Keywords
Lehmann Type – II Distribution; Exponential Distribution; Hazard Rate Function; Moments; Rényi Entropy; Maximum Likelihood Estimation, Simulation.
Lehmann Type – II Distribution; Exponential Distribution; Hazard Rate Function; Moments; Rényi Entropy; Maximum Likelihood Estimation, Simulation.
Over the past two decades, the growing attention of researchers towards the development of new G families has explored the remarkable characteristics of baseline models. New models open new horizons for theoretical and applied researchers to address real-world problems, to proficiently and adequately fit them to asymmetric and complex random phenomena. Accordingly, several classes of distributions have been developed and discussed in the literature. For more details, we encourage the reader to see the credible work of some notable scientists including Marshall and Olkin1 , who developed a new technique to generate models; Eugene et al.,2 who proposed beta generated-G class ; the quadratic rank transmutation map technique introduced by Shaw and Buckley3 ; the Kumaraswamy generalized-G class proposed by Cordeiro and Castro4 ; the gamma-G class proposed by Ristic and Balakrishnan5 ; the exponentiated generalized (EG) class proposed by Cordeiro et al.6 ; the T–X family proposed by Alzaatreh et al.7 ; the Weibull–G family proposed by Bourguignon et al.8 ; the beta Marshall–Olkin–G class proposed by Alizadeh et al.9 ; the logistic-X family proposed by Tahir et al.10 ; Kumar et al.11 proposed DUS transformation ; Mahdavi and Kundu12 proposed Alpha transformation ; Elbatal et al.13 proposed a new Alpha power transformed family of distributions ; and recently, Ijaz et al.14 proposed a Gull alpha power Weibull family ; among others.
This paper is organised into the following sections. A new modified Lehmann Type–II (ML–II) G class of distributions accompanied by a table of some special models is proposed and developed in A new modified Lehmann Type – II–G Class of distributions. A special model of ML–II–G class, known as a modified Lehmann Type–II exponential (ML–II–Exp) distribution, along with its mathematical and reliability measures are derived and discussed in Mathematical properties. The method of maximum likelihood estimation is used to estimate the unknown model parameters and develop some simulation results to assess the performance of maximum likelihood estimations (MLEs) in Inference. Applications are discussed in four real data applications and finally, the conclusion is reported in Conclusions.
Lehmann15 proposed the Lehmann Type–I (L - I) distribution, which was the simple exponentiated version of any arbitrary baseline model. Accordingly, the first credit goes to Gupta et al.16 because they applied L – I on exponential distribution. The associated cumulative distribution function (CDF) is given by
Cordeiro et al.4 deserves to be acknowledged as they use dual transformation that yielded the Lehmann Type – II (L–II) G class of distributions. The associated CDF is given by
The closed-form feature of the L–II distribution assists one to derive and study its numerous properties and in literature, both the approaches (L–I and L–II) have been extensively utilized to study the unexplored characteristics of the classical and modified models.
We develop a new G class, known as a modified Lehmann Type–II (ML–II) G class of distributions. The corresponding CDF is given by
where is a CDF of any arbitrary baseline model based on the parametric vector , dependent on (r x 1) with and are the scale and shape parameters, respectively. Let be the density function of any baseline model. The associated probability density function (PDF), hazard rate function (HRF), and quantile function of ML–II–G class of distributions are given by, respectively
Now and onward, the modified Lehmann Type–II–G random variable X corresponding to will be denoted by X~ML– II–
This study aimed to propose a new G class of distributions that generates more flexible alternative continuous models relative to its parent distribution. From a computational point of view, new models are very simple to interpret. New models offer greater distributional flexibility and can provide a better fit over the complex random phenomena that exclusively arise in engineering sciences. However, to the best of our knowledge, no study has been conducted previously that discusses our new G class, deliberates the unexplained complex random phenomena so well and advances the fit to a diverse range of sophisticated lifetime data.
Linear combination provides a much more informal approach to discuss the CDF and PDF than the conventional integral computation when determining the mathematical properties. For this, binomial expansion is given as follows:
Infinite linear combinations of CDF (1) and PDF (2) of ML–II–G class are given by, respectively
The r-th ordinary moment (say ) of X is given by
where coefficient , , and
Further, by (1), Lehmann Type–II–G class and baseline model can be traced back at , and , respectively. The expansions of CDF (5) and PDF (6) provide us with the Exp-G class, which is quite useful for the generalization of models.
In reliability analysis and life testing of a component in quality control, order statistics (OS) and its moments are considered as a noteworthy measure. Let be a random sample of size n that follows the Lehmann Type–II–G class and be the corresponding OS. The random variables and be the i-th, minimum, and maximum OS of .
where , and are the associated CDF (5) with corresponding PDF (6) of the Lehmann Type–II–G family. Using the fact that
By placing the last expression in , we get the most refined form of OS PDF and one may determine it by integrating (5–6) and the expression may be given as follows
In this section, we introduce a sub-model of ML–II–G class of distributions, known as a ML–II–Exp distribution. For this, we have the CDF and PDF of the exponential distribution and respectively. The associated CDF and corresponding PDF of the ML–II–Exp distribution are obtained by following (1–2) and its analytical expressions are given by respectively:
where is a scale and are the shape parameters, respectively. By following (1–2), linear representation of CDF and PDF are given as follows, respectively
where ,
Expression in (11) is expected to be quite supportive in the forthcoming computations of various mathematical properties of the ML–II–Exp distribution.
One of the imperative roles of probability distribution in reliability engineering is to analyze and predict the life of a component. One may define the reliability function as the probability that a component survives until the time x and analytically it can be written as .
The reliability function of X is given by
In reliability theory, the significant contribution of a function that measures the failure rate of a component in a particular time t is sometimes referred to as the HRF, failure rate function, or the force of mortality, and mathematically it can be written as
Numerous notable reliability measures for the ML–II–Exp distribution can be discussed and derived, such as reverse HRF by Mills ratio by and Odd function by
Different plots of PDF and HRFs of the ML–II–Exp distribution are sketched over the selected and fixed combinations of the model parameters, respectively. Figure 1 (a, b, c) presents the reversed-J, constant, unimodal, and right-skewed shapes of the PDF and Figure 2 (a, b, c) illustrates the decreasing and increasing HRF. However, an increasing HRF with some interesting facts are identified when suddenly spikes arise at the tail end of HRF is unexpectedly detected. Such kinds of trends are often observed in non-stationary time series lifetime phenomena.
| Model | G(x) | S(x) | ξ |
|---|---|---|---|
| Rayleigh () | |||
| Gompertz () | |||
| Pareto () | |||
| Fréchet () | |||
| Burr X () | |||
| Weibull () | |||
| Lomax () |
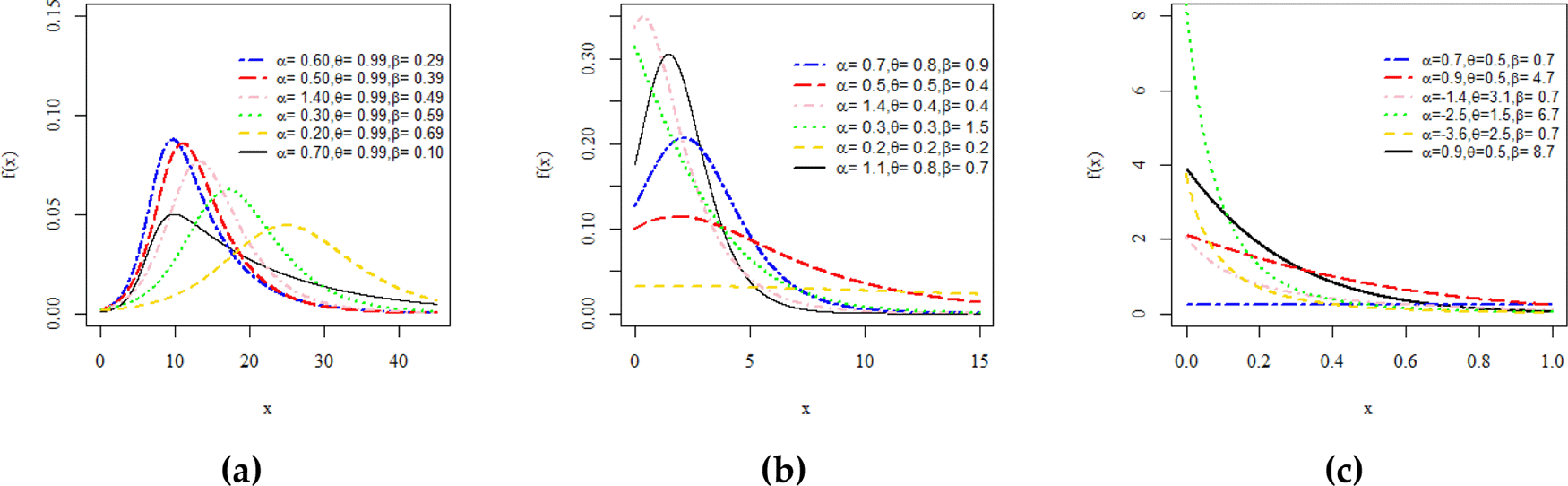
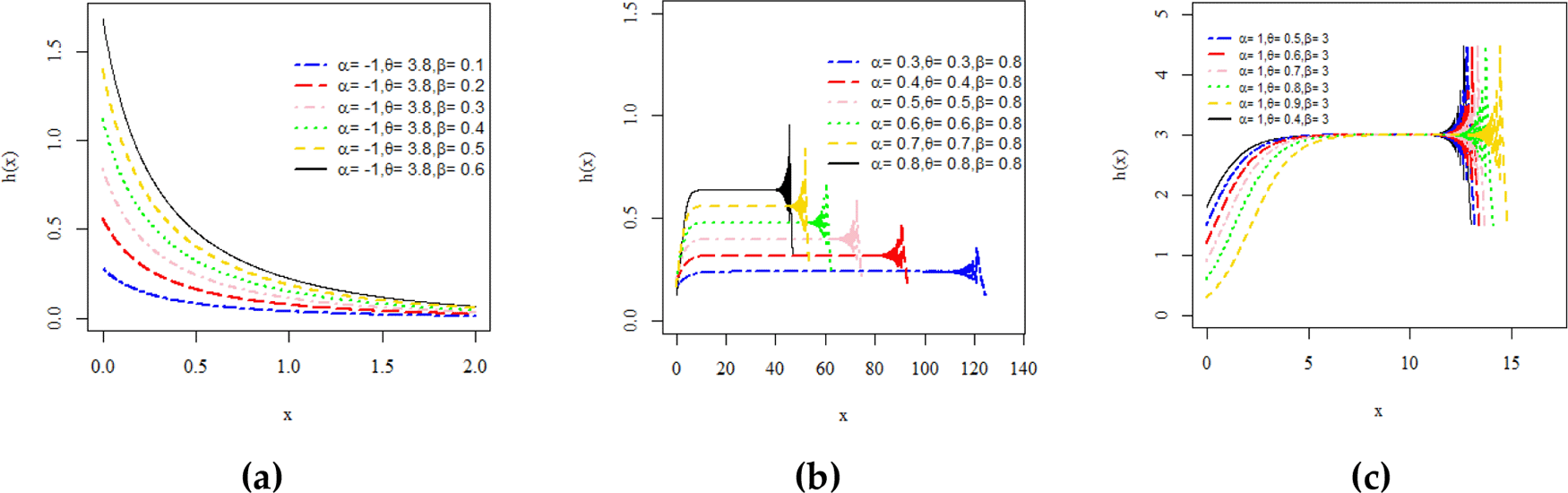
Here we study the limiting behavior of CDF, PDF, reliability, and HRFs of the ML–II–Exp distribution present in (8), (9), (13), and (14) at x and x.
Proposition-1: Limiting behavior of CDF, PDF, reliability, and HRFs of the ML–II–Exp distribution at x is followed by
Proposition-2: Limiting behavior of CDF, PDF, reliability, and HRFs of the ML–II–Exp distribution at x is followed by
Limiting behaviors developed in the above expressions may illustrate the effect of parameters on the tail of the ML–II–Exp distribution.
Moments have a remarkable role in the discussion of the distribution theory, to study the significant characteristics of a probability distribution such as mean; variance; skewness, and kurtosis.
Theorem 1: If X ML–II–Exp (), for , with , then the r-th ordinary moment (say ) of X is given by
where
Proof: can be written by following (11), as
Let’s suppose
limits: as
By placing the above information in (15), we get
by making simple computation on the last expression leads us to the r-th ordinary moment, in terms of the gamma function and it is given by
where is a gamma function, and
The derived expression in (16) may serve a supportive and useful role in the development of several statistical measures. For instance: to deduce the mean of X, placer = 1 in (16). For the higher-order ordinary moments of X approximating to 2nd, 3rd, and 4th, and higher, these moments can be formulated by setting r = 2, 3, and 4 in (16), respectively. Additionally, to discuss the variability in X, the Fisher index (F. I = ()) may play a significant role in this scenario. To derive the negative moments of X, simply substitute r by –w in (16). One may perhaps further determine the well-established statistics such as skewness (), and kurtosis (), of X by integrating (16). A well-established relationship between the central moments and cumulants () of X may easily be defined by ordinary moments . Hence, the first four cumulants can be calculated by , , , and , etc., respectively.
In Table 2, some numerical results of the first eight ordinary moments, = variance, skewness, and kurtosis for some chosen parameters are presented in S-I (), S-II (), S-III (), and S-IV ().
The residual life function/conditional survivor function of random variable X is the probability that a component whose life says x, survives in an additional interval at . Analytically it can be written as
The residual life function of X is given by
PDF and HRF corresponding to (18) are given as follows, respectively
Mean residual life function is given by
Moreover, the reverse residual life can be defined as: .
The reverse residual life function of X is given by
PDF and HRF corresponding to (22) are given as follows, respectively
Mean reversed residual life function/mean waiting time is given by
One may derive the strong mean inactivity time of X by following
where is the r–th incomplete moment, and By following (16), we may derive directly the and by holding “” as the upper bound. Furthermore, and are termed as the first and second lower incomplete moments of X, respectively, with and
When a system is quantified by disorderedness, randomness, diversity, or uncertainty, in general, it is known as entropy.
Rényi17 entropy of X is given by
By following (9), we simplify in terms of , we get
by placing the above expression in (25), we get
hence, solving simple mathematics on the previous equation leads us to the most simplified form of the Rényi entropy of X and it is given by
where
The qth quantile function of ML–II–Exp distribution is obtained by inverting the CDF. Quantile function is defined as
The quantile function of X is given by
To obtain the 1st quartile, median and 3rd quartile of X, place q = 0.25, 0.5, and 0.75 respectively in (26). Henceforth, to generate random numbers, one may assume that the CDF in (8) follows the uniform distribution u = U (0, 1).
The modal value of X is calculated by following the constraint For convenience, can be rewritten as
The simplified form of is given by
Hence, solving simple algebra on the previous equation may provide us with the most suitable form of the mode of X in support of and it is given by
Let X1 and X2 be defined to discuss the strength and stress of a component, respectively, followed by the same uni-variate family of distributions, which will work in order if . To discuss the reliability (say R) of X, it is given by
Theorem 2: Let ML–II–Exp () and ML–II–Exp () be independent random variables following the ML–II–Exp distribution; then the reliability is given by
Proof: Reliability (R) is defined as
R of X can be written by following (9), as
Let’s suppose
limits: as
By placing the above information in (27), we have
Hence, the simple computation of the above expression provides us with the reduced form of R in terms of and , as we presume that the R is a function of with increasing behavior and it is given by
In reliability analysis and life testing of a component in quality control, order statistics OS and its moments are considered as a noteworthy measure. Let be a random sample of size n following the ML–II–Exp distribution and be the corresponding OS. The random variables and be the i-th, minimum, and maximum OS of .
By following (8) and (9), the PDF of takes the form
by utilizing some the techniques of binomial expansion (mentioned in the new modified Lehmann Type – II–G Class of distributions) to simplify (28), we get the reduced form of and it is given as follows
and we determine the linear representation of (29) and it can be written as
Indeed, (29) has a supportive role in the calculation of r-th moment OS and hereafter, straightforward computation of (29) leads us to the r-th moment OS of X and it is given as follows
Furthermore, the minimum and maximum OS of X follows directly from (28) with i = 1 and i = n, respectively.
In this section, we estimate the parameters of the ML–II–Exp distribution by following the method of MLE, as this method provides the maximum information about the unknown model parameter. Let be a random sample of size n from the ML–II–Exp distribution, then the likelihood function of X is given by
The log-likelihood function, is given by
Partial derivatives of (33) w.r.t. and yield, respectively
The maximum likelihood estimates ( ) of the ML–II–Exp distribution can be obtained by maximizing (33) or by solving the above non-linear equations simultaneously. These non-linear equations, however, do not provide an analytical solution for the MLEs and the optimum value of , and . Consequently, iterative techniques such as the Newton-Raphson type algorithm are an appropriate choice in the support of MLEs.
In this sub-section, we discuss the performance of MLEs using the following algorithm.
Step 1: A random sample x1, x2, x3 , ..., xn of sizes n = 25, 50, 100, 200, 300, 400, and 500 are generated from (26).
Step 2: The required results are obtained based on the different combinations of the model parameters placed in S-V (), S-VI (), and S-VII (), S-VIII (), S-IX () and S-X ().
Step 3: Average MLEs and their corresponding standard errors (SEs) (in parenthesis) are presented in Table 4.
Step 4: Estimated bias, root mean square error (RMSE), variance, and mean values are presented in Table 5.
Step 5: Each sample is replicated N = 500 times.
Step 6: A gradual decrease in SEs, biases, RMSE, variances, means, and MLEs pretty close to the true parameters are observed with increase in the sample sizes.
Step 7: Finally, the estimates present in Tables 4 and 5 help us to specify that the method of maximum likelihood works consistently for the ML–II–Exp distribution.
The in-practice measures for the development of average estimate (AE), SE, bias, and RMSE are given as follows:
In this section, we explore four suitable lifetime datasets to model the ML–II–Exp distribution. These datasets are associated with the engineering sector. The first dataset relates to the study of failure times of 84 windshields for a particular model of aircraft (the unit for measurement is 1000 hours) that was first discussed by Ramos et al.18 The second dataset relates to the study of service times of 63 aircraft windshields (the unit for measurement is 1000 hours) that was discussed by Tahir et al.19 The third dataset follows the discussion of the breaking stress of carbon fibers (in Gba) that was initially developed by Nicholas and Padgett20 and finally the fourth one relates to the study of fatigue life of 6061 - T6 aluminum coupons cut parallel to the direction of rolling and oscillated at 18 cycles per second. The data set consists of 101 observations with maximum stress per cycle of 31,000 psi. This dataset was pioneered by Birnbaum and Saunders.21 Subsequently, this data was discussed by Shanker et al.,22 after subtracting 65 from each observation. The datasets are given in the underlying data.
The ML–II–Exp distribution is compared with the well-known models (CDF list is mentioned in Table 6). We follow some recognized selection criteria including -Log-likelihood (-LL), Anderson-Darling (A*), Cramer-Von Mises (W*), and Kolmogorov-Smirnov (K-S) test statistics. Some common results of descriptive statistics such as minimum value, 1st quartile, means, 3rd quartile, 95% confidence interval, and the maximum value, are tabulated in Table 3. The parameter estimates, standard errors (in parenthesis), and the goodness-of-fit are confirmed in Tables 7-10, respectively. The minimum value of the goodness-of-fit is the criteria of the better fit model that the ML–II–Exp distribution perfectly satisfies. Hence, we affirm that the ML–II–Exp distribution is a better fit than its competitors.
| Abbr. | Model | Parameter/ variable range | Reference |
|---|---|---|---|
| HL-Exp | Balakrishnan23 | ||
| E-Exp | Ahuja and Nash24 | ||
| Exp | Nadarajah and Kotz25 | ||
| ETr-Exp | El-Alosey26 | ||
| Logis-Exp | Lan and Leemis27 | ||
| MO-Exp | Salah et al.28 | ||
| NH-Exp | Nadarajah and Haghighi29 | ||
| Ts-Exp | Merovci and Puka30 | ||
| DUS-Exp-Exp | Kumar et al.11 | ||
| Alp-Exp | Mahdavi and Kundu12 |
Furthermore, for a visual comparison the fitted density and distribution functions, Kaplan-Meier survival and probability-probability (PP) plots, total time on test transform (TTT), and box plots, are presented in Figures 3–6 (a, b, c, d, e, f, g, h), respectively. These plots provide sufficient information about the closest fit to the data. All the numerical results in the subsequent tables are calculated with the assistance of statistical software RStudio-1.2.5033. with its package AdequacyModel. The explored datasets are given in the underlying data.
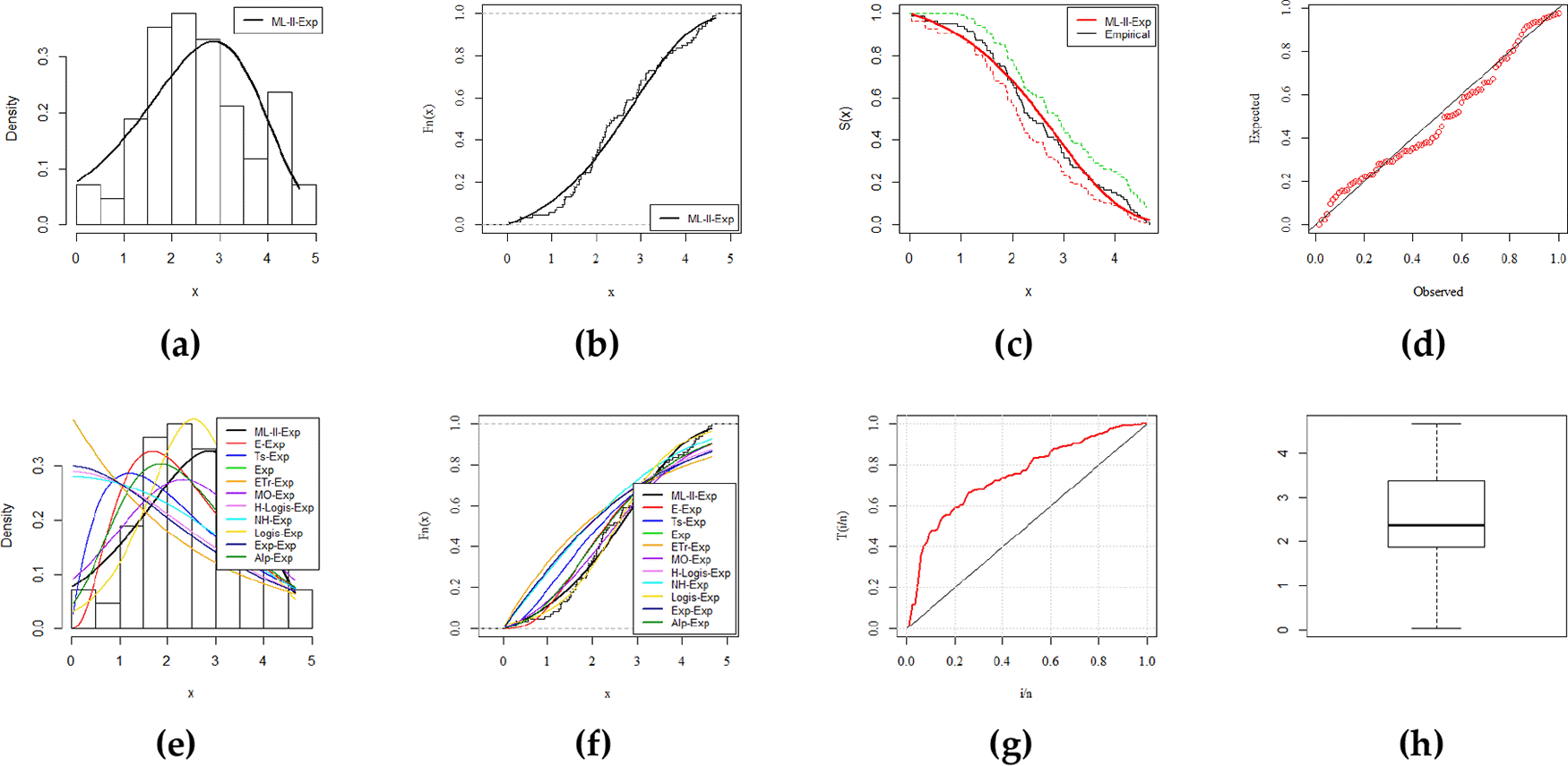
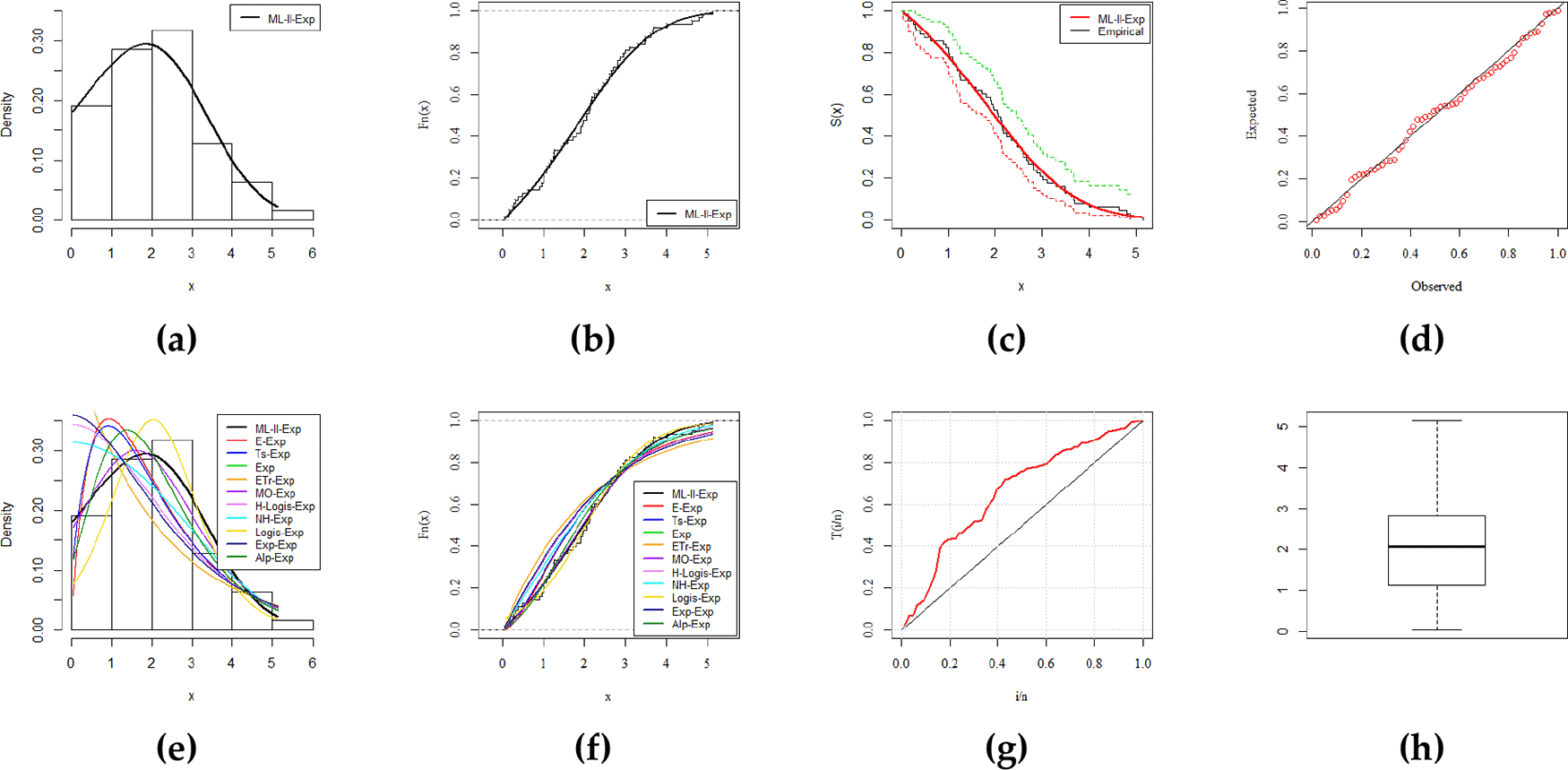
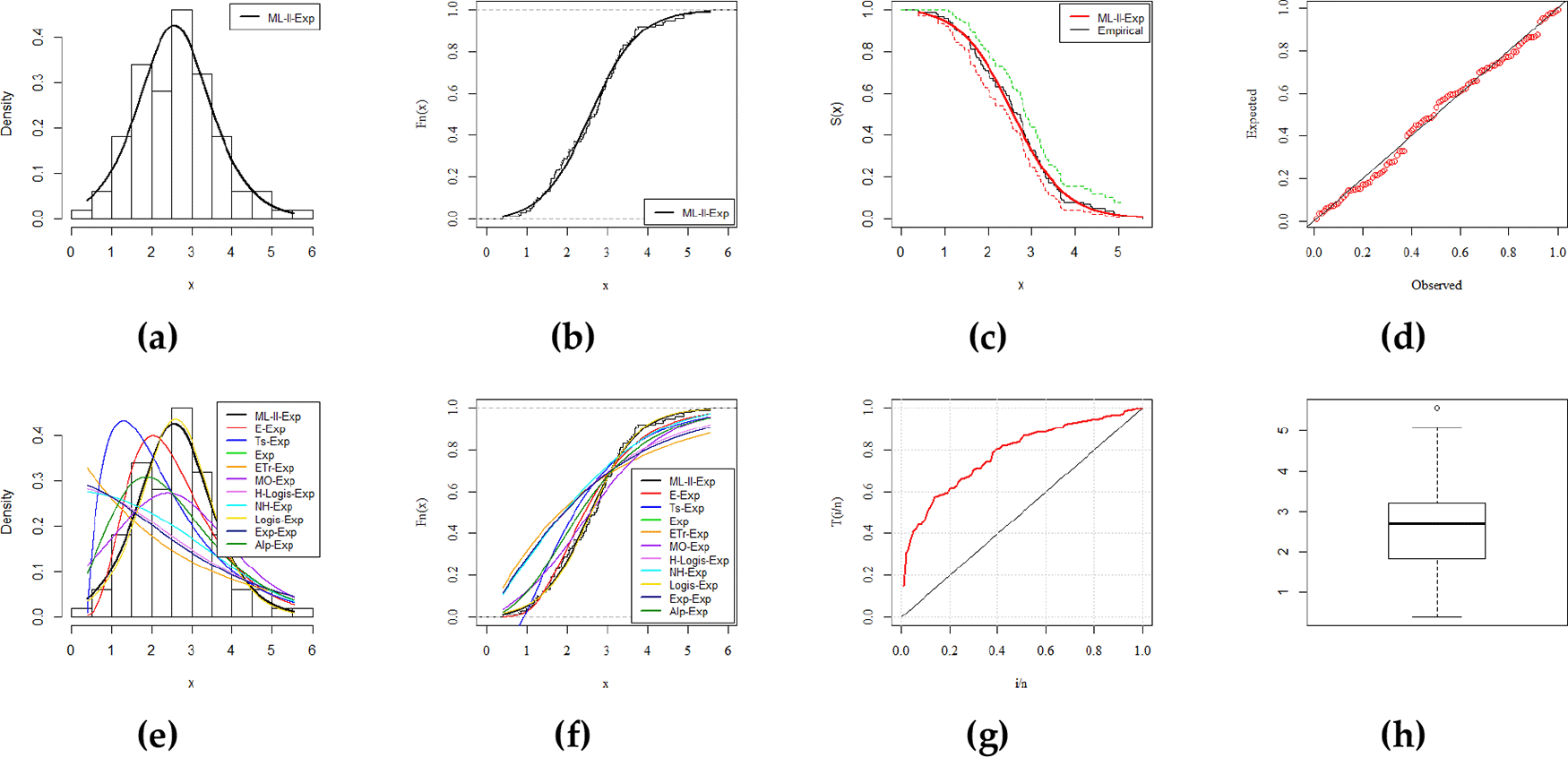
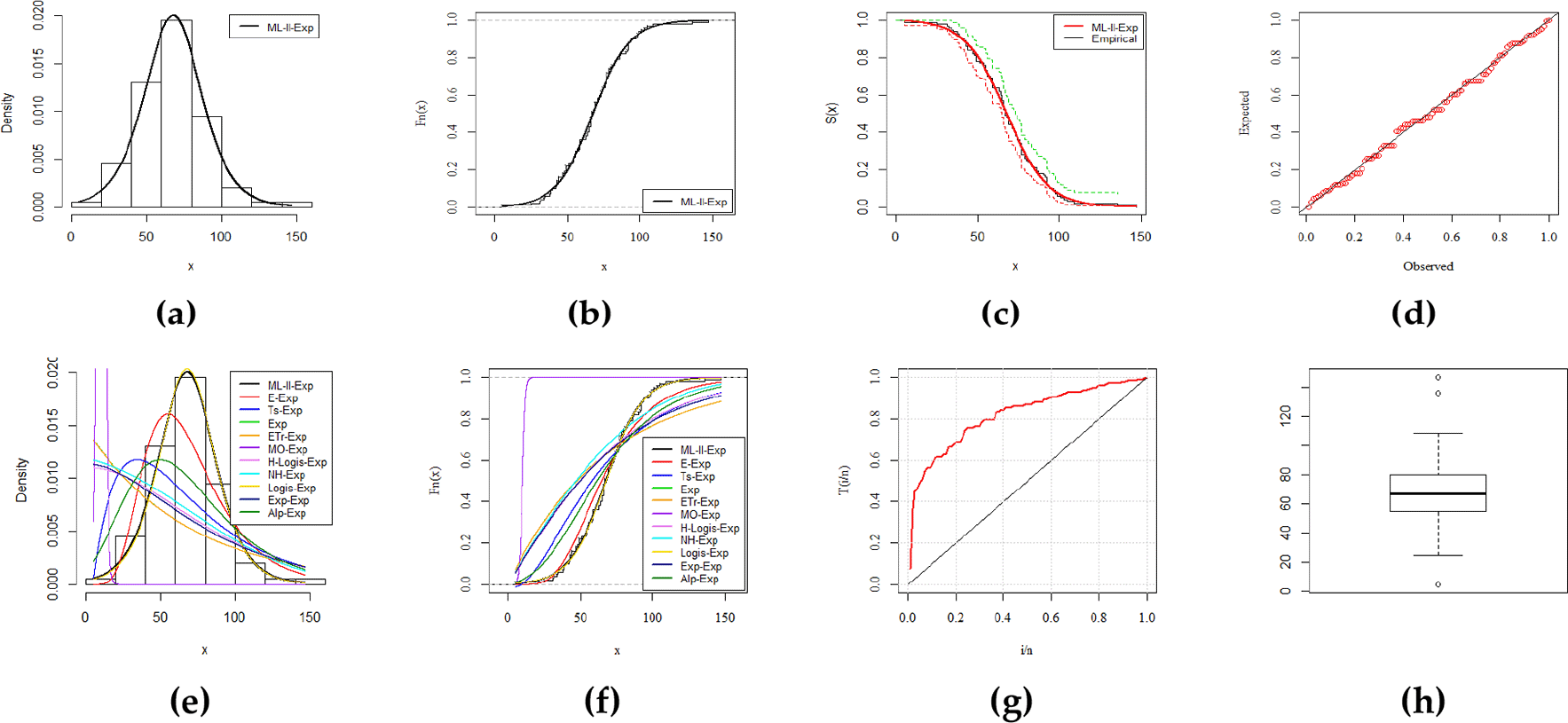
In this article, we introduced and studied a more flexible G class, called the modified Lehmann Type–II (ML–II) G class of distributions along with explicit expressions for the moments, quantile function, and OS. The exponential distribution was used as the baseline distribution for ML–II–G class, known as ML–II–Exp distribution. It was discussed comprehensively, which demonstrated the reversed-J, constant, unimodal, and right-skewed shapes of a density function. The method of MLE along with the simulation was carried out to investigate the performance of the proposed method. The efficiency of the ML–II–G class was evaluated when the most efficient and consistent results of ML–II–Exp distribution competed the well-known models and explored the dominance along with a better fit in four real-life datasets.
We hope that in the future, the proposed class and its sub-models will explore the wider range of applications in diverse areas of applied research and will be considered as a choice against the baseline models.
Figshare. four_dataset.csv. DOI: https://doi.org/10.6084/m9.figshare.14518383.v131
This project contains the following extended data:
• Failure Time of 84 Windshield, Service Times of 63 Aircraft Windshield, Breaking Stress of Carbon Fibers and Fatigue Life of 6061 - T6 Aluminum Coupons used for the article titled “A New Modified Lehmann Type – II G Class of Distributions: Exponential Distribution with Theory, Simulation, and Applications to Engineering Sector”
• Ramos et al. dataset
• Tahir et al. dataset
• Nicholas and Padgett dataset
• Birnbaum and Saunders dataset
Data are available under the terms of the Creative Commons Zero “No rights reserved” data waiver (CC BY 4.0 Public domain dedication).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)