Keywords
Contrastive Model, Control Algorithm, CLIP, AI, DALL-E, AR, 3D.
Contrastive Model, Control Algorithm, CLIP, AI, DALL-E, AR, 3D.
This AI is like a human trapped in a museum from its birth. It learns perceiving things from limited resources, the web. It cannot roam in real world like human, so does not have the ability to analysis thing from real world scenario. AI knows how hands looks but not how hands work. The human hand is an intricate and versatile organ, capable of performing a wide range of tasks with precision and dexterity. Despite the advancements in AI and machine learning, accurately modelling and predicting the movements and interactions of human hands remain a significant challenge. This thesis delves into the reasons behind these difficulties and explores the implications for various applications, including robotics, virtual reality, and healthcare. By learning to associate images with text, an artificial intelligence model known as CLIP (Contrastive Language–Image Pretraining) is able to understand and generate visuals in response to textual inputs. When used in conjunction with generative models like DALL-E or diffusion models, CLIP produces images that closely resemble the input descriptions and performs well in AI drawing applications. This function allows for the production of images that follow specific prompts or styles. Although because of its large training set, CLIP might not be able to produce features that are very accurate or realistic, it can help by showing intricate items like human hands. we can systematically address these challenges by using CLIP for evaluation, control algorithms for structure enforcement, DALL-E for generation, AR for gesture tracking, and 3D modeling for anatomical accuracy.
In The ‘bad hands’ phenomena, which artificial intelligence is responsible for creating, emphasizes the value of human creativity and media literacy. Artificial intelligence has advanced to the point where these skills are no longer required, but educators and artists can still employ ‘bad hands’ to push the limits of machine learning and redefine humanity in algorithms.1 Hand surgery requires precise techniques due to the hand’s complexity. Generative AI (GenAI) can enhance this by analyzing data, creating detailed simulations, and personalizing procedures, potentially reducing complications. This review explores how GenAI could improve hand surgery, leading to better patient outcomes and setting new standards in the field.2 The Cascaded Deep Graphical Convolutional Neural Network (DCGCN) framework outperforms state-of-the-art models in accuracy and computational cost for 2D hand pose estimation in AI applications.3 Optimizing human hand gestures for AI systems reduces error rates and effort while maintaining the original gesture trajectory, improving interaction with AI systems.4 Human/computer control of dexterous remote hands presents unique challenges, including grasp stabilization and nonanthromorphic behaviour, but progress has been made in grasp planning and controlled slip techniques.5 This paper reviews current research in hand and finger modeling and animation, highlighting progress towards convincing, detailed motions for virtual characters in areas like manipulation and communication.6 The FF-SSD deep learning network effectively detects and localizes hands in space human-robot interaction, outperforming state-of-the-art methods.7 Pixelor is a competitive drawing AI agent that can achieve human-level performance in a Pictionary-like sketching game by learning optimal stroke sequencing strategies and achieving recognizable results faster than humans.8 A unified control framework for robotic hands can simplify and generalize their control, allowing for more advanced manipulation tasks in industries.9 A knowledge-based approach using a three- phased scheme can effectively simulate human hand motion and grasping of arbitrary objects, reducing search space and improving performance.10 This paper11 presents an algorithm for hand-drawn interfaces that simplifies designs by replacing multiple strokes with a single stroke, rationalizing the designer’s creative intent. The hands-free human-computer interface using facial movements achieved high performance and accuracy, offering increased independence and confidence for patients with limited hand function.12 The designed grasping control strategy effectively adapts an anthropomorphic robotic hand to object contours, achieving human-like behaviour and robustness.13 AI raises issues of responsibility attribution, including the problem of many hands and the temporal dimension of control, affecting transparency and explainability.14 Hand gesture recognition (HGR) is a research hotspot in HMI due to its high degree of differentiation, strong flexibility, and efficiency of information transmission.15 The AI edge computing-based system uses gesture tracking and recognition techniques to detect the correctness of stroke trajectory during writing or drawing.16 Combinatorial generalization and structured representations are key to achieving human-like abilities in AI, such as drawing human hands.17
There are various types of model that can be used for explain how the AI generates an image. One such fine example is of CLIP. It is a type of contrastive model that obtains knowledge of semantic information and contextual relationships by learning visual representations of large undefined text data. The following illustration represents a clearer view over this matter. The illustration in Figure 1 is about a detailed overview of UnCLIP. Above the dashed line is the CLIP training process, through which we learn a unified presentation space for text and images. Our text-to image conversion process involves feeding the CLIP text into an autoregressive or diffusion system before embedding the image, followed by conditioning the diffusion decoder that generates the final image. Picture Note that the CLIP model is blocked during feedforward and decoder training. Success and careful manual guidance.
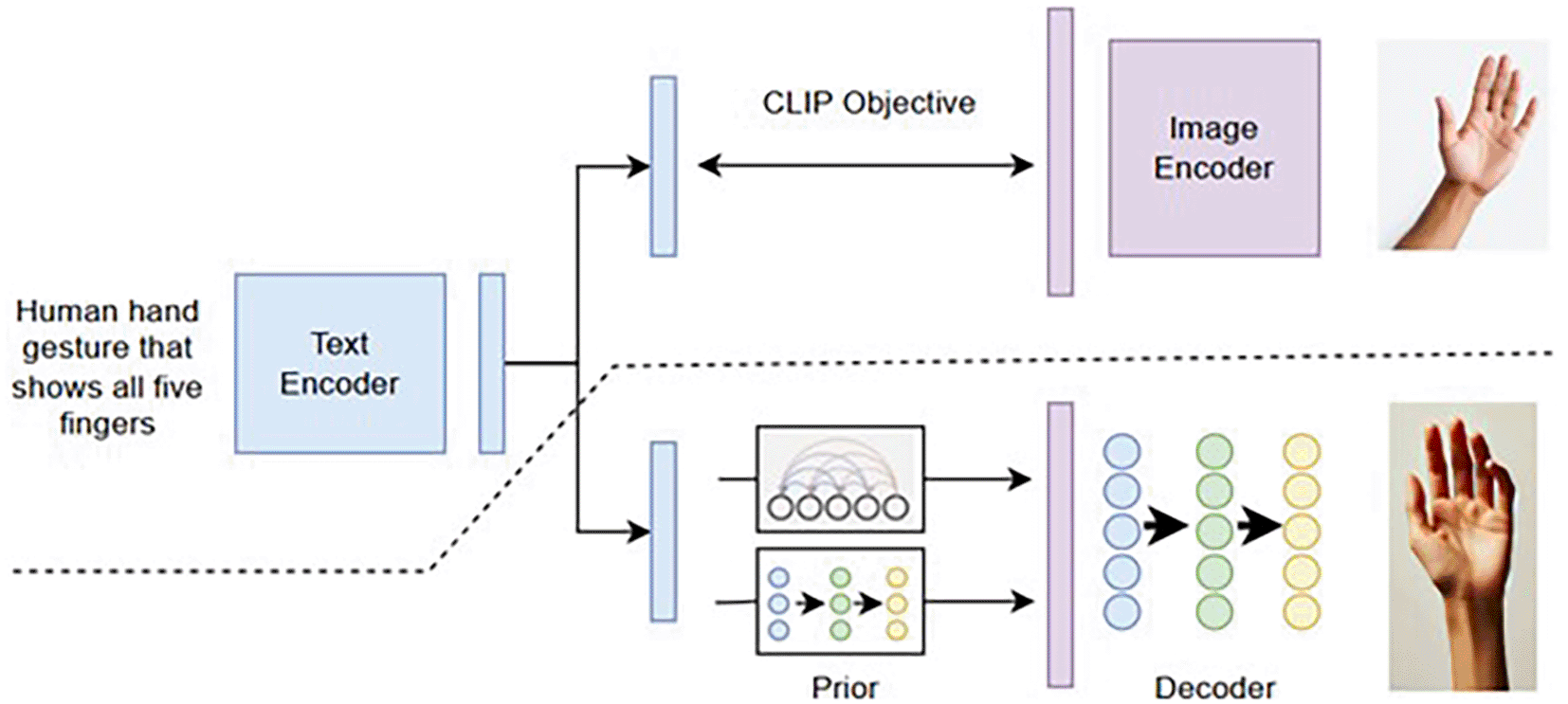
In addition, encoding and decoding images also gives us a tool to observe which image features are detected or ignored by CLIP. By integrating a CLIP image embedding decoder into an earlier model that creates a potential CLIPS image embedded in arbitrary text, we can create generative image models from scratch. Our text-to-image system is compared to DALL-E and GLIDE by researchers, who observe that our samples are similar in quality to SLID, but our generations differ more. Our research demonstrates that propagation priors can be trained in hidden space while still performing at the same level of performance as autoregressive prior, with better computational efficiency. Due to the CLIP codec being flipped, the full-text conditional image generation stack is known as unclip. This methodology provides a technical and detailed approach to analyzing why AI models, particularly those leveraging contrastive learning such as CLIP, struggle with accurately drawing hands. The analysis involves model evaluation, latent space examination, quantitative metrics, and dataset scrutiny. The specific component flow works in the following way:
i) Text encoder: The input is a textual description: “Human hand gesture that shows all five fingers” This text is passed through a text encoder, which converts the text into a latent vector representation.
ii) CLIP objective: The CLIP (Contrastive Language-Image Pretraining) objective is used to align the text and image representations in the same latent space. This means that the text encoder and image encoder are trained together so that the latent vectors for matching text and images are close to each other in the latent space. The encoded text vector is compared to encoded image vectors using this CLIP objective. The goal is to ensure that the text encoding is close to the image encoding of the corresponding image (in this case, an image of a human hand with all of its five fingers being visible).
iii) Image encoder: An image that corresponds to the text prompt is passed through an image encoder, producing an image latent vector. This vector representation of the image is used in conjunction with the text encoding to ensure alignment in the latent space via the CLIP objective.
iv) Prior network: The prior network generates a distribution of potential image representations based on the text encoding. This step is crucial for creating diverse image outputs from the same text prompt. It takes the text latent vector and processes it to generate a set of potential latent vectors that could correspond to images matching the description. Two different model classes for the prior model are available:
v) Decoder: The decoder takes the generated image latent vector from the prior network and converts it into a full-resolution image. This involves a generative model, such as a Variational Autoencoder (VAE) or a Generative Adversarial Network (GAN), which can decode the latent representation back into a high-quality image. The result is the final image that visually represents the input text prompt. In this case, it would be an image of a human hand gesture with all its five fingers being exposed.
In the Figure 2 a Model Architecture of CLIP model and its’ interfaces is illustrated as the following, that shows how CLIP generates image from text in a very basic method.
i) Text Encoder: This initial block takes the input text prompt (such as a description or caption) and converts it into a numerical representation. Think of it as translating words into a format that neural networks can understand.
ii) CLIP (Contrastive Language-Image Pretraining): CLIP is a remarkable model that bridges the gap between language and vision. It learns to associate images and text by embedding them into a shared space. This allows it to understand both visual content and textual descriptions.
iii) Image Encoder: Once we have an image, the image encoder processes it and generates a feature vector. This vector captures relevant information about the image, which can be used for subsequent steps.
iv) Prior and Diffusion Decoder Blocks: These are critical for image synthesis. The “prior” refers to a learned distribution of latent variables (essentially, hidden factors), while the “diffusion decoder” reconstructs the image from these latent variables. Together, they enable controlled image generation.
v) Additional Conditioning Steps: These steps refine the process. They might involve fine-tuning based on specific attributes mentioned in the text prompt. For example, if the prompt specifies “a sunny beach,” the conditioning steps adjust the generated image accordingly.

A. Data preparation
Dataset selection: A dataset D consisting of paired text descriptions T and corresponding images I of hands is used. This dataset should cover a diverse range of hand poses, shapes, and contexts to ensure a comprehensive analysis. Using this method, an optimal solution can be found alongwith the following equation (1).
B. Model components
i) Text encoder: A transformer-based text encoder ET is used to convert textual descriptions into latent vector representations z T. This can be obtained by the following equation (2).
ii) Image encoder: An image encoder EI is used to convert images into latent vector representations zI, which is gained by equation (3).
iii) CLIP objective: The CLIP (Contrastive Language-Image Pretraining) objective is employed to align the text and image representations in the latent space. The objective function for a batch of size N is defined as the following expression (4):
C. Analysis procedure
i) Model performance analysis: Evaluate the performance of the text-to-image generation model specifically on hand images. The text encoder ET processes descriptions of hand images, and the image encoder EI processes the corresponding images. Analyze the alignment of text and image representations in the latent space. This whole analysis can be analyzed with the following equation (5),
ii) Latent space visualization: Use dimensionality reduction techniques like t-SNE or PCA to visualize the latent space of text and image encodings. The visualization helps in understanding the clustering of hand images and their textual descriptions in the latent space. This visualization follows the expression (6),
iii) Qualitative analysis: Generate images from text descriptions of hands using the trained model. Visually inspect the generated images for common errors and patterns, focusing on aspects such as finger placement, proportions, and overall hand shape. This is expressed by equation (7)
iv) Quantitative metrics: Employ quantitative metrics to assess the quality of hand images generated by the model. Metrics like Structural Similarity Index (SSIM) and Mean Squared Error (MSE) between generated and real hand images are used. Here these metrics are expressed by equation (8) and (9) for SSIM and MSE.
v) Error analysis: Perform detailed error analysis to categorize the types of mistakes made by the model. Errors can be classified into anatomical inaccuracies, unnatural poses, missing fingers, etc. (Eanatomical, Epose, Emissing).
vi) Dataset evaluation: Evaluate the dataset D to identify potential biases or gaps in the representation of hands. Assess whether the dataset includes a sufficient variety of hand poses, shapes, and contexts. Identify if the dataset lacks specific types of hand images that might contribute to the model’s difficulties. This evaluation holds the expression (10).
4.1.1 Challenges
4.1.1.1 Structural complexity
i) Bones and joints: The human hand has 27 bones, including the phalanges (finger bones), metacarpals (palm bones), and carpal bones (wrist bones). Each joint, especially in the fingers, allows for a wide range of motion and poses.
ii) Movement dynamics: The fingers can bend, twist, and rotate in various directions. Accurately capturing these movements and the transitions between them is challenging.18
4.1.1.2 Surface anatomy
i) Muscles and tendons: The hand’s surface anatomy includes muscles, tendons, and veins that change appearance based on hand movements and poses.19
ii) Skin texture and wrinkles: The skin on the hand has unique textures, lines, and wrinkles, especially on the palms and knuckles. These details are crucial for realistic rendering.20
4.1.1.3 Articulation and posing
i) Finger poses: Each finger can independently move, creating countless possible poses. The AI must understand the natural range of motion and how fingers interact.21
ii) Hand gestures: Hands can express a wide range of emotions and actions through gestures. Understanding and replicating these gestures adds complexity.22
4.1.1.4 Perspective and proportion
• Foreshortening: Drawing hands from different angles, especially when fingers are pointed towards or away from the viewer, requires accurate foreshortening to maintain realistic proportions.23
• Relative size: Each finger has a different length and thickness, and these proportions must be maintained from various perspectives.
4.1.1.5 Inter-hand interaction influenced hand grips and interactions: When hands hold objects or interact with other body parts, the AI must accurately depict the contact points and the resulting deformations in the skin and muscles.24
4.1.1.6 Lighting and shadows
i) Light interactions: The hand’s complex structure creates intricate patterns of light and shadow, especially in the spaces between fingers and around joints. Capturing these details is crucial for realistic rendering.25
ii) Reflective and translucent properties: The skin of the hand has both reflective and translucent properties, which affect how light interacts with it.26
4.1.1.7 Symmetry and asymmetry
4.1.2 Quantitative measurements
4.1.2.1 Pose estimation accuracy:
a. Keypoint detection:Keypoint detection involves identifying specific points on the hand, such as joints and fingertip positions. To measure the accuracy of keypoint detection, the following metrics are commonly used:
iii) Mean Squared Error (MSE):
• Description: MSE is used to measure the average squared difference between the predicted keypoint coordinates and the ground truth coordinates. This can be expressed by equation (11) as well.
• Application: MSE provides a straightforward indication of the overall prediction error. Lower MSE values indicate higher accuracy.
iv) Percentage of Correct Keypoints (PCK):
• Description: PCK measures the percentage of keypoints that fall within a certain threshold distance from the ground truth and is expressed by equation (12).
• Application: PCK is often used to assess model performance under varying thresholds, providing insight into the robustness of the keypoint detection.
b. Average Distance Error (ADE): ADE measures the average Euclidean distance between the predicted and ground truth keypoints, providing a more intuitive understanding of the prediction error.
• Description: ADE calculates the average Euclidean distance between predicted keypoints and their corresponding ground truth keypoints. This is expressed by the (13) no. formula.
• Application: ADE gives a direct measure of the average error in prediction, making it easier to understand how far off the model’s predictions are from the actual keypoints. Lower ADE values indicate higher accuracy.
4.1.2.2. Shape and proportion accuracy
i) Procrustes analysis: Use Procrustes distance to measure the similarity between predicted hand shapes and ground truth shapes after removing differences in scale, rotation, and translation.29
ii) Aspect ratio consistency: Measure the consistency of aspect ratios of fingers and the overall hand structure.30
4.1.2.3. Surface detail and texture accuracy
The Figure 3 gives an overview on texture analysis base on outlines the steps involved in image classification, emphasizing the role of textural features and the Random Forest algorithm on a selected image segment that follows the flowchart given below:
i) Input data (Labelled images): The process starts with a set of labelled images. These images have known class labels (e.g., “cat,” “dog,” “car,” etc.).
ii) Feature extraction (Textural features): Next, we extract relevant features from these labelled images. These features capture the visual characteristics of the images. Textural features play a crucial role in image classification. They describe patterns, textures, and spatial relationships within the image.
iii) Engineered & learned features: The flowchart mentions both “engineered” and “learned” features. Engineered Features: These are handcrafted features designed by domain experts. Examples include texture descriptors, color histograms, and edge-based features.
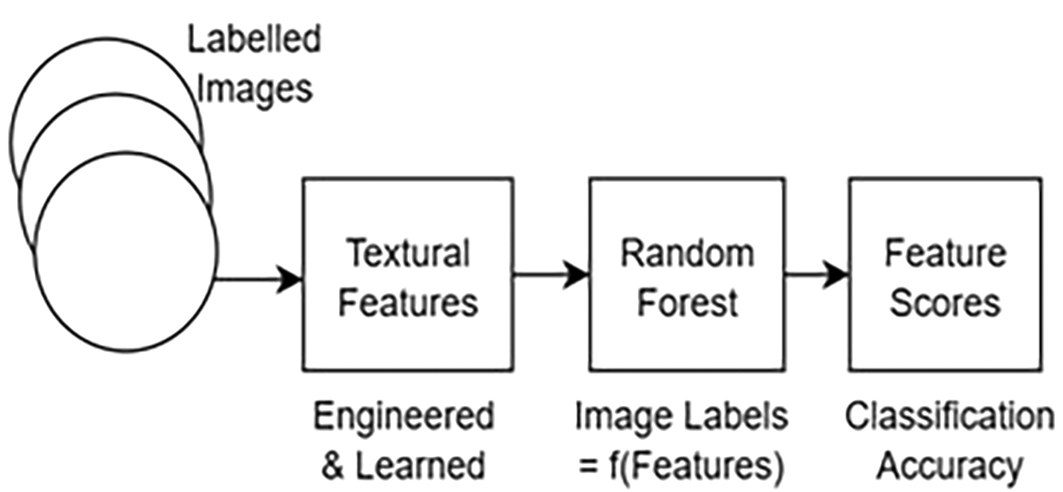
Learned features: These are automatically learned by neural networks or other machine learning models during training. Convolutional Neural Networks (CNNs) excel at learning hierarchical features from raw pixel data.
i) Random forest algorithm:The flowchart includes a “Random Forest” algorithm. Random Forest is an approach for ensemble learning that combines several decision trees. Each decision tree is trained on a set of attributes and data points. The final prediction is based on the majority vote of individual trees.
ii) Image labels (Classification): Using the extracted features, the Random Forest predicts the class labels for unlabelled images. The function “=f (Features)” represents this classification process.
iii) Feature scores & classification accuracy: The output of the Random Forest includes feature scores, which indicate the importance of each feature. Classification accuracy measures how well the model performs on unseen data.
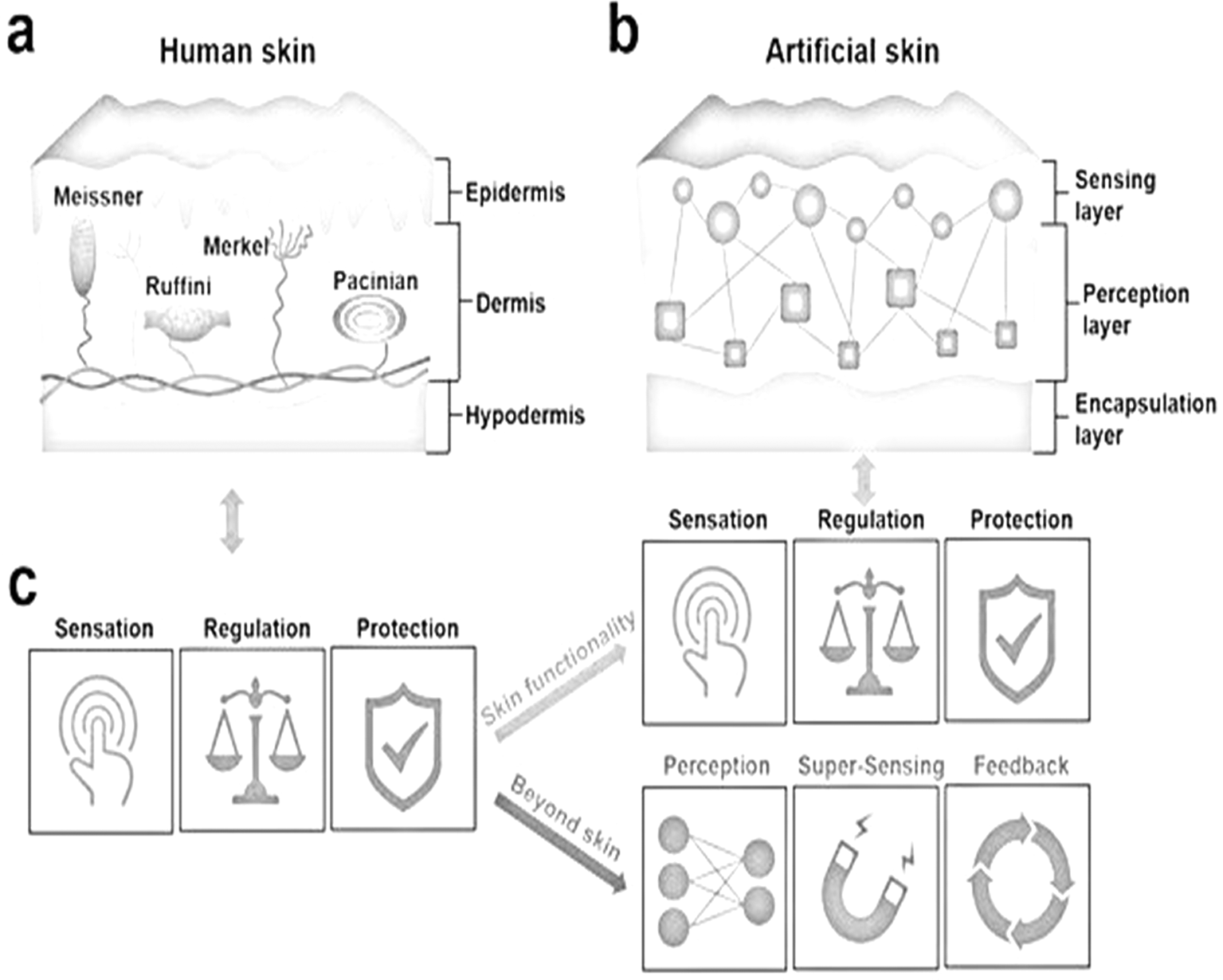
The image in Figure 4 depicts a comparison between human skin and artificial skin, highlighting their respective structures and functionalities.
1. Human skin (Left side): The cross-section of human skin reveals its layers: epidermis and dermis. Within these layers, various sensory receptors are labeled:
2. Artificial skin (Right side): The artificial skin structure consists of sensor nodes interconnected by lines, forming a network. An encapsulation layer covers these nodes. Icons below the illustrations compare functionalities:
• Sensation: Human skin vs. artificial skin.
• Regulation: Human skin maintains temperature; artificial skin aims to do the same.
• Protection: Both provide protective functions.
Additional icons represent advanced features of artificial skin
• Super-sensing: Enhanced perception (depicted by an eye with circuit patterns).
• Beyond-skin perception: Connectivity (depicted by a Wi-Fi symbol).
• Feedback: Loop of information exchange.
i) Texture similarity metrics: Use metrics like Structural Similarity Index (SSIM) or Peak Signal-to-Noise Ratio (PSNR) to compare the textures of AI-generated hands with ground truth images.31
ii) Wrinkle and line detection: Measure the presence and accuracy of skin details such as wrinkles and lines using edge detection algorithms.32
4.1.2.4 Movement dynamics and articulation
i) Temporal consistency: For sequences of hand movements, measure the temporal consistency of keypoints and shapes across frames33
Temporal consistency is crucial when working with video data, especially in the context of artificial intelligence. Applying spatial augmentations to video data, considering temporal consistency is essential. It helps maintain the coherence of the sequence and improves the quality of learned representations. In the image provided in Figure 5 it shows various ways it impacts spatial augmentation.33 It is shown with three rows demonstrating different approaches to spatial augmentation:34
a) Original video clip (Top row): This row contains four frames showing a horse in various positions as it moves. These frames represent the natural progression of the video clip.
b) Frame-level spatial augmentation (Middle row): In this row, we also have four frames, but each frame has undergone individual augmentations. These augmentations include changes in brightness, contrast, and color saturation. However, the key issue here is that these augmentations were applied independently to each frame, without considering the context of the previous or next frame. As a result, the appearance across the sequence lacks consistency. This lack of temporal consistency can be problematic for AI models that learn from video data because it disrupts the natural flow of movement.
c) Temporally consistent spatial augmentation (Bottom row): The bottom row shows four frames where augmentations have been applied while maintaining temporal consistency. Temporally consistent augmentations smoothly transition from one frame to another. This ensures that the changes in brightness, contrast, and color saturation align with the video’s natural progression. By preserving temporal consistency, AI models can learn more effectively from video clips.

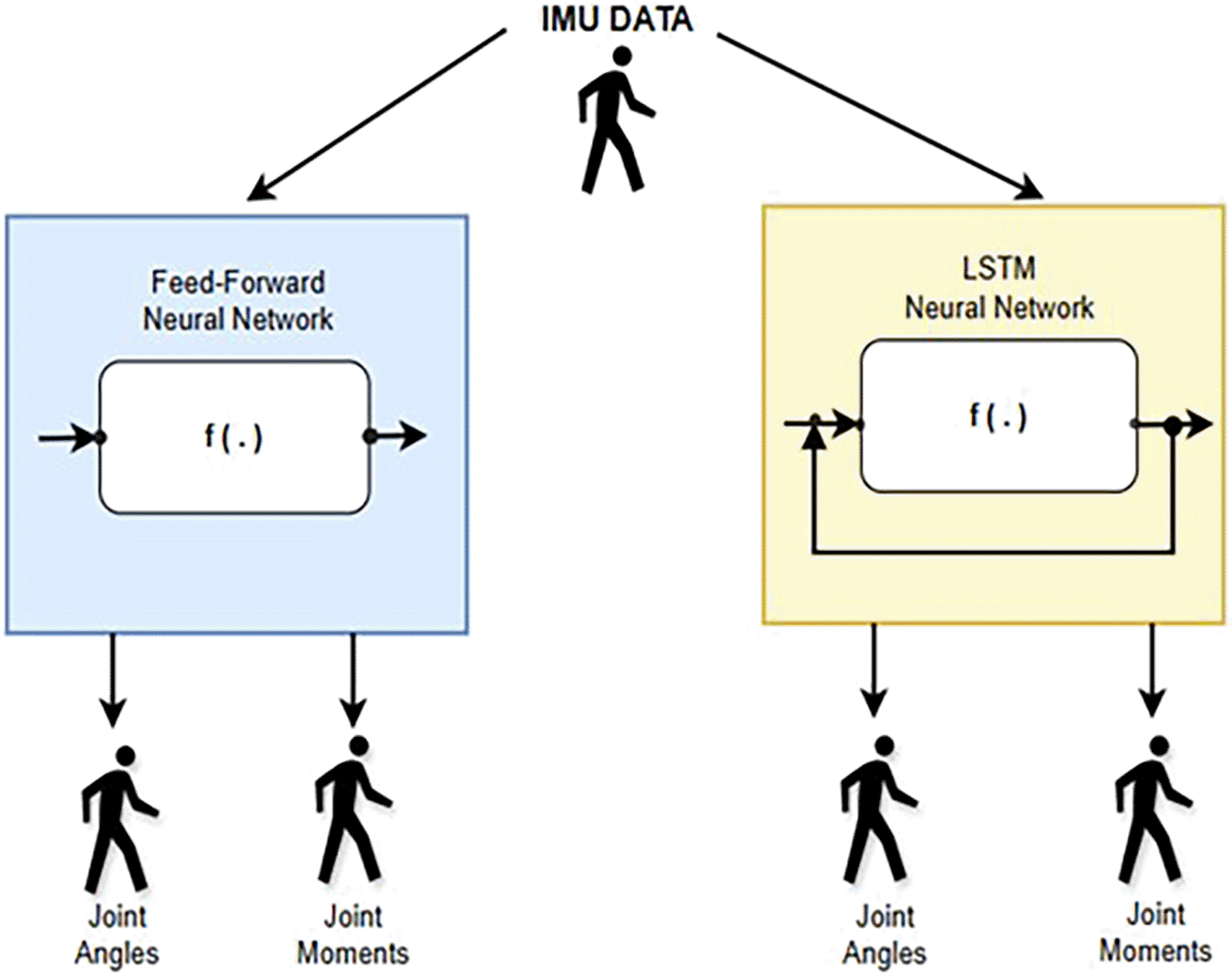
ii) Joint angle accuracy: Compare the predicted joint angles with ground truth angles using angular error metrics.35 The image in Figure 6 illustrates a model architecture for predicting lower limb joint angles and moments during gait using artificial neural networks. It compares two approaches: a feed-forward neural network and an LSTM (Long Short-Term Memory) neural network. Although it suggests that both feed-forward and LSTM neural networks can be used for this prediction task but the LSTM is expected to perform better due to its ability to consider the temporal context of the IMU data. This process flows through following method.
a) IMU data: The process starts with IMU (Inertial Measurement Unit) data, which likely captures information about acceleration and angular velocity during movement.
b) Neural networks: It is consisted with two different paths.
1st. Feed-forward neural network: The IMU data is fed into a feed-forward neural network. This type of network processes data in one direction, from input to output, without forming loops or cycles.
2nd. LSTM neural network: Alternatively, the IMU data is fed into an LSTM neural network. LSTMs are specifically designed to handle sequential data like time series, allowing them to capture temporal dependencies in the data.
c) Output: Both networks generate predictions for joint angles and moments. These represent the estimated positions and forces at the lower limb joints during gait.
4.1.2.5 Lighting and shadow realism
i) Light direction and intensity consistency: Measure the accuracy of predicted lighting directions and intensities using photometric error metrics.36
ii) Shadow accuracy: Compare the predicted shadow patterns with ground truth shadows using metrics like Shadow Similarity Index.37
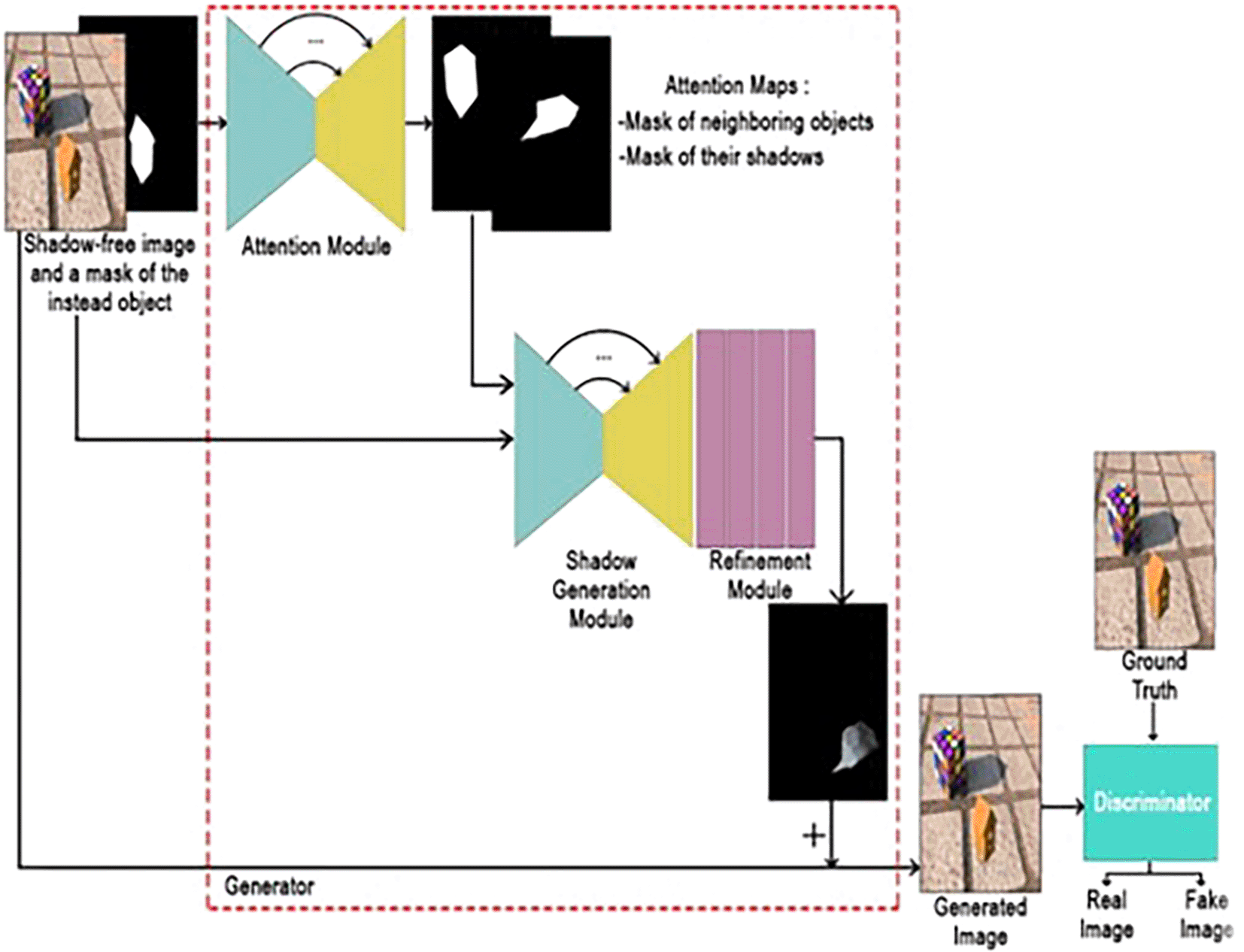
In Figure 7 it is shown how ARShadowGAN-like training scheme in AI37 generates realistic shadow (Lighting and Shadow Realism) in a picture works. This process ensures that the generated shadows blend seamlessly into the scene, enhancing visual realism.
a) Shadow-free image and mask: Start with a shadow-free image (an image without any shadows) and a mask that highlights the object of interest.
b) Attention module: The attention module analyzes the input and produces attention maps. These attention maps include a mask for neighboring objects and their shadows.
c) Shadow generation module: Based on the attention maps, the shadow generation module creates a shadow for the object.
d) Refinement module ground truth: The generated shadow undergoes further refinement to make it realistic.
e) Discriminator: The discriminator compares the refined shadow with a real image to assess its authenticity.
4.2.1 Expert evaluation
i) Human evaluators: Have experts (e.g., artists, anatomists) assess the realism and accuracy of AI-generated hand drawings based on various criteria such as anatomical correctness, proportion, and movement.38
ii) Visual turing test: Evaluate if human observers can distinguish between AI-generated and real hand drawings.39
4.2.2 User studies:
4.2.3 Comparative analysis:
i) Benchmarking against datasets: Compare AI-generated hand drawings against established benchmarks and datasets (e.g., Human3.6M, RHD) to measure performance against known standards.42
ii) A/B Testing: Perform A/B tests with different versions of AI-generated hand drawings to determine improvements and preferences.43
4.3.1 3D Hand models: Use 3D hand models and motion capture data to create accurate ground truth references for measuring AI performance. Employ 3D reconstruction techniques to compare predicted hand poses with 3D ground truth data.
4.3.2 Machine learning metrics: Utilize common machine learning metrics such as accuracy, precision, recall, F1 score, and area under the curve (AUC) for classification tasks related to hand gesture recognition.
4.3.3 Computer vision techniques: Implement computer vision algorithms for keypoint detection, segmentation, and texture analysis to evaluate the quality of AI-generated hand drawings.
Collecting high-quality data on hand movements is a significant hurdle. Traditional motion capture systems can be cumbersome and expensive, while video-based methods often lack the necessary precision. Additionally, annotating hand movement data requires expert knowledge and can be time-consuming, leading to limited availability of large, annotated datasets that are essential for training AI models. Some detailed and specific breakdown of data collection and annotation for measuring the complexity and accuracy of AI-generated human hand drawings.
4.4.1 Data collection
4.4.1.1 Publicly available datasets
i) MPII+NZ Hand Pose Dataset: Contains hand images with annotated keypoints and 3D poses.
ii) FreiHAND: Includes color images, depth maps, and corresponding 3D hand models.
iii) Rendered Hand Pose Dataset (RHD): Offers synthetic images of hands with keypoint annotations.
iv) CMU Panoptic Hand Dataset: Provides multi-view images and 3D keypoints of hand poses.
4.4.1.2 Custom data collection
i) High-resolution imaging: Capture images using high-resolution cameras to ensure detailed features of hands are recorded.
ii) Diverse subjects: Include a variety of subjects with different hand shapes, sizes, skin tones, and ages to create a comprehensive dataset.
iii) Varied poses: Ensure hands are captured in a wide range of poses, including open, closed, gripping objects, and interacting with other hands or objects.
iv) Lighting conditions: Collect data under different lighting conditions to help the model learn how lighting affects hand appearance.
4.4.1.3 Extended data
Some resources can be adapted from OpenAI CLIP simple implementation that consists of CLIP models on Keras code from scratch in PyTorch.44 Although OpenAI has open-sourced parts of CLIP,e.g.-a dataset of OpenAI’s CLIP model, VIT-LARGE-14-PATCH,45 the code can be complex and overwhelming.
4.4.1.4 3D hand models
i) 3D scanning: Use 3D scanners like Artec Eva or Structure Sensor to capture high-resolution 3D models of hands in various poses.46
ii) Synthetic data generation: Create synthetic hand models using software like Blender or Unity. Apply different textures and poses to these models to augment the dataset.47
4.4.2 Data annotation
4.4.2.1 Keypoint annotation
i) Manual annotation: Mannual Annotation includes tools like - Labelbox, VGG Image Annotator, or custom software and the process work by Annotating keypoints such as wrist, knuckles, and finger joints (21 keypoints: 4 per finger, 1 at the wrist). For example- Label the base, middle, and tip joints for each finger, and the wrist joint.
ii) Automated annotation tools: Use pre-trained models like OpenPose to predict keypoints, then manually correct them for accuracy.48
4.4.2.2 3D pose annotation
i) Motion capture: Motion capturing can be achieved by systems like Vicon or OptiTrack. The process may work by the Record hand movements and generate 3D keypoints. Ensure accurate calibration for precise annotations.
ii) Multi-view stereo: The Setup of multi view stereo Captures images from multiple angles using synchronized cameras. And the Reconstruction is done by Using stereo vision techniques to reconstruct 3D hand poses.
4.4.2.3 Surface detail and texture annotation: For manual Annotation tools or software like Adobe Photoshop or custom annotation tools are used. And the process follows by Annotation of fine details such as skin texture, wrinkles, and veins manually.
4.4.2.4 Shadow and lighting annotation is done by:
• Tools: Use software like Labelbox or custom annotation tools.
• Process: Annotate regions of shadows and light sources in the images.
4.4.3 Annotation tools and software are suggested as below:
• Labeling software: For this purpose, tools like Label Studio49 can be used. Also VIA50 and CVAT51,52 a good choice for analyzing as they have free source.
• 3D Modeling software: Softwares like Maya53 and Godot54 are very adequate for 3D modeling and animation.
• Motion capture systems: OpenPose54 for real-time human pose and key point detection for AI, VR/AR, and research, OpenMoCap55 for motion capturing for 2D/3D tracking using cameras or video footage, or Kinovea56 for simple 2D motion analysis for sports and rehabilitation satisfy for such systemic requirements.
4.4.4 Quality control is chosen on the basis of these two mentioned below:
• Inter-annotator agreement process: Have multiple annotators label the same data and calculate Cohen’s Kappa to assess consistency.
• Annotation validation process: Review and correct annotations in a validation set by experts. Regularly update annotations to maintain high quality.
4.4.5 Data augmentation
4.4.6 Documentation and metadata
• Annotation guidelines and documentation: Create detailed guidelines for annotators, specifying how to label key points, 3D poses, textures, and interactions. Include examples and edge cases.
4.4.7 Annotation guidelines
4.4.7.1 Keypoint annotation
• Wrist: The joint where the hand connects to the forearm.
• Knuckles: The joints at the base of each finger.
• Finger joints: Annotate the base, middle, and tip of each finger.
4.4.7.2 3D Pose annotation
Real-time processing in the context of AI-generated human hand drawings involves the rapid detection, analysis, and generation of hand images or movements. This is crucial for applications like virtual reality (VR), augmented reality (AR), and real-time interaction systems. Here’s a detailed breakdown of the technical aspects involved in real-time processing:
4.5.1 Real-time hand detection and tracking
i) Hand Detection is done by Object Detection Models such as,
ii) Keypoint Detection is accomplished by Pose Estimation Models such as:
4.5.2 Real-time 3D pose estimation
• Depth cameras: Use depth cameras like Intel RealSense or Microsoft Kinect to capture depth in-formation for 3D pose estimation.
• Stereo vision: Employ stereo cameras to calculate depth and reconstruct 3D hand poses.
4.5.3 Real-time Gesture Recognition withGesture Classification Models: Use trained machine learning models to classify hand gestures in real-time. Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks can be used for sequence prediction.
4.5.4 Real-time rendering and visualization
• Graphics libraries: Use OpenGL, DirectX, or Vulkan for rendering hand models and animations in real-time.
• Game engines: Unity58 or Unreal Engine can be used for real-time rendering in VR/AR applications.
4.5.5 Real-time interaction and feedback
• Haptic feedback: Use haptic devices to provide real-time tactile feedback based on hand interactions.
• Real-time collaboration: Enable multiple users to interact with hand gestures in a shared virtual environment.
4.5.6 Performance optimization
• Hardware acceleration: Use GPUs or specialized hardware like NVIDIA Jetson for faster processing.
• Model optimization: Apply model compression techniques like quantization and pruning to reduce latency.
• Parallel processing: Use multi-threading or parallel processing to handle multiple tasks simultaneously.
Human hands vary widely in shape, size, and dexterity. AI models trained on a limited dataset may not generalize well to the diverse range of human hands. This variability necessitates the creation of more robust models that can accommodate different hand anatomies, which is a challenging task given the current state of AI technology.
5.1.1 Anatomical complexity on bone structure based 3D skeletal models: AI systems should use detailed 3D skeletal models that include the 27 bones of the hand, such as the carpals, metacarpals, and phalanges. These models can be created from 3D scans of real hands using tools like photogrammetry or depth sensors. This consists example of 3D scanning tools like Artec Eva to capture hand models and use software like Blender57 or Autodesk Maya53 to create and manipulate these models.
5.1.1.1 Joint flexibility based articulated hand models: Implement articulated hand models with kinematic chains to represent the finger joints. This allows each finger joint to move independently within physiological limits, using forward and inverse kinematics for realistic hand movements. This includes example of Using a physics engine like Bullet or PhysX to handle joint constraints and movements like- Load hand model URDF.
5.1.1.2 Musculature and tendons based muscle simulation: Simulate muscle contraction and tendon forces to produce realistic hand movements. This can be achieved with biomechanical models that translate muscle activations into joint torques. For example, of using the Finite Element Method (FEM) to simulate the deformation of muscles and tendons like system defining the mesh and function space for FEM simulation.
5.1.2 Biological diversity and dataset diversity comprehended data collection: Collect datasets with diverse hand shapes, sizes, and conditions, ensuring representation across age, gender, ethnicity, and hand condition. For example, the use of data augmentation techniques to artificially increase dataset diversity.
5.1.2.1 Adaptive algorithms influenced neural networks: Utilize models like Adaptive Resonance Theory (ART) or dynamic neural networks that can adjust to new data during inference. For example, the Implement online learning algorithms to continuously update the model with new hand data.
5.1.2.2 Hierarchical model based layered representation: Develop a hierarchical hand model where bones, joints, muscles, and skin are modelled separately but interactively. For example, the Use of a physics engine like PyBullet to simulate interactions between these layers like Simulate muscle contraction affecting joint angles
Human hands rely heavily on sensory feedback from the environment to perform tasks. This feedback loop allows for continuous adjustment and adaptation, enabling precise control of hand movements. AI systems, however, lack this inherent sensory feedback mechanism, making it difficult for them to adapt to dynamic environments and perform tasks with the same level of precision as human hands.
5.2.1 Proprioception and tactile sensation for proprioception on sensor integration: Integrate sensors to capture hand position and movement data. Use IMUs (Inertial Measurement Units) and joint angle sensors. For example: Implement sensor fusion algorithms to combine data from multiple sensors for improved accuracy like - Kalman filter for sensor fusion.
5.2.1.1 Tactile sensation and haptic feedback: Use haptic devices to simulate tactile sensations. Devices like the Geomatic Touch provide force feedback to simulate touch. For example: Implement haptic rendering algorithms to convert virtual interactions into haptic feedback.
5.2.1.2 Real-time motor controlled algorithms: Use PID controllers or neural network-based controllers to adjust hand movements in real-time based on sensory feedback. Such proper example is of Implement PID control for precise hand movement adjustments.
5.2.2 Neural plasticity and learning and adaptive models: Develop models that can adapt to changes in sensory input over time. Use reinforcement learning or continual learning techniques to improve performance with experience. This consists example of Train agents using reinforcement learning to adapt to dynamic environments and varying sensory feedback.
5.2.2.1 Experience and learning (Supervised and unsupervised learning): Combine supervised learning for initial training with unsupervised learning to refine the model based on new data. For Example: Use self-supervised learning techniques to label data automatically and improve the model’s performance without extensive manual labeling.
6.1.1 Human-robot interaction: Grasping and Manipulation consists of Robots equipped with advanced AI hand models can perform complex tasks involving human-like dexterity, such as handling delicate objects, opening containers, or assembling intricate components. For example, a robot arm with an adaptive hand model can pick up various objects, from fragile glassware to irregularly shaped tools, by dynamically adjusting its grip based on real-time feedback. Another example is Load the robot model and configure the hand: Loading and configuring a robotic hand involves initializing models, calibrating sensors, and setting up real-time control and feedback mechanisms to ensure precise and adaptive functionality. This includes steps like: Load the Robot Model (Initialization,Hand Configuration), Sensor Calibration (Tactile and Position/Force Sensors), Real-time Feedback and Control (Control Algorithms, Feedback Loops), Object Interaction and Adaptation (Dynamic Grip Adjustment), Testing and Validation (Task Simulation).
6.1.2 Adaptive control systems: This includes properties like Real-time Adjustments. This includes Use real-time control algorithms and sensory feedback to adapt robot actions based on dynamic environments or varying object properties. For example- a robotic hand can use PID controllers to adjust its grip strength in response to changes in object texture or weight.
6.1.3 Collaborative robots: Collaboration with robots embodies Human-Robot Collaboration. This Be composed of Implementation robots that can work alongside humans, using AI-driven hand models to perform tasks that complement human abilities. For example- A collaborative robot (cobot) in a manufacturing line can assist human workers by handling heavy or repetitive tasks while adapting to the worker’s movements and actions.
6.2.1 Realistic interaction: This area is incorporated with phenomenon like Immersive Experiences. Here, AI-generated hand models in VR/AR can enhance user immersion by providing realistic and responsive interactions with virtual objects. For example- In VR, accurate hand models enable users to manipulate virtual objects with natural gestures and movements, improving the realism of the experience. Another example is Simulate hand interaction in a virtual environment
6.2.2 Haptic feedback: This Encompasses Enhanced Feedback. The use of AI to simulate tactile sensations in VR/AR environments, allowing users to feel textures, resistances, and forces. For example- Haptic gloves or controllers equipped with AI can provide feedback corresponding to virtual objects, enhancing the sense of touch and improving user interaction.
6.2.3 Training and simulation: This may include Skill Development. The use VR/AR for training scenarios that require precise hand movements or interactions, such as surgical simulations or mechanical repairs. For example- Surgeons can practice complex procedures in a virtual environment with realistic hand movements and haptic feedback, improving their skills without real-world consequences.
6.3.1 Rehabilitation: This consists of Assistive Devices that includes AI-driven hand models which can be integrated into rehabilitation devices to assist patients in regaining hand function after injuries or surgeries. For example- Robotic exoskeletons with adaptive hand models can assist patients in performing exercises, adjusting the level of assistance based on real-time feedback from the patient. Load exoskeleton model and simulate rehabilitation exercises is the process where the involvement of initializing the exoskeleton model and simulating various rehabilitation exercises to evaluate and enhance the effectiveness of the exoskeleton in supporting patient recovery. This includes Load the Exoskeleton Model (Model Initialization, Configure the Model) and Simulate Rehabilitation Exercises (Defining Exercises, Run Simulations).
6.3.2 Prosthetics: This includes technology like Advanced Prosthetic Hands. This consists the Develop prosthetic hands that mimic the complexity of natural hand movements, offering improved functionality and user experience. For example, AI-driven prosthetics with adaptive hand models can provide more natural grasping and manipulation capabilities, allowing users to perform daily tasks with greater ease.
6.3.3 Diagnosis and monitoring: This forms concepts like Gesture Analysis. This includes the Use AI to analyse hand gestures and movements for diagnosing conditions or monitoring recovery progress. For example- AI systems can assess hand tremors or dexterity levels to help diagnose neurological conditions or track the effectiveness of rehabilitation interventions.
Due to several complex problems, AI finds it difficult to draw human hands, particularly when using models like CLIP. Human hands differ widely in size, shape, and movement, therefore obtaining a good approximation requires a huge and diverse training set. The intricate musculature, joints, and bones of the hands add to the difficulty of the work. Replicating movement and detail accurately requires complex models. Artificial intelligence (AI) models find it challenging to dynamically adjust to changing settings because they frequently lack the sensory feedback associated with human control. Even with recent improvements, real-time hand identification and keypoint tracking are still unable to fully capture the subtleties of hand interactions and motions. Applications like virtual and augmented reality, robotics, and healthcare all depend on high fidelity hand modeling. The current limitations of AI in this field highlight the need for continual advancements in data collection, model training, and real-time processing. These cutting-edge technologies could enhance AI’s ability to more accurately and efficiently mimic and sketch human hands.
One of the biggest challenges in accurately modeling the human hand is capturing the body tissue. These improvements enable AI systems to better understand and reproduce simple movements and gestures, resulting in more precise and accurate gestures. Crowdsourcing platforms provide a low-cost, cost-effective way to collect this data and ensure that AI models can be integrated and transferred to diverse populations. Research on new neural network architectures such as Transformers and graph neural networks will provide powerful tools for modeling human muscles. These architectures improve vision and shape recognition, resulting in more accurate hand patterns. Training models and multiple data, including images, statistics, and motion, can provide a comprehensive understanding of hand movements, and the technology can improve the ability of artificial intelligence to repeat hand movements and daily behaviours. Developing real-time tracking and rendering software solutions can reduce downtime and improve the user experience in applications such as VR and AR. Develop highly optimized algorithms (low-latency algorithms) to analyze hand movements in real time to ensure that artificial intelligence systems can run smoothly on consumer devices. It could include additional tactile feedback, adaptive control systems, and more. Combined with an advanced tactile system, different emotions can be simulated, making the hand model generated by artificial intelligence more realistic and effective. These improvements can improve the user experience in virtual environments by providing an immersive and interactive experience. Developing control systems that adapt AI feedback based on real-time input will lead to more accurate manual interactions. This approach can improve the fidelity of hand movements generated by artificial intelligence and assistive applications such as medical simulation and prosthetic design. Analyzing the diversity of hand shape, size, and movement patterns across different populations will help create more inclusive and accurate AI models. For human-robot interactions, this can improve the grasping algorithms in robots to handle various objects of different shapes, sizes and textures, thus increasing the effectiveness of clever hand patterns. These avatars can provide users with a natural and immersive experience, making the virtual environment even more immersive. Using artificial intelligence to develop smart functions that can adapt to a user’s unique movement patterns and provide sensory feedback improves performance and user experience. These prosthetics can provide natural and intelligent interactions and improve the lives of their users. The next innovation is the use of artificial intelligence to create interactive learning platforms that interpret hand movements to enable hands-on learning experiences in virtual environments. Other efforts include developing features to make interactive wearable technology more accessible to people with disabilities, which is important for inclusive design. This ability allows everyone to benefit from the advances in hand-sensing modeling, regardless of physical ability. Working with neuroscientists to better understand the brain’s control of hand movements and incorporating these insights into artificial intelligence models can demonstrate the accuracy and precision of the hand. Developing cognitive models that simulate human cognitive processes related to hand movements can improve artificial intelligence to predict and repeat complex movements. These models provide a deeper understanding of human hand dynamics and improve AI performance. Other research suggests research and development of systems that allow humans and AI to adapt, learn from each other to improve manual interaction and control in over time, AI systems will become more intelligent and effective.
All data, figures, and diagrams used in this study were either generated by the author(s) or obtained from publicly available repositories on platforms such as Kaggle and GitHub.
The data used from these platforms are subject to the respective licensing terms provided by the original contributors. The author(s) confirm that:
• For data obtained from Kaggle, usage complied with the terms of the associated license specified by the dataset creator. Any restrictions or conditions set forth by the dataset provider have been respected.
• For code or resources obtained from GitHub, usage adhered to the terms of the repository’s stated license (e.g., MIT License, Apache License, GPL). Proper credit has been provided to the original contributors where required.
No sensitive or personally identifiable information is included in the data. As the datasets and resources are publicly available and appropriately licensed, no additional ethical approval was required for their use in this study.
The author(s) affirm that all figures, diagrams, and outputs derived from these sources were created with due consideration of copyright, licensing, and usage rights. If requested, the detailed license information and attribution for any third-party data or code used can be provided.
No ethical approval needed as data used from online repository.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)