Keywords
In-house validation study, reproducibility precision, measurement uncertainty, prediction interval, uncertainty interval
In-house validation study, reproducibility precision, measurement uncertainty, prediction interval, uncertainty interval
In this paper, a “top-down” approach for the calculation of measurement uncertainty is presented, in the sense that the estimate of measurement uncertainty is supported by precision data from a validation study.
Measurement uncertainty is defined in JCGM 100 as a parameter that “characterizes the dispersion of the values that could reasonably be attributed to the measurand”.1 This parameter is often expressed as a standard deviation which is then used to obtain a symmetric uncertainty interval around the measurement result. In the following, the approach yielding symmetric uncertainty intervals will be referred to as the approach.
As will be discussed below, in the case of heteroscedasticity, the approach can yield misleading uncertainty intervals. For this reason, a different approach for determining measurement uncertainty is presented. This approach is suitable when precision data from a validation study conducted with test samples with known concentrations are available. While the focus in this paper is in-house validation, the approach presented here can also be applied for data from an interlaboratory validation study. It will be shown how, under certain circumstances, asymmetric uncertainty intervals arise quite naturally. For this reason, the approach presented here will be referred to in the following as the asymmetric measurement uncertainty approach (short form: asymmetric approach).
The asymmetric approach is perfectly consistent with the JCGM definition given above. Indeed, in the asymmetric approach, the focus is explicitly on the “dispersion of values which could reasonably be attributed to the measurand.” Furthermore, it draws the same distinction between measurand () and measurement () as JCGM 106.2 Even though the approach presented here is not Bayesian, there are important connections with JCGM 106, such as the definition of the best estimate of the measurand as .
First, an experimental design for an in-house validation study and a statistical model are presented, allowing the calculation of in-house reproducibility precision as a function of concentration. Then it is shown how uncertainty intervals are calculated from such precision data. The inconsistencies of the approach are then discussed, and the asymmetric approach is presented. Throughout, the various concepts are illustrated with examples.
It is assumed that an in-house validation study has been conducted with samples with known concentrations. In the simplest case, the samples with known concentrations are obtained by diluting certified reference material. For each concentration level, several measurement results are obtained under in-house reproducibility conditions. This is best achieved via a factorial design, such as described in ISO/TS 23471.3
The following table (Table 1) provides an example of a factorial design with 7 factors and 8 factor level combinations.
| Factor level combination | Block (e.g. week) | Factors | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 1 |
| 2 | 2 | 1 | 1 | 2 | 2 | 1 | 1 | 2 |
| 3 | 3 | 1 | 2 | 1 | 1 | 2 | 1 | 2 |
| 4 | 4 | 1 | 2 | 2 | 1 | 1 | 2 | 1 |
| 5 | 5 | 2 | 1 | 1 | 1 | 1 | 2 | 2 |
| 6 | 6 | 2 | 1 | 2 | 1 | 2 | 1 | 1 |
| 7 | 7 | 2 | 2 | 1 | 2 | 1 | 1 | 1 |
| 8 | 8 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
More generally, the number of factor level combinations is denoted . With (known) concentration levels and replicates per concentration level, a total of measurements are performed.
The statistical model (mixed linear model) is as follows:
denotes the measurement result at concentration level for factor level combination and replicate
denotes the known concentration,
and denote the absolute and the relative components of method bias. The curve represents the expected measured concentration at known concentration and will be referred to in the following as the mean curve.
and denote the absolute and the relative components of the effect of factor level combination (each of these terms results from summing effects of the individual factors).
and denote the absolute and the relative components of block effect
and denote the absolute and the relative components of the repeatability error for measurement result .
In the following, two in-house validation data sets will be considered: Thiamphenicol in milk (Example 1) and Clopidol in egg (Example 2).
The following table (Table 2) provide test results for Example 1 ( known concentration levels, replicate).
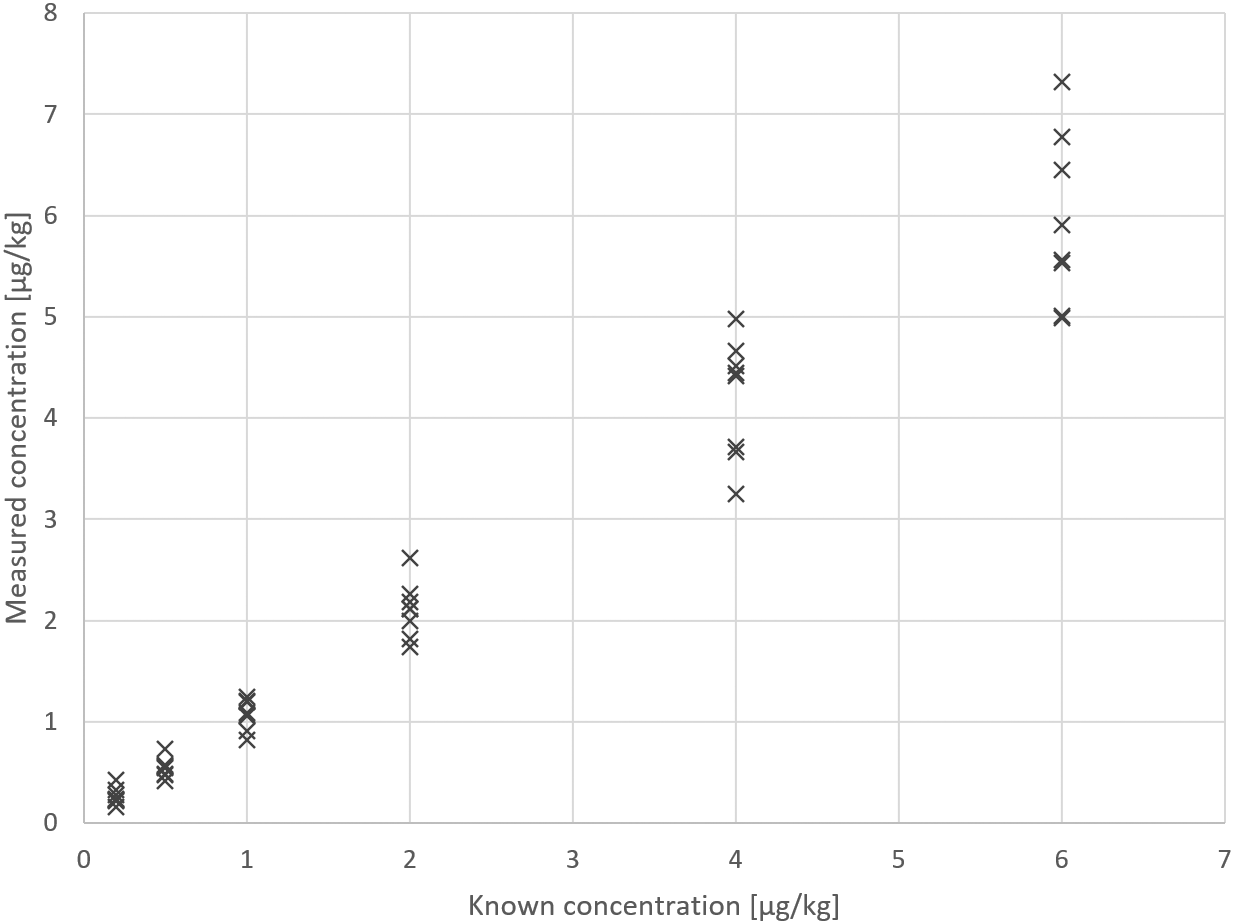
The test results for Example 1 are displayed in Figure 1.
The following table (Table 3) provides test results for Example 2 ( known concentration levels, replicate).
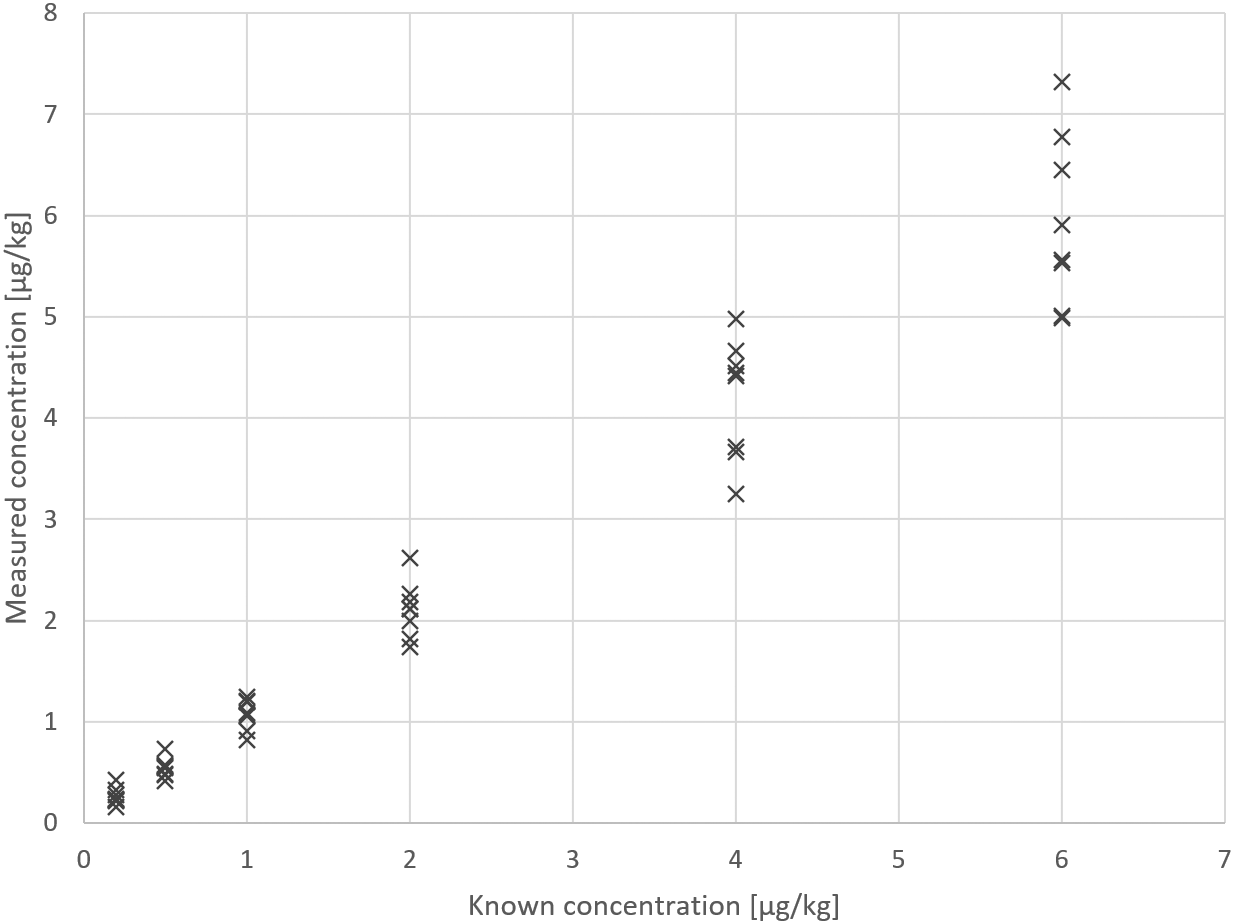
The test results for Example 2 are displayed in Figure 2.
For each example, reproducibility standard deviation values are calculated by means of Equation 1. With the exception of the two fixed effects and , the terms on the right side of Equation 1 are modelled as random variables. The corresponding variance components are denoted as follows:
whereare random variables with zero mean and variances , respectively
are random variables with zero mean and variances , respectively and where
denotes the vector of factor levels for the factors and for factor level combination
Moreover,
are random variables with zero mean and variance
are random variables with zero mean and variance .
are random variables with zero mean and variance
are random variables with zero mean and variance
The estimation of variance components in mixed linear models is described, for example, in Searle et al.,4 McCulloch et al.5 and Clarke.6 Estimates for Example 1 are provided Table 4.
The in-house precision parameters for Example 1 for four different concentrations are provided in Table 5. At a given known concentration , the in-house reproducibility standard deviation is calculated as follows:
The following two tables (Table 6 & Table 7) provide variance and precision estimates for Example 2.
The estimate of reproducibility at concentration (see Equation 2) can be used to derive an estimate of the standard measurement uncertainty for the measurand as a function of :
The expanded measurement uncertainty is then obtained as follows:
where denotes the coverage factor.
It should be noted that it may be necessary to include the uncertainty of bias correction and the uncertainty of the (certified reference) values for the known concentrations used in the validation study, as appropriate. (see step 3 of Asymmetric measurement uncertainty approach).
Based on the precision values from the previous section, and using (for the sake of simplicity), one obtains the following expanded uncertainty values (Table 8 & Table 9):
| Concentration [μg/kg] | Expanded measurement uncertainty [%] | Expanded measurement uncertainty [μg/kg] |
|---|---|---|
| 25 | 17.1 | 4.28 |
| 50 | 9.1 | 4.56 |
| 75 | 6.7 | 5.00 |
| 100 | 5.5 | 5.54 |
Typically, the expanded measurement uncertainty is used to construct a measurement uncertainty interval of the form . Such symmetric measurement uncertainty intervals are not always appropriate. This will be demonstrated on the basis of a theoretical example.
In this example, it is assumed that the relative measurement uncertainty is already known and is constant at 35% across the applicable range of concentrations as specified in the scope of the analytical method. If the measurement result is (in this theoretical example, the unit plays no role and is therefore suppressed), then, applying the approach with (for the sake of simplicity) and with the standard uncertainty obtained from the known 35% relative standard deviation (RSD) value, a measurement uncertainty interval of [3, 17] is obtained. According to the JCGM definition of measurement uncertainty discussed in the introduction, this means that the value could reasonably be attributed to the measurand. However, if the measurement result had been (instead of ), applying the same 35 % relative measurement uncertainty would result in an uncertainty interval of [0.9, 5.1]. Since the original value of does not lie within this second interval, it can be seen that the approach is inconsistent in such a situation.
The two uncertainty intervals just discussed are summarized in the following table (Table 10).
(In this theoretical example, the unit plays no role and is therefore suppressed.)
| Lower limit | Measurement result | Upper limit |
|---|---|---|
| 0.9 | 3 | 5.1 |
| 3 | 10 | 17 |
The inconsistency of the approach discussed above is illustrated in the following figure (Figure 3). Due to the constant RSD of 35 %, the width of the uncertainty interval (in the diagram: the height of the uncertainty interval) depends on the measurement result. Considered on its own, each uncertainty interval characterizes the dispersion of values that could be reasonably be attributed to the measurand on the basis of the measurement result. However, considered together, the different uncertainty intervals display inconsistencies. In particular, the value does not lie within the uncertainty interval for the measurement result , even though the latter lies within the uncertainty interval constructed around the former.
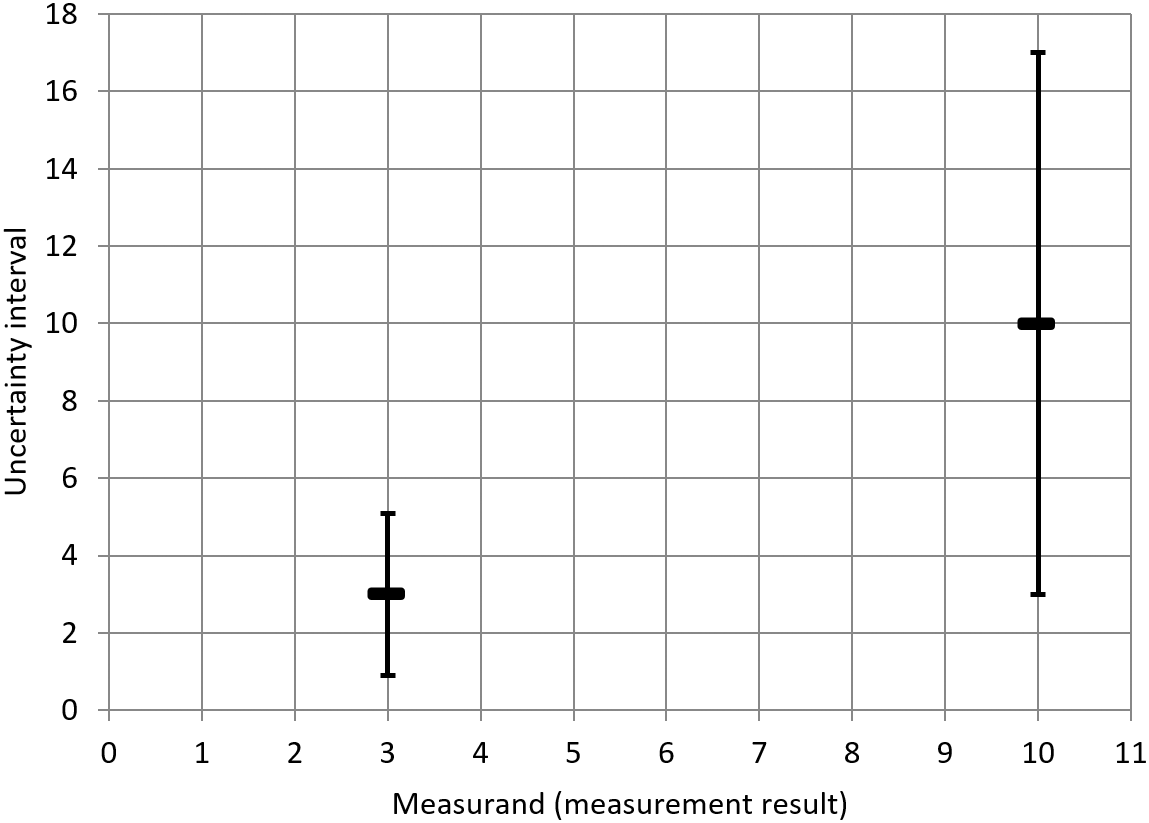
(In this theoretical example, the unit plays no role and is therefore suppressed).
The inconsistency of the approach will now be shown on the basis of the uncertainty intervals for Example 2 provided in Table 9. At a Clopidol concentration of 4 μg/kg Clopidol, the approach yields the uncertainty interval y ± 1.19 μg/kg. In routine testing, if the measurement result is is obtained, it will be concluded that values above 5.19 μg/kg cannot reasonably be attributed to the measurand. However, from the same Table 9, we know that the lower limit of the uncertainty interval for a sample with 5.5 μg/kg Clopidol concentration is 3.88 μg/kg (or 3.98 μg/kg if bias is considered). In other words, we know that a measurand value of 5.5 μg/kg is perfectly compatible with a measurement result of 4 μg/kg. It follows that the value 5.5 μg/kg should lie within the measurement uncertainty interval for a measurement result of 4 μg/kg. This is not the case for the uncertainty interval obtained via the approach. This is illustrated in the following figure (Figure 4).
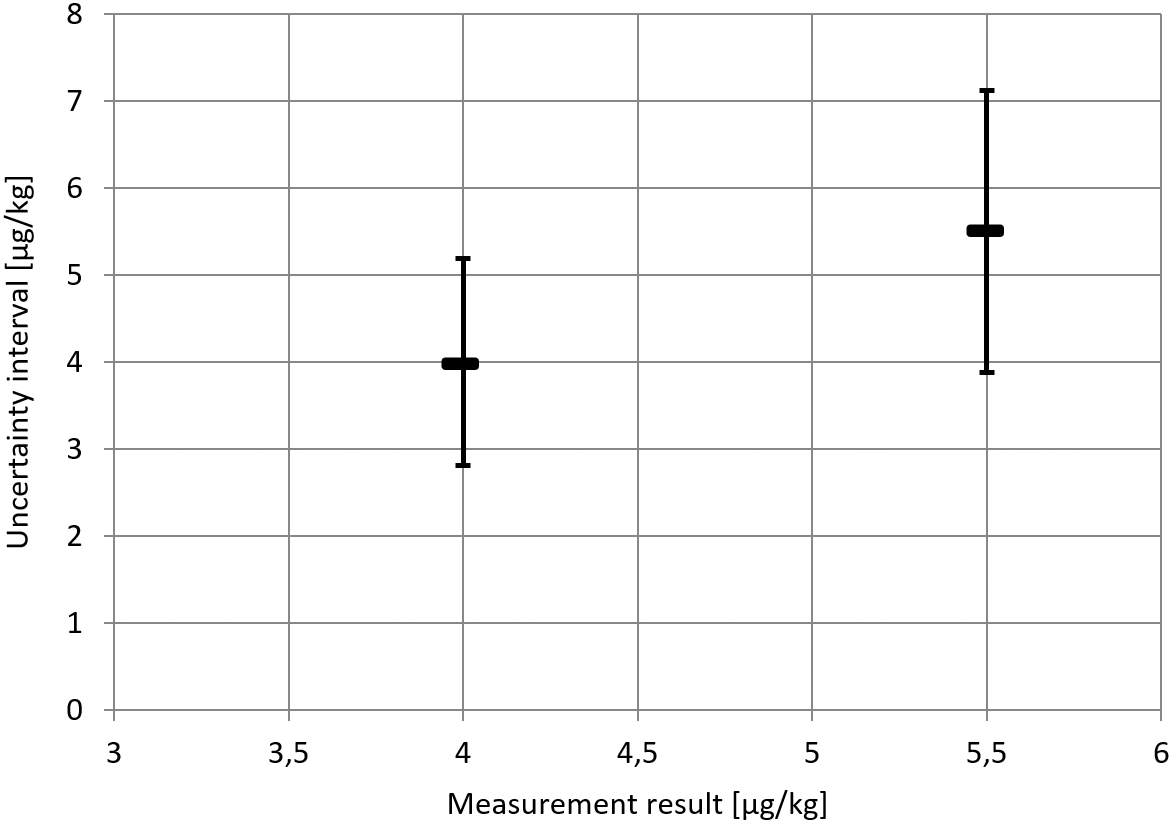
For a measurement result of 4 μg/kg (say in routine testing), values above 5.19 do not lie within the uncertainty interval. However, according to the evaluation of the data from the in-house validation study, measurement results 4 μg/kg were consistent with a measurand value of 5.5 μg/kg.
As has just been seen, in the presence of heteroscedasticity, the approach leads to inconsistencies. For this reason, a different approach for the determination of measurement uncertainty in the case to heteroscedastic data is required. Such an approach will now be presented.
Step 1: prediction range
For each known concentration, the distribution of test results can be characterized in terms of a prediction interval. This interval reflects the degree to which the test results agree with one another, at the given concentration level and under the specified conditions (e.g. repeatability or in-house reproducibility). For a chosen prediction probability level (e.g. ), a subsequent test result will lie inside the prediction interval with probability .
If measurements are performed at different known concentrations, then it is possible to construct a prediction range, rather than individual prediction intervals. This step involves applying one statistical model to all the data, as described the previous section. The construction of a prediction range is described in the following figure (Figure 5).
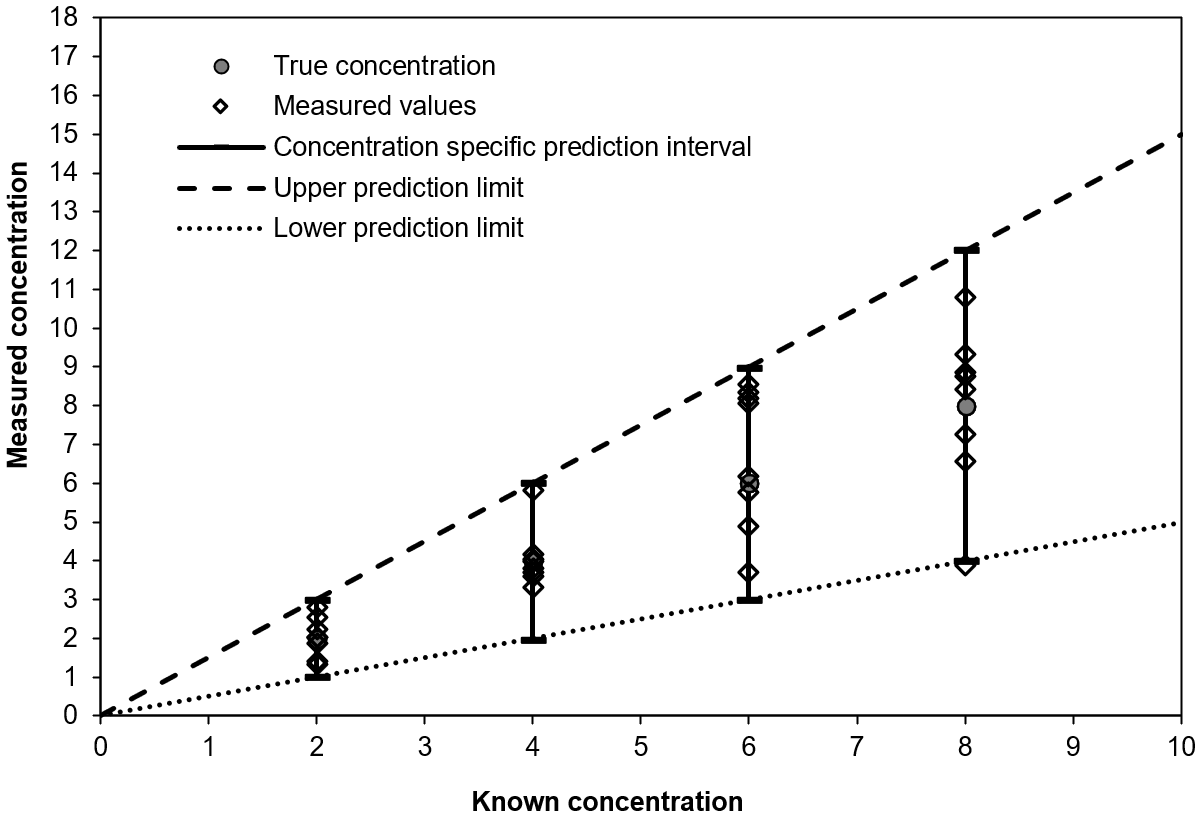
For each known concentration, the diamonds represent the measurement results and the solid vertical line represents the prediction interval. The prediction range is represented by the dashed lines.
For further information regarding the computation of a prediction range, the reader is referred to the discussion of variance functions in ISO 5725-27 and to the in-house validation approach described in Gowik et al.8 and Jülicher et al.9 [1].
Step 2: measurement uncertainty interval
Once a prediction range has been calculated, the measurement uncertainty interval for a given test results (obtained e.g. in routine testing) can be determined. Step 2 no longer involves the data from the validation study. Rather, for Step 2, it is assumed that a prediction range has previously been calculated and is thus available.
Accordingly, the meaning of the axes is now different. The vertical axis now represents the measurement result obtained, say, in routine testing and denoted , while the horizontal axis now represents the measurand (which is to be characterized via the measurement) denoted (This notation is chosen so as to be consistent with JCGM 106, though, strictly speaking, is one realization of a random variable and is one realization of a random variable . However, a distinction between random variables and their realizations is not required in this paper.).
The starting point for Step 2 is a test result, displayed on the -axis. The intersection of the -value with the upper prediction curve is projected onto the -axis to obtain the lower measurement uncertainty limit. Indeed, for measurand values below this -value, measurement results can be expected to be less than the -value. Secondly, the intersection of the -value with the lower prediction curve is projected onto the -axis to obtain the upper measurement uncertainty limit. Indeed, for a measurand values above this -value, measurement results can be expected to be greater than the -value. The resulting -axis interval (grey horizontal band hugging the y-axis) thus corresponds to the values which could “reasonably be attributed to the measurand.”
This procedure is illustrated in Figure 6.

Step 3: best estimate for the measurand
The “best estimate of the measurand” is the projection onto the -axis of the intersection of the measurement result (-value) with the mean curve (see previous section with the measurand replacing the known concentration ). If the bias is negligible (i.e. is close to zero and is close to 1), then this -value will be close to the -value. However, if a bias is present, then the two values will differ, and taking the -axis projection corresponds to a bias or recovery correction. For this reason, the -axis projection is denoted . If such a bias or recovery correction is performed, it is recommended to include the “uncertainty of the bias correction” (see Ref. 1) as an additional variance component in the calculation of the prediction intervals at each known concentration during the validation study. The uncertainty of bias correction, in turn, may consist of various sources of uncertainty such as the statistical uncertainty of the parameters and and the uncertainty of reference values used as known concentrations.
Finally, it should be noted that the symmetry of the measurement uncertainty interval is determined in relation to .
In this section, it is shown how to calculate the lower and upper limits of asymmetric measurement uncertainty intervals.
It is assumed that there is no bias and that, for each concentration level in the recovery experiment, the measurement results follow a normal distribution.
Let denote the lower limit of the expanded uncertainty interval and the corresponding upper limit. Furthermore, let denote the upper limit of the prediction interval at measurand value , and let denote the lower limit of the prediction interval at . For a given measurement result , the two limits and can then be computed iteratively, using the implicit relationships
In the case of a constant relative standard deviation across all concentration levels, and in the absence of bias, explicit expressions for and can be provided. Indeed, in such a situation, a given measurement result obtained to characterize the (unknown) measurand will lie with 95 % probability [2] in the interval , i.e.
The above inequality can be rewritten as
Thus, the measurand will lie in the interval with 95% probability.
For example, for a constant relative standard deviation of 40% (i.e. ) and for the measurement result , the lower and upper uncertainty limits are computed as:
As long as the exact quantile is used and the assumptions are valid, this uncertainty interval is statistically exact in the sense that the coverage probability is exactly 95%.
When is the proposed uncertainty interval symmetric?
If the prediction limits run parallel to the mean curve (see Section 0), the uncertainty interval is perfectly symmetric. This is the case when it is the absolute rather than the relative standard deviation which is constant across concentration levels. It should also be noted that, when the prediction limits run parallel to the mean curve and when there is no bias (100 % recovery), then the prediction and measurement uncertainty intervals are identical. This is illustrated in the following figure (Figure 7).

If there is no bias and if the prediction limits run parallel to the mean curve , then the intervals obtained from the two approaches are identical.
The assumption that an uncertainty interval is symmetric is justified if the following two conditions are met:
Condition 1: Measurement results are distributed symmetrically around the corresponding mean value at a given known concentration in the validation study.
Condition 2: Heteroscedasticity is negligible.
When is the proposed uncertainty interval asymmetric?
In the field of analytical chemistry, in most cases, the distribution of results obtained from measurements performed on one and the same sample is more or less symmetric, so that symmetry condition 1 above is met. Condition 2, however, is almost never met. In the case of weakly heterogeneous variances, uncertainty intervals may still be approximately symmetric. Similarly, if the spread of measurement results at any given concentration level remains small (i.e. the relative standard deviations are small), uncertainty intervals may still be approximately symmetric. However, if the dispersions vary considerably across concentration levels and the corresponding relative standard deviations are large (say, greater than 10 %), then it is necessary to take the asymmetry of the uncertainty intervals into account. Restricting the concentration range under consideration in order to avoid variance heterogeneity is common analytical practice. In some cases, this expedient may allow the symmetry assumption to be applied.
The following figure (Figure 8) illustrates the relationship between magnitude of dispersion and symmetry of the uncertainty interval.

The degree of asymmetry depends on the magnitude of the variance.
The uncertainty intervals for Example 1 and Example 2 are provided in the following tables (Table 11 & Table 12). The degree of asymmetry of a given uncertainty interval can be gauged by comparing the values of the differences and (See earlier sections for the notation , and .). The two values and can also be compared with the expanded uncertainty from the approach. Accordingly, the values from Table 8 and Table 9 are reproduced here for convenient reference.
As can be seen, for Example 1, the values for the differences and lie relatively close to one another and to the values. By contrast, for Example 2, the difference values differ considerably from one another and from the values. For instance, for μg/kg, we have
whileThe calculation of the upper and lower limits, as well as the best estimate of the measurand is illustrated in the following figure (Figure 9).
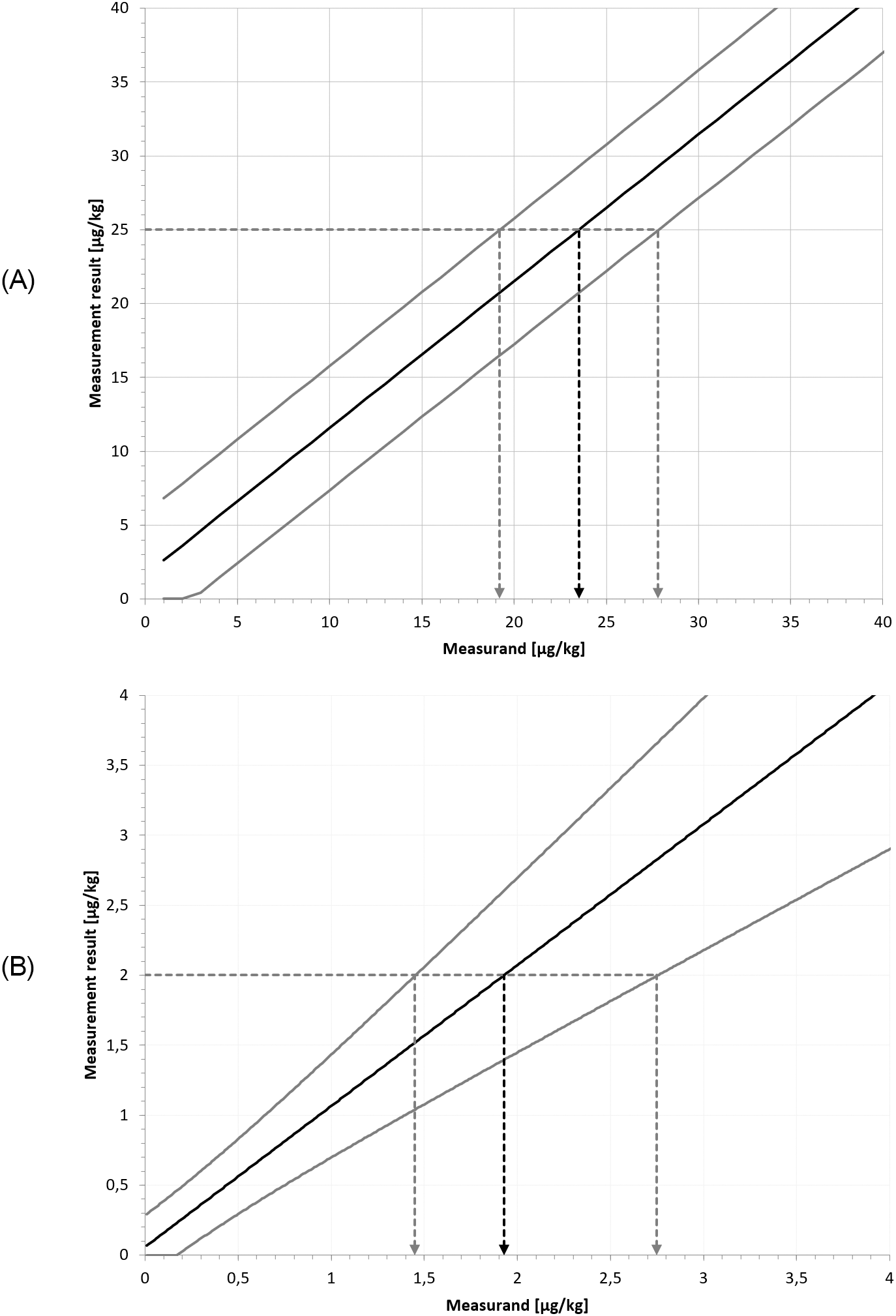
As has been seen, asymmetric measurement uncertainty intervals arise naturally in the case of heteroscedasticity. Accordingly, in such cases, the symmetric uncertainty interval should be seen as a mere approximation of the exact measurement uncertainty interval. This approximation is adequate if variability is low (say, less than 10 % RSD). In the case of both high variability and heteroscedasticity, symmetric measurement uncertainty intervals can be misleading. An awareness of these issues is thus particularly important in fields where these two conditions are expected, such as chemical trace analysis.
In the examples considered in this paper, it is assumed that data follow a normal distribution. If data follow another distribution, the uncertainty interval is different. Lognormal data are a familiar case in point. Indeed, consider the case that for any given concentration , the log-transformed test results can be expected to lie between and . Then, in the original domain (i.e. prior to the log-transformation), the RSD will remain constant across concentration levels and the dispersion will thus incre ase monotonically with the concentration.
In many cases a log-transformation stabilizes the variance, meaning that, in the log domain, all the data are normally distributed with one and the same standard deviation , independently of the concentration. Back-transformation (“anti-log”) then again provides asymmetric uncertainty intervals, from to . These intervals are asymmetric, but to a lesser extent that the interval derived under the assumption that the original data follow a normal distribution. Take the case and . Then the asymmetric uncertainty interval based on the assumption that the original data follow a normal distribution (see Equation 5) is , and the asymmetric uncertainty interval based on the log-normal distribution is .
However, a log-transformation does not always have this variance stabilization effect, even if the data follow a lognormal distribution. For instance, if the standard deviations in the original domain are constant across concentrations, then, in the log domain, the value will depend on the concentration.
More generally, this article establishes a conceptual framework in which measurement uncertainty can be derived from precision whenever the relationship between the latter and concentration has been characterized. Closed expressions for the limits of the uncertainty interval were provided for the simple case of normally distributed test results and constant relative standard deviation. In more complex cases, it may not be possible to provide closed expressions. However, iterative calculation procedures can be applied, and further work may be required to illustrate appropriate context-specific approaches.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)