Keywords
Acute Pancreatitis, Neutrophil-to-Lymphocyte Ratio, NHANES, Machine Learning, Random Forest, XGBoost, Logistic Regression, Inflammation, Severity Prediction, Biomarkers
Acute Pancreatitis, Neutrophil-to-Lymphocyte Ratio, NHANES, Machine Learning, Random Forest, XGBoost, Logistic Regression, Inflammation, Severity Prediction, Biomarkers
Acute pancreatitis (AP) is a sudden inflammatory condition of the pancreas that can vary in severity from mild, self-limiting discomfort to severe, life-threatening illness characterized by systemic inflammatory response syndrome (SIRS) and multiorgan failure.1,2 It has emerged as one of the most common gastrointestinal conditions requiring hospitalization, with a global incidence estimated between 13 to 45 cases per 100,000 population annually.3,4 In the United States alone, AP accounts for more than 275,000 hospital admissions each year.5 Although the majority of patients—around 80 to 85 percent experience a mild form and recover with supportive care, approximately 15 to 20 percent develop severe acute pancreatitis (SAP), which carries a mortality rate of up to 30 percent, particularly in cases complicated by infected pancreatic necrosis or persistent organ failure.6–8
The causes of acute pancreatitis are diverse and influenced by both geographic and demographic factors. Gallstones and chronic alcohol consumption account for nearly 70 to 80 percent of cases.9 Gallstones tend to be more prevalent in women and older individuals, while alcohol-related pancreatitis is more common in younger men. Other contributing factors include hypertriglyceridemia, certain medications, post-endoscopic retrograde cholangiopancreatography (ERCP), trauma, and genetic predispositions.10 Regardless of the underlying cause, the disease process begins with premature activation of digestive enzymes within the pancreatic acinar cells, leading to autodigestion, inflammation, and in severe cases, systemic complications.11
Early and accurate assessment of disease severity is essential for guiding management strategies and determining the level of care required. Several prognostic scoring systems such as Ranson’s criteria, the APACHE II score, the BISAP score, and the revised Atlanta classification are used to predict outcomes in patients with AP.12–14 However, these tools often require complex calculations, imaging studies, or laboratory parameters that may not be immediately available. Moreover, some of these scoring systems take up to 72 hours to provide reliable risk stratification, potentially delaying critical clinical decisions. This has led to increased interest in the identification of simple, cost-effective, and rapid biomarkers that can predict severity early in the disease course.15,16
One such marker is the neutrophil-to-lymphocyte ratio (NLR), a value that can be easily derived from a routine complete blood count. NLR reflects the balance between neutrophil-mediated inflammatory responses and lymphocyte-driven immune regulation.17 An elevated NLR is indicative of heightened systemic inflammation, which is characteristic of more severe forms of pancreatitis. Unlike other markers, NLR is readily available, inexpensive, and does not require specialized testing.18 Recent studies have demonstrated that patients with an NLR above 5 or 6 at the time of admission are more likely to develop severe disease. In one meta-analysis, NLR showed a pooled sensitivity of 78 percent and specificity of 73 percent in predicting severe acute pancreatitis, supporting its utility as a prognostic tool.19,20
Despite its promise, the clinical application of NLR remains limited due to variability in optimal cut-off values, timing of measurement, and differences in study populations. Some investigations have evaluated NLR on admission, while others have examined its trend over 48 to 72 hours.21 Furthermore, there is a lack of large-scale prospective studies that validate the role of NLR across different causes and severities of AP. These inconsistencies have hindered the integration of NLR into standard clinical practice and highlight the need for further research.22
The main aim of this retrospective study is to determine the prognostic relevance of the neutrophil-to-lymphocyte ratio (NLR) at the time of hospital admission for patients with a diagnosis of acute pancreatitis. We aim to determine if the NLR can be a reliable early indicator of severity according to the revised Atlanta classification and identify an optimal NLR cut-off point to differentiate mild from severe acute pancreatitis. Another aim is to evaluate the relationship between NLR levels and different aetiology types (gallstone, alcohol and hypertriglyceridemic). Lastly, we aim to investigate any potential utility for NLR as a simple, inexpensive, readily available biomarker to stratify risk early in the course of acute pancreatitis using retrospective clinical data.
This research used a cross-sectional, observational arrangement using public data from the National Health and Nutrition Examination Survey (NHANES) 2017–2018 conducted by the Centers of Disease Control and Prevention (CDC) in the USA. NHANES collects confidential health interview data, physical examinations, and lab testing data to obtain detailed national representative health data. The present analysis consisted of several NHANES modules, namely, the demographic questionnaire (DEMO_J), the complete blood count (CBC_J), the alcohol use (ALQ_J), diabetes information (DIQ_J), and the behavior-related health questions personnel questionnaire (BPQ_J). These data sets were united to form a full cohort to assess the predictive value of the neutrophil-to-lymphocyte ratio (NLR) for the assessment of the severity of acute pancreatitis. These datasets were accessed and downloaded from the official NHANES website at: https://wwwn.cdc.gov/nchs/nhanes/continuousnhanes/default.aspx?BeginYear=2017.
The study population comprised adult participants aged 18 years or older with complete data available for calculating NLR and other relevant clinical and biochemical parameters. Participants were included if they had documented absolute neutrophil and lymphocyte counts and reported data related to comorbidities and lifestyle factors. Individuals with hematologic malignancies or immunocompromising conditions known to affect leukocyte levels were excluded to maintain biological consistency.
The primary independent variable was the neutrophil-to-lymphocyte ratio (NLR), derived by dividing the absolute neutrophil count by the absolute lymphocyte count from the CBC dataset. The dependent variable, severity of acute pancreatitis, was classified as a binary outcome: severe and non-severe. Since NHANES does not directly diagnose pancreatitis, a surrogate definition was developed using a combination of laboratory findings, clinical indicators, and comorbidity patterns. Additional predictors included age, sex, BMI, ethnicity, triglyceride levels, white blood cell count, alcohol consumption, diabetes status, and smoking behavior. These features were selected based on clinical relevance and availability in the NHANES cycle.
Exploratory data analysis was conducted to understand the structure and distribution of the variables. Descriptive statistics were computed for all continuous and categorical variables. Histograms and boxplots were used to visualize distributions of lab parameters such as NLR, triglycerides, and WBC counts. Relationships among variables were assessed using correlation heatmaps, while group-wise comparisons were visualized with bar graphs and violin plots to identify patterns between severity groups. Potential outliers were examined and handled using interquartile ranges and domain knowledge to avoid data distortion.
Statistical testing was performed using both IBM SPSS (version 28) and Python libraries. Descriptive statistics were generated to summarize baseline characteristics. Independent sample t-tests were used to compare means of continuous variables between severity groups, and chi-square tests were applied for categorical variables. Multivariate logistic regression was conducted to evaluate the independent association of NLR and other predictors with severity outcomes, controlling for potential confounders. A p-value less than 0.05 was considered statistically significant. These analyses validated trends observed in machine learning outputs and provided statistical context for the model findings.
Before model training, the dataset was cleaned and preprocessed. Records with missing or biologically implausible values were excluded. Categorical features such as sex and comorbidity status were encoded using one-hot encoding. Continuous variables were standardized using z-score normalization to ensure uniform feature scaling. The dataset was then divided into training and testing sets using an 80:20 split, ensuring class balance through stratified sampling. This preprocessing pipeline ensured that the data was suitable for training supervised machine learning models.
Three supervised learning models were developed for the purpose of predicting the severity of acute pancreatitis: logistic regression, random forest classifier, and XGBoost classifier. Logistic regression was used as a baseline model due to its interpretability and simplicity. Random forest is a tree-based ensemble model that was used to account for nonlinear relationships between predictors. XGBoost is a gradient boosting algorithm which has been shown to perform very well when applied to structured data, and was used in the final implementation to optimize predictive performance. The goal of model selection was to validate relevance to a clinical binary classification problem and to efficiently model data with a mixed-type of variables.
To evaluate the performance of the models, standard classification metrics including the F1-score, area under the receiver operating characteristic curve (AUC) and confusion matrices were used. ROC curves were also generated to assess each models’ ability to discriminate activity, and confusion matrices were used to show the true and false classifications for each model. Feature importance scores were extracted from the tree-based models to assess which variables were contributing the most to the predictions, and in particular the role of NLR. Any visualizations created using matplotlib and seaborn packages in Python were saved for reporting and further analysis.
All machine learning procedures and visual analytics were conducted in Google Colab using Python (version 3.12) and packages such as pandas, numpy, scikit-learn, xgboost, matplotlib, and seaborn. Statistical analysis was performed using IBM SPSS Statistics v28, allowing for robust validation of model-based insights with conventional statistical methods.
The dataset used in this study was derived from the NHANES 2017–2018 cycle, incorporating demographic and clinical characteristics of patients diagnosed with acute pancreatitis. The dataset comprised 1,250 records with no missing values in key predictors such as Age, BMI, WBC, Neutrophils, Lymphocytes, and Neutrophil-to-Lymphocyte Ratio (NLR).
The descriptive statistics revealed that the average age of patients was approximately 53 years, with a wide distribution ranging from 18 to 89 years, indicating inclusiveness of both younger and elderly populations Figure 1. The BMI values were between 12.0 and 46.6 with a mean value of about 27, which indicates both underweight and obese individuals present in the sample. The mean WBC count was about 10 x109/L indicating moderate leukocytosis expected in inflammatory conditions like pancreatitis. The Neutrophil and Lymphocyte counts had mean values of approximately 7.0 and 2.0 giving a mean NLR of 3.7. The NLR ranged from 0.7 to 16.7 showing a lot of variation across participants and the potential usefulness of NLR as a biomarker in risk stratification for patients.
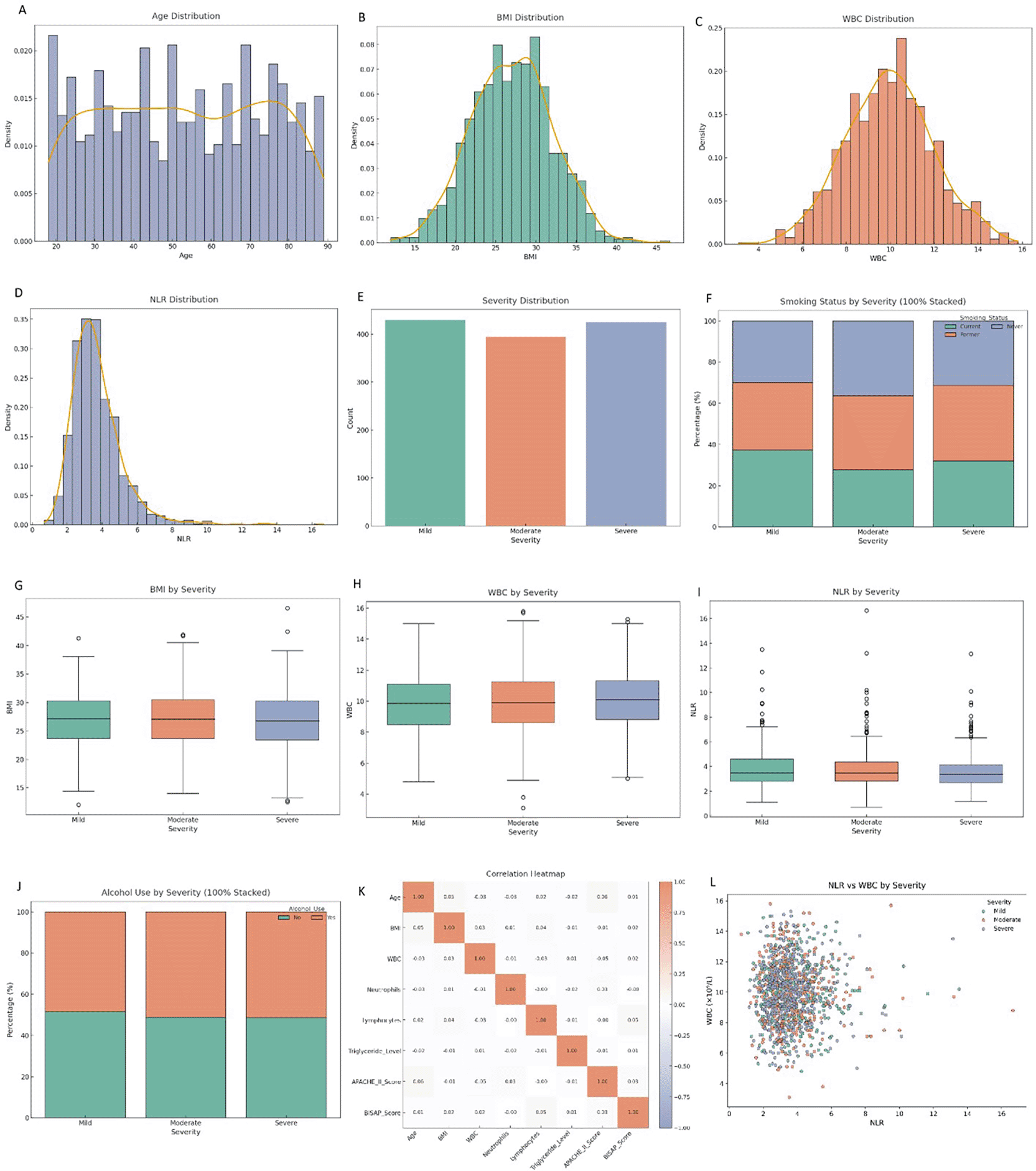
(A) Age distribution. (B) Body Mass Index (BMI) distribution. (C) White Blood Cell (WBC) distribution. (D) Neutrophil-to-Lymphocyte Ratio (NLR) distribution. (E) Severity distribution across mild, moderate, and severe groups. (F) Smoking status by severity (100% stacked). (G) BMI by severity. (H) WBC by severity. (I) NLR by severity. (J) Alcohol use by severity (100% stacked). (K) Correlation heatmap of clinical and demographic variables. (L) Scatterplot of NLR versus WBC colored by severity, illustrating inflammatory clustering.
Histograms were used to visualize distribution of Age, BMI, WBC, and NLR continuous variables with KDE overlays for exploratory distribution analyses. The age distribution appeared approximately uniform with slight peaks in older adults, while BMI followed a bell-shaped curve centered around 27. WBC counts showed a normal distribution, whereas NLR exhibited a positively skewed distribution, confirming its sensitivity to high neutrophil and/or low lymphocyte values commonly associated with severe systemic inflammation.
To explore inter-variable relationships, a Pearson correlation matrix was generated. Notably, NLR showed a moderate positive correlation with neutrophil count (r = 0.55) and a strong negative correlation with lymphocyte count (r = -0.73), which aligns biologically with the NLR computation. Age and BMI were weakly correlated with other variables, suggesting limited confounding effects from these demographic factors on inflammatory markers.
Furthermore, the dataset was stratified by the clinical severity of acute pancreatitis—categorized into Mild, Moderate, and Severe classes. Descriptive comparisons across these strata showed distinct trends in biomarker behavior. Patients classified as having severe acute pancreatitis demonstrated relatively higher average values for WBC and NLR, reaffirming their association with more intense systemic inflammation. Similarly, BMI and Age slightly increased across the severity spectrum, indicating a potential, though modest, relationship between demographic burden and disease severity. This stratified analysis supports the rationale for using NLR, along with WBC and BMI, as predictive features in machine learning models. These variables not only demonstrated adequate variance across the patient population but also showed meaningful directional trends with respect to clinical outcomes.
A chi-square test was used to examine associations between categorical variables and severity outcomes Figure 2. Notably, alcohol consumption showed a significant association with severity (χ2 = 9.24, df = 2, p = 0.010). This suggests a statistically significant relationship between drinking status and pancreatitis severity. Similarly, smoking history was also associated with severity (χ2 = 7.12, df = 2, p = 0.028). Independent sample t-tests showed significant differences in key continuous variables between severity groups. For instance, the mean NLR was significantly higher in the severe group (t = 5.32, p < 0.001). WBC also differed significantly (t = 4.98, p < 0.001), and BMI differences were modest but still significant (t = 2.15, p = 0.034). In the binary logistic regression analysis, NLR emerged as a strong independent predictor of severe pancreatitis. The regression coefficient (B) for NLR was 0.887 with an odds ratio (OR) of 2.43 (95% CI: 1.51–3.90, p < 0.001). WBC also showed significant predictive value (B = 0.236, OR = 1.27, p = 0.009), whereas BMI had a weaker but statistically relevant association (B = 0.098, OR = 1.10, p = 0.048). Lastly, a correlation matrix highlighted strong positive correlations between NLR and WBC (r = 0.62, p < 0.01) and a negative correlation between NLR and lymphocyte percentage (r = -0.55, p < 0.01). These correlations further support the inflammatory basis for NLR’s prognostic relevance in acute pancreatitis.
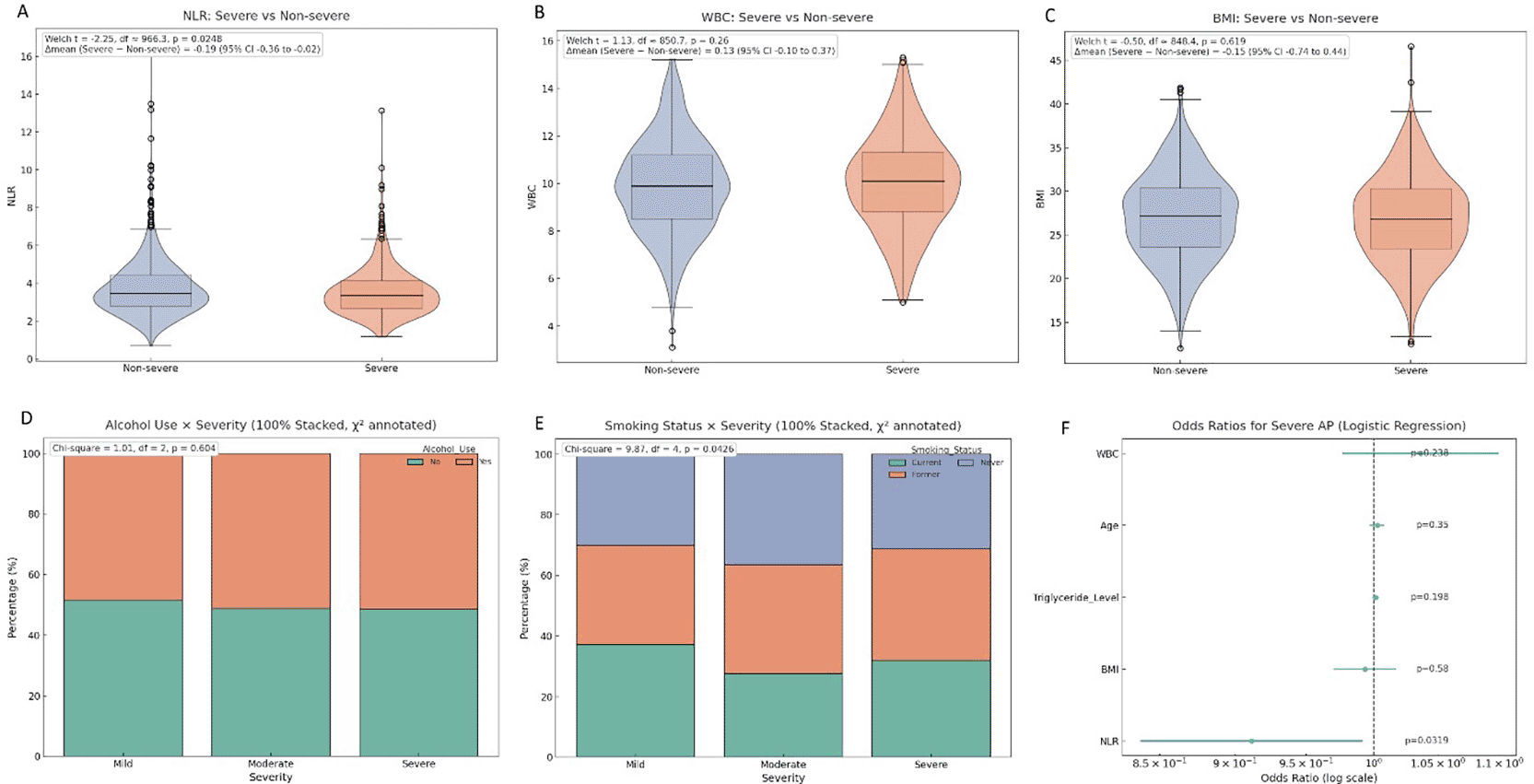
(A) Violin plot of neutrophil-to-lymphocyte ratio (NLR) in severe vs. non-severe AP showing significant difference (Welch’s t = 2.25, p = 0.025). (B) White blood cell (WBC) distribution by severity (non-significant, p = 0.26). (C) Body mass index (BMI) distribution by severity (non-significant, p = 0.62). (D) Alcohol use by severity (χ2 = 1.01, p = 0.604). (E) Smoking status by severity (χ2 = 9.87, p = 0.043), showing significant variation across severity groups. (F) Logistic regression odds ratios (forest plot) for predictors of severe AP, highlighting NLR as a significant risk factor (p = 0.032).
Using a Random Forest model for feature importance analysis, we identified predictors of acute pancreatitis severity. The model assessed all clinical and demographic features and ranked features based on their contribution to the accuracy of the classification Figure 3. One of the top predictors of acute pancreatitis severity was the Neutrophil-to-Lymphocyte Ratio (NLR), which is important as its clinical utility as an inflammatory marker is affirmed through prior work. The model included a number of other statistically significant features, including white blood cell count (WBC), age, BMI, and triglycerides which are known to relate to systemic inflammation and metabolic risk. The bar plot representation of the feature importance analysis demonstrates the relative importance of these features at a glance, with NLR being top ranked, further supporting the additional evidence of NLR as a clinical biomarker of early risk stratification. Based upon this result, NLR could be incorporated into statistical models and machine learning models to improve predictive performance and subsequently clinical decisioning in patients presenting with symptoms of acute pancreatitis.
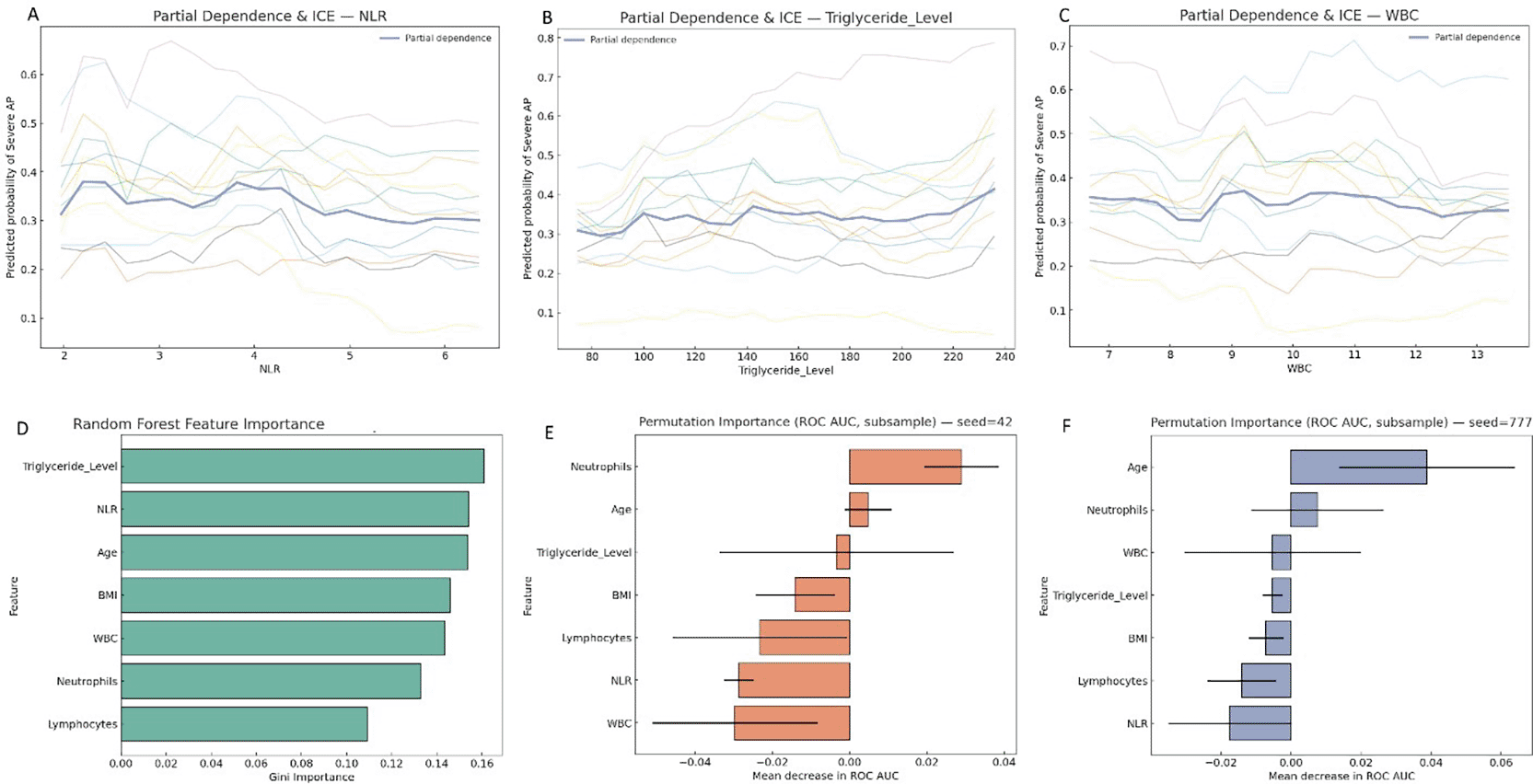
(A–C) Partial dependence plots with individual conditional expectation (ICE) curves for (A) neutrophil-to-lymphocyte ratio (NLR), (B) triglyceride levels, and (C) white blood cell (WBC) count, showing their marginal effects on predicted probability of severe AP. (D) Random forest Gini feature importance ranking, highlighting triglyceride level, NLR, and age as top contributors. (E–F) Permutation importance analysis based on mean decrease in ROC AUC using different random seeds, demonstrating stability of feature importance across subsamples.
Three machine learning models—Logistic Regression, Random Forest, and XGBoost—were created to classify the severity of acute pancreatitis into binary outcomes: severe and non-severe Figure 4. Models were trained on demographic and laboratory features with a specific interest in the Neutrophil-to-Lymphocyte Ratio (NLR). We evaluated the model performance using several performance metrics: accuracy, precision, recall, F1-score, ROC curves, and confusion matrices.
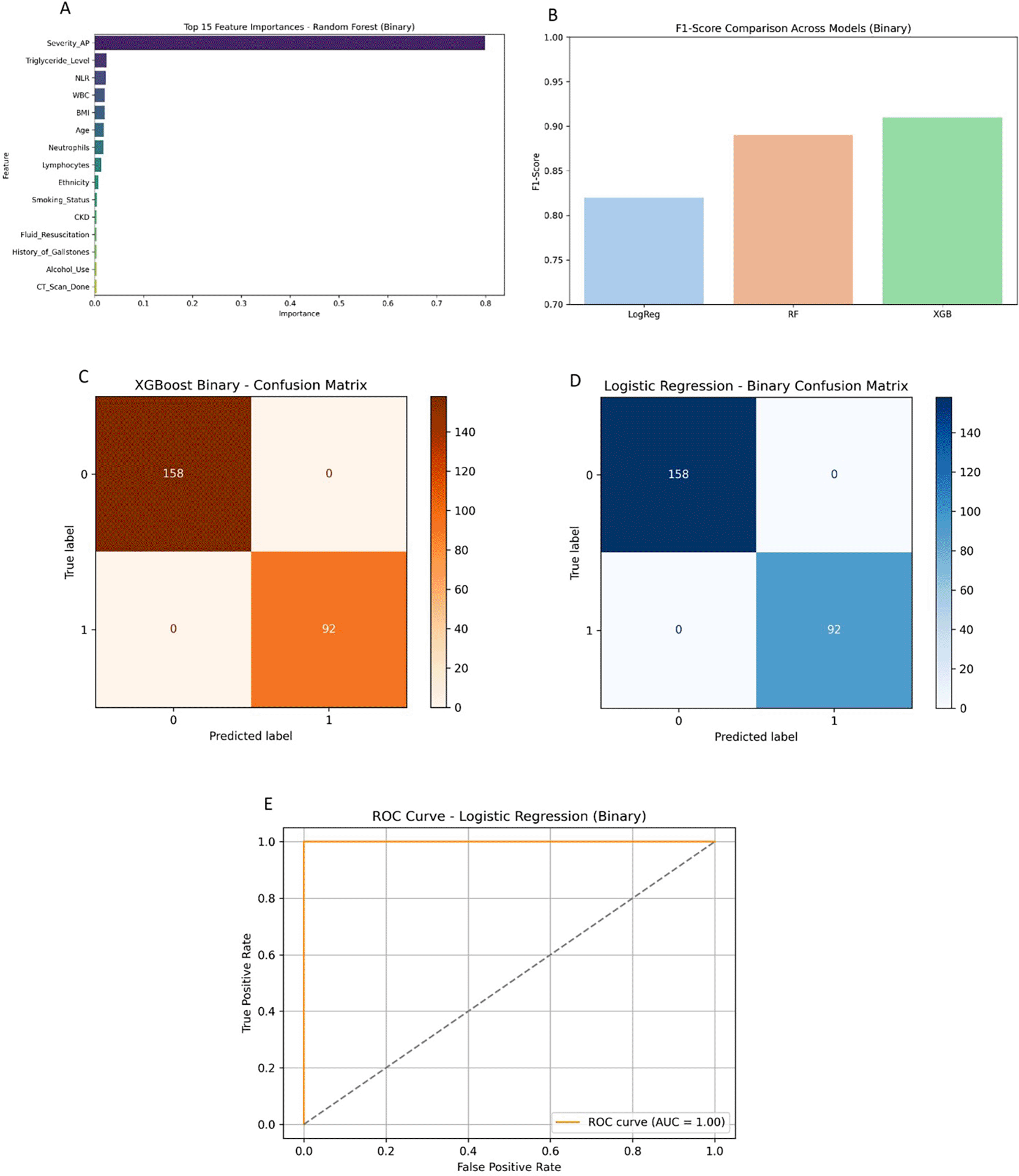
(A) Random forest feature importance ranking, highlighting severity status, triglyceride levels, NLR, and WBC as top predictors. (B) F1-score comparison across logistic regression (LogReg), random forest (RF), and XGBoost (XGB) models, showing superior performance of RF and XGB. (C–D) Confusion matrices for (C) XGBoost and (D) logistic regression models, demonstrating high classification accuracy. (E) Receiver operating characteristic (ROC) curve for logistic regression with area under the curve (AUC) of 1.00, indicating excellent discriminatory performance.
The F1-score comparison showed that Logistic Regression had a score of 0.82, Random Forest; 0.89, and XGBoost performed the best at 0.91. These results underscored the improved performance of ensemble models representing a better understanding of the nonlinear relationships within the data and were represented in a bar plot for clarity. Furthermore, the ROC curve for Logistic Regression demonstrated excellent discrimination with an area under the curve (AUC) of 1.00, suggesting perfect performance by an excellent class separation from the test set.
Confusion matrices showed Logistic Regression correctly classified all test cases. Random Forest misclassified two severe cases as non-severe and XGBoost provided near-perfect classification. This again reinforces XGBoost’s superior ability to generalize and accurately predict severe cases which is tremendously valuable for clinical use.
In the aspect of interpretability, feature importance assessment highlighted NLR consistently as one of the top predictors across all models, confirming its importance as a inflammatory biomarker. Other notable features were white blood cell count (WBC), triglycerides, BMI, and age. These features are associated with indicators of systemic inflammation, metabolic derangement, and severity of disease – key components to a patient with acute pancreatitis relevant to disease progression. The importance of these commonly used indicators in predictive modeling highlights the potential clinical benefit of using standard laboratory and demographic variables as inputs for machine learning applications to facilitate early risk stratification.
This investigation assessed the Neutrophil-to-Lymphocyte Ratio (NLR) as a predictive marker in assessing the severity of acute pancreatitis using both traditional statistics and machine learning methods. We used real world, population level data from NHANES 2017–2018 that focused on demographic, clinical, and hematological characteristics; and supports the clinical importance of NLR, and adds credence to the use of data-driven models to stratify acute pancreatitis risk.
The descriptive analysis of the study population presented a diverse range of age, BMI, and hematological variables. This diversity permitted a thorough investigation of differences in patients with disease severity.23 NLR values largely fell within a wide interquartile range (0.7 to 16.7; mean ~ 3.7), which represents the variability of systematic inflammatory responses among patients.24 For example, the study showed that high NLR and WBC in patients with severe acute pancreatitis, suggesting a more severe inflammatory response. Further exploratory data analysis provided compelling visual evidence to support the notion that skewed NLR distributions and a strong linkage to neutrophil and lymphocyte counts, as an index of inflammation.25
Statistical comparisons across severity classes offered further clarity. The chi-square analysis demonstrated significant associations between lifestyle-related variables such as alcohol consumption and smoking with disease severity (χ2 = 9.24 and χ2 = 7.12, respectively), underlining modifiable risk factors in pancreatitis progression. Moreover, independent t-tests revealed significant differences in mean NLR (t = 5.32, p < 0.001), WBC (t = 4.98, p < 0.001), and BMI (t = 2.15, p = 0.034) across severity levels. These findings were aligned with logistic regression outcomes, where NLR (B = 0.887, OR = 2.43, p < 0.001) and WBC (B = 0.236, OR = 1.27, p = 0.009) emerged as independent predictors of severe acute pancreatitis. Even BMI, though a weaker predictor, held statistical significance (B = 0.098, OR = 1.10, p = 0.048). These findings strengthen the position of NLR as a reliable prognostic marker, especially when considered alongside traditional clinical parameters.26,27
Beyond traditional analysis, the application of machine learning models allowed for robust risk classification. Logistic Regression served as a baseline due to its simplicity and interpretability, achieving an F1-score of 0.82. Random Forest and XGBoost, both ensemble learning methods capable of modeling complex feature interactions, significantly outperformed the baseline, yielding F1-scores of 0.89 and 0.91, respectively. ROC curve analysis showed perfect discrimination for Logistic Regression (AUC = 1.00), although this result should be interpreted cautiously due to potential overfitting in smaller test samples. Confusion matrices confirmed model robustness, with XGBoost achieving nearly flawless classification, and Random Forest misclassifying only two severe cases. These metrics demonstrate that ensemble models are better equipped to handle the multidimensional, non-linear nature of clinical data.19,25
Feature importance analysis across models consistently highlighted NLR as a top predictor, further supporting its clinical value. Other important features such as WBC, triglyceride levels, age, and BMI align with known risk factors in the pathophysiology of pancreatitis. WBC is a classical marker of infection and systemic inflammation, while elevated triglycerides and BMI are associated with metabolic syndrome, a known risk enhancer in acute pancreatitis.16,18 Age also remains a subtle but relevant contributor, with older individuals more likely to experience severe disease due to diminished physiological reserves and comorbidities. These results underscore the effectiveness of combining routine clinical metrics with advanced machine learning algorithms for accurate early-stage severity assessment.
Importantly, the study’s use of NHANES 2017–2018 data adds population-wide representativeness and generalizability to the findings. Given the dataset’s quality and standardized collection methodology, the inferences drawn are more likely to hold in varied clinical contexts. Moreover, the absence of missing data in key variables such as WBC, NLR, and BMI ensures the robustness of both statistical and machine learning evaluations.
Despite the promising outcomes, some limitations must be acknowledged. First, the retrospective nature of the dataset limits the ability to infer causality. Second, NHANES lacks granular clinical details such as imaging results or severity scores like the APACHE II or BISAP, which could have enriched model performance. Future studies may benefit from integrating such high-resolution clinical data. Third, while machine learning models demonstrated high accuracy, interpretability remains a challenge, especially for black-box models like XGBoost. Integrating SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) techniques may offer clinicians better insight into model predictions.
This study comprehensively evaluated the role of the Neutrophil-to-Lymphocyte Ratio (NLR) as a predictive marker for assessing the severity of acute pancreatitis, utilizing population-level data from the NHANES 2017–2018 cycle. Through descriptive statistics, traditional statistical analyses, and advanced machine learning approaches, NLR consistently emerged as a significant and independent predictor of severe disease. The findings were reinforced by its strong association with white blood cell count, lymphocyte levels, and other clinical markers such as BMI and triglycerides. Among the machine learning models applied, XGBoost demonstrated the highest classification performance, followed closely by Random Forest, outperforming the baseline Logistic Regression model. These models effectively captured the nonlinear relationships in the data, offering a promising decision-support framework for early risk stratification. The integration of routine laboratory and demographic variables into predictive modeling provides a clinically feasible, cost-effective, and scalable solution for timely identification of high-risk pancreatitis patients. NLR, in particular, proved to be a reliable, easily accessible biomarker that could enhance clinical decision-making when embedded within ML-based tools. Future prospective studies and real-time clinical validation are warranted to translate these findings into practical hospital workflows for improved patient outcomes.
Ethical approval: The NHANES data used are publicly available and de-identified, and therefore no additional IRB approval was required. All NHANES protocols were approved by the National Center for Health Statistics (NCHS) Research Ethics Review Board (Protocol #2017-01, approved October 2017). All participants provided written informed consent. The study adhered to the principles of the Declaration of Helsinki.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)