Keywords
AI, artificial intelligence, authorship, ChatGPT, comparison, rater, reader perception, scientific title, scientific writing, title
This article is included in the Artificial Intelligence and Machine Learning gateway.
This article is included in the Research on Research, Policy & Culture gateway.
AI, artificial intelligence, authorship, ChatGPT, comparison, rater, reader perception, scientific title, scientific writing, title
In this revised version, we addressed all reviewer comments and made several important methodological and conceptual clarifications.
First, we corrected an inconsistency in the reported rating scale. The questionnaire used a 0–10 scale (not 1–10), and we have now standardized this throughout the manuscript.
Second, we improved the statistical modeling. The previously used negative binomial models for rating outcomes have been replaced with mixed-effects ordinal logistic regression models, which better reflect the bounded ordinal nature of the data.
Third, we expanded the description of the article sampling procedure and clarified the standardization of title formatting.
Finally, we refined the conceptual framing and interpretation, including clearer wording around “perceived accuracy” (now explicitly defined as perceived alignment with the abstract), stronger emphasis on temporal and contextual limitations, and more cautious generalization of findings.
To read any peer review reports and author responses for this article, follow the "read" links in the Open Peer Review table.
The title of a scientific article plays a critical role in academic communication. More than a simple label, it serves as the first point of contact between the research and its potential audience, potentially influencing whether the article is read, cited, or even submitted for peer review. Several studies have shown that titles affect readership and citation rates,1–8 an effect that may be especially pronounced in high-impact journals, where competition for visibility is intense. A well-crafted title must strike a balance between scientific accuracy and appeal, providing a succinct yet informative summary of the study’s main objective or findings, while simultaneously engaging the curiosity of readers.8–14
Crafting such titles is a complex task. Authors must condense their work into a limited number of words without compromising on clarity, scientific integrity, or appeal. The title must reflect the content of the study while remaining concise and readable. Moreover, researchers often face additional constraints such as journal-specific formatting rules, word limits, or stylistic preferences.13–16 In this context, the choice of words and tone can affect how a study is perceived and disseminated across the scientific community. For example, titles that use assertive or attention-grabbing language may be more memorable or appealing, yet they risk overstating the results or introducing bias in interpretation.17,18
Recent advancements in natural language processing (NLP) have opened new avenues in scientific writing. Large language models (LLMs) such as ChatGPT, developed by OpenAI, have demonstrated the ability to generate fluent, coherent, and contextually appropriate texts in response to user prompts.19–29 These tools are increasingly being adopted to assist with various writing tasks, including summarization, translation, and scientific manuscript generation. While preliminary evidence suggests that LLMs can support academic writing tasks, their potential role in title generation remains largely unexplored.30,31
Chen and Eger (2023) assessed the performance of transformer-based models—including ChatGPT—in generating scientific titles from abstracts in the domains of NLP and machine learning.30 Their study focused on stylistic aspects such as humor and novelty, and introduced the first large-scale dataset of humorous scientific titles. Although certain models (e.g., BARTxsum) produced titles approaching human-level quality, effectively capturing authentic humor remained a notable challenge. Rehman et al. (2024) used multiple pre-trained language models to generate titles for biomedical research articles and compared them to human-written titles using standard textual similarity metrics such as ROUGE, BLEU, and METEOR.31 The AI-generated titles showed high lexical similarity with human titles, suggesting that these models can replicate conventional title structures. However, the study relied exclusively on automated metrics, without assessing how readers actually perceive these titles in terms of accuracy, appeal, or credibility. Moreover, the articles used in their study were from the post-2020 era, raising the possibility that human-written titles may themselves have been influenced by AI-assisted tools. As a result, it remains unclear whether LLMs like ChatGPT can independently produce high-quality scientific titles that are preferred by human readers.
Building on research showing that scientific titles may influence visibility, readership, and citation patterns, we extend this perspective to examine how AI-generated titles are perceived by human readers. In this context, the present study was designed to evaluate whether ChatGPT-4.0 can generate titles that are perceived as aligned with the abstract content (as a surrogate for perceived accuracy), appealing, and overall preferable compared to those written by human authors. Our study is unique in three main respects. First, it uses articles from a period before AI tools existed, ensuring that the original titles are purely human-authored. Second, it evaluates the quality of titles using human perceptions (rather than automated similarity metrics) on key dimensions of interest to readers. Third, it uses ChatGPT-4.0, one of the most advanced publicly available LLMs to date, as a title-generation tool in a zero-shot setting, reflecting its potential use by researchers without engineering expertise. We hypothesized that titles generated by ChatGPT would be perceived as better aligned with the abstract content and more appealing than those written by humans, and potentially preferred overall.
This study aimed to evaluate the capacity of ChatGPT-4.0 to produce scientific article titles that are accurate, i.e., well aligned with the abstract content, appealing, and preferred by readers. We compared AI-generated titles with original human-written titles drawn from high-impact journals in general internal medicine. Our objective was to assess whether ChatGPT could match or surpass human authors in crafting titles that attract readers’ interest while accurately reflecting the abstract. To this end, we conducted a cross-sectional survey in which independent academic raters evaluated paired titles for each of fifty scientific abstracts. Each abstract was presented with two titles, one written by a human, the other generated by ChatGPT, in randomized order to avoid bias.
We first identified the ten general internal medicine journals with the highest impact factors in the 2023 Journal Citation Reports (JCR). To ensure consistency and relevance across journals, only those fulfilling all of the following criteria were eligible: they had to regularly publish original research and/or systematic reviews; they had to use structured abstracts for both types of articles; and they had to have been in continuous publication since at least January 2000. The year 2000 was deliberately chosen as the target publication period because it predates the availability of generative AI tools, eliminating any possibility that the original titles were AI-assisted. Based on these criteria, the following journals were selected: The Lancet (IF 98.4), The New England Journal of Medicine (IF 96.3), The BMJ (IF 93.7), JAMA (IF 63.5), Archives of Internal Medicine (IF 22.3), Annals of Internal Medicine (IF 19.6), CMAJ (IF 12.9), Journal of Travel Medicine (IF 9.1), Journal of Internal Medicine (IF 9.0), and Mayo Clinic Proceedings (IF 6.9).
From each eligible journal, we randomly selected five articles published between January 1 and December 31, 2000. These articles were either original research studies or systematic reviews. This sampling strategy resulted in a total of fifty abstracts, each with a corresponding human-written title. For each journal, the sampling frame consisted of all eligible articles published in 2000 that met the inclusion criteria. Articles were assigned numeric identifiers and selected using a computer-generated random number sequence.
To generate alternative titles, we used the ChatGPT-4.0 model developed by OpenAI, which represents one of the most advanced publicly available LLMs at the time of the study. For each abstract, we initiated a new chat session with the model. This was done intentionally to eliminate contextual memory carryover and ensure that each title was generated independently of the others.
In each new session, the following standardized prompt was submitted: “Write a title for this scientific article based on the abstract below”. Immediately after entering the prompt, we pasted the full abstract of the selected article. The AI-generated title that resulted from this process was recorded verbatim and was not edited, reformulated, or shortened in any way by the researchers, except for standardizing capitalization: words were converted to lowercase when uppercase was not required (e.g., unless referring to names, countries, or other proper nouns). Capitalization was standardized across both human-written and AI-generated titles. This step was repeated for all fifty abstracts, yielding fifty unique AI-generated titles. The human-written and ChatGPT-generated titles are presented in the Supplementary Material.
Each abstract was thus associated with two titles: one written by the original human authors and the other generated by ChatGPT-4.0. For evaluation purposes, the two titles were assigned randomized positions as either “Title A” or “Title B” using a computer-generated random allocation procedure. This random order was intended to prevent raters from identifying which title had been written by a human and which by an AI, thereby minimizing bias during the evaluation process.
A structured evaluation questionnaire was developed to assess rater perceptions of the two titles accompanying each abstract. The survey presented all fifty abstracts, each introduced by two titles in randomized order (Title A and Title B), followed by the abstract itself. Each rater was asked to assess each title separately on two dimensions: first, how well the title represented the content of the abstract, and second, how much the title made them want to read the abstract or the full article.
These two dimensions (i.e., perceived alignment with the abstract content and appeal) were each rated using an ordinal scale ranging from 0 to 10. On this scale, a rating of 0 indicated an extremely negative judgment (e.g., not accurate or not appealing at all), a rating of 5 reflected a neutral or moderate assessment, and a rating of 10 indicated a highly positive evaluation (e.g., perfectly accurate or extremely appealing). Perceived alignment reflects how well the title was judged to match the content of the abstract, rather than verification of the factual or methodological correctness of the study itself.
After rating both titles on these two aspects, the raters were also asked to indicate which of the two titles they preferred overall, choosing either “Title A” or “Title B” for each abstract. The questionnaire and rating form are available in the Supplementary Material.
Twenty-one raters participated in the evaluation phase of the study. All were researchers who had authored at least one peer-reviewed academic publication. Eleven of these raters were recruited and contacted by one co-author (BN), and the remaining ten by another (PS), to ensure balanced recruitment. All participants provided informed consent in written electronic form (email agreement and completion of the questionnaire).
To avoid bias and maintain ecological validity, raters were not informed that one of the two titles had been generated by AI. They were simply told that the study aimed to examine how different formulations of article titles affect readers’ perceptions. No specific mention was made of ChatGPT or AI-based generation to preserve the authenticity of the evaluations.
The process of generating AI-based titles was completed in May 2025. The rating process, during which the twenty-one recruited raters completed the questionnaire, was conducted throughout June 2025. All ratings were submitted electronically and compiled in a central database for further statistical analysis.
This study did not require ethics committee approval under Swiss law, as no personal health data were collected (Human Research Act, HRA, art.2). All participants were adult researchers, informed about the study’s purpose (evaluating perceptions of different title formulations), voluntary participation, and anonymized handling of responses. To minimize bias, they were not told that one of the titles was AI-generated. Written informed consent was obtained via email agreement and completion of the questionnaire.
For each title, we calculated the mean (standard deviation, SD) and median (interquartile range, IQR) of rater scores for perceived alignment and appeal. To compare ratings between human-written and AI-generated titles, we used the Wilcoxon signed-rank test for paired data, as the ratings were ordinal and not normally distributed. For title preferences, we calculated the proportion of times each title was selected. Differences in preference proportions were tested using McNemar’s test, which is appropriate for paired categorical data.
In addition to these non-parametric tests, we conducted multilevel regression analyses to quantify effect sizes. Mixed-effects ordinal logistic regression models with random intercepts for both rater and article were used to compare perceived alignment and appeal ratings, yielding odds ratios (ORs). A mixed-effects logistic regression model with a random intercept for rater was used to assess the odds of preferring an AI-generated title over a human-written one.
To assess inter-rater agreement, we computed two measures separately for AI-generated and human-written titles: percent agreement and Gwet’s agreement coefficient (AC), using quadratic weights to account for the ordinal nature of the 0–10 rating scale.32–34 Agreement levels were computed across the 21 raters and stratified by rating dimension (perceived alignment and appeal). The weighted analysis assigns partial credit for near agreement, making it more appropriate for ordinal data. We interpreted Gwet’s AC using the classification proposed by Landis and Koch (1977): values <0.00 indicate poor agreement, 0.00–0.20 slight, 0.21–0.40 fair, 0.41–0.60 moderate, 0.61–0.80 substantial, and 0.81–1.00 almost perfect agreement.35
We did not perform subgroup analyses based on rater characteristics, as the limited number of raters (N = 21) would not have allowed for statistically meaningful comparisons. All analyses were conducted using Stata version 15.1 (StataCorp, College Station, TX, USA). A two-sided p-value < 0.05 was considered statistically significant.
The main characteristics of the 21 raters who participated in the study are presented in Table 1. Twelve were women and nine were men. Twelve were under 40 years of age, eight were between 40 and 60 years, and one was over 60 years old. The raters were primarily from China (n = 11) and Switzerland (n = 8), with one rater each from the United States and France. They had diverse academic and professional backgrounds. Among them, five specialized in library and information science, and seven in general internal medicine.
For consistency with the original rating instrument, the term “perceived accuracy” is retained in this section. In the context of this study, this term refers to raters’ perceived alignment between the title and the abstract content, rather than verification of factual or methodological correctness.
Table 2 presents the median, IQR, and minimum–maximum values of rater scores for perceived accuracy and appeal, stratified by title type (AI-generated vs. human-written) and by individual rater. Figures 1 and 2 display these distributions using boxplots, one per rater, for perceived accuracy and appeal, respectively. Overall, AI-generated titles received more favorable ratings. For perceived accuracy, 18 raters rated AI-generated titles higher than human-written titles, three gave equal ratings, and none rated AI-generated titles lower. For appeal, 12 raters rated AI-generated titles higher, five gave equal ratings, and four preferred human-written titles.
| Rater ID | Title type | Dimension | Median | P251 | P751 | Min | Max |
|---|---|---|---|---|---|---|---|
| 1 | AI | accuracy | 9 | 8 | 9 | 6 | 10 |
| 1 | AI | appeal | 8 | 7 | 9 | 6 | 10 |
| 1 | Human | accuracy | 7 | 6 | 8 | 1 | 10 |
| 1 | Human | appeal | 7 | 7 | 8 | 5 | 10 |
| 2 | AI | accuracy | 9 | 8 | 10 | 5 | 10 |
| 2 | AI | appeal | 9 | 7 | 9 | 5 | 10 |
| 2 | Human | accuracy | 8 | 7 | 9 | 2 | 10 |
| 2 | Human | appeal | 8 | 7 | 9 | 4 | 10 |
| 3 | AI | accuracy | 9 | 9 | 10 | 5 | 10 |
| 3 | AI | appeal | 8 | 7 | 9 | 6 | 10 |
| 3 | Human | accuracy | 7 | 6 | 8 | 3 | 10 |
| 3 | Human | appeal | 8 | 6 | 9 | 3 | 10 |
| 4 | AI | accuracy | 10 | 10 | 10 | 7 | 10 |
| 4 | AI | appeal | 10 | 9 | 10 | 7 | 10 |
| 4 | Human | accuracy | 8 | 7 | 10 | 4 | 10 |
| 4 | Human | appeal | 8 | 7 | 9 | 3 | 10 |
| 5 | AI | accuracy | 10 | 10 | 10 | 5 | 10 |
| 5 | AI | appeal | 10 | 10 | 10 | 5 | 10 |
| 5 | Human | accuracy | 5 | 5 | 9 | 5 | 10 |
| 5 | Human | appeal | 5 | 5 | 10 | 5 | 10 |
| 6 | AI | accuracy | 10 | 10 | 10 | 8 | 10 |
| 6 | AI | appeal | 10 | 8 | 10 | 6 | 10 |
| 6 | Human | accuracy | 8 | 7 | 10 | 3 | 10 |
| 6 | Human | appeal | 8 | 7 | 9 | 5 | 10 |
| 7 | AI | accuracy | 7 | 6 | 8 | 3 | 9 |
| 7 | AI | appeal | 6 | 5 | 6 | 3 | 8 |
| 7 | Human | accuracy | 7 | 7 | 8 | 3 | 10 |
| 7 | Human | appeal | 6 | 5 | 7 | 3 | 9 |
| 8 | AI | accuracy | 6 | 4 | 6 | 2 | 9 |
| 8 | AI | appeal | 5 | 3 | 6 | 1 | 9 |
| 8 | Human | accuracy | 5 | 5 | 6 | 2 | 9 |
| 8 | Human | appeal | 5 | 4 | 6 | 1 | 8 |
| 9 | AI | accuracy | 7 | 6 | 7 | 4 | 9 |
| 9 | AI | appeal | 4 | 3 | 5 | 2 | 8 |
| 9 | Human | accuracy | 6 | 5 | 7 | 3 | 9 |
| 9 | Human | appeal | 5 | 4 | 6 | 2 | 8 |
| 10 | AI | accuracy | 7 | 6 | 8 | 3 | 9 |
| 10 | AI | appeal | 5 | 4 | 7 | 3 | 8 |
| 10 | Human | accuracy | 6 | 5 | 7 | 3 | 9 |
| 10 | Human | appeal | 6 | 5 | 7 | 3 | 9 |
| 11 | AI | accuracy | 9 | 8 | 9 | 6 | 10 |
| 11 | AI | appeal | 8 | 7 | 9 | 6 | 9 |
| 11 | Human | accuracy | 7 | 7 | 8 | 6 | 10 |
| 11 | Human | appeal | 8 | 7 | 8 | 6 | 9 |
| 12 | AI | accuracy | 8 | 8 | 9 | 5 | 9 |
| 12 | AI | appeal | 7 | 6 | 8 | 2 | 10 |
| 12 | Human | accuracy | 7 | 6 | 8 | 4 | 9 |
| 12 | Human | appeal | 6 | 5 | 7 | 2 | 10 |
| 13 | AI | accuracy | 7 | 5 | 8 | 4 | 9 |
| 13 | AI | appeal | 7 | 6 | 8 | 4 | 8 |
| 13 | Human | accuracy | 6 | 5 | 6 | 3 | 8 |
| 13 | Human | appeal | 6 | 5 | 7 | 3 | 9 |
| 14 | AI | accuracy | 6 | 5 | 7 | 2 | 8 |
| 14 | AI | appeal | 5 | 4 | 6 | 1 | 8 |
| 14 | Human | accuracy | 5 | 4 | 6 | 2 | 8 |
| 14 | Human | appeal | 6 | 5 | 8 | 2 | 8 |
| 15 | AI | accuracy | 8 | 6 | 9 | 2 | 10 |
| 15 | AI | appeal | 7 | 5 | 8 | 3 | 10 |
| 15 | Human | accuracy | 6 | 4 | 8 | 2 | 10 |
| 15 | Human | appeal | 5 | 5 | 7 | 2 | 9 |
| 16 | AI | accuracy | 7 | 7 | 8 | 5 | 8 |
| 16 | AI | appeal | 7 | 6 | 8 | 5 | 8 |
| 16 | Human | accuracy | 6 | 5 | 7 | 3 | 8 |
| 16 | Human | appeal | 7 | 5 | 7 | 4 | 8 |
| 17 | AI | accuracy | 7 | 5 | 8 | 3 | 10 |
| 17 | AI | appeal | 6 | 5 | 8 | 3 | 10 |
| 17 | Human | accuracy | 5 | 5 | 7 | 1 | 9 |
| 17 | Human | appeal | 5 | 4 | 7 | 1 | 9 |
| 18 | AI | accuracy | 8 | 7 | 9 | 5 | 10 |
| 18 | AI | appeal | 8 | 6 | 9 | 3 | 10 |
| 18 | Human | accuracy | 8 | 6 | 9 | 4 | 10 |
| 18 | Human | appeal | 7 | 5 | 8 | 4 | 10 |
| 19 | AI | accuracy | 9 | 8 | 10 | 6 | 10 |
| 19 | AI | appeal | 8 | 6 | 9 | 4 | 10 |
| 19 | Human | accuracy | 8 | 7 | 9 | 5 | 10 |
| 19 | Human | appeal | 7 | 6 | 8 | 4 | 10 |
| 20 | AI | accuracy | 8 | 6 | 8 | 5 | 10 |
| 20 | AI | appeal | 7 | 6 | 8 | 4 | 8 |
| 20 | Human | accuracy | 6 | 4 | 7 | 3 | 9 |
| 20 | Human | appeal | 8 | 7 | 8 | 3 | 8 |
| 21 | AI | accuracy | 10 | 10 | 10 | 7 | 10 |
| 21 | AI | appeal | 10 | 9 | 10 | 7 | 10 |
| 21 | Human | accuracy | 10 | 8 | 10 | 5 | 10 |
| 21 | Human | appeal | 9 | 8 | 10 | 5 | 10 |
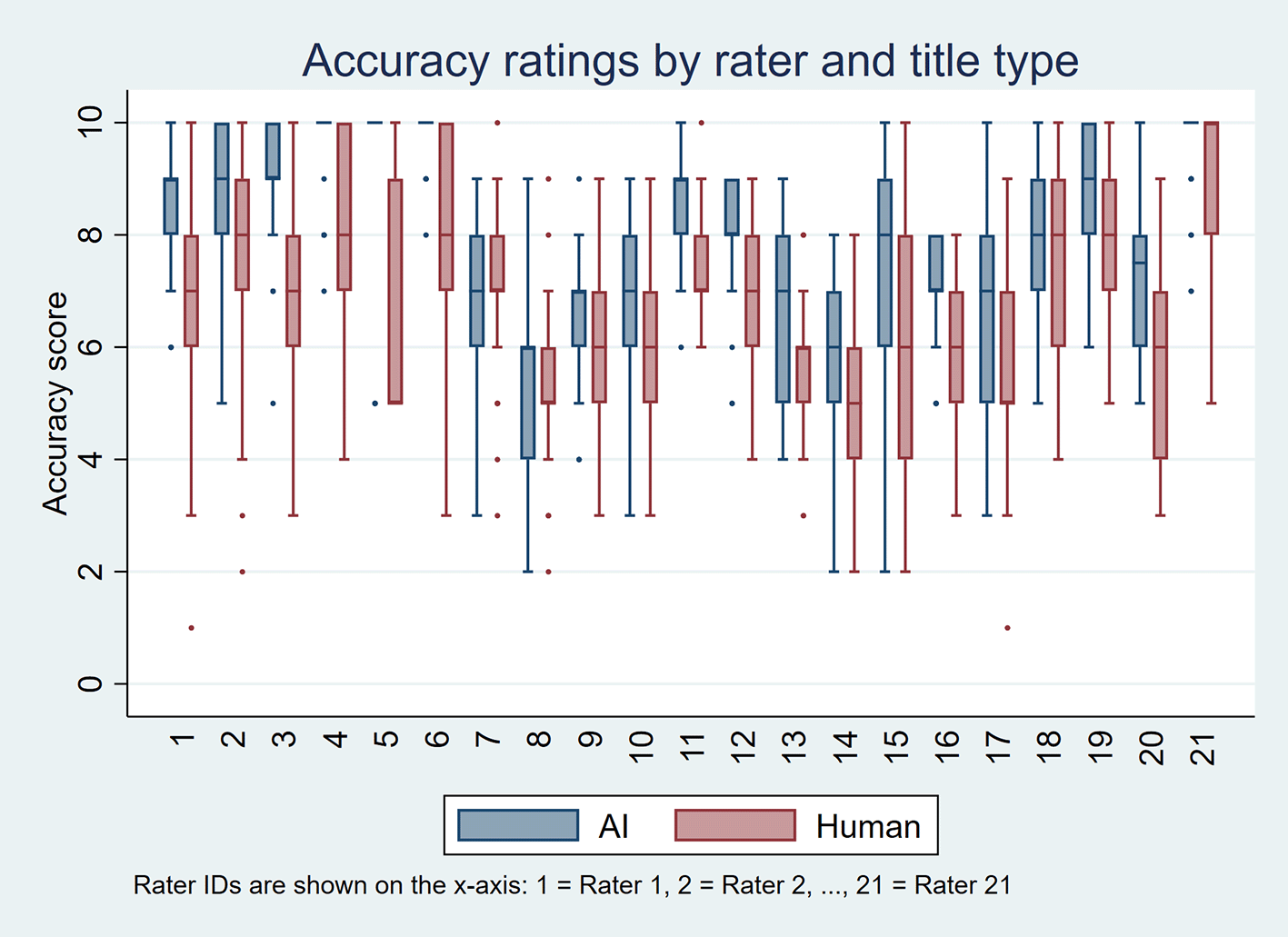
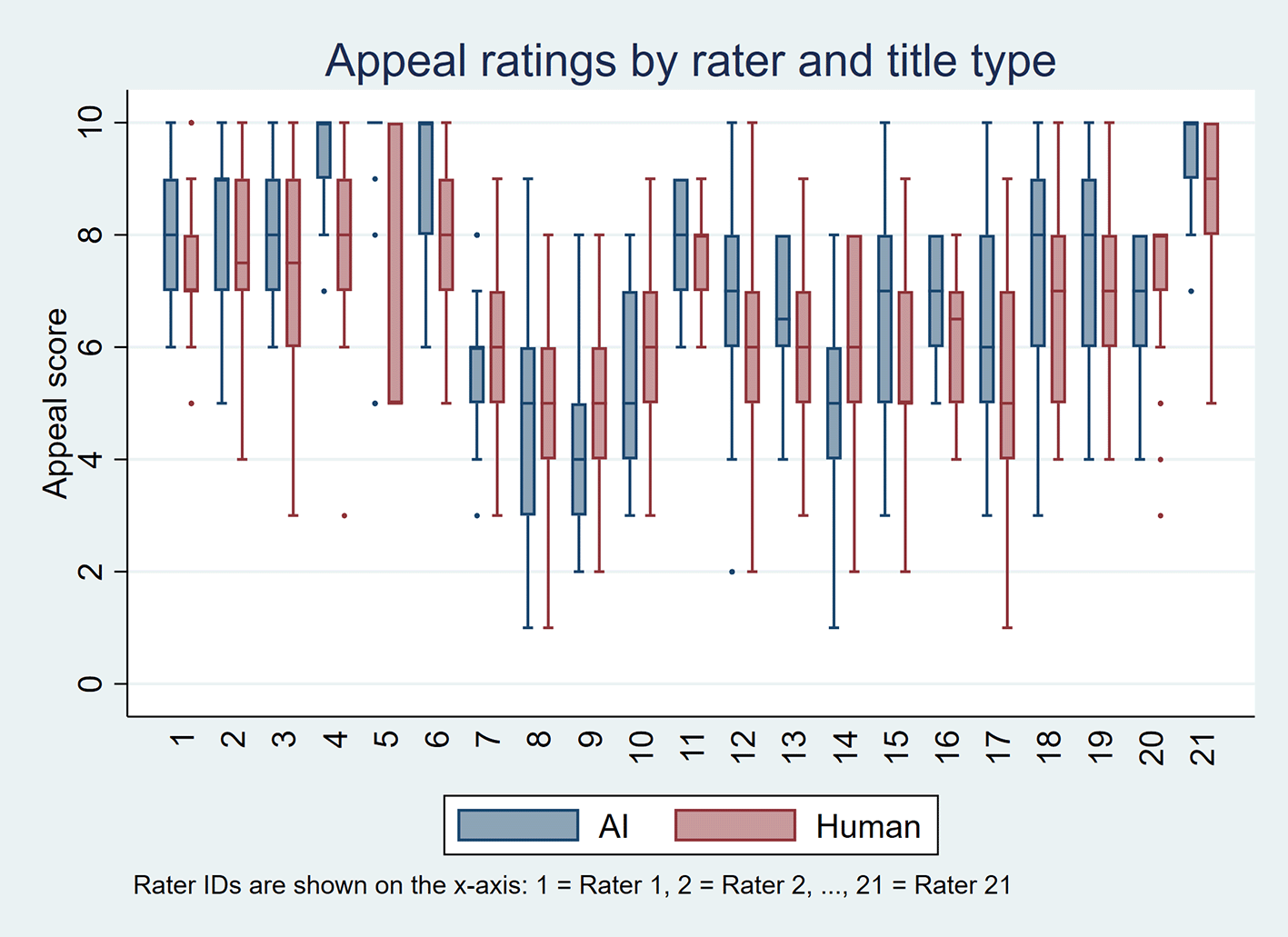
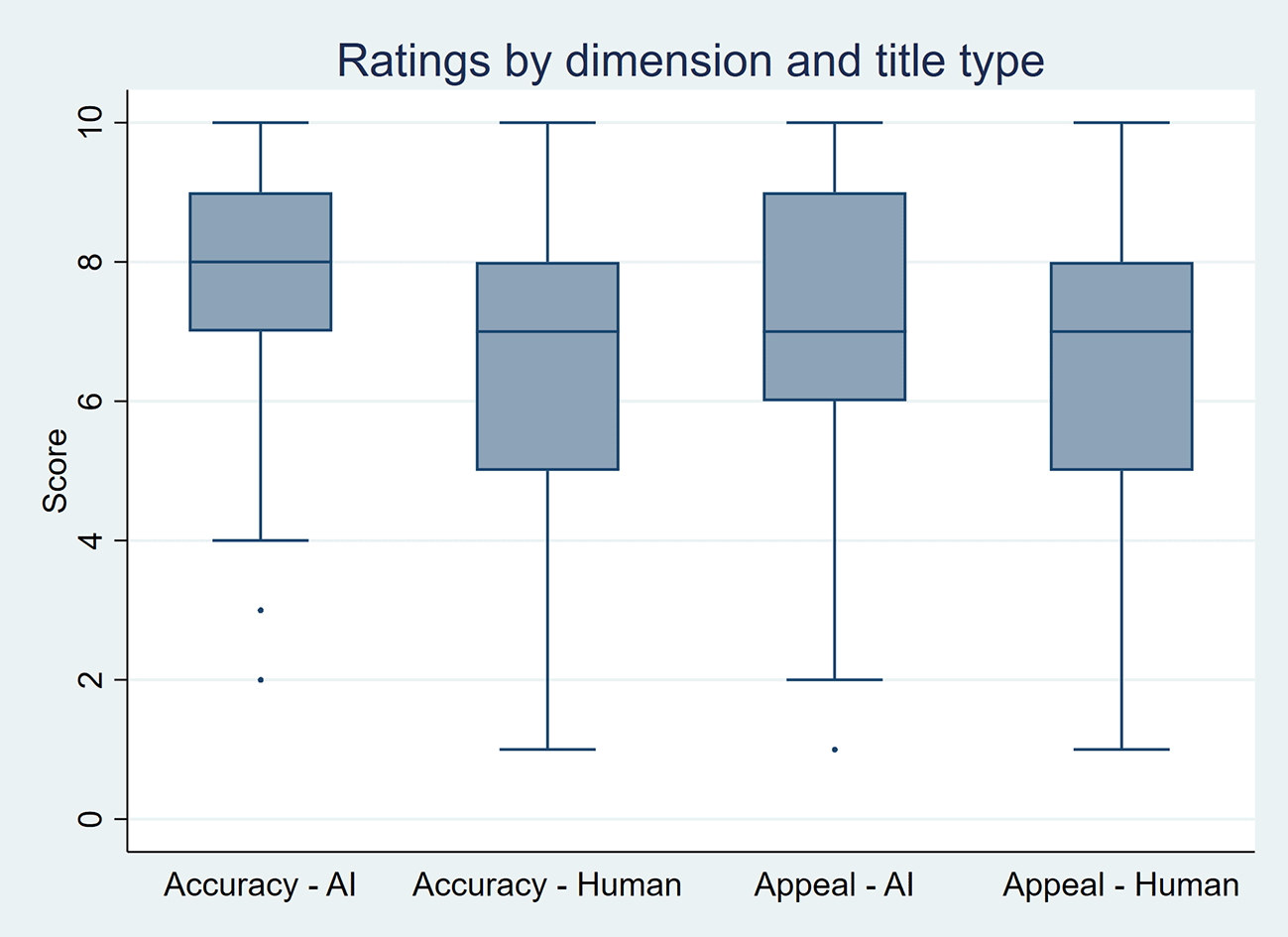
As summarized in Table 3 and visualized in Figure 3, AI-generated titles received significantly higher scores. For perceived accuracy, the mean score was 7.9 for AI-generated titles compared to 6.7 for human-written titles, with a median of 8 versus 7 (p-value < 0.001). For appeal, the mean score was 7.1 for AI-generated titles versus 6.7 for human-written titles, with a median of 7 for both (p-value < 0.001). In multilevel models, AI-generated titles had higher odds of receiving higher ratings for perceived accuracy (OR 4.4, 95% CI 3.7–5.2; p-value < 0.001) and appeal (OR 1.7, 95% CI 1.5–2.0; p-value < 0.001) than human-written titles.
| Number of ratings/total | Mean (SD) | Median (IQR) | Min-max | N (%) | p-value | OR (95% CI) | p-value | |
|---|---|---|---|---|---|---|---|---|
| Perceived accuracy | <0.0011 | <0.0013 | ||||||
| AI-generated title | 1049/1050 | 7.9 (1.8) | 8 (7-9) | 2-10 | 4.4 (3.7-5.2) | |||
| Human title | 1049/1050 | 6.7 (1.9) | 7 (5-8) | 1-10 | 1 (ref ) | |||
| Appeal | <0.0011 | <0.0013 | ||||||
| AI-generated title | 1049/1050 | 7.1 (2.1) | 7 (6-9) | 1-10 | 1.7 (1.5-2.0) | |||
| Human title | 1049/1050 | 6.7 (1.8) | 7 (5-8) | 1-10 | 1 (ref ) | |||
| Preference | <0.0012 | 0.0014 | ||||||
| AI-generated title | 1049/1050 | 648 (61.8) | 1.7 (1.3-2.3) | |||||
| Human title | 1049/1050 | 401 (38.2) | 1 (ref ) |
Overall preferences also favored AI-generated titles. As shown in Figure 4, 16 out of 21 raters preferred AI-generated titles, while five preferred human-written ones. Among the 1,049 pairwise preference judgments (out of a possible 1,050; one missing value), 61.8% favored the AI-generated title and 38.2% favored the human-written title (p-value < 0.001; Table 3). The odds of preferring an AI-generated title were 1.7 times higher than those of preferring a human-written title (p-value = 0.001).
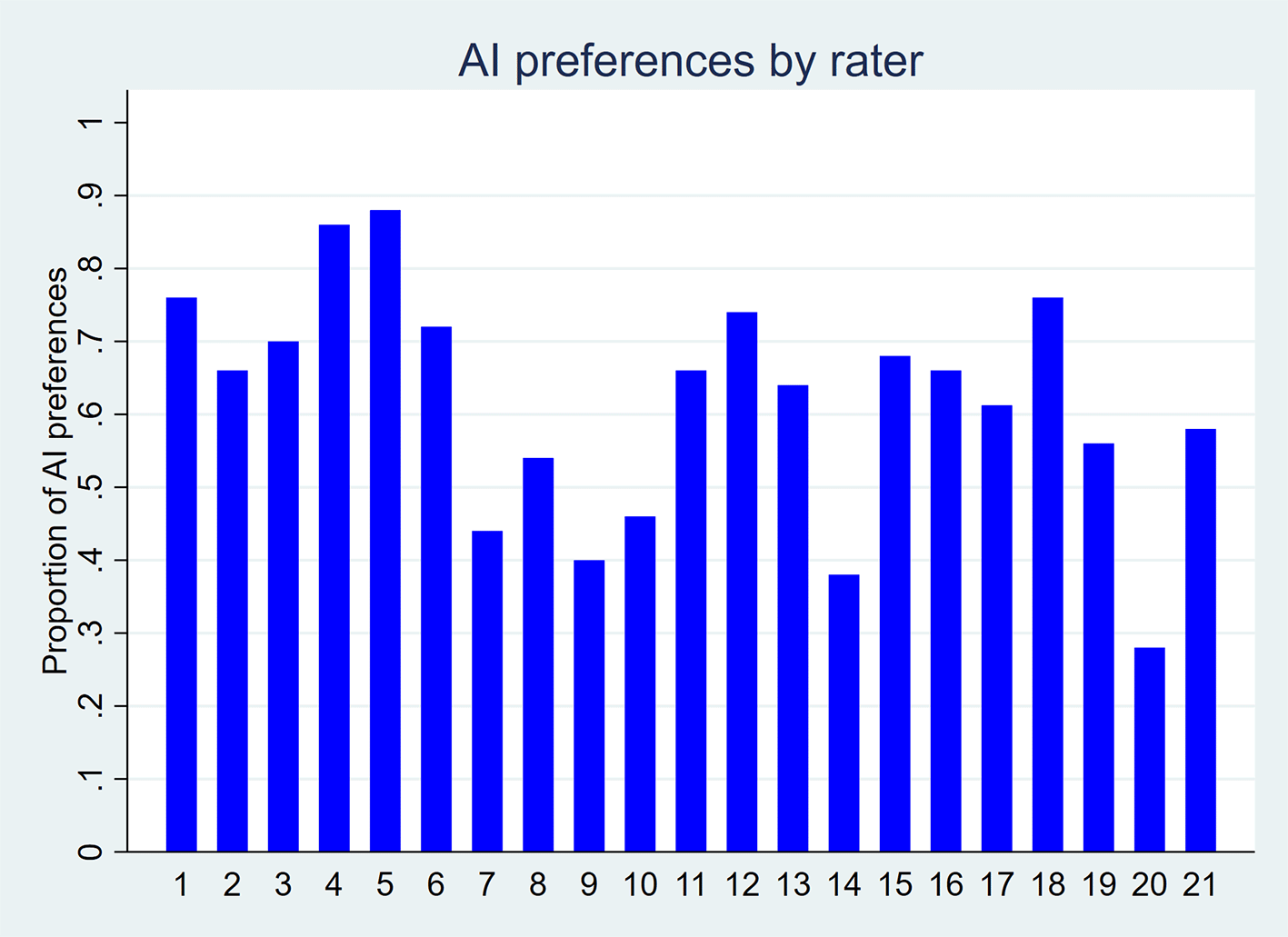
Table 4 presents inter-rater agreement measures by title type. Percent agreement ranged from 88.9% to 92.5%, while Gwet’s ACs, calculated using quadratic weights for ordinal scales, ranged from 0.54 to 0.70. These values indicate moderate to substantial agreement according to the benchmark scale proposed by Landis and Koch (1977),35 suggesting consistent tendencies across raters while also highlighting that judgments of title quality remain partly subjective.
This study evaluated how 21 raters assessed the perceived alignment between title and abstract, appeal, and overall preference of 50 scientific titles, comparing AI-generated and human-written versions. AI-generated titles received significantly higher ratings for both perceived alignment and appeal, with most raters favoring them over human-written alternatives. In total, 61.8% of preference judgments were in favor of AI-generated titles, and inter-rater agreement ranged from moderate to substantial.
Our findings are consistent with a growing body of literature suggesting that LLMs such as GPT-4.0 can generate high-quality scientific text that is often indistinguishable from human-written content.20,36–42 Our results go beyond prior work by focusing specifically on titles, a concise yet crucial form of scientific communication. Unlike abstracts or full texts, titles must strike a balance between informativeness, clarity, and appeal in a highly constrained format. While some recent studies have explored AI-generated titles, they have either emphasized stylistic aspects such as humor and novelty in technical fields or evaluated output using only automated similarity metrics, without considering how human readers perceive title quality.30,31 The fact that AI-generated titles scored higher on both perceived alignment with the abstract content and appeal challenges assumptions that LLMs lack the nuance or domain expertise to outperform human authors in such a delicate task. This suggests that LLMs may be particularly well suited for short-form scientific writing, where lexical clarity and stylistic optimization matter more than in-depth reasoning.
Importantly, our study focused exclusively on articles from high-impact general internal medicine journals, where title quality is expected to be particularly high due to rigorous editorial and peer-review processes. If AI-generated titles can outperform those published in such venues, the gap may be even greater for titles in lower-tier journals, where writing quality is more variable. Future research should investigate whether similar results hold across different fields, disciplines, and levels of journal prestige.
Collectively, our study complements and extends previous research by offering a detailed, comparative analysis of AI vs. human performance in scientific titling, a topic that has received relatively little empirical attention but has major implications for academic publishing practices. However, our findings should be interpreted primarily within contexts similar to those examined in our study (e.g., biomedical research evaluated by non-specialist academic readers).
From a practical standpoint, the finding that AI-generated titles are rated more highly than human-written ones suggests that LLMs could be reliably used to assist researchers in generating or refining article titles. Given that titles play a key role in shaping reader perceptions, citation rates, and online discoverability, tools that enhance title quality could have a direct impact on dissemination and academic impact. In particular, researchers with limited writing experience or for whom English is not a first language might benefit from LLM-based titling tools to improve clarity and reader engagement.
The observed preferences imply that AI-generated suggestions may outperform human intuition in specific aspects of scientific writing, such as title generation. This raises the possibility of integrating AI assistance more formally into journal workflows, for example through automated title suggestions during the submission process or editorial review. While this would require careful oversight, our data indicate that such tools would not compromise, and may even enhance, perceived quality.
However, it is important to note that higher appeal or preference does not necessarily imply greater epistemic rigor. Titles optimized for engagement may emphasize clarity or assertiveness while potentially downplaying uncertainty or methodological nuance. Moreover, the integration of AI into scholarly communication also raises critical ethical questions.29,43–46 These concerns echo ongoing debates about the role of LLMs in scientific authorship and the boundaries of acceptable assistance. Our findings underline the importance of maintaining transparent authorship practices and labeling AI contributions in scientific writing, even if such tools are only used to generate the title of the article. Beyond ethical issues, the widespread application of AI in generating titles may lead to homogenization in academic writing, resulting in titles that tend to fall within a narrow stylistic range and suppress the diversity, creativity, and uniqueness of the disciplines. These considerations relate to ongoing discussions in scholarly publishing regarding whether AI-assisted writing should be regarded as authorship, editorial assistance, or technical support, and how journals might operationalize transparent disclosure of AI use.
From a research perspective, our study opens several avenues for further investigation. One important direction is to test the generalizability of these findings across disciplines, languages, and types of scientific content. It is possible that preferences for AI-generated titles vary depending on disciplinary norms or journal styles. In addition, future work could examine how title preferences correlate with actual article impact, such as downloads, citations, or Altmetric scores, to determine whether rater judgments align with broader readership behavior. Another key area for future research is to understand the mechanisms behind rater preferences. For example, are AI-generated titles preferred because of greater lexical simplicity, more direct structure, or the avoidance of technical jargon? Applying NLP tools to analyze linguistic features could shed light on what drives these preferences and help refine AI title generation even further. Lastly, as LLMs continue to evolve, longitudinal studies will be needed to assess how perceptions of AI-generated text change over time and whether improvements in model quality lead to higher standards or greater acceptance.
This study has several limitations that should be acknowledged. First, although the use of articles from the year 2000 ensured that original titles were free from AI influence, it also introduces a potential temporal bias. Scientific writing conventions and stylistic preferences may have evolved over the past two decades, and what was considered an effective title in 2000 may differ from current standards. In other words, because AI-generated titles are produced by models trained largely on contemporary scientific language, differences may partly reflect shifts in stylistic conventions and reader expectations over time. Second, although we recruited raters with relevant academic experience, the sample size (N = 21) remains relatively small, and their subjective preferences may not fully represent broader readership or editorial perspectives. Third, while the zero-shot setting of ChatGPT-4.0 reflects real-world usage by non-expert users, it may not capture the full potential of LLMs when used with prompt optimization or human-in-the-loop refinement. Additionally, the evaluation focused on only two dimensions (i.e., perceived accuracy and appeal) along with an overall preference rating. Other important aspects of scientific titles, such as precision, cautiousness of claims, clarity, informativeness, tone, and appropriateness for indexing or search engine optimization, were not explicitly assessed. In particular, titles rated as more appealing may not necessarily reflect more rigorous or conservative scientific framing, and this potential trade-off warrants further investigation. Lastly, the study did not include domain experts for each article’s specific topic area, which may have influenced the ability of raters to judge how well a title reflected the article’s nuanced content.
Future research could expand upon this work by including more diverse raters, evaluating newer articles, testing various prompting strategies, and incorporating additional dimensions of title quality. Despite these limitations, our findings provide valuable insights into the potential of LLMs to assist in academic title generation and highlight the subjective nature of title preferences.
In the context of high-impact general internal medicine journals, AI-generated scientific titles were rated more favorably than human-written titles from the year 2000 in terms of perceived alignment with the abstract content, appeal, and overall preference, with moderate to substantial agreement between raters. While these results reflect perceptions in this specific study context, they suggest that LLMs like GPT-4.0 are not only capable of producing linguistically fluent content but may also enhance key aspects of scientific communication within similar biomedical context. As AI tools become more integrated into the research and publishing process, there is a timely opportunity to harness their strengths while remaining attentive to ethical considerations, disciplinary norms, and the evolving expectations of scientific readers.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)