Keywords
Paddy Crop, Machine Learning, Ensemble Regression, AdaBoost, XGBoost
This article is included in the Agriculture, Food and Nutrition gateway.
Paddy Crop, Machine Learning, Ensemble Regression, AdaBoost, XGBoost
Agriculture is the world’s oldest and most common occupation in the world. Since farming is the primary source of life sustenance in Odisha, it is the most popular practice. Precision agriculture, sometimes referred to as “digital farming,” is a management approach that makes better use of information technology to boost agricultural output and decision-making.1 Precision agriculture helps farmers monitor crop health, maximize resource use, and boost overall farm output by gathering and calculating data from multiple sources such as weather stations, satellite imaging, and soil sensors.2 Using this method, farmers may decide when, where, and how much to water, fertilize, or apply pesticides based on data. Precision farming also reduces waste and its consequences on the environment by using less water, fertilizers, and pesticides, among other inputs. The increasing need for food production due to the growing global population presents major problems for farmers seeking to maximize agricultural productivity.
The Indian state of Odisha is located in the north-eastern region of the peninsula, with latitudes ranging from 17°31′N to 20°31′N and longitudes from 81°31′E to 87°30′ E. Its overall size is 15.57 million hectares, or roughly 4.7% of India’s total land area.3
In the 2011 Census, Odisha had a population of 4.20 crore. Approximately 76% of the total population works in the agricultural sector. There are 52.66 lakh hectares of net cultivated area. There is 87.94 lakh hectares of gross cultivated area. The remainder consisted of pastures, forests, and cultivable waste. Ten agro-climatic zones, encompassing landform, terrain, climate, and soil, were established for the State. Eight major soil groups, red soil, black soil, Mixed Red and Yellow Soil, Brown Forest soil, laterite soil, Deltaic Alluvial soil, Coastal Saline and Alluvial soil, and red soil, have been identified in Odisha’s soils.4
For optimal growth, each plant type requires certain soil and location conditions. The physicochemical properties and microenvironment of soils regulate the availability of water and plant nutrients; growth or lack thereof is dependent on these elements. Studies on soil sites cover how many factors, such as soil depth, texture, salinity, pH, drainage, humidity, and nutrient availability affect plant growth and yield.5
Summers (from March to June), monsoons (from July to September), and winters (from October to February) are the three primary seasons of Odisha. Its tropical environment is characterized by high humidity, high temperature, and medium to heavy rainfall. Rainfall averages approximately 451.2 mm. A repeat monsoon also hit Odisha in October and November.
Odisha has a plentiful supply of water for disposal.6 It is also endowed with an extensive river-stream network. The state’s agricultural expansion is driven mostly by irrigation. Growing a number of commercial crops is acceptable when sprinkler irrigation is performed.
It has been determined that even a 10% improvement in irrigation water-use efficiency above the current level can assist in providing crops in sizable regions with irrigation that could save their lives. It is necessary to gather current climatic and soil characteristics from several districts. Precision agriculture has become a game-changing strategy that uses information technology to improve farming techniques in response to these issues.7 With this creative approach, farmers can make data-driven decisions that result in better crop health, more sustainable practices, and more effective resource usage.
Machine learning in precision agriculture requires accurate and diverse datasets for training the models.8 It relies on data sources, such as remote sensing, satellite imagery, weather records, soil measurements, and field observations. The insights generated by machine learning models help farmers make data-driven decisions, optimize resource management, minimize environmental impacts, and maximize crop productivity in a precise and sustainable manner.9 Algorithms for machine learning were used to ensure optimal water consumption in the field.10 Because of the relatively higher climate and water content in the fields during the rainy season, less water is needed overall than during the summer.
This will assist farmers in obtaining accurate information on the soil’s water content and climate, enabling them to make the right agricultural decisions for optimal crop growth and high yield.
It has been observed that 97% accuracy results in production using Gaussian ELM techniques. When different regression techniques are applied in crop recommendation, the accuracy is greater than 90% for every technique applied.
C. Murugamani et al.11 emphasized the use of machine learning methods in precision farming. Determining the proper plant development parameters was the primary goal. Plant growth and high output are the best ways to encourage clever and intelligent farming and lower agricultural risks. They employed sensors to gather parameters. Quickly and clearly improving your content. To investigate and identify diseases in cotton crops, they used machine learning techniques, such as regression, naïve Bayes, and support vector machines, on an IoT platform. They found that the results obtained using Support Vector Machine techniques were extremely accurate. They focused on the use of pesticides, fertilizers, and water because the overuse of these substances deteriorates groundwater quality and destroys crops.
Combining the research efforts of Prabhavathi et al.12 and Swami Durai et al.,13 a comprehensive approach emerged for enhancing agricultural productivity through data-driven methodologies. Prabhavathi et al. investigated soil variables for forecasting agricultural outcomes using a range of machine learning algorithms with a Gaussian Extreme Learning Machine, notably achieving 97% accuracy in predicting crop yield, highlighting its effectiveness. Meanwhile, Senthil Kumar Swami Durai et al.’s focus on farming recommendations based on soil and weather parameters yielded a suite of modules within a Django web application framework that integrated Deep Learning and Machine Learning techniques. Their study showed high accuracies across multiple algorithms, with the Random Forest Classifier which have Randomized CV identified as the optimal model for crop recommendation, boasting a 95.45% accuracy rate. Together, these findings help us understand the potential of advanced computational methods to revolutionize agricultural methods, offering promising avenues for global implementation to benefit farmers worldwide.
Priyani et al.14 and Treboux et al.15 contributed to the advancement of smart agriculture and precision farming using machine-learning techniques. Priyani et al. focused on enhancing agricultural efficiency by leveraging IoT, automation, and hybrid machine learning algorithms to forecast crop and soil moisture levels using data provided by the state of Gujarat. Their approach resulted in more accurate predictions with lower error rates, highlighting the potential of the smart agriculture infrastructure. On the other hand, Treboux et al. concentrated on precision farming in vineyards, employing image recognition on high-precision aerial pictures to analyze color variations and intensities. By utilizing a Decision Tree Ensemble and morphological approaches, they achieved a high accuracy rate of 94.275% for identifying crop features. However, they noted the importance of manually exploring datasets for further accuracy improvement. Together, these studies demonstrate how machine learning can be used to optimize agricultural practices and maximize crop yield, paving the way for more efficient and sustainable farming methods.
Sajjad Ahmad et al.16 studied soil moisture, which is a crucial component of hydrology and climate. This is an essential variable for precision farming. This significantly affects the dispersion of water in the water cycle. Remote sensing was used to examine the percentage of soil moisture using a machine learning technique. Their research focused on the Colorado River Basin and the current drought in the southwestern United States. They developed a state-of-the-art statistical learning methodology. They employed models such as SVM, ANN, and MLR to estimate soil moisture using data from the Tropical Rainfall Measuring Mission Precipitation Radar (TRMMPR) and Normalized Difference Vegetation Index. The Support Vector Machine model captured the connections between soil moisture and agriculture.
Bakthavatchalam, et al.17 used machine learning systems to anticipate crops. Meteorological and soil parameters such as N, P, K, pH, temperature, humidity, and rainfall were recorded. Creating a model for high-yield and precision agriculture is the primary objective. For learning, they used models and the WEKA Supervised Machine Learning method.
The three machine learning techniques used for classification are Rule-based JRip, Decision table classifier, and multilayer perceptron-based algorithms. These three classifiers yield very few errors. The accuracy increased from 96.23% to 98.22% in the first iteration of the second iteration using MLP, from 88.59% to 88.5909% in the second iteration using JRip, and from 96.0% in the second iteration using the Decision Table. The machine-learning model was found to assist in producing a precision model.
Farhat Abbas et al.18 attempted to increase potato crop yield. Datasets of soil parameters collected from six fields in Atlantic Canada were used in their investigation. Machine learning techniques, such as K-Nearest Neighbor, Elastic Net, Linear Regression, and Support Vector Regression, were used to forecast the yield and quality of potatoes. Yield projections were created using modeling techniques and subsequently assessed using a range of statistical features. SVR outperformed the other models for every dataset collected. KNN did not perform up to par. Because machine learning techniques could explain approximately 60% of the potato yield in terms of soil attributes and 40% in terms of meteorological and environmental parameters, it was concluded that they were effective. Because machine learning techniques could explain approximately 60% of the potato yield in terms of soil attributes and 40% in terms of meteorological and environmental parameters, it was concluded that they were effective. It was shown that if the datasets were larger, the model might produce more accurate findings.
Savvas Dimitriadis et al.19 investigated the ways in which precision agriculture uses machine learning to better manage natural resources, such as water, and extract new knowledge. For this reason, efforts have been made to appropriately monitor crops, soil, and climate. They combined a black-box technique with evolutionary algorithms to optimize the control system. Pre-classified examples comprise the datasets used in this study. Their main objective was to create a new dynamic model using the currently available knowledge. Method that made machine learning effective in addressing real-world challenges in precision agriculture. They used WEKA to run machine-learning algorithms on all datasets, yielding several useful guidelines. The false-positive rate was lower at 0.07 percent, but the accuracy was higher at 91.59%.
A. Sharma et al.20 examined India’s prospects for precision agriculture. They found that the technology used in precision agriculture includes robotics, sensors, drones, the Internet of Things, GPS, and machine-learning algorithms. They are used in data collection, pre-processing, filtering, and decision applications based on dependable information. Their research indicates that these are particularly helpful for gathering soil and climate characteristic datasets. They observed that optimizing natural resources and agricultural inputs was necessary for high yields and higher crop growth. They found that because precision agriculture is an Internet-connected, data-driven farming technology, farmers must receive the necessary training to use these methods for the best possible use of resources and to enable them to make the right decisions that will support the expansion of our economy.
T. Talaviya et al.21 concentrated on real-time machine learning, which was applied to weed detection and the classification of agrochemicals applied in different concentrations per acre of cropland. They created a Computer Vision for Real-Time Distinguishing between Crop/Weed for Precision Weedicides Application or Any Chemicals in order to protect the crop and increase productivity. The dataset was subjected to a Random Forest Classifier prior to conducting an outside test. The accuracy was determined to be 95% when all features were selected, but only 90% when only a few features were selected.
Marcelo Chan Fu Wei et al.22 centered on mapping the carrot yield. A method for producing a carrot yield map was the main target using the dataset and the Random Forest Regression algorithm. The dataset was gathered from satellite images. The Training and Testing sets were created using the entire Dataset, To statistical parameters were employed to calculate and estimate the performance of the model. The Random Forest Regression model has been shown to be a successful machine-learning method for commercial carrot yield prediction.
Kumar et al. Researcher23 used the proposed DCNN to evaluate soil moisture and schedule irrigation for precision agriculture producers to integrate IoT applications into agriculture, decrease the amount of water needed for cultivation, and enhance agricultural output by monitoring water content at different stages of plant growth. Additionally, it adjusts the water level so that future irrigation decisions can preserve water stability and crop growth. Apriori and GRU require the data to be delivered and stored in a grid view (gated recurrent unit). This system helps forecast irrigation plans based on needs by utilizing many sensor and parameter modeling approaches. Temperature, humidity, and soil moisture were anticipated characteristics. When producing crops with great harvest and minimal water consumption, smart irrigation is supported by the observed experimental results. With a 98.5% accuracy rate in the testing results, the DCNN predicted an MSE (Mean Squared Error) value of 99.25% of the time.
Srinivasa Rao Burri et al.24 developed an advanced-level machine learning model that can predict soil moisture levels and help to optimize the use of water in agriculture, which can potentially be utilized to build intelligent irrigation systems. Data from the “Smart Irrigation System Dataset,” an open-source dataset provided by the University of California, Irvine, was used to assess and train the model. The model performance factors were assumed by the Area under the ROC curve (AUC), accuracy, recall, precision, and other classification factors. They employed a transfer- learned ResNet-50 model. The results demonstrated an AUC of 0.95, indicating that the model correctly distinguished between soil moisture conditions 95% of the time.
The prediction of overall water usage was performed in various steps. Figure 1 shows the steps followed.
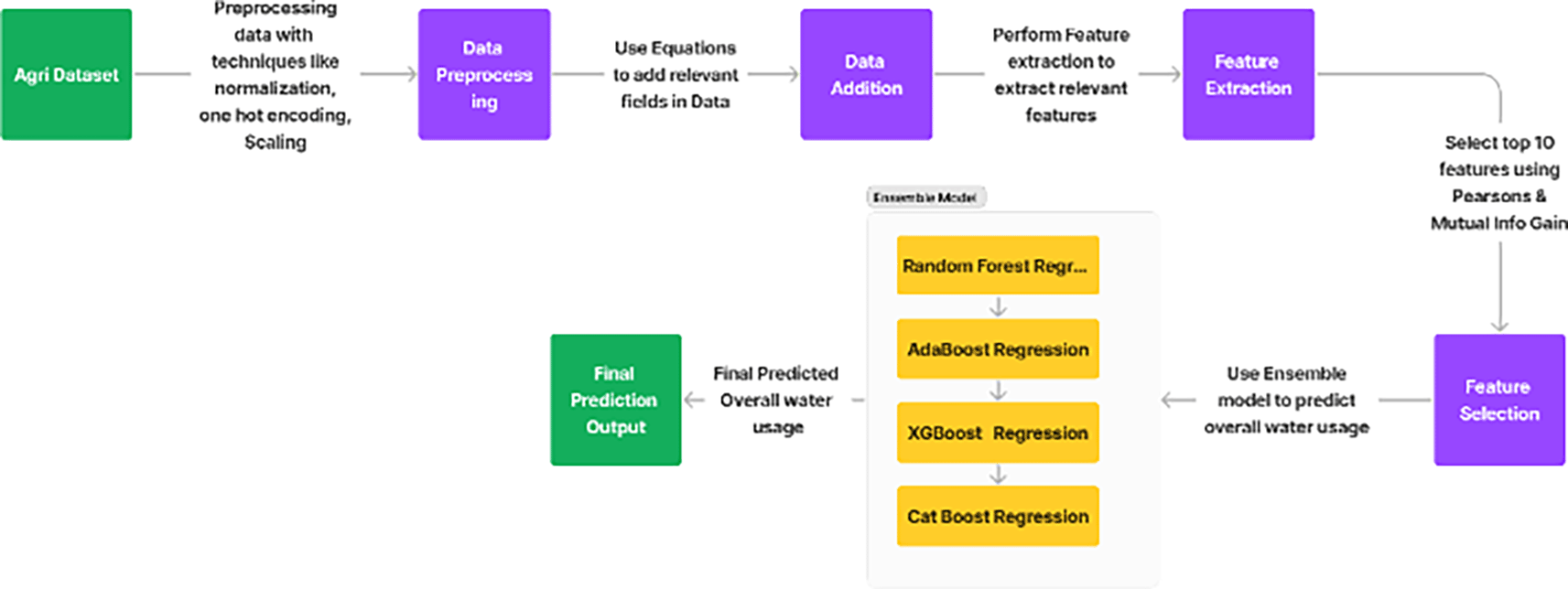
Data collection and details
The dataset under consideration for this study is derived from Open-Meteo and encompasses a comprehensive representation of paddy crop cultivation near Bhubaneswar, Odisha, India. This dataset comprises 29 columns and 15284 rows of meticulously collected data, providing a detailed insight into various facets of paddy cultivation. Notably, this dataset specifically focuses on the cultivation of the MR84 variety of paddy,50 a widely cultivated strain known for its adaptability and yield potential in the region.
The dataset was meticulously curated to exclude data related to snow precipitation and other irrelevant factors, ensuring a focused analysis of the growth dynamics of paddy crops in the given geographic location. Each column in the dataset offers unique dimensions of information, ranging from meteorological parameters to growth coefficients,25,26 facilitating a comprehensive understanding of the factors influencing paddy cultivation. Additionally, the inclusion of growth coefficient data for the three stages of the MR84 variety further enhanced the granularity of the analysis, enabling researchers to assess the growth progression and performance of the crop across different developmental phases.
Data preprocessing
Following the initial loading of AgriDataset_2. csv’ file into the Python environment using the Pandas library,27 and additional preprocessing steps were performed to ensure that the dataset was integrable and usable for subsequent analyses. After excluding non-numeric columns to focus solely on numerical features, further preprocessing techniques, such as normalization,28 one-hot encoding,29 and scaling30 were applied.
Normalization, denoted as , is used to normalize numerical features to a standard range, typically between 0 and 1, thereby stopping a single feature from showing dominance due to its larger magnitude. This step is crucial for preserving the relative significance of each feature in the dataset.28 Mathematically, normalization can be expressed as
In addition, one-hot encoding was utilized for this binary transformation method, which allows categorical features to be properly incorporated, creating separate binary columns for each category within a categorical variable. This technique ensures that categorical variables are appropriately represented in a numerical format, allowing their inclusion in subsequent analyses such as regression or classification models.29
Furthermore, scaling was implemented to standardize the range of the numerical features, ensuring that they exhibited similar scales and variances. This step is necessary for algorithms that react sensitively to feature scaling, such as support vector machines and k-nearest neighbors, to perform optimally and to avoid biased results. Mathematically, scaling can be expressed as
By incorporating these preprocessing techniques into the data preparation pipeline, the ‘AgriDataset_2. csv’ file was transformed into a robust and standardized dataset ready for in-depth analysis and modeling to gain insights into the factors influencing paddy crop cultivation near Bhubaneswar, Odisha, India.30
Data addition
To enhance the utility of the dataset and provide a more thorough understanding of water management practices in paddy cultivation31 near Bhubaneswar, Odisha, India, a data augmentation process was initiated. This augmentation primarily involved the calculation of the net water usage for different growth stages of paddy crops, incorporating specific crop coefficient (Kc) values tailored to each stage.
For each target column (‘water_usage_kc20’, ‘water_usage_kc40’, ‘water_usage_kc60’, and ‘overall_water_usage’), the net water usage was computed based on a comprehensive formula. This formula encompasses various variables, including precipitation, rain, snowfall, crop coefficient for the respective growth stage, FAO reference evapotranspiration (ET0), and irrigation.32 The formula is as follows:
Here, (Kc_day) represents the crop coefficient for a specific growth stage (days 20, 40, or 60), and ET0 denotes the reference evapotranspiration. Precipitation refers to the form of water that falls to the ground in the form of rain, snow, or hail, whereas rain specifically denotes liquid precipitation. Snowfall indicates the quantity of snow precipitation received. Additionally, irrigation signifies supplementary water applied to crops through artificial means.
The ‘overall_water_usage’ column was derived by summing the net water usage across all growth stages and adjusting for the corresponding crop coefficient-modulated evapotranspiration values. This comprehensive approach facilitates a holistic evaluation of the total water requirements throughout the paddy crop lifecycle, providing valuable insights into water management strategies and their implications for sustainable cultivation practices.
Following the computation of net water usage, the updated dataset enriched with these calculations was stored in the form of a CSV file for further research and model development. This marked a significant advancement in refining the dataset and paving the way for a deeper exploration of the dynamics of water usage in paddy cultivation within a specified geographic context.
Data extraction - Principal Component Analysis (PCA)
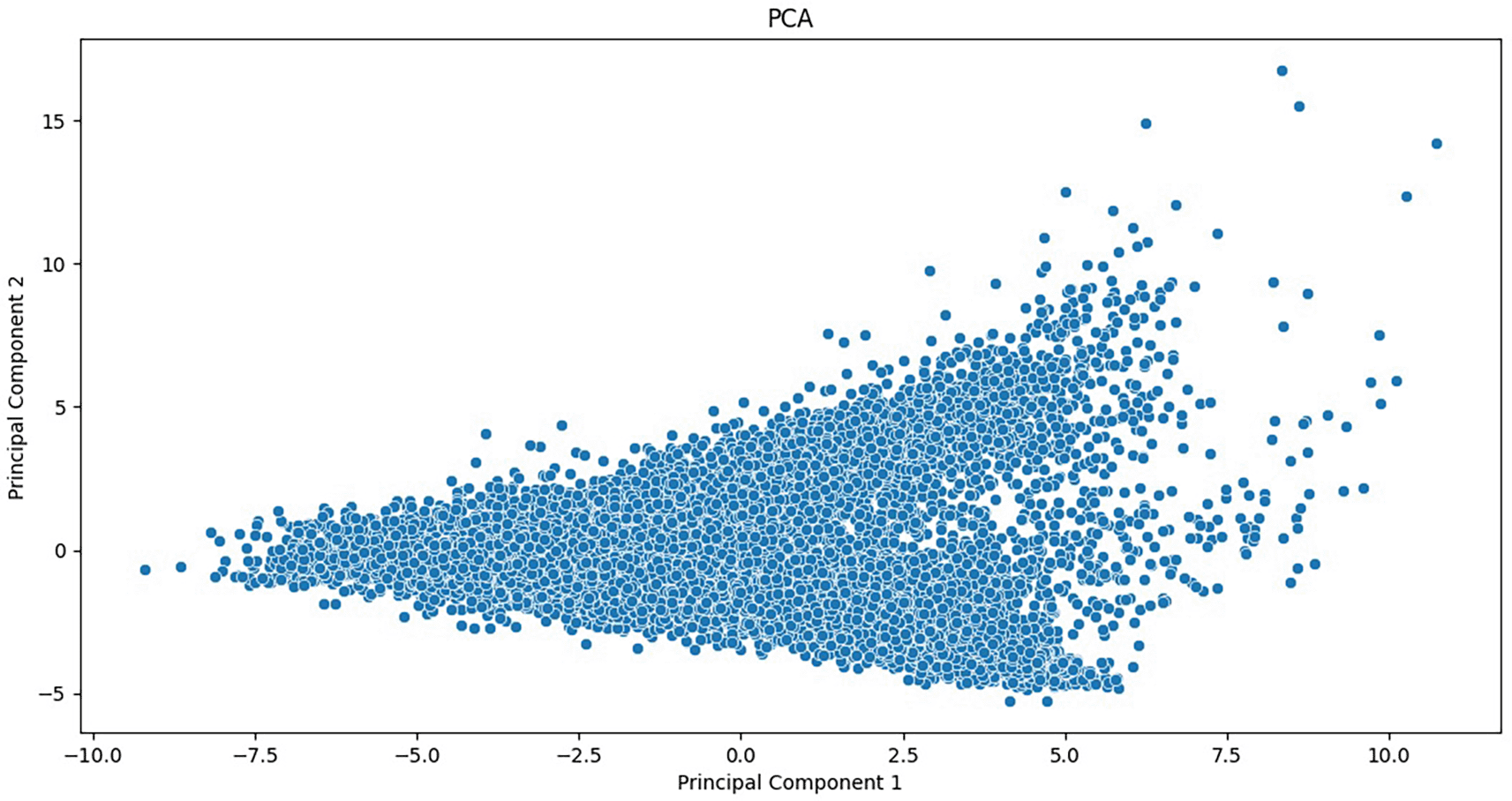
Principal Component Analysis (PCA)33 was used to reduce the dimensionality of the dataset while retaining all essential information. Prior to PCA, the data underwent standardization using the StandardScaler function from the Scikit-learn library.34,35 All features should contribute equally, which ensures that by scaling them, they have a mean of 0 and 1 as the standard deviation.
PCA was applied to convert the original features into a new set of uncorrelated variables, termed principal components. The amount of variance retained from the original dataset depended on the number of principal components chosen. In this study, two principal components were selected for visualization purposes.36
The resulting principal components were visualized in a scatterplot (see Figure 251) to observe any discernible patterns or clusters within the data.
Feature selection and correlation analysis
To optimize the performance of the predictive model, we should carefully select the input features. This section delineates the meticulous process of feature selection and correlation analysis, aimed at identifying pertinent variables and understanding their interrelationships.37
Initially, non-numeric columns, such as ‘time,’ were expunged from the dataset as they did not contribute to the numerical analysis. Additionally, the target variable ‘overall_water_usage’ was excluded given its role as the dependent variable in the prediction model.
A comprehensive correlation analysis38 was then undertaken to unravel the intricate relationships between the remaining numeric features. This analysis involved computing Pearson correlation coefficients,39 which quantitatively show the linear association between every feature and its respective target variables. Simultaneously, Mutual Information Gain was employed to uncover nonlinear and non-monotonic relationships, providing valuable insights into the information obtained regarding one variable through another.40
For each target variable (‘overall_water_usage,’ ‘coeff20,’ ‘coeff40,’ and ‘coeff60’), feature selection was conducted individually. The features were iteratively pruned based on the specific target variable under consideration, ensuring the inclusion of only relevant features in subsequent analyses.
Furthermore, to visualize the correlations more intuitively, a pair plot41 was generated to show the relationship between the top ten selected features and the target variables. This plot provides a comprehensive overview of data distribution and discernible patterns or clusters within the dataset.
The results of feature selection, including Pearson correlation coefficients, Mutual Information Gain scores, and pair plots (ref Figure 351), were meticulously presented in tabular and graphical formats. These comprehensive analyses serve to guide the selection of optimal features for subsequent modeling and prediction tasks, thereby enhancing the robustness and accuracy of the predictive model.

After augmenting the dataset with additional columns to enhance the feature space, the feature selection process was revisited to identify the most relevant features for predicting the target variable ‘overall_water_usage.’ Mutual information gain was employed as the criterion for feature selection, with a threshold set at 0.55 to retain features with high predictive power.
Subsequently, ensemble learning models were trained using the selected features to predict ‘overall_water_usage.’ The ensemble comprises the following algorithms.
Random forest regression: A decision tree-based approach that creates multiple decision trees and ensembles all of their output to improve accuracy and robustness.42 The formula used for Random Forest Regression is:
Where:
- denotes the predicted value of the target variable.
- is the prediction of the -th decision tree.
- is the total number of decision trees.
AdaBoost regression: This enhances the performance of the regression by merging all the weak predictors into a stronger, more accurate model, and hence enhances both performance and accuracy.43 The formula for AdaBoost is as follows:
XGBoost regression: An optimized gradient boosting algorithm, which is known for its efficiency and scalability, employs a gradient boosting framework.44 The formula for XGBoost is as follows:
CatBoost regression: A gradient boosting library that utilizes category-specific computation to seamlessly handle categorical features.45 The formula for CatBoost is similar to that for XGBoost, which involves the summation of predictions from individual trees.
Each model was trained on the selected features, and its performance was calculated using different matrices, including Mean Squared Error (MSE), Mean Absolute Error (MAE), and R-squared scores.
Mean Squared Error (MSE): MSE is used to measure the mean squared difference between the predicted values and actual given values. More weight is assigned to larger errors, that is, they are sensitive to outliers.
Where:
is the Number of samples.
is the actual value of the target variable for the -th sample.
is the predicted value of the target variable for the -th sample.
Mean Absolute Error (MAE): The MAE is the average of the exact differences between the predicted and actual values. This shows us how far away the predicted value is from the actual given values.
Where:
is the Number of samples.
is the actual value of the target variable for the -th sample.
is the predicted value of the target variable for the -th sample.
R-squared Score: R-squared calculates how the independent variables explain the variability of the dependent variable and shows that the proportion of variance in the dependent variable is predictable from the independent variable.
Where:
is the Number of samples.
is the actual value of the target variable for the -th sample.
is the predicted value of the target variable for the -th sample.
is the Mean of the actual values of the target variable.
These metrics provide valuable information regarding the performance of regression models by quantifying the accuracy and goodness of fit of the predictions.
Ensemble the strength of different models into one model by averaging the predictions from all individual models. The ensemble’s predictive performance was evaluated using the same evaluation metrics as those of individual models. 46
Additionally, learning curves were generated to visualize and understand the performance of the model as a function of the training set size, aiding in identifying potential issues such as overfitting or underfitting, as shown in Figure 4.51
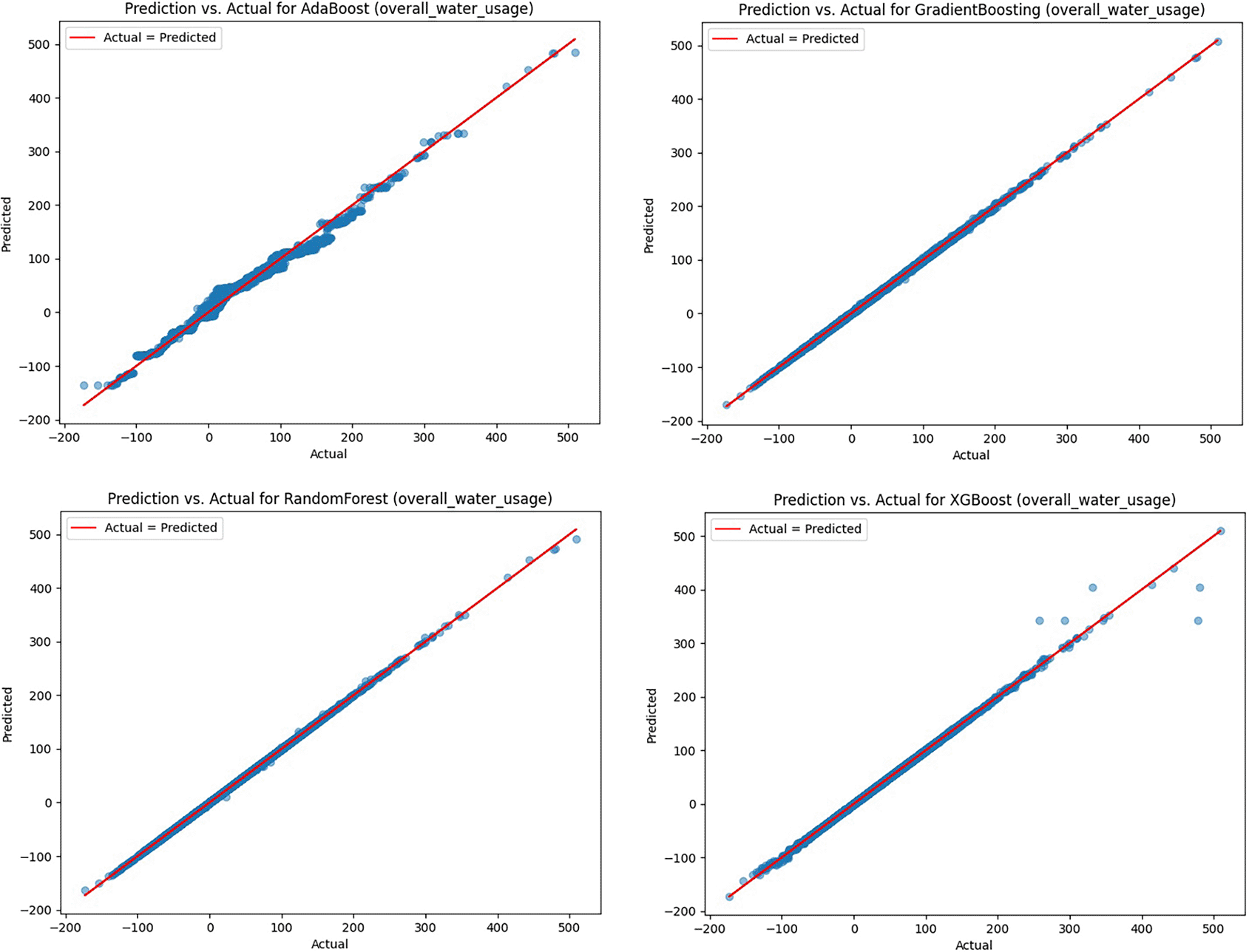



Finally, prediction vs. actual plots were generated for each model to visually assess the agreement between the predicted and actual values of ‘overall_water_usage and use the insider information about the models’ predictive capabilities.
In this section, we present the outcomes of evaluating various machine learning algorithms for predicting ‘overall_water_usage’ using three key metrics: the Mean Squared Error (MSE), Mean Absolute Error (MAE),47 and R-squared (R2) score.48 Additionally, we identified important features that contribute to the prediction of ‘overall_water_usage’ through Mutual Information Regression.
The performance of each algorithm in predicting ‘overall_water_usage’ is summarized in Table 1.
The important features contributing significantly to the prediction of ‘overall_water_usage,’ identified through Mutual Information Regression, are presented in Table 2.
These features play a pivotal role in accurately assessing comprehensive water consumption in paddy cultivation, offering invaluable insights for devising agricultural water management strategies.
In summary, the ensemble model demonstrated superior predictive capability compared to the individual algorithms, with reduced Mean Squared Error (MSE) and Mean Absolute Error (MAE) values, along with an elevated R-squared (R2) score. The delineated significant features provide crucial insights into the primary determinants affecting water utilization in paddy cultivation, facilitating the formulation of potent water conservation and irrigation approaches.
This study presents a comprehensive analysis for predicting ‘overall_water_usage’ in paddy cultivation using machine learning algorithms. The results highlight the efficacy of ensemble modeling, particularly in terms of predictive accuracy, as indicated by the reduced Mean Squared Error (MSE) and Mean Absolute Error (MAE) values, along with an elevated R-squared (R2) score. Additionally, important features identified through Mutual Information Regression offer valuable insights into the primary determinants affecting water utilization in paddy cultivation, which can inform the development of effective water management strategies.
The superiority of the ensemble model over individual algorithms underscores the benefit of leveraging diverse modeling techniques to enhance the predictive performance. By combining the features and strengths of different algorithms, the ensemble model achieves greater robustness and generalizability, thereby improving the accuracy of the predictions.
However, it is important to understand the limitations of this study. First, predictive models rely on the assumption that historical data accurately represents future trends. Changes in environmental conditions, agricultural practices, and socioeconomic factors may impact water usage patterns, potentially affecting the models’ predictive capabilities. Additionally, the quality and completeness of the dataset can influence the model performance. Incomplete or noisy data may introduce biases and affect the reliability of the predictions.
Furthermore, the scope of the study is limited to predicting ‘overall_water_usage’ in paddy cultivation, overlooking other essential aspects, such as crop yield prediction or soil health assessment. Future research could involve additional dependent factors, such as soil moisture content, temperature, or crop growth stage, to develop more comprehensive predictive models. Moreover, incorporating remote sensing data49 or satellite imagery can provide valuable spatial information, enabling more precise predictions and insights into agricultural practices.
In terms of methodology, exploring advanced machine learning techniques, such as deep learning or ensemble methods, with more sophisticated feature engineering approaches could yield further improvements in predictive accuracy. Additionally, conducting sensitivity analyses to evaluate the robustness of the models to variations in the input parameters would enhance the reliability of the predictions.
In this study, we employed machine learning algorithms to predict overallwaterusage in paddy cultivation. Through rigorous evaluation, we found that the ensemble model outperformed individual approaches, demonstrating superior predictive capability with reduced Mean Squared Error (MSE), Mean Absolute Error (MAE), and an elevated R-squared (R2) score.
Mutual Information Regression helped to identify key features influencing water usage in paddy cultivation, providing valuable insights for effective water management strategies. Despite limitations, such as reliance on historical data and the study’s narrow focus, our findings pave the way for future research in refining predictive models and expanding the scope of analysis.
Integrating advanced techniques and additional variables could enhance predictive accuracy and foster more sustainable agricultural practices and environmental conservation efforts.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)