Keywords
Diabetic Retinopathy Grading, Ensemble Learning, Imbalanced Data, Vision Transformer, Self-attention Mechanism
This article is included in the Research Synergy Foundation gateway.
Diabetic Retinopathy Grading, Ensemble Learning, Imbalanced Data, Vision Transformer, Self-attention Mechanism
Diabetes mellitus (DM) is a group of metabolic disorders that are characterized by high levels of blood glucose and are caused by either the deficient secretion of the hormone insulin, its inaction, or both. Chronically high levels of glucose in the blood that come with DM may bring about long-term damage to several different organs, such as the eyes.1,2 DM is a pandemic of great concern3-6 as approximately 463 million adults were living with DM in 2019. This number is expected to rise to about 700 million by the year 2045.4
High levels of glucose in the blood damage the capillaries of the retina (diabetic retinopathy [DR]) or the optic nerve (glaucoma), cloud the lens (cataract), or cause fluid to build up in the macula (diabetic macular edema), thereby causing diabetic eye disease.6-11 DR is the leading cause of blindness among adults in the working age12 and has brought about several personal and socioeconomic consequences,13 and a greater risk of developing other complications of DM and of dying.14 According to a meta-analysis that reviewed 35 studies worldwide from 1980 to 2008, 34.6% of all patients with DM globally have DR of some form, while 10.2% of all patients with DM have vision-threatening DR.15
A study found that screening for DR and the early treatment thereof could lower the risk of vision loss by about 56%,16 proving that blindness due to DR is highly preventable. Moreover, the World Health Organization (WHO) Universal Eye Health: A Global Action Plan 2014–2019 advocated for efforts to reduce the prevalence of preventable visual impairments and blindness including those that arise as complications of DM.
Many tests can be used for the screening of DR. While sensitivity and specificity are certainly important, the data about performance of tests for DR are different. Researchers employ different outcomes to measure sensitivity, e.g., the ability of a screening test to detect any form of retinopathy, and the ability to detect vision-threatening DR. Additionally, some tests may detect diabetic macular edema better than the different grades of DR according to World Health Organization. Diabetic retinopathy screening: a short guide. Copenhagen: WHO Regional Office for Europe. The examiner’s skill is also a source of variation in the test results. A systematic review found that the sensitivity of direct ophthalmoscopy (DO) varies greatly when performed by general practitioners (25%–66%) and by ophthalmologists (43%–79%).17
DR grading is an essential step in the early diagnosis and effective treatment of the disease. Manual grading is based on high-resolution retinal images examined by a clinician. However, the process is time-consuming and is prone to misdiagnosis. This paper aims to address the matter by developing a fast and accurate automated DR grading system. Here, a novel solution that is based on an ensemble of vision transformers was proposed to enhance grading. Moreover, a public DR dataset proposed in a 2015 Kaggle challenge was used for the training and evaluation.
Traditional machine learning (ML) methods have been used to detect DR. Typically, these ML methods require hand-tuned features extracted from small datasets to aid in classification. These traditional methods may involve ensemble learning18; the calculation of the mean, standard deviation, and edge strength19; and the segmentation of hard macular exudates.20,21 However, these methods require tedious and time-consuming feature engineering steps that are sensitive to the chosen set of features. Work that employs traditional ML methods to detect DR usually yield favorable results using one dataset but fail to obtain a similar success when another dataset is used.18,19 This is a common limitation of hand-crafted features.
Deep neural networks, such as CNNs, with much larger datasets have also been used for classification tasks in the diagnosis and grading of DR. These methods involve CNNs developed from scratch to grade the disease using images of the retinal fundus22; transfer learning based on Inception-v3 neural network to perform multiple binary classification (moderate versus worse DR, and severe or worse DR)23; segmentation prior to detection by pixel classification24 or patch classification.25 A deep learning (DL)-based framework that uses advanced image processing and a boosting algorithm for grading of DR was also proposed by.26 This is one of only a handful of works that have effectively employed transfer learning to train large neural networks for this purpose. Recently, ResNet, a deep CNN, was proposed to address the problem brought about by imbalanced datasets in DR grading.27 Additionally, a bagging ensemble of three CNNs: a shallow CNN, VGG16, and InceptionV3, was used to classify images as DR, glaucoma, myopia and normal.28
Previously, a transformer was also proposed by Vaswani et al.29 for natural language processing tasks especially for machine translation. Inspired by the successes of the transformers in NLP, transformers were transferred to computer vision tasks e.g. image classification.
In this section, the DR detection dataset is explored. Additionally, the vision transformer, a DL model that was used on these data, is discussed in detail.
The DR detection dataset is highly imbalanced and consists of high-resolution images with five levels of severity including No_DR, Mild, Moderate, Severe, and Proliferative_DR. It has significantly more samples for the negative (No_DR) category than for the four positive categories. Table 1 shows the class distribution of the training and testing sets. Figure 1, on the other hand, shows a few samples from each class. The images come with different conditions and were labeled with subject IDs. The left and right fields were provided for every subject. The images were captured by different cameras, thus affecting the visual appearance of the images of left and right eyes.
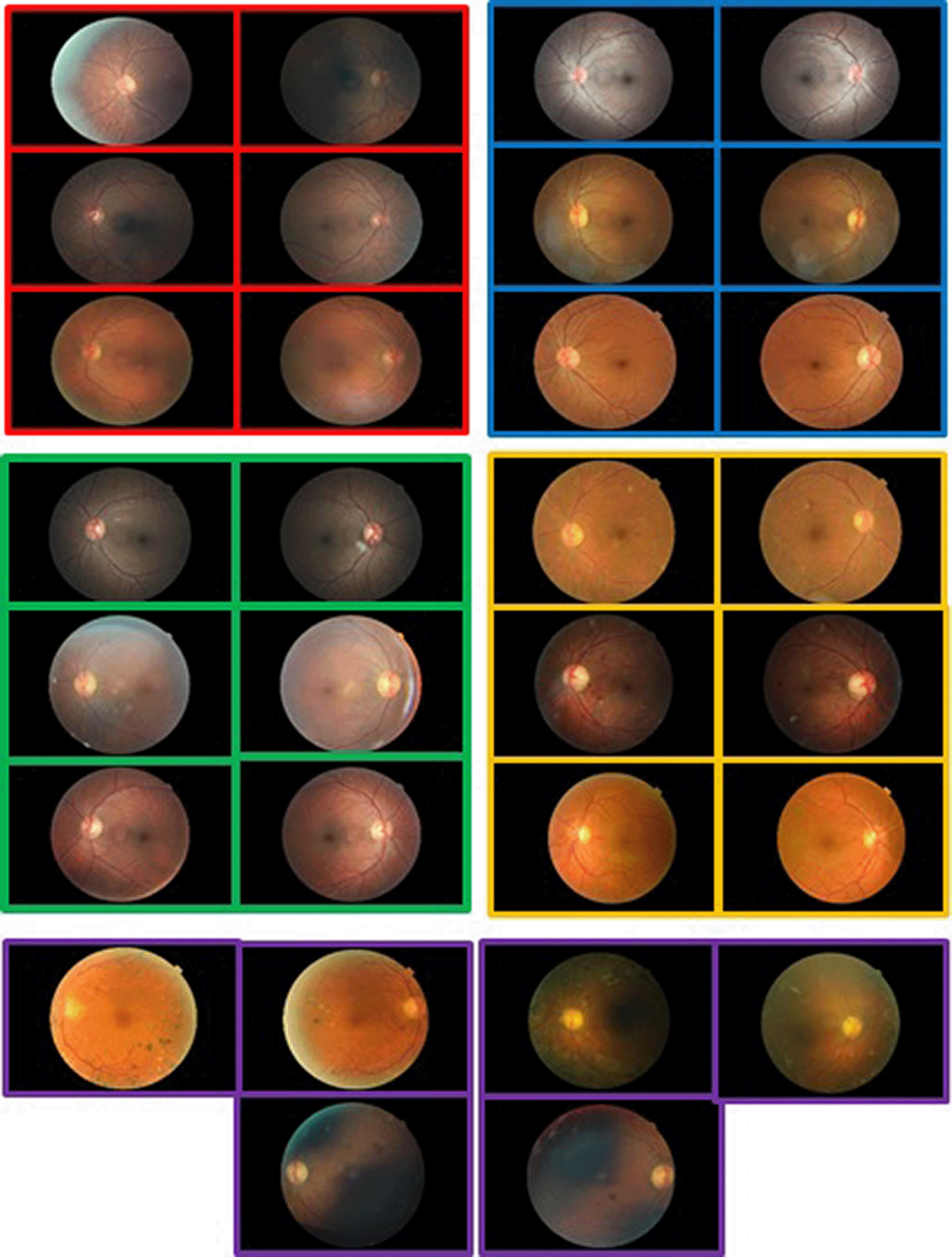
The images have various sizes but were resized uniformly.
| Class | Training | Testing |
|---|---|---|
| No_DR | 25810 | 39533 |
| Mild | 2443 | 3762 |
| Moderate | 5292 | 7861 |
| Severe | 873 | 1214 |
| Proliferative_DR | 708 | 1206 |
The samples of the training set were rescaled between , cropped to remove their black borders, and augmented by randomly flipping the samples horizontally and vertically, and by randomly rotating the samples by . The samples of the test set were only cropped and rescaled. Figure 2 shows a few augmented samples from the training set.

A vision transformer is a state-of-the-art DL model that is used for image classification and was inspired by Dosovitskiy et al.30 Figure 3 shows the architecture of the vision transformer. In this paper, a retinal image that has a sequence of patches encoded as a set of words was applied to the transformer encoder as shown in Figure 3. The original image’s patcheswere extracted with a fixed patch size where , W is the image width, is the image height, and is the number of patches. The extracted patches were flattened and each patch belonged to , where is the number of channels.
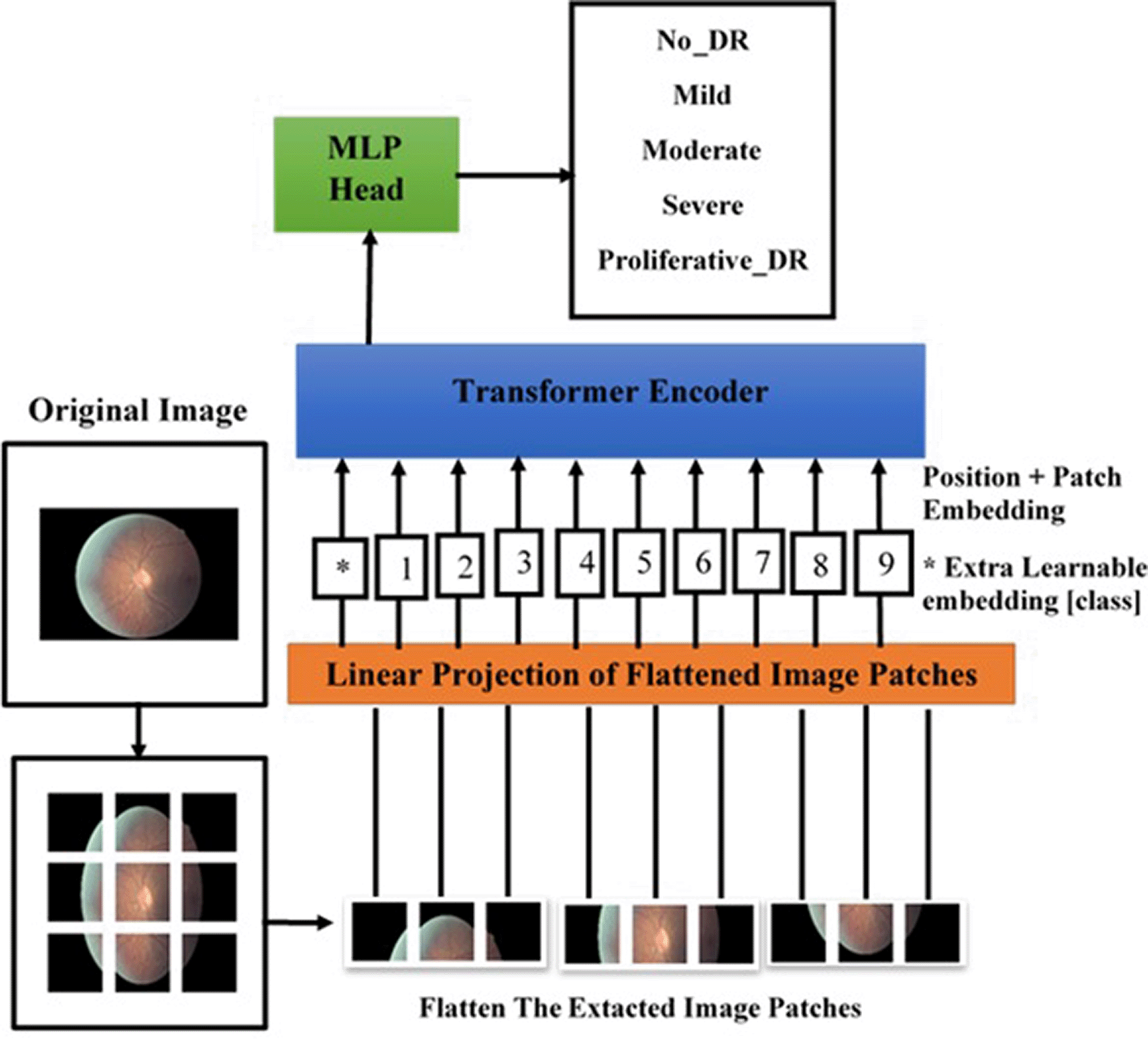
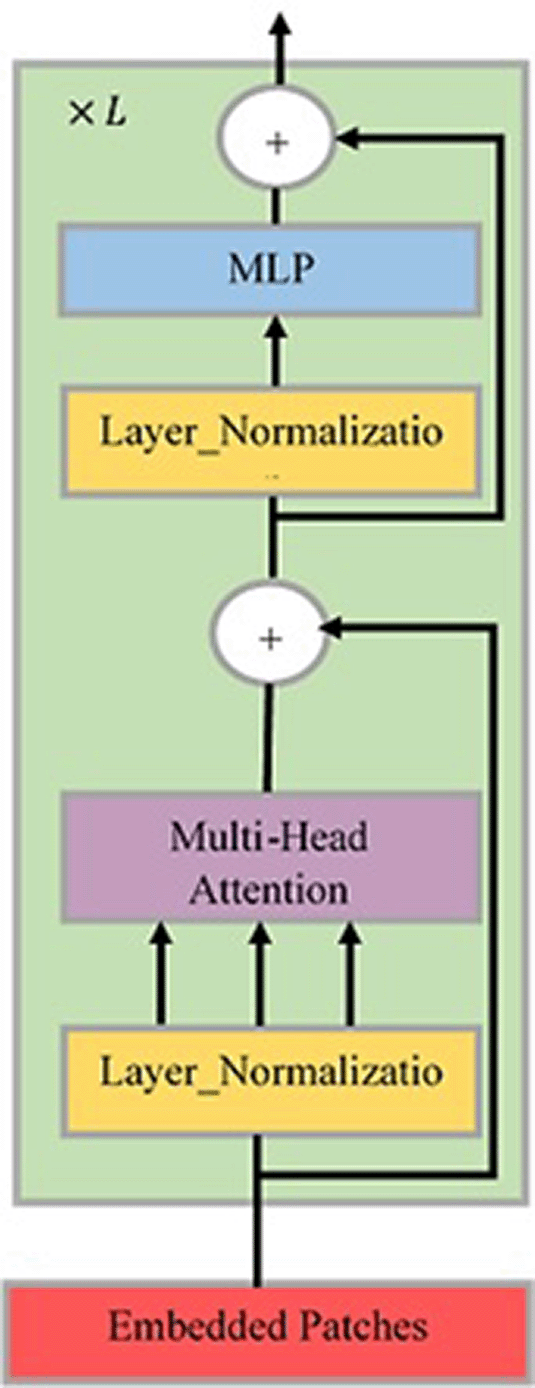
As a result, the 2D image was converted into a sequence of patches . Each patch in the sequence was mapped to a latent vector with hidden size . A learnable class embedding was prepended for the embedded patches, whose state at the output of the transformer’s encoder serves as the representation of the image. After that, a classifier was attached to the image representation . Additionally, a position embedding was added to the patch embeddings to capture the order of patches that were fed into the transformer encoder. Figure 4 illustrates the architecture of transformer’s encoder with blocks, each block containing alternating layers of multi-head self-attention (MSA)29 and multi-layer perceptron (MLP) blocks. The layer normalization (LN)31 was applied before every block, while residual connections were applied after every block.30
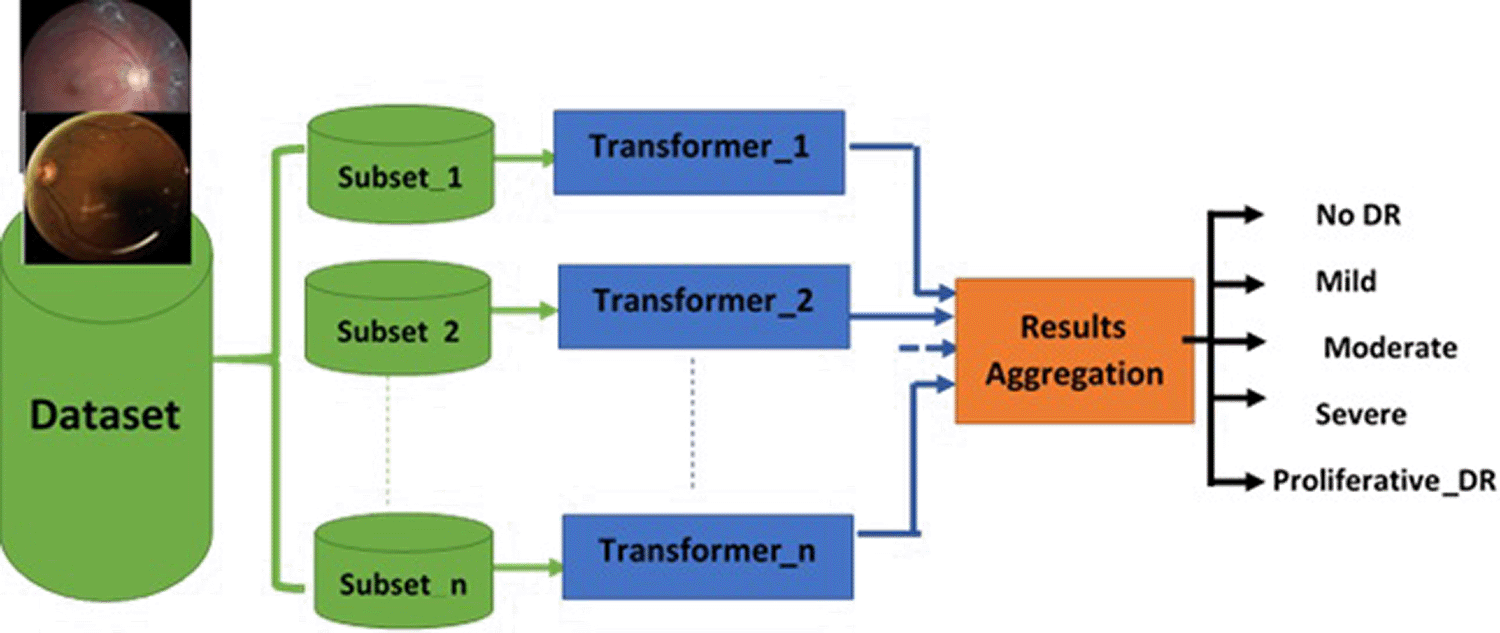
Ensemble learning is a ML ensemble meta-algorithm. Bagging (Bootstrap Aggregating) is a type of ensemble learning that uses “majority voting” to combine the output of different base models to produce one optimal predictive model and improve the stability and accuracy.32
The advantage of ensemble bagging several transformers is that aggregation of several transformers, each trained on a subset of the dataset, outperforms a single transformer trained over the entire set. In other words, it leads to less overfit by removing variance in high-variance low-bias datasets. To increase the speed of training, the training can be done in parallel by running each transformer on its own data prior to result aggregation, as shown in Figure 5.
The images available in this dataset were resized to , the latent vector hidden size was set to , the number of layers of the transformer to , the to , the to 12, and the default value of the patch size to . Thus, the sequence’s number was 256.
In the experiments conducted, from each class in the training set were selected for validation. All transformers were fine-tuned using the weights of the transformer pre-trained on ImageNet-21K.33
For optimization, the ADAM algorithm34 was utilized with a batch size of 8. Furthermore, the mean squared error loss function was used. The training process for each transformer consists of two stages:
1) All layers in the transformer backbone were frozen and the regression head that was initialized randomly was unfrozen. Then, the regression head was trained for five epochs.
2) The entire model (transformer backbone + regression head) which was trained for 40 epochs was unfrozen.
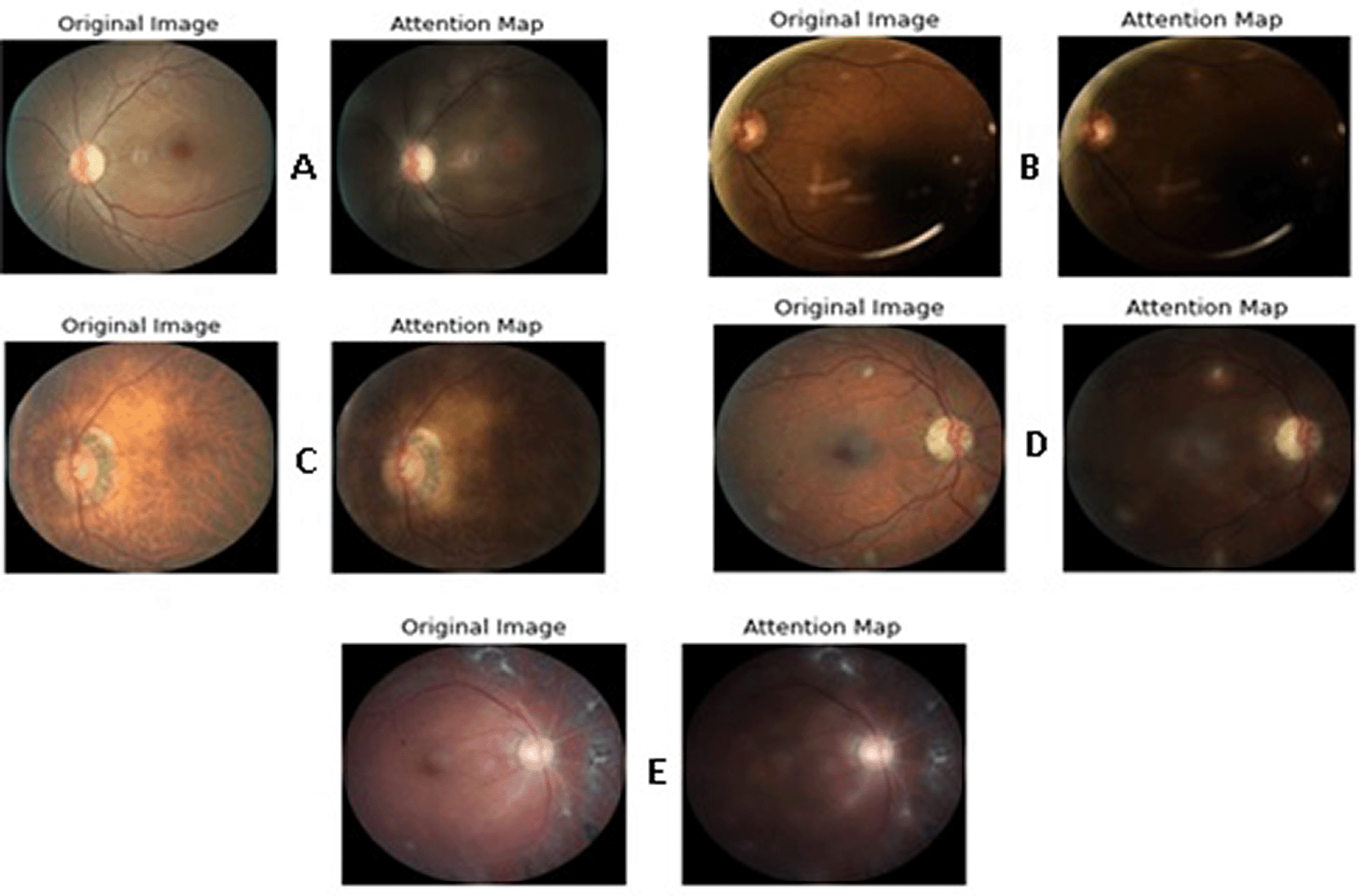
Data augmentation, early stopping, dropout, and learning rate schedules were used to prevent overfitting and loss divergence. Figure 6 shows the attention map of a few samples extracted from the transformer.
The classification heads of all transformers were removed and replaced by a regression head with one node instead of logits. The regression output of a transformer was interpreted as shown in Table 2 to be converted into a category.
An ensemble of ten transformers with similar architectures and hyperparameters was used. The samples were divided randomly into ten sets and each transformer was trained on each one. After interpreting the regression output from each transformer, the predicted classes from ten transformers were aggregated with “majority voting” to predict the final class.
Training, validation, and testing were carried out using the TensorFlow framework on an NVIDIA Tesla T4 GPU.
In this section, the results of the proposed ensemble of transformers are discussed. The performance metrics, such as precision, recall, and F1 score were calculated. Additionally, the quadratic weighted kappa (QWK) metric was utilized in this dataset because these data needed specialists to label the images manually since the small differences among the classes can only be recognized by specialist physicians. QWK which lies in the range measures the agreement between two ratings and is calculated between the scores assigned by human raters (doctors) and predicted scores (models) as shown in Table 3. The dataset has five ratings: 0, 1, 2, 3, 4.
| Kappa | Agreement |
|---|---|
| < 0 | No |
| 0.01 – 0.20 | Slight |
| 0.21 – 0.40 | Fair |
| 0.41 – 0.60 | Moderate |
| 0.61 – 0.80 | Substantial |
| 0.81 – 0.99 | Almost perfect |
QWK was calculated as follows:
1) The confusion matrix O between predicted and actual ratings was calculated.
2) A histogram vector was computed for each rating in the predictions and in the actual.
3) The matrix which represents the outer product between the two histogram vectors was calculated.
4) The () weight matrix was constructed representing the difference between the ratings as shown in Table 4.35
Where 1 ≤ i ≤ 5, 1 ≤ j ≤ 5
5) QWK was defined as follows35:
where N is the number of classes.
Table 5 shows the performance metrics of ten transformers with each one trained on a subset of data. It is obvious that there is a big difference among the performances of these individual transformers. Transformer_1 was able to yield a Kappa of 55.1%. On the other hand, transformer_10 yielded a Kappa of 30.9%. Ensembles of various numbers of transformers including all ten transformers, four transformers (1,3,8,9), and other configurations were also evaluated. The best model was an ensemble of two transformers (1,3) which yielded a Kappa of 60.2%.
This Kappa is at the boundary between moderate and substantial agreement. The previous results confirm that the performance of the ensemble of transformers (1,3) trained with fewer training images outperformed the ensemble of ten transformers trained with five times the number of images. Table 6 compares the performance of the ensemble of transformers with the ensemble of ResNet50 CNNs. The ResNet50 CNN was transferred from ImageNet 1K. The top layers were replaced by a support vector machine that was tuned with this dataset. The proposed ensemble of transformers outperformed the ensemble of ResNet50 CNNs significantly by >18% Kappa.
| Model | Precision % | Recall % | F1 Score % | QWK% |
|---|---|---|---|---|
| Ensemble of two transformers | 47 | 45 | 42 | 60.2 |
| Ensemble of ten ResNet50 | 32 | 44 | 32 | 36.97 |
| Ensemble of two ResNet50 | 35 | 40 | 35 | 41.52 |
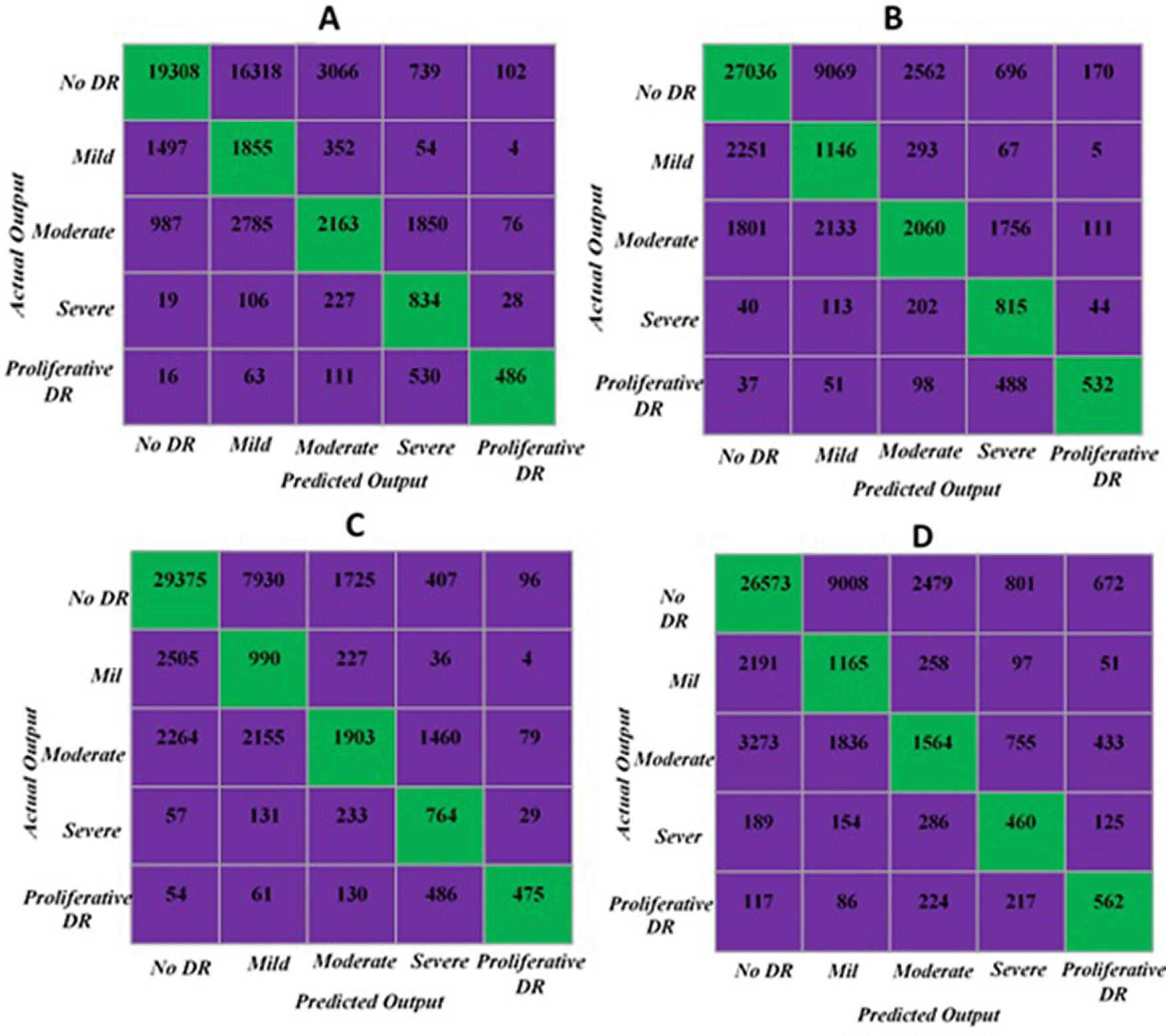
The confusion matrix of each configuration including ensembles of transformers with ten, four, and two transformers, and the ensemble of two ResNet50
CNNs were shown in Figure 7. The confusion matrix (c) which represents the best Kappa of 60.2% shows that the model was able to recognize the categories of severe and proliferative DR from one side, and NO DR and mild DR from the second side.
This study is a new attempt to demonstrate the capability of the ensemble bagging of vision transformers applied on retinal image classification for the grading of DR into five levels of severity. The experiments conducted showed that even when the dataset was challenging, the proposed method was able to yield promising performance measures in terms of precision (47%), recall (45%), F1 score (42%), and QWK (60.2%). Furthermore, the inference time was low at 1.12 seconds. Hence, we intend to enhance the performance by utilizing a collection of various DR datasets. This can increase the size and variety of training data to train the proposed model from scratch instead of starting from the weights of the ImageNet 21K-based model. By doing so, we can ultimately enhance performance.
Conceptualization by N.A., M.A.M.; Data Curation by N.A.; Formal Analysis by N.A., H.A.K., M.A.M.; Funding Acquisition by H.A.K.; Investigation by N.A., J.L.F; Methodology by N.A., H.A.K., M.A.M.; Project Administration by H.A.K.; Software by N.A., M.A.M.; Validation by N.A., M.J.T.T.; Visualization by N.A.; Writing – Original Draft Preparation by N.A., M.A.M, J.L.F.; Writing – Review & Editing by N.A., H.A.K., M.J.T.T., M.A.M, J.L.F.
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
The Retinal images are public third part dataset provided by EyePACS, a free platform for retinopathy screening.
The dataset used in this work is accessible to the public on the Kaggle website. It was created in 2015 for the Kaggle Diabetic Retinopathy Detection competition. This competition is sponsored by the California Healthcare Foundation. Retinal images were provided by EyePACS, a free platform for retinopathy screening.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)