Keywords
Artificial Intelligence, depression, systematic review, machine learning, mental health
This article is included in the AI in Medicine and Healthcare collection.
Artificial Intelligence, depression, systematic review, machine learning, mental health
Depression is one of the most prevalent mental health disorders globally, as evidenced by recent studies, with an estimated lifetime prevalence affecting up to 17% of the population.1,2 The World Health Organization (WHO) defines depression as a condition characterized by a persistently low mood or loss of pleasure in activities, lasting for extended periods of time.3 This duration is generally accepted to be at least two weeks or longer, according to several sources.4,5 While depression manifests in various forms—such as persistent depressive disorder, perinatal depression, and seasonal affective disorder6—the term “depression” typically refers to Major Depressive Disorder (MDD), which is the primary focus of this study.
MDD often goes undiagnosed, especially in regions with limited healthcare resources or a shortage of mental health professionals.7–9 However, even in areas with sufficient access to healthcare, depression can remain untreated as individuals may downplay or hide their symptoms.10 In such cases, automated tools that can assist in accurate diagnosis may play a crucial role in improving detection and early intervention.
Artificial Intelligence (AI) represents a promising avenue for addressing these diagnostic challenges. AI, a field of computer science dedicated to solving complex, nonlinear problems,11 has experienced rapid growth in recent years. Although AI algorithms have existed for decades,12 their recent surge can be attributed to two major factors: the significant increase in computational power and the widespread availability of digital data.13 These algorithms are capable of processing vast quantities of data to identify patterns and relationships, leading to breakthroughs in many scientific and technological fields, including healthcare and mental health.14
AI can leverage different types of data, including multimedia data (such as images, audio, and video) and alphanumeric data (such as written text or clinical records). This review focuses on AI applications that utilize alphanumeric data for diagnosing MDD. This focus is driven by the accessibility of alphanumeric data compared to multimedia data, which has resulted in a greater availability of relevant datasets. Additionally, the widespread availability of these datasets facilitates the potential development of AI tools for real-world diagnostic applications. Among the alphanumeric datasets, sources include unstructured text from social media posts, mobile text messages, and psychological interviews, as well as structured data from electronic health records, standardized psychological questionnaires, and data automatically extracted from mobile devices.
The objective of this systematic review is to provide a comprehensive overview of the current state-of-the-art in AI-based diagnostic tools for MDD using alphanumeric data. By mapping existing research, this review aims to identify gaps in the field, offering insights for future research directions. The research questions outlined in Table 1 guide the analysis of the selected studies.
Following this introduction, the work proceeds with the Methods section, detailing the systematic review process. The Results section presents key findings from the analyzed studies. Finally, the Discussion section provides conclusions and addresses the implications of the results.
The selection of articles for this systematic review was conducted in two stages: an automated search phase followed by a manual screening process. The first phase involved the use of a custom-developed computational tool to retrieve all relevant research studies that met predefined inclusion criteria. The second phase, requiring manual intervention, applied exclusion criteria that could not be automated.
The automated tool was programmed to search across three widely-used academic databases:
The search was conducted on July 1, 2024, and focused on articles published since 2015. The following keyword combinations were used:
• “artificial intelligence” AND “depression diagnosis”
• “artificial intelligence” AND “depression detection”
• “artificial intelligence” AND “depression diagnostic”
• “artificial intelligence” AND “depression estimation”
• “machine learning” AND “depression diagnosis”
• “machine learning” AND “depression detection”
• “machine learning” AND “depression diagnostic”
• “machine learning” AND “depression estimation”
• “deep learning” AND “depression diagnosis”
• “deep learning” AND “depression detection”
• “deep learning” AND “depression diagnostic”
• “deep learning” AND “depression estimation”
• “artificial intelligence” AND “depressive disorder diagnosis”
• “artificial intelligence” AND “depressive disorder detection”
• “artificial intelligence” AND “depressive disorder diagnostic”
• “artificial intelligence” AND “depressive disorder estimation”
• “machine learning” AND “depressive disorder diagnosis”
• “machine learning” AND “depressive disorder detection”
• “machine learning” AND “depressive disorder diagnostic”
• “machine learning” AND “depressive disorder estimation”
• “deep learning” AND “depressive disorder diagnosis”
• “deep learning” AND “depressive disorder detection”
• “deep learning” AND “depressive disorder diagnostic”
The search targeted a broad range of publication types, including conference papers, journal articles, and book chapters, across the title, abstract, and keyword fields of each document.
Following the automated search, a manual review process was undertaken to apply exclusion criteria that could not be addressed programmatically. This step involved a detailed review of each study by three independent reviewers. The following exclusion criteria were applied:
• The study must propose a method to diagnose Major Depressive Disorder (MDD). If the method also addressed other disorders, only the portion relevant to depression was considered.
• The study must employ Artificial Intelligence (AI) for diagnostic purposes.
• The dataset utilized must consist solely of alphanumeric data.
• The study must be written in English.
• Duplicate studies were excluded, with preference given to the most recent version in the case of multiple similar publications.
Once the inclusion and exclusion criteria were applied, the remaining studies were independently reviewed by three screeners to extract relevant data for analysis. In addition to metadata automatically retrieved by the computational tool (e.g., publication year, authors, keywords), a full reading of each article was conducted to collect the following key information:
The different steps of the systematic review are summarized in Figure 1, which outlines the process of narrowing down the initial 1179 studies returned by the automatic tool to the final set of 145 studies included in this research. This filtering process followed the PRISMA guidelines, which ensure a transparent and systematic approach to study selection, incorporating eligibility criteria such as relevance, methodological rigor, and duplication removal.
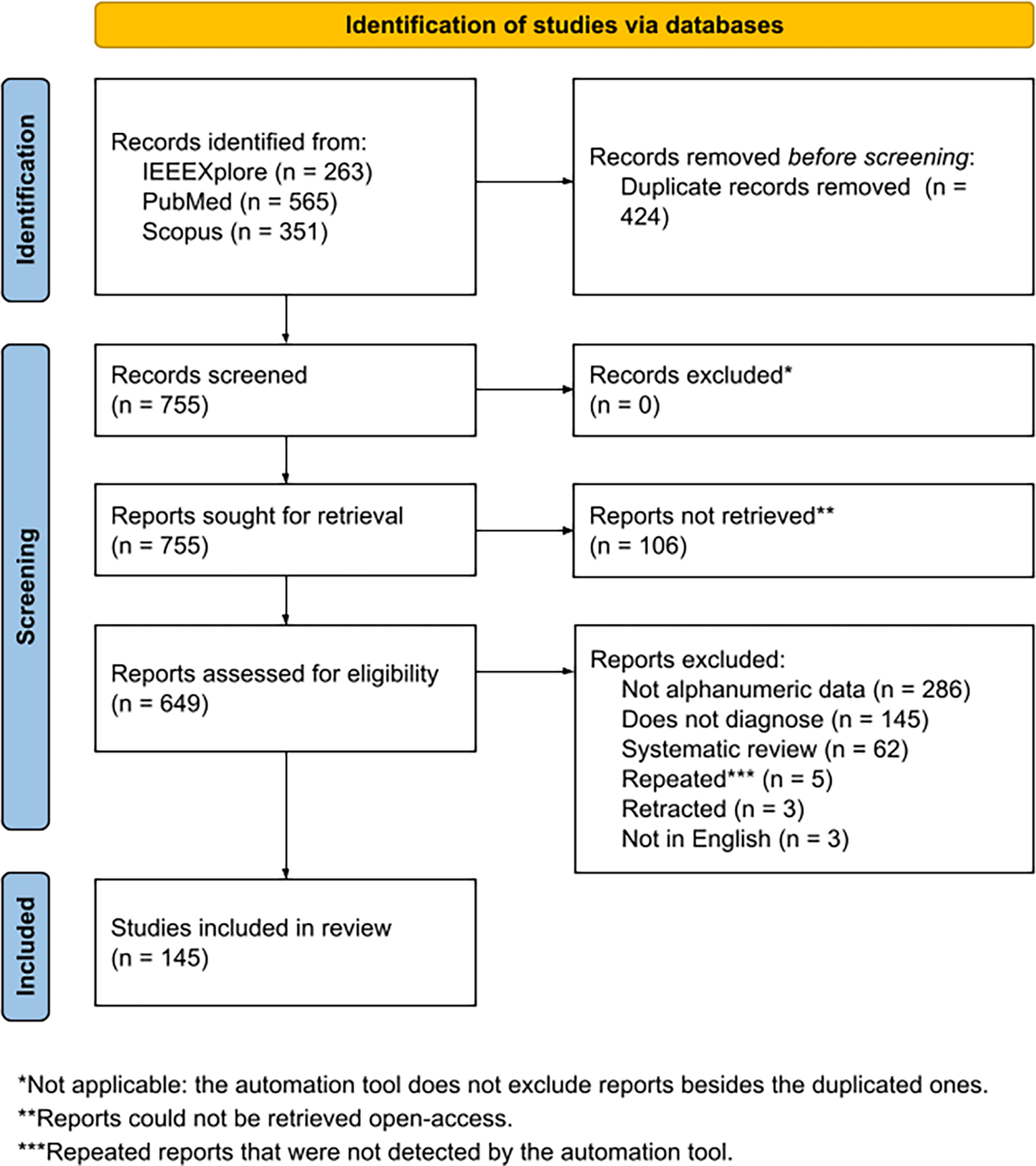
An analysis of the selected studies reveals trends over time. In Figure 2, the number of studies grouped by year is presented, showing an increasing interest in the use of AI for depression diagnosis over the last decade. The rising peak of publications coincides with the rise of social media platforms, mobile health applications, and significant advancements in AI techniques like machine learning and natural language processing.
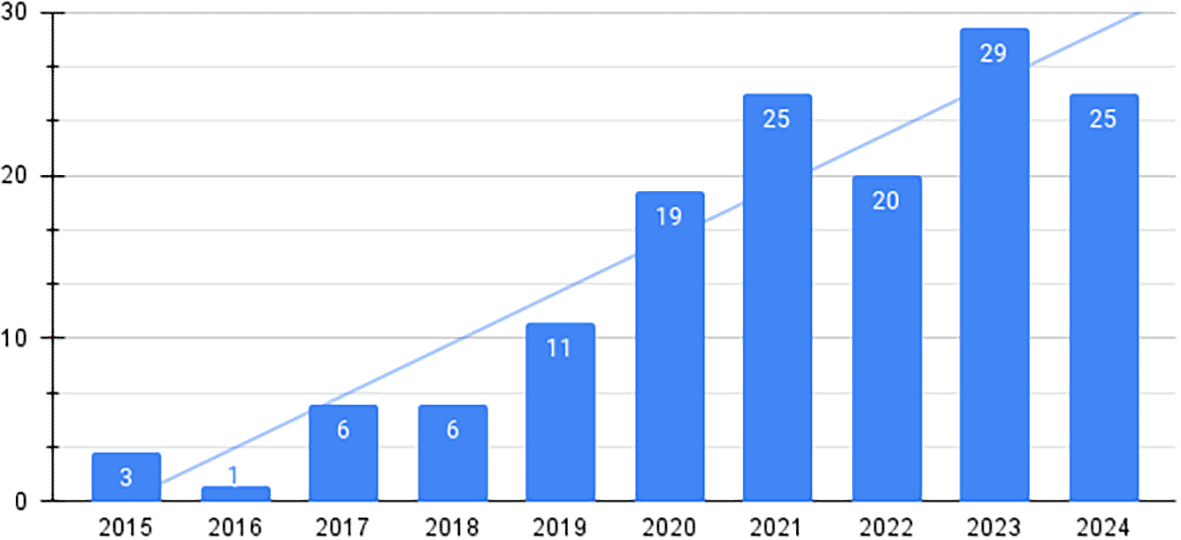
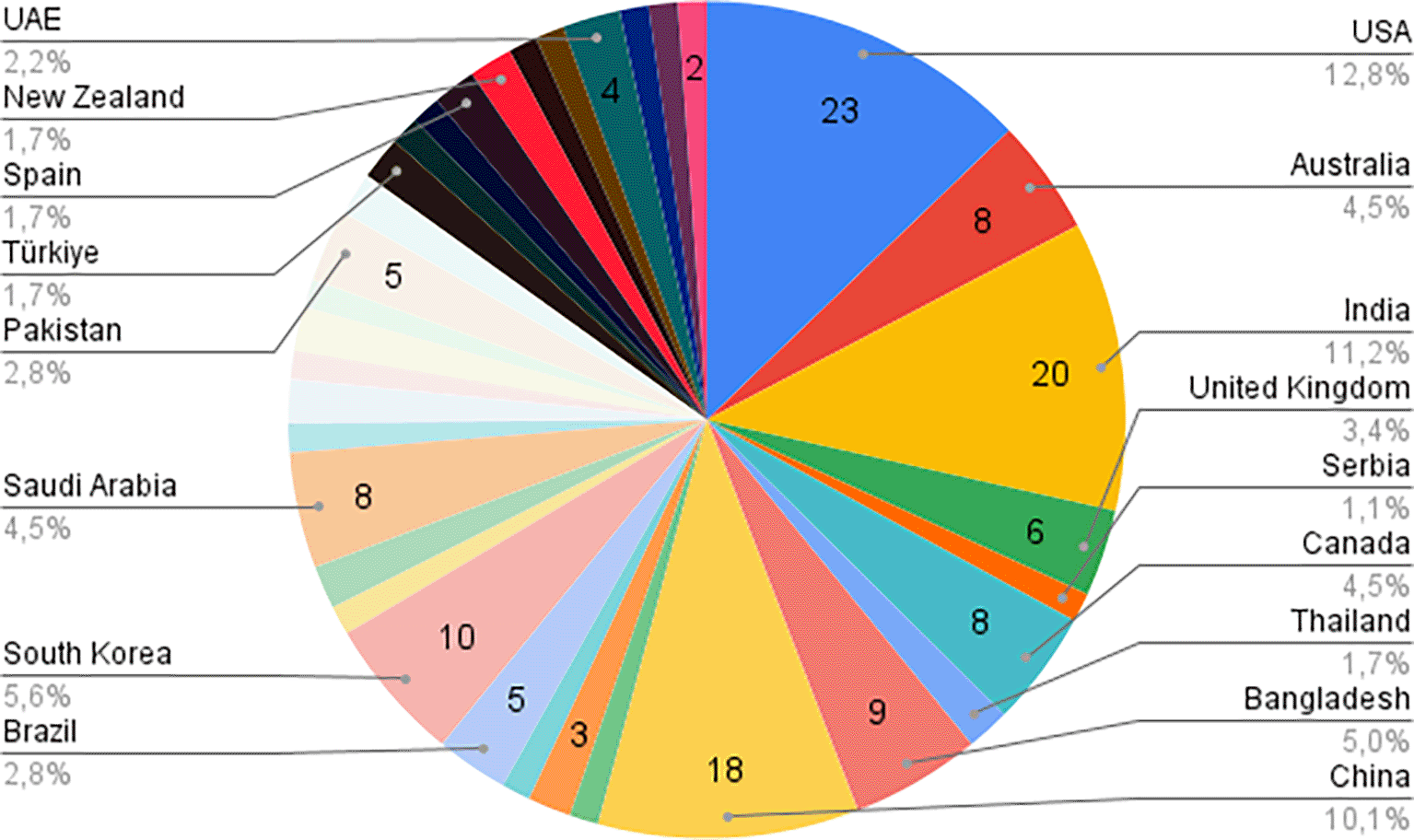
Figure 3 depicts the countries from which the selected studies originate, determined by the first author’s institution. The distribution highlights a concentration of research in countries like the United States, India, and China. Some other countries in different continents also feature prominently, reflecting regional efforts to tackle mental health challenges through AI. However, there is a notable gap in research from lower-income countries, which may reflect the disparity in resources and infrastructure for AI and mental health research.
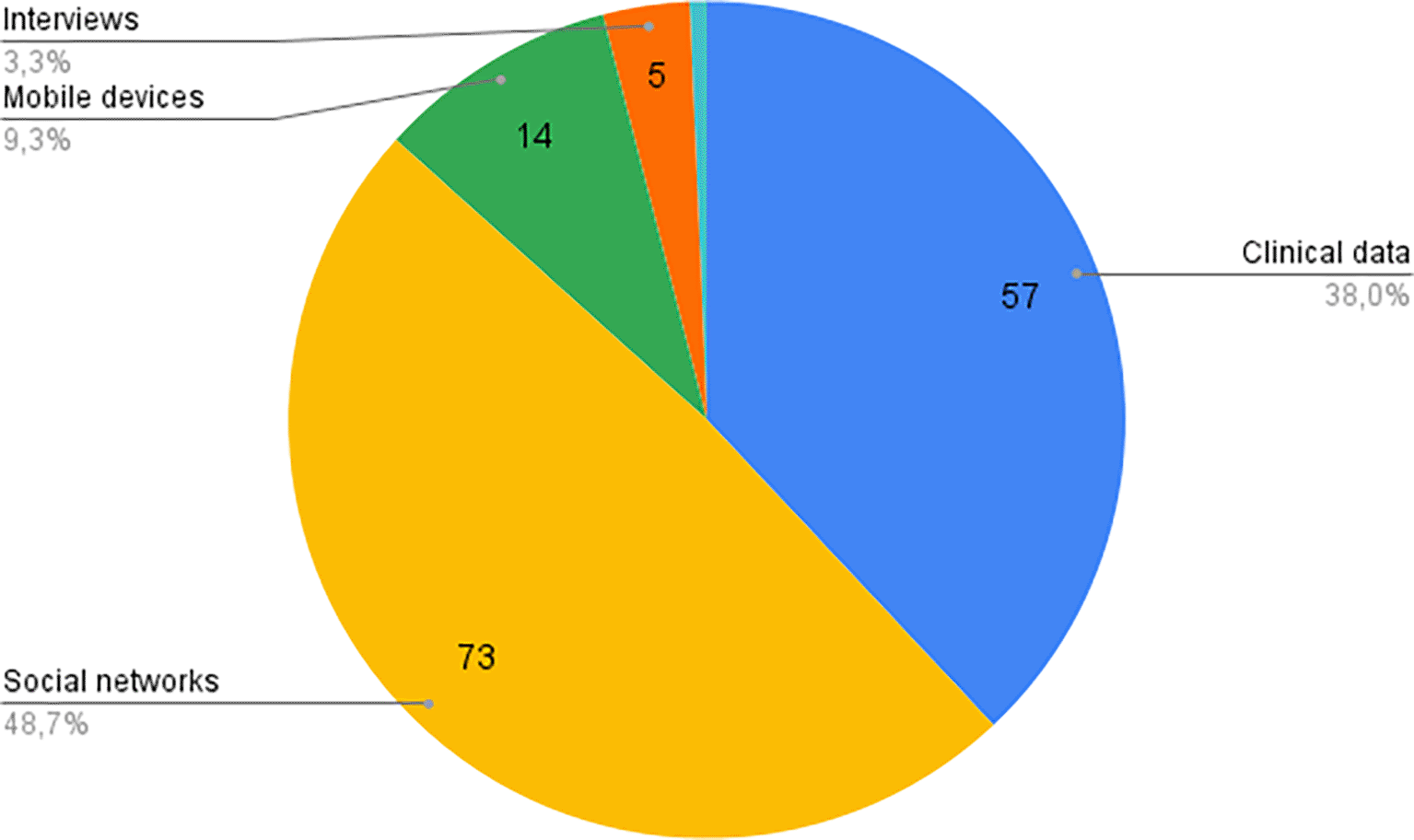
One of the key areas of analysis focused on the datasets used in the reviewed studies. These datasets were categorized based on the source and type of data they contained, as illustrated in Figure 4. The classification was performed based on the authors’ declarations, given that many datasets are not publicly available. This often presents a challenge for reproducibility in future studies.
The dataset types were grouped into five categories:
• Social Networks: These datasets typically consist of unstructured public data from user-generated content such as posts, comments, and reactions. Social networks offer a rich source of spontaneous user behavior, though the data’s unstructured nature requires significant preprocessing. Despite their availability, the reliability of these datasets is sometimes questioned due to ethical concerns regarding user consent.
• Clinical Data: This includes structured data obtained from electronic health records (EHRs), which often combine medical information with demographic details. Such datasets are generally more reliable and precise but are limited in availability due to privacy concerns and data access restrictions.
• Mobile Devices: These datasets include data collected through mobile devices, such as smartphones and wearable technology. The rise of mobile health (mHealth) apps has contributed to this category, where continuous tracking and health monitoring data are utilized to infer depressive tendencies.
• Interviews: Unlike clinical data, interview-based datasets are unstructured but provide qualitative insights. They are usually transcriptions of interactions with healthcare professionals, offering rich context but requiring manual labeling and interpretation.
• Text Messages: These datasets include private text communications, often shared voluntarily. Although these resemble social network data, the private nature of text messages means they are not publicly available. This limits their widespread use but provides a direct line of communication that can capture candid expressions of depressive symptoms.
Figure 4 shows how the studies that are part of this review use the different dataset types.
The analysis reveals that most of the datasets used in the reviewed studies come from social networks, followed by clinical data. However, only a few studies made their datasets publicly available, underscoring a challenge in research replication and model validation.
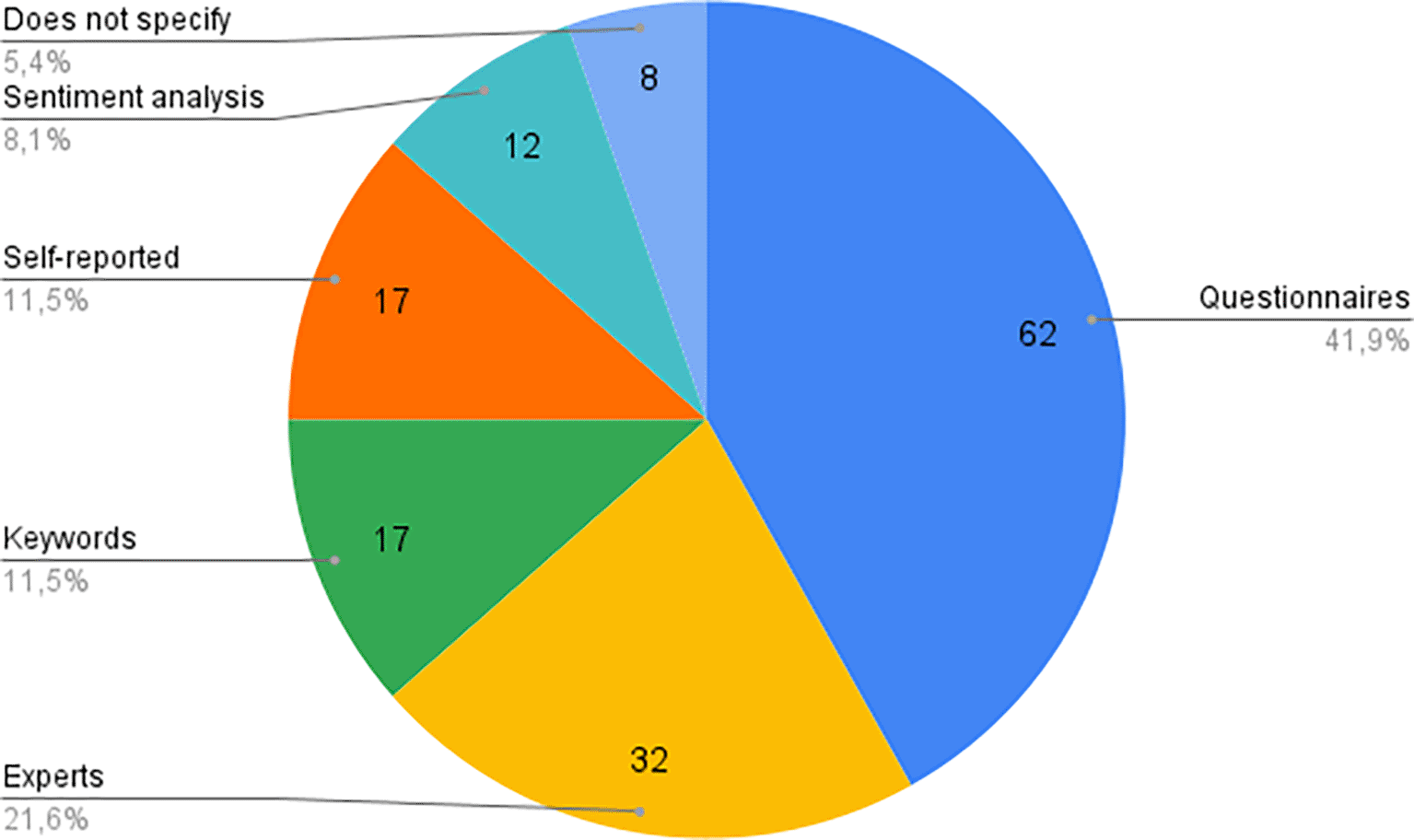
In terms of validation techniques, the reviewed studies adopted various methods depending on the nature of the dataset, as summarized in Figure 5. The datasets were validated using five primary methods:
• Questionnaires: Structured questionnaires, such as the PHQ-9 or BDI, were used to label data. This method was the most commonly used (41.9% of studies), ensuring consistency in diagnosing depression but potentially limiting real-world generalizability.
• Experts: In cases where data were unstructured (e.g., social media posts), mental health professionals validated the data by classifying whether a record could be associated with depressive symptoms. This approach was employed in 21.6% of the studies.
• Keywords: Some studies employed keyword-based validation, where the presence of specific terms associated with depression was used to label data. While simple, this method lacks the nuance of more sophisticated validation techniques
• Sentiment analysis: Advanced sentiment analysis tools were used in some studies to gauge the emotional tone of text data. This approach moves beyond keyword matching to provide a more comprehensive analysis of emotional states.15
• Self-reported: In studies with large datasets, participants self-reported their depression status, often in conjunction with using mobile health apps. While scalable, this method may introduce biases due to the subjective nature of self-reports.
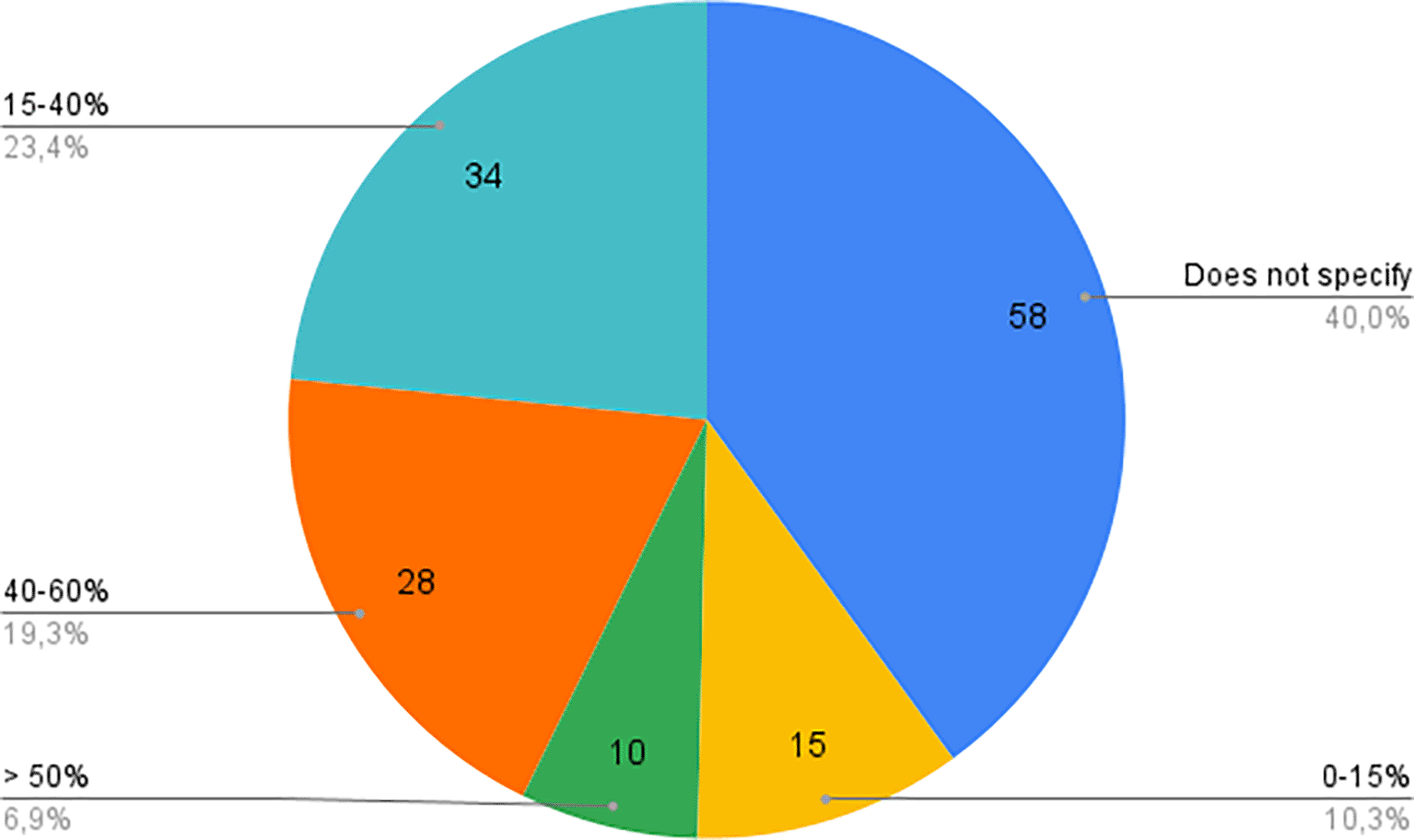
A third analysis focused on the distribution of depressive versus non-depressive subjects within the datasets, as shown in Figure 6. This analysis is crucial for understanding the challenges of imbalanced datasets, a common issue in depression diagnosis where the proportion of depressive individuals in the population is much lower than the non-depressive. The analysis revealed:
• 0-15%: The majority of datasets in this range reflect real-world imbalances, as the prevalence of depression in the general population is often below 15%.
• 15-40%: These datasets still show a majority of non-depressive cases but with a more balanced distribution.
• 40-60%: A few datasets are nearly balanced in terms of depressive and non-depressive subjects.
• >60%: Some datasets contain an artificial overrepresentation of depressive cases, often achieved through oversampling techniques to balance the data for model training.
Many studies applied balancing techniques such as oversampling, undersampling, or synthetic data generation to address the issue of imbalanced datasets.
The analysis of algorithms used in the reviewed studies is summarized in Figure 7. Machine learning algorithms were a critical component of most studies, and the choice of algorithm often depended on the dataset type and the learning task at hand. The most commonly used algorithms were:
• ANN (Artificial Neural Networks): Popular for their ability to handle large, unstructured datasets like those from social media.
• NLP (Natural Language Processing): Used primarily for text-based data, including social network posts and text messages.
• SVM (Support Vector Machines): Effective in handling high-dimensional data and commonly applied to clinical datasets.
• RF (Random Forest): A versatile algorithm used for both structured and unstructured data, known for its robustness against overfitting.
• LR (Logistic Regression): Widely applied for binary classification tasks, particularly when the goal is to predict whether a subject is depressive or non-depressive.
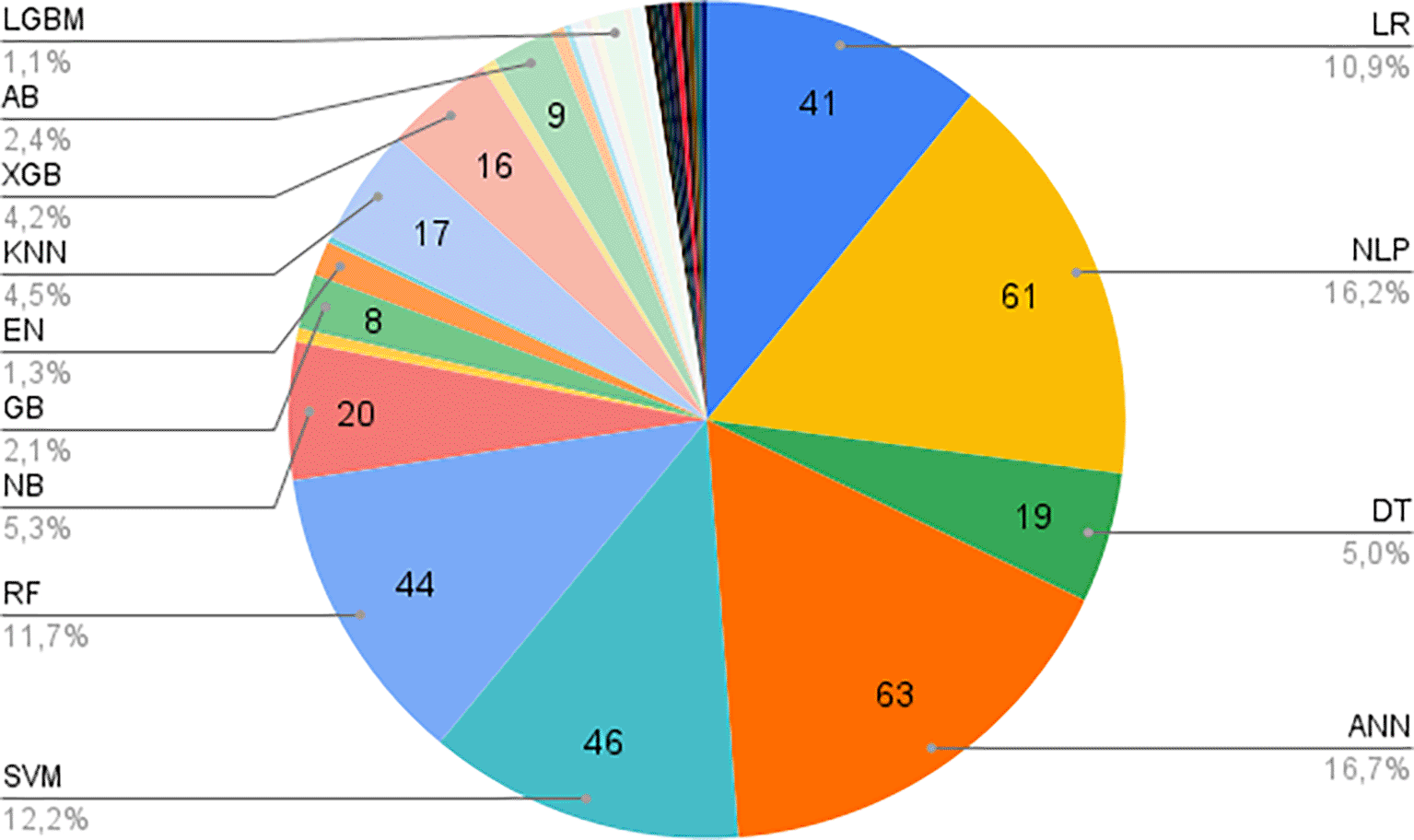
AB: Adaptive Boosting, ANN: Artificial Neural Network, DT: Decision Tree, EN: Elastic Net Regularization, GB: Gradient Boosting, KNN: K Nearest Neighbors, LGBM: Light Gradient Boosting Machine, LR: Logistic Regression, NB: Naive Bayes, NLP: Natural Language Processing, RF: Random Forest, SVM: Support Vector Machines, XGB: Extreme Gradient Boosting.
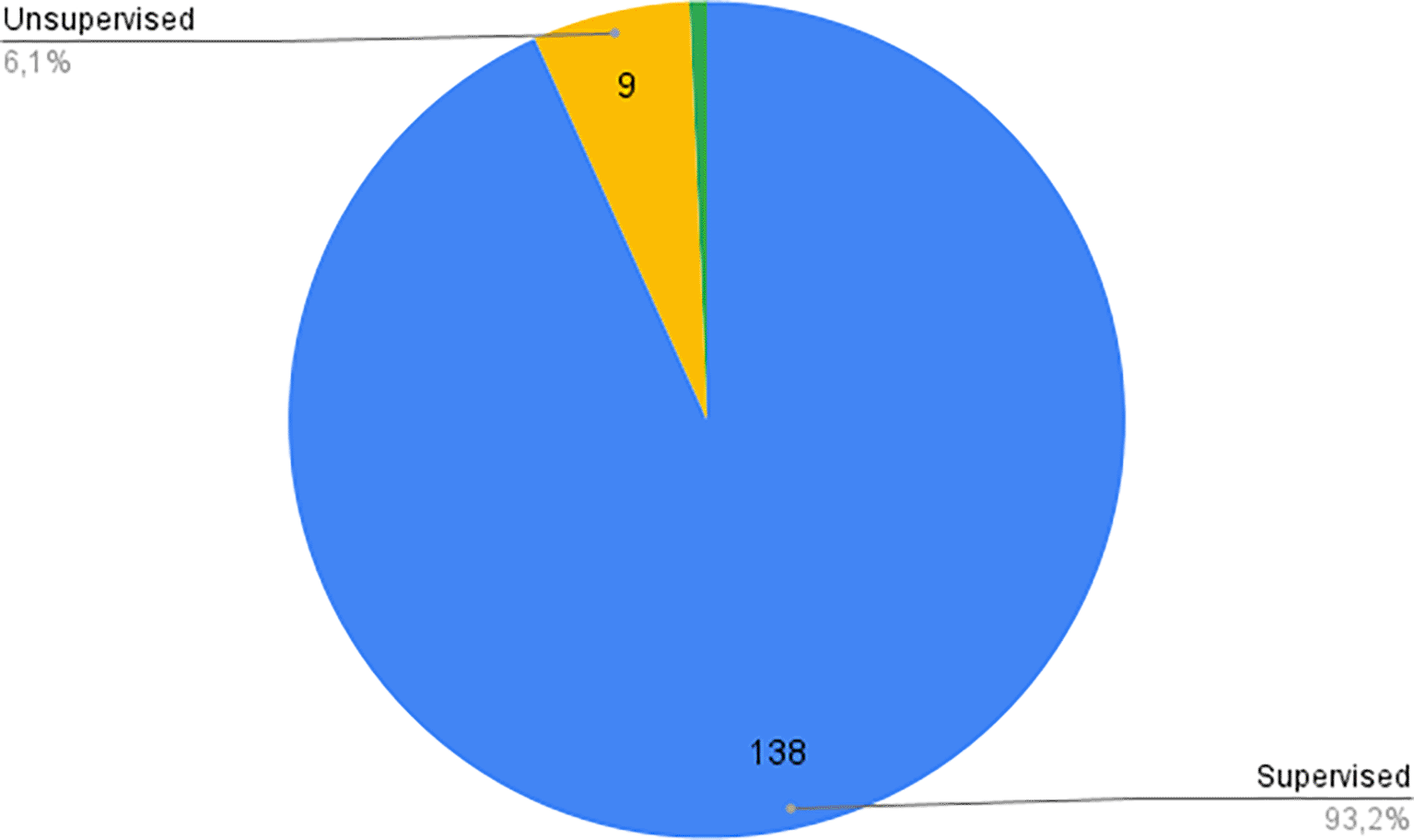
The studies were divided into supervised and unsupervised learning approaches, as shown in Figure 8. Supervised learning dominated the field, with 93.2% of the studies relying on labeled data. Only 6.1% of studies used unsupervised learning, and one study by Choi et al.16 implemented a semi-supervised approach.17 This method used a small portion of labeled data to fine-tune clusters generated by an unsupervised algorithm, showing promising results despite the limited labeled data.
The reviewed studies used a variety of metrics to evaluate the performance of their models, as summarized in Table 2. The most commonly used metrics included:
• Accuracy (57% of studies): The average accuracy was 0.82, indicating good overall performance, but accuracy alone may not be sufficient in the case of imbalanced datasets.
• F1 Score (52% of studies): With an average of 0.75, this metric provides a balance between precision and recall, making it especially useful for imbalanced datasets.
• Precision (45% of studies): At an average of 0.78, precision measures the proportion of correctly predicted positive cases out of all predicted positives.
• Recall (34% of studies): Averaging 0.74, recall measures the proportion of actual positives correctly identified by the model.
• AUC (31%) of studies: The Area Under the Curve metric averaged 0.75, indicating good discriminative ability.
• Specificity and sensitivity (17% of the studies): Both metrics were used less frequently but provided insight into the model’s ability to correctly identify negative and positive cases, respectively.
| Metric | Presence in articles | Average value |
|---|---|---|
| Accuracy | 57% | 0.82 |
| F1 | 52% | 0.75 |
| Precision | 45% | 0.78 |
| Recall | 34% | 0.74 |
| AUC | 31% | 0.75 |
| Specificity | 17% | 0.69 |
| Sensitivity | 17% | 0.74 |
Several studies opted for regression-based models, measuring outcomes using metrics like Mean Absolute Error (MAE) and Root-Mean-Square Error (RMSE). These models focused on predicting depression levels on a continuous scale rather than binary classification. Chatterjee et al.18 and Aziz et al.19 predict the depression level on a scale from 0 to 6, while Crowson et al.20 emulate the answers of the PHQ-9 questionnaire which is a discrete value but with a wide range of options. Oduntan et al.21 and Akyol22 used the usual metrics but also included the Mathews Correlation Coefficient (MCC) metric to compare their models. Oduntan et al.21 also chose the False Discovery Rate (FDR) metric. Tavchioski et al.23 and Trotzek et al.24 presented their studies in the eRisk [1] event. This event is a yearly contest where different researchers present techniques to diagnose depression using Artificial Intelligence techniques. To compare results, the contest provides its own metric, called Early Risk Detection Error (ERDE),25 and they used it in their studies. This metric used the confusion matrix to determine its value, but it considers the instance when the prediction is made, taking into account that these models deal with longitudinal data and the goal is to detect depression symptoms as early as they appear. Inkpen et al.26 and Skaik et al.,27 other eRisk studies, also selected custom metrics: Average Hit Rate (AHR), Average Closeness Rate (ACR), Average Difference between overall Depression Levels (ADL), and Depression Category Hit Rate (DCHR). Lyu et al.28 use the Pearson Correlation Coefficient (PCC) to evaluate their models, also based on supervised learning.
Unsupervised learning studies use heterogeneous metrics. Dipnall et al.29,30 calculated the percentage of depressive people in different clusters to measure their results in two different studies. Choi et al.,16 who mixed unsupervised and semi-supervised learning approaches, used the Analysis of Variance (ANOVA) metric. This study compared the two different kinds of learning techniques and compared their results. For the semi-supervised approach, they labeled a portion of its data using standard psychological questionnaires while the rest of the data remained unclassified. The dataset consisted of demographic and clinical information about the patients, presented structurally. This partial classification was used to fix the clusters created by standard unsupervised learning models. If well the semi-supervised solution used fewer records for its training, it generated better results than the full unsupervised learning technique.
The most commonly suggested future research direction is the improvement of data quality. Many articles recommend incorporating multimedia data (images, audio, and videos) with existing text and numerical data to create more comprehensive diagnostic models. Several studies highlight the potential of combining social media data with clinical and mobile health data to enhance diagnostic accuracy. The integration of longitudinal data—data collected over extended periods—was also proposed to better capture the progression of depression symptoms.
Furthermore, several studies acknowledged the limitations of available data, particularly from social networks. These datasets often lack the accuracy and structure of clinical data, and concerns over privacy and ethical data usage remain a significant challenge. Researchers recommend improving access to clinical datasets and creating public datasets that contain real-world medical data.
1. RQ1 (Dataset Types): The most common dataset types were social networks (unstructured text) and clinical data (structured EHRs). Mobile devices and interviews were less frequently used (13% of the datasets).
2. RQ2 (Validation and Class Distribution): Questionnaires were the most used validation method (42%) followed by experts’ validation (22%), while most datasets showed imbalanced depressive class distributions, requiring balancing techniques.
3. RQ3 (Learning Types): Most studies applied supervised learning models, with limited exploration into unsupervised and semi-supervised methods.
4. RQ4 (Model Performance): The most frequently reported performance metric was accuracy, with an average value of 0.82.
5. RQ5 and RQ6 (Challenges and Future Directions): The most significant challenge is the lack of high-quality, publicly available datasets. Future research should focus on improving data quality, integrating diverse data sources, and addressing ethical concerns around privacy.
The analysis of the reviewed studies highlights a continuous increase in research focused on applying AI techniques for the diagnosis of Major Depressive Disorder (MDD), with a minor decline in 2022, followed by a resurgence in 2023. Given that this review encompasses studies up to mid-2024, it is expected that this growth trend will persist in the coming years, reflecting the increasing relevance of AI in mental health research.
Geographically, research contributions are primarily concentrated in the United States, India, and China, with a total of 35 countries across four continents contributing to the field. This broad international distribution reduces potential bias stemming from geographical constraints, ensuring a more comprehensive understanding of the global progress in this domain. However, it is worth noting that some regions, particularly lower-income countries, remain underrepresented in this research area.
In terms of data sources, over half of the studies rely on datasets extracted from social networks, with clinical data being the second most utilized. While clinical datasets are generally more robust and reliable, social network data is more accessible and easier to collect. This disparity underscores a key trade-off in the field: the use of clinical data enhances the validity of the models, but the acquisition process is often more resource-intensive. Validation methods also align with the type of dataset used, with clinical datasets predominantly validated through questionnaires, while social network datasets employ a variety of validation techniques, including expert validation, keyword-based classification, and sentiment analysis.
Algorithmic approaches in these studies are overwhelmingly dominated by supervised learning techniques, with a particular emphasis on the combination of Natural Language Processing (NLP) and Artificial Neural Networks (ANNs), especially when dealing with unstructured data. Most studies implement multiple algorithms, either through comparative analysis or as part of a pipeline, to achieve optimal performance.
The studies also highlight several limitations, many of which suggest avenues for future research. A primary limitation, cited by the majority of articles, is the availability and quality of datasets. Many studies operate with relatively small datasets, rarely exceeding several thousand records. When larger datasets are available, particularly from social networks, concerns about their reliability arise due to the use of user-generated classifications, such as keyword tagging or sentiment analysis, which are less accurate than clinical methods such as expert evaluations or psychological questionnaires.
Other dataset-related issues include class imbalances, insufficient representation of diverse population groups, and the lack of longitudinal data. These challenges highlight the need for more comprehensive datasets that capture a wider array of features, including demographic diversity, longitudinal records, and data from multiple languages and geographic regions, as well as the integration of multimedia data to enhance diagnostic accuracy.
In recent years, studies have begun to explore the use of large language models,31,32 such as OpenAI’s ChatGPT2 for the diagnosis of MDD. While this represents an exciting advancement, it raises significant concerns regarding the explainability of AI-based solutions, particularly given that such models are often regarded as “black box” systems. This concern is compounded when using proprietary models, where the underlying engineering and decision-making processes are not publicly accessible or transparent.
Overall, while the majority of studies report promising results, there remains considerable room for improvement, particularly in the areas of data acquisition and quality. The lack of comprehensive and diverse datasets is a major limitation, and addressing this issue is critical to improving the generalizability and reliability of AI-driven depression diagnoses. Although algorithmic advances continue to enhance performance, the success of these models will ultimately depend on the availability of high-quality, unbiased, and diverse datasets, which should remain a primary focus for future research in this field. Additionally, the challenge of accurately labeling depressive states, particularly in social media datasets, must be addressed to ensure that AI models can provide valid and clinically meaningful outcomes.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)