Keywords
NIR spectroscopy, mango, sustainable production, local polynomial regression
This article is included in the Agriculture, Food and Nutrition gateway.
NIR spectroscopy, mango, sustainable production, local polynomial regression
In the new version of our manuscript, we add discussion that cited 13 references published in the last five years. The spectral data acquisition setup is also clearly stated by adding a figure namely Figure 1 as an illustration. The existence of outliers and any data that includes outliers have been added to the new version of our manuscript. The authors have also added suggestions to evaluate the robustness of the model using samples across different seasons as testing datasets in future research. We proposed nonparametric regression approach for predicting pH and total soluble solids (TSS) based on local polynomial estimator because it gives more flexibility of the regression curve and the prediction result is highly accurate (less than 10%)
To read any peer review reports and author responses for this article, follow the "read" links in the Open Peer Review table.
Indonesia’s Gadung Klonal 21, commonly known as Avomango, is a popular mango cultivar owing to its thick flesh, low fiber content, and sweet flavor.1 Avomango can be eaten in the same way as an avocado. It was developed in Pasuruan Regency, East Java. Even now, fruit pickers hand-pick mangoes and must determine whether the mango is sufficiently mature for picking. Maturity indices determine the quality and shelf life of harvested fruits, and provide the necessary flexibility for transport and marketing.2 Harvest maturity is the stage of development in climacteric fruits, such as mangoes, when the fruit is harvest-ready and of an acceptable consumer grade. Consumer maturity is achieved when the fruit is ready for consumption or utilized in other ways. In climacteric fruits, consumer maturity is reached after harvest maturity.3 Mature mangoes have a low pH value and high Brix percentage; the pH value increases throughout the maturation period.
Fruit maturity indices can be estimated accurately using destructive methods. These methods are damaging, time-consuming, labor-intensive, and require manual loading.4 Furthermore, they are costly, require a long time for sample preparation, and are wasteful.5 Thus, rapid, non-destructive, and environment-friendly analytical methods are required. Hence, non-destructive techniques, such as visible imaging, colorimetry, visible and near-infrared (NIR) spectroscopy, computed tomography, hyperspectral imaging, fluorescence imaging, and multispectral imaging, have been developed to evaluate fruit maturity.3 NIR spectroscopy is the most widely used non-destructive technique in post-harvest fruit and vegetable quality determination.6 Moreover, NIR spectroscopy techniques have been used to overcome the limitations of destructive methods while maintaining the physicochemical attributes of food and agricultural products. In addition, using NIR spectroscopy technology helps support sustainable production as a sustainable development goal (SDGs).
Physicochemical, physical, and biological changes occur in mangoes during ripening. These changes differ depending on the mango variety. The color does not reflect the stage of maturity in Gadung Klonal 21 as the green color of the mature mango is similar to that of the raw mango. The texture of mature mangoes differs significantly; the tip of the fruit has a soft texture. A significant change is observed in the level of sweetness and acidity of mangoes, which can only be detected by destructive analysis. However, numerous studies have been conducted to predict the sweetness and acidity of mangoes using regression modeling based on spectral data from NIR spectroscopy.7–11
Studies have been conducted to determine and forecast the maturity and quality of mangoes.7–12 Spectral data must be modeled using several regression methods, either as raw spectra or pre-processed spectral data, to estimate the internal quality of mangoes. Most of the previous studies have modeled spectral data using linear regression and nonlinear regression. Linear regression including partial least squares regression (PLSR) and principal component regression are the two most popular approaches for NIR calibration.13 Linear regression is commonly used in parametric regression techniques to predict the internal quality of fruit. Furthermore, nonlinear regression methods have the potential for such application. Forecasting changes in quality in agricultural products requires predictive modeling that considers the effectiveness of a nonlinear regression model.14 To predict the fruit quality, Nicolaï, Theron, and Lammertyn20 employed nonlinear regression analysis involving the kernel partial least squares regression method (KPLSR). Anderson, Walsh, Flynn, and Walsh15 reported using local PLSR to estimate the dry matter content of mango. The application of nonlinear regression to fruit quality prediction is relatively underexplored.
A nonparametric regression approach can be used to model unpatterned data, including the nonlinear cases. Nonparametric regression for predicting the acidity level of mangoes was studied by Ulya and Chamidah.22,23 The prediction of the sweetness level of mangoes has been reported by Ulya, Chamidah, and Saifudin.16 These studies report that nonparametric regression based on local polynomial estimators, particularly, multiple polynomial regression (MPR), results in a better predictive model than the parametric regression approach.
Local polynomial regression can capture nonlinear patterns between the response and the predictor variables.17 This method looks at neighboring data for the specified bandwidth, matches separate piecewise regressions for each part, and combines them.18 The local regression fit is complete when all the data points are identified using the regression function values. Function calculation in local polynomial and local linear regression is performed locally at the point to be estimated.19 This is different from spline regressions.20–23 This local estimation technique captures nonlinearities that may exist without the influence of dataset outliers at each estimation stage.24 This method is data-based and easy to implement. It provides a flexible structure that can capture the nonlinear characteristics present in the data compared to multiple linear regression (MLR).25
Mango pH value prediction using multi-predictor local polynomial regression (MLPR) and MPR was investigated by Ulya et al.26 The results indicate that the MLPR method provides better predictive performance with a lower mean absolute percentage error (MAPE) value than the MPR method. However, some studies have attempted to overcome the problem of nonlinearity when predicting internal fruit quality based on NIR spectroscopy using KPLSR27 and support vector machine regression (SVMR).28,29 These two approaches perform better compared with MLR and PLSR. However, to date, no study has compared the predictive performance of nonparametric regression approaches, such as MLPR with KPLSR and SVMR, in predicting the internal quality of mangoes.
This study aims at comparing the performance of a mango pH and total soluble solid (TSS) prediction model based on MLPR with KPLSR- and SVMR-based models. MLPR was found to be the best regression model; it exhibited a predictive performance with the lowest mean squared error (MSE), root mean squared error (RMSE) and MAPE values, and the highest R2 value. The MLPR algorithm in this study is useful to design instruments to detect the acidity and sweetness of intact mango.
A total of 186 mangoes (Mangifera indica L, Gadung Klonal 21) were collected from a garden in Wonokerto Village, Sukorejo District, Pasuruan Regency, Indonesia. Mango samples weighing 250–300 g at varying stages of ripeness, ranging from unripe to ripe, were chosen. The mangoes were cleaned and air-dried before being wrapped in Styrofoam fruit netting, and were subsequently placed in boxes (approximately 12 mangoes). Fruit boxes were screened to avoid collisions.
The spectral data for intact mangoes was acquired using an NIR spectrometer (OtO Photonics. Inc.) in the range of 900–1650 nm at 7 nm intervals. The samples were scanned in reflectance mode to record the spectral data. The process of NIR spectra measurement was conducted by firing a halogen lamp on the sample, which was positioned at an angle of 45° to the sample, with the detector positioned at 45° to the sample. Each sample was scanned at three separate locations at two side of mango (the shoulder, cheek, and tip of the intact mango) and the obtained scans for each sample were averaged. The setup of spectral data acquisition can be seen in Figure 1. The spectral data were originally presented in terms of the reflectance value (R) and were later converted to the absorbance spectra value (log 1/R).
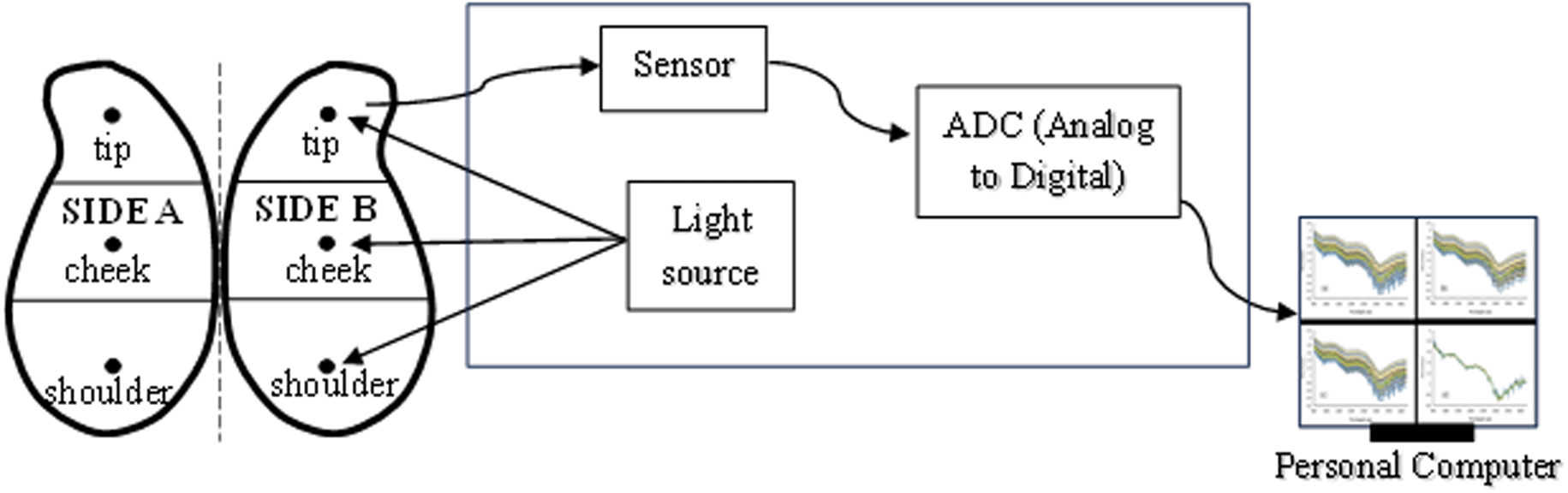
Spectral data pre-treatment
Before developing the prediction models, some pre-treatment methods can eliminate undesired effects, including random noise, high-frequency noise, light scattering, baseline shifts, and any other external effects caused by environmental or instrumental factors. Furthermore, smoothing effectively reduces the high-frequency noise. Among the numerous smoothing approaches in the field, Savitzky–Golay (SG) smoothing is one of the most widely used.30 Using SG can retain the signal properties, including the maximum and minimum relative values, and the width of the peak, which are lost when using other smoothing techniques. In various models, different pre-processing approaches produce varied outcomes. The application of pre-processing techniques in the NIRS modelling process during several harvest times affects NIRS accuracy.31 The present work pre-treated the spectra using SG smoothing generated with two-degree polynomials, Gaussian filter smoothing (GFS), and MSC.
Measurement of pH and TSS
Mango samples (10 g per sample) were blended with 40 ml of distilled water in a fruit blender. Mango juice was measured using a digital pH meter (Lutron pH-208). Triplicate measurements were performed to obtain average values. A small amount of mango juice was dropped onto a pocket digital refractometer (ATAGO PAL-1) to record TSS, expressed in terms of degree Brix (°Bx). The measurements were conducted at room temperature after spectral acquisition.
The pH, TSS, and spectral data was organized into matrices. The matrix rows represent the 186 samples, and the 114 columns represent the predictor (X) and response (Y) variables. The predictor variables were the wavelengths of 112 NIR spectra for each mango sample. The response variables described the measured pH and TSS values associated with each sample in the first and the second column, respectively.
The following steps were to perform dimension reduction using principal component analysis (PCA) to reduce predictor variables into two principal components. When modeling NIR data, the user usually eliminates outliers by implementing advanced statistics including Hotelling’s T2 and Q residuals.32 The study used Hotelling’s T2 ellipse method to remove outliers. Then data excluded outliers analyzed using KPLSR, SVMR, and MLPR. The analysis was performed using calibration and validation models of the pH and TSS values. The Unscrambler X 10.4 software was used to perform spectral pre-processing and model development for pH and TSS values. The open-source software R was used to perform the MLPR method. The calibration and validation models' absorbance spectral data of the reference vs. predicted pH was plotted to investigate the nature of the spectral absorbance distribution.
Modeling using different calibration methods
One of the major issues with NIR spectroscopy for fresh fruit analysis is that the approach requires a pre-calibration procedure before it can be utilized in practice.33 The study used several regression methods in the calibration process. The dataset was divided into two parts 80% as calibration data and the rest as validation data. For multivariate calibration, the data were modeled using a parametric regression method, including KPLSR and SVMR. Additionally, the data were modeled using the nonparametric regression method MLPR.26 Subsequently, predictions were conducted on the validation dataset based on the model developed for the calibration dataset. The prediction performance of the three methods was compared in this study.
Multi-predictor local polynomial regression (MLPR)
MLPR for predicting the internal quality of fruits was proposed by Ulya et al.16 The prediction was obtained using a nonparametric regression approach based on a local polynomial estimator with one response variable and multiple predictors. The MLPR model has a response variable y that depends on the sum of some functions of the predictor variable x and can be written as follows.
is the parameter estimator, which is performed by taking n pairs of samples . The parameters were estimated using the weighted least squares (WLS) method by minimizing the following.
In addition, the optimum bandwidth (h) as a smoothing parameter in the estimation process must be determined using this method. If the bandwidth value decreases, the regression estimation becomes rougher and vice versa. The optimum bandwidth is the bandwidth with the minimum generalized cross-validation (GCV) value34 and is calculated using the following formula.
Model validation
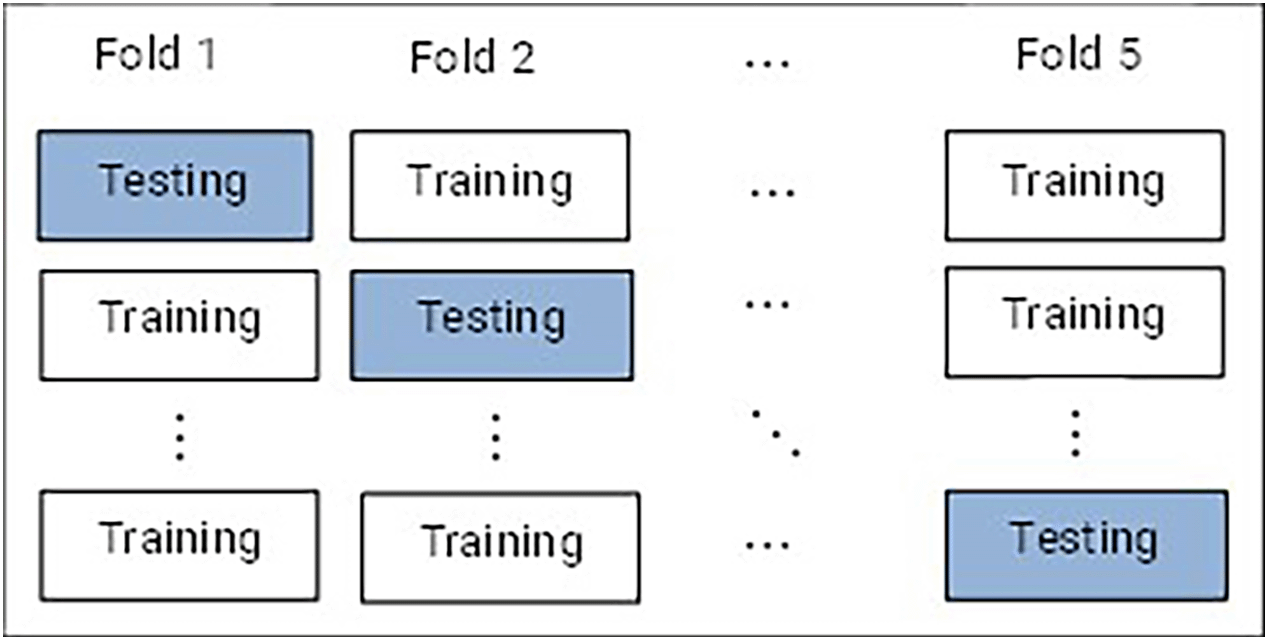
Several methods have been used to assess the algorithm's performance in the prediction results. One such method is K-fold cross-validation, wherein the data is randomly divided into k parts before training or calibrating a classifier with one part and testing or validating it with another.35 This method can reduce sampling bias because the data is randomly divided into several (k) parts.36 The final accuracy of this process is the average accuracy of the number of processes.37 In this study, five-fold cross-validation was used (Figure 2). The 165 samples were split into calibration and validation data, with 80% used as calibration models and the rest as validation models.
Generally, in the studies on predicting the internal quality of fruits using NIR spectroscopy, the evaluation of the predictive performance and accuracy of the models is performed on the validation dataset. Previous studies have used R2 and RMSE to evaluate predictive models. However, this study evaluated the predictive model using MSE and MAPE values. The most frequently used forecasting accuracy measurement is MAPE.38 MAPE has some significant and desirable characteristics, including reliability, unit-free measurement, interpretability, clarity of presentation, statistical evaluation support, and utilization of all error information.39
The aforementioned four criteria are suitable for comparing the predictive performances of parametric and nonparametric regressions. Generally, a good model must have a high R2 value and low RMSE, MSE, and MAPE. The RMSE, R2,29 MAPE,39 MSE,40 and overall of RMSE, MSE, R2 and MAPE formulas can be defined using Equations (5)–(12).
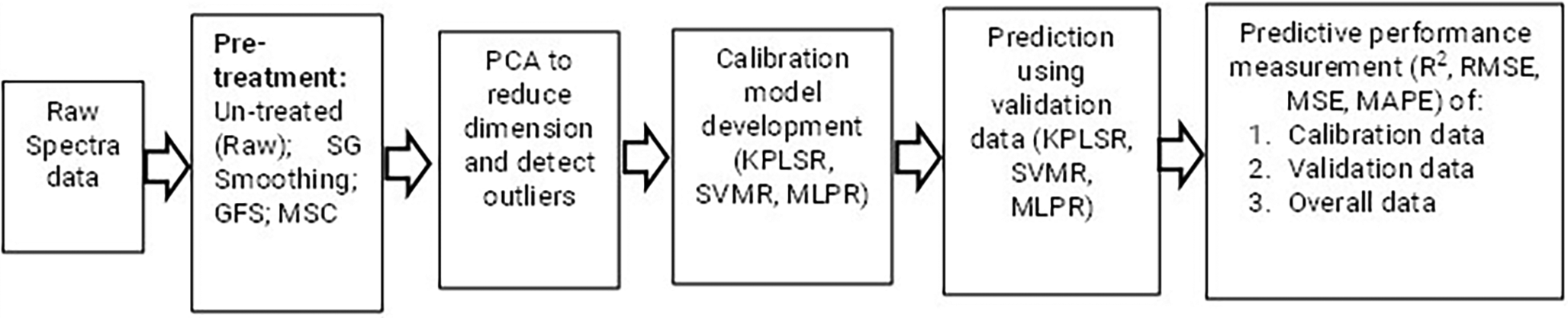
The stages of developing the prediction models and measuring the predictive performance in this study are summarized in Figure 3.
The raw absorption spectra of 186 samples of three different types of mangoes acquired from a spectrometer of wavelength 900–1650 nm are shown in Figure 4(a). The spectral data were pre-treated with SG, a Gaussian filter, and MSC to reduce high-frequency noise, as shown in Figures 4(b)–(d). The MSC technique was used to correct the data by approximating the additive and multiplicative effects of the spectra.41
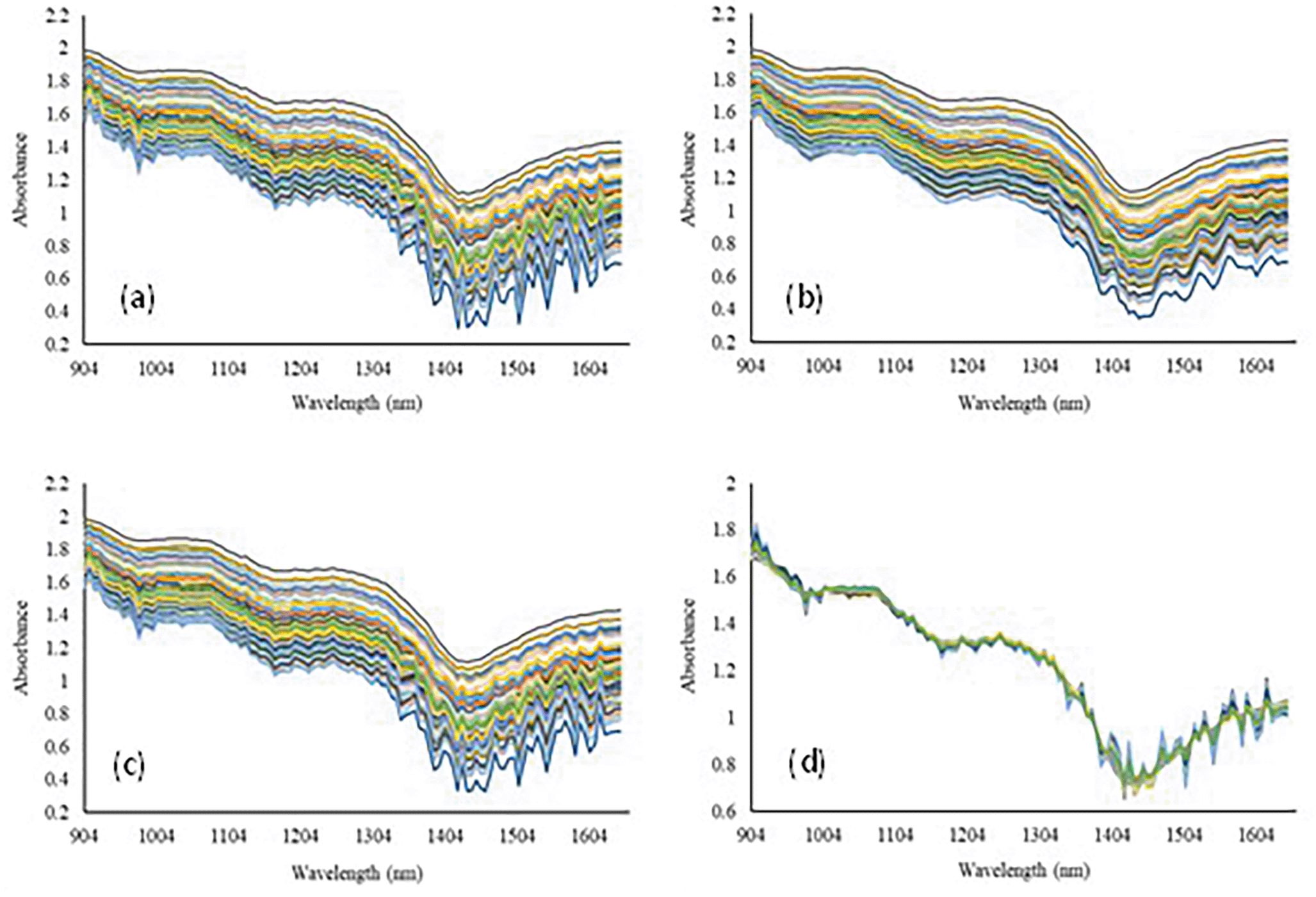
(a) Raw spectra, (b) SG smoothing spectra, (c) Gaussian spectra, and (d) MSC spectra.
After pre-processing the spectral data, the dimension of the absorbance spectra data was reduced by PCA using the singular value decomposition algorithm. Two latent variables representing 99.75% of the variance were selected. Spectral outliers were identified using PCA, subject to Hotelling’s T2 ellipse. In this study, 21 outliers were identified. Most of the outlier data are ripe mango samples. The large number of outliers was caused by the larger number of samples in the form of unripe mangoes, so that some ripe mangoes were outliers because the characteristics were too different. These outliers were excluded because they could have a negative impact on the model. Removing data outliers from a dataset can increase statistical analysis accuracy and avoid misleading findings. Outliers are a significant issue in regression analysis and substantially threaten ordinary least squares analysis results including effect sizes and coefficients.42,43 Sample outliers may provide helpful information, but they can also be non-representative samples that contribute to errors in a model.44 The final sample consisted of 165 observations, divided into two parts: calibration and validation datasets with five-fold cross-validation (see Figure 2). Each fold consisted of 132 calibration data samples and 33 validation data samples.
The descriptive statistical values for the measured pH and TSS are presented in Table 1. The robustness of the calibration models was evaluated using five-fold cross-validation. Three different calibration models (KPLSR, SVMR, and MLPR) were developed using the calibration dataset for each pre-treatment method (raw, SG smoothing, Gaussian filter, and MSC) to predict the pH and TSS values of the mangoes.
Table 2 presents the calibration and validation results for the pH prediction using NIR. The three regressions provided robust models using GFS-treated spectra compared with untreated, SG smoothing, and full MSC spectra. Both calibration and validation in the MSC spectral model yielded higher MAPE values than those of the other two spectral treatments (SG and Gaussian smoothing). The raw spectra model was better than the MSC model but not better than the Gaussian and SG models. This result is similar; the raw spectra model had a worse predictive performance than the pre-treated spectra.
MLPR is the best method for predicting the pH value of mangoes based on the three regression methods used for all spectral data. The prediction model's performance with MLPR had the highest R2 value and the lowest MSE, RMSE, and MAPE values compared with the KPLSR and SVMR methods.
Predictive performance comparisons of the TSS values are listed in Table 3. Predictive models for TSS values have lower performance than predictive models for pH values. The performance of the pH prediction model was better than that of the TSS prediction model because it had a high R2 value with a low MAPE value (3.4–5.8%). The predicted pH value was closer to the observed pH value. Although the R2 value was high in the TSS prediction model, the MAPE value was also relatively high (6.4–8.1%). However, the MAPE value in the TSS model is still classified as highly accurate.39
Pre-processing spectra using SG smoothing for the TSS value parameter gave the best predictive model results, with the lowest RMSE, MSE, and MAPE values and the highest R2 value.
MLPR, SVMR, and KPLSR exhibited excellent predictions of the pH of mangoes. Overall, MLPR using GFS spectra provided the best overall model for pH prediction, with R2 = 0.832, RMSE = 0.187, MSE = 0.036, and MAPE = 3.389% (Table 2). All treatment spectra revealed that the best predictive model used MLPR, with the highest R2 value and the lowest RMSE, MSE, and MAPE values compared with the other regression methods. This is consistent with the results of the previous studies by Ulya et al.16,26
The order of prediction performance based on the regression method from the best is MLPR, SVMR and KPLSR. MLPR is a novel method for predicting the internal quality of fruits developed by Ulya et al.16,26 This study confirms that the MLPR method can produce a robust predictive model for determining the internal quality of mangoes; MLPR (nonparametric regression) has predictive performance with a lower MAPE value than that of the MPR (parametric regression). Table 2 proves that SVMR outperforms KPLSR with higher R2 values, lower MSE, RMSE and MAPE. This is similar to Refs. 45, 46 which shows that predictions using the SVM method are better than PLSR because SVM regression can deal with nonlinearity in spectral data.47 PLSR is a linear regression method which fail to express the linear relationship found in spectral data.
Among the three regression methods, MLPR exhibited lower MAPE values in all treatment spectra. With the Gaussian filter spectra calibration and validation data, MLPR provided the highest R2 and lowest RMSE, MSE, and MAPE compared with the other methods, as shown in Figure 5. Even with the overall data, the R2, RMSE, MSE, and MAPE values were better for MLPR than the those of the other methods, which indicates that the MLPR method provides an accurate prediction of all spectral data with MAPE <10%39 and low RMSE values. The predictive performance of the MLPR model also had a high R2 (0.82–0.9), thus indicating good predictive ability.48
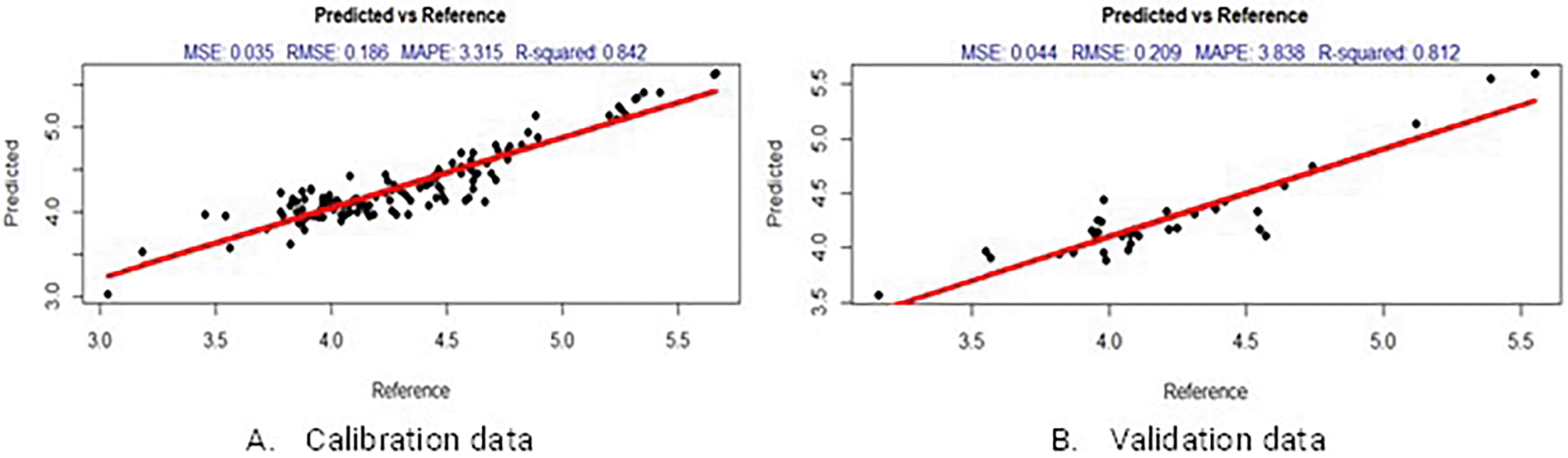
KPLSR method performed the worst in predicting the pH of mangoes. Only a few studies have predicted fruit characteristics using the KPLSR. Most studies use PLSR because of its simplicity and small calculation volume. Partial Least Square (PLS) is a linear method of data analysis.49 Based on untreated spectra, Nicolaï et al.27 used KPLSR to predict apple sugar content.
The prediction of the sugar content of Gannan Navel oranges based on several treated spectra was reported by Liu,44 where KPLSR, particularly the spline PLS model, was superior to others with an R2 of 0.87, RMSE validation of 0.47 °Brix, and standard deviation ratio of 2.34. Kernel PLS is suitable for dealing with nonlinear phenomena; this may be owing to the changes in the chemical interactions of the fruit matrix because unripe and ripe fruits have different structures and varieties.50
The best regression method for predicting the TSS value of mangoes was MLPR, based on SG smoothing. The calibration, validation, and overall models of the MLPR method based on all spectral treatments have higher R2 values and lower RMSE, MSE, and MAPE values than the other methods. The MAPE value is higher than that of the pH prediction model, but the MAPE value is still less than 10%, thus categorizing the method as highly accurate in forecasting.39 Figure 6 shows the MLPR predictive performance based on SG smoothing. Previous research has shown that a small set of reference attributes and spectral behavior changes influenced by cultivar, fruit size, and fruit origin significantly impact model robustness.6,51,52 Moreover, the prediction performance was affected by the lack of variability in the calibration model. When validated by samples outside the prediction model range, the prediction model performance in a study investigating the total acid content of Japanese plums decreased.51 Subedi, Walsh, and Owens53 reported that a TSS prediction model developed from fruits at late stages of ripening failed to predict the TSS of fruits at earlier stages of ripening.
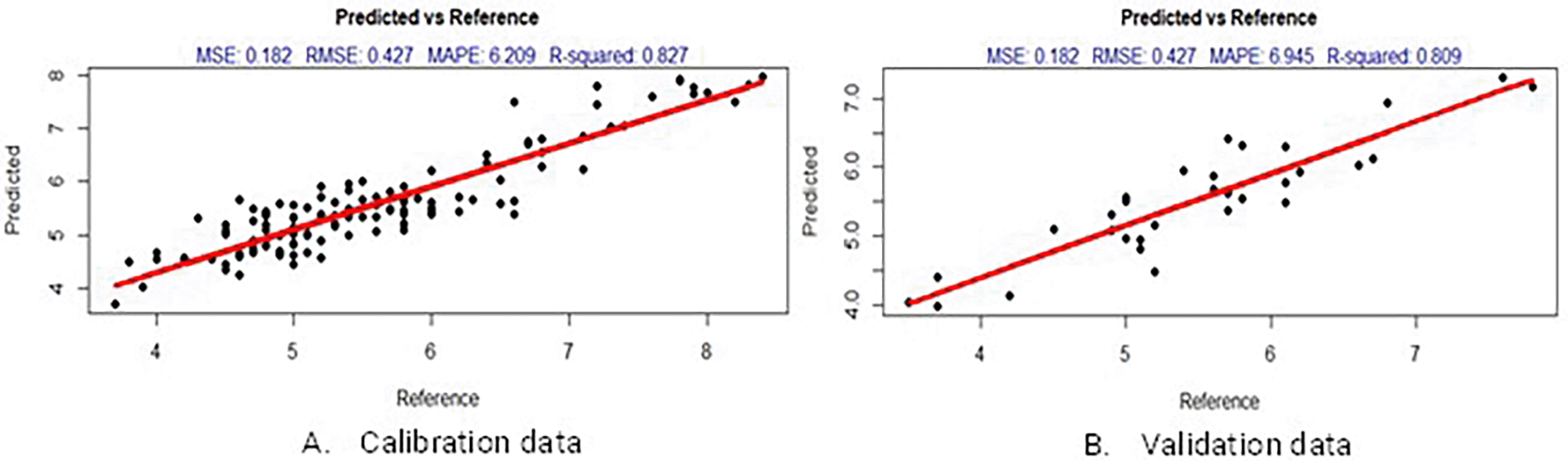
The order of the best regression methods in predicting mango TSS is MLPR, SVMR and Kernel PLSR. The utilization of partial least square regression (PLSR) has the benefit of dealing with irrelevant and noisy variables. However, when the number of samples is substantially fewer than the number of variables, as in the case of spectral data, the prediction ability of PLSR is lowered.54 Because the relationship between near-infrared spectra and targeted components to be simulated is not strictly linear in many existing and established NIR spectroscopic measurement applications, the cause of nonlinearity can vary greatly and is hard to identify. This means there are better solutions that conventional linear regression approaches like PLSR.55 Similar findings were made by another researcher, who concluded that SVMR outperformed PLSR in prediction performance.45,46,55,56 In this study, the best prediction performance values are provided by MLPR, a nonparametric regression. Applying a nonparametric regression model based on a local polynomial estimator outperforms a mathematical computation technique, including the support vector machine approach.57 This is comparable to research58,59 which reveals that nonparametric regression approaches based on local polynomial estimators outperform parametric regression in the case of prediction models.
The best pre-treatment spectral data for predicting the TSS value was SG smoothing. Overall, MLPR with SG smoothing spectra was the best model, with an R2 value of 0.805, RMSE value of 0.436, MSE value of 0.192, and MAPE value of 6.454. This is in agreement with the findings39 that the SG smoothing spectral model for predicting the tannin content of persimmon fruit is better than MSC. The R2 values for SG smoothing and MSC were 0.107 and 0.016, respectively.29 In contrast to,28 the prediction of the mangoes’ TSS values using SVMR based on extended MSC gave an R2 validation of 0.86 and an RMSE of 0.66.
Generally, all spectral treatment and regression methods on the calibration model have an R2 value higher than that of the validation model, with a small gap between them; this indicates that the k-fold cross-validation method can balance the prediction results of the calibration and validation datasets. The k-fold cross-validation method can reduce bias in sampling.36 If the test matrix method is used, the R2 of the validation models would be less than the R2 of the calibration model. Louw and Theron51 reported that the prediction model's performance for the total acid content of Japanese plums decreased when samples outside the prediction model range were validated.
Prediction of the internal quality of mangoes, including pH and TSS, can be performed rapidly and non-destructively using NIR spectroscopy. Spectral pre-treatment, such as SG smoothing, GFS, and MSC, affects the ability of the prediction model to use KPLSR, SVMR, and MLPR. The best regression model for pH prediction is MLPR based on a GFS spectra. In addition, KPLSR, SVMR, and MLPR based on raw spectra, SG smoothing, and MSC also provided highly accurate prediction performance, with MAPE values of less than 10%, low MSE and RMSE, and high R2.
The best regression model for TSS prediction was MLPR based on SG smoothing. In addition, KPLSR, SVMR, and MLPR based on raw spectra, GFS, and MSC also provided highly accurate prediction performance, with MAPE values of less than 10%, low MSE and RMSE, and high R2. We believe that NIR spectroscopy can be used to determine the internal quality of mangoes. However, further research is required to improve the prediction model performance of TSS values using MLPR based on a combination of several pre-treatment spectra. In conclusion, NIR spectroscopy combined with nonparametric regression MLPR could become a rapid and non-destructive alternative method for predicting the internal quality of mangoes. The robustness of the model based on MLPR could potentially be investigated in further study using test data sets built up of samples from various seasons. Likewise, the quality of sample collection in further study needs to be improved to reduce the number of outliers.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)