Keywords
Machine Learning, Deep Learning, Neural Networks, Affect Recognition, In-The-Wild, Facial Expression Recognition, Cross-Dataset Accuracy
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Research Synergy Foundation gateway.
Machine Learning, Deep Learning, Neural Networks, Affect Recognition, In-The-Wild, Facial Expression Recognition, Cross-Dataset Accuracy
This paper is an examination of facial expression recognition (FER) in the context of artificial intelligence. It aims to look at the field of FER critically by studying its sub-fields and summarizing its state-of-the-art methods.
There are plenty of methods and techniques for facial expression recognition out there. However, these methods are not without limitations. The primary issue with current methods of FER is that they do not work in real life despite showing high-accuracy results in the lab. This incongruence prevents the utilization of FER in the mainstream industry. That is the main problem that this paper is addressing.
The literature review section will start by looking at current research in the field and will identify the trends that the field is taking. The section will summarize several research papers outlining various methods and end with the findings from the review of the current literature.
The methods section will give the theoretical framework needed for the project and outline the research methodology and the criteria used for evaluation. Then it will go to an in-depth layout of the proposed improvements and how they will be arrived at, implemented, and tested.
The evaluation section will examine, evaluate, and compare the results of training and testing to select the best performing model.
The last section will conclude by specifying ways to improve the methods and to implement future work.
Facial expression recognition began more than two decades ago, and since that time, many developments have taken place.1 The general process for FER starts with face detection, which is fairly accurate and is easy to implement. Next, we preprocess the dataset images for feature extraction. This step was done separately before the advent of deep neural networks. Methods like local binary pattern (LBP),2 local gradient coding (LGC),3 local directional pattern (LDP),4 histogram of gradients (HOG),5 etc.6 are used. Then the classification process is done using k-nearest neighbor (KNN) or support vector machines (SVM). To classify emotions, we need to categorize them first. There are two main kinds of categorizations that are commonly used for classification. The first one is the descriptive coding scheme which uses action units to describe facial features. Action units do not describe facial expressions directly. Instead, they describe how a face looks which in turn helps us classify the emotion behind the expression (since there is no apparent link between how a facial expression is and the emotion that generates it).1,7 Here, the classification model classifies the action units in a face so that a combination of action units will likely correspond to a particular emotion.
The second is the judgment model, which, on the other hand, describes expressions based on the latent emotions that generate the facial expression. So instead of describing what the face looks like, it directly classifies the emotion that generates it, resulting in a multi-class classification of 6 or 7 primary emotions, usually based on the Ekman model.8 The classification can also be on static images or on sequences of images that start from a neutral expression and then proceed to shift to the full extent of the emotion.9
Deep neural networks have been very powerful in FER tasks.1 However, most of the experiments carried out were on datasets that were in controlled environments, where the subjects were either asked to show a particular emotion or were shown videos that induced the needed emotion. The accuracy metrics seen for these models are very high. However, when we test the same methods on in-the-wild datasets, the results are comparatively poor.10 In-the-wild datasets include images captured where people were not aware that they were being filmed, making the expressions natural and spontaneous, or in harsh lighting conditions, tilted head angles, obstructed or occluded subjects, making classification more challenging. In-the-wild datasets were rare, but now more of them are made publicly available. Some examples include AffectNet,11 and RAF-DB12 dataset. Other trends that are now common include ensemble methods, where multiple techniques are combined; Many more deep learning models combine multiple neural networks that focus on different parts of the FER process.
Another important thing to note is that most FER models are trained and tested on the same dataset, making these models prone to biases present in the dataset. These models, therefore, perform poorly when tested on datasets that are different from the ones on which they were trained.13
One of the research gaps that we identified from the challenges in the field is the shortage of models trained on challenging in-the-wild datasets. Training is usually done on datasets created in lab-controlled environments, which lack the nuance and variety present in real-life, in-the-wild scenarios. Since these datasets are relatively new, they were not explored enough, and very few models were built and tailored for these datasets.
In addition, the evaluation metrics used for these kinds of datasets are limited to the old metrics that relied only on the accuracy level. These metrics worked well when the datasets were simple. Therefore, there is a need for incorporating more effective performance metrics, like cross-dataset accuracy, cross-dataset accuracy drop, and other similar metrics that better test the robustness of the model by exposing it to different data.13 Combining in-the-wild datasets and enhanced metrics will limit dataset bias and give us a better idea of how the model would perform in novel conditions.
This paper aims to:
• Study and analyze the best state-of-the-art methods for FER. This is important because an exploration of the field helps improve the understanding of the technologies, patterns, and research methodologies used to improve currents methods or introduce new ones
• Evaluate the current best methods and compare them to one another using various metrics to find the best optimal methods
• Introduce newer metrics that are not widely adopted but are nonetheless better at evaluating the proposed models
• Improve the current methods by devising new algorithms or improving the current ones. The goal here is to maximize the best results in at least one of the evaluation metrics generally used in the field or the newly introduced metrics
The proposed method attempts to address the gaps in the literature by using the most extensive in-the-wild dataset available. The model is also a deep neural network, which are the most accurate types of FER classification models thus far.14 Finally, we have used metrics that will reduce dataset bias and address the current limitations of FER evaluation methods.
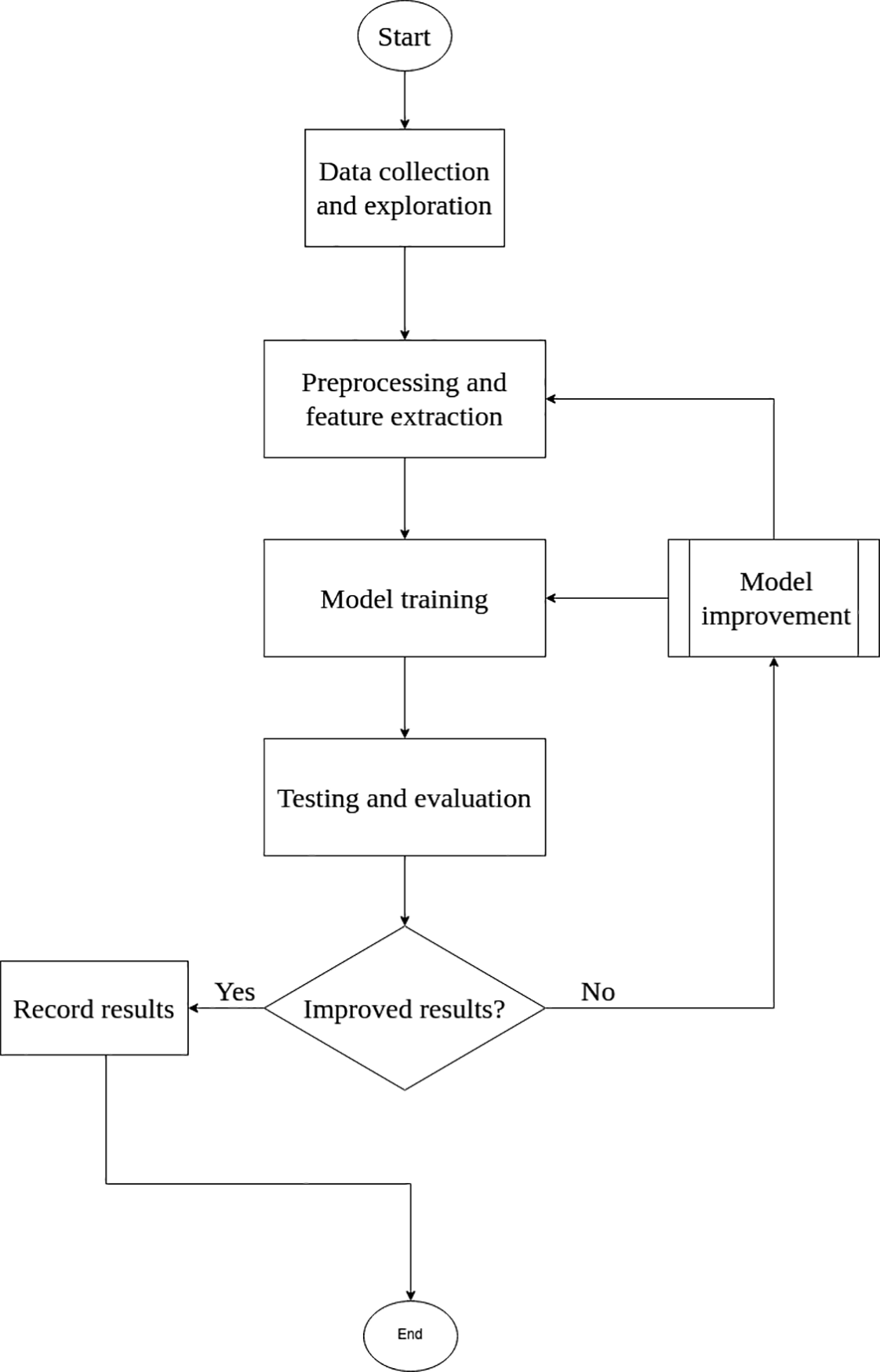
The process used to arrive at the model involves data collection, preprocessing, model building and improvement over existing state-of-the-art deep learning models, model training, and evaluation. We check the results to see if there are any improvements in the metrics measured. If not, we improve upon the model by tweaking the neural network parameters, and the process reiterates until a better model is achieved. Figure 1 gives an overview of the process used.
The primary dataset used for training the models is AffectNet.11 The dataset contains 450,000 manually annotated images, out of which 27,000 were used for the training. We made this reduction because of the enormous size of the dataset and the long training time, especially without graphical processing units (GPUs).
Another dataset used was the Japanese Female Facial Expression (JAFFE) dataset.15 It is a simple dataset, collected in controlled conditions, and contains a little over 600 images. The dataset has female subjects pose and act out expressions to create five classes.
Training the deep learning models on JAFFE yields an accuracy of 100% due to the simplicity of the dataset. However, in this project, it is only used for cross-dataset accuracy. The models were trained on AffectNet, and then JAFFE was used as a validation set. This is because JAFFE is one of the most widely used classical datasets for FER research.
The AffectNet dataset is divided into multiple directories with randomly allocated images in each directory. The dataset is indexed using a CSV file, with the first column containing the directory and name of the images. The other columns contain all the details of the images: the expression class, valence, arousal, and other properties. Therefore, most of the preprocessing work was done on the index file. This includes removing valence and arousal and other data points that we did not need for this model, the random selection of 27,000 images, and finally, the arrangement of these images.
A problem arises with the unequal distribution of data. For example, there are more images of the “Happy” class compared to other classes. This bias in the data sample distribution will make the model biased towards some classes since they are statistically more likely to appear, resulting in a model that does not generalize well.16 Therefore, we set a class weight attribute that gives higher weights to classes with fewer images. This helps in improving the results and compensates for the low volume of images in certain classes. The class weights are presented in Table 1.
The proposed model is a variant of VGG16. It predicts seven primary expressions: Neutral, Happy, Angry, Sad, Surprised, Afraid, and Disgusted. Below are the specifications of the most optimum model found after the iterative process:
We fine-tuned the model using the ImageNet weights.17,18 Fine-tuning or transfer learning is a deep learning technique in which models are first trained to a high classification accuracy on one general purpose dataset (general object recognition using the ImageNet dataset in this case) and the learned weights are transferred to another model. The model is re-purposed by freezing the last couple of layers and retraining them with a different dataset for a more domain-specific classification task (facial expression recognition in this case, using AffectNet). This is done to speed up the training and to improve the classification accuracy.
We did not have to train the VGG16 model on ImageNet because it comes pre-trained and the weights pre-installed with Keras. We retrained the last six layers of the model and added four more layers. The top of the model was not included so that the output layer can be changed to match the seven classes of expressions. We also modified the model by adding a few layers to it:
1. Flattening layer. This is done to flatten the output of the previous layer to a one-dimensional vector
2. A Dense layer or a fully-connected layer with an output of 1024 and ReLU activation function
3. A Dropout layer with a dropout rate of 0.5
4. A Dense layer with seven outputs (for seven classes) and a Softmax activation function.
These last ten layers were trained on AffectNet. The loss function used is categorical crossentropy, which has shown the best results for deep neural networks. We set the learning rate at 0.0001 and then trained the model for ten epochs, with a batch size of 100. We used the Keras library (version 2.3.0) built on top of TensorFlow (version 2.3.0) and programmed in Python (version 3.6) to build and train the model.
Evaluation metrics are an essential part of the process. They should give us a good idea of the robustness of the model. Standard metrics like accuracy are helpful, but they do not assess how adaptive the model is to different settings where the images used as input are taken in conditions completely different from the controlled environment of the lab. Therefore, we use cross-dataset accuracy or mean cross-dataset accuracy as additional metrics.
The main metrics used for evaluation are:
• Accuracy – This metric measures the percentage of the labels guessed correctly by the model for the testing sample provided. It is the most widely used metric in all of the previously conducted research. The dataset needs to be divided into a training set and a test set to implement this metric. This will be done using k-fold cross-validation.19
We can determine the accuracy value by calculating the sum of true positive () and true negative (), dividing by the total number of samples.
• Cross-dataset accuracy – This metric is rarely used (because it is newly introduced in FER) but is important nonetheless. It measures the model’s accuracy by training it on one dataset and testing it on a different dataset. This metric is important because it shows how well the model generalizes in very challenging, dataset-independent conditions. It reduces dataset bias while training models and is a much more solid metric to use for evaluation.20,13
• Mean cross-dataset accuracy drop – Similar to the previous metric, except that it measures the percentage of the drop in accuracy when the model is trained on one dataset and tested on another.
If denotes the accuracy of the model when tested on the training dataset and is the accuracy of the model when tested on dataset , then the mean accuracy drop for datasets is given by the equation:
The lower the percentage of the drop, the better the results. However, this metric is tricky since it only shows the relative accuracy of the model between datasets but does not show the absolute robustness of the model. Therefore, it must be used with great care and scrutiny of the results.
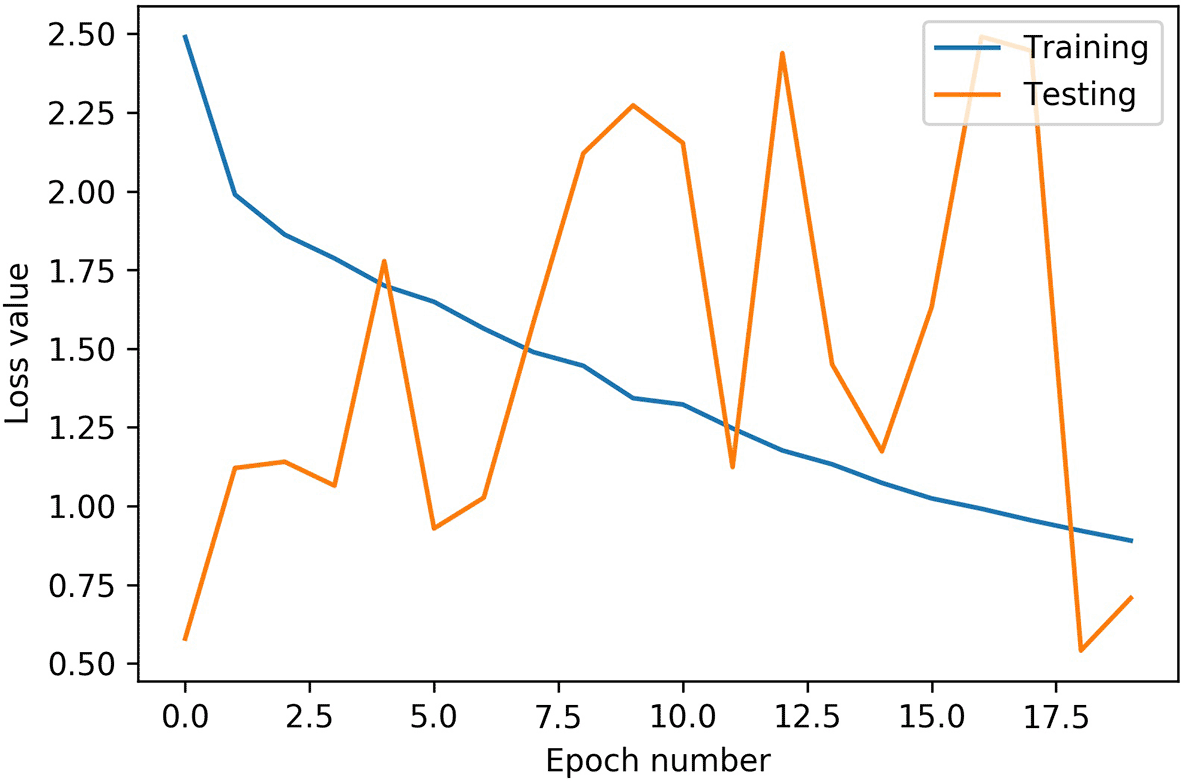
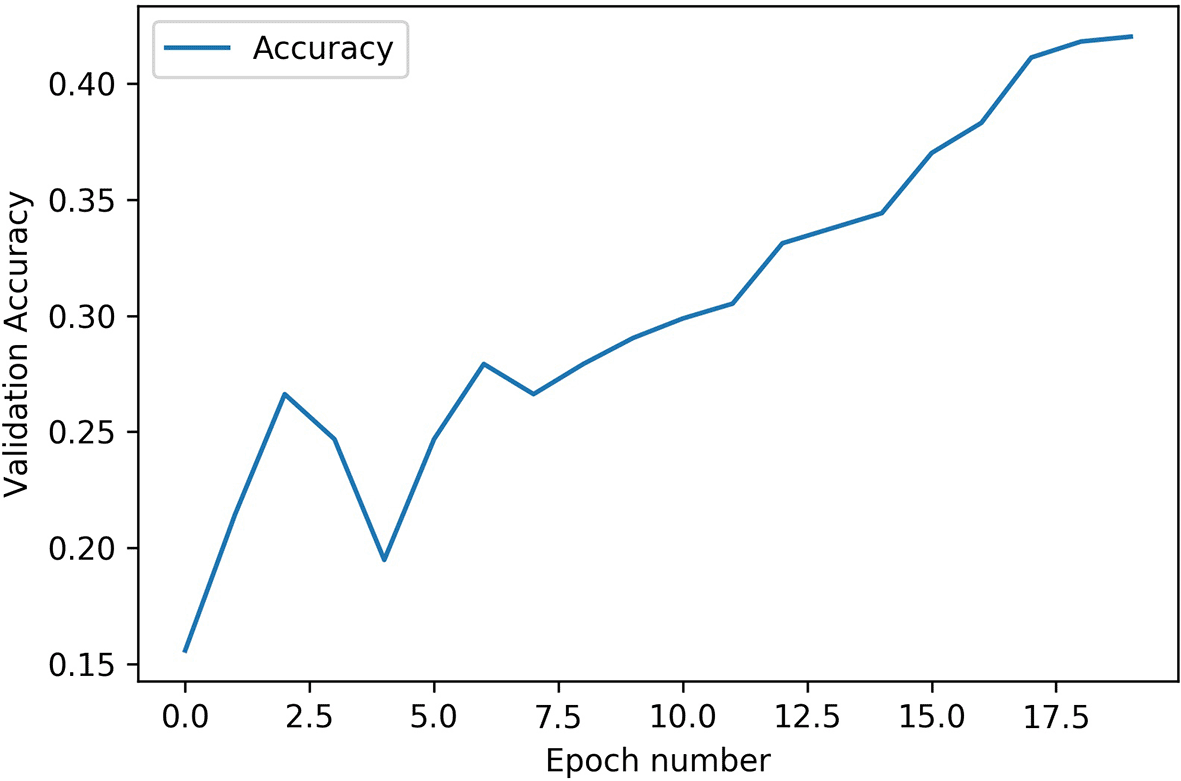
This section will cover the results of training the VGG16 model on the AffectNet dataset. First, we will look at the accuracy results that were measured using k-fold cross-validation. Then we will look at the results from the cross-dataset accuracy evaluation using the JAFFE dataset. Figures 2 to 4 shows the training accuracy, testing accuracy, and loss respectively for VGG16 model over the number of epochs. Figure 5 shows the cross-dataset accuracy with the training on AffectNet dataset and testing on JAFFE dataset.
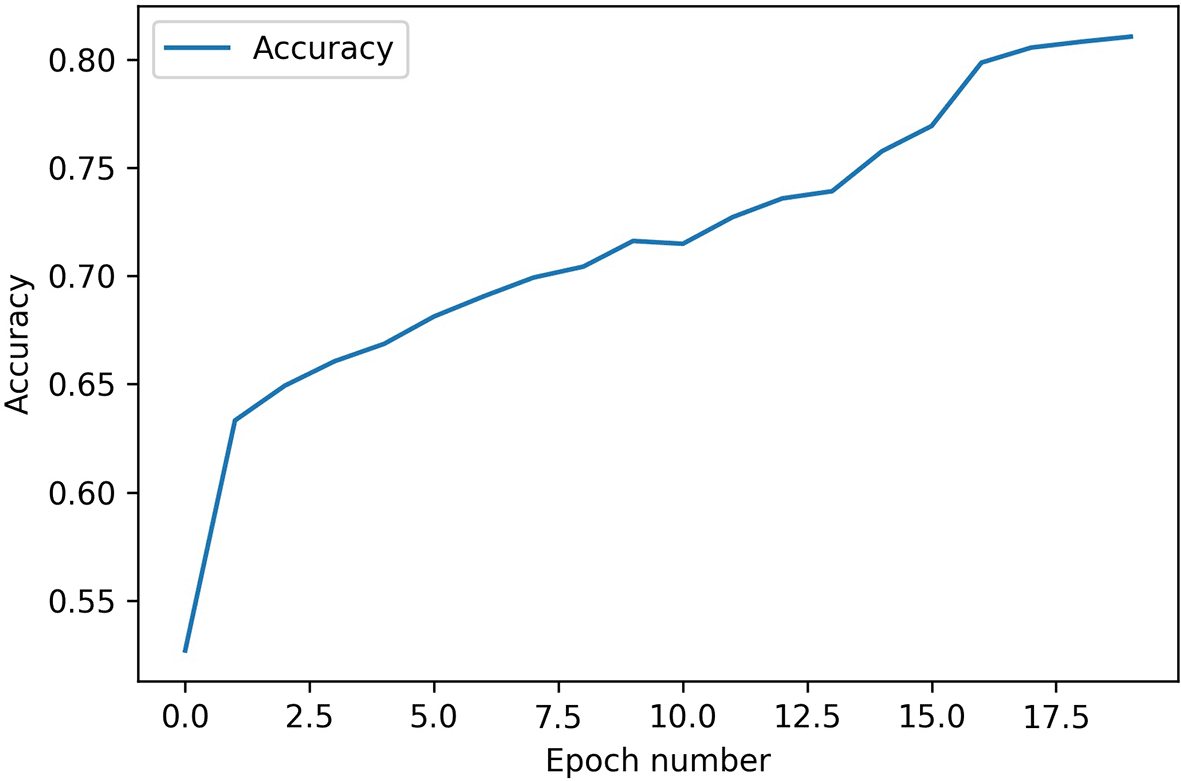

The accuracy of the VGG16 model is higher than the other models tested as shown in Table 2 and is also higher than the models in other studies as shown in Table 3. It peaks at 81.05% for the training set as seen in Figure 2 and 70.69% for the test set as seen in Figure 3.
| Model tested | Training accuracy | Testing accuracy | Cross-dataset accuracy |
|---|---|---|---|
| AlexNet11 | 72% | 54% | N/A |
| Inception V3 | 59.88% | 24% | 28.96% |
| ResNet50 | 70.66% | 15.38% | 28.41% |
| ResNext101 | 29.31% | 15.38% | 24.88% |
| VGG16 | 81.05% | 70.69% | 42.02% |
Also, looking at the loss values in Figure 4, it is clear that the model gets better with more epochs, and the loss values for both testing and training sets are steadily decreasing, despite some fluctuations in the test set’s loss value. These fluctuations can occur due to the weights not being reset after each epoch, which preserves the model’s weights from previous epochs. The training loss, however, is not affected by that.
Using the AffectNet dataset for training and JAFFE dataset for cross-dataset testing, we can see improved results for VGG16 model compared to the other models tested by us, as shown in Table 2. Figure 5 shows that the cross-dataset accuracy is steadily increasing, peaking at 42.02%. Unfortunately, we cannot use this value to compare this model with models from other studies since it is a metric that is not widely adopted by the field yet, and most of these studies did not use it.
As we can see from Table 2, the fine-tuned VGG16 model has proven to have the highest accuracy. This is because of its appropriate size and its utilization of the pre-trained ImageNet weights. We tweaked and evaluated several additional models to arrive at this result. We tested the inception V3, ResNet50, and ResNext101 with different configurations and listed the results of their best variations in Table 2. Unfortunately, their performance does not come close to VGG16. The table also includes the AlexNet model proposed by the creators of the AffectNet dataset. To the best of our knowledge, it was the only proposed model that was trained on the same dataset we used and is a perfect candidate for comparison.
Table 3 shows a comparison of our model with other similar models that were trained on different datasets. We can see that the first two models, being trained on classic datasets (MMI and JAFFE), generally have lower accuracy when compared with models that were trained on In-The-wild datasets (FER2013 and RAF-DB).
| Method | Dataset used | Accuracy |
|---|---|---|
| Miao et al.21 | MMI + JAFFE | 65% |
| Mayer et al.22 | MMI | 66% |
| Wen et al.23 | FER2013 | 76% |
| DETN14 | RAF-DB | 78% |
| Mollahosseini et al.11 | AffectNet | 72% |
| Our Model (VGG16) | AffectNet | 81% |
Since the AffectNet dataset is relatively new, many more studies must be conducted to better utilize this huge dataset along with all the possibilities it has to offer.
The given models can be improved if the following is applied:
• Training with a larger number of images, preferably the entire manually annotated dataset
• Training on an in-the-wild video dataset
• The hardware is improved by utilizing GPUs for the training process
• The model is trained for a larger number of epochs
In addition to improving the models, the findings can be improved if the existing FER techniques from other papers were tested using cross-dataset accuracy and then compared since it is a better metric for comparison. This can also be done by cross-testing on multiple datasets to better understand how the models compare to each other.
We can also apply these metrics to individual classes to give us a better idea about which expressions are easier to classify and which ones need more data.
The research in facial expression recognition is an exciting frontier for machine learning. This paper lays out a systematic proposal for a model that attempts to improve the current best models and uses better metrics for evaluation.
The paper started by examining the current literature of the field through a critical lens. We reviewed current trends and state-of-the-art methods used for FER. We then identified a research gap in which a contribution can be made: the lack of models trained on challenging datasets and evaluated through newer, more robust metrics like cross-dataset accuracy.
The proposed method had better accuracy compared to similar models trained on the same dataset. In addition, we evaluated it using cross-dataset accuracy, a metric that is better at assessing the utility of the model in real-life scenarios and challenging conditions.
The field of FER is still primarily confined to the lab. There is a lot more that we can do to improve the robustness of FER models so they can see broader adoption in the mainstream industry. Having systems that can read and understand our emotions is the next big step in human-computer interactions, and this is only the beginning!
This paper primarily uses the AffectNet dataset11 for training and accuracy testing. The dataset can be found in the AffectNet Dataset website. The dataset is strictly for non-commercial research use. Permission to use the dataset is obtained by directly contacting the creators of the dataset through this request form.
The second dataset, which is used for cross-dataset accuracy testing is the Japanese Female Facial Expression (JAFFE) dataset.15 It can be found at the JAFFE Dataset repository. It is also strictly for non-commercial scientific research and permission to use the dataset can be obtained through this request form after accepting the terms and conditions of use.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)