Keywords
Cardiovascular Disease, Machine Learning, One-vs-One, One-vs-All, Feature Selection.
Cardiovascular Disease, Machine Learning, One-vs-One, One-vs-All, Feature Selection.
Cardiovascular disease (CVD) refers to any obstruction in the normal functioning of the heart. Myocardial Infarction (MI) is a type of heart disease caused by decreased or complete stoppage of blood flow to a portion of the myocardium. It is a condition in which the heart muscle dies because of reduced or inhibited flow of oxygenated blood caused by partial occlusion of the coronary artery. Factors such as diets rich in fat, alcohol consumption, sedentary lifestyle, lack of proper sleep, work stress and many more usually lead to such obstructions or blockages that inhibit the proper flow of blood resulting to a heart attack. Myocardial infarction may be “silent,” and go undetected, or could lead to a catastrophic event leading like sudden death. The primary cause of amplification of MI cases in the US is the prevalence of coronary artery disease among people. Based on the statistics provided by WHO, around 17.9 million annual deaths occur due to CVD globally.1 In India, the increase in heart failure cases is mostly due to coronary heart disease, diabetes, hypertension, obesity, etc.2 People who are suffering or are likely to suffer from cardiovascular disease show symptoms such a rise in blood pressure, increased glucose levels, overweight, etc.3
However, today it has become possible to combat the increasing mortality rates due to MI, or CVD in general. Powerful and optimized machine learning models are able to predict the disease at an early stage and also recommend ways to cure it.4 Most ML models developed categorize heart disease patients into two classes: healthy or affected, however models that classify patients into multiple classes based on level of impact of disease is somewhat limited. This research work focuses on multiclass classification of heart disease patients using a Myocardial Infarction dataset taken from the UCI repository. To diminish the burden of training on the model, the number of predictors were reduced using feature selection techniques like Variance-based, Mutual Information (MI) based, Maximum Relevance Minimum Redundancy (MRMR), Boruta, and Recursive Feature Elimination (RFE) based methods. These feature-reduced datasets were partitioned into training and testing data followed by training ML models like LR, SVM, DT, and Adaboost. These algorithms were executed in their traditional procedure, using One-vs-all (OVA) method, and using One-vs-one (OVO) method and all these models were analyzed with respect to the accuracy, recall, and precision provided by them. Besides these performance metrics, a comparison of the model training times taken by the 60 models using the 6 feature selection scenarios is also illustrated.
Section 2 discusses some of the research works that have played a crucial role in providing a foundation for this research work. Section 3 discusses the flow of work and describes the dataset and algorithms applied in this research. Section 4 presents the results obtained and finally the paper is concluded in Section 5.
Rashmi G. Saboji et al.5 have used genetic search to obtain 13 important predictors out of 76 attributes of Cleveland heart disease dataset. They also used the Switzerland and Hungary heart disease datasets containing the same 13 predictors. Upon these datasets, Random forest and Naive Bayes algorithms were applied on varying training dataset sizes (200,400, 600 instances). Both algorithms were compared in terms of the accuracy obtained and it was observed that the RF model gave better accuracy than NB for all 3 training data sizes, that is, 88%, 96%, and 98% for 200 instances, 400 instances, and 600 instances respectively in the training data.
Kirsi Varpa et al.1 have conducted experiments on an Otoneurological Disorder dataset containing a multinomial target attribute (nine classes in the target attribute) by implementing KNN and SVM in ordinary, OVA, and OVO methodologies. SVM was implemented using both linear and RBF kernel functions. All the nine models were compared against a 5-NN baseline model (which gave 89.5% accuracy) and it was observed that 5-NN with OVO yielded the best performance with 95% accuracy.
G. Manikandan et al.6 have compared the LR, DT, SVM, RF, and XGBoost models for predicting heart disease. First the Boruta feature selection technique was applied on the Cleveland heart disease dataset, which resulted in selection of 6 out of 13 predictors, followed by application of the aforementioned ML models on the reduced dataset. This research concluded that the LR combined with Boruta model outperformed all the other models with an accuracy of 88.52%.
Asif Nawaz et al.,7 in their work, suggested a model based on hybridization of data sampling and cost-sensitive learning for handling imbalanced dataset. They have used the Myocardial Infarction (MI) dataset which contained 1700 patient records and was highly imbalanced at the ratio 1:5.67. They have compared multiple class balancing methods like SMOTE, ADASYN, Tomek-link, ENN, weighted XGBoost with their proposed method which gave a better performance in terms of accuracy, ROC-AUC, and MCC. The combination of data sampling and cost-sensitive learning using XGBoost for classification gave an accuracy of 91.98%.
Abedayo Ogunpola et al.8 compared seven different ML and DL algorithms like, LR, SVM, KNN, RF, Gradient boosting, XGBoost, and CNN by applying them on two datasets: Cardiovascular Heart disease dataset from Mendeley database and Cleveland Heart disease dataset from Kaggle database. These algorithms were compared based on their accuracy, precision, recall, and F1-score, and it was observed that XGBoost outperformed the other models.
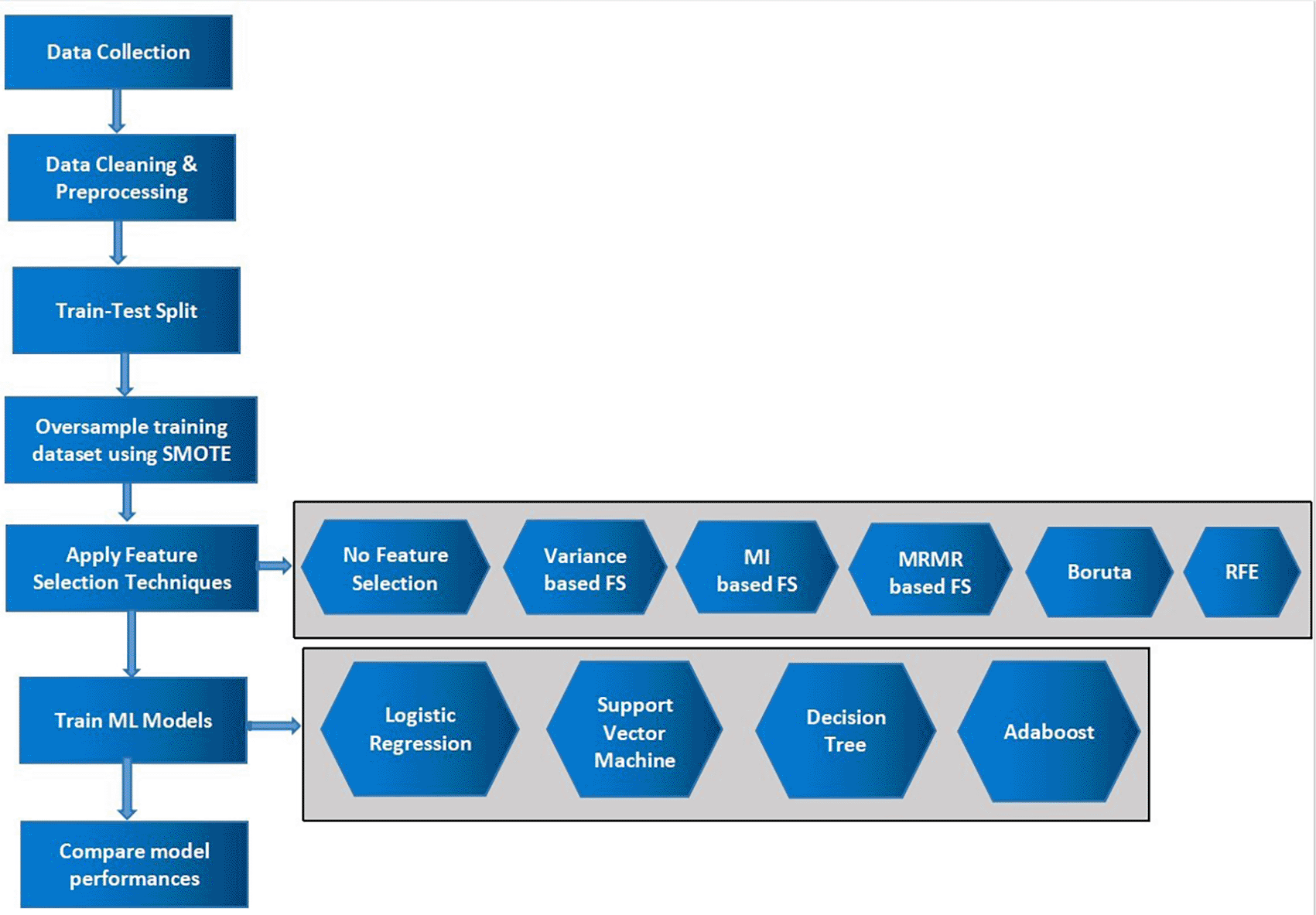
This section discusses the flow of work of this research work. First, the MI patients dataset was collected from the UCI repository and was preprocessed to handle missing values and removal of trivial attributes like patient Id. Next, the original dataset was split into training and testing datasets followed by balancing the classes in training dataset using SMOTE. Further, feature selection techniques are applied on the dataset to select a smaller number of relevant predictors followed by classification algorithms to predict the patient class. The Figure 1 below shows the workflow of the implementation.
Synthetic Minority Oversampling Technique (SMOTE) is a class balancing method in which synthetic instances are created for minority class using some simple statistical operations. In this method, first the difference between any two neighboring samples (Xi and Xj) of minority class is computed and this difference is multiplied with a random value between 0 to 1, referred to as lambda. The resultant set of values is added to Xi or Xj to produce a new instance.
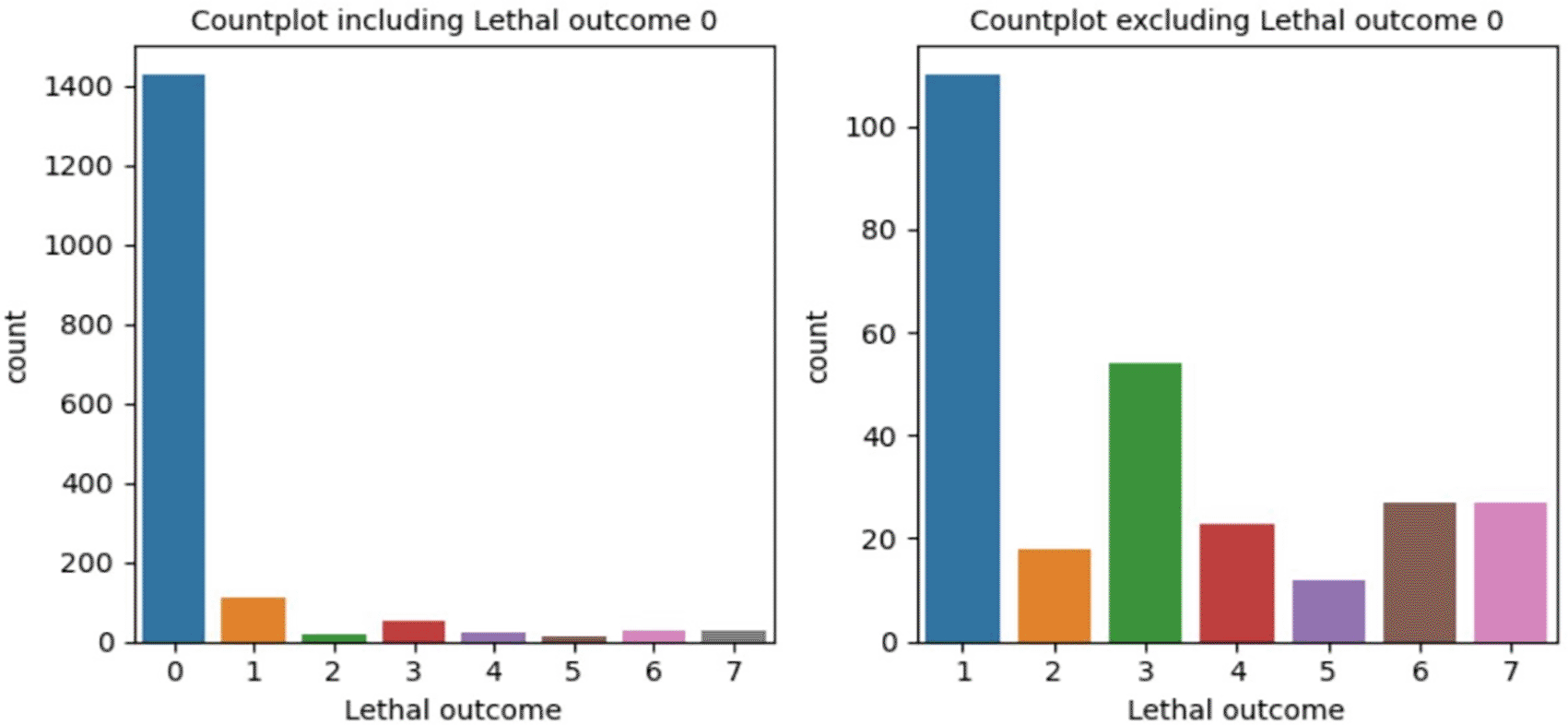
This study considers a Myocardial Infarction dataset containing 1700 patient records from the Krasnoyarsk Inter-district Clinical Hospital, Russia, available in the UCI repository. This dataset has 124 attributes including one patient Id column, one target attribute called Lethal Outcome, and remaining 122 attributes include information like patient’s demographic details, heart disease history, patient condition during admission to hospital, condition after 24 hours, 48 hours, and 72 hours of admission, patient condition during admission to ICU, condition after 24 hours, 48 hours, and 72 hours of admission to ICU, use of several drugs and condition of the patient after 24 hours, 48 hours and 72 hours of use of the drug. The target attribute has 8 classes from 0 to 7, indicating the cause of death of the patient.
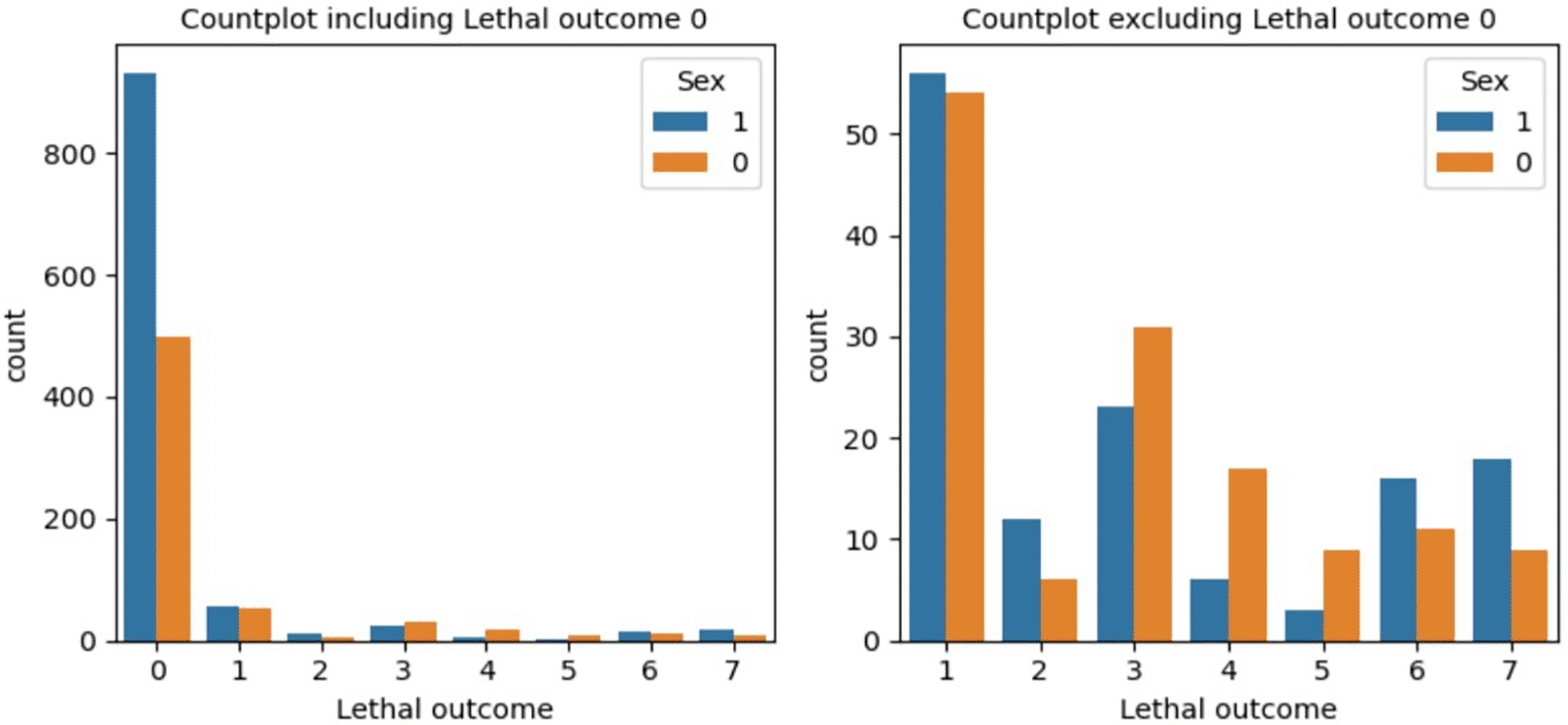
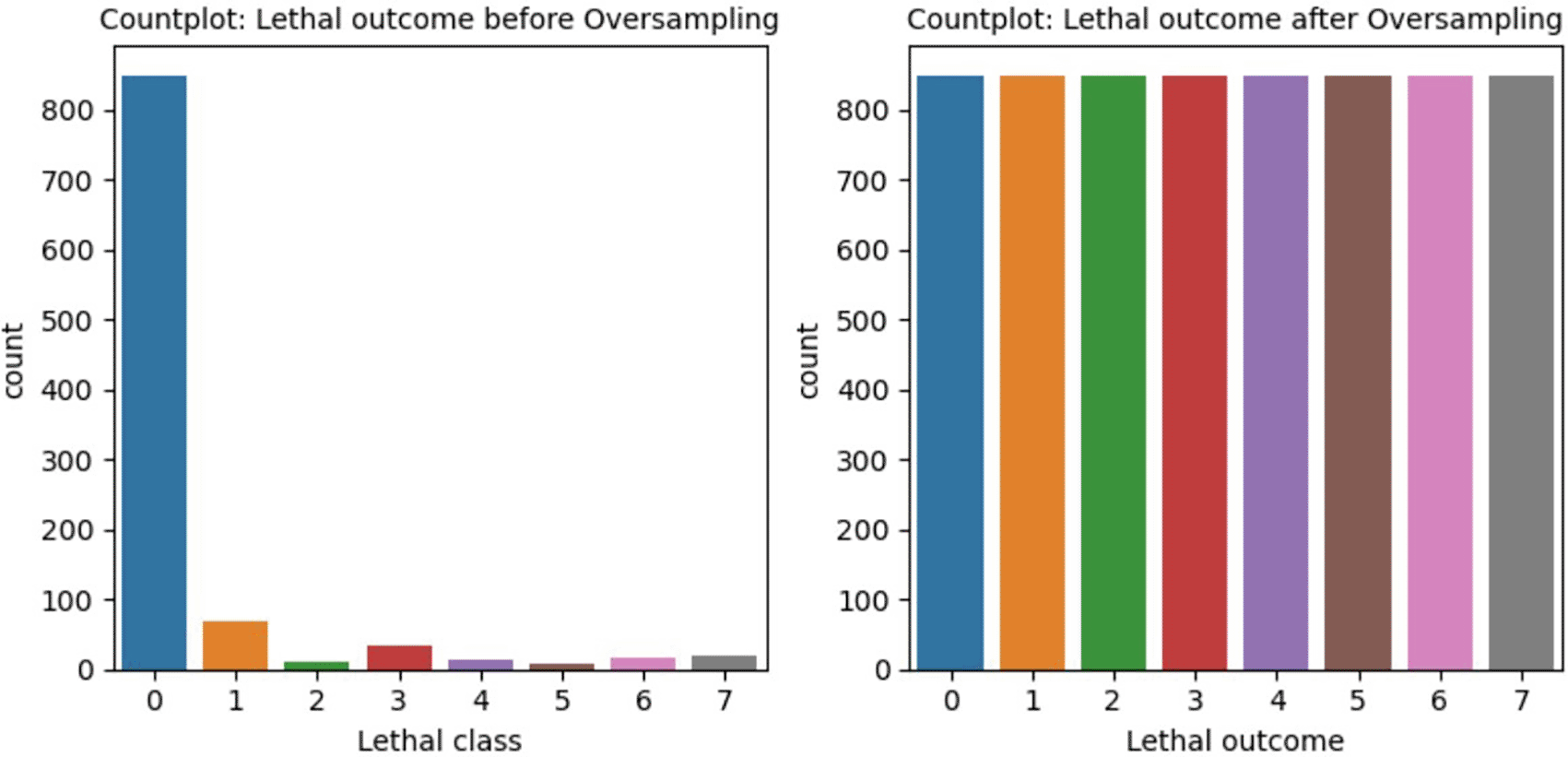
This dataset is designed such a way that maximum importance is given to the initial hours of the patient’s condition after a particular treatment. The below Figure 2, Figure 3, and Figure 4 represent the count of target attribute classes, count of target attribute classes with respect to the gender of patient, and the count of target attribute classes after balancing the dataset using SMOTE. In Figure 2 and 3, the count of target attribute classes is shown including and excluding class 0 in order to highlight the imbalance in class.
Feature selection is a crucial pre-processing activity before making predictions using ML models. It helps in reducing the burden of training the model by selecting a few selective predictors from all available features of the dataset.9–11 Several algorithms exist for the selection of relevant features which can be categorized into three methods: Filter method, Wrapper method, and Embedded method.
Filter method feature selection techniques individually check the relationship between each feature and the target attribute. It uses correlation to compute the dependency of the target attribute on a particular feature, and determines whether the target is negatively or positively correlated with the feature. Examples of filter methods include Chi-square test, Variance based, Mutual Information, Fisher’s score, etc. Wrapper method feature selection techniques involve testing the classification model performance based of different feature subsets, that is, the features are added and removed dynamically and the model is trained upon every possible combination. The feature subset that gives the best performance is selected as the most optimal set of features. Due to its working method, it is also known as greedy method of feature selection. Examples of wrapper method include Forward Selection, Recursive Feature Elimination, Backward Selection, Boruta, etc. Embedded method feature selection combines the advantages of filter methods and wrapper methods. This method takes care of the machine training iterative process while maintaining the minimum computation cost. Examples of embedded method are Lasso and Ridge Regression.
In this research, five different FS techniques are applied on the Myocardial Infarction dataset, which include the Variance based, Mutual Information based, Maximum Relevance Minimum Redundancy, Boruta and Recursive Feature Elimination based feature selection.
Variance based Feature Selection: Higher the variance of a feature, more is the dependency of target attribute upon that feature, lower the variance, lesser will be the dependency. In this method, the variance of each feature is computed and all features having variance less than a certain threshold are eliminated. In our research, the threshold variance was set to 0.2 and it was observed that out of 124, out 33 features were accepted. The below Figure 5 depicts the pseudo code for selecting features using this method.

Mutual Information (MI) based FS: MI refers to the amount of dependency between two variables. An importance score greater than zero indicates that there exits some dependency between the two variables and an importance score equal to zero implies that the variables are completely independent of each other. The mutual information between 2 variable X and Y, given by I(X,Y), is computed using the following formula:
Such that H(X) indicates the entropy in variable X and H(X|Y) depicts the entropy in X when Y is true. Entropy refers to the amount of information contained in a random variable. In this MI feature selection technique, the MI between the target attribute and every other feature is computed to determine the degree of dependency of the target attribute on that feature. Based on the computed importance scores, the top ‘K’ features are selected for training the model. Figure 6 depicts the pseudocode for selecting features using this method.

The below Figures 7, 8, 9, and 10 provide the ‘Accuracy’ vs ‘Number of features selected using MI’ method plot for the LR, DT SVM, and Adaboost algorithms respectively with the number of features ranging between 1 to 95.


Maximum Relevance Minimum Redundancy (MRMR) based Feature Selection: This technique is an improved form of the MI feature selection approach. MI may lead to selection of all the features that are important for the target attribute. However, this may include multiple features which are highly correlated, that is, extremely similar, therefore having only one of those features would be sufficient to train the model. The MRMR approach handles this issue by retaining only one of the multiple similar features that are equally important for the target attribute. The basic principle of MRMR method lies in computing the importance score of each feature in terms of its relevance and redundancy with respect to the target attribute. At each step, the importance score of each unselected feature is calculated using either the difference (relevance minus redundancy) or quotient (relevance divided by redundancy) approach. The below Figure 11 depicts the pseudo code for selecting features using this method.

The below Figures 12, 13, 14, and 15 provide the ‘Accuracy’ vs ‘Number of features selected using MRMR method plot for the LR, DT SVM, and Adaboost algorithms respectively with the number of features ranging between 1 to 95.




Boruta: In this technique, a copy of all original features, with shuffled rows are created and added to the original dataset. This additional set of features is commonly referred to as Shadow features.12 The new dataset is then provided to a random forest model which computes the importance of each feature and the shadow feature having the highest importance is identified. All features of the original dataset that have an importance value higher than the identified shadow feature are retained. This process is repeated for certain number of times (minimum 20 times), and the original features that are retained for majority of the iterations are selected for final model training. In our study, we have used 100 iterations to select the optimal features. Figure 16 depicts the pseudo code for selecting features using this method.

Recursive Feature Elimination (RFE) based feature selection is another attribute selection method which attempts to obtain the best feature subset of size ‘K’ where ‘K’ is the number of features required. This objective is achieved by eliminating the less important features and retaining the relevant ones which help in improving the model performance. In this method, the predictors are assigned ranks based on the feature_importances_ attribute of the predictive model being used removing the ones with lowest importance. This process was performed iteratively using the reduced feature-subset until the desired number of features was obtained. Figure 17 depicts the pseudocode for selecting features using this method.

Logistic Regression is a supervised regression and classification algorithm that assumes each data point to be independent of each other and no outliers should be present in the dataset. Ideally it handles datasets having a binomial target attribute, but can handle multinomial target attributes with softmax function. The logistic regression algorithm uses a sigmoid function to generate a probability value that indicates the probability of a tuple belonging to a particular class.13,14
Support Vector Machine is another machine learning algorithm used to classify data points into two or more classes by trying to find an optimal hyperplane that separates the different data points. Out of all the possible hyperplanes, the one that provides the maximum margin, known as the Maximal Margin Hyperplane (MMH), is selected as the most optimal one.15–17 SVM has a kernel hyperparameter which is a mathematical function used to map the instances to a high-dimensional space to be able to easily obtain the MMH if the data is non-linearly separable.18 Some of the commonly used kernel functions are sigmoid, linear, radial basis function, polynomial function, etc.
Decision tree is a tree-structures regression and classification model consisting of test on attributes as internal nodes, values of these attributes as branches to the next level, and class labels as the leaf nodes. At each level, attributes are are chosen based on metrics like gini impurity, entropy, and information gain. This process continues until a pure node is obtained, that is, each value of that attribute belongs to the same class. Entropy refers to the amount of uncertainty in the attribute considered. Information gain refers to the reduction in entropy after splitting the dataset based on a certain attribute.
Adaptive Boosting or Adaboost is an ensemble learning algorithm in which the weak learner is trained iteratively and each successive model gives higher weightage to the misclassified data points. The final Adaboost model is obtained as an ensemble of these weak learners based on the model weights, where the highest weight is given to the model with the highest accuracy and the lowest weight is given to the model with the lowest accuracy.
One-vs-All (OVA) is a way of implementing multinomial classification problem using ‘n’ binary classifiers where ‘n’ implies the number of categories in the target attribute. Each classifier Mi is dedicated to a single class Ci considering class Ci as 1 and other classes as 0. Each binary classifier predicts whether an instance belongs to class Ci or not. The average of the accuracy of each each model is considered to be the final accuracy of the OVA model.16
One-vs-One (OVO) is another method of executing multiclass classification using multiple binary classifiers, where a binary classifier is built for every pair of target classes Ci and Cj, that is, the number of binary classifiers required is n*(n-1)/2, where ‘n’ is the number of classes in the target attribute. Each data point is then classified based on majority vote applied on results of all models.1
The models generated by each of the aforementioned algorithms in their ordinary, one-vs-all, and one-vs-one approaches under various feature selection scenarios are compared in terms of the accuracy, precision, recall, and F1-score provided by each of them. Tables 1 to 6 present the evaluation metrics provided by each algorithm under the six scenarios (with no feature selection, variance based feature selection, mutual information based feature selection, maximum relevance minimum redundancy based feature selection, Boruta feature selection and recursive feature elimination) respectively.
A graphical representation of the aforementioned metrics is also shown below in the bar graphs. Figures 18, 19, 20, 21, 22, and 23 indicate the accuracy, precision, recall, and f1-score of all the four algorithms (in ordinary, OVA, and OVO implementations) under the six scenarios, that is, without any feature selection, with variance based, MI based, MRMR based, Boruta, and RFE based feature selection methods respectively.
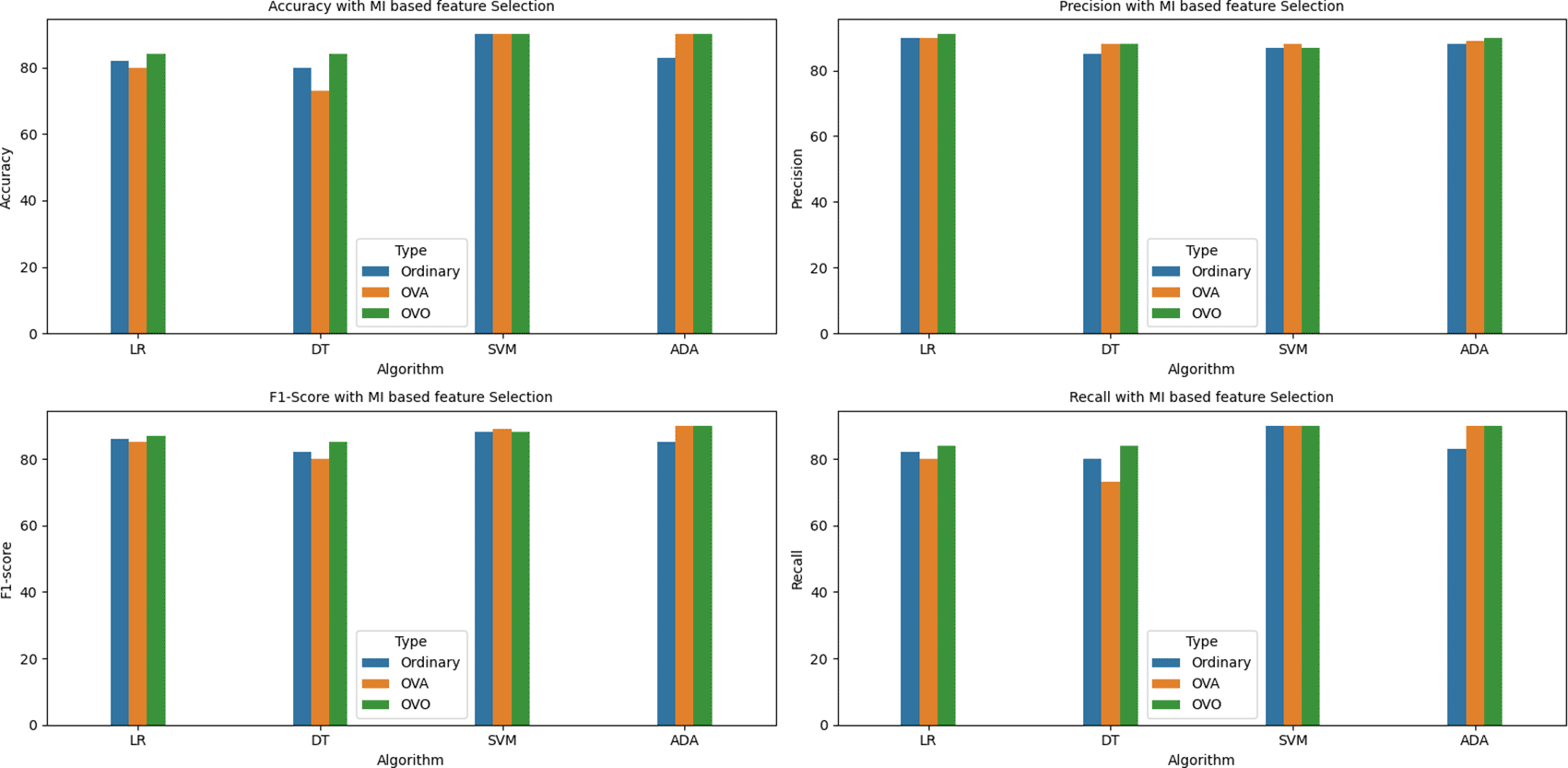
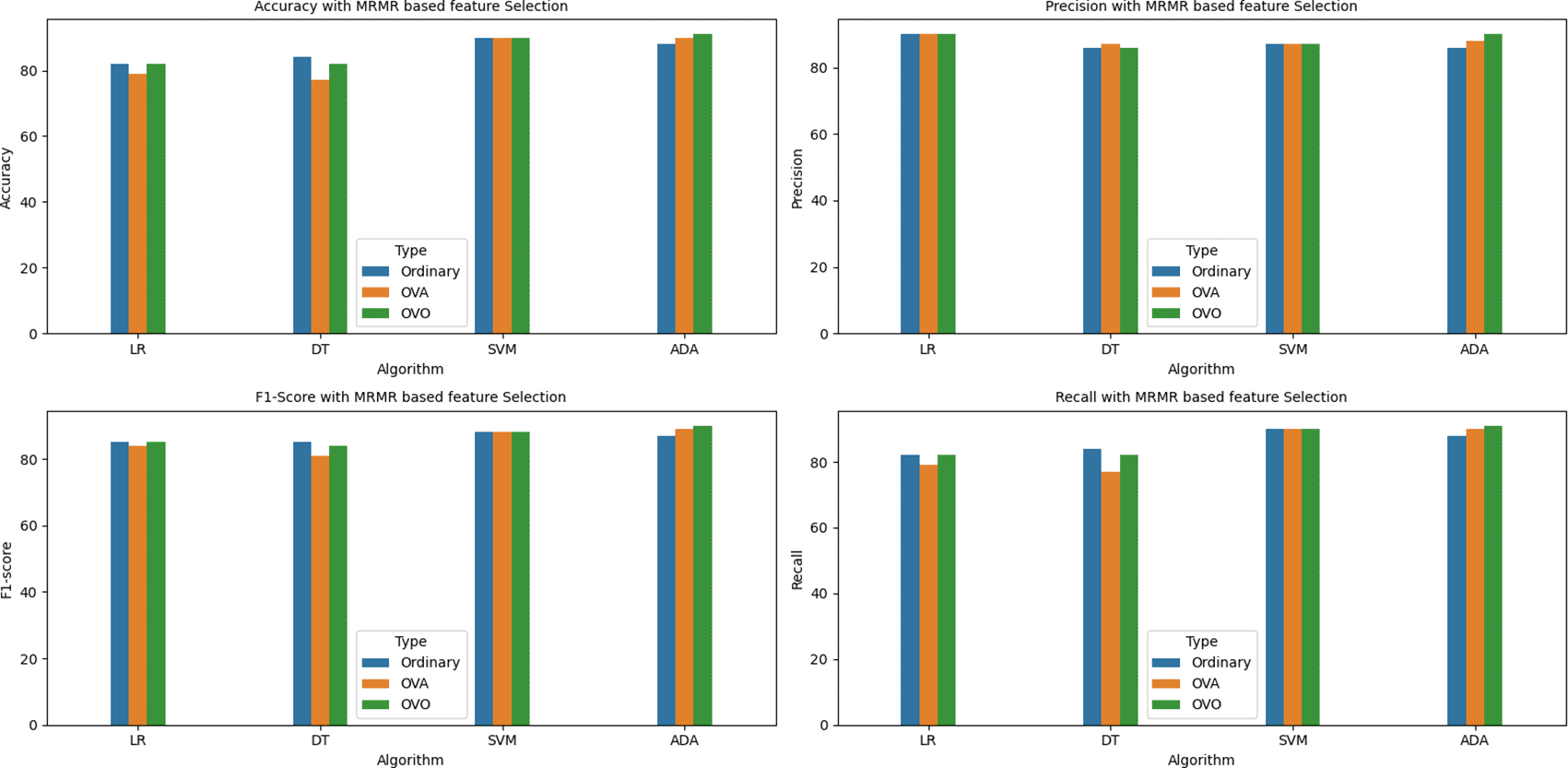
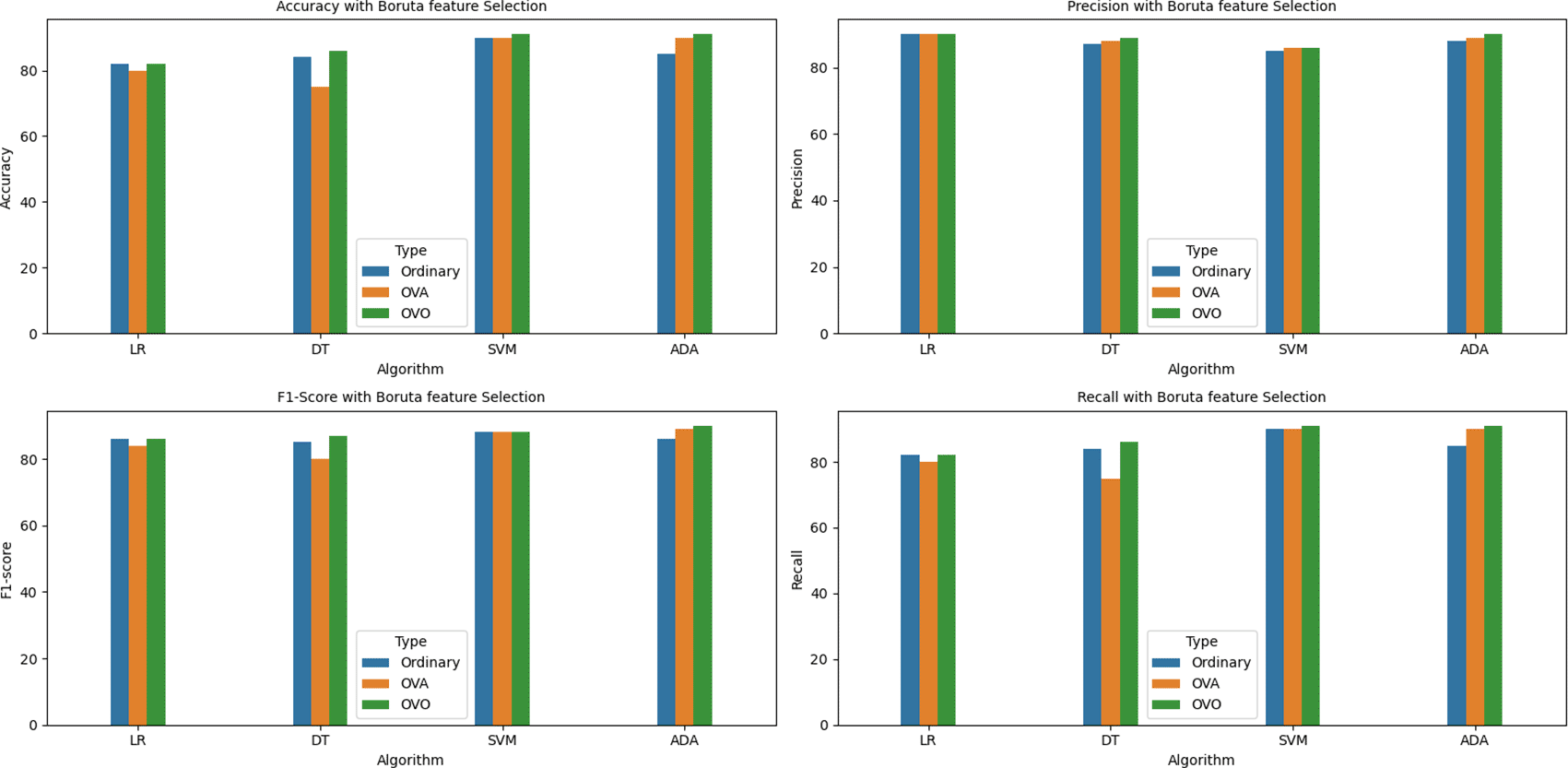
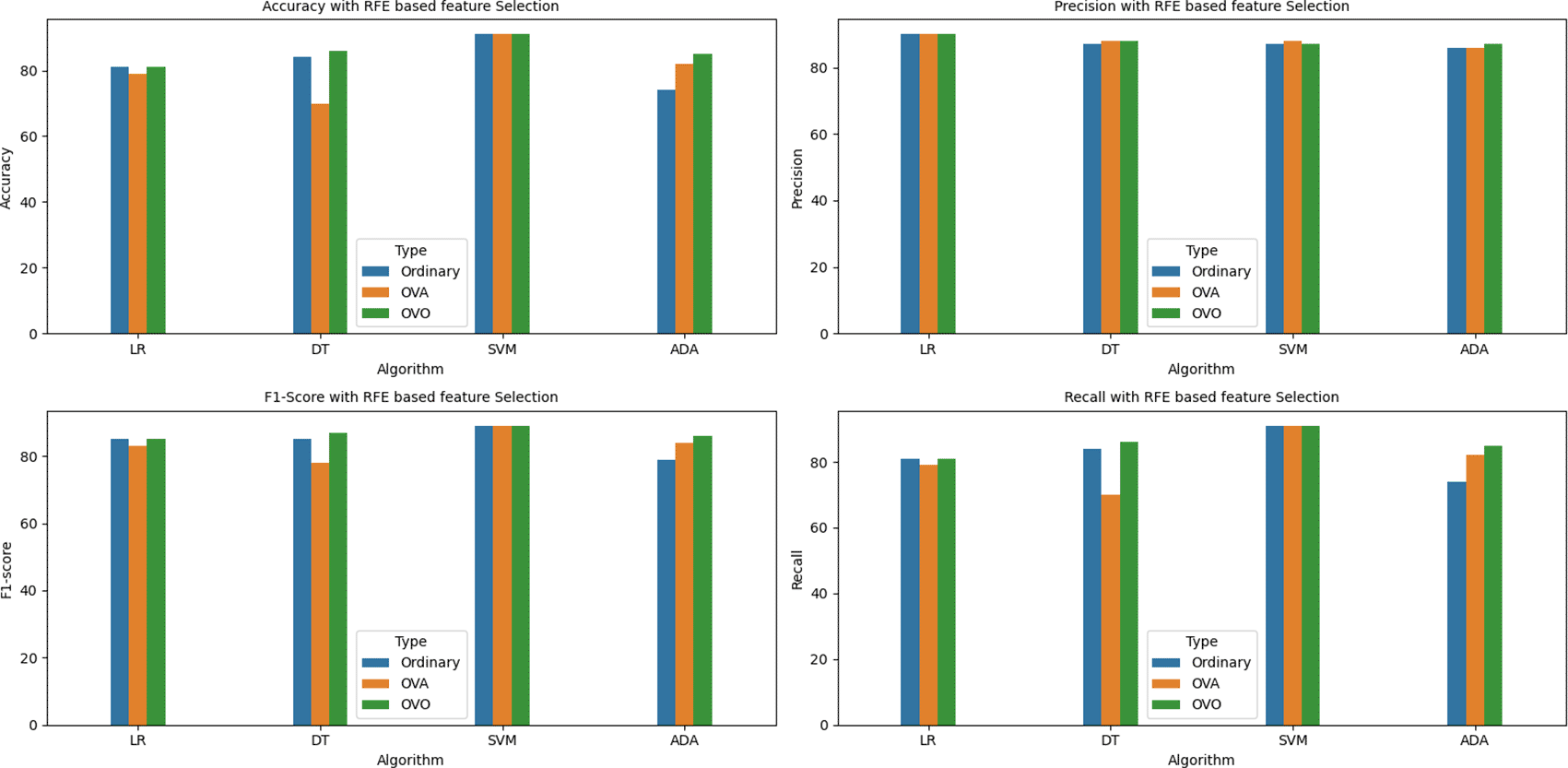
It can be observed from the above tables and graphs that out of the 60 models implemented, the highest accuracy obtained without any feature selection is 91% by SVM-OVO model with 122 features. However, the same accuracy is also achieved by the Adaboost-OVO model with 95 features selected using Boruta and with less than half number of features, i.e., 58 features selected using RFE feature selection and with only 56 features selected using MRMR feature selection.
The second highest accuracy of 90% is provided by the Adaboost-OVO model using 122 features and the same performance is also achieved by the SVM model with only 50 features, 61 features, and 91 features selected using MI based, MRMR based, and Boruta feature selection methods respectively, as well as, by the Adaboost-OVA model with 60 features selected using MI feature selection.
Besides the performance metrics discussed above, emphasis is laid upon the use of various feature selection methods by comparing the model training times taken by all the 60 models with the reduced feature sets. These training times are an indication of burden on the model, lower the training time, lower is the burden on the model. The below Table 7 provides the model training times in seconds.
Figure 24 shows the training times taken by the 4 algorithms for six feature selection scenarios: No feature selection, Variance based FS, Boruta FS, Mutual Information based FS, Minimum Redundancy Maximum Relevance based FS, and Recursive Feature Elimination based FS in their ordinary implementation. Similarly, Figure 19 and Figure 20 show the training times taken by the 4 algorithms for 6 feature selection scenarios in their OVA and OVO implementations respectively.
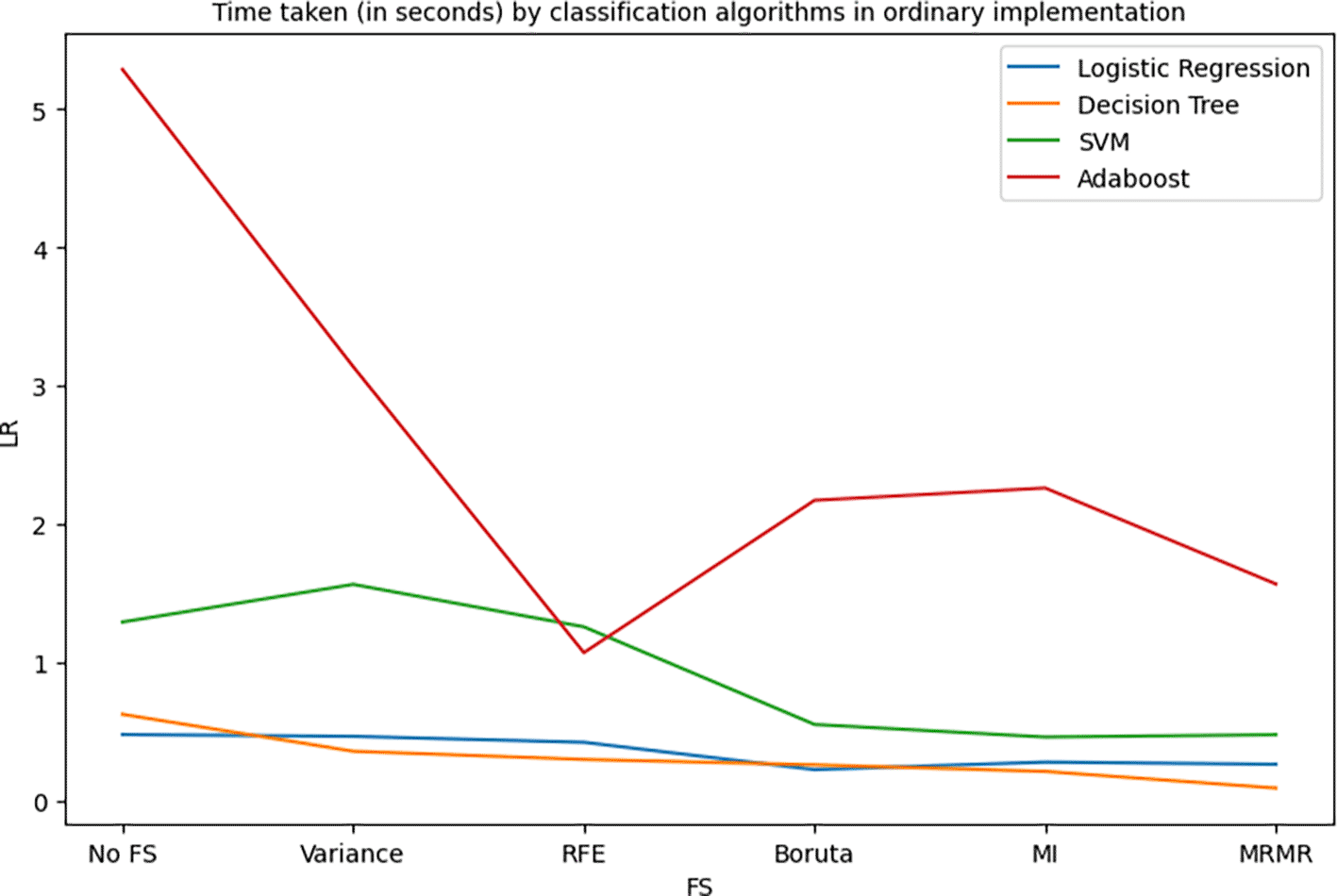
It can be observed from the Figures 24, 25, and 26 that the model training times are somewhat decreasing for the LR and DT models and have significantly reduced for the SVM and Adaboost models. This decrease in training times is a clear implication of the reduced burden upon the prediction models as they do not have to learn large amounts of data while maintaining the model performance.
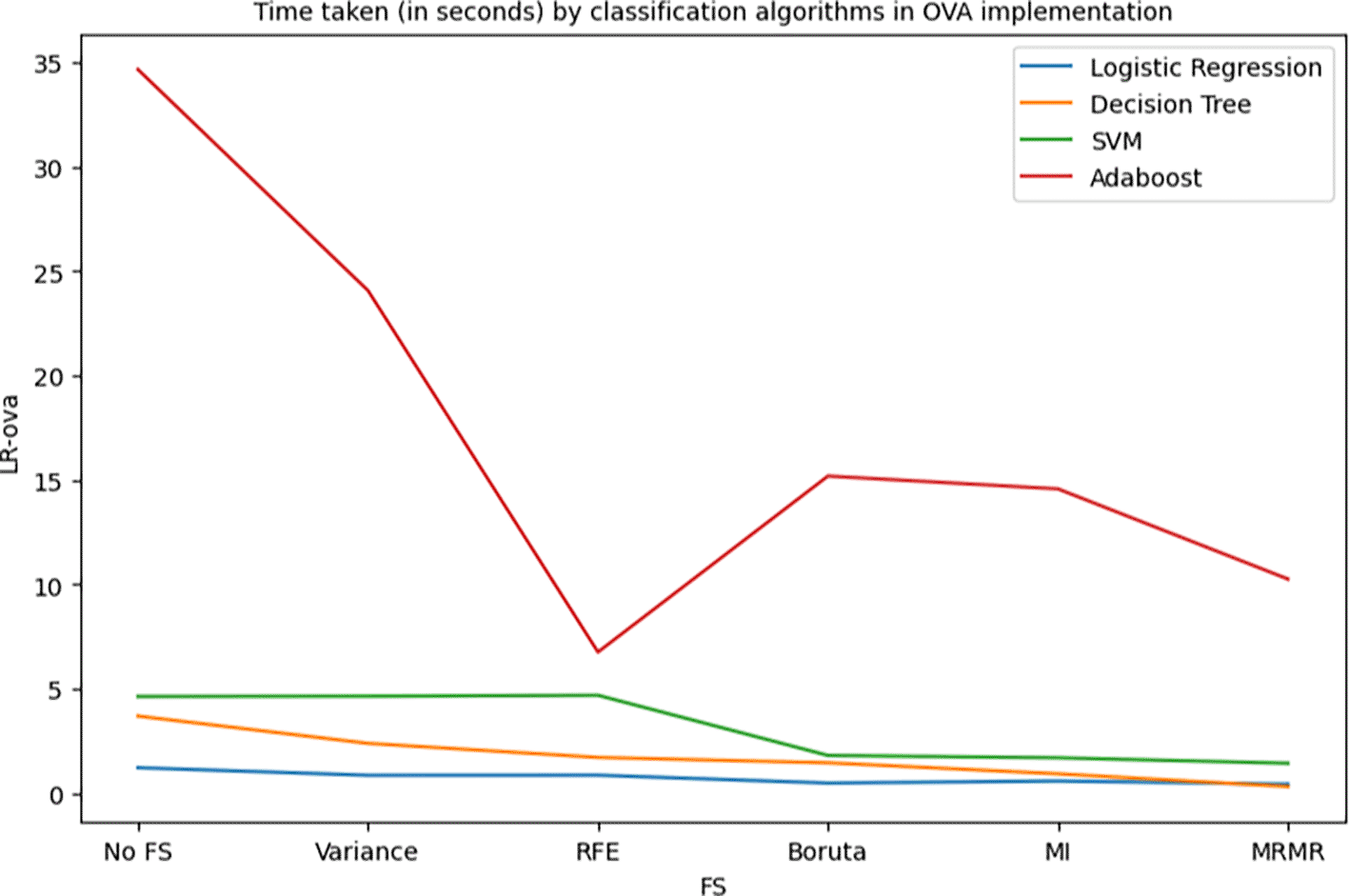
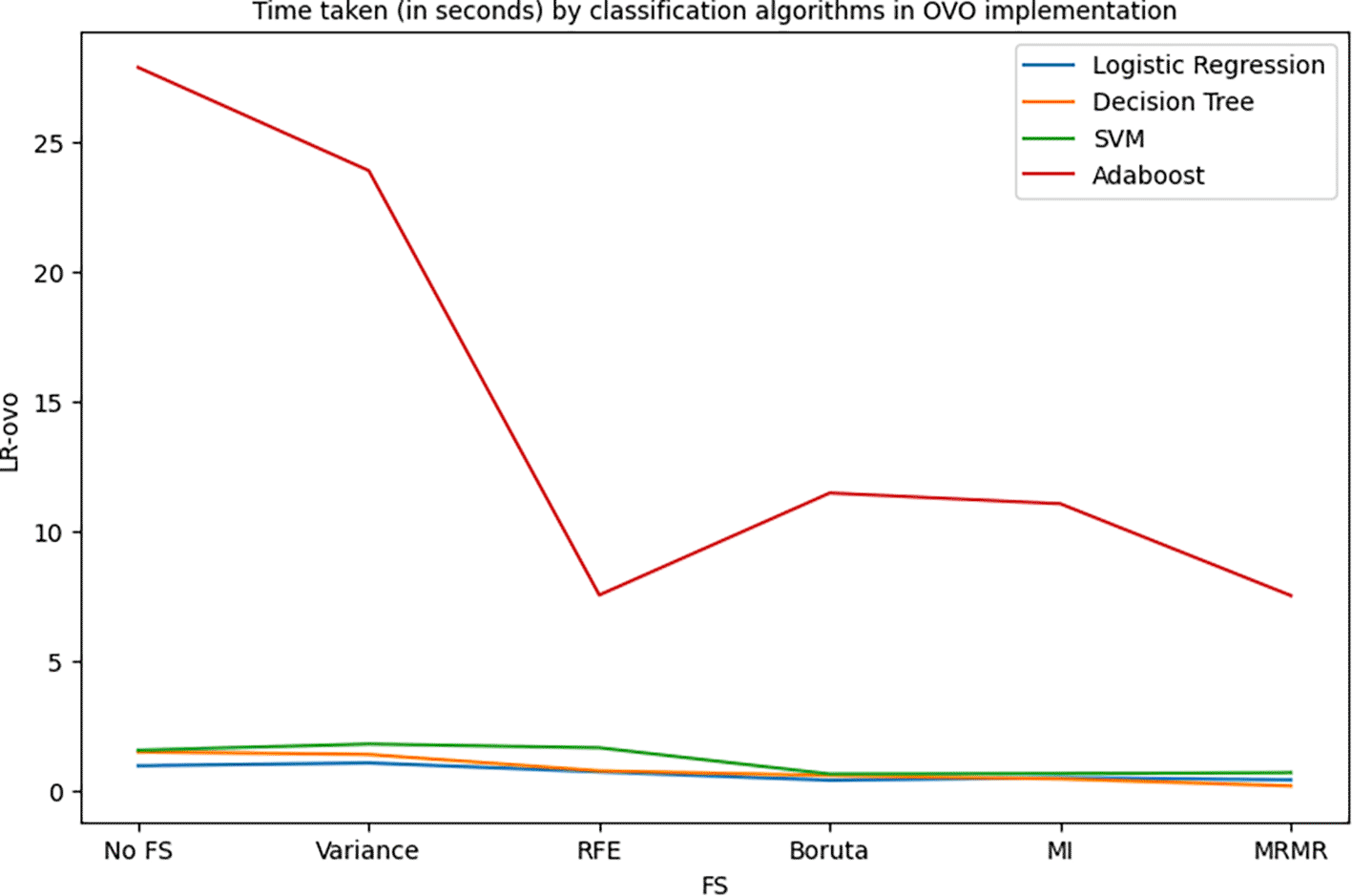
The primary objective of this research work is to strike a balance between the predictive performance of the model and the burden of training the model. As discussed in Section 4, the use of selective predictors extracted by the application of feature selection techniques has provided similar results to those of the models without feature selection. It can also be observed that for some sophisticated models such as Adaboost, the performance has significantly improved by the use of feature selection techniques, that is, the accuracy of 74% (without any feature selection taking 5.3 seconds) is increased to 85% (with Boruta feature selection taking only 2.17 seconds training time) and 88% (with MRMR feature selection taking 1.6 seconds training time). Similarly, the DT-OVO model’s performance has improved from 84% (without any feature selection taking 1.48 seconds training time) to 86% (with Boruta feature selection taking 0.58 training time). It can be noted that the performance of DT-OVO model has improved from 84% accuracy with 122 features (taking 1.48 seconds training time) to 86% with only 40 features (taking only 0.76 seconds training time) selected using RFE. The advantages of these reduced training times can be clearly noticed when dealing with a large number of data instances. Overall from this experiment it is clear that, while maintaining a decent level of predictive performance of the model, it is essential to keep the number of predictors optimal so as to reduce the model training burden. In future, the several feature selection techniques can be hybridized and used upon machine learning models as well as ensembled model to enhance the predictive performance while keeping a check on the number of essential features.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)