Keywords
eBPF, application performance, converged computing, cloud, hpc, kubernetes, instance selection
This article is included in the Software and Hardware Engineering gateway.
eBPF, application performance, converged computing, cloud, hpc, kubernetes, instance selection
Translation of workloads to different environments has been challenging for the high performance computing (HPC) community. The practice of building an application on bare-metal that is optimized for a single system has reflected the fact that systems have been persistently available. As the computing landscape changes and portability becomes a new dimension of performance,1 the ability to move workloads between environments and quickly adapt to change is increasingly important.
A unit of portability is the container, which the HPC community took several years to adopt.2 This delay relative to industry led to several design inefficiencies that were and continue to be relevant to HPC – the requirement of rootless containers, and default isolation that makes seamless integration with environment and libraries on the system more challenging. It is still laborious to use containers on HPC, with issues related to matching libraries with the host, mapping of user identifiers, and building.3 However, containers are not uncommon, with more than 80% of the community using container technologies at least once a week.3 Unfortunately, the decisive difference in preferring a bare-metal binary over a container has further fractured the space between HPC and industry.
Running an application on HPC versus cloud is notably different. An HPC environment starts with building the software, and typically uses system environment modules4 or an HPC oriented package manager.5,6 While some of these tools have been deployed in cloud, to the best of our knowledge none of them are the chosen strategy for any particular cloud community. This means that if a cloud developer wants to understand an HPC application, they must venture into largely uncharted territory. To run or orchestrate experiments with built applications, HPC typically uses custom workload managers7,8 that are tuned to optimize performance and scaling of bare metal builds. Industry primarily uses the cloud orchestrator Kubernetes9 with a focus on generalized portability, reproducibility, dynamism, and automation. While work is underway to deploy Kubernetes within on-premises user space,10,11 Kubernetes is unlikely to be already deployed at centers due to the strict requirements of root daemons and development of features that were not initially oriented for HPC. This lack of overlap in workload manager and orchestration infrastructure will continue to persist unless action is taken to create strategies to bridge the gap between communities.
As emerging complex, heterogeneous workflows become dominant trajectories for solving problems in science, the infrastructure to run them must follow. Kubernetes provides these desired features, but the entire procedure for building, orchestrating, and assessing performance and compatibility of HPC application containers is not well established. The HPC community is presented with two directions: to create or adopt existing, niche HPC tools to support this use case, or to proactively engage with the thousands of developers in existing cloud projects to share expertise and develop solutions that work across communities. The converged computing movement12 champions these ideas, advocating for a synthesis of culture and technology to achieve a best-of-both-worlds in the combined feature space.
The HPC community has a rich history of performance monitoring and comparison13 extending from instrumentation to profiling of applications at scale.14 Instrumentation approaches are invasive, requiring libraries to be built directly into application code, and ideally with separation of configuration and annotation.15 Statistical sampling is another viable approach, and does not require instrumentation into source code.16 At the core of these tools is the goal to identify bottlenecks or “hotspots” in performance, ultimately leading to more efficient applications for computational science. While it is recognized that operating systems (OS) jitter can contribute to performance detriment,17 tools that look at system and kernel calls18 are of a different class. Putting together a holistic picture that includes traditional performance analysis with factors like kernel operations, background processes, and interrupts is a non-trivial task.
As HPC workloads move into the cloud these traditional approaches start to break down due to limitations in environment. Access to performance counters is extremely limited and often not possible.19 While clouds offer specialized “metal” instances that can expose counters, this limited set is not easily extended to highly orchestration environments such as Kubernetes. The task becomes more challenging due to an explosion of services and components that share the host. For Kubernetes, an application running on a node is sharing resources with a Kubelet that serves a container runtime, and is consistently communicating with an API server for orchestration and health checks. A network proxy paired with a fabric and DNS is often present, and production clusters typically come with additional plugins for logging, monitoring, and network.20 Tools for monitoring and observability of clusters broadly collect high-level metrics of system health and look for deviations from normal, and most are related to networking. Performance analysis on the level of the operating system or application beyond CPU and memory,21 and the integration of the two, is uncharted territory.
The extended Berkeley Packet Filter (eBPF) is a exploding technology that enables execution of custom, event-driven programs directly in the Linux kernel.22 The programs are verified and can hook into system calls, network packet processing, and function execution. While the cloud community heavily utilizes it for monitoring primarily related to network,23,24 likely due to security concerns, the HPC community has not fully embraced the technology. This technology is complementary to traditional approaches, offering a bridge between the application-centric world of HPC and the system-centric world of cloud. A unified framework could make it possible to analyze performance for HPC in cloud, and provide a more definitive understanding of overheads that have been previously labeled as “noise” and impossible to diagnose.
Our work aims to enable execution and orchestration of HPC applications in cloud with eBPF. We start with orchestration, presenting a complete strategy for orchestration of scaling studies (Section 2.2) that includes building and selecting compatible containers, running experiments, and assessing performance. To demonstrate the feasibility of this setup, we conduct a scaling study from 4 to 128 nodes for CPU and GPU. We then demonstrate the ability to run eBPF programs with low overhead, assessing different eBPF deployment strategies for four different application builds. We gather insights about the tradeoff between number of programs and performance overhead, and possible connections to application performance (Section 3.1). We next demonstrate a means for automated instance selection, presenting a novel model-based selection strategy based on compatibility artifacts,25 a new standard developed by the Open Containers26 community that describes rules to compare hardware, kernel, and other requirements against a contender host (Section 2.1). We extend the artifact design to be populated with rules and models derived from extensive experiments across a grid of micro-architectures and optimization levels, allowing for intelligent selection of instance types and container images based on node features. We choose tooling and technologies that are well-established in the cloud community, and provide 30 complete applications, each with a container build and automation setup. In our work, we present the following contributions:
• Containers and automated deployment for 37 HPC applications for CPU and GPU in Kubernetes
• Qualitative scaling assessment of 30 apps
• Automation to deploy with eBPF monitoring
• eBPF programs for CPU, futex, memory, TCP, and I/O
• Insights about OS, CPU/GPU, and MPI variants
• Example compatibility assessments for HPC apps
• Model-based instance selection using node features
• eBPF metrics and scaling study for CPU and GPU
In our Methods (Section 2) we first review the technologies involved, including the orchestration engines, eBPF, and compatibility metadata. We describe our methods for containerizing and providing 30 HPC applications using this setup, and experiments that can demonstrate usability. We demonstrate a setup that makes it easy to run a scaling study between 4 and 256 nodes in cloud with Kubernetes, and a strategy to run multiple eBPF programs to monitor performance that does not add significant overhead. Our results provide insights into the design of Kubernetes components, including differences between MPI variants, OS, and execution environment (Section 3). We demonstrate that automated, model-based instance and container selection is a plausible strategy for optimizing metrics of interest, with up to 4.1x improvement in figures of merit (FOM) as compared to random selection. Notably, our work embraces convergence – using an HPC workload manager directly in Kubernetes to orchestrate HPC applications in a cloud-native way. We conclude with a discussion of future work, suggested practices, and vision for the future.
Our study includes three sets of experiments that incrementally build on one another to create a holistic picture of compatibility assessment and automation for HPC applications in cloud. A definition of compatibility between a node and application is bidirectional. We define “application-first” as starting with the requirements for an application and choosing the ideal environment (node) for it, an approach that is more strongly suited to a cloud use-case where environments can be created on demand. We define “environment-first” as having a set of predetermined environments, and selecting an ideal application build. This second form of compatibility matches the HPC use case where clusters already exist and thus the environments are predetermined. In both cases, definitions of compatibility and requirements can be used to optimize the goals of a researcher, which can be scoped to compatibility (the application functions) and optimization (the application minimizes or maximizes some metric of interest). For our work, we will use a hybrid strategy that build models and attempts to optimize across container and instance type variants. Our concern is not to conduct a rigorous performance study, but rather to consider use cases scoped to scheduling, where there are many choices of environments to run an application of interest.
1. Automated Deployment of HPC Applications. For our first experiment (Section 2.2) we will design a suite of HPC applications alongside a novel orchestration tool that can automatically deploy and orchestrate experiments to collect FOM and eBPF metrics. For this experiment, we will demonstrate the function of the orchestration tool, deploying 30 applications on Google Cloud up to 256 CPU nodes, and collecting FOM and durations.
2. eBPF Program Deployment Strategy. Our second experiment (Section 2.3) will add the dimension of eBPF metrics to the setup, and specifically assess strategy for running eBPF programs. We will measure the added overhead to LAMMPS in FOM and running duration of running either multiple or a single program per node. We will do this at a scale of 4 to 128 nodes across 4 different builds of an equivalent application using CPU and GPU nodes.
3. Model-based Compatibility. Our third experiment (Section 2.4) will be concerned with compatibility in the context of optimization, with the use case of choosing a paired instance type and container that optimizes a FOM. We will run a prominent HPC benchmark across a matrix of micro-architectures, optimization levels, and instance types in Amazon Web Services (AWS) and create models that use node features to predict FOM. We will then demonstrate the value of model-based selection by using model-based compatibility artifacts with a novel Kubernetes operator to intelligently choose instance types based on maximizing FOM. We hypothesize that model-based selection can better maximize FOM as compared to random selection.
Our work prioritizes shared, open-source software and tooling. We provide orchestration templates, automated builds, and testing of applications in a public GitHub repository.27 Our experiments will primarily be limited by our ability to get quota for cloud instances and budget, which in total is $8000 USD development and production experiments on Google Cloud. We limited ourselves to $1000 USD for AWS.
We develop a library of HPC applications and automated means to deploy them to demonstrate the value of cloud automation for HPC experiments. We first select a representative sample of HPC benchmarks, proxy apps, and synthetic benchmarks, selecting from the CORAL-2 benchmarks28 used to assess enterprise systems at DOE centers as well as other modern HPC applications. All application containers and orchestration are publicly available27 and descriptions of our reported experiment applications are provided.29 A subset of these will be provisioned for each of CPU and GPU, allowing for experiments to assess the scaling ability of the application within the Google Cloud environment. We will perform a scaling study for a subset of CPU and GPU applications, ranging from 4 to 256 nodes, with a maximum of 128 or 256 nodes depending on when an application stops scaling appropriately. For each application we will collect a FOM that reflects the performance of the app, benchmark, or synthetic benchmark. The study will provide practical demonstration of our orchestration strategy, as well as a glimpse of the performance of a specific cloud instance type. Specifically, this represents follow up work,30 where comparable experiments were run on newer instance types.
Instance and Node Selection. We aimed to get the best resources on Google Cloud that we were allowed quota for. Following best practices,31 we were able to get quota for the H3 instance type, a member of the compute-optimized family (88 cores, 352GB memory, up to 200Gbps egress bandwidth) that are optimized for high performance computing (HPC) workloads.32 Most of the limitations listed by Google are related to data transfer or filesystems, which are less relevant for our applications that do not heavily use I/O or bandwidth. In addition to these instance types, we will use compact placement that is “optimized for tightly-coupled applications that scale across multiple nodes”.32 Finally, while the infrastructure is not opaque, our choice of the H3 instance type also brought in Google’s Titanium,33 a combination of microcontrollers and hardware adapters that provide hardware acceleration and optimized I/O. We were unable to get quota for other compute-optimized instance types including c3 and c4.
For GPU instances, getting a small number of newer GPUs for the minimum time allowed of 24 hours would have been 4x our total budget using the Dynamic Workload Scheduler.34 We instead opted for using the NVIDIA V100 paired with a standard machine type n1-machine-type (N1). This choice was appropriate for our study because we needed to scale to a larger number of nodes (N = 256 with 1 GPU/node) to test the network at a cost per node hour that fit within our budget ($4.92 for CPU and $2.67 for GPU).
Network. The H3 instances were deployed with Google Virtual NIC (gVNIC),35 the virtual network interface designed for Compute Engine. While it is suggested to deploy with Tier 1 networking,32 in our experience the additional boost to bandwidth does not substantially improve HPC application performance, however it can add upwards of half of the cost of compute. While Tier 1 is intended for workloads that require high bandwidth such as artificial intelligence/machine learning (AI/ML), the applications that we tested in this work are not bottlenecked by network bandwidth.
Cluster Orchestration. The Flux Operator36 is a Kubernetes operator that deploys an entire HPC cluster across nodes in Kubernetes. The scheduling and communication between pods is internal to the cluster, avoiding etcd bottlenecks and providing rich features from control of resource topology to graph-based scheduling and queues. It provides several modes of interaction, from deployment of a traditional cluster that can be shelled into and interacted with, to automated orchestration of a workflow that runs like a Kubernetes Job, starting and completing when work is done. For our setup, we take advantage of this second approach, designing templates that are optimized for different types of workload executions.
Deployment. We opted to use the most popular templating engine for Kubernetes, Helm,37 a well-established means to capture and structure parameters and orchestration for an application in Kubernetes. While Helm in its basic design is a templating engine, due to its widespread adoption and use by industry for providing installable units for complex Kubernetes applications, it is called “the package manager for Kubernetes”.37 In practice, entire experiments can be customized and deployed on the command line with one line of execution. Combined with the Flux Operator, these templates can provision an entire HPC cluster in cloud, and run applications across nodes according to a desired design. This strategy provides a powerful means to customize and orchestrate experiments easily across clouds and on-premises environments that support Kubernetes.
For this selection we considered an emerging solution to deploy applications in the HPC community, the library benchpark38 combined with ramble39 that rely primarily on spack to build software and run experiments. These libraries work together to execute a script to run experiments. We opted for a similar templating strategy but decided to use Helm to extend our HPC applications to the existing cloud community that is familiar with it.
Containerization. Moving an application from a traditional HPC environment to Kubernetes in cloud requires building a Linux container that is compatible with a specific cloud environment. We opted for a strategy that would build each application in a reproducible way, using a combination of transparent build steps (direct clones and execution of make or cmake) and HPC package managers (e.g., spack) for applications with more complex dependencies or requirements. While the Flux Operator can add Flux Framework on the fly to an application container, for builds we instead opted to build Flux into the container to maximize reproducibility. To maximize layer redundancy and similarity, an approach that has been shown to be lucrative for cloud,40 we develop a set of base containers that all applications can use, including bases with each of spack, Intel MPI, OpenMPI, Mpich, and for each of Ubuntu 22.04 and 24.04, and a subset with Rocky 8 and CUDA. For each application, we package the Dockerfile directly alongside the template that will deploy it, and provide a Makefile that easily reproduces the build for the specified tag.
For experiments on Google Cloud, there is no specialized network fabric that might afford libfabric or Infiniband, and so we consider our builds to be generic. The containers build with one make command, and deploy to the GitHub packages registry that is served alongside the repository. Containers and associated orchestration in Kubernetes are all tested with continuous integration (CI) in GitHub actions, using Kubernetes in Docker (kind).
An approach that provisions HPC applications as pre-built containers paired with configuration parameters allows for container builds to be done by those with expertise. Without knowing the exact execution environment, it would be required to build a more generic design that can be customized for a specific environment. Choosing portability over optimized specificity presents the tradeoff of building a container that performs well across environments versus spending substantial developer time optimizing a container for a single environment. A portability-first approach flips the traditional paradigm of building applications for specific systems to a more flexible one. Cloud environments can be deployed that match pre-built application containers.
Parameters and Execution Logic. Each application is provided in a directory corresponding to its name. Parameters that should be exposed for execution are provided in a values.yaml file within the directory. The decision of what to expose requires expertise on the part of the container developer, and what defaults to set. For example, for the LAMMPS ReaxFF package, we choose to expose the problem size parameters x, y, z, and the input file and working directory. For each application, a common base template is used for Flux that also exposes parameters for the cluster, including (but not limited to) size, tasks and nodes to run the experiment on, flags for resource affinity related to CPU or GPU, along with an ability to define custom environment variables and other scheduler settings. These variables can be customized on a per-application basis, either by the application or the user on the command line to override that. Since the Flux Operator also provides means to add custom commands to be executed at different stages of execution, each application can easily customize the runtime execution, for example, adding setup or completion logic.
In the case that Flux is added on the fly, the application can choose a matching base OS and version for the default container. The application container can also be customized, meaning that an advanced user can use a custom container, possibly with a different base operating system. A family of variables is also exposed for control of the experiment, including running modes for paired execution (e.g., for point to point benchmarks), single node execution (for single node benchmarks), interactive modes to keep the cluster running before or after execution, and the default mode to assume running some number of iterations of an application across nodes. For each mode, the user can optionally save structured logging that can be parsed and analyzed post-analysis. We used this means for analyzing and plotting the results from our runs. An example command to deploy the application LAMMPS is shown in Figure 1.

We extend our setup to include monitoring with eBPF to assess the performance overhead and tradeoff when running single versus multiple eBPF programs.
We are interested in nuanced differences between using different Message Passing Interface (MPI) implementations and operating systems in the same environment for each of CPU and GPU, and understanding overhead added to application performance when running multiple programs. We thus attempted to build and run a single application, LAMMPS, for operating systems Ubuntu, Rocky Linux, and for each of OpenMPI, Mpich, and Intel MPI for each of CPU and GPU. We note that Google Cloud recommends Rocky Linux with Intel MPI for optimal HPC application performance.31
LAMMPS is the Large-scale Atomic/Molecular Massively Parallel Simulator. It models the reaction of atoms and solves a matrix optimization problem. We are familiar with LAMMPS and chose it to test building multiple variants to run across different scales, environments (CPU and GPU), and eBPF deployment strategies. We used the ReaxFF package, following a suggested practice41 to calculate the millions of atom steps per second for our FOM. A larger value is better, indicating a system can do more calculations per second. We chose a consistent problem size of 32x16x16 to run all experiments with a strong scaling configuration.
Performance Monitoring. The Flux Operator supports the addition of one or more sidecar containers that run alongside the application container, and share a volume with the main application container. Thus, we developed a common sidecar container ( Figure 2) that runs eBPF programs via several popular libraries and tools, including libbpf23 and the BPF Compiler Collection bcc.42 By way of the kernel, an eBPF program can run in a sidecar and provide a complete view of not just the application running on the node, but all containers that use the same kernel ( Figure 2).
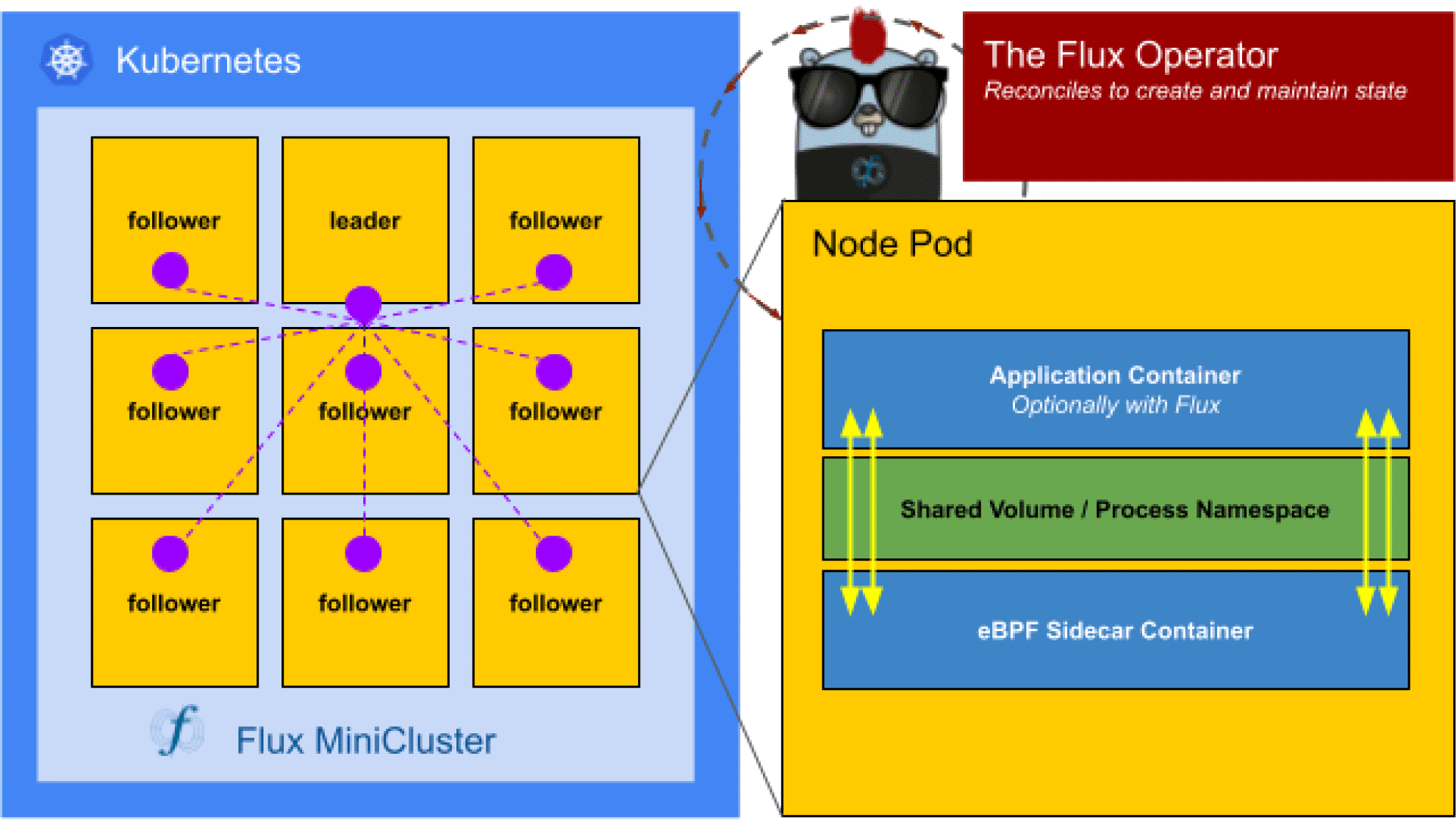
Within each pod, containers (blue) share a volume to allow for shared configuration and filesystem communication. An eBPF program has a holistic view of the application and Kubernetes services via the shared kernel.
From a practical standpoint, we write a common entrypoint in Python, and each program can be imported by name as a module alongside this client. Each program then exposes a common function collect_trace that compiles a program written in C using the Python SDK from bcc that can just-in-time (JIT) compile and validate the program. A developer can add a new program simply by adding a new directory with a C program and corresponding Python user-space module that exposes the common function signature. A parameter provided by the user controls deployment strategy, either deploying multiple sidecar containers to monitor the same processes on a node with multiple programs, or a sampling strategy to run one program (sidecar) per node, and distribute programs evenly across the cluster. Using eBPF is a low overhead strategy to monitor both the application and system level pods (services) running on each node. Monitoring via a shared node kernel can give us insight to not only challenges that application face with scale, but Kubernetes itself.
Kernel Headers Installer. For deployment, we required a custom Daemonset to install kernel development headers for the eBPF sidecar to use. We added this automation to our setup, meaning that the deployment and node update logic is handled by Helm. Since the default operating system for Kubernetes on Google Cloud, the Container Operating System (ContainerOS) is read-only, we deployed Kubernetes with Ubuntu and containerd43 to afford read-write. This would mean that gVNIC would not be supported for both CPU and GPU, and GPU did not support compact mode. We tested runs of our application with and without gVNIC, and did not see any difference in the durations. While the use of gVNIC could improve performance, the goal of our experiments is not to test the performance impact of gVNIC.
The eXtended Berkeley Packet Filter. (eBPF) grew out of BPF,44,45 a tool intended for filtering network packets directly in the kernel via two abstract registers. These registers can be thought of as having a virtual machine directly in the kernel. The “e” was added for “extended” when the original design was improved to use 10 64-bit registers,46 making it possible to attach functions from user-space programs to hooks in the kernel. This led to an explosion of observability tools that range from networking to memory and other resource usage and I/O, and notably, the technology has become a cornerstone of Kubernetes observability tooling.24
While traditional performance monitoring in HPC relies on counters47 or instrumentation directly into source code,15 eBPF requires nothing more than a recent version of the kernel, and careful implementation of user-space functionality to collect metrics in a way that does not overwhelm kernel resources and produces meaningful data. For the cases of performance analysis, since it is possible to attach eBPF programs to different events (e.g., tracepoints, kprobes, perf22) it serves as a powerful, low-overhead tool for such a task. More specifically, it is prime for performance analysis in cloud environments where it is easy to be the root user, and access to performance counters is limited, deeming traditional approaches unable to work. eBPF programs are compiled, validated, and run our custom functions when specific events in the kernel occur. Unlike HPC monitoring solutions that tend to be niche48 between sites or require changing applications or access to performance counters, eBPF has a thriving community and is an untapped resource for the HPC community.
Programs. Monitoring of applications can provide insights into what specific elements of the setup are leading to possible bottlenecks in performance. To demonstrate eBPF running alongside our automated experiments, we developed five novel eBPF programs to assess CPU, futex, shared memory, TCP, and file operations to cover a broad range of system functionality. The design of eBPF programs reflects a strategy for collection of metrics that can provide a specific kind of understanding. While some eBPF programs aim to collect fine-grained timepoints to generate flamegraphs and identify hotspots,49 since we are running applications across node counts, our first goal was to collect a large set of summary metrics that might give insight to scaling behavior. If we were to observe a performance degradation at a particular scale for a metric type, logical follow up work would be to investigate more fine-grained metrics associated with specific timepoints to identify casual reasons for performance differences. Our approach aims to demonstrate the functionality of the setup over providing direct explainability. Thus, we used a common approach across programs to optimize collection of summary metrics, provided either by simple calculations, or streaming machine learning statistical models provided from the RiverML library.50
Our programs share a common client entry and thus common features. First, they can filter commands in the process namespace to include or exclude patterns, or to scope to a specific cgroup identifier, which would limit to a single container in Kubernetes. We did not choose to do this because we are interested in Kubernetes services running in other containers alongside our application pod. A start and stop indicator file are essential, written by the lead broker launching the application to the shared volume across nodes to ensure a synchronized start and stop of eBPF programs. We describe three of the five programs here, and the remainder are provided with our data repository.29
cpu: This program aims to look at CPU scheduling, and specifically the time that a thread is waiting in the queue to run versus running. It uses tracepoints, or hooks into the kernel that programs can be easily attached to. Our program times between when a thread is woken up (sched_wakeup) to running the next task (sched_switch) to calculate total running time and waiting in the queue with counts for each. In the Python user-space program, we poll every 100ms to sum total time by thread in the queue (latency) and running time per interval, and these metrics are saved grouped by Process IDentifier (PID) and command. Finally, Between intervals the BPF map is cleared, and the final program can generate the average on-CPU duration (interval total duration/count) and average queue latency along with RiverML statistics for quantiles, minimums, maximums, and variance. While this approach does not save raw event durations, a change in CPU in the queue time as the cluster scales could suggest strain on the network or CPU. This approach is also ideal for longer running applications. We will report summary metrics for per-thread on-CPU time and running queue latency.
futex: A futex or “fast user-space mutex” is a kernel abstraction that can be used for locking.51 Our program looks at the time that threads spend in FUTEX_WAIT operations, again via attaching to tracepoints. The duration between entry and exit is the time in wait, and akin to cpu, we save statistical summary RiverML models and counts organized by PID and command, and we are interested in how futex wait times change with scale. An increase in this time as the cluster scales could be an indication of synchronization bottlenecks.
file operations: We can look at I/O operations to assess what shared libraries, data, and devices are being probed or used by an application. Our program monitors file open and close operations, counting each time a path is accessed by different PIDs. Akin to the others, it uses tracepoints, but also uses kretprobes52 to get a file descriptor that can be used to look up the path accessed. This program differs from the others in that all aggregation happens in BPF maps, which are read in user-space when the stop indicator is created. We will post-process the data, normalizing paths to generalize PID and library versions to make comparisons between environments. While interval data of I/O access can give hints to bottlenecks, our summary models are better suited to look for high-level differences in access patterns between operating systems (Rocky Linux and Ubuntu), environment (GPU vs. CPU), and MPI variant (OpenMPI vs. MPICH). Looking at these patterns can reveal differences about software packaging, dependency management, runtime interaction, and areas for optimization or troubleshooting. Further, we can investigate the extent to which Kubernetes services have different behavior based on the containers being executed.
We will demonstrate using a model-based compatibility specification to intelligently select an instance and container based on a metric of interest.
We will use a novel Kubernetes controller ( Figure 3) to assess software compatibility and the impact of targeted code generation across diverse compute instances available on AWS. We will first build a single application, HPCG, across a matrix of compiler flags and micro-architectures, and run across instances to assess FOM and eBPF metrics. We will use node features automatically generated for Kubernetes nodes via the Node Feature Discovery (NFD) project53 to predict metrics of interest. We present simple models as examples of how AI/ML can inform instance selection.
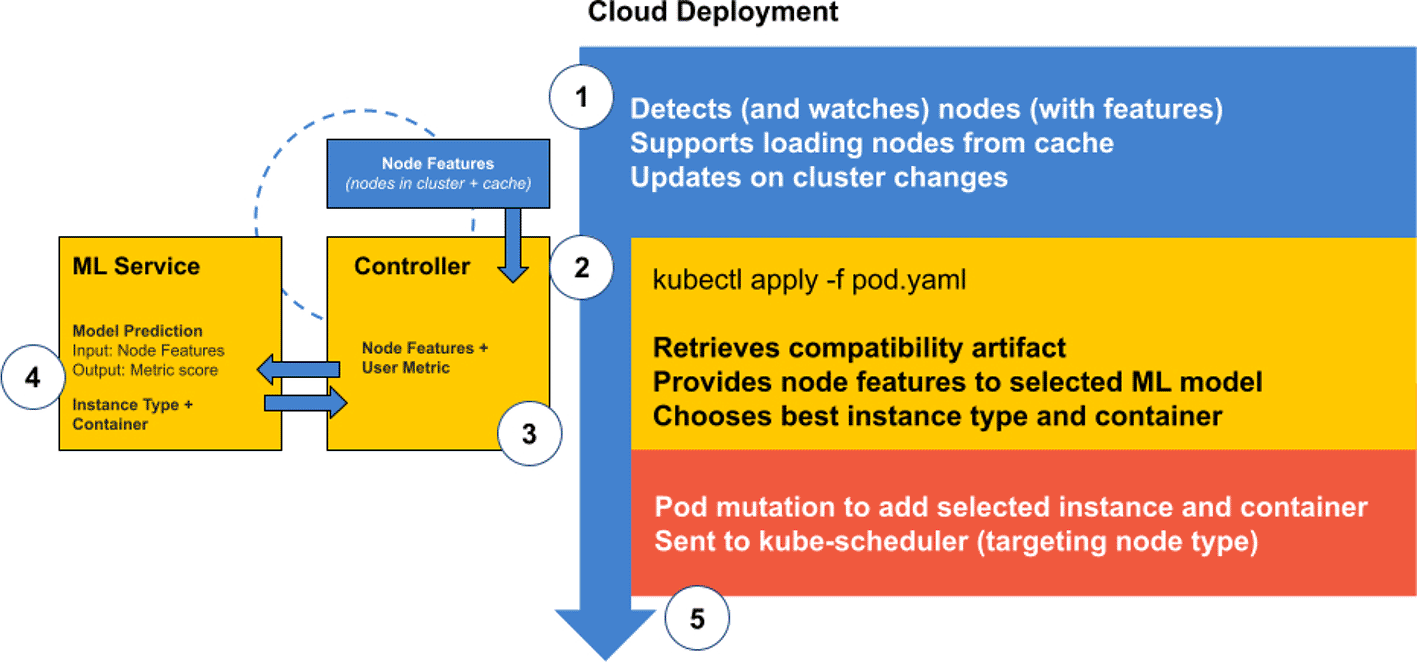
The controller maintains a database of node features automatically discovered or provided via a cache (1). When an annotated pod or MiniCluster is created, model selection user-preferences are retrieved via an OCI artifact (2). The controller (3) sends the desired metric and node features to the model service (4) to get back a chosen instance and container. The pod or MiniCluster is mutated (5) and sent back to the Kubernetes scheduler.

The image-ref points to a compatibility artifact in an OCI registry, and the model to be used by the server “fom” is referenced within. These annotations equivalently work on a Flux Framework MiniCluster.
HPCG Build Matrix. The High Performance Conjugate Gradient is a well-known benchmark for the HPC community, used to evaluate performance of systems for the Top500 ranking. We built HPCG using Docker BuildKit across micro-architectures for each of x86 (N = 17) and ARM (N = 13) and optimization levels (N = 7) for a total of 217 containers. We used BuildKit to generate containers across optimization levels O0 (no optimization), O1 (Basic optimizations) O2 (standard optimization), O3 (aggressive optimization), Ofast (aggressive, non-compliant math), Os (optimize for size), Og (optimize for debugging) for each of arm64 and amd64 platforms. For amd64 we built native, x86-64-v2, x86-64-v3, x86-64-v4 (generic and portable based on instruction set levels), sandybridge, ivybridge, haswell, broadwell, skylake, skylake-avx512, icelake-server, sapphirerapids (Intel-specific), and btver2, bdver4, znver1, znver2, znver3 (AMD-specific). For arm64 we built native, neoverse-n1, neoverse-v1, neoverse-n2, neoverse-v2, ampere1, a64fx, cortex-a72, cortex-a53, cortex-a57, cortex-a76, cortex-x1, and generic micro-architectures.
HPCG reflects performance of a broad range of scientific applications, including sparse matrix computations, data movement, stressing not only floating-point units but also memory subsystem bandwidth and latency within a node. This is important because the size of our matrix and scale of our study (ultimately over 12K individual runs) required a cost- and time- effective strategy for performing the work. We used a local processor matrix size of 40 x 40 x 40 and 15 seconds to aim for valid benchmark results in 20 seconds or under for each run.
For each optimization level, for each micro-architecture, and each of a set of 21 CPU instance types on AWS ( Table 1) we ran three iterations. Instances were selected to be the largest size in a family closest to $3.00. For each configuration we collected eBPF metrics for CPU and futex, two programs that had revealed interesting results for previous experiments. For our own interest, we additionally ran the same containers via Singularity54 on 7 on-premises HPC clusters, including Corona, Borax, Boraxo, Dane, Poodle, Ruby, and Tioga at Lawrence Livermore National Laboratory for a total of 28 systems. While these clusters will not be used for instance selection for the next stage of experimentation, we aimed to demonstrate that node features can be equivalently extracted for HPC systems, a contribution we made to the NFD project for this work.55
Compatibility Artifacts. The Open Containers Initiative26 is a community responsible for container standards related to runtime, distribution, and image manifests. In 2024 a compatibility working group was created that resulted in a proposed image compatibility artifact,25 a data structure that could be stored alongside an application container in a registry to describe application needs with respect to kernel modules, hardware and devices, or other system requirements. An early implementation was added to Node Feature Discovery in Kubernetes56 that allowed defining a set of rules for container tags that would drive selection based on node features. To put compatibility in scope of portability, a more portable container by definition is more compatible across environments. Compatibility ensures that the container will run, but not that it will run optimally.
Our goal in this work is to generate artifacts for HPCG that cater to specific use cases driven by ML models. While the currently proposed specification is rule-based, we find the hard coding of specific node features to be limited. Our work presents using compatibility artifacts to represent models ( Figure 5) that can equivalently choose an optimal container and instance type based on a user preference. We thus extend the artifact to include a model definition that does not hard-code a specific container identifier into the spec, but rather will use the output from a machine learning model to derive it.

The user selects a desired model by the tag, and it is matched to one provisioned in the ML server ( Figure 3). The directionality of the prediction determines whether the service should return the minimum or maximum scored instance.
Orchestration and Environment. We used our equivalent setup and deployment means (Section 2.2) to deploy the build matrix on AWS, simply looping through the list of tags to iterate through configurations. Our kernel header installer warranted a build with a Fedora 43 base, which uses the yum package manager and is closest to the Amazon Linux 2 node. For the addition of running experiments on ARM processors, we required a build of all operators, kernel header installers, and eBPF sidecar containers for the ARM architecture. For example, the task of selecting a correct eBPF program or kernel header installer container is a compatibility assessment.
Model-based Instance Selection
We will build a model to predict HPCG FOM, defined as the GFLOPS rate across several computational kernels. Notably, this model is not intended to be optimized, but rather demonstrate the value of the approach to use compatibility artifacts for selection. Features will include CPU model and vendor types, kernel versions, and operating system metadata. We will use linear regression validated with K-fold cross validation approach (K = 5). We aim to demonstrate the utility of an approach that can use a model to do compatibility-based instance selection. Our approach is simple and there are more sophisticated models that can be used in its place.57–59
Compatibility Artifact Selection
We designed a novel Kubernetes controller ( Figure 3) that works to enable model-based instance and container selection in Kubernetes. The controller works as follows. A Pod or Flux MiniCluster is submit by the user with annotations and labels that target the respective abstraction (Pod or MiniCluster) for OCI selection ( Figure 4). The controller serves a mutating webhook, which means that it has the ability to receive the object and change fields before sending it to the Kubernetes scheduler. The user annotates the object with a unique resource identifier (URI) that specifies a compatibility artifact in an OCI registry and a desired metric model, and the artifact is retrieved and parsed for the model. Node features that are automatically discovered in the cluster or associated with nodes that can be created via a cluster autoscaler are sent to the model server, which returns the instance associated with a minimum or maximum prediction score. The Pod or Flux MiniCluster is then mutated to add a nodeSelector for the chosen instance, and a container image with the correct platform for it. For the Flux MiniCluster, a compatible platform image that provides Flux to the application is also selected. The controller is designed with a watcher to update node features on changes to the cluster, so the nodes always reflect the current state.
We created a total of 41 applications, some including multiple build variants, for a total of 76 builds for the study. We had credits to run 30 applications for our scaling study from size 4 to 256 nodes. Choosing the maximum size (64, 128, or 256) was determined by observing inverse scaling patterns. A subset of results are reported here for well-known applications that test different facets of the setup, and can show common trends. This is not primarily a performance study, so our main concern is to report on trends and usability. We noticed a common trend of benchmarks and proxy apps stopping strong scaling between sizes 32 and 64 nodes, and primarily saw remarked improvement for the OSU Benchmarks as compared to our initial study.30 From a usability point of view, we report an improved user experience in the execution of the study compared to the same initial study. Each application experiment deployment required copy paste of one block, which would create the cluster, orchestrate experiments, and save to output files for further processing.
AMG2023. AMG is a proxy app that stresses the memory subsystem (bandwidth and latency) and interconnect. Results for CPU runs using OpenMPI on Ubuntu are in Figure 6, and only to a maximum size of 32 nodes. AMG starting failing on the IJ vector setup at size 64 nodes, reporting that a bind address was already in use. We believe that for this application, the number of addresses needed exceeded the number that could be provided to OpenMPI.60 To follow reported logic,60 to do an all-to-all each of the node’s 88 processes will try to connect with each other process, and each connection requires a port. The job at size 64 has total processes, and 88 per node. This means that each node needs at least . This number is well above the range that is normally available.61 If this is the case generally at size 64 nodes and an application does not exit, we might see scaling stop here for other applications.
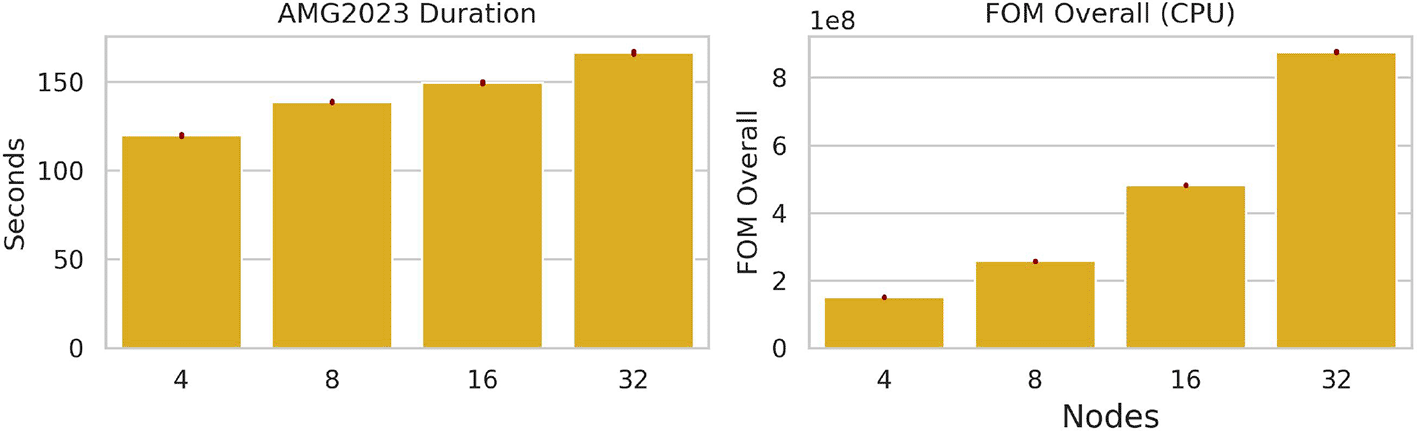
While larger FOMs indicate better performance and we see AMG scaling appropriately based on FOM, the increasing runtime duration is potentially problematic from a practical standpoint of incurring increased cost for a longer time spent using a larger cluster. It is unknown where the FOM would stop increasing due to the address issue.
OSU Benchmarks are concerned with reporting performance of point to point and collective MPI communication patterns. Results are reported in Figure 7. We saw the greatest improvements for point to point latencies compared to our initial performance study, with osu_latency trending under 20 microseconds for message sizes between 0 and 8 bytes, an improvement of approximately 16 microseconds from the initial setup, likely a result of the H3 improved network capabilities provided by Titanium. The improvement to all_reduce was significant, with latencies reducing by half. For example, initial values over approximately 5200 microseconds30 for size 4 reduced to 2595.458 +/- 307.9 microseconds for the smallest message size.

LAMMPS with ReaxFF is a good proxy app to test floating-point performance and network. Results are reported to show the FOM, Matom (million atom) steps per second, in Figure 8. For CPU runs, strong scaling was maintained until a size 32 node cluster, at which point it leveled out and started to inverse scale at 64 nodes. A single NVIDIA V100 GPU, with equivalent cost to the CPU instance type, scaled well until 64 nodes, and was the obvious top performer for the LAMMPS FOM (highest value) and duration (lowest value). This equivalent application with a similar build has scaled successfully up to 256 nodes30 and we suspect a similar problem to that noted for AMG.
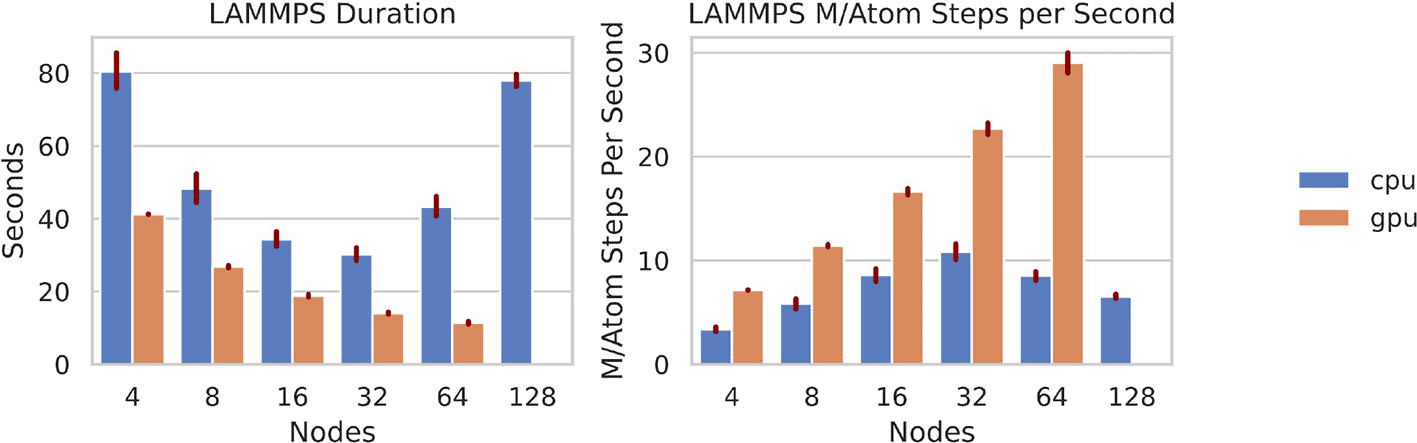
For the FOM, larger values are better. The app strong scaled until 32 nodes for CPU, and 64 nodes for GPU.
Deployment of eBPF programs adds minimum overhead that increases with the number of programs deployed ( Figure 9). A sample strategy is reasonable if the goal is to gather high-level trends. Otherwise, to derive casual factors for performance, multiple programs per node is ideal with collection of interval data.
We were able to build containers for Ubuntu with OpenMPI and MPich, Ubuntu with OpenMPI, MPich and CUDA, Rocky Linux for OpenMPI, Mpich, and the recommended Intel MPI, and Rocky Linux with Intel MPI and CUDA. Of that set, 9 builds were successful, but only 4 completed execution. In Figure 9 we show the overhead to FOM added when running the application with and without eBPF. Running a single eBPF program added trivial overhead (up to 10%), however running multiple eBPF programs contributes to a performance detriment that increases with scale (up to 60%).
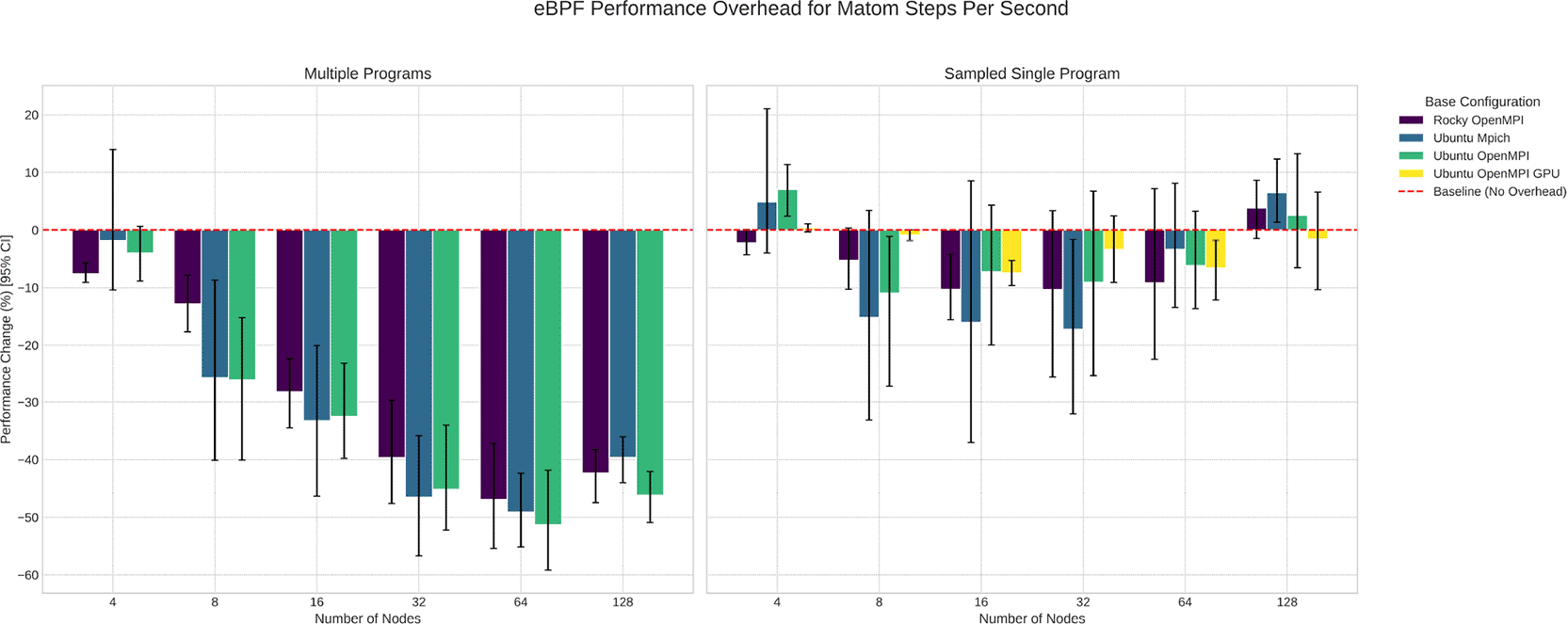
Multiple programs (N=5) lead to up to 50% overhead to performance as compared to without ebpf, an observation that increases with scale. Single sample programs added 10% or less overhead for OpenMPI builds.
Despite being the suggested MPI and using software provided by Google, we were not able to run any containers that used Intel MPI with Rocky Linux, even using Google provided installers. These application container built, but failed to run with either unknown or bus errors. Rocky with Mpich also failed with a bus error. We made several attempts to rebuild the Intel MPI container using different package managers and strategies, and all failed with equivalent errors. Intel MPI was not possible to assess in this work.
Programs. We provide a sample of our exploration into eBPF program output as an example of generating hypotheses that might explain differences in performance. We are interested in the different builds and environments for LAMMPS. While we cannot make inferences about causality due to using summary models, we can point out notable trends.
I/O Access Fingerprints We look at differences in file access fingerprints of running LAMMPS, specifically comparing CPU vs. GPU (holding OS and MPI variant constant), Ubuntu vs. Rocky Linux (holding MPI variant constant) and OpenMPI vs MPICH (holding the OS constant). We derive our findings from 257 unique results. Our first finding is identifying Kubernetes system components that are highly consistent, meaning that the files accessed are equivalent across comparisons. These node components include containerd, the csi-node-driver, dbus-daemon , dnsmasq-nanny , flb-logger , runc, and ip6tables-restore. No differences in access sets despite different application executions suggests that these components have highly standardized runtimes that work independently of underlying hardware, application, node, and configuration nuances, offering stability and predictability for Kubernetes nodes.
We can next look at the LAMMPS binary lmp to see the opposite side of the spectrum – a command that has many differences in file access depending on OS, CPU versus GPU, and MPI variant. During GPU execution, the application accesses the NVIDIA/CUDA stack and drivers (/dev/nvidia*, /proc/driver/nvidia/*) and libraries (e.g., libcudart.so, libcuda.so) to ensure direct GPU hardware and CUDA runtime interaction. We also found that accelerated (GPU) LAMMPS uses FFTW libraries, but not CPU. This was unexpected because we built our CPU variants also with FFT=FFTW3, the library was installed in the container, and configuration with CMake reported no issues. We also learned that GPU execution uses a virtuo block device presented as sda and CPU execution uses nvme0n1 (NVMe storage), a reflection of the underlying node types.32,62 We can also see that the MPI build is CUDA-aware due to the presence of libmca_common_cuda.so.
The CPU LAMMPS variant did more explicit lookups for networking, accessing files for /etc/*host*, and resolv.conf. Further, we saw vader_segment files in the Flux run directory, indicative of Flux influencing OpenMPI’s Vader shared memory BTL.63 CPU LAMMPS also more heavily queried NUMA details, with lookups to /proc/meminfo and/sys/bus/node/devices/<node>/distance. Finally, a large list of shared libraries under /usr/local/lib/openmpi/mca_*.so suggests that the CPU OpenMPI is dynamically loading many components.
When comparing OpenMPI running in Ubuntu versus Rocky, despite equivalent builds of OpenMPI from source, Ubuntu had broader fabric probing, accessing paths for OpenMPI OFI components. The Ubuntu execution also accessed paths that indicated explicit NUMA library usage and direct sysfs node info access (e.g., libnuma.so and /sys/devices/system/node/<node>/meminfo).
When comparing OpenMPI to MPICH, we saw that MPICH loads a much wider array of general system libraries (e.g., OpenCL, X11, crypto, curl, etc.) than OpenMPI. A final finding is the checking of /proc/sys/vm/overcommit_memory, which we saw done by the flux-broker , ZeroMQ, and connector-local processes with higher frequency at larger cluster sizes. This indicates making allocations large enough to trigger mmap calls from glibc that exceed the MMAP_THRESHOLD. The operation that checks this setting is concerned with reclaiming memory,64 and its presence indicates that the application in question is managing previously mmaped chunks. Not seeing the check at smaller sizes indicates the applications not making large allocations, or making and freeing them.
CPU Running and Waiting We can look at the ratio of CPU running versus waiting time to understand if the time of CPU waiting increased relative to running as the cluster size increased, an indication of a possible performance bottleneck ( Figure 10). We observe a similar pattern to Figure 9 where waiting time increases relative to running, with the biggest drop at 128 nodes. This suggests that the increase in LAMMPS duration and decrease in FOM is related to the CPU spending less time running relative to waiting.
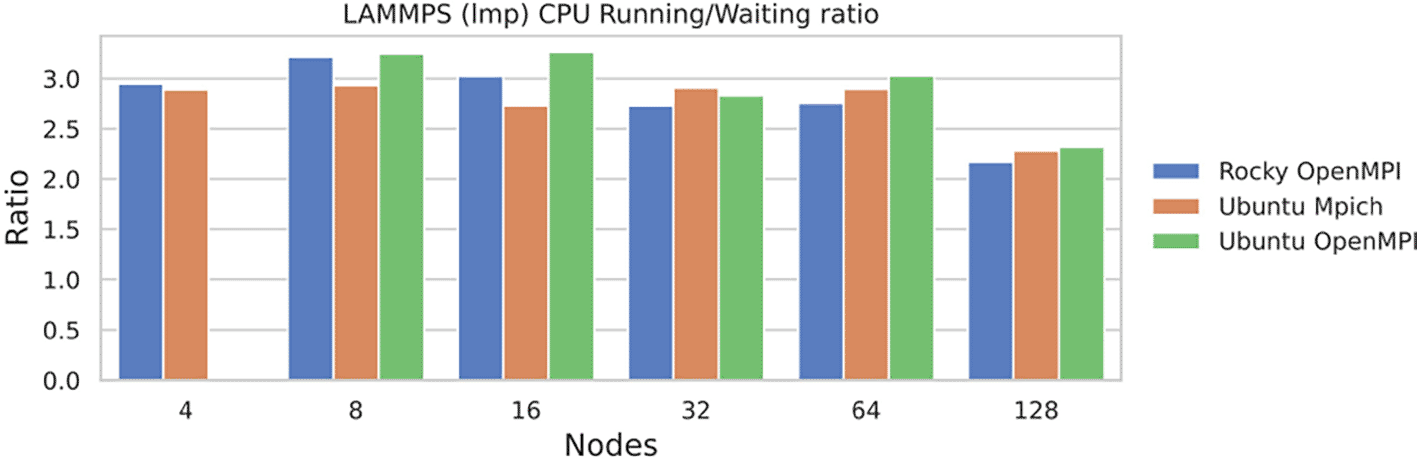
The ratio decreases with increasing size, suggesting more waiting time.
Futex Waiting Times While not revealing to the performance result, our measurement of futex waiting times ( Figure 11) reveals an interesting insight to performance for applications that use GPU. The GPU setup has overall higher futex waiting times (and variability at size 64+), possibly caused by the need to synchronize between CPU and GPU. This finding suggests creating strategies to schedule CPU and GPU that work together to be physically close together. It is not known why one of the CPU setups had higher futex waiting times.
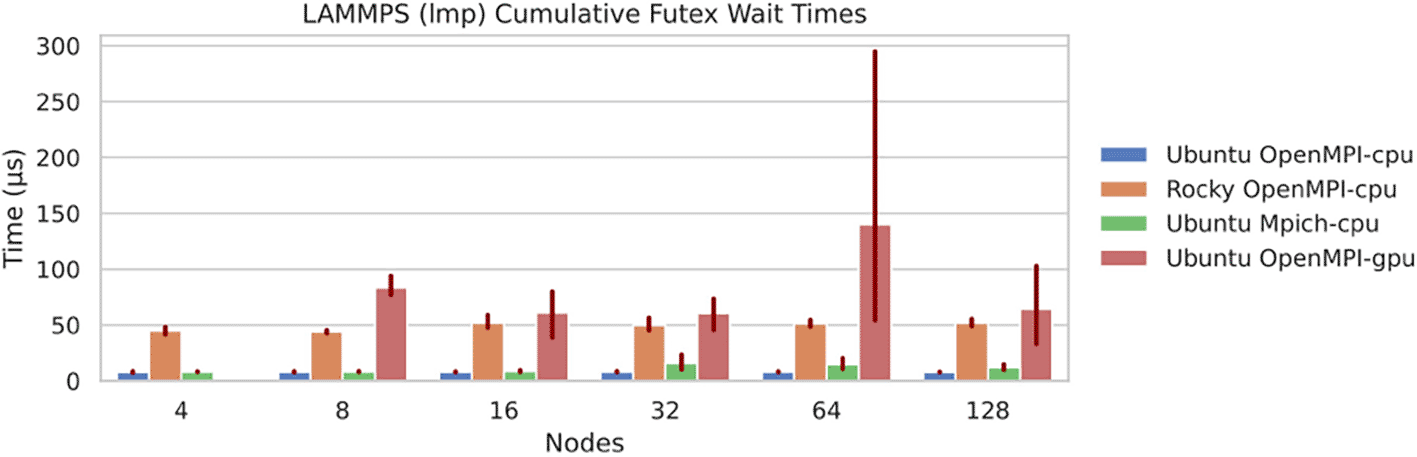
HPCG Matrix
We ran HPCG across 27 node types and 217 containers, each with a different micro-architecture build and optimization level to derive a total of 24 metrics for HPCG. FOM values are shown in Figure 12. The best performing amd64 instance was the r7iz.8xlarge. We believe this is due to the high clock speed and high-bandwidth DDR5 memory provided by the instance type. The frequency (up to 3.9 GHz) means that operations are faster, which is likely advantageous for the Multigrid and SymGS portions of the benchmark, and especially given a small running time. The HPCG benchmark is known to be limited by memory performance.65 In this case, the compute optimize instances (e.g., c7g, c7i) may have many cores, but have less memory bandwidth per core. It could be that these instance types thus spend more time waiting for data to arrive from RAM. We likely accidentally discovered an instance type that is an ideal match in terms of hardware for the benchmark’s needs. The best performing arm64 instance t4g.2xlarge ironically is not available in a size larger than our tested 8 vCPU, and would not scale to a larger experiment. We believe it worked well for HPCG because of the ratio between cores and memory, with a ratio double that of other larger graviton types (4 GB/core vs 2GB/core). Notably missing from this table are HPCG builds that were specifically optimized for one system, which is typically done, and the color scales are biased to our set of builds.
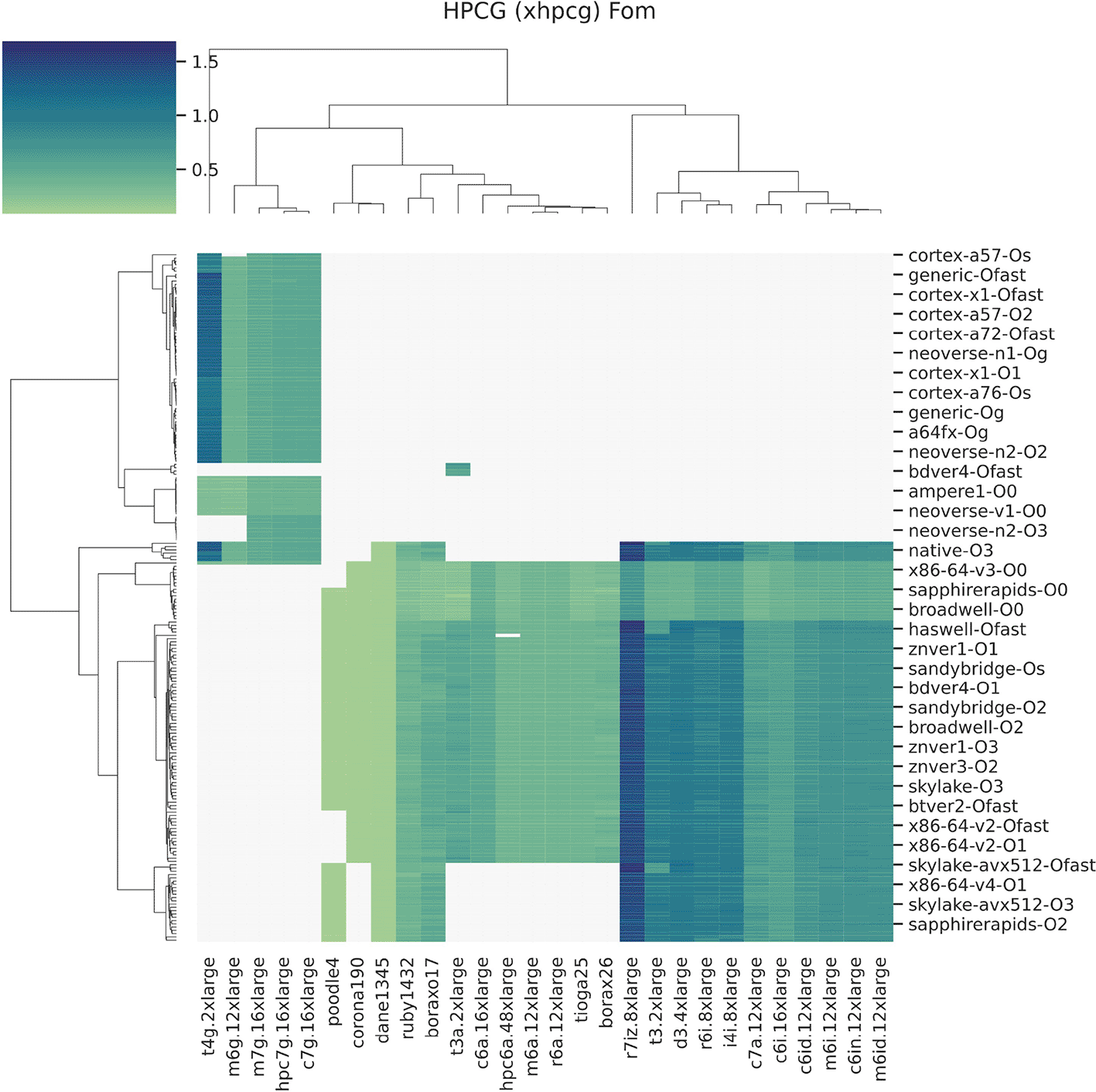
Platforms cluster together (arm64 top left, amd64 bottom right) and clear (values of 0) indicate incompatibility.
Features and Models. We built a model for HPCG to use node features to predict FOM and report on mean absolute error (MAE, 2.3850 0.0156), the R2 score ( , 0.8708 0.0021), and root mean absolute error (RMSE, 3.2656 0.0357). We identified 26/465 features as important based on coefficients not being close to 0.66 Features included threading (N = 4), CPU model families (N = 7) and identifiers (N = 13), and vendor model identifiers (N = 2). Importantly, using this model with node features to perform instance selection far outperformed selection at random.
Model-based Compatibility
We used our model to predict FOM using node features in a basic instance selection experiment. The model was used with our Kubernetes controller and an autoscaler that supported all 21 instance types to compare running HPCG with model-based selection as compared to random selection. The experiment performed selection 30 times, with each selection experiment run for 3 iterations. Results are in Figure 13. The model performed well to optimize the FOM as compared to random (4.1x as compared to random instance selection).
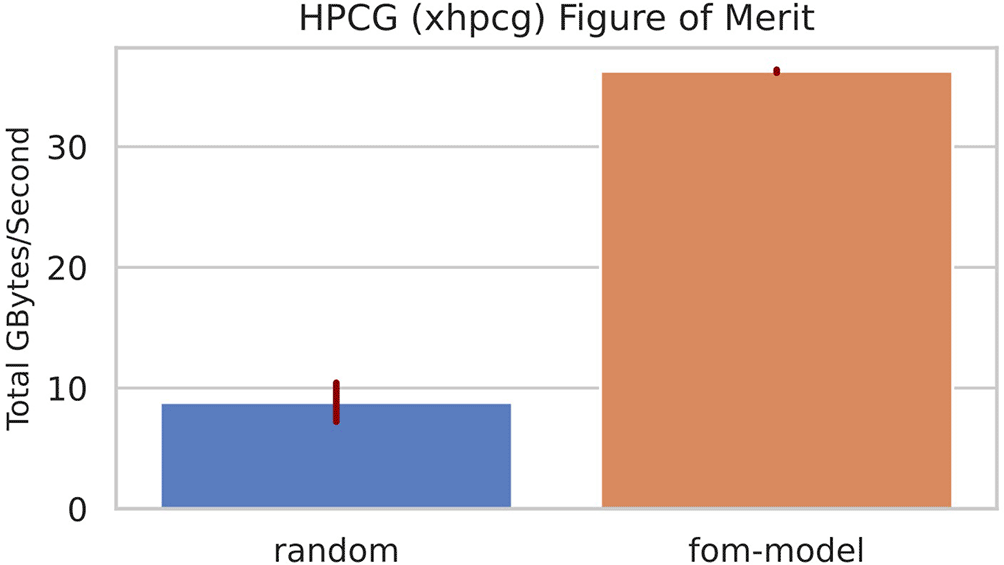
The FOM model selected the hpc7g.16xlarge. The random selection case used a total of 17/21 instance types. All instances were provisioned by the cluster autoscaler.
Waiting times for each experiment also reflected the need to add new instances, with the FOM model that consistently selected an instance type (and used the same machine for the experiment) having to only wait for the new pod to be created (median value of 20 seconds) as compared to random that would request a new instance from the autoscaler (median waiting time of 125 seconds).
In this work, we set the stage for advanced work in cloud to understand HPC applications using eBPF, to automate orchestration, and to use compatibility artifacts with ML models for informed instance selection. Our work includes providing an automated orchestration setup with performance monitoring, along with 30 complete applications for the larger community to sample from. Each application includes a container build and automation setup that exposes salient parameters, and we demonstrate the functionality of these applications by performing a scaling study from 4 to a maximum of 256 nodes for both CPU and GPU applications. We then show the low overhead of eBPF and example insights that can be learned from using it in a Kubernetes environment. Finally, we extend our work to suggest the value of model-driven instance selection using an automated approach with compatibility artifacts.
Portability of technologies and tools
Our work is notable in that we are taking a strategy of convergence – not just running HPC applications in cloud, but making a plan to use the same tooling and approaches across spaces. While our experiments here used cloud-provided Kubernetes, we anticipate the same compatibility artifacts informing scheduling decisions for environment selection using the equivalently modular and programmatic Flux Framework that will also support grow and shrink of jobs and cluster resources. Preparing for this work, we have enabled the same node features to be export in HPC environments.55
Application-first selection as a first-class citizen
Our work represents an “application first” compatibility assessment, where we select an environment for a known application, and notably, an environment that does not need to exist. It flips the traditional HPC paradigm of optimizing an application build for a specific, persistent system on its head, suggesting that we might instead build a portable application and not only deploy the best node, but create the best cluster on the fly for it. Since our controller customizes the Flux MiniCluster abstraction, this would be easy to enable in Kubernetes, allowing for customization of the entire cluster setup based on ML models.
Environment- versus Application-first selection
An application-first approach is in opposition to the HPC use case, where an environment already exists (a homogeneous center cluster) and an application must be selected or optimized for it. In this case, it could be laborious or time consuming to do on-demand builds. Model-based selection in this environment would need to better consider captured attributes of the application needs such as network, I/O, kernel, and devices. This is more suited to the initial vision of the OCI compatibility spec, and more challenging in practice because specifications are often created manually based on reading vendor documentation for exact builds. While our work did not focus on image selection – we observed that specific optimization levels and micro-architecture builds were consistently good across environments and chose them to be consistent for our runs – we do believe work that focuses on the image selection step is important. Our models could not consider features of the application images or instance resource sizes because they were not easily, programatically exposed. Approaches that intelligently combine image and instance selection in an automated fashion are a next stage of work.
Considerations with autoscaling
Autoscaling to enable running HPCG on different instance types for the random setup revealed another tradeoff between options and experiment running time. Needing to wait for instances to be created increases the overall execution time (in our case, waiting time increases by a factor of 6). This dynamism can be advantageous for workflows with different resource needs, but should be use cautiously to not incur excessive costs during waiting.
Limitations
Due to the need to run across many instance types for many thousands of iterations, we limited our application to one node, smaller instance types that fit within a cost per hour of approximately $3.00, and a brief and capped execution time. While this configuration does not represent the scale of a typical HPC application run and does not represent a real-world use case, it was useful to be demonstrative to the value of our orchestration and selection strategies. Follow up work that extends to multiple nodes, more realistic execution cases, and larger problem sizes is needed.
It was a notable finding from our initial models that threading was a highly predictive variable for multiple metrics. However, metadata about resource scale of an instance (memory, CPU, and cache locality) are not typically exposed as node features, which reflect metadata about the hardware and kernel. In that node resources can be valuable for predictive models and NFD supports custom labels, we anticipate engaging with the project to propose means to better expose this metadata, or developing plugins to expose it ourselves.
We are interested in adding instance cost to our models as a predictive outcome, which we were unable to do due to the artificial limitation of the application running time. It could also be the case that the cutoff limited our current models if allowing for a longer running time could have implications for performance metrics. Follow up work is needed that does not limit applications of interest in their execution times, and derivation of robust models to predict duration. We might consider the tradeoff between instance type and using CPU versus more expensive (and potentially harder to obtain, but faster running) GPU.
Finally, we are not experts in performance analysis, and made a best effort to design eBPF programs that collect an interesting range of metrics. We are planning to engage with a larger team that can better inform eBPF program metrics and design.
eBPF Deployment Strategy. There is a tradeoff between number of eBPF programs run and utility of the data. Collecting a fewer number of metrics can minimize application overhead, but it comes at the cost of comparison between metrics. More application runs would be required to run each eBPF program separately, and comparison would not be possible between runs. Choosing to run multiple metrics would make runs comparable, but add overhead. Our approach that derives summary models and runs single programs sampled across a set is ideal for high-level understanding, but not well-suited to fine-grained temporal analysis.
While outside of the scope of the work here, it is important to note that full integration of eBPF tools on a multi-tenant system would be a significant challenge the authors have not fully explored. Extending to a user-space setup (e.g., User-space Kubernetes) would be valuable.
I/O access fingerprints
We unintentionally stumbled on an important insight from our I/O access analysis – Kubernetes components that are related to core system or infrastructure are designed for broad compatibility and standardized operation. Despite running on different node types between experiments, we saw no paths uniquely accessed in any environment. Behavior is not tied to the specifics of a workload or node environment.
The finding of the missing FFTW3 library in the CPU LAMMPS build suggests that even when an application environment has a provided dependency, is built following instructions, and reports no build issues, additional verification might be warranted to assure that the dependency was used. Specific I/O fingerprints tied to evidence of usage during runtime can provide this insight. In our case, it is unclear if FFTW3 would have improved performance.67,68
The differences in file and driver path access between CPU and GPU executions suggest that there is a strong fingerprint to distinguish the two. The probing of MPI to understand the environment is a design choice that reflects the environment in which MPI is executed. HPC environments are typically different, and the software ecosystem has developed to support that. While we did not test an I/O intensive application, differences in storage and MPI communication (e.g., being CUDA-aware vs. Verbs/OFI + Vader) could be candidates for explaining performance variations.
Finally, it is clear that the choice of an operating system base brings in a distribution’s packaging philosophy, default library set, and file system layout. This directly impacts what our proxy application, LAMMPS, sees and links against, and thus what might be probed at runtime. Differences that result from the environment are expected for a complex application that is sensitive to its environment and highlight the challenge of deploying and optimizing such applications.
We believe that this work and the supporting software is invaluable as a suggested direction to both run workloads and better engage with the cloud community. The promising direction of using Kubernetes on-premises offers a glimpse of a future where researchers can be flexible to easily move between environments, using tooling that is developed by a large, cross-interdisciplinary community that champions reproducibility, portability, and automation. While our work was focused in cloud, we have contributed work to the NFD project to make it possible to extract node features on demand without Kubernetes, and plan to follow up with an analogous on-premises setup. Since NFD features are extendable, for this work, we believe it important to include features that better describe compute resources (memory, cores) as well as cache size and hit ratios.
While the programs, analyses, and conclusions is a huge space that warrants much future work, we have provided examples that walk through taking a high level observation about performance (the application FOM) and used eBPF data to verify configuration and generate hypotheses about bottlenecks.
Workflow Portability. It is interesting to think about the process of running experiments holistically. The deployment of any workload first requires a binary or representative build artifact for the application code, a means to run it on a system (VM or other), and then an orchestration strategy, which for simple things might be running iterations of a single execution, and in more complex, a DAG based workflow. There needs to be a vehicle to transport workloads and user understanding between traditional HPC environments and cloud. That vehicle, our unit of operation, is the container. Our work demonstrates this idea by executing the same containers via Singularity on bare-metal systems, however the orchestration and scheduling component warrants further work.
Cloud Configuration. In order to enable auto-scaling, AWS requires the eksctl configuration file to be generated with different node groups that describe the counts and scaling ability for each instance. Importantly, in the case that the desired (starting) size is 0, our controller needs to have a matching set of instance node features in the cache. If this is done incorrectly, an instance can be selected that the autoscaler cannot support, or an instance type that the autoscaler supports can be ignored. While we created one configuration manually for our experiment, we anticipate wanting to create easier and more automated methods to generate these configuration files for future experiments.
We have demonstrated a setup that enables a possible future to bring together traditional HPC performance monitoring with the cloud technology eBPF. While this work did not explicitly assess techniques to combine the two approaches, we anticipate follow up work on this task. Through our provided means to provision and measure a set of over 30 HPC applications in Kubernetes, we hope to provide example to the larger community to encourage next stages of work. Through our model-based instance selection to optimize a metric of interest we encourage utilization of AI/ML techniques to further inform the work. This work is invaluable to the larger HPC community where portability is a metric of performance, and having the choice to move between environments is essential. It’s an immensely exciting time to be working on HPC apps in this space and we look forward to future work extending learning to on-premises or better understanding cloud for the needs of the larger community.
Source code for the Kubernetes controller “ocifit” can be found at https://github.com/compspec/ocifit-k8s/releases/tag/0.0.1 and for the Helm installations and applications: https://github.com/converged-computing/flux-apps-helm. Archived source code at time of publication can be found at https://doi.org/10.5281/zenodo.17433518 and https://doi.org/10.5281/zenodo.15665233, respectively. Both are covered under an MIT License.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)