Keywords
Transformed-transformer family, Quantile function, Statistical properties, Entropies, Estimation Methods, Monte Carlo simulation and Fitting real data.
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
Transformed-transformer family, Quantile function, Statistical properties, Entropies, Estimation Methods, Monte Carlo simulation and Fitting real data.
Statistical modeling is significant compared to other aspects of life, especially in probability theory, which is commonly used to identify variation and make inferences from observable data. Several new generalized distributions have been created and have developed in significance during the past few decades. Developing these distributions was based mostly on the notion that they had more parameters. The data in every part of life is being modeled by a number of extensions of conventional statistical models. Flexible statistical models are still needed in many practical domains to better fit the data, and they usually have significant levels of skewness and kurtosis. Probability theory has developed more quickly because it may be applied to many different aspects of life (such as engineering sciences, survival, and actuarial sciences). Every new breakthrough broadens the scope of the probability theory’s effect.
Most new distributions are created using modern techniques, even if researchers are currently looking into the techniques used for creating new distributions since 1980; see for example Refs. 1–10.
The transformed-transformer technique, created by Alzaatreh et al.,11 will be employed in this study among the more current approaches. In order to obtain the distribution function of a new class of distributions, they transformed additional variable through (-∞, ∞) using the density and distribution functions of a r.v. X with and , respectively.
Where Z(F(X)) belong to [c,d] is monotone increasing, less than infinity, and , with the following matching pdf
The transformed-transformer technique has been used in a number of studies, see for instance, Refs. 12, 13, and 14.
By using quantile function of additional r. v. Y, in relations of instead of the function, a novel family of distributions was created by Aljarrah et al.15; which gave the distribution class.
When F(x) equal to λ and p(y) greater than 0 for all y in neighborhood of Qy (λ), such that 0 < λ < 1, this implies that Y (λ) less than infinity and it is equivalent to P [Qy (λ)]−1.
Therefore, the related pdf of G(x) is
Assume T, R, and Y denote random variables with quantile functions QT(p), QR(p), and QY(p), respectively; suppose that their cdfs are FT(x), FR(x) and FY(x), and their density functions, which is represented as fT(x), fR(x) and fY(x) respectively, with T, Y∈[c, d], and R∈[e, f] for -∞ < c < d < ∞ and -∞ < e < f < ∞.
Afterward, the distribution function of the novel class is provided as
In 2021, Ibeh et al.16; introduce new Weibull -Exponential {Rayleigh} distribution based the idea of T-X {Y} family distribution.
A contemporary statistical technique that provides an adaptable framework for producing novel probability distributions beyond the constraints of traditional models is the Transformed-Transformer (T-X) Family method, which is based on the quantile function. By fusing the quantile function of a generator distribution with the cumulative distribution function (CDF) of a base distribution, this method allows for the creation of personalized statistical models with exact control over shape properties like sleekness, kurtosis, and tail behavior. Its importance stems from its capacity to precisely depict non-standard data, offer direct control over the form of the resulting distribution, and support risk analysis and simulation. This approach is a potent tool for academics and applied statisticians since it has proven successful in a variety of domains, such as industrial engineering, medical statistics, financial modeling, and environmental sciences.
This work aims to present and examine the key mathematical and statistical features of a novel sub-family known as the IDNAI distribution, expressive of the Lomax–Rayleigh {Exponential} distribution.
The following is the structure of the other sections in this article. The Lomax-Rayleigh {Exponential} distribution, which we shall refer to as the IDNAI distribution, is created in Subsection 2-1. Most of the distribution’s characteristics are analyzed and shown in Subsection 2-2. The suggested estimation techniques for the parameters of the IDNAI distribution are discussed in Subsection 2-3. Subsection 2-4 presents the comparison of the estimators with the Monty Carlo simulation study. In Subsection 2-5, the data set’s applicability and fitting real-world dataset are demonstrated. The results are presented in Section 3. Section 4 provides the discussion of the results. Section 5 presents the summary and conclusions of the paper.
Assume a random variable T with the Lomax distribution, including parameter (λ), in addition to cdf, pdf and quantile function which are provided as
Where λ > 0, x > 0, 0 < P < 1.
In the same way, let a random variable R follow the Rayleigh distribution with parameter α as well as the distribution function, probability density function and quantile function of R, are respectively given as
Where α > 0, x > 0, 0 < P < 1.
Moreover, suppose that a random variable Y follows the Exponential distribution with the parameter β, then the cdf, pdf and quantile function are provided as
Where, β > 0, x > 0, 0 < P < 1.
Equation (10), together with Equation (15), gives us
Consequently, based on Equation (7) we obtain
Hence, the cdf of the Lomax-Rayleigh {exponential} distribution or IDNAI distribution is s provided by
Henceforward, from (8) we get
Subsequently, from Equation (14), we obtained
When Equations (11), (17) and (18) are substituted into Equation (6), the matching IDNAI distribution pdf is obtained as
We deduce that the new class IDNAI distribution’s cdf and pdf with three parameters (α,β,λ) are provided by Equations (16) and (19), respectively.
Additionally, based on Equation (16), the IDNAI distribution’s reliability function will be
Furthermost, some fundamental statistical and mathematical characteristics of the IDNAI distribution are presented in this section, as follows:
2-2-1 Additional probability functions of IDNAI distribution
In addition to the three previously discussed functions in Equations (16), (19) and (20), we introduce the majority of probability functions in this section.
2-2-2 The quantile function of IDNAI distribution
The qth quantile function of the IDNAI distribution may be found as
Consequently, the median (xmed) of the IDNAI distribution may be found by setting q = 0.5 as
2-2-3 The mode of IDNAI distribution
The mode of the IDNAI distribution can be calculated as follows
2-2-4 Limit of the pdf and cdf of IDNAI distribution
2-2-5 Moments
In this section, we present the rth moments about origin and the rth moments about mean for IDNAI distribution
2-2-6 Moment generating function M X(t)
It is simple to describe the moment generating function (MGF) of the IDNAI distribution as
2-2-7 Characteristic function Ф X(t)
The characteristic function of the IDNAI distribution can be found as
2-2-8 Factorial generating function З X(t)
One may determine the factorial generating function of the IDNAI distribution as follows
2-2-9 Coefficients
From sub-sections 2-2-5, we infer the following conclusions. This section lists the IDNAI distribution’s Skewness, Kurtosis, and Variation coefficients.
Thus, skewness coefficient for the IDNAI distribution will be
The Kurtosis coefficient (C.K.) is defined as follows.
Thus, Kurtosis coefficient for the IDNAI distribution will be
The Variation coefficient (C.V.) is defined as follows.
C.V. = {[E(X-μ)2]1/2/E(X)}
Consequently, the IDNAI distribution’s variation coefficient will be
2-2-10 Probability density functions of order statistic (O.S.)
Let x1,x2, …, xn be a random sample of size n from IDANI distribution with cdf F(x; ) and pdf f(x; ), where = (α,β,λ). Let y1< y2 < … < yn denote to order statistic for this sample. Then the probability density function of yr (r =1, 2, …, n) is given by f (yr) = ( )= , for (1 < r < n), hence we get
According to this, y1~IDNAI (α,β,nλ)
2-2-11 Cumulative distribution function of order statistic (O.S.)
This section presents the order statistic’s cumulative distribution.
The common formula for the cdf of order statistic is
Hence, the cumulative distribution function of rth order statistic will be
2-2-12 Mean time to failure (death); MTTF
In this section, we introduce the mean time to failure (death)
It was observed that; Γ(1/2) =
2-2-13 The Average failure rate (AFR)
2-2-14 Self-reproducing property
let y1< y2 < … < yn denote to order statistic for the sample x1,x2, …, xn of size n from IDNAI distribution with pdf and cdf defined in Equations (16) and (19).
According to Equation (41) in property 10, the pdf of y1 is; f(y1) =2nαβλ y1 (1+ αβ y12)- (n λ+1)
It is clear that follows . As a result, the self-reproducing property is satisfied by the IDNAI distribution.
2-2-15 Entropies
We present several uncertainty measurements, such as Shannon and Rényi entropies, that may be employed to measure the total amount of data in the system.
Shannon’s entropy has been used in many technical fields, such as physics and economics.
According to Shannon’s 1948 formulation, the entropy of a random variable X with density function f(x) is16
The Shannon entropy for T-R {Y) family distribution was defined as below.17
Additionally, as was previously indicated; T~ Lomax (λ); R~ Rayleigh(α) and Y~ Exponential (β).
Where, the Shannon entropy of T is known as18
Hence, Shannon entropy of IDNAI distribution will be as follow
Where, μT is the mean of the random variable T.
The measure of uncertainty of a random variable X follows IDNAI distribution is determined by its entropy. The Rényi entropy is defined as follows19:
Consequently, The Rényi entropy IDNAI distribution will be as follows
In this section, we present two estimation methods for estimate the parameters of
2-3-1 Maximum Likelihood Estimator (MLE)
Because of its invariance property, the Maximum Likelihood is one of the most important estimation techniques. We look at estimating the unknown parameters of the IDNAI distribution using a maximum likelihood function.
Let x1,x2, …. xn be observed values of a random sample of size n from the .
The pdf of distribution is as below;
The likelihood function with the vector = (α, β, λ) of parameters can be written as:
The log likelihood function will be
The log likelihood function with respect to α, β, and λ is derived as follows:
Setting the above nonlinear equations to zero and solve them using Newton-Raphson method, the maximum likelihood estimates of the three parameters , and were obtained.
2-3-2 Least Squared Estimator (LS)
In this subsection, we discuss the estimator of Least Squares method. This method used for many mathematical and engineering application.20
The main idea for this method is to minimize the sum of square error between the values and the expected value.
To find the estimation of the three parameter of via mentioned least squares method, let: x1, x2, …. xn be observed values of a random sample of size n from the , and
Where, refers to the CDF of which is defined as follows:
And, = , = , =1,2,..,n.
Derive S w.r.t. , we obtained the following three nonlinear equations respectively
Setting the above nonlinear equations to zero and solve them using Newton-Raphson method, the Least Squares estimates of the three parameters , and will be obtained.
The simulation study will be advanced to show estimators’ behaviour of parameters by suggested two mentioned estimation methods and then compare results using the two statistical criteria bias and mean squared error (MSE). The simulation study is repeated (1000) times to obtain independent samples of different sizes.
2-4-1 Generating random variables
Let U be a random variable with a Uniform distribution on the interval (0,1). The data for the IDNAI distribution can be generated using the inverse transformation method for the cumulative distribution function (CDF), where if21:
Then = {[(1- )-1/λ -1] /αβ}1/2
2-4-2 Simulation study
The Monte Carlo simulation software, created in MATLAB 2022, enables the comparison of reliable estimators over the steps that come next:
1. Random samples x1, x2, …, xn, of sizes n, where n = 10, 20, 50, 100, are generated from the IDNAI distribution.
2. The real parameter values are considered for two experiments (α, β, λ) in Table 1:
3. The Bias for all proposed estimators about the parameters was evaluated as follows, utilizing L = 1000 duplicates, which illustrated in Tables 2 and 3:
4. The MSE for all suggested estimators w.r.t. parameters was calculated as below using L = 1000 duplicates: as illustrated in Tables 2 and 3:
This section relates to Tables 4 and 5, which present survival times (in days) and descriptive data, respectively, for 72 guinea pigs infected with virulent tubercle bacilli, as documented by Olubiyi et al.,22 to illustrate the flexibility and applicability of the IDNAI distribution. To determine how well the IDNAI distribution fits the data, seven models that comprise the baseline distribution would be compared: the Weibull Gumbel type II distribution (WGuTII), the Exponentiated Gumbel type II (EGuTII) distribution, the Gumbel type II (GuTII) distribution, the Weibull Rayleigh distribution (WRD), the Exponential Lomax distribution (ELD), the Exponential Rayleigh distribution (ERD), and the Logistic distribution. Akaike information criteria (AIC), Bayesian information criteria (BIC), corrected Akaike information criterion (AICC), Hannan-Quinn information criterion (HQIC), consistent Akaike information criterion (CAIC), Kolmogorov-Smirnov K-S distance with P-values, and a minus two times of the negative log-likelihood value are used to confirm that the IDNAI distribution is a suitable model for the data set. The basis for comparing the models would be the reduced log-likelihood estimate and the mentioned information criteria. Having the lowest minimized log-likelihood and information statistics value is the ideal model. Accordingly, based on the findings in Table 6, the IDNAI might be chosen as the dataset’s best fit model.
| Stats names | Stats values |
|---|---|
| Mean | 1.7682 |
| Median | 1.4950 |
| Mode | 1.0800 |
| Std. Dev. | 1.0345 |
| Skewness | 1.3419 |
| Kurtosis | 4.9911 |
| Sample size | 72 |
The following may be concluded from the proposed IDNAI distribution’s PDF in Equation (19).
(i) The IDNAI (α,β,λ) distribution follows the Beta prime distribution with parameters 1 and λ for the random variable y = αβX2.
(ii) When the random variable Z = βX2, then the IDNAI (α,β,λ) distribution is interpreted to Lomax distribution with two parameters (α,λ).
(iii) When the random variable W = α X2, then the IDNAI (α,β,λ) distribution reduce to Lomax distribution with two parameters (β,λ).
(iv) When the random variable V = X2,then the IDNAI (α,β,λ) distribution reduce to Lomax distribution with three parameters (α,β,λ).
(v) When the random variable T = αβx2, then the IDNAI (α,β,λ) distribution reduce to Power function distribution with one parameter λ.
Figure 1 shows the graph of the probability density function for the IDNAI distribution with certain parameter values. The PDF graph in Figure 1 above demonstrates that the density of the IDNAI distribution might be symmetric, adjacent symmetric, right-skewed, or bimodal.
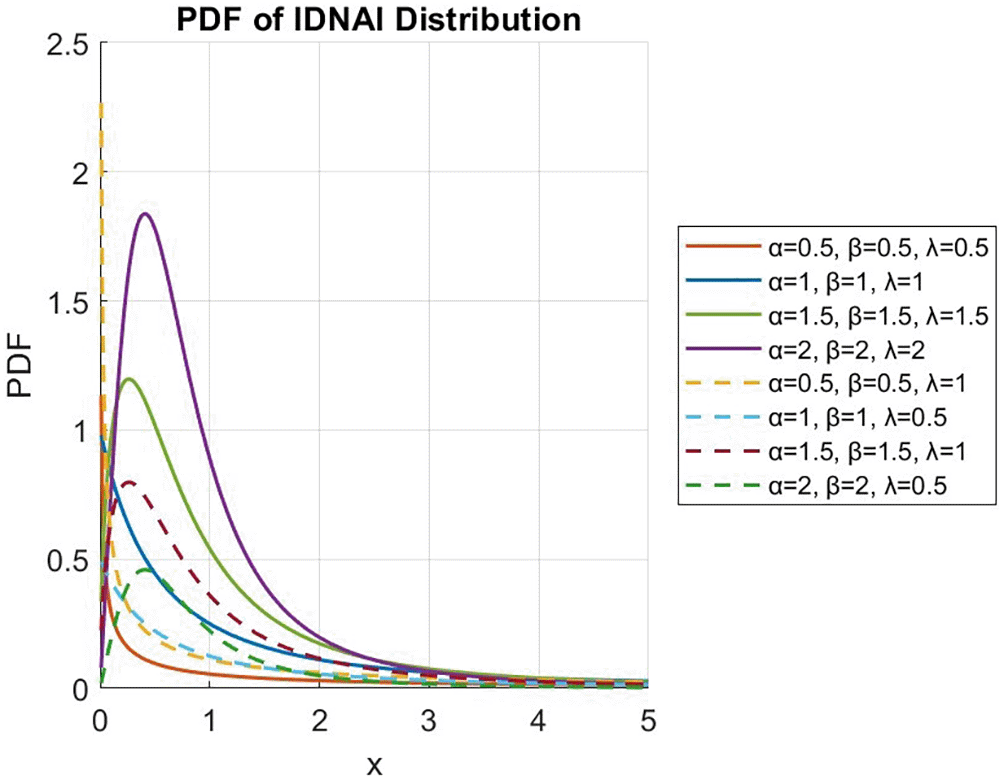
Figure 2 shows the cumulative distribution function graph for the IDNAI distribution with certain parameter values. The CDF graph in Figure 2 shows that the cumulative distribution function of the IDNAI distribution is a function that does not decrease.
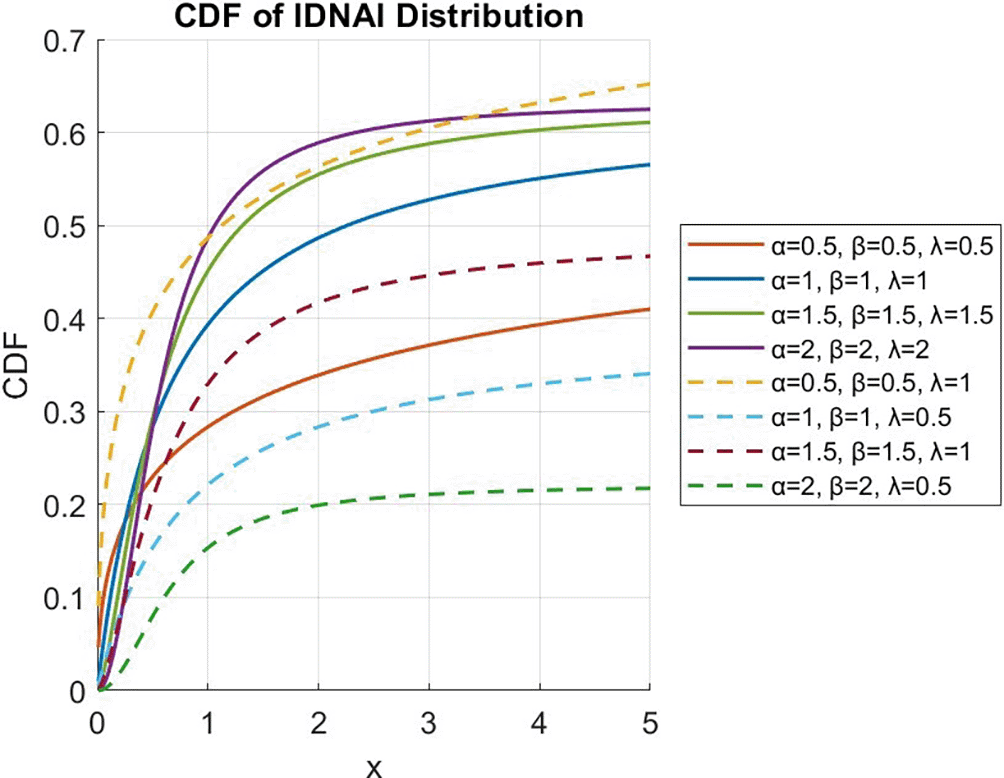
The graph in Figure 3 shows the Reliability function for the IDNAI distribution with certain parameter values. The reliability function graph in Figure 3 shows that the reliability function of IDNAI distribution is a non-increasing function, which is what most people already know.
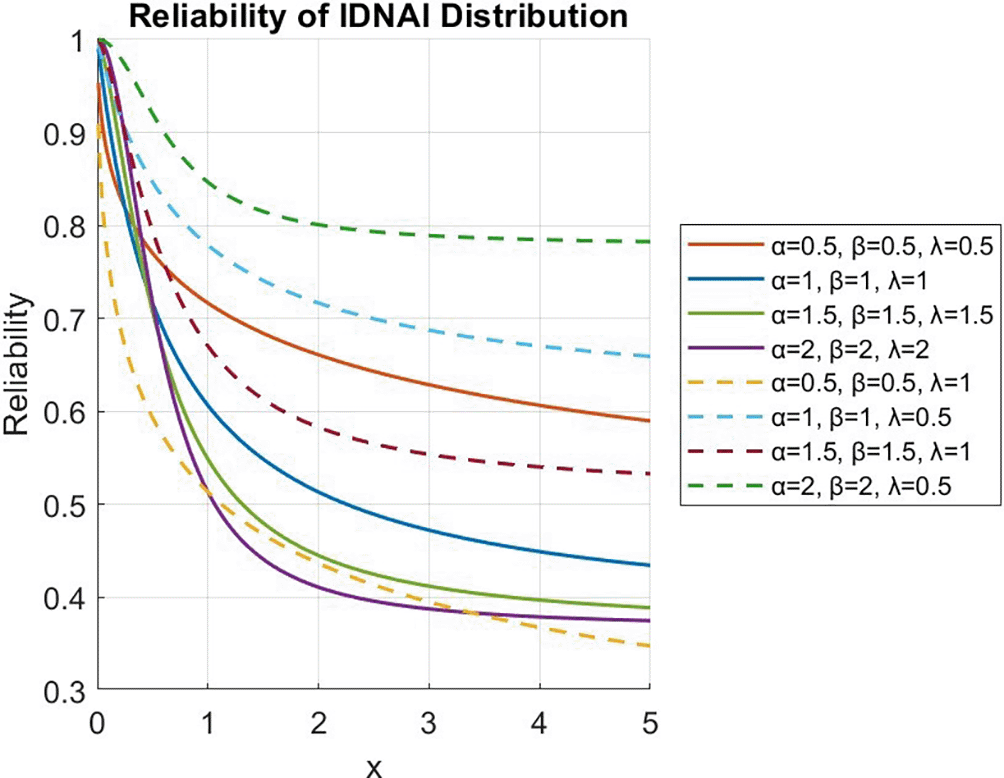
Figure 4’s graph of the Hazard function illustrates that the IDNAI distribution’s hazard rate has a convex form for different values of the parameters.
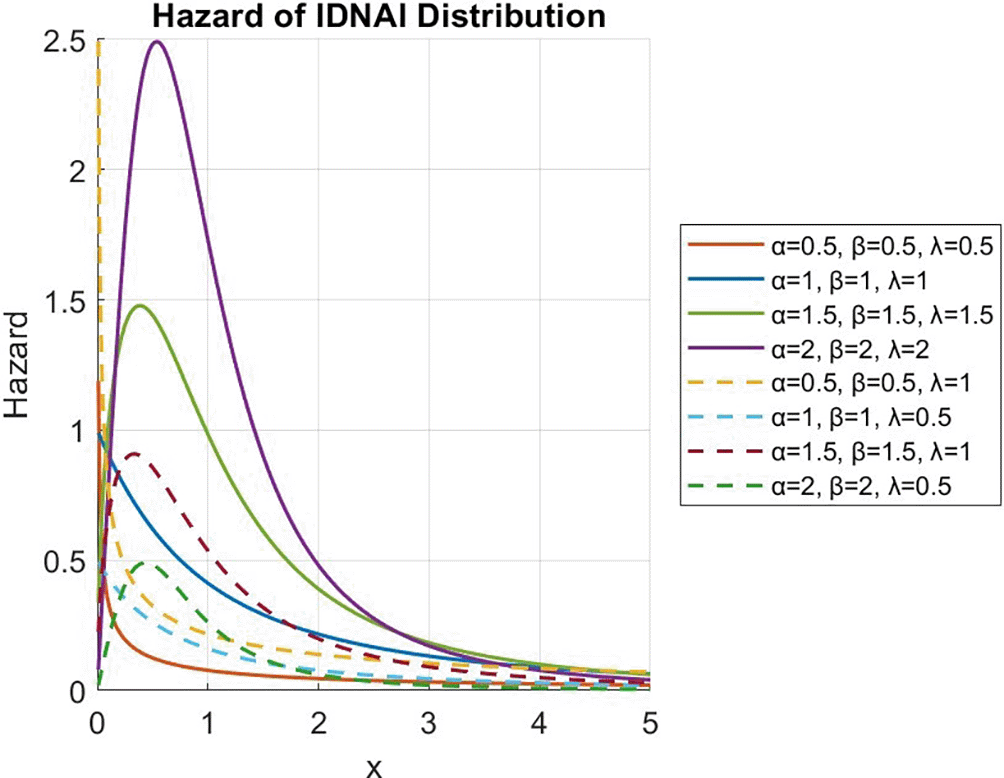
Figure 5 shows the cumulative hazard function of the IDNAI distribution. This shows how it may be used in survival analysis and reliability theory by showing the overall failure risk up to time x. It demonstrates that when x increases, the cumulative danger escalates, conforming to standard survival model expectations. When λ is larger, the hazard accumulation is higher, which means the failure rates are higher. When α and β are removed, the curves are flatter, which means the risk increase is lower. The graphic shows how the properties of the IDNAI distribution change based on different dependability scenarios.
The graph in Figure 6 shows how the reverse hazard function of the IDNAI distribution changes when different parameters are used, especially λ, which affects failure rates. This function is very important for survival modeling and reliability analysis since it shows how strong the distribution is in situations when reliability is important.
Figure 7 shows that the odd function grows quickly as x gets bigger, especially when the parameters α, β, and λ are big. Solid curves with λ = 1 expand a lot faster than those with λ = 0.5, which shows that the tail behavior is stronger. This function is a good way to show how flexible a model is and how well it controls its tail because it is very sensitive to changes in its parameters.
The graph in Figure 8 shows how well a model fits by comparing the empirical cumulative distribution function (CDF) of a dataset with many fitted CDFs from theoretical models. The empirical CDF and IDNAI and LOGISTIC are very near, while WGUTII, EGUTII, and GUTII are only moderately close. WRD and ELD, on the other hand, are very different from each other.
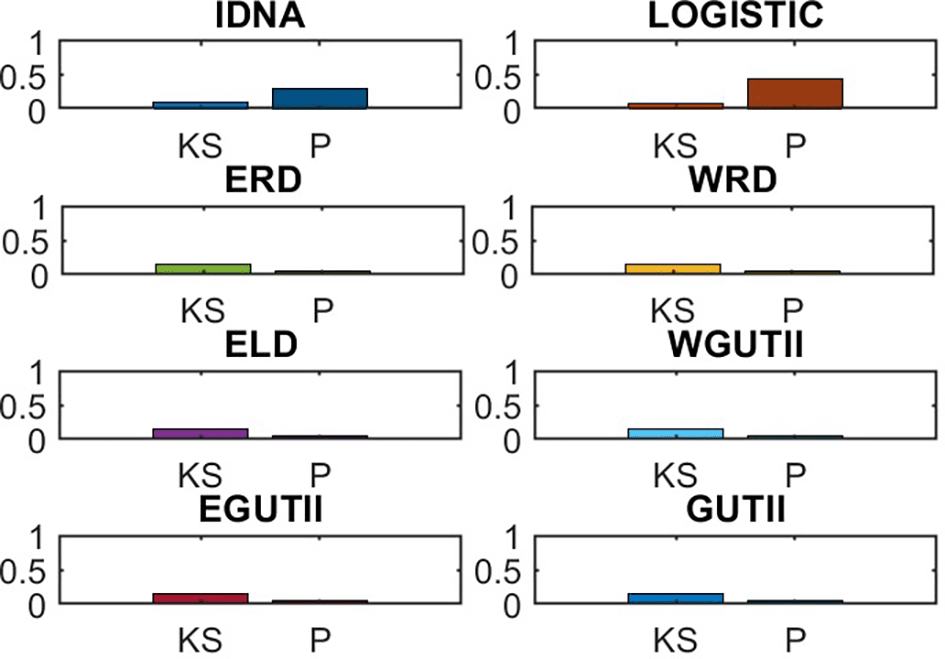
The graph in Figure 9 shows the p-values and Kolmogorov-Smirnov (K-S) statistics for eight fitted distributions side by side. The IDNAI and logistic models provide a strong fit to the data, as evidenced by their minimal K-S value and maximal p-value. On the other hand, the models WRD, ELD, ERD, WGUTII, EGUTII, and GUTII have low p-values, which mean they don’t fit the real data as well. The way the models are set up makes it easy to compare them and choose the best one.
The proposed real parameters are shown in Table 1, and the MSE and Bias calculations for the proposed estimators are provided in Tables 2 and 3. Tables 4 and 5 contain the dataset and its descriptive statistics, respectively. Table 6 displays the information criterion and estimation parameters for each fitted distribution.
Consequently, the MLE method was very stable and efficient in a wide range of situations. It is a strong nominee for use in the real world especially when the data is complex or not normal.
Having the lowest minimized log-likelihood and information statistics value is the ideal model. Accordingly, the IDNAI may be selected as the dataset’s optimal fit model in the sense of minimum information criteria based on the Table 6.
Over the past ten years, numerous novel distributions introduced in the literature appear to emphasize more general and adaptable types. By utilizing the method that creates the T-X family, it is possible to establish creative distributions that can either be exceptionally general and flexible or specifically tailored to fit certain kinds of data distributions, such as those that are highly left-tailed (right-tailed, thin-tailed, or heavy-tailed) as well as those that are bimodal. This study presents a novel family of probability distributions known as the T–R {Y} distribution family. The resulting family distribution has a number of statistical and mathematical characteristics. Numerous statistical and mathematical characteristics of these distributions are derived, including the related probability functions, the moments, the failure rate, the cumulative hazard functions, the entropies, the moments, order statistics … etc. To encourage the new family members’ suitability for fitting real-world data sets, we developed a specific member of the new family called the Lomax–Rayleigh {Exponential} and named it by IDNA distribution. the literature on the family of probability distributions for complex applications is expected to use the new family. Two approaches were used to estimate parameters for IDNAI, and their effectiveness was then assessed using Monte Carlo simulation. According to the results, the Maximum likelihood technique performed better than the least square method when evaluated in terms of mean squared error and bias. After applying the suggested distribution to empirical data, a comparison showed that it performed better than some models based on goodness-of-fit standards like the Bayesian Information Criteria (BIC), Akaike Information Criteria (AIC), and others.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)