Keywords
Sustainable Development Goals (SDGs), Artificial Neural Networks (ANN), Non-parametric regression, Machine Learning (ML), Artificial Intelligence (AI), complexity.
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Climate gateway.
Sustainable Development Goals (SDGs), Artificial Neural Networks (ANN), Non-parametric regression, Machine Learning (ML), Artificial Intelligence (AI), complexity.
The Agenda 2030 (TA2030) is a global action plan adopted by the United Nations to eradicate poverty, protect the planet, and ensure prosperity.1 TA2030 consists of a set of SDGs, also known as Global Goals, covering a wide range of topics from poverty eradication to combating climate change,1 and has been committed by Mexico to the UN. Each SDGs has several specific and measurable targets that every country can achieve by the end of 2030. These goals and targets seek to address the major challenges facing the world today, including poverty, inequality, climate change, environmental degradation, a lack of access to education and healthcare, violence, and injustice. TA2030 and the SDGs call for governments, businesses, civil society, and citizens to work together to build a more just, prosperous, and sustainable world.2 TA2030 can be defined as a complex phenomenon because it involves an analysis of multiple interconnected factors3 that influence the implementation and achievement of set objectives.4
TA2030 and the SDGs offer a tremendous opportunity for Mexico to transform its development model into one that is more sustainable, inclusive, and resilient (Villanueva Ulfgard, 2019). Their implementation will not only address current challenges but also lay the foundation for a prosperous and equitable future (Goldrich & Carruthers, 1992). However, their success will depend on political will, citizen participation, and collaboration among all sectors of society, as well as greater coordination between the government, the private sector, and civil society; the strengthening of public policies based on evidence and data; the use of technology and innovation to accelerate the achievement of the SDGs; investment in education and health to close inequality gaps; and a commitment to environmental sustainability and climate action. Despite its ambition and scope, the implementation of the 2030 Agenda faces several challenges (Villanueva Ulfgard, 2019):
1. Insufficient financing: It is estimated that between $5 and $7 trillion annually are needed to achieve the SDGs, but many countries, especially developing ones, lack the necessary resources.
2. Lack of coordination: Implementation requires collaboration between governments, the private sector, civil society, and international organizations, which can be difficult to achieve.
3. Conflicts and crises: Armed conflicts, migration crises, and pandemics (such as COVID-19) have delayed progress in many countries.
4. Persistent inequalities: Gender, economic, and social gaps remain an obstacle to sustainable development.
5. Climate change: The climate crisis threatens to reverse the progress made on many SDGs, especially those related to poverty, hunger, and health.
Since their adoption in 2015, significant progress has been made on some SDGs, such as reducing extreme poverty and increasing access to primary education (Villanueva Ulfgard, 2019). However, progress has been uneven and, in some cases, insufficient. According to United Nations reports, the COVID-19 pandemic has exacerbated many existing challenges, delaying the achievement of the SDGs (UN DESA, 2023).
The 2030 Agenda and the SDGs represent a bold and transformative vision for the future of humanity (Villanueva Ulfgard, 2017a). Although the challenges are significant, there are also unprecedented opportunities to build a more just, sustainable, and resilient world. The key to success lies in global collaboration, innovation, and the commitment of all actors, from governments to individual citizens (Maysoun Ibrahim, 2016). Time is limited, and the window for action is closing, but with concerted efforts, achieving the SDGs by 2030 is still possible.
TA2030 shares some characteristics with complex systems, such as sets of interconnected elements that exhibit emergent behaviors and properties that cannot be explained by the individual behavior of each element.5 A complex system is a set of parts that interact with each other in a nonlinear manner, and its overall behavior is difficult to predict from an understanding of their individual parts.6 Thus, TA2030 can be considered as a complex system owing to its interconnectedness, nonlinearity, self-organization, feedback, emerging properties, and dynamism. It has several characteristics that shares with complex systems.3
1. Interconnectedness and interdependence: SDGs are interconnected and interdependent. Achieving this can have direct or indirect impacts on others. For example, improving education (SDG 4) positively affects health (SDG 3) and gender equality (SDG 5). This interconnection creates a system in which the changes in one part can affect the entire system.
2. Diversity of actors: The Implementation of SDGs involves the participation of governments, businesses, civil society, non-governmental organizations, and other stakeholders. The diversity of actors, each with their own interests, objectives, and approaches, adds complexity to the system.
3. Ambiguity and multidimensionality: Each SDG addresses complex and multidimensional problems such as poverty, hunger, health, education, gender equality, clean water, and sanitation. These problems do not have simple solutions, and often require integrated and multidisciplinary approaches.
4. Local contextualization: The Implementation of SDGs must be adapted to local conditions and contexts, adding an additional layer of complexity. What works in one place may not be directly applicable to another, because of cultural, economic, political, and environmental differences.
5. Feedback: The Implementation of SDGs involves feedback systems in which the results of past actions affect future decisions. Successes and failures in achieving objectives can influence decision making and strategies.
6. Constant change: The environment in which the SDGs are implemented is constantly changing owing to factors such as technological advances, changes in the global economy, extreme climate events, and international crises. This requires continuous adaptability and ability to respond to changing environmental conditions.
These characteristics imply that the TA2030s approach and compliance require a systemic and integrated perspective that considers multiple interactions and problem complexity.5 To address the forecast of compliance with the SDGs in Mexico as a complex phenomenon from a transdisciplinary perspective,7 we needed to select the variables, analyze their interactions, develop a predictive model, and validate it. Interdisciplinary collaboration is essential for a complete and in-depth understanding of the complex SDG compliance phenomenon in Mexico.
This study aims to 1) build a forecast model to predict Mexico’s Sustainability Score by 2030 and 2) perform a scenario analysis after grouping categories of variables for Mexico. To achieve these goals, we first searched for datasets related to the SDGs. We obtained four sources of time-series variables with statistical data of the three categories that are part of sustainability (economic, environmental, and social): the World Bank Open Data Bank,8 the UN Data Explorer (United Nations Statistics Division),9 the academic repository of the sustainability index,10 and the National Institute of Statistics, Geography and Informatics (INEGI) Agenda 2030 site of the Government of Mexico.11 We selected 166 time series for interpolation using the arithmetic mean method to generate quarterly and scaled data for the input variables. We selected these variables from the four data sources choosing those that achieved at least 95% completion of the time series values available for the 1990-2020 period. Initially, we obtained 190 time series, which we reduced to 166 after filtering the afore mentioned process.
We considered 166 variables as representing the SDGs because they are matched each of the SDGs at least once and are identified by the source itself with its respective SDG. It should be noted that we chose to use the largest possible number of variables to extract the most information possible from the system, although some variables (time series) may present redundant information because the source itself presents them as disaggregated information from another variable. “Neural networks do not fundamentally require balanced inputs. They are flexible learners and can adapt to various input distributions”. This is the case of the variables SDG2.3.0 Employment in agriculture % of total employment, SDG3.2.1 Mortality rate, SDG3.4.1 Mortality from CVD, SDG3.4.2 Suicide mortality rate, SDG3.9.3 Mortality rate attributed to unintentional poisoning, SDG8.5 Contributing family workers, SDG8.5.2 Unemployment, and SDG9.2.2 Employment.
To assess the suitability of the data for model analysis, the study underwent several code scripting pre-processing steps, including web scraping, data format conversion, missing value imputation, column merging and splitting, identification of positive and negative indicators, and data normalization. This research utilized R version 4.4.0 for data preprocessing and RStudio 2024.04.1+748 “Chocolate Cosmos” Release.12 neuralnet, NeuralNetTools, tidyverse, zoo, forecast, rmote, tseries, imputeTS and mice libraries were employed to process the data and imputed when necessary. Specific rules such as unique identification codes for sustainability indicators were used to facilitate data recognition by the model.
Once the yearly time series were selected for use as variables, the missing values in the series were imputed using the interpolation method na_interpolation: missing value imputation by interpolation within imputeTS R library, choosing “linear” for linear interpolation using approx. function, which uses a function performs linear interpolation13 to impute the missing values.14 To obtain a broader universe to provide data to train the model, the values were interpolated twice to artificially generate simulated quarterly values for all time series. Thus, a universe of 120 quarterly readings was used for each of the 166 chosen variables, obtaining a 120 (quarters) × 166 (variables) matrix similar to the dataset. The last step in the variable preparation before model training was scaling. This implies that each original value was converted into a z-score.
Although efforts have already been made to predict sustainable development, in this study we used our own set of variables for our own ANN-based model.
In addition to the variables, the assessment of the system requires an independent but equal-length time series of those variables to globally rate sustainability. There are already institutional evaluators that were built with specific characteristics to measure sustainability. We chose the economic complexity index (ECI),15 the sustainability index (SDI),10 and the UN sustainability report (SDR)9 for Mexico due to their availability, the concepts they involve or consider and the reliability of the sources. Our ANN will be used to perform a simultaneous non-parametric fit with these three indices to model the progress of sustainability in Mexico.
SDI
The SDI10 is a comprehensive tool designed to assess the sustainability performance of countries across the various dimensions of sustainable development. It provides a global ranking of countries based on their performance in three key areas: social, economic and environmental. This index is particularly aimed at guiding policymakers, businesses, and individuals toward achieving long-term sustainability by providing an integrated measure of how well countries manage their development sustainably.
The SDI uses data from globally recognized organizations such as the World Bank, the United Nations, and the World Health Organization (WHO) to ensure consistency and credibility. These sources help track progress toward the SDGs and provide insights into how countries are performing. Countries were ranked according to their SDI scores, with higher scores indicating a better sustainable development performance. This ranking can be used to compare countries’ sustainability efforts and to identify leaders and laggards in global sustainability initiatives.
The SDI methodology is a weighted index that involves the following steps: a) indicator selection from social, economic, and environmental categories relevant to measuring sustainability and b) normalization, where indicators are standardized or normalized to ensure comparability across countries, regardless of differences in units or scales. c) Weighting, where each indicator is assigned a weight based on its importance to sustainable development, and d) aggregation, where these weighted indicators are then aggregated to form the final SDI score for each country.10
The most frequent criticism of the SDI is that, in some cases, environmental ponderation is not well balanced and is sometimes overestimated.16 The evaluation of the SDI is beyond the scope of this work, but it is relevant to point out these issues, given its relevance to the model. SDI is not the only index, we also selected ECI and ISDG individually at the beginning and simultaneously later.
ISDG
The UN has a scoring system to rank and evaluate nations.17 The SDG Index (ISDG) and Dashboards are frameworks developed by the Sustainable Development Solutions Network (SDSN) to track the progress of countries in achieving the SDGs. The key component of the ISDG is the SDG Index Score, which measures the overall progress of a country toward achieving the SDGs. Countries are ranked based on their performance, with higher scores indicating greater progress. These are visual representations of a country’s progress in each SDG. Dashboards provide detailed information on where a country performs well and where improvements are required.
The ISDG is based on a set of 17 goals, with 169 targets and 232 indicators. The methodology involves aggregating data on these indicators to calculate the SDG Index score, ranking countries from best to worst based on their performance, and identifying where a country is on track, facing challenges, or lagging specific goals. The 2018 SDG Global Index Methodology18 explains the methodology used to construct the SDG Index and Dashboards in more detail. Some of the highlights of the methodology include indicators.
The ISDG uses a broad set of indicators, some of which are direct measures of progress (e.g., literacy rates, greenhouse gas emissions) and others that are more complex or indirect and data normalization: Given the diversity of indicators, data normalization methods are used to ensure that all indicators are comparable across countries, allowing for an aggregate score, as well as a scoring system where a combination of statistical techniques (e.g., geometric mean, weighting) is used to combine the various indicators into a single, composite score for each country. The report generally includes data on several key aspects, such as social dimensions (e.g., education, health, and inequality), environmental dimensions (e.g., climate action, life on land, and sea), and economic dimensions (e.g., sustainable economic growth and decent work).17
Although the ISDG includes numerical assessments, there are thresholds to indicate direction and effort, rather than to assess compliance. However, the ISDG also indicates an ideal state (100%) of compliance, which allows for reference not only to the current but also to desirable values. Therefore, as we calculated the future values, it was possible to assess them against that reference. Rather, it evaluates them based on the direction and magnitude of the changes with respect to the previous measurement, thereby allowing contextualization. While the ISDG offers an ideal parameter of compliance of 100%, for the ECI and SDI, there is no compliance reference; therefore, we assume that for the ISDG, for the ECI and SDI, more is better.18 This allows for a comparison of countries on SDG progress and highlights the global challenges that require collective action.17
This system is crucial for helping the international community assess whether the world is on track to meet the SDGs by 2030, and is useful for monitoring the effectiveness of various policies and interventions aimed at achieving sustainable development.18
ECI
Economic Complexity19 is the realization of determining the effects of commercial, cultural, and scientific environments on macroeconomic variables. The ECI is a measure developed to quantify the complexity of an economy based on the diversity and sophistication of the products it exports. Essentially, it aims to capture how “complex” a country’s economy is, not by the sheer size of its GDP or total exports, but by analyzing the composition of its exports in terms of the number of distinct products it produces and the know-how required to produce them.
The ECI provides insights into a country’s capacity to produce advanced, high-value goods and services that are often associated with higher levels of economic development, innovation, and long-term growth potential.20
We chose to include this index as a reference for sustainability achievement because it is often compared with other measures of economic development such as GDP or the Human Development Index (HDI). However, it provides additional insights into the diversity and sophistication of a country’s economy, which are not directly captured by these other indices. Unlike GDP, which is simply a measure of economic output, or HDI, which combines health, education, and income, ECI provides a more granular view of the underlying structural capabilities of an economy.
These three indices provide a reference framework and a system parameter to assess progress in achieving the sustainability commitments of the signatory States.
Because of the shared characteristics of the SDG System (TA2030) and complex systems,21 we modeled the SDGs through ML. This involves collecting and preparing data, selecting variables and ML algorithms, training and evaluating the model,22 and creating statistical models based on data that allow the analysis and prediction of progress toward achieving development goals and interpreting the results to inform decision making. According to,23 “machine learning procedures use statistical tools to find patterns in the data that reveal new and relevant information that may prove useful for performing an action or task.”
A review of the literature indicates that various earlier studies have predicted the attainment of SDG targets using ARIMA or Linear regression models,24 whereas others have recognized the challenges and opportunities by analyzing the use of AI in relation to SDGs.25,26 There seems to be a lack of research regarding the forecasting of SDG scores using ANN with the use of targets.24
Our ANN-based model is a simultaneous fit as it is trained with multiple numerical outputs at the same time. It is also nonparametric because it adapts to the data’s structure rather than forcing the data to fit a predefined structure. In essence, ANNs learn the function from the data itself, rather than assuming a specific functional form.
The value of our research lies in employing an ANN and pinpointing key areas where effective measures can be taken to enhance the SDG scores. The findings of this study will highlight significant issues regarding both the quantity and quality advancement of SDG scores by 2030 in Mexico. ANNs can be used to analyze the factors that influence the achievement of the SDGs. These outcomes could aid policymakers and stakeholders (nations, organizations, and individuals) in making relevant choices, formulating strategies to enhance SDG scores, and minimizing inequalities among countries by ensuring equitable resource distribution. ANNs can also be trained to identify the complex relationships between the SDGs and their interactions,2 and to prioritize interventions that need to be implemented to achieve these goals.3
As supervised learning ML models, ANN networks are provided with labeled datasets that return answers in advance. Our ANN was initially trained with ECI, SDI, and ISDG indices simultaneously as outputs and 166 time series as inputs, with topics related to demographics, environment, and economics, all within the same range of years: from 2000 to 2020 time series for all variables and indices. Figure 1 schematically illustrates the ANN architecture.
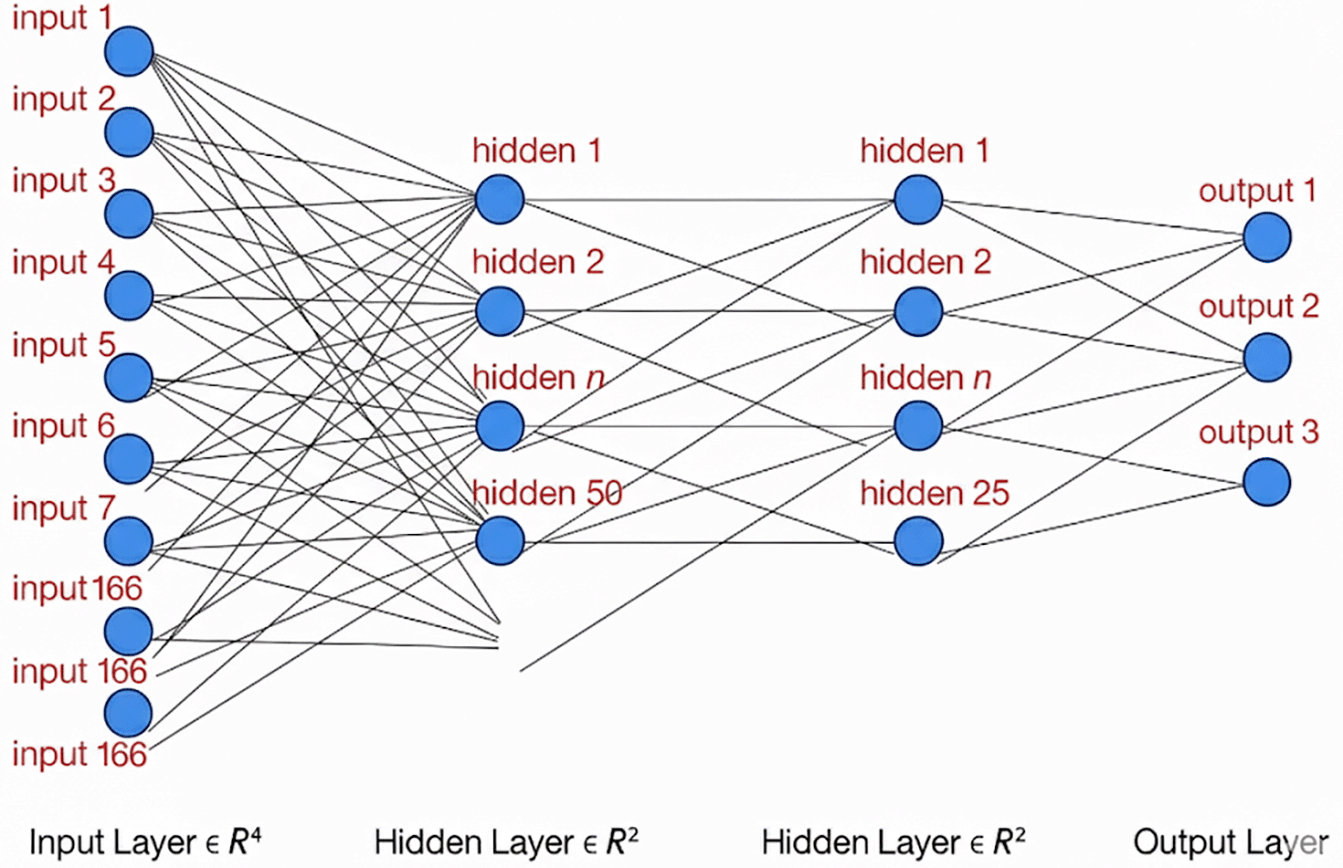
An artificial neural network (ANN) processes input data through layers of interconnected nodes (neurons), applying weighted connections and activation functions to learn patterns and make predictions. The model was trained using variables as inputs to fit the indices as outputs. The ANN starts with randomly initialized weights and biases to break symmetry and ensure that the network can learn different patterns. The learning rate hyperparameter controls the step size during weight updates.27
We selected the model architecture through Grid Search. It works by systematically trying out every possible combination of hyperparameter values within a predefined grid. This exhaustive approach ensures that the best possible combination is found, but it can be computationally expensive, especially with a large number of hyperparameters or a wide range of values. Each neural network was trained using the neuralnet package. We then calculated the mean squared error (MSE) for each of the three target variables. MSE is the average of the squared differences between the predicted and actual values, a standard measure of regression accuracy (lower MSE indicates the model’s predictions are closer to the true values).
Once the grid search is complete, the script identified the best configuration by finding the minimum MSE in the results. It uses which.min on the mse_total column to locate the row with the smallest error. This is reported as the best configuration found. According to the output of the script, the lowest total MSE was achieved by a network with two hidden layers, with 49 neurons in the first layer and 35 neurons in the second layer. In the results data frame, this configuration corresponds to a “layers = 2” and “neurons = 49-35”. This two-layer network produced a mean squared error of approximately 4.47E-06 (in the original scale of the target variables), which is denoted in the script’s output. This was the smallest MSE among all 702 models tested, making it the optimal architecture within the considered range.
This R script systematically explored a range of neural network topologies to model a multi-output regression problem, predicting ECI, SDI, and ISDG indices from a set of variables. The objective was to minimize the error (MSE) across all targets. Through exhaustive training of 700+ candidate models, the process identified a two-hidden-layer network (49 neurons in the first layer, 35 in the second) as the top performer, with an overall mean squared error of about 4.47E-06 on the training data. This rigorous search gives confidence that, within the tested range, no simpler architecture achieved a lower error. It provides a strong candidate model for further analysis.
Overall, the script employed a thorough approach to model selection for a neural network: it prepared the data (including normalization for stable training), explored a broad space of network architectures, and used a clear quantitative metric (MSE) to choose the best model.
Other parameters that we considered in the training of the neural network were a threshold of 2e-04,28 a learning rate of 1e-1, the SAG algorithm, the sum of squared errors (SSE) function, the logistic activation function,29 and the linear output for the use of the network as a regression and not a classification, which is another common use of ANN.30 The SAG is a method for optimizing the sum of a finite number of smooth convex functions. Similar to SG methods, the iteration cost of the SAG method is independent of the number of terms in the sum.27 The parameters of the trained ANN model are shown in Table 1.
| Setting | Value |
|---|---|
| Activation Function | Logistic function |
| Hidden Neurons | 49,35 |
| Threshold | 2e-04 |
| Learning rate | 1e-1 |
| Error function | SSE |
| Learning Algorithm | SAG |
The final layer produces the network output. In this study, our goal was to train the network to fit the three indices simultaneously. This model was used to forecast the indices and predict scenarios.
This ANN training was used to calculate, through this nonparametric regression, the values of the outputs (ECI, SDI, and ISDG) and compare them with the current values of the aforementioned indices. The first step was to compare the range of years for the values available for all the three indices. These ranges were from to 2000-2019 for the time series. The results of this comparison using the trained ANN showed that the values calculated for the three indices were very similar to their real values, with ECI being the most approximated and SDI the least approximated, but all of them were within an accurate range to consider the training as valid and able to be used for scenarios or forecasting.
Although there was a risk of overtraining the model with many variables, we chose to use the largest possible number of variables to extract the most information available for the system. We got a good simultaneous regression for all the three indices. SDI fit was less good than the others because it had sharper variations. The Root Mean Square Error (RMSE) for the ECI regression indicates that the average difference between the projected and actual values produced by the model is low enough to confirm this. We quote RMSE instead of χ2 due to the nonparametric nature of the model.
Figure 2 presents a comparison of the actual and calculated values of the SDI index over the period 2000–2019. It also includes a plot of the residuals. The red circles represent the actual SDI values. The blue circles represent the calculated SDI values. The calculated values generally closely tracked the actual values with some deviations, particularly at the maximum and minimum values.
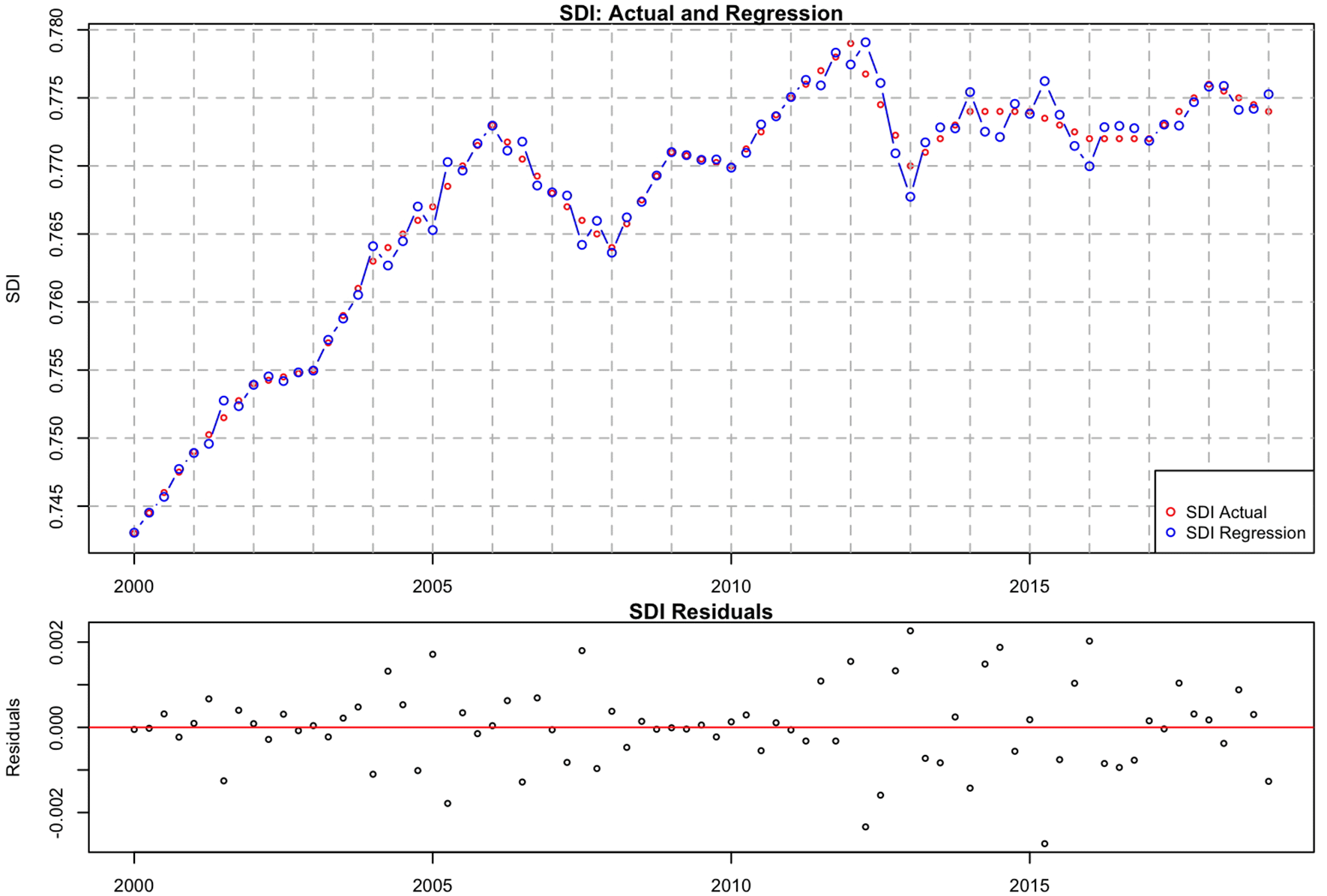
The graph suggests that the current model provides a reasonable approximation of the SDI values. An RMSE of 0.00217 indicates a relatively small error, suggesting that the model used for the calculation was generally accurate. The spread of residuals (Constant Variance) seems relatively consistent across the period. The calculated values closely followed the actual values and the RMSE was relatively low. The residuals plot also indicates that the model errors were small and random.
Figure 3 presents a comparison of the actual and calculated ISDG index values from 2000 to 2019. It also includes a plot of the residuals.
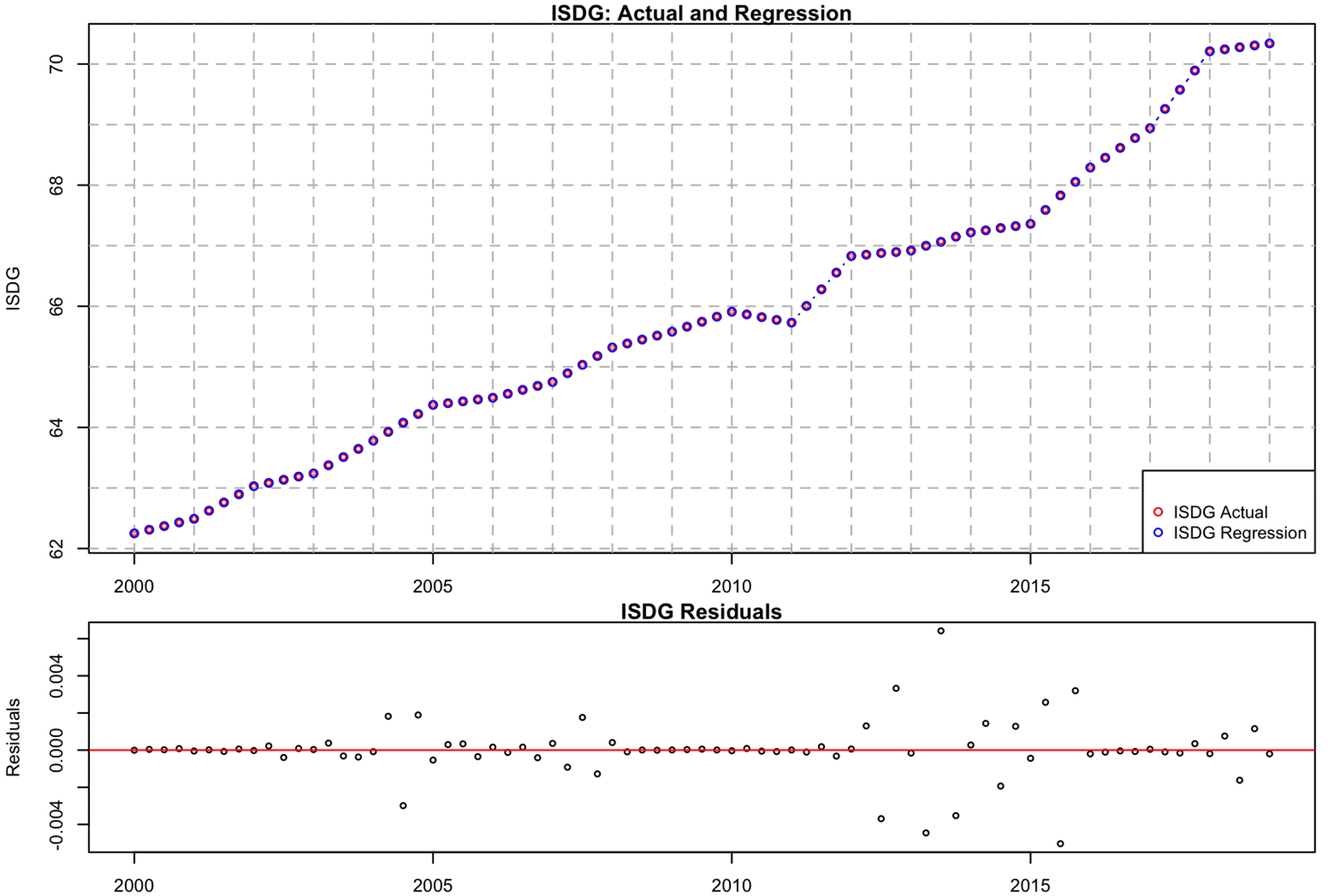
The red circles represent the actual ISDG values. The blue circles represent the calculated ISDG values. The calculated values generally track the actual values closely, with some deviations, particularly toward the end of the period.
The graph suggests that the current model provides a reasonable approximation of ISDG values. An RMSE of 0.00074 is a relatively small error, suggesting that the model used for the calculation is reasonably accurate. The residuals appeared to be randomly distributed around the zero line. This suggests that the model’s errors are not systematically biased. Constant variance appears to be relatively consistent across periods. The calculated values closely followed the actual values and the RMSE was relatively low. The residual plot also indicates that the model errors were small and random.
Figure 4 presents a comparison of the actual and calculated values for the ECI from 2000 to 2019. It also includes a plot of the residuals. The red circles represent the actual ECI values. The blue circles represent the ECI values calculated using ANN. The calculated values generally track the actual values closely, with some deviations, particularly toward the end of the period.
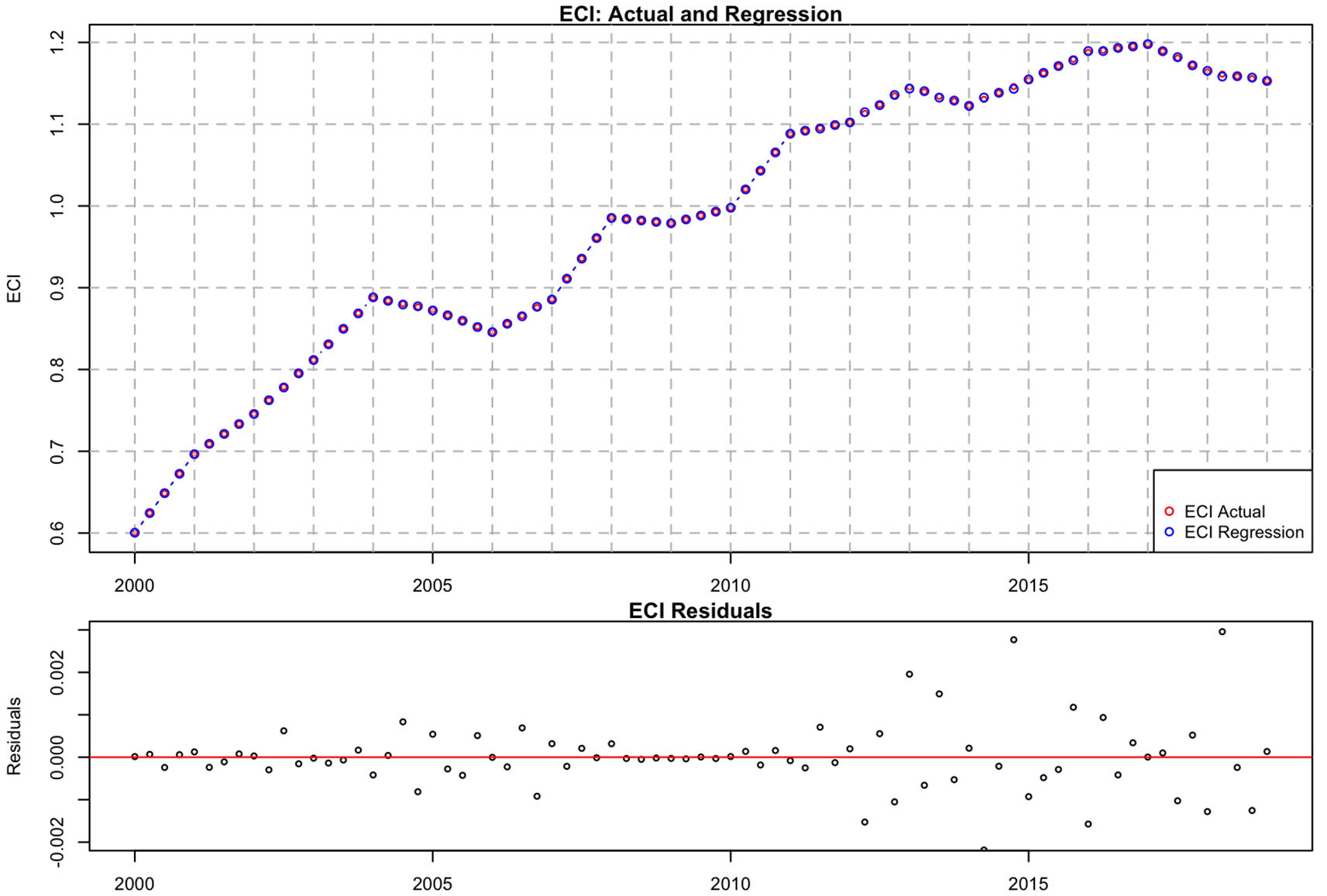
The RMSE is 0.00081. This error was relatively small, suggesting that the model used for the calculation was generally accurate. The residuals appeared to be randomly distributed around the zero line. This suggests that the model’s errors are not systematically biased. The spread of the residuals seems relatively consistent across the period. The calculated values closely followed the actual values and the RMSE was relatively low. The residual plot also indicates that the model errors were small and random.
One of the possibilities of the model is to use it to calculate the index values corresponding to a) future values, or b) sets of variables that can be assigned to the scenarios.
For future values, it is necessary to have sets of inputs that can be associated with subsequent values of each time series. The future values from 2019 to 2030 for each input variable were calculated using the ARIMA method, individually choosing the most suitable parameters automatically through R’s auto.arima () function from the forecast package for the full time series. The autoregressive integrated moving average (AutoARIMA) method is popular for time-series prediction for several reasons that make it suitable for providing the consecutive valuesof the variables required by the ANN to predict the indices. The Automatic Parameter Selection feature is one of the main advantages of AutoARIMA because it automates the selection of the optimal parameters of the ARIMA model, that is, the number of autoregressive (p), differentiation (d), and moving average (q) terms. These parameters are key to correctly modeling a time series; however, their correct choice can be difficult if one is not experienced. AutoARIMA automatically searches for different combinations of these parameters and selects the one that minimizes the prediction error (usually measured using certain criteria such as the AIC, BIC, or RMSE). Furthermore, the flexibility in modeling different time-series patterns allows the ARIMA model to be very flexible, as it can capture various patterns in time series, such as trends (through integration and seasonalities) (through autoregressive and moving average terms). AutoARIMA can automatically identify whether the time series has a trend or seasonality, and adjusts its parameters to reflect these behaviors efficiently. Another feature is the detection of seasonality, because AutoARIMA could also incorporate seasonal ARIMA models if it detects that the series has a seasonal pattern, which is common in many real-world applications. This means that it not only fits the time series in general but can also model seasonal effects appropriately. In addition, ARIMA is a well-founded model in statistical theory; therefore, its use is not arbitrary. Although AutoARIMA simplifies this task, it is still based on a robust approach to time-series modeling, which provides confidence in its results. Although robust, ARIMA does not account for disruptive external events such as pandemics, economic crises, or climate-related disasters. Once the future valuesof the time series are calculated for each variable, they are used as new inputs for the ANN to calculate the future values of the indices.
Figure 5 illustrates the prediction of the Sustainable Development Index (SDI) through the year 2030, using two different techniques: an Artificial Neural Network (ANN) and an ARIMA model. The vertical axis represents the SDI values, while the horizontal axis spans from the year 2000 to 2030. A prominent orange dashed vertical line marks the year 2019, signaling the point at which the forecasting period begins and the historical data ends.
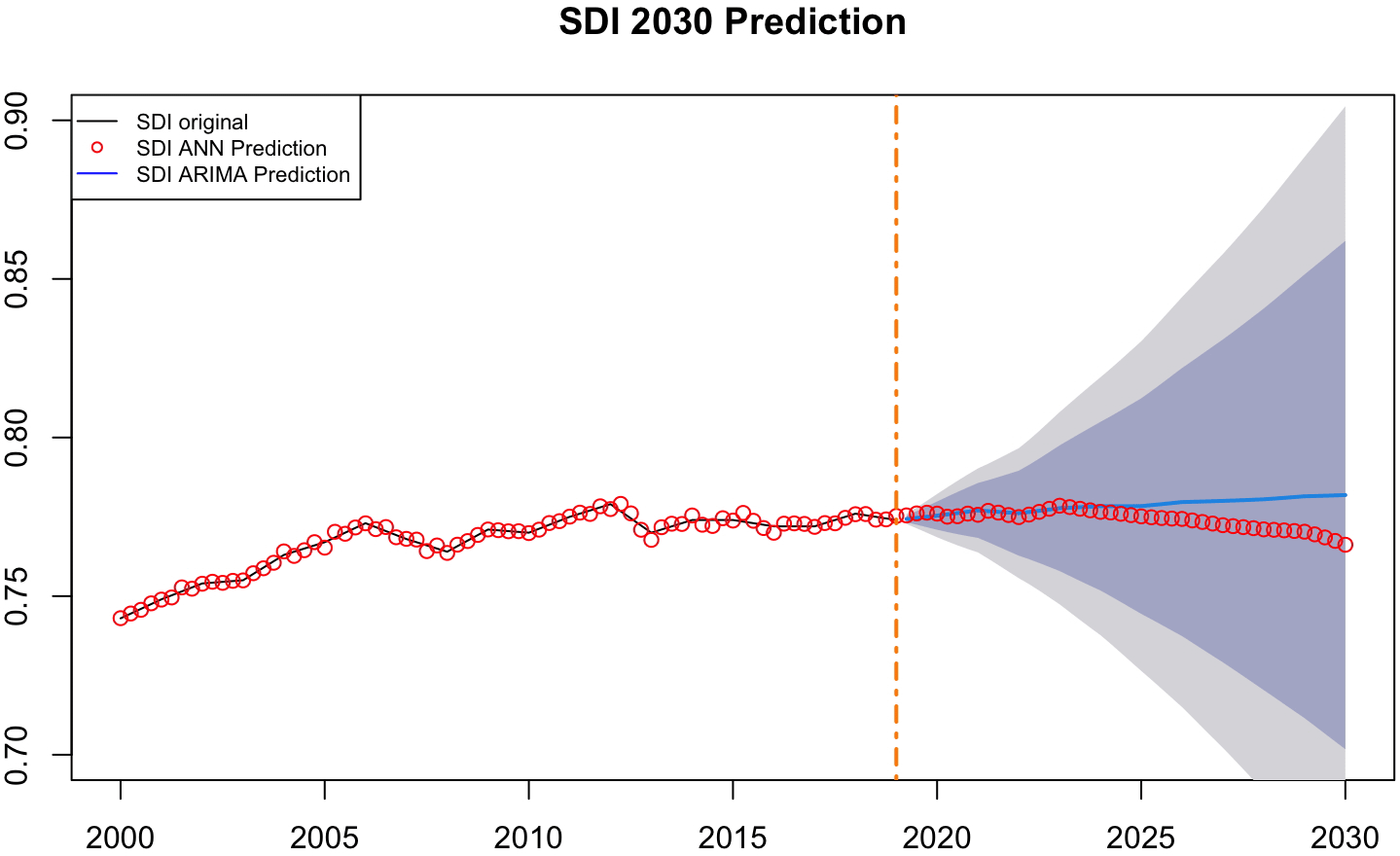
To the left of the orange line, the black curve represents the actual, observed SDI values. These values reflect a gradual and relatively stable improvement in SDI over the two decades prior to 2020, with minor fluctuations but no extreme variability. Overlaying this historical portion are red circular markers, denoting the outputs of the ANN model fits the actual data. The ANN model closely follows the observed values, indicating a high degree of accuracy in capturing the underlying trends during the period for which real data is available.
To the right of the orange line begins the forecasting horizon. Here, both the ANN and ARIMA models provide projections of future SDI values. The ANN prediction, represented by a continuation of red circles, begins to decline subtly after 2022 and continues on a mild downward trajectory toward 2030. This suggests that the ANN model, having learned from recent patterns in the data, anticipates a possible slowdown or even a reversal in progress on sustainable development indicators in the coming decade. The forecast may be reflecting signals of stagnation or cyclical downturns embedded in the last observed years of the training data.
In contrast, the ARIMA model’s prediction is depicted as a smooth blue line extending beyond 2020. Unlike the ANN forecast, the ARIMA model projects a very slight upward trend, maintaining a mostly stable outlook for SDI values through 2030. Around the ARIMA line is a shaded region of uncertainty. The darkest band represents a narrower confidence interval (e.g., 80%), while the lighter outer bands indicate a broader range (e.g., 95%). As time progresses, these intervals widen, illustrating the growing uncertainty of predictions the further one moves away from the known data.
The divergence between the ANN and ARIMA forecasts is significant, as it reflects two fundamentally different perspectives on future development. The ANN, being data-driven and nonlinear, reacts sensitively to subtle variations and possibly interprets them as signals of deterioration. Meanwhile, ARIMA, based on statistical autoregression and differencing, interprets the time series as largely mean-reverting and projects a more conservative and stable continuation of historical trends. The figure, therefore, invites reflection on the assumptions behind forecasting models and the extent to which they may reflect emerging realities in sustainable development progress. This contrast underscores the importance of evaluating multiple models when making long-term sustainability projections.
Figure 6 presents the projected trajectory of the UN Sustainable Development Goals Index (ISDG) through the year 2030, employing two distinct forecasting approaches: Artificial Neural Networks (ANN) and ARIMA. The plot is structured along a horizontal timeline from the year 2000 to 2030, while the vertical axis represents the value of the ISDG index, The orange vertical dashed line indicates the year 2019, marking the division between the observed historical data on the left and the model-based forecasts on the right.
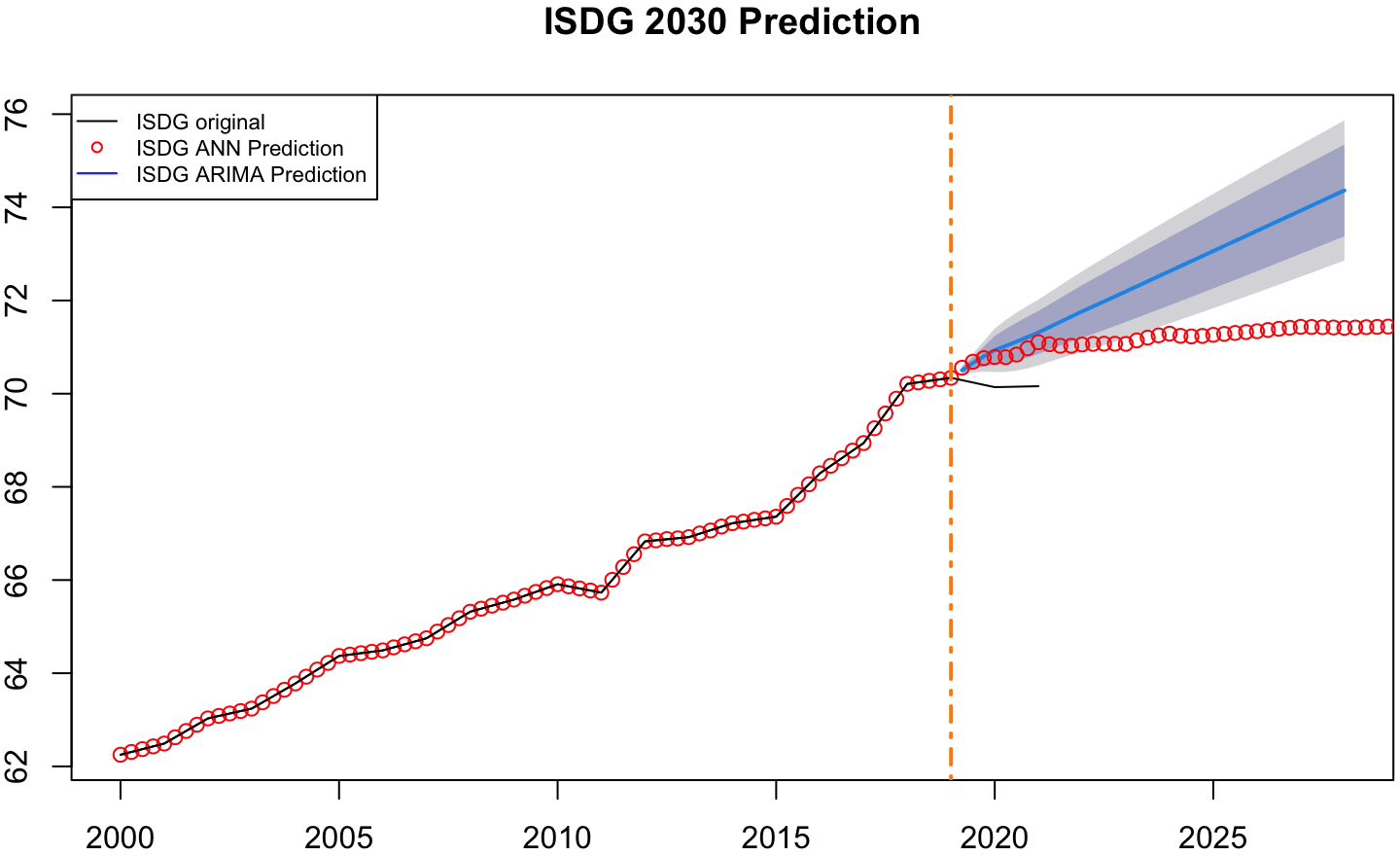
From 2000 to 2019, the ISDG index demonstrates a clear and consistent upward trend. The index climbs steadily over two decades, approaching the value of 71 by the end of the observed period. This suggests a progressive improvement in the country or region’s performance with respect to the United Nations’ Sustainable Development Goals, which include diverse indicators such as poverty reduction, education, health, environmental sustainability, and institutional quality. The red circular points throughout the graph represent the ANN model’s replication of both historical and forecasted values. Prior to 2019, the ANN’s output is nearly indistinguishable from the original data, revealing its ability to learn and reproduce the dynamics of long-term development patterns with high fidelity.
Beyond the training data, the ANN model predicts a smooth, slightly decelerated increase in the ISDG index, maintaining a gentle positive slope that flattens modestly as it approaches 2030. This suggests that the ANN model anticipates continued but slower progress on sustainable development, possibly reflecting saturation effects or structural constraints in the underlying indicators. It is a conservative yet optimistic outlook, which assumes that prior gains will be maintained but not dramatically accelerated in the coming decade.
Meanwhile, the ARIMA model’s forecast is represented by a smooth blue line beginning at the same transition point. Unlike the ANN, the ARIMA model anticipates a more pronounced and steadily accelerating growth in the ISDG index over the next decade. The ARIMA forecast, plotted as a blue line, rises with increasing optimism as it moves further from the present. In contrast, the ARIMA forecast, while capturing the general upward trajectory, unfolds with broader confidence bands and drifts slightly higher, reflecting greater uncertainty and a looser prediction than the ANN. After the prediction begins (orange vertical dotted line), the ANN predicted values (red circles line) are closer to the actual indices (black continuous line) than those the ARIMA prediction (blue continuous line).
The contrast between the two trajectories serves as a reminder that forecasts are never neutral—they are influenced by the structure of the models and the temporal behaviors they prioritize. In the context of sustainable development, this divergence has meaningful implications for policy planning, as it highlights the range of possible futures and the need to account for both optimism and caution in long-term strategic frameworks. According to our prediction, Mexico will achieve a score of 72 by 2030, leaving a significant gap in achieving the desired score of 100.
Figure 7 presents a comparative analysis of forecasted values for the Economic Complexity Index (ECI) extending to the year 2030, utilizing two predictive modeling techniques: Artificial Neural Networks (ANN) and the ARIMA statistical model. The orange vertical dashed line marks the year 2019, which acts as the demarcation between the historical data and the forecast horizon. Everything to the left of this line represents actual observations of the ECI from 2000 to 2019, while the values to the right are model-based predictions.
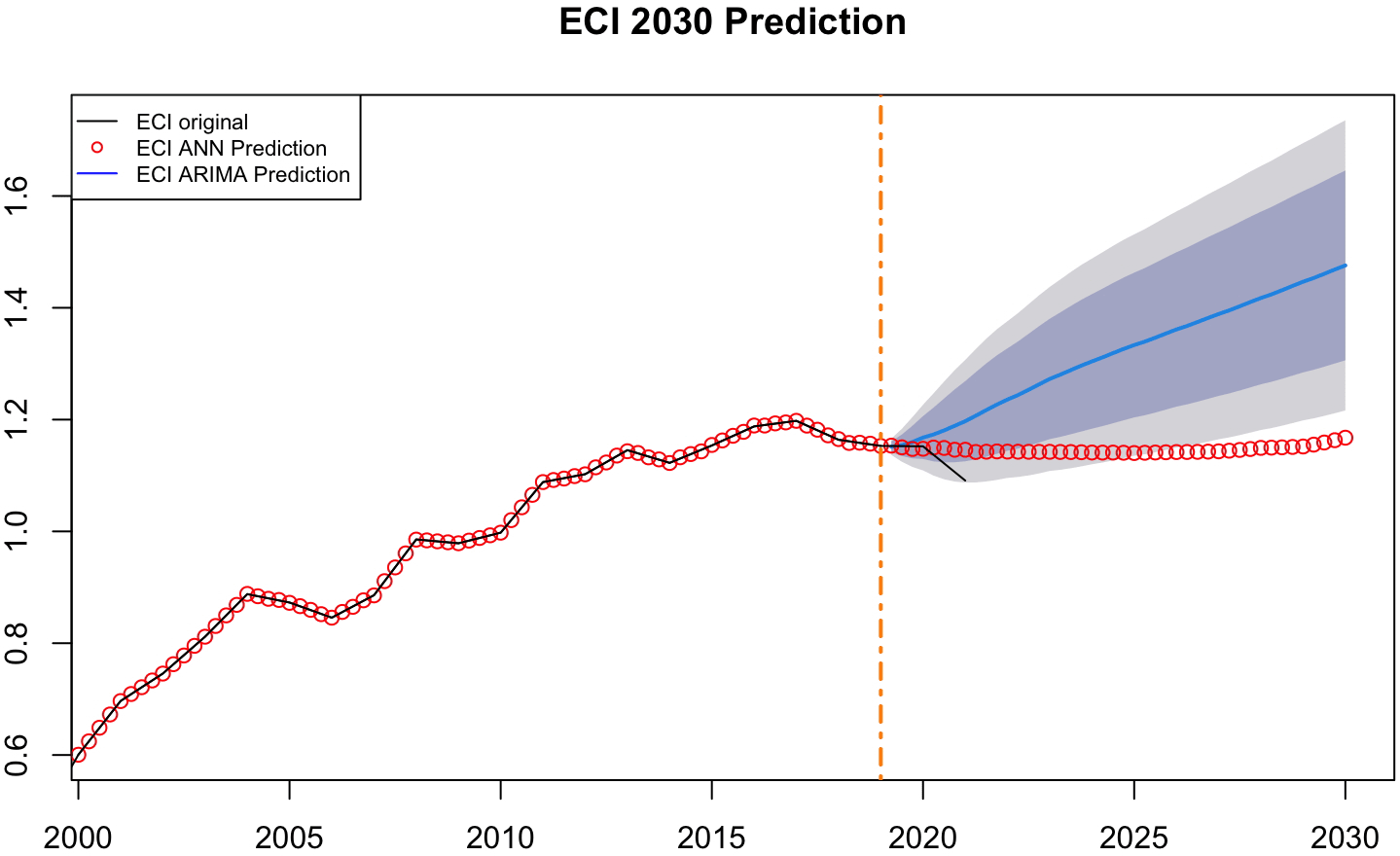
The black continuous line in the plot indicates the original ECI data, and it shows a sustained upward trajectory over nearly two decades, growing from the year 2000 to 2019. This trend suggests an economy that has been gradually increasing in complexity, reflecting structural shifts toward more knowledge-intensive production and export capacities. The red circles represent the ANN’s attempt to replicate the historical series. The ANN model tracks the original data with high precision. The ANN prediction, shown as a continuation of the red circular markers, flattens out significantly. Rather than continuing the steep growth of the previous two decades, the ANN anticipates a near-stagnant path for ECI. This suggests the model has learned from the most recent slowdowns in the data and projects a conservative or even cautious outlook for future economic complexity. The ANN may be reflecting signals of saturation or structural inertia, interpreting the end-of-sample behavior as indicative of broader limitations to further complexity gains in the short to medium term.
Unlike the ANN, the ARIMA model appears to extrapolate from the general long-term trend without adjusting heavily for the slight stagnation seen in the final years of the historical data, it unfolds within much broader confidence bands, signaling large dispersion and less precise adherence to the historical series than the ANN’s near-term predictions. After the prediction begins (orange vertical dotted line), the ANN predicted values (red circles line) are closer to the actual indices (black continuous line) than those the ARIMA prediction (blue continuous line).
Overall, this figure reveals a stark contrast in how two different models interpret the future of economic complexity. The ANN offers a conservative and perhaps more cautious scenario, embedding the effects of recent deceleration into its prediction. Meanwhile, ARIMA maintains a more optimistic outlook, assuming a resumption or continuation of the pre-2019 growth trend. This divergence underscores the importance of combining different modeling perspectives when informing economic policy or strategic planning, especially for variables as multifaceted and structural as the Economic Complexity Index.
Another application of a trained ANN is the analysis of the individual and group contributions. We grouped the variables according to their type (environmental, economic, or social) to observe the effects of these three groups of variables on each of the three indices. The scenario consisted of observing the effect on each of the three reference indices by assigning the future value calculated using the auto.arima () function and ANN for each group of variables, leaving the rest of the variables stable with the last observed value.
In general, we observed that social variables had a greater influence on the SDI and ECI indices, while economic variables most influenced the ISDG. The type of variable with the lowest representation corresponded to the environment (29 variables), whereas the highest representation was economic (71 variables). Social type (66 variables) classified in that category.
Figure 8 shows SDI prediction by categories, where social variables have the greatest influence. This may be due to the way the index is calculated, which places a significant weight on human development. While environmental variables are essential components of the SDI’s construction, they exhibit a lower relative importance in predictive modeling of the SDI. Economic variables have the least influence on this indicator, in addition to showing a stable almost horizontal trend.
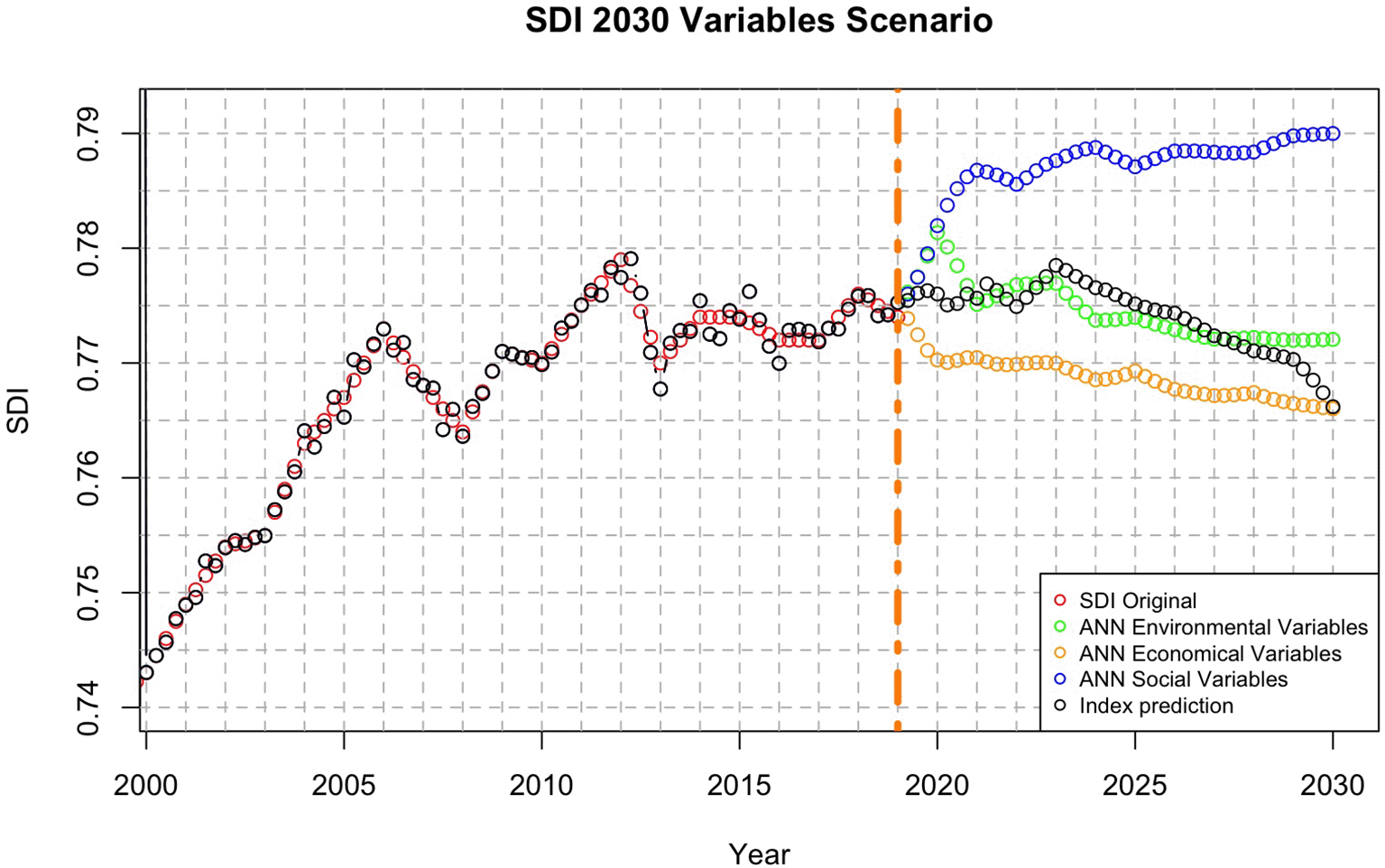
The red circles, representing the original SDI data, indicate a steady rise in Sustainable Development Index until 2012. Around 2015, the growth rate of SDI began to decelerate and plateaued after 2015.
The trend for environmental variables (green circles) shows a modest increase followed by stabilization post-2025. A steady trend could imply that environmental efforts are becoming more normalized (e.g., mainstream adoption of green technologies), which helps maintain progress but does not produce dramatic shifts.
The economic variables (orange circles) show a steady increase in the SDI until they stabilize. This suggests that focusing purely on economic growth (e.g., GDP, trade, and investment) leads to minimal changes in the SDI over time. This finding suggests that economic growth alone does not translate to greater sustainability or equity. For instance, while higher GDP per capita may indicate wealth, it does not necessarily reflect improvements in health, education, or environmental protection.
Social variables (blue circles) show considerable fluctuations. This pattern suggests that social sustainability (e.g., health, education, and inequality) has a highly variable effect on the SDI, with potential periods of stagnation or even decline. This suggests that social factors such as inequality, education, healthcare access, and social security are critical to overall SDI improvement but can be subject to political, economic, and cultural constraints.
The combined index prediction (black circles) trend, which represents the integrated model combining environmental, economic, and social factors, shows a smoother progression compared to the social variable scenario alone but still reaches a plateau by the mid-2020s. This finding suggests that, while producing more stable growth, the combined approach faces the issue of decreasing yields. There is clear evidence that a complex approach (i.e., integrating environmental, economic, and social factors) can lead to more stable progress. The stabilization phase might indicate that while sustainability improvements continue, they require more significant, innovative efforts to break the plateau.
As a conclusion of SDI variables scenario, we may say the graph clearly suggests that sustainability efforts based on environmental, economic, and social factors each contribute to the overall SDI. However, the plateau in projections indicates the need for more integrated, innovative, and systemic policy changes. A combination of technological advancements, inclusive economic growth, and social equity measures is crucial for breaking the current stabilization trend and ensuring continued progress toward sustainable development goals.
The ISDG shown in Figure 9 allows visualization of the trajectory of this index from 2000 to 2030 and its prediction under various scenarios. It compares the “original” projected trend of the index with three different scenarios based on environmental, economic, and social variables, each analyzed through an ANN. The black circles represent the original ISDG projection. The green circles represent projections based on the environmental variables. The orange circles represent projections based on the economic variables. Blue circles represent projections based on social variables. Black circles represent the actual index values from 2000 to 2019. The orange dashed line indicates the start time of the prediction.
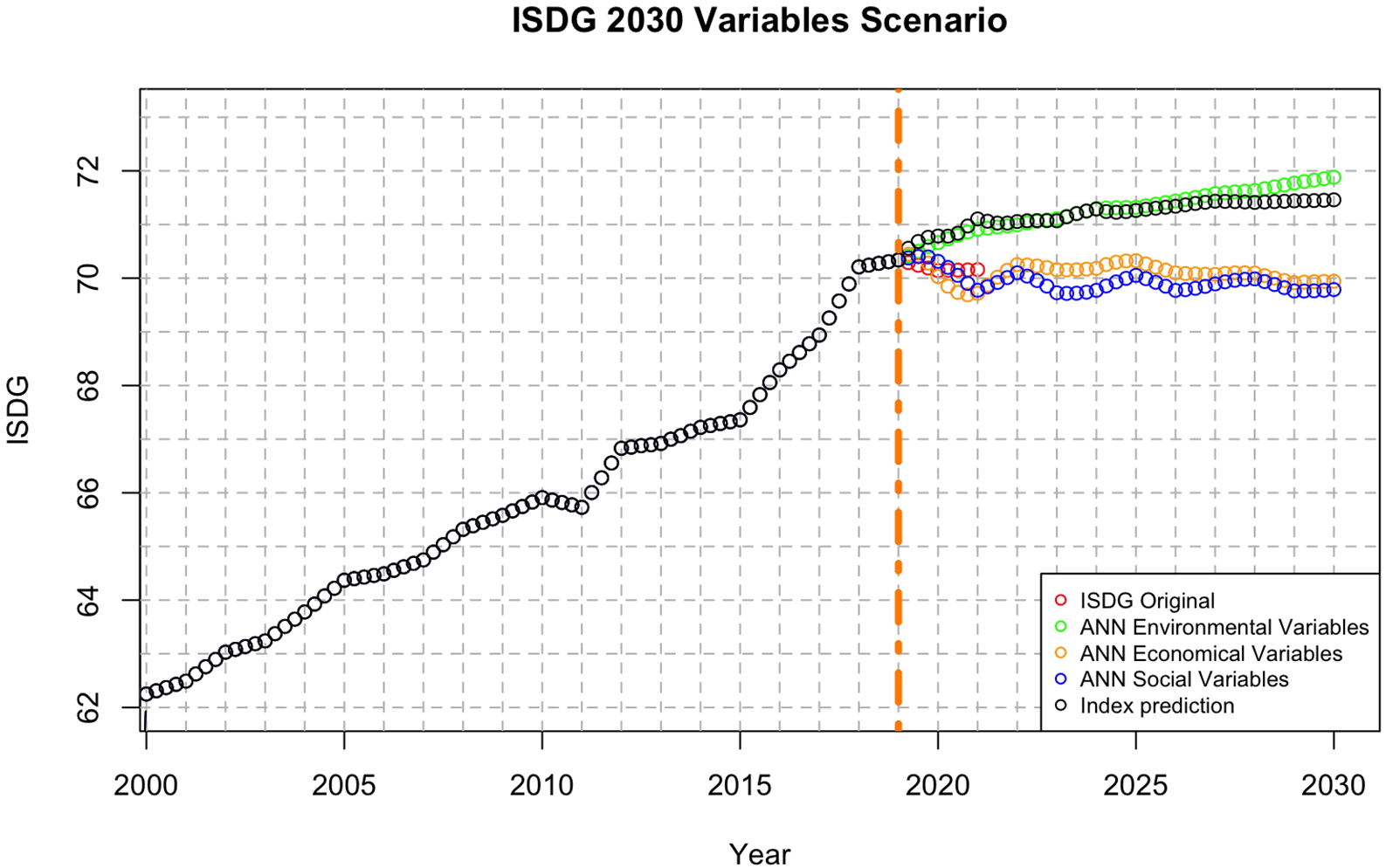
The original projection (black circles) showed a steady increase in the ISDG index from 2000 to 2030. In the prediction of ISDG values, environmental variables showed the greatest stability in their influence, whereas economic variables alternated from having less influence at the beginning of the prediction to becoming the most influential after the middle. The social variables in this index showed a slightly downward, but constant trend. Overall, the graph suggests that economic variables may have the strongest positive influence on the ISDG index, whereas environmental variables may play a significant role. Social variables appeared to have a less pronounced impact.
The projection based on the environmental variables (green circles) suggests a slightly steeper increase than that of the original projection. This finding implies that environmental factors may positively influence the ISDG index.
The projection based on the economic variables (orange circles) showed a more pronounced increase than the original and environmental projections. This finding suggests that economic factors can have a significantly positive impact on the ISDG index.
The projection based on social variables (blue circles) showed a moderate increase, like the original projection. This suggests that social factors may not strongly influence the ISDG index.
Overall, the graph provides a valuable starting point for understanding the potential trajectories of the ISDG index in different scenarios. However, a more in-depth analysis that considers the specific context and limitations of the data and methodology is necessary to draw robust conclusions and to inform effective policy actions.
The Economic Complexity Index (ECI) measures the economy’s ability to produce complex goods based on productive knowledge. Figure 10 shows the ECI trends under the environmental, economic, and social scenarios.
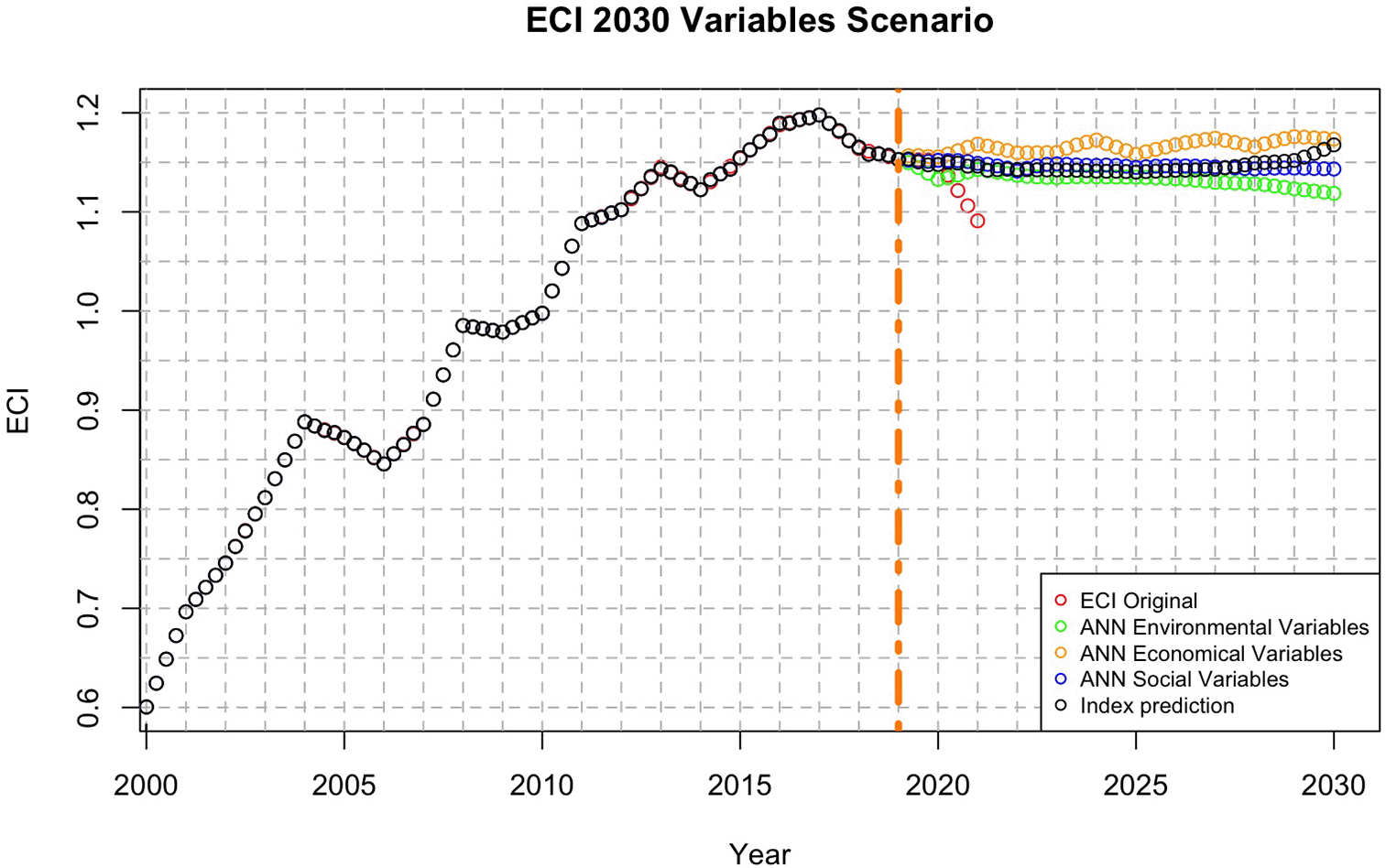
From 2000 to 2020, ECI showed gradual growth, reflecting increased diversification due to investments, education, and trade integration. However, stabilization since 2015 suggests structural challenges or stagnation in key sectors.
Environmental scenario (green circles) shows a limited growth and stabilization, indicating that sustainability efforts maintain stability but do not significantly boost ECI. Green investment is still in its early stages of development.
Economic scenario (yellow circles) indicates a moderate growth, suggesting that current conditions are sustained, but do not significantly increase complexity. Traditional growth alone may slow diversification.
Social Scenario (blue circles) shows downward trend, highlighting gaps in education, inequality, and lack of inclusive policies, hindering innovation and complexity.
The combined prediction (black) shows stable but limited growth, indicating a balance among factors, but no disruptive progress. Addressing social inequalities and investing in innovation is critical.
In the ECI prediction, economic variables had the greatest relevance, social variables the least, and environmental variables initially provided intermediate influence, becoming the most influential in the latter half of the predicted period.
It is possible to consider TA2030 as a complex system. Because of the complexity of the system, measuring its fulfillment requires the use of an ANN. ANNs are tools for modeling complex nonlinear relationships, such as those found within SDGs. They can be effective in modeling nonlinear relationships through propagation functions because unlike linear models, ANNs use networking architectures that introduce nonlinearity.31 These functions allow the network to learn complex patterns between variables in the SDGs, such as how economic growth may not always lead to a direct reduction in poverty.
Tracking progress toward goals requires measurable indicators, both quantitative (e.g., poverty rates) and qualitative (e.g., gender equality progress). Because the SDGs are interconnected, small changes in one area can affect others. ANNs, which are inspired by the human brain, effectively model these complex nonlinear relationships. They analyze datasets, identify patterns, and predict future SDG progress, and may help policymakers allocate resources and prioritize interventions.
The quality of data determines the model. Highlighting the model’s reliance on training data effectively relay its inherent limitations. A model with high-quality and quantity of indices and variables will be more effective than a model with low-quality data. Since the model performs a regression on the indices, its findings are intrinsically dependent on the information within those indices.
When testing different architectures to search for network optimization, we observed that the training clearly recovered the characteristics of the time series of the indices. It is likely that it would have been possible to train the model better; therefore, one of the future directions of our research could be to determine the ideal architecture and parameterization of the network.
Several techniques can be used with ANNs to understand the variables that hold greater influence in the model’s predictions. These techniques analyze the contribution of each input variable to the final output, highlighting the SDGs that play a more significant role in achieving a specific goal. Many attempts have been made to use neural networks to determine the individual relevance of variables (importance). A continuation of this work could be to find an algorithm that would allow the identification of the importance of system variables. This would allow us to describe the behavior of the system more precisely and propose more accurate public policies, both in terms of sense and magnitude. Another follow-up of this research could be a sensitivity analysis performed by slightly changing the values of the input variables and observing the model’s output so that the SDGs that are most sensitive to change can be assessed. This could help to identify critical factors that require focused attention to achieve progress.
By grouping variables into categories, a scenario analysis could be performed to observe and identify the types of variables that have an unexpected effect on improving the national sustainability indicator. The idea of grouping variables by category and observing their effects on the scope of sustainability is to suggest a guide on where decision-makers should focus their efforts and resources. It would even be possible to identify variables whose improvement would offer a lower cost and substantial improvement in the index.
The results obtained in this study demonstrate the potential of ANNs to predict Mexico’s progress toward achieving the SDGs by 2030. The trained ANN model provided a reliable regression for three key sustainability indices: the Sustainable Development Index (SDI), the UN Sustainable Development Goals Index (ISDG) and the Economic Complexity Index (ECI). The findings indicate that, while the ANN-based model effectively captures historical trends, it tends to project conservative future estimates, suggesting potential stabilization in progress.
One key observation is that social variables exert the most significant influence on SDI and ECI, whereas economic variables have the strongest impact on ISDG. This aligns with the existing literature, emphasizing the role of economic growth in achieving sustainable development, while highlighting the importance of social equity and human development. However, despite their relevance, the environmental variables displayed the least influence across all indices, suggesting the need for enhanced environmental policies to drive progress. This could indicate that current environmental efforts are insufficient, or that economic and social factors are disproportionately prioritized in sustainability metrics.
According to our prediction, Mexico will achieve a score of 72 by 2030, leaving a significant gap in achieving the desired score of 100. The ANN forecasts for the SDI and ISDG suggest a deceleration in progress beyond 2020, potentially due to external economic and policy constraints. This slowdown implies that while Mexico has made notable advances, sustaining further improvements requires targeted interventions. The economic complexity index (ECI) also follows a stable trend post-2020, reinforcing concerns about Mexico’s capacity for continued diversification and technological innovation. A key takeaway from this analysis is that economic resilience and technological advancement must be actively fostered to counteract stagnation and to sustain long-term progress.
This analysis of categories’ contribution underscores the importance of social investment in driving sustainable development. Social variables, such as education, health, and inequality reduction, appear to be the most influential in improving sustainability scores. This finding highlights the need for integrated policies that balance economic growth with social and environmental sustainability to ensure long-term progress. Notably, a lack of alignment between policy implementation and actual social improvements could explain some of the projected slowdown. Future studies should explore whether discrepancies between policy intention and execution contribute to these trends.
Potential limitations include the relatively short time series used for training, which may limit the ANN model. Additionally, the model does not account for disruptive external events such as pandemics, economic crises, or climate-related disasters, which could significantly alter sustainability trajectories. The absence of exogenous variables such as policy changes or global economic shocks could also result in conservative forecasts. Future studies could improve the model by incorporating a broader range of variables and leveraging alternative ML approaches, such as deep learning architectures or hybrid models.
Although ANNs provide valuable insights, their interpretability remains challenging. Unlike traditional regression models, neural networks function as ‘black boxes,’ which makes it difficult to extract explicit causal relationships between variables. This requires the integration of AI techniques to provide policymakers with a clearer understanding of the driving forces behind sustainability progress.
Our ANN-based predictive model provides valuable insights into Mexico’s potential progress toward the SDGs, but continued efforts are necessary to address emerging challenges. Policymakers should prioritize targeted investments in education, healthcare, and economic diversification, while strengthening environmental initiatives. Additionally, proactive policy adjustments, improved monitoring frameworks, and interdisciplinary research collaborations are essential for refining predictive models and ensuring more effective decision making. Further refinement of predictive models and continuous monitoring of key sustainability indicators are crucial for ensuring that Mexico remains on track to achieve its SDG commitments by 2030.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)