Keywords
Qualia, Diversity, Magnitude, Spread, Qualia Structure, Similarity Judgments
This article is included in the Japan Institutional Gateway gateway.
Qualia, Diversity, Magnitude, Spread, Qualia Structure, Similarity Judgments
Qualia, or qualitative aspects of subjective experiences, remain among the most profound unsolved mysteries in science and have long captivated scholars. The term “qualia” refers to a broad range of qualities of experiences, for example, the feel of a cool babbling stream, the chill of a breeze on the skin, or the orange hue of the evening sky. Some philosophers (e.g., Ref. 1) have claimed that qualia are private, ineffable, intrinsic, and so on, such that they cannot be scientifically studied. Indeed, any individual person cannot share their qualia directly with others (with the current scientific technology) and we humans have difficulty communicating what it feels like to others. Having said that, we believe that it is inaccurate to claim it is “impossible” to share any aspects of qualia with others; purely subjective differences in color qualia,2 synesthetic experience,3 hallucination,4 dreaming5 and so on, have gathered their converging physical substrates to support initially purely subjective experience.
To facilitate empirical progress on the science of qualia, a structural approach has been proposed.6–10 The central hypothesis (explicitly or implicitly) shared in these views is that qualia and their relationships instantiate a mathematical structure. Further, it has been proposed that we can use behavioral data in psychophysical experiments to infer this structure and to compare it across individuals.6,11 Structures of qualia in two individuals are “similar” when there is a structure-preserving map in the mathematical sense. The degree of structural similarity can be characterized through the strength of the structure preservation (from the existence of functors, adjoint functors, categorical equivalence, to categorical isomorphism).12 In this way, the otherwise unverifiable “sameness” of subjective experience can be operationalized and given a mathematical definition. This research program is known as the qualia structure paradigm.6,11
In this paradigm, high-dimensional mathematical structures are inferred from relations among qualia. In practice, the primary relation currently proposed is pairwise similarity, obtained from similarity-rating tasks. For example, in a study of color qualia,13,14 participants with typical and atypical color vision rated the similarity of color-patch pairs on an 8-grade scale. Ratings across 93 colors were then converted into a dissimilarity matrix, from which the underlying mathematical structure was estimated for each group13 or for each participant.14
However, calculating a high-dimensional structure from behavioral data alone is insufficient to characterize its properties. Interpretation is required to analyze and compare these structures. For this purpose, several mathematical methods have been proposed. Multidimensional scaling (MDS), for instance, projects high-dimensional structures into lower-dimensional spaces for visualization and qualitative comparison.15 Gromov–Wasserstein optimal transport (GWOT)16 aligns two structures in an unsupervised manner without the labels of nodes of the two structures to be compared.13,14,17 MDS does not readily yield a single quantitative index, whereas GWOT is computationally demanding and undefined for a single structure. This motivates the need for indices defined on individual structures that capture the intrinsic characteristic of a given qualia structure—specifically, their diversity.
Guided by this motivation, we introduce three diversity indices: magnitude, generalized magnitude, and spread.
What are “diversity indices”? They are indices that quantify the “diversity” of a space or a structure consisting of points. Intuitively, they measure the size of a space or the effective number of points in a structure.18,19 To get a rough idea, let’s imagine zoos with a fixed number of animals. One zoo has very dissimilar species, such as birds, mammals, and amphibians. Another zoo has only very similar species, like all animals being in the hippopotamus family. Which one do you think is a “diverse” zoo? Probably, we will think the first one is “more diverse” than the latter. The diversity index quantifies this idea. The first zoo is likely to have a higher diversity index value than the latter one.
How do these indices behave? The magnitude,18,19 generalized magnitude,20 and spread21 differ in detail, but—paraphrasing Willerton—the rough picture is this: If all pairwise distances between points in a set of points, , are very small, then would look like a clamped cluster/cloud (composed of indistinguishable single points). We would like to have a diversity index that, in such a case, ideally assigns 1. In another case, if is a set of points with very large distances between all pairs, then would look like a collection of separate points, with its diversity index ideally equal to the number of points.21 Importantly, whether a cloud of points looks like a clamped single point or distinct points depends on how “far” an (ideal) observer is located from the points. In mathematical terms, under a homothetic enlargement of a structure, the interpoint distances increase, and the indices tend to increase. While a homothetic contraction, they decrease. They are scale-dependent indices.
Originally, Leinster and Cobbold introduced the Leinster-Cobbold “diversity” measures and the maximum diversity in the context of biodiversity.18,19 One of their goals was to quantify the diversity of an environment by incorporating species similarity (represented by a similarity matrix ), species distributions (e.g., the proportional abundance of individuals), and the weighting of rare versus common species. The quantity denotes the maximum diversity achievable for a fixed similarity matrix ; it answers how diverse a given species list can be when the proportional abundances are allowed to vary. However, calculating and can be computationally demanding. To address this, Leinster proposed the “magnitude” as an approximation to . Moreover, under certain conditions on (when is positive definite), the magnitude equals (p. 201,19 Examples 6.3.20 and 6.3.21). Still, the magnitude has several practical problems. For example, we cannot define the magnitude for arbitrary matrices.
Chen and Vigneaux later defined the notion of generalized magnitude, extending the formulation to arbitrary matrices over a subfield of complex number, , to cover cases in which the classical magnitude is not definable.20 They proved that the generalized magnitude is identical to the magnitude when the magnitude can be defined (p. 8,20 Theorem 4.1). Since the generalized magnitude is well defined for any arbitrary matrix and, even in cases where the magnitude exists, generally yields smaller numerical errors due to the properties of its computational method, we compute the generalized magnitude instead of the magnitude in this paper.
Also, Willerton introduced the spread as an alternative approximation, restricting attention to the uniform distribution to improve certain behaviors.21 From a practical viewpoint, the spread does not require computing an inverse matrix; thus, it can assign values even to points where the magnitude is undefined, like the generalized magnitude. Yet, as we demonstrate with empirical data below, the behavior of the spread differs from that of generalized magnitude.
Our aim in this paper is to apply these diversity indices to data from similarity rating experiments. By employing these diversity indices, we can quantify the diversity of a dissimilarity structure in an individual’s experience and compute their structural “size”. We analyze similarity rating data and present a detailed procedure for calculating the diversity indices, together with an explanation of their behavior. We propose that these indices can serve as a measure to infer the nature of a qualia structure.
In this section, we provide a brief introduction to the main definitions and theorems related to diversity indices, the generalized magnitude20 and the spread.21 These theoretical results are used throughout this paper to compute the indices and to interpret the analytical findings.
2.1.1 Generalized magnitude
Before introducing the generalized magnitude, we first review the notion of magnitude (of a finite metric space) proposed by Leinster.19
As written in section 1.2, the magnitude is an approximation of the Leinster-Cobbold diversity.
Let be a finite metric space with metric function d. Its similarity matrix is defined by . A weighting on is a function such that for all . The space has magnitude if it admits at least one weighting; its magnitude is then for any weighting , and is independent of the weighting chosen. A finite metric space is said to have Möbius inversion if is invertible and the inverse of is called the Möbius matrix of . For a metric space that has Möbius inversion, the magnitude is calculated as the sum of all the elements of the Möbius matrix, i.e., . (Lemma 1.1.4).
In summary, the definition of the magnitude of a finite metric space having Möbius inversion is:
In the above definition of magnitude, we have assumed that X is a metric space, i.e., a set with a metric function that satisfies the metric axioms ( , : non-degeneracy, : positivity, : symmetry, and : triangle inequality). Moreover, if the similarity matrix is not invertible, the magnitude may not be defined. (Actually, there exist metric spaces that do not have any weighting). In practice, the results of psychophysical dissimilarity measurements often violate the triangle inequality.22,23 Also, as we encountered below, the invertibility of the similarity matrix is not always guaranteed. For this reason, we use a more general index with weaker definitional assumptions: the generalized magnitude.
The generalized magnitude of an -matrix over a subfield of is defined as follows (Definition 4.9;20 with a typographical error corrected by the authors):
Here, denotes the Moore-Penrose pseudoinverse of . Both and also lie in (Lemma 3.4). Compared with the original definition of magnitude for the invertible matrix case, the computational procedure is almost the same, except that the Moore-Penrose pseudoinverse is used in place of the matrix inverse.
The Moore-Penrose pseudoinverse is a generalized inverse: its result coincides with the matrix inverse whenever the latter exists. Furthermore, over , the Moore-Penrose pseudoinverse exists for any rectangular matrix. Thus, the domain of definition can be extended to arbitrary rectangular matrices. In general, it can be shown that generalized magnitude coincides for the matrices admitting weighting.
To analyze the behavior of the generalized magnitude, we recall the notion that Leinster called “magnitude function”.19 In this paper, we refer to it as the “(generalized) magnitude profile”. You can think of a “profile” as a function of the scale parameter t. This terminology is chosen to maintain consistency with Willerton’s “spread profile” and to avoid potential confusion. When we refer simply to a “profile,” we collectively mean the profiles of both generalized magnitude and spread.
Specifically, we are interested in how the indices change when a space with points is scaled by a parameter . We denote the generalized magnitude under scaling by . The magnitude profile of a finite metric space , is defined as (Proposition 2.2.624). This magnitude profile has the following properties:
The magnitude profile and the generalized magnitude profile share these properties.
2.1.2 Spread
Same as the magnitude, the spread is also an approximation to the Leinster-Cobbold diversity index, which limits the population probability to a uniform distribution.21
Given a finite metric space with a metric function , the spread is defined as follows:
Next, consider the behavior of the spread when scaling a metric space with points by a parameter . Willerton called the function the spread profile, and it is analogous to the magnitude profile.
For the spread profile, Willerton established the following properties (Theorem 1):
In this section, we describe the psychophysical experiment on which our analyses are based. Since the specific content of the data is not the focus of this paper, we provide only the minimal details necessary to understand our analytical procedure and to interpret the results. For further details, see Aisbett, Kusano and Tsuchiya (in preparation).
In this experiment, we collected the data from 120 adult participants online (Ethics were approved by Monash University Human Research Ethics Committee, approval number: 17674, approval date: 5th Feb 2024), and all participants completed all procedures. Before participation, all participants were presented with an online study information statement. Electronic written informed consent was obtained through the online platform, and consent was indicated by clicking the “NEXT” button before proceeding to the experiment. In the similarity rating task, participants were presented with pairs of words, one pair at a time. The stimulus set consisted of 23 words: 10 color words (e.g., red, blue) and 13 emotion words (e.g., happy, anger). For each trial, participants rated the perceived subjective similarity between the two words on a scale from −4 (very different) to +4 (very similar), with no neutral option at 0. All participants rated all word pairs, except those with the same words (253 trials). Additionally, they performed 47 repetitions to verify the consistency of their responses. For our analysis, we used only the first 253 trials.
From the similarity-rating data described above, we computed two diversity indices: the generalized magnitude and the spread, as follows.
2.3.1 Generalized magnitude
We followed the procedures below to calculate the generalized magnitude.
1. Conversion from similarity ratings to dissimilarities. For each participant, raw similarity ratings on the 8-point scale were remapped to integer dissimilarities , respectively; thus, a raw score of maps to dissimilarity , and maps to dissimilarity . The resulting matrix, in this case, a 23 × 23 matrix ( Figure 1a), is referred to as the dissimilarity matrix.
2. (Semi) metrics conversion. We interpret the dissimilarity between words as . This need not satisfy the metric axioms.
3. Scaling. For a scale parameter , we form the scaled dissimilarities .
4. Computation of a similarity matrix. We construct the similarity matrix by
5. Pseudoinverse and summation. We compute the Moore-Penrose pseudoinverse and obtain the generalized magnitude as the sum of all its entries:
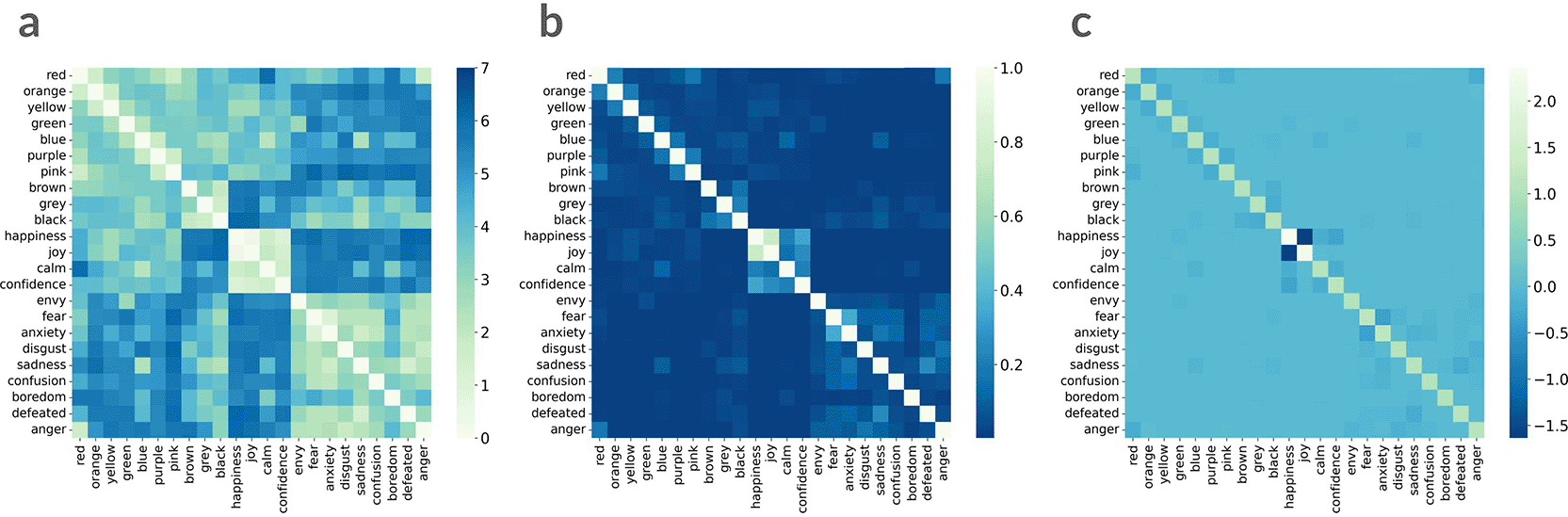
a: the dissimilarity matrix with the value range from 0 to 7. b: the similarity matrix with the value range from 0 to 1. c: the Moore-Penrose pseudoinverse matrix.
2.3.2 Spread
We calculated the spread for the same data.
Procedure.
Steps 1–3 are identical to those for the generalized magnitude.
4. Using the scaled similarities , compute the following quantity for each , by summing over x′ over the row (or column).
Then, take its reciprocal .
5. Sum these reciprocals over x to obtain the spread:
We will take a look at the calculation results of the generalized magnitude and spread, which were applied to real psychophysical experimental data. In previous studies, when examining the behavior of diversity indices, a common approach has been to investigate how their values change as the distance scale changes.19–21 This is because, even if the ratios between all distances remain the same, the absolute distances can still yield different values for these diversity indices; these diversity indices are scale-dependent. Therefore, it is useful to understand how the index values change as we vary the scale parameter t to obtain different scale values. In this study, we adopt the same approach to observe each index’s behavior.
Figure 2 shows the changes in the generalized magnitude and spread computed from a single dissimilarity matrix obtained by averaging the dissimilarity matrices across all participants, as the scale parameter t varies. The smaller t contracts the entire structure, focusing on only coarse differences. The larger t expands the entire structure, magnifying fine differences as distinct points. The blue line, spread, exhibits a smooth, sigmoid-like curve, whereas the orange line, generalized magnitude, follows a similar global trend but contains several local discontinuities. Although the dissimilarity data do not strictly satisfy the metric axioms, the qualitative behavior of the spread remains consistent with the theoretical properties described by Willerton.
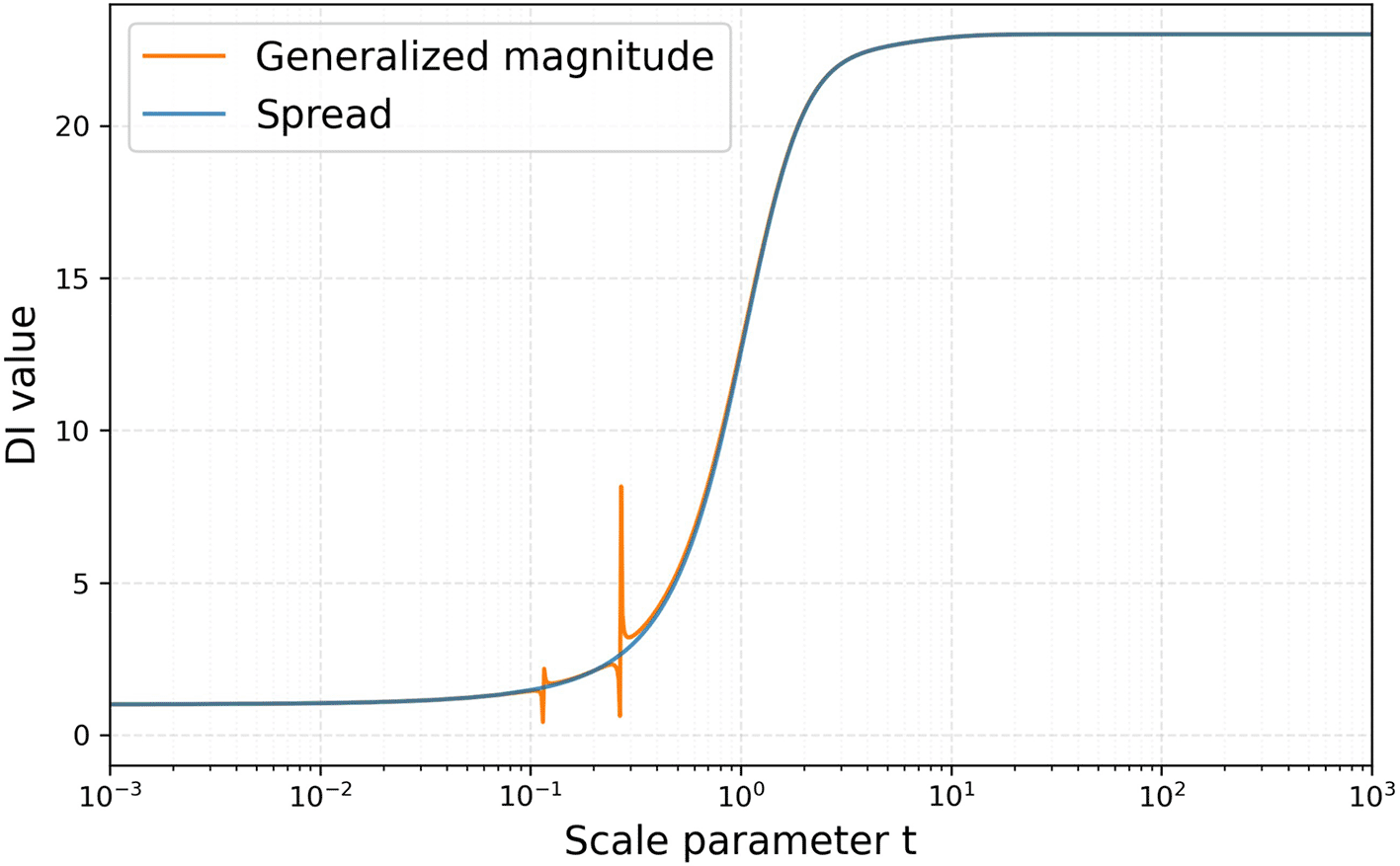
An orange line denotes the generalized magnitude and a blue one denotes the spread. The scale parameter t is the ratio multiplied by each value in the dissimilarity matrix generated from participants’ responses when computing distances.
Figure 3 illustrates the changes in generalized magnitude and spread for all participants as a function of the scale parameter t. The solid lines and shaded areas represent the median values and interquartile ranges (25–75 percentiles) across the population. The median was selected to mitigate the influence of extreme, discontinuous values observed in some participants.
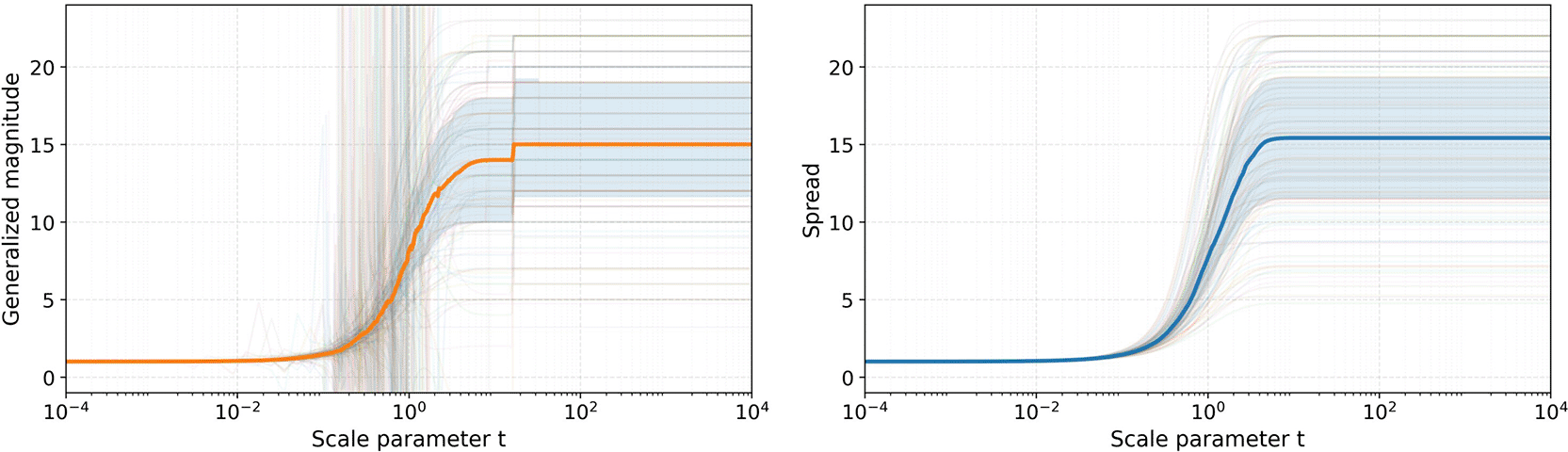
For each participant and each t, generalized magnitude and spread were calculated, and the median across all participants was taken and shown as solid lines. A solid orange line denotes the generalized magnitude, and a solid blue one denotes the spread. Shaded areas represent interquartile ranges (25–75 percentiles). The scale parameter t is the ratio multiplied by each value in the dissimilarity matrix generated from participants’ responses when computing distances.
Consistent with Figure 2, both indices exhibited a sharp, sigmoidal increase as t increased, particularly within the range of t = 0.1 to 10. Notably, the generalized magnitude profile shows a discontinuous increase around t = 15. This discontinuity stems from abrupt upward jumps observed in 68 out of 120 participants near this threshold. In contrast, the spread profile remained smooth across the entire range of t. At sufficiently large scales, both metrics reached a plateau, saturating at different levels: approximately 15 for generalized magnitude and 16 for spread.
Figure 4 illustrates the correspondence between the profiles of generalized magnitude (orange line) and spread (blue line) calculated at the individual level. We chose 4 representative participants whose profiles exhibited notable characteristics. Spread profiles are always smooth, yet they reach a different plateau value for each participant. Generalized magnitude profiles, however, exhibit discontinuities in some cases. The functions for Participant ID 2 and 3 have stepwise discontinuities around t = 15 (grey dotted line), similar to that observed in Figure 3. As t increases, both indices converge to constant values, which differ among participants. Qualitatively, it appears that the larger the white areas in the dissimilarity matrix, indicating pairs of stimuli judged by the participant as highly similar, the lower the overall diversity index tends to be.
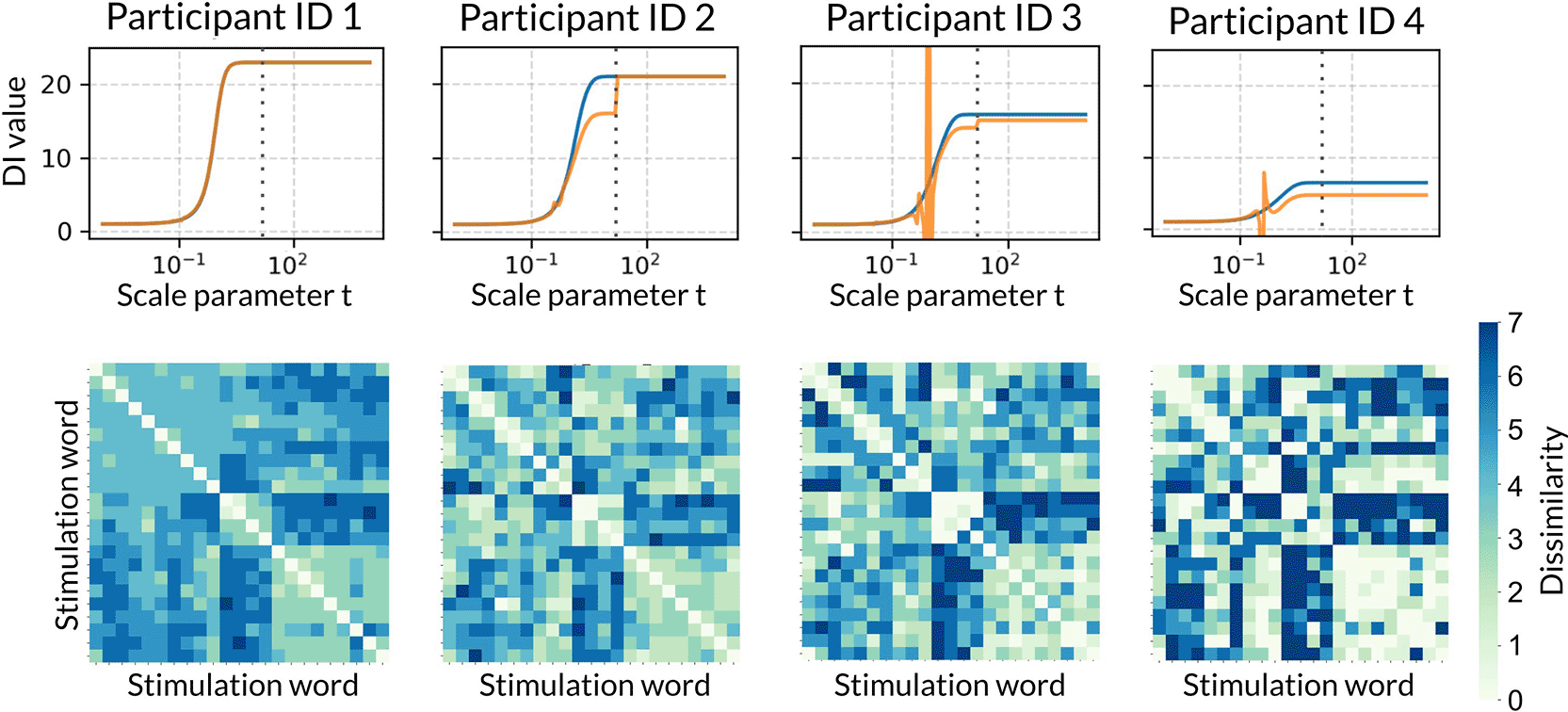
(Above) The horizontal axes represent the scale parameter t on a log scale. Vertical grey dotted lines represent t = 15. (Below) The vertical and horizontal axes of heatmaps are omitted for clarity, but they are the same as in Figure 1. The axes and color bars of the dissimilarity matrices are common across all participants.
In the results section, we calculated the generalized magnitude and spread for the empirical data from the similarity rating experiment on color words and emotion words, and examined the characteristics of their behavior. Both indices exhibited shapes similar to sigmoidal curves. When the scale parameter t gets closer to zero, the indices approach 1; as t increases, the indices increase and eventually reach a plateau at a certain value. A distinctive feature observed only in the generalized magnitude was the presence of points that appeared to diverge and points exhibiting discontinuous changes.
As shown by Theorem 4.1 in,20 the generalized magnitude coincides with the original magnitude when the matrix has a weighting and a coweighting. Because of that, as , the generalized magnitude approaches the number of stimuli, if the data satisfies the metric axioms. This is because after computing the distances, all entries in the resulting matrix become nearly zero except for the cells corresponding to pairs judged to have zero dissimilarity. In particular, if only identical stimuli have zero dissimilarity, the distance matrix becomes diagonal, and as a result, the generalized magnitude takes the value equal to the number of stimuli. (Note that as , all entries in the matrix asymptotically approach 1, i.e., the matrix and its inverse tend towards the unit matrix, and then the generalized magnitude converges to the number of stimuli.)
However, in cases like the present data, where dissimilarity can be zero for different stimuli, the situation becomes more complicated. In particular, if the relationship of zero dissimilarity is not transitive, the limiting value becomes non-trivial. Nevertheless, the generalized magnitude can be calculated by calculating the Moore-Penrose pseudoinverse of a matrix in which the components corresponding to pairs of stimuli with zero dissimilarity are set to 1, and the rest are set to 0, and then summing these components.
Which measure is generally preferable, generalized magnitude or spread? From an intuitive standpoint, spread offers higher interpretability due to its smoothness and the absence of discontinuities. In particular, employing spread is a viable approach when the data largely satisfy the metric axioms. Conversely, generalized magnitude does not necessitate these axioms—though it does require a defined similarity matrix (see section 4.2.1)—thereby allowing for broader computational applicability. Furthermore, as discussed later, we hypothesize that the discontinuities in the generalized magnitude profile encode essential information regarding the high-dimensional structures of the dissimilarity matrix. We therefore argue that generalized magnitude may provide a richer representation of the underlying data.
Having established that the diversity indices exhibit the above behaviors on empirical psychophysical experiment data, and that the resulting profiles differ across participants, we now address the central question: what interpretation, if any, can be given to a qualia structure constructed from qualia and their dissimilarities? At present, we do not have a definitive answer; this remains an open question. Here, we therefore present a partial, primarily mathematical understanding of these indices and their interpretation, with the aim of providing a starting point for future discussion.
4.2.1 The shape of the profile
We consider the profile itself—the full functional shape of the index as a function of the scale parameter t—to be the most important object when interpreting both the generalized magnitude and the spread. This is because the profile’s shape, including its value at the limit and any discontinuities, is expected to reflect the underlying structure of the graph on which we compute the generalized magnitude and the spread. Consequently, we think it will be fruitful to develop methods to evaluate and compare profiles directly.
In the present dataset, almost all participants exhibited a sigmoid-like profile. However, this need not hold in general. For example, in a graph such as the one Willerton showed21—where among three points, two are very close while the third is far—both the generalized magnitude and the spread profiles exhibit two plateaus (Figure 5).
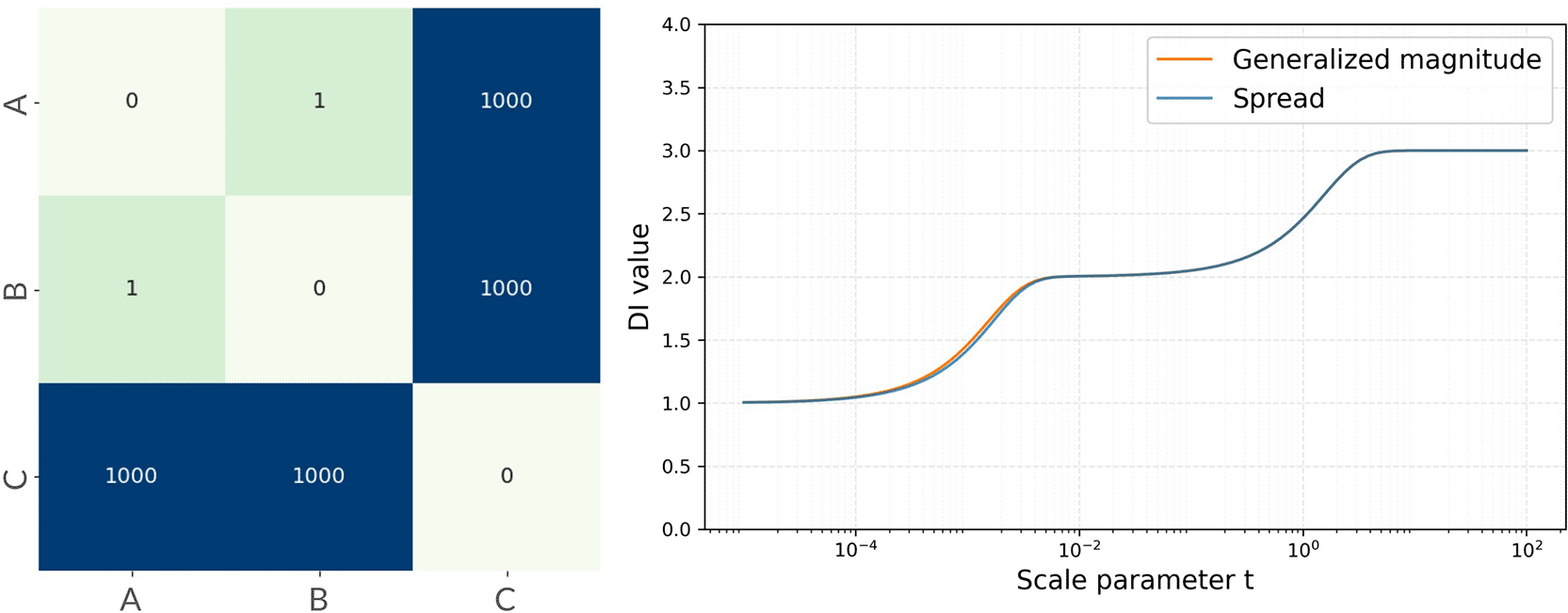
The matrix on the left is the distance matrix. A number in each cell corresponds to the distance. The distance matrix has three items. The distance between A and B is 1, and the distance between B and C is 1000, so you can think of a very sharp triangle. The profile on the right is calculated from the distance matrix and has two plateaus, with the limit being 3.
We also note, as a practical observation, that when the data violate the metric axioms more severely—for example, when the dissimilarity matrix is asymmetric or has non-zero diagonal entries—both the generalized magnitude and the spread profiles may display poorly interpretable behavior, such as divergence to infinity as t increases (Figure 6).
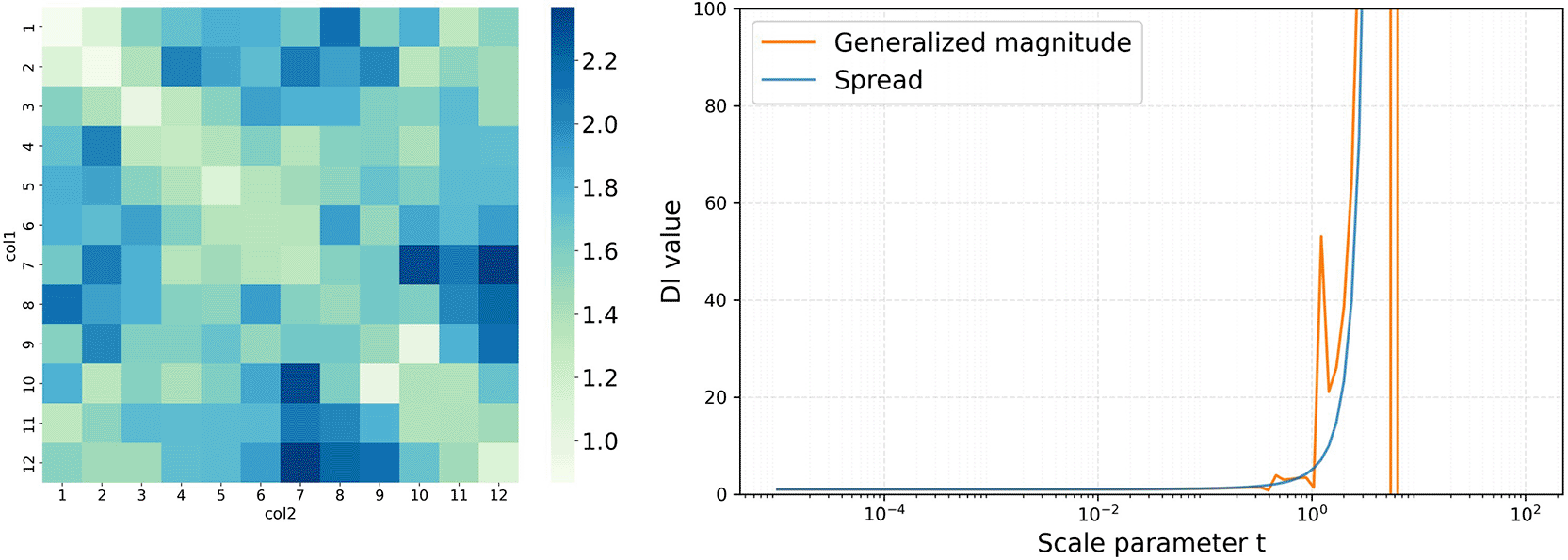
The left panel shows a distance matrix for 12 items (No. 1 to No. 12). Colors indicate the distances between them. In this data, participants were asked to rate the same items, so the diagonal elements are not zero. The limit would be 12 if the dissimilarity satisfies metric axioms, but the profiles diverge rapidly to infinity in a wide range of t.
Willerton defined the spread on the metric space, so it is natural that the spread profile shows violent behavior when the dissimilarity matrix does not satisfy the metric axioms, since the spread’s smooth behavior is guaranteed only on the metric space. Therefore, if the data do not satisfy the metric axioms, we should not naively consider that the spread is always a correct measure of diversity.
On the other hand, since the generalized magnitude is defined on an arbitrary matrix, it might seem that the result is always interpretable as a measure of diversity, regardless of the input. However, we need careful consideration. Leinster’s original notion of magnitude is formulated for a “similarity matrix” , which is defined as an matrix satisfying for all , and for all . He further suggests (while not requiring) additional properties such as , , and symmetry (see,19 p. 172). These conditions reflect the intended interpretation of as encoding pairwise similarities in a way compatible with our intuition of the concept diversity.
In their work on the generalized magnitude, Chen and Vigneaux20 do not impose the same restrictions on similarity matrices as Leinster’s original formulation. Their formulation is more algebraically general, and they explicitly note that “the results discussed in this paper are applicable to finite metric spaces, for which the matrix , called the similarity matrix in24”. In this sense, the similarity matrix setting is a special case of the generalized magnitude. Nevertheless, Chen and Vigneaux do not discuss whether this generalization preserves the interpretation in terms of diversity. Consequently, when we apply generalized magnitude to matrices that depart from Leinster’s setting, such as asymmetric matrices (e.g., incorporating order effects) or matrices with a non-unit diagonal (i.e., non-zero self-dissimilarity), its interpretation as a diversity measure is no longer straightforward.
4.2.2 Limit
Among the features of the profile, the limit (as ) is comparatively intuitive to interpret. Informally, the limit corresponds to the “effective number of clusters” in the highest resolution maximally expanded structure, where even small differences are treated as distinct. For intuition, see Supplementary Fig. S1, which shows MDS visualizations of dissimilarity matrices for participants with large versus small limits (as ).
In the simplest case—when the data satisfy the metric axioms and the dissimilarity matrix is an structure with non-zero off-diagonal distances—the profile converges to . When these conditions do not hold, the limit can be non-trivial.
A key issue is the violation of the conditions for an equivalence relation. A relation is an equivalence relation if it satisfies reflexivity ( ), symmetry (if then ), and transitivity (if and then ). In our data, the relation “dissimilarity is zero” is not generally transitive. For instance, a participant’s data is , and , while (Figure 7). In such cases, “zero dissimilarity” is not an equivalence relation, and the profile need not converge to ; instead, it can approach a non-trivial limit.
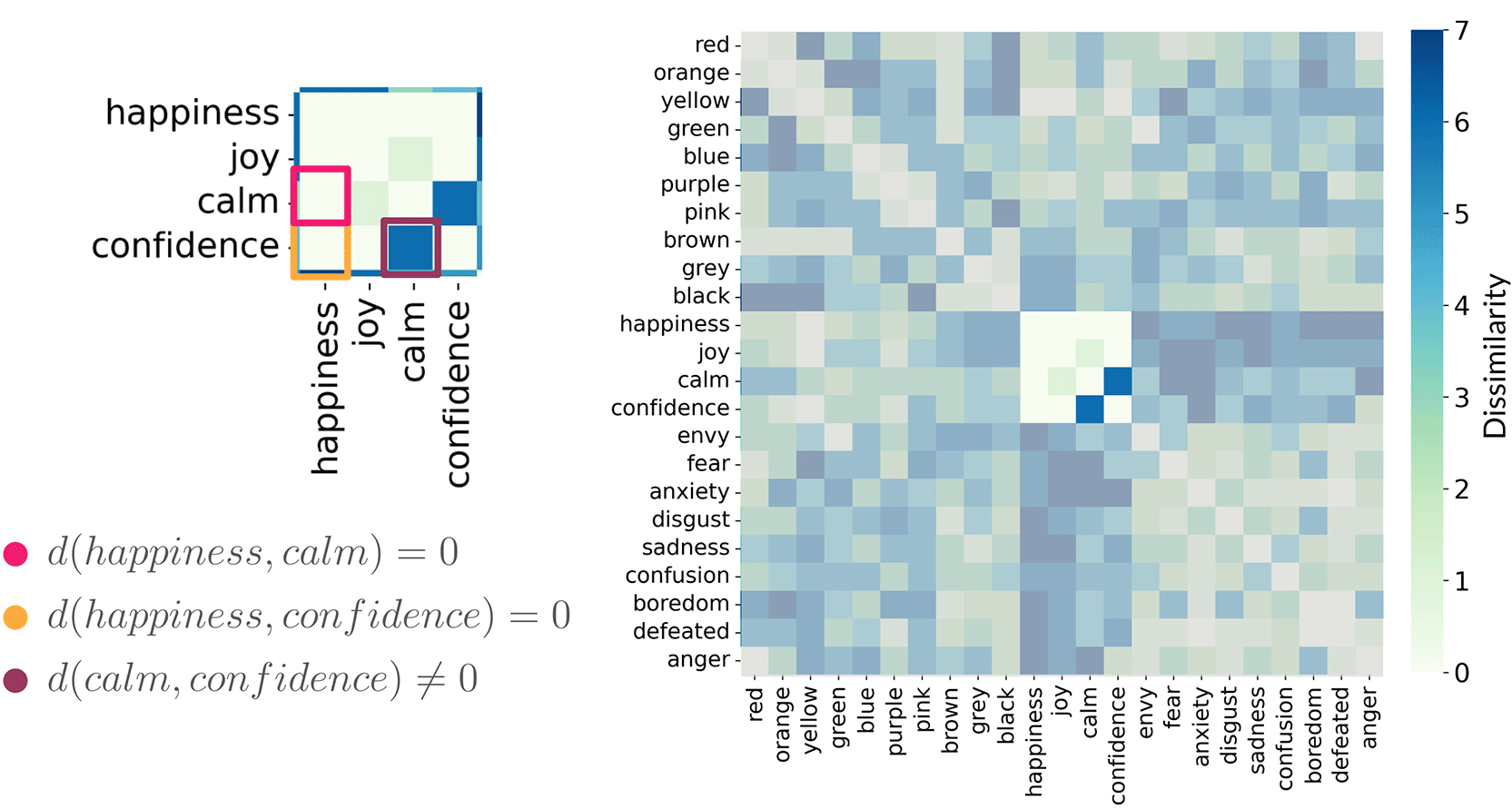
In this participant’s data, , and , while .
Moreover, even if these equivalence-relation conditions hold, the profile may not converge to an integer if the following condition is violated: whenever two items have zero dissimilarity for each other, their dissimilarities to all other items agree. We refer to this as a “consistency condition”. If this consistency condition does not hold, the limit may again be non-integer.
In our case, some participants appeared to have the diversity indices converging to a non-integer value (for example, see Fig. S1). This is consistent with violations of transitivity of zero dissimilarity and/or the consistency condition. Indeed, we can show that the limit is an integer when “zero dissimilarity” defines an equivalence relation and the consistency condition holds (e.g., when only diagonal entries correspond to zero dissimilarity). Otherwise, non-integer limits can occur.
Although an integer limit does not guarantee that equivalence and consistency conditions hold, a non-integer limit indicates that the data violates at least one of these conditions. In other words, the convergence to a non-integer value in the generalized magnitude serves as a diagnostic indicator of broken equivalence structure and/or the consistency condition. This supports the conjecture that generalized magnitude captures non-trivial aspects of cluster structure beyond simple partitions.
4.2.3 Positivity and discontinuities
We observed that the generalized magnitude profile is not always fully smooth and exhibits discontinuities. These points correspond to points at which the (original) magnitude ceases to exist.
Under what conditions do such discontinuities arise? If, for all t, the similarity matrix is positive definite, then the (original) magnitude exists, and the magnitude coincides with the generalized magnitude. In this case, no discontinuity can occur. This follows because the function “take the sum of entries of the inverse matrix” is continuous on the set of invertible matrices.
Furthermore, by a corollary of Schoenberg’s theorem,25 the condition that the similarity matrix is positive definite for all t is equivalent to the condition that the dissimilarity matrix A is of negative type.
A dissimilarity is of negative type if, for all real coefficients satisfying , the following inequality holds:
Dissimilarity matrices that are not of negative type have a form of “twisting” of the space, as seen in structures such as complete bipartite graphs, cycles, or configurations that violate the triangle inequality.
As discussed in the Introduction, the qualia structure approach currently relies primarily on two methods for evaluating and comparing structures: MDS and GWOT. Among these, GWOT provides a quantitative method, but it is fundamentally a method for comparing two structures. Once a structure is obtained from experimental data, we still require ways to interpret it: what are the characteristic features of an individual’s or a group’s qualia structure?
To extract richer meaning from an obtained structure, it is desirable to use multiple indices that represent different important aspects of the qualia type. As one such interpretive index—one that highlights a specific structural feature—we argue that diversity indices, especially the generalized magnitude and the spread, are useful because they provide a quantitative measure of diversity of the qualia structure.
At the same time, they appear to offer more than a scalar summary of “diversity.” As discussed above, the generalized magnitude profile—particularly through features such as discontinuities—suggests that it may reflect geometric characteristics of high-dimensional structure. To date, discussions have often relied on projecting high-dimensional structures into low-dimensional embeddings or on analyzing element-to-element correspondences between two structures.13,14,26 By adding profile-based analyses, it may become possible to bring certain high-dimensional structural features into discussion in a comparatively direct and accessible manner.
In this paper, we quantify diversity in the dissimilarity matrices, which reflects some aspects of qualia structure. But characterizing diversity through its profile via either spread or generalized magnitude is not limited to this use. For example, we can apply them to the similarity matrices derived from neural activity patterns that are believed to be correlated with some aspects of consciousness.27–31
The diversity indices—generalized magnitude and spread—can be applied to analyze similarity rating experiments within the qualia structure approach, and they can provide novel insights that are not available from existing methods alone. In particular, when we interpret it as a diversity profile, it does not merely quantify one aspect that has long been emphasized in consciousness research, namely the diversity of qualia, but also appears to reflect geometric characteristics of high-dimensional structure. We expect that further theoretical and empirical work will deepen the interpretation of these indices and lead to a richer understanding of the structure through diversity-based analyses.
For the data analyzed in this research, ethics was amended and approved by Monash University Human Research Ethics Committee (approval number: 17674). All participants provided informed consent prior to participation. A more detailed description of the experimental procedures and related ethical considerations will be reported in a separate paper (Aisbett, Kusano and Tsuchiya, in prep).
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)