Keywords
Compact High-Accuracy PINNs, Physics-Consistent Normalization, Loss-Balancing Elimination
This article is included in the HEAL1000 gateway.
Compact High-Accuracy PINNs, Physics-Consistent Normalization, Loss-Balancing Elimination
This revised version of the manuscript addresses the comments raised during open peer review. In particular, the presentation of the proposed SEE-PINN framework has been clarified with respect to its motivation, novelty, and positioning relative to existing PINN formulations. Additional explanations have been provided regarding the choice of training settings, validation data, and case-study comparisons, while quantitative error metrics have been included to complement the performance analysis. The discussion section has been revised to more explicitly highlight the advantages, limitations, and implications of the proposed approach. Figures have also been updated. These revisions aim to improve clarity, transparency, and reproducibility, while preserving the original scope and contributions of the study.
See the authors' detailed response to the review by Thossaporn Wijakmatee
Current state of the art. Physics-Informed Neural Networks (PINNs)1 have emerged as a powerful and innovative approach to solving ordinary and partial differential equations (ODEs/PDEs). By integrating deep or shallow machine learning with physical principles, PINNs approximate solutions to these differential equations through optimization techniques. The process involves constructing a composite loss function that includes several components: (a) the residual of the ODE/PDE, which measures how well the solution satisfies the equation, (b) the initial conditions, which represent the state at the starting point, and (c) the boundary conditions, which describe the behavior at the edges of the domain. This method has shown great promise in various fields, such as fluid dynamics, material science, and inverse problems, because it can effectively handle complex, high-dimensional systems without relying on traditional numerical discretization methods. However, despite their potential, PINNs face a significant challenge: unbalanced loss terms. This issue can slow down convergence, reduce accuracy, and limit scalability.
The challenge of unbalanced loss terms arises from the fact that different components of the loss function frequently operate on significantly varying scales. For example, the magnitude of the residual may be substantially larger or smaller than that of the boundary condition term. This imbalance results in uneven gradients during the backpropagation process, which may lead to the optimization process favoring one term over the others. Consequently, the neural network may converge to a suboptimal solution or, in some cases, fail to converge entirely. To mitigate this issue, researchers have proposed a range of strategies, each exhibiting distinct advantages and disadvantages.
Recent advancements have explored regularization strategies and specialized network architectures aimed at enhancing the performance of PINNs. For instance, grouping regularization strategies alter the conventional loss function by implementing distinct scaling factors for each loss term, thereby ensuring that all terms are of similar magnitude and can be optimized concurrently.2 DN-PINNs3 have been designed to facilitate an even distribution of multiple back-propagated gradient components throughout the training process. By assessing the relative weights of initial or boundary condition losses in accordance with gradient norms, DN-PINNs dynamically adjust these weights to guarantee balanced training.
An extension of loss-term scaling involves adaptive weighting schemes, which adjust the weights of loss terms dynamically throughout the training process. For instance, Gaussian probabilistic models employ maximum likelihood estimation to update the weights of each loss term during each training epoch, thereby ensuring that the network concentrates on the most critical terms.4 Another notable method is the min-max algorithm, which identifies data points that present greater difficulty for training and mandates that the network prioritizes these challenging instances in subsequent iterations.5 The wbPINN method6 introduces an adaptive loss weighting strategy and a newly developed loss function that incorporates a correlation loss term and a penalty term to effectively address the interrelationships among the various loss terms.
Furthermore, weighting schemes based on gradient statistics evaluate the gradients of individual loss terms during backpropagation and make necessary adjustments to their weights, promoting balanced training7; this work has been further refined through the introduction of kurtosis-standard deviation-based weighting and combined mean and standard deviation-based schemes, both of which enhance the accuracy of solutions to partial differential equations. Improved adaptive weighting PINNs based on Gaussian likelihood estimation have been applied to solve nonlinear PDEs.8 Learning rate annealing algorithms also employ gradient statistics during training to balance the contributions of different loss terms, thus, reducing the risk of training failure.9 Another innovative approach is the Stochastic Dimension Gradient Descent (SDGD) method,10 which decomposes the gradient of the residual into smaller components corresponding to various dimensions. The SDGD method then randomly samples subsets of these components, thereby ensuring efficient optimization for high-dimensional challenges. Gradient-enhanced PINNs (gPINNs) incorporate gradient information of the PDE residual into the loss function to improve accuracy, especially for problems with steep gradients.11 Residual-Quantile Adjustment (RQA), reassigns weights based on the distribution of residuals, ensuring a more balanced training process.12
Another line of inquiry examines optimization-driven methodologies aimed at balancing loss components. For instance, the augmented Lagrangian relaxation technique converts the constrained optimization problem into a series of max-min problems, enabling the network to adaptively equilibrate each loss term.13
Numerical treatments of the PDE and tweaking the neural network architecture is another promising path. The normalized reduced-order physics-informed neural network (nr-PINN)14 converts the original PDE into a system of normalized lower-order equations. This technique employs scaling factors to mitigate gradient failures resulting from substantial PDE parameters or source functions and introduces a mechanism to automatically fulfill boundary conditions by redefining the outputs of the neural network. Integration of derivative information into the loss function has been further explored in.15 This study constructs a loss function that includes both the differential equation and its derivative, enabling the network to automatically satisfy boundary conditions without explicit training at boundary points.
Challenges & Research gap. Despite their notable success, the selected method categories still encounter various challenges. For instance, PINNs based on Gaussian likelihood estimation struggle with solutions that exhibit sharp changes or discontinuities and gPINNs often require integration with other methods to achieve optimal performance. Moreover, these methodologies heavily depend on machine learning components while often overlooking the treatment of mathematical formulations. As a result, demonstrating their efficacy typically requires complex optimization processes and extensive hyperparameter tuning, which imposes significant computational demands.
In contrast to existing PINN formulations that attempt to balance loss terms during training, this study proposes a fundamentally different approach based on physically consistent scaling of the governing differential equations prior to loss construction. Contrary to existing methodologies that concentrate on adjusting weights during the training phase or modifying network architectures, our approach involves preprocessing the PDE terms to ensure that they function on comparably scaled values. This strategy alleviates the burden on the machine learning component during the optimization process, thereby enhancing convergence, accuracy, and scalability while preserving the flexibility and robustness inherent in PINNs. By bridging the existing research gap regarding the treatment of unbalanced loss terms, our methodology offers an efficient framework for solving differential equations utilizing PINNs. Furthermore, our proposed method is straightforward to implement, as demonstrated through a step-by-step application to two distinct mechanical problems: an elastic rod and an Euler beam.
The selection of the elastic rod and Euler–Bernoulli beam as case studies is intentional. These problems represent canonical one-dimensional boundary value problems in computational mechanics and are frequently adopted as benchmarks in the PINN literature, allowing direct comparison with existing approaches. Although both problems are one-dimensional, they differ fundamentally in the order of their governing equations (second-order for the rod and fourth-order for the beam) and in the number and nature of boundary conditions. This enables a clear demonstration that the proposed PINN framework is not limited to a specific equation order or boundary-condition structure. Moreover, both formulations naturally allow for spatially varying material and geometric properties, which induce strong imbalance among equation terms and therefore provide an ideal testbed for evaluating the effectiveness of direct differential equation term scaling.
In both cases, we follow the exact same procedural framework, highlighting the method’s consistency and ease of use. The only variation lies in the number of variables and functions that require normalization, reinforcing the generality and adaptability of our approach across different types of differential equations. It has to be noted that the benchmark problem refer to cases with variable material and geometrical properties, which cannot be solved using traditional finite element methods.
Novelity. Although several scale-consistent, normalized, or equation-enhanced PINN variants have been proposed in the literature, most of these approaches address imbalance indirectly by introducing adaptive weights, auxiliary optimization strategies, or additional loss terms. In contrast, the proposed Scaled Equation-Enhanced PINN (SEE-PINN) introduces a fundamentally different paradigm: the governing differential equation itself is rescaled prior to training using physically meaningful characteristic quantities. This preprocessing step ensures that all residual terms naturally operate at comparable magnitudes, thereby eliminating the need for loss-balancing mechanisms altogether. As a result, SEE-PINN transforms the PINN training process into a simpler, deterministic, and computationally efficient workflow, without altering the mathematical structure of the problem or introducing additional hyperparameters.
Paper structure. The remainder of this paper is organized as follows: Section 2 presents the theoretical foundations of neural networks and PINNs. As these are well-established methodologies, only a brief introduction is provided, with appropriate references for further details. The section also introduces a general approach for scaling terms in differential equations, with specific examples applied to fundamental elasticity problems. Additionally, it explores extensions to more complex cases where analytical solutions are unavailable. Section 3 provides a comprehensive presentation of numerical experiments and results, covering validation cases ranging from simple models with constant properties to those with varying and nonlinear characteristics. The methodology’s efficiency is evaluated through comparisons with case studies from the literature. Finally, Section 5 summarizes the key findings, discusses current limitations, and outlines potential directions for future research.
Neural networks are computational models inspired by the structure and function of biological neural systems, specifically designed to learn complex patterns and relationships from data.16 The fundamental unit of a neural network is the neuron or perceptron, which processes an input to produce an output through the function , where the parameters and are referred to as the weight and bias, respectively, learnt during training.17 The ‘activation function’ introduces nonlinearity and the network to model complex problems. Multiple neurons are clustered into groups known as layers, collectively forming a neural network ( Figure 1). Each layer may have several inputs and outputs, which are connected through an extension of the fundamental neuron equation.
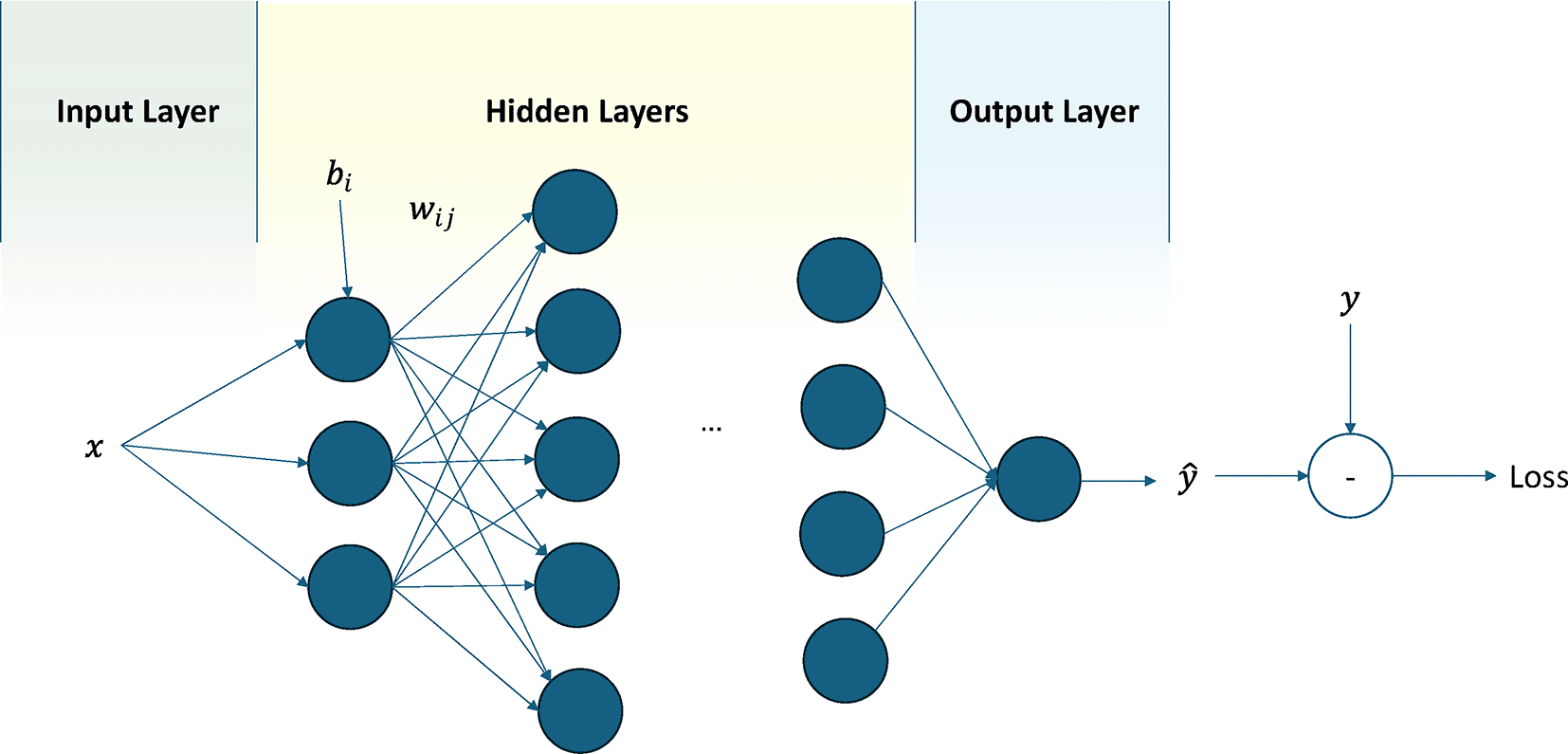
According to the universal approximation theorem, a neural network has the capacity to approximate any function with arbitrary precision18; however, the required connectivity of the neurons, referred to as network architecture, must be thoroughly examined. Generally, deep architectures, consisting of a multiple hidden layers, are utilized to capture hierarchical features, whereas shallow networks, which consist of fewer layers, are deployed in scenarios where data or computational resources are limited.19 The training process entails the formulation of a ‘Loss function’ to compare the outputs generated by the neural network against an established ground truth , followed by the targeted adjustment of weights and biases.
In the context of PINNs, neural networks are extended to incorporate physical constraints directly into the training process. Unlike conventional neural networks that rely solely on data-driven learning, PINNs integrate information from governing equations and boundary conditions into the loss function, ensuring that the learned solutions adhere to underlying physical laws.1 The loss function in PINNs comprises three main components: (i) a data loss term that ensures consistency with available observations, (ii) a physics loss term that enforces compliance with differential equations, and (iii) a boundary/initial condition loss term that satisfies prescribed constraints.
PINNs can be categorized into two main types: data-driven approaches, which infer hidden relationships from experimental data, and physics-driven approaches, which directly solve differential equations while enforcing physical consistency.20,21 It has been demonstrated that the integration of physical principles into neural network architectures improves their interpretability, generalizability, and applicability across a diverse array of scientific and engineering challenges.22 This study focuses on the latter category, specifically employing physics-driven PINNs to solve differential equations while addressing challenges associated with unbalanced loss terms.
An effective introduction to the scaling treatment of differential equations is presented herein, based on generalized scaling methods.23 The objective of scaling is to render both the dependent and independent variables dimensionless, while simultaneously positioning them within the unit range. Each variable is normalized using a characteristic quantity relevant to the specific problem. For instance, the spatial variable may be normalized in relation to the length of a structure. Subsequently, all terms and derivatives appearing in the differential equation are expressed in terms of their dimensionless equivalents. Any unestablished scaling coefficients are approximated by requiring that the corresponding terms of the equation remain proximate to unity. Upon resolving the equation in its normalized form, a reverse process is employed to retrieve the solution in the physical domain.
The proposed method, referred to as Scaled Equation-Enhanced Physics Informed Neural Network (SEE-PINN), for handling unbalanced loss terms in PINNs, is built directly on this scaling framework. By ensuring that all terms of the differential equation operate on comparable scales before constructing the loss function, our approach simplifies implementation while improving optimization efficiency. This is demonstrated through its application to two distinct mechanical problems: an elastic rod and an Euler beam. In both cases, the exact same procedural steps are followed, emphasizing the method’s consistency and ease of use. The only variation lies in the number of variables and functions requiring normalization, reinforcing its generality and adaptability across different types of differential equations. The following paragraphs provide the numerical formulation of equations typically encountered in the literature, incorporating this systematic scaling approach.
It is important to distinguish the proposed SEE-PINN framework from existing approaches that aim to alleviate loss-term imbalance in PINNs. Adaptive weighting methods dynamically modify the contribution of each loss term during training, often relying on gradient statistics, probabilistic models, or auxiliary optimization loops. Gradient-enhanced or equation-augmented PINNs enrich the loss function by incorporating higher-order derivatives or additional residual constraints, increasing both computational cost and implementation complexity.
In contrast, SEE-PINN operates exclusively at the level of the governing differential equation. By rescaling each term using characteristic physical quantities prior to training, the resulting normalized equation is inherently balanced. Consequently, the loss function remains simple and fixed throughout training, and standard optimizers can be employed without tuning or adaptive mechanisms. This shift of complexity from the optimization stage to a one-time, physics-driven preprocessing step constitutes the central novelty of the proposed framework.
2.2.1 Elastic rod
The response of an elastic rod is described by the 1D Poisson equation:
To derive the normalized formulation of Eq. (3) each term is normalized using a characteristic quantity. Initially, the normalized spatial variable is defined as
For no assumption can be made at this point, since the value of remains unknown; consequently, it must be approximated through an alternative method.
The respective spatial derivatives appearing in Eq. (3) are expressed in normalized form using Eqs.(4)-(8):
Then, Eq. (3) can be reformulated utilizing the normalized quantities:
After simplifying the equation:
To confine the last term within the interval [0,1] as well, its coefficient is set equal unity, yielding the value of the normalizing parameter :
2.2.2 Elastic Euler beam
The response of an elastic Euler beam is described by the well-known equation:
To derive the normalized formulation of Eq. (18), each term is normalized using a characteristic quantity. The normalized spatial variable, Young modulus and applied load are defined again as in Eqs. (4), (5) and (8) using the same scaling coefficients as in Eq. (9). In the same sense the normalized inertial moment and transverse deflection are defined as:
The respective spatial derivatives appearing in Eq. (18) are expressed in normalized form:
Then, Eq. (18) can then be recast using the normalized quantities:
In order to constrain the last term in [0,1] as well, its coefficient is set equal unity, yielding the value of the normalizing parameter :
In this section, the architecture of the proposed SEE-PINN framework is first introduced, detailing the network structure, activation functions, training procedure, and implementation of the term-scaling approach. This ensures a comprehensive understanding of the methodology before proceeding to validation and performance evaluation.
Following this, the proposed method is validated through a series of test cases and subsequently compared to solutions found in the literature to illustrate its computational efficiency. The objective is not to undermine existing methods but to demonstrate that they can benefit from our approach and achieve enhanced accuracy and robustness.
Both simple and complex case studies are examined concerning the problems associated with the elastic rod and the elastic Euler beam to validate the proposed method. For straightforward cases, the solution obtained through PINNs is compared against analytical solutions. In more complex scenarios, where no analytical solution is available, the PINN solution is contrasted with numerical solutions.
Following the term scaling methodology description, a comprehensive architecture is provided here. The fundamental framework is presented for the rod and beam problems. This design is intended to be easily adaptable, enabling other researchers to extend it to various problems with minimal effort.
The proposed approach begins with a normalization step applied to the coefficients of the ODE terms before they are introduced into the input layer. These normalized coefficients, together with the neural network outputs, undergo automatic differentiation to compute the gradients of the required to form the ODE. The resulting terms are then incorporated into the loss function, which typically consists of one term for the ODE residual and additional terms for each boundary condition. In this work, the mean squared error is employed for the terms of the loss function. If the total loss converges below a predefined threshold, the process proceeds to de-normalization, producing the final solution. Otherwise, backpropagation updates the network’s weights and biases until convergence is reached.
The architecture for the elastic rod is illustrated in Figure 2 and can be readily adapted to the beam problem (or other related problems) by modifying the predicted quantities and the computed gradients. Specifically, for the beam, the output variable changes from the axial displacement (for the rod) to the transverse deflection , while the required gradients expand significantly. The rod problem involves computing and , whereas the beam problem requires additional terms, namely and . Likewise, the rod problem is solved using two boundary conditions, e.g. a Dirichlet and a Neumann condition (denoted in Figure 2 by and respectively), while the beam problem requires four boundary conditions. Although the mathematical complexity increases significantly (as detailed in the respective sections), the transition from the rod to the beam remains conceptually straightforward. The same principle applies when extending the approach to other problems.
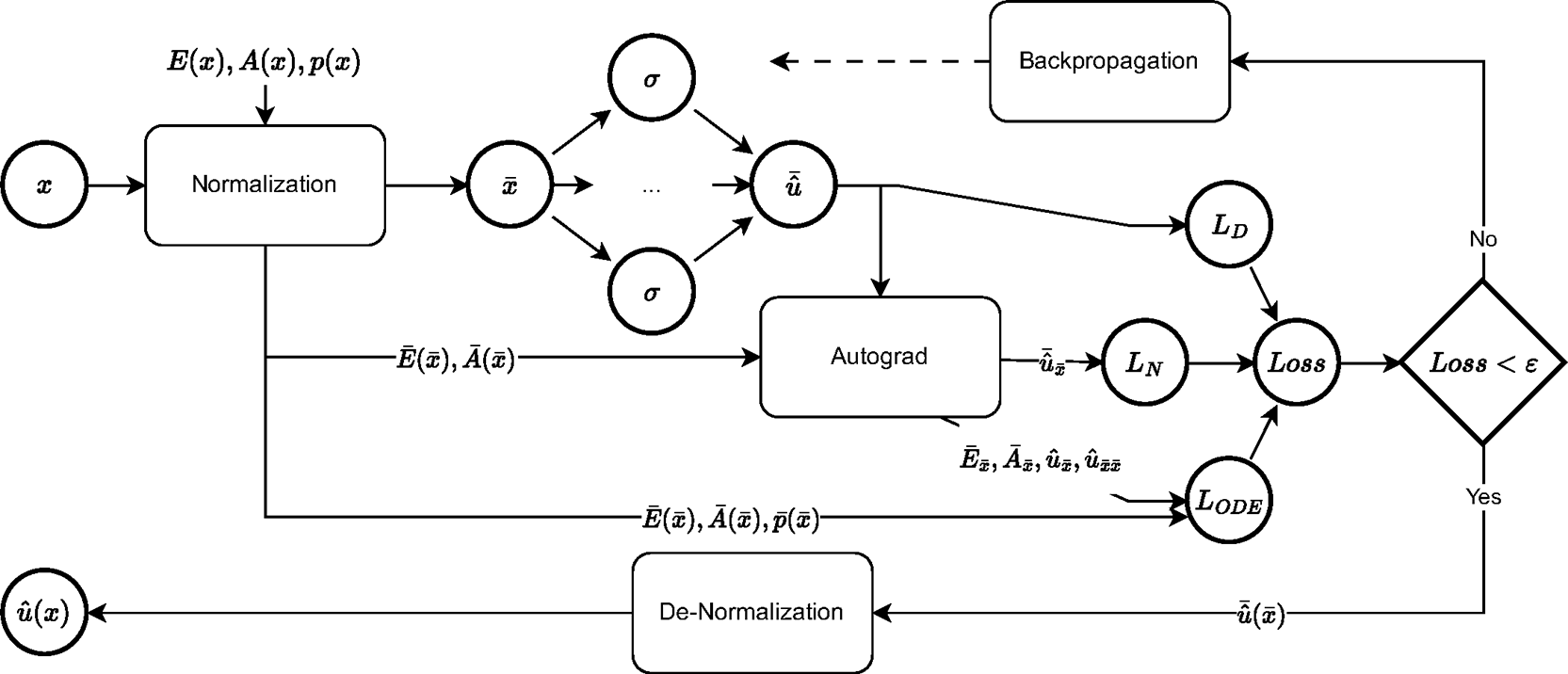
The network is implemented in PyTorch, to take advantage of computational optimizations, and automatic computing (Autograd) of derivatives in the loss function.
3.2.1 Fixed uniform rod with distributed load
Statement of the problem. This represents a straightforward scenario. A homogenous rod with a uniform cross-section is subjected to an axially distributed load. The left end of the rod is fixed, while the right one is free. The axial displacement along the rod is analyzed. Numerical values are:
Since properties are constant along the rod, Eq. (2) is diminished to
SEE-PINN solution. An appropriate neural network is designed to approximate the displacement field of the rod. The input of the neural network is the spatial coordinate , and its output is the predicted displacement . The network consists of only one fully connected layer, with 10 neurons, and each neuron employs the tanh activation function. The network is trained at 75 points using the Adam optimizer with learning rate 0.01 for 5000 epochs.
Comparison and error analysis. The predicted solution the PINN is validated against the analytical solution – Eq. (35). Figure 3a demonstrates that the analytic and the PINN solution are indistinguishable from each other, as verified by the parity plot in Figure 3b. The prediction quality is further assessed using the normalized relative error, where the relative error is scaled according to the magnitude of the displacement values to prevent numerical artifacts from division by very small numbers.
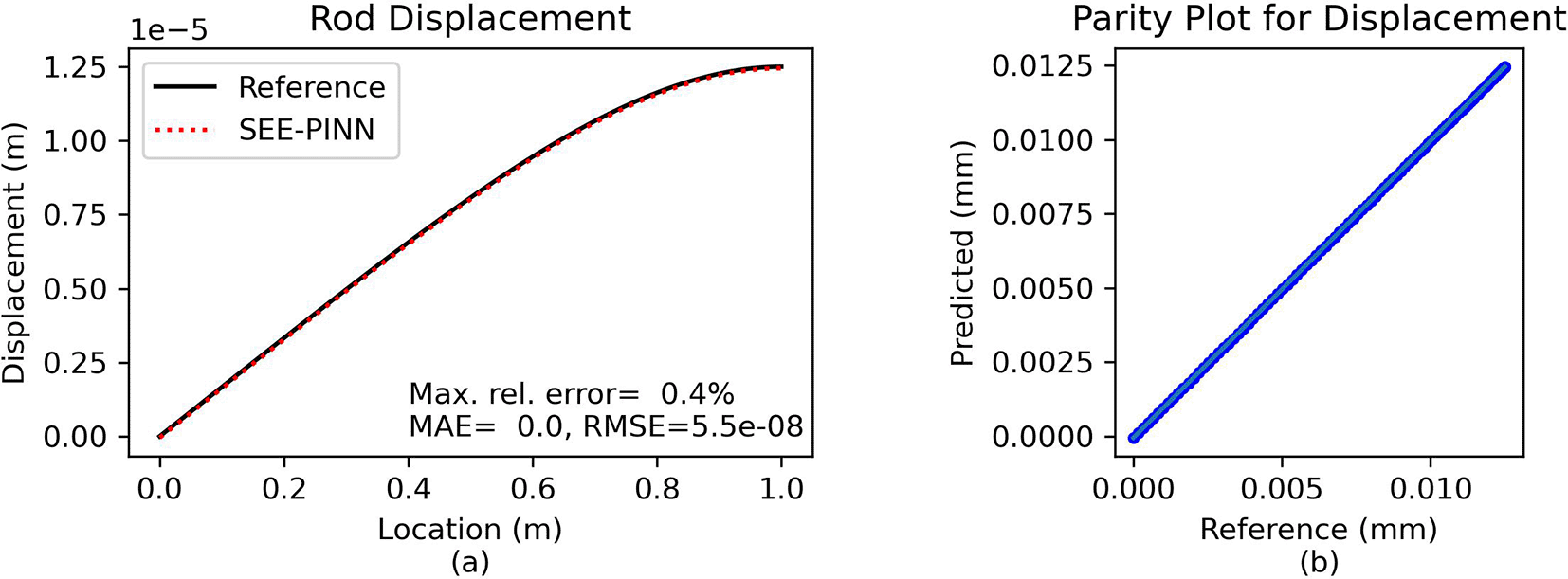
(a) Direct comparison of predictions. (b) Parity plot of predicted vs. reference solution.
The maximum relative error is ca. 0.4%, which demonstrates the PINN approach achieves nearly exact agreement with the analytical solution.
3.2.2 Fixed rod with variable cross-section and distributed load
Statement of the problem. This case builds upon the previous problem by introducing a nonlinear variation in the cross-sectional area.
SEE-PINN solution. The same neural network has been employed to approximate the displacement field of the rod; i.e. one fully connected layer, with 10 neurons, and each neuron employs the tanh activation function. The network is trained at 75 points using the Adam optimizer with learning rate 0.01 for 5000 epochs.
Comparison and error analysis. The predicted solution is compared against a numerical reference for validation. Figure 4 illustrates that the analytic and the PINN solution are again indistinguishable. With a maximum relative error of approximately 0.04%, the PINN approach demonstrates an excellent agreement with the analytical solution.
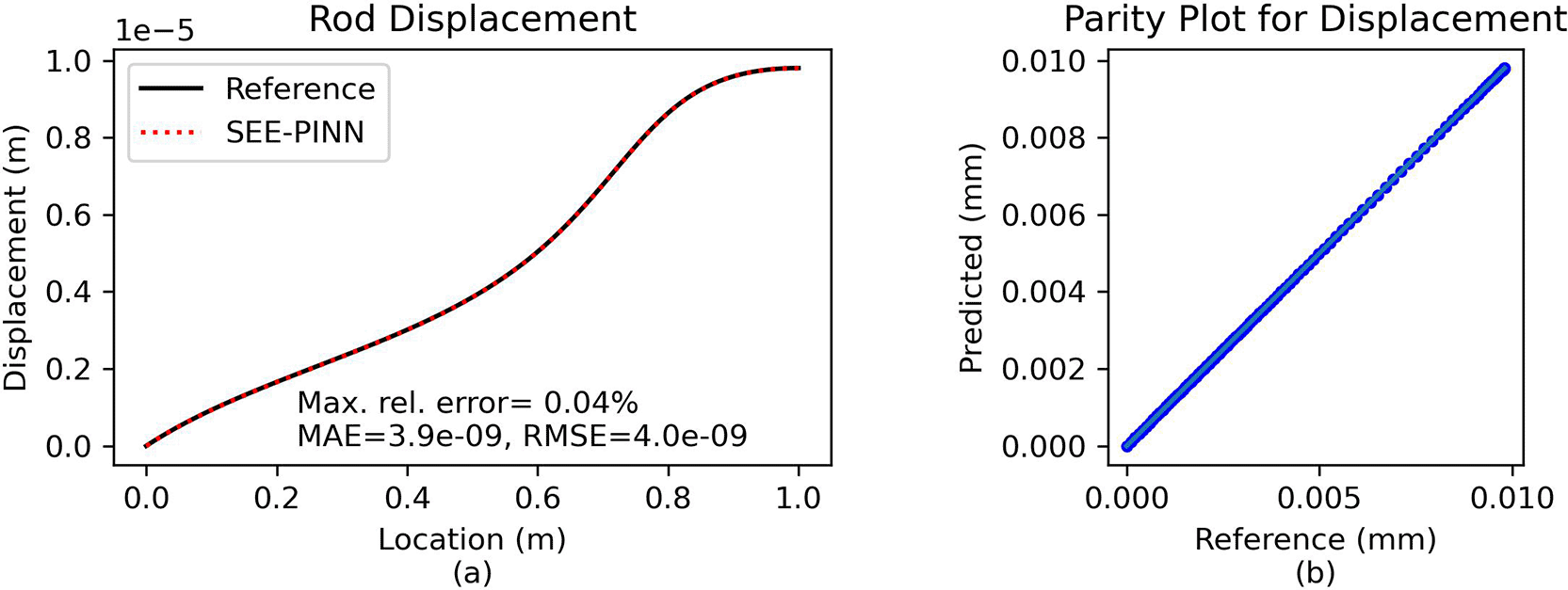
(a) Direct comparison of predictions. (b) Parity plot of predicted vs. reference solution.
3.2.3 Fixed rod with variable Young’s modulus and cross-section, and distributed load
Statement of the problem. The complexity is further increased by incorporating a nonlinear variation in the Young’s modulus of the rod.
SEE-PINN solution. The same neural network has been employed to approximate the displacement field of the rod; i.e. one fully connected layer, with 10 neurons, and each neuron employs the tanh activation function. The network is trained at 75 points using the Adam optimizer with learning rate 0.01 for 5000 epochs.
Comparison and error analysis. The predicted solution validated against is validated against a numerical reference. As shown in Figure 5, the analytical and PINN solutions are virtually identical. The maximum relative error is approximately 0.05%, indicating that the PINN approach achieves an almost exact match with the analytical solution.
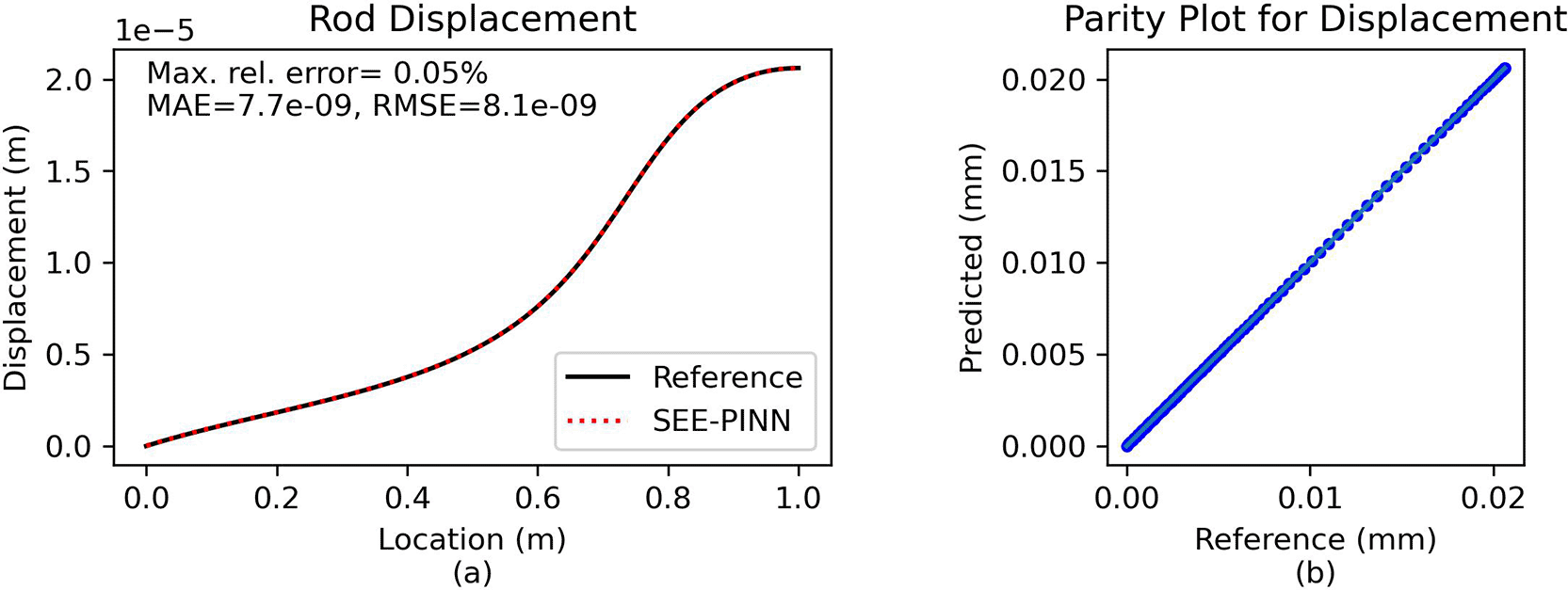
(a) Direct comparison of predictions. (b) Parity plot of predicted vs. reference solution.
3.2.4 Uniform Euler beam with distributed load
Statement of the problem. The second part of the validation examines three beam problems. The first case considers a uniform, homogeneous elastic beam with a length of m. The beam has a rectangular cross-section of and is composed of a material with . The left end of the rod is fixed, while the right one is simply supported. The beam is subjected to a transverse load of , and its transverse deflection is analyzed.
This problem can be easily solved through the analytical solution of Eq. (17) with constant properties and boundary conditions:
SEE-PINN solution. An appropriate neural network is designed to approximate the deflection of the beam. The input of the neural network is the spatial coordinate , and its output is the predicted transverse displacement . The network consists of only one fully connected layer, with 10 neurons, and each neuron employs the tanh activation function. The network is trained at 75 points using the Adam optimizer with learning rate 0.001 for 10000 epochs.
Comparison and error analysis. The predicted solution is validated against the analytical reference ( Figure 6), showing that the analytical and PINN solutions are virtually identical ( Figure 6a); this is further supported by the parity plot ( Figure 6b), where all data points practically lay along the diagonal. With a maximum relative error of approximately 0.2%, the PINN approach achieves exceptional accuracy in comparison to the analytical solution.
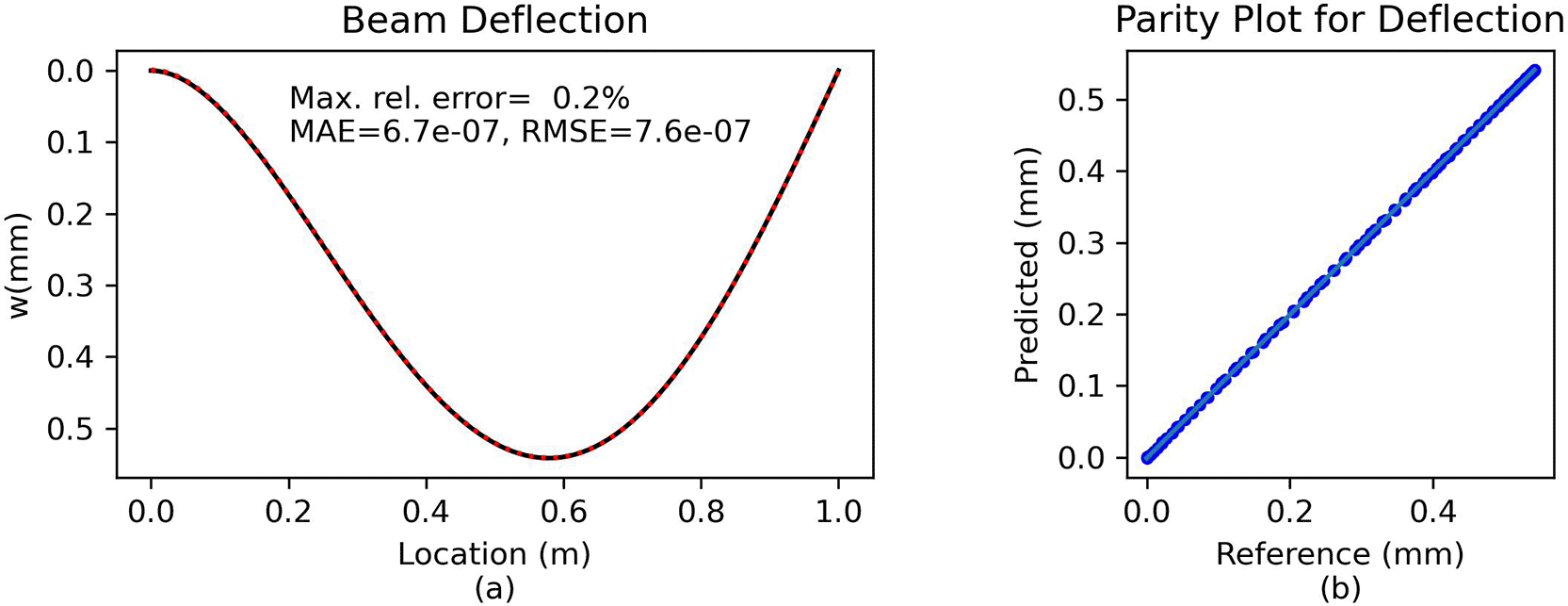
(a) Direct comparison of predictions. (b) Parity plot of predicted vs. reference solution.
3.2.5 Euler beam with variable cross-section and distributed load
Statement of the problem. This case builds upon the previous problem by introducing a nonlinear transition in the inertial moment of the cross-section, represented by :
PINN solution. A shallow architecture has been employed to approximate the deflection of the beam; i.e. one fully connected layer, with 10 neurons, and each neuron employs the tanh activation function. The network is trained at 75 points using the Adam optimizer with learning rate 0.001 for 10000 epochs.
Comparison and error analysis. The predicted solution is compared against a numerical reference for validation. Figure 7 illustrates that the analytic and the PINN solution are again indistinguishable. With a maximum relative error of approximately 0.35%, the PINN approach demonstrates an excellent agreement with the analytical solution.
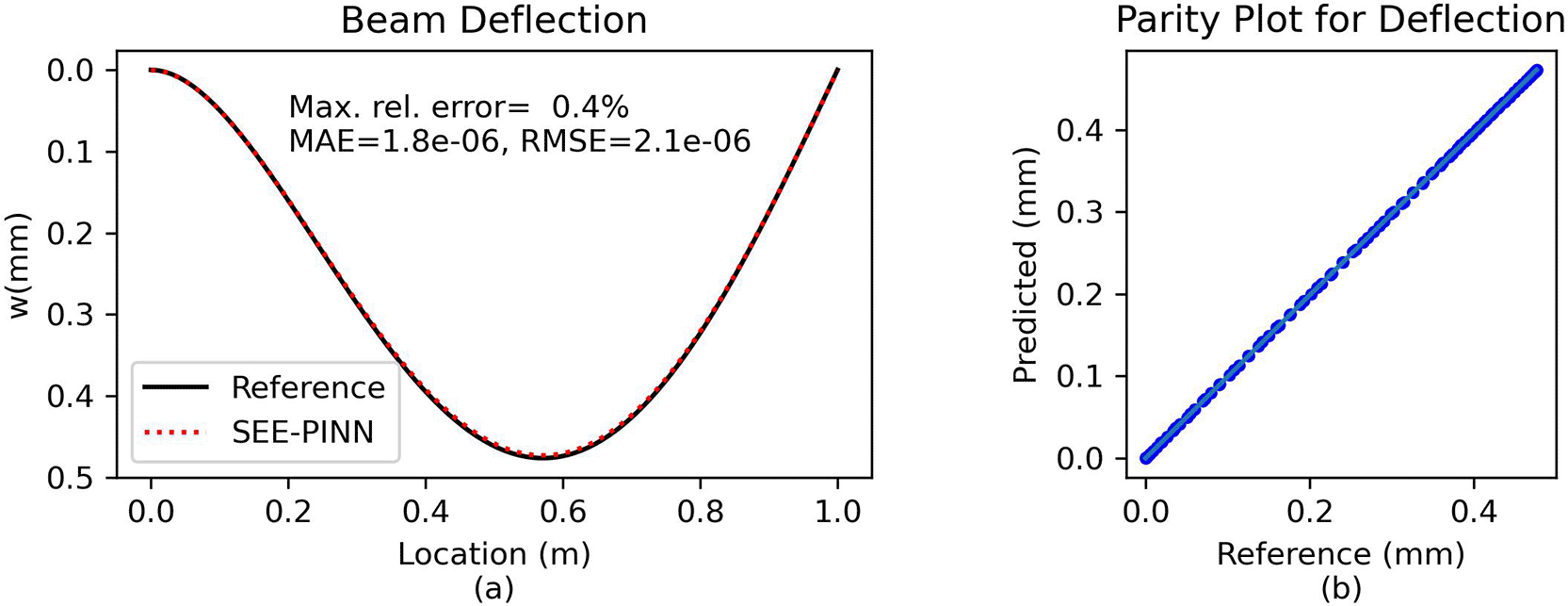
(a) Direct comparison of predictions. (b) Parity plot of predicted vs. reference solution.
3.2.6 Euler beam with variable Young’s modulus and cross-section, and distributed load
Statement of the problem. The complexity is further enhanced by introducing a nonlinear variation in the Young’s modulus of the beam,
SEE-PINN solution. The same neural network has been employed to approximate the deflection of the beam; one fully connected layer, with 10 neurons, and each neuron employs the tanh activation function. The network is trained at 75 points using the Adam optimizer with learning rate 0.001 for 10000 epochs.
Comparison and error analysis. The predicted solution is compared against a numerical reference for validation. Figure 8 illustrates that the analytic and the PINN solution are again indistinguishable. With a maximum relative error of approximately 0.4%, the PINN approach demonstrates an excellent agreement with the analytical solution.
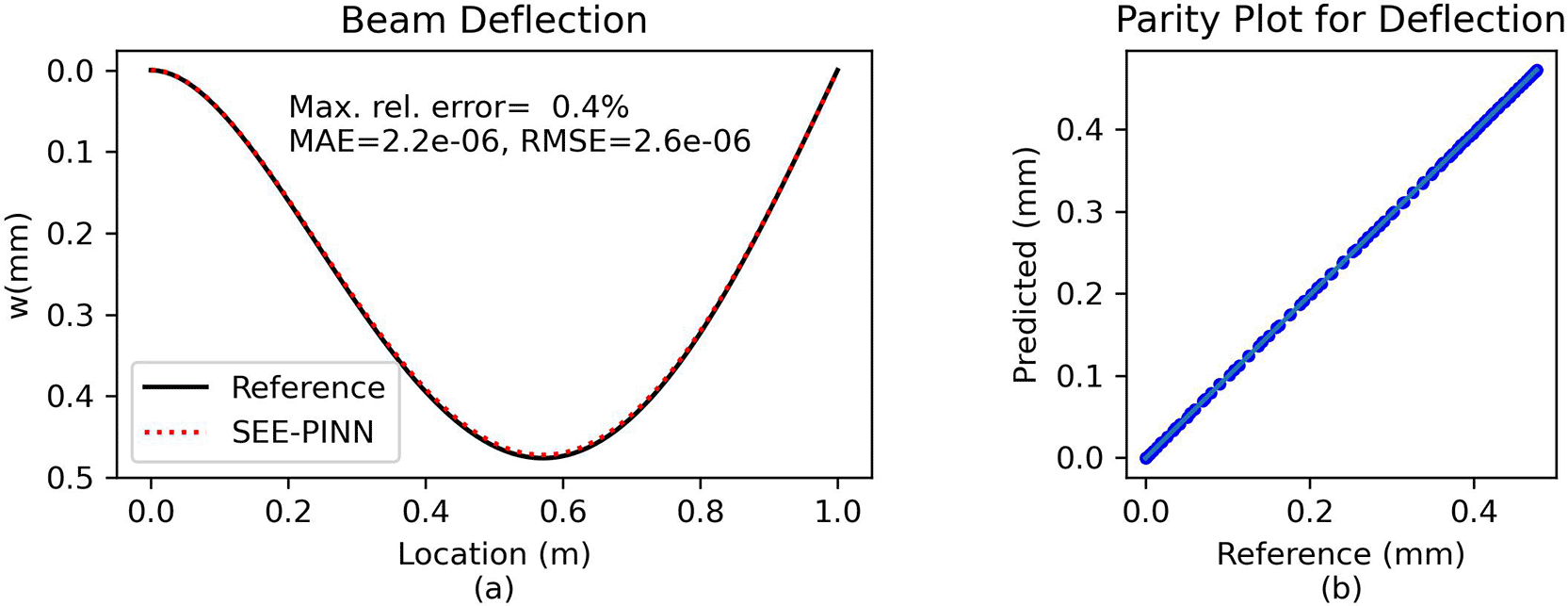
(a) Direct comparison of predictions. (b) Parity plot of predicted vs. reference solution.
The performance of the introduced methodology is assessed by comparison to existing models. The objective is to demonstrate that the suggested approach yields the same solution while utilizing significantly fewer computational resources. Given that the precise technical details of each study are not known, theoretical estimates of computational requirements and complexity have been derived from the respective network architectures.
3.3.1 Performance metric
This analysis evaluates the floating point operations (FLOPs) required for both the forward and backward passes as a key metric for assessing the performance of a neural network. While other metrics, such as the memory needed to store weights, biases, and intermediate results, could also be considered, a more detailed examination of these factors is beyond the scope of this paper.
According to Eq. (1), a neuron in fully connected layer performs three basic operations: (a) multiplication of every input with a weight, i.e. operations, (b) summation of all input-weight products, i.e. operations, and (c) addition of a bias, i.e. operation. Thus, for a layer with inputs an outputs, the required number of FLOPs for a forward pass is:
The backpropagation process is more complex than the forward pass and is assumed to require three times as many FLOPs; . For simplicity, the computations needed for activation functions are considered minimal, so any additional overhead calculations—which may vary by implementation—are not included. Therefore, the total computational load is calculated by multiplying the total number of FLOPs required for both the forward pass and backpropagation by the number of training points and the number of epochs.
Wang et al.24 have conducted simulations on a 10 m long homogeneous rod featuring a cross-sectional area of 1 m2, composed of a material characterized by a Young’s modulus of 175 Pa. The rod was fixed at both ends and subjected to a distributed load:
The authors addressed the problem by utilizing a PINN comprising 6 hidden layers, with each layer containing 512 neurons employing the ReLU activation function. The model was trained for epochs using data points.
The computational cost for a forward pass is the total sum of FLOPs for the input layer, the six hidden layers, and the output layer, i.e.
When including the cost of back-propagation and considering the number of training points, the total computational cost becomes:
The solution was subsequently validated against an analytical benchmark solution:
The same problem was solved using the proposed approach but with a significantly smaller network, specifically two layers containing 20 neurons each, trained on 100 points for 30,000 epochs. A comparison of the predictions with the provided analytical solution in Figure 9 shows excellent agreement.
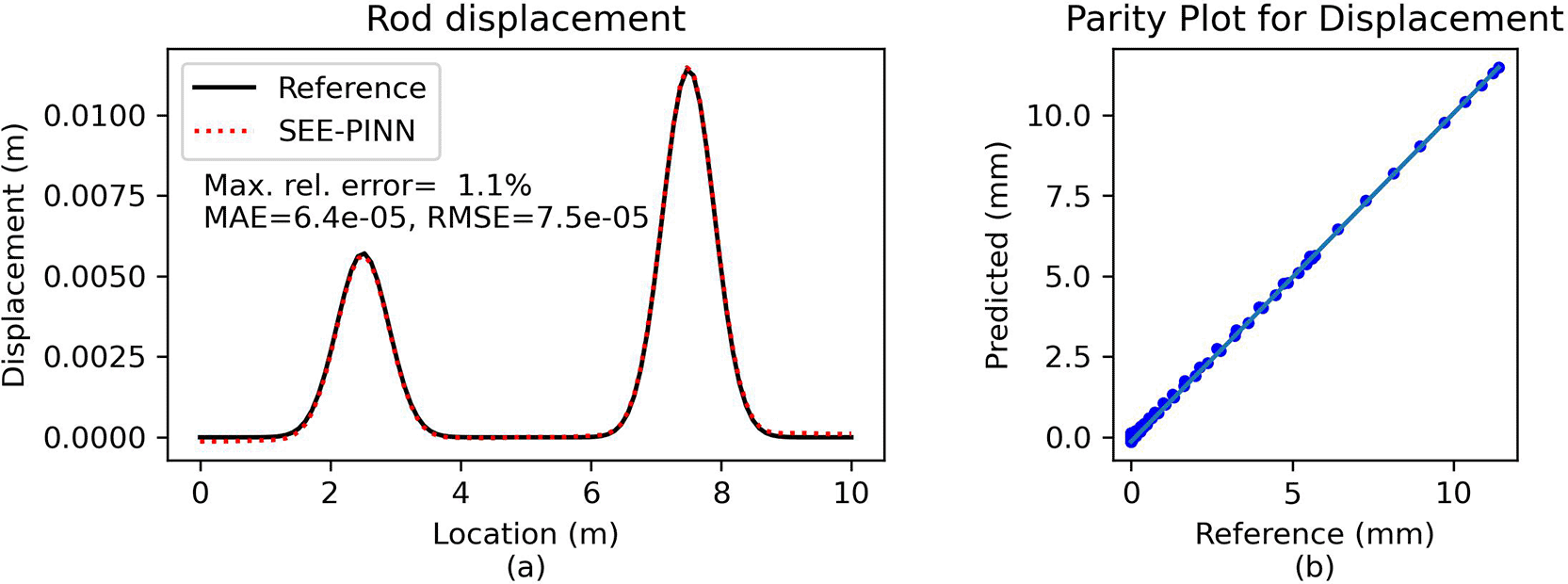
(a) Direct comparison of predictions. (b) Parity plot of predicted vs. reference solution.
The computational cost for a forward pass in this configuration is given:
Singh et al.25 simulated the bending of a 1 m long homogeneous Euler beam with a moment of inertia I = 1.0, made of a material with Young’s modulus of 1.0 Pa. The beam was fixed at one end and subjected to a distributed load:
To solve this problem, the authors employed a PINN with 5 hidden layers, each containing 50 neurons using the tanh activation function. The model was trained for epochs using data points.
The computational cost for a forward pass is the total sum of FLOPs for the input layer, the five hidden layers, and the output layer, i.e.
Taking into account the cost of back-propagation, the number of training points and the number of epochs, the total computational cost is given by:
The solution was validated against an analytical benchmark solution:
The same problem was solved using the proposed approach but with a significantly smaller network: a single hidden layer with 10 neurons, trained on 75 points for 1,000 epochs. As shown in Figure 10, the predictions closely match the analytical solution, demonstrating excellent agreement.
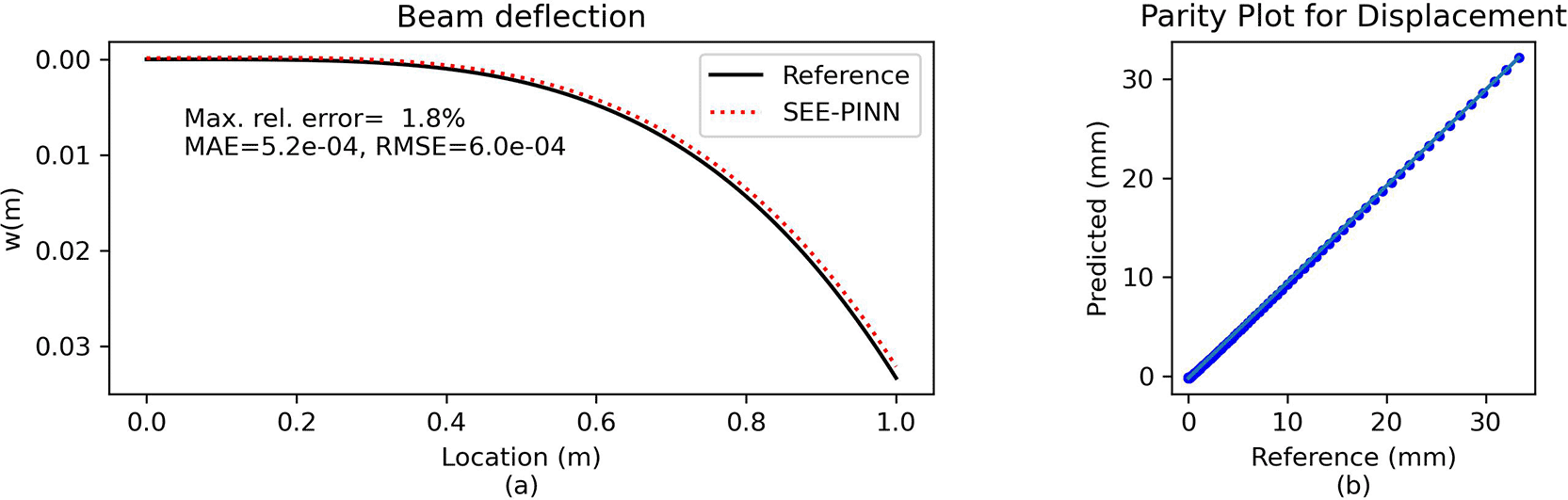
(a) Direct comparison of predictions. (b) Parity plot of predicted vs. reference solution.
The computational cost for a forward pass using the SEE-PINN configuration is given:
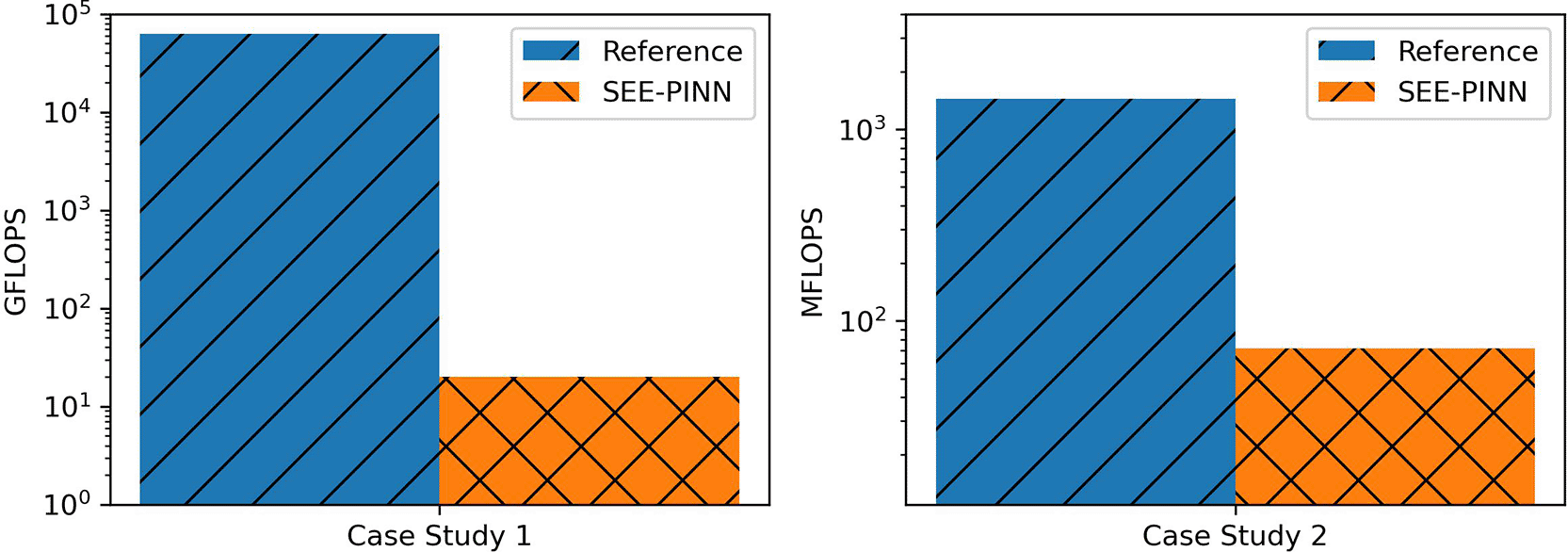
The proposed approach requires 2-3 times less FLOPs.
The proposed methodology offers an efficient and streamlined approach for solving ordinary differential equations (ODEs) with Physics-Informed Neural Networks (PINNs) by directly scaling the terms of the governing equations, rather than introducing balancing weights within the loss function. Each term is normalized using characteristic physical dimensions, bringing all contributions to a similar order of magnitude close to unity. This ensures numerical consistency and eliminates the need for complex and computationally intensive loss-balancing procedures. The scaled equations are solved within a PINN framework, after which a reverse scaling step restores the solution to the physical domain.
The method has been demonstrated through nonlinear one-dimensional elasticity problems, including rod and Euler–Bernoulli beam cases. The results show that high accuracy can be achieved with extremely compact network architectures – even a single hidden layer with ten nodes – while maintaining negligible maximum percentage error across collocation points. Benchmarking against existing PINN approaches reveals that the proposed scaling strategy reduces floating-point operations (FLOPs) by at least two orders of magnitude, underscoring its potential to deliver substantial computational savings without compromising precision.
While promising, the method also presents opportunities for further development:
1. Optimal Hyperparameter Selection: Automated, self-tuning strategies remain an open research goal to avoid case-by-case manual tuning.
2. Extension to Higher Dimensions: Applying the methodology to 2D and 3D problems, where term coupling increases complexity, is a priority.
3. Highly Nonlinear and Discontinuous Cases: Future work will target problems with sharp gradients, contact conditions, discontinuities, and dynamic effects.
4. Time-Dependent Problems: These can be addressed by treating time as an additional dimension or by adopting time-aware neural architectures such as LSTMs.
In conclusion, the proposed scaling-based PINN framework (SEE-PINN) demonstrates that direct differential equation term scaling can fundamentally simplify and accelerate the training of PINNs for nonlinear problems. By completely removing the reliance on elaborate and costly loss-balancing mechanisms, it enables the use of compact, fast, and accurate models that are easier to deploy in real-world engineering settings. The combination of high accuracy, drastic computational savings, and straightforward implementation positions SEE-PINN as a practical and scalable tool, with the potential to reshape how machine learning is applied to challenging differential equation problems in computational mechanics and beyond.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)