Keywords
Body Gesture Recognition, Human-Computer Interaction, Watershed Algorithm, Optimized Probabilistic Neural Network, Crow Search Algorithm.
This article is included in the Artificial Intelligence and Machine Learning gateway.
Body Gesture Recognition, Human-Computer Interaction, Watershed Algorithm, Optimized Probabilistic Neural Network, Crow Search Algorithm.
Body gesture recognition is an emerging area of computer vision and artificial intelligence that focuses on interpreting and comprehending human body motions, postures, and emotions.1 It is crucial in human-computer interaction, with applications ranging from improving gaming experiences to transforming healthcare, surveillance, and communication.2 Body gesture recognition’s major goal is to enable machines to read the intents and emotions given by human body language. This technology uses image and video analysis techniques to identify and classify different body movements such as gestures of the hands, facial expressions, and full-body poses.3 These movements can express a wide range of information, including commands, emotions, and intentions. As a result, body gesture recognition has the potential to improve the intuitiveness, naturalness, and efficiency of human-computer interaction.4 Image or video data gathering, pre-processing, feature extraction, segmentation, and classification are all important components of body gesture recognition systems. Deep learning approaches, particularly CNNs, have considerably increased the accuracy and resilience of gesture recognition systems by automating the extraction of essential characteristics from visual data.5 Many fields, such as sign language translation, virtual reality, robotics, healthcare, and interactive multimedia, use body gesture detection.6 Body gesture recognition’s capabilities are anticipated to improve as technology advances, making it an interesting and promising topic with several practical and inventive applications.7
In the realm of HCI, Body Gesture Recognition (BGR) is a significant development that will fundamentally change how people interact with technology.8 BGR goes beyond conventional input techniques like keyboards and touchscreens, enabling machines to comprehend and react to human body language and gestures, improving HCI’s inclusivity and intuitiveness. This technology meets a variety of demands, including accessibility for those with physical limitations, immersive gaming experiences, and efficient control in a variety of sectors ranging from healthcare to smart homes. One of its key benefits is improved accessibility. BGR enables people with limited mobility to interact with computers, tablets, and smartphones, promoting autonomy and inclusiveness. It enables a more natural and expressive style of communication, paving the path for sign language translation and allowing those with speech problems to successfully communicate their thoughts and emotions. BGR enhances gaming experiences by letting players to control their games using body movements and gestures, resulting in a greater sense of immersion and engagement.9 BGR contributes to the development of telemedicine and rehabilitation applications in healthcare, allowing for remote patient monitoring and therapy. It simplifies difficult activities like operating smart home devices with natural hand gestures or facial expressions.10 The significance of BGR in HCI stems from its ability to link the gap between human intention and machine action, allowing technology to become more adaptive and receptive to our natural patterns of communication and engagement.
Recent years have seen significant progress in body gesture recognition, providing a wide range of approaches and strategies for precise and instantaneous identification of human body movements.11 To extract features from image and video data and enable reliable and effective recognition, convolutional neural networks, or CNNs, have become the preferred method. CNNs are particularly useful for identifying dynamic motions because they automatically learn to record spatial data.12 RNNs and their offspring, e.g., LSTM networks, play a crucial role in handling temporal characteristics, which makes them perfect for gesture identification in videos.13 For gesture identification, conventional computer vision methods like Haar-like features and the Histogram of Oriented Gradients (HOG) are still useful, particularly for real-time applications.14 They can record texture and edge information, which is important for some kinds of movements. Time-of-flight cameras and Microsoft Kinect, two depth sensors, have become more popular in 3D gesture detection. Because they include depth information, motions can be recognized without relying just on colour and even in dimly lit environments.15 Handmade features have demonstrated success in gesture detection tasks when paired with machine learning techniques like SVMs and Random Forests.16 A popular trend in obtaining more reliable and precise results is the fusion of multimodal data, which combines information from different sensors or sources. The dynamic nature of body gesture detection is reflected in the wide number of approaches that are currently available, which may be tailored to suit different use cases and ambient situations.
Existing approaches for body gesture identification, while constantly improving, have some problems and limits. Many traditional computer vision approaches rely largely on well-defined and controlled surroundings, making them difficult to adapt to real-world scenarios with changing lighting, occlusions, or background clutter.17 They may necessitate significant human feature engineering, making them less scalable. Although deep learning methods are strong, they frequently need considerable computer resources and big datasets for training. When dealing with fine-grained or sophisticated motions, recognition accuracy can be degraded in some circumstances.18 Multimodal fusion might complicate and complicate synchronization. To address these constraints, continued research is required to improve robustness, efficiency, and flexibility in a variety of practical scenarios. The suggested work presents a novel approach to Body Gesture Recognition, hence improving Human-Computer Interaction. It uses a Probabilistic Neural Network (PNN) and the Crow Search Algorithm (CSA) to optimize the CNN. The goal of this innovative approach is to solve the problems with the methods that are currently in use. By optimizing the PNN’s parameters, CSA raises the efficiency and accuracy of classification. Better performance in dynamic surroundings and while handling complex motions is promised by this adaptive method. The study aims to improve the robustness and real-time applicability of gesture detection by introducing CSA-PNN, which will be an important addition to the field of HCI and have wider applications in dynamic digital media, gaming, and accessibility. The following are the key contributions of this study,
• Wavelet Transform pre-processing improves the quality of input data, providing a more reliable and accurate basis for the gesture detection procedure.
• By precisely segmenting the input data using the Marker-Based Watershed Algorithm, it is possible to isolate and distinguish individual body motions in an efficient manner, which enhances the accuracy of recognition.
• Convolutional Neural Networks (CNNs) are a strong tool for feature extraction that may be used to collect and represent the prominent elements of body motions, leading to more precise and in-depth detection.
• The novel addition of the Crow Search Algorithm increases the performance of the model as a whole, improving its effectiveness and versatility while lowering computing complexity.
• Using an Optimized Probabilistic Neural Network for gesture classification solves the drawbacks of previous classification techniques and improves system responsiveness by ensuring precise and effective identification.
The following is a structured format for the paper. Section 2 investigates comparable works in the field, Section 3 outlines the issue statement, and Section 4 describes the approach of the proposed model, encompassing numerous components. Section 5 summarizes the findings and leads a discussion, while Section 6 wraps up the work by summarizing the findings and considering future ramifications.
The investigation of depth cameras is prompted by RGB cameras’ difficulties with variable lighting. León et al. proposed a work that used depth cameras and lightweight convolutional neural networks (CNN) to create a video-based hand gesture identification system.19 A curated dataset was employed to effectively identify and categorize hand movements. The assessment of categorization accuracy with a finite number of frames per gesture in videos was emphasized. The performance of RGB cameras was compared with depth cameras. Based on accuracy and inference time, the model’s performance on edge computing devices was assessed and compared to other models. The present research provides a thorough examination of video-based hand gesture detection and makes the case for lightweight CNN models and depth camera systems to enhance their practicality. The study’s limitation is its restricted investigation of the suggested video-based hand gesture detection system’s real-world application and generalizability. While the use of depth cameras addresses the lighting issue associated with RGB cameras, the study does not thoroughly analyse the possible challenges in various and complicated real-world situations. The evaluation on edge computing devices and comparison to benchmark models is valuable; nevertheless, it lacks a complete investigation of the system’s performance in numerous practical settings, such as crowded backgrounds, multiple users, or complex lighting conditions.
The increasing number of individuals who are deaf or hard of hearing, along with the shifting applications landscape of vision-based applications and touchless control in ubiquitous gadgets, have led to an increased importance of automatic hand gesture detection in recent years. A dependable system that considers both temporal and geographical aspects is necessary for hand gesture identification, which is crucial to sign language interpretation. Determining distinctive spatiotemporal features for hand motion sequences remains a challenging task. Al-Hammadi, Muhammad, Abdul, Alsulaiman, Bencherif, and Mekhtiche provide an effective technique for hand gesture detection using deep convolutional neural networks, with a focus on utilizing transfer learning to solve the limited availability of large labelled hand gesture datasets.20 The complexity and resource-intensiveness of the suggested approach, in particular the utilization of three instances of 3DCNN for feature extraction from various video segments, are a downside of this study. The study also notes that hyperparameter tuning is necessary, implying that the Configuration of the suggested model might not be optimized, which could make it more difficult to implement in practical settings.
The gated recurrent unit (GRU) neural network layer finds long-term dependencies in hand gesture temporal sequences, whereas the attention layers identify short-term patterns. Khodabandelou et al. extensively evaluates the suggested model’s effectiveness and compare it to cutting-edge techniques in the area based on several factors.21 The challenge of detecting human hand gestures using deep learning techniques is discussed in this essay for practitioners. By utilizing natural correlations and extracting the most important elements of historical motion sequences such as their temporal, complex, and nonlinear characteristics—the model can anticipate hand gestures using wearable capacitance sensors. The study looks at how different lengths of historical motion sequences affect prediction accuracy, providing a more efficient alternative to time-consuming data collecting, expensive data processing, and high computational needs. The model demonstrates its competitiveness and capacity to replicate big activity trends in key channels by exhibiting good performance on real-world data and comparisons with known classifiers. However, several drawbacks could make the study less useful in real-world scenarios. For example, the suggested model might be sensitive to the historical motion sequence length used, necessitating fine-tuning for best results. The model’s acceptance in the actual world may be impacted by concerns concerning wearing capacitance sensor comfort and user acceptability. The results’ generalizability might also be restricted because the model’s performance is mostly evaluated using data from real-world applications; its applicability in various uncontrolled contexts is still unknown.
Hand gesture recognition is emerging as a viable solution in the world of digital entertainment, due to developments in sensors and machine learning. Nonetheless, the complicated structure of hand gesture identification offers difficulty in many existing models, owing to factors such as backdrop clutter, motion blur, fluctuations in illumination, and occlusions. In this study, Madni, Vijaya et al. proposed a dynamic method for identifying hand gestures is introduced to improve the overall performance of this activity.22 Initially, a normalization technique is used to improve the visibility of gesture photos supplied from the Indian sign language dataset. Following that, a semi-vectorial multilevel segmentation algorithm is used to precisely identify the gesture regions within the normalized images. The procedure is then repeated using an updated relief algorithm and K-nearest neighbour classifiers. It is important to recognize some limitations even if the enhanced relief-KNN model shows notable improvements in hand gesture recognition. Firstly, most evaluations of the model’s performance are conducted in the controlled setting of the Indian sign language database, which might not adequately capture the nuances of real-world scenarios with different lighting and backgrounds. When handling dynamic or unpredictable hand movements, the segmentation and preprocessing processes of the model may not be as reliable, which affects its efficacy. Although efficient, the KNN classifier’s reliance may not be as appropriate for handling bigger or more varied gesture datasets, and its computational requirements may provide difficulties in real-time applications.
Facial expression-based emotion identification is a key area in the field of human-computer interaction. Numerous problems, such as position fluctuations, uneven illumination, and facial accessories, are encountered in this field. Due to the requirement for simultaneous feature extraction and classifier optimization, traditional techniques for emotion detection have constraints. An increasing amount of attention has been paid to using deep learning techniques to address this. Deep learning techniques are now the most popular for handling classification jobs. Using transfer learning techniques, the inquiry in this paper is focused on emotion recognition. Pre-trained networks like Resnet50, vgg19, Inception V3, and Mobile Net are used in this approach by (Chowdary, Nguyen, and Hemanth.23 These pre-trained Conv-Nets’ fully connected layers are eliminated and swapped out for specially designed completely connected layers that are suited to the demands of the particular emotion recognition task at hand. Notwithstanding the encouraging outcomes, it is important to recognize the limitations of this study. A single database, in this case CK+, is predominantly used for the evaluation of the proposed facial expression detection system, which may not accurately reflect the variety of real-world circumstances, emotions, or demographic variances. Examining the model’s performance on a wider variety of datasets with more variability would allow for more in-depth analysis. Although the accuracy of pre-trained convolutional neural networks is outstanding, there has been little research done on the computational resources needed, which might be a drawback for real-time or resource-constrained applications.
The fields of hand gesture recognition and facial emotion detection have benefited greatly from the recent research in human-computer interaction. To overcome the shortcomings of RGB cameras, hand gesture recognition research focuses on depth cameras and lightweight convolutional neural networks, but it also calls for resource-intensive models. In the meantime, face expression identification using deep learning algorithms is state-of-the-art. Nevertheless, the evaluation of this research frequently depends on a single dataset, which may limit their practical relevance. Real-time or resource-constrained applications have difficulties due to the computing demands of deep learning models. Although human-computer interaction is being advanced by these studies, they also highlight the necessity for flexible solutions that can address a variety of real-world issues in these rapidly developing sectors.
The lack of attention paid to adaptability to different and complex situations and real-world applicability is the common fault throughout the above literature studies. The video-based hand gesture detection system with depth cameras provides an answer to the problems associated with RGB cameras’ lighting conditions, but it does not fully handle the problems that could occur in real-world situations, such as crowded backgrounds, multiple users, and changing lighting conditions. Motion sequence-based hand gesture recognition exhibits strong performance in both signer-independent and signer-dependent modes; however, it faces challenges related to the demands on computational resources, sequence length sensitivity, and practical optimization, which may hinder its applicability for real-time applications and edge devices. Few studies have explored the computational resource requirements for broader real-time or resource-constrained applications, and the facial expression recognition models that have been primarily evaluated on a single dataset may not adequately account for the complexities of real-world scenarios, emotions, and demographic variations.23 Altogether, these constraints highlight the need for more all-encompassing and flexible solutions to deal with the complex issues these developing fields present.
The proposed model’s methodology part is organized in an organized way. To improve the quality of the incoming data, Wavelet Transform-based pre-processing is first used. Then, the Marker-Based Watershed Algorithm is used to segment the data so that different body movements may be recognized. Convolutional Neural Networks (CNNs) are used for feature extraction. This method is novel in that it incorporates the Crow Search Algorithm, which improves the model’s performance to a great extent. An Optimized Probabilistic Neural Network is used to accurately classify body motions in the context of human-computer interaction. This all-encompassing approach blends several tried-and-true methods with state-of-the-art algorithms to produce a strong framework that enhances body gesture identification and advances the field of human-computer interaction. Figure 1 describes the block diagram of the proposed method.
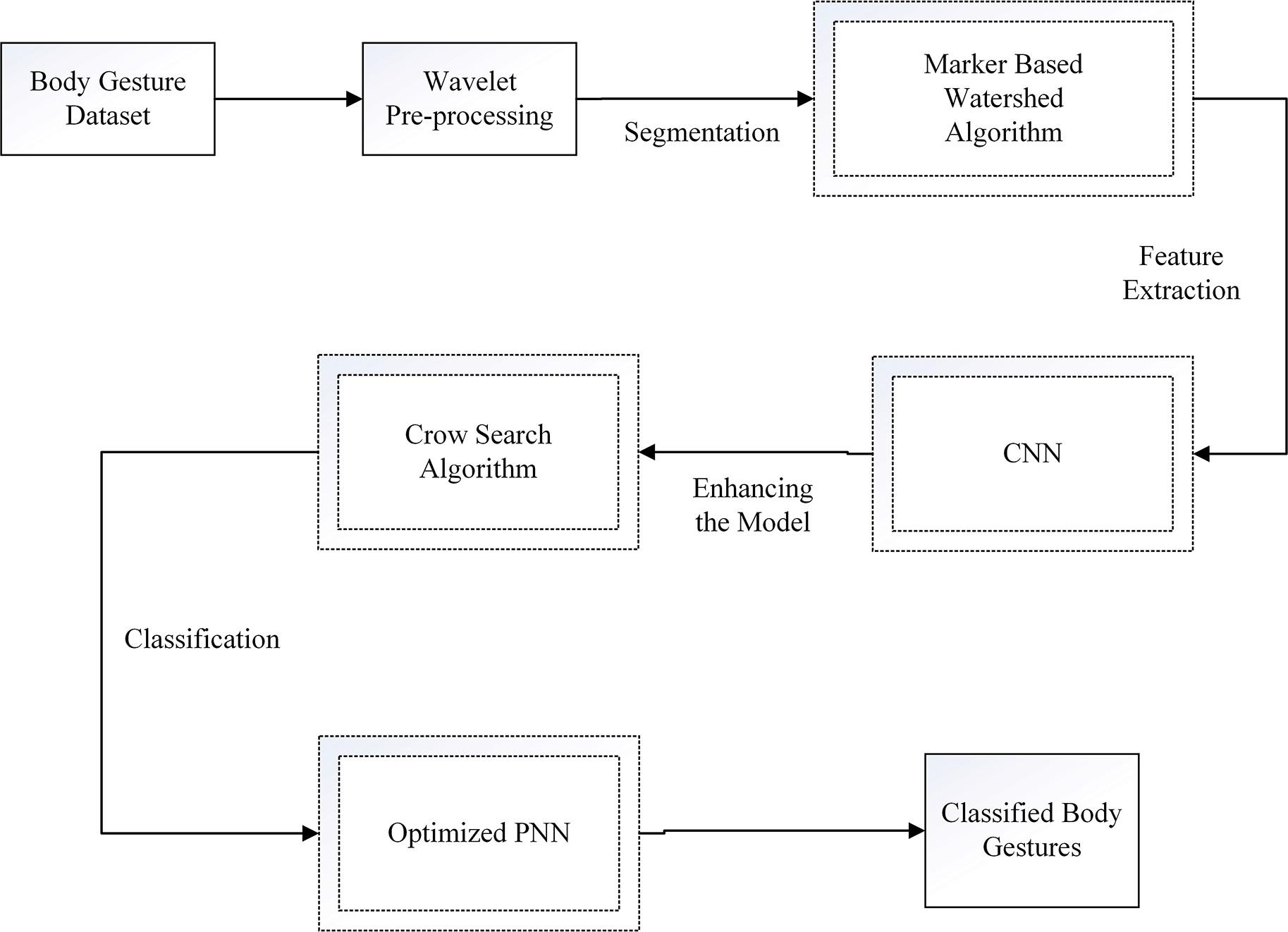
A significant issue continues in the area of data collecting for synthesizing realistic and human-like conversational gestures due to the scarcity of datasets, models, and consistent evaluation standards. The Body-Expression-Audio-Text dataset, or BEAT, was created as a solution to this challenge. This BEAT dataset is used in this study to recognize body gestures. BEAT contains 76 hours of high-quality multi-modal data collected from 30 speakers engaged in conversations with eight various emotions and in four various languages. This dataset also includes a thorough annotation of 32 million frame-level emotion and semantic relevance annotations. An in-depth analytical examination of BEAT finds relationships between communicative gestures and numerous aspects such as facial expressions, emotions, semantics, audio, text, and speaker identity.24
The accuracy of data preprocessing, the initial stage after data collection, is critical to the success of gesture recognition systems. This preprocessing procedure is critical to improving the dataset’s quality and usefulness. Wavelet denoising is a potent method for cutting noise from pictures and videos without sacrificing key details. Using a wavelet transform, thresholding the wavelet coefficients to eliminate noise, and finally rebuilding the denoised image are the steps in the process.
A wavelet transforms, usually the discrete wavelet transform (DWT) or the continuous wavelet transform (CWT), is used to convert the image into the wavelet domain. The DWT is frequently employed in real-world applications.
In Eqn. (1), the wavelet coefficient at scale x and location y is represented by the symbol . The initial image or signal is represented by . The wavelet function at scale x and location y is represented by the symbol .
To eliminate noise, the coefficients are threshold in the wavelet domain. Either hard or soft thresholding can be used to complete the thresholding. It is given in Eqn. (2).
The denoised image or video is obtained by transforming the denoised wavelet coefficients back to the spatial domain is given in Eqn. (3).25
Marker-based watershed segmentation is an important image processing approach that is utilized in a variety of applications, including body gesture recognition. This technique is frequently used after wavelet preprocessing to segment and identify regions of interest in an image. An approach for segmenting images is the marker-based watershed algorithm. The concept is predicated on viewing a picture as a topographic surface, with elevations represented by grayscale values. The algorithm uses “markers” or seeds to flood this surface, dividing it into regions, or catchment basins. The markers in the figure represent the desired locations of interest. To recognize body gestures, a pre-processed image can be divided into regions representing various body parts, including the head, arms, legs, and torso, using the marker-based watershed technique. Later analysis, such as tracking body motions or identifying certain gestures, can be done using these divided sections.
To identify suitable markers for the watershed technique, the gradient image of the pre-processed image is generated. This could be shown in Eqn. (4).
In Eqn. (4), the gradient at pixel is represented by . The pre-processed image is represented by . Potential markers are represented as local minima in the gradient image. These minima represent the starting points for the flooding process. The regional minima can be defined in Eqn. (5).
The gradient image is transformed into catchment basins using the watershed transformation. This can be expressed in Eqn. (6)
In Eqn. (6), is the segmented image. The image with gradients is 26 The marker image is . For segmenting body gestures in pre-processed images, the marker-based watershed algorithm can be an effective tool. It uses gradient information and markers to segment an image into discrete sections that can then be used for gesture detection or additional analysis.
Convolutional Neural Networks (CNNs) are used to autonomously identify and extract significant properties from the segmented regions after the segmentation stage. CNNs are very good at recognizing spatial and hierarchical information inside the segmented areas, which makes them ideal for body gesture recognition. The CNN layers, comprising the pooling and convolutional layers, facilitate the network’s ability to acquire and portray discriminative characteristics from every divided area. CNNs identify and extract local patterns and features from the input images by using convolutional layers. A collection of learnable filters, commonly referred to as kernels, are applied to the input image during the convolution process. To create feature maps, each filter computes the dot product after swiping a window across the image.
Whereas Eqn. (7), the value at points the feature map is . The input image is denoted by . The filter is denoted by k. The filter’s indices are m and n.
An activation function is added to the network following the convolution operation to add non-linearity. A popular option is the Rectified Linear Unit (ReLU). In Eqn. (8), the output of the activation function is . The supplied value is x.
The feature maps are down-sampled by using pooling layers, which lowers their spatial dimensions. A common technique is called “max pooling,” in which the maximum value is held for each zone. is the value in the pooled feature map. A value in the initial feature map is denoted by . It is given in Eqn. (9).
The completely connected layers receive the flattened feature maps as their input. It is shown in Eqn. (10).
The feature vectors that have been flattened are linked to one or more dense layers, or completely connected layers. Based on the learnt attributes, these layers carry out classification and decision-making. More neurons than classifications or motions in the dataset are usually seen in the final fully connected layer. Using a SoftMax function, class probabilities are obtained. It is given in Eqn. (11).
The probability of class x is given by . The feature vector is denoted by X. The weights and biases for class x is denoted by and . The total number of classes is denoted by C.27
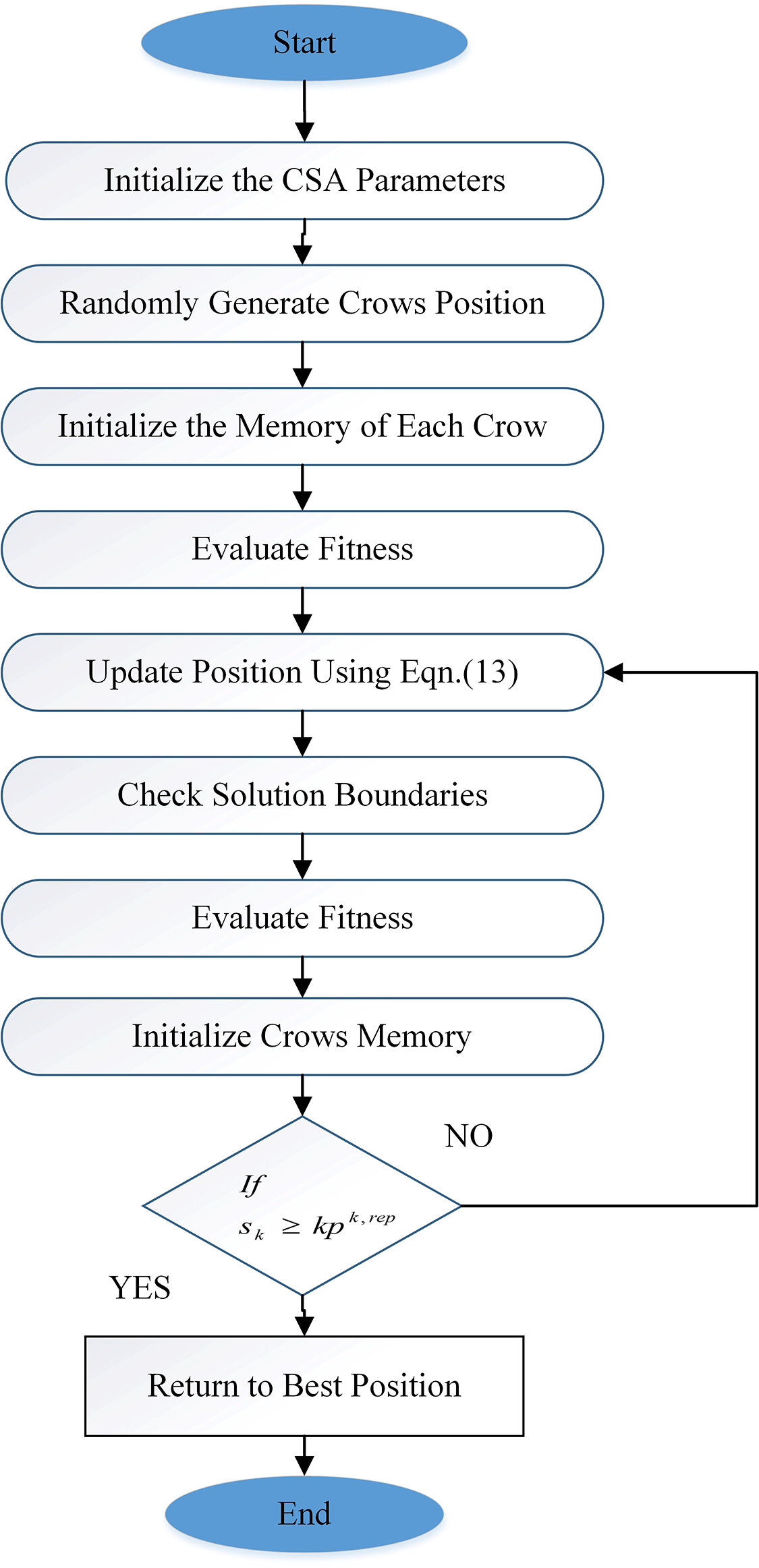
Crow search algorithm is focused in the proposed model to enhance the with all possibilities.28 Inspired by the extraordinary cognitive abilities of crows—which are considered to be among the brightest bird species because to their comparatively large brains compared to their body size—the CSA is a novel meta-heuristic algorithm that has gained recognition for its intelligence. Crows are incredibly intelligent animals that have been well-studied and documented. They are self-aware in mirror tests, skilled tool makers, have perfect facial recognition, and have an amazing memory for storing food for months at a time. CSA uses the idea that crows are perceptive observers and learners of their environment to improve the suggested model for body gesture detection. Crows use their prior experiences to anticipate and avert prospective problems, much as they keep an eye on other birds to locate hiding spots and take advantage of food opportunities. CSA refers to a group of crows who collaborate to optimize tactics for the recognition model, remember important sites collectively, and protect against unforeseen obstacles. An effective and flexible method for improving the body gesture recognition model is made possible by the similarities between the actions of the crow and CSA. The algorithm of crow search optimization is depicted in Figure 2.
To find out where Crow K is hiding this iteration, Crow j wishes to follow Crow K. In this situation, the following conditions could manifest:
Condition 1 : The goal of crow j in this scenario is to find crow k’s hiding place without crow k’s help or prior knowledge. This procedure is used to decide Crow J’s new position, given in Eqn. (12)
A random number produced from a uniform distribution covering the interval between 0 and 1 is referred to in this context as the variable . The flight length of Crow during the repetition designated as is indicated by the notation .
Condition 2 : Crow k may effectively share its expertise with Crow J by guiding the latter to its cache. In the second case, though, crow k might decide to trick crow j by moving to a new spot in the search space, knowing that crow j is pursuing it, and protecting its cache from possible theft. Eqn. (13) can be used to sum up these two states:
The following briefly describes the CSA implementation:
Step. 1. Identify the variables that can be changed in CSA, such as flock size (N), maximum repetitions , flight duration ( ), and knowledge probability.
Step. 2 . In an a-dimensional search space, distribute N crows at random; each crow indicates a workable solution with a set of decision variables using Eqn. (14).
This is where each crow’s memory is initialized. The birds’ food at the first positions is thought to have vanished since they were inexperienced at the first repetition. It is given in Eqn. (15).
Step 3 . Based on the values of its decision variables, the fitness of each crow is evaluated in the objective function to determine its position.
Step.4. Crows in the search area reposition themselves by arbitrarily choosing a different crow (such as crow k) to use as a point of reference to gauge its success ( ). The new locations for every crow in the field are determined using equation (13).
Step 5 . Check if the new locations of each crow are stable. Crows only adjust their places if the new locations are stable; if not, they stay where they are.
Step.6. Determine the value of fitness for every new location of the crow.
Step 7. Each crow’s memory is updated using Eqn. (16).
Step 8 . Repeat steps 4–7 until the is obtained. As the optimization problem is solved, the optimal memory location about the objective function value will be displayed after the termination requirement is satisfied.29
The input layer, pattern layer, summation layer, and output layer make up the four layers of the hierarchical architecture of the Probabilistic Neural Network (PNN), a potent classifier. PNN’s supervised learning method, which takes its cues from Bayesian networks, makes it very good at pattern recognition tasks. Though PNN already performs admirably in many applications, optimization strategies can further increase its accuracy and efficiency. One improvement is the PNN model’s fine-tuning through the bid of the CSA. The crow’s hunting habit served as the inspiration for CSA, a nature-inspired optimization algorithm that is well-known for its ability to quickly find the best answers in challenging problem spaces. By utilizing the CSA on PNN, it is possible to enhance the network’s parameters and hyperparameters, resulting in a classifier that is more reliable and accurate. This optimization procedure aids in determining the PNN’s ideal design, improving its capacity to handle challenging classification tasks. A probabilistic neural network that is optimized for classification is produced when PNN and the Crow Search Algorithm are combined. Along with maintaining the intrinsic strengths of PNN, namely its capacity to deal with nonlinear issues well, this improved model also gains from the CSA’s optimization powers. Figure 3 describes the architecture diagram of PNN.
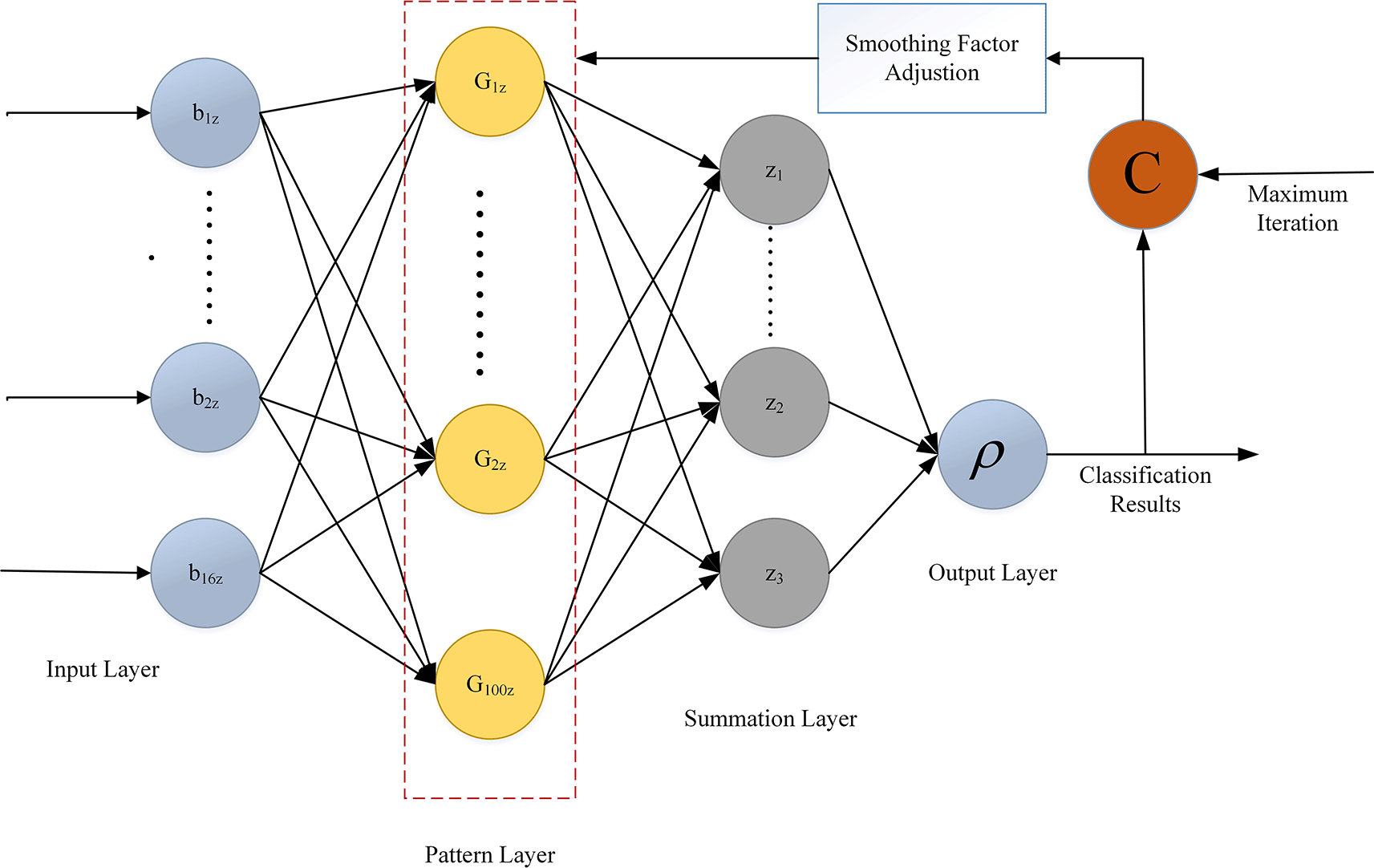
Normalized characteristic vector ‘B’ of intrusion category ‘z’ for test samples is accepted by the input layer. Eqn. (17) defines the connection weighting ‘W,’ which is the transpose of ‘B’ and is multiplied by this vector. Next, as indicated by Eqn. (18) the resultant value ‘I’ is transferred to the pattern layer.
The characteristic vector’s dimensions and the total number of training samples are matched by the number of neurons in the pattern layer and input layer, respectively. 16 calculated characteristics are used as target parameters in the PNN model during training. 100 neurons are set aside in the pattern layer for every category of intrusion. For each element in the training sample and test sample, these neurons calculate the Euclidean distance using a Gaussian function. Eqn. (19) specifies the output result for pattern nodes of category z, represented as .
Within the intrusion category z, where ‘s’ varies from 1 to 100, denotes the centre of training sample ‘s’. The distance between two vectors is calculated using the function indicated by the notation ‘||·||’. Within the summing layer, the total amount of intrusive event types is matched by the number of summation nodes. Each neuron in this layer calculates the sum of the outputs from the pattern nodes associated with the same category. This summation is then divided by the total number of neurons in the pattern layer, as expressed in Eqn. (20).
Neuron ‘z’s estimated density function is represented by the symbol in the output layer. The output result is represented as . It is given in Eqn. (21).
The fitness function that can be used to assess the similarity or equivalency between the expected and actual outcomes in the PNN model when the neuron in the summation layer has the highest predicted probability value is defined by Eqn. (22), which also determines cost function C.
With the smoothing factor adjusted, a more accurate forecast is indicated by the decreasing cross-entropy cost function C. The objective of these experiments is to improve classification precision by using the Improved Salp Swarm Algorithm (ISSA) as the optimizer to find the ideal smoothing factor, denoted as ‘Salp’.
An extensive analysis of the suggested model and its parts is provided in the study’s results section. Python is the implementation tool for this study. It has been shown that using the Wavelet Transform for pre-processing can improve gesture identification by lowering noise and improving data quality. Accurate feature extraction has been made possible by the segmentation process brought about by the Marker-Based Watershed Algorithm. As a result, the model’s capacity to recognize complex movements is improved. CNN-Based Feature Extraction has demonstrated its ability to identify subtle patterns and nuances in body gestures. The model’s accuracy and performance in gesture identification have improved with the addition of the Crow Search Algorithm. The model’s robustness and dependability are demonstrated by the high accuracy and decreased classification errors obtained from using the Optimized Probabilistic Neural Network for classification. Together, these findings demonstrate the effectiveness and promise of the suggested strategy in improving human-computer interaction by accurately and effectively recognizing body gestures.
Precision, sensitivity, F1-score, and accuracy are among the evaluation metrics used to analyse the performance of the body gesture recognition model. These parameters are presented below and serve as measures for model evaluation:
Accuracy: It calculates the percentage of correct predictions, including both TP and TN, over all occurrences examined. It is referred to as Eqn. (23).
Precision: The ratio of accurately anticipated positive instances to total expected positive instances is denoted as precision. Precision is calculated using Eqn. (24).
Sensitivity: Eqn. (25) shows how to calculate recall, where denotes false positives, refers false negatives, denotes true positives, and is true negatives.
F1 score: High recall and high accuracy are desirable in the context of body gesture identification, but they frequently come at a cost. The F1-score—the harmonic means of recall and accuracy is used to take into consideration both factors, as demonstrated by Eqn. (26).
Specificity: It is depicted in Eqn. (27).
A statistical assessment technique called accuracy analysis is employed to evaluate a model’s overall prediction accuracy in a binary or multiclass classification problem. To determine the overall performance of the model, it computes the ratio of accurate predictions (including true positives and true negatives) to the total number of examples analysed.
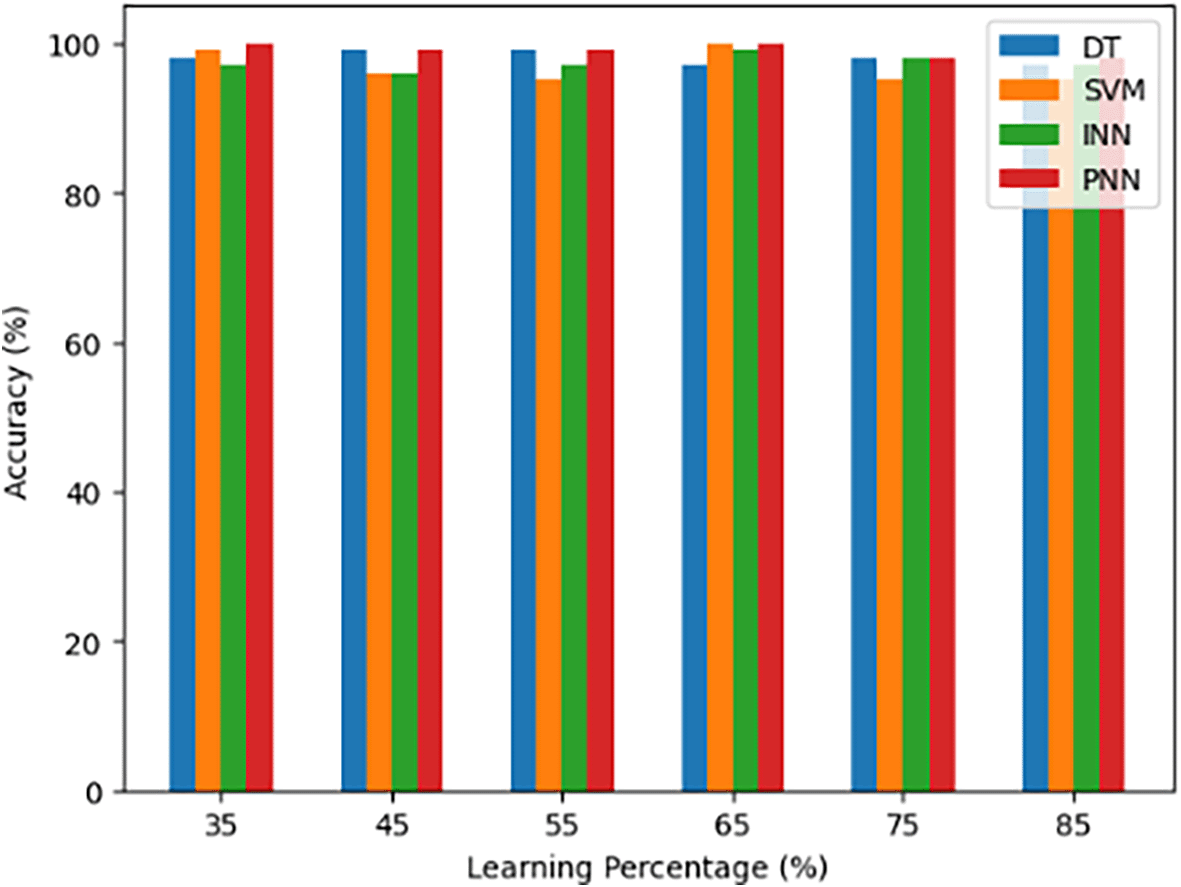
A evaluation of the proposed body gesture recognition method (PNN) with the existing models—DT, SVM and INN—is shown in Figure 4. The models’ various learning percentages are shown on the x-axis, and the accuracy values that correspond to them are shown on the y-axis. The suggested model’s improved accuracy in body gesture recognition over the alternatives is illustrated by the graph, which offers a clear visual depiction of how it performs better or matches existing models across various learning percentages.
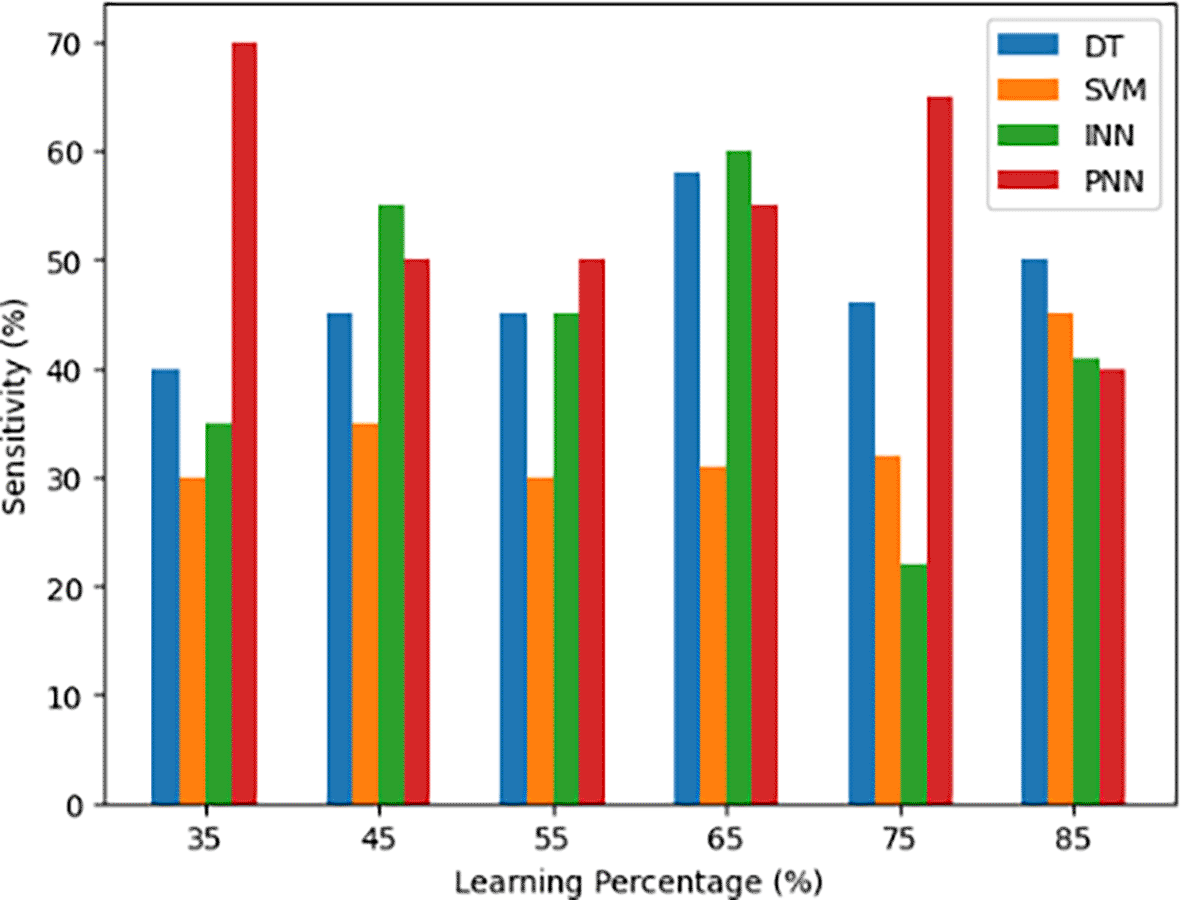
A statistical metric called sensitivity, which is often referred to as true positive rate or recall, counts the percentage of real positive cases that a model or test accurately recognized. In binary classification and medical diagnostics, it is an essential indicator that shows how well the model can identify and categorize real positive cases while reducing false negatives. Calculating sensitivity involves dividing the total number of true positives by the total number of false negatives.
The proposed body gesture recognition model (PNN)’s sensitivity and recall are compared to those of other models, such as DT, SVM and INN, in the Figure 5 graph. The models’ different learning percentages are displayed on the x-axis, while the appropriate sensitivity values are displayed on the y-axis. This graph shows how well the suggested model and the current models identify and accurately categorize genuine positive events when it comes to body gesture recognition over various learning percentages. It highlights the model’s sensitivity performance by showcasing its capacity to reduce false negatives and successfully identify real positive cases.
The proposed body gesture recognition model (PNN) is evaluated in comparison to other models, including DT, SVM and INN, in Figure 6. Specificity is a measure of the true negative rate. The y-axis shows the corresponding specificity values, while the x-axis shows the various learning percentages applied to these models. This graph presents a visual representation of each model’s performance over different learning percentages in terms of how well it detects non-target situations or true negatives. It offers important information on the specificity of the models for body gesture recognition by demonstrating their capacity to reduce false positives and correctly identify cases that do not belong to the target class.
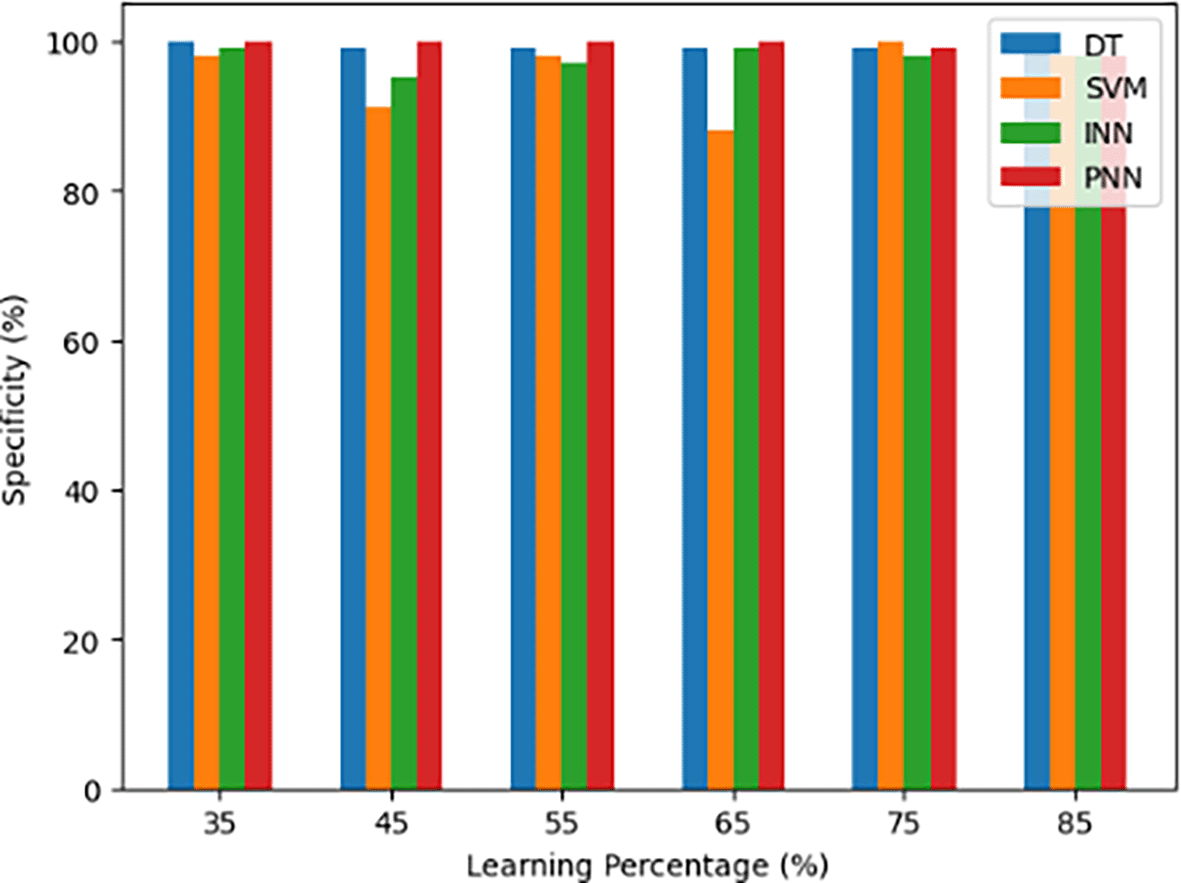
A statistical measure known as precision assesses how well a model predicts the positive outcomes of a binary or multiclass classification task. It provides information on the model’s capacity to reduce false positive mistakes and generate accurate positive predictions. It is computed as the ratio of true positive cases to the total instances projected as positive.
The suggested body gesture recognition model (PNN) is compared to other models, such as DT, SVM, and INN, in Figure 7. Precision is a metric that quantifies the accuracy of positive predictions. The precision values are displayed on the y-axis, while the x-axis shows the different learning percentages that were applied to these models. This graphic illustrates how well each model performs in terms of reducing false positive mistakes and producing precise positive predictions, especially when it comes to body gesture recognition at various learning percentages. The graph highlights the models’ success in minimizing false positive predictions while maximizing correct ones, giving insights into their capacity to generate accurate positive outcomes.

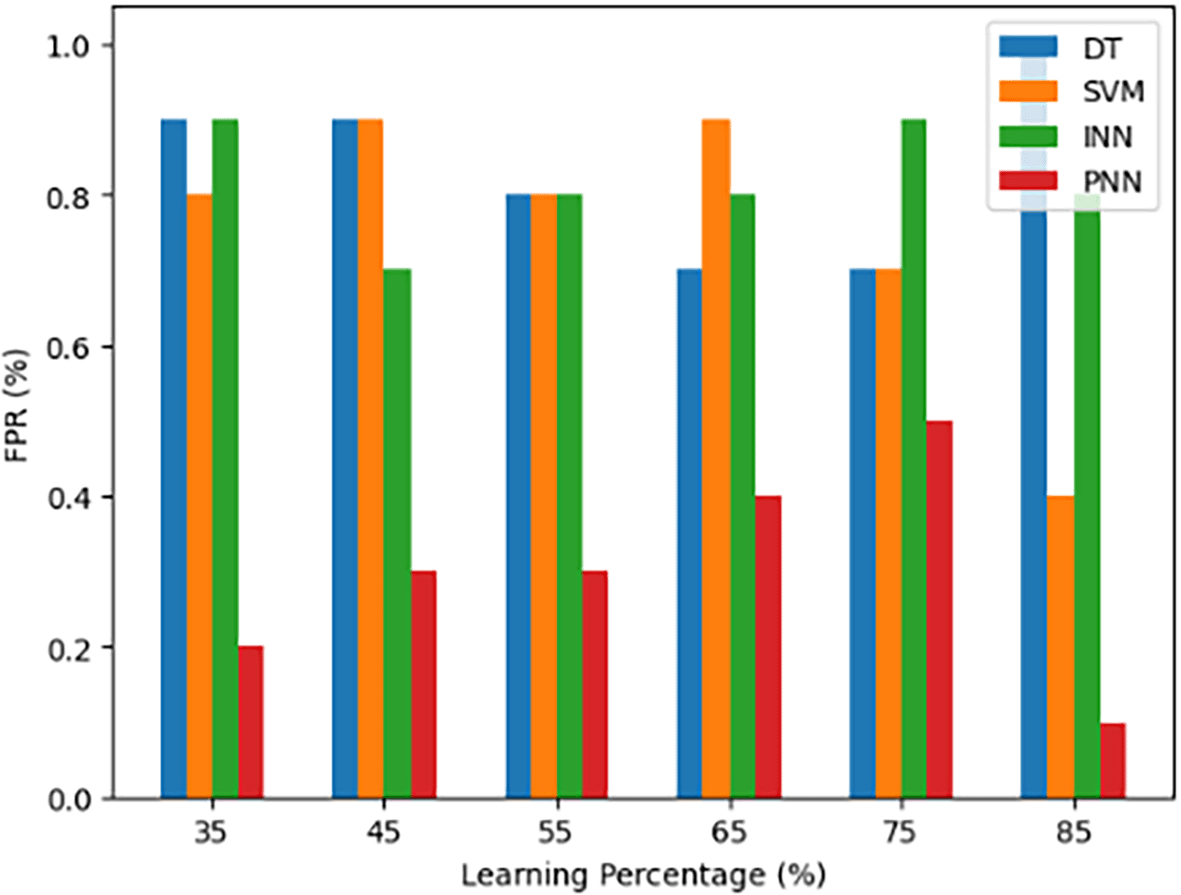
A statistical indicator used to assess a model’s performance, especially in binary classification problems, is the FPR, often called the False Alarm Rate. The percentage of negative cases (true negatives) that the model mistakenly classifies as positive (false positives) is what it measures. FPR is a useful supplementary measure to True Negative Rate (TNR), which measures the model’s accuracy in classifying negative instances. It offers information on the model’s ability to differentiate between true negative cases and false positive predictions. A crucial indicator for evaluating a model’s specificity and capacity to reduce false positive or false alarm errors is false positive rate (FPR).
Figure 8 presents a comparative study of the False Positive Rate (FPR) for several models. The models that have been trained at different learning percentages include the proposed body gesture recognition model (PNN), DT, INN, and SVM. The y-axis shows the relevant accuracy numbers, while the x-axis shows these learning percentages. This graph provides a visual depiction of each model’s performance in terms of FPR when it comes to body gesture recognition, showing how well it can differentiate between real negative instances and false positive predictions. It offers important insights into the models’ capacity to reduce false positive errors while preserving overall body gesture recognition accuracy.
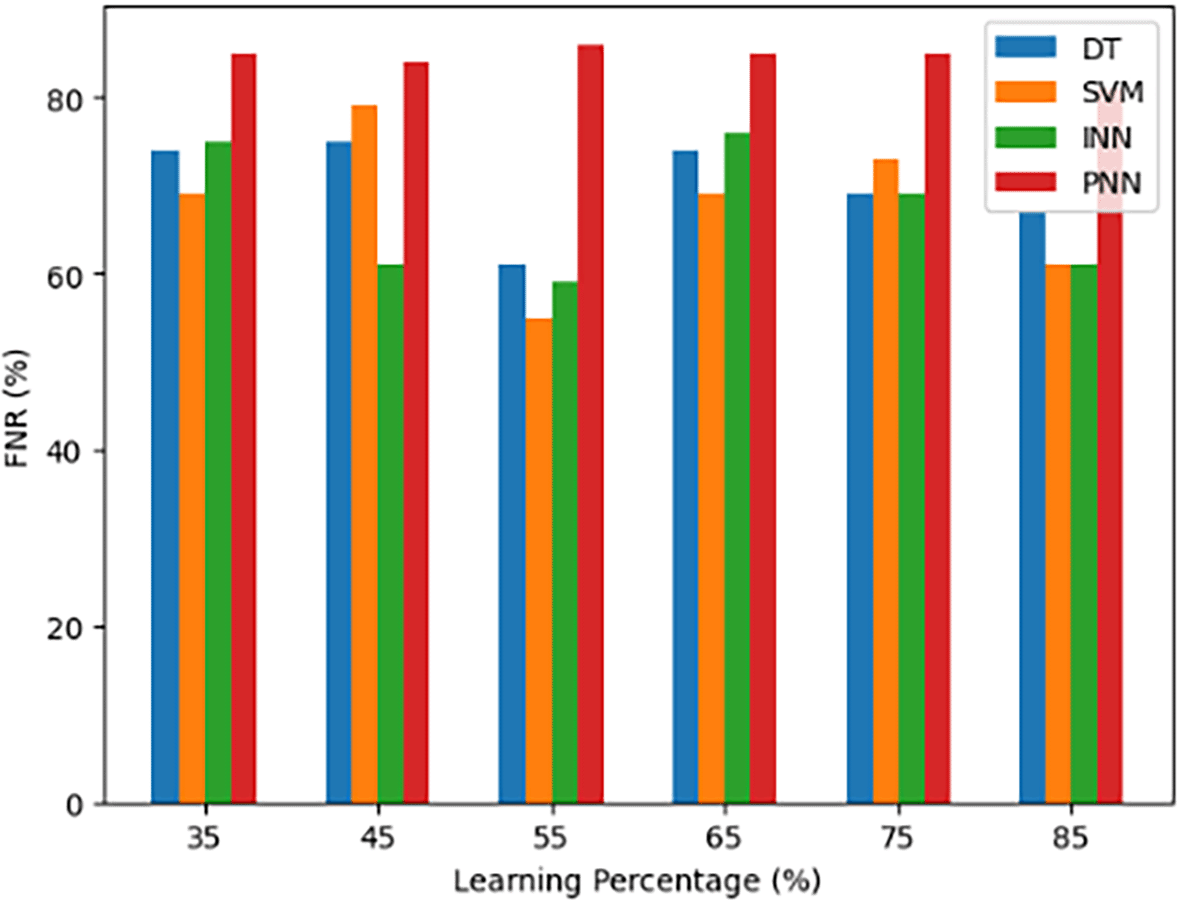
A statistical parameter called the False Negative Rate (FNR), sometimes referred to as the Miss Rate, is used to assess a model’s performance, especially in binary classification issues. It calculates the percentage of positive cases (true positives) that the model mistakenly labels as negative (false negatives). FNR measures the rate at which positive examples are overlooked or mistakenly classified as negative, and it offers insights on the model’s capacity to identify and accurately categorize genuine positive cases. FNR is frequently used to evaluate a model’s sensitivity and capacity to reduce false negative rates.
Figure 9 compares the False Negative Rate (FNR) of various models, including the DT, Support Vector Machine (SVM), INN and the proposed body gesture recognition model (PNN). On the x-axis, these models are assessed across various learning percentages. The appropriate accuracy numbers are shown on the y-axis. This graph shows how well each model finds and classifies true positive instances while quantifying the rate at which positive examples are ignored or wrongly labelled as negative. It provides useful insights into the models’ sensitivity and performance in reducing the rate of false negatives in the context of body gesture recognition while preserving overall accuracy.
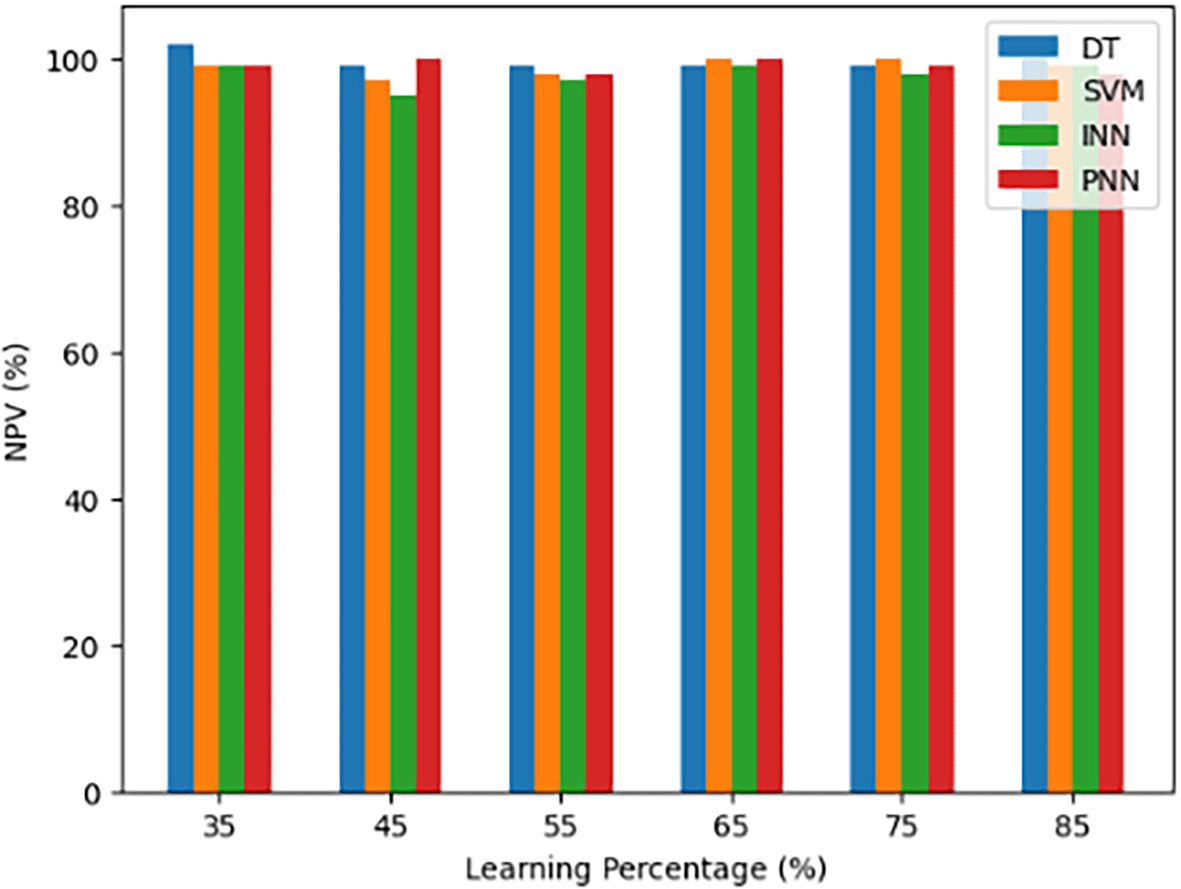
A statistical measure called Negative Predictive Value (NPV) is used to evaluate a model’s accuracy, especially in binary classification issues. It measures the ratio of accurately predicted negative instances, or true negative instances, to all instances that were anticipated to be negative. NPV gives information on how well the model can remove cases that do not fall into the positive class and minimize false negative errors by accurately identifying true negatives.
Figure 10 compares the Negative Predictive Value (NPV) of an INN, DT, Support Vector Machine (SVM), and the suggested body gesture recognition model (PNN) among other models. The accuracy values are displayed on the y-axis, while the x-axis shows different learning percentages applied to these models. Specifically in the context of body gesture recognition at various learning percentages, this graph shows how well each model detects real negative instances and minimizes false negative errors. It sheds light on the models’ overall accuracy in negative predictions as well as their dependability in rejecting examples that do not fall into the positive class.
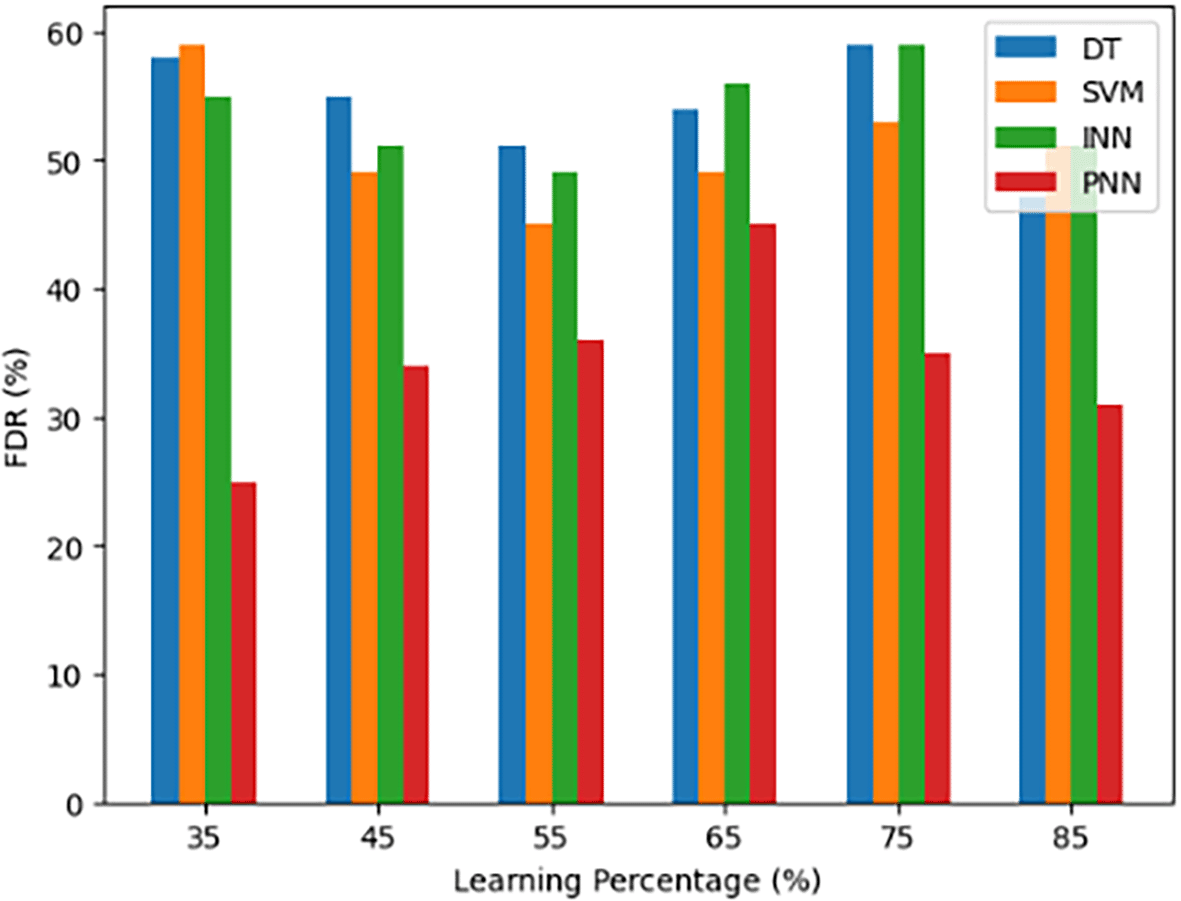
In the context of multiple hypothesis testing, the FDR is a statistical indicator that is employed to evaluate the precision of positive predictions. The ratio of false positive cases to all cases anticipated as positive is its definition. Put otherwise, the false discovery rate (FDR) quantifies the frequency at which a model’s positive predictions are shown to be falsified or inaccurate. It finds frequent application in fields like scientific research or genetics where limiting the rate of false discoveries is essential.
The False Discovery Rate (FDR) for various models, including the DT, Support Vector Machine (SVM), INN and the proposed body gesture recognition model (PNN), is compared in Figure 11. This graph shows how well each model manages and minimizes the rate of false discoveries over different learning percentages. It provides insight into the models’ capacity to detect positive instances and restrict the frequency of false positive mistakes while preserving overall accuracy.
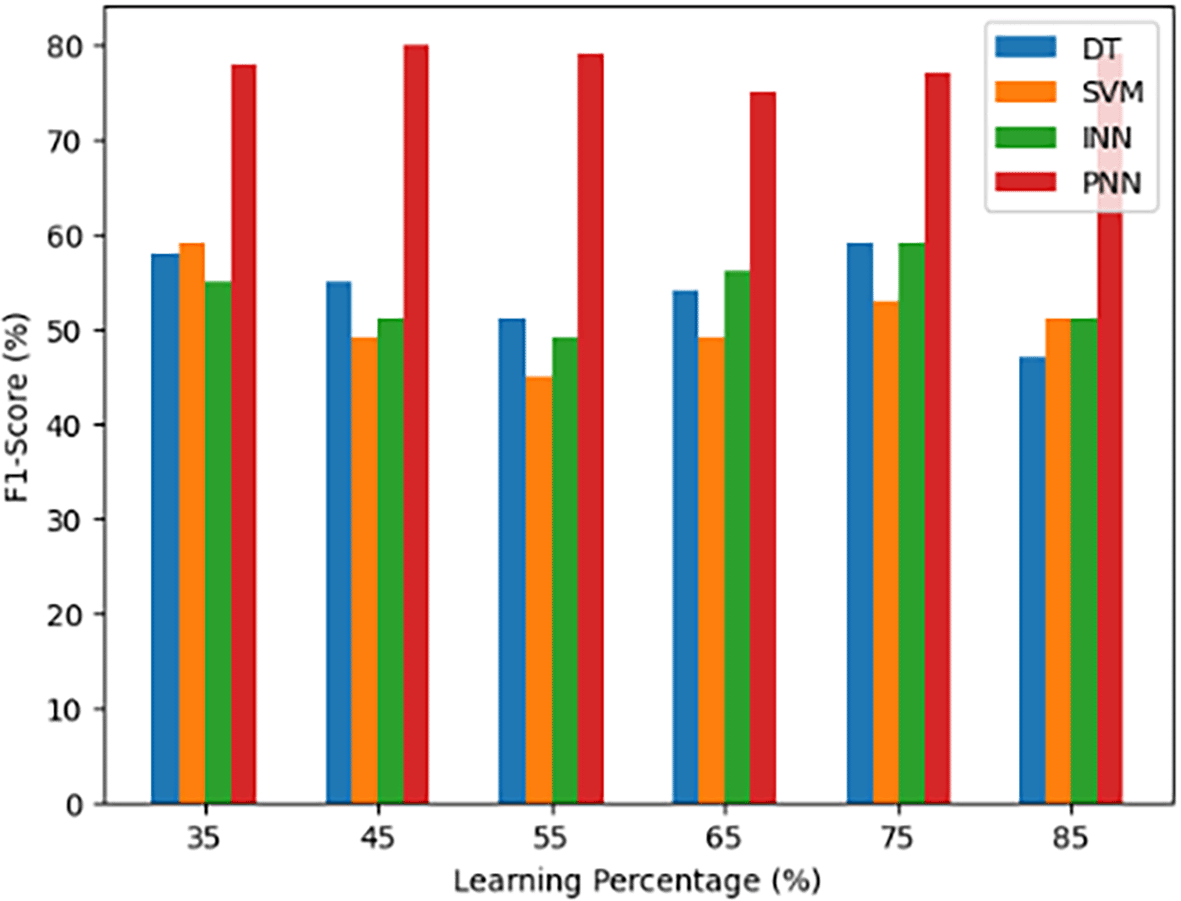
A statistical indicator called the F1 Score is used to evaluate a model’s classification accuracy, especially in binary or multiclass issues. It is a balanced assessment of a model’s performance that takes into account both precision and memory. When there is an unequal distribution of classes, the F1 Score is especially helpful since it strikes the ideal balance between reducing false positives and false negatives. Better overall model performance is indicated by a higher F1 Score is the ideal score.
Figure 12 presents a comparative evaluation of the F1 Score for several models, such as the suggested body gesture recognition model (PNN), DT, Support Vector Machine (SVM), and INN. The y-axis shows the relevant accuracy scores, while the x-axis shows different learning percentages applied to these models. This graph provides a unified assessment of each model’s overall performance in identifying body motions across various learning percentages by providing a visual depiction of how well it balances recall and precision.
An analytical tool for evaluating binary classification models’ quality is the Matthews Correlation Coefficient (MCC), which is especially useful when class distributions are unbalanced. In order to quantify the degree of correlation between the true class labels and the model’s predictions, true positives, true negatives, false positives, and false negatives are examined. MCC provides a fair assessment of a model’s performance by determining the relationship’s strength and direction. The scale goes from 0 (no association) to +1 (perfect prediction) (perfect inverse prediction). MCC is frequently used in many domains, such as machine learning, epidemiology, and bioinformatics, to assess the performance of classification models. It is especially helpful when the dataset includes unequal class proportions.
A comparison of the Matthews Correlation Coefficient (MCC) for several models, including the suggested body gesture recognition model (PNN), DT, SVM, and INN, is provided in Figure 13. Taking into account true positives, true negatives, false positives, and false negatives, this graph shows how well each model builds the relationship between its predictions and actual class labels. MCC is an important indicator since it provides a fair assessment of the model’s performance, especially when it comes to body gesture recognition at varying learning percentages. It provides a trustworthy indicator of the models’ classification quality and enables a thorough understanding of how well they can manage unbalanced class distributions.
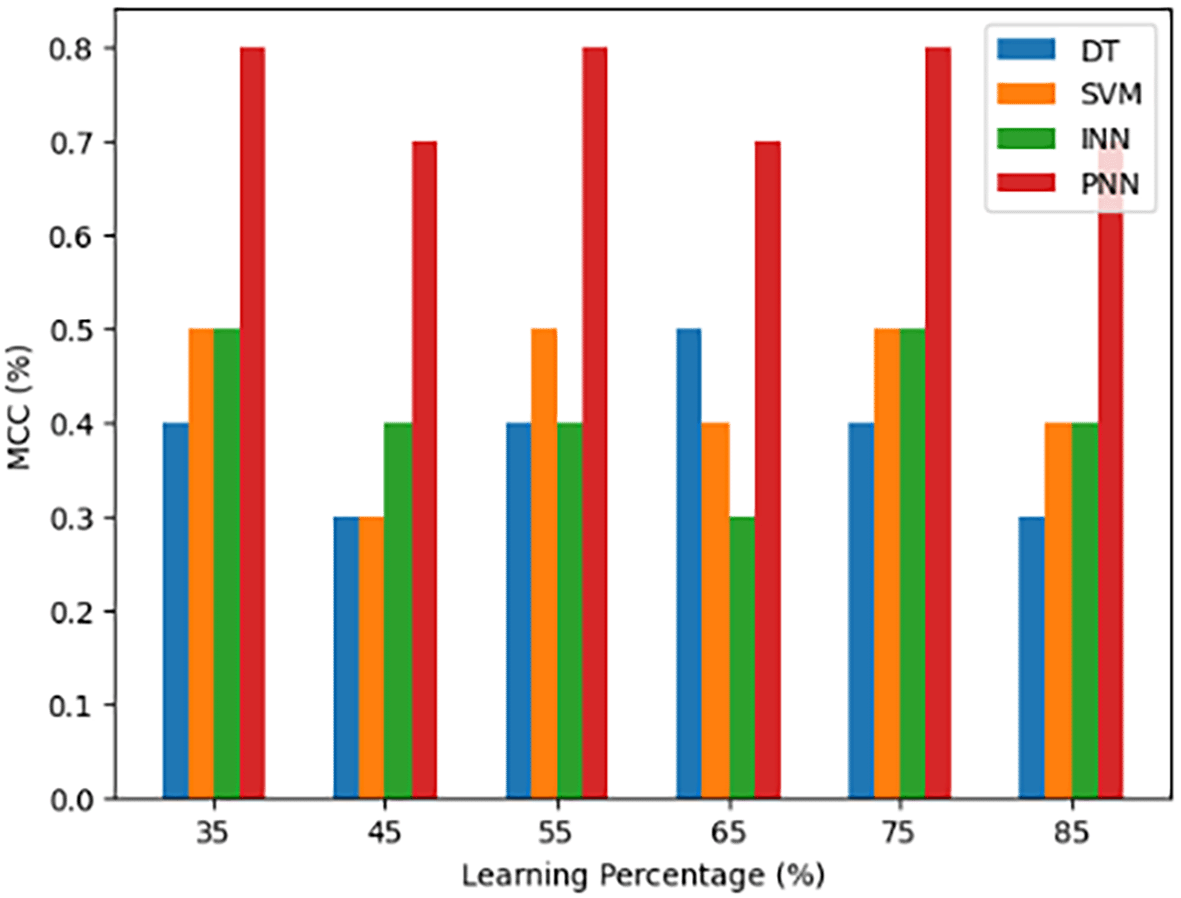
Table 1 and Figure 14 shows a comparison of four distinct machine learning techniques: DT, Support Vector Machines (SVM), an INN and a Proposed Optimized Probabilistic Neural Network (PNN). Although the DT approach produced an F1-score of 54%, its accuracy was the greatest at 98%; nevertheless, its precision and recall were comparatively lower at 53.3% and 47.3%, respectively. A 51% F1-score was obtained by SVM, which had an accuracy of 96.6%, precision and recall values of 51% and 33.8%. With a 97.3% accuracy rate, precision and recall rates of 53.5% and 43%, respectively, and an F1-score of 53.5%, the INN model outperformed the others on the little margin.
| Methods | Accuracy (%) | Precision (%) | Recall (%) | F1-score (%) |
|---|---|---|---|---|
| DT | 98 | 53.3 | 47.3 | 54 |
| SVM | 96.6 | 51 | 33.8 | 51 |
| INN | 97.3 | 53.5 | 43 | 53.5 |
| Proposed Optimized PNN | 99 | 84.3 | 55 | 78 |
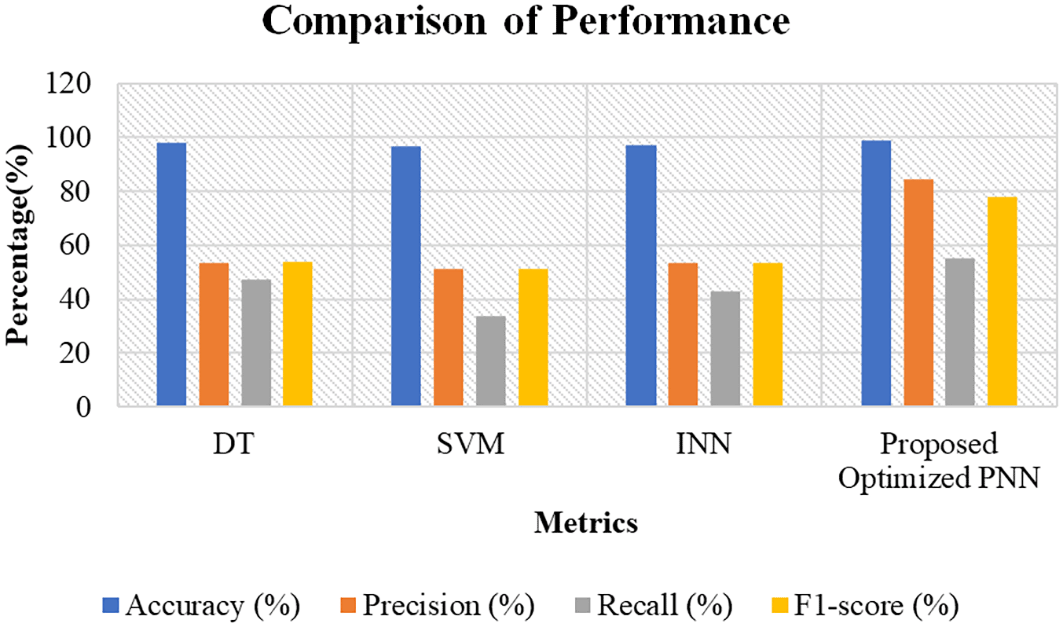
With a remarkable accuracy of 99%, a far higher precision rate of 84.3%, a recall of 55%, and an F1-score of 78, the Proposed Optimized PNN beat the other approaches, indicating that it would be a good option for the current task.
The results section includes a thorough analysis of the suggested model’s performance in comparison to other models. Numerous metrics are covered by the analysis, such as F1-Score, Mathew’s correlation coefficient, accuracy, sensitivity, specificity, precision, FPR, FNR, NPV, and FDR. This comprehensive analysis makes it possible to comprehend the model’s body gesture recognition abilities and usefulness in the context of human-computer interaction. By taking into account these many criteria, the debate offers insightful information on the advantages and disadvantages of the suggested approach as well as how it might improve gesture recognition technology’s ability to facilitate human-computer interaction.
The field of gesture recognition technology has advanced significantly as a result of this work. Using a multimodal strategy that includes CNN Based Feature Extraction, Marker Based Watershed Algorithm for Segmentation, Wavelet Transform Based Pre-Processing, Crow Search Algorithm for Model Enhancement, and an Optimized Probabilistic Neural Network for Classification, this study has shown promise for improving gesture recognition in human-computer interaction. Promising results have been obtained by integrating the Crow Search Algorithm and the Probabilistic Neural Network optimization; these demonstrate the model’s high degree of efficiency and precision in recognizing and classifying body motions. The model’s resilience has been increased while the accuracy has been further improved by applying the Marker Based Watershed Algorithm for segmentation. These accomplishments have the potential to completely transform how we engage with technology, improving its accessibility and intuitiveness. The suggested paradigm creates opportunities in a variety of industries, including industrial automation, assistive technology, gaming, healthcare, and more by precisely recognizing and reacting to human movements. This research offers a significant addition to the constantly changing field of human-computer interaction and has the potential to revolutionize how humans interact with technology and communicate. This work represents a major advancement in the use of novel algorithms and creative approaches to harness the power of body gesture detection for more effective, realistic, and engaging interactions with computers and other digital devices. This study has intriguing potential for future studies. To improve the model’s flexibility and inclusivity, future research might concentrate on growing the dataset to include a greater variety of motions and user demographics. Second, there is a chance for practical implementation by looking at real-time applications and incorporating the system into other interfaces including virtual reality, healthcare, and smart homes. Further research into how well the model performs in various environmental settings and the development of robustness against noise and occlusions would be beneficial.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)