Keywords
Power Function Distribution; Lehmann Type I, II Distribution; Failure Rate Function; Moments; Maximum Likelihood; Order Statistics; Quantile; Rényi Entropy.
Power Function Distribution; Lehmann Type I, II Distribution; Failure Rate Function; Moments; Maximum Likelihood; Order Statistics; Quantile; Rényi Entropy.
Over the last two decades, researchers' increasing interest in the development of new models has explored the remarkable characteristics of the baseline model. As a result, new models open new avenues for theoretical and applied researchers to address real-world problems, allowing them to fit asymmetric and complex random phenomena more proficiently and adequately. As a result, several modifications, extensions, and generalizations have been developed and discussed in the literature, with the Lehmann1 type – I (L – I) and Lehmann type – II (L – II) models being among the simplest and most useful. The simple exponentiation of any arbitrary baseline model is given by L – I.
where , and is a shape parameter.
Gupta et al.2 are credited with the use of L–I on exponential distributions. On the other hand, Cordeiro et al.3 established the L–II–G class of distributions and developed a dual transformation of L–I, which is given by
where is cumulative distribution function (CDF) of the arbitrary baseline model, based on the parametric vector with as a shape parameter.
The closed-form feature of L–II allows one to derive and study its numerous properties, and in the literature, both approaches (L–I and L–II) have been extensively used in favor of the power function (PF) model, to study the unexplored characteristics of the classical and modified models. Recently, Arshad et al.4,5 developed bathtub-shaped failure rate and PF models followed by L–II and L–I families, respectively, and explored their applications in engineering data. Awodutire et al.6 generalized the half-logistic via L–II class, and Akilandeswari et al.7 proposed the Laplace L–I reliability growth model and discussed its application in the early detection of software failure based on time between failure observations.
The PF is a special case of the beta distribution in distribution theory, and its significance can be evaluated using statistical tests such as the likelihood ratio test. The PF's simplicity and utility has compelled researchers to investigate its further generalizations and applications in various fields of science. For this, we recommend that the reader look at Dallas's illustrious work.8 He discovered an intriguing relationship between PF and Pareto models when the inverse transformation of the Pareto variable explored the PF.8 Meanwhile, Meniconi and Barry9 discovered the PF as a best-fit model on electronic component data. Characterization is based on the independence of record values and order statistics, with lower record values attributed to Chang10 and Tavangar,11 respectively. Cordeiro and Brito12 created the beta version of the PF and discussed its use in petroleum reservoir and milk production data. The PF was characterized by Ahsanullah et al.13 using lower record values. Zaka et al.14 discussed techniques for estimating PF parameters such as least square (LS), relative least square (RLS), and ridge regression (RR). Tahir et al.15 generalized the PF via the Weibull-G class and applied it to bathtub-shaped data. Shahzad et al.16 used the techniques of L-, TL-, LL-, and LH moments to calculate the PF moments. Haq et al.17 generalized the PF via the QRTM-G class and investigated its application in two-lifetime data. Okorie et al.18 generalized the PF via the Marshall-Olkin-G class (Marshall and Olkin19) and investigated its application in data on anxiety in women and evaporation. Usman et al.20 proposed an exponentiated version of transmuted PF and investigated its application in biological and engineering data. Hassan et al.21 generalized the PF by following the odd exponential-G class (Tahir et al.22) and discussed its application in three-lifetime data. Zaka et al.23 developed a new reflected PF and investigated its application in medical sciences data, while Al-Mutairi24 discussed the weighted PF via the QRTM G-class and investigated its application in the engineering sector.
We developed a potentiated lifetime model known as the modified Lehmann type II (ML-II) model. It is constrained by the interval (0, 1). The ML-II is extremely well suited to modeling asymmetric and bathtub-shaped phenomena. By including a scale parameter (), in the baseline model, it begins to outperform its competitors in terms of fit and robustness of the tail weight/skewness of the density function.
The ML-II is said to follow a random variable X if its associated CDF and corresponding probability density function (PDF) are given by
where , and are the scale and shape parameters, respectively. For = 0, the ML-II reduces to the L–II (baseline model).
Balogun et al.,25,26 has developed the generalized version and G-class of ML-II (Equation (1)), respectively, and explored their applications in multidisciplinary areas of science.
We had the following objectives:
(i) to develop a two-parameter model with an approach that had not been studied and discussed in the past;
(ii) For the new model to have attractive closed-form features for CDF, PDF, and a likelihood function that is simple to interpret,;
(iii) PDF and HRF to hold J, reversed-J, and bathtub shapes;
(iv) To provide comparative results and a better fit than competing models.
This article is divided into the following sections:’Linear representation’ presents a mixture representation as well as numerous structural and reliability measures. ‘Estimation’ includes the estimation of model parameters using the maximum likelihood estimation (MLE) method, as well as a simulation study. ‘Application’ discusses real-world applications, and the final section summarizes the conclusion.
The linear representations of CDF and PDF make the calculations much easier than the traditional integral computation for determining the mathematical properties. We consider the binomial expansion for this.
Hence, the mixture representation of CDF is given as
where
The probability model plays an important role in reliability engineering by analyzing and predicting the lifespan of a component. Notable contributions include the survival function S(x), hazard rate function h(x), cumulative hazard rate function hc(x), reverse hazard rate function hr(x), Mills ratio M(x), and odd function O(x)).
The reliability function can be defined as the probability that a component will survive at time x. It is defined analytically as . The survival/reliability function of X is denoted by
Terms such as “failure rate function”, “hazard rate function”, and “force of mortality” are frequently discussed in the literature. These terms are used to describe the failure rate of a component over a specific time period (say x). It is mathematically defined as .
The failure rate function of X is denoted by
The mechanical components/parts of some systems are frequently assumed to follow the bathtub-shaped failure rate phenomenon. To discuss the significance of the MLII, several well-established and useful reliability measures are available in the literature. One of them is the cumulative hazard rate function, which is defined as The cumulative hazard rate function of X is denoted by
The reverse hazard rate function is defined by The reverse hazard rate function of X is given by
Mills ratio is defined by Mills ratio of X is given by
The odd function is defined by The odd function of X is given by
As mentioned above, we can obtain the linear expression for reliability characteristics. In terms of linear expression, the reliability and failure rate functions of X are given by
Propositions 1 and 2 discuss the limiting behavior of the ML-II's cumulative distribution (CDF), density (PDF), reliability (S(x)), and failure rate (h(x)) functions for x and x
Proposition-1. The limiting behavior of the CDF, PDF, S(x), and h(x) of the ML-II at x is given below.
Proposition-2. The limiting behavior of CDF, PDF, S(x), and h(x) of the ML-II at x is given as follows, respectively.
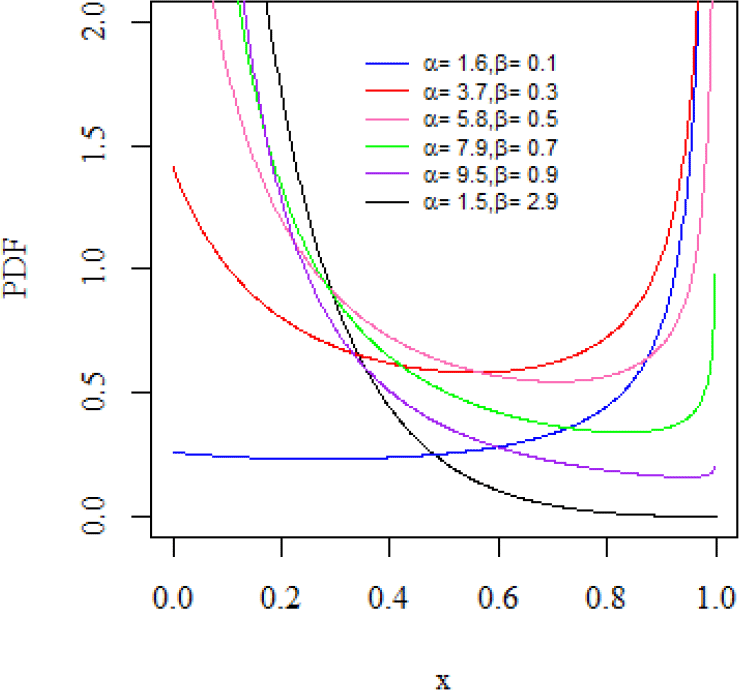
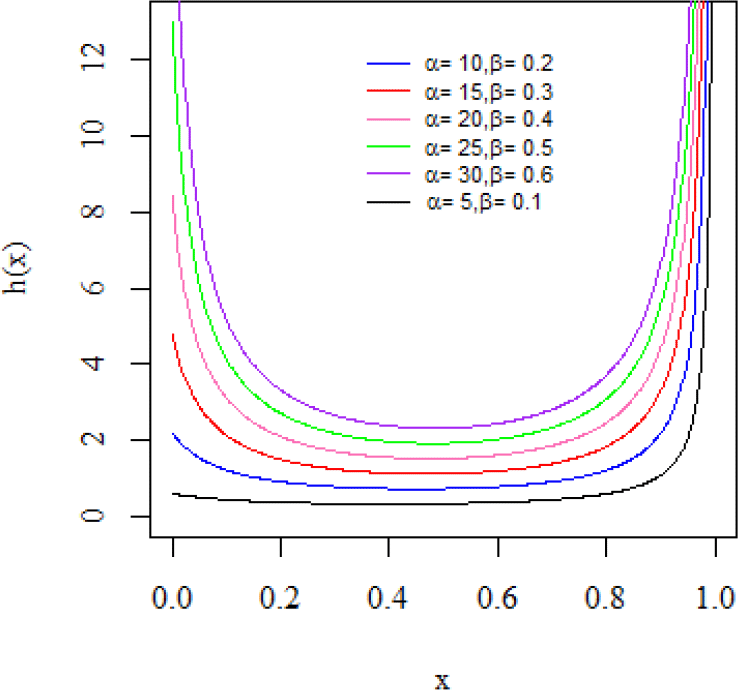
The possible shapes of the ML-II's density and failure rate functions are sketched over various model parameter choices shown in Figures 1 and 2. Figure 1 depicts the J, reverse-J, and bathtub shapes of the density function, while Figure 2 depicts the U, bathtub, and reverse-J shapes of the failure rate function.
The concept of quantile function was introduced by Hyndman and Fan.27 Inverting the CDF yields the pth quantile function of ML-II (Equation (1)). The quantile function is defined as follows: Then, the quantile function of X is given by
Put p = 0.25, 0.50, and 0.75 in Equation (3) to get the first quartile, median, and third quartile of X. To generate random numbers in the future, we will assume that the CDF in Equation (1) follows a uniform distribution u = U. (0, 1).
The mode of X is calculated by taking the first derivative of PDF (Equation (2)) and equating it to zero, as shown by
As a result, a simplified form of the mode is given by
Measures of skewness and kurtosis based on quartiles and octiles are less sensitive to outliers and work well against models, but they are deficient in moments.
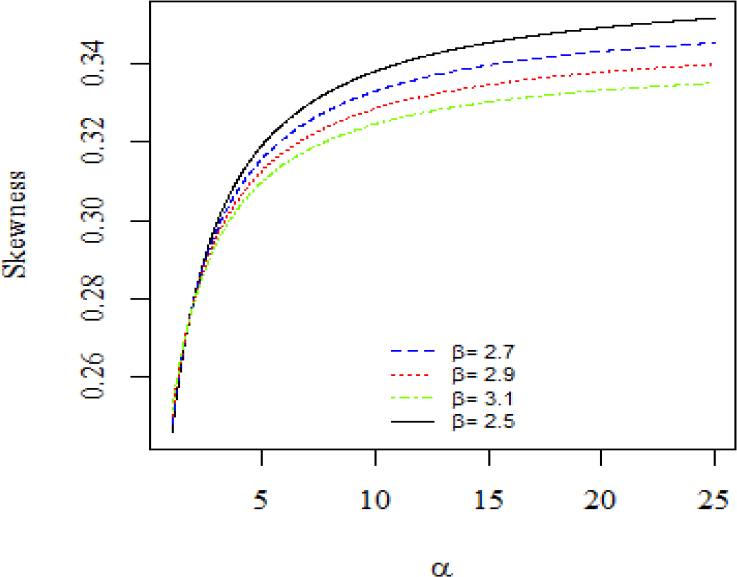
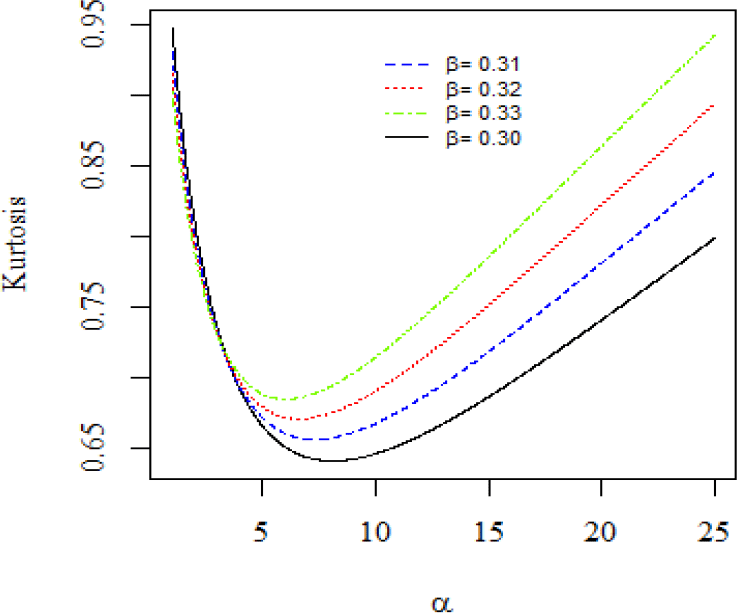
According to Figures 3 and 4, the skewness and kurtosis plots of the ML-II may be positively skewed.
Moments play a significant role in distribution theory, where they are used to discuss the various characteristics and important features of the probability model.
Theorem 1. Let X ML-II (), with , then the r-th ordinary moment (say ) of X is given by
where E =
Proof: r-th ordinary moment can be written by following Equation (2) as
As a result, the above integral reduces to the r-th moment, which is given by
where B() = is the beta function, E = and
The r-th moment is quite helpful in the development of several statistics. For instance, the mean of X can be obtained by setting r =1 in Equation (6) and is given by
Moment generating function is defined as . It is obtained by following Equation (6) and is given by
Characteristic function is defined as . It is obtained by following Equation (6) and is given by
The factorial generating function of X is defined as It is obtained by following Equation (6) and is given by
The Fisher index may play a supportive role in the discussion of variability in X and it is given by
For the negative moments of X, substitute r by – w in Equation (6) and it is given by
Furthermore, for fractional positive and fractional negative moments of X, substitute r by and in Equation (6), respectively.
The Mellin transformation is well-known in statistics as a product distribution as well as a quotient for independent random variables. The Mellin transformation is presented by The Mellin transformation of X is given by
where B() = is the beta function, E = and .
One may perhaps further determine the well-established statistics such as skewness (), and kurtosis (), of X by integrating Equation (6). A well-established relationship between the central moments and cumulants () of X may easily be defined by ordinary moments by . Hence, the first four cumulants can be calculated by , , , and .
Some numerical results of the first four ordinary moments (), mode (a value that appears frequently in data), = variance (a measure of dispersion), skewness (measure of asymmetry), and kurtosis (a measure to discuss the heaviness of the distribution tails) for some chosen parameters are presented in Table 1 for S-I (), S-II (), S-III (), S-IV (), and S-V (). Note that the results of moments and variance decrease gradually, while skewness falls between 0 and 1, mode increases, and kurtosis can be negative subject to the model parameter combinations.
Numerical results of moments (), variance (), skewness (), and kurtosis ().
Incomplete moments
Lower incomplete (LI) and upper incomplete moments are the two types of incomplete moments. LI moments are defined by . The LI moments of X are given as
The residual life function of random variable X, , is the likelihood that a component whose life says x, survives in the different time intervals at . Analytically, it can be written as follows:
with the associated CDF is given as follows
The mean residual life function of X is given by
Further, the reverse residual life can be defined as
Reverse residual life function of X
with the associated CDF is given as follows
The mean reversed residual life function/mean waiting time is given by
where B() = is the beta function, E = and
Order statistics and its moments play an important role in reliability analysis and life testing of a component in quality control. Let X1, X2, X3 , ..., Xn be a random sample of size n following the ML-II model and {X(1) < X(2) < X(3) < ... < X(n)} be the corresponding order statistics. The random variables X(i) , X(1) , X(n) are the i-th, minimum, and maximum order statistics of X, respectively.
The PDF of the i-th order statistics is given by
i = 1,2, 3, … , n.By incorporating Equations (1) and (2), the PDF of the i-th order statistics is given by
Equation (8) can be written as
Straightforward computation of Equation (9) leads to the w-th moment order statistics of X and it is given by
where Further, the minimum and maximum order statistics of follow directly from Equation (8) with i = 1 and i = n, respectively.
Let X1 and X2 represent a component's strength and stress, respectively, following the same univariate distribution. The inadequacy or effectiveness of a component is dependent on whether and , respectively. Stress – strength reliability can be written as
Theorem 2. Let ML-II () and ML-II () be independent ML-II distributed random variables; then the reliability R is defined as
Proof: Reliability R is defined as
Hence the above integral reduces R in terms of and , refers to the stress-strength reliability of the ML-II, and it is given by
There are a number of schools of thought about defining entropy measures. Entropy can be the quantity of disorderedness, randomness, diversity, or sometimes an uncertainty in a system.
The Rényi30 entropy of X is defined by
First, we simplify in terms of by considering Equation (2)
by applying the binomial expansion to this equation, we get
and by placing this information in , we get
hence, by integrating the last equation we obtain the reduced form of the Rényi entropy of X and it is given by
where
A generalization of the Boltzmann-Gibbs entropy is the – entropy, although in physics, it is referred to as the Tsallis entropy. The Tsallis31 entropy/ – entropy is described by
The Tsallis Entropy of X is given by
where
Havrda and Charvat32 introduced entropy measure. It is presented by
The Havrda and Charvat entropy of X is given by
where
Arimoto33 generalized the work of32 by introducing entropy measure. It is presented by
The Arimoto entropy of X is given by
where
Boekee and Lubba34 developed the entropy measure. It is presented by
Boekee and Lubba entropy of X is given by
where
Mathai and Haubold35 generalized the classical Shannon entropy known as entropy. It is presented by
The Mathai and Haubold entropy of X is given by
where
Table 2 presents the flexible behavior of the entropy measures for some chosen model parameters for S-VI (), S-VII (), and S-VIII ().
Numerical results of Rényi, Tsallis, Havrda and Charvat, Arimoto, Boekee and Lubba, and Mathai and Haubold entropy measures.
In this section, we estimate the parameters of the ML-II by following the method of MLE as this method provides the maximum information about the unknown model parameters. Let be a random sample of size n from the ML-II, then the likelihood function of X is given by
The log-likelihood function of X is
Now, we are concerned about obtaining the MLEs of the ML-II. For this, first, we maximize the Equation (12) and second, we calculate the partial derivatives w.r.t., the unknown parameters () and equate to zero, respectively. The score vector components are given by
Partial derivatives w.r.t. are given as follows, respectively
The last two non-linear equations do not provide the analytical solution for the MLEs and the optimum value of , and . The Newton-Raphson (an appropriate) algorithm plays a supportive role in these kinds of ML estimates. Numerical solutions and estimates of the parameters are calculated using R version 3.6.2 (statistical software).
In this sub-section, to observe the asymptotic performance of MLE's , we discuss the following algorithm.
Step - 1: A random sample x1, x2, x3 , ..., xn of sizes n = 150, 200, 250, 300, 350, 400, 450, and 500 from Equation (5).
Step - 2: The required results are obtained based on the different combinations of the model parameters placed in S-IX ( = 3.2, = 2.5), S-X ( = 0.2, = 0.9), and S-XI ( = 0.2, = 1.5).
Step - 3: Results of mean, variance (Var.), bias, mean square error (MSE), coverage probability (CP), and average width (AW) are calculated via nlmib in R. These results are presented in Tables 3 to 8.
Mean, variance (Var.), bias, mean square error (MSE), coverage probability (CP), and average width (AW) of () for S-IX.
Mean, variance (Var.), bias, mean square error (MSE), coverage probability (CP), and average width (AW) of () for S-IX.
Mean, variance (Var.), bias, mean square error (MSE), coverage probability (CP), and average width (AW) of () for S-X.
Mean, variance (Var.), bias, mean square error (MSE), coverage probability (CP), and average width (AW) of () for S-X.
Mean, variance (Var.), bias, mean square error (MSE), coverage probability (CP), and average width (AW) of () for S-XI.
Mean, variance (Var.), bias, mean square error (MSE), coverage probability (CP), and average width (AW) of () for S-XI.
Step - 4: Each sample is replicated 1000 times.
Step - 5: A gradual decrease with the increase in sample size is observed in mean, biases, MSEs, and Var.
Step - 6: CPs of all the parameters are approximately 0.975, approaching the nominal value, and AW decreases when sample sizes increases.
Furthermore, the frequent use of the measures in the development of average estimate (AE), bias, MSE, CP, AW, are given as follows:
In this section, we explore the application of ML-II in medical science and engineering data. For this, we consider two lifetime datasets. The first dataset was originally reported by Smithson and Verkuilen.36 They studied a group of 166 healthy women's anxiety performance, i.e., outside of a pathological clinical setting, from Townsville, Queensland, Australia; data points are 0.01, 0.17, 0.01, 0.05, 0.09, 0.41, 0.05, 0.01, 0.13, 0.01, 0.05, 0.17, 0.01, 0.09, 0.01, 0.05, 0.09, 0.09, 0.05, 0.01, 0.01, 0.01, 0.29, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.09, 0.37, 0.05, 0.01, 0.05, 0.29, 0.09, 0.01, 0.25, 0.01, 0.09, 0.01, 0.05, 0.21, 0.01, 0.01, 0.01, 0.13, 0.17, 0.37, 0.01, 0.01, 0.09, 0.57, 0.01, 0.01, 0.13, 0.05, 0.01, 0.01, 0.01, 0.01, 0.09, 0.13, 0.01, 0.01, 0.09, 0.09, 0.37, 0.01, 0.05, 0.01, 0.01, 0.13, 0.01, 0.57, 0.01, 0.01, 0.09, 0.01, 0.01, 0.01, 0.01, 0.01, 0.01, 0.05, 0.01, 0.01, 0.01, 0.13, 0.01, 0.25, 0.01, 0.01, 0.09, 0.13, 0.01, 0.01, 0.05, 0.13, 0.01, 0.09, 0.01, 0.05, 0.01, 0.05, 0.01, 0.09, 0.01, 0.37, 0.25, 0.05, 0.05, 0.25, 0.05, 0.05, 0.01, 0.05, 0.01, 0.01, 0.01, 0.17, 0.29, 0.57, 0.01, 0.05, 0.01, 0.09, 0.01, 0.09, 0.49, 0.45, 0.01, 0.01, 0.01, 0.05, 0.01, 0.17, 0.01, 0.13, 0.01, 0.21, 0.13, 0.01, 0.01, 0.17, 0.01, 0.01, 0.21, 0.13, 0.69, 0.25, 0.01, 0.01, 0.09, 0.13, 0.01, 0.05, 0.01, 0.01, 0.29, 0.25, 0.49, 0.01,0.01.
The second dataset was recently reported by Rahman et al.37 They studied the lifetime (in days) of 30 electronic devices and the dataset was as follows: 0.020, 0.029, 0.034, 0.044, 0.057, 0.096, 0.106, 0.139, 0.156, 0.164, 0.167, 0.177, 0.250, 0.326, 0.406, 0.607, 0.650, 0.672, 0.676, 0.736, 0.817, 0.838, 0.910, 0.931, 0.946, 0.953, 0.961, 0.981, 0.982, 0.990.
The ML-II is compared with its competing models (presented in Table 9) based on a series of criteria, namely, -Log-likelihood (-LL), Akaike information criterion (AIC), Bayesian information criterion (BIC), consistent Akaike information criterion (CAIC), and Kolmogorov Smirnov test (K-S) test statistics. Table 10 presents a set of descriptive statistics and Tables 11 and 12 present the parameter estimates and standard errors (in parenthesis) along the goodness-of-fit test. As seen in Tables 11 and 12, the performance of the ML-II abundantly satisfies the criteria of a better fit model. Consequently, we declare that the ML-II is a better fit among all competing models on the anxiety in women data. Moreover, Figures 5 and 6 present the empirically fitted plots comprising PDF (a), CDF (b), Kaplan-Meier Survival (c), Probability-Probability (P-P) (d), Box (e), and total test time (TTT) (f) plots (see Aarset38), which confirm the close fit to the data as well.
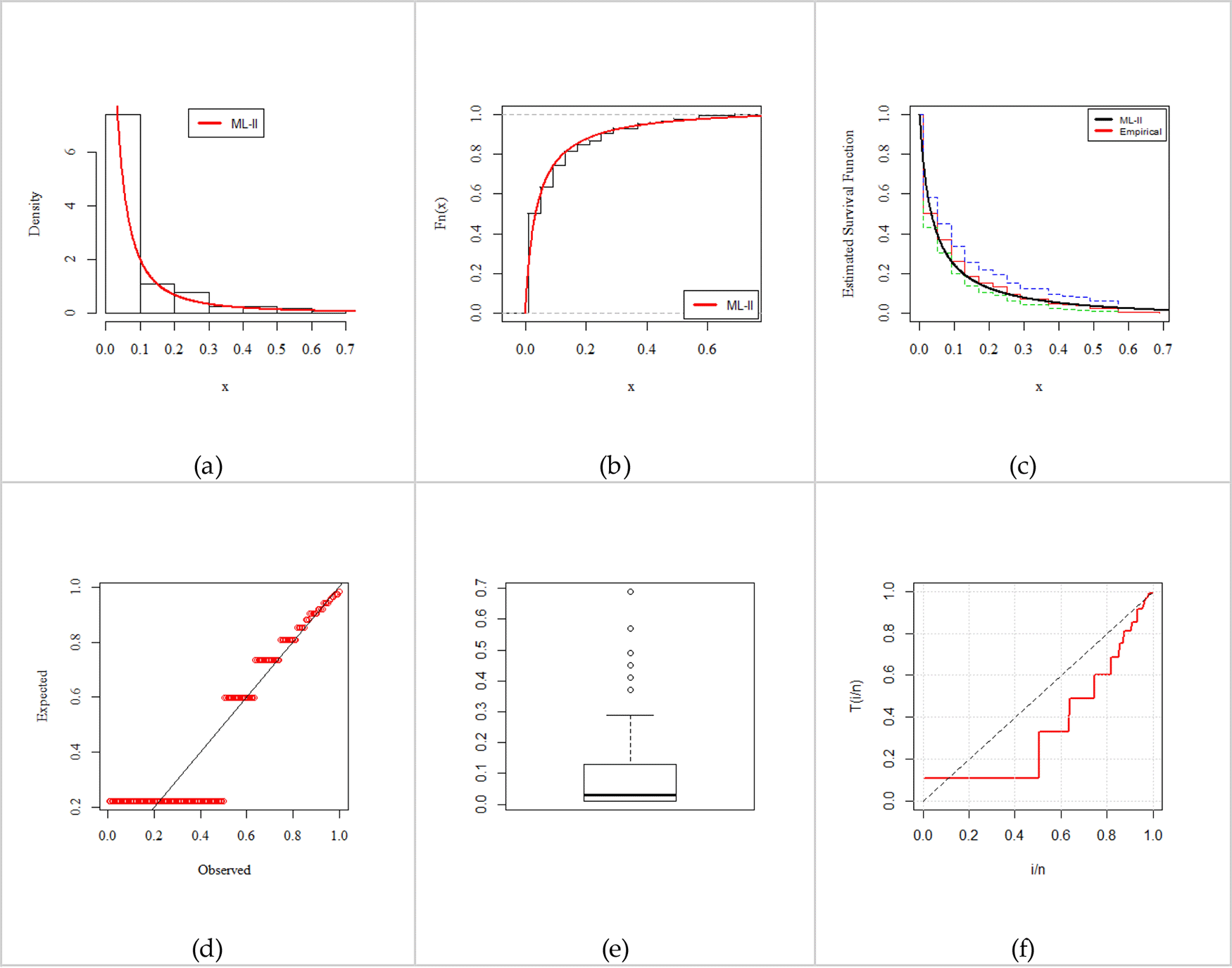
Fitted Probability density function (PDF) (a), Cumulative distribution function (CDF) (b), Kaplan-Meier survival (c), Probability – Probability (PP) (d), Box (e), and Total Test Time (TTT) (f) Plots for women’s anxiety data.
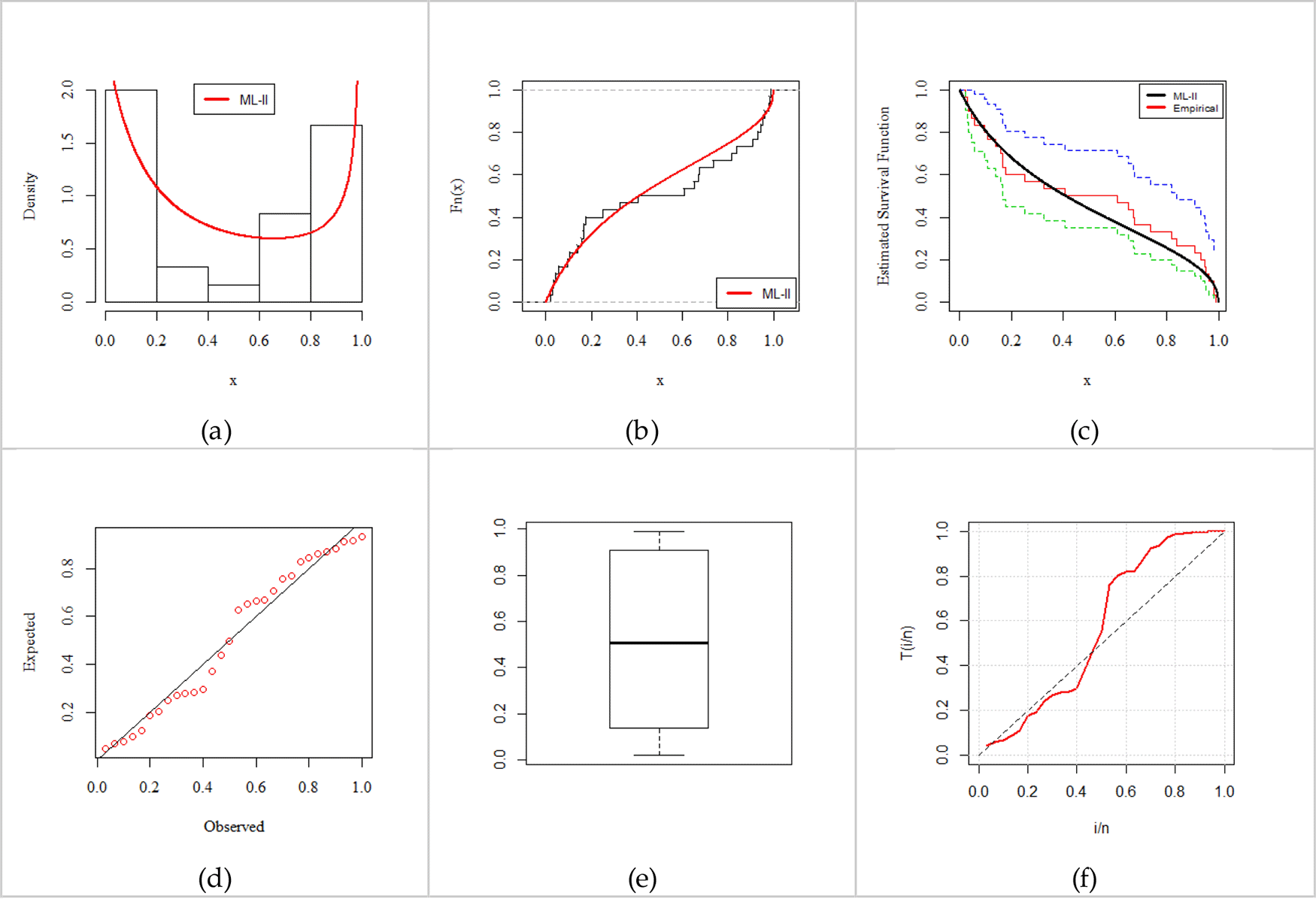
Fitted Probability density function (a), Cumulative distribution function (b), Kaplan-Meier survival (c), Probability-Probability (d), Box (e), and Total Test Time (f) Plots for 30 electronic devices data.
Kum = Kumaraswamy distribution ; L–I = Lehmann type I distribution; L–II = Lehmann type II distribution ; T-Kum = transmuted Kumaraswamy distribution ; Mostafa type-II distribution ; T-GPW = transmuted generalized power Weibull distribution; T-Lin = transmuted Lindley distribution.
| Abbreviations | Model | Parameter/variable range | Reference |
|---|---|---|---|
| Kum | 0 < x < 1 | Kumaraswamy39 | |
| L-I | 0 < x < 1 | Lehmann1 | |
| L-II | 0 < x < 1 | ||
| T-Kum | | x > 0 | Khan et al.40 |
| MT-II | 0 < x < 1 | Muhammad41 | |
| T-GPW | , , x > 0 | Khan42 | |
| T-Lin | x > 0 | Khan et al.43 |
| Data | Minimum | 1st Quart | Mean | 3rd Quart | Skewness | Kurtosis | 95% C.I. | Maximum |
|---|---|---|---|---|---|---|---|---|
| Women’s anxiety | 0.010 | 0.010 | 0.091 | 0.130 | 2.212 | 7.959 | (0.071,0.112) | 0.690 |
| Electronic devices | 0.020 | 0.143 | 0.494 | 0.892 | 0.062 | 1.312 | (0.353,0.634) | 0.990 |
We developed a potentiated lifetime model that exhibited the bathtub-shaped failure rate and addressed the most efficient and consistent results over complex random phenomena in this article. We called the proposed model a modified Lehmann type II (ML-II) model because it was a modified version of the Lehmann type II model. Several structural and reliability measures were developed and discussed. We used the maximum likelihood estimation method to estimate model parameters, and we also ran a simulation study to investigate the asymptotic performance of the MLEs. Data on anxiety in women from Smithson and Verkuilen36 and data on 30 electronic devices from Rahman et al.,37 were modeled to reveal the dominance ML-II over its competitors. It is hoped that in the future, the ML-II will be regarded as a superior alternative to the baseline model.
Figshare: two_dataset.doc, https://doi.org/10.6084/m9.figshare.14903142.45
This project contains the following extended data:
• Smithson and Verkuilen dataset: anxiety test scores from a group of 166 healthy women
• Rahman et al., dataset: lifetime (in days) of 30 electronic devices
The authors of this work sought and obtained consent to use the dataset from the respective authors. The dataset from Smithson and Verkuilen37 was originally published on Smithson's website and saved under Example 2.text. Rahman et al.'s dataset is available in their publication.38 The dataset was published in an open repository with the authors' permission.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)