Keywords
machine learning; deep learning; natural language processing; large language models; generative AI; ChatGPT; sentiment analysis; implementation research; decision support; health systems
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Research on Research, Policy & Culture gateway.
This article is included in the University College London collection.
machine learning; deep learning; natural language processing; large language models; generative AI; ChatGPT; sentiment analysis; implementation research; decision support; health systems
We made minor edits in response to Reviewer 1: we now spell out Knowledge-to-Action (KTA) at first mention, and we added an early, concise definition of a living scoping review before the rationale. We clarified in the eligibility criteria that included studies must be situated in implementation science within health-related domains/settings.
See the authors' detailed response to the review by Julia Brasileiro
Health systems grapple with the overuse of harmful, wasteful, or ineffective interventions, commonly referred to as “low-value care,” while underutilizing evidence-based interventions, leading to gaps in the delivery of “high-value care.”1,2 Implementation science, defined as the study of methods and strategies that facilitate the integration of evidence-based interventions, programs, and policies into health systems,3 holds considerable promise in addressing these challenges across a range of clinical contexts.4–10 It seeks to understand how, why, and under what conditions implementation succeeds or fails across varying contexts, and how best to support healthcare provider behaviour and system change.11,12 Implementation research refers to the rigorous investigation of these methods and strategies, while implementation practice concerns their application by practitioners, health system leaders, and policymakers in real-world settings.13 However, implementation efforts to adopt and sustain evidence-based interventions are constrained by the time- and resource-intensive processes required to identify, synthesize, and apply implementation evidence, including context-specific barriers, facilitators, and strategies.14,15 Additional challenges, including the heterogeneity of implementation data, variability in outcomes, and the underrepresentation of key populations, hinder timely, equitable, and context-responsive implementation.16 These limitations also undermine sustainability.17
In recent years, the integration of artificial intelligence (AI) in science and practice has rapidly advanced across sectors.18 AI has long been implemented in healthcare across diagnostics, treatment, population health management, patient care, and healthcare professional training and decision support, utilizing a wide range of AI innovations.19,20 It is helpful to distinguish between the major categories of AI and the methods that power them. Machine learning (ML) is a foundational approach in which systems learn patterns from data, with deep learning (DL) being a specialized subset that uses multi-layered neural networks for complex pattern recognition. Natural language processing (NLP) is a field of AI focused on enabling machines to understand and generate human language, often powered by DL-based models such as large language models (LLMs).19,20 LLMs are also an example of generative AI, which encompasses models capable of creating new content, such as text or images.21–23
Most healthcare-related systems use ML, DL and generative AI methods.19 ML and DL models have improved diagnostic accuracy by analyzing medical images and large datasets, reducing human error in disease detection24,25; for example, in breast cancer screening, they can lower both false positives and false negatives.26,27 ML-based methods are advancing personalized medicine, particularly in oncology, where it aids in genomic analysis to predict drug responses and disease predispositions.28–30 ML-driven predictive analytics support population health management by identifying at-risk individuals and enabling early interventions, thereby reducing hospital readmissions and healthcare costs.31 Virtual assistants powered by NLP are automating routine tasks, providing continuous support, and even offering mental health support through web-based cognitive-behavioral therapy.32,33
The recent momentum in AI-driven healthcare is largely propelled by advancements in generative AI in the form of LLMs, such as Open AI’s GPT,21 Meta AI’s LLaMA22 and Google DeepMind’s Gemma,23 which introduce new possibilities in medical documentation, patient risk assessment, and clinical decision-making.34 LLMs are AI models trained on vast amounts of textual data to process, understand, and generate human-like language.21–23 These models are based on deep learning architectures, such as transformers, which allow them to analyze and predict text patterns effectively.34 Their applications are wide-ranging; for example, it is claimed that they can assist healthcare professionals by summarizing clinical encounters, automating medical notetaking, and generating real-time responses to complex medical queries, providing support that can increase efficiency and allow healthcare professionals to focus more on patient care.34 They may also contribute to the education and training of health professionals and patients.35,36 LLMs like ChatGPT may benefit medical education by supporting differential diagnosis brainstorming and providing interactive clinical cases for practice.34 LLMs have also shown effectiveness in patient education by delivering accurate answers to questions, enriching and tailoring existing educational resources, and simplifying complex medical language into more accessible terms.35,36
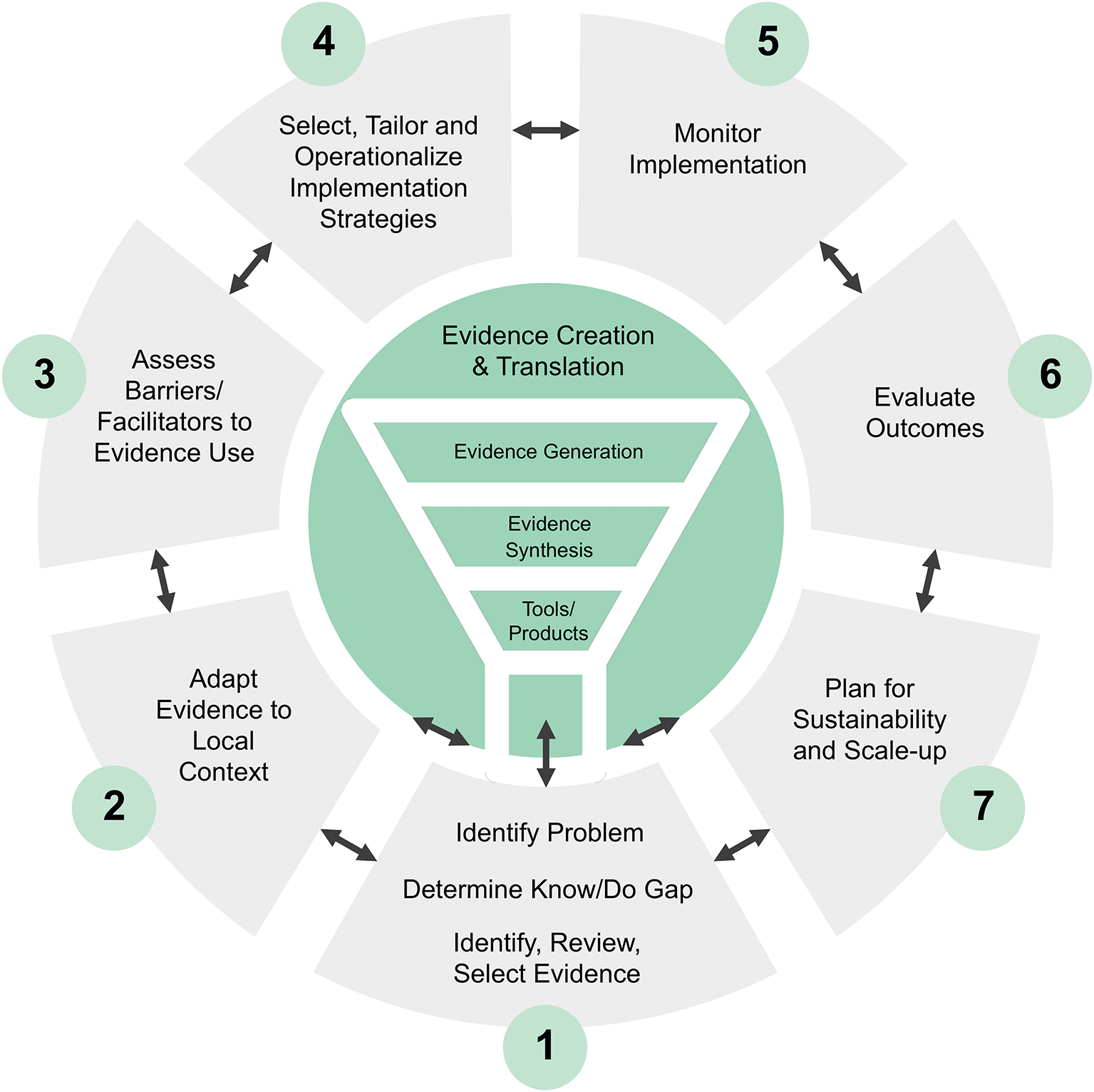
Given this momentum, interest in harnessing AI for implementation research and practice is rapidly growing.37 AI offers new opportunities to improve the speed and efficiency of all steps of the Knowledge-to-Action (KTA) Model,38 from conducting the synthesis of implementation evidence to planning for sustainability and scale-up (see Figure 1). Recent advances in AI-driven evidence synthesis and decision-making support for human behavior change and implementation science39,40 are exemplified by the Human Behaviour-Change Project (HBCP), which employs AI and ML to extract, synthesize, interpret, and predict findings from behavior change interventions, thereby guiding practitioners, policymakers, and researchers on what works, for whom, under which conditions.39,41,42 AI has also been leveraged to explore contextual factors influencing clinician adherence to guidelines.43 Additionally, NLP has been applied to qualitative data analysis, identifying codes and major themes.42,44,45 Overall, AI can help address critical challenges in implementation science by enabling rapid evidence synthesis, enhancing data analysis, supporting complex decision-making, and improving the translation of evidence into practice.
Despite its potential, AI remains susceptible to a range of ethical, clinical, technical, and environmental risks. Ethically, algorithmic bias can perpetuate or exacerbate health disparities when training datasets underrepresent certain populations, while data privacy concerns regarding the storage and sharing of sensitive patient data also poses ethical challenges.46,47 AI’s “black box” nature also complicates interpretability and accountability, posing challenges for both clinicians and regulators.48 Clinically, overdiagnosis and overtreatment may occur when AI systems identify ambiguous findings or produce erroneous recommendations.46,47 Technically, LLMs and other DL algorithms can generate “hallucinations”.34 While all outputs generated by these algorithms are synthetic and probabilistic constructions, “hallucinations” refer to outputs that are convincing but factually inaccurate, which may mislead healthcare providers.34 Finally, from an environmental perspective, energy-intensive AI training and deployment contribute to a sizeable carbon footprint.49 Addressing these intersecting risks will be essential to harness AI’s benefits while mitigating potential harms in the context of implementation research and practice.
To address the need to track and map quickly evolving fields, authors have proposed a living scoping review approach.50 A living scoping review is a scoping review that is kept continually up to date through ongoing, planned searches and screening at regular intervals, with new eligible evidence incorporated as it appears and the public record refreshed (e.g., updated results, tables, figures, and versioned updates) so the map of the literature remains current.50 This living scoping review aims to provide a comprehensive mapping of the applications of AI relevant to implementation research and practice. The findings will offer a foundation for guidance on harnessing AI to accelerate the adoption of evidence-based practices in healthcare.
The primary objective of this living scoping review is to systematically map and characterize how AI is used to support implementation research and practice. Specifically, we will:
1. Map applications of AI across implementation research and practice activities, including their features, characteristics and implementation contexts, using the KTA Model as an organizing framework.
2. Identify the evaluation approaches, outcomes, and risks reported in AI-enabled implementation research and practice, with attention to technical performance, equity considerations, and unintended consequences.
3. Synthesize evidence gaps and future directions for advancing the responsible and equitable use of AI in implementation science.
A secondary objective is to maintain an up-to-date evidence base using a living scoping review approach, enabling continuous integration of new findings in this fast-evolving field.
The proposed review will be conducted following the Joanna Briggs Institute (JBI) methodology for scoping reviews,51 and Cochrane’s guidance for living systematic reviews.52 This topic lends itself to a living scoping review approach for several reasons. First, AI technologies and methods are evolving at an unprecedented pace, leading to rapid shifts in the evidence base. Second, implementation science is inherently dynamic and context-specific, necessitating regular updates to capture emerging data, methods, and applications. Third, bridging AI and implementation science is still an emerging area, and a living review ensures that newly published insights are promptly synthesized and integrated. Finally, maintaining an up-to-date map of AI’s potential contributions to implementation science can guide researchers, policymakers, and practitioners as they refine methodologies, prioritize resource allocation, and incorporate novel AI tools into practice.
This protocol addresses the first three steps of JBI’s nine-step approach: first, defining the review objectives and questions; second, developing and aligning the inclusion criteria with these objectives and questions; and third, specifying the methods for evidence searching, selection, data extraction, and presentation. The next four steps will involve evidence searching, selection, extraction, and analysis. The eighth step focuses on presenting the results, while the ninth and final step involves summarizing the evidence, drawing conclusions, and discussing the implications of the findings.51 The reporting of the scoping review will follow the Preferred Reporting Items for Systematic Reviews and Meta-Analyses for Scoping Reviews (PRISMA-ScR)53 and its extension for living systematic reviews (PRISMA-LSR).54
Our interdisciplinary team brings extensive, internationally recognized expertise in implementation science, AI, behavioral science, and evidence synthesis. Team members have led or contributed to major advancements in the use of AI in implementation science. For example, Susan Michie and Janna Hastings have been central to the Human Behaviour-Change Project, which pioneered the integration of machine learning and ontology-informed modeling to synthesize and interpret behavior change intervention evidence.41 James Thomas at the EPPI Centre has developed AI tools and living evidence platforms for automating literature screening and synthesis, contributing extensively to methodological innovation in systematic review automation.55 Our team also includes researchers with expertise in applying AI to automate the extraction of implementation-relevant data such as barriers, facilitators, and strategies from qualitative and quantitative sources (e.g., Chan, Taylor).40 Several team members (e.g., Abbasgholizadeh-Rahimi, Légaré, Graham, Welch, Presseau, Straus) are leading experts in informatics, data science, and implementation evaluation, and bring deep experience in using implementation science frameworks (e.g., CFIR, KTA, RE-AIM, NASSS) in both high-income and resource-limited settings. Several investigators (e.g., Fontaine, Welch, Straus, Graham, Taylor) have led large-scale knowledge syntheses, scoping reviews, and methodological studies that shape the implementation science evidence base. Others (e.g., Graham, Powell, Michie, Presseau) have co-developed or refined key frameworks and taxonomies for implementation strategies and behavior change techniques that underpin this review’s analytic structure. Together, our team has the methodological, technical, and domain-specific expertise to conduct a comprehensive, high-quality, and policy-relevant review that will support the responsible and equitable integration of AI in implementation research and practice.
The eligibility criteria for this scoping review are designed to align with JBI’s Population, Concept, and Context (PCC).51 Studies and reports will be included if they meet the following eligibility criteria.
Population
We will consider studies involving any individuals or organizations actively engaged in implementation research and practice. This includes researchers, practitioners, administrators, and other stakeholders who focus on any of the KTA key steps including, but not limited to AI-driven synthesis of implementation evidence, identifying and prioritizing the problem, adapting evidence to local contexts, assessing barriers and facilitators, selecting, tailoring and operationalizing implementation strategies, monitoring outcomes and fidelity, evaluating impact on practice and population, and ultimately sustaining and scaling knowledge use. We will include studies only if the focus is on using AI to facilitate these steps, rather than on AI as the intervention itself.
Concept
The concept for inclusion requires that studies or reports specifically address the use of AI to support implementation research or practice. As presented in Table 1, we will consider studies or reports that describe AI-assisted approaches encompassing ML, DL, NLP, LLMs or other technologies across all steps of the KTA Model. We will also include cross-cutting features of AI technologies, such as data analysis or predictive modeling, that may not align precisely with a single KTA step but facilitate implementation activities throughout the cycle.
We will exclude studies in which AI is purely employed as the primary clinical or public health intervention (e.g., a clinical decision support system used directly for patient diagnosis, an AI-driven therapy tool) without a clear focus on supporting or studying the implementation process itself. We will exclude studies that do not address steps in the KTA Model, or do not articulate outcomes related to implementation processes (e.g., fidelity, adoption, reach) or implementation-related impact (e.g., changes in practice, sustainability). We will exclude documents that do not present empirical evidence or methodological details about the use of AI in supporting implementation (e.g., purely theoretical or opinion-based articles without data or systematic description of AI application).
Context
AI applications relevant to various health domains of implementation science, including but not limited to healthcare settings, health policy implementation, and community-based healthcare interventions, will be included.
Evidence sources
We will include primary research studies, scoping reviews, systematic reviews, case reports, grey literature, conference abstracts, and policy documents that describe or evaluate AI applications in implementation science. Both quantitative and qualitative studies are eligible, as well as mixed-methods studies that examine AI’s impact on implementation processes or outcomes.
Language and date restrictions
Studies and reports will be limited to those available in English and French, and published within the last 15 years, given the recent advancements in AI technologies.
Information sources
The bibliographical databases to be searched include CINAHL, Embase, IEEExplore, MEDLINE, PsycINFO and Web of Science. Furthermore, we will hand-search relevant journals and conference proceedings to identify additional records. Examples of journals may include: BMJ Quality & Safety, Implementation Science, Implementation Science Communications, BMC Health Services Research, Implementation research and Practice, and Health Research Policy and Systems. Examples of relevant conferences include EMNLP/ICML. We will screen the reference list of included records to identify additional records. We will also search relevant pre-print servers (e.g., arXiv). Finally, we will identify a limited number of ‘core papers’ and perform a citation search.
Search strategy
Our search strategy has been developed in collaboration with a research librarian (RL) and AI specialists (JC, JH, SAR). It uses a combination of MeSH terms and search terms structured around two core concepts: “artificial intelligence technologies” AND “implementation science activities.” The Medline search strategy is presented in Table 2.
Update frequency
We will perform search updates every six months to identify newly published peer-reviewed studies, preprints, and grey literature. The frequency may be adjusted based on the volume of newly identified records and available team capacity. Each update cycle will include re-running the database searches, screening, full-text review, and data extraction following the same procedures as the original review.
Versioning and reporting
All updates will be tracked and versioned. New findings and changes in key concepts, classifications, or gaps will be reported in a cumulative manner and noted clearly in any published outputs. A dedicated section will be added to the online supplementary materials or review platform (if hosted) to indicate the date of the last update and planned date for the next update. We will consider developing an interactive database and data visualization if resources allow it.
Team roles and governance
GF, NT and other team members will be responsible for overseeing the living component of the review. Team meetings will be scheduled at each update point to discuss inclusion of new evidence and refine the approach if needed.
Triggers for substantive review revision
A full update of the review (including potential resubmission for publication) will be triggered if: (i) there is a critical mass of new studies (e.g., >20% increase in included records); (ii) stakeholder priorities or core concepts in implementation science shift meaningfully; (iii) major AI-related methodological and technological breakthroughs occur; or (iv) regulatory/policy developments occur (e.g., WHO guidance on AI in public health).
After completing the search, all identified citations will be compiled and uploaded into Covidence, where duplicates will be removed. Two independent reviewers will screen all titles and abstracts independently to determine eligibility based on the inclusion criteria for the review. The full texts of selected citations will then be thoroughly evaluated against the inclusion criteria by two independent reviewers. Any disagreements during the selection process will be resolved through discussion or, if necessary, by consulting an additional reviewer. The search results and study selection process will be fully detailed in the final scoping review and displayed in a PRISMA-ScR flow diagram.53
We will systematically extract detailed information from each included study or other relevant sources to address the review objectives. A structured data extraction form will be developed and piloted to ensure consistent data collection across studies covering article characteristics, evaluation methodology, AI application, comparator, outcomes, adverse effects, and research gaps. Two independent reviewers will conduct the data extraction, after a calibration exercise on 10 articles. Any inconsistencies will be discussed and resolved, and the extraction guide adapted as needed.
Article characteristics
We will first extract key article characteristics, including article type, author(s), health and social care categories, year of publication, country of origin, population(s) and setting.
Evaluation methodology
We will extract the evaluation methodologies used to assess AI-supported implementation science activities, including quantitative (e.g., RCTs, observational, simulation), qualitative (e.g., interviews, focus groups), and mixed-methods approaches. We will also capture human-centered evaluations (e.g., usability testing), AI-specific techniques (e.g., cross-validation, explainability assessments), and use of implementation science frameworks (e.g., RE-AIM, CFIR, NASSS). This will inform a taxonomy of evaluation approaches for AI-enabled implementation science activities.
AI application
We will extract detailed information on the AI application. We will use established classifications, such as the Living Map of Generative LLM-Based Tools for Health and Social Care Applications55 (developed by JT), to guide data collection across the following dimensions:
(i) Application class (es) (e.g., clinical service delivery, public health, or policy implementation);
(ii) AI technology (e.g., knowledge-based or rules-based AI using explicit knowledge representation and reasoning, traditional [“shallow”] machine learning [e.g., logistic regression, SVMs], deep learning but without any generative capability or transfer learning, transfer learning including fine-tuning pre-trained foundation models, generative AI, potentially with in-context learning, but without significant additional fine-tuning);
(iii) Model(s), ontology(ies), platform(s) or tool(s) used (e.g., decision trees, neural networks, Bayesian networks; GPT-4, BERT);
(iv) Training datasets and training design used across model(s);
(v) Mode(s) of model use;
(vi) Model version;
(vii) Maturity level of the AI application (e.g., MSc thesis prototype vs. commercial tool);
(viii) Degree of testing and deployment of AI application;
(ix) Implementation science task type(s) of the AI application, categorized according to core implementation science activities (e.g., as per the KTA Model in Table 1).
Comparator
For studies that include a comparator, we will document the type of comparator used (e.g., human researcher or clinician, standard manual process, non-AI technology, or another AI model), and the function being compared (e.g., diagnostic accuracy, decision-making, time to task completion). This information will help contextualize the performance of AI applications and support future benchmarking efforts.
Outcomes
We will extract information on performance indicators and outcome types reported in relation to AI-supported implementation science activities. While we will not extract specific effect sizes or interpret the direction of effects, we aim to comprehensively map and categorize the types of outcomes assessed across studies. These outcomes will inform the development of a future taxonomy for evaluating AI in implementation science. Outcome types may include:
(i) Time-related outcomes: Time to complete tasks, time to implementation, delays, etc.
(ii) Cost-related outcomes: Development costs, operational costs, cost-effectiveness metrics, etc.
(iii) Accuracy: Concordance with gold standard or expert judgement, reduction in errors, etc.
(iv) Task-specific technical metrics, depending on the nature of the AI model:
a. Classification tasks: Precision, recall, F1-score, AUC-ROC, specificity, sensitivity.
b. Regression tasks: Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), R2.
c. Generative tasks: BLEU, ROUGE, METEOR, GLEU, perplexity scores.
d. Ranking or recommendation tasks: NDCG, MAP, MRR.
e. Human factors: Usability, user satisfaction, acceptability, and trust in the system.
(v) Implementation-specific outcomes: Adoption, fidelity, reach, sustainability, feasibility, etc.
(vi) Equity-related outcomes: Disparities in performance across subgroups, etc.
(vii) Clinical and health system outcomes (where relevant): Patient satisfaction, clinical workflow improvements, adherence to guidelines, or patient safety markers.
Adverse effects
We will extract any reported or potential adverse effects or unintended consequences associated with AI use in implementation science. This includes clinical or patient harms, such as treatment errors; systemic issues like increased clinician workload, workflow disruptions, or exacerbation of disparities caused by existing biases in training data; and AI-specific risks, including algorithmic drift, hallucinations in generative models, or overreliance on automated systems. We will also document user-level effects such as reduced trust, cognitive overload, decision fatigue, or de-skilling of professionals. All identified harms will be classified and mapped to support future risk assessment and mitigation efforts.
Research gaps
Finally, we will identify both explicitly stated and inferred research gaps to enhance the role of AI in implementation science. These may include gaps in knowledge or evidence related to AI’s effectiveness, scalability, or sustainability in implementation contexts; underexplored domains of application (e.g., underrepresented populations, low-resource settings), methodological gaps (e.g., lack of robust evaluation, absence of longitudinal studies), and conceptual or theoretical gaps (e.g., insufficient use of implementation science frameworks, lack of interdisciplinary integration). We will also capture recommendations made by study authors for future AI development, evaluation, or use in implementation science, needs for standards, reporting guidelines, or regulatory frameworks to support responsible AI use. These gaps will inform a future research agenda and highlight opportunities to enhance the value and equity of AI in implementation science.
We will conduct a structured analysis of included studies to address the review’s objectives. First, we will generate a descriptive summary capturing key characteristics such as publication year, country of origin, study design, setting, population, and area of application. This will allow us to identify trends in how AI is being used within implementation science. AI applications will be categorized by the implementation activity they support, the type of technology used, the specific tools or models described, and their level of maturity. Outcomes will be grouped and summarized based on their relevance to performance, implementation, human factors, equity, and system-level impact. We will describe how outcomes are measured and reported, but not interpret effect sizes. Findings will be integrated into a narrative synthesis that links AI applications, implementation activities, outcomes, and research gaps.
This living scoping review will offer a comprehensive overview of how AI is being applied across the spectrum of implementation science activities. It will map the current landscape, synthesize reported outcomes, and identify key research gaps. The findings will serve as a foundation for advancing the responsible and equitable integration of AI in implementation research and practice, with the potential to accelerate the adoption, scale-up, and sustainability of evidence-based interventions. Target audiences include implementation scientists, applied researchers, funding agencies, computer scientists seeking to engage with real-world challenges, implementation practitioners, and policymakers.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)