Keywords
Medical Nutrition Therapy, Generative AI, Large Language Models, ChatGPT
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Datta Meghe Institute of Higher Education and Research collection.
Medical Nutrition Therapy, Generative AI, Large Language Models, ChatGPT
Noncommunicable diseases (NCDs), which are also called chronic diseases, are long-lasting and occur because of a combination of factors including genetics, physiology, environment, and behavior.1 The major categories of NCDs are known as chronic diseases, and they include cardiovascular diseases, which cause 17.9 million deaths every year across the globe. Cancers also contribute significantly to chronic disease, causing 9 million deaths annually. Additionally, chronic respiratory diseases result in 3.9 million deaths each year, and diabetes causes 1.6 million deaths per year.1
The rising incidence of chronic illnesses is having a significant financial impact on healthcare systems worldwide, and it has attracted the interest and attention of policymakers and researchers at all levels of government.2 Typically, the methods employed to manage chronic illnesses are multifaceted, and they revolve around dietary or nutritional interventions, consistent physical exercise, and lifestyle adjustments at their core.3
Studies have demonstrated that low-glycemic index (GI) and low-carbohydrate diets are successful in treating type 2 diabetes, and there has been extensive research into the use of unsaturated fatty acids, vitamins, and bioactive compounds in the management of chronic diseases. Although multidimensional approaches are crucial in managing these chronic illnesses, dietary interventions are of paramount importance and occupy a significant role in these strategies.2
A chatbot powered by artificial intelligence (AI), ChatGPT (Chat Generative Pre-Trained Transformer), was launched by OpenAI in November 2022. With both supervised and reinforcement learning techniques, it is built on top of OpenAI’s GPT-3.5 and GPT-4 large language models (LLMs).4 By using a two-stage training process, large language models learn from data more efficiently than traditional deep learning models, as they begin self-supervised learning on huge amounts of unannotated data, then fine-tune their performance on smaller, task-specific, annotated datasets based on user specifications.5
The original ChatGPT release was based on GPT-3.5 as the foundation, an LLM (Large Language Model) with over 175 billion parameters.6 The newest OpenAI model, GPT-4 was released on March 14, 2023. It is important to note that ChatGPT’s training data is derived from a wide range of online sources, including books, articles, and websites. Utilizing reinforcement learning from human feedback in conversational tasks,7 ChatGPT can consider the complexity of users’ intentions to respond effectively to a variety of end-user tasks, such as medical queries.
A growing amount of medical data and the complexity of clinical decision-making could theoretically benefit clinicians through NLP tools, allowing doctors to make timely, informed decisions. In addition, technological advancements have democratized knowledge, enabling patients to access medical information without relying solely on healthcare professionals. Instead, they are increasingly using search engines, and now artificial intelligence chatbots, to find medical information.8
By engaging in conversational interactions, Chat GPT and other recent chatbots provide authoritative-sounding responses to complicated medical queries. Even though ChatGPT is a promising technology, it often produces inaccurate results, meaning caution is warranted when applying it to medical practice and research.9–13 These engines have not been evaluated for accuracy and reliability, especially in terms of open-ended medical questions that doctors and patients might ask.10–12
Our study aims to assess ChatGPT’s ability to generate accurate and comprehensive responses to nutritional queries created by Nutritionist/Dietician. In addition, this will provide an early indication of ChatGPT’s reliability as a provider of accurate and complete information. Furthermore, this study will highlight limitations and propose an approach for addressing those.
All participants gave written informed consent. Ethical approval was not required as the study had low risk to participants.
The study uses a case study approach to achieve the research objectives stated in the earlier section. It provides rich and detailed data that can be used to gain a deep understanding of a particular case. It allows for the exploration of complex phenomena that cannot be easily studied through other research methods.14 Although there are limitations to the case study method it is one of the most useful tools in the exploratory study of abstract and evolving phenomena. The type of case study method utilized in this study is Illustrative case studies.15 The approach used in this study is borrowed from functional testing and quality Assurance practices in software development. Functional testing involves creating test cases based on the functional requirements of the software application. These test cases are designed to evaluate whether the software performs as expected. Functional testing is typically performed using black box testing techniques, which means that the tester does not have access to the source code of the software application. In this case, ChatGPT acts as a black box for the researchers involved in this study.
To evaluate the performance of ChatGPT in medical nutrition therapy a well-defined Study Protocol was used. The steps followed in the study as follows:
Step 1: Creation of questions (scenarios) of varied complexity by public health professionals. The questions were selected by the licensed medial nutrition therapist working in UAE. The selected scenario was simple diet consultation to patient with comorbid conditions.
Step 2: The response of ChatGPT was taken and recorded for further analysis.
Step 3: The responses from Step 2 were evaluated by a registered nutritionist for accuracy.
Step 4: Based on the accuracy the potential of harm score for the response was created.
Step 5: Data was summarized and analyzed by the expert group used in Step 1.
The expert group for deciding complexity contained five public health professionals working in the United Arab Emirates. The experts were selected from Gulf Medical University, UAE and method of selection was nonrandom purposive sampling. The inclusion criteria for the expert were master’s degree and clinical experience greater than five years. The researchers involved in this study approached 7 healthcare professionals out of which five agreed to be part of the expert group. The researchers wanted to recruit five to nine experts as a number greater than that if difficult to handle and a number less than that may result in bias.
For accuracy, one registered nutritionist’s response was taken for step 3. The nutritionist gave a score on a ordinal scale of one to ten where one being least and ten being most accurate.
To ascertain the potential of harm in Step 4 all five experts discussed earlier worked together.
The method utilized for reaching consensus was the Delphi method depicted in Figure 1.16 Using the steps mentioned above and data provided in the support material the reproducibility of the research can be established. Again, a scale of one to ten was used to ascertain the potential to harm where one being least and ten being highest.
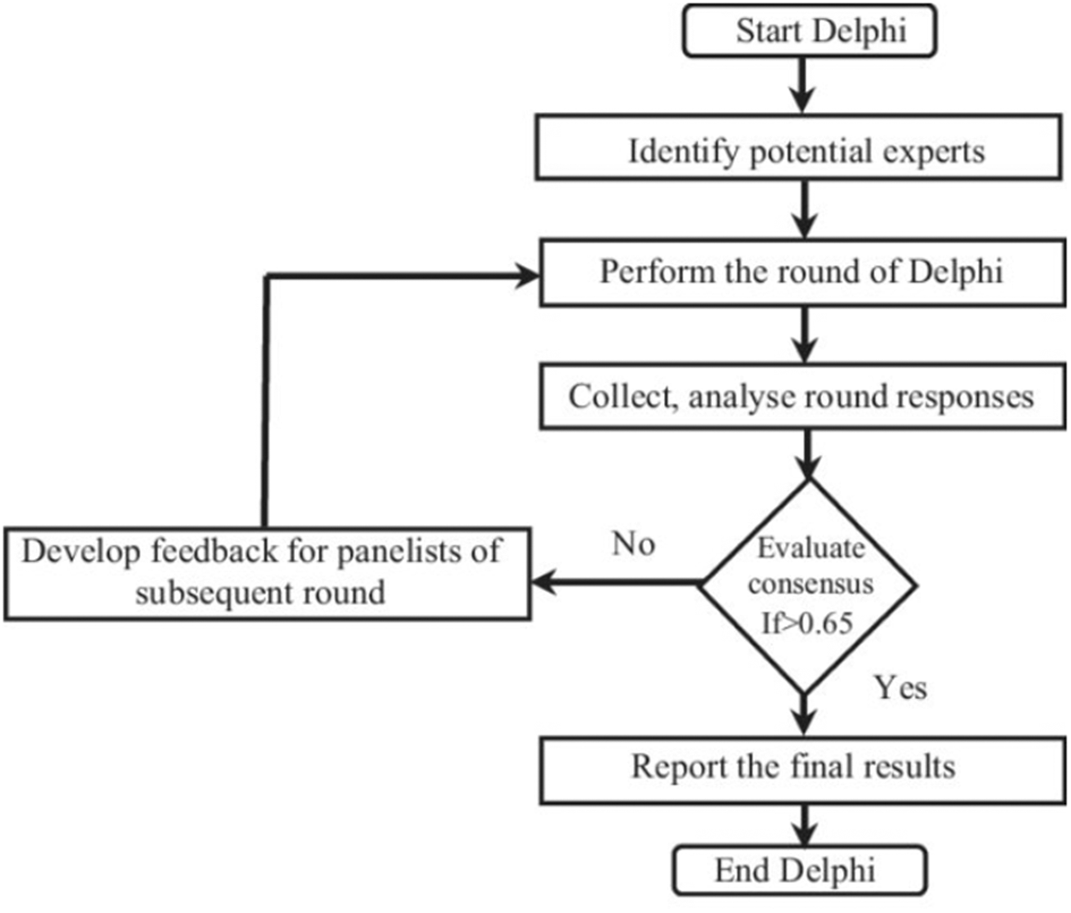
Source: Author’s Compilation.
The Delphi method is a structured communication technique originally developed as a systematic, interactive forecasting method that relies on a panel of experts. The experts answered questionnaires in three rounds. After each round, a researcher VM provides an anonymous summary of the from the previous round as well as the reasons they provided for their judgments. Thus, the experts are encouraged to revise their earlier answers considering the replies of other members of their panel. It was observed that the range of the answers decreased, and the group converged. Finally, the process is stopped after a predefined stop and the median scores of the final rounds determined the results (Figure 1).
The conceptual definitions of the terms used in the study are as follows:
Clinical Accuracy: “A clinical accuracy is a qualitative approach that describes the clinical outcome of basing a treatment decision on the result of a measurement method being evaluated”.17
Complexity of the Clinical Problem: “Clinical complexity is a protean term encompassing multiple levels and domains. Illustratively, a prominent concern in health care involves a multiplicity of disorders and conditions experienced by a person along with their cross-sectional and longitudinal contexts”.18
Potential for Harm: “Harm means an injury to the rights, safety or welfare of a research participant that may include physical, psychological, social, financial or economic factors”.19
This section discusses the results obtained from the illustrative case study method described in the earlier section.
The question is simple, with age, gender, and a weight loss goal provided. The statement emphasizes the importance of sustainable weight loss and the potential risks of rapid weight loss. The provided diet chart is low carb, high fiber/protein, suitable for the given condition. There is a negligible risk for a user following this diet unless they have comorbid conditions. The statement that a diet chart need not contain caloric information is not true, as it serves as a guideline for achieving a caloric deficit to aid in weight loss. In terms of the evaluation criteria, the statement receives a complexity score of 2, an accuracy score of 8, and a potential risk score of 1. This result suggests that in case of lower complexity the accuracy of the information is higher and potential risk is lower.
The question is slightly more complex than the previous one, with the addition of BMI information. For a person with a BMI of 34, a calorie-deficit diet is required for weight loss. The diet, however, does not specify the amount of oil to be consumed, which can significantly increase the calorie count. The diet is not specific, and portions are assumed, which may result in a diet of around 1400-1500 calories, which may not be enough to achieve the target weight loss. A layperson following this guide may not achieve their weight loss target as the diet provided is not guided. In terms of the evaluation criteria, the statement receives a complexity score of 3, an accuracy score of 7, and a potential risk score of 3. This result again supports the finding of the case 1 as increase in the complexity score reduces the accuracy while increasing the potential to harm.
The complexity of the question increases with the addition of the condition of PCOS. The diet provided is like the previous question with the addition of extra guidelines for PCOS, which is general information. However, the diet provided is not specific to the condition, and a user following it may not achieve their weight loss target, but they are not at potential risk for harm. In terms of the evaluation criteria, the statement receives a complexity score of 4, an accuracy score of 6, and a potential risk score of 4. The result of this case is also concurring the hypothesis complexity to question asked results in less accuracy and higher risk to harm.
The question is complex due to the mention of diabetes, which requires consideration of many factors before preparing a diet chart. A simple statement of diabetes does not provide enough information, and the patient should be asked about the type of diabetes, medications, and recent blood reports. Calories, BMI, and current physical activity are critical considerations for a diabetic diet. The patient is at risk of developing hypoglycemia if they are on insulin and have a low BMI or high activity levels. A dietitian would consider all these factors while preparing a plan for a diabetic patient. In terms of the evaluation criteria, the statement receives a complexity score of 4, an accuracy score of 5, and a potential risk score of 6. The complexity score of four for an older patient has less accuracy and high potential of harm. Does age contribute to potential to harm? This question needs to be further tested empirically.
The complexity of the question increases with the addition of chronic kidney disease (CKD), which requires consideration of several factors while preparing a diet chart, such as the stage of CKD and the current level of potassium and sodium in the blood. However, the statement receives a low accuracy score of 4 as the diet generated does not mention limiting the sodium intake to at least 1.5 g/day, which is essential for CKD patients. Additionally, the diet contains high sources of protein, 75-80 g, which is much higher than what is recommended for a CKD patient and not calculated as per patient weight and CKD level. As a result, a layperson following this diet may be at a high potential for risk, indicating a high potential for risk score of 8. In terms of the evaluation criteria, the statement receives a complexity score of 5, an accuracy score of 4, and a potential risk score of 8. Increasing complexity of the query from 4 to 5 increases the potential of risk from 6 to 8. This makes us conclude that with increasing complexity the increase in potential harm increases exponentially after a point. This phenomenon needs to be further tested empirically.
The complexity of the question increases with the addition of hypertension as a comorbidity. However, the diet chart provided is the same as the previous question, which does not pose much risk for diabetes and hypertension but poses all the risks previously mentioned for CKD. Therefore, the statement receives a low accuracy score of 4. Additionally, patients need to be educated about sugar and salt sources, and general guidelines are not enough. Measurements should be incorporated into the diet plan itself to avoid potential risks. As a result, the statement receives a high potential for risk score of 8. In terms of the evaluation criteria, the statement receives a complexity score of 6, an accuracy score of 4, and a potential risk score of 8. The finding of this study doesn’t concurs the finding of the case 5 that increase in potential harm with increase in exponential as increasing complexity potential risk remains same.
The complexity of the question increases with the addition of gluten sensitivity. As a result, a proper dietitian is required to prepare a diet plan that takes into consideration the patient’s multiple comorbidities and dietary restrictions. However, the statement is lacking in accuracy as it does not provide any specific information on how to prepare a diet plan for a person with these conditions. Therefore, the accuracy score is low at 4. Additionally, without a specific diet plan, there is potential for risk for the patient with so many comorbidities and dietary restrictions. As a result, the statement receives a high potential for risk score of 8. In terms of the evaluation criteria, the statement receives a complexity score of 7, an accuracy score of 4, and a potential risk score of 8. The findings from this case also concurs the finding from the earlier cases. The increase in complexity is inversely proportional to accuracy while directly proportional to the potential risk.
This question is extraordinarily complex with multiple parameters given, including the condition of hypothyroidism. The ideal diet for this patient is a low-carb, high-protein, anti-inflammatory diet, with the need to avoid goitrogenic foods like soy products. However, the accuracy of the given information is relatively low, and there is still a potential risk for the patient if not properly guided by a qualified dietitian. Overall scores are as follows: Complexity - 8, Accuracy - 3, Potential for Risk - 6. This study examines the case of highest complexity and hence minimum accuracy. The risk score for this study was expected to be highest but that is not the case. This finding does not concur the findings from the earlier seven cases.
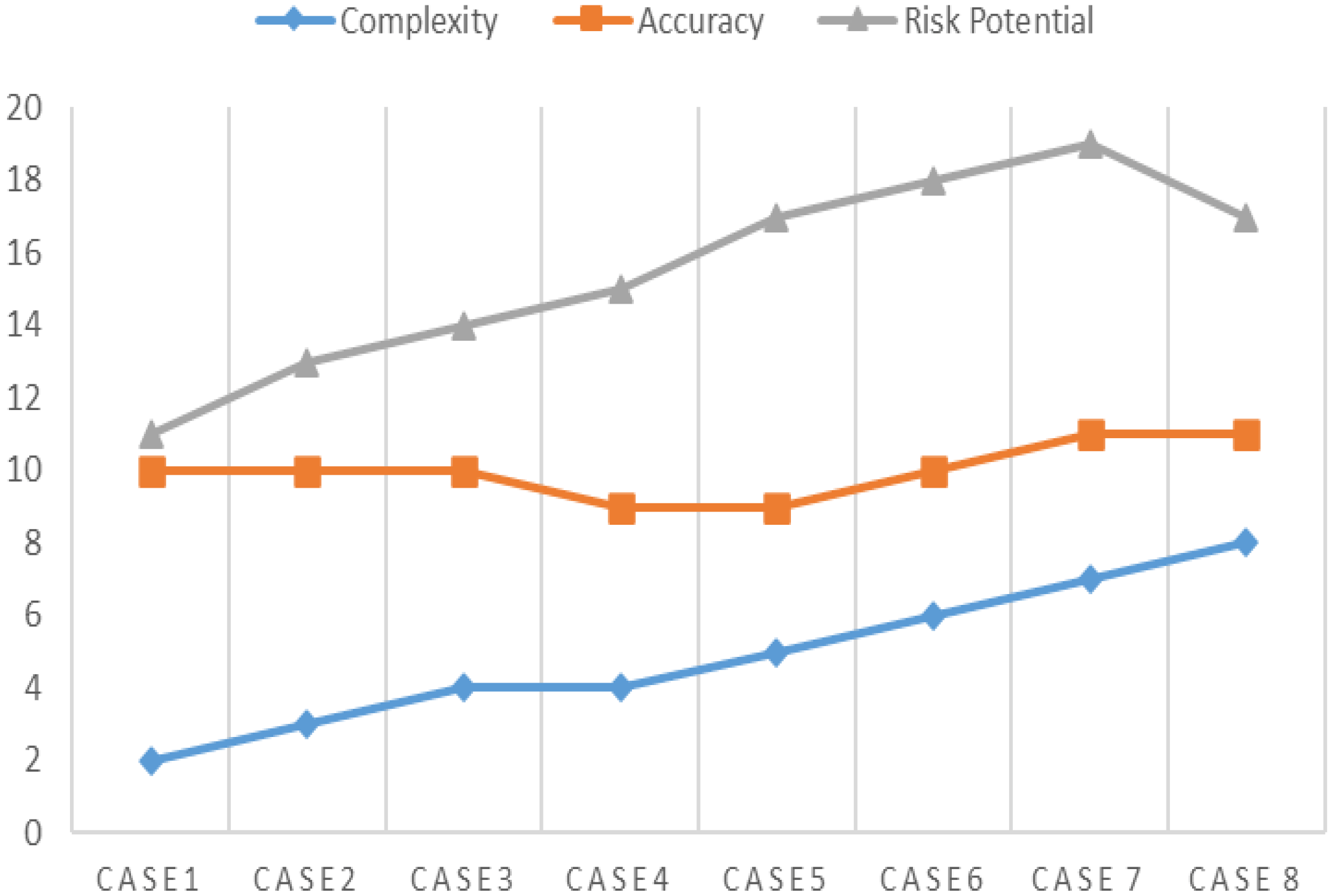
The summary of the analysis of eight cases is listed in Table 1.
| Case number | Complexity | Accuracy | Potential to harm |
|---|---|---|---|
| Case 1 | 2 | 8 | 1 |
| Case 2 | 3 | 7 | 3 |
| Case 3 | 4 | 6 | 4 |
| Case 4 | 4 | 5 | 6 |
| Case 5 | 5 | 4 | 8 |
| Case 6 | 6 | 4 | 8 |
| Case 7 | 7 | 4 | 8 |
| Case 8 | 8 | 3 | 6 |
As depicted in Figure 2, the complexity of the scenario increases risk potential also increases. That suggests that ChatGPT should be avoided for complex medical conditions/scenarios. Researchers believe accuracy does not change much with an increase in complexity and needs to be further evaluated empirically.
The findings of the study are supported by the researcher Johnson et al. (2023). They observed that ChatGPT can produce accurate information to diverse medical queries as judged by academic physician specialists although with important limitations. Further research and model development are needed to correct inaccuracies and for validation.20 Another group of researchers found that ChatGPT provides medical information of comparable quality to available static internet information.21 Another recent study suggests cautious approach against use of the ChatGPT in clinical practice. They lament that it doesn’t provide references for the information hence is not reliable for clinical use. Thus, the findings of this study also suggest the cautious use of ChatGPT in medical nutrition therapy as irresponsible use has potential harm for the user. The study assessing the accuracy and potential risks of using nutrition therapy information provided by ChatGPT, evaluated by nutritionists and a group of experts, has several limitations that must be considered when interpreting its results. ChatGPT’s responses are based on the information available up to its last training data, which might not include the latest research or updated guidelines in nutrition therapy. This time-lag in information can introduce a bias towards outdated practices or missing new evidence-based approaches. The accuracy and risk assessments made by the nutritionists and experts are subjective and can vary based on their individual experiences, knowledge, and biases. This variability can introduce both direction and magnitude biases in the evaluation process. The experts and nutritionists might have preconceived notions about the reliability of AI-generated information, which could influence their assessment of ChatGPT’s responses, either positively or negatively. The range and type of nutrition therapy questions asked may not comprehensively cover the vast field of nutrition. Thus, the study’s findings might not be generalizable across all areas of nutrition therapy.
The primary objective of the present study was to assess the accuracy and comprehensiveness of ChatGPT’s responses to nutritional queries generated by nutritionists/dieticians. To achieve this, an in-depth case study approach was employed. Functional testing was conducted by creating test cases that aligned with the functional requirements of the software application. ChatGPT’s responses were evaluated and analyzed in different scenarios that involved medical nutritional therapy, varying in complexity. The accuracy of the generated data was assessed by a registered nutritionist, and a potential harm score was used to evaluate the responses provided by ChatGPT.
When several case scenarios with varying levels of complexity were evaluated for their risk potential, it was demonstrated that as the complexity increased, so did the potential risk. The study suggests that the ChatGPT should not be used for complex medical nutrition situations and conditions, even though the accuracy of the generated response does not change much with the complexity of the case scenario.
The study’s findings have important clinical implications for practitioners, particularly nutritionists, and dieticians, who may use ChatGPT or similar AI-powered tools in their practice. Practitioners should exercise caution and avoid relying solely on ChatGPT for complex cases that require specialized knowledge and expertise.
The study’s findings underscore the importance of using ChatGPT or similar AI-powered tools appropriately in clinical practice. It should not be used as a replacement for professional judgment or clinical decision-making, particularly in complex medical nutrition situations. Practitioners, especially nutritionists and dietitians, should consider ChatGPT as a complementary tool to support their clinical practice, and not solely rely on it for making critical nutrition-related decisions. This study emphasizes the importance of human verification and not solely relying on AI-generated information.
The findings of the study have important implications for policymakers. One key recommendation is to exercise caution when implementing generative AI, such as ChatGPT, in clinical practice. Rushing to adopt such tools without thorough evaluation and validation may not be advisable. While generative AI has the potential to improve efficiency in healthcare operations, it should be considered as a decision support system for registered practitioners, rather than a standalone tool for making clinical decisions.
It is important to note that patients should not rely solely on generative AI for self-medication or medical nutrition therapy, especially in situations where multiple health conditions (comorbidities) are involved. This is because generative AI tools like ChatGPT may not have the ability to fully assess and address the complexities of comorbid conditions, which could potentially result in harm to patients.22
In conclusion, a collaborative effort involving all stakeholders in healthcare education, research, and practice is urgently needed to establish guidelines for the responsible use of ChatGPT by educators, researchers, and practitioners.
The study used a small sample size which could affect the accuracy of the results. Another limitation is the dynamic nature of technology. Since technology is constantly evolving and improving, the results of the study may need to be reevaluated after a few days or weeks to account for any changes or updates. Additionally, the study’s reliance on only one nutritionist to assess accuracy introduces the possibility of bias and human errors.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)