Keywords
student performance, survey, optimization, metaheuristic, hybrid
This article is included in the Artificial Intelligence and Machine Learning gateway.
student performance, survey, optimization, metaheuristic, hybrid
Education is widely recognized as a fundamental human right essential for personal and national development. Over the years, education systems have faced numerous challenges and changes in their approaches. Today, institutions are increasingly focused on retaining students and providing engaging, effective teaching. However, assessing students’ abilities in various areas remains a challenge, as many institutions still heavily rely on written exams for evaluation. This narrow focus can overlook important skills, leaving students unprepared in areas beyond academics. A potential solution is to adopt smarter, data-driven methods for evaluating students’ strengths and weaknesses. This would enable faster and more personalized assessments through computational intelligence.
Constrained optimization problems often transform subjective human judgments into structured mathematical models. Classic NP-hard problems (Karp, 1972), such as the Traveling Salesman Problem (TSP) (Sharma, 2024), optimize routing for scheduling and deliveries, while the Knapsack Problem (He et al., 2024) determines optimal selections under constraints. Boolean satisfiability (SAT) (Boulebnane & Montanaro, 2024) deals with binary variable conditions, and MAX-SAT (Das et al., 2025) focuses on maximizing satisfied clauses. These mathematical frameworks enable the systematic evaluation of subjective tasks, such as student assessments, for objective decision-making.
Metaheuristic algorithms are powerful optimization techniques inspired by natural processes, designed to efficiently tackle complex problems where traditional methods are inadequate. They balance exploration and exploitation to achieve near-optimal solutions. For instance, the Genetic Algorithm (Tang et al., 1996) simulates natural selection, while Particle Swarm Optimization (Kennedy & Eberhart, 1995) models collective behaviour. Teaching-Learning-Based Optimization (TLBO) (Rao et al., 2012) is based on the teacher-student knowledge transfer mechanism, Ant Colony Optimization (Dorigo et al., 1996) replicates how ants use pheromone trails to find optimal paths, and Light Spectrum Optimization (Abdel-Basset et al., 2022) is inspired by light dispersion. Due to their adaptability and effectiveness, these methods are widely applied across various domains.
The structure of the paper is as follows: Introduction section and Literature Review section examines prior research on the topic, providing a critical evaluation of different perspectives while highlighting their strengths and limitations. Problem Definition section establishes the problem framework and presents a mathematical formulation, including an objective function, a constraint equation, and equations for evaluating effectiveness and stress levels. Datasets section details the datasets compiled from various studies and survey papers. Hybrid PSO-GA approach section introduces a novel metaheuristic algorithm designed to address the problem. In Results and Discussion section, multiple simulations are conducted to assess the algorithm’s performance in terms of optimization accuracy and computational efficiency, with results ranked using standard statistical techniques. Finally, Conclusion summarizes the key contributions and outlines potential directions for future research.
This section will review several recent papers published addressing the student evaluation and prediction problem through the application of computational intelligence.
To begin with, Lakshmi et al. (Miranda Lakshmi et al., 2013) conducted a study that explored the use of genetic algorithms as an effective method for analyzing complex educational data (Batool et al., 2023). By applying principles of natural evolution, their model identified significant factors affecting student performance through a quantitative evaluation of various academic metrics, such as theoretical, mathematical, and practical scores. This approach not only assisted educational institutions in improving teaching quality by analyzing student marks but also served as a valuable tool for classifying and examining performance determinants throughout the academic year. The findings indicated that even minor adjustments to the genetic algorithm’s parameters could yield significant insights into key performance indicators. Ultimately, the model provided students with a self-assessment mechanism to better understand their academic standing and identify areas for improvement, underscoring the effectiveness of genetic algorithms in predicting student performance and enhancing educational development across various contexts.
Another similar study, done by Hamsa et al. (Hamsa et al., 2016) developed a hybrid model that combines decision tree algorithms with a fuzzy genetic algorithm to predict student academic performance (Yağcı, 2022) in bachelor’s and master’s programs. By analyzing various parameters such as internal marks, sessional scores, and admission scores, the model evaluates each student’s subject-specific outcomes and provides educators with a valuable tool to promote academic success (Jin, 2023). The decision tree (“Predictive Analytics in Business Analytics,” 2022) component effectively identifies at-risk students, enabling instructors to offer additional support to improve final exam results, while the fuzzy genetic algorithm classifies more students as passing by accommodating borderline cases, reassuring them and allowing for indirect monitoring of their progress. This balanced approach fosters a supportive learning environment (Niu et al., 2022) and helps high-performing students attract early recruitment from reputable companies, ultimately benefiting both the students and the institution’s reputation.
Gomede et al. (Gomede et al., 2018) developed a computational intelligence model (Ikegwu et al., 2024) to improve education quality and support decision-making, particularly in regions with limited access to quality education (Timotheou et al., 2023). Using data science and mining techniques (Shu & Ye, 2023), the model generated personalized knowledge profiles, helping teachers monitor key performance indicators (KPIs) (Joppen et al., 2019) and make informed decisions. Based on real K–9 student data from a private school in Brazil, it utilized graph-based visualization, recommendation systems, and random forest algorithms for classification (Shaik & Srinivasan, 2019) and prediction (Schonlau & Zou, 2020). This approach enabled performance forecasting, identified key links, and provided tailored recommendations to enhance learning outcomes. Operating within a PDCA (Plan, Do, Check, Act) cycle, the model improved prediction accuracy and aligned indicators with educational system goals.
Furthermore, in a paper by Taylan et al. (Taylan et al., 2017), the authors analyzed learning objectives for graduate and program-level industrial engineering students by developing the “house of cognitive learning,” which emphasizes cognitive depth, outcome components, and conceptual understanding. To address challenges in assessment and measurement, they proposed a “learning index” derived using an integrated integer programming model. This index was refined through statistical methods and quality control charts to provide a comprehensive and longitudinal view of student progress (Ifenthaler & Yau, 2020b, 2020a). Their findings underscored the importance of clearly defined learning objectives and shared instructor-student expectations in driving effective curriculum outcomes (Ifenthaler et al., 2019). The study reinforced the growing role of data-driven course design in enhancing learning impact, while also promoting self-directed learning and personalized feedback mechanisms to foster continuous student engagement and responsibility.
Agaarna et al. (Michael & Amenawon, 2015) analyzed factors influencing academic performance in world-class universities using a linear programming model (Mayer, 2022). Key elements included entry points, student-to-staff ratio, library spending, accommodation quality, teaching assessments, research ratings, and international student presence. Using the simplex method (Huiberts et al., 2022) and MAPLE14 software, the model standardized these factors to assess their significance. Results showed teaching assessment as the most critical factor, followed by entry points. The study underscored the importance of high teaching quality, library engagement, and proper admission criteria. A comprehensive understanding of these variables was found to be essential for optimizing student outcomes in higher education.
We consider a set of task categories indexed by i ∊ {1,2, …, n}, each associated with a cognitive load value ci. The objective is to optimize the allocation of effort xi to maximize the total cognitive benefit, formulated as:
• Cognitive Capacity (Baseline) Assessed through historical academic performance or aptitude scores.
• Time Availability Measured in terms of structured task hours available per day.
• Fatigue & Stress Levels Evaluated through self-reported metrics, including stress surveys, sleep quality, and mental fatigue levels.
• Task Complexity & Adaptability Determined via problem-solving assessments reflecting adaptability to cognitive challenges.
For this study, we focus on task categories that have quantifiable cognitive workload based on survey-derived satisfaction metrics. These categories are:
• Academic Performance
Mapped to: Memory & Learning, Analytical & Problem-Solving
• Assignments & Projects
Mapped to: Memory & Learning, Analytical & Problem-Solving
• Co-curricular & Extra-curricular Engagement
Mapped to: Social & Communication, Multitasking
• Clubs & Societies
Mapped to: Social & Communication
• Sports & Cultural Participation
Mapped to: Physical & Sensorimotor, Social & Communication
These categories were selected based on strong representation in the dataset and clear association with distinct cognitive domains, enabling an evidence-based approach to modeling student workload and performance.
Cognitive load value (ci):
The dataset utilized in this study was extracted from Table 2, Table 3, and Table 4 of a survey-based study conducted by Yangdon et al. (Karma et al., 2021). The mean satisfaction scores for each category, based on Likert-scale responses, were normalized using Equation 3 to map the values onto a scale from 0 to 1. Here, M denotes the average satisfaction rating for a given category. To represent cognitive workload instead of satisfaction, the normalized values were inverted by subtracting them from 1.
Five academic task categories were considered in this study, denoted as C1 to C5. C1 corresponds to Academic Performance, while C2 represents Assignments & Projects. Co-curricular & Extra-curricular Engagement is categorized under C3, whereas C4 refers to Clubs & Societies. Finally, C5 is assigned to Sports & Cultural Participation. Each task category is mapped to one or more cognitive domains, forming the basis for workload estimation and cognitive effort distribution in this study.
The values taken from the survey paper are shown in Table 1 and the resulting workload scores are summarized in Table 2.
| Category | Cognitive domain(s) | Source Table/Section | Workload (0–1) |
|---|---|---|---|
| Academic Performance | Memory & Learning, Analytical & Problem-Solving | Table 4 (M = 3.42) | 0.57 |
| Assignments & Projects | Memory & Learning, Analytical & Problem-Solving | Table 4 (M = 2.83) | 0.71 |
| Co-curricular & Extra-curricular Engagement | Social & Communication, Multitasking | Table 2 (Recreation M = 3.08) | 0.65 |
| Clubs & Societies | Social & Communication | Table 3 (Tutor Support M = 3.16) | 0.68 |
| Sports & Cultural Participation | Physical & Sensorimotor, Social & Communication | Table 2 (Sports M = 3.25) | 0.65 |
| C1 | C2 | C3 | C4 | C5 |
|---|---|---|---|---|
| 0.57 | 0.71 | 0.65 | 0.68 | 0.65 |
Personal cognitive limit (λ):
The personal cognitive limit λ was assumed to be influenced by four key factors: cognitive capacity, time availability, fatigue & stress levels, and task complexity & adaptability. These factors were represented as l1, l2, l3, and l4, respectively. Since precise values for these factors were unavailable, they were randomly chosen within a reasonable range for the scope of this study.
The cognitive limit λ was computed using the following equation:
The Hybrid PSO-GA algorithm synergizes the exploration capabilities of Genetic Algorithms (GA) with the exploitation strengths of Particle Swarm Optimization (PSO) to achieve more robust optimization. Each particle in the population acts as a self-contained agent that holds several key pieces of memory throughout the search process. These include its current position in the solution space, its velocity, its personal best position (the most optimal solution it has found so far), the fitness value of that best position, and crucially, the iteration index at which it achieved this personal best. This extra memory component allows the algorithm to keep track of stagnation at an individual level. The entire structure of a single particle in the whole population can be seen in Figure 1. A hyperparameter called the iteration threshold determines how long a particle can go without improving before triggering an alternative search behaviour.

When a particle exceeds this stagnation threshold, it is subjected to Genetic Algorithm operations instead of standard PSO updates. Specifically, the particle is selected for crossover with another randomly chosen particle from the population. A subset of genes (position values) is swapped between the two using a defined crossover probability and window size. After crossover, each gene has a chance to undergo mutation, governed by a mutation probability. Once the new candidate solutions are formed, they are passed through a repair function r(x) to ensure that all variables remain within the problem’s constraints of [0,1], which basically is a slightly modified sigmoid function as shown in Equation 5. The fitness of these modified solutions is then evaluated. This GA-based route reinjects diversity into the population and allows the algorithm to escape local optima.
If a particle has not yet stagnated, it continues to evolve using the conventional PSO dynamics. The velocity is updated based on its inertia and the difference vectors between its current position and both its personal best and the global best found in the population, with some randomness injected to encourage exploration. The new position is computed, repaired if needed, and evaluated for fitness. If the new fitness surpasses its personal best, the personal best is updated along with the iteration in which the improvement occurred. Simultaneously, the global best is also updated whenever a particle exceeds the previous best. This hybrid framework ensures a balance between local refinement and global exploration, leading to higher resilience against premature convergence and better performance in complex, multimodal search landscapes.
The whole flowchart of the algorithm can be seen in Figure 2.
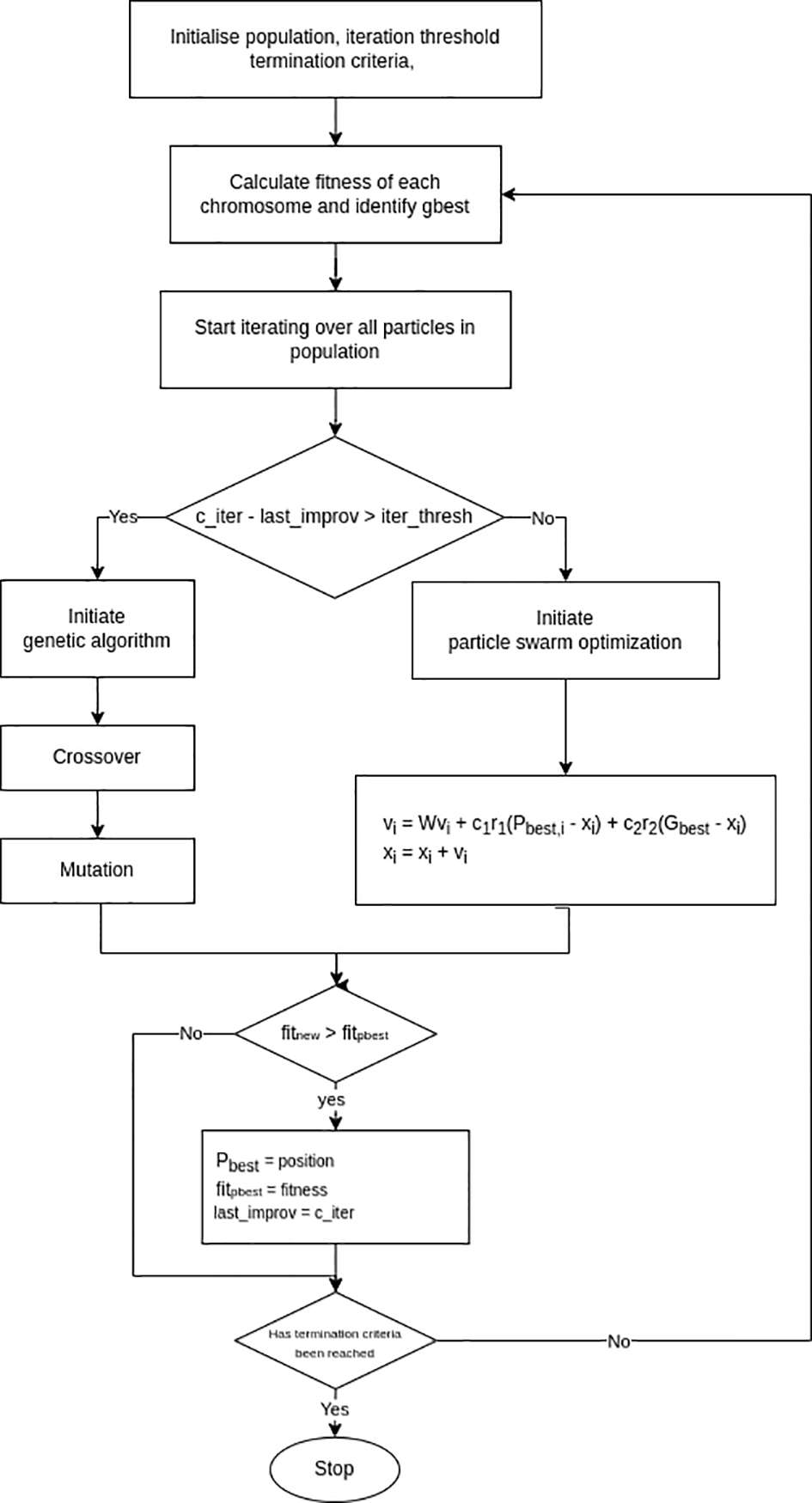
1: Init particle population: positions, velocities
2: Evaluate fitness, set personal and global bests
3: for each generation do
4: for each particle p do
5: if no improv. for p in threshold iterations then
6: Select particle q randomly
7: Crossover p and q with Pc
8: Mutate p’s genes with Pm
9: Repair invalid genes using r(x)
10: Evaluate fitness of p, q
11: else
12: Update p’s velocity and position (PSO)
13: Repair and evaluate fitness
14: end if
15: if fitness(p) > personal best then
16: Update personal best, note iteration
17: end if
18: if fitness(p) > global best then
19: Update global best
20: end if
21: end for
22: end for
The simulations were implemented in C++ with GCC version 14.2.1, while Python 3.12 was employed for the statistical analysis of the results. The tests were conducted on a system with an Intel Core i7-1255U processor and 16GB of RAM, running Fedora Linux 40. The final fitness values were ranked using a standard ranking method, preserving the initial values for each algorithm to ensure a fair comparison. This approach allowed for an objective assessment of each algorithm’s performance, providing a detailed overview of their efficiency and convergence. Each sub-experiment was executed 50 times to ensure a statistically valid comparison between all the algorithms, resulting in a total of 3 × 3 × 50 = 450 simulation runs across all configurations.
Experiment A (Population: 25, Iterations: 50):
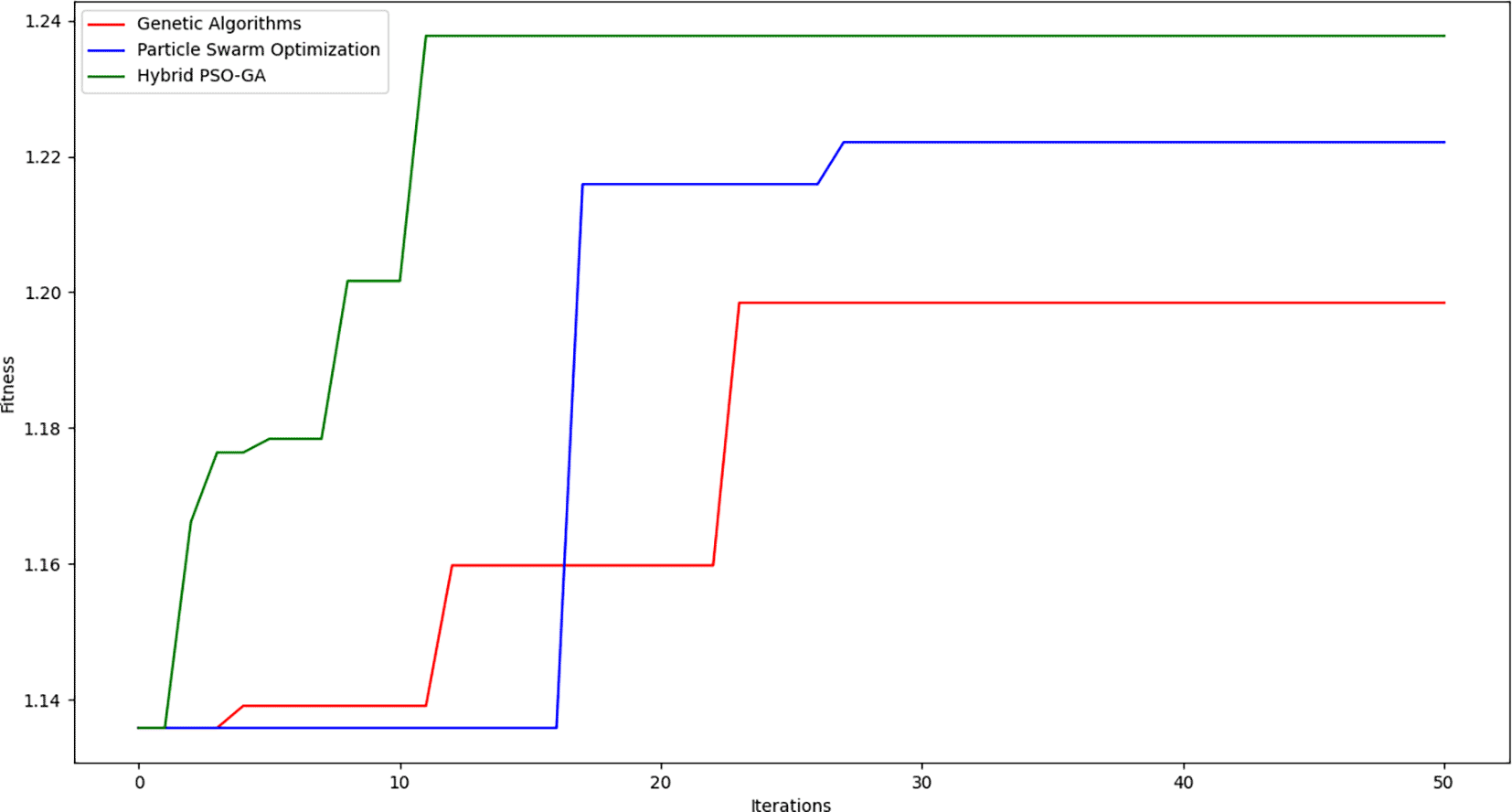
The first experiment in Set S-1 evaluates algorithmic performance under a limited computational budget, using a population size of 25 and 50 iterations. The results show a clear advantage for the Hybrid PSO-GA algorithm over the standalone GA and PSO variants. It achieves the highest average fitness value of 1.254 and maintains the lowest standard deviation of 0.015, highlighting both its superior optimization capability and enhanced stability across five problem cases.
To validate these observations statistically, a non-parametric Friedman test was conducted. The test yielded a Chi-Square value of 75.9192 with a p-value of 0.0000, indicating that the observed performance differences among the three algorithms are statistically significant at the 95% confidence level (p < 0.05).
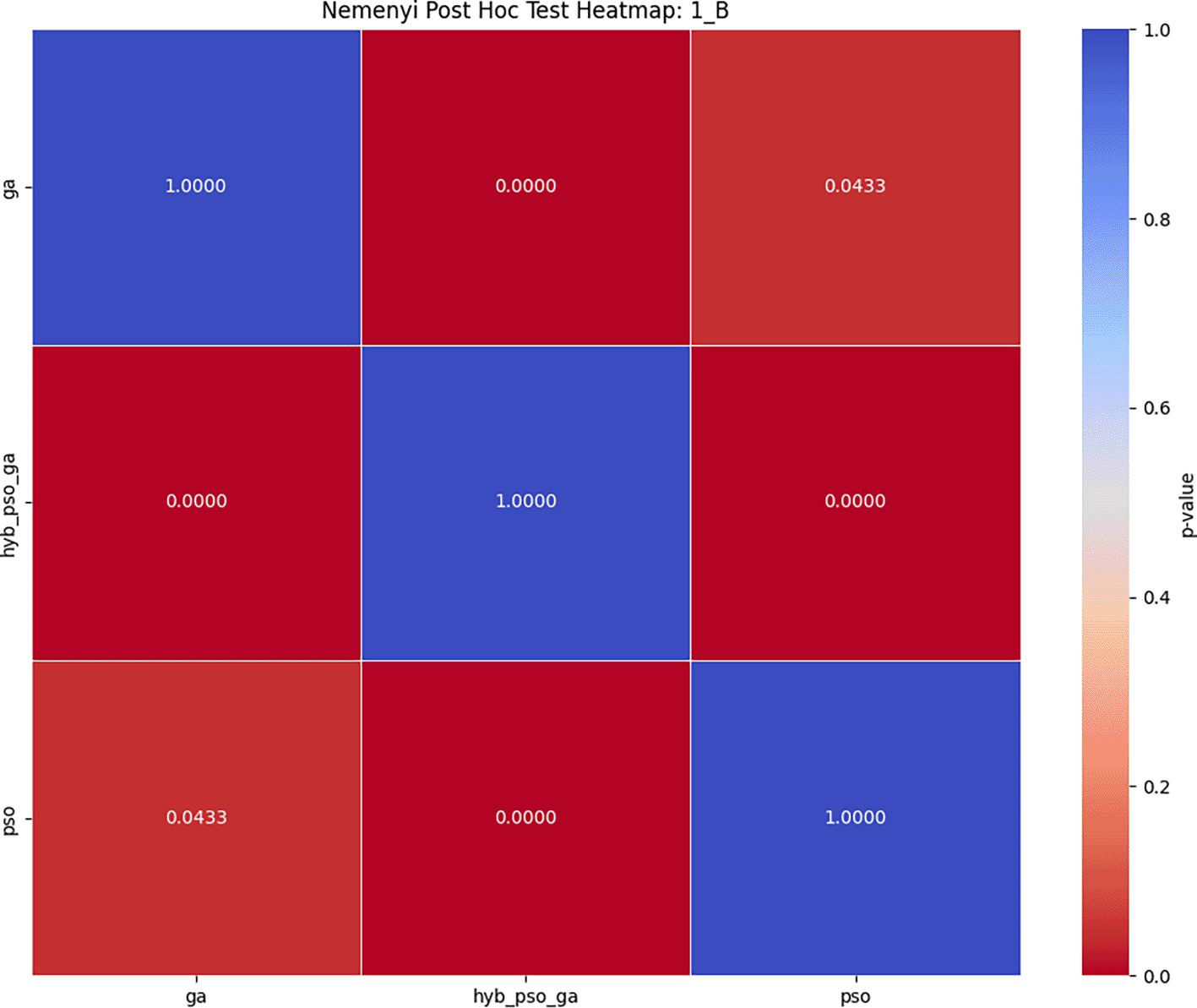
Subsequently, the Nemenyi posthoc test was applied to evaluate pairwise significance. The resulting p-values demonstrated that Hybrid PSO-GA significantly outperforms both GA and PSO individually, with p-values of 4.07 × 10−14 and 8.63 × 10−13 respectively. However, no significant difference was observed between GA and PSO (p = 0.9156). This highlights the strength of the hybrid strategy, especially in lower-resource environments. The Nemenyi matrix and the convergence trend are shown in Figures 3 and 4, respectively. Detailed fitness results are reported in Table 4.

| Algorithm | C1 | C2 | C3 | C4 | C5 | Mean | Standard deviation | Rank |
|---|---|---|---|---|---|---|---|---|
| GA | 0.071 | 0.678 | 0.341 | 0.457 | 0.251 | 1.217 | 0.025 | 3 |
| PSO | 0.046 | 0.649 | 0.369 | 0.488 | 0.246 | 1.219 | 0.023 | 2 |
| Hybrid PSO-GA | 0.013 | 0.914 | 0.136 | 0.605 | 0.150 | 1.254 | 0.015 | 1 |
Experiment B (Population: 50, Iterations: 100):
In the second experiment, the population and iteration counts were doubled to examine scalability and robustness in a more resource-rich environment. With a population of 50 and 100 iterations, the Hybrid PSO-GA continued to outperform the standalone GA and PSO, achieving the highest mean fitness of 1.265 and the lowest standard deviation of 0.009, further reinforcing its robustness.
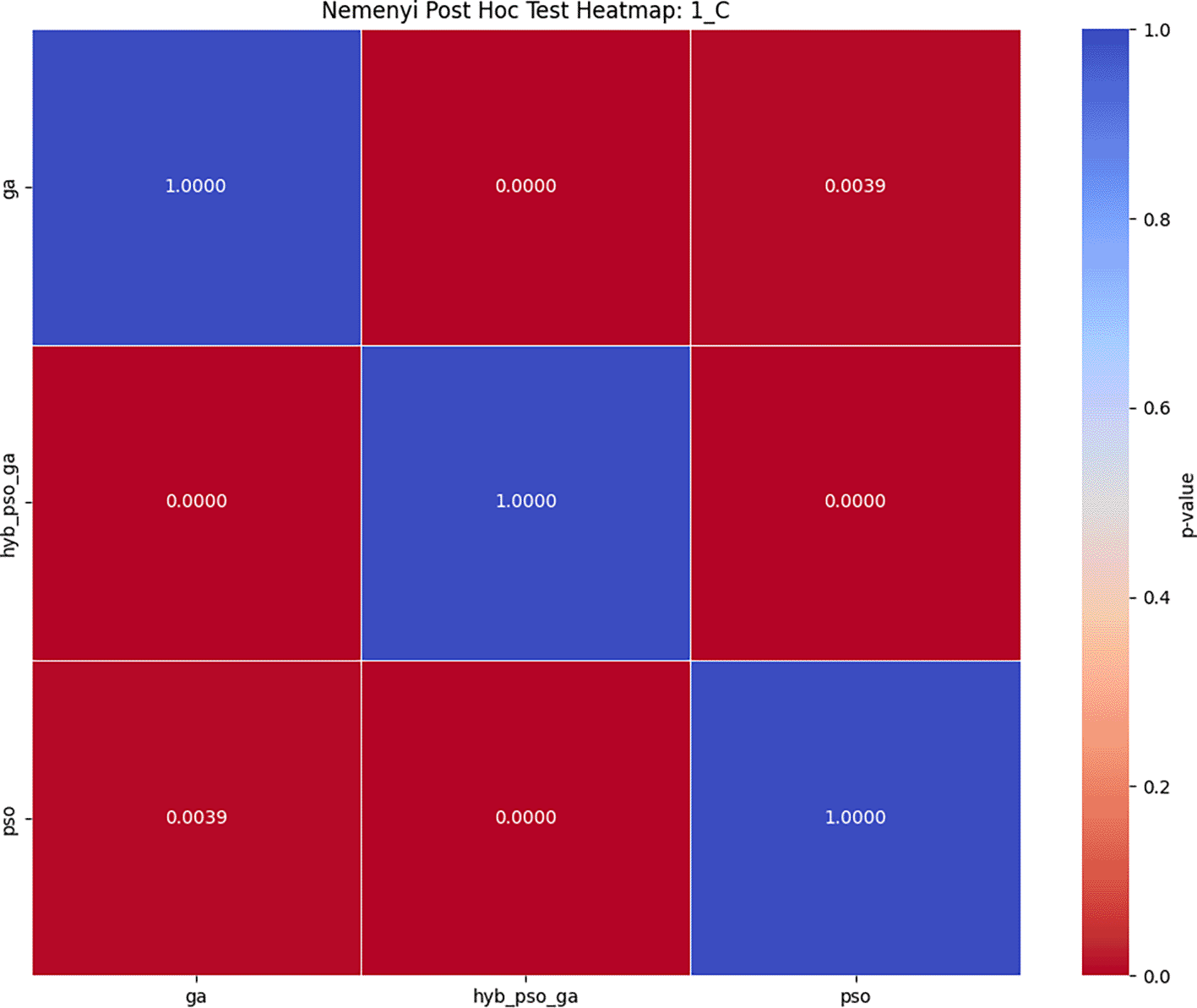
The Friedman test for this setup produced a Chi-Square value of 81.5758 and a p-value of 0.0000, indicating statistically significant differences in algorithm performance. The Nemenyi test showed that Hybrid PSO-GA significantly surpassed GA (p = 2.88 × 10−13) and PSO (p = 5.66 × 10−11), while the difference between GA and PSO remained statistically insignificant (p = 0.6079).
These results demonstrate the hybrid algorithm’s consistent advantage, even when more iterations and population diversity are available. The Nemenyi significance matrix and the convergence curve are shown in Figures 5 and 6, while the numeric results are reported in Table 5.

| Algorithm | C1 | C2 | C3 | C4 | C5 | Mean | Standard deviation | Rank |
|---|---|---|---|---|---|---|---|---|
| GA | 0.021 | 0.885 | 0.218 | 0.570 | 0.113 | 1.243 | 0.016 | 3 |
| PSO | 0.005 | 0.910 | 0.218 | 0.551 | 0.133 | 1.251 | 0.013 | 2 |
| Hybrid PSO-GA | 0.006 | 0.929 | 0.029 | 0.785 | 0.076 | 1.265 | 0.009 | 1 |
Experiment C (Population: 100, Iterations: 200):
The third and final experiment in Set S-1 investigates performance under the maximum resource allocation—100 individuals over 200 iterations. Once again, Hybrid PSO-GA achieved the best fitness results, with a mean of 1.273 and a remarkably low standard deviation of 0.004. This emphasizes the algorithm’s convergence efficiency and reliability under extended search conditions.
The Friedman test produced a Chi-Square value of 85.2400 and a p-value of 0.0000, confirming the significance of the observed differences. The Nemenyi test revealed that Hybrid PSO-GA significantly outperforms GA (p = 6.43 × 10−12) and PSO (p = 2.74 × 10−10), while GA vs PSO remained statistically non-significant (p = 0.4863).
Figures 7 and 8 display the statistical and convergence analyses. Table 6 presents the corresponding quantitative results.

| Algorithm | C1 | C2 | C3 | C4 | C5 | Mean | Standard deviation | Rank |
|---|---|---|---|---|---|---|---|---|
| GA | 0.009 | 0.925 | 0.111 | 0.755 | 0.018 | 1.259 | 0.013 | 3 |
| PSO | 0.002 | 0.928 | 0.005 | 0.859 | 0.035 | 1.270 | 0.005 | 2 |
| Hybrid PSO-GA | 0.003 | 0.981 | 0.007 | 0.832 | 0.008 | 1.273 | 0.004 | 1 |
Summary of experiment set S-1:
Across all three configurations in Experiment Set S-1, the Hybrid PSO-GA consistently outperforms both GA and PSO in terms of mean fitness and stability (as measured by standard deviation). Table 7 summarizes the average ranks, with Hybrid PSO-GA maintaining a perfect harmonic rank of 1.0 across all experiments.
Experiment A (Population: 25, Iterations: 50):
The first experiment in Set S-2 assesses algorithmic efficiency under constrained computational conditions, using a small population of 25 over 50 iterations. The Hybrid PSO-GA again demonstrates superior performance, yielding the highest average fitness of 1.074 and the lowest standard deviation of 0.019. This suggests a strong capability for both exploration and exploitation even with limited resources.
The Friedman test reported a Chi-Square value of 79.8071 and a p-value of 0.0000, affirming statistically significant differences between the three algorithms. The Nemenyi posthoc analysis further validated these differences, with Hybrid PSO-GA showing significant superiority over GA (p = 1.11 × 10−16) and PSO (p = 1.73 × 10−10). However, the difference between GA and PSO was not statistically significant (p = 0.1386).
Figures 9 and 10 present the Nemenyi matrix and the convergence trend respectively. The corresponding fitness values are listed in Table 8.


| Algorithm | C1 | C2 | C3 | C4 | C5 | Mean | Standard deviation | Rank |
|---|---|---|---|---|---|---|---|---|
| GA | 0.107 | 0.545 | 0.268 | 0.389 | 0.204 | 1.019 | 0.045 | 3 |
| PSO | 0.037 | 0.547 | 0.291 | 0.324 | 0.339 | 1.039 | 0.027 | 2 |
| Hybrid PSO-GA | 0.013 | 0.782 | 0.148 | 0.428 | 0.190 | 1.074 | 0.019 | 1 |
Experiment B (Population: 50, Iterations: 100):
The second experiment expands the search horizon with a population of 50 and 100 iterations. Hybrid PSO-GA maintained its lead with a mean fitness of 1.089 and a minimal standard deviation of 0.011. These results further indicate its ability to adapt and scale effectively with larger computational budgets.
The Friedman test yielded a Chi-Square value of 77.5600 and a p-value of 0.0000, confirming statistically significant performance variation. The Nemenyi posthoc analysis confirmed that Hybrid PSO-GA significantly outperformed GA (p = 3.33 × 10−16) and PSO (p = 6.25 × 10−11), while the GA-PSO comparison remained statistically non-significant (p = 0.2456).
Figures 11 and 12 illustrate the significance matrix and convergence behavior. Table 9 details the numerical results.


| Algorithm | C1 | C2 | C3 | C4 | C5 | Mean | Standard deviation | Rank |
|---|---|---|---|---|---|---|---|---|
| GA | 0.050 | 0.826 | 0.231 | 0.295 | 0.150 | 1.064 | 0.020 | 3 |
| PSO | 0.015 | 0.856 | 0.174 | 0.354 | 0.159 | 1.074 | 0.016 | 2 |
| Hybrid PSO-GA | 0.008 | 0.910 | 0.074 | 0.476 | 0.102 | 1.089 | 0.011 | 1 |
Experiment C (Population: 100, Iterations: 200):
The final experiment in Set S-2 evaluates algorithmic performance under the highest computational allowance: 100 individuals across 200 iterations. Here, Hybrid PSO-GA again achieved the top performance, reporting a mean fitness of 1.098 and an impressively low standard deviation of 0.005, reflecting highly stable convergence.
The Friedman test indicated a Chi-Square value of 89.4400 with a p-value of 0.0000, highlighting statistically significant differences. The Nemenyi test showed Hybrid PSO-GA to be significantly better than both GA (p = 0.0000) and PSO (p = 6.42 × 10−8). Even the GA vs PSO comparison reached significance (p = 4.25 × 10−4), suggesting improved resolution of differences at higher resources.
Figures 13 and 14 depict the statistical and convergence visuals, and the fitness scores are shown in Table 10.


| Algorithm | C1 | C2 | C3 | C4 | C5 | Mean | Standard deviation | Rank |
|---|---|---|---|---|---|---|---|---|
| GA | 0.030 | 0.838 | 0.146 | 0.483 | 0.069 | 1.080 | 0.012 | 3 |
| PSO | 0.001 | 0.928 | 0.040 | 0.529 | 0.074 | 1.093 | 0.006 | 2 |
| Hybrid PSO-GA | 0.005 | 0.980 | 0.048 | 0.525 | 0.017 | 1.098 | 0.005 | 1 |
Summary of experiment set S-2:
Across the entire Experiment Set S-2, the Hybrid PSO-GA consistently demonstrated the highest average fitness and the lowest standard deviation, confirming both its optimization strength and reliability under varying resource conditions. Table 11 presents the rank summary, where the hybrid method once again maintained an optimal harmonic mean rank of 1.0.
Experiment A (Population: 25, Iterations: 50):
Experiment 3-A evaluates algorithmic efficiency in low-resource conditions, using a population size of 25 and 50 iterations. Hybrid PSO-GA again demonstrated superior optimization, achieving the highest mean fitness value of 0.863 with the lowest standard deviation of 0.014, indicating stable and effective performance under constraints.
The Friedman test reported a Chi-Square value of 77.6382 and a p-value of 0.0000, confirming statistically significant performance differences. The Nemenyi posthoc test established that Hybrid PSO-GA significantly outperformed GA (p = 5.55 × 10−16) and PSO (p = 4.44 × 10−11), while GA and PSO showed no statistically significant difference (p = 0.2909).
Figures 15 and 16 show the significance heatmap and the convergence graph respectively. Detailed fitness values are provided in Table 12.


| Algorithm | C1 | C2 | C3 | C4 | C5 | Mean | Standard deviation | Rank |
|---|---|---|---|---|---|---|---|---|
| GA | 0.039 | 0.618 | 0.224 | 0.210 | 0.093 | 0.810 | 0.034 | 3 |
| PSO | 0.029 | 0.446 | 0.190 | 0.374 | 0.177 | 0.826 | 0.023 | 2 |
| Hybrid PSO-GA | 0.034 | 0.881 | 0.110 | 0.154 | 0.064 | 0.863 | 0.014 | 1 |
Experiment B (Population: 50, Iterations: 100):
In Experiment 3-B, the population size and iterations were doubled, increasing the search horizon. Hybrid PSO-GA remained the top performer, achieving a mean fitness of 0.874 and a standard deviation of 0.008, indicating reliable convergence with higher resource allocation.
The Friedman test produced a Chi-Square value of 79.8400 and a p-value of 0.0000, revealing statistically significant differences among the algorithms. According to the Nemenyi posthoc analysis, Hybrid PSO-GA significantly outperformed GA (p = 0.0000) and PSO (p = 4.66 × 10−10), while GA and PSO remained statistically similar (p = 0.0712).
Figures 17 and 18 depict the statistical and convergence results. Corresponding numerical results are shown in Table 13.


| Algorithm | C1 | C2 | C3 | C4 | C5 | Mean | Standard deviation | Rank |
|---|---|---|---|---|---|---|---|---|
| GA | 0.021 | 0.753 | 0.116 | 0.269 | 0.053 | 0.839 | 0.028 | 3 |
| PSO | 0.007 | 0.816 | 0.078 | 0.262 | 0.075 | 0.861 | 0.012 | 2 |
| Hybrid PSO-GA | 0.005 | 0.960 | 0.042 | 0.183 | 0.058 | 0.874 | 0.008 | 1 |
Experiment C (Population: 100, Iterations: 200):
The final experiment in Set S-3 tests scalability under maximum computational allowance. Hybrid PSO-GA once again led with a mean fitness of 0.880 and a very low standard deviation of 0.003, reflecting strong optimization capabilities and stability at scale.
The Friedman test yielded a Chi-Square value of 91.0000 with a p-value of 0.0000, confirming significance. The Nemenyi test validated Hybrid PSO-GA’s advantage over both GA (p = 0.0000) and PSO (p = 1.14×10−7). Interestingly, even GA and PSO showed significant differences in this configuration (p = 1.87 × 10−4).
Figures 19 and 20 show the test results, with the raw performance scores summarized in Table 14.


| Algorithm | C1 | C2 | C3 | C4 | C5 | Mean | Standard deviation | Rank |
|---|---|---|---|---|---|---|---|---|
| GA | 0.015 | 0.937 | 0.097 | 0.143 | 0.041 | 0.861 | 0.017 | 3 |
| PSO | 0.001 | 0.949 | 0.061 | 0.191 | 0.049 | 0.875 | 0.006 | 2 |
| Hybrid PSO-GA | 0.004 | 0.998 | 0.016 | 0.219 | 0.014 | 0.880 | 0.003 | 1 |
Summary of experiment set S-3:
Throughout Experiment Set S-3, Hybrid PSO-GA outperformed both GA and PSO in all configurations, maintaining the highest mean fitness and lowest variance. The harmonic mean rank across the experiments as shown in Table 15 further emphasizes its consistent superiority.
This paper explores the use of metaheuristic algorithms for constrained decision-making, focusing on student performance optimization. Six key areas are identified for student workload optimization: Cognitive Capacity, Time Availability, Fatigue & Stress Levels and Task Complexity & Adaptability. These adaptable areas provide a flexible framework for optimization across various contexts.
A Hybrid PSO-GA (Particle Swarm Optimization - Genetic Algorithm) approach was employed to balance effort allocation among these areas. Multiple metaheuristic algorithms were tested and compared, with final results presented as the harmonic mean of multiple simulation runs to ensure reliability.
The statistical analysis in this study was conducted across three experimental sets (S-1, S-2, and S-3), each executed under three configurations with varying population sizes (25, 50, 100) and iteration counts (50, 100, 200). Each set compared the performance of Genetic Algorithm (GA), Particle Swarm Optimization (PSO), and the proposed Hybrid PSO-GA. The evaluation metrics included mean fitness value, standard deviation, and algorithmic rank, while statistical significance was assessed using the Friedman test and Nemenyi posthoc test. In all experiments, the Hybrid PSO-GA consistently achieved the highest mean fitness and the lowest standard deviation, maintaining a harmonic mean rank of 1.0 throughout. In Experiment Set S-1, the hybrid algorithm attained a peak mean fitness of 1.273 with a standard deviation of 0.004. Similar patterns were observed in Sets S-2 and S-3, where the maximum fitness values reached 1.098 and 0.880, respectively. The Friedman test results indicated statistically significant differences in performance (p-value = 0.0000) across all configurations. The Nemenyi test further confirmed that the Hybrid PSO-GA significantly outperformed both GA and PSO. At the same time, the performance gap between GA and PSO remained statistically insignificant in most cases, except under maximum computational resources. These findings collectively demonstrated the hybrid algorithm’s robustness, scalability, and superior optimization performance across various student workload evaluation scenarios.
Future research should focus on empirical validation with diverse datasets, refining weight calibration, and comparing traditional assessment models. Enhancing computational efficiency through selective optimization and parameter tuning could improve scalability. Additionally, integrating machine learning for automated calibration and analyzing longitudinal data may further refine dynamic constraints. Cross-domain applications in employee assessment and personalized healthcare could extend this framework’s utility.
This research was conducted in accordance with the highest standards of academic integrity and ethical responsibility. The study utilized only anonymized secondary data, with no direct involvement of human participants. As such, issues of informed consent or potential risk to individuals do not arise, and formal ethical approval was not required.
All datasets were handled responsibly, ensuring confidentiality, fairness, and compliance with institutional and international research ethics guidelines. The reporting of this study maintains transparency, accuracy, and integrity, in line with best practices for responsible research conduct.
The authors declare adherence to ethical guidelines for responsible research conduct, including avoidance of plagiarism, proper attribution of intellectual property, and accurate reporting of results.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)