Keywords
intestine, neural network, activation function
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Japan Institutional Gateway gateway.
intestine, neural network, activation function
Neural networks (NNs), which were first introduced by Amari (1967) and later improved by Rumelhart et al. (1986), are mathematical models that are inspired by the structure and function of the central nervous system (CNS). A critical aspect of NNs is their nonlinearity, which is provided by activation functions that control the nodes’ outputs, similar to biological neurons.
Despite their important impact on neural network behavior, many activation functions have been proposed without theoretical justification (Glorot et al., 2011; Hahnloser et al., 2000; Jarrett et al., 2009; Nair & Hinton, 2010; Ramachandran et al., 2017; Misra, 2020). Therefore, the use of biologically verified activation functions, such as those derived from the enteric nervous system, may improve the performance of existing activation functions. The enteric nervous system shares many features with the central nervous system (Goyal & Hirano, 1996; Rao & Gershon, 2016) and may show promise for the development of unconventional neural network models.
The intestine, which is sometimes referred to as the “second brain” (Mayer, 2011; Obata & Pachnis, 2016; Rao & Gershon, 2016; Maniscalco & Rinaman, 2018), responds to external stimuli. Its smooth muscle undergoes reversible contractions in response to acetylcholine (ACh) in a dose-dependent manner (Burgen & Spero, 1997; Rao & Gershon, 2016). These contractions conform to a dose–response curve that reflects the activation of ACh receptors and subsequent signal pathways; thus, contraction responses are macroscopic expressions of biochemical reactions. Therefore, intestinal contraction data may be a valuable resource for developing novel biologically inspired activation functions.
In this study, we developed an intestinal data-based neural network (INN) by incorporating pharmacological data based on intestinal contractions into a neural network model. We hypothesized that the INN model could perform classification tasks as effectively as neural networks based on the central nervous system.
The intestinal tissues used in this study were surplus samples in a university student practical course that would otherwise have been discarded. Specifically, retired male breeder guinea pigs weighing 300–400 g (n = 14; SLC, Shizuoka, Japan) were used in our experiments. Consequently, the sample size was dictated by the enrollment of students in the course. The animals were housed in a temperature-controlled room (22 ± 1°C) with a 12-hour light-dark cycle (light from 07:00 to 19:00) and given ad libitum access to food and water. All animal experiments were performed with the approval of the Animal Experiment Ethics Committee of the University of Tokyo (approval number: P24-1) and in accordance with the University of Tokyo guidelines for the care and use of laboratory animals. Our experimental protocols adhered to the Fundamental Guidelines for Proper Conduct of Animal Experiments and Related Activities in Academic Research Institutions (Ministry of Education, Culture, Sports, Science and Technology, Notice No. 71 of 2006), the Standards for Breeding and Housing of and Pain Alleviation for Experimental Animals (Ministry of the Environment, Notice No. 88 of 2006), and the Guidelines on the Method of Animal Disposal (Prime Minister’s Office, Notice No. 40 of 1995). The primary outcome measure was the variation in ileum tissue length when subjected to different concentrations of acetylcholine (ACh) in a controlled bath setting. Animal identifiers were not identifiable to data analysts. All efforts were made to ameliorate the suffering of animals. Euthanasia methods involved intraperitoneal injection of sodium pentobarbital at a lethal dose of 100 mg/kg body weight to ensure a humane termination of life. Additionally, pre-established criteria for euthanizing animals displaying severe distress or declining health included indicators such as unexplained weight loss of over 20%, labored breathing, and other signs of suffering; however, none of the animals met these criteria. At the conclusion of the educational pharmacology course, all surviving animals were humanely euthanized, adhering to the same ethical standards, and were not used for subsequent experiments or educational activities.
Acetylcholine chloride (C7H16ClNO2; Wako, Japan) was dissolved in double distilled water at concentrations of 2×10−7, 2×10−6, 2×10−5, 2×10−4, 2×10−3, 2×10−2, and 2×10−2 M.
To isolate ileum tissue, guinea pigs were deeply anesthetized with 100 mg/kg pentobarbital (i.p.). The chest was opened, and the ileum was removed and washed with nutrient solution (in mM: NaCl 137, KCl 2.7, NaHCO3 11.9, CaCl2 1.8, MgCl2 1.0, D-glucose 5.5) that was bubbled with 5% CO2/95% O2. The tissue was cut to a length of approximately 3 cm, and mesenteric arteries were removed. Two hooks were used to mount the tissue; one hook was inserted at one end of the tissue and fixed to the tip of an aeration tube, while the other was connected to an isotonic displacement transducer (45347, NEC San-ei Instrument, Tokyo, Japan). The transducer was connected to an amplifier (AS1202, NEC San-ei Instruments) and a flatbed recorder (FBR-251A, TOA Electronics, Tokyo, Japan), which was used to record the ileum tissue responses (Figure 1A). Before starting the experiments, the ileum tissue strips were equilibrated, and a stable baseline recording was obtained at a resting tension of 0.5 g. Acetylcholine (ACh) solutions were then sequentially bath-applied to the organ bath at the following concentrations (in M): 1×10−9, 3×10−9, 1×10−8, 3×10−8, 1×10−7, 3×10−7, 1×10−6, 3×10−6, 1×10−5, 3×10−5, 1×10−4, 3×10−4, 1×10−3, and 3×10−3. Bath application was performed when a local maximum of the contraction reaction at the previous ACh concentration was confirmed. The ACh concentration [M] and intestine length [cm] were recorded, and these steps were repeated 2–3 times. The intestinal contraction rate [%] was calculated by averaging the contraction lengths over different trials and dividing the mean values by the maximum value. We collected the data for the dose–response curves from 512 ileum samples.
For each of the 512 data pairs, the ACh concentration was natural-log-transformed:
Thus, = and = 0 (Figure 1C).
The mean square error (MSE) between the fitted sigmoid curve and the corresponding sample was calculated. Samples that fell outside the range of the mean ± 3 standard deviations (SDs) in the ||, ||, or MSE value for the ith intestine sample were excluded from further analyses, leaving 503 intestine samples. It is important to emphasize that these criteria were not predetermined.
The three-layer perceptron (control) and INN model had the same structure except for their activation functions. The common structure is written as follows:
: input vector (: dimension of the input vector)
: the weight between the ith unit in the input layer and the jth unit in the hidden layer (j = 1, 2, …, 100)
: 1, the bias of the jth unit in the hidden layer
: the activation function of the jth unit in the hidden layer
: the weight between the jth unit in the hidden layer and the kth unit in the output layer (k = 1, 2, …, is dimension of the output vector)
: 1, the bias of the kth unit in the hidden layer
: the activation function of the kth unit in the output layer
On the other hand, the activation functions of the INN model, and , included two random variables and as parameters:
Note that Eq. 13 and Eq. 14 are identical when (, ) = (1, 0). For each INN activation function, namely, (j = 1, 2, …, ) and (k = 1, 2, …, ), the random variables , ) and , ) were sampled from 503 sets of experimentally obtained parameters {(), (), …, ()} (Eqs. 1–6). The source code for the three-layer perceptron and INN is available on our GitHub repository: https://github.com/ywatanabe1989/intestelligence.
The cross-entropy loss was adopted as the cost function, which was calculated as follows:
The backpropagation method (Rumelhart et al., 1986) was adopted to efficiently calculate the gradient of the cost function, .
The following notation was introduced:
According to Eq. 10, we have
Substituting Eqs. 17 and 20 into Eq. 16, we obtain
For the s of the hidden units, the chain rule for partial derivatives is applied to obtain:
By substituting Eq. 17 into Eq. 22 and using Eqs. 9 and 10, the following backpropagation formula is obtained:
Thus, the gradient of the cost function can be calculated using the backpropagation method.
The model was trained using the stochastic gradient descent (SGD) algorithm.
If the error function consists of a sum over data points, , after the presentation of pattern n, the SGD algorithm updates the parameter vector using the following formula:
Here, τ denotes the iteration number, and η is the learning rate parameter.
The MNIST database of handwritten digits (LeCun et al., 1998) was used for the experiments in this study. The control and INN models were trained based on 60,000 training data points and evaluated based on 10,000 test data points. Each image was 784 pixels (= 28 columns×28 rows), and the images were fed into models after being flattened into a vector. The mini-batch size was set to 100, and the learning rate was set to 0.05.
The INN models were simulated by sampling the fitting parameters and . Dummy fitting parameters = (, )T were sampled from a bimodal Gaussian distribution, as described below.
When the slope at the inflection point of the simulated sigmoid function was negative ( > 0), was resampled. A total of 140 (= 8 × 15) experiments were performed.
A total of 1,200 images of edible objects and 1,200 images of inedible objects were randomly sampled from https://www.sozaijiten.com. Then, 1,000 images from each class (edible/inedible) were used as training data, and the remaining 200 images from each class were used as test data.
The edible images included images of cooked meals and raw foods such as fruits, vegetables, and fish. The inedible images included images of tools, parts, coins, and other objects.
The images were converted into feature vectors using a pretrained convolutional neural network model (AlexNet; Krizhevsky et al., 2012) based on the Caffe deep learning framework (Jia et al., 2014). Specifically, for every input image, the output of the activation of the fc6 layer (4,096-dimension vector) was extracted.
These feature vectors were fed into the INN model instead of the original images to perform the 2-class classification task. The model consists of three layers: an input layer, a hidden layer, and an output layer. The input layer contains 4,097 nodes, including a bias unit. The hidden layer has 101 nodes, also inclusive of a bias unit. The output layer consists of 2 nodes corresponding to two classes: edible or inedible. The learning rate was set to 0.6.
To compare classification accuracies of INN and Control, we employed the Mann-Whitney U test due to the absence of any specific parametric hypotheses. The test was conducted using the Python package SciPy (https://scipy.org/). The rank-biserial correlation was used as the effect size measure.
After different concentrations of Ach were sequentially applied, the lengths of the isolated ileum tissues decreased. We used an experimental device to measure the isotonic contraction of the intestinal tract (Figure 1A) and recorded the dose–response curves of the ilea during bath application of ACh at concentrations ranging from 10−9 to 10−3 M (Figure 1B, n = 512 tissues from 14 guinea pigs). Each dose–response curve was obtained from a single tissue and was normalized and fitted to a sigmoid function (Figure 1C) using two fitting parameters, and (Eqs. 1–6). The MSE between the experimentally recorded data and the fitted sigmoid curve was calculated for all 512 samples. Data samples for which the ||, || or MSE values exceeded the mean ± 3SD were omitted from the following analysis, and the remaining 503 data points were used to construct the INN model. The distributions of and are plotted in Figure 1D and 1E. For , the sample mean was 3.06, and the sample variance was 1.38; for , the sample mean was 0.00 (due to the adjustment), and the sample variance was 3.23).
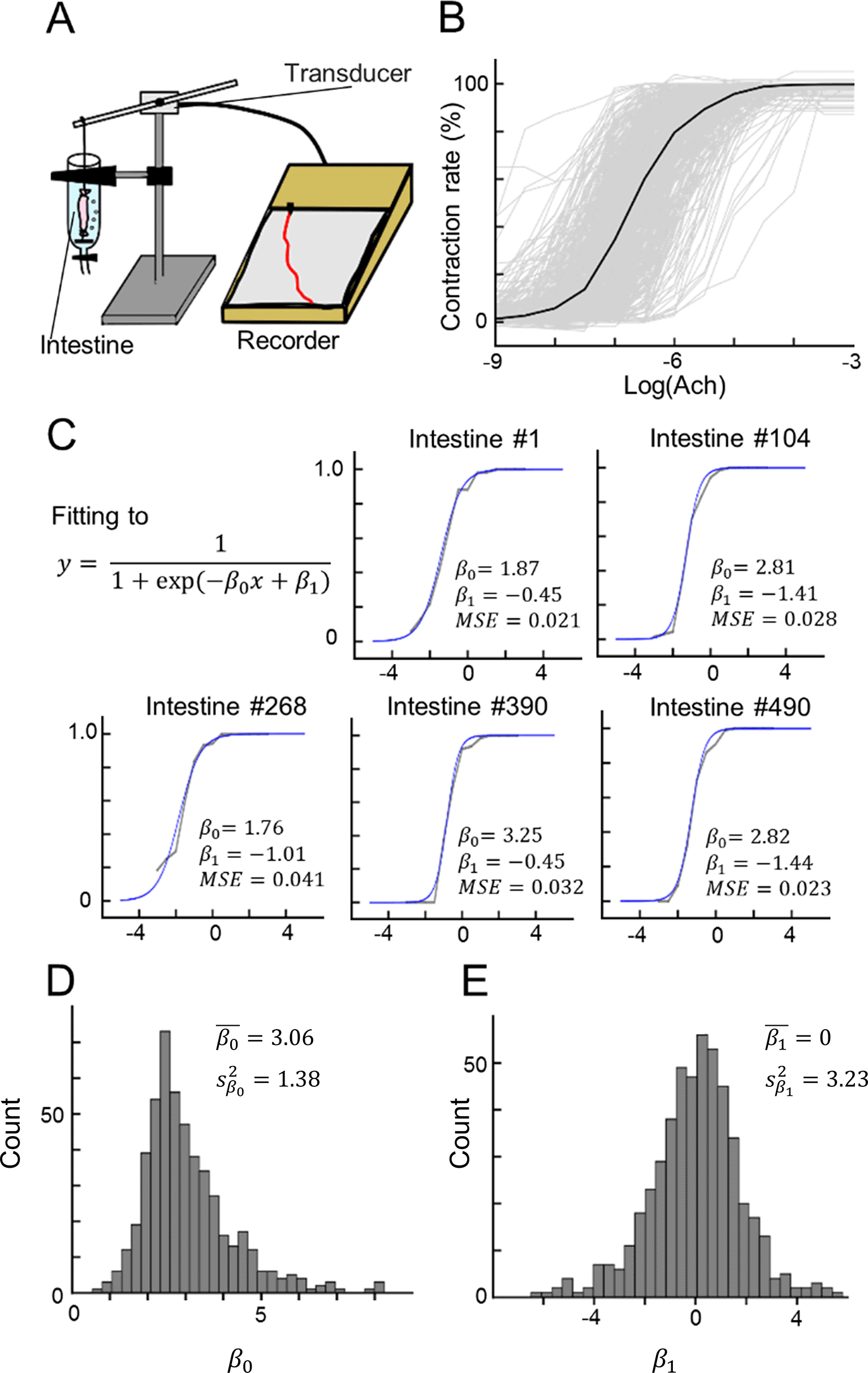
(A) Illustration of our experimental devices for measuring ileum contraction.
(B) The dose–response curves of 512 data points for contractions in response to bath application of ACh. Each gray line indicates a single data point, whereas the black line indicates the mean.
(C) Five examples of sigmoid fitting of the dose–response curves of ACh-induced ileum contraction. Note that and are fitting parameters.
(D, E) Distributions of the fitting parameters (D) and (E).
We constructed a three-layer perceptron (Control) and an INN, both with the same structure as illustrated in Figure 2A. These models were used for a 10-class classification task using handwritten digits from the MNIST database (LeCun et al., 1998). During 6,000 rounds of training, the cost of the Control model was lower than that of the INN model (Figure 2B; at Loop #6,000, Control: 0.558 ± 0.097; INN: 0.923 ± 0.188; p < 0.001; ns = 40; U = 1,556; Mann–Whitney U test; the rank-biserial correlation = - 0.945). Both models converged, but the sum of the absolute weight update of the Control model was lower than that of the INN model (Figure 2C; at Loop #6,000, Control: 1.83 ± 0.86; INN: 2.58 ± 0.94; p < 0.001; ns = 40; U = 1,182; Mann–Whitney U test; the rank-biserial correlation = - 0.478). The accuracy of the Control model was higher than that of the INN model (Figure 2D; at Loop #6,000, Control: 92.3 ± 0.4; INN: 85.7 ± 0.6; Chance: 10%; p < 0.001; ns = 40; U = 0; Mann–Whitney U test; the rank-biserial correlation = 1.000).
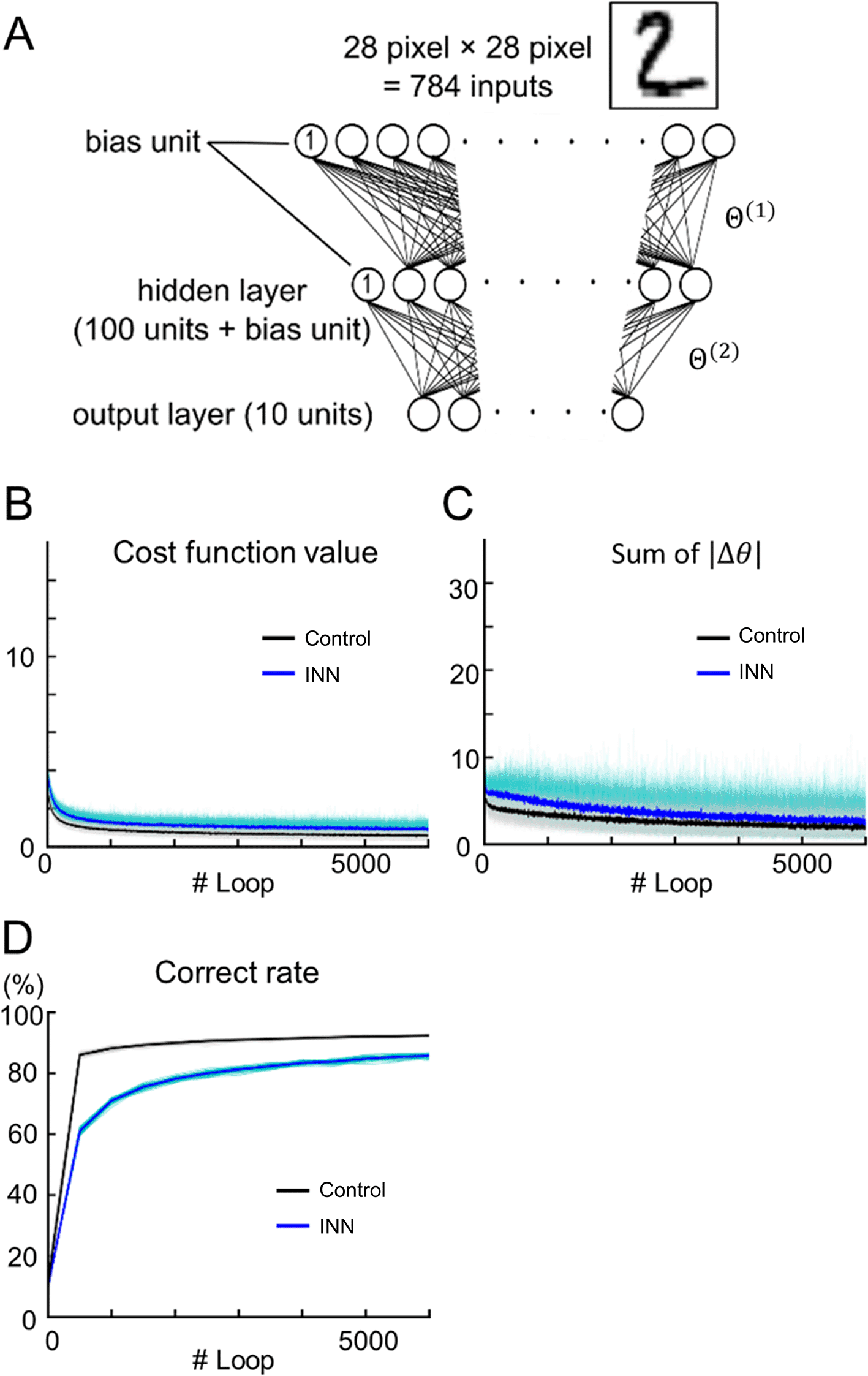
(A) A schematic diagram of the three-layer INN model. A conventional perceptron with the same structure was used as the control.
(B–D) Output values of test data during training. B, cost function; C, sum of the absolute weight updates; D, classification accuracy. The blue and black lines represent the INN and control model results, respectively. Each line indicates a single data point (n = 32 tuning trials), whereas the thick line indicates the mean.
We also observed the sample variance in the fitting parameters and (Figure 1D and 1E). These fluctuations might originate from (i) biological noise and (ii) differences in the experimental conditions. We hypothesized that the variations in and (, ) affect the classification accuracy of the model based on the MNIST dataset. To test this hypothesis, we simulated INNs using various values of and . Figure 3 shows the accuracies of the virtually generated INNs in a pseudocolor map. The highest mean accuracy was 92.3% ± 0.3% for = 0.0 and = 0.0, and the lowest mean accuracy was 57.3% ± 5.5% for = 3.0 and = 50.
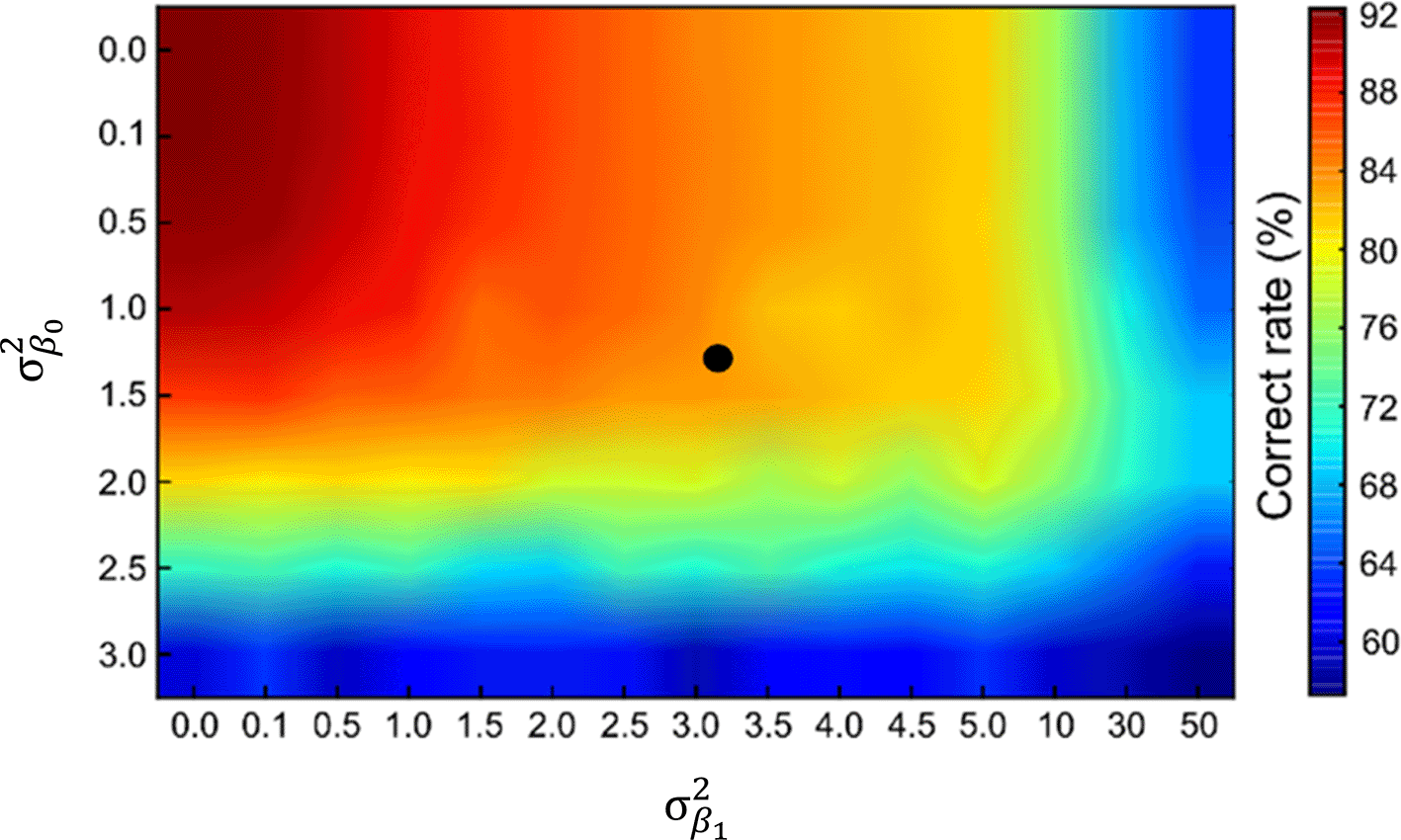
Accuracies of INNs as a function of the variance in the hyperparameters and ( and ). The experimentally obtained sample variance ( = 1.38; = 3.23) is indicated by the black dot.
A total of 1,200 images of edible and inedible objects were randomly chosen from the dataset and split into training/test datasets at a ratio of 5:1 (Figure 4A). The accuracies of the model based on the test data were evaluated during training. At loop #6,000, the accuracy was 88.5% ± 0.9% (Figure 4; n = 32 cross-validations).
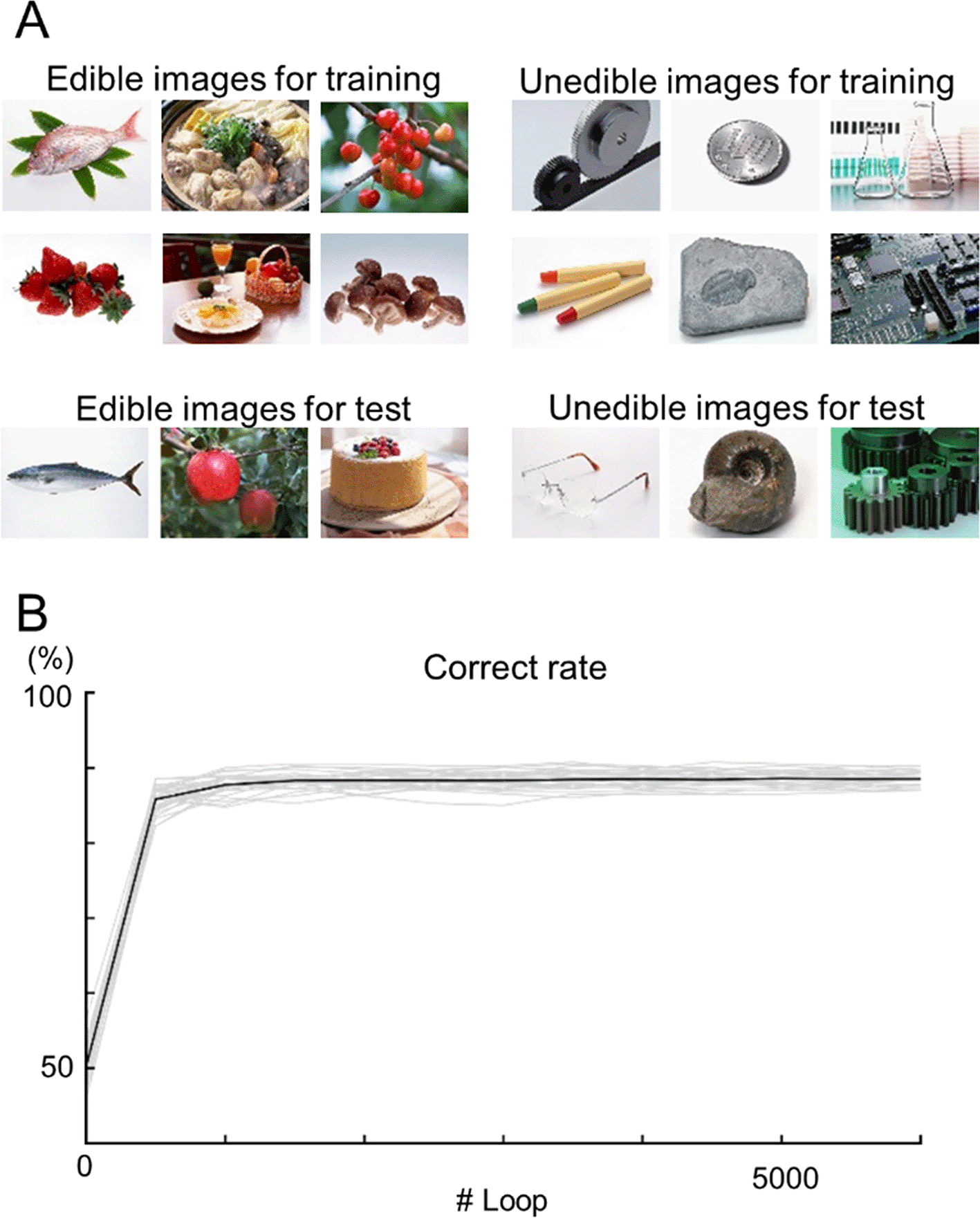
(A) Examples of edible (left) and inedible (right) images in the dataset. The top images were used for training, and the bottom images were used for testing. (B) The learning curves of the INN prediction results for the test data. Each gray line indicates a single data point (n = 32 cross-validation), whereas the black line indicates the mean.
In this study, we confirmed that different intestine samples exhibited distinct contraction responses to ACh (Figure 1B and 1C). Using the response curves, we built an INN model and demonstrated that the INN model could be used to precisely classify handwritten digits. Furthermore, we artificially generated various INN models and found that the INN model with the average activation function, or the three-layer perceptron, achieved the highest accuracy (92.3% ± 0.3%). Finally, the INN model could be used to classify edible/inedible images, achieving a classification accuracy of 88.5% ± 0.9%.
This study presents a novel approach for building neural networks using biological data and demonstrates the potential of the enteric nervous system for developing activation functions for machine learning models. Existing activation functions can be broadly classified into two groups: (i) the sigmoid group, including the logistic sigmoid function and the hyperbolic tangent function, and (ii) the V-shaped group, including the ReLU (Hasnloser et al., 2000; Nair & Hinton, 2010), Leaky ReLU (Maas et al., 2013), PReLU (He et al., 2015), Swish (Ramachandran et al., 2017), and Mish (Misra, 2019) activation functions. However, the use of sigmoid functions has recently decreased because sigmoid functions lead to slow weight updates and vanishing gradients (Bengio et al., 1994) in the backpropagation framework (Rumelhart et al., 1986). Despite this disadvantage, sigmoid functions remain important for biologically inspired network models (Shinozaki, 2021; Zhan et al., 2023), as backpropagation is unlikely to occur in a real brain (Bartunov et al., 2018). Sigmoid curves are known to emerge as cumulative functions for bell-shaped curves, such as normal distributions. The sigmoid curves observed in our pharmacological experiments are regarded as macroscopic expressions of decision-making processes at the biomolecular level in the enteric nervous system because the ACh signaling pathways via muscarinic receptors trigger contractions in smooth muscles (Eglen et al., 1996).
One limitation of our study is the granularity of the model. Our intestine samples were modeled as nodes in an INN, rather than as the network itself. Thus, the developed INN can be viewed as an ensemble model based on intestine samples. This modeling approach was necessitated by the difficulty in recording a large number of individual neurons and receptors. Our model may not necessarily be inaccurate because the central and enteric nervous system exhibit plasticity (e.g., updated functional connectivity at synapses; Citri & Malenka, 2008) and can be viewed as an ensemble model of different network states at various timepoints. On the other hand, we observed different ACh responsiveness among individual intestine samples (approximately 102 scale). This variation may be caused by biological noise, as indicated by the observed parameters and , which were located in local maxima. Due to these variations, the INN model may have shown different sensitivity to various input data (Figure 2B) and plasticity (Figure 2C), which are desirable characteristics in real-world settings, in which the data are often unpredictable and unfixed and balancing the explore-exploit tradeoff is important. To verify this hypothesis, novel datasets and evaluation methods that closely mimic real-world scenarios should be developed to make fair comparisons between in silico and biological models.
This study has pioneered the development of an INN model based on biological intestine data, offering a novel approach to neural network construction. While the model’s performance in image classification tasks may currently be inferior to traditional three-layer perceptrons, this work focuses on the innovative methodology and its potential for future improvements. The model demonstrates the feasibility and uniqueness of using biological data as a basis for neural network development. Future work could explore the effects of biological diversity among ileum samples in their responsiveness to acetylcholine on the generalization ability of such networks. This could advance our understanding and the practical utility of biologically inspired models.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)