Keywords
preterm, machine learning, artificial intelligence, prediction, mortality
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Python collection.
preterm, machine learning, artificial intelligence, prediction, mortality
Despite the fact that child mortality has decreased significantly in recent decades, neonatal mortality remains the major contributor1 and prematurity is the largest direct cause of death in this population.2 More than half of neonatal deaths occur within the first three days of life.3 In this context, several predictive models use prenatal and immediately post-natal factors to predict death. However, in the neonatal intensive care unit (NICU) the patient’s condition changes over time. Moreover, more than 30% of neonatal deaths occur after three days of life.3 Real-time features, rather than non-modifiable baseline variables, may provide a more customized evaluation of mortality risk.
Predictive models are becoming increasingly popular in clinical research. A number of conditions have been predicted using machine learning techniques, from mortality in intensive care units to morbidities, such as acute kidney injury, septic shock, and heart failure.4 The models that are now available for assessing neonatal mortality risk are mostly focused on NICU admission.5–9 Unfortunately, few models use objective criteria to evaluate mortality risk in real-time.
To address this knowledge gap, we conducted a study to compare the effectiveness of machine learning algorithms for predicting NICU mortality using objective laboratorial features. The objective of this study was to evaluate serum lactate and blood gas analysis as a predictor of mortality in extremely low birth weight infants using machine learning algorithms.
The study protocol was approved by the institutional ethics committee – Comitê de Ética do Hospital das Clínicas da Faculdade de Medicina da Universidade de São Paulo, approval number: CAAE 15762719.6.0000.0068. The requirement for informed consent was waived by the committee given the retrospective nature of the study.
We analyzed data of extremely low birth weight infants born at a single-center tertiary neonatal intensive care unit in São Paulo, Brazil, between 2012 and 2017. The data collection and the methods have already been published in our previous study.10 All data were obtained from electronic medical records of each patient using specific keywords related to clinical and laboratorial parameters in December 2019 and extracted to a CSV file.22 All neonates with birth weight lower than 1000 grams born between 2012 and 2017 and who had at least one arterial blood gas analysis with paired serum lactate level during neonatal intensive care stay were included. Neonates with severe malformation, complex congenital heart disease, or transferred to another unit before discharge were excluded. Baseline characteristics included birth gestational age (in weeks), birth weight (grams), CRIB II score (Clinical Risk Index for Babies), small for gestational age (defined as birth weight < p10 Fenton growth scale), female gender, 5-minute APGAR score, vaginal birth, twin birth, antenatal corticoid, endotracheal intubation in the delivery room, epinephrine necessity in the delivery room, chorioamnionitis, and the lowest temperature in the first 12 hours of life. Serum lactate levels are presented in mmoL/L.
A total of seven feasible parameters were introduced into the machine learning algorithms. These parameters included blood gas analysis features (pH, pCO2, HCO3, base excess), serum lactate, and general characteristics (days of life and corrected gestational age at the time of laboratory measurement).
We compared the performance of three machine learning methods to assess 24-hour mortality risk: Logistic Regression,11 Extreme Gradient Boosting,12 and AutoML Tables.13 Patient data were randomly divided into two subsets: a training subset (80%) for hyperparameter tuning to create a plausible model, and a validation subset (20%) for testing the model’s performance. All data with missing values were excluded from the analysis. To select the optimal model, we performed hyperparameter tuning for the Extreme Gradient Boosting model. Hyperparameters are a set of extra parameters that must be established before the learning process to improve the algorithm performance.
Logistic regression classification is a machine learning technique that predicts outcomes using dependent variables and a logit function. It is frequently used as a baseline comparison for binary classifications because it is not only simple to construct but also capable of high performance.11 Extreme Gradient Boosting is an ensemble machine learning technique of weak prediction models. These weak models are added one at a time and fit to correct the prediction errors made by prior models.14 For Extreme Gradient Boosting the following hyperparameters were used: LEARN_RATE = 0.1, BOOSTER_TYPE = ‘GBTREE’, MAX_TREE_DEPTH = 3, SUBSAMPLE = 0.85, EARLY_STOP = TRUE. AutoML Tables is a Google Cloud Platform feature that automatically starts training for multiple model architectures (Linear, Feedforward deep neural network, Gradient Boosted Decision Tree, AdaNet, Ensembles), and it determines the best model. The primary outcome was death within 24 hours after collecting arterial blood gas and lactate.
Continuous variables were tested for normality using Kolmogorov-Smirnov test. To compare demographic characteristics, we used chi-square for categorical variables and Mann-Whitney test for continuous variables. After the optimal hyperparameters were determined for each ML algorithm, we calculated the area under the receiver operating characteristics (AUROC), accuracy, precision, and recall. All analyses were conducted using Python version 3.6.915 and Google Cloud Platform. All patients with missing data were excluded from the study.
We identified a total of 257 neonates who had at least one blood gas analysis and a paired serum lactate during neonatal intensive care unit stay from 2012 to 2017. Eleven patients were excluded because of missing data. Baseline characteristics are presented in Table 1. The median gestational age was 27.1 (26 – 29.1) weeks and the median birth weight was 746 (600 – 880) grams. We found 1932 blood gas samples with corresponding serum lactate levels.
All models demonstrated good accuracy (91 – 94%) and AUROC results (0.807 – 0.898) when using blood gas measurements with lactate as features. However, their recall (9-29%) was low. The Extreme Gradient Boosting algorithm obtained the highest AUROC score (0.898), accuracy (94.1%), and precision (87.5%) (Table 2). We then used AutoML Tables to determine the importance of each feature associated with 24-hour mortality, and the top three features were, in order: base excess, lactate, and pH levels (Figure 1).
AUROC, area under the receiver operating characteristic.
| Accuracy | Precision | Recall | AUROC | |
|---|---|---|---|---|
| Extreme Gradient Boosting | 0.941 | 0.875 | 0.25 | 0.898 |
| AutoML Tables | 0.933 | 0.833 | 0.29 | 0.826 |
| Logistic Regression | 0.913 | 0.375 | 0.09 | 0.807 |
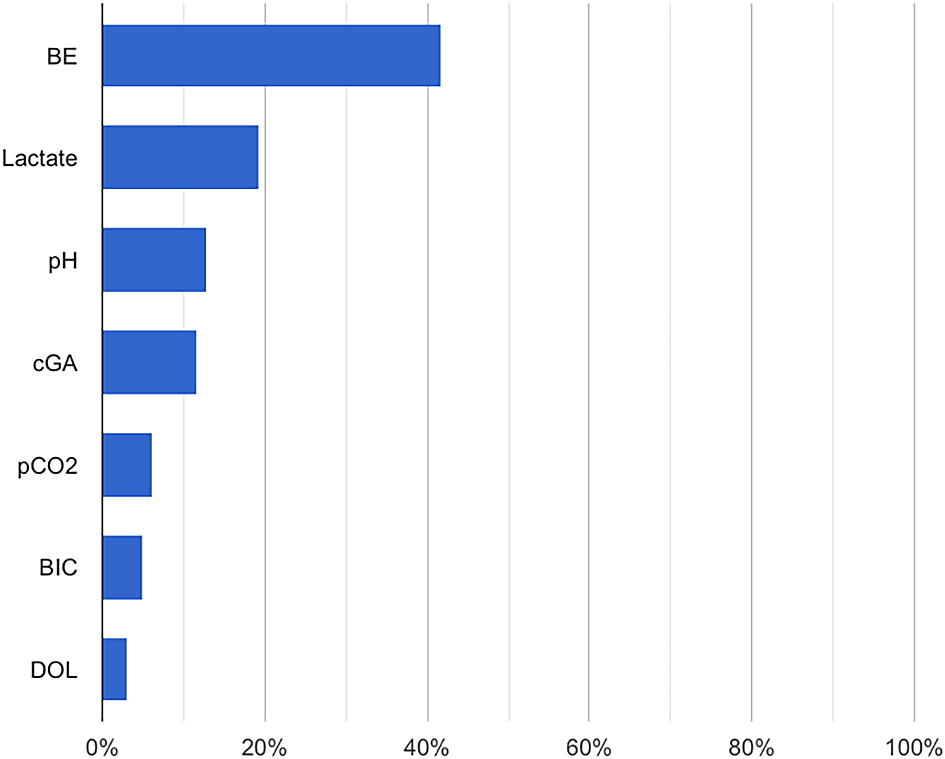
BE: Base excess; cGA: Corrected gestational age; BIC: HCO3; DOL: Days of life.
When lactate was removed as a feature in machine learning models, the AUROC score of the Extreme Gradient Boosting model dropped considerably (0.807) (Table 3).
AUROC, area under the receiver operating characteristic.
| Accuracy | Precision | Recall | AUROC | |
|---|---|---|---|---|
| AutoML Tables | 0.938 | 1.000 | 0.294 | 0.857 |
| Logistic Regression | 0.940 | 0.600 | 0.130 | 0.848 |
| Extreme Gradient Boosting | 0.942 | 0.666 | 0.173 | 0.807 |
Our research found that utilizing blood gas samples and lactate, the Extreme Gradient Boosting algorithm may predict 24-hour mortality in extremely low birth weight infants. Lactate can be used to improve predictive models.
In the NICU, an accurate mortality estimate is a valuable tool that assists healthcare providers. However, most mortality predictive models in preterm infants are limited to NICU admission. For assessing the mortality risk in NICU admission, the Score for Neonatal Acute Physiology Perinatal Extension-II (SNAPPE-II) includes vital signs, laboratory, and baseline characteristics.5 The Clinical Risk for Infants and Babies (CRIB-II) score considers sex, birth weight, gestational age, temperature, and base excess to assess the mortality risk upon NICU admission. TRIPS-II,7 NMR-2000,8 and PISA9 are other recent models that predict mortality after admission. However, dynamic events in the critical care unit may have an impact on the initial risk. Combining baseline characteristics and real-time features provides a more individualized assessment of mortality risk that evolves as the patient’s health changes. To overcome this problem, Jaskari J et al.,16 Lee J et al.,17 and Feng J et al.18 created predictive mortality models based on vital sign data collected during the NICU stay. However, vital signs such as respiratory rate, heart rate, and blood pressure may vary amongst neonates and there is no consensus on what constitutes a normal reference range.19,20 Furthermore, in Lee J et al. study, baseline variables (birth weight and gestational age at birth) were more important than vital sign readings.
Lactate and blood gas values can be acquired quickly and is currently a standard clinical practice in intensive care units. The lack of bias from the examiner which contributes to objectivity is an advantage over clinical examination.21 As a result, our research combines the predictive capability of machine learning models with the objectivity of a blood gas analysis, which is a simple readily available, and widely used test. Our findings imply that machine learning models based on lactate and blood gas indicators appears to be superior to logistic regression classifiers in predicting 24-hour mortality in extremely low birth weight infants. To our knowledge, this is the first study to include real-time objective laboratorial features to predict death in preterm infants.
Our research has some limitations, which should be noted. First, this is a single-center retrospective study, and generalizing our findings is challenging. Second, larger datasets assist machine learning predictive models, therefore a larger study is required. Third, it is worth noting that using blood gas analysis to forecast mortality is a highly unbalanced problem; in other words, there are far more blood gas samples than events (death). In unbalanced data, we can acquire a high accuracy and AUROC score by simply predicting that all observations belong to the majority class. Lastly, it is important to note that our models had very high precision with low recall, and it should not be used for screening purposes.
Incorporating lactate and blood gas measurements into mortality predictive models may improve real-time risk stratification in preterm infants. Traditional logistic classification models appear to be outperformed by more robust machine learning algorithms. Extreme Gradient Boosting models could be used as a support tool for clinical risk stratification of extremely low birth weight infants in the neonatal intensive care unit.
As this study involved extracting data from patient records, these records/patient files are considered the raw, source data. The raw data (patient files) are not available to readers and reviewers for data protection.
Harvard Dataverse: Blood Gas – Preterm. https://doi.org/10.7910/DVN/LFRNJE.22
This project contains the following underlying data: Lactate_Mortality – Sheet1.csv (contains 1932 serum lactate and blood gas analysis along with days of life and corrected gestational age at the time of measurement).
Harvard Dataverse: Blood Gas – Preterm. https://doi.org/10.7910/DVN/LFRNJE.22
This project contains the following extended data: Data key.docx (contains key to make data more accessible)
Data are available under the terms of the Creative Commons Zero “No rights reserved” data waiver (CC0 1.0 Public domain dedication).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)