Keywords
cognitive linguistics, corpus analysis, syntax, semantics, syntax-semantics interactions, efficient communication, dependency grammars, Universal Dependencies, null results
cognitive linguistics, corpus analysis, syntax, semantics, syntax-semantics interactions, efficient communication, dependency grammars, Universal Dependencies, null results
The syntactic complexity and semantic difficulty of a sentence are two different aspects of language, each requiring an independent amount of processing effort.1 Many linguists also assume that the interplay between different linguistic levels can facilitate efficient communication.2
A relatively popular assumption is that syntax facilitates semantics.1,3–5 Several linguists and philosophers of language assume that grammar was optimized for rational and efficient communication.6 Various recent studies that have looked into the question from an evolutionary and typological viewpoint also support the idea that the drive for communicative efficiency has shaped syntactic features such as subject-verb-object order7 or average dependency length,8 and semantic domains such as numeral systems9 and colour terms.10 Concerning grammar, it seems safe to suppose that denser semantic content tends to reduce syntactic complexity. This notion is an explicit part of some linguistic theories, e.g., systemic functional grammar,11 and is in harmony with other theories, e.g., the uniform information density hypothesis.12–14 However, despite an increasing body of research, a large-scale study of synchronic data, comparing a semantic with a syntactic analysis, is still missing.
Under the view that syntax facilitates semantics, it is plausible to assume that on average writers and speakers will deliver difficult semantics via simpler syntax and simplify semantics in the presence of difficult syntax in order to ensure a healthy level of communicative complexity - price the risk of misunderstanding. That is, we expect a tendentially inverse relationship between semantic and syntactic complexity. Whether real data corroborates this expectation is the research question framing this report. We elaborate it through two competing hypotheses.
H0: There is no systematic interaction between semantic complexity and syntactic complexity.
H1: There is an inverse relationship between semantic complexity and syntactic complexity: as lexical semantics complexity increases, syntactic complexity decreases, and vice versa.
A repository containing all files relevant for replication of this research can be found online.33,34
To test the hypotheses, we used the corpora made available through the Universal Dependencies (UD) projecta, accessed in June 2020. The UD corpora are, especially for large languages, a mix of different registers and domains, ranging from blog posts to legal texts, the vast majority of which comes from contemporary sources. Critically, the corpora contain manually annotated syntactic information in the form of dependency relations. The fact that syntactic annotation was done manually and not automatically is beneficial for our goals, since it removes the risk of systematic mistakes introduced by automatic syntactic annotation. For any language with more than one (sub)corpus, we merged the corpora and only included languages for which we have more than 0.1m tokens in total. Further, we only considered languages that have their lemmas specified, which leaves us with the languages we list in Table 1.
An asterisk indicates a p<=0.05. The median sentence length for any given language is in the “med. len.” column. “N” is the number of sentences analyzed. “r long” is the correlation coefficient for twice the median sentence length.
We measured semantic complexity with a canonical and straightforward measure: the sum of the log frequencies of a sentence’s lemmasb. The inverse correlation between word frequency and its processing difficulty is widely known,15,16 while lemmas and inflected forms do not appear to behave very differently in terms of distribution.17 If readers encounter a particular word several times, they become more effective in processing it both at the orthographic and semantic levels; and the more they encounter the word, the more effective they become. Thus, all other things being equal, a sentence’s sum of log lemma frequency should be a proxy for its processing cost. The reason why we did not opt for sequence surprisal or perplexity, for example, is that sequences longer than one word necessarily reflect syntactic behaviours. That is, at an n-gram level, surprisal and perplexity contain both semantic and syntactic information. They are functionally equivalent to the frequency measure at a unigram level, so we use the latter as our semantic measure.
We used the UD framework to measure syntactic complexity. The UD framework expresses syntactic relations through dependencies: each element depends on another element, its head.18 In UD, the head is the semantically most salient element, and the dependent modifies the head. The top-level head is the root of a sequence, typically the main verb of the matrix clause. Critical to our syntactic measure is the notion of dependency length. For each element, we can calculate the distance to its head, where each intervening element increases the distance by one, and for each sentence, we can add up the distances for a sentence’s elements, which results in the sum of dependency lengths. Figure 1 illustrates a dependency analysis; the sum of distances in that example is 6 (2+1+2+1). The measure is taken from the literature.2,19–21 We consider this an intuitive measure: all other things being equal, sentences with shorter dependency lengths will be easier to process.2,22
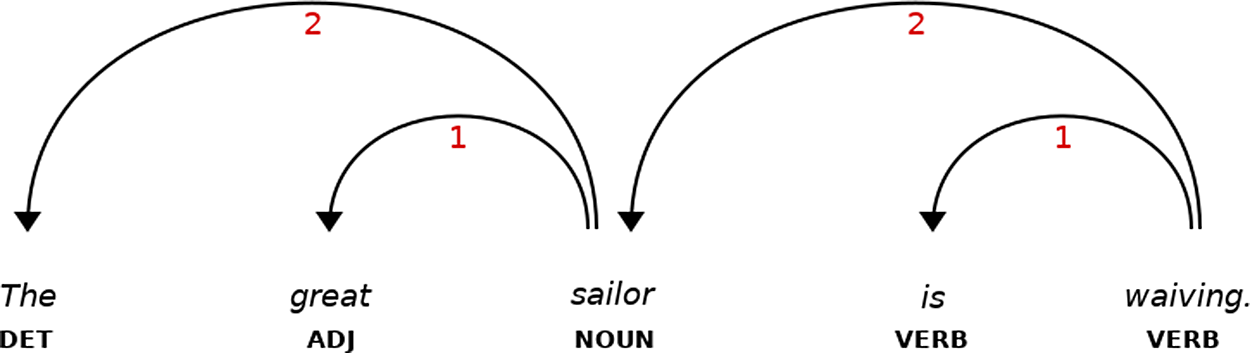
(Created with spaCy: https://spacy.io/.)
Since the relationship between sentence length and summed dependency distances is not necessarily linear,2 there is no simple way to normalise for sentence length. Thus, to remove the risk of spurious sentence length effects, we computed our correlation only at the median sentence length per language, excluding punctuation.c For example, the median sentence length for English is 12 tokens, while for Dutch, it is 6. Another aspect we controlled for is word length. Word length is known to roughly correlate with information content,23 so for any median token length, we further extracted the median character length and considered a range of +/-10%. For instance, the median character length for English sentences of 12 tokens is 47 characters, so we only considered sentences with 12 tokens that are within a range of 42 to 52 characters. Since the median sentence length is relatively short for some languages, we also analysed longer sentences, viz. twice the median sentence length, which is the ‘long’ condition.
We calculated the Pearson correlation coefficient between the summed logged frequencies and the summed dependency distances for each language, using R.24 For our two measures, positive correlation coefficients are evidence for H1: We expect low frequencies (high semantic complexity) to correlate with shortened dependency lengths (low syntactic complexity).
The results are given in Table 1 and are in parts illustrated in Figure 2. Due to space limitations, we omitted the N for the long condition. In total, we analyzed about 31.6k sentences in the normal condition and about 16.1k sentences in the long condition.
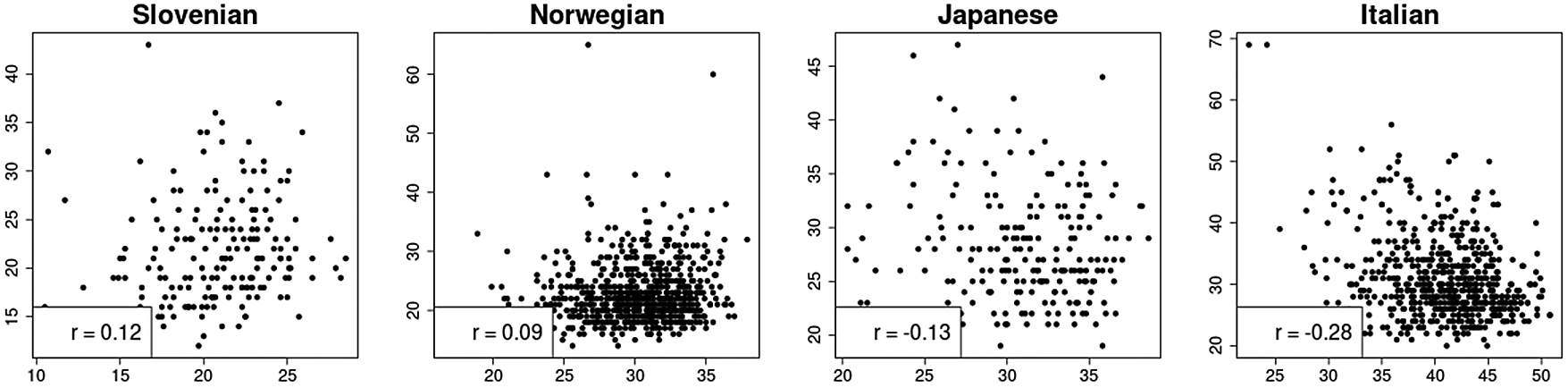
Each dot represents the results for a certain sentence. Within a language, all sentences are of the same token length. (Created with R.24)
Our results are mixed-to-negative and seem to be language-dependent. There is a rather high variance centred around a mean near zero: 21 languages display the expected positive correlations, 9 of which are significant, but 17 languages display negative correlations, 5 of which are significant. We cannot interpret these findings as evidence for H1, and while it is difficult to affirm H0, we cannot reject it.
Taken at face value, this would mean that in some languages, an increase in semantic complexity implies an increase in syntactic complexity, which seems implausible, also since there is quite some variation within language groups, e.g., Slovenian and Bulgarian or Swedish and Dutch. There could be various other causes for the observed variation and the lack of a systematic correlation as discussed below.
We used a canonical, easy to compute, and corpus-dependent semantic measure, amply verified in linguistics, information theory, and cognitive science. While it is a proxy for semantic complexity, as such it leaves room for improvement, we find it unlikely that the mixed results we observe are entirely due to our measure of complexity.
Our syntactic measure depends on the UD framework’s validity, which aims to be language universal.18 We cannot exclude that there are inconsistencies in theoretical choices across languages, e.g., how prepositions or relativizers are attached.25 An in-depth qualitative analysis is needed to follow up on this, and those choices might have contributed to some variance. The extensive amount of work gone into the formulation of the UD framework, together with the efforts made to ensure the consistency of UD syntactic annotations across different languages, makes us think that internal inconsistencies should not shift the mean to a degree such that it conceals a real effect.
Specific registers, or even domains, might be characterised by an unusual complexity of both the semantic and the syntactic side, or have a technical vocabulary that becomes “simple” to their usual readers, leaving room for more syntactic complexity. However, the fact that we draw our semantic measures from the corpora themselves should mitigate such an effect: if a rare semantic unit frequently appears in one of our corpora, its frequency increases, and its complexity level decreases. While differences in the corpora’s makeup could cause parts of the observed variance, there is no apparent reason why they should have caused the mean to shift towards zero.
Other factors that we could not account for could be at play. This concerns pragmatic aspects26 or even morpho-phonetic aspects of the lexicon.27–30 Another source of noise in our data could be that syntactic structures can increase in complexity to a good extent without requiring any semantic simplification or even favoring semantic complexity.31
We have identified some factors that could cause the observed variance. However, if the interaction between syntax and semantics was as strong as we assumed, then there should have been a measurable shift towards a positive mean in most languages. That means that there should have been some signal from the data at hand “shining through” the noise. Nonetheless, the results are not evidence of our H0: the absence of evidence is not the evidence of absence.32 A practical takeaway could be that the interaction between syntax and semantics is more complex and more subtle than we sometimes conceived it to be, certainly at a synchronic level.
This brief report explored in how far syntax and semantics interact in synchronic, large-scale data from 38 languages. To compute syntactic and semantic complexity, we relied on two common measures: dependency length and unigram frequency. These measures are only one way to approach the problem, but their simplicity and empirical robustness make them powerful and unassuming proxies, widely employed in computational and cognitive linguistics. Against our expectation, the analysis did not produce a widespread positive correlation between the two measures that would express an inverse correlation between syntactic and semantic complexity. In many of the languages represented in our data, even when the semantic processing load is high, its syntactic complexity does not appear systematically lowered. Since we used the most straightforward method we conceived of to test our hypothesis, we think that if the effect we hypothesised was obvious and consistent across languages, it should have been visible with the methodology we used, i.e., the mean of all correlations should have had a clear positive tendency. Since this is not the case, our results hint at the possibility that the interaction we are looking for is more subtle than one could have assumed. We find our negative results surprising, and we hope that our report stimulates both discussion and further research.
Zenodo: Syntax-semantics interactions – seeking evidence froma synchronic analysis of 38 languages: dataset repository. https://doi.org/10.5281/zenodo.4542536.
This project contains the following underlying data:
Apache 2.0 license, with the Universal Dependency Consortium holding the copyright.
Zenodo: Syntax-semantics interactions – seeking evidence froma synchronic analysis of 38 languages: scripts repository. https://zenodo.org/record/4643152.
This project contains the following extended data:
The scripts are available under a CC0 license (”No rights reserved”). While the scripts modify the data sets, the modified data sets continue to be subject to the same Apache 2.0 license as the original data sets.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)