Keywords
Generative AI in teaching, large language models, PLS-SEM, artificial neural networks, in-service teacher training
This article is included in the Artificial Intelligence and Machine Learning gateway.
Generative AI in teaching, large language models, PLS-SEM, artificial neural networks, in-service teacher training
Large Language Models (LLMs) are advanced Artificial Intelligence (AI) technologies that are trained on extensive datasets to process and generate natural language responses to text inputs. LLMs rely on key components such as transformers for input representation, deep and self-supervised learning, pre-training, and fine-tuning (Zhou et al., 2024; Guo et al., 2022). LLMs have found their ways into almost all human endeavours, including education. As Large Language Models (LLMs), for instance, Generative Artificial Intelligence (GenAI) deeply find their ways into education, their transformative potentials in education offer unprecedented opportunities via automated assessment, personalized learning, and enhanced educational resources to help educators improve their practices in a wide range of pedagogical scenarios (Pozdniakov et a., 2024). As artificial intelligence (AI), especially GenAI continues to emerge and reshape education by enhancing content creation (Denny et al., 2023), ease of creating multiple-choice questions (Bulathwela et al., 2023), AI-generated educational video clips (Leiker et al., 2023), and adaptive learning tools (Jury et al., 2024). GenAI also supports assessments through feedback automation for students (Han et al., 2023) while also improving personalized and innovative educational experiences for both students and their teachers.
Empirical reports support GenAI and related AI-based technologies capacity to revolutionize traditional pedagogical approaches thereby enabling more adaptive and responsive teaching methods at all levels of education (Biswas, 2023; Dowling & Lucey, 2023; El Naqa et al., 2023; Huang et al., 2023; Lund et al., 2023; Meskó & Topol, 2023; Baclic et al., 2020). However, the successful integration of these technologies in educational domains is dependent upon teachers’ acceptance because their perspectives and behavioural intentions to use the technologies play critical roles concerning their innovative adoption (Ayanwale et al., 2022).
Understanding teachers’ intention to integrate and use GenAI in education is important for facilitating effective implementation (Aghaziarati et al., 2023; Ayanwale et al., 2022) especially in resource-constrained environments such as Nigeria where the application and use of GenAI by teachers is still limited due to systemic challenges. Teachers in these settings often face inadequate access to digital infrastructure, insufficient training, ongoing digital inequalities, data privacy, technological infrastructure, and the importance of aligning AI tools with pedagogical goals (Nguyen et al., 2023b; Shahzad et al., 2024; Walter, 2024) all of which hinder the effective use of GenAI (Essien et al., 2024). As education undergoes digital transformation leading to innovative learning spaces in which humans and machines collaborate based on AI’s transformative infiltration into education, the need arises to further examine teachers’ intention to use the technology going forward (Lu et al., 2024). In view of this, we hypothesize that Perceived Ease of Use (PEU), Perceived Usefulness (PUC), Attitude Toward ChatGPT (ATC), Teachers’ Trust in ChatGPT (TTC), and Your Colleagues and Your Use of ChatGPT (YCC) positively influence teachers’ Behavioral Intention (BI) to adopt ChatGPT. Conversely, we propose that Technology Anxiety (TA) and Privacy Issues (PIU) negatively impact BI.
Our study is anchored on hypotheses that guide the examination of both linear and nonlinear relationships among variables. Following structured training on ChatGPT applications, we assess Nigerian in-service teachers’ perspectives using a hybrid methodology. By integrating Partial Least Squares Structural Equation Modeling (PLS-SEM) and Artificial Neural Networks (ANN), we identify key drivers and obstacles to ChatGPT adoption. PLS-SEM facilitates the analysis of linear relationships, reliability assessment, and evaluation of direct and indirect effects, while ANN captures intricate nonlinear interactions and prioritizes predictor importance. This combined approach offers a comprehensive understanding of factors influencing teachers’ readiness and intention to incorporate AI tools into their educational practices. Our study there examines in-service teachers’ behavioural intention to use LMM’s GenAI from which we construct a model of teachers’ intention to use the technology in education by drawing on the TAM framework to explore the influencing factors of their intention. In view of this, our study addresses the contextual challenges of AI adoption in resource-limited settings and provides actionable insights to empower teachers, promoting equitable, innovative, and sustainable educational practices in developing countries.
The rapid development of artificial intelligence (AI) technologies in recent years, especially the widespread use of large language models (LLMs), has sparked much scholarly discussion about their possible uses in the classroom. LLMs, as AI systems leveraging natural language processing capabilities, can comprehend and generate human language. This feature makes them appropriate for various learning tasks, such as feedback mechanisms, individualized instruction, and automated question-answering systems (Zhang et al., 2024). One essential use of large language model (LLM) technology in the field of education is personalized learning. LLMs can optimize educational outcomes by creating customized learning trajectories and recommending resources based on students’ interests and progress (Zhang et al., 2024). Bhutoria (2022) emphasized that LLMs can provide individualized learning recommendations and feedback by analyzing students’ assignments, classroom performance, and learning behaviors. This approach enables learners to acquire knowledge at their own pace. This type of data-driven, individualized instruction improves the learning process overall and significantly increases student autonomy.
The large language models known as LLM-based evaluators are made to evaluate the quality of samples according to predetermined standards. These evaluators can be configured to evaluate individual samples by assigning scores, such as Likert-scale ratings ranging from 1 to 5 (Likert, 1932), or to compare the quality of paired samples and determine which is superior (Chiang & Lee, 2023; Zheng et al., 2023). Following the demonstrated capabilities of proprietary LLMs, including ChatGPT, GPT-4, and Claude (Chiang et al., 2024), as robust LLM-based evaluators (Chiang & Lee, 2023; Liu et al., 2023; Zheng et al., 2023), subsequent research has focused on enhancing the alignment of their scoring with human evaluators (Chiang & Lee, 2023; Yuan et al., 2023). Concurrently, another stream of research seeks to improve the performance of open-source LLMs, such as Llama (Zheng et al., 2023) and Mistral (Jiang et al., 2023), as evaluators by developing specialized training datasets and employing fine-tuning techniques (Kim et al., 2023; Li et al., 2023; Kim et al., 2024). Most studies investigating the efficacy of LLMs as automated graders utilize datasets containing student submissions alongside human-assigned scores to evaluate whether LLM-generated assessments align with those of human evaluators (Latif & Zhai, 2024; Lee et al., 2024). These studies generally operate in controlled settings where LLM-generated scores do not influence students’ grades, and direct interaction between students and the LLMs is absent.
Generative Artificial Intelligence (GenAI) has become widely available since the launch of ChatGPT in late 2022, affecting both students and teachers in education. The term “GenAI” describes sophisticated AI systems that can predict the next piece of content and produce outputs that resemble those of a person, including text, photos, speech, music, video, and more (Tillmanns et al., 2025). For instance, Large Language Models (LLMs) like ChatGPT produce text by predicting the most likely next word in a sequence, enabling outputs that often appear plausible but are not inherently accurate (Cascella et al., 2023; Fui-Hoon Nah et al., 2023). Beyond ChatGPT, other GenAI tools, such as Claude, Gemini, DALL-E, and MidJourney, have gained popularity and accessibility, offering diverse applications across educational contexts. Both students and teachers stand to gain from the revolutionary potential that GenAI presents for education. Students can use GenAI for brainstorming ideas, drafting essays, simulating real-world scenarios, clarifying complex concepts, generating practice exam questions, and receiving personalized feedback (Atlas, 2023; Fui-Hoon Nah et al., 2023). Time-consuming chores for lecturers, like developing lesson plans, producing practice questions, and giving students tailored answers, are greatly streamlined by GenAI. Teachers can spend more time improving student comprehension and creating more in-depth learning experiences because of these efficiencies (Ivanov, 2023). While GenAI provides significant benefits, its integration into education also raises ethical concerns. Numerous concerns have been covered, including plagiarism, the spread of false information, bias in AI outputs, and issues with the validity of distant assessments (Wu & Zhang, 2023). These challenges underscore the importance of educating both students and lecturers on the responsible use of GenAI tools. Notably, banning GenAI entirely, as some higher education institutions initially attempted, has proven difficult to enforce and counterproductive, highlighting the need for guidance and structured policies for its responsible adoption (Eke, 2023).
Teachers’ perceptions of Generative AI (GenAI) are shaped by their familiarity with the technology, their understanding of its capabilities, and their beliefs regarding its potential benefits and risks. Studies indicate that educators who view GenAI as a tool to enhance instructional practices are more likely to adopt it in the classroom (Kaplan-Rakowski et al., 2023). Positive perceptions often arise from recognizing GenAI’s capacity to personalize learning experiences, alleviate administrative burdens, and provide innovative teaching resources. For instance, Collie and Martin (2024) observed that teachers’ engagement with GenAI is significantly influenced by factors such as their perception of autonomy-supportive leadership, a commitment to professional growth, and stress associated with adapting to technological changes. Despite these benefits, significant concerns persist. Some educators view GenAI as a potential threat to their professional roles, fearing that it may replace specific teaching functions or reduce the demand for human educators. Ethical concerns further exacerbate resistance, with apprehensions about biased outputs, pseudo-bias, a decline in originality, and issues related to data privacy and security (Zhai & Krajcik, 2024). Such challenges contribute to skepticism, particularly among educators with limited exposure to or understanding of GenAI’s applications.
The Technology Acceptance Model (TAM), developed by Davis (1989), serves as the theoretical framework for this study. TAM is a widely recognized model for understanding technology adoption and use, particularly in educational contexts. It posits that two primary determinants influence an individual’s behavioral intention (BI) to adopt a technology: Perceived Usefulness (PU) and Perceived Ease of Use (PEU). Perceived Usefulness refers to the degree to which an individual believes that using a technology will enhance their performance, while Perceived Ease of Use reflects the extent to which a person finds the technology easy to use and free of effort. These constructs are mediated by an individual’s attitude toward the technology (AT), which directly impacts their behavioral intention to adopt it. TAM is particularly well-suited to this study as it aligns closely with the variables under investigation. For instance, Perceived Ease of Use (PEU) in this study corresponds directly to PEOU in TAM, as it examines the extent to which Nigerian in-service teachers perceive ChatGPT as user-friendly and easy to integrate into their teaching practices. Similarly, Perceived Usefulness (PUC) aligns with PU in TAM, representing the teachers’ belief that ChatGPT can enhance their teaching efficiency, support instructional quality, and streamline administrative tasks.
The construct of Attitude Toward ChatGPT (ATC) also maps onto TAM’s focus on user attitudes, capturing teachers’ overall positive or negative feelings about using ChatGPT in their classrooms. Furthermore, Behavioral Intention (BI) in this study is directly derived from TAM and measures teachers’ willingness and intention to adopt ChatGPT as an educational tool. To account for the unique challenges of adopting AI in resource-constrained environments, we extend TAM by incorporating additional variables. For example, Your Colleagues and Your Use of ChatGPT (YCC) reflects the role of social factors in shaping attitudes and behaviors, which is particularly relevant in collaborative teaching environments. Teachers’ Trust in ChatGPT (TTC) introduces the dimension of trust, reflecting teachers’ confidence in ChatGPT’s reliability, accuracy, and ethical considerations. These extensions align with findings from previous research that highlight the importance of trust in adopting new technologies (Gefen et al., 2003). We also examine Technology Anxiety (TA) and Privacy Issues (PIU) as external variables that may influence PEOU and BI. Technology Anxiety captures the fear or discomfort associated with using AI-based tools, which has been shown to negatively affect technology adoption (Venkatesh et al., 2003). Similarly, Privacy Issues represent concerns about data security and ethical use, which may diminish teachers’ confidence in ChatGPT and hinder its adoption.
By integrating these constructs, TAM provides a robust framework for exploring both the linear and nonlinear relationships among the variables in this study. The model not only explains how teachers perceive and evaluate ChatGPT but also highlights the contextual barriers that influence their readiness and intention to adopt this technology. This approach ensures a comprehensive analysis of the factors shaping teachers’ behavioral intentions, particularly in resource-constrained environments like Nigeria. The choice of TAM is further supported by its widespread application in educational settings. Studies investigating the adoption of digital classrooms, learning management systems, and AI-based platforms have demonstrated its relevance in capturing user acceptance and identifying key drivers of technology use (Davis, 1989; Venkatesh & Davis, 2000). Additionally, TAM’s flexibility allows for the integration of external variables, enabling us to adapt the framework to the unique context of ChatGPT adoption in Nigeria.
Based on the identified constructs and prior research, the following hypotheses are proposed:
Perceived Ease of Use (PEU) is the degree to which a person thinks a certain technology must be used with little effort. It is a key component of the Technology Acceptance Model (TAM), which holds that consumers’ attitudes and intentions to accept technology are significantly influenced by both perceived utility and PEU (Misra et al., 2023; Zogheib & Zogheib, 2024). Empirical evidence consistently demonstrates that higher levels of PEU positively influence behavioral intentions to use technologies such as ChatGPT. For example, research conducted among university students revealed that when ChatGPT is perceived as user-friendly, students exhibit a significantly greater intention to adopt it (Zogheib & Zogheib, 2024; Almogren et al., 2024). These findings align with broader studies underscoring the critical role of both PEU and perceived usefulness in predicting behavioral intentions within educational settings (Peng & Yan, 2022). In the study by Yang and Wang (2019), perceived ease of use was found to have a significant positive influence on students’ behavioral intentions to adopt machine translation. Similarly, Shiau and Chau (2016) argue that when individuals perceive a technological tool as requiring minimal effort to use, they are more likely to adopt it. Based on these findings, this hypothesis is proposed:
H1: Perceived Ease of Use (PEU) has a significant positive effect on Behavioral Intention (BI) to adopt ChatGPT.
Studies have demonstrated a significant positive correlation between perceived usefulness and behavioral intention. For instance, research focusing on doctoral students revealed that when ChatGPT is perceived as beneficial for improving academic writing, students exhibit a substantially higher intention to adopt it (Zou & Huang, 2023). This finding aligns with the core principles of the Technology Acceptance Model (TAM), which identifies perceived usefulness as a key determinant of technology adoption (Yang & Wang, 2019). Accordingly, the following hypothesis is proposed:
H2: Perceived Usefulness (PUC) has a significant positive effect on Behavioral Intention (BI) to adopt ChatGPT.
Attitude refers to the psychological system individuals use to evaluate the effects of a particular act, encompassing beliefs, emotions, and behaviors toward an object, event, or person. This directly influences behavioral intentions to take action (Athiyaman, 2002; Davis, 1989). Within the frameworks of the Technology Acceptance Model (TAM) and the Theory of Reasoned Action (Fishbein & Ajzen, 1977), attitude has been extensively studied. Students’ attitudes toward using ChatGPT for educational purposes can vary, ranging from positive to negative. In TAM, perceived ease of use significantly impacts perceived usefulness and attitudes, which in turn strengthens behavioral intention (Davis, 1989; Alfadda & Mahdi, 2021). When a technological tool is perceived as easy to use, students are more likely to find it helpful, develop a positive attitude, and show a strong willingness to utilize it, particularly in academic writing (Alfadda & Mahdi, 2021). Consequently, this study hypothesizes that attitudes toward using ChatGPT for learning significantly influence their behavioral intentions, leading to the following hypothesis.
H3: Attitude Toward ChatGPT (ATC) has a significant positive effect on Behavioral Intention (BI) to adopt ChatGPT.
Research demonstrates that higher levels of trust in ChatGPT significantly increase teachers’ behavioral intentions to adopt the technology. Studies show that when educators perceive ChatGPT as a reliable and trustworthy resource, they are more inclined to integrate it into their teaching practices (Bhaskar et al., 2024; Bhat et al., 2024). Trust also serves as a moderating factor in the relationship between perceived usefulness and behavioral intention. When teachers trust ChatGPT, their confidence in its capabilities enhances their perception of its usefulness, which in turn strengthens their intention to utilize it (Bhaskar et al., 2024). Moreover, teachers who trust the technology are more likely to incorporate it consistently into their classrooms, reinforcing their initial intentions to use it (Choudhury & Shamszare, 2023). Supporting this, a survey of 359 participants found that users’ trust in chatbot services significantly influenced their intention to continue using them (Nguyen et al., 2021). These findings underscore the critical role of trust in the adoption and implementation of ChatGPT, affirming its positive impact on actual usage. Based on this, the following hypothesis was formulated:
H4: Teachers’ Trust in ChatGPT (TTC) has a significant positive effect on Behavioral Intention (BI) to adopt ChatGPT.
Technology anxiety refers to the apprehension or fear individuals experience when interacting with technology, often stemming from concerns about its usability, reliability, or potential negative outcomes (Budhathoki et al., 2024). Research consistently shows that higher levels of technology anxiety are associated with lower behavioral intentions to adopt ChatGPT. Studies applying the Unified Theory of Acceptance and Use of Technology (UTAUT) framework found that anxiety significantly negatively impacted students’ intentions to use ChatGPT in educational contexts across diverse regions, including the UK and Nepal (Budhathoki et al., 2024). Additionally, research on the moderated mediation model of technology anxiety highlights its multifaceted impact. Technology anxiety not only directly influences behavioral intention but also interacts with other factors, such as technostress, exacerbating stress levels associated with using ChatGPT. This heightened stress further reduces the likelihood of adopting the technology (Duong et al., 2024). Based on these findings, the following hypothesis was proposed:
H5: Technology Anxiety (TA) has a significant negative effect on Behavioral Intention (BI) to adopt ChatGPT.
Privacy concerns center on how personal data is collected, stored, and utilized by technologies like ChatGPT, often leading to user apprehension. Studies show that perceived privacy risks significantly reduce users’ intentions to adopt such technologies. For instance, unresolved privacy concerns have been found to undermine trust, resulting in reluctance to engage with AI tools perceived as risky in terms of data security (Wu et al., 2024). When users believe their personal information may be mishandled or insufficiently protected, their willingness to use ChatGPT declines. Based on these insights, the following hypothesis was proposed:
H6: Privacy Issues (PIU) have a significant negative effect on Behavioral Intention (BI) to adopt ChatGPT.
The adoption of ChatGPT is significantly influenced by the behavior and attitudes of peers and colleagues. When individuals observe their colleagues using ChatGPT effectively, they are more likely to form a favorable attitude toward the tool and develop an intention to adopt it themselves. Research highlights that positive word-of-mouth and peer recommendations play a crucial role in enhancing users’ adoption intentions (Al-Kfairy, 2024; Jo & Bang, 2023). Observing peers benefit from the technology reinforces an individual’s belief in its usefulness, further increasing their likelihood of engagement (Al-Kfairy, 2024). The Theory of Planned Behavior underscores the role of subjective norms, which are shaped by the behaviors and expectations of colleagues, in influencing individual attitudes toward adopting new technologies. When individuals perceive a social expectation to use ChatGPT, their intention to adopt it is strengthened (Al-Kfairy, 2024). Based on these findings, the following hypothesis was proposed:
H7: Your Colleagues and Your Use of ChatGPT (YCC) have a significant positive effect on Behavioral Intention (BI) to adopt ChatGPT.
Despite the growing integration of GenAI, formalized frameworks for its ethical and practical use in education remain underdeveloped. Unlike the generally accepted principles for robotics, such as Asimov’s Three Laws (Asimov, 2004), there are no universally established guidelines for GenAI in education. Previous literature reviews have explored topics such as the role of ChatGPT in higher education (Bhullar et al., 2024), AI chatbots (Labadze et al., 2023), and ethical principles (Nguyen et al., 2023a). However, limited research has explored the integration of LLMs into real-world classroom environments where students can interact with these evaluative tools (Nilsson & Tuvstedt, 2023). Consequently, the impact of LLM-based evaluators on teachers’ experiences and perceptions within authentic educational contexts remains largely underexplored. Addressing these concerns is crucial to fostering wider acceptance and integration of GenAI in education.
Our study examines the in-service teachers’ behavioral intentions to use GenAI in their teaching practices. A total of 260 in-service teachers participated in the study after receiving training on the applications of AI in education (AIED). While a majority of the teachers are not new to AIED, yet they further received trainings on the overview of AI concepts, its educational applications, and practical tools for integrating AI technologies into classroom environments. Thereafter, the teachers were invited to willingly participate in completing a standardized survey designed using Google Forms (Google LLC, Mountain View, CA, USA) to capture their insights on the adoption of AI in education. The Google Forms-based survey was distributed through teachers’ professional platforms, specifically WhatsApp (Meta Platforms, Inc., Menlo Park, CA, USA), ensuring easy access for interested participants. This approach facilitated data collection from a broad and diverse sample of educators, allowing them to confidentially share their experiences and expectations regarding AI tools in education. Table 1 below shows the demographic profile of the 260 respondents who participated in the survey.
Table 1 provides a comprehensive overview of the demographic profile of our respondents, detailing their gender, age, subject area, school type, school location, and technology usage competency level. Our results reveal that most respondents are female, with male participants forming a smaller proportion of the sample. Most respondents are mid-career professionals, predominantly between 30 and 49, while younger and older teachers are less represented. Regarding subject specialization, a significant portion of the respondents teach Science and Technology-related subjects, while a smaller proportion specialize in Arts, Humanities, and other disciplines. Regarding school type, more teachers are employed in public schools, although private school teachers also constitute a notable segment, ensuring balanced representation from both educational settings. Our results further indicate that most respondents work in urban areas, followed by those in semi-urban and rural locations. This suggests that technology exposure and accessibility may be higher in urban settings. Additionally, most participants demonstrate a strong level of digital competence, with most identifying as intermediate or advanced technology users. Only a small fraction considers themselves beginners or novices, highlighting teachers’ overall familiarity and confidence in engaging with digital tools in their professional practice.
The data for this study were collected from in-service teachers through a Google Forms-based survey distributed across their professional platforms. The survey was adapted from the works of Ayanwale et al. (2022) and Nazaretsky et al. (2021) to align with the specific objectives of this research. The constructs related to trust were adapted from Nazaretsky et al. (2021), while other constructs were drawn from Ayanwale et al. (2022). Additional items were incorporated into the final instrument to better suit the context of our study. Prior to administration, the survey underwent a reliability test (refer to Table 2 for indicator reliability summary). The final version of the instrument consisted of nine sections, which were reviewed and validated by experts in the fields of AI in education (AIED), Test and Measurement, and Educational Technology. The first section of the survey gathered demographic information from participants, including gender, age, subject taught, school type, school location, and ICT competency level. The remaining eight sections measured the key constructs – perceived usefulness of ChatGPT (PUC), perceived ease of use of ChatGPT (PEU), teachers’ trust in ChatGPT (TTC), privacy issues and use of ChatGPT (PIU), your colleagues and your use of ChatGPT (YCC), technology [ChatGPT] anxiety (TA), attitude towards ChatGPT (ATC), and behavioural intention to use ChatGPT (BI) – of the study. The 45-item survey was then distributed online to the teachers, with responses rated on a Likert scale ranging from “strongly disagree” (1) to “strongly agree” (6). The survey remained open for data collection for two months, during which daily reminders were sent across professional platforms to encourage voluntary participation. After the two-month period, the survey was closed, and no further responses were accepted. This approach allowed us to gather a diverse range of responses while ensuring that all participants had equal opportunity to contribute.
To ensure the content validity of the survey instrument, the final version was reviewed and validated by experts in the fields of AI in education (AIED), Test and Measurement, and Educational Technology. This ensured that the instrument accurately represents the construct it is intended to measure. The goal of our study was to capture in-service teachers’ perspectives and intention to integration of AI tools and the survey was designed to achieve this goal. The validation process involved expert reviews where each item was scrutinized for relevance, clarity, and alignment with the research objectives. The experts also provided feedback on the wording of certain questions to ensure they were accessible to a diverse population of teachers with varying levels of expertise in AI. Thereafter, the final instrument was considered both comprehensive and contextually appropriate for capturing the data necessary to address the hypotheses raised in this study.
The data for this study (Ayanwale et al., 2025) were collected through a Google Forms-based survey, which was shared with participants via teachers’ professional platforms, particularly WhatsApp. This method of distribution ensured that the survey was easily accessible to a wide audience of educators who were part of professional networks. Participants were provided with clear instructions and were required to give informed consent before completing the survey online. Basically, by accepting to fill the survey, a teacher accepts to willingly participate in the study. This was crucial to ensure participants understood the purpose of the study, the voluntary nature of their participation, and the confidentiality of their responses, the information of which was provided along with the survey online. By using professional platforms like WhatsApp, we were able to reach a broad and diverse sample of teachers, including those from varying geographic locations, subject areas, and teaching levels. This approach also enabled participants to share their experiences and expectations regarding AI tools in education in a confidential and comfortable setting. The survey was structured to be straightforward, allowing teachers to respond based on their own experiences and perspectives on AI adoption. The survey remained open for a period of two months to allow ample time for participation. After the two-month data collection window, the survey was closed, and no further responses were accepted.
In our study, we employed a dual-stage approach that integrated Partial Least Squares Structural Equation Modeling (PLS-SEM) with Artificial Neural Networks (ANN) to predict Nigerian in-service teachers’ behavioral intention (BI) to adopt ChatGPT. This hybrid methodology allowed us to leverage the strengths of both techniques: PLS-SEM offered insights into linear relationships and supported theory development, while ANN uncovered complex, nonlinear interactions and ranked the importance of predictors. Together, these methods provided a comprehensive understanding of the key drivers and barriers to ChatGPT adoption. We chose PLS-SEM for its effectiveness in predictive research, particularly with small sample sizes, as noted by Hair et al. (2021), who affirm its reliability with as few as five cases per parameter. PLS-SEM also adeptly handles non-normal data distributions, making it well-suited for our dataset. Using the seminr and plspm packages (Hair et al. 2021) in RStudio (version 4.3.3) (R Core Team, 2021), we specified the measurement and structural models. Constructs were defined as reflective, and we assessed their reliability and validity using Cronbach’s alpha, composite reliability, and Average Variance Extracted (AVE). We confirmed discriminant validity through the Heterotrait-Monotrait (HTMT) ratio. The structural model was analyzed to estimate path coefficients and their significance using bootstrapping with 10,000 resamples. Additionally, we evaluated model fit using the Standardized Root Mean Residual (SRMR) and, calculated R2 values to measure the explained variance in BI, f2 effect sizes for predictors, and Q2 values via PLSpredict to assess predictive relevance.
To complement the linear insights from PLS-SEM, we employed ANN to investigate nonlinear relationships using the neuralnet and NeuralNetTools packages. Our ANN model was trained with a backpropagation algorithm, specifically through feed-forward networks, which adjusted weights iteratively to minimize prediction errors. The model architecture comprised an input layer, two hidden layers with five and three neurons, respectively, and an output layer (see Figure 1). We assessed the model’s predictive performance through Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE), confirming its high accuracy. We also utilized Garson’s and Olden’s algorithms to rank the importance of predictors, identifying key factors such as PEU, PUC, and ATC as critical determinants. This analysis validated the linear results from PLS-SEM and offered additional insights into the nonlinear dynamics influencing BI. By integrating PLS-SEM and ANN, we not only confirmed our model’s findings but also deepened our understanding of the factors influencing teachers’ readiness to adopt ChatGPT. This combined approach aligns with previous research highlighting the complementary strengths of SEM and ANN in predictive studies (Hair et al., 2021; Leong et al., 2024). The detailed R codes used in our analysis are provided in the supplementary file for transparency and replicability.
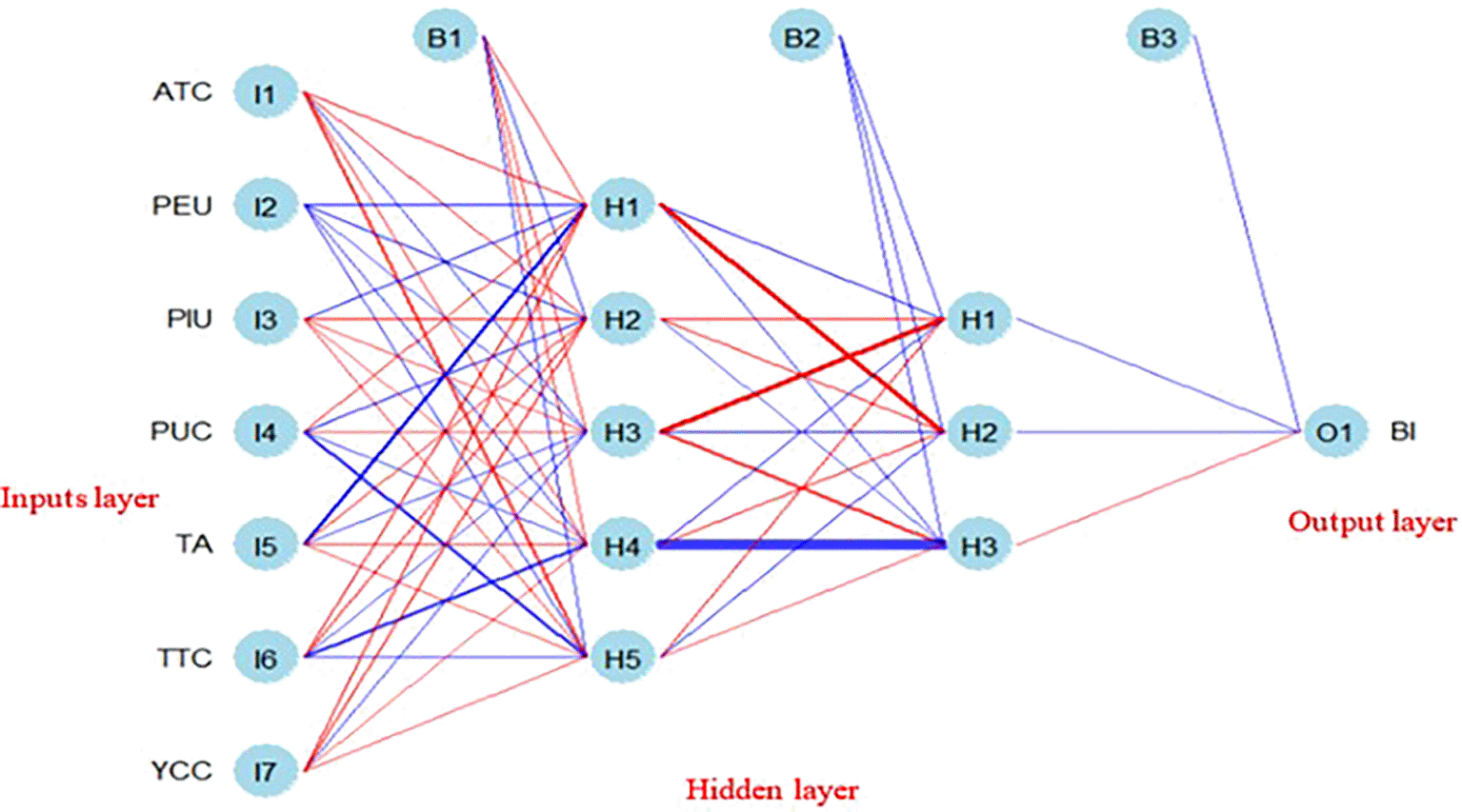
(Source: figure created by authors).
In our study, we emphasized ethical considerations to ensure the integrity of our research process. Ethical clearance was obtained from the Department of Counseling Psychology and Educational Foundation Ethical Review Board at Tai Solarin University of Education, with approval granted on July 22, 2024, under Ethical Clearance Number ECN 07-2024-15. This approval confirmed our adherence to established ethical standards for studies involving human participants and aligned with the principles outlined in the Declaration of Helsinki, which governs research involving human subjects. To uphold these ethical standards, we ensured that respondents were fully informed about the purpose of the research, the voluntary nature of their participation, and the confidentiality of their responses. This information was provided alongside the survey, which was shared on professional teachers’ platforms. Respondents could not proceed to complete the online form without first reading and accepting this information. This process guaranteed that written informed consent was obtained electronically before participation, reinforcing their right to decide voluntarily about their involvement. Additionally, we maintained strict confidentiality throughout the study. Responses were securely stored in password-protected digital files and were accessible only to the research team, safeguarding participant privacy. By completing the survey, respondents willingly agreed to participate, fully aware of their rights and the protective measures in place. These ethical commitments underscore our dedication to responsible research practices and the ethical integrity of our study.
We present the results highlighting key predictors of teachers’ behavioral intention to adopt ChatGPT, based on a hybrid approach that combines PLS-SEM and ANN analyses.
We established a model fit assessment that demonstrates our structural model fits the data well. The SRMR value of 0.049, well below the threshold of 0.08, indicates excellent alignment between observed and predicted correlations (Hair et al., 2021). Both the Unweighted Least Squares Discrepancy (d_ULS) value of 1.419 and the Geodesic Discrepancy (d_G) value of 7.718 reflect minimal discrepancies, further supporting the model’s adequacy. Although the chi-square value of 6774.515 is influenced by sample size and model complexity, we find it reasonable in context. The NFI value of 0.880, nearing the recommended threshold of 0.90, suggests an acceptable model fit. Overall, these results confirm that our model provides a solid foundation for analyzing relationships and validates our study.
In our PLS-SEM analysis, we evaluated the measurement model to ensure that the constructs used in the study met the necessary reliability and validity benchmarks. This assessment focused on three key areas: reliability, convergent validity, and discriminant validity, which are essential for establishing the robustness and accuracy of the structural model results.
To assess reliability, we examined indicator reliability, Cronbach’s alpha, and composite reliability coefficients (rho_c). These measures indicate the internal consistency of the constructs, ensuring that the indicators within each construct consistently measure the underlying variable. According to Hair et al. (2019, 2021), a threshold of 0.70 is recommended for all three metrics. In our study, indicator reliability values ranged from 0.878 to 0.985 (see Table 2), while Cronbach’s alpha values ranged from 0.953 to 0.980, and rho_c values ranged from 0.962 to 0.985 (see Figure 2). These results confirm that all constructs in the model were well above the thresholds and demonstrated strong internal consistency, highlighting the reliability of the latent variables used. Convergent validity was evaluated to determine whether the indicators of each latent construct adequately explain its variance. Following Hair et al. (2022), and Magno et al. (2024), we used the average variance extracted (AVE) as the primary metric for this assessment, with a recommended threshold of 0.50. In our study, AVE values ranged from 0.807 to 0.943, well above the benchmark (see Figure 2).
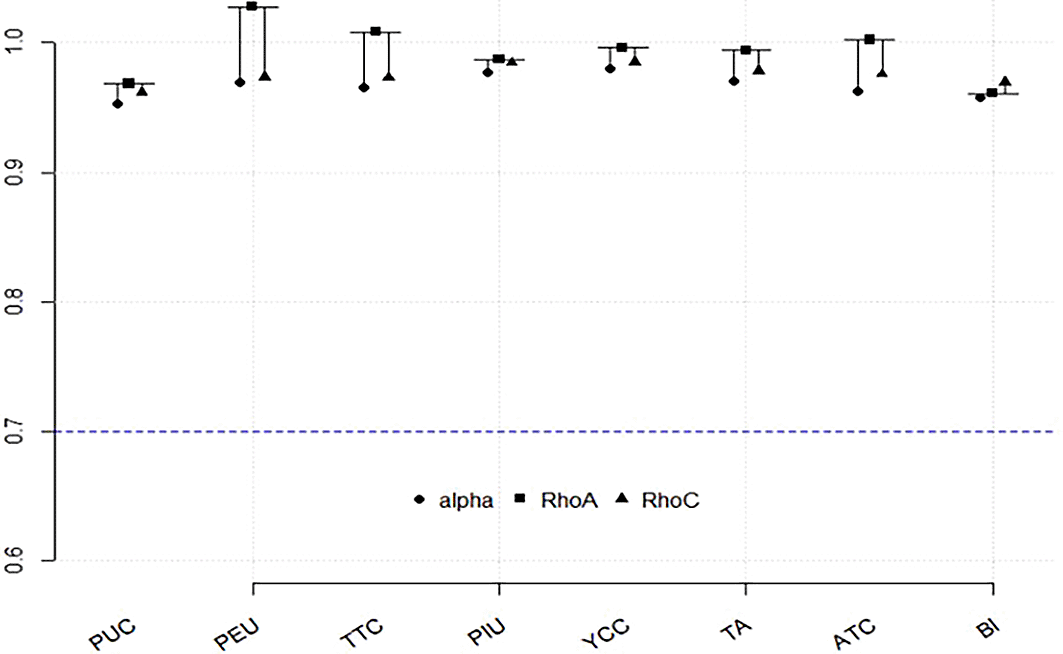
(Source: figure created by authors).
Furthermore, we assessed discriminant validity using the heterotrait-monotrait ratio (HTMT) proposed by Henseler et al. (2015) to ensure that the constructs were distinct and measured their intended concepts. Discriminant validity ensures that a construct is empirically distinct from other constructs in the model. For HTMT, a value below 0.85 (or 0.90 in specific contexts) is considered acceptable (Henseler et al., 2015). In our analysis, all HTMT values (see Table 3) fell below the threshold of 0.85, confirming that our constructs were empirically distinct from one another.
After confirming the reliability and validity of the measurement model, we evaluated the structural model to test the hypothesized relationships among constructs and assess the model’s predictive power. This evaluation included analyzing path coefficients, R2 values, f2 effect sizes, and predictive relevance using PLSpredict. Path coefficients, which represent the strength and direction of relationships between constructs, were assessed using a bootstrapping procedure with 10,000 resamples to determine significance levels (see Table 4). In our study, PUC, TA, YCC, and PEU showed significant relationships with BI. PUC had the most potent positive effect (β=0.879, p<0.05), emphasizing its critical role in predicting teachers’ intention to adopt ChatGPT. Conversely, TA and PEU significantly negatively affected BI (β=−0.548, p<0.05; β=−0.451, p<0.05), indicating that higher anxiety levels reduce behavioral intention. Meanwhile, YCC (β=0.546, p<0.05) contributed positively, underscoring the influence of peer support in adoption decisions. The coefficient of determination (R2), which measures the variance in the dependent variable explained by the independent variables, was 0.158 for BI, indicating that 15.8% of the variance in BI was explained by the model. While moderate, this value reflects the exploratory nature of our study.
Additionally, effect sizes (f2) were calculated to evaluate the relative importance of each predictor (see Table 5). Following Cohen (1992) guidelines, f2 values of 0.02, 0.15, and 0.35 indicate small, moderate, and large effects, respectively. In our model, PEU, PUC, TA, and TTC had a moderate effect size, while the other constructs showed small or negligible effects. To assess predictive relevance, we employed PLSpredict, which evaluates the model’s performance in predicting new observations. The Q2 value, derived through PLSpredict, was 0.137 for BI, confirming the model’s predictive relevance. This value demonstrates that the model can make meaningful out-of-sample predictions, an essential feature for practical application and validation.
To complement our findings from the PLS-SEM analysis and to uncover complex nonlinear relationships among variables, we employed Artificial Neural Network (ANN) analysis. Initially, we used PLS-SEM to examine the hypothesized relationships and to identify key factors influencing in-service teachers’ behavioral intention (BI) to adopt ChatGPT in their classrooms. In the second phase, we utilized ANN analysis to rank the predictors affecting BI and to provide deeper insights into the adoption dynamics. Following the methodology outlined by Liébana-Cabanillas et al. (2017), we integrated the PLS-SEM latent scores as neural inputs for the ANN model. This dual-stage approach enabled us to validate the statistical significance of predictors while capturing intricate nonlinear interactions. Prior to training the ANN model, we conducted data preprocessing to ensure compatibility. This involved normalizing all variables using min-max scaling, which transformed values into a range of 0 to 1 to prevent variables with larger scales from exerting disproportionate influence. The dataset was subsequently split into a training set (70%) and a testing set (30%), in line with Leong et al. (2024), ensuring effective learning while maintaining generalizability. To mitigate overfitting, we implemented a ten-fold cross-validation procedure, as recommended by Ooi and Tan (2016), allowing us to obtain the Root Mean Squared Error (RMSE) and enhance predictive accuracy.
The ANN model comprised an input layer with seven neurons corresponding to the independent variables: PEU, PUC, ATC, TTC, TA, PIU, and YCC. A multilayer perceptron architecture was adopted, incorporating two hidden layers with five and three neurons, respectively. These configurations were determined heuristically to balance computational efficiency with predictive capability. The output layer contained a single neuron representing the dependent variable, BI. Model training was conducted using the feed-forward-backward propagation (FFBP) algorithm, which forwards inputs and refines error estimations through backward propagation (Taneja & Arora, 2019). This iterative learning process allowed the model to continuously adjust weights, enhancing prediction accuracy. The training phase involved a forward pass, during which input data was processed through the network, followed by error calculation using Mean Squared Error (MSE). A backward pass then optimized the weights through gradient descent, ensuring the model learned from past errors and improved accuracy with each iteration. Sigmoid activation functions were employed in both the input and hidden layers to introduce nonlinearity, thereby enabling the model to capture intricate relationships. The training process continued until errors were minimized, further refining the network’s predictive performance.
We computed key performance metrics to assess the model’s accuracy, including RMSE and Mean Absolute Error (MAE). The ANN model yielded an RMSE value of 0.87, demonstrating strong predictive performance and confirming its effectiveness in identifying patterns within the dataset. Additionally, we employed Garson’s and Olden’s algorithms to analyze connection weights and determine the relative importance of each predictor influencing BI (see Table 6). The results indicated that PEU was the most influential predictor, followed by ATC and PUC, underscoring the critical roles of ease of use, positive attitudes, and perceived benefits in driving ChatGPT adoption. YCC and TTC exhibited moderate influence, whereas TA had a slight but notable negative impact. PIU was identified as the least significant factor, suggesting that privacy concerns did not constitute a major barrier in this context. The ANN model visualization provided further insight into the strength of connections between variables and neurons, reinforcing the ranking of predictor importance (see Figure 3). Additionally, a scatter plot comparing actual versus predicted BI values (see Figure 4) illustrated the model’s ability to produce accurate predictions. The ANN analysis not only validated but also extended the findings from PLS-SEM by uncovering nonlinear relationships and ranking predictors based on their impact. While PLS-SEM confirmed significant linear relationships, ANN revealed additional complexities in the data that traditional regression techniques might overlook.
| Ranking | Variable importance | Path weights |
|---|---|---|
| 1 | PUC | 0.879 |
| 2 | TA | -0.548 |
| 3 | YCC | 0.546 |
| 4 | PEU | -0.451 |
| 5 | TTC | -0.262 |
| 6 | ATC | 0.244 |
| 7 | PIU | -0.179 |
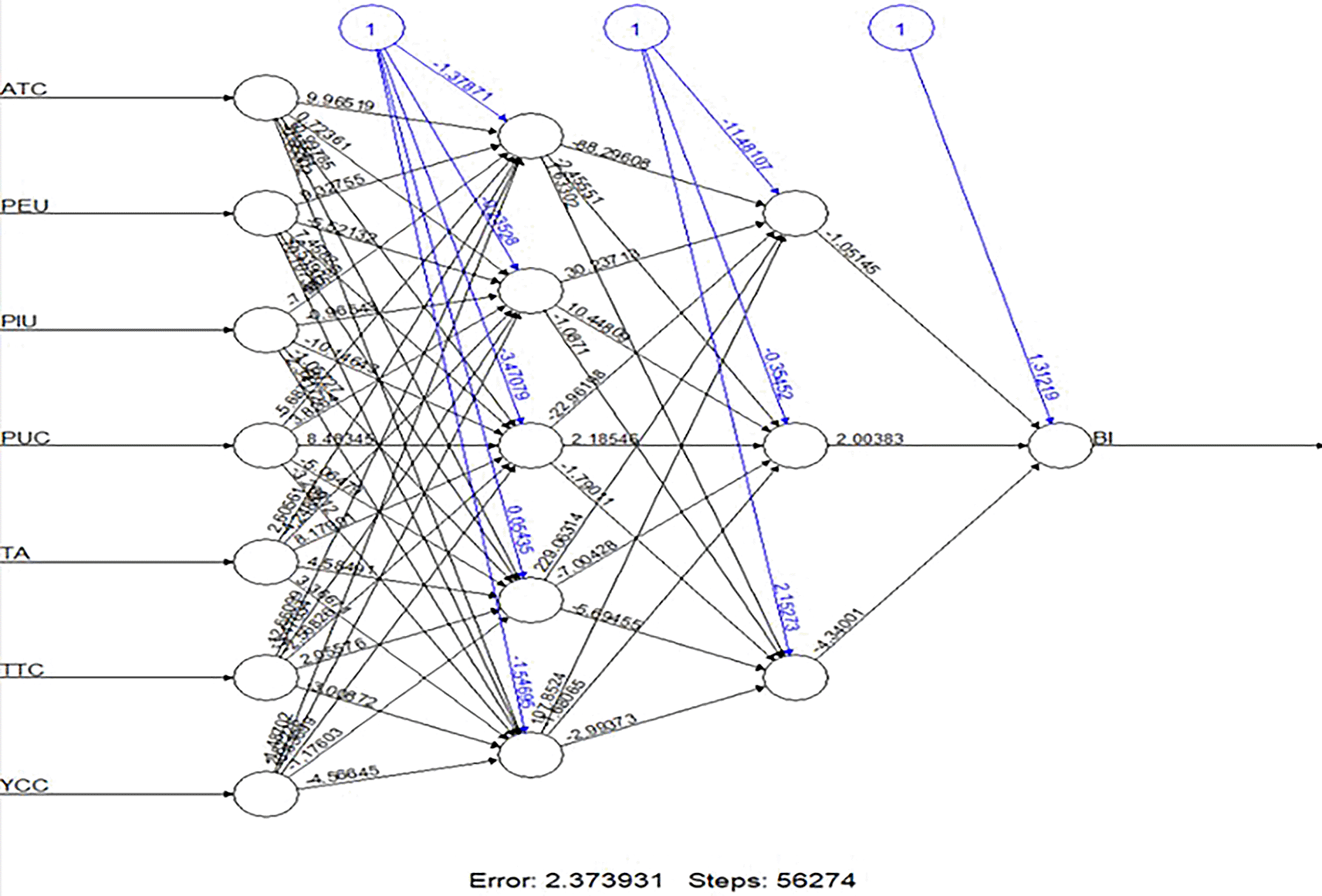
(Source: figure created by authors).
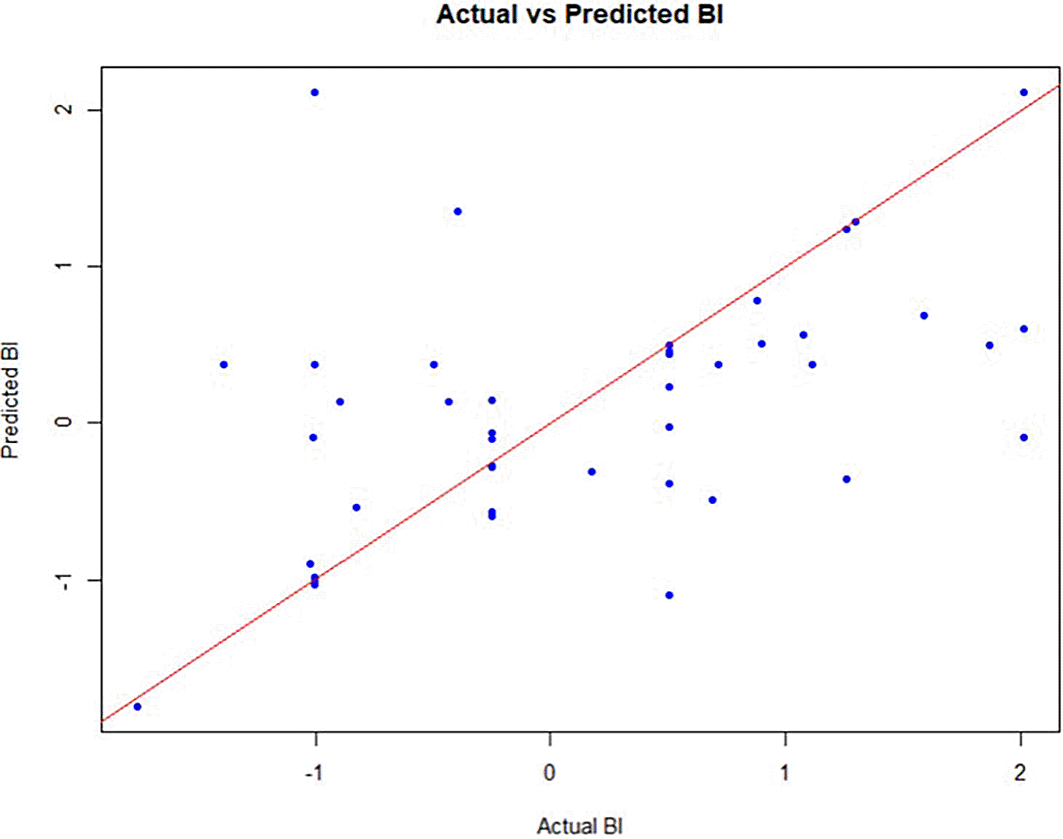
(Source: figure created by authors).
We also compare the rankings and importance of variables identified by PLS-SEM (see Table 4) and ANN (see Table 5). Both methods offer valuable yet distinct insights into the determinants of behavioral intention (BI). PLS-SEM reveals statistically significant relationships among variables, emphasizing a linear perspective that highlights direct connections between factors and BI. It underscores the importance of PUC and TA, indicating that teachers’ perceptions of usefulness strongly drive adoption, with anxiety acting as a significant deterrent. In contrast, ANN uncovers more complex, nonlinear interactions and prioritizes PEU and ATC as the most critical factors. This suggests that ease of use and attitude are fundamental to adoption, even though their direct effects were weaker in the PLS-SEM analysis. The differing rankings of PUC indicate that while PLS-SEM identifies usefulness as the primary driver, ANN recognizes that usability (PEU) is a crucial first step toward making ChatGPT valuable. Additionally, TA’s lower ranking in the ANN analysis implies that, despite its significant direct effect in PLS-SEM, it may exert indirect or nonlinear influences that ANN does not fully capture.
Our study adopted a hybrid analytical approach combining Partial Least Squares Structural Equation Modeling (PLS-SEM) and Artificial Neural Networks (ANN) to identify key predictors of teachers’ BI to adopt ChatGPT in educational settings. This innovative method allowed us to examine both the linear relationships between variables and more complex, nonlinear interactions which provided a platform to better understand the factors driving AI adoption by in-service teachers in education.
Our results show that notably, PUC emerged as the most influential predictor of BI, with a strong positive effect. This reinforces the idea that teachers are more likely to adopt ChatGPT if they perceive it as useful in their teaching practices (Alfadda & Mahdi, 2021; Athiyaman, 2002). On the other hand, TA and PEU were found to negatively affect BI (Wu et al., 2024; Zou & Huang, 2023; Yang & Wang, 2019). These results suggest that anxiety about using the technology and perceived difficulty in operating it can serve as significant barriers to adoption. Social influences, particularly YCC, also played a crucial role, indicating that teachers are more likely to adopt ChatGPT if their colleagues are doing so (Williams et al., 2014; Wang & Chou, 2014; Venkatesh et al., 2003). Our model’s coefficient of determination for BI was 0.158, meaning that the model explained 15.8% of the variance in teachers’ behavioral intentions to use ChatGPT. Although this value is moderate, it reflects the complexity of real-world adoption processes, where many external factors could influence decisions. On the other hand, effect sizes revealed that PUC had a large effect size, emphasizing its importance, while PEU, TA, and TTC had moderate effects (Ayanwale et al., 2024; Wu et al., 2024; Zou & Huang, 2023). These findings provide better understanding into the factors having the greatest influence on teachers’ intentions to adopt ChatGPT.
To complement the results from PLS-SEM, our study employed ANN analysis. This allowed for the identification of more intricate, nonlinear relationships among the predictors. The ANN model confirmed that PEU was the most influential factor in predicting teachers’ behavioral intentions to use ChatGPT (Wu et al., 2024; Zou & Huang, 2023), followed by ATC and PUC. This suggests that, while PLS-SEM identified linear relationships, ANN was able to capture more complex interactions that might not be fully explained by traditional models. Interestingly, while TA had a strong negative effect in PLS-SEM, its importance was much lower in the ANN model, suggesting that its influence could be indirect or dependent on other factors that were not captured in a linear framework. The ANN analysis provided a ranking of the predictors, reinforcing that PEU and ATC were central to teachers’ decisions to adopt ChatGPT, even though their direct effects were weaker in the PLS-SEM analysis. This further show the value of using a hybrid approach to capturing both linear and nonlinear dynamics in technology adoption studies.
Our study’s hybrid approach which combined PLS-SEM and ANN was able to provide a peak into understanding the factors influencing teachers’ behavioral intention to adopt ChatGPT in educational settings. While PLS-SEM validated the significance of linear relationships, ANN revealed the nonlinear complexities underlining the adoption process. Key predictors such as perceived ease of use, perceived usefulness, and attitude were identified as pivotal in the adoption of ChatGPT in education, with social influence and technology anxiety also playing significant roles. This dual-method approach offers a more nuanced perspective on AI adoption in education, emphasizing the importance of both technical factors (ease of use and usefulness) and social considerations (peer influence) in facilitating the integration of AI into teaching practices among teachers. Finally, our results contribute to the ongoing discussion concerning the adoption of AI in educational domains by revealing the complex interplay among cognitive, emotional, and social factors shaping in-service teachers’ intentions to embrace emerging technologies in education, especially those relating to AI.
Our results provide actionable insights for policymakers, educators, and technology developers aiming to facilitate the adoption of ChatGPT among in-service teachers. The strong influence of PEU and PUC highlights the need for user-friendly AI interfaces and practical training programs. We recommend that institutions focus on capacity-building initiatives to enhance teachers’ confidence in using ChatGPT, ensuring its seamless integration into teaching practices. Additionally, YCC significantly impacts adoption, suggesting that collaborative professional development programs and peer-led training workshops can enhance engagement and increase trust in AI tools. The negative impact of TA underscores the importance of providing continuous support systems, including help desks, troubleshooting resources, and professional learning communities, to alleviate fears associated with AI adoption. Although PIU ranked as the least significant factor, ensuring robust data security policies can further strengthen teachers’ confidence in AI-driven tools. We recommend that policymakers develop clear ethical guidelines for AI use in classrooms to address concerns about bias, misinformation, and AI over-reliance. A multi-stakeholder approach, involving education ministries, teacher training institutes, and AI developers, is crucial for building an inclusive, innovative, and AI-ready educational ecosystem that maximizes the benefits of GenAI in teaching and learning.
Our study provides critical insights into the factors influencing Nigerian in-service teachers’ adoption of ChatGPT, leveraging a hybrid approach that integrates PLS-SEM and ANN. Our results reveal that PEU, PUC, and YCC are the strongest drivers of behavioral intention, emphasizing the role of usability, perceived benefits, and peer influence in AI adoption. Conversely, TA negatively affects adoption, highlighting the need for strategies to reduce fear and uncertainty associated with AI integration. The ANN model captured complex nonlinear interactions, reinforcing the importance of usability as a foundation for perceived usefulness. By combining PLS-SEM’s statistical rigor with ANN’s ability to detect hidden patterns, we offer a comprehensive understanding of AI adoption dynamics. These insights inform policy recommendations, teacher training initiatives, and future research, emphasizing the importance of user-centered AI design and institutional support in fostering sustainable GenAI integration in education. Our findings highlight the need for targeted interventions that address both technical usability and psychological readiness, ensuring that teachers can effectively leverage ChatGPT for instructional purposes.
Despite our contributions, this study has several limitations that should be addressed in future research. First, our sample was limited to Nigerian in-service teachers, which may restrict generalizability to other educational contexts. Future studies should explore cross-cultural comparisons to examine variations in GenAI adoption. Second, while our hybrid PLS-SEM and ANN approach provided deep insights, it did not capture qualitative perspectives on teachers’ experiences with ChatGPT. We recommend incorporating mixed-method approaches, including focus group interviews, to gain richer contextual insights. Additionally, we focused on behavioral intention (BI) rather than actual usage behavior. Future longitudinal studies tracking teachers’ actual adoption trends over time would enhance our understanding of sustained AI integration. Lastly, further research should explore the role of AI ethics, digital literacy levels, and institutional policies in shaping teachers’ engagement with large language models (LLMs) and GenAI in education. By addressing these gaps, future studies can provide more comprehensive strategies for ensuring AI adoption in diverse educational settings.
Ethical clearance was obtained from the Department of Counseling Psychology and Educational Foundation Ethical Review Board at Tai Solarin University of Education, with approval granted on July 22, 2024, under Ethical Clearance Number ECN 07-2024-15. This approval confirmed our adherence to established ethical standards for studies involving human participants and aligned with the principles outlined in the Declaration of Helsinki, which governs research involving human subjects.
To uphold these ethical standards, we ensured that respondents were fully informed about the purpose of the research, the voluntary nature of their participation, and the confidentiality of their responses. This information was provided alongside the survey, which was shared on professional teachers’ platforms. Respondents could not proceed to complete the online form without first reading and accepting this information. This process guaranteed that written informed consent was obtained electronically before participation, reinforcing their right to decide voluntarily about their involvement. Additionally, we maintained strict confidentiality throughout the study. Responses were securely stored in password-protected digital files and were accessible only to the research team, safeguarding participant privacy. By completing the survey, respondents willingly agreed to participate, fully aware of their rights and the protective measures in place. These ethical commitments underscore our dedication to responsible research practices and the ethical integrity of our study.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (1)