Keywords
Keywords: pseudo-random numbers, PRNG, MAXEM, random number generator, run test for randomness Mathematics subject classification: 62P99
This article is included in the Computational Modelling and Numerical Aspects in Engineering collection.
Keywords: pseudo-random numbers, PRNG, MAXEM, random number generator, run test for randomness Mathematics subject classification: 62P99
By the law of statistical regularity, a sample can be thought of as a good representation of the population only when it is selected randomly.1 The significance of randomness in sampling lies at the heart of various applications in statistics, computer science, and cryptography. Pseudo-random number generators (PRNGs) serve as a crucial tool in generating sequences of numbers that approximate the properties of random samples, enabling robust simulations and analyses across diverse fields.
Donald Knuth, in his work, The Art of Computer Programming,2 emphasizes the significance of pseudo-random number generators (PRNGs) in computational processes. PRNGs are essential for simulating randomness in algorithms, particularly in areas such as cryptography, statistical sampling, and simulations. Their efficiency and unpredictability are crucial for ensuring that algorithms perform effectively under varied conditions and for testing hypotheses under controlled “random” scenarios.
A lot of research has been carried out to come up with efficient and reliable PRNGs has led to numerous advancements over the years. Traditional algorithms, such as the Linear Congruential Generator (LCG), are straightforward to implement and exhibit constant-time performance. However, they often fall short in terms of statistical quality and unpredictability, leading to correlations that can skew results.2 On the other hand, the Mersenne Twister, introduced by Matsumoto and Nishimura,3 boasts a remarkable period and strong equidistribution properties, making it a popular choice for various applications despite its relative complexity. Recent advancements in the cryptographic applications of PRNGs emphasize the role of secure random number generators in preventing vulnerabilities like side-channel attacks.4
In a more recent context, the second author has significantly advanced the understanding of randomness through his research. In a prior paper “On Why and What of Randomness,”5 he explores the fundamental nature and necessity of randomness in various computational processes. His work emphasizes how randomness is not only vital for ensuring unpredictability in algorithms but also for enhancing the overall reliability of systems that depend on random number generation. By addressing the characteristics and sources of randomness, his research highlights its importance in mitigating risks associated with predictability and biases in computational settings.
This paper proposes a novel PRNG algorithm that utilizes modular arithmetic, bitwise operations, and an innovative approach to entropy modulation. By incorporating prime-based entropy, this algorithm aims to enhance unpredictability and reduce periodic cycle formation. The algorithm incorporates techniques of Modulo Arithmetic, XORShift and Entropy Modulation, and is thus called MAXEM.
In the domain of random number generators by the means of algorithms, also called Pseudo-Random Number Generators (PRNGs),2 wide gaps are left within the algorithms in terms of their distributions or in the method of their generation. The MAXEM algorithm proposed hereafter works on fulfilling some of these gaps, such as negating the possibility of any periodiic cycle formation in a sequence, or having the ability to choose any arbitrary number as a seed without affecting the quality of randomness of the generated sequence.
As observed by Berezowski,6 the distribution of prime numbers exhibits chaotic behavior, making their prediction and arrangement highly non-trivial. This was the first thought for selection of a proper seed to generate a sequence of pseudo-random numbers. A seed can be selected as an arbitrary prime number whose magnitude depends on the magnitude of the random numbers that need to be generated. Therefore, we define the seed to be:
Here, is the number of bits used to represent the integers in the sequence. If , then the numbers in the sequence will be bounded by , meaning they can take values between and (for 32-bit integers). Thus, this function takes an arbitrary integer value between 100 and the maximum value between and 1000, and chooses the closest prime number greater than that integer, which gives a wide range of prime numbers for the algorithm to choose from. We use as an upper limit to make the initial seed comparatively lower in magnitude to the largest magnitude of random number that the algorithm can generate, as shall be discussed later.
The initial idea for developing this algorithm was to reduce, or, if possible, remove the repeating periodic cycles that appeared in the use of LCG (Linear Congruential Generators),7 one of the most primitive algorithms to generate pseudo-random numbers. This led to the thought of using a non-constant entropy term which would oscillate between increasing and decreasing the current number that is being generated.
Here, one would notice the presence of the term , which speaks a lot about our algorithm. We do not simply discard the initial seed after generating the first term of the sequence. We keep our notion of the distribution of prime numbers being chaotic in nature,6 and hence use a term which is the next prime number after . Thus, would be the next prime number after , would be the next prime number after and so on.
This, again, is a very simple idea, inspired from LCG7 where the first component of the algorithm is of the form , where the previous term is simply multiplied by a constant. We can modify it so that the term has a bit more randomness in the following way: , where the function describes the multiplication of the two terms from its previous iteration.
It is important to mention that every term that the algorithm generates is always limited to bits. This is achieved by taking a operation on every term that is generated. This gives us the advantage of limiting the number of bits to the necessary amount, i.e., , as per the use case. In order to add an extra layer of complexity, with the intention to further reduce the chance of periodic cycle formation in the sequence, a bit-wise shifting operation is introduced. The value of this shift itself is not predetermined and depends on a modulus of the iteration counter such that,
This ensures that the number of bits shifted always falls in the range . Thus, the term is right-shifted according to the above idea and can be represented as follows:
Since is of m bits, the term produced above is of m-bits. Again, on applying a on the multiplier term, we can also guarantee it to have the same number of bits. With this knowledge, we can easily apply an ‘ExclusiveOR’ or ‘XOR’ operation on these two terms to get a fairly convoluted string of bits. Marsaglia stated that in the context of random number generation, the use of XOR operations has been shown to enhance the efficiency and unpredictability of pseudo-random number generators. As demonstrated by him in 2003,8 XORShift random number generators utilize bit-wise XOR operations to produce sequences of numbers that exhibit desirable statistical properties, making them suitable for a variety of applications. Therefore, these operations can be combined to form the whole m-bit term as follows:
The XOR operation is mathematically represented by the symbol.
The final output sequence at each step , denoted by , is generated using a combination of Modular Arithmetic, bit-wise manipulation (XORshift), and Entropy Modulation as is a culmination of the ideas discussed above and can be represented as follows:
Where:
• denotes the iteration counter,
• is the previous number in the sequence, i.e., the term generated at iteration ,
• is the prime seed at iteration ,
• denotes the bitwise XOR operation,
• ensures the number stays within an -bit range,
• is a bitwise shift operation,
• introduces alternating addition and subtraction to the entropy term,
• adds entropy based on the iteration and prime seed.
The algorithm for this can be given as follows:
seed next prime from random number in range Initialize sequence as an empty list current seed
next_num (current seed) next_num next_num (current next_num (next_num + ) Append next_num to sequence seed next prime after seed current next_num
return sequence
Python language9 was used to code this algorithm due to the simplicity of the language and the wide range of libraries suited for scientific computing. Additionally, Google Colab, which has proven to be a valuable platform for running Python code in a cloud environment in the form of notebooks, enabling easy collaboration and access to powerful computational resources without the need for local hardware,10 was used as the primary development environment. The allocated runtime came with a system RAM of 12.7 GB, a disk memory of 107.7 GB and no dedicated memory for graphics processing. In this section, we discuss a test run of the above algorithm with the following parameters:
Figure 1 shows the distribution of random numbers generated as a scatter plot with the index values of the random number sequence on the x-axis and the value of the random numbers on the y-axis. It is quite evident that this scatter plot shows a discrete uniform distribution of random numbers in the range , given, .
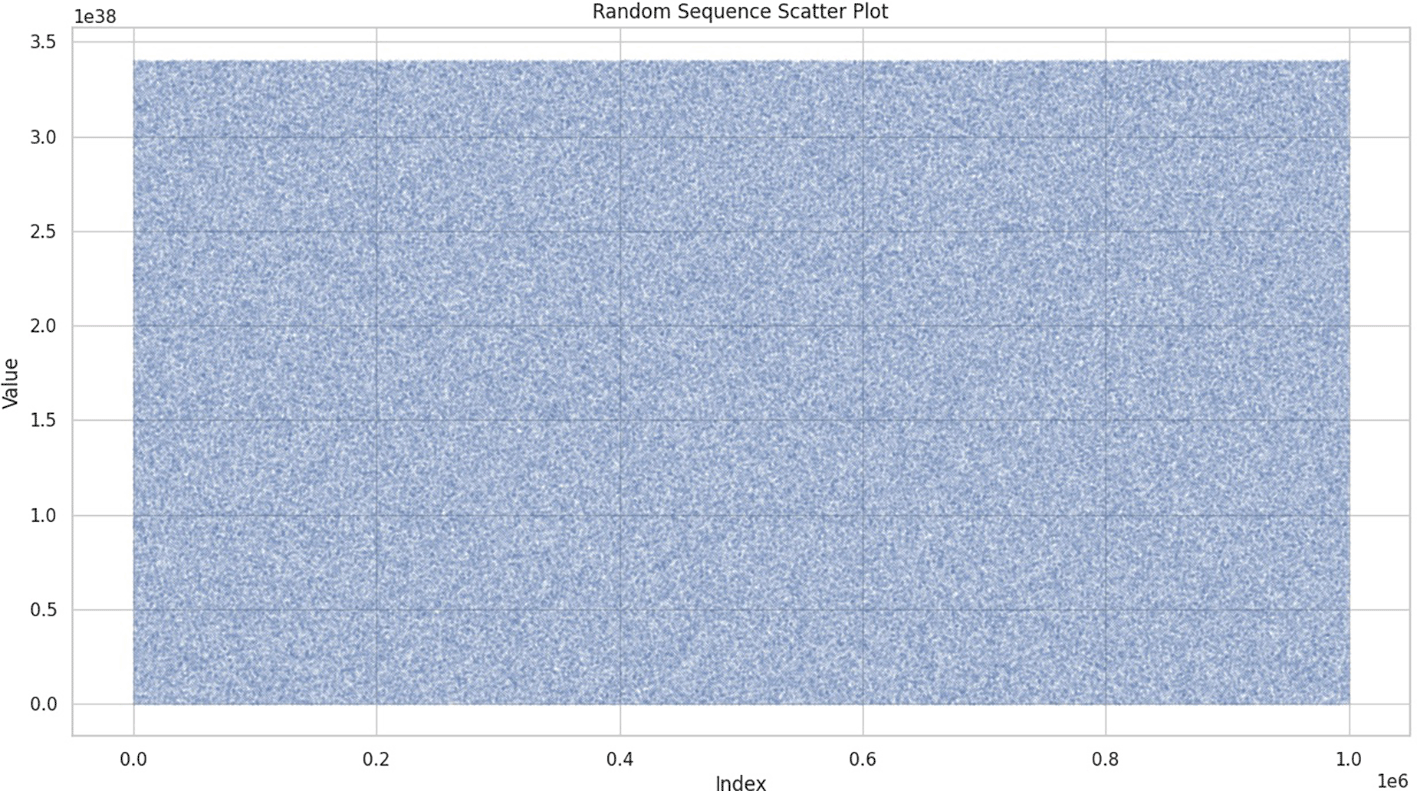
The mean, variance, standard deviation, median, minimum, maximum, and range of the generated numbers are summarized in Table 1.
| Statistic | Value |
|---|---|
| Mean | |
| Error in Mean | |
| Variance | |
| Standard Deviation | |
| Median | |
| Minimum | |
| Maximum | |
| Range | |
| 25th Percentile | |
| 75th Percentile | |
| Interquartile Range (IQR) |
The population mean of a discrete uniform distribution can be calculated using the formula:
For the value of used in our simulations, this results in an approximate mean of . The error in mean calculated for our chosen sample size is:
On a broader scale, the results from a large number of simulations conducted using this algorithm indicate that the error in mean consistently remains below . This demonstrates the reliability and accuracy of the algorithm in generating random numbers that closely adhere to the expected mean of the underlying distribution.
The test for the quality of the algorithm and the randomness of the sequence thus generated can be conducted under four different parts, each checking a different aspect of the sequence. From the example above ( section 3), here is the sequence of random numbers that were obtained:
The algorithm itself is defined in a way to function well with an arbitrary seed. The choice of seed as mentioned in equation ([eq:seed]) shows that this algorithm trivially has the notion of an arbitrary seed selection system, thus, freeing it from the problem of selecting seeds that do not yield good results. It is important to note that the algorithm always selects a prime number as its seed, by definition, even if a non-prime integer is given as an input. In case a non-prime integer is given as an input, the algorithm selects the closest prime number greater than that integer as the seed . The range of has only been introduced as a convention to reduce the computational overhead of just selecting a seed. The only constraint that we’ve faced is when the value of the seed is very small compared to . In this case, the first few numbers of the generated sequence are also smaller values and thus shift away from the notion of randomness in the whole distribution. In such a case, the lower bound of the range can be chosen to be a higher number masted on the magnitude of .
A common problem of PRNG’s are the occurrence of periodic cycles in the sequence. Since the algorithms are deterministic, once a random number is generated that is equal to some previous number in the sequence, the whole algorithm starts repeating itself, or atleast has a chance to do so. The is the most common problem for using LCG’s,7 where one must be really careful in the selection of seeds and parameters for maximal cycle formation. However, in MAXEM, the possibility of a periodic cycle formation has simply been eliminated. The same number may be generated more than once, but the scenario will not lead to the repetition of the whole sequence. We can see that, from equation ([eq:entropy]), the term depends directly on the product of the terms and . It is going to be highly unlikely for [equation([eq:entropy])] to generate the same term as it had before, because both and are changing. Thus, the chances that the whole sequence repeats is almost equal to null. This has also been verified by simulation after running the algorithm many times, with not a single case of formation of periodic cycles.
As discussed by Ross in Introductory Statistics (Third Edition),11 non-parametric hypothesis tests, such as the Wald Wolfowitz run test for randomness, are useful when no specific distribution is assumed. The run test evaluates the randomness of a sequence by analyzing the occurrence of ‘runs’—sequences of consecutive identical elements. A significant deviation in the number of runs from what is expected under randomness suggests the sequence may not be random. The Run test has been carried out on the whole sequence with the following hypothesis:
We have failed to reject the Null Hypothesis ( ) for every single time the algorithm has been run, thus concluding that the sequence thus generated by MAXEM can be considered random.
From the example above ( section 3), here is the sequence of letters that were generated and considered for the run test:
Here, . We can see that the sequence has neither way too many runs, nor way too less of them, suggesting that there is very little chance of patterns forming in the sequence. If be the total number of runs in a sequence and be the number of ’s and ’s in the sequence respectively, we can calculate:
Martin-Löf12 introduced a formal way to define random sequences using algorithmic complexity. While a sequence might be considered random as a whole, this doesn’t mean that every subsequence will also be random. The randomness of a full sequence doesn’t carry over automatically to its parts, as a subsequence might still follow some patterns depending on how it’s selected.
With this in mind, we tested the sequence generated by MAXEM following a simple algorithm as given below.
Choose an initial value for len Choose an arbitrary number Select subsequence of length len starting at position Conduct a run test on each subsequence. Let = number of times the run test is satisfied Compute Increase len gradually, starting with small intervals and increasing the gap for larger values.
Figure 2 shows the results of local randomness test for values like 30, 40, 50, 100, 150, 200, 400,…, upto 20000. The high success results prove how the sequence generated by MAXEM is not only random globally, but also locally.
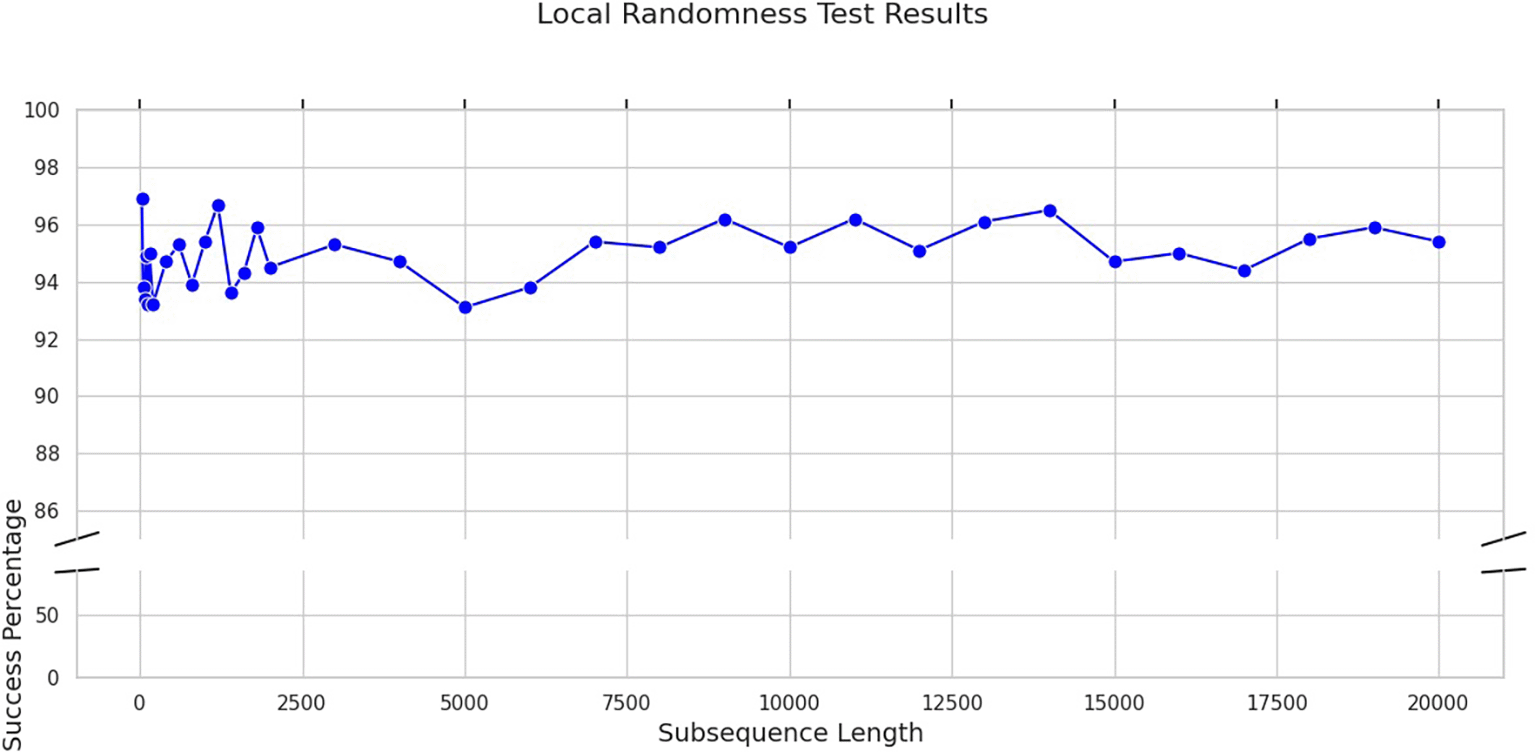
These analyses indicate that MAXEM provides a high level of randomness with good scalability. Benchmarks like TestU01, designed by L’Ecuyer and Simard,13 provide a comprehensive framework to evaluate PRNG performance, and can be used to conduct further analyses on the robustness of the MAXEM algorithm.
The proposed PRNG algorithm suggests a new way of creating pseudo-random numbers through the use of a combination of modular arithmetic, bitwise operations, and entropy modulation. This section summarizes the main features of the algorithm, its capabilities, and its pros and cons.
The worst-case time complexity of the algorithm is primarily dominated by the modular multiplication and can be given as if faster and more optimized multiplication such as Karatsuba’s algorithm14 is used. This algorithmic complexity does not take into account the complexity of the separate function that finds the nearest prime number for the seed, as it can be (and should be) done separately or by parallel methods. We can see that this is computationally more expensive that other common PRNGs succh as the Mersenne Twister algorithm.3 However, the trade-off is justified by increased entropy and unpredictability.
The space complexity of MAXEM remains to be , as is the case with most other common PRNGs.
The major goals of the MAXEM algorithm are to negate the formation of periodic cycles in a sequence of random numbers and also preserve the quality (randomness) of the sequence with the selection of an arbitrary seed. This makes MAXEM stand apart from the other traditional PRNGs like the Linear Congruential Generator.2
This algorithm, given a high value of , also has great security. Due to the intrinsic features of this algorithm, reverse engineering this without a good guess on the final seed would be difficult as one would need to guess both the iteration number and the seed, given that the seed is a prime number of x bits, where x is quite large. This task is not impossible but quite arduous. Hence, this algorithm can also be great for use in cryptography15 and other security measures.
The ability to adjust the bit range offers significant flexibility. By selecting appropriate values for , the generator can be tuned for different use cases, whether it’s cryptographic applications or scientific simulations.
Despite the advantages of the MAXEM algorithm, the inherent high computational complexity can be a limiting factor and make the generation of sequences for large values of very slow to the extent that it becomes unsuitable for real-time applications. However, taking advantage of these modern techniques such as parallel computing can significantly help in the process of improving the efficiency of the system without a sacrifice of quality.
The MAXEM algorithm has its own perks and limitations. Here listed are a few directions in which research can be conducted to contribute to MAXEM, making it even more powerful and efficient:
• MAXEM can be modified by combining it with other PRNGs with better computational complexity to balance its speed with its quality. A hybrid approach might help to create an even stronger algorithm that combines the strength of the other PRNGs.
• Analysing the algorithm for its resistance to common cryptanalytic attacks such as brute-force or statistical attacks, with formal proofs, can help to establish the viability of the algorithm for cryptographic applications.
• Given the computational expense of modular arithmetic, parallelizing the algorithm could improve its performance in generating large sequences. Research into parallel or distributed implementations of the algorithm could make it more scalable.
The authors further declare that the data used in the work was not obtained from any external sources. All data supporting the results in this study were generated by the authors using the MAXEM algorithm, using their own code. The full dataset (random sequences, statistical measures, and plots) and the implementation code are publicly available on Zenodo at: https://doi.org/10.5281/zenodo.15631843.16
Data are available under the terms of the Creative Commons Attribution 4.0 International license (CC-BY 4.0).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)