Keywords
artificial intelligence, cardiovascular
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the University College London collection.
This article is included in the AI in Medicine and Healthcare collection.
artificial intelligence, cardiovascular
Machine learning is a broad name that encompasses both ‘shallow learning’ and ‘deep learning’ methods. Machine learning started in 1957 with the development of Perceptron.1 Since then, the use of artificial intelligence through machine learning has exponentially grown with an estimated compound annual growth rate of approximately 40% until 2029.2
When machine learning techniques were initially developed, a feed-forward method was utilised whereby a set of predictors were analysed with the goal of identifying a singular outcome. However, as machine learning has developed, the complexity of the algorithms has too. A deep learning model utilises the principles of shallow learning but with tens if not hundreds of pathways that interact to generate a prediction model. These are known as neural networks. The aim of a deep learning model is for the first neural network layer to recognise the pattern of data presented. Thereafter, further convolutional layers interact to form a prediction of the outcome. There are variations in how these models work, with both feed-forward and feed-backwards methods to focus on complex issues3 whether in healthcare or the rest of society.4
Deep learning employs complex and extensive computer algorithms that have varying methods of development and validation. This was shown in a recent meta-analysis by Siontis et al. Given the heterogeneity of this data and the methods of validation and development, it highlights issues regarding the risk of bias in these studies.5
There is an increasing drive to utilise prognostic machine-learned models as a predictive mechanism for medical conditions. A prognostic model is based on numerous variables selected at a given time point with the aim is that these variables are able to detect the risk of developing a specific complication or condition.
As discussed, one of the many potential goals of a machine-learned prediction model might be to identify those at greatest risk of developing a medical condition or rather have an increased risk of a complication of treatment. Having the ability to focus resources on those with the greatest chance of developing a medical condition means that limited resources can be reallocated. Moreover, if we can accurately predict, who for example, will develop ventricular fibrillation and have an increased risk of cardiac arrest then this could improve the outcomes for patients and their families.
Following the significant rise in machine-learned models being developed, there are disparities in the quality of the research generated.6 Therefore, when systematic reviews and meta-analyses are generated there is often a high risk of bias in these studies with poor methodological quality.7 At present, there is only one wide-spread tool known as PROBAST8 which is used for the assessment of the risk of bias in prediction model studies. Although it has many benefits, PROBAST involves twenty seven questions and is time-consuming.
We aimed to generate a tool that had a specific focus on artificial intelligence and machine learning algorithms which was succinct and efficient whilst maintaining reliability. Our null hypothesis was that our tool was as effective as PROBAST in assessing the risk of bias in machine learning and artificial intelligence models in Cardiology. To validate our tool, we assessed it against cardiology papers that either developed or validated a machine-learned model. Cardiology, in particular, is generating a significant volume of machine learning, therefore this was the focus of our paper due to the ability to validate this.
To commence, we reviewed and extracted data from multiple risk-of-bias tools. We assessed the benefits and limitations of each tool and designed a tool analysing the risk of bias with a specific focus on machine learning for prediction models. The tools analysed were as follows with their desired paper for analysis: JBI checklist (prognostic prevalence studies),9 QUADAS (diagnostic accuracy studies),10 ROBINS-E (observational studies of exposures),11 QUIPS (prognostic factors),12 ROBINS-I (non-randomised trials of interventions),13 Cochrane RoB 2.0 (randomised trials)14 and with a particular focus on PROBAST (prognostic tool for prediction model studies).8 These tools were chosen as they are well validated.
We utilised this data alongside external feedback from three experts in this field to refine our tool. We separated the tool into three domains:
1. Domain One – Participants/Data Selection
2. Domain Two – Predictors and Outcomes
3. Domain Three – Analysis
Research regarding artificial intelligence/machine-learned models often has a section whereby the model is developed and then will sometimes be externally validated to further strengthen the design. At other times, research will seek to externally validate a previously produced model. We developed two different tools depending on the aims of the paper we are analysing. Tool number one is for the analysis of a study which analyses either the development or external validation of a model. The second tool is utilised for the combination of these which incorporates development with external validation. Each question was answered with the same signalling code as proposed by Cochrane: Yes (Y), Probably Yes (PY), Probably No (PN), No (N) and No Information (NI).15 Guidance was given for answering each question and the risk of bias was assessed at the end of each domain and overall. This was validated by pilot data before developing the final tool. See Figure 1.

To validate our risk of bias tool, we utilised the pre-analysed ‘example papers’ shown on PROBAST’s website. We selected three papers, two of which solely focussed on development or validation and one which focussed on both.16–18 We conducted a blinded assessment of the risk of bias using these papers and subsequently compared this to the already analysed papers with the PROBAST tool. Following a preliminary successful analysis, we compared our tool to PROBAST with recent machine-learned studies with a focus on Cardiology. This was then used to refine the tool further.
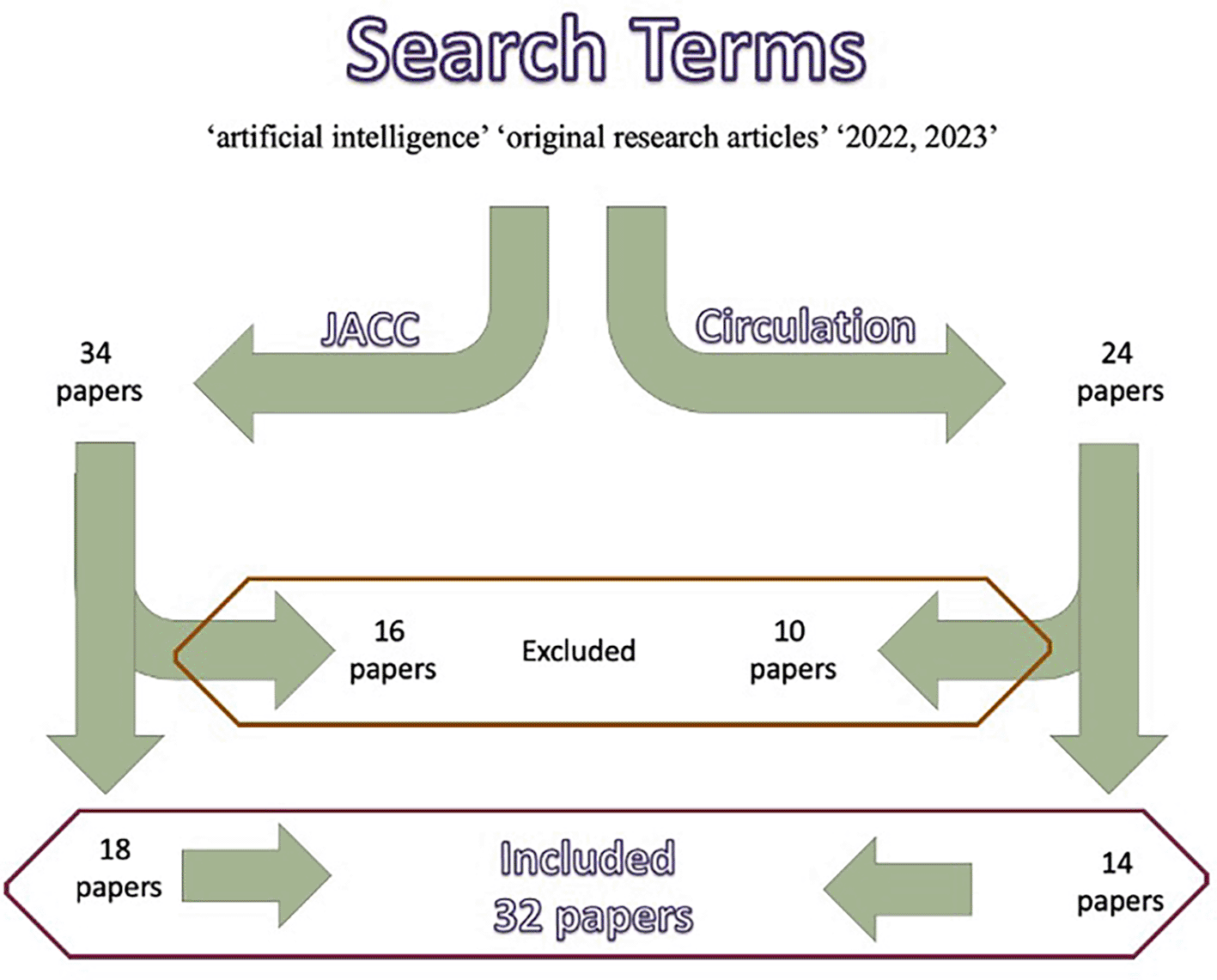
We used the search terms ‘artificial intelligence’, ‘machine learning’, ‘original research articles’ ‘2022, 2023’ in both JACC and Circulation on the 12th May 2023. This generated 58 papers. 24 papers were excluded based on the abstract. On reviewing the full-text papers, a further two papers were excluded due to not using a prognostic model. The included list of papers can be seen in Appendix 1. See Figure 2 for further information regarding paper selection.
We conducted two blinded rounds of data extraction regarding the risk of bias, four authors in round one (MHS, SR, AA, KS) and two individuals in round two (GS, HG). Each paper was allocated to an individual and was analysed using PROBAST and our new tool (AIr). Throughout the process, we discussed any issues and adjusted the wording accordingly. All disputes were settled by an arbitrator (HG, SM, KM). Data was collected using Google Forms and analysed using R (version 4.3.2).
We developed a tool in two formats both with three domains. The domains are Participants/Data Selection, Predictors and Outcomes, and Analysis. There are 10 questions, one in Domain One (Participants/Data Selection), three in Domain Two (Predictors and Outcomes) and six in Domain Three (Analysis). There is variation in questions five and nine depending on whether a model development or external validation study is being analysed. Similarly, question ten is solely for a model development study. Our questions are demonstrated in Table 1.
As aforementioned some machine-learned models will either develop, externally validate or both develop and externally validate a model. In a joint analysis, Domains One and Three are duplicated with some variation, whereas Domain Two is combined given the utilisation of the same machine-learned model. Tool One is to be used if analysing the risk of bias of either a sole development or validation paper and Tool Two if these are combined. The risk of bias is assessed at the end of each domain and the tool. Please see Appendix 2 and 3 for the completed tools for utilisation in research/clinical work.
We utilised these questions alongside PROBAST’s tool to blindly assess the risk of bias in 32 cardiology papers in JACC and Circulation. We hypothesised that our tool would be as effective as PROBAST in assessing for the risk of bias. Our analysis demonstrates no difference between AIr or PROBAST in either Round 1 or Round 2 (X-squared = 0.234, df = 2, p-value = 0.890; X-squared = 0.541, df = 2, p-value = 0.763, respectively) and therefore was as effective at PROBAST in assessing the risk of bias. The distribution of each round and the arbitrated results can be seen in Figure 3 and 4.
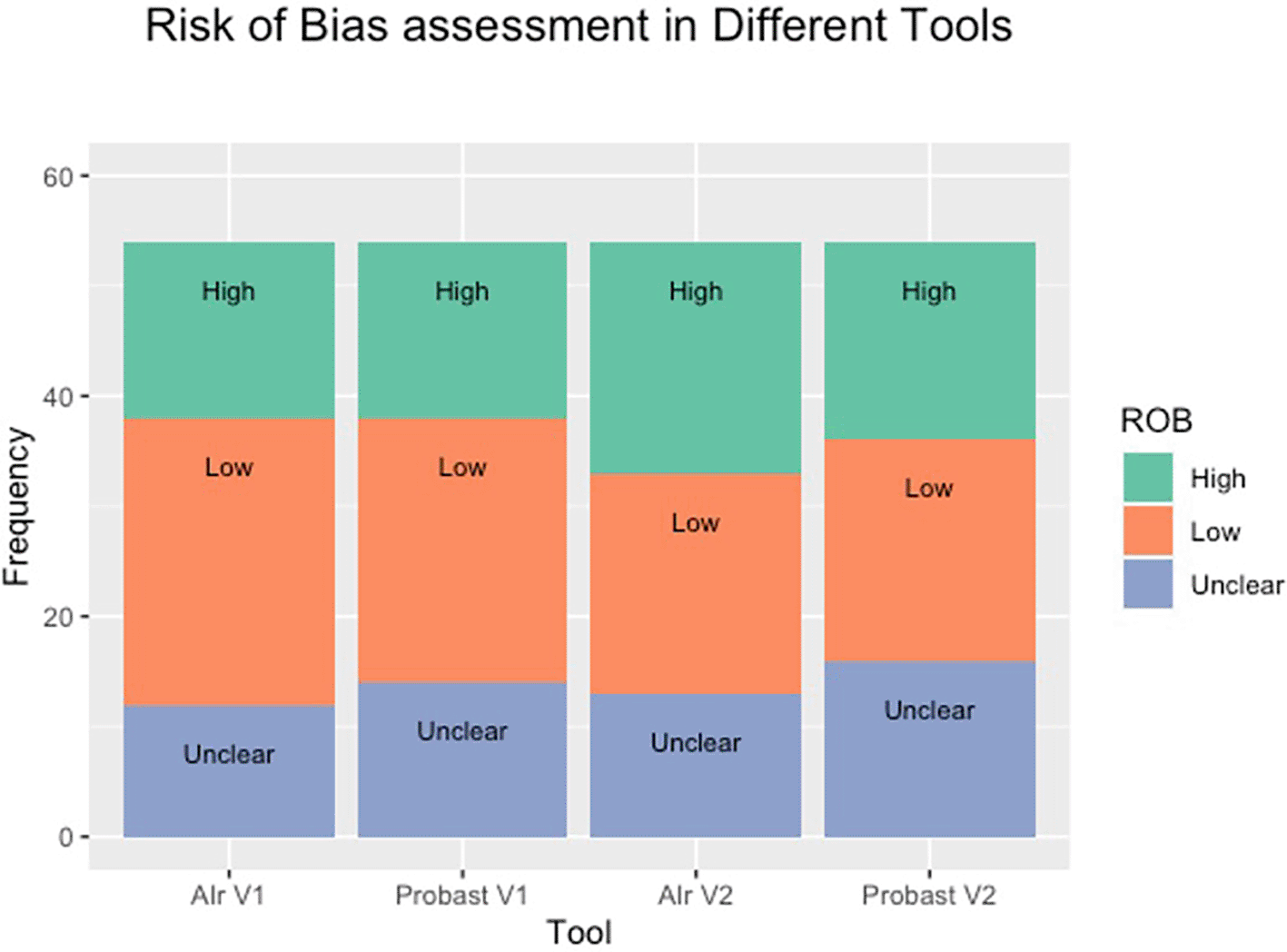
(V1 and V2 stand for Round One and Round Two respectively. ROB is the risk of bias).
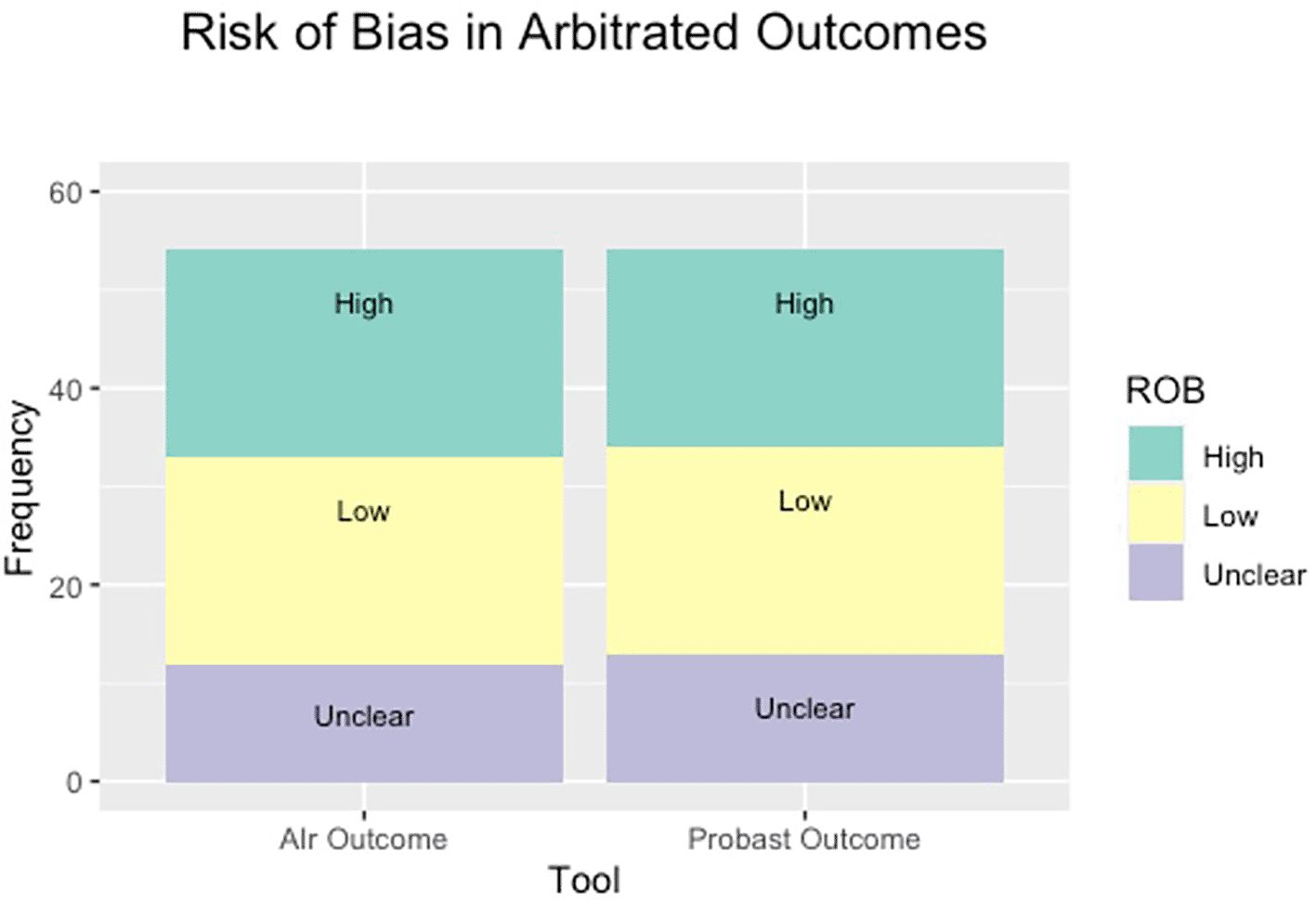
(ROB is the risk of bias).
Analysis of inter-rater reliability via Weighted Cohens Kappa showed a ‘moderate agreement’ for AIr with a weight value of 0.47. In comparison, there was less inter-rater reliability with a ‘fair agreement’ between analyses for PROBAST with a Weighted Cohens Kappa of 0.35.
At present, PROBAST is the sole tool for assessing the ROB in artificial intelligence/machine learned models. As aforementioned, AI models are frequently developed but often have a high risk of bias and therefore this needs to be accurately assessed.
Our results suggest that for a tool with significantly fewer questions, twenty seven versus ten, AIr was as effective as PROBAST in assessing the risk of bias whilst improving the inter-rater reliability of the results. This suggests that our tool is effective in assessing the risk of bias and can be applied to further artificial intelligence/machine-learned studies.
This is an area in which there is only one widely used tool which makes it the only possible comparison. One potential limitation of our analysis is that we are comparing our tool to a different tool rather than directly assessing its validity. This could be an issue if there were errors within PROBAST as this would be more likely to bias our results. This was mitigated by the papers produced by PROBAST demonstrating its validity and therefore making this a suitable comparison for our tool.
The AIr tool has only ten questions which makes it shorter than the PROBAST tool but makes it easier to use. We only concentrated on papers in high impact Cardiology journals making it difficult to predict further about this tool and its usage in fields outside of cardiology and in papers outside of these journals.
AIr is a tool analysing the risk of bias in studies using artificial intelligence or machine learning to predict an outcome or a complication. This is as effective as the current leading tool and has a greater degree of inter-rater reliability. It is much easier to use than the most widely used tool, i.e. PROBAST. This is a promising means of measuring risk of bias in Artificial intelligence papers. It needs further validation outside of cardiology.
Repository name: AIr - Artificial Intelligence Risk of bias tool appendices. https://doi.org/10.5281/zenodo.17130713.19
The project contains the following underlying data:
- Appendix 1 – Table of included studies
- Appendix 2 - AIr - Tool 1 – for studies that either develop or externally validate an artificial intelligence/machine learning model
- Appendix 3 - AIr - Tool 2 – for studies that develop AND externally validate an artificial intelligence/machine-learned model
Data are available under the terms of the Creative Commons Zero “No rights reserved” data waiver (CC0 1.0 Public domain dedication).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)