Keywords
Medical Education, Generative Artificial Intelligence, Key Feature Problems
This article is included in the Artificial Intelligence and Machine Learning gateway.
Medical Education, Generative Artificial Intelligence, Key Feature Problems
Key Feature Problems (KFPs) are an established assessment tool in medical education, designed to evaluate clinical decision-making skills among medical students and practitioners. KFP focus on the “key features” of a clinical case, those critical steps or decisions that are most essential to managing the clinical case scenario effectively (Page et al., 1995). By concentrating on these pivotal elements, a KFPs offer a focused and efficient means of assessing learners’ clinical decisions in context, thereby bridging the gap between theoretical knowledge and practical application (Farmer & Page, 2005).
Incorporating KFPs into medical education supports the integration of foundational scientific knowledge with clinical practice. The application of basic science principles within clinical reasoning is fundamental to competent medical decision-making. KFPs facilitate this integration by requiring learners to apply their understanding of underlying scientific mechanisms when evaluating clinical scenarios (Farmer & Page, 2005; Nayer et al., 2018). This alignment ensures that students are not only acquiring factual knowledge but are also developing the capacity to apply that knowledge in nuanced, real-world clinical situations.
Moreover, the growing emphasis on clinical reasoning and self-directed learning in contemporary medical curricula underscores the relevance of KFPs. As assessment tools, KFPs are well-suited to evaluating higher-order thinking skills and have demonstrated reliability and validity in this domain (Farmer & Page, 2005). By simulating authentic clinical decisions, KFPs support the development of critical thinking, promote problem-solving, and prepare learners to handle clinical complexity with confidence (Farmer & Page, 2005; Nayer et al., 2018).
Developing high-quality Key Feature Problems (KFPs) questions presents several challenges, particularly in ensuring clinical accuracy, curricular alignment, and educational relevance. Unlike traditional multiple-choice questions, KFPs aim to assess clinical decision-making skills through context-rich scenarios that mirror real-life practice, making their construction inherently complex (Nayer et al., 2018).
Clinical accuracy is essential for maintaining the quality and integrity of assessments. A KFP often span multiple disciplines and include nuanced decision points; therefore, any factual inaccuracies can compromise validity and undermine the assessment of decision-making skills. With the rapid evolution of medical knowledge, it is essential to regularly update KFPs content to reflect current guidelines and best practices (Farmer & Page, 2005; Nayer et al., 2018).
Effective KFP design requires alignment with clearly defined learning outcomes. Each scenario should target specific competencies expected of learners, thereby reinforcing curricular goals and ensuring that assessment remains educationally relevant (Nayer et al., 2018). This is especially critical within the framework of competency-based medical education (CBME), where the emphasis is on demonstrable, practice-ready skills rather than rote memorization (Connor et al., 2020). When strategically embedded across the curriculum, KFP offer longitudinal reinforcement of essential clinical competencies, supporting both horizontal and vertical integration of knowledge.
KFPs also offer opportunities to promote and evaluate ethical reasoning and professionalism. By incorporating patient-centered dilemmas or moral conflicts, KFPs can assess not only technical knowledge but also character formation and decision-making in ethically complex situations (Andrade et al., 2024).
Authenticity is a defining characteristic of effective KFPs. Scenarios should reflect real-world clinical contexts, be appropriately pitched to the learner’s stage of training, and avoid cognitive overload. Appropriately scaffolded cases enhance engagement, reduce anxiety, and improve confidence (Nayer et al., 2018). Emphasizing decision points related to diagnosis, management, and follow-up reinforces the transfer of knowledge to clinical settings (Hrynchak et al., 2014).
Finally, eliminating extraneous information is critical. Irrelevant details can distract learners from key issues, increase cognitive load, and hinder performance. Streamlined scenarios sharpen focus on the essential decisions, promoting efficient and accurate reasoning skills vital in high-stakes clinical environments. Well-crafted KFPs thus strike a balance between realism, challenge, and educational purpose, serving as a robust tool for developing and evaluating clinical reasoning throughout medical training (Nayer et al., 2018).
Artificial intelligence is reshaping medical education through adaptive, data-informed tools that can strengthen both learning and assessment. Generative models, including large language models and simulation platforms, can rapidly produce realistic Key Feature Problems that align with explicit learning outcomes, match intended cognitive levels, and reflect authentic clinical contexts. This capacity accelerates the creation of item banks while supporting coherence with curricular blueprints and competency frameworks (Indran et al., 2024; Qiu & Liu, 2025).
Beyond item drafting, AI enables innovations that are directly relevant to KFPs design and use. Systems can generate virtual patients and interactive clinical vignettes that situate key decisions within believable settings, which promotes transfer of reasoning across variants and settings (Potter & Jefferies, 2024; Sardesai et al., 2024). AI-supported analytics can provide real-time or near-real-time feedback, surface common reasoning errors, and personalize practice based on learner performance patterns, thereby improving formative value and supporting programmatic assessment (Mishra et al., 2024). Exposure to these tools also advances AI literacy, a competency that future clinicians increasingly require (Subaveerapandiyan et al., 2024).
Once deployed, AI can assist with continuous quality improvement of KFPs. Models can analyze response data to detect weak distractors, ambiguous wording, and miscalibrated difficulty, then propose targeted revisions for expert review. Where governance and privacy protections are in place, linkage to de-identified clinical data or the use of synthetic datasets can further enhance authenticity by anchoring scenarios in realistic patterns of presentation and management. However, such integrations require careful oversight by institutions and remain context-dependent (Blau et al., 2024).
These opportunities come with risks that must be actively managed. Generative systems can hallucinate facts, propagate outdated guidelines, and encode or amplify social and clinical biases. Responsible adoption, therefore, requires transparent processes, faculty development, and explicit ethical and data governance frameworks. Human subject matter expertise remains essential for verifying clinical accuracy, ensuring fairness, calibrating cognitive demand, and protecting item security (Franco D’Souza et al., 2024; Tolsgaard et al., 2023).
In sum, strategic use of AI offers a scalable and evidence-informed approach to designing, validating, and iteratively improving KFPs. The following ten tips translate these opportunities and caution into concrete steps that educators can apply to create high-quality, learner-appropriate, and ethically sound KFPs.
We developed the ten tips through a staged process that combined theory, existing assessment standards, and iterative Subject-Matter Expert (SME) review. First, we mapped recurrent problems in AI-generated KFPs (construct drift, shallow recall, unsafe feedback, weak item documentation) against established assessment sources in medical education (key-feature literature, blueprinting and OSCE validation guidance, Messick-style (1995) validity argumentation). From this mapping we kept only frameworks that could be implemented in low- and medium-stakes contexts and that preserved the key-feature construct. Second, we used AI to draft multiple versions of each tip (purpose, action, example), then circulated these drafts to SME (assessment and clinical) to remove clinically unsafe suggestions, localize to GCC (Gulf Cooperation Council) countries practice, and align with curriculum learning outcomes’. Third, we trialed the tips on real AI outputs to see which ones actually improved item quality; tips that did not change SME ratings were merged or dropped. The final ten tips, therefore, represent the set that was (a) evidence-attuned, (b) feasible for routine faculty use, and (c) auditable through the adapted 5-step validation workflow.
This section provides ten practical and evidence-informed tips to help medical educators integrate generative AI into the design of KFPs. Each tip is aimed at ensuring that AI-generated questions are pedagogically sound, clinically relevant, and aligned with curricular goals. By applying these strategies, educators can enhance the quality of assessment tools used to evaluate clinical decision-making, while also improving the efficiency of content development.
Before using generative AI to develop Key Feature Problems (KFPs), educators should first define clear, measurable learning outcomes and derive the corresponding key features. Key features represent the critical decisions or actions that determine effective clinical management (Farmer & Page, 2005; Nayer et al., 2018). Establishing these foundations ensures that AI-generated content is grounded in explicit educational intent and that each scenario targets competencies essential to clinical reasoning. Developing learning outcomes and key features in advance prevents the creation of unfocused or misaligned cases and supports validity by ensuring that each question assesses a decision point directly related to the intended outcome.
Once the initial key features are identified, AI can assist in refining and expanding them. By analyzing large datasets or educational case repositories, AI can identify additional high-yield decision points that may not be apparent through manual analysis. Drawing upon diverse clinical information allows educators to uncover patterns and associations that enhance authenticity and completeness. This process strengthens alignment between curricular objectives and the reasoning steps that differentiate expert from novice performance (Farmer & Page, 2005; Nayer et al., 2018).
Example 1:
Learning Objective:
Demonstrate the ability to diagnose and manage acute asthma in adult patients.
Identified Key Features:
1. Assess severity of the asthma exacerbation.
2. Initiate immediate treatment.
3. Decide on patient disposition (admitting or discharge).
AI-Generated Case (Short Clinical Vignette):
A 30-year-old patient presents to the emergency department with shortness of breath and audible wheezing for the past two hours. The patient has a known history of asthma and seasonal allergies.
Key Feature Questions:
1. (Write-in) What two clinical assessments are most important for determining the severity of this exacerbation?
2. (Short-menu) Select the three most appropriate immediate treatments:
• Inhaled β2-agonist
• Systemic corticosteroid
• Oxygen therapy
• Antibiotic therapy
• Antihistamine
3. (Short-menu) Which criteria would guide your decision to discharge the patient? (Select all that apply.)
This sequence (learning outcome → key features → case → questions) illustrates the structured logic of KFP design and specifies the item format and number of responses required, consistent with established methodology (Farmer & Page, 2005; Nayer et al., 2018).
Example 2:
Educators who identify preliminary key features for managing acute chest pain, such as:
1. Obtaining an appropriate history and identifying red-flag symptoms,
2. Initiating essential diagnostic investigations, and
3. Deciding on immediate management priorities, can use AI tools to refine and extend these features.
Large language models may reveal additional decision points, including:
• Differentiating cardiac from non-cardiac causes (for example, pulmonary embolism or aortic dissection).
• Recognizing atypical presentations in diabetic or female patients.
• Applying Risk Stratification Tools in clinical decision making.
These refinements help ensure that the resulting KFPs capture a broader spectrum of clinical complexity and reflect authentic decision-making challenges encountered in practice (Farmer & Page, 2005; Nayer et al., 2018).
Note: KFPs may be presented as write-in or short-menu (SM) items. In SM formats, response options and the number of required selections must always be explicitly stated. At this stage, AI assists in improving the quality and breadth of key features, but the educator retains responsibility for selecting which AI-suggested features to include when constructing the final clinical vignette and corresponding questions.
Creating realistic and contextually grounded clinical scenarios is essential to the educational value of KFPs. Once key features have been identified and refined, generative AI can be used to construct authentic vignettes that situate these decisions within believable clinical contexts (Berbenyuk et al., 2024; Qiu & Liu, 2025). By incorporating relevant demographic, environmental, and psychosocial details, AI helps simulate the complexity of real-world medical encounters (Potter & Jefferies, 2024; Sardesai et al., 2024).
AI tools can also vary contextual parameters, such as disease stage, comorbidities, or resource limitations, to produce multiple versions of the same case. This contextual diversity strengthens students’ ability to transfer reasoning across scenarios and enhances case authenticity without adding to faculty workload (Berbenyuk et al., 2024; Indran et al., 2024).
Example:
AI-Enhanced Realistic KFP Scenario (Short Vignette)
Mr. Ali K., a 58-year-old taxi driver with long-standing hypertension and type 2 diabetes, arrives at a community clinic complaining of mild chest discomfort radiating to his jaw. He reports the pain began after climbing stairs 30 minutes ago and has gradually subsided. He takes metformin and amlodipine irregularly. Vital signs: BP 160/95 mmHg, HR 88 bpm, SpO2 97%, BMI 31 kg/m2. The nearest hospital is 25 km away.
Key Feature Questions:
1. (Write-in) What initial clinical assessments are essential before deciding whether this patient can safely remain in the clinic? List up to two.
2. (Short-menu) What are the two most critical diagnostic tests to confirm your leading diagnosis? List up to two.
• 12-lead ECG
• Cardiac troponin I
• Chest X-ray
• D-dimer
3. (Short-menu) Which management action should be taken immediately? (Select one.)
• Administer oral Aspirin and arrange urgent transfer
• Begin oral antihypertensive therapy and review next week
• Provide reassurance and schedule stress test
By prompting AI to integrate demographic, psychosocial, and logistic details, educators can generate scenarios that are not only clinically coherent but also contextually realistic (Potter & Jefferies, 2024; Qiu & Liu, 2025). Such authenticity strengthens cognitive fidelity, meaning that decisions made in the scenario closely mirror real clinical reasoning, thereby enhancing learners’ engagement and readiness for practice (Preiksaitis & Rose, 2023; Sardesai et al., 2024).
Note: While AI can enhance realism, each generated scenario must undergo expert review to verify clinical accuracy and appropriateness for the target learner level (Farmer & Page, 2005; Nayer et al., 2018).
Generative AI can be strategically used to create multiple, pedagogically distinct versions of clinical scenarios centered on the same medical condition. This approach promotes both educational richness and psychometric robustness by exposing learners to varied but conceptually equivalent challenges (Berbenyuk et al., 2024; Indran et al., 2024).
By varying contextual elements such as patient demographics, comorbidities, access to resources, and disease stage, AI helps educators design cases that assess the transfer of learning rather than rote recall (Hrynchak et al., 2014). For instance, a single learning outcome on “acute coronary syndrome management” can be represented through different case variants: a young woman with atypical chest pain, an elderly diabetic with silent ischemia, or a middle-aged smoker with classic symptoms. Each variant targets the same underlying key features but tests adaptive reasoning in distinct contexts (Farmer & Page, 2005; Nayer et al., 2018).
AI can also support psychometric balance by generating parallel cases matched on cognitive level and difficulty, aiding blueprinting and longitudinal assessment across cohorts (Indran et al., 2024). Through controlled prompting, educators can maintain item equivalence while ensuring content freshness and reduced cueing effects. This capacity is especially useful for formative assessments, progress tests, and multi-institutional benchmarking.
Example:
Learning Objective: Manage patients presenting with myocardial infarction.
Common Key Features:
1. Identify ischemic symptoms and risk factors.
2. Interpret ECG and cardiac biomarkers.
3. Initiate evidence-based acute management.
By generating structured variants like these, AI helps educators evaluate consistency in reasoning across different contexts while maintaining construct validity. Moreover, such diversity supports inclusivity, ensuring exposure to a range of patient profiles and system-level challenges (Mishra et al., 2024; Teferi et al., 2023).
When educators vary contextual parameters such as disease stage, comorbidities, or resource limitations, AI can produce multiple case versions to strengthen transfer of reasoning ( Table 1).
Note: Each AI-generated variant should be reviewed for alignment with curricular outcomes and calibrated for difficulty using item analysis or expert consensus (Farmer & Page, 2005; Nayer et al., 2018).
Effective KFPs go beyond factual recall and assess a learner’s ability to analyze, synthesize, and evaluate complex clinical information at the upper levels of Bloom’s taxonomy (Zaidi et al., 2018). Generative AI can assist educators in scaffolding these higher-order cognitive processes by helping design questions that explicitly demand interpretation, prioritization, and reasoning rather than mere recognition (Berbenyuk et al., 2024; Indran et al., 2024).
By adjusting prompts and parameters, educators can use AI to generate versions of KFP that target specific cognitive levels, for example, distinguishing between tasks that ask students to identify key findings (lower order) and those that require them to justify management decisions or evaluate competing interventions (higher order) (Farmer & Page, 2005; Nayer et al., 2018). This calibrated complexity enhances both formative and summative assessment design within competency-based curricula (Jantausch et al., 2023).
AI can also suggest reasoning scaffolds such as stepwise justification prompts, conditional branching, or “what-if” variations that help learners articulate the logic behind their choices. When combined with faculty validation, these features turn KFPs into active reasoning exercises that closely resemble real-world diagnostic and management decision-making (Araújo et al., 2024).
Example:
Learning Objective: Apply critical reasoning to prioritize diagnostic steps in a patient with acute shortness of breath.
Key Features:
1. Interpret initial presentation and vital signs.
2. Identify the most urgent diagnostic investigation.
3. Evaluate management priorities based on evolving information.
AI-Generated Higher-Order Question Sequence
1. (Write-in) Based on this patient’s presentation, what is your leading differential diagnosis? List up to two.
2. (Short-menu) Select the two investigations that will most efficiently confirm your diagnosis.
3. (Write-in) The chest X-ray reveals a right-sided pneumothorax. Outline the next two management steps and justify their sequence.
This structure progresses from analysis to evaluation, showing how AI can scaffold increasing levels of cognitive complexity within a single clinical context.
By refining prompts to elicit reasoning, educators ensure that AI-generated KFP assess how students think, not just what they know (Araújo et al., 2024; Jantausch et al., 2023).
Note: While AI can help generate cognitively rich content, final validation by subject-matter experts is essential to confirm that each question targets the intended cognitive level and aligns with learning outcomes (Farmer & Page, 2005; Nayer et al., 2018).
Generative AI can accelerate the development of draft Key Feature Problems (KFPs), but educator oversight remains essential to ensure that items are constructively aligned with curricular outcomes, competency frameworks, and learner progression (Farmer & Page, 2005; Harden et al., 1999). AI-generated content should also be contextualized to the institution’s clinical setting, patient population, and healthcare realities, enhancing authenticity and local relevance (Berbenyuk et al., 2024; McLaughlin et al., 2019).
Item complexity must match the learner’s cognitive and experiential readiness. Early-phase students benefit from single-decision questions emphasizing recognition, while advanced learners should tackle multi-step cases demanding integration and prioritization (Farmer & Page, 2005; Nayer et al., 2018). AI can scaffold difficulty by varying diagnostic ambiguity, patient stability, or data availability, supporting progressive learning across preclinical and clinical phases (Berbenyuk et al., 2024; Indran et al., 2024; Tolsgaard et al., 2023).
An illustrative example of progressive complexity across learner levels focused on managing diabetic ketoacidosis (DKA) is provided in Table 2. This example demonstrates how item difficulty can be structured according to learner competence, from early recognition to advanced management and prioritization.
AI can further diversify assessment by reformatting a single clinical concept into multiple item types, such as short-answer, extended-matching, or multiple-response questions, while maintaining the same cognitive intent (Indran et al., 2024; Javaeed, 2018). This enhances reliability and fairness by sampling reasoning across modalities and supports triangulation in programmatic assessment frameworks (Connor et al., 2020; Fatima et al., 2024; Tolsgaard et al., 2023).
Example:
A 28-year-old man presents with sudden onset of severe shortness of breath after a long-haul flight. He is tachycardic and mildly hypoxic.
Original KFP:
What is the most likely diagnosis, and what is the next immediate investigation? (Write-in ).
An illustrative transformation of a single vignette into multiple formats is provided in Table 3.
By aligning complexity, format, and learner stage, AI enables coherent and longitudinal assessment design that reinforces stage-appropriate competencies while maintaining curricular coherence (Berbenyuk et al., 2024; Harden et al., 1999; Indran et al., 2024).
Note: While AI can automate scaffolding and reformatting, faculty judgment remains indispensable to verify that each item accurately represents the intended cognitive process and meets clinical and psychometric standards (Farmer & Page, 2005; Nayer et al., 2018).
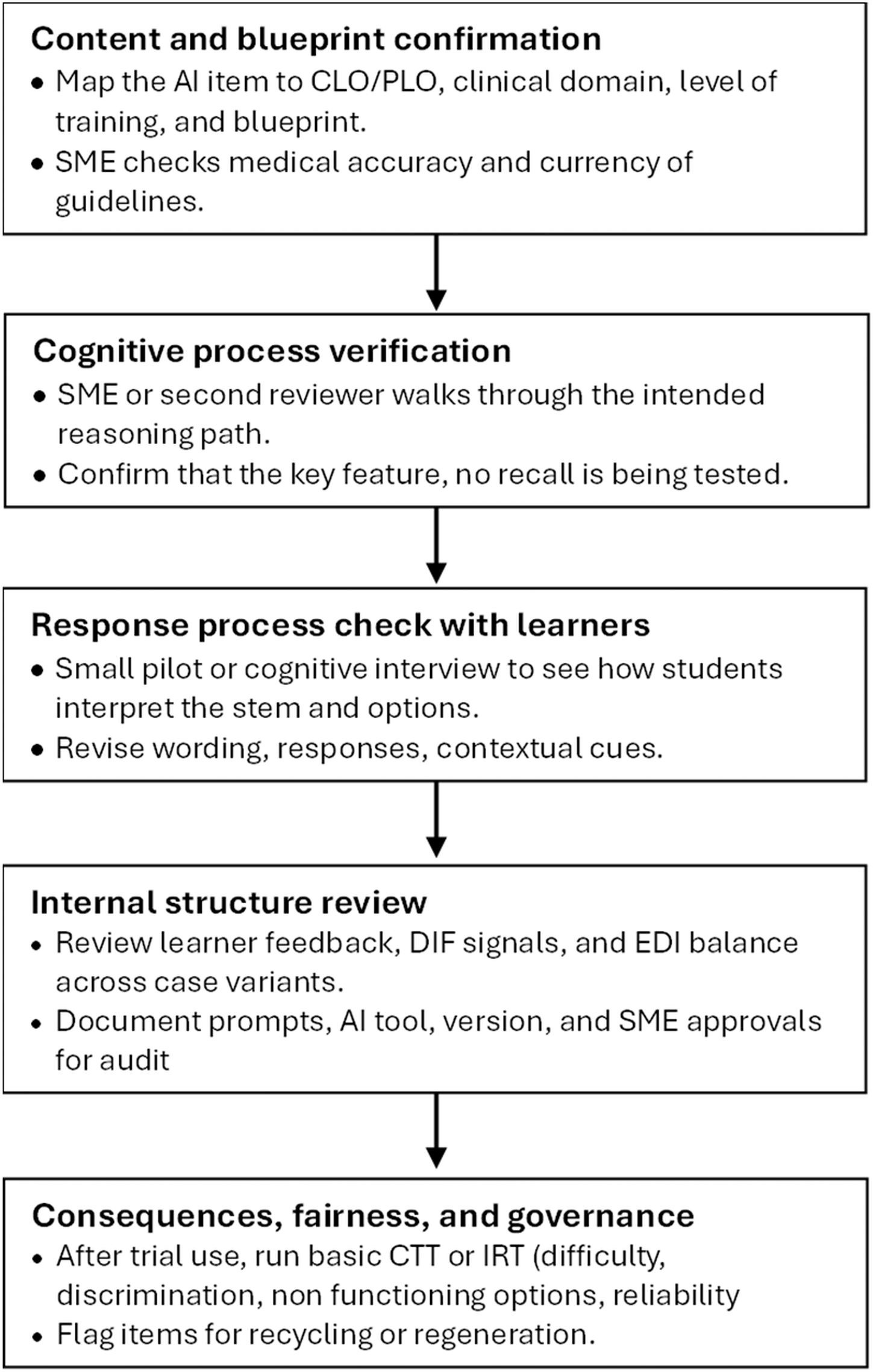
The rapid generation of KFPs by generative AI demands a structured and defensible validation process to ensure that the resulting items meet accepted standards of quality, fairness, and educational relevance. To address this need, we adapted an evidence-based framework for validating AI-generated assessment content, drawing upon widely recognized validity models from Messick (1995), Kane (2013), Downing (2002), and Cook et al. (2015).
This adapted process integrates principles of content validity, cognitive process verification, response process accuracy, internal structure coherence, and consequential validity, contextualized for AI-assisted item generation (Farmer & Page, 2005; Nayer et al., 2018; Tolsgaard et al., 2023). It provides educators with a transparent and replicable structure for reviewing and approving AI-generated questions prior to implementation ( Table 4).
| Stage | Purpose | Validation evidence/Method | Source framework |
|---|---|---|---|
| 1. Content Validation | Ensure alignment with curriculum outcomes and intended learning objectives. | SME review for relevance, accuracy, and blueprint mapping. | (Downing, 2002; Messick, 1995) |
| 2. Cognitive Process Validation | Confirm that questions elicit the intended reasoning steps (analysis, synthesis, evaluation). | Think-aloud or expert cognitive walkthrough of each question’s reasoning pathway. | (Cook et al., 2015) |
| 3. Response Process Validation | Verify that the expected student response corresponds to the key decision or action. | Pilot testing with small student sample; collect verbal feedback. | (Cook et al., 2015; Kane, 2013) |
| 4. Internal Structure Validation | Examine psychometric properties (difficulty, discrimination, reliability). | Post-administration item analysis (CTT or IRT). | (Cook et al., 2015; Downing, 2004) |
| 5. Consequential Validation | Evaluate educational impact and fairness. | Review of learner performance data, feedback, and potential bias in AI outputs. | (Messick, 1995) |
This structured approach does not replace psychometric analysis but provides a pragmatic validity chain that educators can apply before large-scale deployment. Each step contributes evidence toward construct validity, ensuring that AI-generated KFPs assess genuine clinical reasoning rather than superficial pattern recognition (Farmer & Page, 2005; Nayer et al., 2018; Wade et al., 2012).
The overall process is visualized in Figure 1, which outlines the adapted five-step validation workflow for AI-generated assessment items.
Example Application:
Suppose AI generates a KFP on managing community-acquired pneumonia.
• Stage 1: SMEs confirm the key features (diagnosis, antibiotic choice, admission criteria) match curricular outcomes.
• Stage 2: Cognitive walkthrough reveals the item requires decision-making rather than recall.
• Stage 3: A pilot group of students completes the item; feedback confirms clarity of question intent.
• Stage 4: Item analysis after pilot shows appropriate difficulty (p = 0.65) and discrimination (r = 0.32).
• Stage 5: Post-assessment debrief confirms students perceived the question as realistic and fair.
Note: The five-step validation process is an adaptation of established assessment validity frameworks (Cook et al., 2015; Downing, 2002; Kane, 2013; Messick, 1995), contextualized for the use of generative AI in question development. It aims to provide a practical quality-assurance model for educators rather than propose a novel psychometric paradigm.
Effective feedback in KFPs must be decision-specific, concise, and actionable, focusing on each key feature rather than the case as a whole (Farmer & Page, 2005; Hrynchak et al., 2014; Nayer et al., 2018). Well-designed feedback helps learners understand why a particular decision is correct and why alternatives are less appropriate. Generative AI can assist in drafting such targeted feedback rapidly, but its output must always undergo SME review to verify clinical accuracy, tone, and contextual sensitivity (Farmer & Page, 2005; Nayer et al., 2018; Zhang et al., 2025).
Generative AI can be prompted to produce feedback at different levels of granularity, as summarized in Figure 2, which illustrates how prompts can generate decision-specific feedback messages tailored to each key feature.
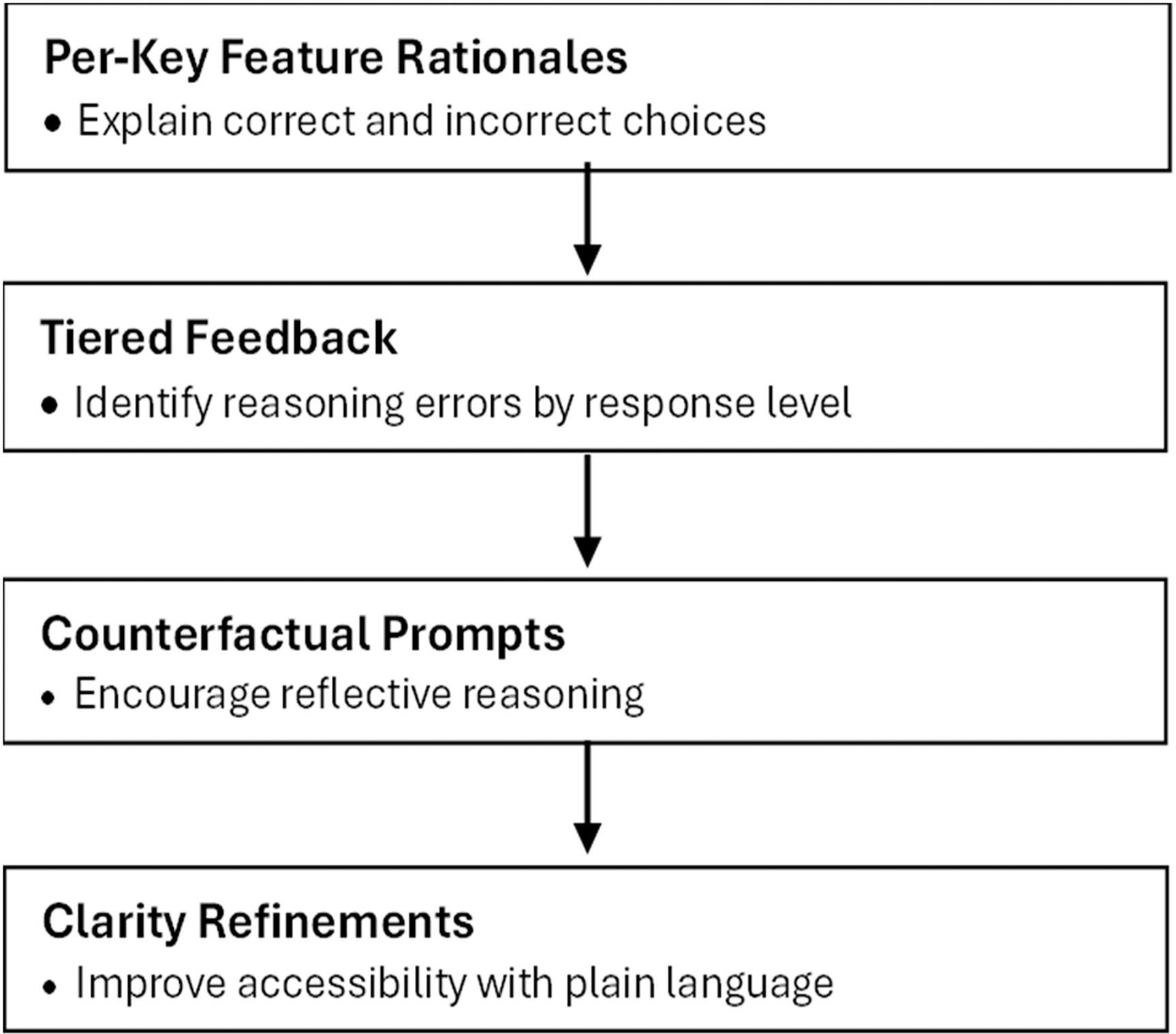
Per-key feature rationales explaining both correct and incorrect choices, particularly valuable for short-menu (SM) items where learners must select a specified number of responses (Farmer & Page, 2005; Nayer et al., 2018).
• Tiered feedback messages for correct, partially correct, and incorrect responses that identify common reasoning errors and suggest appropriate next steps in decision-making (Burner et al., 2025; Lee & Moore, 2024).
• Counterfactual prompts, such as “What if the patient were hypotensive?”, which encourage reflective reasoning without revealing the answer (Burner et al., 2025; Lee & Moore, 2024).
• Clarity refinements using plain-language summaries or controlled length limits to improve accessibility for diverse learners (Burner et al., 2025; Lee & Moore, 2024).
Timing also matters. For formative KFP, immediate, key feature level feedback enhances learning efficiency and self-regulation (Burner et al., 2025; Lee & Moore, 2024). For summative KFP, delayed or aggregate feedback preserves item security while still supporting post-exam reflection (Farmer & Page, 2005; Nayer et al., 2018).
Despite its efficiency, AI-generated feedback may lack nuance and contextual sensitivity in complex or atypical cases, which highlights the need for human oversight, particularly in edge scenarios (Burner et al., 2025). SMEs should verify that AI feedback accurately targets the intended reasoning process and does not introduce misleading or unsafe guidance.
Illustrative Example (Write-in + Short-Menu with Feedback)
Scenario (abridged): A 28-year-old presents with fever, headache, and neck stiffness.
KF-Q1 (write-in): What is the most likely diagnosis?
• Correct feedback: “Bacterial meningitis is most consistent with fever and neck stiffness; treat urgently with empiric antibiotics.”
• Partially correct (‘viral meningitis’): “Consider illness severity and urgency of treatment—what findings suggest bacterial rather than viral?”
KF-Q2 (SM; select 2): Which initial diagnostic investigations are required?
Continuous improvement of AI-generated KFPs depend on systematic analysis of response data and psychometric evidence. Educators should employ both quantitative and qualitative data to identify items that require revision, strengthening validity, reliability, and alignment with learning outcomes (Farmer & Page, 2005; Kim et al., 2022; Nayer et al., 2018; Tolsgaard et al., 2023).
Data sources include item statistics from pilot tests (difficulty, discrimination, non-functioning options) and learner feedback on clarity and realism. When analyzed together, these indicators reveal whether each KFP effectively assesses the intended decision point (Almansour & Alfhaid, 2024; Tolsgaard et al., 2023). For example, very low discrimination may indicate that the question does not differentiate between competent and struggling learners, while an unexpectedly high success rate may suggest over-cueing or insufficient cognitive demand (Kim et al., 2022).
AI can support this process by generating revised item versions based on educator feedback or psychometric findings. Prompted appropriately, the model can reword stems for clarity, modify distractors for plausibility, or adjust contextual parameters to correct misalignment (Berbenyuk et al., 2024; Indran et al., 2024). These revisions must then be revalidated by SMEs before reuse.
Illustrative Example (KFP Improvement via Data Review)
Original AI-Generated KFP (Pre-Revision)
Scenario: A 35-year-old patient presents with pleuritic chest pain and mild dyspnea.
Question (Write-in): What is the most likely diagnosis?
Issue: Student response data showed poor discrimination (r = 0.05); many misidentified pneumonia or pneumothorax.
Data Insight: Qualitative feedback revealed insufficient contextual clues to differentiate pulmonary embolism from other causes of chest pain.
Revised KFP (Post-Review)
Scenario: A 35-year-old female on oral contraceptives presents with sudden pleuritic chest pain and mild dyspnea after a 10-hour flight.
Question (Write-in): What is the most likely diagnosis?
Rationale: Added risk factor and temporal trigger clarified the intended decision focus (PE) without making the question easier. SME review confirmed improved alignment and realism.
This example demonstrates how data-driven iteration enhances clarity, construct validity, and clinical authenticity (Farmer & Page, 2005; Nayer et al., 2018). The implementation steps for this iterative process are illustrated in Figure 3, which presents the data-driven KFP improvement workflow.
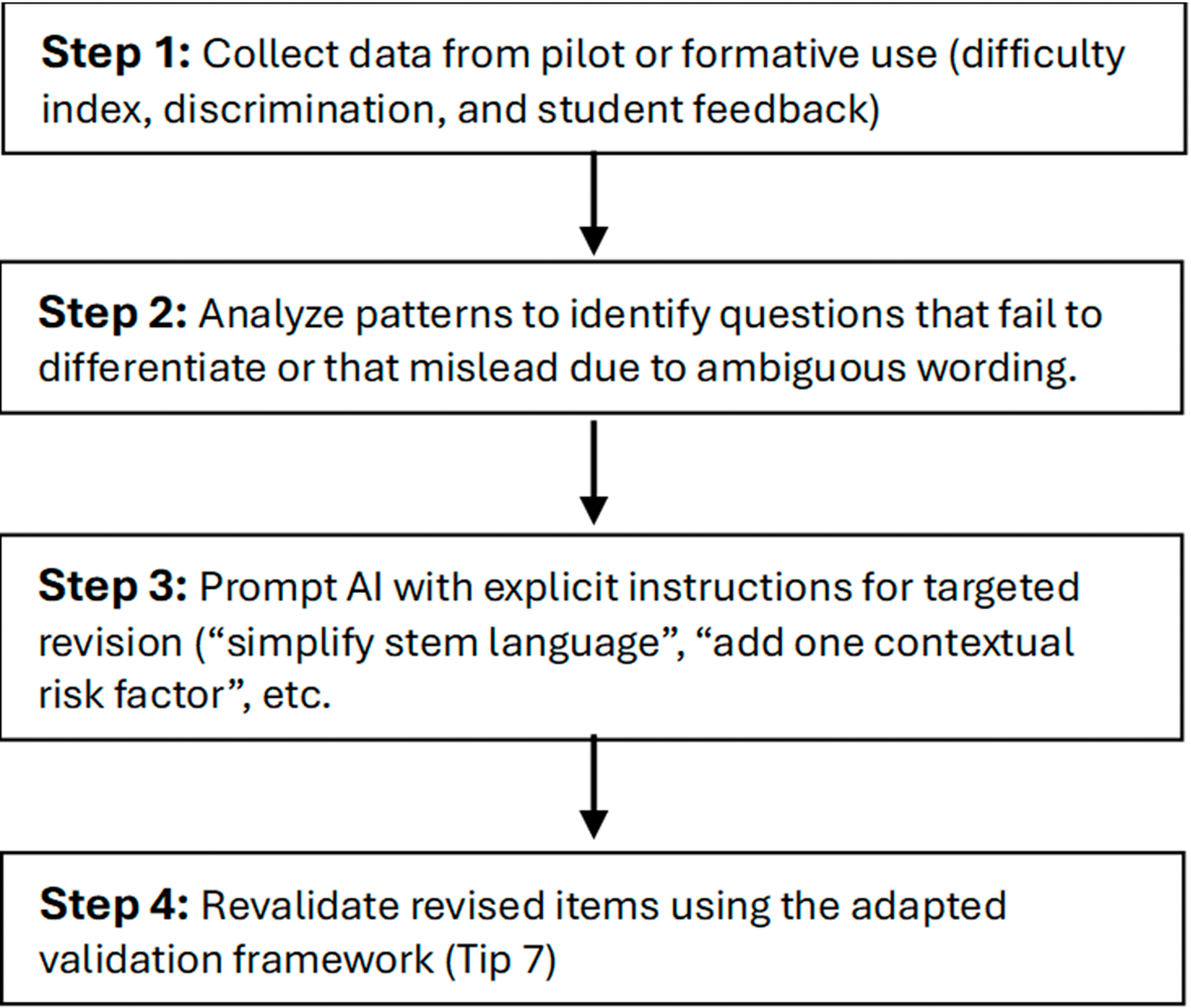
Implementation Steps for Data-Driven KFP Improvement
1. Collect data from pilot or formative use (difficulty index, discrimination, and student feedback).
2. Analyze patterns to identify questions that fail to differentiate or that mislead due to ambiguous wording.
3. Prompt AI with explicit instructions for targeted revision (“simplify stem language,” “add one contextual risk factor,” etc.).
4. Revalidate revised items using the adapted validation framework (Tip 6).
5. Re-analyze post-revision metrics before including items in summative pools (Farmer & Page, 2005; Nayer et al., 2018; Tolsgaard et al., 2023).
Note: This process focuses solely on psychometric and content improvement. Considerations of inclusivity and bias mitigation are addressed separately (see Tip 10).
Equity, diversity, and inclusion (EDI) are essential principles in assessment design. In the context of Key Feature Problems (KFP), EDI ensures that all learners engage with clinically authentic yet culturally fair scenarios that reflect the diversity of real-world patient populations (Kim et al., 2024; Tolsgaard et al., 2023). When generative AI is used to create KFP, additional vigilance is required to prevent the unintentional introduction or amplification of bias in case content, patient descriptors, or reasoning expectations (Kim et al., 2024; Rodman et al., 2024).
Identify and Mitigate Potential Bias in AI Outputs
AI models can inadvertently reproduce societal or dataset biases, leading to stereotypical patient profiles, imbalanced demographic representation, or culturally narrow assumptions (Kim et al., 2024).
To prevent this, educators should:
• Audit AI-generated cases for demographic balance across age, gender, ethnicity, and socioeconomic background.
• Remove stereotypical associations (e.g., linking certain diseases disproportionately to specific ethnic groups without epidemiological justification).
• Diversify contextual variables, such as healthcare setting, geographic region, and access to resources, to mirror real-world practice diversity (Tolsgaard et al., 2023).
• Involve diverse faculty reviewers and learners in item validation to surface biases that might be invisible to homogeneous panels (Rodman et al., 2024).
Promote Inclusive Case Representation
EDI-aligned KFP should expose learners to the breadth of human variation and social determinants that influence diagnosis and management. AI can assist by generating case variants that represent different demographic or psychosocial contexts while maintaining equivalent cognitive challenge (Berbenyuk et al., 2024; Kim et al., 2024).
For example, a case on myocardial infarction can be rendered across:
• A younger female with atypical presentation,
• An older diabetic male with silent ischemia, and
• A rural patient with delayed access to emergency care.
Such diversity fosters equitable preparedness and reduces bias in clinical decision-making (Kim et al., 2024; Rodman et al., 2024; Tolsgaard et al., 2023).
To operationalize inclusivity in AI-assisted KFP design, educators should follow a structured EDI review sequence illustrated in Figure 4, which outlines the bias-mitigation checkpoints during AI generation and validation.
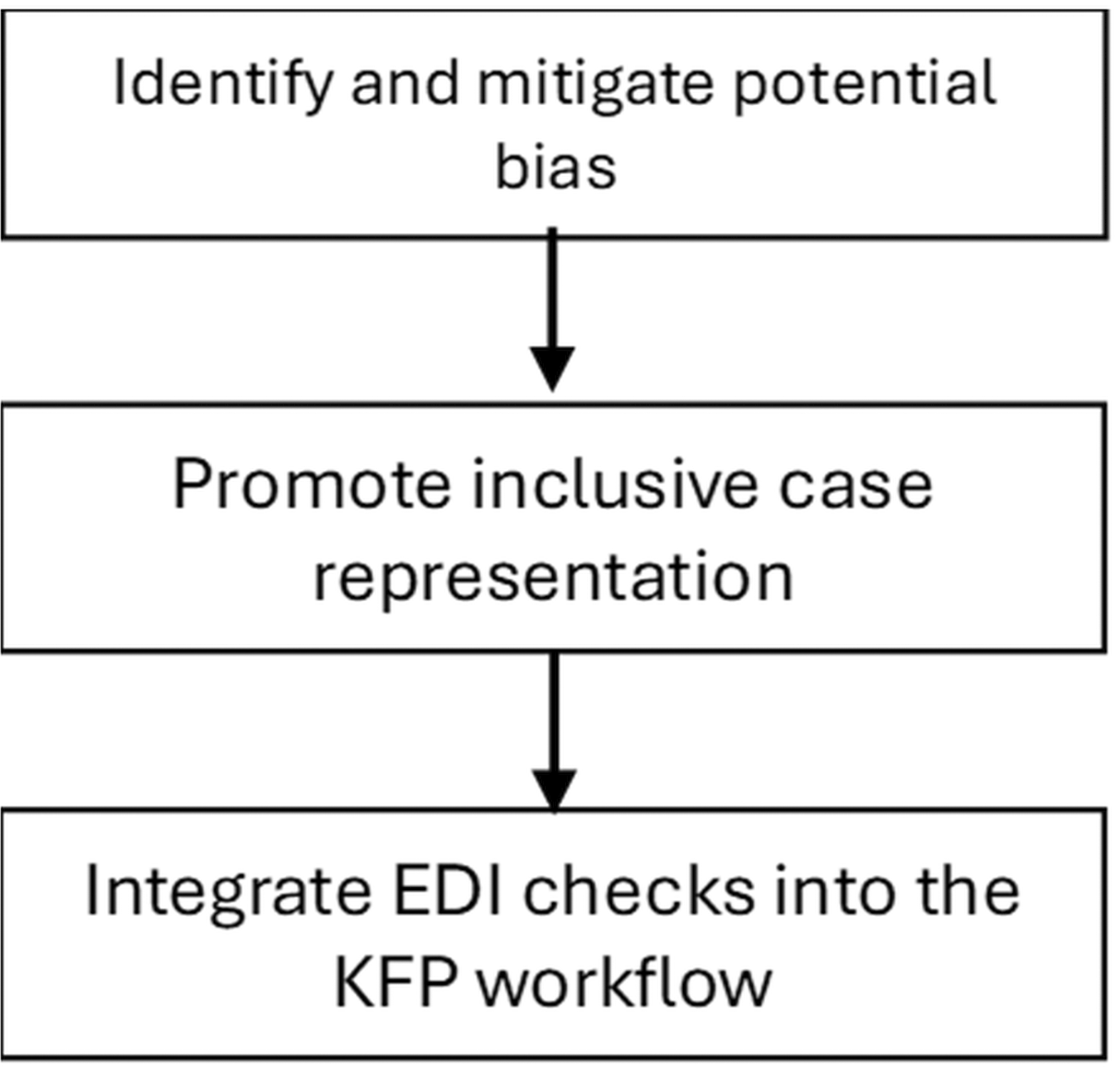
Integrate EDI Checks Into the KFP Workflow
To operationalize inclusivity in AI-assisted KFP design:
1. Set EDI parameters before prompting AI, specifying desired demographic distribution and case diversity.
2. Review all generated content with an EDI checklist (representation balance, language neutrality, accessibility).
3. Pilot-test questions across mixed learner groups to identify differential performance that could signal construct-irrelevant bias (Rodman et al., 2024; Tolsgaard et al., 2023).
4. Document revisions and maintain transparency about the EDI review process as part of assessment governance.
Original AI Output:
A 45-year-old South Asian man with poorly controlled diabetes presents with chest pain after eating a heavy meal.
Issue: The AI model consistently associated “South Asian” with “diabetes,” reinforcing a stereotype without instructional purpose.
Revised Prompt and Case:
Generate a case of a 45-year-old adult presenting with chest pain unrelated to ethnicity. Include relevant lifestyle and risk factors.
Result: The AI produced a balanced scenario highlighting modifiable risks (sedentary lifestyle, hypertension) rather than cultural identity, aligning better with fairness and learning objectives.
Note: EDI alignment is not a single review step but a continuous design principle that parallels psychometric validation. Each AI-generated KFP should undergo both content and equity review before use to ensure fairness, representation, and clinical authenticity (Kim et al., 2024; Rodman et al., 2024).
Use existing pre-trained models rather than developing new ones. Concentrate faculty effort on prompt design, SME review, and validity checks so AI output meets curricular and clinical standards (Berbenyuk et al., 2024; Kovari, 2024; Tolsgaard et al., 2023).
Document for auditability. For each item, record the tool/model and version used, prompt template (and key settings), SME comments, and validation outcomes (see Tip 6). This enables reproducibility and external review by faculty and accreditors (Kovari, 2024; Rodman et al., 2024; Tolsgaard et al., 2023).
Protect boundaries. Never upload identifiable learner or patient data to external tools; clarify authorship when AI contributes text or drafts; require human sign-off on all exam materials (Kovari, 2024; Tolsgaard et al., 2023).
Build capacity. Provide ongoing faculty development in responsible prompting, data stewardship, and bias awareness so that AI augments educational expertise rather than replacing it (Berbenyuk et al., 2024; Indran et al., 2024; Kovari, 2024; Tolsgaard et al., 2023).
Be pragmatic about clinical data. Until secure educational data environments mature, prefer synthetic or de-identified sources and simulated EHR interfaces; full interoperability with real systems is generally not feasible yet (Blau et al., 2024; Razmi, 2024; Tolsgaard et al., 2023).
Quick checklist (for your item bank record):
• Tool/model + version
• Prompt template/context
• SME reviewers + decisions
• Validation evidence (per Tip 6)
• Data handling and disclosure notes
This keeps AI use ethical, transparent, and sustainable while preserving assessment integrity.
A consolidated overview of all ten tips summarizing their purposes, recommended educator actions, and common pitfalls is presented in Table 5.
• Start with outcomes and key features; keep AI inside those boundaries.
• Build realism and parallel variants to test transfer, not recall.
• Calibrate complexity and format to learner level, then validate with a simple 5-step chain.
• Feedback must be decision-specific; use post-delivery data to iterate.
• Bake in EDI checks to avoid bias and construct-irrelevant variance.
• Treat AI as an assistant: document tools, prompts, SME decisions, and data-handling; never upload identifiable data.
This paper is intended as a practice-oriented guide rather than an empirical or psychometric validation study. Its focus is on the educational design and responsible use of generative artificial intelligence (AI) to assist in developing Key Feature Problems (KFP) within undergraduate (UME) and postgraduate medical education (PGME) contexts. The recommendations emphasize conceptual alignment, item quality, and governance rather than quantitative analysis of reliability, validity coefficients, or statistical performance metrics.
The scope of guidance also excludes blueprinting logistics, standard setting, and scoring procedures, which vary across institutions and are beyond the current discussion. While examples provided illustrate typical clinical reasoning domains, they are intended to demonstrate design principles rather than to serve as validated assessment items.
Implementation feasibility may differ depending on institutional infrastructure, data governance maturity, and faculty readiness. The principles described should therefore be adapted to local curricular frameworks, regulatory requirements, and available AI tools. Educators should interpret these tips as a foundation for responsible innovation and not as a prescriptive or exhaustive model for KFP development.
This article offers a practical pathway for integrating generative AI into Key Feature Problem design while preserving educational rigor, fairness, and clinical authenticity. The ten tips anchor AI use to clearly defined outcomes and key features; they promote authentic, context-rich vignettes and parallel variants; they scaffold higher-order reasoning rather than simple recall; and they require systematic validation, targeted feedback, and continuous psychometric refinement. Applied together, these practices turn AI from a novelty into a reliable assistant that strengthens the defensibility and learning value of KFPs within programmatic assessment.
Effective implementation depends on disciplined process rather than advanced modeling. Institutions should prioritize transparent documentation of tools, prompts, SME decisions, and validation evidence; embed equity checks to reduce construct-irrelevant variance; and provide ongoing faculty development in responsible prompting, data stewardship, and bias awareness. Until secure educational data environments mature (e.g., institutionally hosted sandboxes), realism can be achieved through synthetic or de-identified data and simulated EHR interfaces. These guardrails protect privacy and trust while allowing innovation to advance in manageable, auditable steps.
Adopting the ten tips can improve both reliability and educational impact. Items become better aligned to curricular intent and learner level, feedback becomes decision-specific and actionable, and post-administration data drive iterative improvement rather than one-off item use. In this way, AI-supported KFPs contribute to a more coherent and equitable assessment ecosystem that helps learners practice clinical reasoning and transfer it to new settings.
Future work should test these recommendations at scale. Priorities include prospective studies on learning outcomes, stability of psychometric indices across cohorts and subgroups, the effectiveness of bias and equity audits, and the operational value of documentation checklists for accreditation. Cross-institution collaborations and shared repositories of prompts, validation artifacts, and item revision histories will accelerate cumulative knowledge. With careful governance and continuous evaluation, AI can augment rather than replace educational expertise and help institutions deliver assessments that are authentic, defensible, and oriented toward better patient care.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)