Keywords
Artificial intelligence, Type 1 diabetes, Dietary recommendations, ChatGPT, Bard AI, Bing AI, Digital health
This article is included in the Global Public Health gateway.
Artificial intelligence, Type 1 diabetes, Dietary recommendations, ChatGPT, Bard AI, Bing AI, Digital health
Diabetes mellitus represents a growing global public health concern. Although previously more prevalent in high-income countries, the condition now affects populations worldwide. This is largely due to increasingly sedentary lifestyles and the consumption of energy-dense, nutrient-poor diets (Saeedi et al., 2019). Type 1 diabetes (T1D), in particular, is characterised by the autoimmune destruction of pancreatic β-cells, leading to insufficient insulin production and the abnormal regulation of blood glucose levels. Maintaining blood glucose within the target range of 70–180 mg/dL is essential to avoid acute complications such as hypoglycaemia and hyperglycaemia (Ogurtsova et al., 2017). However, achieving this target remains a challenge for most individuals with T1D.
The global burden of diabetes has grown rapidly. The World Health Organization has estimated 422 million cases as of 2014, a fourfold increase since 1980 and approximately two million deaths up until 2019 (Tyler & Jacobs, 2020). Challenges for conventional diabetes care include late diagnosis, limited access to multidisciplinary care, and the need for frequent patient follow-ups. Diabetes management also implies active and constant self-regulation by patients, specifically when it comes to their eating choices, which can considerably impact glycaemic control (Hermanns et al., 2022). There is increasing demand for scalable digital tools to support nutrition guidance, especially in resource-limited settings.
Lately, advanced AI chatbots have been built upon large language models (LLMs), such as ChatGPT, Google Bard, and Microsoft Bing Chat. These chatbots have been investigated in the context of diabetes nutritional counselling. Such systems can digest a patient’s profile and generate personalised meal recommendations, potentially extending professional guidance to increasing numbers of people. For example, a prototype “AI dietitian” leveraging ChatGPT yielded meal plans consistent with expert nutrition standards. Indeed, registered dietitians rated 96% of the responses as appropriate (Sun et al., 2023). Others have noted that ChatGPT could support patient education and individualised dietary advice during diabetes care (Sridhar & Gumpeny, 2025). By embedding LLM chatbots in apps or web portals, patients can receive tailored, on-demand nutrition advice without waiting for clinic appointments (Kassem et al., 2025). This helps improve accessibility and scalability.
These AI tools could also integrate with wearable health sensors, such as continuous glucose monitors, to adjust recommendations in real time (Wang et al., 2025). This can further enhance personalisation. Nevertheless, current LLMs are not diabetes-specific and can “hallucinate” errors if unchecked (Sridhar & Gumpeny, 2025). Any AI-generated diet plan must, therefore, be rigorously evaluated for medical accuracy and appropriateness before clinical use. Ultimately, robust human oversight and validation are essential to ensure that AI-driven guidance is safe, effective, and clinically aligned.
The goal of this study is:
1. Assess whether new dialogue models ChatGPT-4o, Bard AI (Bing AI Reference Design), and Bing AI can provide dietary recommendations for a hypothetical person with T1D.
2. Compare those recommendations to the reference recommendations of a licensed human dietitian.
The results may aid in establishing the extent to which these devices can function as reliable, inexpensive adjuncts to diabetes nutrition education and self-management.
This comparative analysis evaluated the performance of three major LLMs ChatGPT-4o (OpenAI), Bard AI (Google), and Bing AI (Microsoft) when generating dietary recommendations for patients with T1D. A panel of clinical experts developed 60 hypothetical T1D cases. Per case, these incorporated pertinent clinical and lifestyle information, such as insulin regimen, weight, level of activity, and glucose targets.
All three AI models processed each case separately, and a total dietary assessment and an individualised personalised nutrition plan were carried out with the prompt to do so. The outputs were then compared against the standard of care provided by a registered clinical dietitian.
AI responses were independently reviewed by two clinical experts and classified as one of the following two options:
• Correct: Complete and clinically appropriate dietary guidance, comparable to that of a human dietitian.
• Incomplete: Missing essential components, overly generic, or lacking contextual relevance.
Discrepancies between reviewers were resolved by discussion.
The 60 Hypothetical Cases of Type 1 Diabetes were developed in scientific method to guarantee clinical realism and scientific integrity by following these steps:
All statistical analyses were conducted using R version 4.4.0 with relevant packages including dplyr, ggplot2, irr, DescTools, and reshape2. Initial analysis quantified the frequency and percentage of correct versus incomplete responses for each model. Numbers and percentages were used to quantify the data.
To evaluate statistical differences in performance between models, McNemar’s test was applied to pairwise comparisons of model outputs. Cohen’s kappa coefficients were computed for each pair of models to assess the degree of agreement beyond chance. The magnitude of agreement was interpreted using standard benchmarks: slight (κ = 0.01–0.20), fair (κ = 0.21–0.40), moderate (κ = 0.41–0.60), substantial (κ = 0.61–0.80), and almost perfect (κ = 0.81–1.00). Each coefficient was reported with its corresponding p-value.
A complementarity framework was applied to examine the unique and overlapping contributions of each model. Each case was then categorised based on whether only one, multiple, or none of the models provided a correct response. Frequencies for each pattern were calculated to reveal instances where specific models demonstrated a unique value.
To assess model sensitivity to task difficulty, each case was classified into one of three complexity categories based on the number of models that provided a correct response: Simple (all three correct), Moderate (two correct), and Complex (zero or one correct). Model accuracy was then computed within each complexity stratum to explore performance variations across difficulty levels. Model outputs were binaries (1 = Correct, 0 = Incomplete), and Pearson correlation coefficients were calculated among the models to assess pairwise linear relationships in decision patterns.
A heatmap visualisation of the correlation matrix was used to highlight areas of redundancy or divergence in performance. All tests were two-tailed, and statistical significance was determined at an alpha level of 0.05. Finally, ShinyApp (a package in R) was used to create an interactive version of the analysis.
Descriptive analysis of response outcomes revealed clear differences in accuracy among the AI models. ChatGPT-4o demonstrated the highest correctness rate, answering 36 out of 60 cases correctly (60%). Bard AI correctly solved 30 cases (50%). Bing AI only generated 16 correct responses (26.7%) ( Table 1, Figure 1).
| Model | Correct | Incomplete |
|---|---|---|
| ChatGPT-4o | 36 (60%) | 24 (40%) |
| Bard AI | 30 (50%) | 30 (50%) |
| Bing AI | 16 (26.7%) | 44 (73.3%) |
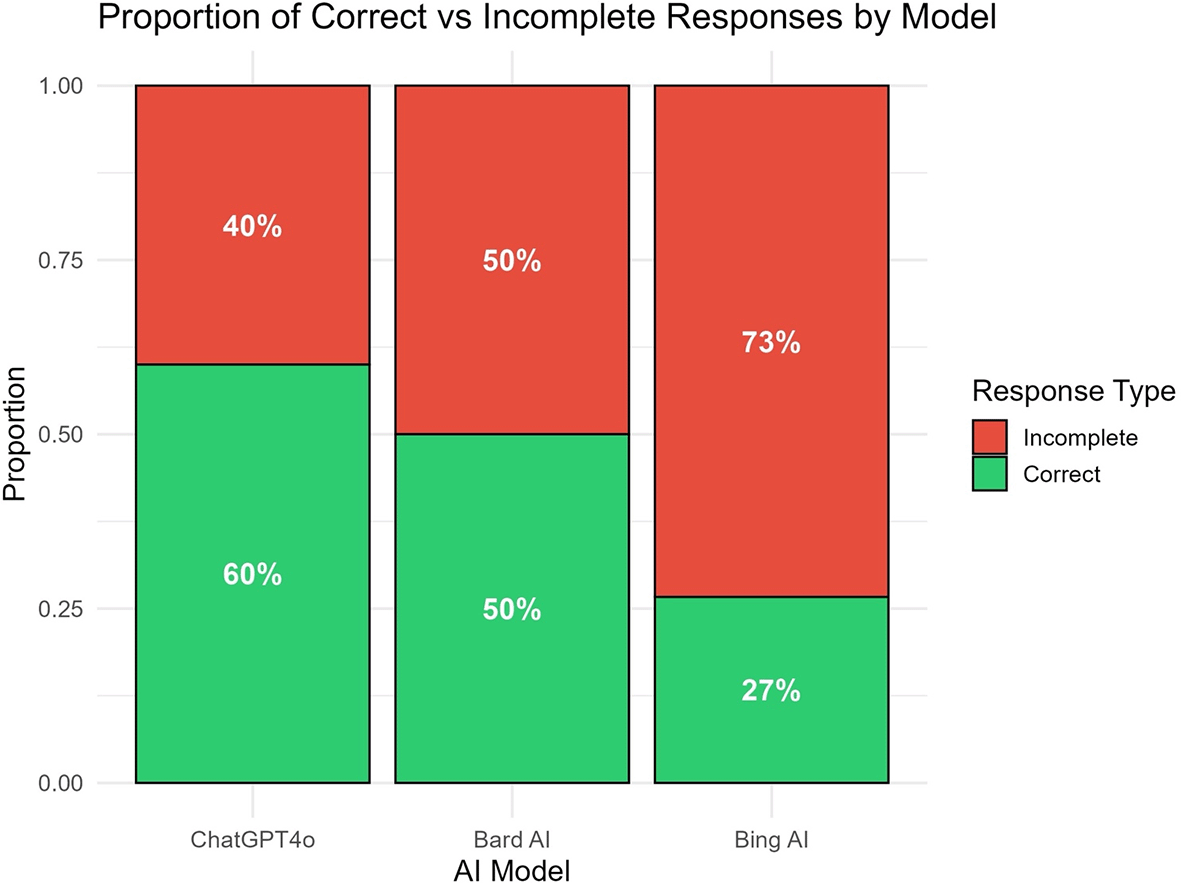
To statistically evaluate differences in model performance across paired comparisons, a McNemar’s chi-square test was conducted for each model pair. The comparison between ChatGPT-4o and Bard AI did not yield a statistically significant difference in accuracy (χ2 = 1.14, p = 0.29). However, significant differences were observed between ChatGPT-4o and Bing AI (χ2 = 10.028, p = 0.002), as well as between Bard AI and Bing AI (χ2 = 5.63, p = 0.02). These findings indicate that both ChatGPT-4o and Bard AI outperform Bing AI at a statistically meaningful level, while the gap between ChatGPT-4o and Bard AI is not significant ( Table 2).
Although overall accuracy is informative, it is also critical to examine how frequently the models agree with one another. Cohen’s kappa was calculated for each model pair to quantify agreement beyond chance. Agreement between ChatGPT-4o and Bard AI was modest (κ = 0.27, p = 0.035), which was categorized as “fair agreement”. The agreement between ChatGPT-4o and Bing AI was slightly negative (κ = -0.097, p = 0.34), indicating less than chance agreement. Bard AI and Bing AI yielded a κ of 0 (p = 1), reflecting slight or no agreement ( Table 3).
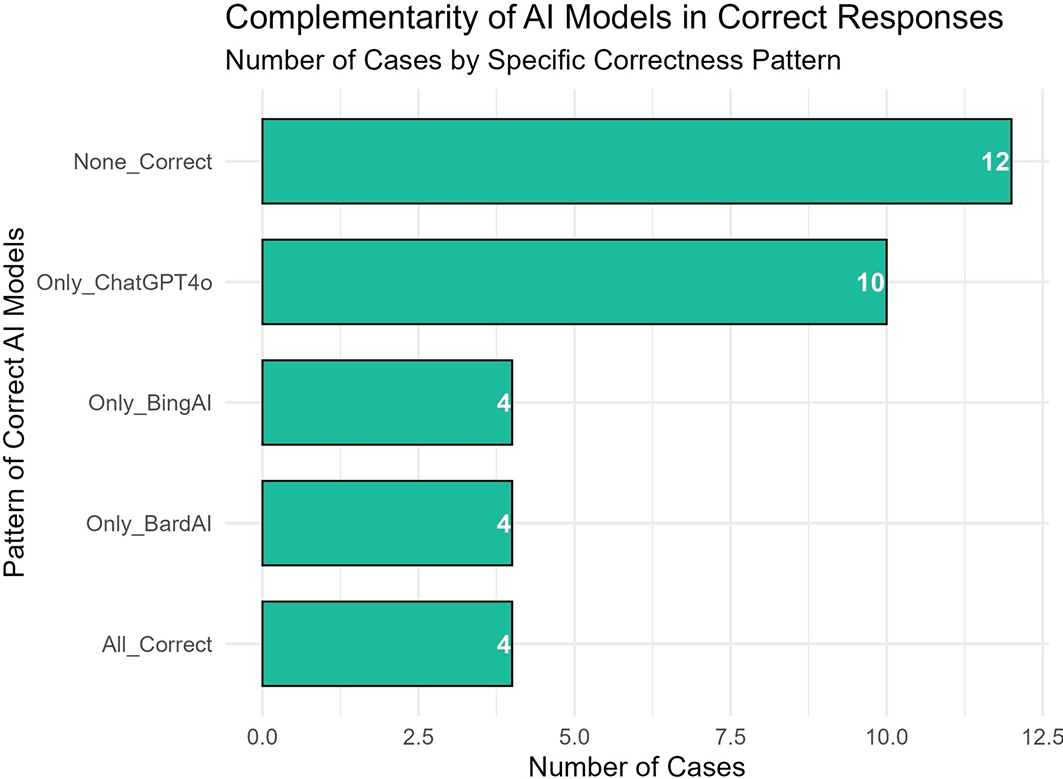
Complementarity, or the ability of different models to independently provide correct answers when others fail, was examined. For 10 cases, ChatGPT-4o uniquely answered correctly while Bard and Bing AI failed. Bard and Bing AI each had four uniquely correct responses. Only four cases were solved correctly by all three models, while 12 cases were missed by all. These results align with the overall accuracy findings in this study and demonstrate that ChatGPT-4o not only outperforms the other two AI models but also provides the most correct responses in cases where Bard AI and Bing AI both fail ( Figure 2).
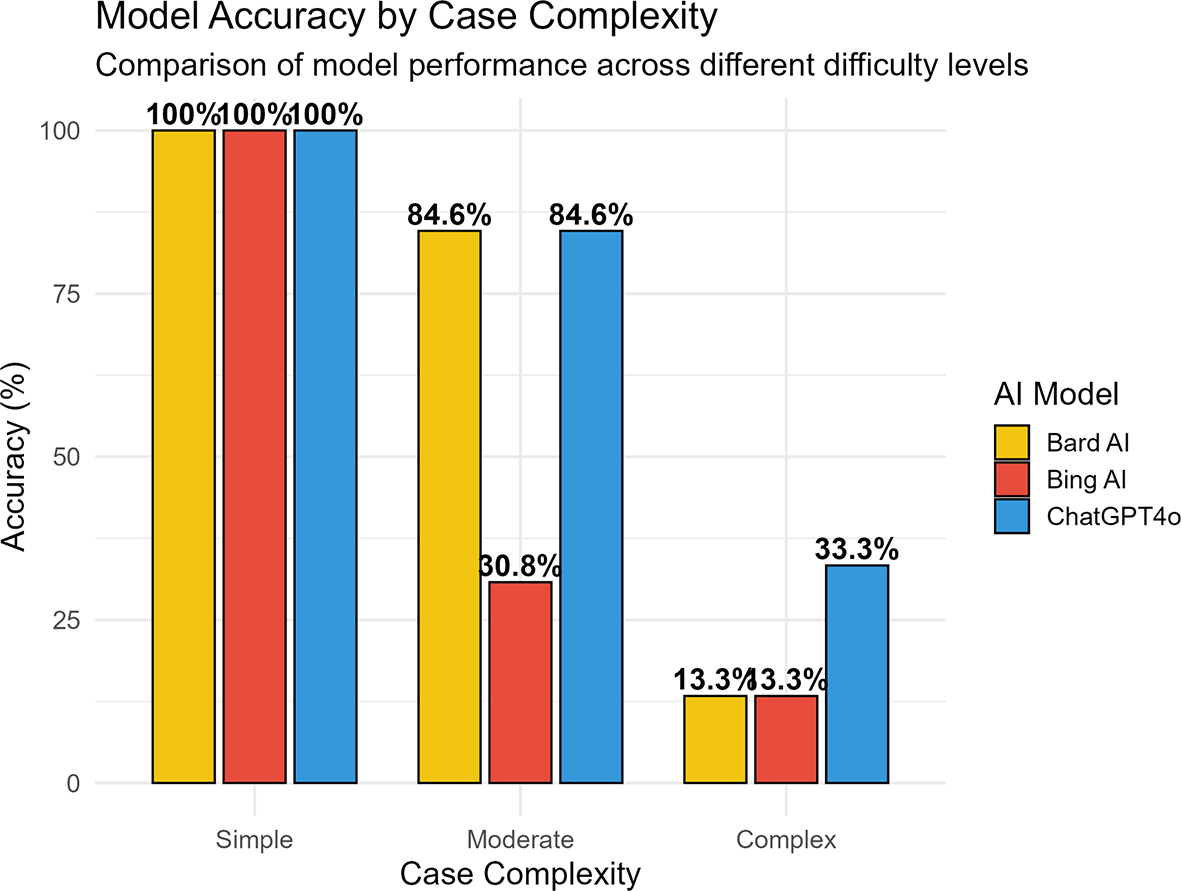
To explore performance sensitivity across varying levels of question difficulty, the dataset was stratified into three cases: Simple (three models correct), Moderate (two models correct), and Complex (zero or one models correct). Accuracy rates across these categories are visualized in Figure 3. In simple cases, all models performed at 100% accuracy. For Moderate cases, ChatGPT-4o continued to perform strongly (86.4% accuracy), while Bing AI dropped to 30.8%. The trend held in Complex cases, where ChatGPT-4o maintained 33.3% accuracy, outperforming Bard AI (13.3%) and Bing AI (13.3%). These findings suggest that ChatGPT-4o is more resilient to complexity, while the other models degrade more sharply in performance under challenging conditions ( Figure 3).
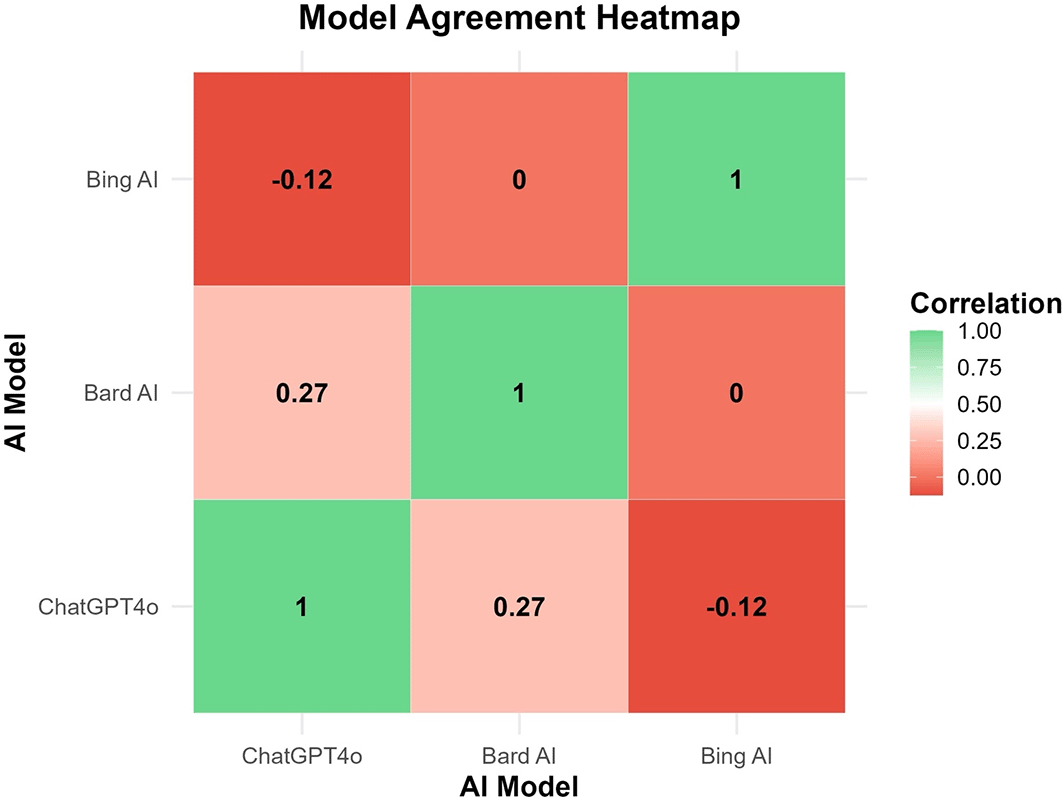
Finally, the degree of linear correlation between model outputs was examined using a Pearson correlation heatmap ( Figure 4). The correlation matrix confirms limited agreement between model predictions, which is consistent with previous findings. Notably, ChatGPT-4o and Bard AI showed a moderate positive correlation (r = 0.27), while ChatGPT-4o and Bing AI displayed a weak negative correlation (r = -0.12) ( Figure 4).
An interactive version of the analysis can be accessed here: https://cnpdata.shinyapps.io/ai_diabetes/
The above comparative analysis demonstrates that LLM chatbots can often produce appropriate dietary guidance for T1D patients, with ChatGPT-4o performing best. In this study, ChatGPT-4o provided fully correct nutrition plans in 60% of cases, compared to 50% for Google Bard and 26.7% for Microsoft Bing. Both ChatGPT-4o and Bard significantly outperformed Bing AI (McNemar’s test, p < 0.05), while the difference between ChatGPT-4o and Bard was not statistically significant. Notably, in 10 cases, ChatGPT-4o uniquely answered correctly while both other models failed. Only four cases were solved correctly by all three models.
These results are consistent with emerging literature on AI-supported nutrition counselling. Recent studies have found that ChatGPT’s dietary advice often aligns with expert standards. Sun et al. (2023), for instance, showed that ChatGPT’s nutrition recommendations for diabetes were largely consistent with best practices, and professional dietitians rated most of its answers as appropriate. Another analysis likewise found that ChatGPT-generated meal plans for diabetes closely follow the American Diabetes Association’s plate method (Chatelan et al., 2023). In that evaluation, the meals included the recommended balance of non-starchy vegetables, proteins, and carbohydrates.
However, the study also highlighted some of ChatGPT’s known limitations. It was found that repeated queries could yield varying menus due to the model’s non-determinism (Chatelan et al., 2023), and some menus included suboptimal or inappropriate foods without warning (e.g. spinach and avocado in a renal diet plan). Even ChatGPT-4o left a substantial minority of scenarios unaddressed, indicating that current chatbots still miss important details in complex diabetic meal planning. The above findings reinforce that although LLMs can simulate expert guidance, their outputs must be carefully reviewed. This is because the models can occasionally produce misleading or incomplete advice.
There are several reasons why ChatGPT-4o is able to outperform ChatGPT-2o in generating dietetic recommendations. First, its big model size and breadth of available training data on medical literature, nutritional science (Garcia, 2023), and conversational language (Sharma & Gaur, 2024) allow the model to answer both scientifically grounded questions and generalise across various dietary situations. This kind of extensive pre-training enables ChatGPT-4o to emulate evidence-based clinical inferences and personalised nutritional advice (Garcia, 2023; Sharma & Gaur, 2024). ChatGPT-4o also works in real time and tends to generate responses that are immediate, uniform, and standardised. In contrast, dieticians’ recommendations can vary according to individual experiences and/or understandings (Bayram & Ozturkcan, 2024; Papastratis et al., 2024). These aspects likely enabled ChatGPT-4o to (a) exhibit higher performance than Bard and Bing AI and (b) perform similar to, or better than, human dietitians in controlled settings (Papastratis et al., 2024).
From a practical standpoint, AI-based tools such as ChatGPT-4o might function as useful supplements for dietitians engaged in T1D care (Tyler & Jacobs, 2020; Guan et al., 2023). In particular, there is the potential to provide rapid, accessible guideline-adherent recommendations that improve care delivery, particularly in areas with limited access to trained nutrition specialists (ElSayed & Aleppo, 2023). This is especially relevant in low-resource settings, where AI might function as ‘gap filler’ in patient care (Hou et al., 2023). It could also promote patient self-administration by providing users with instant, individualised dietary advice (Garcia, 2023; Sharma & Gaur, 2024). As intimated, these tools should not replace human insight and clinical (re) assessment, especially not in complex cases that require nuanced judgement (Papastratis et al., 2024; Hieronimus et al., 2024). That said, they could play a valuable role in diabetes care by extending coverage, amplifying effectiveness, and empowering patients (Tyler & Jacobs, 2020; Guan et al., 2023).
The evolving literature favours extending AI’s reach into the broader realm of diabetes care. Indeed, recent evidence suggests that AI-enabled systems (including LLMs) have tremendous potential to support and even impact decision-making, remote monitoring, and personalised treatment (Tyler & Jacobs, 2020; Guan et al., 2023; ElSayed & Aleppo, 2023). Technologies that enhance patient access and engagement in care support while promoting glycaemic control, especially in underserved populations, are available for use (Hou et al., 2023; Daly & Hovorka, 2021). Thus, the present study not only validates the utility of ChatGPT-4o as an adjunct dietary tool but also adds to the increasing range of roles AI technologies are playing in areas such as precision medicine and chronic condition management (Guan et al., 2023; Tyler & Jacobs, 2020).
The potential clinical impact of reliable AI dietary advice in diabetes is substantial. Sun et al. have, for instance, emphasised how diabetes nutrition management is often hindered by a “low supply of registered clinical dietitians” (2023, p. 1). In many health systems, patients face long waits or a lack of coverage for nutrition counselling. An AI chatbot such as ChatGPT can, in contrast, provide on-demand, personalised guidance 24 hours a day. ChatGPT is also available via smartphone or computer and can deliver immediate meal suggestions or educational explanations. This can help patients make healthier choices between clinic visits. Early evidence also suggests that people find such AI guidance motivating. A recent study reported that patients using ChatGPT described receiving informational support, personalised recommendations, reminders, and encouragement, with an overall “positive impact on [diabetes mellitus] self-management” (Alanzi et al., 2025, p. 1). Thus, if properly integrated (e.g. with glucose-monitoring apps or telehealth services), AI-driven advice could reinforce dietary adherence and thereby improve glycaemic control and reduce complications.
This study has several strengths, which point to its credibility and clinical value. First, the carefully constructed, real-world, contextualised, hypothetical cases maximise conformity between the dietary scenarios presented and what clinical care providers face during daily T1D management activities (Joslin, 2021). Such an approach enhances the results’ generalisability to real healthcare conditions. Second, integrating AI models (ChatGPT-4o, Bard AI, and Bing AI) allows one to compare a wide range of industry-standard digital health technologies. This can, in turn, engender a holistic view of AI performance in dietary recommendation tasks (Papastratis et al., 2024; Sharma & Gaur, 2024). Finally, the use of well-established statistical approaches (e.g. McNemar’s test and paired t-tests) resulted in robust evidence for comparing the relative accuracy between the models (Garcia, 2023). These techniques increased the results’ credibility and the conclusions’ appropriateness vis-à-vis AI’s comparative effects in dietetic practice (Sharma et al., 2023).
Despite the above strengths, there are some limitations to this study. Although designed by experts, the sample of theoretical cases does not exactly reproduce the multiple facets involved when dealing with actual patients. This could impact the results’ generalisability to live clinic settings (ElSayed & Aleppo, 2023). The AI-created dietary recommendations were also not subjected to clinical trials or related to patient outcomes. This prevents one from drawing any conclusions related to those recommendations’ efficacy or safety in clinical terms (Papastratis et al., 2024).
Another limitation is that evaluation judgments related to whether responses were “correct” versus “incomplete” were the classification criteria, which may introduce bias. This is because, even when based on expert feedback (Hieronimus et al., 2024), decisions entail some necessary subjectivity. Moreover, as AI continues to develop rapidly, tools such as ChatGPT-4o, Bard AI, and Bing AI will improve rapidly. The results from this study might, therefore, become redundant as subsequent versions of the model are developed (Sharma et al., 2023). Finally, the evaluation provided each chatbot with a single prompt and did not permit interactive follow-ups. In real clinical use, patients or clinicians would likely refine their questions over multiple turns, which can improve accuracy.
Ethical and safety concerns must be considered when incorporating AI tools such as ChatGPT-4o into clinical nutrition and diabetes care. While it is possible that AI systems would provide convenient and timely dietary recommendations, rigorous validation and clinical oversight must be available to ensure that the advice is correct, safe, and consistent with evidence-based recommendations (Papastratis et al., 2024; Sharma et al., 2023). Unless thoroughly tested, AI-generated guidance runs the risk of recommending the wrong diet, particularly in complex cases (Hieronimus et al., 2024). It is also necessary to individualise recommendations according to each patient’s needs. AI systems might oversimplify or fail to consider the context of coexisting conditions, psychosocial influences, and cultural preferences. These are factors that a human dietitian tends to properly account for (Chatelan et al., 2023; Sharma et al., 2023).
In sum, the danger of excessive dependence on unsupervised AI is clear. Although AI can improve care, it should not be used to substitute the subtle clinical judgment and empathy of skilled professionals (Garcia, 2023; Sharma & Gaur, 2024). The need for a balanced implementation of AI as a supportive, rather than an equal partner, is critical to protect patient safety and maintain ethical standards during care provision (ElSayed & Aleppo, 2023).
Further investigations into AI-based dietary advice could validate its effectiveness through the use of actual patient data and clinical results. Research based on real patient presentations and care would, in turn, be stronger evidence of AI’s use and constraints in real-life scenarios. There is also a need for longitudinal studies to determine the potential longer-range clinical effects of AI-guided dietary planning on glycaemic control, adherence to dietary plan, and the complication rate in people with T1D. Moreover, investigating how AI systems such as ChatGPT-4o can be suitably integrated into the care ecosystem (e.g., EHR) would reduce the time taken to get to care. AI might also bypass being too subjective and avoid basing decisions on a patient’s partial record by providing personalised suggestions that consider the individual’s whole medical history.
Promising directions in computational modelling include the process of hybrid models. These can take advantage of AI-generated insights in combination with clinician reviews, thereby balancing efficiency and clinical safety. These sorts of models could, in turn, harness the AI’s speed and scale while retaining the essential human oversight that is critical for nuanced decision-making during patient care.
In conclusion, the above comparative evaluation suggests that modern AI Chabot particularly ChatGPT-4o, show real promise in their ability to serve as supplementary tools during diabetes nutrition therapy. These models can rapidly generate individualised meal guidance and thereby potentially expand access to expert-level advice. This aligns with a growing consensus that AI can enhance chronic disease self-management. Indeed, patients are increasingly reporting the benefits of using ChatGPT for health education and support.
Moving forward, clinical trials are needed to test whether integrating AI chatbots into diabetes care through mobile apps or telehealth platforms genuinely improves adherence, patient satisfaction, and metabolic outcomes. If successfully implemented, AI-driven dietary counselling could reduce the burden on healthcare providers and empower patients to more effectively manage their condition. This can ultimately improve both clinical outcomes and overall quality of life.
This study did not involve human participants, real patient data, or animal subjects. Instead, it utilised hypothetical clinical scenarios. Ethical approval and informed consent were, therefore, not required. All AI-generated responses were assessed in a research context without interacting with the actual individuals.
The AI models used in this study, including ChatGPT-4o, Bard AI, and Bing AI, were accessed via their respective web-based platforms. These tools are proprietary large language models (LLMs) developed by OpenAI, Google, and Microsoft, respectively. While the models themselves are proprietary and not available for direct download, access to these AI platforms can be obtained by visiting their respective websites:
• ChatGPT-4o: Accessed via Open AI’s platform .
• Bard AI: Accessed via Google Bard .
• Bing AI: Accessed via Microsoft Bing .
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)