Keywords
statistical simulation, risk of bias, bias assessment tool, protocol, systematic review
statistical simulation, risk of bias, bias assessment tool, protocol, systematic review
Statistical simulation studies are the principal methodology for examining how well a set of statistical methods perform against a known truth. This is achieved by generating hypothetical data sets based on known characteristics, applying the statistical method(s) to the data sets and comparing the results with the known characteristics.2,3 Statistical simulation can be used to evaluate whether a statistical method performs as intended, to examine the robustness of a statistical method or to compare multiple statistical methods (either as a comparison of previously published methods or to compare the performance of a newly developed method) (see Table 1). Statistical simulation is also used for other purposes, such as to construct empirical sampling distributions (e.g., bootstrapped confidence intervals) or to determine the power or sample size when designing a study, although such uses are beyond the scope of the current project.
| Reference | Purpose of simulation study | Description of simulation study |
|---|---|---|
| Li, 2024 44 | Evaluate whether a statistical method performs as intended. | Develop a method for small samples that extends standard longitudinal models to accommodate informative observations in clinical studies; simulation was used to show that the proposed estimators performed as expected from theory. |
| Abbas-Aghababazadeh, 202345 | Examine the robustness of a statistical method to violations in the assumptions underpinning the method. | Compare meta-analysis methods for gene-drug associations or biomarker discovery using preclinical pharmacogenomics data; simulation was used to evaluate the performance of the standard meta-analysis methods, which assume independence between included studies, when this assumption was violated. |
| Jiang, 202346 | Compare a newly developed method with multiple previously published statistical methods. | Develop a mediation modelling approach that addresses zero-inflated mediators containing both true zeros and false zeros, and compare this approach to existing standard causal mediation analysis approaches; simulation was used compare the performance of the approaches across a range of scenarios. |
| Cho, 2024 47 | Compare multiple previously published statistical methods (sometimes referred to as a neutral comparison study). | Compare existing reliability estimators for single-administration test scores; simulation was used to evaluate the accuracy of each estimator under a range of scenarios. |
One of the primary purposes of statistical simulation studies is to guide researchers in statistical decision making, for example, in selecting statistical methodology for a particular scenario. For instance, simulation studies might be used to select which small sample correction to make in a cluster randomised trial with few clusters.4 Researchers may refer to individual simulation studies, or evidence syntheses that combine the results from multiple simulation studies (e.g., a systematic review of simulation studies that evaluated the properties of small sample corrections in cluster randomised trials5). However, both individual statistical simulation studies and evidence syntheses of them may unfairly represent the true performance of the statistical methods, if the simulation results are biased or unrepresentative of the situation to which they are applied.
Bias is defined as a “systematic error, or deviation from the truth, in the results”.6 In the context of statistical simulation studies, the ‘results’ are performance metrics used to quantify how well the statistical methods under evaluation are behaving, and these may be evaluated under multiple scenarios (see Table 2 for definitions and examples of terms in bold). Note that ‘bias’ is a key performance metric commonly used in simulations studies to quantify systematic error in statistical method’s estimator relative to the true parameter value (see footnote [1]). To distinguish this ‘bias’ from the bias we are referring to, we use the terminology ‘bias in the simulation study results’.
The structure of this glossary follows the ADEMP system from Morris et al.2 The terms in brackets refer to alternate usage for the term.
| Term | Definition | Example from Turner et al. 2021 |
|---|---|---|
| Statistical simulation study (study) | A statistical simulation study is a computer experiment designed to evaluate a specific aim, using data created from pseudo-random sampling of known probability distributions. | “In this study, we therefore aimed to examine the performance of a range of statistical methods for analysing interrupted time series studies with a continuous outcome using segmented linear models.” |
| Data-generating mechanism | The data-generating mechanism is the process of using random numbers to generate (simulate) one or more data sets.2 | “We simulated continuous data from ITS studies by randomly sampling from a parametric model [a segmented linear regression model], with a single interruption at the midpoint, and first order autoregressive errors. We multiplied the first error term by [where is the lag-1 autocorrelation of the errors] so that the variance of the error term was constant at all time points.” |
| Statistical model (model) | A statistical model describes the assumed mathematical relationship between the data points. | “We use a segmented linear regression model with a single interruption, which can be written using the parameterisation [defined below] proposed by Huitema and McKean as: Yt = β0 + β1t + β2Dt + β3[t-TI] Dt + εt” |
| Variable | The variables in the statistical model are the quantities that can vary across data points. | “Yt represents the continuous outcome variable at time point t of N time points [t is a variable]. Dt is an indicator variable that represents the post-interruption interval (i.e. Dt = 1 (t ≥ TI)) where TI represents the time of the interruption [TI is a parameter, defined below].” |
| Parameter | The parameters of the statistical model are the fixed quantities that define the data-generating process. | “The model parameters, β0, β1, β2 and β3 represent the intercept (e.g., baseline rate), slope in the pre-interruption interval, the change in level and the change in slope, respectively. The error term, εt, represents deviations from the fitted model.” |
| Parameter value (Factor) | Parameter values (Factors) are the values given to the parameters underlying the data and other experimental design choices that the researcher specifies in the data-generating mechanism, (e.g. (true value of a data characteristic such as the mean)). | “We created a range of simulation scenarios including different values of the model parameters and different numbers of data points per series. … All combinations of these parameter values (factors) were simulated, leading to 800 different simulation scenarios.” |
| Simulation scenario (scenario) | The factors used to specify a data-generating mechanism define a single simulation scenario. There are typically multiple scenarios considered in each statistical simulation study. | “We created a range of simulation scenarios including different values of the model parameters and different numbers of data points per series. … All combinations of these factors were simulated, leading to 800 different simulation scenarios.” |
| Data set | A data set contains set of data points. Each simulation scenario uses a unique data-generating mechanism to generate multiple data sets. | “Design parameter values (factors) were combined using a fully factorial design with 10,000 data sets generated per combination.” |
| Data point | A data point is a single observation, case or record within the data set. | An example data point is t = 20 months, Dt = 1, Y20 = 0.50 C. difficile infections per 1,000 patient-days. |
| Estimand | The estimand is a population quantity, or true characteristic of the data, that is estimated by the statistical methods in the statistical simulation study. | “The primary estimands of the simulation study are the parameters of the model, β2 (level change) and β3 (slope change).” |
| Statistical method (method) | Statistical method typically refers to a model used for data analysis but can also refer to the procedure used to choose an analysis.2 A statistical simulation study may evaluate the performance of a single method or compare the performance of multiple methods. | “We focus on statistical methods that have been more commonly used (Ordinary Least Square (OLS), Generalised Least Squares (GLS), Newey-West (NW), Autoregressive Integrated Moving Average (ARIMA)). In addition, we have included Restricted Maximum Likelihood (REML) (with and without the Satterthwaite adjustment), which although is not a method in common use, is included because of its potential for reduced bias in the estimation of the autocorrelation parameter, as has been discussed for general (non-interrupted) time series.” |
| Performance metrics | The performance metrics generate the numerical quantities, i.e., the results, used to assess the performance of the method(s) under evaluation (e.g., bias, confidence interval coverage, mean square error). | “The performance of the methods was evaluated by examining bias*, empirical standard error, model-based standard error, 95% confidence interval coverage and power.” |
Bias may occur in the simulation results when, for example, researchers alter the study design after seeing the initial results to favour a preferred method.7–10 Additionally, the composition of the research team can introduce bias if the researchers have varying expertise, experience or preferences regarding the methods being compared.7,11–14 This could result, for example, in study design decisions that favour particular methods,7–11,13,14 or identification of implementation errors more readily for some methods over others.7,11,12
Many choices are made when designing a simulation study, and while some of these choices may not introduce bias into the simulation results, they can still lead to unfair representation of the performance of the methods under evaluation. For example, researchers must choose the statistical methods to be compared, the data-generating mechanism and performance metrics, and the approach used to evaluate the performance of the methods when the simulation results are missing (as occurs, for example, when methods fail to converge for some of the data sets in a particular scenario).2,3,8,11,15,16 Different design choices can lead to different findings for the performance of a statistical method, which in turn can lead users of statistical simulation studies to make a different decision when selecting statistical methodology. Such researcher choices can also lead to optimism bias, which refers to the tendency of a newly introduced method to perform better in the original publication than in subsequent comparison studies.7,14,17–19
Non-reporting bias is another type of bias that is of concern for simulation studies. Simulation studies may remain entirely unpublished due to their findings (known as publication bias),11,20–22 or there may be selective non-reporting of results within individual studies (known as selective non-reporting bias).7,11,22 Unlike other forms of research (e.g., randomised trials), there is not a culture or requirement to register simulation studies or publish protocols for them, and because simulation studies (mostly) do not include patient data, they are exempt from ethical review. These factors hinder the ability to identify a sample of simulation studies before their results are known and hence to assess the risk of bias due to non-reporting.
There exist several risk of bias tools for a range of study designs such as RoB 2 for randomised trials,23 ROBINS-I for non-randomised studies of interventions,24 ROBIS for systematic reviews,25 and PROBAST for prediction modelling studies.26 However, we are unaware of such a tool for assessing the risk of bias in the results and unfair representation of the performance of the methods in statistical simulation studies. While reporting guidelines and recommendations for the developers of statistical simulation studies exist,2,3,13,15,27–30 these publications are not aimed at the users of simulation studies. Assessing potential for bias in findings from simulation studies is important for researchers using the findings to guide their statistical decision making, and for those undertaking evidence syntheses of statistical simulation studies. The aim of this research is therefore to develop a tool to evaluate whether statistical simulation studies provide a fair representation of how the statistical methods under investigation are expected to perform.
We aim to develop a tool to evaluate whether statistical simulation studies provide a fair representation of how statistical methods are expected to perform. Development will be based on guidance by Whiting et al.31 and Moher et al.,32 and informed by methods used in the development of other related tools.26,33–36 We describe the activities planned at each proposed stage. The development process for the tool is shown in Figure 1.
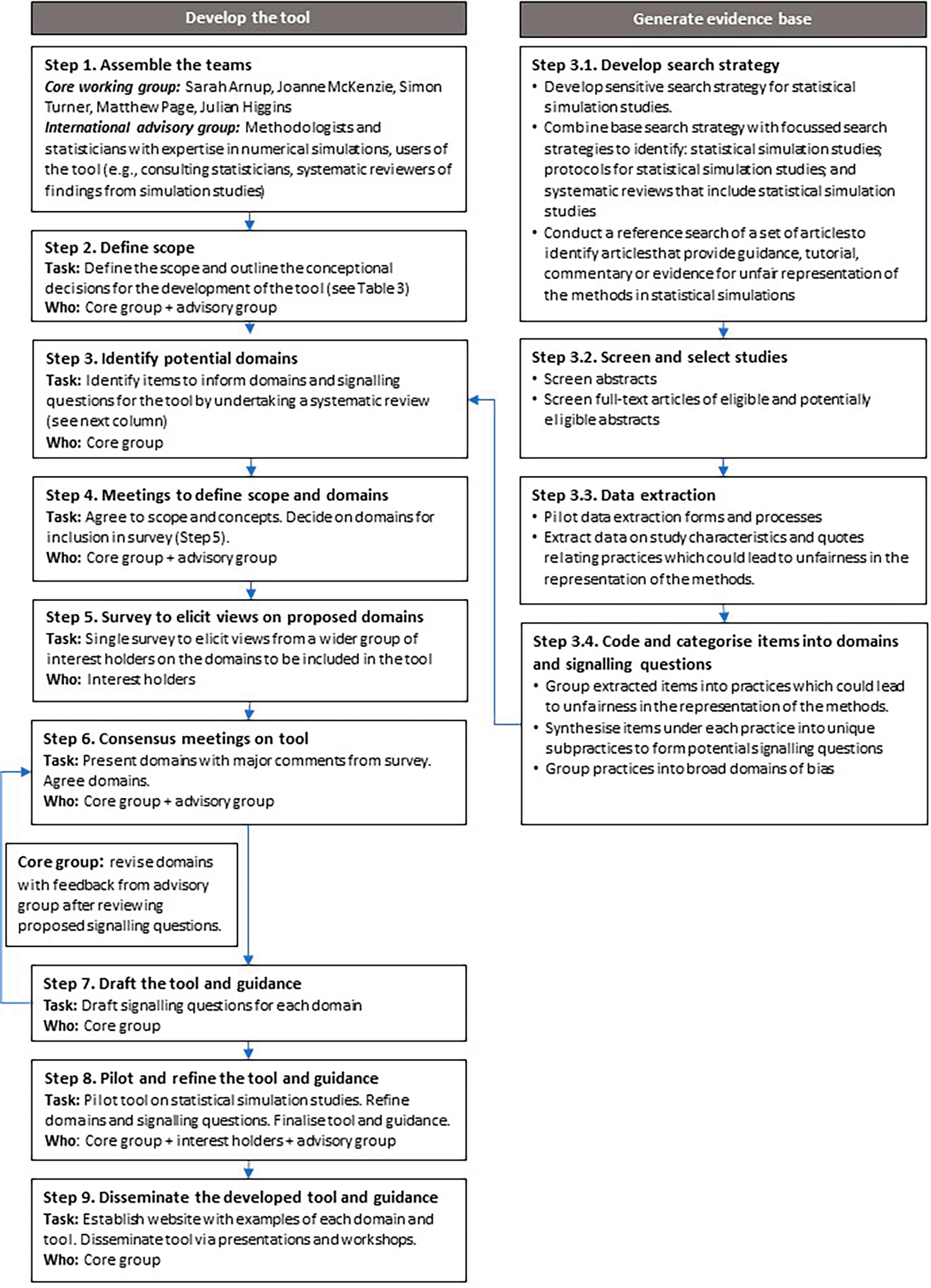
The project team will consist of a core working group and an international advisory group. The core group includes: Sarah Arnup (co-lead), Joanne McKenzie (co-lead), Simon Turner, and Matthew Page, based at the School of Public Health and Preventive Medicine at Monash University, and Julian Higgins (University of Bristol). The core group consists of researchers with expertise in the design, conduct and analysis of statistical simulation studies; experience in using statistical simulation studies to inform their statistical practice; knowledge of bias in different study designs; and experience developing risk of bias tools (e.g., RoB2,23 ROB-MEN,22 ROB-ME37). The core group will be responsible for leading the tool development and undertaking the research (e.g., systematic review to inform the content of the tool, conduct and analyse the survey used to generate potential items for the tool, organising consensus meetings).
An international advisory group will be established to provide advice to the core working group throughout the development process. The advisory group will consist of international interest holders including methodologists and statisticians with expertise in numerical simulations, and likely users of the tool (e.g., consulting statisticians, systematic reviewers of findings from simulation studies).
During the first virtual meeting with members of the core and advisory group, we will seek agreement on the conceptual decisions outlined in Table 3.
| Conceptual decisions to make | Considerations and examples |
|---|---|
| What is the definition of a statistical simulation study? | We will seek agreement on the definition of a statistical simulation study.
The terminology used to refer to a statistical simulation study varies with discipline, and can include, for example, simulation study, Monte Carlo simulation, stochastic simulation, computer simulation, numerical simulation study, computational research and benchmark/ing study. Examples of published definitions for a statistical simulation study include:
|
| Which applications of statistical simulation studies will be targeted by the risk of bias tool? | We propose to restrict the tool to studies evaluating statistical methods but will seek agreement on the exclusion of other uses of statistical simulation.
Statistical simulation studies are used for different purposes. Common aims of a statistical simulation study, including studies that use different terminology but meet the definition of a statistical simulation study, can include both studies that evaluate statistical methods and apply statistical methods. (See also Table 1): Evaluation Example aims of studies that evaluate whether a statistical method performs as intended:
Example aims of studies that compare multiple statistical methods:
Example aims of studies that apply simulation methods:
|
| How is risk of bias defined? | We will seek agreement on the definition of the risk of bias.
There are at least two options of what could be assessed for risk of bias in a simulation study. Firstly, risk of bias of the individual results of performance metrics; that is, deviation in the numerical quantities used to estimate the performance of the methods under evaluation, from the results that would have been reached in a study with no flaws in the design, conduct or analysis. Secondly, risk of bias of the overall conclusions that the simulation study authors draw about the performance of the methods. |
| Will the tool consider only risk of bias of the results (internal validity) or will it also be concerned with assessing applicability (external validity) and possibly reporting quality and missing results? | We will seek agreement on whether the tool should consider only risk of bias in the simulation study results, or in addition, assess broader issues of unfair representation of the performance of the methods.
Consideration of unfair representation of the methods will include an assessment of the potential for design choices to misrepresent methods, in addition to bias in the simulation results (i.e., internal validity). Examples of practices that may introduce bias into the simulation results or misrepresent the methods (presented in italics) are provided below:
|
| Who is the target audience? | We have decided to develop a tool for researchers who use the findings of statistical simulation studies to guide their statistical decision making (e.g., consulting statisticians), and researchers undertaking evidence syntheses of statistical simulation studies. |
| What type of tool structure will be adopted, e.g., simple checklist design or a domain-based approach? | We have decided to develop a domain-based tool with signalling questions, as per, for example, RoB2,23 ROBIS.25 |
| How will quality items be rated within the tool? | We will seek agreement on the response options for the signalling questions and the domains.
As a starting point, we will consider using the response options used for other risk of bias tools; that is high/low/some concerns for the domain, and yes/no/unclear or yes/probably yes/probably no/no/no information for the signalling questions. |
We will identify items to inform the content (e.g. domains and signalling questions) for the proposed tool by undertaking a systematic review. We will obtain evidence from four article types: statistical simulation studies (type 1); protocols for statistical simulation studies (type 2); articles that provide guidance, tutorial, commentary or evidence for unfair representation of the methods in statistical simulations (type 3); and systematic reviews that include statistical simulation studies (type 4). Details of the eligibility criteria for each article are available in Appendix Table A1.1
The Ovid MEDLINE search strategies have been iteratively developed with the assistance of an experienced information specialist (SM). We have designed a base search strategy that is highly sensitive for statistical simulation studies (see Appendix Table A21). This base search strategy was developed and tested using a set of 32 articles; 8 articles were obtained from a recent study examining the replicability of highly cited statistical simulation studies,38 6 articles from statistical simulation studies published in Biometrical Journal as part of the collection “Neutral comparison studies in methodological research”,39 and 20 articles from a convenience sample of articles identified by early iterations of the search strategy. Because the search strategy is expected to return an infeasible number of articles to screen, we will combine the base strategy with more focussed search terms for article types 1, 2 and 4. For article type 3, we will identify articles by conducting a cited reference search (forward and backward citations) of a set of articles known to the authors. Descriptions and rationale for the search strategies, and the search syntax (where applicable), are available in Appendix Table A2.1
Citations identified from the search will be imported to Microsoft Excel (Microsoft Office LTSC Professional Plus 2021). One author (SA) will screen all abstracts against the eligibility criteria and classify them as eligible, ineligible or potentially eligible. Full-text articles will be retrieved for all abstracts classified as eligible and potentially eligible articles. Where eligibility is unclear, the article will be reviewed by the core group. For type 1 (statistical simulation) articles, and for reasons of feasibility, we will randomly select and screen abstracts and full-text articles until we identify 50 eligible studies. Eligible articles will be imported to EndNote X8 (Clarivate Analytics, Philadelphia) to remove duplicates.
Data will be extracted from eligible articles using a data collection form developed in Research Electronic Data Capture (REDCap) online designer.40,41 The core working group will pilot the data extraction form for article types 3 and 4. For article type 3, the core working group will independently extract data from the same set of articles because we anticipate subjectivity in identifying and categorising data for extraction. For article type 4, two authors, SA and another (EK, SLT, MJP or JEM), will independently extract data from a set of articles. SA will identify discrepancies from the piloting and present these at meetings for discussion. The data extraction form and guidance will be refined through this process. No piloting of article types 1 and 2 will be undertaken because the guidance developed for articles type 3 and 4 will also apply to articles types 1 and 2. The remainder of articles will be extracted by one author (SA), with any uncertainties discussed with the core working group.
We will extract data on study characteristics (Appendix Table A31). For all article types we will identify whether the authors discuss a potential source of bias in the simulation study results; state or discuss potential flaws in the design of the study; state or discuss a design, conduct or reporting practice which signals, mitigates or allows the assessment of flaws in the design of the study, or provide empirical evidence for bias in statistical simulation studies. We will extract the quote, and write a sentence summarising the concept (which we call an item), categorise the item according to the reason for inclusion and select practises that could lead to the type of bias identified in the item (e.g., we extract the quote: “In case of simulated data, organize a fair comparison in terms of the relation between the methods under study and the data-generating mechanisms of the simulations, with fair meaning that one should not exclusively rely on mechanisms that unilaterally favour methods which explicitly or implicitly assume that these mechanisms are in place”; summarise the concept: “The data-generating mechanism should produce data that allows a fair assessment of the performance the methods under investigation”; categorise the quote: “Discuss a potential source of bias in the results of the simulation study” and we select the practice leading to this bias as: “Data-generating mechanism.”) This latter selection is important for informing potential signalling questions.
One author (SA) will: (1) group the items by the types of practices that could lead to bias in the simulation study results (items may be grouped under multiple practices); (2) synthesize and reword similar items under each practice to create a unique set of items; (3) categorise the practices into broad domains of bias (e.g., selective outcome reporting), generalisability (e.g., choice of simulation scenarios), and an unclear category for further discussion. We will provide a definition for each domain, provide a rationale for including the domain, and give example signalling questions. This initial draft set of domains will then be distributed to the advisory group for review. Analyses of the extracted data will be undertaken in Stata version 18.042 and Microsoft Excel (Microsoft Office LTSC Professional Plus 2021).
Following distribution of the initial set of domains, we will hold virtual consensus meeting(s) with the advisory group to discuss which domains should be retained, which require modification, and whether there are any missing domains. We will also seek feedback on the definitions of the domains. The domains and their definitions will be revised in response to this feedback and used as the basis for the subsequent survey of interest holders.
We will undertake a survey of a broader group of interest holders to seek wider input on the domains to include in the tool. The interest holders will be selected to ensure representation from researchers with statistical simulation experience, methodologists and statisticians with expertise in statistical simulation design and users of the research. Potential participants will be identified by members of core and advisory groups. In addition, we will advertise the survey via relevant mailing lists (e.g., Statistical Society of Australia).
The core group will draft the survey and pilot test with members of the advisory committee. The survey will be created and distributed using Qualtrics online survey software (Qualtrics, Provo, Utah, USA. https://www.qualtrics.com). Participants will be presented with domains and their definitions, and asked to rate the importance of each domain. They will be given the opportunity to provide comments on the domains, definitions and whether there are any missing domains. We will also collect brief demographic information and ask whether participants would be willing to pilot test the tool.
We will calculate summary statistics to quantify participants’ views of the importance of the domains. Responses to the open-ended question will be summarised, keeping all unique ideas (regardless of the frequency with which they were made).
Ethics approval for the survey will be sought from the Monash University Human Research Ethics Committee.
We will hold virtual consensus meeting(s), to discuss the survey results with the advisory group. Each domain will be introduced by a core group member, together with the summary statistics of the importance rating and any major comments. We will focus our discussion on domains that the survey participants have rated as not important, and on any additional domains suggested by the participants. The core group will revise the domains in response to these meetings.
The core group will prepare a list of potential signalling questions, elaborations and response options for each domain. The wording for the signalling questions will be informed by the unique items identified within each practice from the systematic review (step 3). The core group will seek feedback from the advisory group, revise the domains, signalling questions, and other content, and continue this process until major concerns are addressed.
The draft tool will be piloted on a random sample of statistical simulation studies identified in article type 1 of the systematic review by two reviewers. The reviewers will be identified from among the survey respondents who indicated a willingness to pilot the tool. We will ask the reviewers to record any issues with interpreting or applying each signalling question, or with the accompanying elaborations. Identified issues with domains and signalling questions will be discussed by the core group and refined. In addition, we will invite members of the advisory group to provide feedback. The core group will discuss and further refine any problematic signalling questions, before finalising the tool.
A paper describing the tool will be published in an open-access format. The tool and guidance document will be made available on a website housing risk of bias tools (https://www.riskofbias.info/). The tool will be disseminated via presentations and workshops at relevant conferences and workshops and via social media, and in a series of international webinars.
As of 3 June 2026, we have run the searches and screened, identified and extracted data from 44 statistical simulation studies; 47 protocols for statistical simulation studies; 56 articles that provide guidance, tutorial, commentary or evidence for unfair representation of the methods in statistical simulations; and 42 systematic reviews that include statistical simulation studies. We have commenced grouping the extracted items by practices that could lead to bias and synthesizing similar items under each practice.
We plan to develop a tool to assess the potential for bias in the results of statistical simulation studies and unfair representation of the performance of statistical methods in statistical simulation studies. While there are reporting and conduct guidelines available for statistical simulation studies,2,3,13,15,27–30 to our knowledge, this will be the first tool for systematically evaluating whether a statistical simulation study presents a fair representation of how the statistical methods under investigation are expected to perform. The developed tool is intended to assist researchers in determining which statistical methods to use in their statistical decision making, and inform evidence syntheses of statistical simulation studies.
To ensure the tool is relevant and useful to the end-users of statistical simulation studies, the tool will be developed through co-design with end-users, who are part of the core working group and the international advisory group, and whose views will be sought through the survey and piloting processes. To ensure a comprehensive list of possible domains are considered when developing the tool, we will first undertake a systematic review of the statistical simulation literature to identify domains. Recognising the challenge of identifying studies from this literature, we have involved an information specialist to develop the search strategies and utilise cited reference searches (forward and backward citations) of key methodological articles. In addition, the identified list of domains will be supplemented by input from the international advisory group and survey respondents.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)