Keywords
Workflow Optimization, Experimental Design, Reproducibility, High-Throughput Assays, Gantt Chart, Operations Research, R, Shiny
This article is included in the RPackage gateway.
Workflow Optimization, Experimental Design, Reproducibility, High-Throughput Assays, Gantt Chart, Operations Research, R, Shiny
Note, the positioning of figures were also “rearranged” in version 3 of the manuscript in order to put them in their correct positions reflected in my original version 2 submission:
Between version 2 and version 3 of the article, the zenodo repository link was updated to the most recent version of StaggR that fixes critical bugs introduced by transferring core scheduling logic outside of the Shiny server function. The app no longer disconnects when changing sample names/count or clicking example protocols, and the first three "?" icons now display appropriate information. A “Download Sample Session (.json)” button was added to the application to better help users understand the format and parameters input to the application. These changes promote the ethos of StaggR to be simple to use and customize.
See the author's detailed response to the review by Charuka D Wickramasinghe
See the author's detailed response to the review by Thomas Darde
Biological processes, such as pre-mRNA splicing, intracellular signaling cascades, and protein decay occur on rapid timescales ranging from microseconds to days (Shamir et al., 2016). Therefore, to capture these dynamic events, research in fields such as pharmacology, biochemistry, and genomics often relies on complex and time-sensitive sample workflows. To execute protocols across multiple conditions with multiple replicates, an experimentalist will often stagger their treatments so that some samples can be handled during the waiting periods of others. When experiments are sensitive to small time variations, staggering treatments can be an effective tool for reducing experimental noise while simultaneously increasing productivity by reducing the time required to handle multiple samples. However, calculating a valid, let alone minimized, staggering interval is a non-trivial cognitive task.
An excessively long staggering interval can make experiments too long to fit within the work period. Conversely, reducing the interval too much can be overwhelming for an experimentalist to keep track of. Mishandling of samples due to poor experimental design can lead to compromised reproducibility and loss of valuable materials.
While simple protocols can be scheduled with a spreadsheet, complex workflows with numerous, non-uniform operations quickly become intractable to plan manually. Each additional time-sensitive task and sample added to the workflow creates a new potential scheduling conflict. Furthermore, some staggered experimental setups may have no conflict-free solutions. However, without extensive trial and error during planning, it is difficult to determine whether a schedule is possible. This challenge is a practical instance of a well-defined class of optimization problems in operations research, known as the Permutation Flow Shop Scheduling Problem (FSSP) (Emmons, 2013). FSSP approaches optimize how agents (in this case humans) perform sequential jobs (sample processing pipelines) which consist of multiple operations (sample processing steps) of discrete durations with the constraint that operations must occur in the same order. In this case, there is a single operator responsible for all tasks who cannot be engaged with two tasks simultaneously. Typical solutions in this space are designed for machining applications. However, open-source tools to optimize the workflows for average users on the bench are lacking.
To address this problem intuitively, I present StaggR, an interactive platform that serves to optimize, simulate, and facilitate staggered experimental protocols with identical processing workflows. StaggR provides a graphical user interface for defining the number of samples to be processed in parallel and the key operations of a protocol consisting of “hands-on” durations (i.e. the estimated time required to execute an operation) and “wait times” (i.e. how long between the completion of one operation and the start of the next). Based on this plan, StaggR will attempt to optimize the minimal valid staggering interval allotting for a known amount of user imprecision and provide 1) a Gantt chart that visualizes a work schedule for processing the user-defined samples in parallel, 2) a downloadable table with step-by-step instructions showing the chronological series of events that comprise the solved workflow, and 3) a tool to dynamically track the progression of a workflow plan in real time to assist in the timely execution of operations. StaggR is a simple application designed to provide a clean, easy-to-use interface that quickly expands the capacity of experimentalists to explore and execute complex sample-processing pipelines.
At the core of StaggR is a scheduling algorithm that uses an iterative search heuristic which simulates an experimental schedule to process an arbitrary number of samples, each starting at times offset by a fixed interval automatically identified by the application or manually input by the user (Figure 1 and Figure 2). In “automatic” mode, StaggR tests increasing staggering intervals until a valid schedule is identified. A “granularity” parameter (default of 0.25 min) defines the initial protocol staggering interval and the increment by which the interval is iteratively increased. For a given interval, StaggR checks for time points where the researcher is simultaneously occupied by the hands-on time requirements for more than one task. If a conflict is detected, the staggering interval is increased by the granularity value and the simulation is repeated until a conflict-free schedule is found. This approach approximates the shortest possible total experiment time without creating logistical impossibility. The algorithm also accounts for user-defined “buffer time” (e.g., 1 min) a short duration added to the end of each operation to model the time it takes to switch between tasks. If the staggering interval exceeds the base duration required for a single protocol, then the optimization will end as it failed to identify a valid interval and the user will be prompted to adjust the input parameters. StaggR runs the optimization by default. By enabling “manual” mode, the user may experiment with different staggering intervals to examine alternate treatment schedules.
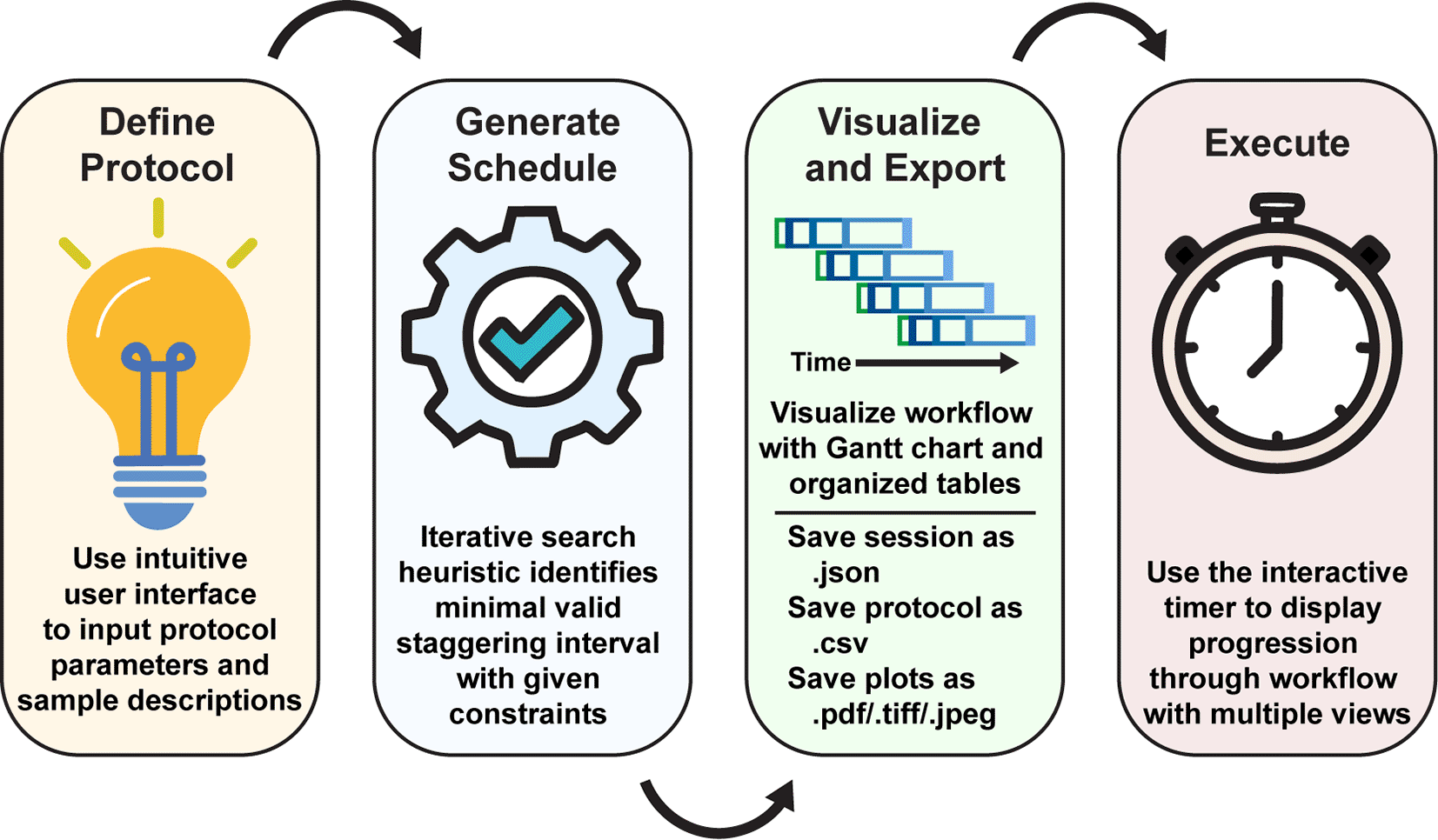
Upon initialization of the application, the user inputs the experimental parameters and generates a schedule automatically with a manually-provided or automatically-determined staggering interval. The workflow is then visualized with a Gantt chart and tables illustrating the staggered processing protocols for each sample or batch of samples. Using the “Live Time Course” tab, users can easily track the progression of their charted experimental workflow.
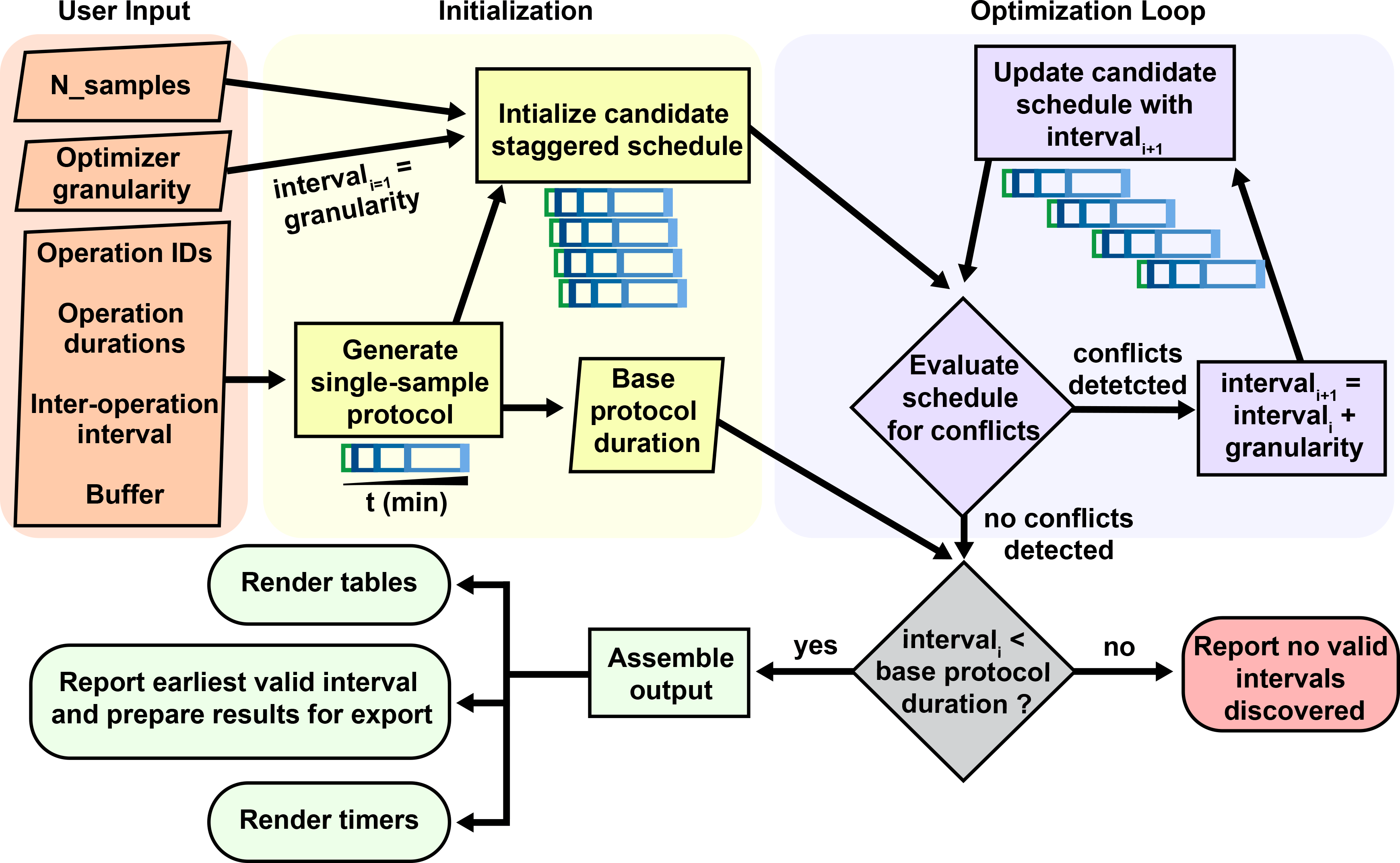
Conceptual diagram of the architecture behind the staggering interval optimization algorithm of StaggR. Upon receiving a user defined protocol, a treatment schedule is generated depicting the time for which an operation is scheduled to be executed (e.g. pipetting a drug into a sample) extended by a buffer duration, and the wait time between one task and the next (e.g. incubation period). Identical protocols are initialized for each sample input staggered by the granularity time increment. This initial prospective schedule is evaluated for incompatibilities where more than one task is scheduled at the same time (invalid). If incompatible, the schedule is recalculated with an incrementally larger interval and re-evaluated until a compatible schedule is found or the interval exceeds the base duration of the single-sample protocol. If the user manually provides an interval, this process skips directly to a GUI rendering highlighting any detected scheduling conflicts.
Although more complex optimization methods exist, this iterative search heuristic was chosen for its straightforward implementation, computational speed for typical lab-scale problems, and its ability to guarantee a conflict-free, if not globally optimal, solution. Classical approaches have steep learning curves and will often produce asynchronous staggering intervals perfect for machine operation. However, human agents are poorly suited to handle the resultant chaotic schedules. The heuristic behind StaggR is developed primarily to be accessible for a broad user base, focusing on ease of understanding, input, and execution with a regular cadence.
The StaggR algorithm imposes key constraints. Identical protocol schedules for each sample are assumed. Therefore, heterogeneous treatment schedules with samples undergoing differently spaced protocol steps are not permitted to be entered. StaggR also assumes an identical staggering interval for all samples and incurs a flat buffering period for all tasks. The granularity defined by the user further limits how close the reported staggering interval is to the true optimal interval. For example, increasing the granularity from the 0.25 min default to 5 min means that only staggering intervals which are a multiple of 5 min (10 min, 15 min, 20 min, etc.) will be examined. Therefore, if the optimal staggering interval was not an interval of 5 min (e.g. 7 min), it will be skipped over and remain unchecked. This can lead to a failure (no solution) or a sub-optimal, but valid, solution unless the granularity is reduced.
The core scheduling logic of StaggR was implemented in base R (v4.4.0), with data manipulation handled by the dplyr package (Wickham et al., 2019). The interactive Gantt chart was generated using ggplot2 (v3.5.2) (Wickham, 2011), and the user interface was built using shiny (v1.11.1) and shinyjs (v2.1.0) for dynamic reactivity. Data tables were rendered using the DT package (v0.33). The application is designed to run locally from the source code or be accessed as a hosted web service. The initial drafts of this code and manuscript were edited with the assistance of ChatGPT o3 (OpenAI) and Gemini 2.5 Pro (Google). All figure panels demonstrating use cases are derived from screenshot images natively generated using the StaggR app.
The StaggR interface is divided into a control sidebar for the parameter input and a main panel for visualizing the output. The workflow is described (Figure 1).
1. Define Protocol - The user first provides the following information to the scheduler:
• Sample descriptions: The number and names of samples used for the protocol.
• Operation descriptions: The number and names of the operations used in the protocol. Each operation is an action or a series of actions that require constant attention.
• Step duration: The hands-on duration in min for each operation. This is the maximum time allotted to an individual operation to take place. For example, a user may estimate that it takes 2 min to add a drug to a sample, put that sample away, and move on to the next. This parameter may be shorter for a more experienced experimentalist or longer for trainees new to the protocol. For the best results, it is recommended that inexperienced users perform a dry run for each operation to obtain a better understanding of their individual pacing.
• Time between steps: The inter-operation interval or “wait time” that occurs between the end of one manual operation and the beginning of the next (e.g., the duration of an incubation after adding a drug, or the duration of a centrifugation step after loading a centrifuge).
The user may additionally utilize the “Time Course Helper” to easily insert a simple time series by first choosing an anchoring operation (e.g., the start of a drug treatment), then defining an operation to be repeated (e.g., harvest cells) and lastly identifying the time points to enact the repeating operation (e.g., 5, 15, 30, and 60 min). All parameters may be saved and edited externally for re-uploading if desired.
(Optional) Additional Parameters - StaggR provides additional flexibility in the planning through additional parameters that may be modified but are pre-populated with convenient values by default.
• Buffer time: The user may specify a defined “buffer time” to allow switching between tasks. For example, the default buffer time of 1 min means a staggering interval will not be accepted if another manual operation is scheduled to begin within 1 min after the end of any other operation. This is designed to accommodate for a known degree of human imprecision during protocol execution.
• Optimizer granularity: The user can define the lengths of the time steps for which the optimizer checks for conflict. This value will also be used as the first test interval. For example, the default granularity of 0.25 min means an initial schedule with a 0.25 min staggering of each sample will be tested. If conflicts are detected, a 0.5 min staggering will be evaluated and so on until the staggering interval exceeds the duration of a single protocol at which point samples would be processed sequentially and not staggered. A smaller granularity often leads to a solution closer to the optimal solution, but requires greater computational resources. Adjust according to the time scale of the workflow.
• Graphical parameters: The user can also modulate several features of the output displays including the colors of each operation used for visualization, a base color to generate a spread of colors for samples, and the X-axis tick interval.
2. Generate Schedule: Upon clicking “Generate Schedule,” StaggR calculates the start time for every operation of every sample. In the optimization mode, it iteratively tests increasing staggering intervals until it finds the shortest interval that results in no temporal overlap of manual tasks.
3. Visualize and Export: The results are presented in three tabs:
• Gantt Chart: A comprehensive visualization of the entire experimental timeline showing the timing for each sample and operation. It also includes a “Hands-On Time” track that aggregates all manual tasks, clearly indicating when the researcher is busy, free, or has scheduling conflicts (in manual mode).
• Schedule by Time: A chronological, time-stamped list of every action to be performed.
• Schedule by Sample: A table detailing the start time of each operation for each sample.
4. Execute: StaggR provides multiple views that can assist in the execution of charted workflows. The “Live Time Course” tab helps you execute the plan, providing live updates as operations become due. Under the “Schedule by Time” tab, the chronological table provides live updates for constant clarity in the execution of the past, current, and forthcoming operations. The “Schedule by Sample” tab shows the timing for processing grouped by each sample. All outputs, including the plot (PDF, PNG, etc.), parameter set, and data tables can be downloaded individually as a zip report for record-keeping and sharing workflows.
To demonstrate the utility of StaggR, I provide three pre-loaded protocols that exemplify setups common in laboratory work. These use cases can be directly loaded from the “About” tab and act as templates for workflow design with minimal modification.
Fixatives such as formaldehyde crosslink proteins and nucleic acids to preserve their cellular state for applications such as imaging, immunoprecipitation, and mass spectrometry. However, over- and underfixation can easily introduce artifacts that affect reproducibility (Baranello et al., 2016; Schnell et al., 2012). In this use case, the user has a 12-well dish of coverslips bearing cells of different genetic backgrounds. Each coverslip will receive a 60-min drug or mock (vehicle) treatment after which the cells will be prepared for confocal imaging targeting a protein of interest. They plan to fix each coverslip for 15 min. The user estimates that it will take 0.5 min to add the drug, but each sample will require ~5 min to wash and start the fixation, and another 5 min to wash and halt the fixation.
The user opens the app and defines the samples and operations used to process each sample, as well as the hands-on duration to execute each operation using the side bar ( Figure 3A). The user then clicks “Generate Schedule” and discovers that a 14.5 min staggering would be the best solution if they desired to handle each sample individually ( Figure 3B). By enabling the manual mode and inputting a 6-minute interval, the user can immediately visualize the resulting scheduling conflicts ( Figure 3C). This application of StaggR highlights its utility in allowing the exploration of viable and inviable workflows.
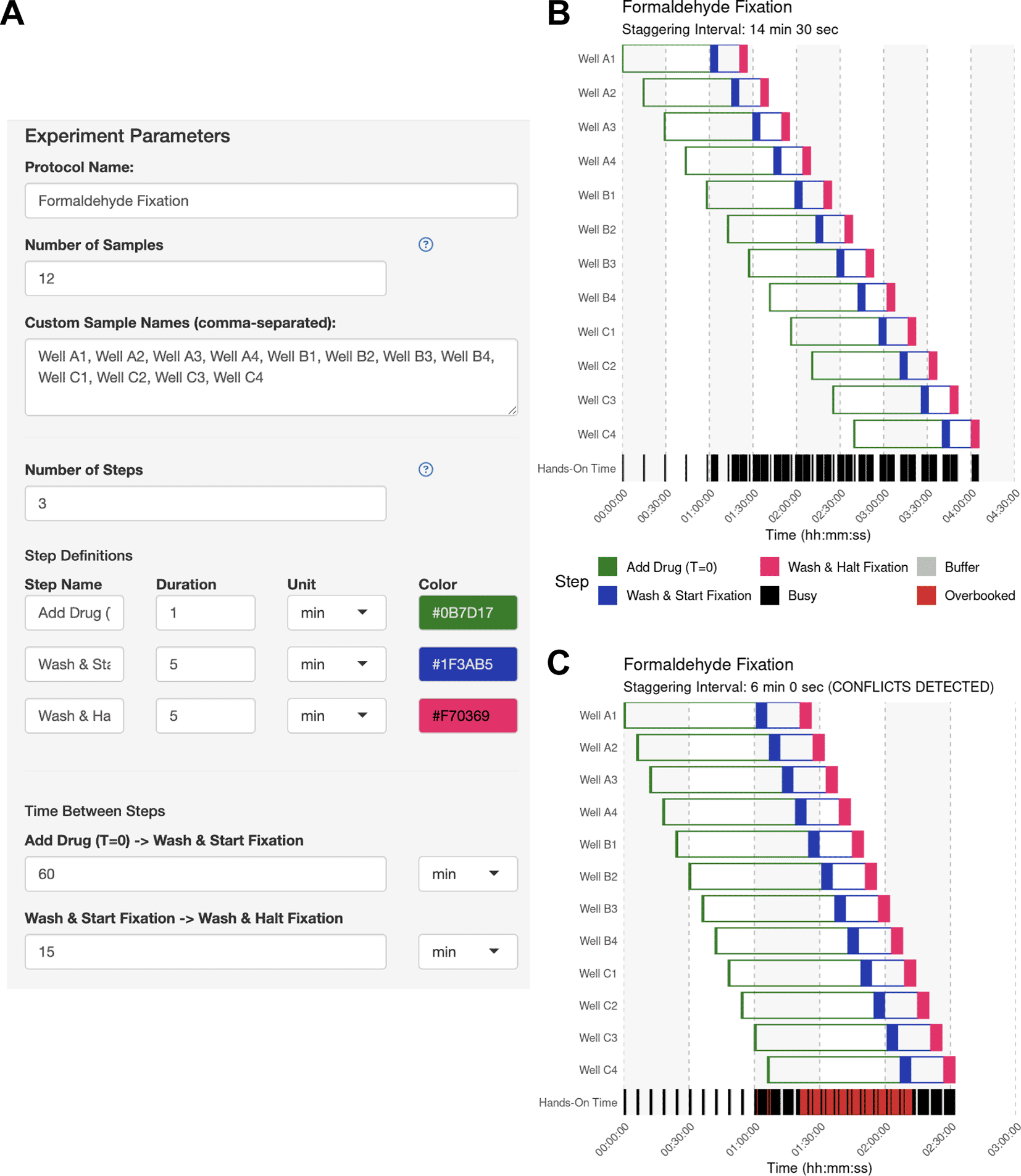
(A) The experiment parameter side panel is used to define the protocol. Users input sample descriptions and define each protocol step, including its name, color, hands-on duration, and the subsequent inter-step interval (wait time). In this example, each sample receives a 60-min drug treatment followed by a 15-min fixation. (B) Automatically identified interval for Use Case #1. Upon generating the schedule, the main panel of StaggR updates with a Gantt chart displaying a viable workflow, minimizing the staggering interval with the given constraints. The “Hands-On Time” row indicates periods that will require the user’s attention and periods where the user is expected to be unoccupied. (C) Manually defined interval for Use Case #1. Users may also provide a pre-defined staggering interval that may or may not produce a viable workflow. Conflicts between steps are immediately apparent and visualized in red in the “Hands-on Time” row. Users are further alerted to an incompatible schedule using a manually-defined interval in the subtitle of the Gantt chart.
In this use case, the user wishes to track genome-wide RNA synthesis and decay kinetics in yeast cells after depleting a transcription factor. To do this, they will add 4-thiouracil (4tU), which metabolically labels newly synthesized transcripts, allowing for the measurement of RNA synthesis and decay kinetics. The collection of RNA for 4tU-sequencing experiments (Barrass et al., 2015), provides genome-wide measurements of RNA production and degradation for every gene. However, this type of experiment is critically sensitive to the labeling time. For their experiment, the user will harvest cell pellets after 5, 15, 30, and 60 min of RNA labeling. They wish to perform these experiments in biological triplicate across four cell lines.
The user wants to know if they should schedule their experiments across multiple days, or if they can perform 12 independent time courses in parallel. The user performs a dry run of the experiment and thinks that they can initiate the 4tU treatment within 1 min and harvest the cells within 3 min. The user simply defines the anchor step (adding 4tU) and harvest step in the side bar ( Figure 4A) and enables the Time Course Helper, in which they specify the harvesting time points of 5, 15, 30, and 60 min after 4tU addition ( Figure 4B). After applying the time course, the step parameters were automatically updated ( Figure 4C), and the user immediately generates their optimal schedule with a 22-min staggering period ( Figure 4D). Here, the user leveraged StaggR to quickly and easily produce a viable time course and execute a procedure in one day, which might otherwise have taken several days.
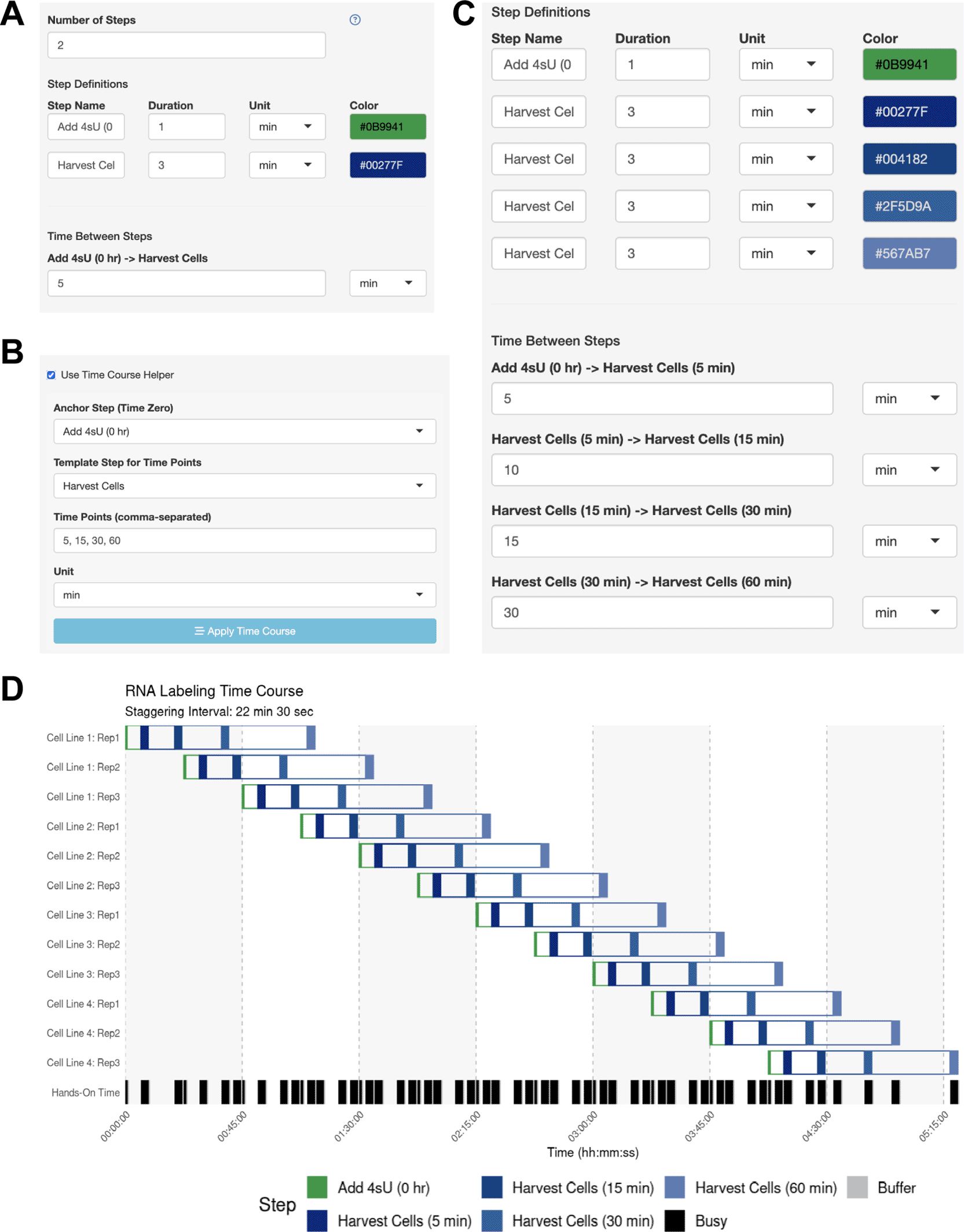
(A-C) Using the Time Course Helper. To use the Time Course Helper, the user will (A) define the “Anchoring” step for initiating the time course and the “Template” step to be repeated throughout (e.g., quench a reaction or harvest a sample), (B) activate the time course helper panel to select the appropriate steps and input the time points of the time course, and (C) apply the time course to automatically insert the time-stamped template steps with the appropriate inter-step interval. (D) Automatically identified interval for Use Case #2. Gantt chart illustrating the automatically-generated interval for Use Case #2.
This example outlines a complex workflow to process cultures of human K562 chronic myeloid leukemia cells, in which a protein of interest has been engineered to contain an auxin-inducible degron tag (Nishimura et al., 2009). The user wishes to examine how cells respond to DNA damage when the protein of interest has been depleted. The objective is to deplete the protein for 4 h with the drug auxin, and then challenge the cells with hydroxyurea (HU), an agent that promotes the accumulation of DNA damage (Yarbro, 1992). Over 4 h, the user plans to collect protein extracts to probe for levels of γH2AX, a marker of the DNA damage response (Mah et al., 2010) at time points of 0.5, 1, 2, and 4 h. The user plans to perform this experiment on two cell lines, but each cell line requires four conditions (+auxin/+HU, -auxin/+HU, +auxin/-HU, and-auxin/-HU) for a total of eight independent time courses. They estimated 0.5 min to add each drug, and 6 min to harvest at each time point.
The user sets up their sample parameters using the Time Course Helper, as in Case #2. After generating the schedule, they find that a 28-min staggering would work ( Figure 5A). Their trainee wishes to perform a similar protocol, so the mentor downloads the session to share as a.json file ( Figure 5B) which their trainee uploads into their own StaggR instance. However, after a dry run, the trainee estimates that it would take approximately 10 minutes to run the harvest themselves. Inputting 10 min for each harvest and re-generating the schedule shows that in this case, the workflow would require an 84 min stagger between each sample to execute ( Figure 5C). The trainee decides that they will need to either perform a faster harvesting step or split the experiment over multiple days. The trainee practices the harvest procedure to reduce the time to 6 min per step, loads the original workflow, and navigates to the Live Time Course tab. Here, they initiate the timer to show well-telegraphed step-by-step instructions for sample processing ( Figure 6). Using StaggR, the trainee avoids what would have been an inevitable and critical error in executing this complex workflow.
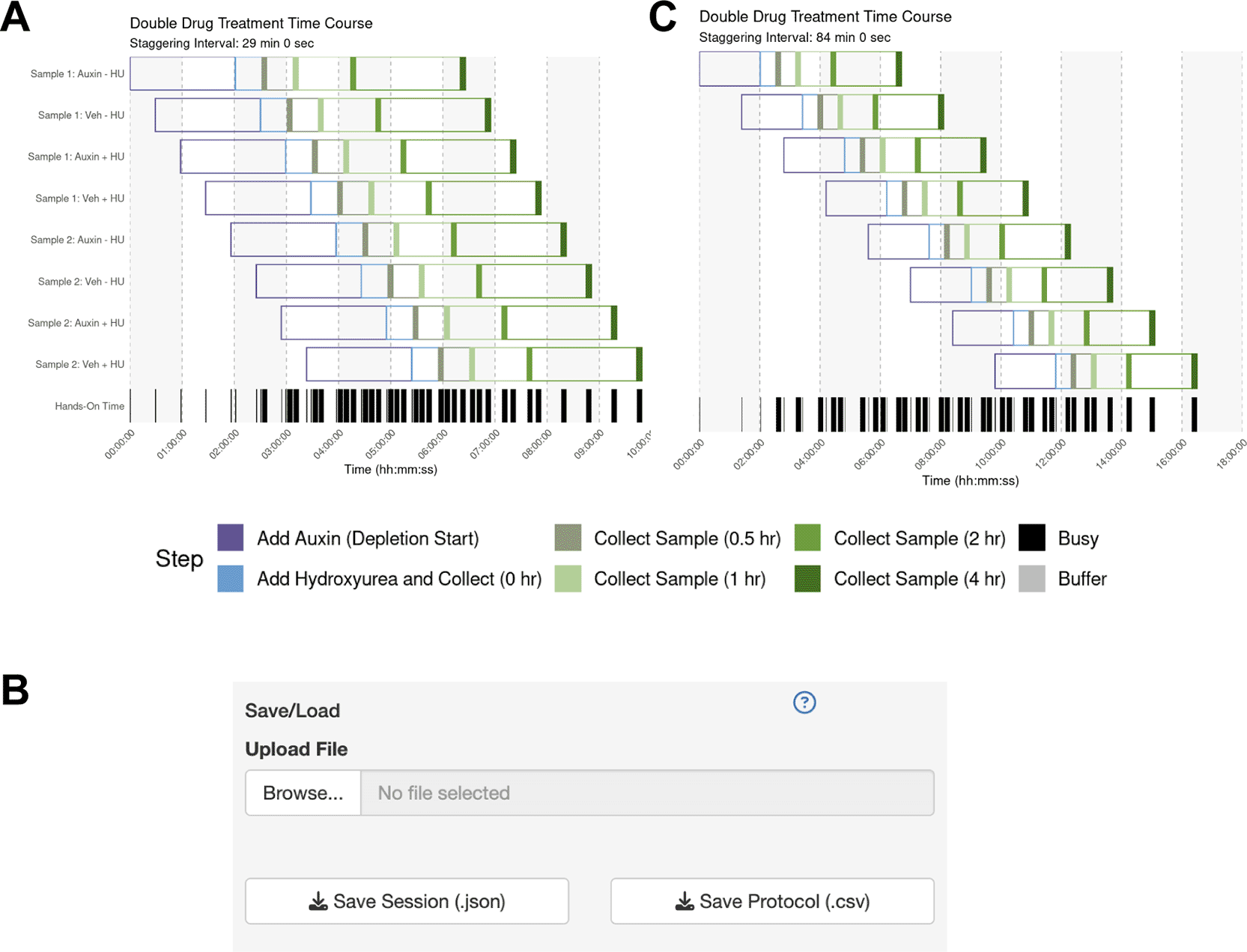
(A) Gantt chart showing the optimized schedule for a complex workflow assuming a 6-min harvest time, resulting in a 28-minute staggering interval. (B) The UI allows the protocol to be saved and shared with a trainee. (C) When the trainee adjusts the harvest duration to their estimated 10 min, the regenerated schedule shows that a conflict-free workflow now requires a much longer 84 min staggering interval, highlighting a potential bottleneck.
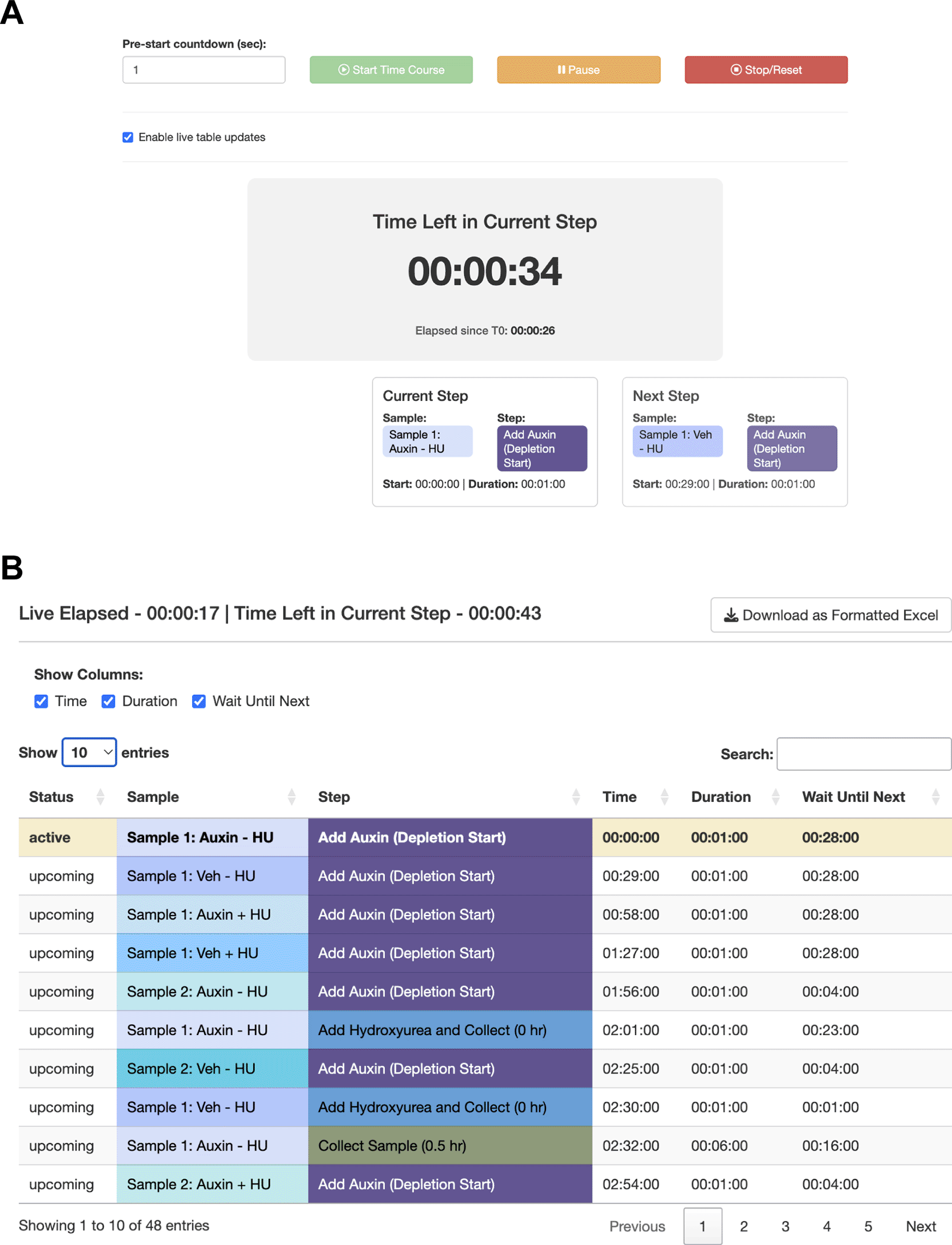
StaggR provides live guidance for executing a planned workflow. (A) The timer counts down to the start of the next required hands-on action for any sample. (B) The “Schedule by Time” table provides a chronological list of all steps, with live highlighting to track progression through the protocol.
To establish how user-defined parameters impact the performance of StaggR, the core “findOptimalInterval” function was isolated and benchmarked against 500 iterations of schedule optimization with varying input parameters (Figure 7). As granularity decreases, the cost to run StaggR increases exponentially (Figure 7A-B). While increasing the number of samples processed elevates resource usage, this effect quickly plateaus (Figure 7C-D). However, increasing the number of discrete operations for each protocol (complexity) does incur escalating cost to optimize (Figure 7E-F). The density of hands-on time for a given protocol has a minimal impact on the performance of StaggR, and these costs quickly saturate once the density exceeds a point where a viable staggering schedule can no longer be found (Figure 7G-H). Decreasing optimization granularity combined with increased protocol complexity leads to sharp increases in resource usage (Figure 7I-J). However, even in the most extreme scenarios examined the wall-time remains under one minute and RAM usage remains under 125 MB.
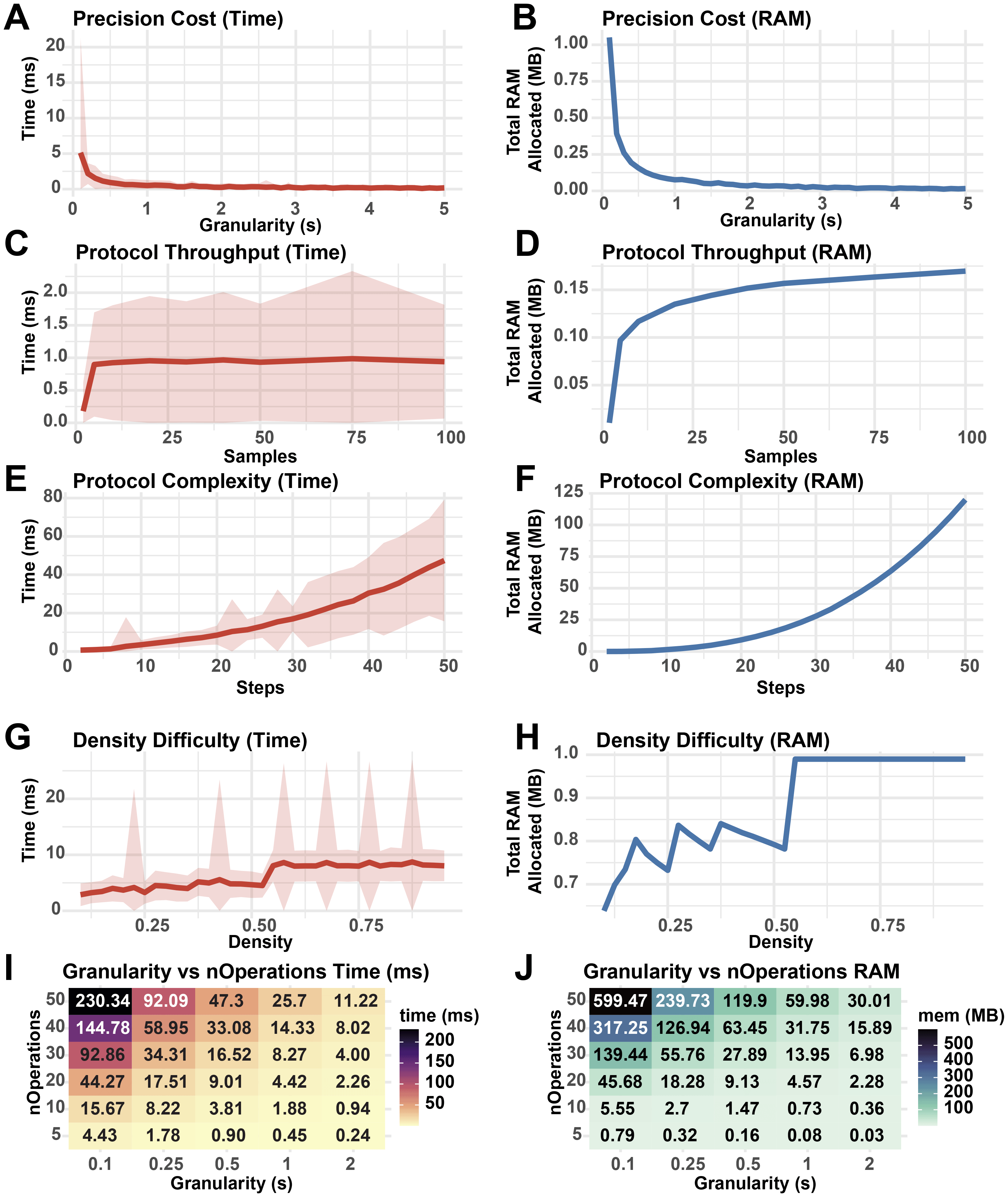
Performance metrics from 500 runs of StaggR schedule optimization logic against simulated protocols. A base protocol was defined with 5 steps of equal duration, optimization granularity = 0.5 min, nSamples = 50, buffer time = 0.25 min, and a total protocol time of nSteps * 10 min. The fraction of each protocol occupied by hands-on time was given by a density parameter from 0-1 where a density of 0.3 means 30% of the protocol duration was hands-on. Density was set to 0.5 unless otherwise stated. Each protocol was evaluated for the time to complete the optimization (A, C, E, G, I) and the total RAM used in the process (B, D, F, H, J). (A, B) Performance cost with increasing protocol granularity. (C, D) Performance cost with increasing sample throughput. (E, F) Performance cost with increasing number of operations per protocol. (G, H) Performance cost with increasing hands-on time density. (I, J) Resource usage with co-varying granularity and number of operations. Shaded areas represent the standard deviation in run times.
Overall, this analysis reveals that simulation granularity and the total number of operations to execute each protocol are the major performance bottlenecks of the scheduling algorithm. Given that realistic sample treatment regimens executed by humans are unlikely to exceed 50 sequential operations requiring extreme temporal precision, StaggR is expected to rapidly generate a report for most standard and non-standard protocols. However, users with highly complex protocols or large sample numbers are encouraged to run the application locally to utilize full system RAM.
StaggR reduces the cognitive load when managing multiple samples with identical treatment schedules by compressing the planning process. This enables the rapid exploration of alternative workflows so that users can quickly assess what is feasible, where conflicts might arise, and where natural breaks occur. This is particularly helpful when protocols are transferred between labs or users, as new execution-time constraints can introduce scheduling conflicts. Sharing protocols and sessions with StaggR makes such conflicts readily apparent and easily preventable. StaggR also boosts the laboratory throughput by minimizing the time required to handle batches of samples.
Many strategies exist to address the FSSP, such as Genetic Algorithms, Simulated Annealing, and Tabu Search (Komaki et al., 2018) which can efficiently search the space of heterogeneous sample processing regimes to provide an optimal solution. StaggR is not designed to present a novel solution to the FSSP but to provide a convenient platform for experimental design and execution. Future versions of StaggR may implement more nuanced FSSP strategies that make fewer assumptions regarding the homogeneity of each treatment schedule and more efficiently search the space of potential treatment workflows. Nonetheless, as a standalone planning and execution tool, StaggR reduces cognitive barriers to provide immediate value for any lab that aims to perform time-sensitive assays in parallel.
By removing the guesswork and potential error in scheduling identical procedures with asynchronous start times, StaggR can empower researchers from diverse fields to perform high-throughput experiments with greater confidence, efficiency, and reproducibility. Its open source and interactive nature makes it an ideal and broadly applicable tool for planning novel experiments and training personnel on established laboratory workflows.
• Web Application: StaggR is available for immediate use at https://alexfrancette.shinyapps.io/staggr/
• Source code available from: The complete R source code is available on GitHub: https://github.com/amfrancette/StaggR
• Archived source code at time of publication: https://doi.org/10.5281/zenodo.18132229
• License: StaggR is distributed under the MIT License.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)