Keywords
bread wheat traits and phenotypes, data interoperability, information retrieval, ontology alignment, ontology mapping representation, wheat breeding
bread wheat traits and phenotypes, data interoperability, information retrieval, ontology alignment, ontology mapping representation, wheat breeding
Plant phenotyping aims to understand how genetic variations and environmental factors influence plant traits. It plays a critical role in crop improvement and precision agriculture to enable sustainable food production and adaptation to climate change. Protocols are being developed to measure phenotypes of plants such as wheat in order to speed up breeding. Wheat is one of the most widely cultivated cereal crops playing a vital role in human nutrition, agriculture, cultural and economic development.1,2
Phenotyping generates large amounts of heterogeneous data such as field and greenhouse observations and measurements.3 These phenotypic experimental data include raw and computed traits standardized and FAIRified in database.4 They inform and validate scientific conclusions published in scholarly articles. Therefore, phenotypic experimental data and the description of their corresponding traits in scholarly articles differ in scope and type. On the first hand, experimental data quantify measurable properties of the plant within a limited spatial and temporal scope (cf. Table 1). On the other hand, traits descriptions in the text of scholarly articles qualify the characteristics of wheat varieties (cf. Figure 1). Table 1 gives an example of the observation data available in the GnpIS information system: https://urgi.versailles.inrae.fr/ephesis/ephesis/viewer.do#dataResults/trialIds=801.
| Lot Number | Accession Number | Accession Name | sept: Septoria score |
|---|---|---|---|
| Grapeli | 36801 | GRAPELI | 3 |
| AO13031 | AO13031 | AO13031 | 3,5 |
| Apache | 13481 | APACHE | 5 |
| AO14001 | AO14001 | AO14001 | 5,5 |
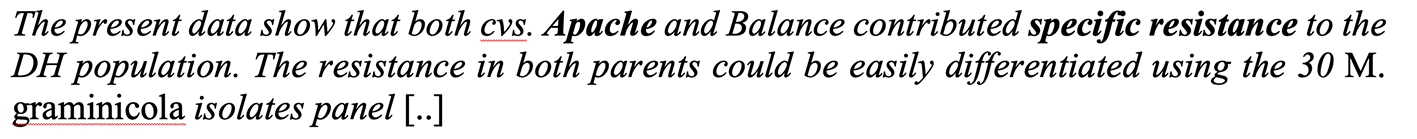
The specific resistance value of the trait has been drawn from the synthesis of multiple trials measures.
It has been collected for the trial BTH_Lusignan_2014_SetB1 in Lusignan, France in 2014. The Septoria score (Septoria tritici blotch incidence) value of Apache variety for this specific trial is 5 on a scale 1 to 9, from resistant to susceptible.
The example from the scholarly article5 in Figure 1 summarizes the conclusion of the analysis of several trials on resistance phenotypic trait of Apache variety to Septoria tritici blotch disease. Compared to experimental data, this excerpt presents a more general and synthesized finding.
The aim of our study is to integrate information coming from these two sources, (1) experimental data, (2) scholarly articles, and to propose generic and reusable methods and tools beyond our use case. Our operational goal is their integration in the WheatIS and FAIDARE data discovery portals (https://urgi.versailles.inrae.fr/wheatis/, https://urgi.versailles.inrae.fr/faidare/).6 They are web-based one-stop portals developed to access all available plant data resources that result from the international initiatives ELIXIR (https://elixir-europe.org/) and the WheatIS expert working group of the Wheat Initiative (https://www.wheatinitiative.org/).7 The data interoperability is ensured by semantic indexing by ontologies.
The two sources of experimental and scholarly articles data we considered in this study use specific conceptualizations (concepts and relations), and are managed in two different information systems, but both address bread wheat phenotyping.
The two types of data are indexed by two ontologies, respectively, the Wheat Crop Ontology (CO_321)8 and the Wheat Trait and Phenotype Ontology (WTO; http://agroportal.lirmm.fr/ontologies/WHEATPHENOTYPE).9 For example, the experimental data scores of Table 1 are indexed by CO_321:0000919 which label is Septoria tritici blotch incidence measured on the whole plant by the direct measurement method. The scholarly article example of Figure 1 is indexed by WTO:0000554 resistance to Septoria leaf blotch. The choice of ontology for indexing both data sources was made based on historical and conceptual considerations, specifically due to differences in the scope and nature of their conceptual classes. In order to fully capitalize on the complementary attributes of the two primary data sources, the essential goal of facilitating federated search requires mapping the classes of the two ontologies. Indeed, the WheatIS and FAIDARE data portals offer full-text search and resource annotation that can both take advantage of a mapping between CO_321 and WTO to easily find experimental and scholarly article trait-related data.
The conceptual differences between the two ontologies make the alignment a complex task. Although their hierarchical structures are similar, organizing the trait classes from general to specific, the trait classes of CO_321 and WTO represent different levels of abstraction and information aggregation. The first is tailored to the needs of data producers and experimenters, while the latter is organizing scientific knowledge as synthetized in scholarly articles.
Indeed, WTO mostly defines and ontologically organizes atomic concepts that represent different traits, while Crop Ontology is a list of phenotypic variables based on the entity-attribute-value (EAV) model. Each variable is a triplet semantically aggregating a trait, a measurement method and a unit or scale.
(1) is an illustrative example.
(1) The single stay-green trait of WTO characterizes the wheat variety’s general capability to maintain its green leaves and photosynthetic capacity after anthesis. In CO_321 multiple traits qualify the measurement of observable vegetative greenness and canopy photosynthetic size, including the Normalized difference vegetation index or the Canopy green normalized difference vegetation index. Each of these traits is associated to a method and scale.
Therefore, to enable an integrated search of heterogeneous data in WheatIS and FAIDARE data portals, we studied the conceptual differences, defined alignment procedures and identified all alignments between the WTO trait classes and the CO_321 trait classes.
Before describing the alignments between the two ontologies (Result section), we will introduce the method used to obtain them and the Simple Standard for Sharing Ontological Mappings (SSSOM) representation (Method section). The next section (Background section) is dedicated to the two ontology specificities and alignment methods and representation.
The Crop Ontology (CO) was created by the CGIAR in 2008 to describe the traits of 17 crops. (https://cropontology.org/). CO_321 is dedicated to bread wheat (https://github.com/Planteome/CO_321-wheat-traits). It contains 467 trait classes and 87 synonyms in 16 subtrees of depth 2. The crop ontologies follow a conceptual model that defines a phenotypic variable as a combination of a trait, a method and a scale. The CO format is adopted by the Minimum Information About a Plant Phenotype Experiment (MIAPPE, https://www.miappe.org/)10 and the Breeding Application Programming Interface (BrAPI, https://brapi.org/).11 CO_321 has been used for the phenotypic variables of the experimental data generated by the European Whealbi (https://wheat-urgi.versailles.inrae.fr/Projects/Achieved-projects/Whealbi) (12 trials) and the French BreedWheat (https://wheat-urgi.versailles.inrae.fr/Projects/BreedWheat) (60 trials) projects.
The Wheat Trait Ontology (WTO) was developed by the MaIAGE research laboratory within the SamBlé project to facilitate the annotation of textual data using ontologies. The WTO is accessible on AgroPortal (https://agroportal.lirmm.fr/ontologies/WHEATPHENOTYPE/) in both OBO and OWL formats. It comprises two main sections: the Environmental Condition subtree, which includes 236 classes, and the Plant Property subtree. The latter is further divided into the Trait subtree (WTO:0000006) and the Phenotype subtree (WTO:0000005), resulting in a total of 514 classes. These classes encompass all aspects of plant properties across six primary categories: development, growth, morphology, quality, reproduction, and response to environmental conditions. The WTO model is deeply structured to facilitate navigation and reuse for data and knowledge discovery. The maximum depth of WTO is 9 and includes 486 synonyms. The plant property trait and phenotype classes are respectively used to annotate the trait and phenotype values in scientific documents.12 The SamBlé application provides an AlvisIR-based search engine where plant properties are linked to genes and varieties in PubMed references (https://bibliome.migale.inrae.fr/wheat/alvisir/webapi/search?q=wheat+LR*+%28resistance+to+pathogen%29).
Both ontologies are presently employed within the FAIDARE and WheatIS portals for indexing wheat experimental and PubMed literature data. This functionality enables users to filter data using the Ontology Annotation facet and search for results associated with ontology terms (e.g., mapped, synonyms). However, the federated information retrieval currently utilizes only the alignment of 59 class labels that are identical in both ontologies. The presence of many more shared concepts could be exploited with the creation of new formal alignments.
Ontologies provide a formal description of a set of concepts and the relations between them in a domain area. Therefore, it represents the shared meaning of this domain, that is machine-processable and allows reasoning, i.e. generation of new knowledge, and automatic detection of inconsistencies in the semantic model. Ideally, each domain should be described by a single ontology, but numerous overlapping ontologies exist, having their own scope, and purposes and annotating a specific type of information. This is the case for WTO and CO_321 ontologies.
Ontology matching is the process of identifying semantic correspondences between ontology concepts and relations.13 A number of automatic and semi-automatic ontology matching methods were developed.14–16 Since 2004, OAEI (ontology alignment evaluation initiative) (https://oaei.ontologymatching.org/) organizes annual campaigns aiming at their evaluations on different test sets. Results for OAEI 2023 were published in17 and highlights the diversity of the methods.
As demonstrated in Ref. 18, the majority of semi-automated and automated alignment techniques primarily focus on identifying one-to-one equivalence and subsumption relationships. However, real-world ontologies often require more sophisticated set operations, such as union, intersection, disjunction, and cardinality restriction, collectively referred to as complex alignments. The evaluation of complex alignments was first introduced in OAEI 2018,19 which underscored the absence of benchmarks that include complex relations, as well as the lack of appropriate metrics for assessing the outcomes of ontology matching techniques. Both WTO and CO_321 are available on the AgroPortal ontology repository.14 AgroPortal integrates a basic ontology alignment method, called LOOM, which finds 271 mappings between WTO and CO_321 classes.
The 2021 version of AgreementMakerLight (AML) [https://www.semantic-web-journal.net/content/agreementmakerlight-0], one of the ontology matching available systems, found 93 mappings. A deep analysis of the complexity of potential alignments with respect to the state-of-the art convinced us to build them manually.
In order to make the result of the alignment task (re) usable by both humans and machines, the choice of its representation is essential. Taking into account the goals of the application that exploits the WTO and CO_321 alignments as well as the community recommendations to produce FAIR mappings,20 the target representation model should meet several needs. The mappings need to be documented with comprehensive and adequate metadata, including 1) the purpose and application domain of the alignment, here information retrieval, 2) the alignment method used, and 3) the scientific justification for each mapping. The model must allow the use of standard, possibly oriented, mapping predicates from the semantic web community, like owl:equivalentClass and skos:match and the representation of complex (1 to N) mappings. As for other data, it is also important that resources involved in the alignment are precisely identified, successive versions of the alignment are marked, and the authors and reviewers of the mappings are credited for their work.
We found a couple of representation models that were good candidates to represent alignments independently of the semantic artifacts aligned. The summary of their evaluation with respect to the needs is given in Table 2.
First of all, as the ontologies were already hosted in the AgroPortal, we considered the model used in this repository of ontologies. Indeed, AgroPortal, like other OntoPortal instances, makes it possible to store, describe and retrieve alignments between the hosted resources. It includes some elements of context such as the author (meta:creator) or an open text field to provide additional details (meta:comment). But it quickly became clear that the metadata available in this model did not sufficiently document the alignment. For example, we could not indicate a direction in the alignment, which can be problematic in the case of “narrower” or “broader” mappings.
The Alignment Format Model13 allows complex alignments to be represented but it does not fully meet the needs formulated above. Its extension, the Expressive and Declarative Ontology Alignment Language (EDOAL) model is much more complete [https://moex.gitlabpages.inria.fr/alignapi/edoal.html] but also more focused on complex alignments. Still, it is dedicated to research purposes and evaluation challenges.
During the benchmarking work, the scholarly article “A Simple Standard for Sharing Ontological Mappings (SSSOM)” was published, presenting the model developed by the biomedical community involved in the OBO Foundry.21 This standard meets the majority of our expectations and the SSSOM community is open to suggestions for improvement. SSSOM was developed to meet several objectives: to offer a standard easy-to-use representation, with rich metadata to best represent alignments and facilitate their understanding, integration and reusability. For example, the SSSOM framework provides both RDF (Resource Description Framework) and OWL (Web Ontology Language) serialization for people working in the Semantic Web framework and a TSV format for a wider audience, including domain experts.
We therefore used the SSSOM framework to represent the alignment set. Compared to others, this emerging format offers several advantages for both the alignment producers and users as discussed above. Yet, SSSOM does not allow the representation of compound (or complex) mappings, which has been identified as a current limitation by the authors and is subject to discussions in fora and community events to propose evolutions.
Interestingly, SSSOM meets our need to share alignments that respect the FAIR principles and the open science approach. In addition, it is strongly endorsed within the European Open Science Cloud (EOSC, https://eosc.eu/) and other international projects to facilitate the interoperability of participating information systems that share scientific data.
The overall goal for aligning the classes of WTO and CO_321 ontologies is to enable information retrieval from the indexed datasets regardless of the ontology used to index the data. The target users are researchers, experimenters and breeders who are not familiar with the indexing and inference principles. We defined the following competency questions that cover various topics and are representative of their needs.
- CQ1: Which scholarly articles and experiments pertain to insect resistance in wheat varieties?
- CQ2: Which scholarly articles and experiments evaluate the flour protein content of wheat varieties?
- CQ3: Which scholarly articles discuss the resistance of wheat varieties to specific diseases or pathogens, and which experiments report on wheat responses?
- CQ4: Which variety has the highest grain manganese content?
- CQ5: Which variety exhibits the greatest soil coverage?
- CQ6: What scholarly articles and experiments are available on the milling quality of wheat?
To answer these kinds of questions, information retrieval involves two types of inference, (1) the usual subsumption mechanism that retrieves the data indexed by all classes that are logically subsumed by the class of the query and (2) the logical equivalence that retrieves the data indexed by all classes that are logically equivalent to the class of the query. The first involves inference within the same ontology while the second uses the alignment between the classes of two ontologies. The two combined inference mechanisms go down into the ontologies and back and forth from one ontology to the other. The answer set of a user query class C contains the data annotated with C and all its subclasses C, and the data annotated with the aligned classes of C and C and their subclasses. Figure 2 shows the graphical representation of an abstract example.
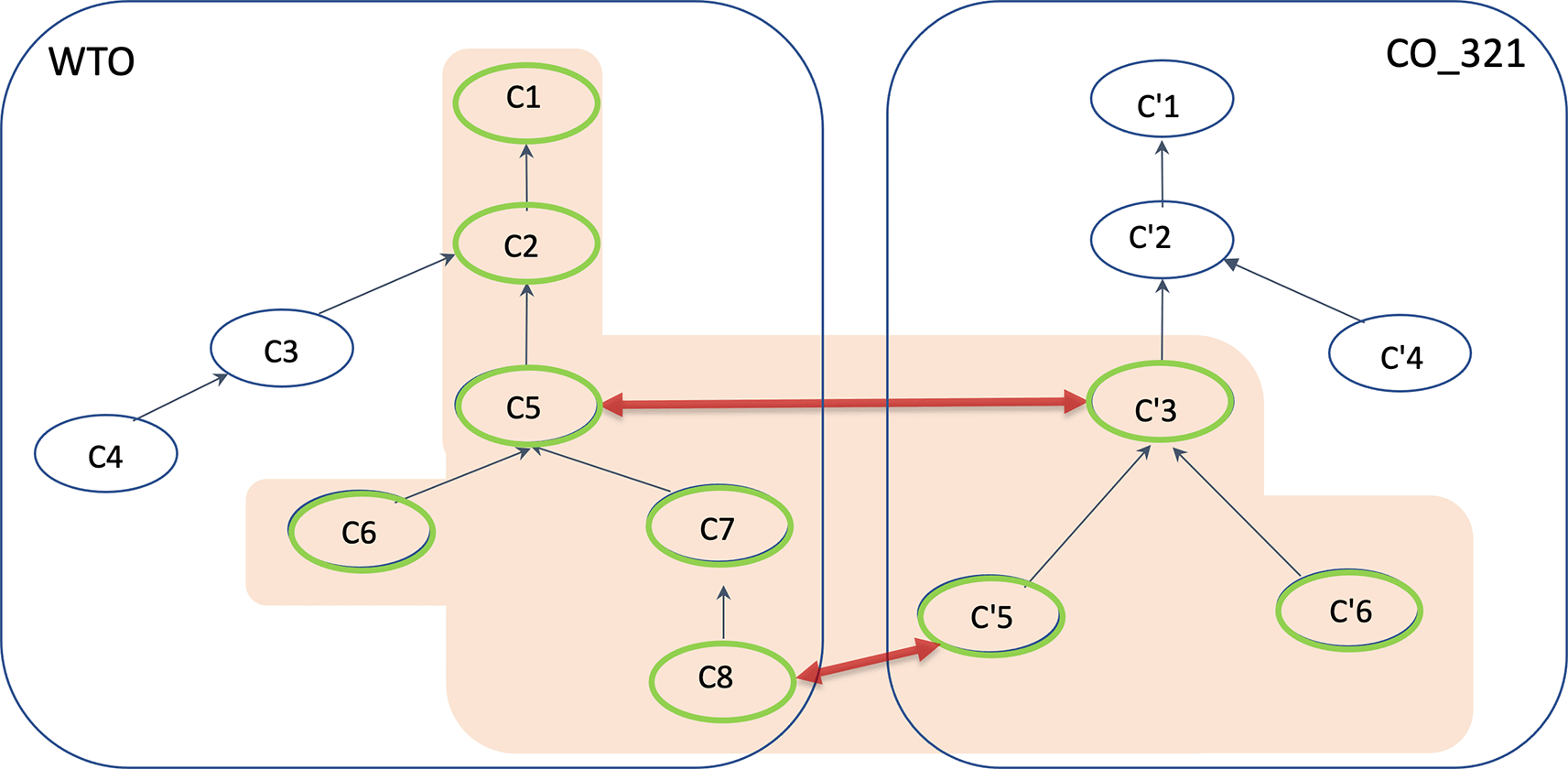
The query is on class C1. By subsumption in WTO, the data indexed by the classes C2, C5, C6, C7 and C8 are retrieved together with the initial class C1 indexed data. Given the equivalence alignment between C5 and C’3, the data indexed by C’3 are also retrieved. The subsumed classes C’5 and C’6 in CO_321are then considered. Finally, the equivalence alignment between C’5 and C8 also retrieves the data they index. The final derived class set is C1, C2, C5, C6, C7, C8 and C’3, C’5 and C’6.
To illustrate this with an example, we handle the competency question CQ6 “What scholarly articles and experiments are available on the milling quality of wheat?”. Figure 3 illustrates that the Milling quality class in WTO has two subclasses: Amount of damaged starch and Moisture content of grain. Milling quality in CO_321 is a subclass of Quality trait, while Grain moisture content is a subclass of Agronomical trait. We identified two alignments:
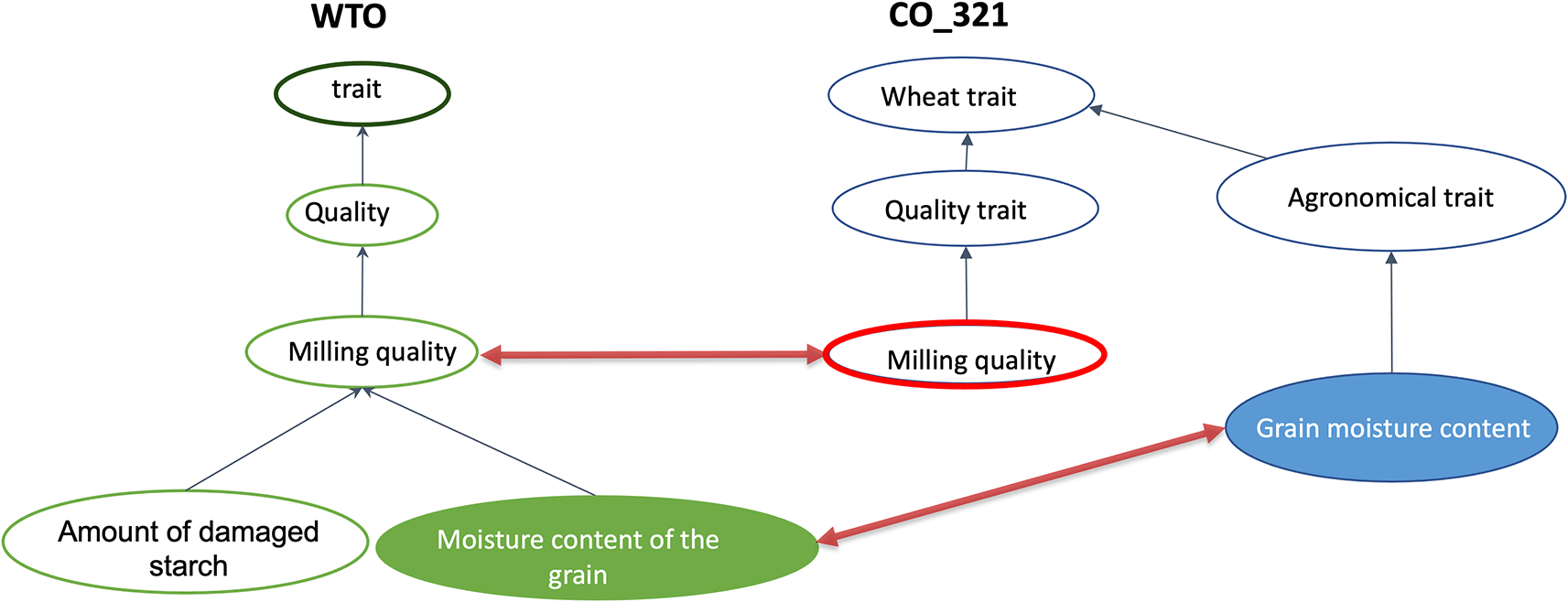
<alig1, WTO:Milling quality, CO_321:Milling quality>
<alig2, WTO:Moisture content of the grain, CO_321:Grain Moisture content>
The answer for the query Q:“milling quality” retrieves the scholarly article information indexed by WTO:Milling quality and its subclasses and the experimental data indexed by CO_321:Milling quality according to alig1 alignment. Using alig2 alignment, information retrieval also gathers the experiments indexed by CO_321:Grain moisture content.
It is worth noting that the procedure is formally complete. For instance, although the ancestors of the two classes “CO_321:Grain moisture content” and “WTO:Moisture content of the grain” are different, the answer set will be the same regardless of the starting class of the query belonging to WTO or CO_321. Our mapping decision principle is task-oriented. Two classes will be declared aligned if the user’s expectation is to retrieve the data indexed by both classes. This leads to a less restrictive meaning of the equivalence relation.
Until then we have considered the aligned classes as equivalent. It happens that there is no equivalence possible for a class C but only a more specific candidate C’. In this case, our strategy is to create an asymmetric alignment between C and C’ where C’ is subsumed by C. For instance “WTO: Leaf senescence time” is more general than “CO_321:Flag leaf senescence time” and WTO does not contain better candidate to align with. Considering such asymmetric alignments extend the retrieval capability of the system while preserving its soundness.
Regardless of differences in structure and the inference choices that result, we encountered differences in the traits due to the two ontology purposes and expert disagreement. We present in this section a detailed analysis of these differences and the alignment principles that we have adopted for aligning ontology classes.
Class naming variations
Some of the variations among the class names are shallow and are more related to a mismatch at the language level, i.e. using different terms to denote the same concept.22 An example is the pair <WTO:Moisture content of the grain, CO_321:Grain Moisture content> where the name differs by a syntactical variation. Such variations are easy to handle in an automatic way but less frequent than deeper semantic differences.
The first type of discrepancy is caused by the differences in the objective of the data annotation by the ontologies, which are the annotation of the characteristics of the plant for WTO, and the annotation of the plant precise observations for CO_321. We distinguish four cases related to (E1) whole plant vs plant part description, (E2) measurement methods, (E3) different words for expressing stress effects, and (E4) differences in modality. Examples for each of them are given in Table 3.
CO_321 does not fully follow the EAV model in that the names of the traits contain information about the entity observed (e.g. whole plant, plant part) and the method (e.g. alveograph measure), which are also formally defined. This leads to name variations corresponding to a single trait in WTO that omits the entity observed and method names from trait labels when relevant. This leads to the cases (E1) and (E2).
(E1) is an illustrative example where CO_321 trait distinguishes the part of the plant where the trait is measured, while WTO traits qualify the properties of the whole plant.
Different traits in CO_321 may qualify the same property but differ by the method that is used to observe or calculate their values. (E2) is an illustrative example.
CO_321 trait labels combine the names of biotic or abiotic stresses with eleven different words that express the effect of the stress and depend on the method and the plant part considered: score, notes, incidence, severity, response, coefficient of infection, index, AUDPC, damage, tolerance, and susceptibility. Conversely, the ability of the plant to resist microbial biotic stresses, the main source of stress, is expressed in WTO trait labels by the single word resistance. The words tolerance (to micronutrient deficiency and to extreme temperature), susceptibility (to lodging), toxicity (i.e., rhyzotoxicity), and response (to macronutrient deficiency, to animal damage, and to general stresses) are used in a complementarily way. Example (E3) illustrates these naming variations.
To deal with cases (E1), (E2) and (E3), in order to achieve our overall interoperability goal, we considered a multiple alignment of the single class in one ontology with the distinct classes in the other ontology, so that queries on any of the classes retrieve the same dataset indexed by any of the aligned classes.
It may also happen that the labels induce negative or positive values in opposite directions in the two ontologies, as in (E4), although trait names should be neutral. The decision to consider them aligned despite this requires that the user using the retrieved data be informed.
In these four cases, our mapping strategy in line with our overall interoperability goal is to align the classes if they do not otherwise differ.
Agent and disease misalignment
A large number of the class labels and definitions relate to the names of diseases and pathogenic agents and how plants respond to the biotic stress they cause. The second major source of discrepancy is the disagreement among the experts about the identification of the pathogen agents that cause diseases (cf. examples in Table 4).
First, the diseases caused by the same pathogen on different organs can be different diseases. The classes that relate to resistance to these diseases must therefore not be aligned. (E5) is an illustrative example.
The names of diseases are sometimes different in Europe, where WTO is developed, and the USA, where CO_321 is mostly developed, or may even differ more locally. In addition, the names of diseases may change over time as scientific knowledge advances.
Two different diseases in CO_321 may be considered the same in WTO, or conversely. It yields two resistance traits on one side and a single resistance trait on the other side. (E6) is an example of this case. This violates the principle of concept uniqueness.
In a simpler case, each ontology defines a single class for a given disease resistance trait, but they differ on which species names are synonyms for the pathogen agents involved. Example (E7) illustrates this case. We decided to consider the two classes aligned despite their taxonomic choice differences because in this case, the two ontologies agree on the causal pathogen agents of the disease, and the disagreement concerns naming. Therefore, the decision is to align the classes. It is worth noting that the identification and naming of pathogens evolve over time; for some, no definitive conclusions can be drawn. The pathogens may have many names that are not all reported in the ontologies.
A more complex case, as illustrated by (E8), is the case where the causal agents of the diseases to which resistance is reported, are different depending on the ontologies. Using an external taxonomic reference may help to build the alignments. Similarly to the disease distinction case above, multiple alignments have to be considered to reconcile the different agent-disease relation points of view and achieve our interoperability objective.
Finally, the level of precision in taxonomy may also vary. One ontology may group pathogen subspecies together, while the other will distinguish them into different classes. The (E9) case involves a difference in the taxonomic level where WTO class species A and B are subspecies of CO_321 class species C. The desired behavior of the information system is that queries on C would retrieve data indexed by A and B, not vice versa. Therefore, we define an asymmetric alignment to meet this requirement.
It should be emphasized that the knowledge about the identification of the causal agents of wheat diseases is constantly being revised, which explains these ontology differences.
To ensure consistency and to formalize the alignment principles at a fine-grained level, we have defined three strategies that we describe in this section.
A set of rules formalizes the naming variations of the label classes that are acceptable to align them according to the principles above (section Alignment mismatches).
A typology of alignment types defines the nature of the lexical and semantic relationships between the aligned classes.
Additional documentation describes the external source of information when it is needed, e.g., the project expertise, scientific documents, and reference taxonomy.
Alignment rules
We identified and defined 17 rules for naming variations of the label classes (Table 5). Each rule has a name, a definition in the form of a regular expression. It includes some illustrative examples, an explanation when relevant, and a comment to clarify its meaning or limitation.
For instance, the rule R1.4 Bio_Plant_response in Table 5 is about the term used to name the response to a biotic stress and is detailed in Table 6. Notice that the name of the rule was chosen to include the main words involved in the lexical variation. The full list of rules is given in https://entrepot.recherche.data.gouv.fr/dataset.xhtml?persistentId=doi:10.57745/ZLJYQO.
Alignment typology
We identified and defined alignment types to characterize the relation logically (Tables 7 and 8). The equivalence type (T1) is subdivided into five subtypes with regard to the reasons for the alignment of the classes.
| Label | Type of the alignment |
|---|---|
| T1 | Equivalence of the classes. |
| T1.1 | The two traits have the same meaning. Their labels are the same or differ slightly. |
| T1.2 | The two traits have the same meaning. The label of one of the classes is identical or slightly different from a synonym in the other class. |
| T1.3 | The two traits have different labels, but their definitions are in agreement. |
| T1.4 | The labels of the two classes match according to one of the rules of Table 4. |
| T1.5 | The two traits match according to supplementary information from external sources (e.g., scientific publications). |
| T7 | The CO_321 class is more general than the WTO class. |
| T8 | The WTO class is more general than the CO_321 class. |
Five other alignment types have been defined for the documentation of complex alignments (Table 8). Although they have been defined, the alignments of these types are not included in the published alignment file because they cannot be easily represented in SSSOM. Only the simple alignment types in Table 5 are included in the formal mapping set.
Competencies and roles of the participants of the alignment task
The highly technical nature of the phenotyping field calls for the participation of two wheat experts and five knowledge engineers who elicit the knowledge of the domain experts and represent it according to the formal framework. Characterizing the relationship between the two ontology sets of classes involves broad expertise not only in phenotyping measurement, but also in plant biology, physiology, pathology, agronomy, and food processing. The role of the knowledge engineers was divided between formulating alignment proposals, reviewing them with the help of experts when necessary, revising them, and coordinating the overall task.
Collaborative process and tools
Naturally, we have examined the candidate classes for mapping by subfields in order to concentrate the interactions into limited areas taking advantage of the highly structured nature of WTO. The classes of each subfield with their properties, labels, definitions, and synonyms were listed in a depth-first order in separate tables. Tables were used because no suitable user-friendly interface could be found to edit and visualize the alignments in a collaborative and flexible way. Once all WTO classes had been handled, we examined the remaining CO_321 classes that were still not aligned. The flat structure of CO_321 means that the knowledge engineer was constantly moving from one topic to another.
The successive versions of the alignment tables were kept in the INRAE GitLab (https://forgemia.inra.fr/urgi-is/ontologies/-/tree/feat/mapping-wheat/mapping). The two main knowledge engineers used GitLab issues to discuss with the rest of the team alignment proposals that fell outside their expertise and the scope of the name variation rules.
The issues that required the in-depth expertise of the two specialists have been dealt with in a separate file, which was more convenient for them than GitLab issues. It gathers 72 numbered questions in 32 pages broken down into sub-fields which were answered by their respective experts. Each question was answered with a paragraph of varying length depending on the complexity of the issue. The answer is followed by the decision and closed with a ‘done’ mark.
Validation and revision procedure
Once the discussion was closed, the main arguments and decisions were summarized in the comment section of the alignment tables. The mapping type, the reasons for the alignment in free text form, and the external references, when relevant, were also recorded in the alignment tables. All alignments were reviewed by one or two knowledge engineers with backgrounds in wheat breeding and knowledge representation. The review of the alignment has generated new sequences of discussions and revisions in an iterative way.
The traits of the whole CO_321 and the traits of WTO subtree have been examined and aligned when appropriate. Table 9 gives the total number of classes and the number of classes for which an alignment has been found; only 140 WTO and 109 CO_321 classes could not be aligned, i.e., 23% of the total.
| # WTO trait classes | 596 |
| # WTO aligned classes | 456 |
| # CO_321 classes | 467 |
| # CO_321 aligned classes | 358 |
Figure 4 shows the distribution of the mapping types from 0 to 8 (section Alignment typology). As expected, the most frequent types are 0 (no alignment found) and 1 (equivalence). The 7 and 8 alignment types represent the asymmetric relations where the pair members are not equivalent but one is more general than the other. As expected, type 7 (the WTO class is more specific) is less frequent than 8 (the WTO class is more general) since the depth of CO_321 is low with only 3 levels.
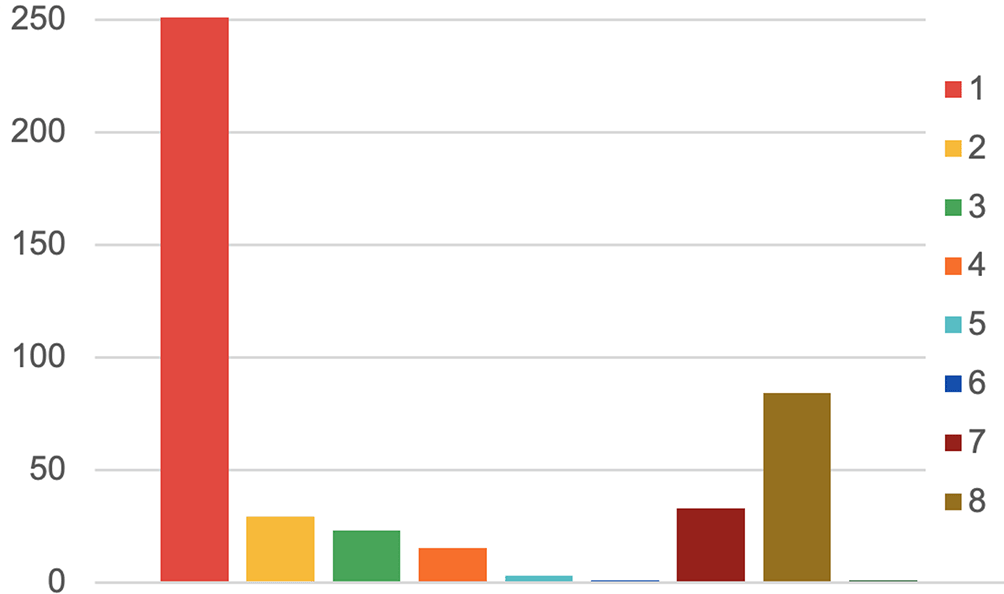
1: equivalence; 2 to 6: complex; 7: broader WTO class; 8: broader CO_321 class.
Only alignments of type 1, 7 and 8 can be represented in SSSOM.
- The subcategories of type 1 (equivalence) have been represented by skos:exactMatch (types 1.1, 1.2 and 1.3), skos:closeMatch (type 1.4) and skos:relatedMatch (type 1.5).
- Types 7 and 8 are represented respectively by skos:narrowMatch and skos:broadMatch.
Table 10 gives the number of alignments represented in SSSOM per type of skos match.
| Type of alignment | Number |
|---|---|
| skos:exactMatch | 76 |
| skos:narrowMatch | 81 |
| skos:broadMatch | 32 |
| skos:closeMatch | 161 |
| skos:relatedMatch | 0 |
| TOTAL alignments | 350 |
As detailed in section Class naming variations, the lexical and semantic variations among the two class sets led to extending the bijective frame to multiple mappings where a class in one ontology may have more than one image class in the other ontology. Figures 5a and 5b show the distribution of multiple mappings of the two ontologies. Multiple mappings have different causes that are related to differences in class granularity and disagreements on pathogen agents causing diseases (section Agent and disease misalignment).
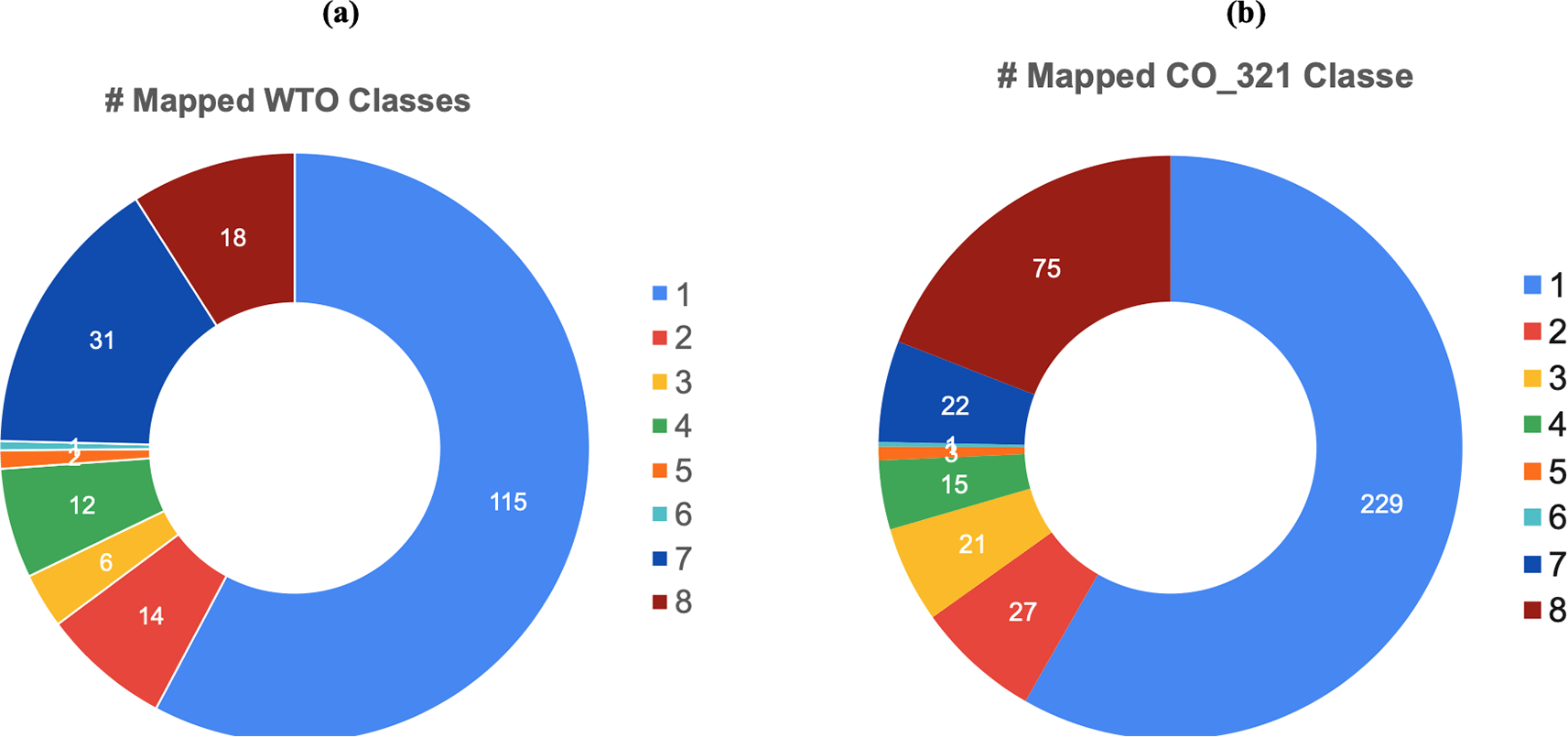
The high number of multiple mappings (up to 8 WTO classes mappings to CO_321 classes) are due to three causes: (E1) whole plant vs plant part description, (E2) measurement methods, and (E3) different words for expressing stress effect measure (e.g. note, score, incidence). Multiple classes detailing the different plant parts affected, the different measurement methods used slightly varying by their labels were considered as equivalent in order to ensure the retrieval of all data related to a given trait.
Table 11 gives an example of a multiple mapping of type T1 (equivalence) (Table 5) of the class resistance to Fusarium head blight (WTO:0000483). It is aligned to 7 classes from CO_321 that differ by the words expressing biotic stress effect measures.
These alignments are all justified by the application of one of the rules. Therefore, the alignment type of Table 9 example is T1.4, i.e. The labels of the two classes match according to one of the rules, according to the alignment typology.
The result of this alignment task is a mapping set published as a tabular file (TSV format) that conforms to the SSSOM specifications1 and includes the information listed in Tables 12 and 13. In the TSV format, the mapping set metadata is described in the header of the file (Table 12). In the body of the file, each line contains a mapping (subject - predicate - object) with its own metadata (Table 13).
| Property | Description | Example |
|---|---|---|
| creator_id | Identifies the persons or groups responsible for the creation of the mapping. | “https://ror.org/02kvxyf05” |
| creator_label | A string identifying the creator of this mapping. | “INRAE” |
| curie_map | A valid curie map that allows the unambiguous interpretation of CURIEs | #skos: “http://www.w3.org/2004/02/skos/core” |
| license | A url to the license of the mapping. In absence of a license, we assumed no license. | “https://www.etalab.gouv.fr/licence-ouverte-open-licence/” |
| mapping_set_id | A globally unique identifier for the mapping set (not each individual mapping). Should be IRI, ideally resolvable. | “https://doi.org/10.57745/ZLJYQO” |
| object_source | URI of vocabulary or identifier source for the object. | “https://cropontology.org/term/CO_321” |
| object_source_version | Version IRI or version string of the source of the object term. | “July 2018” |
| subject_source | URI of ontology source for the subject. | “http://opendata.inrae.fr/wto” |
| subject_source_version | Version IRI or version string of the source of the subject term. | “3.0” |
| Property | Description | Example |
|---|---|---|
| author_id | Identifies the persons or groups responsible for asserting the mappings. Recommended to be a list of ORCIDs or otherwise identifying URIs. | “https://orcid.org/0000-0002-1110-8004” |
| author_label | A string identifying the author of this mapping. In the spirit of provenance, consider using author_id instead. | “Claire Nédellec” |
| comment | Free text field containing either curator notes or text generated by a tool providing additional informative information. | “The definitions of both traits correspond to the date of ear emergence.” |
| curation_rule | A (potentially) complex condition executed by an agent that led to the establishment of a mapping. | “https://doi.org/10.57745/MRGHPA” - Rule 4 |
| mapping_cardinality | A string indicating whether this mapping is from a 1:1 (the subject_id maps to a single object_id), 1:n (the subject maps to more than one object_id), n:1, 1:0, 0:1 or n:n group. Note that this is a convenience field that should be derivable from the mapping set. | “1:1” |
| mapping_date | The date the mapping was asserted. This is different from the date the mapping was published or compiled in a SSSOM file. | 2022 |
| mapping_justification | A mapping justification is an action (or the written representation of that action) of showing a mapping to be right or reasonable. | semapv: ManualMappingCuration |
| object_id | The ID of the object of the mapping. | CO_321:0000982 |
| object_label | The label of object of the mapping. | Anther extrusion |
| object_type | The type of entity that is being mapped. | owl class |
| predicate_id | The ID of the predicate or relation that relates the subject and object of this match. | skos:exactMatch |
| reviewer_id | Identifies the persons or groups that reviewed and confirmed the mapping. Recommended to be a list of ORCIDs or otherwise identifying URIs. | “https://orcid.org/0000-0001-9356-4072” |
| reviewer_label | A string identifying the reviewer of this mapping. In the spirit of provenance, consider using reviewer_id instead. | “Michael Alaux” |
| subject_id | The ID of the subject of the mapping. | WTO:0000065 |
| subject label | The label of subject of the mapping. | anther extrusion |
| subject type | The type of entity that is being mapped. | skos concept |
All the metadata elements are explained in the SSSOM documentation available online [1]. We associated the mapping set with a PDF file containing the mapping rules, i.e. the domain-related explanations for creating the mappings. References to these rules are included in the mapping file for 123 mappings, i.e. the mapping of type T1.4 (the labels of the two classes match according to one of the rules). When producing mappings manually, it is crucial to document the work done by the experts and be transparent on the reasons for creating the mappings. The curation rule and mapping justification metadata contribute to the trustworthiness and reusability of the mapping set.
The objective of our research is to consolidate experimental and scientific data pertaining to wheat breeding sourced from phenotyping experiments and scholarly articles. These datasets are indexed using two distinct ontologies CO_321 and WTO which both delineate plant traits through hierarchical class structures. However, discrepancies in ontology modeling have arisen due to conceptual differences. To leverage the wealth and complementarity of both data reservoirs, we recognize the mapping of classes as a crucial step toward ensuring data interoperability.
We qualified each alignment with the appropriate semantic relation depending on the degree of equivalence and we provided mapping justification for an effective intended use in the information retrieval task. These alignments, curated and validated through an iterative procedure involving wheat experts, are a valuable resource for researchers in wheat breeding. Furthermore, the decision to make these alignments available in SSSOM format21 greatly enhances their interoperability and usability within the broader context of knowledge graphs and ontological mappings. The conclusions drawn from this specific alignment task appear to be valuable within the broader context of integrating scientific and experimental data.
The FAIRification of phenotyping data through WheatIS and FAIDARE data discovery portals is a major challenge as there is no generic repository for trait data.4,23 WheatIS and FAIDARE are widely used by the international wheat research community and the European plant research community to find and exploit these data.
The initial application of this research will involve enhancing data discovery within WheatIS and FAIDARE through formal alignments of the WTO and CO_321 ontologies. Prior efforts within the European OpenMinTeD project established an initial set of alignments between WTO and WIPO (Wheat INRA Phenotyping Ontology), subsequently integrated with CO_321. This process involves a preprocessing saturation step, expanding the “annotation id” field (for CO_321 and WTO) and “observation variable id” (for CO_321), and incorporating all equivalent and subsumed class labels and synonyms. This augmentation simplifies the information retrieval process to a filtering task (see Figure 6).

We will enhance and refine the existing scripts to leverage ontology mapping, facilitating the retrieval of results indexed with classes mapped from one ontology to another (CO_321 to WTO or WTO to CO_321). This enhancement will enable the correlation of experimental data with literature data and vice versa. The implementation of this development is anticipated to be swift and will significantly augment the functionality of the tool.
In the medium term, we envision establishing a graphical representation of the data sources based on annotation classes and mapping. This visualization will empower users to intuitively explore the mappings and navigate through them with ease.
Furthermore, these mapped ontologies and corresponding data will be seamlessly integrated into the wheat knowledge graph, under development at INRAE-URGI, leveraging Neo4J (Network Exploration and Optimization 4 Java) technology (https://neo4j.com/). This knowledge graph encompasses accessions and related phenotypic experimental data annotated with CO_321 (Figure 7). The integration of literature data annotated with WTO in this graph will create a comprehensive knowledge system for exploring the biological mechanisms underlying phenotypic expressions.
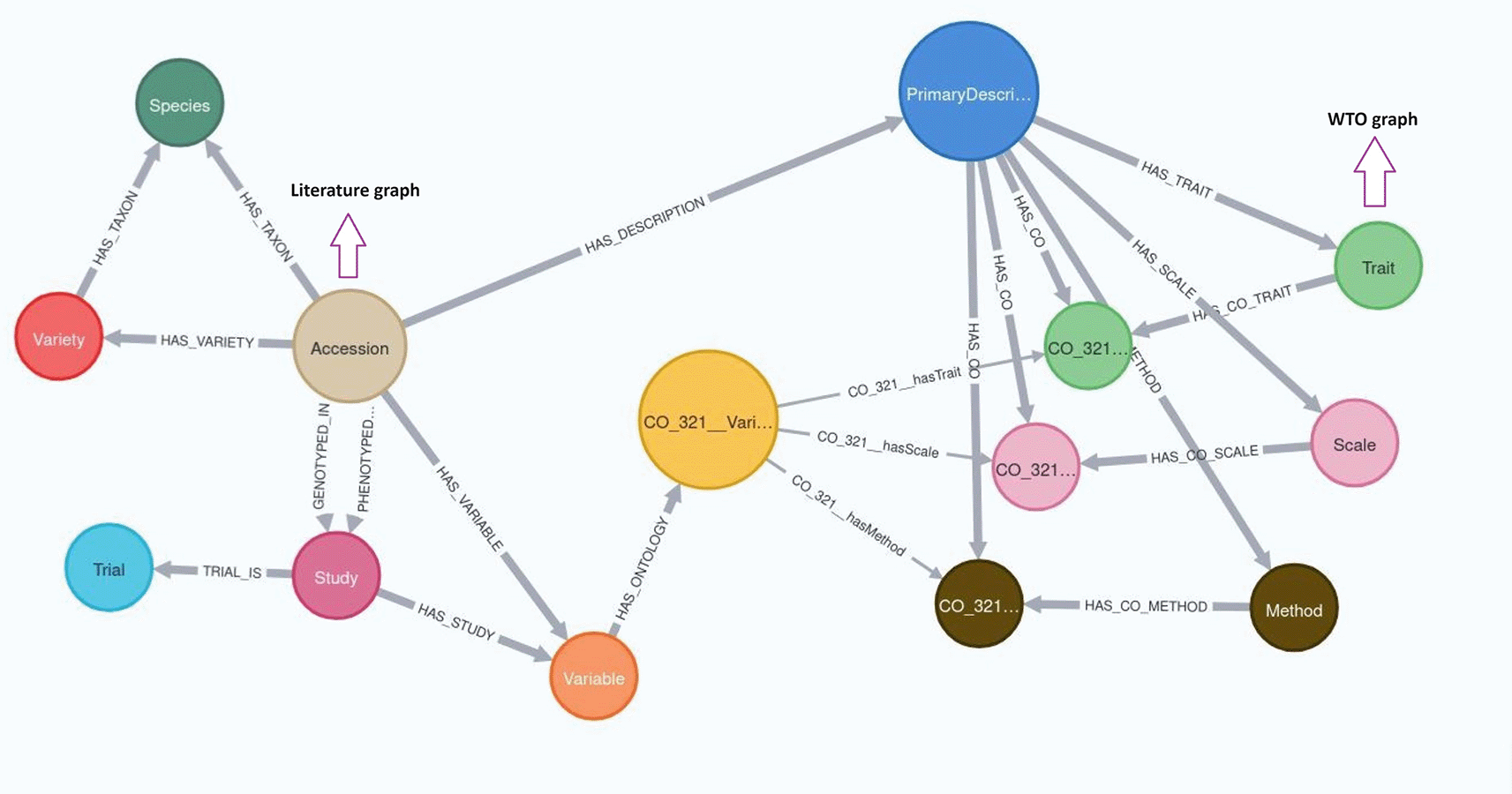
The information retrieval system within the data discovery portals is intended for wheat breeders, experimenters and researchers. A test phase is planned to identify any errors or deviations from the intended use. Beta versions of the WheatIS and FAIDARE data discovery portals will be set up to test queries, the consistency of the results and the clarity of the explanations of retrieved data. These explanations will enable users to scrutinize the data retrieval mechanisms and suggest revisions. In addition, future updates will be triggered by revisions to the WTO and CO_321 ontologies, including the addition of new classes, as well as class merging or deletion.
We chose SSSOM as the standard for representation due to its relevance in depicting alignments, their sources, and justifications. In selecting SSSOM we sought to identify a methodology that was relevant in this particular context. Following this representation work, we identify a number of avenues for further reflection regarding the limitations of our use of SSSOM. SSSOM offers functionalities that we have not yet used, which could prove useful in the future. The level of confidence of the experts is one of them. In our work, the experts were confident in their alignments. Uncertainties, such as those concerning disease-causing pathogens, are shared by the scientific community as a whole.
The main issue we encounter in the use of SSSOM concerns multiple mappings that associate a class from one ontology with several disjoint classes from the other ontology, as exemplified by the example of Table 11. The SSSOM metadata mapping_cardinality provides insight into the alignment quality by indicating the cardinality of relations, thus potentially detecting inconsistencies in SKOS mappings. The mapping_cardinality metadata takes values of 1:n in our dataset. Specifically, in the 24 cases of multiple mappings, some are of the exactMatch type. According to SKOS specifications, skos:exactMatch should have a cardinality of “1:1”. Any deviation from this rule may indicate either erroneous mappings or duplicate classes or concepts in one or both of the aligned semantic resources. We assume that the mappings of our dataset are correct. Moreover, the designers of both ontologies consider that the classes in their ontologies are not duplicated: neither the relations in WTO nor those in CO_321 include equivalence relations between classes, and they are not linked by skos:exactMatch relations.
It is the mapping process that creates pseudo-duplication of classes from the perspective of the source ontology onto the target ontology. Therefore, our current usage contravenes SKOS specifications without us having identified a satisfactory solution. Our SSSOM representation fulfills our need for formalization and sharing of our results, but its utilization will need to consider this peculiarity of multiple correspondences.
We believe that the issue raised by aligning sets of classes with different degrees of precision is a general representation problem that deserves further investigation, particularly within the context of indexing scientific and experimental data by a shared conceptualization.
Conceptualization: Claire Nédellec, Sophie Aubin, Michael Alaux, Cyril Pommier, Liliana Ibanescu,
Data curation: Clara Sauvion, Claire Nédellec, Michael Alaux, Cyril Pommier, Jacques Le Gouis, Thierry C. Marcel
Formal Analysis: Robert Bossy
Funding acquisition: Claire Nédellec, Sophie Aubin, Cyril Pommier, Michael Alaux
Investigation: Claire Nédellec, Michael Alaux
Methodology: Claire Nédellec, Sophie Aubin, Michael Alaux, Liliana Ibanescu
Project administration: Claire Nédellec
Resources: Robert Bossy
Software: Robert Bossy, Sonia Bravo, Sophie Aubin
Supervision: Claire Nédellec, Michael Alaux, Sophie Aubin
Validation: Cyril Pommier
Writing – original draft: Claire Nédellec, Sophie Aubin, Cyril Pommier, Michael Alaux, Liliana Ibanescu, Sonia Bravo
Writing – review & editing: Jacques Le Gouis, Thierry C. Marcel, Robert Bossy, Clara Sauvion
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)