Keywords
Business Process Redesign, Directed andWeighted Graph, e-Commerce, Propagation Model, Security Threats, Social Network Strength
Business Process Redesign, Directed andWeighted Graph, e-Commerce, Propagation Model, Security Threats, Social Network Strength
Business process redesign (BPR) refers to the intentional change of business processes 1 and aims at changing the way work is accomplished, and value is delivered. 2 BPR occurs in cross-functional organizations and often precipitates changes in job descriptions within the organizational structure. 3 BPR can include adding, simplifying, changing, or automating a set of initial process models resulting in to-be process models. The to-be process model (to-be model) is defined as a model that results from applying improvement opportunities to the current (as-is) business environment. BPR efforts are always followed by adaptive maintenance on supporting applications. However, module changes in the application can lead to new information security vulnerabilities. 4 New vulnerabilities arise caused by software programming bugs and design flaws. 5 For example, a module change related to modifying the form for data input. The most common vulnerability that occurs due to exploiting software programming bugs is in user input validation (Common Weakness Enumeration 20 [CWE-20]). Input validation is the process of ensuring that the input data follows specific rules. Incorrect data validation can cause data corruption, as seen in structured query language (SQL) injection (CWE-89). SQL injection is a technique for exploiting program bugs in a website. The attacker injects SQL commands from web forms to either modify database contents or dump database information such as credit cards or passwords to the attacker. BPR also affects information security controls applied to business processes and applications, and changes to these controls can cause vulnerabilities in applications. As vulnerabilities can propagate between resources, vulnerabilities in business processes that propagate to an application module will also propagate to other modules. 6 Vulnerabilities that propagate to applications following BPR should be predicted as early as possible to allow system developers to become aware of security threats that may arise from these vulnerabilities.
IT architecture describes the relationship between business processes and their supporting applications. As part of the organization’s enterprise architecture, IT architecture describes current and future designs. An organization can develop enterprise architecture using several frameworks. Most frameworks have four architectural domains: business process, information, application systems, and technology. In addition, IT architecture consists of three layers: business processes, IT services (including data and applications), and technology. 7
Researchers have developed vulnerability propagation models that serve different purposes. For instance, models have identified vulnerabilities at the technology layer, including in the hardware, network, or infrastructure, 8 – 11 and between information security controls regarding specific standards. 12 Previously developed models have used weighted and directed graphs, 8 , 9 Bayesian networks, 12 dynamic systems, 10 and Petri nets 11 as visual representations. Some models have adaptive capabilities that allow them to adjust to changes in expert knowledge and risk history 12 as well as changes in investment strategies. 10 In reviewing application vulnerabilities from BPR, we need a model that illustrates vulnerability propagation at the business process and IT service layers. Moreover, the model should have an adaptive mechanism that responds to changes in business processes.
Our study aims to develop a method for modeling vulnerability propagation in the business process and IT service layers and makes two contributions to previous research. First, the model can illustrate vulnerability propagation in these two layers. Vulnerability propagation occurs horizontally between tasks in the business process layer and between application modules in the IT service layer, while vulnerability propagation occurs vertically from business processes to applications in the IT service layer. Second, the model has an adaptive mechanism that reorders the layout when new business processes are added following BPR.
Our method can be briefly described as follows. First, we represented the vulnerability propagation model using a weighted and directed graph. We applied the concept of social network strength to assess the propagation of vulnerabilities between nodes. This approach was used to build an initial model before BPR occurred. Second, we developed adaptive mechanisms that allow the model to reorder the layout in response to the introduction of new business processes, thus changing the initial model into the to-be model through a series of procedures. We used three different methods for calculating prediction scores in the to-be model: the influential node approach, the proportion approach, and the ranking approach based on the propagation strength of the nodes. Finally, we evaluated the vulnerability propagation model by comparing the predicted vulnerability scores from the model with the actual scores of e-commerce applications in the National Vulnerability Database (NVD).
The rest of the paper is organized as follows. Section 2 describes related works. Section 3 introduces the proposed method, while Section 4 discusses the results, main findings, limitations, and provisions for future work. Finally, Section 5 presents our conclusions.
This section reviews previous studies on BPR, the vulnerability dictionary and its metrics, vulnerability propagation models, directed and weighted graphs, and social network strength. Business process redesign BPR is one type of business process change that an organization undergoes. These changes occur in an organization’s elements, including participant groups, roles, and systems; events, activities (tasks and sub-processes), data objects, and gateways; and sequence flow, message flow, and associations. 13 In addition to BPR, there are two other levels of business process changes: business process improvement (BPI) and business process reengineering (BPRe). 3
BPI and BPR are incremental (bottom-up) process improvements. BPR occurs across an organization’s functions, while BPI only occurs in one organizational function. Both BPR and BPI focus on continuous improvement. 14 In contrast to BPI and BPR, BPRe is a top-down approach that re-examines broad and fundamental business processes. BPRe involves rethinking and developing radical business process redesigns, resulting in a new process with a very different design from the previous one. 15 organizations perform BPRe for various reasons, including both internal and external factors. 16 Our research focuses on assessing the impact of vulnerabilities introduced by BPR, tracking process changes, and developing a new business process model that does not differ greatly from older ones.
Previous research has developed the concept of risk-aware business process management. This concept aims to create effective and efficient business processes while minimizing security risks. 17 Knorr and Röhrig 18 developed a framework for analyzing the security requirements of business processes in e-commerce. To determine security requirements for business processes on legacy systems, Argyropoulos et al. 19 built a new process model that contains its information security requirements. Taubenberger et al. 20 developed the security requirements risk assessment tool to analyze a business process model’s security requirement and identify vulnerability errors in the process. Meanwhile, Jakoubi et al. 17 created a risk-aware business process simulation to determine the cost and time required to execute business process model activities. Ahmed and Matulevičius 21 and Varela-Vaca et al. 22 proposed a method for modeling secure business processes using security patterns, while Varela-Vaca et al. 23 developed tools to evaluate security risks in business process models. Chergui and Benslimane 24 added notations related to information security requirements in the modeling language. These studies focused on developing secure business process models. In general, business process modeling involves collaboration between process analysts and information security experts to identify information security requirements.
Vulnerabilities can also be predicted and detected in application development at the design, implementation, and deployment stages. Information security experts can perform threat modeling to predict emerging threats based on the application design using methods such as data flow diagrams. 25 At the implementation stage, programmers can conduct source code reviews to detect vulnerabilities in the application. Researchers have developed automated tools to detect vulnerabilities in high-level languages such as C, C++, Java and Python source code. 26 – 31 In addition, there are also those developed for script-based programming languages such as PHP. 32 Vulnerability scanning can also be done with automated tools while the application is running in its operational environment. We previously developed a Task-based Vulnerability Prediction method that can predict vulnerabilities based on business process models earlier than other methods. 33
Researchers have developed propagation models for information security vulnerabilities. Feng et al. 12 developed a security risk analysis model that simultaneously defines risk factors and their causal relationships. This study used quantitative data from organizational risk history and qualitative data from experts’ opinions and NIST information security standards. The model used a Bayesian network and ant colony optimization methods.
Shin et al. 34 developed a cybersecurity risk model to evaluate cybersecurity in a reactor protection system (RPS), integrating procedural and technical aspects. They designed a procedural model using an activity-quality analysis approach to evaluate the compliance of people and organizations with regulations. Procedural and technical models were integrated with a Bayesian network, and the node probability table value was based on the expert’s opinion.
Later, De Gusmão et al. 35 improved Feng et al. 12 risk analysis model by incorporating a mechanism to overcome uncertainty factors when determining the vulnerability level. The risk analysis model identified and evaluated a series of risk events, along with several alternatives, in potential incident scenarios after an initial incident resulting from the misuse of information technology. This model was developed using event tree analysis combined with fuzzy decision theory.
Previous studies have also used graph theory for risk analysis and to develop mitigation strategies. Kotzanikolaou et al. 8 used a dependency graph for risk assessment on critical infrastructure, depicting a multi-risk dependency analysis from first-order dependencies to nth-order dependencies. Furthermore, Stergiopoulos et al. 36 developed a mitigation strategy by placing proper security controls on prioritized infrastructure nodes based on graph centrality analysis to streamline the risk mitigation strategy. Meanwhile, Naghmouchi et al. 9 used a weighted and directed graph to model vulnerability propagation caused by internal and external intruders on computer networks. Szpyrka and Jasiul 11 modified Petri nets to build a cybersecurity vulnerability propagation model, developing algorithms to generate propagation nets that were based on colored Petri nets. Nazareth and Choi 10 used a dynamic system approach to evaluate alternative information security risk management (ISRM) strategies, considering both costs and investment. They employed a design science research approach with causal loop analysis and a dynamic system. In their model, the analysis of the investment’s impact on the organization’s assets occurs in the technology layer.
Researchers have also developed vulnerability models with adaptive capabilities following specific conditions. Feng et al. 12 developed a security risk model with learning mechanisms. Their model learns from expert knowledge and risk history factors. If new vulnerabilities occur, the model updates the previously estimated probability of the relationship between the nodes. Additionally, Nazareth and Choi 10 ISRM model, which simulates the investment’s impact on the overall costs required for managing information security, contains adaptive mechanisms that are affected by the organization’s investment scenario.
Hangal et al. 37 first introduced the concept of social network strength, demonstrating that the relationship strength (tie strength) between two people in a social network is asymmetrical. That is, one person must have a more significant influence over the other. A directed and weighted graph describes how the influence of a person spreads across a social network. The influence of person A on person B is defined as the proportion of B’s investment to A. Hangal et al. 37 conducted a case study using the science bibliography network and retweet data on Twitter. Below, we describe essential concepts relevant to social network strength.
Influential ties refer to the influence strength between people on social networks. An analogy can be made with an investment case to understand influence ties and show how one person distributes their investment among others. For example, if person B invests most of his time in person A, then A has a great deal of influence over him. The influence A has on B, Influence(A,B), is defined as the proportion of B’s investment in A, or the amount of time B invests in A, Invest(B,A), compared to B’s total investment in a group of n people in the social network, Invest(B,X). This formula is shown in Eq. (1), which reveals that the relationship between people in a social network is asymmetrical: one person has a stronger influence than the other.
A person in a social network is identified as an influential individual if they strongly influence others. The influence of a node is the sum of the power of that node’s influence on n people in the network. Thus, the influence of node A is expressed by Eq. (2). We used the concepts of influential ties and influential individuals to calculate prediction scores in the vulnerability propagation model.
This section describes our proposed method for modeling vulnerability propagation in the business process and IT service layers. We use Business Process Model and Notation (BPMN) as a notation for the process model. We call this new method Node Strength-based Vulnerability Modeling (NSVM). Our method applies the concepts of influential ties and influential individuals to node strength to describe the strength of the vulnerability propagation between nodes and within a node.
We used the CWE dictionary as a reference for vulnerability data. CWE is an online dictionary that lists the vulnerabilities found in software and focuses on general software vulnerabilities that are not specific to individual software products 38 Each CWE represents one type of vulnerability and has a hierarchical structure that allows for the review of vulnerabilities at different levels of abstraction. 39
We used the Magento e-commerce platform as a case study. Magento is a digital commerce platform providing online merchants unparalleled flexibility and control over their online stores’ look, content, and functionality. 40 We used Magento for the following reasons. We need case studies of BPR and the accompanying information security vulnerability data to test our method. We used common vulnerabilities and exposures (CVE) from the National Vulnerability Database (NVD) maintained by the United States government. 41 CVEs are specific publicly disclosed information security vulnerabilities found in software applications. We used NVD as a data source for information security vulnerabilities because it is more up-to-date and reliable than other vulnerability databases. 42 We have listed the CVE of all e-commerce platforms published from December 2017 to November 2021. We found 551 CVEs from 17 e-commerce platforms, corresponding to 39 CWEs. As many as 205 CVEs relating to 36 CWEs (92.31%) were Magento’s vulnerabilities. Magento provides a complete user guide for each released version so we can track its process model changes caused by BPR.
We used six BPR case studies that occurred in Magento 2.1 43 to 2.2 44 and Magento 2.2 to 2.3. 40 We built a dataset to represent the interrelationships between tasks in the Magento business process model and between tasks and the Magento modules. In the dataset, we described each task and module with the data related to information security vulnerabilities. 45 This dataset was used as input for the propagation modeling of information security vulnerabilities. We used this dataset to build an initial model of vulnerability propagation. We also used the dataset to construct a to-be model by adding new tasks/modules resulting from BPR to see the impact on the initial model.
In Magento 2.1 to 2.2, BPR occurred in consumer accounts and dashboards, communication channels, and payments management. Consumer account management added a process for creating a company account designed to meet the needs of B2B commerce, enabling a company to manage its accounts, roles and access rights for its teams. Changes in the consumer dashboard were related to the emergence of several new functions, including managing payment methods, redeeming gift card balances, and using credit balances to make transactions. Regarding communication channels management, a new Magento social feature was incorporated into the marketing strategy, containing links that connect Magento with the social media platform. The payment management system added a Signifyd Fraud Protection feature to detect fraudulent chargebacks and determines which orders can be filled and which should be rejected.
In the upgrade from Magento 2.2 to 2.3, BPR appeared in inventory management, shipping management, and payment management. Inventory management in Magento 2.3 can include multiple sources from several warehouses, whereas in Magento 2.2, it only involves a single source. Magento 2.3 uses two new payment methods, adding existing methods in Magento 2.2. The shipping management in Magento 2.3 added a ‘click & collect’ feature. This feature allows sellers to provide shipping options to consumers that directly deliver goods from multiple origin locations (stores/warehouses).
To evaluate the model, we retrieved Magento’s CVE as actual vulnerability scores and compared them with predicted scores from the vulnerability propagation model. We used the Common Vulnerability Scoring System (CVSS) version 3 as a vulnerability scoring standard for each CWE and CVE. The CVSS provides a standard for measuring vulnerabilities in software, generating a score between 0 and 10 to represent the severity of the exposure. 46
Our model is represented as a directed and weighted graph. Vertices are referred to as nodes and arcs as edges. We used the Neo4j graph database platform to build a vulnerability propagation graph model. A graph database uses highly interlinked data structures built from nodes, relationships, and properties. A graph database builds a network of interconnected entities representing its domain. 47 Neo4j has been widely used to model graph-based systems. 48
Nodes represent resources consisting of process, module, and exploited module nodes. The process node (yellow node) represents the task in the process model. This node has the attributes name, task_name, type, vuln, vuln_score, and max_score, representing task ID, task name, task type, list of CWEs, vulnerability scores of each CWE, and maximum CWE score, respectively. Vulnerabilities at the process node represent predicted vulnerabilities for each task. The module (green node) and exploited module node (red node) describe the application’s modules. This representation depends on whether the vulnerability materializes in the application. This node has the attributes name, module_name, vuln, vuln_score, and max_score; each represents module ID, module name, list of CWEs, vulnerability scores of each CWE, and maximum CWE score, respectively. Vulnerabilities at the module node mean predicted vulnerabilities based on propagation from other nodes. Meanwhile, vulnerabilities at exploited module node represent actual vulnerabilities that materialized in the application and were obtained from the NVD. We used Query 1 to form three types of nodes in the graph.
#Formation of task node
CREATE (n:Process {name:id_task, task_name:nama_task, type:jenis_task, vuln:list_CWE, vuln_score:list_CWE_score, max_score:maks_CWE_score})
#Formation of module node
CREATE (n:(Module atau Exploited_Module {name:id_modul, module_name:nama_modul, vuln:list_CWE, vuln_score:list_CWE_score, max_score:maks_CWE_score})
In the model, an edge is formed between two nodes, representing the vulnerability propagation between resources. Each edge has a score or weight. The direction of the edge indicates the direction of the vulnerability propagation between nodes. For instance, an edge with a direction from node A to node B indicates the vulnerability propagation from resource A to resource B. This propagation model contains three types of edges: process, service, and implementation edges. The process and service edges represent horizontal propagation. Specifically, the process edge represents propagation between tasks at the business process layer, while the service edge signifies propagation between modules at the IT service layer. In contrast, the implementation edge represents vertical propagation from the business process layer to the IT service layer.
Query 2 was used to form edges between nodes in the graph. The edge connects the node containing id_origin_node to the node with id_destination_node. Each edge has a type, which is designated as the variable r:edge_type.
MATCH (a),(b) WHERE a.name=id_origin_node AND b.name=id_destination_node CREATE (a)-[r:edge_type] -> (b)
We applied the concept of social network strength to build the vulnerability propagation model. We calculated the weight of each edge by using the propagation strength (PS) formula in Eq. (1). The PS from node A to node B is calculated based on the number of CWEs in node A that are also found in B. PS between these nodes is the edge’s weight A to B and is calculated by Eq. (3).
Query 3 calculated common CWEs between two nodes n and m through a relation r, namely r.common.
MATCH(n)-[r]-(m) SET r.common=size([x in n.vuln WHERE x in m.vuln]) RETURN n.name, m.name, r.common
Consider the graph related to the module in Figure 1. has four incoming nodes, , , P53, and P54, with the common CWEs shown in Table 1 The PS for each edge can then be calculated by 3. Table 1 displays PS scores for each edge between and its incoming node.
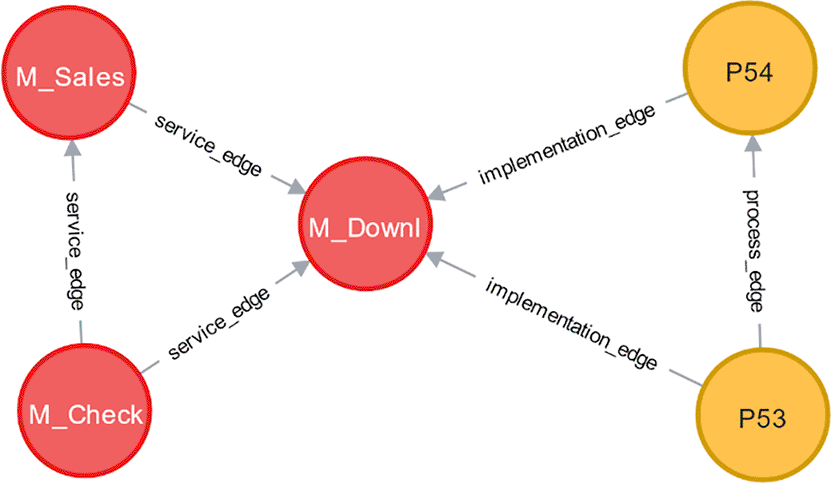
Each node also has a propagation strength. As formulated in Eq. (4), the propagation strength of Node A, denoted PS(A), is the sum of the propagation strength of all of its outgoing nodes. This equation is adopted from Eq. (2) on the concept of influential individuals. Each node has an additional new attribute related to propagation strength at this stage.
Query 4 was used to calculate the weight or PS from node m to n connected by r in the graph. If no common CWEs exist between the two nodes or the value of r.common equals zero, the weight is determined as zero. If there is a common CWE, the weight is calculated by dividing the r.common of the edge with the total r.common of all incoming edges to n.
MATCH (n)<-[r]-(m) WITH n, sum(r.common) AS total SET n.total_comm=total RETURN n.name, n.total_comm MATCH (n)<-[r]-(m) SET (CASE WHEN n.total_comm=0 THEN r END).weight=0 SET (CASE WHEN n.total_comm<>0 THEN r END).weight=round(toFloat(r.common)/n.total_comm,2) RETURN n.name, m.name, r.weight
Query 5 was then used to calculate the propagation strength of a node in the graph. A node’s PS is represented by the variable out_weight, which is the sum of all of the outgoing nodes’ weights, r_weight. The outgoing edge between nodes n and m is denoted by the edge r, (n)-[r]->(m).
MATCH (n)-[r]->(m) WITH n, sum(r.weight) AS total SET n.out_weight=round(total,2) RETURN n.name, n.out_weight
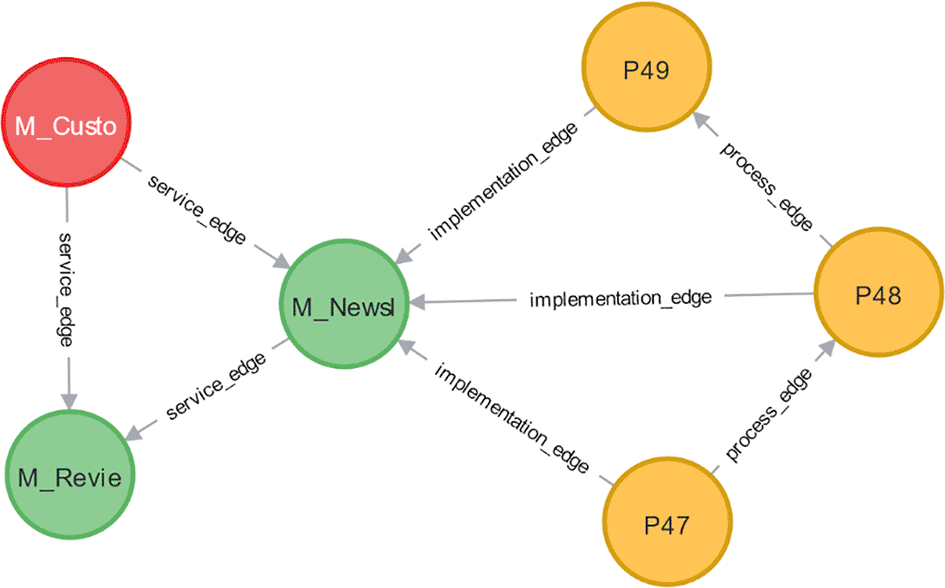
To illustrate, Figure 2 shows a graph snippet related to the module. This node is connected to other nodes through its outgoing edges, with PS scores for each outgoing node shown in Table 2 Then, the PS is calculated for the node using Eq. (4), which results in PS( ) = 1.90.

We developed an adaptive mechanism that enables the model to change automatically if new tasks and vulnerabilities are introduced to the initial model. Changes in the initial model follow a new process model and module dependencies in the new system architecture due to BPR. Changes in vulnerability attributes and vulnerability scores at nodes in the model were implemented using several approaches.
In the to-be model, the vulnerability scores for IT service layer nodes are predicted based on two scores: the adjacency score (AS) and the initial score (IS). The AS is obtained from the vulnerability scores of the to-be model’s incoming nodes, while the IS is taken from the actual vulnerability score of a module in the initial model. We used three methods to determine the AS: the influential node, proportion, and ranking approaches.
The influential node approach determines the AS score by taking the vulnerability score from the influence node. The influence node of node A, Influence(A), is the incoming node with the highest PS score and is thus considered to have the most influence on the vulnerability propagation model. The formula for determining the AS score for node A is calculated by Eq. (5).
The proportion approach determines the AS score by calculating the total proportion of its incoming node vulnerabilities. The AS score for a node is the sum of its incoming node vulnerability scores, vuln(Xi), multiplied by its propagation strength, PS(Xi). The result is divided by the incoming node’s total propagation strength, as stated in Eq. (6).
The ranking approach determines the AS score at a node by listing vulnerabilities in the incoming node, vuln(Xi), in ascending order. Each incoming node is given a weight according to its rank. Then, the AS score is calculated by adding the vulnerability scores of the incoming nodes, vuln(Xi), with the incoming node’s ranking weight, rank(Xi), and the result is divided by the total ranking weight, as shown in Eq. (7):
Figure 3 illustrates the influential node, proportion, and ranking approaches. As an example, we can determine the AS score for the module. This module contains the incoming nodes , P47, P48, and P49, with their PS and vulnerability scores given in Table 3.
| Measures | Incoming node | Total | |||
|---|---|---|---|---|---|
| P47 | P48 | P49 | |||
| Vulnerability | 7.50 | 8.19 | 7.09 | 8.19 | |
| PS | 0.77 | 0.10 | 0.05 | 0.15 | 1.07 |
| Rank | 4 | 2 | 1 | 3 | 10 |
The influential node approach determines the AS score from the vulnerability score of the node with the largest PS, = 0.77. Therefore, the AS score for equals the vulnerability score for , which Eq. (5) gives as 7.50. The proportion approach calculates the AS score using the formula in Eq. (6). The PS of each incoming node is multiplied by its vulnerability score. Next, the results are summed and divided by the total PS for all incoming nodes. Thus, the AS score for is 7.64. Then, the ranking approach is used to assign weights sequentially to PS scores and calculate AS scores using Eq. (7). First, the ranking weight for each incoming node is multiplied by its vulnerability score. The results are then summed and divided by the total weight of the ranking, yielding an AS score for of 7.8.
We also predicted a node’s vulnerability score by considering the actual vulnerability score from the initial model (the IS). This score represents the magnitude of the vulnerability that has appeared in the application. It is necessary to aggregate the AS and IS values to calculate the predicted vulnerability score.
We carried out two experiments to aggregate the AS and IS values. For the first experiment, we used the maximum principle, choosing the maximum score between the AS and IS values as the final prediction score. This concept is based on the first principle of risk aggregation. 49 We used the average calculation between the AS and IS values in the second approach based on Rezvani et al. 50 research. For example, suppose that in the initial model, the module has a vulnerability score of 7.5. Then, as Table 4 shows, the predicted vulnerability score for in the to-be model can be calculated with both aggregation methods for each of the three AS calculation approaches.
We evaluated the vulnerability propagation model by comparing the predicted scores from the to-be model with the actual vulnerabilities in the NVD. As described in the dataset, we took BPR case studies from Magento 2.1 to 2.2 and Magento 2.2 to 2.3. We used the initial version of Magento, before BPR, as a reference for building the initial model. Next, the adaptive mechanism described in Section 3.4 changed the initial model to the to-be model. In the evaluation, we compared predicted scores in the to-be model with actual Magento vulnerability scores in the NVD using three evaluation measures, the mean absolute error (MAE), the mean squared error (MSE), and the root mean squared error (RMSE). These measurements are frequently used to compare predicted and actual values. 51
This section describes the results of implementing NSVM in the case studies. 52 We also discuss our main findings and the study’s limitations and directions for future research.
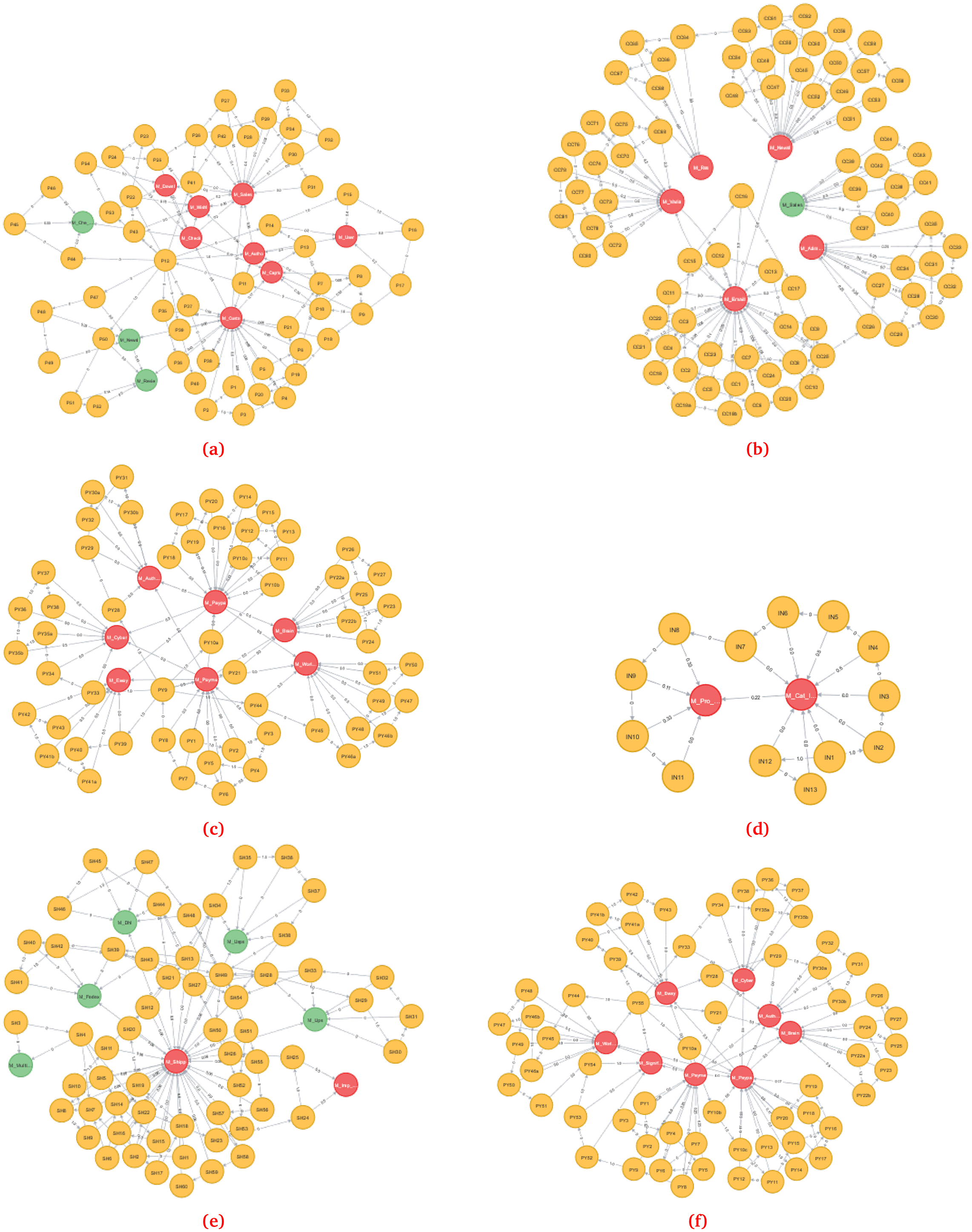
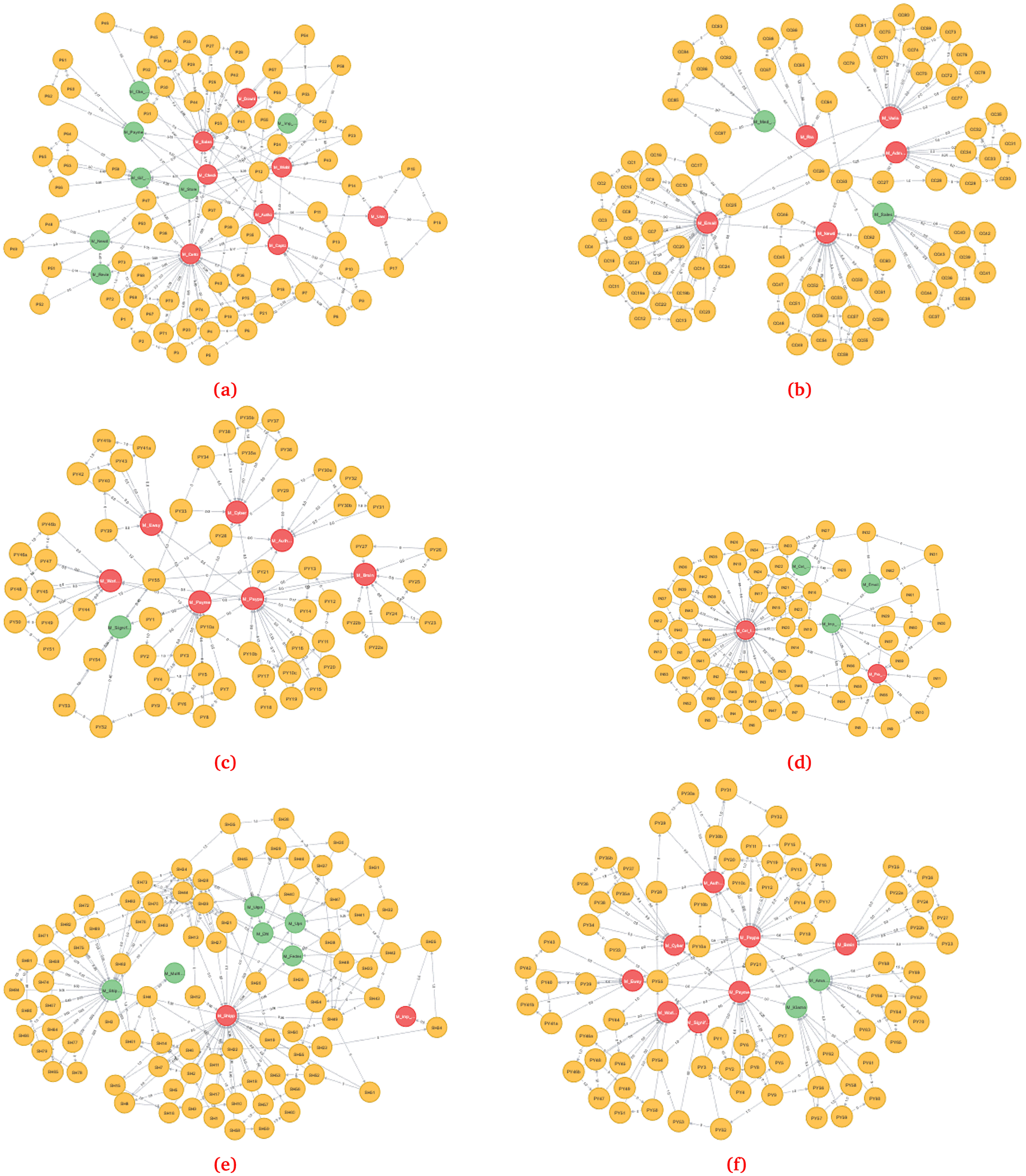
Since we used six business processes from Magento 2.1 and 2.2 as case studies, we developed six initial models, as shown in Figure 4a through 4f. For example, we used the account management system in Magento 2.1 to show how to build an initial model based on the process model and its vulnerability data. The account management system consists of six main processes, including ‘create user account’, ‘sign in’, ‘reset password’, ‘update profile information’, ‘continue shopping’, and ‘display dashboard’, as shown in Figure 5. We would review the vulnerability model for the sign-in process, which consists of nine tasks connected to the following primary process, ‘reset password’, as shown in Figure 6.

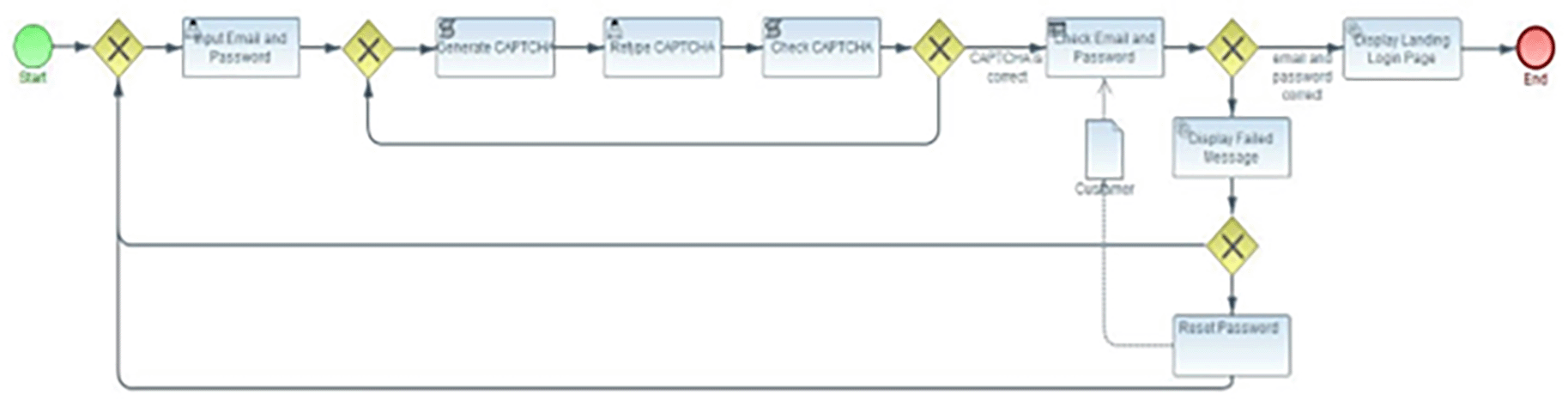
Magento 2.1 implements the sign-in process through the module-authorization and module-captcha. The module-authorization manages access control according to the application’s roles and rules. The module-captcha verifies the authentication process through the captcha code. In the Magento architecture, both modules are dependent on the module-customer. Table 5 shows the vulnerabilities for each task and module, which then become attributes for each node in the vulnerability propagation model. Figure 7 depicts the graph representing the vulnerability propagation model for the sign-in process.
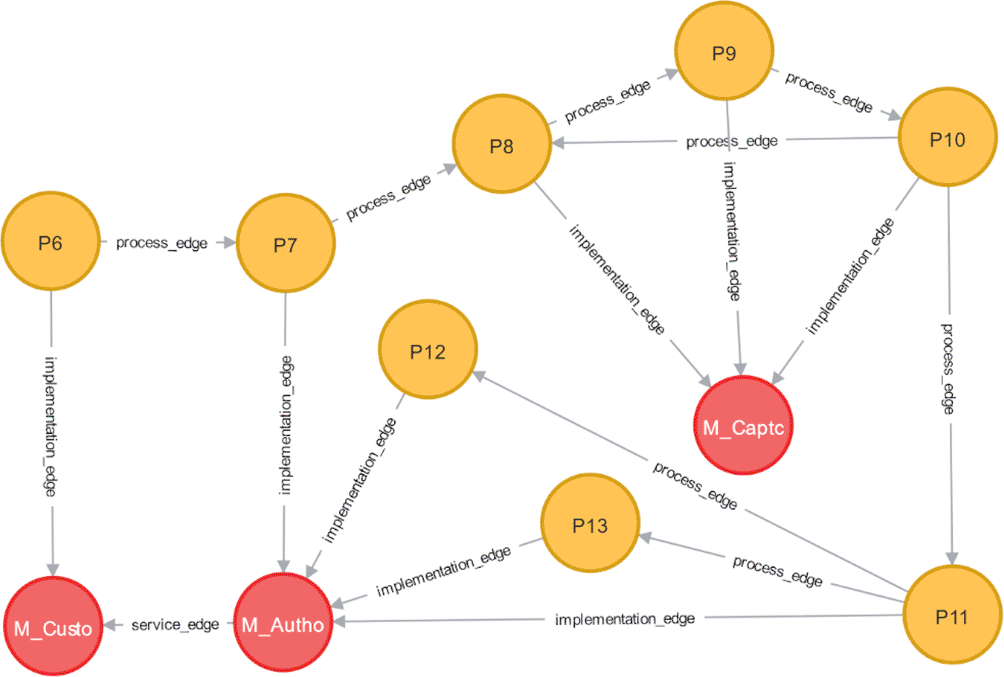
A directed and weighted graph best describes vulnerability propagation at the business process and IT service layers. Vertical propagation is unidirectional, moving from business processes to applications, and cannot be reversed. The weight of the edge represents the propagation strength from one node to another. Some edges have a PS value of zero, indicating a feeble propagation strength. This zero-score phenomenon mainly occurs on edges between process nodes with different task types. These edges were not removed from the initial model because the relationship between nodes is used as a reference when adding new nodes to develop the to-be model. However, further research is needed to develop a modeling method that considers task type as one of the factors affecting vulnerability propagation at the business process layer.
We used three BPR case studies from Magento 2.1 to 2.2 and three from Magento 2.2 to 2.3 to experiment with adaptive mechanisms in the vulnerability propagation model. Figure 8(a) and (b) provide an example of a process model for managing consumer accounts before BPR in Magento 2.1 and after BPR in Magento 2.2. This case involves additional sub-processes related to company account management. Figure 8(c) shows a series of tasks included in the company account management sub-process.
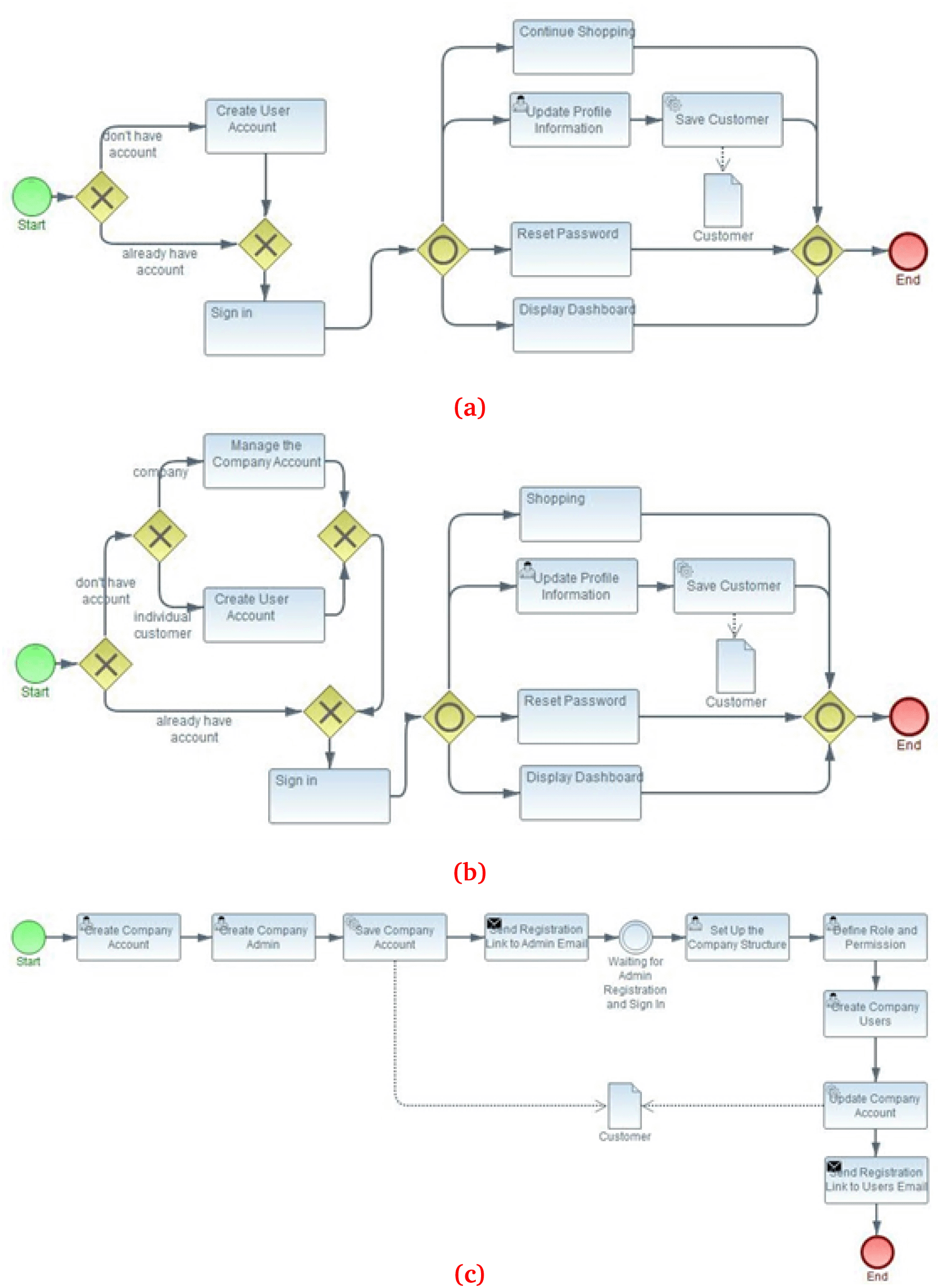
In Magento 2.1 to 2.2 and Magento 2.2 to 2.3, BPR added processes with a series of sequential, parallel, and looping tasks. The adaptive mechanism developed in this study can operate with these three types of task series. The tasks in the newly added process model are represented as a series of new nodes formed in the graph using Queries 1 and 2. Following the new IT architecture and process model, the new node series were added to the to-be model structure. The following discussion offers an example of each BPR scenario that results from adding a new series of tasks to the to-be model.
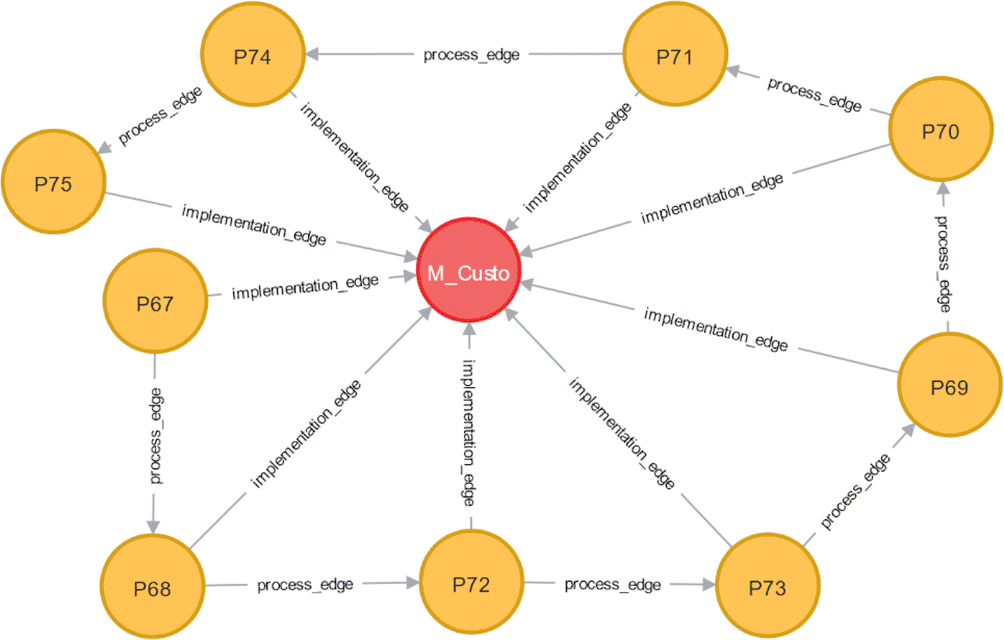
Figure 8(c) shows a sequential series of tasks that must be completed to create company accounts. The process of creating a company account is related to the customer module in Magento 2.2. Table 6 shows the vulnerabilities of tasks related to this process.
We introduced new nodes into the initial model and added new tasks and their vulnerabilities with Query 1. The edges connecting the new nodes were then formed using Query 2. The graph in Figure 9 was made based on the new series of tasks shown in Figure 8(c). This graph was added to the initial company account management process model in Figure 4(a). Next, the mechanism for changing the model was implemented using Queries 3 to 5, and the vulnerability score was predicted using the three approaches shown in Eq. (5), (6), and (7). After BPR, the graph of the sign-in process in Figure 7 was integrated with the graph for creating a company account, as shown in Figure 10. A complete graph of managing customer accounts after BPR can be seen in Figure 11.
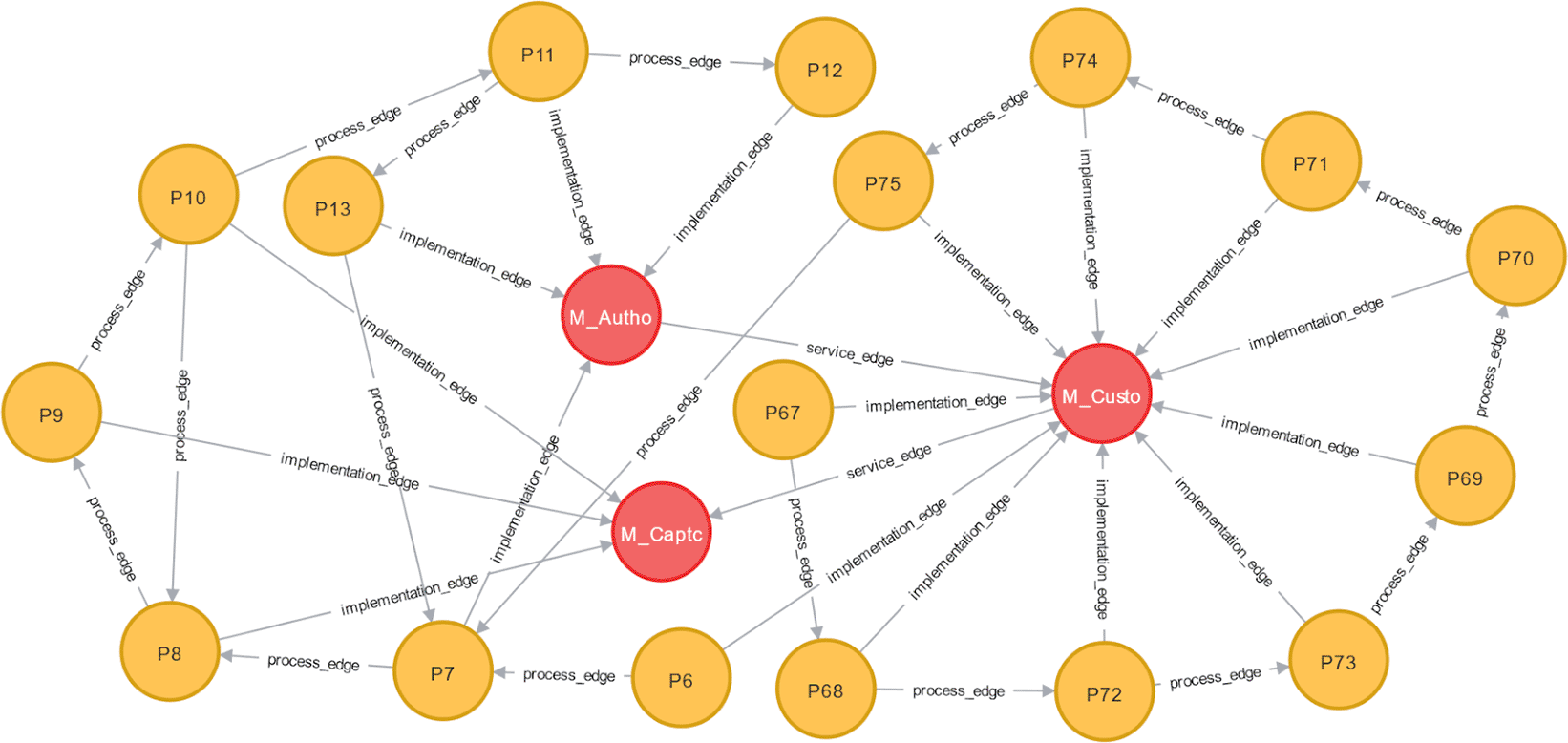
After adding a new series of tasks, we calculated the prediction scores of the to-be model. Table 7 shows the AS for each module node in the IT service layer, which was calculated using the influential node, proportion, and ranking approaches. Table 7 also presents the predicted scores by aggregating the AS and the IS using three approaches.
Figure 11(a) through (f) depict the to-be models of the six BPR cases. In the application layer, the module node’s vulnerability scores represent predicted vulnerabilities affected by the vulnerability propagation of associated nodes. After using the three approaches for calculating the AS, we found that each module node has three susceptibility scores. The final prediction scores were obtained by aggregating the AS and IS values.
We predicted vulnerability scores for each module node using three approaches for calculating the AS and two approaches to aggregate the AS and IS values. We then compared the predicted scores with the actual vulnerability scores in Magento 2.2 obtained from the NVD. Next, we evaluated six BPR cases (see Table 7).
From Table 7, we can see that the prediction score using only the AS score from the three approaches has a high error score. The lowest MAE, RMSE, and MSE values are 0.93, 2.00, and 2.09, respectively. The experimental results from calculating the AS with the influential node, proportion, and ranking approaches show that the error scores do not greatly differ. Therefore, we can choose one of these three approaches to calculate AS.
The evaluation results of the prediction scores obtained from the aggregation of AS and IS reveal a lower error score, indicating that it is essential to consider vulnerability scores in the initial model. The evaluation aggregates AS and IS values with the maximum principle results in a lower error than the average calculation approach. Using the ranking approach for AS calculation, the MAE, RMSE, and MSE values are 0.60, 1.44, and 1.16, respectively. In our study, the maximum principle approach is most appropriate for aggregating AS and IS values. However, Rezvani et al. 50 used the average calculation approach to aggregate vulnerability scores on the computer network.
This study used BPR in the Magento application as a case study. Choosing a different application will inevitably lead to different predictions of vulnerabilities, and this is because the business process model underlies the application is also different. The vulnerability propagation model developed using our method is strongly influenced by the structure of the business process model.
The NSVM method can develop a propagation model for analyzing information security vulnerabilities from the business process to the IT services layers. Moreover, the NSVM method adapts the model when new processes are introduced. This method can also be used to manage the addition of new processes that involve a series of sequential, parallel, or looping tasks. Organizations can use our method to build vulnerability deployment models based on their business process models. This model can early predict applications’ security vulnerabilities before application development, in contrast to previous studies that detect security vulnerabilities during or after application development. 26 – 29
Organizations must have an initial IT architecture model and its security vulnerability data to build a vulnerability propagation model. Then the organization can build a predictive model based on the to-be model of the IT architecture resulting from BPR. The business process model as a part of the IT architecture must be developed using BPMN. This is different from threat modeling, which uses data flow diagrams as the basic model for prediction. 25
Our method can automatically predict vulnerability scores for each resource (tasks and application modules) on the to-be model. Process designers can obtain early information about security vulnerabilities posed by BPR. Our method can reduce reliance on security experts to predict vulnerabilities in the process model, unlike threat modeling, which only depends on experts to predict vulnerabilities in the process model. 25
We also compare the NSVM method and other methods, focusing specifically on the modeled architecture layer, the modeling representation, the approach, and the adaptive mechanism, as shown in Table 8. The NSVM method uses a business process model and IT architecture to form a graph. As such, our method differs from other modeling methods, which use the relationship between components of IT assets, such as hardware or infrastructure, 9 , 11 , 34 , 36 or security controls that refer to specific standards. 12
| Method | Architectural layer | Model representation | Approach | Adaptive mechanism |
|---|---|---|---|---|
| Node Strength-based Vulnerability Modeling | Business process and IT service | Directed and weighted graph | Social network strength | Yes, BPR |
| Feng et al. 12 | IT asset | Bayesian network | Ant colony optimisation | Yes, security incidents |
| Stergiopoulos et al. 36 | IT asset | Directed and weighted graph | Centrality metrics | No |
| Naghmouchi et al. 9 | IT asset | Directed and weighted graph | Binomial distribution | No |
| Szpyrka and Jasiul 11 | IT asset | Petri nets | Labelled transition system | No |
| Shin et al. 34 | IT service | Bayesian network | Activity quality analysis | No |
Additionally, the NSVM method uses the CWE dictionary as a vulnerability reference and determines a prediction score by referring to the CVSS metric. In contrast, other studies have predicted risks by calculating the percentage of opportunities of threats arising from a lack of control. 12 , 34 Our method can also be distinguished from Naghmouchi et al., 9 which used the vulnerability propagation model to predict the critical time at which the highest vulnerability propagation occurs. Likewise, Stergiopoulos et al. 36 employed a vulnerability model to analyze the effectiveness of risk mitigation efforts. The NSVM method is the first vulnerability modeling method that uses a business process model and IT architecture as its basis. It uses the model to predict vulnerability scores in application modules based on CVSS metrics.
This research has succeeded in developing node strength-based vulnerability modeling and applying the concept of social network strength to construct a vulnerability propagation model with an adaptive mechanism based on BPR. The propagation strength between nodes (node strength) is influenced by common CWEs between the two nodes. Hence, the vulnerability propagation model can predict vulnerability scores at module nodes in the IT service layer after new processes are introduced. In the NSVM, the best prediction scores were obtained by aggregating the adjacency and initial scores using the maximum principle approach. The best evaluation results from case studies show MAE, RMSE, and MSE scores of 0.60, 1.44, and 1.16, respectively.
However, this study has limitations that should be addressed in future research. Some of the model’s edges have a propagation strength score equal to zero, especially those between process nodes with different task types. The modeling method should address this issue by considering the task type as a factor that affects vulnerability propagation at the business process layer. The NSVM method develops a vulnerability propagation model that should be used to track the resources that affect the vulnerabilities in each application module in the IT service layer. This tracking is necessary to locate the critical path that leads to the most vulnerable module. Further research can be conducted to find this critical path in the vulnerability propagation model.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)