Keywords
Artificial Intelligence; Hand Fractures; Wrist Fractures; Deep Learning; Machine Learning; Neural Network.
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the AI in Medicine and Healthcare collection.
Artificial Intelligence; Hand Fractures; Wrist Fractures; Deep Learning; Machine Learning; Neural Network.
Bone fractures are common public health problems worldwide,1 with wrist fractures accounting for most fractures in general and in paediatric patients.2,3 Some of its negative health outcomes include absenteeism from work, disability, reduced quality of life, health-related complications, and high healthcare costs that drain individuals, families, and societies financially, emotionally, and mentally.4,5
X-ray, Computed Tomography (CT), and Magnetic Resonance Imaging (MRI) are the most popular imaging techniques in medical diagnostics used to diagnose fractures. The most used technique is X-ray due to its cost-effectiveness, though it depends on suboptimal positioning techniques and patient cooperation.6,7
In their study, Gäbler et al.8 reported that radiographs in emergency departments were mainly evaluated by non-specialized physicians or junior orthopedic residents, increasing the likelihood of missed fracture diagnosis. Likewise, studies by Donald and Barnard9 and Berlin10 reported that interpretational errors resulting from missed fractures were common among physicians interpreting musculoskeletal radiographs. Studies by Guly11 and Mattijssen-Horstink et al.12 reported that four out of five diagnostic errors in emergency departments involved missed fractures, with wrists accounting for 13–17% of these cases. Thus, artificial intelligence could help physicians detect wrist fractures more accurately than humans.
On the same note, the problem of missed detection could lead to treatment delays among false negatives, resulting in malunion or pseudoarthrosis with attendant morbidity. These complications can be avoided through the adoption of artificial intelligence in wrist fracture detection.13
Clinical inexperience, fatigue, distractions, and poor eyesight all contribute to interpretation errors on radiographs.14 The author further recommends the use of automated analysis with consistent and indefatigable computers to complement the diagnostic skills of physicians, orthopedists, and radiologists in the emergency department.
In the recent past, artificial intelligence, machine learning, and deep learning have been used for fracture detection, classification, and prediction. The use of powerful computers and algorithms has paved the way for rapid and consistent analysis, which is valuable to the healthcare industry globally.
The present systematic review evaluates the effectiveness of artificial intelligence in detecting hand and wrist fractures compared to manual radiographic interpretation by clinicians. The review analyzes and evaluates various artificial intelligence algorithms, seeking to provide evidence-based insights for hospitals and healthcare institutions intending to integrate artificial intelligence models into their clinical systems.
The aim of the following systematic review is to determine the effectiveness of artificial intelligence (AI) in accurately detecting hand and wrist fractures compared to traditional diagnostic methods, such as a clinician’s manual reading of radiographs.
The PICO framework was used to investigate the effectiveness of Artificial Intelligence in accurate detection of hand and wrist fractures compared to traditional diagnostic methods such as clinicians’ manual reading of radiographs. The systematic review involved all age groups with suspected hand and wrist fractures. The intervention aimed to studies that used artificial intelligence, including machine learning and deep learning algorithms, for detecting hand and wrist fractures. These techniques were compared with traditional diagnostic methods, such as manual reading of radiographs by clinicians. The outcome sort were diagnostic accuracy metrics including sensitivity, specificity, positive predictive value, and negative predictive value. The target studies had prospective or retrospective cohort studies, randomized controlled trials, and observational study designs.
2.2.1 Databases searched
The search was conducted across multiple electronic databases: PubMed, Google Scholar, Wiley Online Library, and Science Direct.
2.2.2 Search terms and keywords used
The search terms and keywords used a combination of both standard terms and general keywords, which were refined into proper MeSH-based queries. The search terms and keywords utilized a combination of Boolean operators (AND, OR, AND) to effectively combine key terms and retrieve the desired literature from the searched databases.
The search criteria for Google Scholar, Wiley Online Library, and Science Direct involved keywords indexing system to capture results across all platforms.
(“Hand fracture” OR “Hand fractures” OR “Hand injury” OR “Hand injuries” OR “Wrist fracture” OR “Wrist fractures” OR “Wrist injury” OR “Wrist injuries”)
AND
(“Artificial Intelligence” OR “Machine Learning” OR “Deep Learning” OR “Neural Networks” OR “AI in healthcare” OR “AI for injury detection” OR “Machine learning for orthopedic diagnosis”)
The MeSH terms were used for the PubMed database as indicated in the query below:
(“Hand Injuries”[MeSH] OR “Wrist Injuries”[MeSH] OR (“Fractures, Bone”[MeSH] AND (“Hand” OR “Wrist”)))
AND
(“Artificial Intelligence”[MeSH] OR “Machine Learning”[MeSH] OR “Neural Networks, Computer”[MeSH]).
2.2.3 Study selection process
The selection process started with a thorough search of the electronic databases (Google Scholar, Wiley Online Library, and Science Direct, and PubMed), followed by uploading the results to Rayyan software to identify and remove duplicate entries using two distinct phases carried out independently by three researchers. In phase one, the title and the abstract of each study was reviewed to determine their eligibility criteria, while excluding those that did not meet the criteria.
The inclusion criteria encompassed prospective or retrospective cohort studies, randomized controlled trials, and observational studies published in English, with no time frame limitations, involving patients of all ages with suspected hand and wrist fractures, were included in the systematic review. The reviewed studies focused on relevant outcomes using artificial intelligence (AI), including machine learning and deep learning algorithms, to detect hand and wrist fractures and compare their performance with traditional diagnostic methods, such as the manual interpretation of radiographs by clinicians.
Studies involving animals or cadavers, those not published in English, those not using artificial intelligence for hand and wrist fracture detection, studies lacking a comparator group or comparison with conventional diagnosis methods, and studies lacking sufficient data to build a contingency table were among the excluded criteria. Omitted were reviews, case studies, letters, editorials, and conference abstracts. Studies with a high risk of bias or low quality based on the assessment of study design, sample size, data collection and analysis and lacking relevant factors were excluded.
A standardized form was created to summarize the data relevant factors to the research questions. The variables in the extraction form included general information about the study, author, year, study design, sample size, population characteristics, type of Al algorithm used, imaging modality, sensitivity, specificity, positive predictive value, negative predictive value, area under the curve (AUC), type of fracture detected, comparison group, data preprocessing methods, handling of imbalanced data, external validation, risk of bias, and funding sources.
The selected studies were screened for duplication which were dropped from the systematic review. The risk of bias was assessed using the Methodological Index for Non-Randomized Studies (MINORS) for observational and non-randomized designs, as well as ROBINS-I for non-randomized comparative studies. Studies identified as having a serious risk of bias were excluded from the review.
2.6.1 Treatment of missing data
Missing data was handled by checking the completeness of reported outcomes in the included studies. The final included articles were identified based on the methodological index for non-randomized studies – MINORS – a tool used to screen prospective, retrospective or case-control studies to be included in the systematic review. The studies assessed for bias were 23 in total, out of which only one study had used a prospective study design, while the rest used a retrospective study design.
2.6.2 Assessment of Bias
Two reviewers independently used the methodological index for nonrandomized studies (MINORS) to assess the risk of bias in retrospective and prospective non-randomized studies. This is a validated 12-item tool designed to assess the quality of non-randomized surgical studies. Each included article was assessed for risk of bias using the MINORS tool by the two reviewers, with disagreements resolved through discussion or consultation with a third author.
The PRISMA 2020 flow diagram was generated in R15 to summarize study selection. As shown in Figure 1, we identified 526 records; after removing duplicates, 447 remained. We assessed 22 full-text articles and included 18 studies in the review.
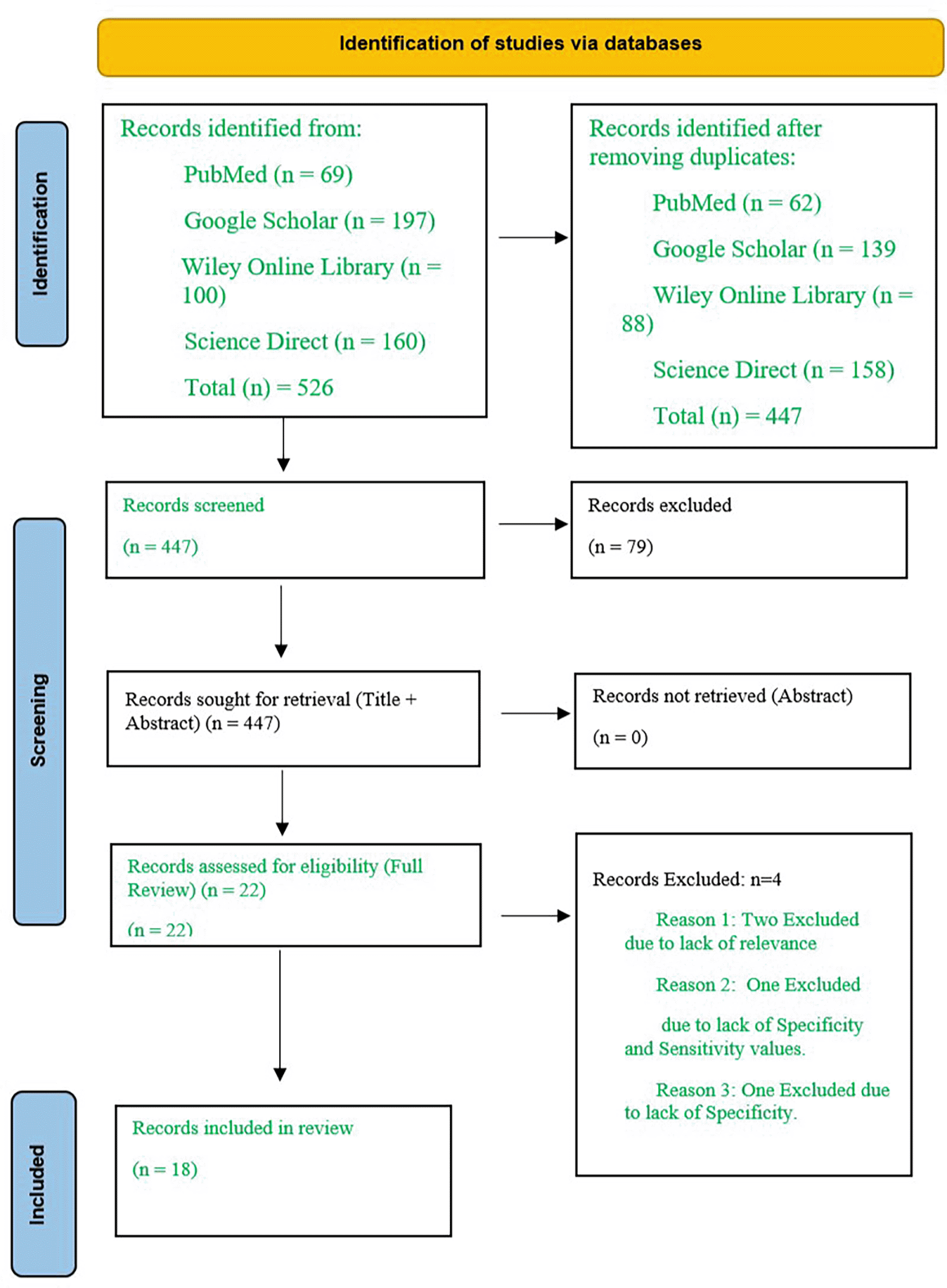
Abbreviations: PRISMA = Preferred Reporting Items for Systematic Reviews and Meta-Analyses.
A total of twenty studies were included in the study where were nine studies were retrospective cohort studies,16–24 two were retrospective diagnostic25,26; two retrospective experimental study27,28; one retrospective validation study29; four retrospective studies30–33; and two prospective diagnostic studies,34,35 Table 1. A retrospective cohort study identifies risk factors and associations, with follow-up at risk groups over time as a key feature. A retrospective diagnostic study evaluates the test accuracy and compares diagnostic results to a gold standard. A retrospective experimental study assesses past interventions using historical intervention data. A retrospective validation study tests models/methods as it validates previous findings on new past data. A prospective diagnostic study assesses the effectiveness of a diagnostic test in detecting conditions.
| Author | Outcomes measured | Type of intervention AI method/algorithm | Comparison group-manual reading |
|---|---|---|---|
| Zech et al.33 | AUC, Accuracy, Sensitivity, and Specificity | Faster R-CNN | PGY-2 and PGY-4 Pediatrics Resident/fellow, and a PGY-2 and PGY-4 Radiology Resident |
| Raisuddin et al.32 | AUROC, AUPR, Sensitivity, Recall, TPR, Specificity, Selectivity, TNR, Precision, PPV, and F1 score | Deep Wrist pipeline | Two Board-Certified Radiologists, and Two primary care physicians |
| Cohen et al.30 | Sensitivity, Specificity, PPV, and NPV | BoneView (Gleamer) Deep CNN algorithm | 41 Radiologists |
| Hardalaç et al.18 | Average precision (AP50) | Deep-learning-based object detection models | 1 Radiologist, 2 Orthopedists |
| Anttila et al.16 | Sensitivity, Specificity, Accuracy, NPV, PPV, ROC, AUC, Inter-observer reliability (kappa coefficient) | Segmentation-based U-net architecture with 25 layers | 1 Hand Surgery Resident, and 3 Consultant hand Surgeons |
| Üreten et al.24 | Accuracy, Sensitivity, Specificity, Precision | VGG-16, ResNet-50, and GoogLeNet | 1 Orthopedist, and 1 Radiologist |
| Oka et al.23 | Accuracy, Sensitivity, Specificity, AUC | VGG-16 (16-layer CNN modeL) | Specialized Orthopedic surgeons |
| Zhang et al.35 | Sensitivity, Specificity, PPV, NPV, AUC, Interrater reliability (Cohen’s Kappa) | 3D ultrasound, using a Philips IU22 machine | 1 Radiologist, 1 Medical Student, and 1 Fellow |
| Blüthgen et al.17 | AUC, Sensitivity, and Specificity | Generic image analysis software (ViDi Suite Version 2.0) | 2 Radiologists Consultants, and 1 Radiology Resident |
| Min et al.26 | AUC, Accuracy, TPR, FPR, and Specificity | YOLOv5, and EfficientNet-B3 | 3 Orthopedic Training Registrars, and an Orthopedic Consultant |
| Ju and Cai28 | Mean average precision (mAP 50) | YOLOv8 algorithm | Radiologists |
| Gan et al.25 | Accuracy, Sensitivity, Specificity, Youden Index, and AUC | CNN-Inception-v4 | Radiologists, and Orthopedists |
| Hendrix et al.27 | Sensitivity, Specificity, PPV, AUC, Cohen’s kappa coefficient, and fracture localization precision | YOLOv5s, and InceptionV3 | 5 Radiologists |
| Lee et al.29 | Sensitivity, Specificity, Accuracy, and AUC | CNN-RetinaNet, DeepLab v3, NasNet | 2 Radiologists, and 1 Radiology Resident |
| Knight et al.34 | Sensitivity, Specificity, PPV, NPV, Accuracy, and AUROC | CNN-ResNet34, and DenseNet121 | 3 novice, 2 intermediate, and 2 expert readers |
| Lee et al.20 | Accuracy, Sensitivity, Specificity, Correlation coefficient and DSC (Dice similarity coefficient) | U-Net, and detection and classification model based on RetinaNet | 1 Orthopedic surgeon |
| Li et al.21 | Sensitivity, Specificity, AUROC, Fleiss’ Kappa, Cohen’s Kappa | CNN-YOLOv3 and MobileNetV3 | 4 Hand Surgeons |
| Jacques et al.19 | Sensitivity, Specificity, PPV, NPV, and AUROC | Boneview (Gleamer) | 23 Radiologists |
| Mert et al.22 | Sensitivity, Specificity, and AUC | ChatGPT 4 | 1 Radiologist, 1 Hand Surgery Resident, 1 Medical Student and Gleamer BoneViewTM |
| Kim and MacKinnon31 | ROC, AUC, Specificity, and Sensitivity | Deep CNNs | 1 Radiology Registrar |
The MINORS quality appraisal results for each study appear in ( Table 2). Individual item scores (0–2) and total scores are reported for each study; items 9–12 apply only to comparative designs.
| Study ID | Study design | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | Total |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zech et al.33 | Retrospective study | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 21 |
| Raisuddin et al.32 | Retrospective study | 2 | 2 | 1 | 2 | 0 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 20 |
| Cohen et al.30 | Retrospective study | 2 | 1 | 1 | 2 | 2 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 21 |
| Hardalaç et al.18 | Retrospective cohort study | 2 | 2 | 1 | 2 | 1 | 0 | 2 | 0 | 2 | 2 | 2 | 2 | 18 |
| Anttila et al.16 | Retrospective cohort study | 2 | 2 | 1 | 2 | 1 | 1 | 2 | 1 | 2 | 2 | 2 | 2 | 20 |
| Üreten et al.24 | Retrospective cohort study | 2 | 1 | 1 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 21 |
| Oka et al.23 | Retrospective cohort study | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 21 |
| Zhang et al.35 | Prospective diagnostic study | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 24 |
| Blüthgen et al.17 | Retrospective cohort study | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 21 |
| Min et al.26 | Retrospective diagnostic study | 2 | 2 | 1 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 22 |
| Ju and Cai28 | Technical/Methodological study | 2 | 1 | 0 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 20 |
| Gan et al.25 | Retrospective study | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 22 |
| Hendrix et al.27 | Retrospective study | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 1 | 2 | 2 | 0 | 2 | 20 |
| Lee et al.29 | Retrospective study | 2 | 1 | 1 | 2 | 1 | 2 | 2 | 0 | 1 | 1 | 1 | 2 | 16 |
| Knight et al.34 | Prospective diagnostic study | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 2 | 2 | 2 | 22 |
| Lee et al.20 | Retrospective study | 2 | 1 | 1 | 2 | 1 | 2 | 2 | 0 | 1 | 2 | 2 | 2 | 18 |
| Li et al.21 | Retrospective study | 2 | 1 | 1 | 2 | 1 | 2 | 2 | 0 | 1 | 2 | 2 | 2 | 18 |
| Jacques et al.19 | Retrospective study | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 0 | 1 | 2 | 2 | 2 | 20 |
| Mert et al.22 | Retrospective study | 2 | 1 | 1 | 2 | 2 | 2 | 2 | 0 | 2 | 2 | 2 | 2 | 20 |
| Kim and MacKinnon31 | Retrospective study | 2 | 1 | 1 | 2 | 2 | 2 | 2 | 0 | 1 | 2 | 2 | 2 | 19 |
3.4.1 Forest Plot of Sensitivity and Specificity
The forest plots display sensitivity and specificity for individual studies along with the pooled estimates. ( Figure 2) shows sensitivity and ( Figure 3) shows specificity. This showed the variations among studies and how each contributed to the overall results. The studies selected for final inclusion were 18. However, you will notice that 22 entries were included in the forest plot. This is because some studies reported investigations using more than two algorithms, and to avoid overlapping, it was necessary to report each algorithm individually.
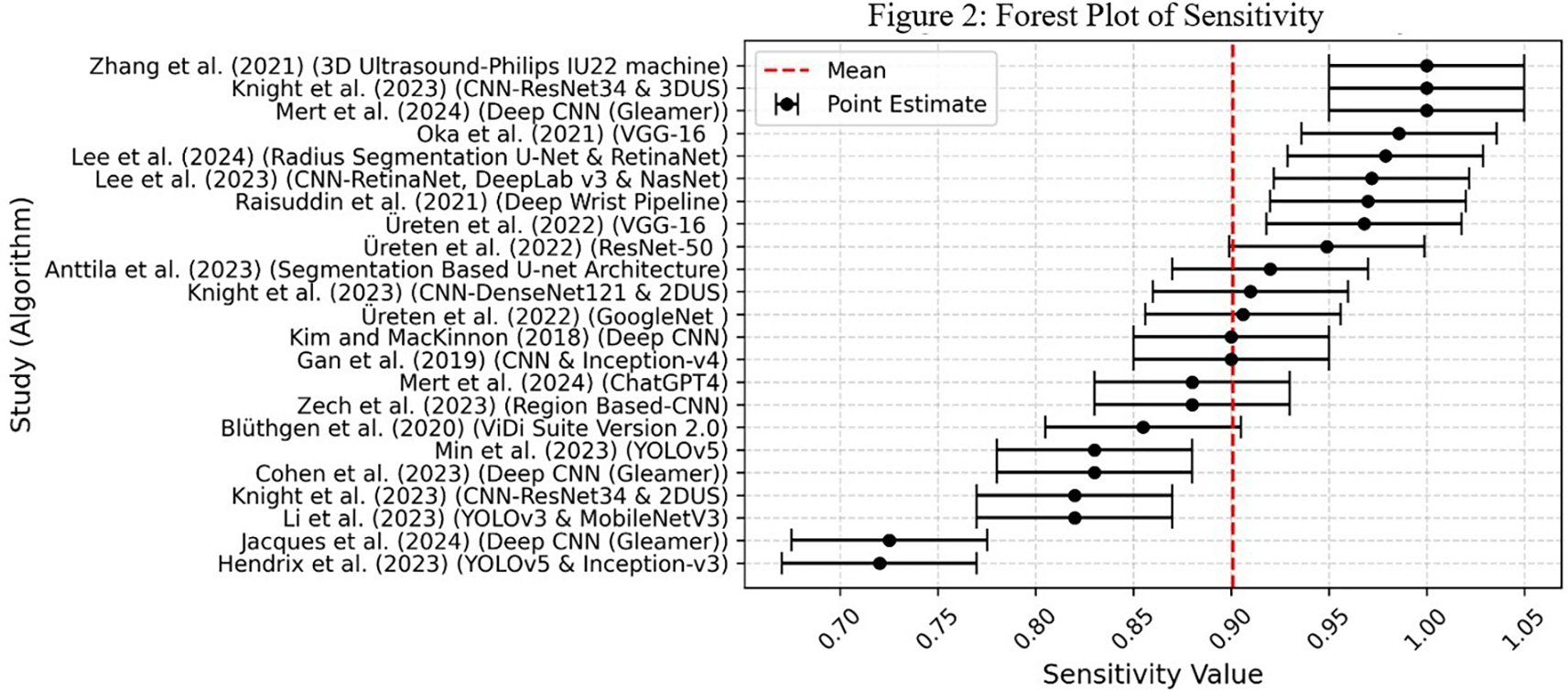
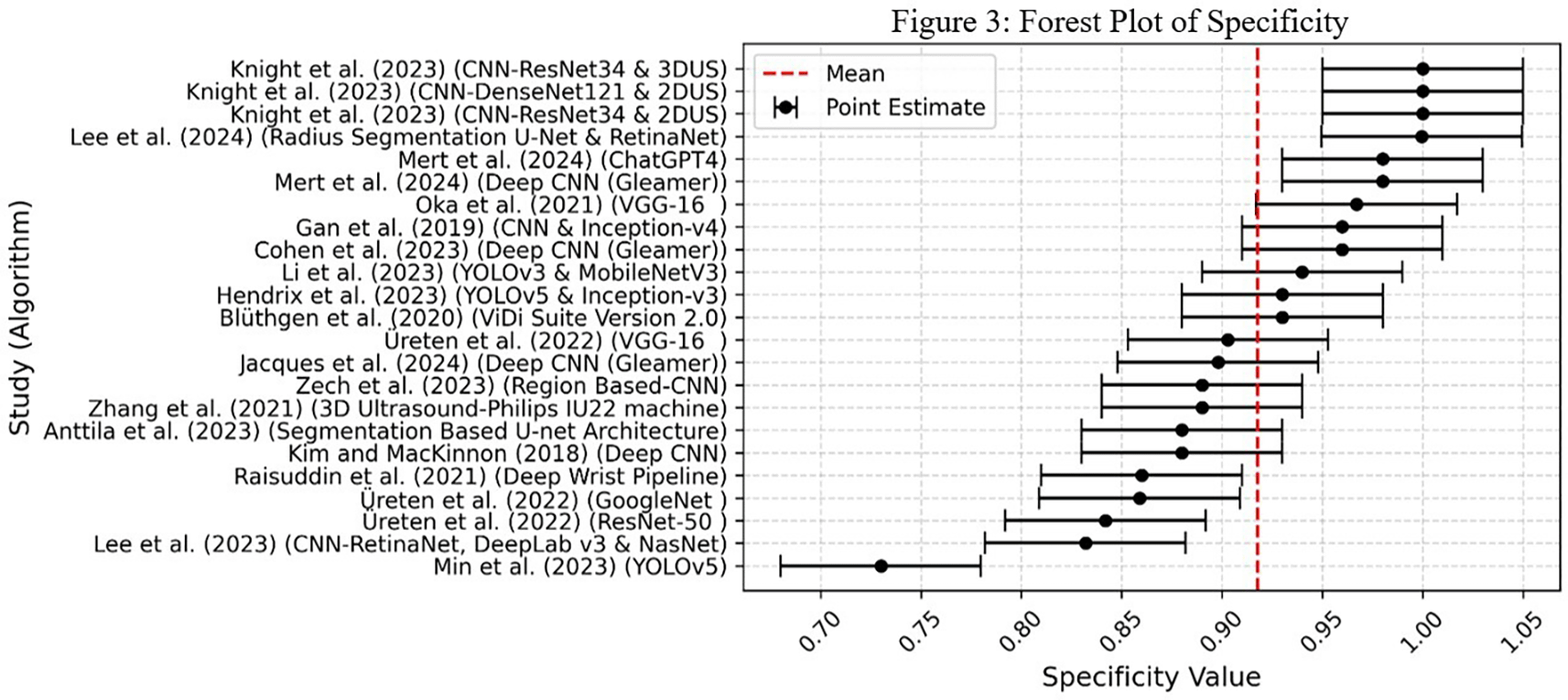
Figure 4 above shows the forest plot for sensitivity estimates. Logit sensitivity was estimated instead of logit specificity because it was the primary target for the systematic review—detection of hand and wrist fractures using AI. The true positive rate (sensitivity) was important because the AI models were designed for detecting hand and wrist fractures, as missing a fracture could have detrimental side effects due to delayed interventions.
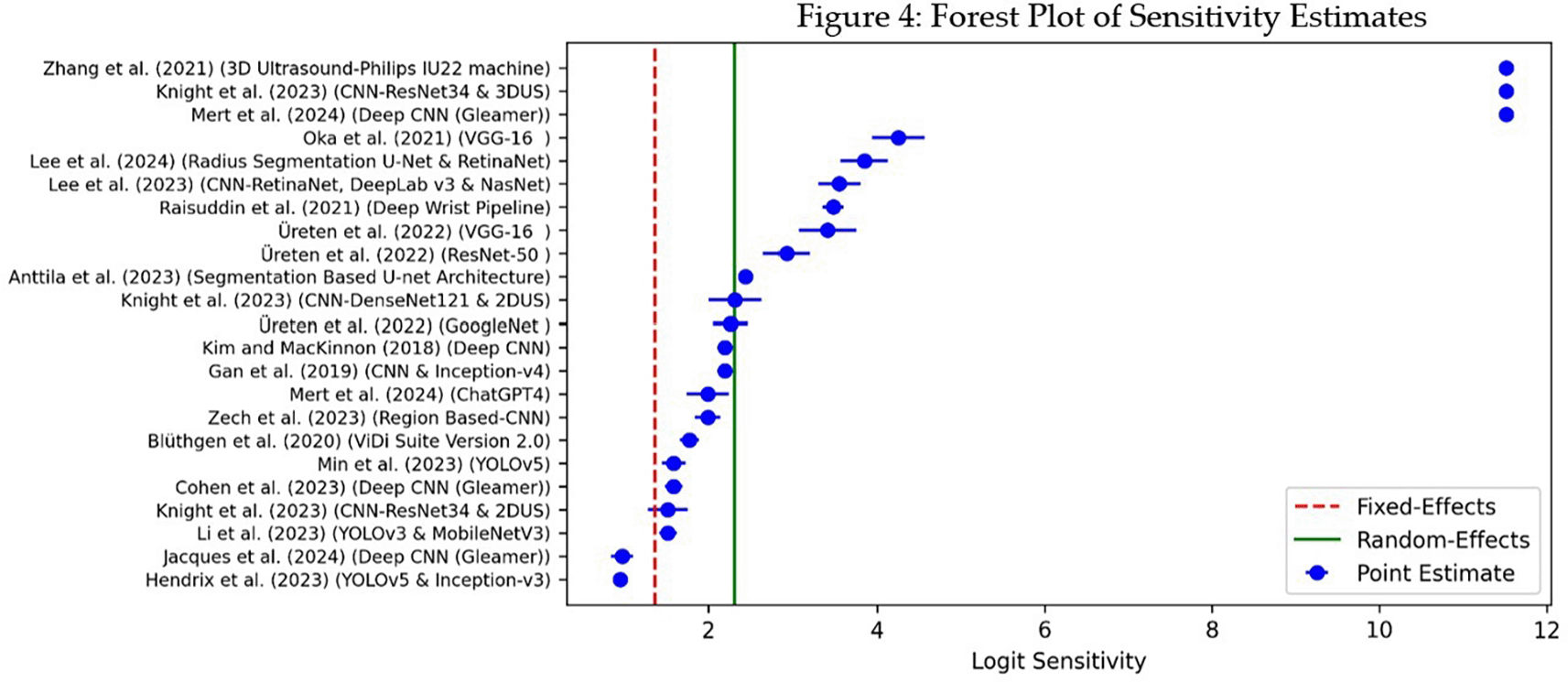
Abbreviations: CI = Confidence Interval; AI = Artificial Intelligence.
Most of the AI models, as shown in Figure 4, cluster around a logit sensitivity of 3–5, which is a positive sign that most models had strong diagnostic performance. The logit sensitivity shows that three AI models—3D ultrasound-Philips, CNN-ResNet34, and Deep CNN Gleamer—had logit sensitivity values closer to 12, suggesting exceptional sensitivity. Models such as VGG-16 and Radius Segmentation U-Net & RetinaNet showed competitive sensitivity with estimates of around 4–5. These variations illustrate the different capabilities of deep learning techniques in detecting hand and wrist fractures. The blue spots in Figure 4 also display lines (confidence intervals), highlighting variations in performance across the different datasets.
High sensitivity scores across most models indicate that the AI models used for detecting hand and wrist fractures were effective at identifying fractures. This is very important in a clinical setup where missing a fracture (false negatives) could have serious consequences, as patients might miss urgent intervention.
3.4.2 Fixed-effects meta-analysis for sensitivity and specificity
The sensitivity and specificity values from multiple studies were combined using a fixed-effects model. The assumption was that all 18 studies were estimating the same true effect, with any differences arising from chance. Consequently, the pooled sensitivity and specificity were estimated as weighted averages, with studies having lower variance receiving more weight.
3.4.3 Logit transformation
The logit transformation function normalizes the data, increasing the reliability of its calculation. The data was normalized and then transformed back to the probability scale for easier interpretation. Since sensitivity and specificity values typically range between 0 and 1, their transformation to the logit scale was necessary.
3.4.4 Heterogeneity analysis and random effect
The Cochran’s Q test and I2 statistic were used to measure the variability among the 18 studies. Higher values indicated large variations, suggesting that the 18 studies were not measuring the same thing. To further investigate this high variation, a random-effects model was performed, as it relies on the assumption that each individual study analyzed in the present systematic review had its own true effect rather than relying on a single common effect.
Figure 5 above shows the funnel plot that was plotted with studies, showing the relationship between study precisions (standard errors) and effect sizes. The identifiers were annotated with numbers, along with their specific labels and the AI models used. The shape of the plot is asymmetrical, meaning that there was publication bias, specifically a small study effect. In the absence of publication bias, the study points would have been evenly scattered around the red vertical line. The vertical red line represents the overall mean log (DOR)—the log of the Diagnostic Odds Ratios, which measures the effectiveness of a diagnostic test and is calculated as the ratio of the odds of a true positive to the odds of a false positive. A closer observation of Figure 5 shows that 16 AI models are on the left side of the vertical red line, and 7 on the right. The studies on the left side suggest that the AI models reviewed had lower DOR, which could be translated as potentially lower test accuracy or effect size. The seven AI models on the right side suggest a higher DOR, which could be translated as potentially higher test accuracy or effect size.
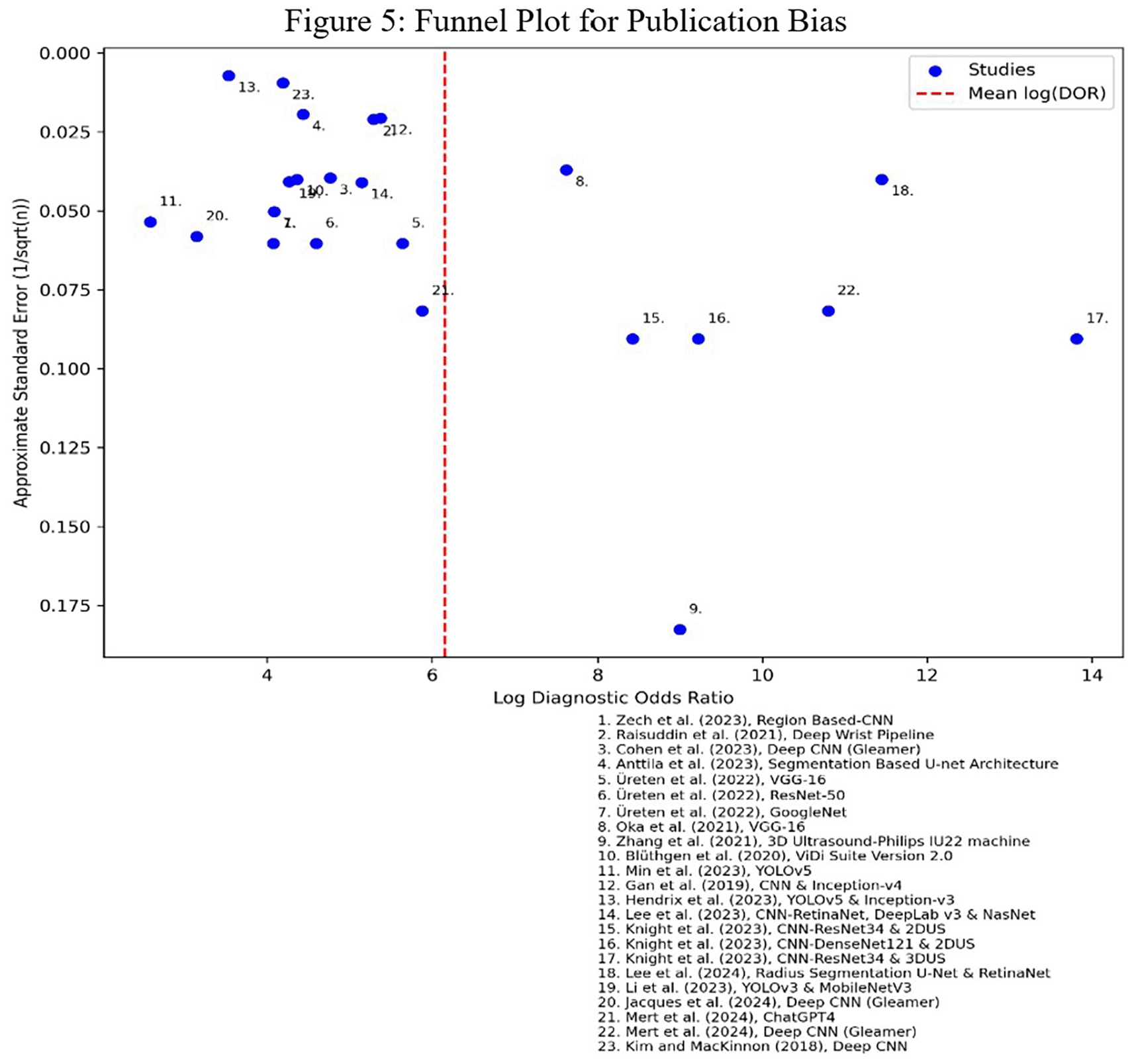
Abbreviations: DOR = Diagnostic Odds Ratio; SE = Standard Error.
The imbalance – asymmetrical funnel plot – suggests potential publication bias, which resulted from the studies using different AI models and algorithms with variations in sample sizes. The AI models on the left side were clustered closer together, indicating that their results were more consistent with each other, while the clustering of the AI models on the right side is spread out, indicating more variability in their results and uncertainty. The precision was approximated by the standard error as reflected in the y-axis. The studies with higher precision (smaller error) appeared at the top – closer to the 0 value, while the studies with lower precision (larger errors) appeared at the bottom of the funnel plot. The studies,16,25,27,31–33 had standard errors below 0.025, which are closer to 0. This suggests their results are highly precise, probably due to their large sample sizes – an indication that they carried more weight in the overall conclusion. The study by Zhang et al.,35 had a standard error placed at the far bottom of the funnel plot, indicating that its AI model had a higher uncertainty in its estimate, thus less reliable (lower precision). Its placement on the right side of the funnel is indicative of a higher diagnostic odds ratio – better diagnostic performance of the AI model. Nevertheless, the model shows a large standard error, which makes it less trustworthy due to its lower precision value, and thus not as reliable as studies with lower SE, clustered near the top on the right side.
The Egger’s test shown in Table 4 indicates that the precision value was statistically significant (p < 0.001), confirming the presence of publication bias in the published AI models. The R-squared score indicated that 83.4% of the variability in the standardized effect (log_DOR/SE) explained the precision (inverse of SE) in the final model, suggesting that the model accounted for most of the variance in detecting hand and wrist fractures using AI models. Thus, precision was an important predictor of the standardized effect. The adjusted R-squared variance of 82.6% suggested that the variability in the standardized effect was explained by precision.
| Heterogeneity & Random effect | Sensitivity | Specificity |
|---|---|---|
| Fixed-Effects Pooled | 0.796 | 0.903 |
| Random-Effects Pooled | 0.910 | 0.912 |
| Heterogeneity (I2) | 99.09% | 96.43% |
In recent years, artificial intelligence has been spreading into various aspects of life, such as finance, education, manufacturing and Industry 4.0, retail and e-commerce, transport and logistics, agriculture, cybersecurity, media and entertainment, energy and environment, human resources and recruitment, legal and compliance, and healthcare. In healthcare, AI has driven innovations in medical imaging—cancer,36,37 fractures,38,39 and brain disorders40,41—personalized treatment plans,42,43 drug discovery and development,44,45 AI-assisted surgeries,46,47 and predictive analytics for patient outcomes.48,49 Therefore, this systematic review investigates the accuracy of artificial intelligence (AI) in detecting hand and wrist fractures.
A substantial variability was observed across the studies in terms of sensitivity and specificity. The sensitivity (0.796) and specificity (0.903) in the fixed-effects pooled estimates indicate that the fixed-effects model had higher specificity compared to sensitivity. However, the random-effects model showed higher values for both sensitivity (0.910) and specificity (0.912), suggesting that the random-effects model demonstrated better diagnostic performance for AI in detecting hand and wrist fractures.
The heterogeneity scores for sensitivity (99.09%) and specificity (96.43%) were very high, as shown in Table 3. This indicates substantial inconsistencies across the studies, likely due to variations in the devices and algorithms used across the 18 reviewed studies. As a result, caution is necessary when generalizing these findings across different clinical settings.
In terms of sensitivity of the devices and their respective algorithms, the 3D Ultrasound-Philips IU22 machine,35 CNN-ResNet34 & 3DU,34 and Deep CNN-Gleamer22 reported the highest scores, as shown in Figure 2. The mean sensitivity was approximately 90%.
Studies by Hendrix et al.,27 - (YOLOv5 & Inception-v3), Jacques et al.,19 - (Deep CNN-Gleamer), Li et al.,21- (YOLOv3 & MobileNetV3), Knight et al.,34- (CNN-ResNet34 & 2DU), Cohen et al.,30- (Deep CNN-Gleamer), Min et al.,26- (YOLOv5), Blüthgen et al.,17- (ViDi Suite Version), Zech et al.,33- (Region-Based CNN), and Mert et al.,22- (ChatGPT4) all had sensitivity values below 90%. This indicates that the algorithms used in these studies were less effective in identifying positive cases (true positives) compared to studies with sensitivity values above 90%.
The lower sensitivity in these studies could be attributed to a higher percentage of missed true positive cases (false negatives) when detecting hand and wrist fractures. Therefore, studies with specificity values below 90% signal that the AI models used may not be fully reliable for diagnosing hand and wrist fractures, increasing the risk of missed diagnoses.
The specificity identified algorithms that can distinguish individuals without hand and wrist fractures (true negatives) from those incorrectly identified as having fractures (false positives). The mean specificity was approximately 90%. Therefore, studies with higher specificities (greater than 90%) demonstrated that the algorithms correctly identified individuals without hand or wrist fractures, indicating a minimized risk of false positives, and vice versa.
Studies by Min et al.26 – YOLOv5, Lee et al.29 – CNN-RetinaNet, DeepLabv3 & NasNet, Üreten et al.24 – ResNet-50, Üreten et al.24 – GoogleNet, Raisuddin et al.32 – Deep Wrist Pipeline, Kim and MacKinnon31 – Deep CNN, Anttila et al.16 – Segmentation-Based U-Net Architecture, Zhang et al.35 – 3D Ultrasound (Philips IU22 machine), Zech et al.33 – Region-Based CNN, and Jacques et al.19 all reported specificity values below 90%. Nevertheless, studies with higher specificity scores indicated that their AI models performed better in avoiding false alarms.
Like any other study, the present systematic review had its own strengths and limitations. Its strengths included the fact that most of the studies reported high scores for both sensitivity (14 out of 23 AI models) and specificity (12 out of 23 AI models), with values ≥90%. Higher sensitivity scores indicated fewer missed fractures, suggesting that radiologists could potentially rely on these AI models to detect hand and wrist fractures, and vice versa.
The systematic review indicated that deep learning models, particularly those based on CNNs, dominated the performance of the AI models reviewed. This pattern was reflected in the forest plot of both sensitivity and specificity, where the top quarter was largely occupied by CNN-based AI models. However, this review does not advocate that CNN models are inherently superior to other models; rather, it highlights opportunities for further improvements and modifications to develop better algorithms or models. Enhancements could include training the models on larger sample sizes or fine-tuning hyperparameters to improve predictive performance.
One of the limitations of this review was that some studies had smaller sample sizes compared to others. However, logit transformation was applied to convert the proportions to an unbounded scale in preparation for statistical modelling and meta-analysis, which helped stabilize variance resulting from different sample sizes. The logit function was then back transformed to the inverse logit function for easier interpretation of sensitivity and specificity scores. Additionally, sample weighting was performed to ensure that the final estimates of pooled sensitivity and specificity were reliable. Future AI studies can enhance their models by training on larger datasets and continuously reviewing and improving their performance.
Another limitation arose from the interpretation of the confidence intervals presented in the forest plots. The results indicated that 9 out of the 18 studies had sensitivity values below 90%, which was concerning as it suggested a higher risk of missing hand and wrist fractures.
Lastly, the systematic review aimed to evaluate sensitivity and specificity and ensure that the meta-analysis provided robust evidence for the clinical superiority of one AI model over other comparative AI models. The approach involved assessing bias and robustness in terms of publication bias and sensitivity analysis. Most studies failed to report the AUC, NPV, PPV, and even confidence intervals. As a result, the study relied on sensitivity, specificity, and sample sizes to determine publication bias.
Most AI models demonstrated good diagnostic accuracy, with high sensitivity and specificity scores (≥90%). However, some models fell short in sensitivity and specificity (≤90%), indicating performance variations across different AI models or algorithms.
From a clinical perspective, AI models with lower sensitivity scores may fail to detect hand and wrist fractures, potentially delaying treatment, while those with lower specificity scores could lead to unnecessary interventions—treating hands and wrists that are not fractured. The AI models were trained on datasets with varying sample sizes, using different devices and algorithms. Therefore, it is essential to standardize training datasets and algorithms and strive for greater consistency in AI models.
Not applicable. This study is a systematic review of published literature and did not involve human or animal subjects.
This article follows the PRISMA 2020 reporting guideline for systematic reviews.50
The completed PRISMA checklist and flowchart are available at: https://zenodo.org/records/16749232.
Data are available under the terms Creative Commons Zero v1.0 Universal (CC0)
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)