Keywords
LiDAR, feature extraction, ridge and valley.
LiDAR, feature extraction, ridge and valley.
Light detection and ranging (LiDAR) technology has gained increasing prominence because of its capacity to rapidly generate voluminous amounts of three-dimensional (3D) point clouds, enabling expedient characterization of Earth’s topography.
LiDAR can quickly provide a large amount of terrain data that is useful for building reconstruction, extraction of road paths, construction of topography, and terrain change monitoring etc.1–7 LiDAR is also employed for environmental protection, soil and water conservation, and the hydrological structure of mountainous areas, which are important issues.8–10 Furthermore, LiDAR is a very useful tool for monitoring forest growth and forest area changes, especially for estimating vegetation height, canopy cover, and tree species in mountainous areas.11–13
Compared with photogrammetric data, LiDAR data offer a more straightforward approach for understanding changes in 3D topography. However, the irregular distribution of LiDAR point clouds can pose a challenge, particularly when shaping complex terrain within topological data. This paper introduces a method for extracting ridge and valley lines from low-density point clouds in mountainous regions.
Edge detection is an established technique in computer vision. Various algorithms, such as Sobel, Prewitt, and Laplacian algorithms, have been developed to identify line features.14 Image data are stored in pixel format, and moving masks can easily navigate this regular grid to extract line features. Conversely, the data storage format for irregularly discrete LiDAR data consists of the point coordinates. If image extraction techniques are employed, the point coordinates must be interpolated into a pixel format, which can influence the accuracy depending on the interpolation method used.
Scholars have proposed various methods for extracting line features from LiDAR data. Zhao and You4 focused on extracting road networks. Their approach entails the removal of points associated with buildings and trees by applying the elevation criteria. Subsequently, they employed the intensity data and variance between the tangent vectors to define the line segments. Given that roads possess a certain non-negligible width, a sufficient number of point clouds are usually present on road surfaces to enable line segment extraction. To deal with narrower features, such as power lines, McLaughlin15 proposed a method that uses covariance to calculate the eigenvalues. These eigenvalues can be employed to categorize the point clouds into three groups: vegetation, surfaces, and power lines. Cable-specific formulas are applied to the point clouds allocated to the power line category to yield complete power-line representations. Guan16 used ground-based LiDAR scanning to obtain point cloud data of street views and extracted individual power lines using Hough transformation and Euclidean distance clustering.
Line features that do not correspond to existing lines typically exist at points of change, such as turns and junction areas. Both sharp and gradual turns affect the position of the final extracted line segment. Bailly et al.17 used wavelet transformation and a flooding algorithm to identify the ditch lines in artificial drainage networks. In their study on mountainous settings, Chang et al.18 proposed a profile recognition and polygon-breaking algorithm (PPA) that performs target recognition, target connection, segment verification, and line smoothing. In the PPA approach, elevation grids from digital terrain models (DTMs) were used, and moving masks were employed to extend the ridge and valley lines. Gülgen and Gökgöz19 modified PPA to reduce the computational time required for the DTM generation process. However, PPA is easily influenced by noise, which may lead to redundant lines and non-matched results. A pre-processing procedure is necessary to obtain reliable valley and ridge lines.
A new type of data, termed feature strength, was introduced to aid feature extraction. Medioni et al.20 applied the tensor voting method (TVM) to image data to obtain the eigenvalues and eigenvectors. This method enables the classification of image pixels into various features based on their strengths. TVM has also been demonstrated to be applicable to point-cloud data. You and Lin1 utilized feature strength to extract surfaces and lines from data in urban settings. Furthermore, in the context of urban regions, feature strength data can serve as raw data for calibrating biases between LiDAR strips during the preprocessing stage.21 In urban environments, where buildings and roofs exhibit regular patterns, point clouds on surfaces are readily distinguishable from others owing to their high surface feature strength. Lines can be identified at the intersections of two adjacent surfaces. However, because of the irregular nature of mountainous regions, this approach may result in more fragmented surfaces, making it challenging to intersect ridge and valley lines. The aim of this study is to analyze and discuss the feature strength of point clouds in mountainous regions, particularly the line feature strength extracted by TVM.
TVM encompasses three stages: tensor representation, tensor communication, and tensor decomposition/encoding.20,22 First, a tensor field was established by setting up a disk tensor for each LiDAR point, as proposed by You and Lin,1 and the geometric character of each LiDAR point was represented by a second symmetric tensor. Using tensor communication, each point collects the tensors of neighboring LiDAR points to form its final tensor. Consequently, each point has a strong geometric relationship with its neighboring points based on the final tensor, which is helpful for the extraction of ridge and valley lines in mountainous areas. After tensor communication, the final tensor of each point was decomposed into surface features, line features, and noise point features by tensor encoding.20 You and Lin1,2 used a normal vector field to obtain the surface feature strengths using the TVM and applied the region-growing method to extract surface features from LiDAR point clouds for urban regions. For our purpose, the line feature strength (denoted as C here) is more suitable for extracting valley and river lines in mountainous regions than the other types of feature strength. This aspect is elaborated in the subsequent section.
C data can be obtained using the TVM. This section describes the characteristics of C data. Figure 1 shows the same mountainous region from various perspectives and data modes. In Figure 1(a), the ridge and valley regions appear in the 2.5D view, with an elevation range of approximately 1,400 meters. Figure 1(b) shows the elevation data from a 2D view. Figure 1(c) presents the C data from a 2D view.
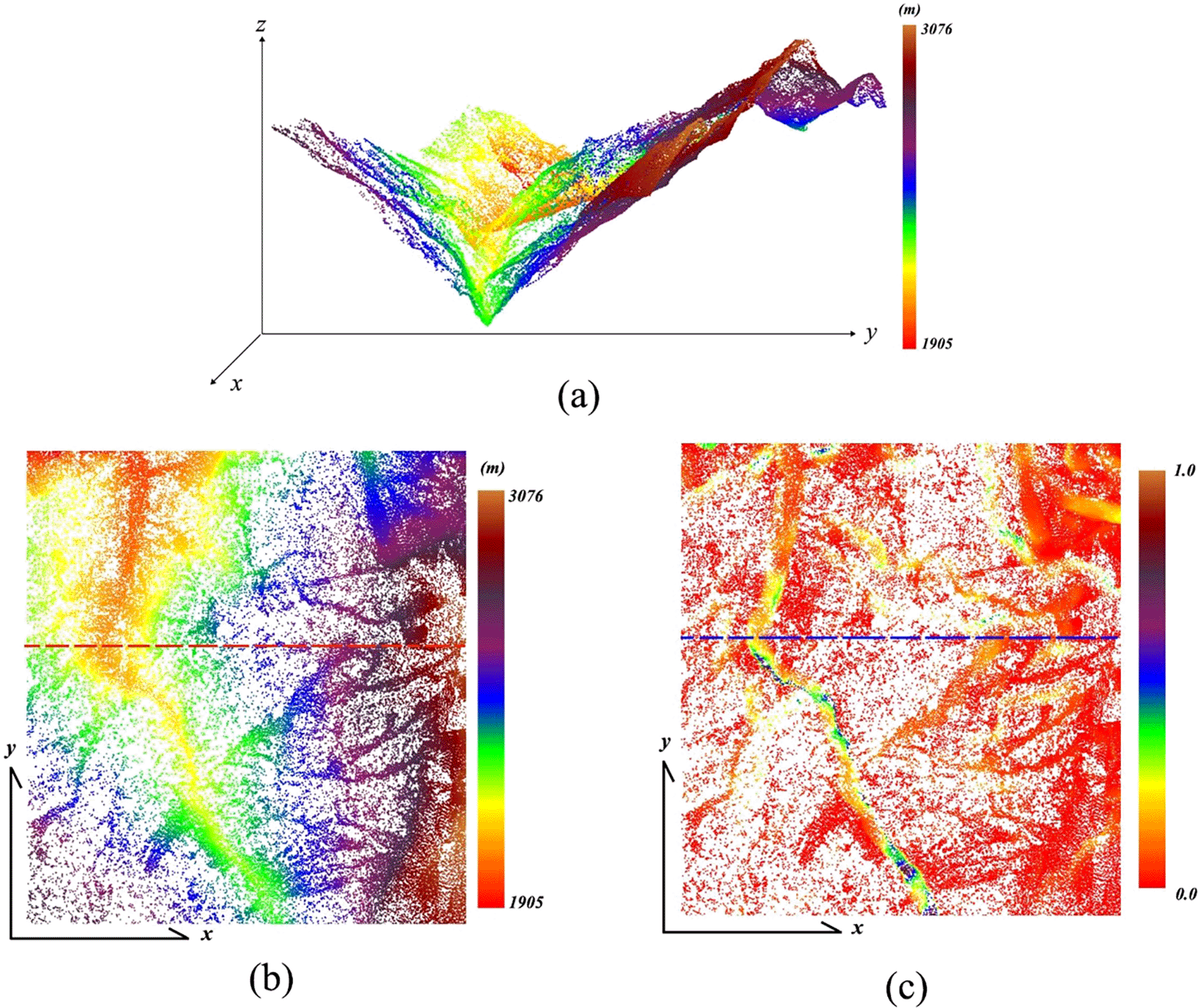
NOTE: (a) Point clouds illustrated in 2.5D view; (b) Elevation data illustrated in 2D view; (c) C data illustrated in 2D view. Own work.
To analyze the characteristics of the C data in relation to variations in elevation, this study established a section line. In Figure 2, the red line represents the elevation data and the blue line represents C data from the section lines shown in Figure 1(b) and (c). As depicted in Figure 2, C was higher in regions with large elevation gradients, and its magnitude was influenced by the extent of the elevation gradient. In areas with smaller elevation gradients, C was relatively stable. Hence, establishing a single threshold for identifying all points in the valley versus ridge regions is infeasible. In Figure 2, points near the ridge and valley regions display local maxima in the C data curves, confirming that C data can effectively assist in the identification of nodes of line features.
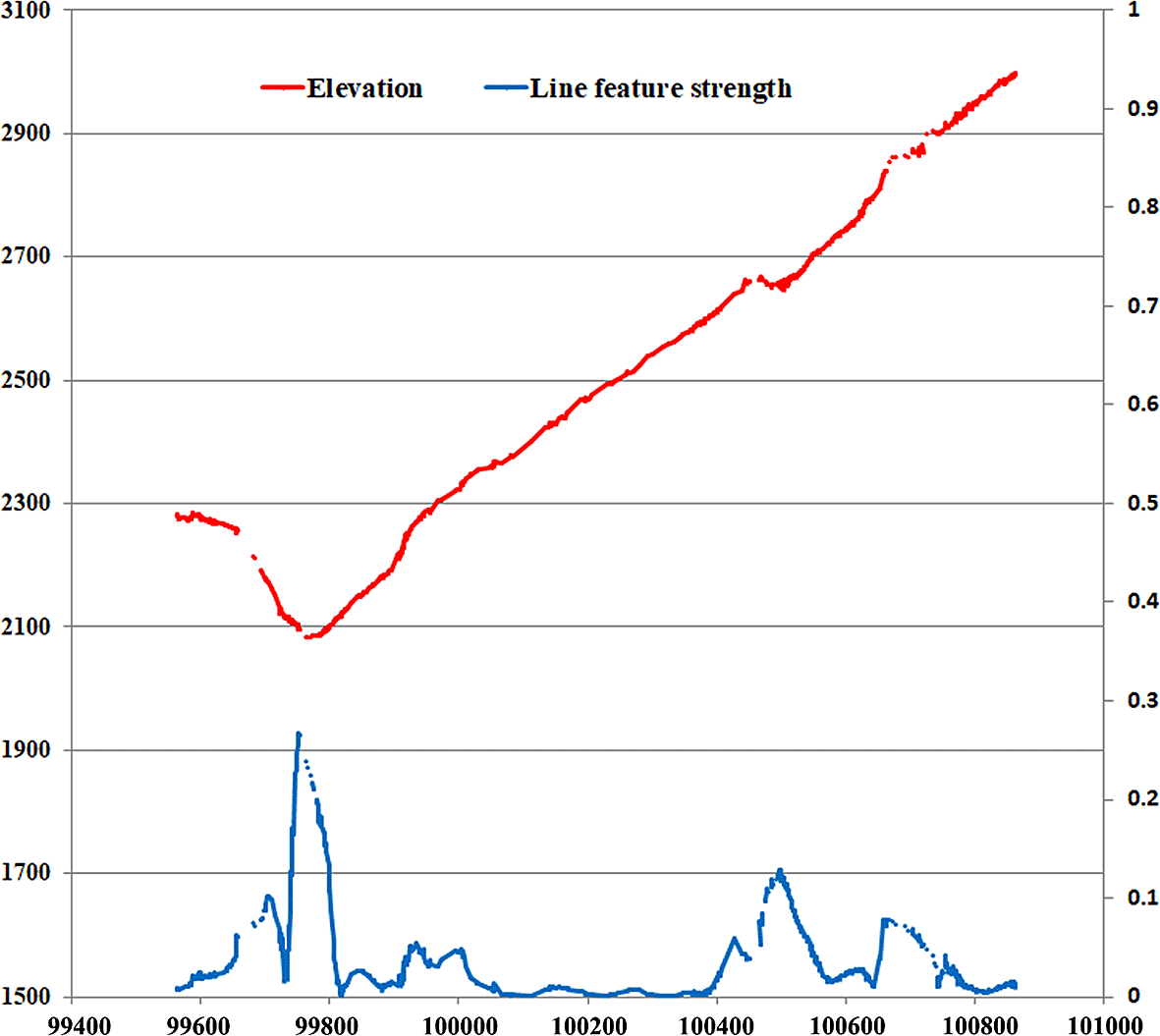
NOTE: Red line, elevation data; blue line, line feature strength data in section line of Figure 1(b) and (c). Own work.
The eigenvectors for LiDAR point clouds can be derived using the TVM. Each point cloud possessed three associated eigenvectors, each with a distinct interpretation. For points located on a surface, the first eigenvector is the vector that is normal to the surface. Conversely, for points situated on a line, the third eigenvector is the tangent vector along the direction of the line, as shown by Medioni et al.20 and You and Lin.1,2 Given that this study focuses on the extraction of ridge and valley lines, the tangent vector v for each point is considered. This vector is derived using the TVM and is crucial for eliminating extraneous point clouds.
Drawing inspiration from the region-growing method, this study established line growth criteria by choosing seed points and setting item thresholds. According to the next section, points located on the ridge or valley regions have higher C values than their surrounding points. Hence, points with local maxima C values serve as seeds for initiating line growth. Second, the v vectors of adjacent points located in the same valley or ridge line are similar. These two considerations guide the line-growth process, the specifics of which are explained in the following section.
This study establishes that such local maxima are directional in nature to provide a detailed explanation of how they are identified in 3D point cloud data. Vector v, derived from the TVM, is a critical factor. Points (i = 1, 2, …, k) considered centers within a specified search radius are divided into right (a = 1, …, m) and left (b = 1, …, n) subsets based on v, which serves as a divide. A center point cloud is deemed to be a local maxima in terms of C when the average C values on the two sides are lower than the C value of the center point. This is formalized in the following equations:
Subscript i indicates point i located on a line. represents the C value in point cloud a on the right-hand side of v (a = 1, …, m). represents the C value in point cloud b on the left-hand side of v (b = 1, …, n).
As depicted in Figure 3, points within the search radius are divided into right (R1, R2, R3, and R4) and left (L1 and L2) subsets based on v of P1. Point P1 is classified as the local maxima of C when it satisfies Equation (1). This criterion was employed to eliminate redundant points in the line growth process. Points satisfying Eq. (1) serve as candidate seeds for line growth.
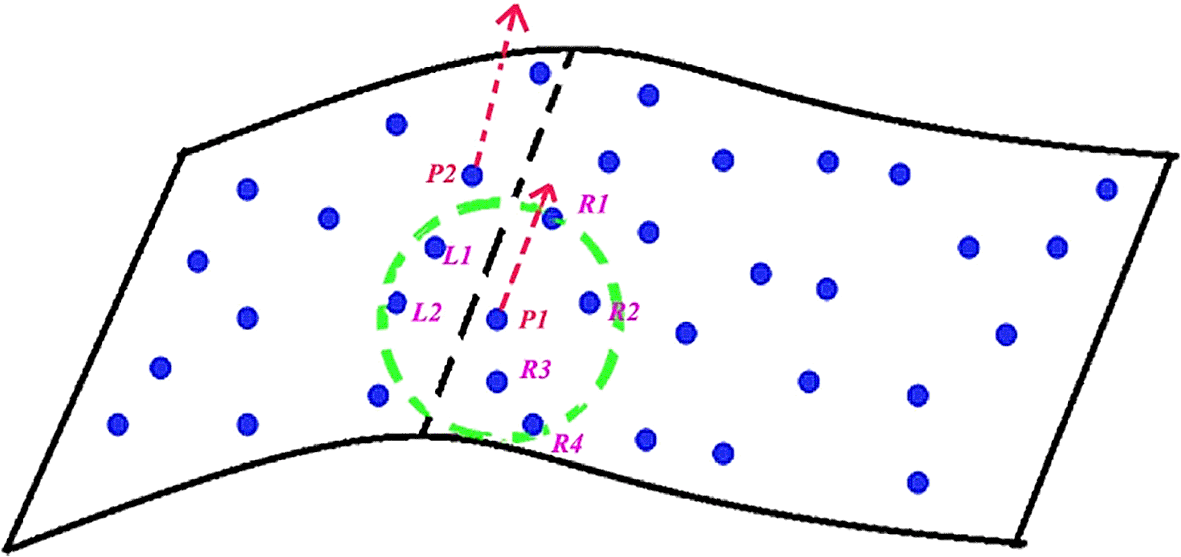
NOTE: points within the search radius are divided into right (R1, R2, R3, and R4) and left (L1 and L2) subsets based on v of P1. Point P1 is classified as the local maxima of C when it satisfies Equation (1). Own work.
When employing a large search radius, numerous point clouds not located on the line were included in the calculations. Conversely, when the search radius is small, many point clouds near the line segment are excluded, leading to incomplete line segments, particularly in the case of low-density point clouds. In this study, the radius used to identify point clouds with local maxima was consistent with the radius employed in TVM applications.
A threshold of C value may be chosen to determine all candidate seeds whose C values are larger than that threshold, as in the conventional growing method. The result would lead to the extraction of the primary ridge and valley lines only, but might filter out other minor lines. Different from the conventional method, candidate seeds are identified by seeking local C maxima for the line-growing in this article. Using this line-growing method, more details of the ridge and valley lines can be obtained. Points with higher C values are more likely to be located on lines and are therefore prioritized for line growth. According to empirical observations, neighboring points on a line should have similar tangent vectors. The threshold angle between the two v vectors can then be defined.
To meet the criteria of the angle threshold, the five points with the largest C value are regarded as the center of the ball in the TV’s searching radius, and the tangent vectors of points that meet the local maxima C value within the range are the calculated angles between the center points. The average angle value of the five groups was used as the basic threshold (ω), and three times the average value (3ω) was used as the threshold value in this study. An excessively large threshold can introduce inaccuracies by leading to the inclusion of numerous point clouds that are not actually part of the line segment, skewing the final calculations. Conversely, a too-small threshold can lead to the omission of relevant clouds and fragmentation of lines; the procedure cuts off branch lines to multiple single lines.
To preserve the detailed line features, the proposed approach adopts a moving mask algorithm from computer vision and employs an overlapping mechanism. The size of the moving ball matches that of the search ball used in the TVM, and its moving distance equals the radius of the ball. Points that satisfy both the angle threshold and Equation (1) are considered, with their C values serving as weights because a higher C value implies a higher likelihood that the point is part of a line. The node of a line and its associated tangent vector were then calculated using the following equations:
i: node i of a line. j: point j within the search ball.
n the number of nodes in a line. m: number of points within the search ball.
and tangent vector. The subsequent node of the line was determined using the following equation:
In line with the techniques used in computer vision for line extraction, overlapping regions were maintained between the moving masks. In this study, approximately half of the search balls were designed to overlap adjacent balls.
P0 [Figure 4(a)] was selected as the initial seed. Points that satisfy both Equation (1) and the angle threshold within searching ball O1 are evaluated using Equations (2) and (3), which yield new values for P1 and v1, respectively. Search ball O2 is generated through Equation (4), and the procedure is repeated to obtain P2, v2, and so on until no points within the search ball meet the criteria. At this juncture, P1, P2, and P3 become the nodes of the line, as illustrated in Figure 4(b), and new seeds are selected for the growth of additional lines until all the points satisfying Equation (1) are used.
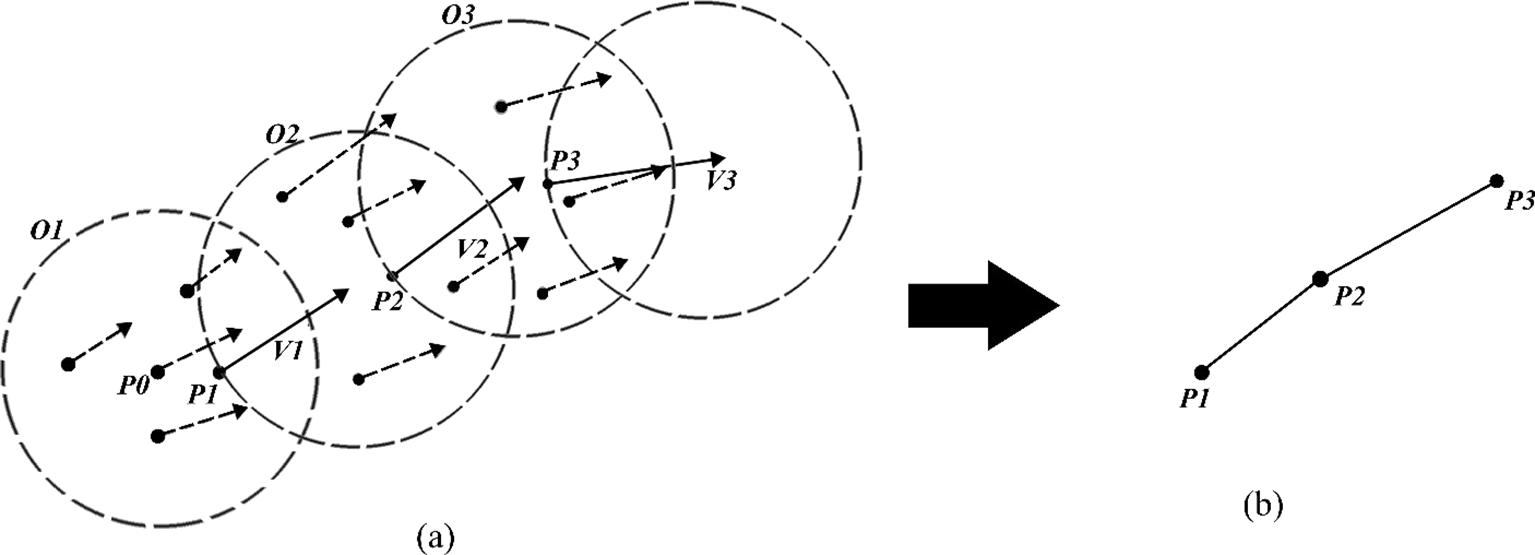
NOTE: (a) Move the searching ball to grow nodes and vectors on the basis of multiple criteria. (b) Connect the nodes to obtain a complete line. Own work.
Node-point coordinates were calculated by weighting them in accordance with their C values. Equation (4) describes the method used to determine the node coordinates. To ascertain the theoretical accuracy, error propagation calculations were conducted for each point i, as outlined in Equation (5). For simplicity, any correlations among xi, yi, and zi were disregarded.
Another quality indicator of a node point is interpolated accuracy using contour data obtained by Delauney triangulation. The formula is as follows:
i: node i of a line. n the number of nodes in a line.
: elevation from point D to plane ABC in Figure 5.
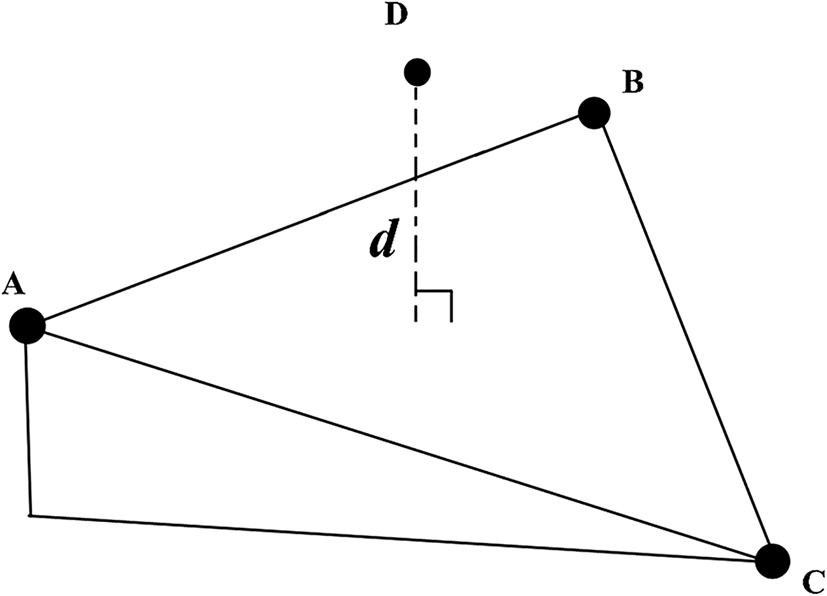
NOTE: Interpolated accuracy using contour data is obtained by Delauney triangulation. Elevation d is applied in Equation (6). Own work.
Contour data were used to produce a Delauney triangulation network. The nodes of the line are interpolated to obtain the difference in the elevation data and calculate the interpolated accuracy for each line. Once the theoretical and interpolated accuracies of each node of a line segment have been determined, the error propagation technique can be used to obtain the error band of the segment (Figure 6). Here, x and y are treated as independent uncorrelated random variables, as indicated by the following formula:

(a) Angle θ between two coordinate systems. (b) The confidence interval established between two known nodes on the basis of the selected significance level. From “a stochastic process-based model for the positional error of line segments in GIS.” by Shi, W., Liu, W., 2000, International Journal of Geographical Information Science, 14(1), 51-66.
When () and () follow a normal distribution, the transformed coordinates (x,y) and (x’,y’) also have a normal distribution. Given a significance level of α, the confidence interval for the line on the y’-axis can be calculated as ( . ). Plotting and connecting all points within this confidence level yields Figure 6, which is similar to the GIS result.23
The LiDAR data employed in this study were collected in a mountainous region using an Optech Galaxy ALTM™ 30/70 scanner provided by Chung-Hsing Surveying, Taichung, Taiwan. The flight altitude was set at 4,400 m. Non-terrain LiDAR point clouds were filtered out of the data. The LiDAR system captured data at a density of 0.05 points/m2 and had horizontal and vertical accuracies of approximately 2.2 and 0.35 m, respectively. The authors have provided flow diagram of line growin to benefit readers and peers to replicate our work in Figure 10. The mountainous region investigated in this study is shown in Figure 1(a). Given the low density of LiDAR data, a search radius of 50 m was selected to capture a sufficient number of point clouds for depicting ridge and valley lines.
Identifying local maxima in C values is critical for designating seed points to initiate the growth of ridge and valley lines. In Figure 7, the point clouds are classified into two types using Equation (1).

NOTE: Candidate seeds are indicated in orange, and other points are in green. Own work.
Following the initial phase, the line growth was executed using Equations (2)–(4). In this step, redundant point clouds were eliminated, and points were connected to form ridges or valley lines. Figure 8 illustrates the results with different colors demarcating the various line segments. The search radius was 50 m. The basic threshold (ω) is approximately 5°, and three times the average value (3ω) is 15°applied as the threshold value in this study. Although some fragmented ridge and valley lines were obtained, the line growth algorithm effectively extracted both prominent and subtle line features, despite the low point cloud density.

NOTE: Each with a unique color. The most crucial lines were successfully extracted. Own work.
Ridges and valley lines were obtained following the line-growing procedure, although these lines consisted of fragmented segments (Figure 8). The theoretical accuracies of the ridge and valley lines were calculated and the corresponding data are listed in Table 1. The lowest horizontal and vertical theoretical accuracies are approximately 2.5 and 0.40 m. These values closely match the accuracies reported in LiDAR instrument documentation. In some instances, the theoretical accuracy surpassed the reported instrument accuracy. Notably, applying the line-growing method resulted in considerably greater line accuracy, as indicated by a 90% enhancement in both horizontal and vertical measurements (2.508 vs. 0.253 m and 0.398 vs. 0.040 m, respectively; Table 1).
| Theory accuracy | Horizontal (m) | Vertical (m) |
|---|---|---|
| Min | 0.253 | 0.04 |
| Max | 2.508 | 0.398 |
| Avg | 1.239 | 0.197 |
In this region, a contour map was drawn by experienced survey workers using stereo plotters. The interval height of the contour lines was 20 m, and the nodes of the contour lines were applied to produce a Delauney triangulation network. The extracted nodes of the line in Figure 8 were interpolated using Equation (6), and the interpolated accuracy is displayed in Table 2. The worst interpolated accuracy (approximately 16.102 m) is still less than the interval height of contour lines (20m), therefore the method is effective in enhancing the accuracy, even at 98% (16.102 vs. 0.205 m).
| Interpolation accuracy | Vertical (m) |
|---|---|
| Min | 0.205 |
| Max | 16.102 |
| Avg | 3.403 |
Figure 9 shows the contour lines together with the results, and indicates the favorable accuracy and reliability of the results. Automated processes can reduce the required time and effort by eliminating redundant tasks.
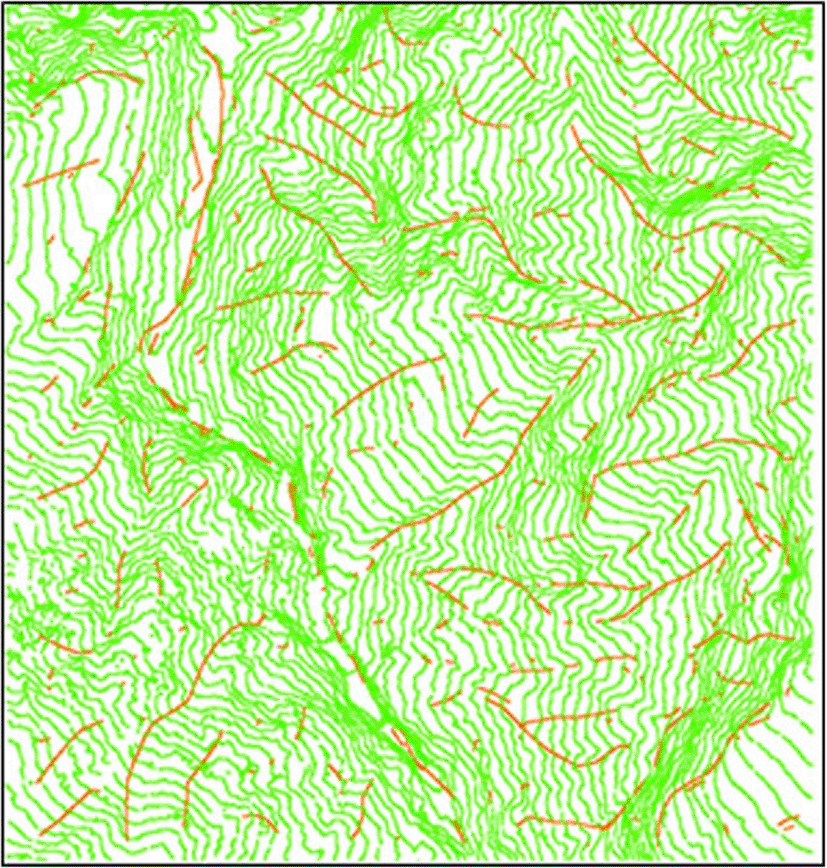
NOTE: Lines extracted through line growth (red) and contour lines (green). Own work.

This study employed the TVM to obtain the line feature strength C and its corresponding eigenvector v of discrete LiDAR point clouds, which are helpful parameters for extracting valley and ridge lines from LiDAR datasets on mountainous terrain. By utilizing the local C maxima, redundant data points can be effectively eliminated, and the computational efficiency can be enhanced. Furthermore, the angles between successive v vectors serve as crucial metrics for refining the alignment of adjacent points along the lines. C and v values contribute substantially to the line-growing technique applied to mountainous regions in this study. The concept of a moving mask was adopted to maintain intricate line details. Employing the line-growing technique enables the extraction of primary and minor ridge and valley lines contingent upon specific project requirements. The method can be applied to any terrain to extract line features, which is different from setting thresholds to affect the final results.
The line-growing technique developed in this study can yield highly accurate line nodes for the extraction of ridge and valley lines in mountainous regions. The proposed approach is effective in capturing both primary and minor ridges but tends to produce lines that are short and fragmented. One avenue for improvement lies in connecting these fragmented ridge or valley lines when they belong to the same topographical features that will be studied in the future. The method presented in this paper is fast and automated and can furnish operators with a wealth of detailed information about minor line features. This enables the extraction of ridge and valley lines that are tailored to specific requirements. Undoubtedly, the method developed here can be generalized to a large amount of LiDAR data.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)