the process is repeated for each of the resulting data fragments.37 |
| Gaussian Naive Bayes (NB) | Gaussian Naive Bayes is a particular case of probabilistic networks that allows the treatment of continuous variables. It is a generalisation of Naive Bayes Networks. The Naïve Bayes Classifiers are based on the Theorem of Bayes. One of the assumptions taken is the apparent presumption of freedom between functions. Furthermore, these classifiers assume that a particular function's value is unaffected by the value of any other feature. Therefore, naive Bayed Classifiers require a small amount of training data.38 |
| Support Vector Machine (SVM) | Support vector machines (SVMs) are supervised learning methods known as regression, used for classification. Support vector machine (SVM) uses machine learning theory to classifier and regression prediction to maximise predictive accuracy while preventing overfitting the training. In general, SVMs may be thought of as systems that utilise functions in a high-dimensional feature space and are taught using an optimisation theory-based learning method that promotes statistical learning.39 |
The following paragraphs explain the determinants of customer churn considered in this study. Figure 2 depicts four primary structures that may influence potential customer churn and the indirect effects of NPS feedback.
Service Request
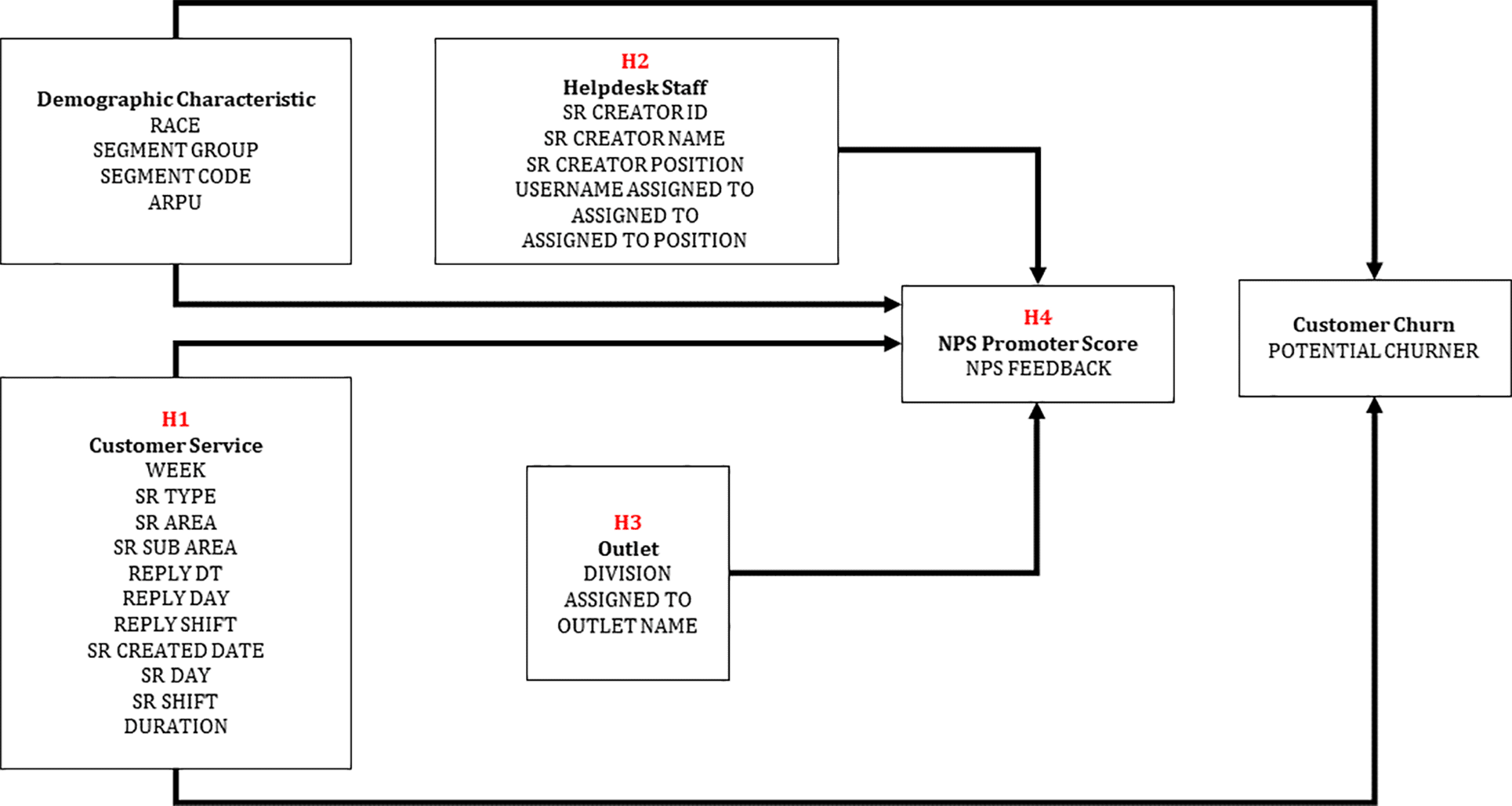
Companies recognise that poor customer service jeopardises customer relationships and revenue in the highly competitive telecommunications industry. Therefore, the degree to which telecommunications companies disconnect services indicates customer satisfaction and is directly proportional to customer turnover40 (Table 5).
As competition grows and consumers place a higher value on service quality, service providers may find it increasingly difficult to succeed unless they pay greater attention to consumer reviews and concerns.41
Helpdesk Staff
Several customers stop doing business with a company when they feel unappreciated, unable to get the information they want to speak to them or an unreasonably rude and unhelpful employee42 (Table 6).
Poor customer service, such as rude employees, delays in service, or incorrect details, can cause customer frustration and increase the churn rate.43
Outlet
Professionalism, friendliness, knowledge, communication, and sales skills are a few examples. Additionally, providers can reduce customer churn by adjusting service prices, policies, and branching44 (Table 7).
| H3a | DIVISION ASSIGNED TO are positively associated with the customer churn probability |
| H3b | OUTLET NAME is positively associated with the customer churn probability |
An important management assumption is that employee attitudes and reactions to organisational changes are related to department performance.45
NPS score feedback
Collecting NPS surveys is a great way to get customer feedback and send them to the right team. For example, promoters should send a customer's name to the team for testimonials and case studies or sign up for a customer loyalty programme.46 The survey divided over a thousand NPS feedback types into three categories: distractor, passive, and promoter (Table 8).
A mediating variable links the independent and dependent variables. Its existence explains why the other two variables have a mediator relationship.47 Some churn predictors may impact customer churn directly, indirectly, or both. This study defines partial defection as an NPS feedback rating from promoter to passive and total defection as passive to the distractor. Thus, it acts as a link between churn predictors and customer loss. Partial defection's mediation effects on churn determinants and total defection are investigated. Hence, an NPS feedback status is hypothesised to mediate the relationship (Table 9).
This empirical study used 7776 random samples from a database of one of Malaysia's leading telecommunications service providers, spanning from two datasets ((MTD) September 2019 and (MTD) September 2020)) (Table 10). The primary key results from the discovery process can be seen in Table 11.
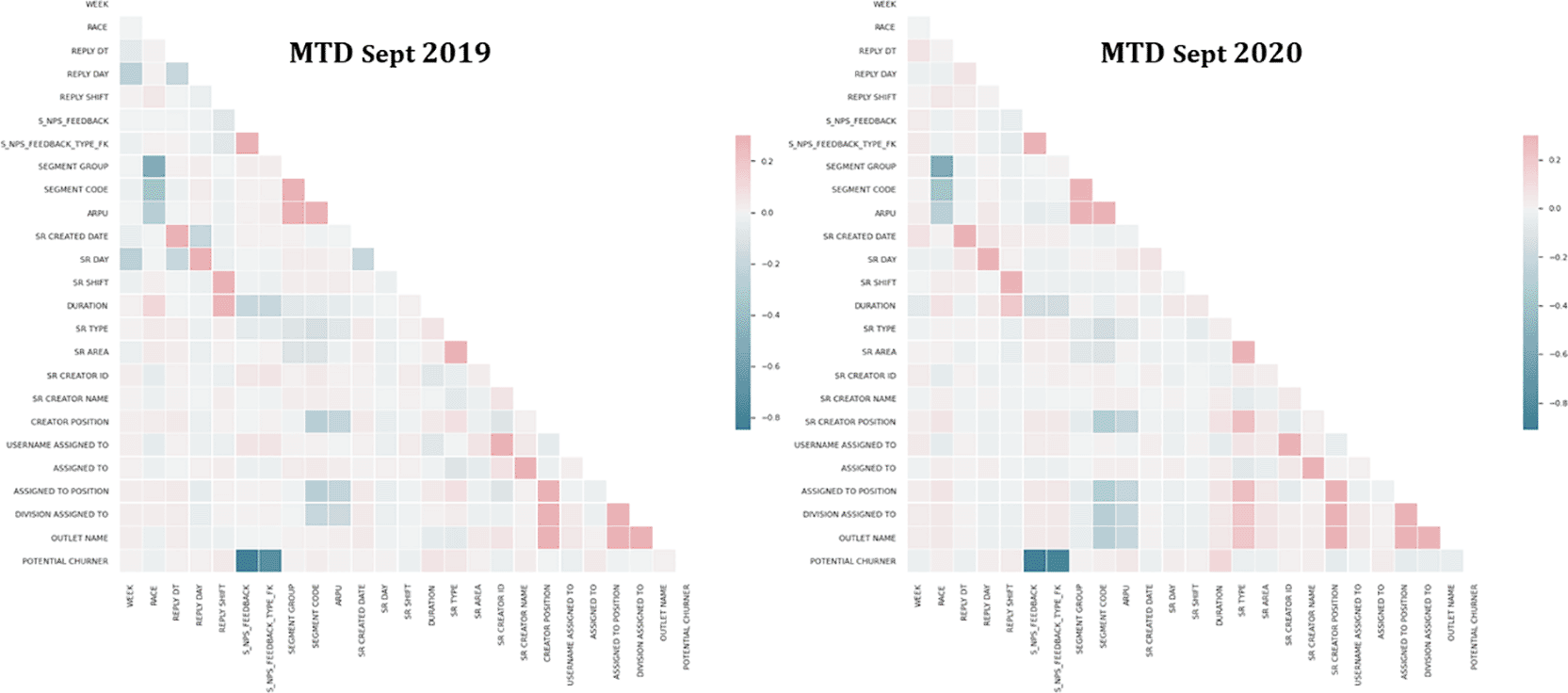
The dependent variables for potential churner are binary, with 1 representing “yes” and 0 representing “no”. In addition, a multinomial variable for each account indicates promoter, passive, and distractor NPS feedback. Thus, a positive correlation coefficient implies a direct relationship between the two variables. Conversely, inverse correlation occurs when one variable rises while the other falls.48 Finally, after data pre-processing, eight irrelevant variables were dropped, and 25 variables were selected and converted numerically to avoid unstable coefficient estimates and difficult model interpretation (Table 12) (Underlying data).49
The study found high correlations between variables. Figure 3 shows the most positive correlation between helpdesk staff and assigned officer in charge (r = 0.98 & 0.96) and the most negative correlation between NPS feedback and potential churner (r = −0.85 & −0.91). The potential churner is found to be negatively related to NPS Feedback. Customers with lower NPS ratings are more likely to churn than those with higher ratings.
This study tested a harness to use 10-fold cross-validation, builds multiple models to predict measurements, and selects the best model. As a result, CART has the highest estimated accuracy score of 0.98 or 98% (Table 13).
In Figure 4, the box and whisker plots at the top of the range, with CART, SVM, and KNN evaluations achieving 100% accuracy and NB, LDA, and LR evaluations falling into the low 41% accuracy range.
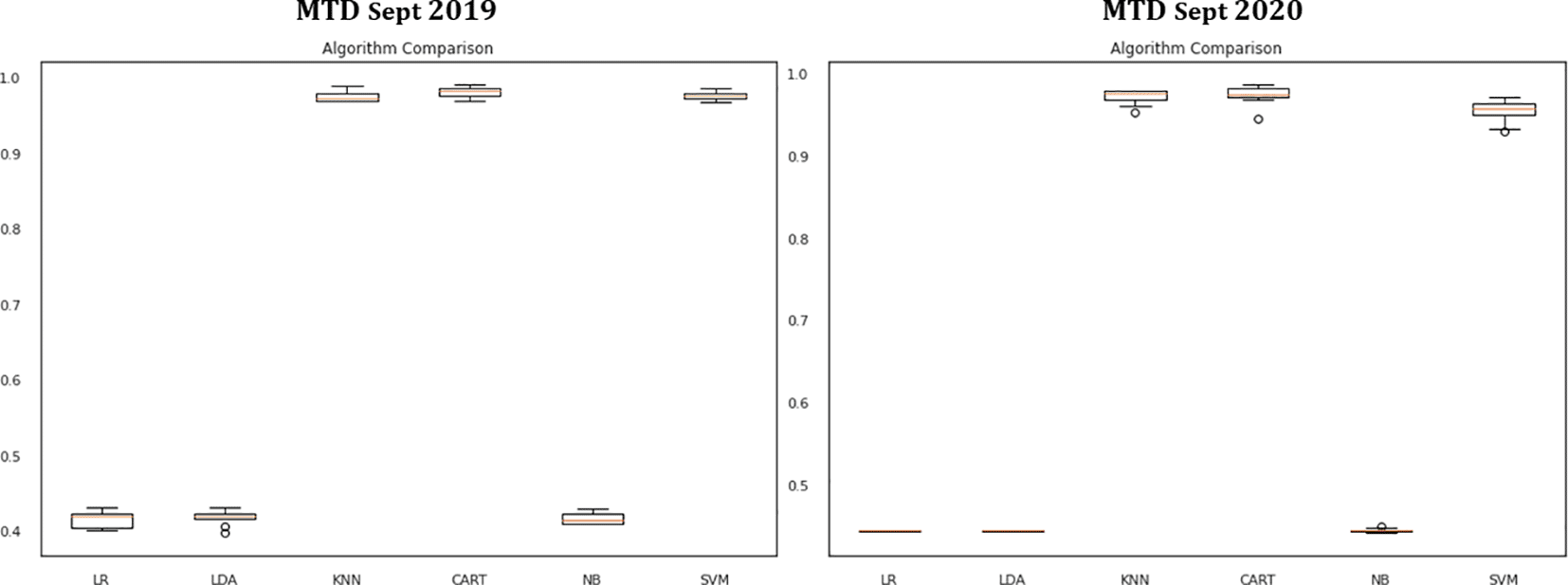
Table 14 shows the findings of the mediation effects, with statistical significance presented as a p-value less than 0.05. According to the results of this study, the NPS feedback rating appears to be a partial mediator between some churn determinants and customer churn. NPS Feedback is found to be a significant mediator of several churn determinants. The NPS feedback rating change partially mediates the following variables' effects on the probability of customer churn, Duration, Reply Shift, Service Request Type, Helpdesk Staff ID, and Assigned Officer to handle the task have a significant relationship with potential churn customer.
| X: Independent variable | ||||
|---|---|---|---|---|
| M: NPS feedback | ||||
| Y: Potential churner | ||||
| X | X and M (p-value) | X and Y (p-value) | X, M and Y (p-value) sobel test | Significant relationship X and Y via M |
| WEEK | 0.5365 | 0.7852 | 0.5365 | No |
| SR TYPE* | 0.0001 | 0.0024 | 0.0001 | Yes |
| SR AREA | 0.6196 | 0.7088 | 0.6195 | No |
| REPLY DT | 0.5634 | 0.8215 | 0.5634 | No |
| REPLY DAY | 0.4331 | 0.4755 | 0.4331 | No |
| REPLY SHIFT* | 0.0001 | 0.0138 | 0.0001 | Yes |
| SR CREATED DATE | 0.7494 | 0.8044 | 0.7494 | No |
| SR DAY | 0.7311 | 0.7859 | 0.7311 | No |
| SR SHIFT | 0.4008 | 0.2146 | 0.4008 | No |
| DURATION* | 0.0001 | 0.0001 | 0.0001 | Yes |
| SR CREATOR ID* | 0.0009 | 0.0653 | 0.0009 | Yes |
| SR CREATOR NAME | 0.5596 | 0.1048 | 0.5596 | No |
| SR CREATOR POSITION | 0.7382 | 0.7535 | 0.7382 | No |
| USERNAME ASSIGNED TO* | 0.0002 | 0.0292 | 0.0002 | Yes |
| ASSIGNED TO | 0.1727 | 0.0206 | 0.1727 | No |
| ASSIGNED TO POSITION | 0.9376 | 0.4814 | 0.9376 | No |
| DIVISION ASSIGNED TO | 0.9622 | 0.6390 | 0.9622 | No |
| OUTLET NAME | 0.6197 | 0.5280 | 0.6197 | No |
H1b reveals that SR TYPE (Service Request Type) has a significant impact on the probability of churn (Table 15). This finding is supported by Solution Partner (2019) that customers' requests should be centralised to avoid multiple ticket opening sources. One-stop-centre to answer requests, provide helpful information, and engage with customers until the problem is solved.50
H1f reveals that REPLY SHIFT (Respond Day Shift) significantly impacts the probability of churn. It is consistent with past research; the speed of customer service responses is also important. Thus, the solution can influence employee and customer engagement when seeking solutions.51
H1j reveals that DURATION (Respond Time Duration) has a significant impact on the probability of churn. This result supports Scout (2020) that time is an important factor in determining customer service quality. According to Forrester Research, 77% of customers believe that respecting their time is the most important online customer service.52
H2d reveals that USERNAME ASSIGNED (Officer in Charge Username) significantly impacts the probability of churn. However, H2f does not. As a result, help desk staff must assign problems to experts based on case-by-case categories. Adebiyi et al. (2016) found that failing to respond to customer complaints or provide solutions may result in poor service delivery and contract termination.53
This study found that customer satisfaction with helpdesk service affects NPS scores. Each rating meets customers' expectations. Understanding the provider's potential churner will also reveal how the company operates, whether it provides a high-quality product with excellent customer service or needs to improve significantly to compete.
It is important to acknowledge customers' contributions to the product or service's value. Responding to complaints is a good start, but if the provider wants to stay in business, they will need to do more. Providers will be delighted if they meet all customers' needs while providing the highest quality services.54
From 7776 records, 5% of customers with NPS ratings below 6 are potential churners. The Customer Relationship Management (CRM) team will find potential churners with the initiative and techniques to retain customers using the same framework. Pope (2020) research the customers' lifetime value entirely depends on how hard the businesses work to maintain them. Providing a personalised customer experience will keep them coming back. It will also turn ardent supporters into online, social media, and in-person brand advocates. But building the brand momentum through happy customers takes time and effort. A good product is not enough. When consumers make purchases, they anticipate an experience. Numerous businesses use retention marketing to ensure brand consistency. The third and final phase, retention marketing, is the most critical. Providers must focus on customer relationships.55
This research used data from September 2019 and September 2020 to predict churn potential among Malaysian telecommunications customers. According to the results, the immediate helpdesk response can ensure that customers' needs are met and act as mediators in determining an employee's ability to satisfy customers. This study evaluated six machine learning algorithms, with CART having the most accurate performance (98%). The NPS feedback rating partially mediates customer churn. The proposed framework will help providers accurately predict potential churn customers and help CRM teams offer targeted churning customers win-back programmes. For better findings and analysis, more research should be done on NPS rating and provided customer feedback.
Zenodo: Customer Churn Prediction for telecommunication Industry: A Malaysian Case Study.
DOI: https://doi.org/10.5281/zenodo.5758742.49
This project contains the following underlying data:
• Dataset MTD Sept 2019.csv (The file contains Net Promoter Score (NPS) in Month to Date (MTD) September 2019 of a telecommunication company. 25 variables were used to determine potential churn customer).
• Dataset MTD Sept 2020.csv (The file contains Net Promoter Score (NPS) in Month to Date (MTD) September 2020 of a telecommunication company. 25 variables were used to determine potential churn customer).
Data are available under the terms of the Creative Commons Attribution 4.0 International license (CC-BY 4.0).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)