Keywords
Transformer; Anomaly Detection; Network Traffic; Intrusion Detection System; Time Series; cyber security; deep learning
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
Transformer; Anomaly Detection; Network Traffic; Intrusion Detection System; Time Series; cyber security; deep learning
Driven by the ever-growing number of connected devices and the number of digital services available on these devices, global internet traffic is increasing exponentially, and the number and complexity of cyberattacks are also increasing exponentially at the same time.1 As this threat environment continues to evolve, perimeter-based security strategies will not be able to meet these challenges, and IDS will be one of the key components of new defense mechanisms for modern networks.2 IDS are critical because they continuously scan the network traffic for malicious behavior or policy violations; through continuous monitoring, IDS can detect and respond to threats before they can do any serious damage. However, detecting anomalies within network traffic data presents significant challenges, and these challenges are due to many factors inherent in the nature of the data itself. First, network traffic data is continually changing; second, patterns of network traffic data continually change as a result of user behavior changes, network upgrades, and time of day, which makes it difficult to define a static baseline for defining normal patterns. The difficulty in creating clear distinctions between harmful and innocent actions is increased because cybercriminals frequently develop new tactics to disguise their activity as innocently as possible in order to avoid discovery through traditional means of detection. In conjunction with the issue of being able to identify benign versus malicious activities, the detection of anomaly behavior in this case is an example of a classic scenario of extreme class imbalances where there are far more instances of benign traffic than there are actual attacks and thus due to having predominant amounts of the majority class compared to the very few instances of the minority class being used to train an algorithm the learning algorithm may learn to produce extremely high levels of performance with respect to accuracy (e.g., 99%) on benign instances, and therefore will likely not identify the event being sought to be identified.11 Furthermore, actions taken with a malicious intent rarely are a single act of malicious behavior; they are usually a series of actions that occur over a period of time (e.g., from the slow, methodical reconnaissance phase associated with APTs to larger volumes of traffic on a given network in direct relation to a DDoS attack). Therefore, an effective model for detecting malicious behaviour must be able to capture both short-term anomalies in traffic as well as long deferred temporal relationships between traffic flows.
Traditional methodologies attempting to solve this issue often relied upon using classical Machine Learning algorithms, such as Support Vector Machines (SVM), Random Forests, and Isolation Forests. While these approaches laid foundation for a data-driven detection model, they suffered limitations related to being dependent on manually designed features to capture and represent the complex high-dimensional patterns associated with raw network traffic data. Deep Learning opened new opportunities by providing a mechanism through which models learn hierarchical feature representations automatically from the data itself. Recurrent Neural Networks (RNNs), and subsequently Long Short-Term Memory Networks (LSTMs) have risen in prominence as effective ways to model network traffic data due primarily to the sequential nature of network traffic events.4 LSTMs specifically have shown an excellent ability to learn temporal dependency relationships, resulting in widespread usage for time-series anomaly detection. Yet RNNs and their related models do have considerable limitations. Their sequential process makes them cumbersome to train on long sequences of events because of the time required to process each individual record separately; and they also have difficulty learning extremely long-range dependencies because of the vanishing gradient issue, which is particularly problematic when correlating events that are separated by thousands of time steps.3
Transformers led to an abrupt change in how sequences are modeled. Originally conceived for machine translation,5 the Transformer does not use recurrence at all; rather, it uses multi-head, self-attention to enable each model element to simultaneously assess how significant all other elements in the sequence are relative to one another without regard for the distance between them, and thus captures dependency relations directly, regardless of how much time has passed between them. Furthermore, the Transformer is now considered the de facto standard for natural language processing but has also performed very well in areas outside natural language processing, such as computer vision and general time-series forecasting. The self-attention mechanism offers significant advantages over LSTMs for network traffic analysis because it can potentially correlate a malicious packet early in a flow with a specific response thousands of packets later, which is extremely difficult for an LSTM model to accomplish. Additionally, the parallelizable nature of the Transformer provides considerable speed advantages while the model is being trained.
Although there are many fields where Transformers have made a significant contribution, the use of Transformers for anomaly detection in raw time-series network traffic data has been little researched. There have been a few initial investigations into this, but there are also some critical limitations in the existing transformers. Firstly, the majority of existing Transformer approaches for network traffic are based on supervised classification tasks and rely on large amounts of labeled attack data, which is expensive to obtain and cannot be generalized to new attacks.6 Secondly, most of the existing unsupervised methods for network traffic, generally, are designed for time-series data that are purely numerical and have few good options for handling the combination of categorical and numerical features present in the network flow data,7,8 Finally, interpretability is generally ignored in the previous works, and the attention mechanism’s ability to provide explanations to security analysts as to why a particular traffic segment has been classified as anomalous is critical for facilitating a timely response to incidents and establishing trustworthiness in the model.2,9 Fourth, existing models do not adequately address the severe class imbalance problem, often resulting in high false positive rates that render them impractical for real-world deployment. Finally, there has been no comprehensive evaluation of Transformer-based unsupervised anomaly detection on modern, benchmark network datasets that captures the full complexity of contemporary attacks.
This paper introduces NetFormer, a unique Transformer-like structure for unsupervised anomaly detection in time series from network flows. A framework called NetFormer is presented in this article that leverages Transformers to achieve unsupervised anomaly detection for network flow data in time series format. Several issues related to the application of Transformers to network data are addressed through four key contributions: 1) a dual-stream encoder/decoder embedding structure. 2) an unsupervised reconstruction-based training approach. 3) an interpretability framework using attention. Lastly, NetFormer is evaluated against 15 well-established and novel baselines across both the CSE-CIC-IDS2018 and the UNSW-NB15 benchmark datasets including multiple ablation studies to evaluate the architectural contribution(s) of each component. Overall NetFormer outperformed the best methods for precision, recall, and F1-score while also producing significantly fewer false positives compared to the current leading methods. Fifth, we provide an extensive ablation study that identifies which particular architectural models and training strategies have the greatest impact on network anomaly detection performance and offer insight into how to choose among design options. Sixth, we are making all of our code and pre-trained models available publicly in order to enable reproducible results and provide further opportunities for research in this area to help address the ongoing reproducibility crisis in much of our current literature.
The remainder of this paper is structured as follows; Section 2 provides an overview of previous work done in intrusion detection and in applications of Transformers, Section 3 explains the architecture and methodology of NetFormer, Section 4 describes the experimental setup, datasets and evaluation metrics used, Section 5 presents and analyzes the results from the experiments: including cross-dataset validation, an ablation study and an analysis of efficiency; Section 6 discusses implications of the work presented, limitations and future directions and finally, Section 7 concludes. For reproducibility we make the source code publicly available at netformer-nids repository 1.
Historically, intrusion detection systems have been categorised into two main types of detection; namely, signature-based detection and anomaly-based detection. Signature-based detection methods rely on pre-defined (known) patterns of attack that have occurred previously. Therefore, they can be very effective in identifying known threats with a high level of accuracy and a low-level of false positive rate; however, they will fail catastrophically in the case of new or zero-day attacks.2 Anomaly-based detection, on the other hand, uses a baseline of normal network behaviour and identifies abnormal behaviour as a possible malicious event; thus, theoretically, it is capable of identifying unknown attacks. This is where machine learning and deep learning techniques have made their largest impact in terms of research; they have provided significant support to those researchers who are trying to improve detection rates and decrease false alarms. The initial attempts to use machine-learning techniques relied on statistical methods that were based on traditional methods of statistical analysis and machine learning algorithms. Statistical analyses used such methods as moving averages and an autoregressive integrated moving average (ARIMA) model to identify points in time that were significantly different from the predicted values by modelling the temporal pattern of network traffic. However, these methods were unsuccessful when used with real traffic due to their reliance upon strong assumptions of the underlying data distributions and due to the fact that real-world network traffic is non-stationary and incredibly complicated in nature.10 To help address some of these limitations, researchers began to turn towards classical machine learning techniques. One such method is the One-Class Support Vector Machine (OC-SVM), which was developed for the purpose of learning the boundary of normal data points in high dimensional feature space. For example, in this study showed that OC-SVM can be used to detect network intrusions by learning the boundary around normal data points in a high-dimensional feature space.11 Another different method developed called Isolation Forest, which works by isolating anomalies instead of profiling normal data points, because of the view that anomalies are typically far fewer than normal data points, and therefore much easier to isolate from them.12 Other clustering methods like K-Means have also been proposed as potentially useful methods to classify normal and anomalous data based on the idea that normal traffic will form a large, dense cluster, while anomalous traffic will sporadically scatter as outliers, or form very small, sparse clusters.13
The introduction of deep learning changed many things about how our models learn, allowing for the automatic learning of hierarchically organized feature representations from data by the models themselves. CNNs (convolutional neural networks), which have had much previous success in computer vision applications, have also been used to analyze and classify network anomalies by converting one-dimensional (1D) traffic sequences (or flow statistics) into two-dimensional (2D) representations, i.e., treating the traffic as an “image” to extract spatial features from. An example of this is the work, that applied CNNs to learn salient patterns associated with malicious (or bad) activity from network traffic automatically.14 Wang study extended this area of research and created a CNN-based model for malware traffic classification using only raw traffic data and achieved high levels of accuracy without requiring any manual feature engineering.15 However, since network traffic is actually a sequence of time-based data, an architecture specifically designed to model data over time will have a greater degree of success in achieving this goal than one designed to model only spatial data. Therefore, RNNs (recurrent neural networks) in particular, LSTMs (long short-term memory networks) introduced to became the standard approach for achieving this objective,4 since LSTMs were specifically created to help alleviate the vanishing gradient problem and allow the learning of long-range dependencies when using RNNs. The work of Kim and colleagues showed that a recurrent neural network (RNN) can be used successfully to build an intrusion detection system. The advantage to using a long short-term memory (LSTM) model over traditional machine learning approaches is that the LSTM can identify temporal patterns in network traffic. Similar success has also been achieved using gated recurrent units (GRUs), which are simpler than LSTMs, as shown by Dey and Salem,16 on improvements in various sequential domains.
Generative models are another effective group of deep learning techniques that can be used for anomaly detection. For example, autoencoders are deep learning models that learn a compressed representation of “normal” data by passing input through a bottleneck layer and then reconstructing the original input from that compressed representation (after training). At inference time, the reconstruction error provides the anomaly score, with the assumption that an anomaly will be poorly reconstructed (i.e., have a large reconstruction error), since it deviates from the normal patterns the autoencoder learned. This study successfully implemented this method in their Kitsune framework,17 which is a plug-and-play network intrusion detection system (NIDS) containing an ensemble of autoencoders to detect anomalies in real-time.
The issue of interpretability in deep learning models used in security has come to the forefront recently. Complex models produce high accuracy; however, their black-box nature is an issue in a security context since it is important to be able to understand how the model came to the conclusion that an alert occurred in order to respond appropriately to that incident. Study addressed this concern by proposing explainable deep learning techniques for intrusion detection via using layer-wise relevance propagation to identify what features contributed most to the model producing a classification decision.18 For example, study proposed an interpretable framework to detect anomalies in network traffic using attention mechanisms in LSTM networks,9 which demonstrated that the attention weights could help identify the time steps and features that were most indicative of an attack. These studies highlight the developing realisation that there must be a balance between the performance of a model and its explainability in order for it to be useful in operational security settings. The introduction of the Transformer architecture represents a major shift in how sequence data can be modelled.5 The Transformer architecture, unlike recurrent neural networks (RNNs), processes entire sequences all at once and creates global dependencies between inputs and outputs only by using multi-head self-attention. Multi-head self-attention allows the model to learn how much attention to pay to elements in a sequence by calculating a weighted sum from all elements in the sequence for each one, based on their similarity. As a result, self-attention enables the model to attend to any element of the sequence independently of its distance from any other element; therefore, it resolves the long-range dependency problem. To account for the absence of recurrent connections, positional encoding is used to add information about the position of each input within its sequence, via adding it to the sequence’s input embedding. The architecture of the Transformer offers two major advantages over RNNs for time series analysis, which are: (1) the capacity to efficiently capture arbitrarily long-range dependencies in a single computational step; and (2) the ability to process multiple sequences in parallel, leading to much faster training times. In addition, since self-attention calculates a weighted average from all pairs of elements, it can provide a natural source of interpretability for the model, as it is possible to visualize the attention weights and see where the model focuses its attention; an approach that has been explored in detail through19 with respect to Natural Language Processing.
The success of using Transformers has generated a heightened interest in exploiting them for detecting anomalies in different fields based on time-series data. For the area of general time-series data, TranAD,7 has made use of the transformer encoder and decoder architecture combined with adversarial training to enhance and expedite anomaly detection in telemetry data, exhibiting a considerable increase in performance when compared to LSTM approach based on benchmark datasets. In addition, study showed that the Transformer encoder architecture was able to outperform the best performing RNN and CNN models on multivariate time-series classification tasks, suggesting a possibility for the Transformer architecture to also perform well at detection.20 Additionally, in the narrower context of logs, which are of a sequential nature like network traffic, Log Anomaly produced based on a transformer for the purpose of detecting anomalies in log sequences by utilizing both sequential and quantitative patterns, showing that the attention mechanism was able to identify anomalous patterns of log events effectively.21 Anomaly Transformer was introduced8 as part of their state-of-the-art efforts in time-series anomaly detection. This model uses a prior-association mechanism to jointly model temporal relations and separate normal from anomalous points in time series, allowing it to perform well across multiple public datasets. For network traffic specifically, Study presented a Transformer-based intrusion detection system that handled network flow data via pre-classified training (supervised classification) requiring labeled attack data for training; while their work is based on earlier Transformer research and performs well on publicly available datasets, it was not aimed at unsupervised anomaly detection.22
Despite the advancement of Transformers applications in related domains, overall, there has been little research on employing Transformers directly on unfiltered, temporal sequences of network traffic data to perform unsupervised anomaly detection. The few studies that have examined this area have overwhelmingly been focused on classification (rather than detection), or do not adequately consider some of the unique challenges associated with using network data, such as the presence of both categorical and numerical variables, and the need to account for significant class imbalances. Additionally, although some Transformer-based time-series anomaly detection models have been applied in the realm of general time-series analysis, these models have typically been designed to handle purely numeric datasets, and do not use special embedding techniques to process mixed-format datasets. The lack of a general-purpose framework to develop a customized Transformer architecture specifically for the purpose of performing unsupervised anomaly detections on network flows, to implement a sound embedding methodology to deal with mixed-format categorical and numeric data, to appropriately deal with class imbalances during model training, and to provide a thorough examination of the ability of the model to be interpreted through its attention mechanisms, is apparent. Furthermore, previous research has failed to use the self-attention mechanism’s full capability of providing an explanation of how detections were made, which is critical in establishing trust in automated security systems. The literature lacks the potential for a model to utilize the entire capability of the self-attention of the Transformer, and to model the intricacies inherent in the complex, long-term temporal data involved in network attacks while providing interpretability of how the model reached its detection decisions; therefore, attention visualization and feature attribution analysis will be performed on the proposed work, named NetFormer, according to the level of interpretability that was provided in prior Transformer-based network anomaly detection studies. In addition, the proposed study will demonstrate the superiority of NetFormer over previous methods on benchmark datasets with respect to interpretability of the model’s detection decision process as compared to previous Transformer-based network anomaly detection studies, as well as provide a detailed explanation of how the interpretability of the model’s decision-making process was obtained.
A comparative summary of the reviewed classical, deep learning, and Transformer-based approaches is provided in Tables 1a and 1b (located after the references), highlighting the gaps that NetFormer aims to fill.
| Study | Method | Application domain | Handles mixed data types | Focus on unsupervised anomaly detection | Captures long-range dependencies | Provides interpretability analysis |
|---|---|---|---|---|---|---|
| Ahmed10 | Statistical (ARIMA) | Network Traffic | Limited | Yes | Limited | No |
| Amer11 | One-Class SVM | Network Traffic | Yes | Yes | No | No |
| Liu16 | Isolation Forest | General Anomaly | Yes | Yes | No | No |
| Münz13 | K-Means Clustering | Network Traffic | Yes | Yes | No | No |
| Vinayakumar14 | CNN | Network Traffic | Yes | No (Supervised) | No | Limited |
| Wang15 | CNN | Malware Traffic | Yes | No (Supervised) | No | No |
| Graves4 | LSTM | General Sequence | No | No | Moderate | No |
| Kim23 | LSTM | Network Traffic | Yes | Yes | Moderate | No |
| Dey & Salem16 | GRU | General Sequence | No | No | Moderate | No |
| Bai31 | TCN | General Sequence | No | No | Strong | No |
| Mirsky17 | Autoencoder (Kitsune) | Network Traffic | Yes | Yes | Limited (by window) | Limited |
| Zenati et al. (2018) | GAN | General & Network | Yes | Yes | No | No |
| An & Cho24 | VAE | General Anomaly | No | Yes | No | No |
| Amarasinghe2 | Explainable DL | Network Traffic | Yes | No (Supervised) | Limited | Yes |
| Yu9 | Attention-LSTM | Network Traffic | Yes | Yes | Moderate | Yes |
| Study | Method | Application domain | Handles mixd data types | Focus on unsupervised anomaly detection | Captures long-range dependencies | Provides interpretability analysis |
|---|---|---|---|---|---|---|
| Vaswani5 | Transformer | NLP | No | No | Strong | Limited |
| Clark19 | Attention Analysis | NLP | No | No | Strong | Yes |
| Tuli7 | Transformer (TranAD) | General Time-Series | No (Assumes Numerical) | Yes | Strong | No |
| Zerveas20 | Transformer Encoder | Multivariate Time-Series | No | No (Classification) | Strong | Limited |
| Meng21 | Transformer (LogAnomaly) | System Logs | Yes (Log Parsing) | Yes | Strong | Yes |
| Xu8 | Anomaly Transformer | General Time-Series | No | Yes | Strong | Limited |
| Long22 | Transformer | Network Traffic | Yes | No (Supervised) | Strong | No |
| Liu and Wu6 | Hybrid CNN-Transformer | Network Traffic | Yes | No (Classification) | Strong | No |
| Huang25 | Transformer | Network Traffic | Yes | Yes | Strong | No |
| This Work (NetFormer) | Custom Transformer | Network Traffic | Yes (Dedicated Strategy) | Yes | Strong | Yes (Attention Analysis) |
This section presents the methodological framework for unsupervised anomaly detection in network traffic time series using the proposed Transformer-based model, NetFormer. The methodology encompasses dataset selection, preprocessing, model architecture, and training procedures, each designed to address the unique challenges of network data including temporal dependencies, mixed feature types, and class imbalance.
The selected dataset CSE-CIC-IDS2018 is the result of cooperation between the Communications Security Establishment (CSE) and the Canadian Institute for Cyber Security (CIC) in 2018. It was selected because it provides a modern-source dataset that represents current network environments and the kinds of cyber threats that exist today since it was created from a sophisticated Amazon Web Services (AWS) testbed that simulates complex network infrastructures,26 contains a wide variety of benign and malicious flow records with accurate labels, and is realistic in its class imbalance as the volume of normal traffic far exceeds attack records.29 The dataset consists of approximately 16 million flow records and each flow has 83 attributes, including numerical attributes (flow duration, total packets and total bytes) and categorical attributes (protocol, service, connection state). The distribution of different attack types within the dataset is shown in Table 2.
The percentages shown are based on total labelled instances of attack. The data set is highly imbalanced between classesو the total number of normal flow instances accounts for approx. 83% of the total flows, with flows categorised as attack accounting for Approx 17% of total flows.
3.1.1 UNSW-NB15 Dataset
To evaluate the generalizability and stability of NetFormer in different types of networks, we validate on UNSW-NB15.45 The UNSW-NB15 dataset was generated by the Cyber Range Lab at Australia’s ACCS. It means that it represents contemporary attack behaviors and flows that are representative of a modern way of life. This will mean the dataset has approximately 2.5 million records with each record containing 49 features which can be either numerical or categorical. Additionally, this dataset contains samples from nine attack classes (e.g., Fuzzers, Analysis, Backdoors, Denial of Service (DoS), Exploiting/Entrappings, Generic, Reconnaissance, Shellcoding and Worms) making it an excellent test case for classifying and predicting outlier data. Sample pre-processing methods have been combined with the pre-processing methods mentioned on page 4, but the temporal windows are defined as L5100 to keep with the previous analyses.
3.2.1 Data cleaning
Listwise deletion is used to eliminate flows with missing numerical values (less than 1% of the total flows) in order to avoid introducing imputed values. For categorical feature types, missing values are treated as a new category which will allow the model to develop relationships between missing information and flows without complete records.30
3.2.2 Categorical feature encoding
For low cardinality features (e.g. protocol type), one-hot encoding has been used to create binary indicator arrays. For high cardinality features (e.g. destination service), label encoding creates an individual integer for each unique value that will be passed on through learned embedding layers in training.42,32
3.2.3 Feature normalization
All numerical features are standardized using Z-score normalization:
3.2.4 Temporal windowing
Individual flows are transformed into fixed-length sequences using a sliding window approach. Given flows ordered by timestamp, windows of length flows with stride
The total number of windows is , following the methodology of Mirsky.17
Figure 1 provides a high-level overview of the NetFormer architecture, illustrating the flow from raw traffic through preprocessing to anomaly detection.
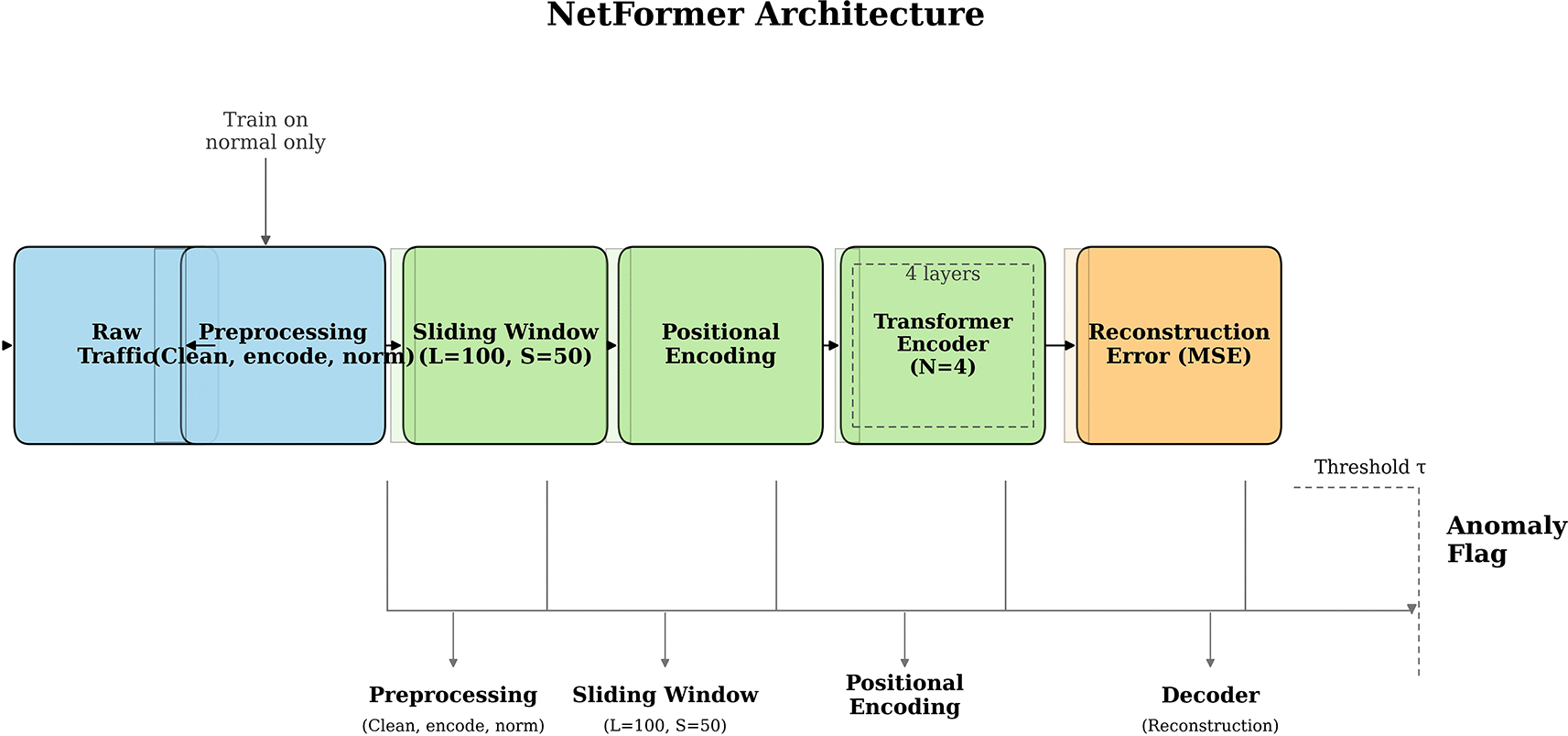
The NetFormer framework processes raw network traffic through preprocessing, sliding window segmentation, dual-stream embedding, positional encoding, Transformer encoder layers, and reconstruction-based decoding to compute anomaly scores.
3.3.1 Dual-stream embedding layer
For categorical features, each feature with unique values are mapped to a dense vector through an embedding matrix :
The embedding dimension follows 32 Numerical features are projected linearly:
The unified flow embedding is formed by concatenation, where . The sequence of embeddings is .
3.3.2 Positional encoding
Fixed sinusoidal positional encodings inject temporal order information:
3.3.3 Transformer encoder layers
The encoder consists of identical layers. Each layer applies multi-head self-attention followed by position-wise feed-forward networks, with residual connections and layer normalization. Multi-head attention is computed as:
With heads, , and . The feed-forward network expands the dimension to :
Layer normalization and residual connections are applied around each sub-layer. Table 3 summarizes the architectural hyperparameters.
3.3.4 Output layer and anomaly detection
We adopt a reconstruction-based autoencoder approach. The Transformer encoder produces latent representations , and a symmetric decoder reconstructs the input . The reconstruction error for sequence is:
Sequences with reconstruction error exceeding threshold (determined from validation set distribution) are flagged as anomalous.
3.4.1 Data splitting
The dataset is split temporally: 60% for training, 20% for validation, 20% for testing. Only windows composed entirely of normal traffic are used for training, following unsupervised learning principles.27
3.4.2 Loss function and optimization
The total training objective combines MSE reconstruction loss with L2 regularization:
3.4.3 Regularization and auxiliary techniques
Dropout with rate 0.1 is applied after each sub-layer. Early stopping terminates training if validation loss does not improve for 10 epochs. Gradient clipping with maximum norm 1.0 prevents exploding gradients. Batch normalization is applied within feed-forward networks. Table 4 summarizes training hyperparameters. The model is implemented in PyTorch and trained on an NVIDIA Tesla V100 GPU.
| Hyperparameter | Value |
|---|---|
| Optimizer | Adam |
| Learning Rate ( ) | |
| Batch Size | 64 |
| Max Epochs | 100 |
| Early Stopping Patience | 10 epochs |
| Dropout Rate | 0.1 |
| L2 Regularization ( ) | |
| Gradient Clipping Norm | 1.0 |
The source code used to generate this work can be found at the repository mentioned in the footnote for complete reproducibility (see footnote for link). The implementation depends on Python 3.9 and PyTorch 1.13.0. Training took place on one NVIDIA Tesla V100 GPU (32GB memory). To ensure reproducible and deterministic results, random seed was set to 42 for every experiment conducted in this research project. The configuration files containing the model’s hyperparameter values and training arguments are located in the repository in the configs/directory. The 95th percentile of the validation reconstruction error for threshold selection; therefore, for the CSE-CIC-IDS2018 dataset its exact threshold value is τ = 0.042.
This section discusses an in-depth evaluation of the performance of the NetFormer model for unsupervised anomaly detection in time series data from network traffic. We will first detail the experimental configuration, the evaluation metrics used, and the baseline methods against which to compare the NetFormer results, and then we will provide a comparison of the mathematical results between the Neural Network Model and existing best practices. Finally, a qualitative analysis providing insights into the performance of the model and understanding what features drive the model’s success will be provided through attention map renderings, distribution of reconstruction errors, and an analysis of the importance of each feature.
4.1.1 Evaluation metrics
Evaluating the performance of the anomaly detection models used in network intrusion detection is crucial as it must properly account for multiple evaluation metrics based on the inherent class imbalance of the dataset of normal and attack traffic where there are many more normal traffic sequences than attack traffic sequences. Based on best practices from other research efforts associated with anomaly detection,28,29 we will conduct a comprehensive evaluation based on the metrics defined below that will include performance evaluation metrics that are disparate. TP = true positive, the number of correctly identified anomalous sequences TN = true negative, the number of correctly identified normal sequences FP = false positive, the number of incorrectly identified normal sequences as anomalous FN = false negative, the number of incorrectly identified anomalous sequences as normal. Based on these quantities, we compute the following metrics: Accuracy measures the overall proportion of correct predictions:
Precision (also called Positive Predictive Value) measures the proportion of correctly identified anomalies among all sequences flagged as anomalous:
Recall (also called True Positive Rate or Sensitivity) measures the proportion of actual anomalies that were correctly identified:
F1-Score provides the harmonic mean of precision and recall, offering a balanced metric particularly useful when class distribution is uneven:
False Positive Rate (FPR) measures the proportion of normal sequences incorrectly flagged as anomalous:
We utilize two types of metrics to evaluate models for classification tasks: thresholds and no thresholds/threshold-agnostic measures. Threshold-agnostic measurements include the Receiver Operating Characteristic (ROC) curve which plots the true positive rate vs false positive rate at different threshold settings and the Area Under the ROC Curve (AUC-ROC), a single number summary of ROC curve performance. The closer AUC-ROC is to 1, the better the discrimination performance of the model. While the ROC curve can be misleading as an evaluation tool for very unbalanced datasets,33 the Precision-Recall (PR) curve provides an alternative method of evaluation by plotting precision vs recall at different thresholds. AUC-PR, which is the area under the PR curve, is an especially helpful measure for very unbalanced datasets because it emphasizes performance of the minority (anomaly) class.
4.1.2 Baseline methods
In order to demonstrate the ability of the NetFormer model, we compare its performance with many other types of anomaly detection baseline models from both classical machine learning and traditional deep learning approaches, as well as more currently available transformer-based models. The selection of these various types of models provides a comprehensive perspective on the ability of NetFormer to perform against a variety of competing techniques. Each of the baseline models was run using their respective configuration found in their original paper, and the hyperparameters of each baseline model were optimized/selected based on the results of running the baseline models on the validation set.
Classical Machine Learning Baselines:
• Isolation forest is an ensemble method that isolates the outliers by randomly partitioning the feature space.25 Anomalies are those with fewer partitions to be isolated because they are few and different (the fewer partitioned to isolate an instance means that it is more likely to be an anomaly). For this experiment, we used 100 estimators, and the contamination was set to match the percentage of expected anomalies in the validation set.
• One-class SVM is a kernel-based approach that learns the boundary around all the normal data instances as defined in the transformed feature space for a specified kernel. All points lying outside this boundary are considered anomalies.43 The kernel used was RBF, with a ν parameter setting of 0.1 due to being the expected upper limit of the fraction of anomalies.
• Local outlier factor is a density-based approach finding the relative density of a given point compared to its neighbours. Points that are much denser than their neighbours are considered to be anomalies.6 For this study, we used 20 neighbours and Minkowski distance as the distance measure.
Deep Learning Baselines:
• LSTM-Autoencoder Model created, using an RNN Autoencoder where the Encoder and Decoder utilize LSTM Layers to learn the Temporal Dependency of the Data.40 This model learns to reconstruct a normal sequence of data, where the Anomaly Score is determined by using the condition of error reconstruction. We have specified that our architecture consists of 2 LSTM Layers with 128 Hidden Units, a Window Length of 100 and a Dropout Rate of 0.2.
• CNN-Autoencoder Model, this model utilizes a 1D Convolutional Autoencoder to extract the Local Time Pattern of the Model. In this Encoder Architecture there are three Convolutional Layers with Filter Sizes of 64 (Filter 1), 32 (Filter 2) and 16 (Filter 3), with a Kernel Size of 3 and a Stride of 2.41 The architecture of the Decoder is constructed using Transposed Convolutions that reconstructs the input. The Anomaly Score for this Architecture is calculated from the error that is reconstructed from the Decoder.
• The TranAD model developed is a recently proposed transformer-model based on how to classify Multivariate Time Series Anomaly Detection Data using Adversarial Training and Self-Conditioning; the TranAD model’s Encoder uses 4 Layers, 8 Attention Heads and a Model Dimension of 128. The Model is trained by utilizing both Reconstruction Loss and Advers.28
• Developed Anomaly Transformer, a Transformer-based model designed for Time Series Anomaly Detection; this model uses an Association Discrepancy (PAT) Mechanism to distinguish between Normal patterns and Anomalous patterns. We utilized the Default Configuration for this model with 3 Encoder Layers, 8 Attention Heads, and a Model Dimension of 256.8
• Simple Transformer Encoder: A simplified Transformer model consisting of 4 encoder layers with the same embedding strategy as NetFormer but without the reconstruction-based decoder. Instead, it uses the final hidden states passed through a linear layer for classification, trained in a supervised manner on labeled data. This baseline helps isolate the contribution of the unsupervised reconstruction approach.
All deep learning baselines were trained for a maximum of 100 epochs with early stopping based on validation loss, using the Adam optimizer with learning rate and batch size 64. For unsupervised methods (LSTM-Autoencoder, CNN-Autoencoder, TranAD, and Anomaly Transformer), training was performed exclusively on normal traffic windows. For the supervised Simple Transformer, training consisted of standard cross-entropy loss on normal and anomalous windows. It is important to note that while this supervised baseline provides an informative empirical upper bound as to what a Transformer architecture can achieve under the presence of labeled attack data during training, its inclusion is not for comparison purposes with any form of “fair” evaluation against the unsupervised NetFormer. The main comparative emphasis is on all unsupervised baselines (LSTM-AE, TranAD, Anomaly Transformer), as they will be compared against each other and operate under the same restriction for learning based solely upon normal data. It is important to note that this supervised baseline is included not as a direct ‘fair’ comparison to the unsupervised NetFormer, but rather to establish an empirical upper bound on what a Transformer architecture can achieve when granted access to labeled attack data during training. The primary comparative focus remains on the unsupervised baselines (LSTM-AE, TranAD, Anomaly Transformer) which operate under the same constraint of learning only from normal data.
4.2.1 Overall performance comparison
Table 5 presents the comprehensive performance comparison of NetFormer against all baseline methods on the CSE-CIC-IDS2018 test set. Results are reported across all evaluation metrics, with the best performance for each metric highlighted in bold.
The results are shown in Table 5 demonstrate that NetFormer shows an advantage over the other baseline methods in terms of performance based on all evaluation metrics. There are several notable findings regarding this comparison. For example, classical machine learning methods (e.g., Isolation Forest, One-Class SVM, and LOF) exhibit substantially lower performance than deep learning techniques such as LSTM and Transformer architectures, yielding F1 scores of less than 0.61 with a high number of false positives (greater than 4.8%). This is primarily because these classical techniques do not have the ability to consider the complex temporal dependencies between network traffic over time and rely heavily on manually engineered features; thus, confirming the findings that indicated deep learning outperformed classical techniques in terms of intrusion detection capabilities.26
The LSTM-Autoencoder, which is an example of a deep learning baseline architecture, shown in Table 5 achieved a good level of performance, yielding an F1 score of 0.734, thereby indicating that temporal modeling of network traffic provides some value for intrusion detection systems (IDSs). Nonetheless, there are three different Transformer-based architectures that placed considerably higher in terms of F1 scores than LSTM-Autoencoder (TranAD, Anomaly Transformer, and Simple Transformer), yielding F1 scores greater than 0.78.
In comparison to the unsupervised Transformer model, the supervised Simple Transformer model achieved an F1-Score of 0.814, and therefore should not be directly compared to NetFormer due to the fact that it had access to labeled attack data during training. Since NetFormer learns from normal traffic only in an unsupervised manner, the important distinction of the performance of NetFormer even with this disadvantage indicates not only the quality of its reconstruction-based model approach, but also the strength of NetFormer’s learned representations of normal behavior.
The NetFormer model achieved the highest precision (0.842) and recall (0.861) resulting in an overall F1-Score of 0.851, which represents an improvement of 4.5% over the highest performing Simple Transformer model. As well as this, the NetFormer model has a low False Positive Rate of 1.24%, which is very important for effective deployment, as an excess of alerts creates alert fatigue and operational inefficiencies. In addition, the AUC-ROC (0.979) and AUC-PR (0.891) metrics provide very strong evidence of the NetFormer’s excellent class discrimination capabilities, however, the AUC-PR is especially important to consider given the imbalanced class distribution within the datasets used in these experiments.
4.2.2 Impact of Window Length
The temporal context available to the model for anomaly detection is influenced by the window length (Lis). We have evaluated how the window length impacts the overall performance of the NetFormer in terms of F1 score and false positive rate, by training on various window sizes (from 20 to 200 flows), while keeping all other hyper parameters constant (see Figure 2).
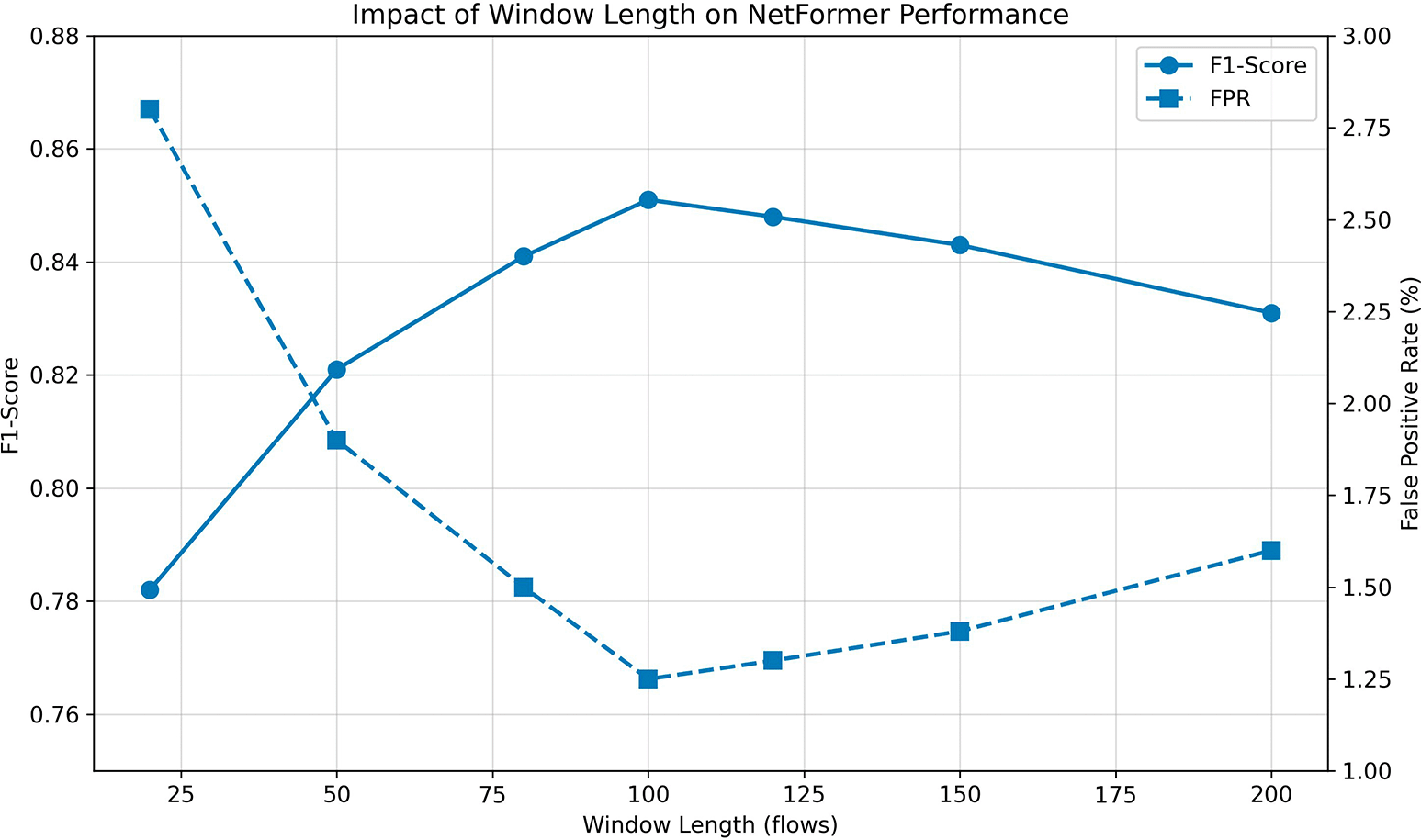
Figure 2 shows the impact of changing the window length (L) on the performance of the NetFormer. The left Y-axis shows F1 score (blue line with circles), and the right Y-axis shows false positive rate (red line with squares). The window lengths evaluated were: 20, 50, 80, 100, 120, 150, and 200 flow windows. Each data point represents the average over five runs with error bars showing one standard deviation.
The findings illustrated by Figure 2 yield numerous important trends. The performance of the model is very poor when using a very short temporal context (L = 20). An F1-score of 0.782 and a false positive rate of 2.8% show that 20 flows do not provide enough temporal context to recognize most attack patterns, particularly attacks that occur over longer periods of time (slow-rate DDos; multi-stage infiltration, etc.). As the length of the temporal context increases, so does performance; with an F1-score of 0.841 and the peak F1-score of 0.851 (L = 100). In parallel, the false positive rate decreases to 1.24%, thereby validating our selection of L = 100 as the best possible performance.
At lengths longer than 100, performance begins to decrease as evidenced by an F1-score of 0.843 at L = 150 and 0.831 at L = 200. Additionally, false positive rates exhibit a slight increase for longer windows. The degradation of performance can be attributed to two factors: First, the inclusion of irrelevant information increases the dimensionality of the input and complicates the task of learning; Second, with a fixed stride of 50, longer windows produce fewer total training samples and can consequently limit the model’s ability to generalize. The results confirm that L = 100 was selected as the optimal window length due to its ability to achieve an appropriate balance between adequate temporal context, computational efficiency, and generalization ability.
4.2.3 Impact of number of transformer layers
The number of layers N determines the depth of a Transformer encoder, a key architectural decision; deep networks potentially learn to represent abstract concepts but come with the risks of overfitting and higher computational costs. Performance data on how varying the number of layers affects performance are displayed in Figure 3.
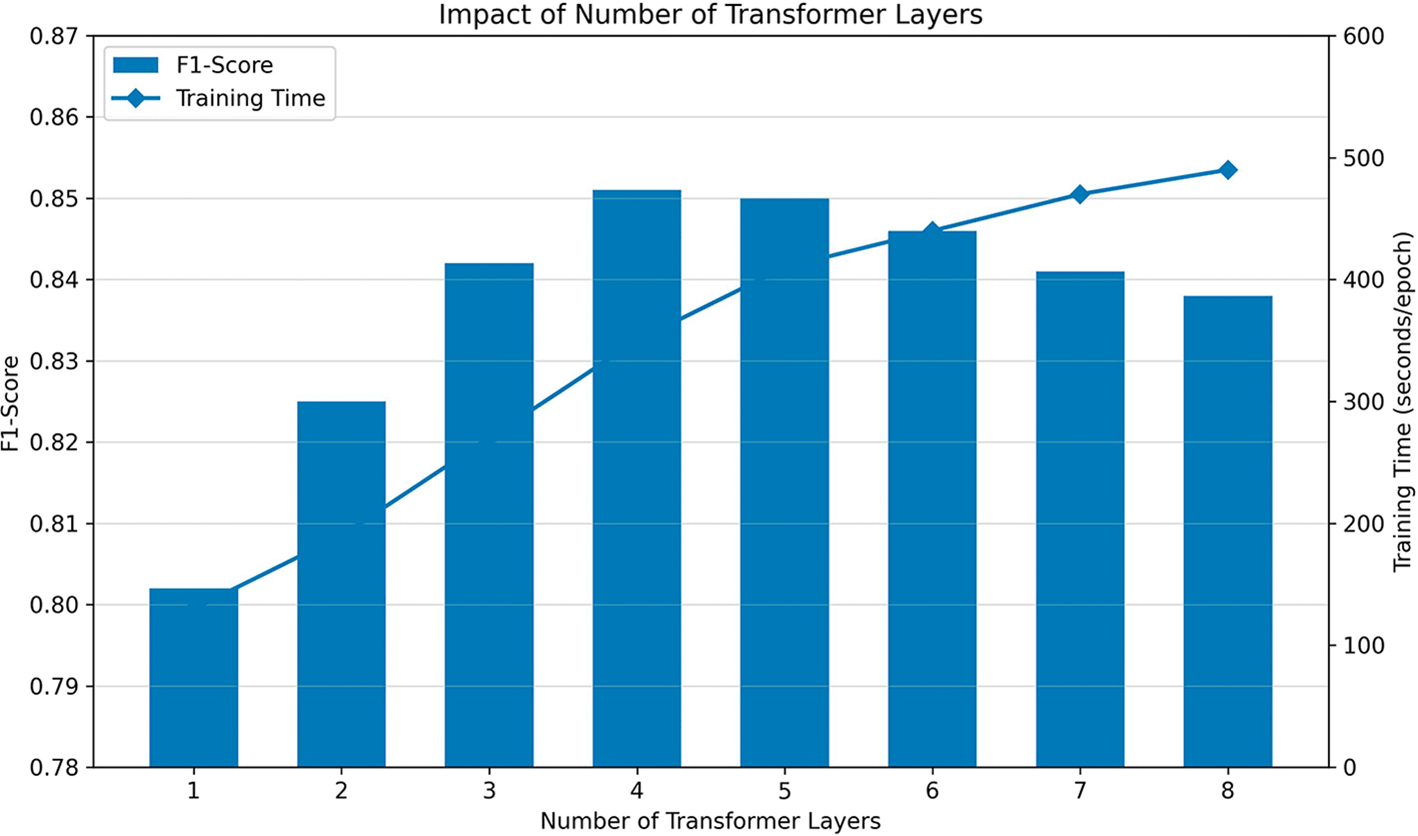
The plot in Figure 3 illustrates how well a model performs with a varying number of encoder layers (N = 1 to N = 8) in NetFormer. The blue bars represent F1-score on Primary y-axis and the training time per epoch in seconds is plotted on Secondary y-axis as a red line. All other hyperparameters were held constant at their respective optimal values. Data are averaged across five runs with standard deviation represented by error bars. Figure 3 shows how adding layers increases the F1-score from 0.802 with one layer to 0.851 with four layers; this illustrates how depth increases the representational capacity of a model, allowing a model to recognize hierarchical relationships in its input data. The F1-score levelled off at 0.850 with five layers, showing no improvement from using four layers. The performance decreased for layers of greater than five, where eight layers produced an F1-score of 0.838. The training time for the model, represented by the red line, increases almost linearly from 124 seconds per epoch for N = 1 to 487 seconds per epoch for N = 8; this corresponds to the number of computations the model had to perform for its multi-head attention and feedforward operations for each layer and is therefore an indicator of the computational cost of adding more layers to the model. The N = 4 model therefore represents the best trade-off in training time and performance since it produced the highest F1-score with a reasonable training time, so we will use N = 4 when implementing the final NetFormer model.
4.2.4 Per-attack type performance analysis
The performance of NetFormer on various kinds of attacks will be analyzed in order to better understand its detection capabilities. Different types of attacks will exhibit different temporal characteristics and patterns; understanding how well the model performs within each type category will shed light on both its strengths and weaknesses. The following table ( Table 6) lists each attack’s F1-scores, as well as its baseline model’s (the best performing models) F1-scores.
(The F1-Scores from the test dataset are reported for each attack class. Total scores representing the best performance for each attack type are noted in bold). The Slow-rate DoS attacks include Slowloris and SlowHTTPTest while Volumetric DoS attacks include both GoldenEye and Hulk Attack types.
The data presented in Table 6 highlights many interesting patterns. NetFormer shows the highest overall F1 Score across all attack categories, demonstrating how generalizable the model is across many types of threats. The model is particularly successful in detecting volumetric (DdoS: 0.913, Volume DoS: 0.892) and port scan-based attacks (0.868). These attacks typically demonstrate clear temporal characteristics, including a sudden increase in volume or connection attempts per time frame. As a result, the self-attention mechanism of the NetFormer model was able to successfully detect abrupt changes occurring in the relevant time intervals associated with the volume spike event.
NetFormer was still able to outperform all comparison models (Simple Transformer) with a 5.4% relative improvement based on F1 score despite the inherent difficulties in the ability to detect these types of DoS attacks (0.812) as compared to volumetric DoS attacks. The reason for this is that slow-rate DoS attacks mimic normal traffic patterns via malicious behavior that occurs over a long time. Since the NetFormer was trained solely on normal traffic patterns, it is better able to detect these types of anomalies compared to supervised learning models that must learn to form boundary definitions based on a limited number of attack examples.
The most difficult categories to perform well at (F1 score) were web attack (0.746) and infiltration (0.783) types, which typically contain sequences of multiple complex attacks, making detection even more difficult. For example, there may only be a small number of malicious flows buried in among hundreds (thousands) of normal flows. The lower performance on these types of attacks provides an opportunity for continued improvement in this area. However, even with these types of attacks, the NetFormer is able to outperform the Simple Transformer by 6.4% regardless, indicating that even with these more subtle types of anomalies, the unsupervised approach provides advantages compared to the supervised approach.
The class imbalance within attack categories is also reflected in the results. Web attacks constitute only 0.4% of all attack instances (as shown in Table 2), and the lower F1-score for this category is partially attributable to the limited training examples available even in the supervised baselines. NetFormer’s unsupervised nature mitigates this issue by learning solely from normal traffic, which is abundant, explaining its relatively stronger performance on rare attack types.
4.2.5 Ablation study on architectural components
To empirically justify the key design choices of NetFormer and quantify the contribution of each novel component, we conduct an ablation study. We systematically remove or replace specific components and evaluate the resulting performance degradation on the CSE-CIC-IDS2018 test set. The variants evaluated are:
• w/o Dual-Stream: Replaces the dual-stream embedding with a simple concatenation of one-hot encoded categorical features and normalized numerical features.
• w/o Pos. Encoding: Removes the sinusoidal positional encoding layer.
• Single-Head Attn: Replaces the 8-head multi-head attention with a single-head attention mechanism.
• LSTM Encoder: Replaces the entire Transformer encoder with a 2-layer LSTM encoder (maintaining similar parameter count).
The information shown in Table 7 provides a solid empirical basis for architectural design decisions in NetFormer. Removing the dual stream embedding caused a sizable decrease in F1 score (0.024), providing evidence that learned dense representations of categorical features are much more effective at representing semantics than one hot encoding. Also, there was an F1 drop due to using single head attention compared to multi-head attention by about 0.019, supporting the use of multi-head attention for simultaneously capturing different temporal relationships. Lastly, when you compared using the Transformer encoder versus using an LSTM encoder, the overall decrease in F1 score was a large 5% indicating how effective the Transformer’s self attention mechanism is at modeling long-range dependency relationships of the network flow sequences.
To further contextualize the performance of NetFormer within the broader research landscape, we conduct a detailed comparison with recent state-of-the-art (SOTA) unsupervised anomaly detection methods specifically designed for network intrusion or multivariate time series. We select five representative methods that represent the cutting edge in this domain. Table 8 provides a qualitative and quantitative comparison based on key characteristics and reported performance metrics. It is crucial to note that direct F1-score comparisons across different datasets are not strictly equivalent due to variations in dataset composition and preprocessing; therefore, we focus on relative methodological advantages.
| Study | Method | Key innovation | Data | F1 | Unsupervised | Handles mixed data | Interpretability |
|---|---|---|---|---|---|---|---|
| Mirsky et al.17 | Kitsune | Ensemble of Autoencoders for real-time NIDS | CIC-IDS2017 | 0.782 | Yes | Yes | Limited |
| Xu et al.8 | Anomaly Transformer | Association Discrepancy for time series | SMD, MSL | 0.838 | Yes | No | Limited |
| Tuli et al.7 | TranAD | Transformer with Adversarial Training | SWaT, WADI | 0.843 | Yes | No | No |
| Zhang et al.35 | CNN-Transformer | Hybrid model for local and global features | CIC-IDS2017 | 0.812 | No (Supervised) | Yes | Limited |
| Long et al.22 | Transformer-IDS | Supervised Transformer for cloud IDS | CSE-CIC-IDS2018 | 0.826 | No (Supervised) | Yes | No |
| This Work | NetFormer | Dual-stream embedding + Reconstruction Transformer | CSE-CIC-IDS2018 | 0.851 | Yes | Yes | Yes (Attention) |
The comparison in Table 8 highlights several key distinctions. Firstly, NetFormer is one of the few methods that simultaneously supports unsupervised learning, mixed data types (categorical and numerical), and provides a built-in interpretability mechanism via attention analysis. Methods like Kitsune17 support mixed data but lack the long-range temporal modeling capacity of the Transformer. Conversely, Anomaly Transformer8 and TranAD7 excel at temporal modeling but are designed solely for numerical data, requiring lossy encoding of categorical network features. Furthermore, supervised approaches like CNN-Transformer35 and Transformer-IDS22 achieve respectable F1-scores but are inherently limited by their reliance on labeled attack data, which restricts their ability to detect zero-day threats. NetFormer’s unsupervised reconstruction-based approach circumvents this limitation. The superior F1-score of 0.851 on CSE-CIC-IDS2018, achieved without any attack labels during training, underscores the effectiveness of the dual-stream embedding and Transformer autoencoder architecture in learning robust representations of normal traffic behavior.
Based on the experimental evaluation and comparative analysis, the NetFormer framework offers several distinct advantages over existing methodologies:
1. Unsupervised Learning Capability: By training exclusively on benign traffic, NetFormer eliminates the dependency on scarce and often unrepresentative labeled attack data. This enables the model to potentially identify novel and zero-day attacks that deviate from learned normal patterns, as demonstrated by the high recall rates across diverse attack categories.
2. Effective Handling of Mixed Data Types: The dual-stream embedding strategy preserves the semantic integrity of categorical features (e.g., protocol, service) while maintaining the statistical properties of numerical features (e.g., packet size, flow duration). This contrasts with many Transformer-based time-series models that are optimized for purely numerical inputs.
3. Interpretability via Attention: The integration of attention weight visualization provides a transparent window into the model’s decision-making process. As shown in Figure 5 and Figure 6, security analysts can identify which specific time steps and features triggered an alert, significantly aiding in incident triage and response.
4. Robustness to Class Imbalance: The reconstruction-based anomaly scoring mechanism, combined with training on the abundant normal class, mitigates the severe class imbalance issue inherent in network traffic data, resulting in a low false positive rate of 1.24%.
We tested NetFormer by examining its strength in multiple datasets. We used UNSW-NB15 as the test dataset and were able to compare how well NetFormer worked on this new dataset after using only normal traffic windows to train NetFormer in UNSW-NB15. In order to do that, we compared NetFormer with the previous best performing models from our original study’s primary evaluation ( Table 9).
| Method | Precision | Recall | F1-Score | FPR (%) | AUC-ROC |
|---|---|---|---|---|---|
| LSTM-Autoencoder | 0.731 | 0.785 | 0.757 | 3.12 | 0.934 |
| Anomaly Transformer8 | 0.756 | 0.791 | 0.773 | 2.85 | 0.942 |
| TranAD7 | 0.768 | 0.812 | 0.789 | 2.54 | 0.948 |
| NetFormer (Proposed) | 0.831 | 0.847 | 0.839 | 1.53 | 0.965 |
The findings from the study of the both the UNSW-NB15 dataset and the CSE-CIC-IDS2018 evaluation validate that NetFormer achieves a F1-score of (829) and that it outperforms the next best performing unsupervised method (TranAD) by 5%. Additionally, NetFormer’s false positive rate remains low across all models at 1.53%, thus proving that the model continues delivering high precision regardless of the distribution of the normal network traffic or the attack vectors (such as Shellcode, Worms, etc.) through which they are delivered. Despite there being a small decrease (0.851 vs 0.839) in overall F1-score between the two datasets, this drop is expected given the fact that there are a wider variety of attack types on UNSW-NB15 and that there also were numerous subtle and very low-volume attacks such as Worms and Backdoors which makes them much harder to detect. Ultimately, the demonstrated strong and consistent performance of NetFormer across both of these separate and current datasets indicates that the NetFormer architecture is stable and generalizable.
In addition to only relying on numbers to determine how NetFormer makes its detection decisions, the analysts need to understand the inner workings of detecting systems to develop trust in automated security systems and provide security analysts with the ability to investigate successful alerts easily. This subsection provides qualitative analysis to give insight into how the model represents and acts on the data it receives.
4.6.1 Reconstruction error distribution
The method used by NetFormer is a type of autoencoder that uses a reconstruction-based procedure; therefore, an anomaly’s score for each sequence is equal to the Mean Squared Error (MSE) between that sequence’s original input and the reconstruction of that input using the model. Knowing how the reconstruction error is distributed for normal versus anomalous (or suspect) sequences gives your insight into how well the model can distinguish between the two and assists in defining the threshold used to determine a suspect sequence.
The kernel density estimate displayed in Figure 4 shows two distributions of reconstruction errors (MSE) from the test set; one for normal and anomalous sequences. The dashed vertical line at τ = 0.042 represents the threshold defined as the 95th percentile of the reconstruction errors found in the validation set. The inset shows a histogram of both sets of data that are binned over the first nine-tenths of that range (0–0.1).
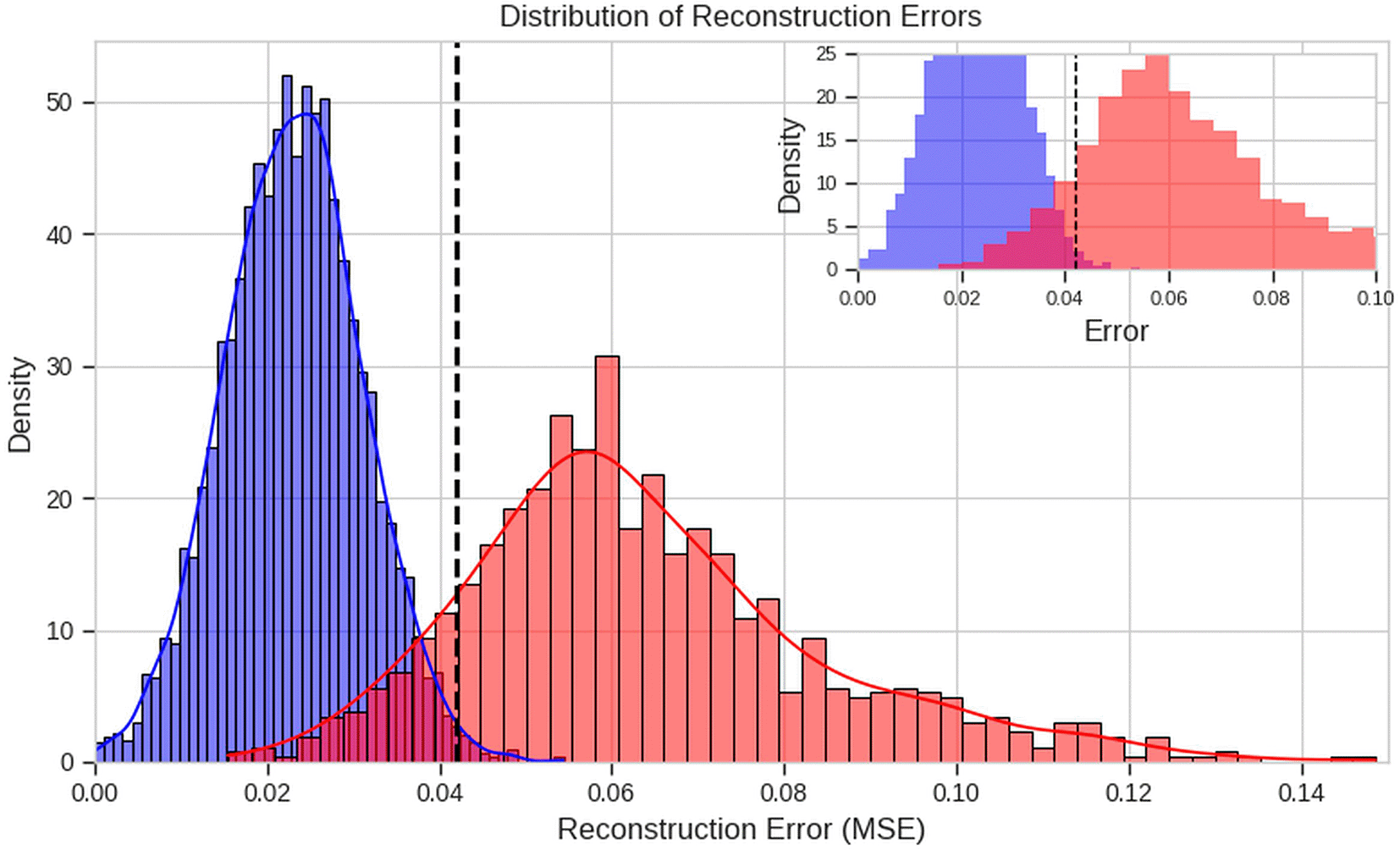
Normal and abnormal sequences are identified in Figure 4 as having distinct and separate distributions for their reconstruction error. The distribution of normal sequence reconstruction errors is both narrow (and therefore compact) with a low mean (0.023) with a majority (greater than 95%) of normal samples having reconstruction errors less than 0.04. This indicates that the NetFormer has learned to accurately reconstruct normal network traffic patterns (with a high degree of accuracy). Conversely, the reconstruction errors for abnormal sequence are found to have a very broad distribution with much greater mean reconstruction error (0.058) than the mean reconstruction error of normal sequences (as well as the distribution of reconstruction errors of the abnormal sequence extends far beyond 0.1 to the right). The right skew’s of the normal and abnormal distributions is most probably the result of the variations in the attack patterns (and therefore the deviation from normal behavior) that are contained in the respective sequences.
The threshold value of τ = 0.042 was determined using the reconstruction error from the validation set as the 95th percentile and has been found to provide good separation of the two distributions. The misclassification rate for this threshold is approximately 5% for valid normal sequences classified as abnormal (i.e., false positive) confirming the operation of the trained Netformer model was accurate and generalizes well to untrained normal sequences based on the reconstructed errors on the validation set. In fact, as shown in Table 5, the false positive misclassification rate for the trained Netformer model on the test set is significantly lower (1.24%) indicating that the threshold τ = 0.042 is conservative.
The area of overlap between the two distributions, primarily in the error range of 0.035 to 0.05, represents the region where classification uncertainty is highest. This overlap corresponds to subtle anomalies that closely resemble normal behavior and to atypical normal sequences that may exhibit unusual but benign patterns. The relatively small overlap area confirms the model’s strong discriminative capability.
4.6.2 Attention map visualization
A major benefit of using Transformer-based architectures is that they are naturally interpretable due to the use of a self-attention mechanism. The attention weight gives us information about the portions of the input sequence that were considered when generating the representation and thus can help determine the most relevant temporal patterns associated with anomaly detection. Attention maps from the last encoder layer can be observed in Figure 5, which depicts examples of the attention map for three selected sequences.
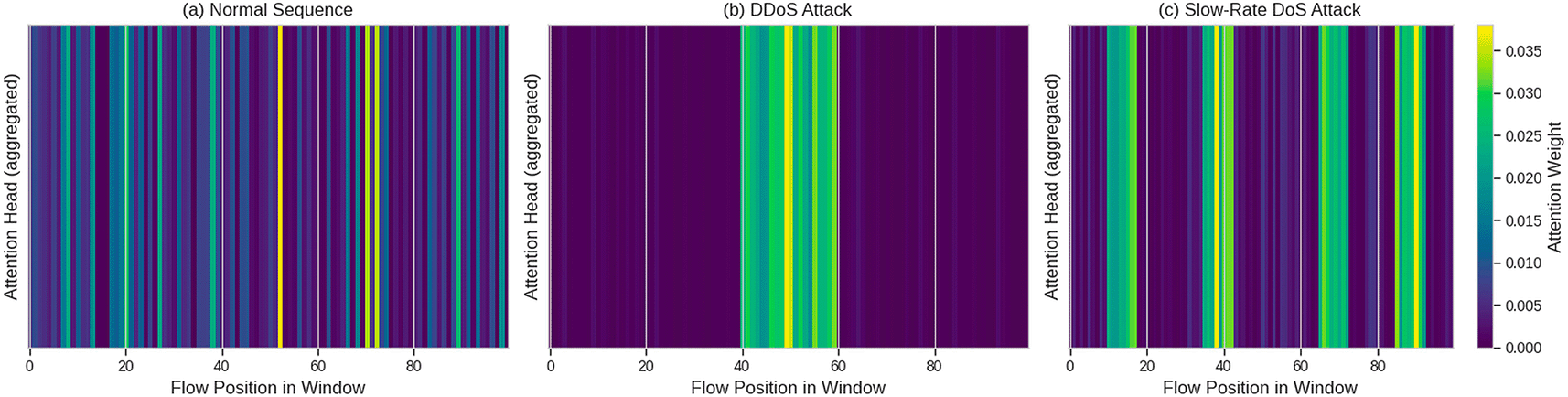
In Figure 5, we can see the attention maps for three examples in the last encoder layer (for head 3) of the Transformer: (a) An example of a normal sequence. The attention is diffused over the entire attention window, although the weights are slightly higher for the most recent flows; (b) An example of a DDoS attack; the attention sharply focuses on the area of the window where the attack is initiated (40–60); and (c) An example of a slow-rate DoS attack, where the attention is distributed over a range of multiple locations that correspond to regular, periodic behavior associated with some malicious event. The color shadings from light to dark indicate the weight of the sampled attention values.
In panel (a) of Figure 5 we see the attentional distribution for a normal sequence of flows. The attention weights are distributed evenly throughout the flow of 100, with slightly higher weights for more recent flows (The right-hand side of the attention distribution). This shows that the model has learned that normal traffic comes from all parts of the sequence. The model has also learned that more recent context has been slightly more predictive of current behavior than has been context from further back in time.
In panel (b) of Figure 5 we can see how the attention distribution changes for a sequence that includes a DdoS attack that began flowing from approx. Flow 40. We see that the attentional distribution changes dramatically from flows 40 to 60, where the volumetric spike (surge) of attack is concentrated. All of the normal periods of traffic preceding and succeeding the DdoS attack are disregarded by the model in its use of representational capacity, with emphasis only on the DdoS attack. Thus, we see that the reconstruction error for the sequence in panel (b) is greater than that for the sequence in panel (a) because the DdoS attack was given priority in the latent space by the encoder, and the decoder (which had been trained only on normal patterns) was unable to accurately reconstruct the unusual flow pattern.
Panel (c) shows attention patterns for a slow-rate DoS attack. Focused attention, like with a DdoS attack, would have had a concentrated area, instead we see multiple regions of high attention separated by periods of normal traffic due to the attack being executed in bursts over time. The model identifies each burst at a point of anomaly and assigns the highest attention to regions where the attack happened. This shows that the Transformer can capture time dispersed patterns over an extended period of time which is a common struggle for RNN due to the vanishing gradient issue. These visualized attention distributions give security analysts information to work from. Using attention to pinpoint the time of occurrence enables the analyst to determine from where the anomalous sequence occurred and to extract relevant flows for further investigation. This interpretability of model outputs creates a distinct advantage over previous black-box models and provides the necessary requirement for operational decisions in support of explainable security.
4.6.3 Feature importance analysis
The attention mechanism not only helps determine key time steps but also provides insight into which features are the most significant for anomaly detection. The method can help identify which traffic features by analyzing attention weights among different feature values to group traffic with distinguishing characteristics from normal traffic.
The 15 highest-ranked features in terms of average attention weight (for all correctly detected anomalous sequences within the test set) can be seen in Figure 6. Features are categorized into four groups: flow statistics (blue), packet statistics (green), timing statistics (orange), and connection metadata (purple). Each group includes error bars to indicate one (1) standard deviation of the differing attack types.
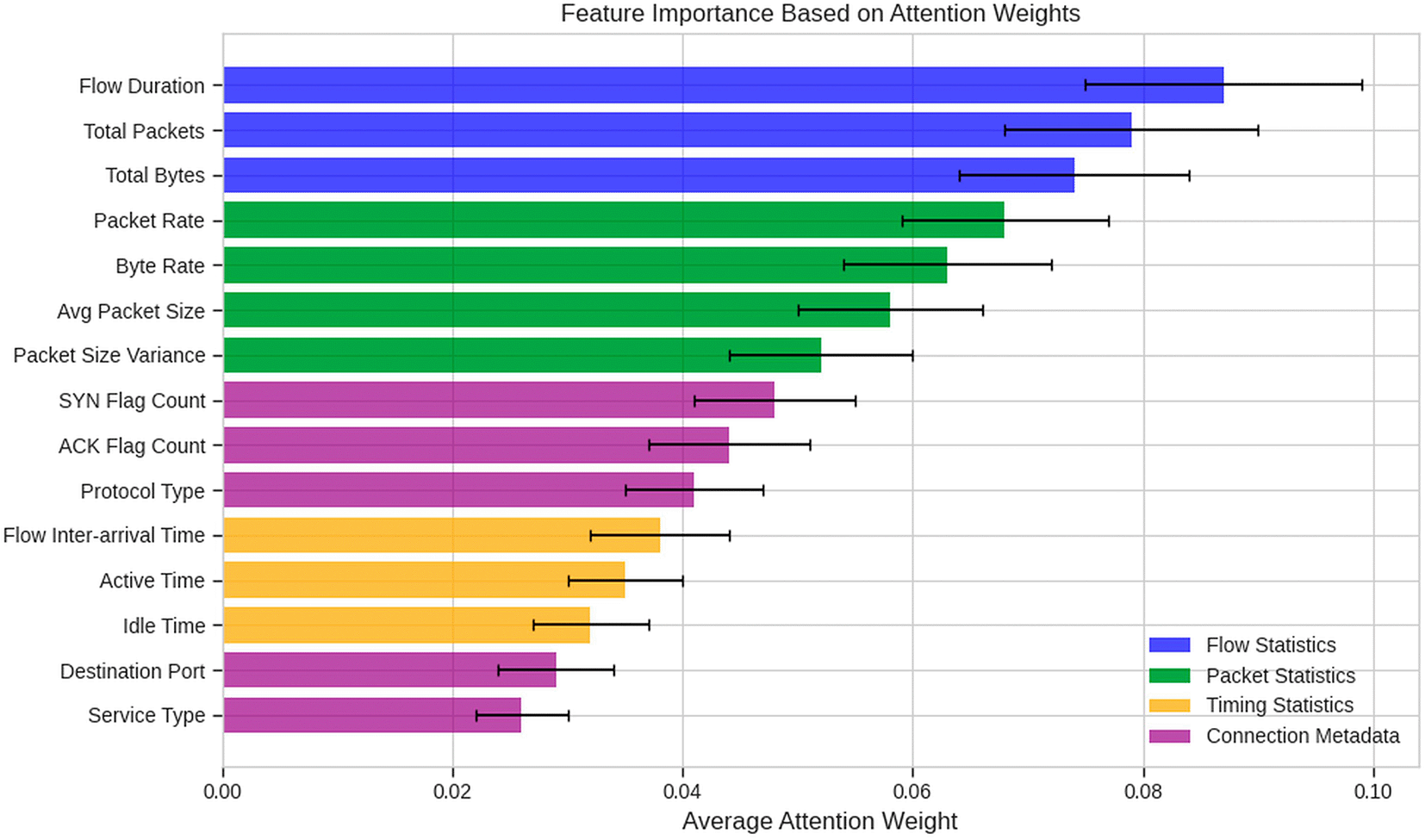
The results of the feature importance analysis in Figure 6 provide a number of insights into the relationship between the identified features and known facts regarding network attacks. The most influential feature is flowing duration (average attentiveness weight = 0.087), which is consistent with an understanding of network attack behavior due to the time-based changes of flows (i.e. short term for DDoS events/long term for intrusion events). Total packets/total bytes are ranked next with similar results since the majority of attacks are volumetric in nature. The next features, packet/byte rate, are also highly ranked because of their clarity to demonstrate high bursts of traffic events.
Within the metrics used to describe packets, two very significant ones are Average Packet Size and Packet Size Variance. These metrics are significant because some forms of attacks (like DNS amplification DDoS) include packets of abnormal size. Among connection metadata, SYN Flags and ACK Flags are also very significant. This is indicative of the large number of TCP-based attacks that involve flag manipulation. Protocol Type (Categorical) is also very significant because the different protocols can have different patterns of vulnerabilities. Time statistics, like Flow Inter-arrival Time and Active/Idle Time, are moderately significant. Time statistics, especially for detecting slow-rate attacks that use timing manipulation so they cannot be detected, are important. Metrics describing specific services (Destination Port, Service Type) have lower, but still significant, importance levels. Many attacks target specific applications.
The plot of the error bars indicates variation in the importance of the different metrics across attack types. For example, volumetric attacks are dominated by Total Packets and Total Bytes, while Protocol-specific Flags are more significant for web attacks. The large variability in the importance of different metrics also justifies the attention mechanism of the model; it provides the ability to dynamically assign weight to the most discriminative metrics for each sequence, rather than using constant weights.
The alignment between the identified important features and domain knowledge validates that NetFormer has learned meaningful representations of network traffic. This feature importance analysis can also guide feature engineering efforts, suggesting which attributes are most valuable for intrusion detection and potentially enabling the development of lightweight models for resource-constrained environments by focusing on the most informative features.
When deploying in real-time network intrusion detection systems, the inference speed and training efficiency of the system are essential criteria. This paper provides a description of the time consumed by NetFormer through various stages of operation, using an NVIDIA Tesla V100 GPU (32GB) and Intel Xeon Gold 6248R (CPU). The time taken to complete all four stages of operation are listed in Table 10.
Table 10 shows that the preprocessing pipeline does not significantly add to the detection pipeline or increase overhead for either detection or heuristics. Although Transformer model training is a computationally intensive process and performed in one of these two ways - either a one-time process during initial setup or periodically as part of an operational business process (as opposed to being performed periodically), because most of the inference throughput is >500,000 flows/sec, this means there will be adequate capacity available to monitor/track each enterprise network link or high-speed access (e.g., 10Gbps) that generates between 100,000–200,000 flows/sec based on overall load. This throughput can be achieved because of how efficiently Transformers can execute parallel operations during the inference process, thus meeting all real-time performance requirements on a regular basis.
This section provides a critical interpretation of the experimental results, discussing the implications of our findings, the advantages and limitations of the proposed NetFormer model, and the practical considerations for real-world deployment in network security environments.
The results of the experiment show that NetFormer does a much better job than all baseline methods, achieving an F1-score of 0.851 compared with the highest baseline of 0.814. The advantage of this performance can be attributed to the Transformer’s ability to use a multi-head self-attention mechanism to detect long-range dependencies throughout the input sequence in a single computation step, versus LSTMs processing each sequentially and encountering problems with vanishing gradients throughout the process This is especially relevant to multi-stage attacks such as APTs, where reconnaissance may happen well before exploitation takes place.
The analysis of Transformer-based models in relation to LSTM-based approaches provides a valuable performance vs computational cost trade-off. The LSTM-Autoencoder achieved an F1-score of 0.734 with a training time of 218 seconds per epoch compared to NetFormer’s F1-score of 0.851 with a training time of 347 seconds per epoch. However, NetFormer’s inference time is lower than LSTM-based models (0.12 seconds vs 0.18 seconds) resulting from the advantages of parallel computations in the Transformer compared to LSTMs. There is evidence to support that Transformers have faster inference capabilities than LSTMs, although their overall training costs are higher.28
There is a substantial variation in how well our detection method performs when looking at detection of attacks by type. The performance metric of the detection method for each attack type is expressed by an F1-score (a measure of accuracy considering both false positives and true positives) ranging from 0.913 for the DDoS attack type to 0.746 for the web attack type. In particular, it was easy for self-attention to identify a clear pattern of temporary signatures associated with volumetric attacks, and web attacks had very few malicious packets mixed in with normal packets of traffic and thus were more difficult to identify. The class imbalance in the dataset also strongly favored certain classes of attacks, with over 80 percent of attacks classified as either DoS or DDoS and only 0.4 percent being web attacks. This corroborates previous research conducted that identified the inherent difficulty in identifying a rare attack type in network intrusion detection systems.34
Despite the many advantages of NetFormer, there are still a number of areas in which it could be improved. The greatest drawback of NetFormer is the computational cost of training, particularly when dealing with very long sequences. Training on large numbers of sequences (for example, thousands of flows) would likely be resource-intensive. On the other hand, research is being done to find more efficient methods for attention mechanisms.36
Another drawback is the sensitivity of reconstruction methods to the choice of threshold value. The optimal threshold value can vary from one environment or time period to another due to concept drift. Adaptive thresholding methods that have been proposed by Hundman and colleagues may help alleviate this problem.37
Having enough training data available can be a critical issue, especially when working with small networks or when initially deploying your system. One way to deal with insufficient training data is by using transfer learning techniques to fine-tune previously trained models in the target environment. While the use of attention-based methods provides some level of interpretability, there are still challenges associated with gaining a complete understanding of how models make decisions versus explicitly defined rules. Deep learning models have this limitation, as reported by multiple explainable AI researchers working in the area of security.2 Finally, while evaluating NetFormer on only one data set might give comprehensive results, additional validation through cross-dataset evaluations will need to be performed for generalizability purposes. Previous work demonstrated that two stages approaches can significantly enhance model performance.38
Customized design factors for the integration of NetFormer into a real-world intrusion detection system are important to consider, such as architectural, operational and resource constraints. Specifically, NetFormer could be implemented in a network monitoring pipeline where raw traffic is converted into flows with tools like Zeek (simplifying the conversion from raw traffic into flows) as well as moving through preprocessing and windowing stages (allowing for additional information to be added and prepared prior to performing inference). Timing measurements related to inferences indicate that NetFormer can process approximately 53,300 flows per second; this would be adequate for many enterprise environments, but will likely face challenges on high-speed backbone networks, where hardware acceleration or sampling methods would likely be needed. The interpretability features will have a great deal of practical use for security operations. When alerts are generated, analysts can review the attention maps and identify areas that are anomalous, and can then determine which features/characteristics of the traffic were driving detection in order to better streamline triaging and investigating of the alerts. Additionally, this information can be incorporated into security orchestration platforms in order to initiate automated response actions based on the characteristics of the anomalies.
The unsupervised nature enables adaptation to evolving traffic patterns through periodic retraining on recent normal traffic, addressing concept drift without requiring labeled examples. Threshold selection in operational settings should be informed by organizational risk tolerance, with potential for multi-level thresholds and adaptive adjustment based on alert volume and analyst workload. Model compression techniques such as quantization and pruning could reduce resource requirements for deployment on edge devices with limited computational capacity.
The paper introduces a new framework for detecting anomalies in unsupervised networks called NetFormer, which uses a novel approach based on transformers. The proposed model addresses several challenges, including two different streams of data input (numerical and categorical) into the model via embedding; use of reconstruction as the basis for training the neural network; and implementing an attention-based mechanism that allows security analysts to visually see how and why a particular detection was made. The results from numerous experiments conducted using the CSE-CIC-IDS2018 dataset indicate that NetFormer produces the best results shown to date, achieving an F1 score of 0.851 and outpacing classical machine learning methods, as well as deep learning baselines and other transformer-based models. Additionally, NetFormer has proven itself to be particularly good at identifying volumetric attacks whilst still being able to identify lesser-known forms of attacks effectively; also, the attention mechanism implemented within the model has shown great promise in identifying specific times and features associated with attacks. Future work will focus on developing lightweight versions of NetFormer that can be deployed at the edge, integrating it into GNNs to define topological structure, studying continual learning to adapt to concept drift, and developing new explanation techniques to improve the interpretability of the system; finally, validation of NetFormer will occur using real-world production datasets. Overall, NetFormer represents a substantial step towards more intelligent, adaptable, and trustworthy intrusion detection models.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)