Keywords
nonparametric survival, positive-support KDE asymmetric kernel families; hazard estimation; cross-validation
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
nonparametric survival, positive-support KDE asymmetric kernel families; hazard estimation; cross-validation
Nonparametric estimation has become an important statistical approach for modeling complex data without imposing restrictive parametric assumptions. In survival and reliability analysis, observed data are frequently positively supported, skewed, and bounded below by zero, which makes flexible estimation methods particularly important. Kernel density estimation (KDE) is one of the most widely used smoothing techniques for estimating unknown probability density functions from observed samples. However, classical symmetric kernels may suffer from substantial boundary bias when applied to positive-support data, especially near zero. To overcome these limitations, asymmetric kernel estimation methods have been developed using positively supported distributions such as Gamma, Inverse-Gaussian, and related skewed families.1–3 These kernels improve estimation accuracy in bounded domains and provide better adaptability for skewed survival and reliability data. Recent developments in asymmetric kernel estimation have demonstrated improved performance in survival applications, hazard estimation, and density reconstruction for nonnegative random variables.4–6 In survival analysis, flexible nonparametric estimation of the survival function and hazard function is essential for accurately representing lifetime behavior without relying on restrictive parametric assumptions. Kernel-based survival estimation provides a useful alternative to classical approaches by combining smoothing flexibility with data-driven estimation.7,8 In addition, several recent studies have emphasized the importance of transformed survival models and algorithm-based estimation methods in reliability and lifetime analysis.9–11 This study adopts a kernel-family framework rather than relying on a single asymmetric kernel. Several positive-support kernel families derived from Log-Lindley, Birnbaum–Saunders, and Inverse-Weibull distributions are constructed and evaluated under unified comparison criteria. The proposed framework extends asymmetric kernel estimation from density estimation to survival and hazard estimation while integrating likelihood cross-validation and Silverman-type bandwidth selection methods. Recent related work and applications can be found in Refs. 12–20. The main contributions of this study can be summarized as follows:
(i) proposing a flexible asymmetric kernel-family framework for positive-support survival estimation;
(ii) extending kernel estimation to density, survival, and hazard function estimation;
(iii) comparing several asymmetric kernel families under unified evaluation criteria;
(iv) integrating data-driven bandwidth selection methods;
(v) evaluating the proposed methodology through simulation studies and real survival data applications.
Kernel density estimation (KDE) is one of the most widely used nonparametric techniques for estimating unknown probability density functions. Given a random sample x1, x2, …, xn from a positive-support distribution, the KDE provides a smooth estimate of the underlying density by averaging localized kernel functions., which leads to a smooth and flexible estimate of the probability density function by kernel functions.21 Given observations x1, x2, …, xn with x i > 0, the kernel density estimator is defined as:
where K (t; x i, h) is a nonnegative asymmetric kernel centered around xi and controlled by the bandwidth parameter h. The kernel integrates to one over (0, ∞), ensuring that the estimator remains a valid density function on positive support. In asymmetric KDE, K depends on xi so that the kernel adapts locally to the positive support and reduces boundary bias.
The following asymmetric kernel families are considered in this study. Each kernel is defined on the positive semi-axis and parameterized locally through the observation xi and the bandwidth parameter h.
Using the transformation Y = exp (−Z), where Z follows the Lindley distribution, the induced Log-Lindley density on (0,1) is obtained as:
Define Then a convenient log-Lindley-based kernel is:
A practical local bandwidth parameterization is adopted through θ i = 1/h, allowing the kernel shape to adapt according to the smoothing level. Birnbaum-Sauders (fatigue-life) kernel.
Considering the standard normal pdf and for the shape parameter
One can use practically local
The Birnbaum–Saunders kernel is suitable for lifetime and fatigue-type data due to its positive support and skewness flexibility.
2. Invers-Weibull kernel
The Inverse-Weibull kernel is particularly useful for modeling heavy-tailed lifetime behavior and decreasing hazard structures.
These asymmetric kernels provide flexible local smoothing mechanisms while preserving the positive support of survival data. Compared with symmetric kernels, they reduce boundary distortion and improve estimation accuracy near zero.
To evaluate the performance of the proposed asymmetric kernel families, several benchmark kernels commonly used in positive-support density estimation are considered for comparison. These include Gamma, Inverse-Gaussian, Lindley-based, and symmetric Epanechnikov-type kernels. Consider the following kernels:
A practical local parameterization is adopted through:
2. Inverse-Gaussian kernel are given by:
The Inverse-Gaussian kernel is suitable for positively skewed lifetime data and provides adaptive smoothing near the boundary.
3. Symmetric Epanechnikov kernel:
For comparison purposes, a symmetric Epanechnikov kernel is adapted to positive support through a logarithmic transformation.
Then the positive support version is
The multiplicative factor 1/ t arises from the logarithmic transformation Jacobian and guarantees proper normalization on the positive semi-axis.
These benchmark kernels provide reference models for evaluating the flexibility and estimation performance of the proposed asymmetric kernel-family framework.
Estimator performance is significantly impacted by bandwidth selection. We employ two complementary approaches: Silverman-type rule adapted to positive support (pilot scale estimate) and Likelihood cross-validation (LCV): choose h that maximizes the leave-one-out log-likelihood
Once the kernel density estimator is obtained, the corresponding distribution and survival functions can be computed numerically.
The corresponding hazard function is estimated as
In the presence of censored observations, the Kaplan–Meier estimator is used as a benchmark nonparametric survival estimator and compared with the kernel-based survival estimate. Kernel-based survival estimation provides a smooth alternative to empirical survival estimation and allows flexible representation of lifetime behavior on positive support.
Algorithm of Asymmetric Kernel-Family Survival Estimation
Step 1: preprocess data and define minimum and maximum of data
Step 2: Preprocess data and define grid T on (min(t), max(t)).
Step 3: For each kernel family j:
(a) Select bandwidth h j via likelihood cross-validation (or Silverman-type rule).
(b) Compute density on T.
(c) Numerically integrate to obtain and = 1− .
(d) Compute hazard = /max( , ε).
Step 4: Compute Kaplan–Meier survival (benchmark, when censoring exists).
Step 5: Fit parametric models M k by MLE under censoring and compute S k(t), h k(t).
Step 6: Evaluate kernels and models using multiple criteria (Section 6) and select the best performer.
Step 7: Report tables and figures for (t), (t), and (t).
We assess performance under two data-generating scenarios to represent different shapes and tail behaviors (e.g., Gamma-like and Lognormal-like). For each scenario, we consider several sample sizes (e.g., n = 25, 50, 100, 200) and repeat the experiment over R replications. For each replication, we compute the kernel estimates and evaluate them using integrated error measures and predictive (CV) scores.
Recommended criteria (replace/extend beyond ISE): Integrated Absolute Error (IAE) Integrated Mean Squared Error (IMSE), Hellinger distance, and likelihood cross-validation score (LCV).
This table reports the Integrated Mean Squared Error (IMSE) of the estimated density under Scenario A using two bandwidth selectors: a Silverman-type rule and likelihood cross-validation (LCV). For each kernel family, the corresponding selected bandwidth values are also reported. Lower IMSE indicates better estimation accuracy. As shown in Table 1, kernel-family performance under, Scenario A varies across bandwidth selection methods, highlighting the impact of the bandwidth choice on estimation accuracy.
This table reports the Integrated Absolute Error (IAE) under Scenario B using two bandwidth selectors (Silverman-type and LCV). The selected bandwidth values are included for each kernel family. Lower IAE indicates better estimation accuracy. Table 2 summarizes kernel-family performance under Scenario B, where accuracy is evaluated using IAE under both Silverman-type and LCV bandwidth selection.
Censoring status: all observations correspond to events (δi = 1 for all i). Therefore, the Kaplan–Meier estimator reduces to the empirical survival function = 1 − ECDF(t). A 95% confidence interval is reported using Greenwood’s formula with the log–log transformation.
Estimated median survival time (KM): 0.75.
Kaplan–Meier (KM) survival probabilities (t) are reported at selected quantiles of the observed survival times. Since all observations correspond to events (δi = 1 for all i), the KM estimator reduces to the empirical survival 1-ECDF(t). A 95% confidence interval is computed using Greenwood’s formula with the log–log transformation. The estimated median survival time is 0.75. such that Empirical/KM survival estimates at key time points are reported in Table 3.
The dataset consists of positive survival times (in the study unit) for patients who underwent catheterization. Since no censoring indicators were provided, the empirical survival is computed as 1 − ECDF, which coincides with the Kaplan–Meier estimator in the absence of censoring.
Summary statistics for the positive survival times (n = 150) are reported, including minimum, quartiles, mean, standard deviation, maximum, interquartile range (IQR), skewness, and coefficient of variation (CV). These statistics provide an overview of the scale and dispersion of the real survival dataset used in the application. Where Descriptive statistics for the real dataset are provided in Table 4.
| n | min | Q1 | median | mean | std | Q3 | max | IQR | skewness | cv |
|---|---|---|---|---|---|---|---|---|---|---|
| 150 | 0.09 | 0.4225 | 0.75 | 0.7496 | 0.383 | 1.0775 | 1.41 | 0.655 | −0.0005 | 0.5115 |
For each asymmetric kernel family, this table reports the bandwidth selected by a Silverman-type rule and by likelihood cross-validation (LCV). The maximized LCV objective value, LCV( h∗) is also reported to quantify the cross-validated fit. These bandwidths are used to construct the kernel-based density and survival estimates in the real-data application. Where Bandwidths selected for the real dataset are summarized in Table 5.
| Kernel family | h (Silverman) | h (LCV) | LCV(h*) |
|---|---|---|---|
| Gamma kernel | 0.149109 | 0.0191596 | −58.0008 |
| Inverse-Gaussian kernel | 0.149109 | 0.137498 | −60.6772 |
| Lognormal kernel | 0.149109 | 0.137498 | −60.6902 |
Maximum likelihood estimates (MLEs) are reported for three non-Weibull parametric survival models (Gamma, Lognormal, Log-logistic), along with the log-likelihood (logL), Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC). Smaller AIC/BIC indicate a better trade-off between goodness-of-fit and model complexity. Parametric competitors and their information-criterion values are reported in Table 6.
This table compares kernel-family survival estimates against the empirical survival function 1 − ECDF(t) (equivalent to KM with no censoring). For each kernel family, the LCV-selected bandwidth h∗, the LCV log-likelihood, and several discrepancy measures between the estimated and empirical survival curves are reported (weighted ISE, ISE, and IAE). The mean hazard (grid average) is included as a descriptive summary of the estimated hazard level over the evaluation grid. Lower error measures indicate closer agreement with the empirical survival. Where Kernel-family survival estimates are quantitatively compared with the empirical survival in Table 7.
This table compares fitted parametric survival models (Gamma, Log-logistic, Lognormal) against the empirical survival 1 − ECDF(t). Discrepancy is quantified using weighted ISE, ISE, and IAE computed over the evaluation grid. Lower values indicate improved agreement with the empirical survival curve. Parametric survival models are compared to the empirical survival in Table 8.
| Parametric model | Weighted ISE on S ( t) | ISE on S ( t) | IAE on S ( t) |
|---|---|---|---|
| Gamma | 0.00525944 | 0.004153 | 0.0680224 |
| Log-logistic | 0.00666845 | 0.00543173 | 0.0760906 |
| Lognormal | 0.0093188 | 0.00740298 | 0.0905809 |
A real survival dataset (survival times) is used to illustrate the proposed methodology. We estimate the density and the survival function using the best-performing asymmetric kernel family and compare it with:
• Kaplan–Meier estimator (nonparametric survival benchmark).
• A selected parametric model (e.g., Lognormal or Log-logistic) fitted by MLE (non-Weibull).
Evaluation focuses on survival-level discrepancies and predictive performance rather than relying only on classical goodness-of-fit tests.
Figures 1–4 summarize the real-data application of the proposed positive-support kernel-family framework. We present kernel-based density estimates under different bandwidth selection strategies and compare the resulting fitted curves with the empirical distribution of the data. In addition, we report normalized error/predictive measures to quantify performance across kernels and bandwidth selectors, and we compare survival curves to evaluate how well the nonparametric estimators reproduce the empirical survival pattern. Together, these figures illustrate the impact of bandwidth selection (Silverman vs LCV), the differences between kernel families on positive support, and the resulting consequences for density and survival estimation.
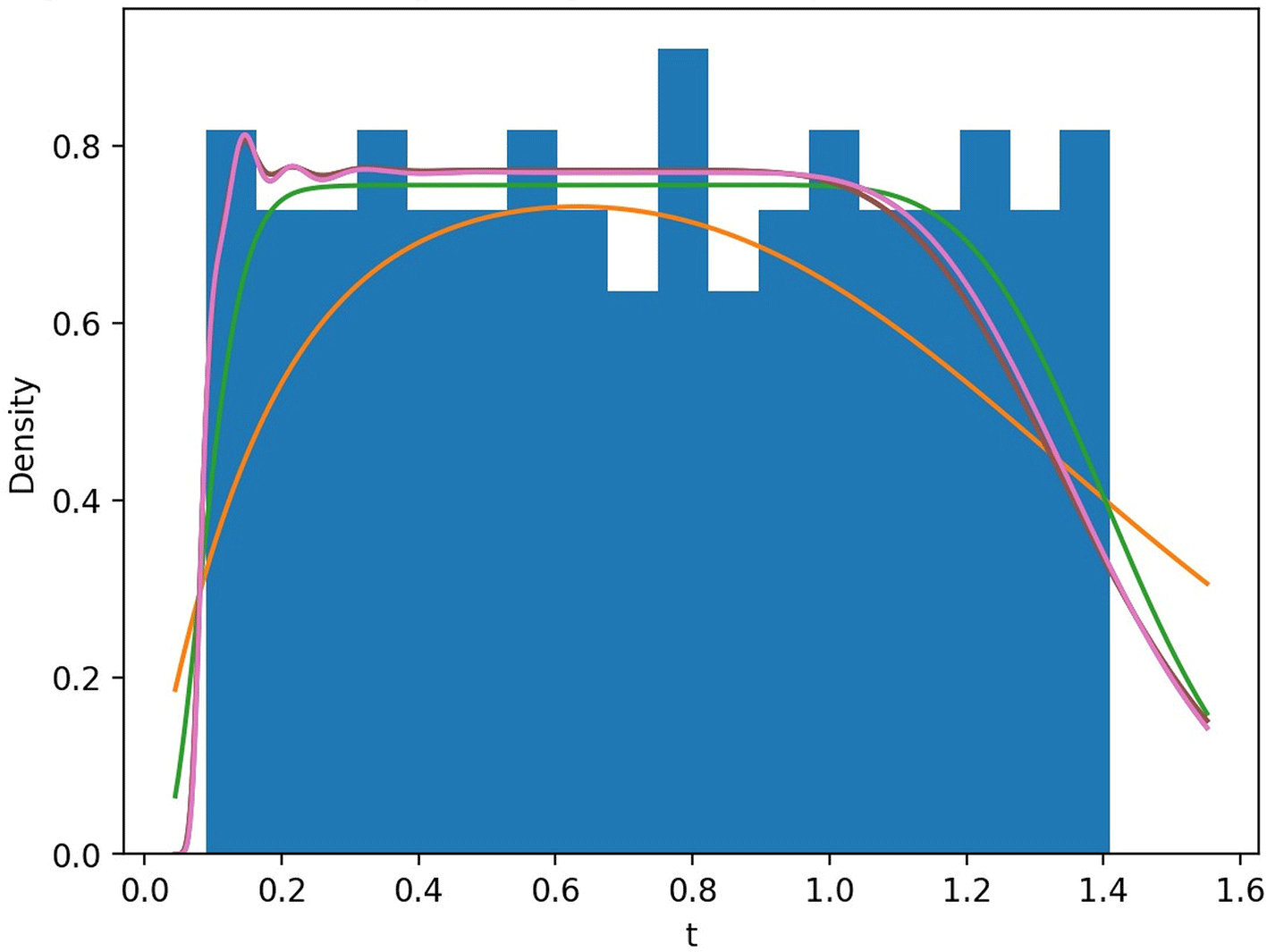
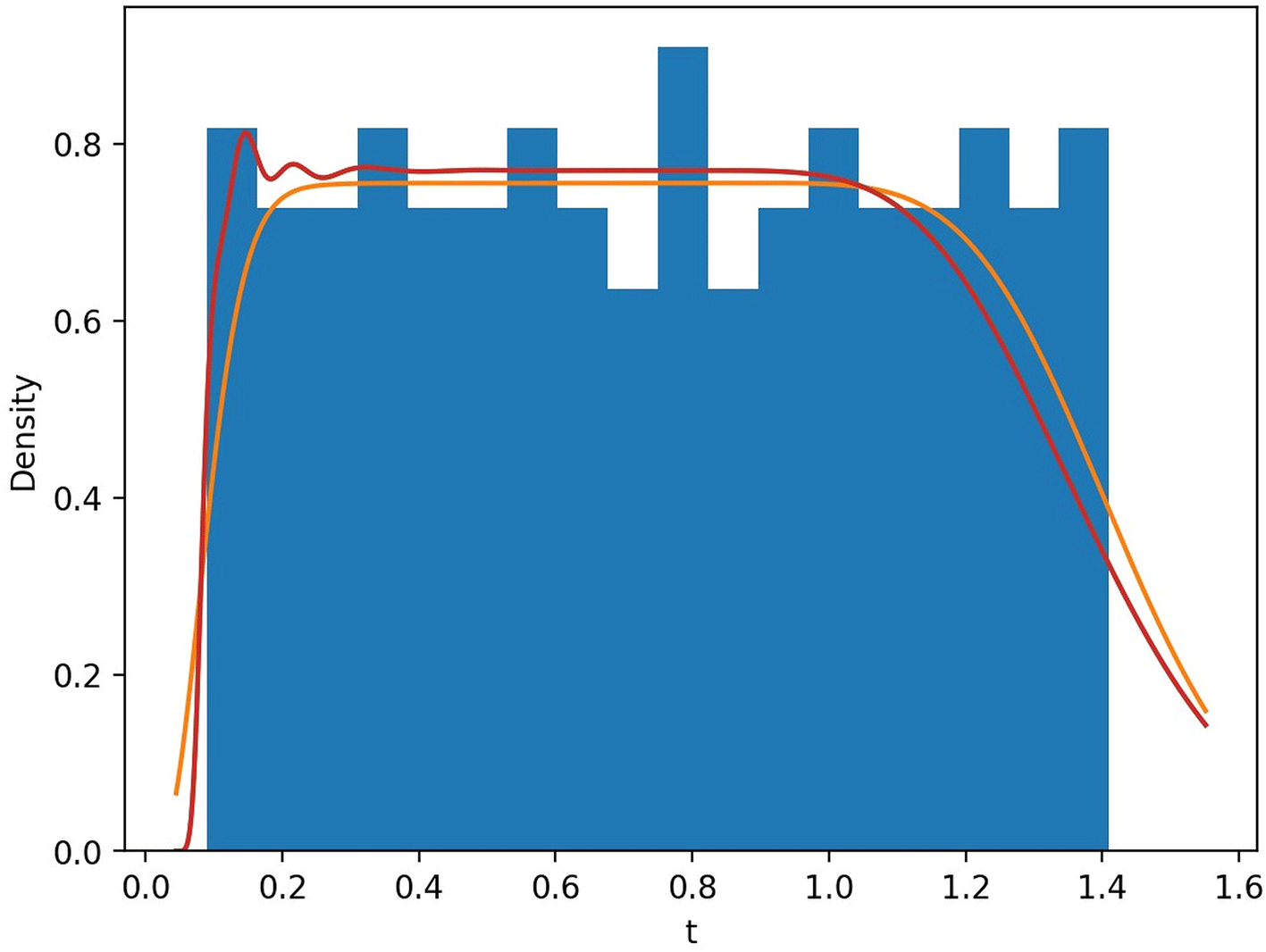
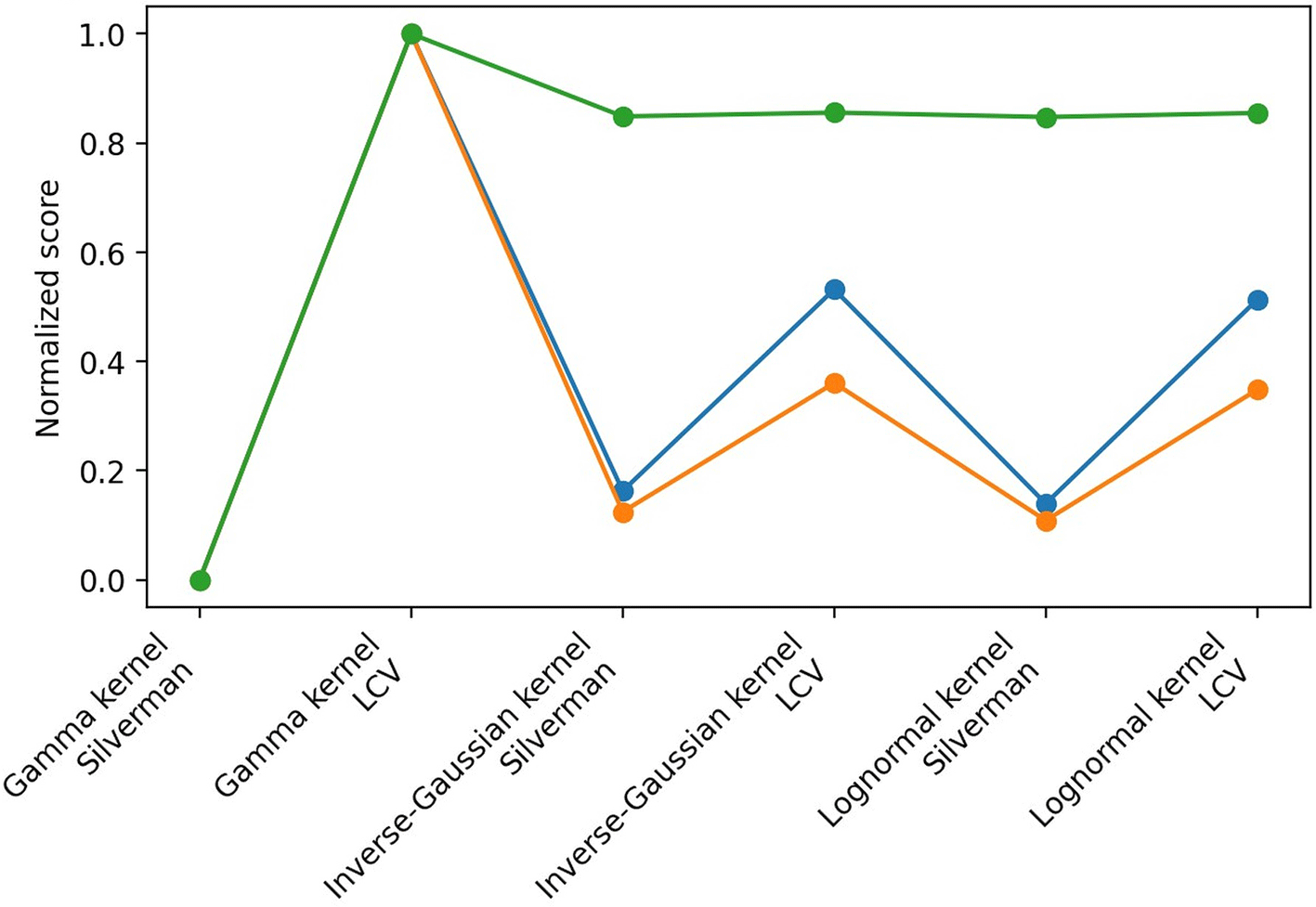
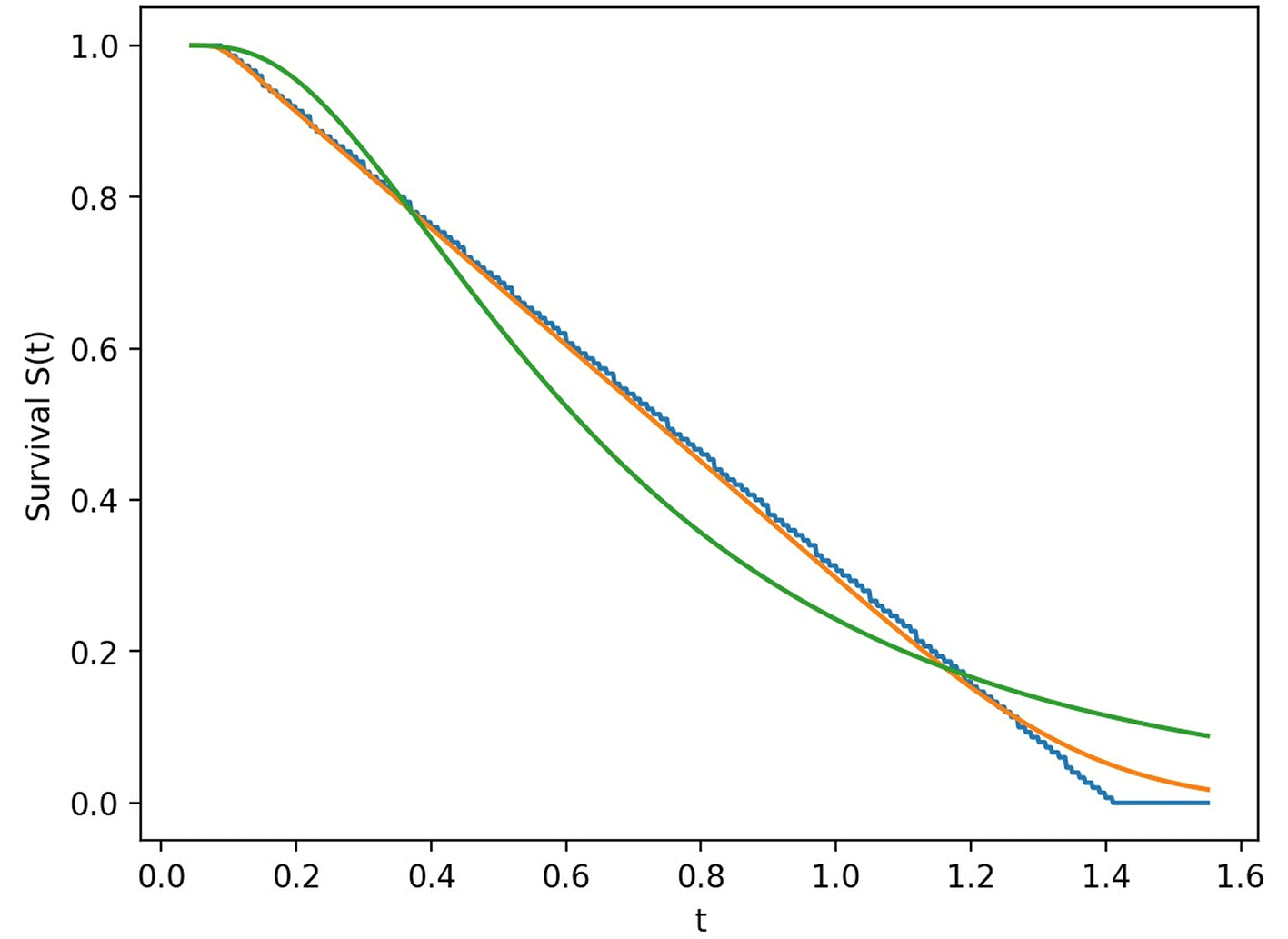
This paper provided a kernel-family system for positive-support nonparametric estimation and applied it to survival evaluation by estimating survival and hazard functions. In contrast to single-kernel methods, the family-based design enables practitioners to choose kernels that correspond to the data’s tail characteristics and boundary behavior. An efficient, data-driven method for choosing bandwidth is likelihood cross-validation. Comparing kernel-based survival with Kaplan-Meier and non-Weibull parametric models in real survival analysis reveals the useful trade-off between interpretability/parsimonious structure (parametric) and flexibility (nonparametric).
All tables have been labeled sequentially ( Tables 1–8), cited in the text, and provided with complete.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)