Introduction
OCR has been performed very well for the English language, but there are some limitations and high error rates for non-English languages such as Arabic due to mixed letters in words (there is no space for most of the letters) and Hungarian has some special characters; therefore, we are going to address the gap for offline handwriting recognition for the Hungarian language, which is the most common deep-learning problem. As Hungarian has a distinctive alphabet and handwriting style, OCR software made specifically for this language may perform better than software made for other languages. To improves the model’s accessibility, new data were gathered for additional training during the first stage or for fine-tuning within the second stage. Therefore, we generated a new synthetic Hungarian dataset by developing an existing tool used for another language, TRDGHuMu23, where more than 3M line (text, image) pairs were used for the training phase, and all the methods used to collect and generate these data are shown in
Table 1 and fine-tuned with human data. Sometimes, we had trouble reading someone else’s handwriting. It is not only humans who have this problem but also computers. Although computers have been able to recognize and transcribe printed text for decades, recognizing handwritten texts has only been possible for the last few years, particularly for non-English languages. We will investigate the SOTA TrOCR1 vision-language model utilizing transfer-learning technology for the downstream task using A100 NIVDA. The Runtime environment includes A100 NIVDA 8 GPUs with 80 GB RAM Digital Hungarian Heritage Lab (DH-Lab), which is fair because fine-tuning was performed with the same hyperparameters, optimizer, and benchmark dataset.
Table 1. Synthetic data for (lines & words) level.
| Data | Samples | Language |
level |
|---|
| lines-hu-v1 | 500 000 | Hu | Line |
| lines-hu-v2 | 500 000 | Hu |
| lines-hu-v2-1 | 935 213 | Hu |
| lines-hu-v3 | 500 000 | Hu |
| lines-hu-v4 | 500 000 | Hu |
| lines-hu-v5 | 500 000 | Hu |
| lines-hu-v7 | 500 000 | Hu |
| Brown-lines
| 96 367 | En |
| Hu-Words-Dict | 60 344 | Hu | Word |
| Hungarian Names | 4 478 | Hu |
| En-Words-Dict | 466 479 | En |
The digitization of handwritten characters is of paramount importance for the preservation of valuable resources and cultural heritage. For this purpose, OCR systems have been introduced.2 In the case of historical sources, automatic transcription is more difficult owing to a lack of data, increased complexity, and lower quality of resources. To solve these problems, transfer learning or the enhancement of pre-trained language models would be a viable solution. Modern transformer OCR3 pipelines are based on transformer architecture, which consists of a vision encoder and text generator decoder that have been utilized to answer the question: Does pre-training of synthetic data and fine-tuning of human data minimize the error rate?
Building on this foundation, the main objective of this study is to fine-tune such language models by using OCR models pre-trained on an international dataset and then use transformer-based language models for the Hungarian language, such as GPT-2, BERT, PULI BERT, RoBERTa,4–7 with vision models such as Deit8 to enhance the fine-tuning results. Several approaches to enhancements have been explored in this study, the first of which was to use the weights of the pre-trained language model to initialize the decoder in the OCR model. The second approach used the sequence-to-sequence (Seq2Seq) approach to integrate the language and visual models in one OCR architecture. These models were fine-tuned after being pre-trained on letters from János Arany (Provided by ELTE DH-Lab) and evaluated according to the CER and WER metrics.9 The output of this thesis is an extensive study of more than 20 experiments targeting different approaches and detailing the performance increase caused by specific SOTA encoder-decoder pairs and architectural changes. Furthermore, the best-performing model is exported for inference, and a tool that could be used by the faculty of humanities researchers will be developed.
The main contribution can be summarized as the following:
I. We generated around three million (feature, label) pairs for synthetic handwritten data and made them publicly available.
II. Leveraging vision-language pre-trained models in Seq2Seq architecture.
III. We see good improvement significantly in the DH-Lab dataset, where the CER and WER were 5.764% and 23.297% has minimized to 3.681% and 16.091%. Thus, the contribution shows the results have been improved by 2.083% and 7.206% for CER and WER, respectively.
So far, there are many reasons that we think leads to this improvement pre-train with more data Syn “e.g.” and data augmentation in an efficient way could lead to more accurate results. All experiments were performed on OCR_HU_Tra2022 repo[1].
The HTR task involves two tasks in the complete life cycle, and this study has limitations, where the focus is on the text generation task. We leave the text detection method for future work models such as YOLOv12, DETER2,10,11 or any SOTA models could be utilized for object detection or localization. Models are trained and fine-tuned with lines in a complete form file format such as PDF or others, but they need to be prepossessed by line segmentation, which is a limitation here. Additionally, these models are limited to a set of languages.
Related work
Optical Character Recognition (OCR) is already in an advanced state, whereas Handwritten Text Recognition (HTR) is still in its early phase.12 OCR, an ancient computer vision task, is a popular and ancient technology used to convert images into searchable text, dating back to 1914, and has been used since 2012. Handwritten recognition can be performed online, such as using a whiteboard for handwriting and converting it to text, or offline, as in this case, with scanned images.
Writing recognition uses hardware and software to convert handwritten documents into text for machine reading with transformer-based OCR and pre-trained models such as TrOCR being later developed. OCR technology powers daily systems and services, including document indexing, personal identification, business cards, and automatic number plate recognition. It also helps understand clients and enhance customer service. Kiela et al. (2020) show in Figure 1 the development of handwritten tasks through 21 centuries.8
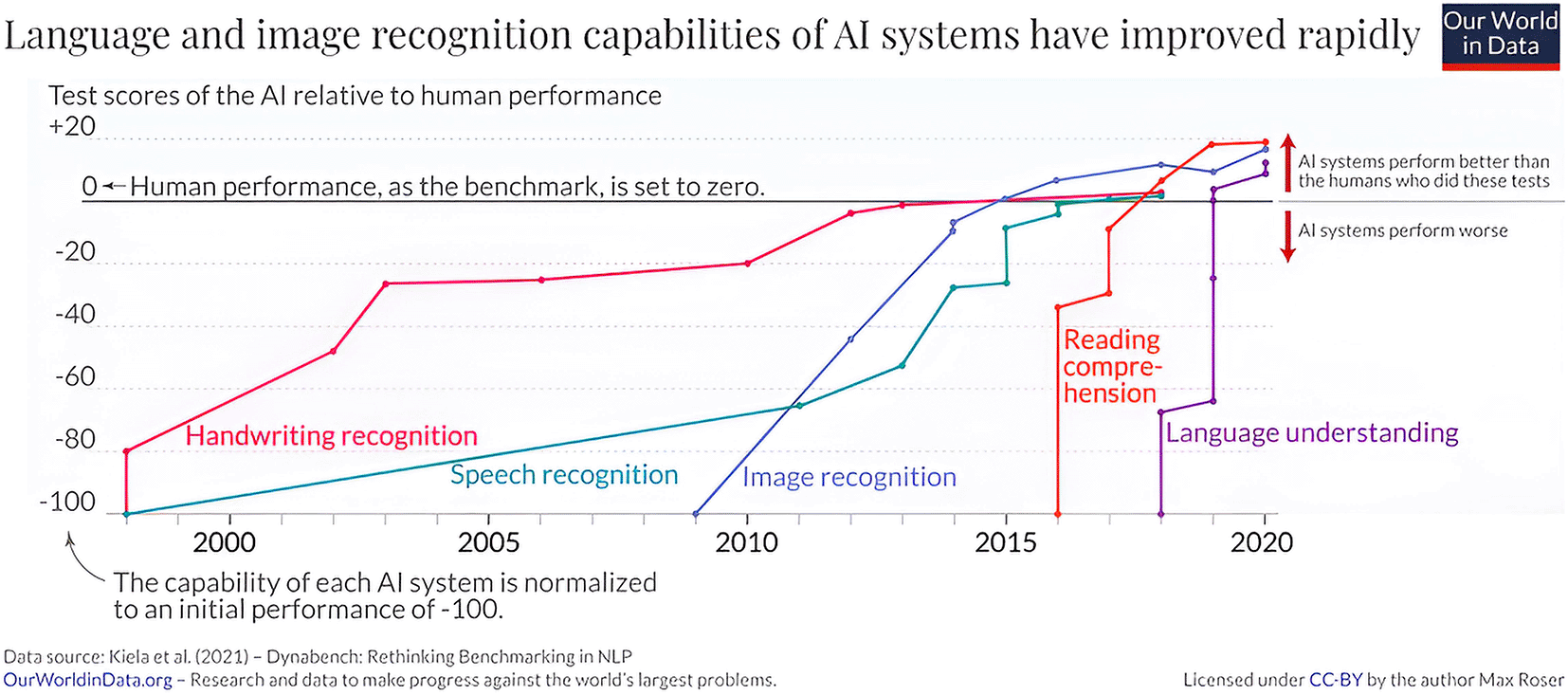
Figure 1. The language and image recognition capabilities of AI systems have improved rapidly.8
Tesseract: An open-source OCR engine called Tesseract was created by HP company approximately 40 years ago. Hewlett-Packard built the open-source OCR software Tesseract in the 1980s. Google is responsible for maintaining it. This is a popular solution for numerous OCR workloads because it handles a large number of languages and has been taught in millions of texts. However, it can have difficulties with handwriting and poor-quality scans, and may require significant human adjustment for particular use scenarios.13
Paddle OCR: This is an OCR engine created using open-source DL algorithms. It can handle a variety of documents of different types and accepts many languages, including Chinese and English. It can be tailored to fit particular scenarios and is intended to be simple to use. It is a free tool that can be used for printed text on different platforms such as the web, mobile apps, and Internet of Things (IoT) devices.14
EasyOCR: Another open-source OCR engine with a user-friendly interface. It can handle a variety of document forms covering over 70 languages, including Hungarian. It analyzes papers using DL and, in some situations, can even read handwriting.15
Kera’s OCR is based on Kera’s DL framework. It can handle a large range of document formats and an enormous variety of languages, and can be used for the Hungarian language after fine-tuning. It can be tailored to fit certain use cases and was created to be simple to use.16 This might not be as precise as the many other OCR machines on this list.
Abbyy OCR is a multilingual business OCR technology with an easy-to-use UI that can correctly process complex documents. It might cost more, but it makes use of sophisticated machine learning techniques.17
Google Cloud Vision is a cloud visual solution that uses deep learning methodologies for analyzing files and images, and can detect text in over 50 languages, such as Hungarian. Although free of charge, it is not appropriate for offline operations or information security.
ViTSTR: Similar to ViT is a Visual Transformer, instead of text tokens, it uses parts (patches) of the image as a token sequence and performs classification based on them.18 Simple Transformer Encoder architecture initialized using DeiTs, as they introduced in pre-trained parameters trained beforehand in the MJSynth, SynthText dataset, and augmentations managed to beat the high baseline in accuracy, using the augmentations contributing +(1.5 − 1.8) to accuracy.19
PARSeq: An ensemble of auto-regressive models with a common architecture and parameters can be viewed as performative language modeling trained (PLM-trained), which is a development of auto-regressive modeling.20
Scene Text Recognition (STR): The strategy is to integrate language data indirectly into the STR. The Character module of the tailored adaptive addressing and aggregation module selects a relevant combination of tokens from the ViT of tokens and merges them into a single output token corresponding to that character.21 To implicitly model linguistic information, subword classification heads based on Byte Pair Encoding (BPE) are employed.22
Masked Image Modeling (MIM): Up to 75 percent of the image regions act as masks at the prior-to-training level. The other patches are assigned to the transformer encoder module. The entire set is subsequently processed by the decoder, which reconstructs the pixels of the original image from the encoded representation after adding the appropriate masking signals. MaskOCR is Encoder Representation for the SOTA, where the encoder is ViT, pre-trained self-supervised, and the decoder is DETR, which is a set-based object detector using a transformer on top of a convolutional backbone DETR-style: self-attention.23 In addition to cross-attention, FFN blocks are pre-trained on synthetic text images, while the encoder weights are frozen.24
Masked Vision-Language Transformers (MVLT) are a cutting-edge model structure that integrates written and visual senses to carry out a number of activities, including picture production, visual question answering, image captioning, and HTR. The widely utilized transformer paradigm, which has shown exceptional performance for applications requiring NLP, is extended by MVLT.25 Understanding and creating significant links between visual and textual data are the primary goals of MVLT. To collect long-term reliance and contextual data in both the vision and language domains, it uses the strength of self-attention processes. An additional ensemble approach can be utilized to enhance character token prediction.26
Sequence-to-sequence (Seq2Seq) Modeling: Tasks such as I2T, T2T, ASR, HTR, I2I, and others are considered as Seq2Seq. Seq2Seq architecture allows the model to capture the dependencies and relationships between different elements in the input and output sequences, enabling it to learn complex mappings between sequences of different lengths and structures.
It was first proposed with the use of RNNs27 were used for the first time for sequence classification and then used for ASR, and now we are using it in HTR[2]. TrOCR is an excellent instance of an e2e problem, and there has been a lot of recent work focusing on different pre-training objectives for transformer-based encoder-decoder models, but the model architecture remains largely unchanged. Seq2Seq challenges can be solved using an encoder-decoder design that employs transformers. Transformers were presented for the first time in “Attention is all you need” (Vaswani et al., 2017)28 papers. It uses an attention method to process both input and output patterns.
Connectionist Temporal Classification (CTC): An ANN approach, termed CTC, is utilized to solve Seq2Seq tasks such as speech and handwriting recognition.29 The CTC method is used to teach a network of neurons to transform variable-length input sequences to variable-length output sequences. The output of a sequence can be shorter, longer, or precisely the same length as its input. The CTC algorithm adds a blank symbol to the input sequences, enabling repeated output and variable length models. It solves tasks such as machine translation, HTR, ASR, and Seq2Seq. Although the TrOCR model outperforms this method, it is still a related technique.
The first stressful work related to generating synthetic data used the nearest-neighbor-based collection OCR.30 Writing strategy, in particular, where there are common characteristics in large data,31 is important in developing pattern recognition challenges.
In this study segmentation-based approaches for cursive script recognition (Saba T, 2014),32 On the contrary hand, end-to-end recognition of handwritten content becomes conceivable by current transformer-based techniques.
Dataset
The dataset used was privately provided by the Hungarian Digital Heritage Lab (DH-Lab). This dataset is the historical handwriting of the famous Hungarian author János Arany. The collection method involves archival research, utilizing private data from DH-Lab and generating synthetic datasets using a public Hungarian corpus to supplement the original handwritten material.
Table 1 shows the data we generated, most of them at the line level and a few at the word level. The data sources are the Hungarian and English Brown corpora[3]. The data used during training is the Hungarian version, with a small English base, where we took samples from this corpus by splitting it into small units and breaking long text into fixed sequences of length between 8 − 12 words per line and cleaning it by keeping only alphanumeric characters with some needed special characters in the first step. In the second step, we reconfigure a new toolkit that generates synthetic data by including Hungarian. All the required development steps can be found on the HuTRDG page of the tool.
Collected existing datasets
The TrOCR model’s initial experiments showed poor results because of the need for more data for convergence, prompting the decision to collect publicly available data for fine tuning. STR was collected only for the test dataset, which represents benchmarks collected in one file (CT80-288, ICDAR2013-857, ICDAR-2013-1015, ICDAR-2013-1095, ICDAR-2015-1811, ICDAR-2015-2077, IIIT5K-3000, SVT-647, SVTP-645).33 And We performed our experiment on DH-Lab for Hungarian and IAM/SROIE34,35 for English to check whether increasing the amount of data minimizes the CER.
Table 2 lists the collected data and corresponding number of samples for each.
Table 2. Collected datasets where Hu represents Hungarian and En for English.
| Data | Samples | Language |
Level |
|---|
| DH-Lab (private) | 5 995 | Hu | Line |
| IAM34 | 13 353 | En |
| SROIE35 | 52 330 | En |
| Washingtondb-v1.036 | 656 | En |
| STR33 | 11 435 | En | Word |
| washingtondb-v1.0 | 4 894 | En |
Generate Synthetic (Syn) Hungarian dataset
Divergent results were obtained with a limited dataset due to the lack of a Hungarian human-annotated handwritten large dataset. Building on an existing tool for international languages to generate synthetic data.37 We used an open-source font by collecting approximately 200 font types38,39 based on Hungarian to present synthetic data. We published a 3M set of line-level (image, text) as part of this work by making them publicly available, Data for English and Hungarian was generated data using seven Hungarian versions with varying parameters for augmentation, including blur, Gaussian, distortion, rotation, color, uncolored text, noise, and skewing, with various background images, as shown in
Table 1 there are some labeling issues where there are some special Hungarian letters not recognized (á,é,í,ö,ó,ő,ü,ú,ú,ű) for some utilized types of fonts. Figure 2 shows a sample algorithmic procedure for converting plain text into HTR data.
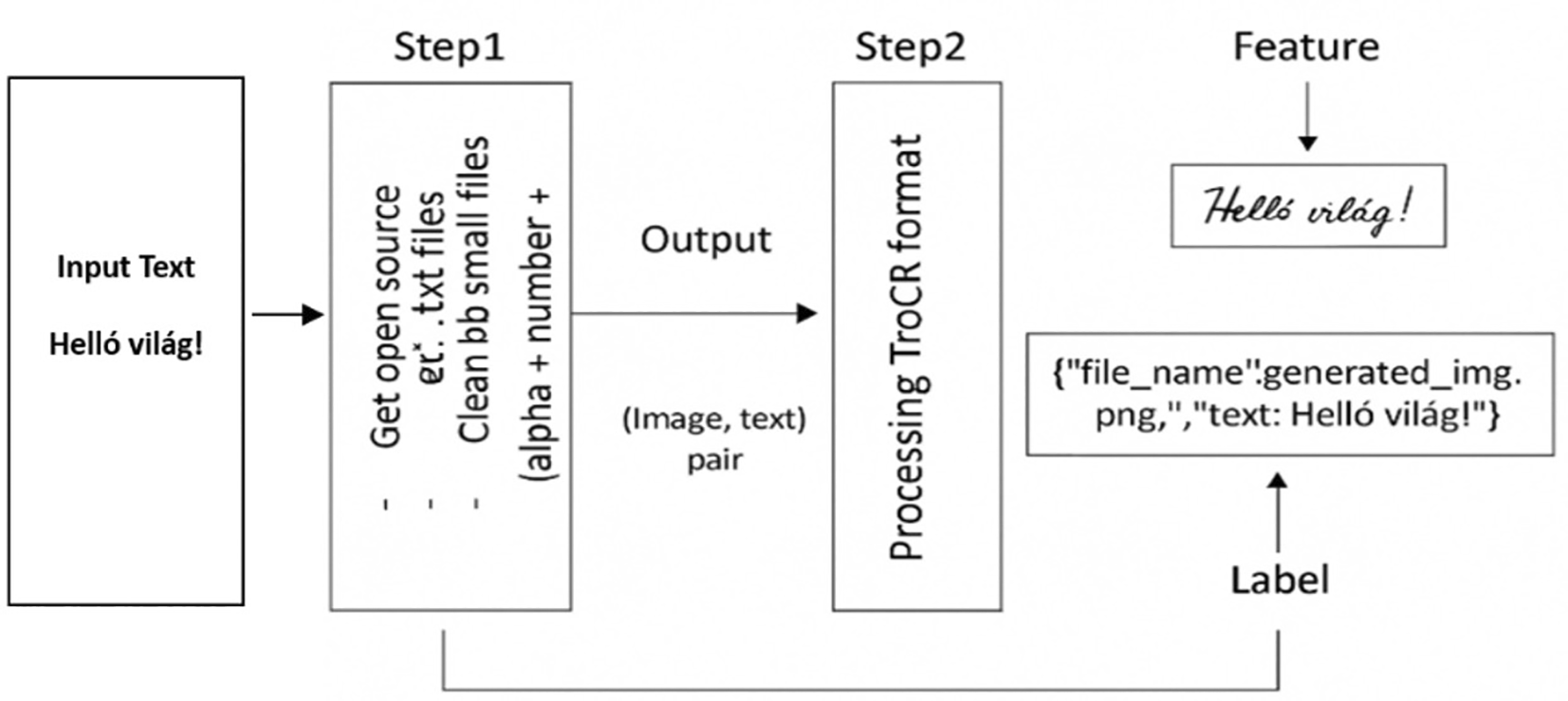
Figure 2.
Figure Shows the whole process for Data Generation.
Data processing and description
The JSON line is used to convert images into labels, ensuring efficient data handling for big-data processing. DH-Lab data are very small, human-annotated (around 200 pages) for training, and it is private and contains images (in jpg format). These images were segmented by lines and annotated with the corresponding text in the text file during the text-detection phase. Annotations in the image include the image name, status, and metadata parameters. The text is separated by (|) characters and the (+) sign concatenates the next line with the current sentence. Figure 3 shows that random sampling is used for different datasets, such as the IAM dataset, which has the same raw data format at different levels.

Figure 3. Samples for different datasets used during this study (Hungarian Language).
There are three methods for synthetic data generation: programmable algorithmic-based, machine learning (ML), and DL-based, with the latter recommended for more human-like handwritten data, but fine-tuning or pre-training on Hungarian text.40
Data Augmentation (Aug.) in an efficient way
We enhanced the DH-Lab dataset using augmentation and CV methods, thereby reducing overfitting and improving generalization. The DH-Lab data are grayscale, focusing on grayscale areas. Morphological alterations alter the appearance of text lines via expansion and erosion. Noise introduction involves pixel color insertion or elimination using dark colors with random distribution for recognition difficulty. Sporadic showers add a rain-like appearance to the image. This approach has been successful with TrOCR and should function effectively in any additional system.41 Three sets were generated from a single dataset. 10% of test sets, 10% of validation, and 80% of train sets. Figure 4 shows random samples from the Aug. data.

Figure 4. The figure shows different augmentation methods; the left-side images are the source, and the right side is the resulting augmented image.
Methodology
Sharing the parameters with the intended learners immediately is a straightforward technique for controlling these parameters. An image encoding module based on ViT and a sequence generation decoder based on transformers improved by language model features are assembled in Figure 5 to create a vision-to-text workflow for Hungarian handwritten text recognition. The handwritten text picture provided was first separated into patches in this process, and these patches were then embedded and enhanced with spatial data. The Vision Transformer encoder layers evaluate these embeddings, enabling the computational model to extract contextual and spatial characteristics using a script. The encoded visual representation is then fed into a transformer decoder, which uses encoder–decoder attention to associate the visual attributes with the produced text and self-attention layers to analyze previous output tokens to perform sequence modeling. Furthermore, BERT layers were added to the decoder to improve contextual knowledge, especially for materials in Hungarian. Text that had been broken down into tokens (words or subwords) was processed by BERT. Embeddings were generated using tokens. Self-attention is used through a transformer encoder for interpretation. BERT can comprehend word relationships and meanings by utilizing contextualized visualizations of the text. Ultimately, the decoder transforms the handwritten source into its digital format by generating an identified string. TrOCR is basically a ViT18 Encoder + Transformer Decoder trained for sequence-to-sequence (Seq2Seq) mapping:
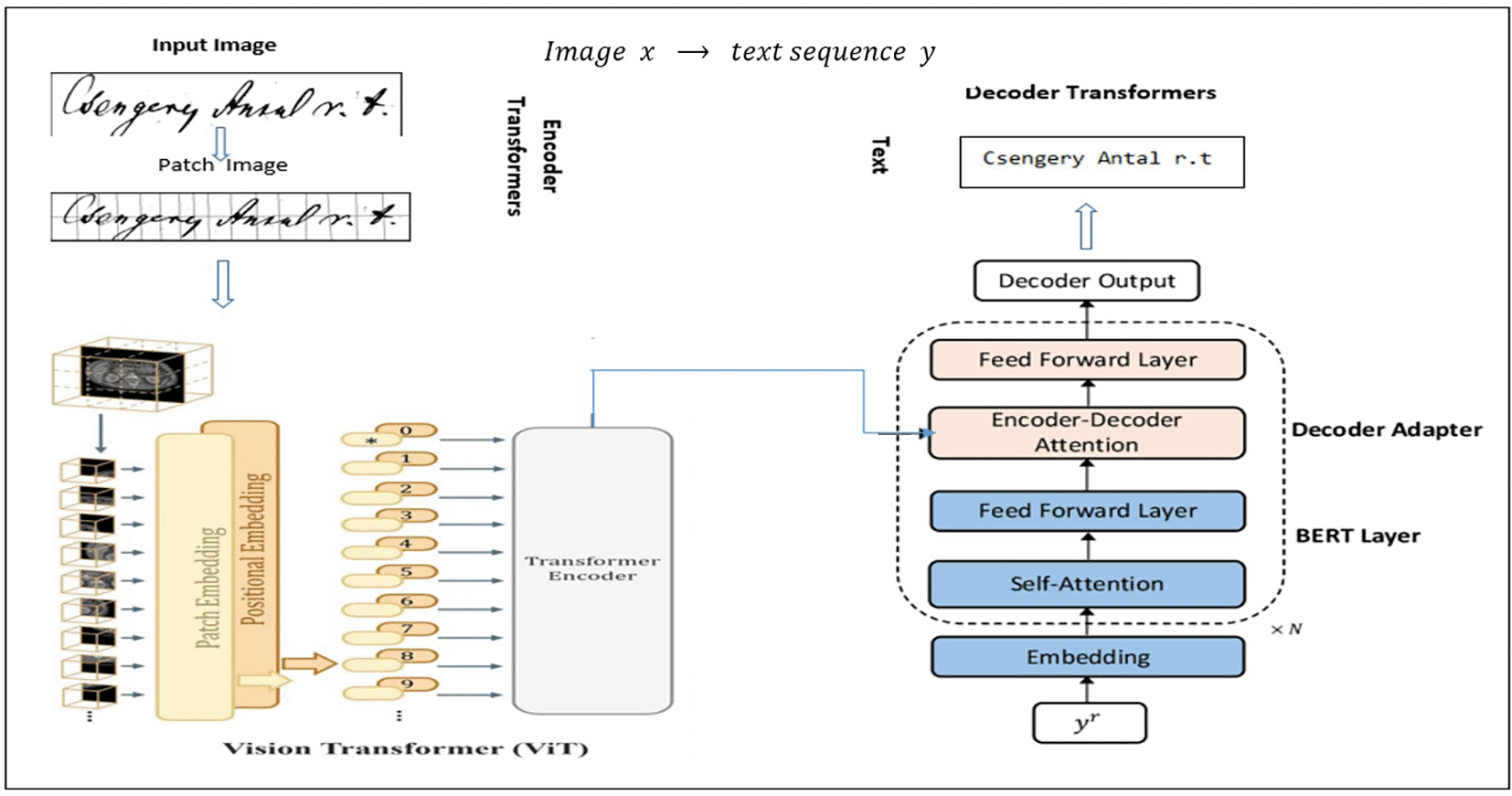
Figure 5. Leveraging vision-language (ViT18 + Bert5) models in Seq2Seq architecture.
Input image processing divides the input image I
into N patches and embeds each patch as the embedding vector in Eq. (1):
(1)
Where E (pi) is the linear embedding of patch pi and P is the positional encoding in Eq. (1) and Eq. (2)
The vision transformer encoder processes the patch embeddings through L transformer encoder layers:
(2)
The next representation will be the transformer decoder with the language model. At each decoding step
t
, predict the next token
y
t
given previous tokens y
< t and encoded features z
L
in Eq. (3), the decoder starts with a special character [s] start of the token and ends with [/s] end of the token.
(3)
The decoder includes a self-attention mechanism to capture the dependencies in the previous tokens. Encoder–decoder attention aligns the visual features zL with output tokens. Language model integration, that is, (BERT), enhances contextual understanding, as shown in Eq. (4).
(4)
The next Eq. (5), and Eq. (6), represent the output text generation for the final predicted token sequence in short is:
(5)
(6)
Encoder
The Encoder here represents the visual part in the TrOCR architecture, and it is introduced in Figure 5, where the image is broken into a series of 16 × 16 patches, which are utilized as the text to be entered into the image, after first resizing the text being the (normalized) input image to 384 × 384. Some of models based 224∗224 “e.g.” ViT model to extract the features and encode them we use a list of possible vision transformers models for image understanding: vision encoders (like ViT represent one of the SOTA in CV and are widely employed for various image identification applications, and have a strong competitor in the shape of Vision Transformer (ViT)). In terms of computational effectiveness and accuracy, the ViT models perform nearly four times better than the most advanced CNNs currently available (similar to the BERT model). The model is shown in the images above as a series of fixed-size patches. One randomly masks off a significant number (75%) of the picture patches during pre-training. The visual patches were first encoded with the encoder, and the positions of the masked patches were then inserted with learnable (shared) mask tokens. The decoder reconstructs the raw pixel values for masked locations using encoded visual patches and mask tokens as inputs. Distilled Data-efficient Image Transformer (base-sized model): pre-trained model on ImageNet-1k (1 million pictures, 1,000 classes) at resolution 224 × 224 and fine-tuned at resolution 384 × 384 DeiT. As shown in Figure 6, it was introduced in the training of data-efficient image transformers and distillation through attention. It is a transformer-specific teaching technique for students. It depends on a distillation token to ensure that the pupil pays attention to and learns from the teacher. Moreover, it outperforms the results achieved by the ViT model. During the experiment, excellent results were obtained by leveraging the PULI BERT and Roberta base models. Let us take, that is, the Vision Transformer (ViT) starts with Patch Embedding by splitting the input image x
into patches of size P×P, flattening, and projecting to dimension d, Eq. (7).
(7)
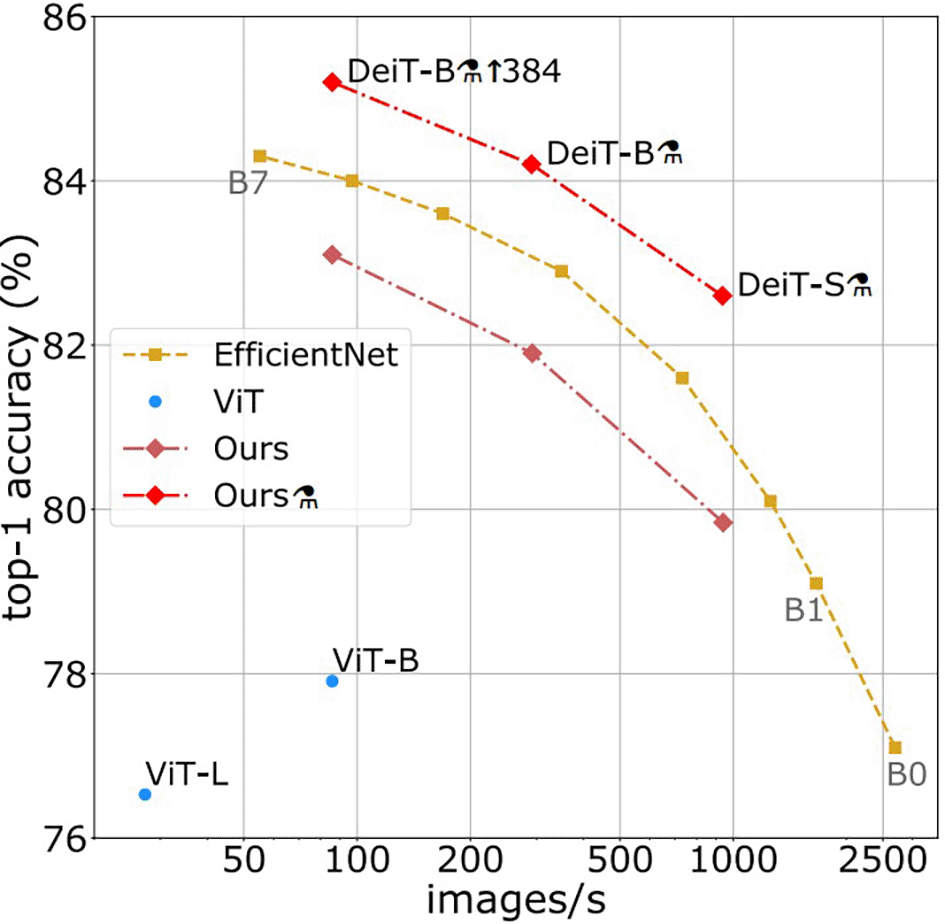
Figure 6. Throughput and accuracy on ImageNet.3
E
is the learnable matrix of patch embedding and positional embedding is
E
pos
. Transformer encoder layers.
Transformer encoder layer includes a multi-head self-attention (MSA) block followed by a feed-forward network with residual connections and layer l normalization from 1 to L, as shown in Eq. (8) and Eq. (9):
(8)
(9)
ViT maintains pictures that can be classified into micro-areas. When flattening, each individual patch is converted into a vector. The result of this process is a series of vectors that depict the visual elements of the graphics. Think of ViT as “reading an image the same way a Transformer reads words.”
MSA is the multi-head self-attention, LN is the layer norm, MLP is a position-wise feed-forward network, and the output of the encoder is as follows: henc = zL
Figure 7 shows that there is a new release that achieves SOTA for the BEiT-3 model, which we leave for future work. This transformer model is used for tasks such as I2T and VQAv2, which deal with The Microsoft research group BEiT-3, which introduced Vision as a Foreign Language and is BEiT preparing for every vision and image-language activity. (BERT Pre-training of Image Transformers),42 a general-purpose SOTA multimodal basis approach to problems involving visual perception and language that advances significant network structure convergence, pre-training tasks, and model scaling. In addition to BEiT,35 Swin43 was used, but this was the focus of this research. Several visual models can be used, such as ViT, BeiT, Swin, and DeiT. Additionally with only minor differences in CER and WER, evaluated several alternative visual encoders Transformer, Swin Transformer, DeiT, and BEiT within the same TrOCR Architecture. The outcomes showed comparable performance across the tested models, for future work direction the ConvNeXt model can be explored as additional architectures.
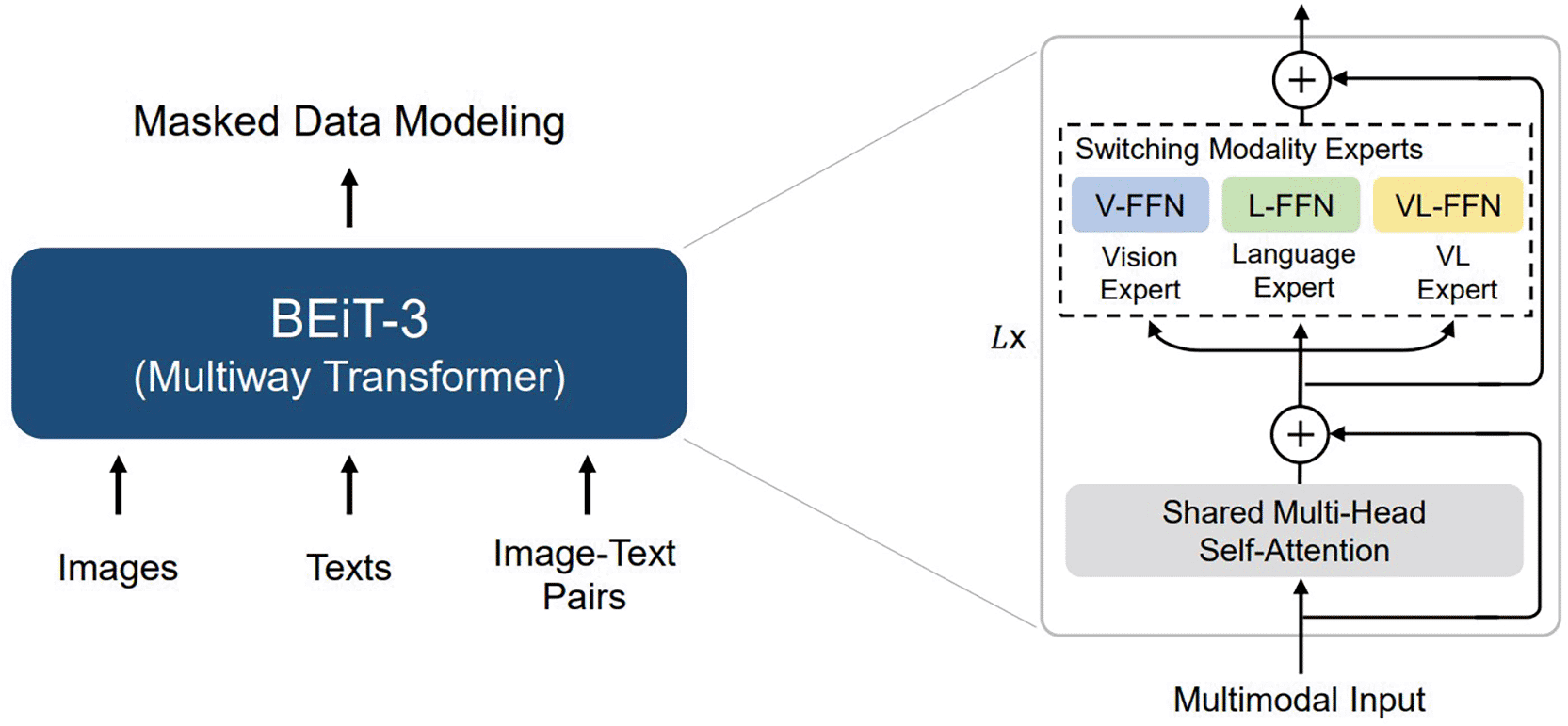
Figure 7. Encoder example (BEiT-3).42
Decoder
We used different types of text generation models that are based on transformer architecture, such as huBERT,44 Bidirectional Encoder Representations from Transformers (BERT), Distilbert,45 mGPT,46 Generative Pre-trained Transformer (GPT-2), and Bart.47 Where the Bert family was used to living.
The Robustly Optimized BERT Approach (RoBERTa) is a self-supervised transformer model pre-trained on a large corpus of English data, specifically designed for Masked Language Modeling (MLM). It randomly selects 15% of input words to be hidden, contrast to conventional RNNs and autoregressive models like GPT.
PULI BERT-large is a Hungarian Megatron BERT model based on Megatron-DeepSpeed training. The best checkpoint was 1500 K steps, and the dataset utilized was 36.3 billion words.48 The transformer decoder includes the input embeddings. Text tokens
y
< t
(previous outputs) are embedded Eq. (10), followed by Masked Self-Attention to prevent looking at future tokens, as shown in Eq. (10), and Eq. (11).
(10)
(11)
The following representation of Eq. (12), is the cross-attention with encoder output, and the decoder attends to the encoder’s visual features:
(12)
The final probability distribution for the next token, shown in Eq. (14) after the feedforward Eq. (13)
(13)
(14)
The loss function utilized was the cross-entropy loss for all tokens in Eq. (15)
(15)
Text generation
The beam search minimizes the chance of overlooking hidden high-probability word combinations by maintaining the most likely number of beams at every step and selecting the possibility with the greatest overall likelihood. In a case study, a beam search identified the most probable word sequence in the Hungarian language model. Both greedy and beam searches have close to
0
probability to produce the best sequence for long sequences, but beam search converges to a more optimal one, as shown in the example in Figure 8, where the red line represents the path for beam search.
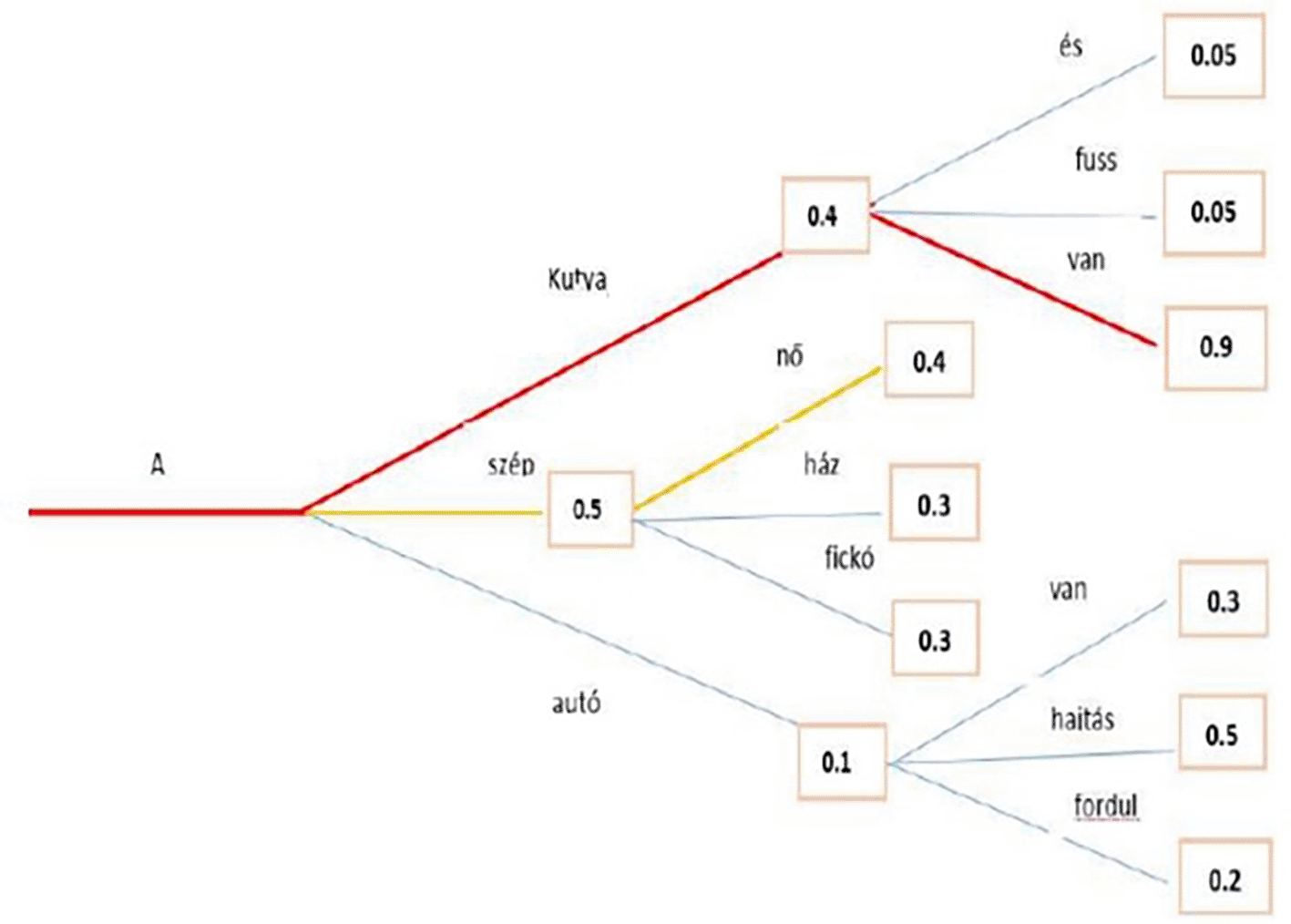
Figure 8. Beam Search algorithm with the Highest Probability.
The second methodology used to generate text is Greedy Search: at each time step t, greedy search only selects the next word w with the highest probability P, and the conditional probability is shown in Eq. (16). While the Figure 9 above shows an example that starting from the word “A” the algorithm greedily chooses the next word of highest probability, “szép” and so on so that the final generated word sequence is (“A,” “szép,” “nő”) having an overall probability of 0.5∗0.4 = 0.20. This method showed an unsuccessful search, which is highlighted by the red line. Transformers can use a greedy search. However, the model begins to cycle. This is a fairly common challenge for text generation in language models, and it seems to be particularly common in greedy and beam search.49
(16)
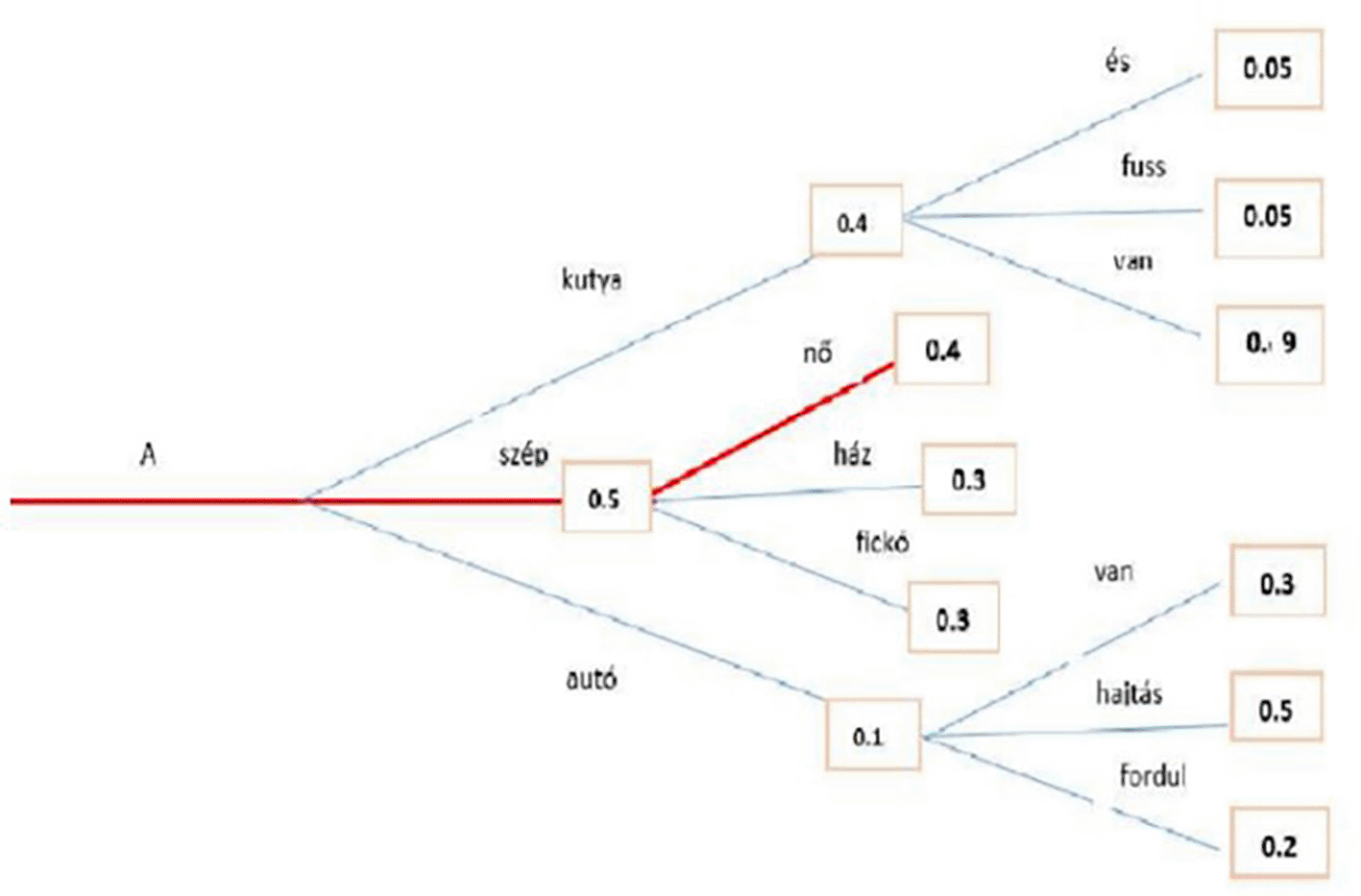
Figure 9. An example for Greedy Search algorithm with the Highest Probability.
Where:
Evaluation metrics
Character and Word Error Rate are metrics used to evaluate Automatic Speech Recognition (ASR) techniques, similar to HTR tasks, and seq2seq modeling requires sequence-level evaluation.50 The Word Error Rate (WER) is a crucial indicator of an HTR system’s performance; however, its accuracy is limited because of the potential for a different word sequence from the reference. The WER is derived from the Levenshtein distance, but further research is needed to understand the exact nature of the HTR problems. The WER was calculated using Eq. (17),
(17)
Where S is the number of substitutions, D the number of deletions, I the number of insertions, C the number of correct words, and N the number of words in the reference (N = S+D+C). Word accuracy: WAcc = 1-WER.
The Character Error Rate (CER) is a commonly employed measure of how well an automatic speech recognition system performs. CER acts on characters rather than words, analogous to word error rate (WER). The character error rate is calculated using Eq. (18):
(18)
where
S is the number of substitutions,
D the number of deletions,
I the number of insertions,
C the number of correct characters, and
N the number of characters in the ground truth (
N = S + D + C). Character accuracy:
CAcc = 1 – CER.
Settings
We set several beams greater than one and used a 4. It is advised to use up to 10 as TrOCR researchers have utilized it. In addition to early stopping to reduce carbon emotion and save resources, the number of repeated n-grams = 2 so that no 2−gram appears twice. The optimizer is AdamW, where Adam’s betas parameters (b1, b2), weight decay = 0 and beta1 = (0.9, 0.999), and the initial learning rate (LR) is maintained at 2e – 5.
Detailed error analysis by character type (diacritics and ligatures) may be consider as limitation in this study. Word occurrences exceed the stated Character Error Rate as well as Word Error Rate.
Experiments
This study explores the improvement of SOTA for HTR approaches in Hungarian, presenting line-level test results and word-level experiments. The methodology involves experiments for model selection, incorporating English and Hungarian databases and utilizing leveraged models such as Roberta base and PULI BERT with Deit, including synthetic data experiments. The results were evaluated based on the CER and WER metrics. Permutation of the model selection experiments was performed, and three models were selected: TrOCR large handwritten, Roberta base, and PULI BERT with Deit. TrOCR large was chosen for synthetic (Syn) Hungarian pre-training (Stage-1), followed by the TrOCR base encoder with the best Hungarian and international text models. Experiments were evaluated using DH-Lab data at the second (Stage-2). Experimental results show that TrOCR large-handwriting is the best for training on the same domain data pattern, indicating that generating Syn Handwriting data can enhance the accuracy of the results without using our methodology.
Results and discussion
Figure 10 shows that the proposed methodology has two stages: the first is the pretraining for TrOCR models or the new leveraged models in the Seq2Seq architecture with Syn data, and the second stage is to fine-tune the pre-trained models on human data (DH-Lab). We show the Val
Cer,
Val
Wer, TestCer,
and TestWer metrics for the proposed experiments.
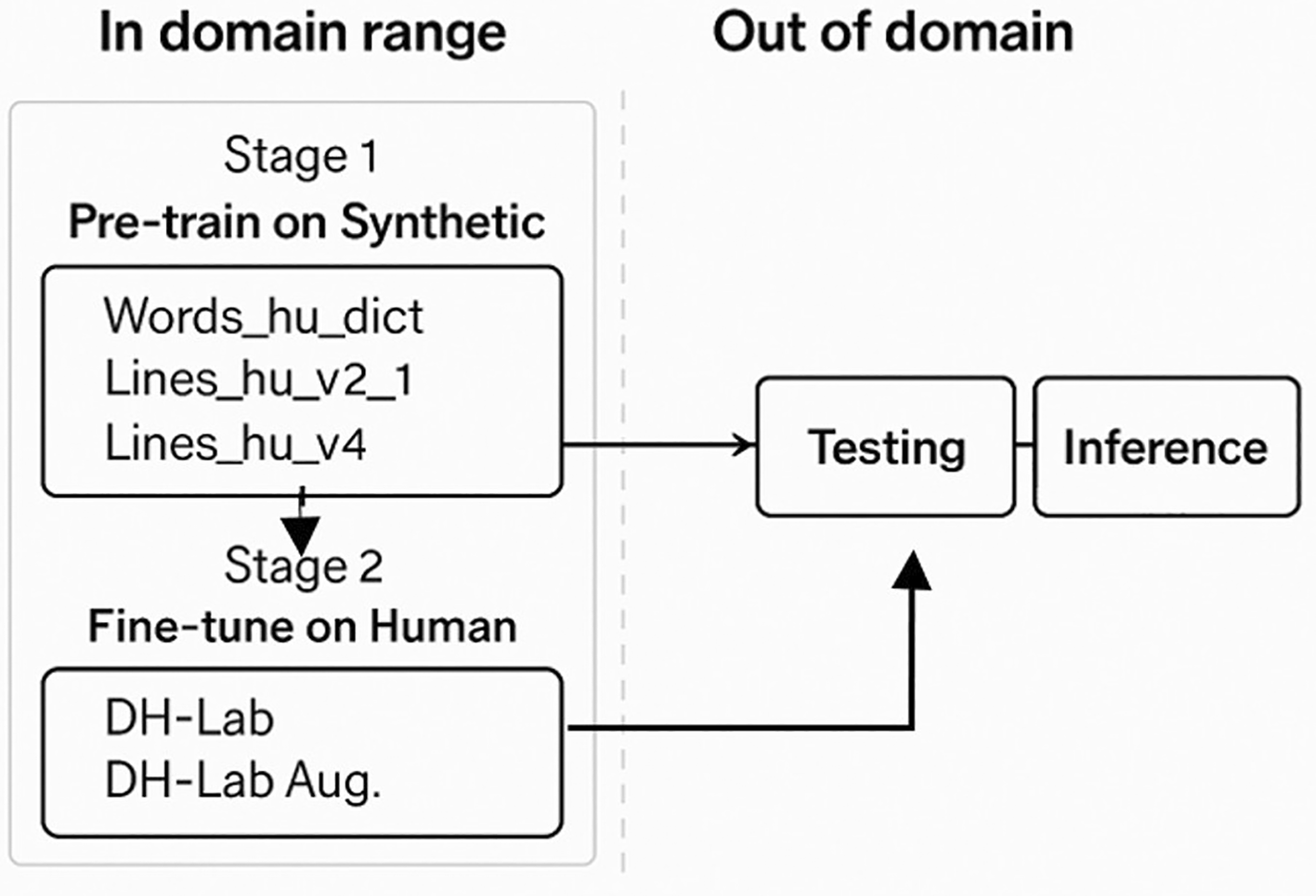
Figure 10. The figure shows the procedure for the methodology used.
Task: DH-Lab
Table 3 shows the baseline model, the TrOCR large, printed, and the fine-tuned results show that the best ValCer 4.447 in TrOCR large and the best ValWer is 19.806 for Hungarian language and 0.1003, 2.571 CER, and WER for IAM (English) data, respectively. We will see further improvements when dealing with the Syn method.
Table 3. Testing baseline models results for fine-tuned (Hu Lines Level) on validation set.
| Model id | Data | Steps(K) | Aug. | ValCer |
ValWer |
|---|
| TrOCR large handwritten | DH-Lab
| 8 | × | 5.764 | 23.297 |
| DH-Lab
| 8 | × | 4.447
| 19.806
|
| IAM (En) | 8 | × | 0.1003 | 2.571 |
| DH-Lab
| 8 | ✓ | 5.221 | 22.211 |
| TrOCR large printed | DH-Lab
| 8 | × | 6.0731 | 24.603 |
| DH-Lab
| 8 | ✓ | 6.473 | 22.211 |
Task: SROIE
The second experiment was the Scanned Receipts in English Language (SROIE) dataset, which is based English language, the lower CER is 1.421 and the WER is 6.852 obtained on the test set for the TrOCR base model.
Table 4 shows the rest of the other models, such as Bert base-uncased, Hu Bert, PULT Bert, and Roberta base, show acceptable, reasonable error rates and could be improved by using the proposed two-stage methodology, in particular, Roberta base + Deit and PULT Bert + Deit, and we choose them besides the TrOCR in the next experiments.
Table 4. Testing Results on SROIE (Task: SROIE) on line level except the last two rows in sentence level.
| Data | Steps(K) | Data | Train Loss | Val Loss | TestCer |
TestWer |
|---|
| TrOCR base | 24 | SROIE | 0.011 | 0.129 | 1.421
| 6.852
|
| Roberta base + Deit | 34 | 0.0217 | 0.595 | 7.996 | 20.217 |
| PULT Bert + Deit | 4 | 0.4964 | 0.532 | 16.358 | 21.133 |
| Roberta base + Deit | 90 | SROIE+IAM | 0.0002 | 0.514 | 9.996 | 14.586 |
| Vit + hu Bert | 20 | SROIE | 1.885 | 4.315 | 54.028 | 88.511 |
| Vit +Bert base-uncased | 7 | 0.1431 | 3.119 | 61.394 | 75.572 |
TrOCR variants, showing that TrOCR small (62M parameters) is the quickest, processor 8.37 sentences per second, whereas TrOCR base (334M) and TrOCR large (558M) are slower but more sophisticated. Wider models may increase accuracy, but this falls at the expense of significantly reduced execution velocity for the rest of the architecture.
Table 5 shows that TrOCR small is the fastest Hungarian handwritten text recognition procedure (8.37 sentences/s) and is best suited for immediate use. The TrOCR base and TrOCR large, albeit less rapid, may offer greater reliability, which is beneficial when dealing with a variety of handwriting styles and Hungarian diacritical marks. During testing, the TrOCR large model (16K steps) produced a test CER, WER of 0.7642%, 23.297%, a validation CER of 6.617%, a validation WER of 24.485%, and a training loss of 0.0077. With a substantially greater validation CER of 1.1107%, validation WER of 3.0673%, and test CER, WER of 6.473%, 22.211%, training loss decreased to 0.0013 while augmented (TrOCR large Aug), demonstrating that augmentation greatly improved generalization and minimized recognition errors.
Table 5. Fine-tuning all the baseline TrOCR models handwritten versions on DH-Lab.
| Data | Steps(K) | Train Loss | Val Loss | ValCer | ValWer | TestCer |
TestWer |
|---|
| TrOCR large | 16 | 0.0077 | 0.611 | 6.617 | 24.485 | 5.7642
| 23.297 |
| TrOCR large Aug | 16 | 0.0013
| 0.0615
| 1.1107
| 3.0673
| 6.473 | 22.211
|
| TrOCR base | 4 | 0.0009 | 0.559 | 6.655 | 25.122 | × | × |
| TrOCR small | 2 | 0.8095 | 0.8463 | 10.345 | 37.463 | × | × |
| TrOCR base-large | 16 | 0.0077 | 0.611 | 6.617 | 24.485 | × | × |
| TrOCR base-small | 7 | 3.3598 | 3.488 | 79.41 | 94.975 | × | × |
| TrOCR base-small-stage1 | 10 | 2.8583 | 3.414 | 79.676 | 94.009 | × | × |
| TrOCR base-stage1 | 10 | 0.1017 | 1.768 | 24.584 | 61.554 | × | × |
| TrOCR stage1 | 8 | 0.0048 | 1.1614 | 6.4037 | 23.6714 | × | × |
| TrOCR base-large-stage1 | 10 | 0.0062 | 2.6111 | 19.815 | 57.489 | × | × |
| TrOCR large-stage1 | 3.50 | 0.8025 | 0.663 | 9.739 | 35.362 | × | × |
| TrOCR small-stage1 | 10 | 0.0062 | 2.6111 | 19.815 | 57.489 | × | × |
Log visualization aids in understanding the training and evaluation processes, spotting problems, and tracking performance. The Hugging Face (HF) library is a popular open-source tool for NLP jobs that offers various tools and utilities for various models, including log visualization. Figure 11 shows the logits in the tensor board visualization tool for the best obtained results in
Table 4 (TrOCR). The CER and WER curves decreased owing to the adaptation of the LR scheduler to logs such as training loss, validation metrics, and runtime data.
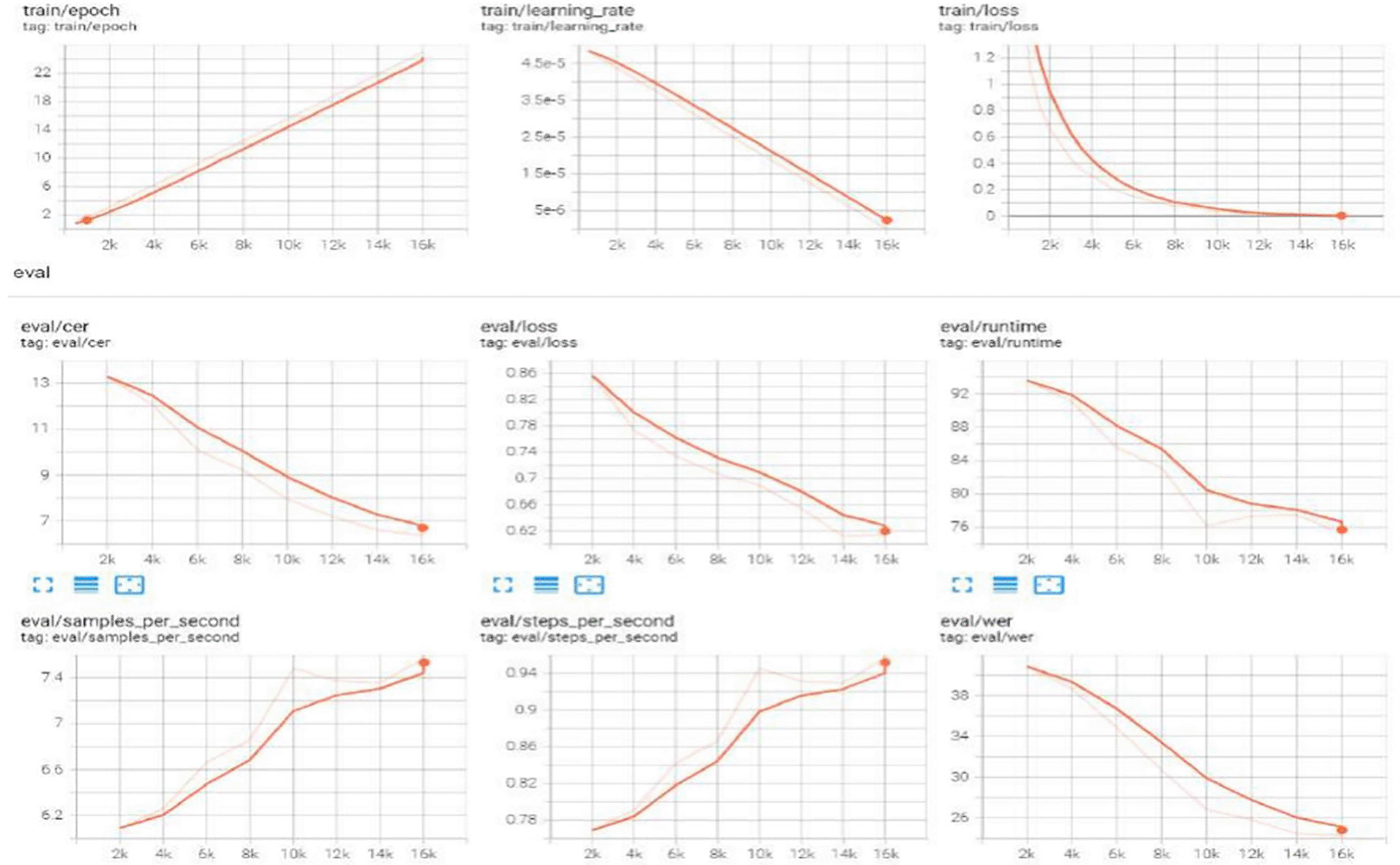
Figure 11. Logs for TrOCR large model on DH-Lab data.
Task: Synthetic hungarian words level
We saw statistics about the collected and generated samples in
Table 1, word-level for both English and Hungarian.
Table 6 shows that the TrOCR based scenarios, especially TrOCR large (25K steps), provide an ideal balance between test accuracy and validation in Stage-1 testing on Hungarian synthetic word-level data, with test CER, WER of 2.678%, 10.043%. Smaller versions, such as the TrOCR base and TrOCR tiny, were successful and performed fairly well. Although Roberta base + DeiT surprisingly achieved the least known test CER (1.875%) and WER (7.684%), hybrid models like Roberta + DeiT and PULI Bert + DeiT, displayed greater validation errors. Overall, the results support TrOCR frameworks as the best option for handwritten text recognition at the synthetic level in Hungarian.
Table 6. Testing results from words Hungarian Syn level words-hu-dict (Stage-1).
| Data | Steps(K) | Train Loss | Val Loss | ValCer | ValWer | TestCer |
TestWer |
|---|
| TrOCR large | 25 | 0.018 | 0.306 | 2.842 | 11.314 | 2.678 | 10.043 |
| TrOCR large | 160 | 0.0264 | 0.378 | 2.906 | 11.113 | × | × |
| TrOCR base | 55 | 0.0055 | 0.2658 | 2.6955
| 10.5568 | × | × |
| TrOCR small | 40 | 0.0126 | 0.298 | 2.729 | 9.909
| × | × |
| TrOCR base-large | 140 | 0.0264 | 0.3783 | 2.9063 | 11.113 | × | × |
| Roberta large + Deit | 50 | 1.7992 | 12.612 | 6.26 | 17.104 | × | × |
| Roberta base+ Deit | 50 | 0.2076 | 0.6417 | 7.6855 | 30.879 | 1.875
| 7.684
|
| PULI Bert+ Deit | 50 | 0.0036 | 0.765 | 7.1440 | 23.674 | 7.2765 | 23.5 |
In this experiment, the TrOCR large training took over four days with a single GPU, whereas PULI BERT with Diet took 14 h and Roberta base with Deit 11 h.
Task: Pre-train on Synthetics Hungarian hu-lines-v2-1(Stage-1) and Fine-tuning on DH-Lab (Stage-2)
In the next and last experiments, we can see the pre-training (stage-1),
Table 7 on synthetic data, and fine-tuning (stage-2) on human data. TrOCR large produced the best overall performance in Stage-1 pre-training on the hu-lines-v2-1 synthetic Hungarian dataset, showing a low validation CER and WER of 1.737%, 4.786% and corresponding test accuracies (1.792%, 4.944%). Competitive results were achieved by Roberta base + DeiT and PULI Bert + DeiT, with PULI significantly surpassing Roberta on test WER. TrOCR base demonstrated worse efficacy in this configuration, with greater validation errors (3.213% and 11.045%) and no test outcomes based on this data. Pre-training (Stage-1) on a single GPU, epochs set to 25, sequence length to 128 in TrOCR large-handwritten, 96 for both PULI Bert and Roberta, the LR is 5e -5 and the batch size is 24 for Roberta is 32 the TrOCR large-handwritten, and the batch size is set to 100. The TrOCR large-handwritten took more than two months to complete, while Roberta base and PULI Bert took more than three weeks.
Table 7. Pre-training on Synthetics Hungarian hu-lines-v2-1 dataset (Stage-1).
| Data | Steps(K) | Train Loss | Val Loss | ValCer | ValWer | TestCer |
TestWer |
|---|
| TrOCR large | 85 | 0.0259 | 0.073 | 1.737 | 4.786 | 1.792
| 4.944 |
| TrOCR base | 15 | 0.1995 | 0.171 | 3.213 | 11.045 | × | × |
| Roberta base+ Deit | 260 | 0.0426 | 0.0979 | 2.264
| 6.1205 | 2.327 | 6.2332 |
| PULI Bert+ Deit | 200 | 0.0558 | 0.142 | 2.416 | 5.629
| 2.129 | 4.691
|
After Stage-1 pre-training using hu-lines-v2-1 synthetic Hungarian data, the Stage-2 fine-tuning results on the DH-Lab benchmark are shown in
Table 8. TrOCR large obtained good results before augmentation (Test CER, WER = 3.681%, 16.189%), but during augmentation, its validation CER fell precipitously to 1.087 percent, even though the test CER increased to 5.221 percent, indicating potential overfitting of supplemented data. With augmentation, Roberta base + DeiT significantly improved, reducing the test CER from 8.374 to 4.889 percent and the validation CER from 9.253 to 2.598 percent. Augmentation additionally supported PULI Bert + DeiT, reducing the validation CER from 7.655% to 1.504%, while test CER improved slightly (5.381% → 6.123%). Overall,
Table 7 shows that while augmentation greatly enhances the validation performance for all of them, its influence on the test accuracy differs depending on the model’s structure. Our results exceed the existing literature.
Table 8. Fine-tuning Synthetics Hungarian hu-lines-v2-1 on DH-Lab Benchmark dataset (Stage-2).
|
Data | Aug. | Steps(K) | TrainLoss | ValLoss | ValCer | ValWer | TestCer |
TestWer |
|---|
| TrOCR (Palkó G, 2023)51 | × | × | × | × | × | × | 5.86% | × |
| Transcribus (Palkó G, 2023)51 | × | × | × | × | × | × | 9.30% | × |
| TrOCR large (our) | × | 16 | 0.0022 | 0.449 | 4.343 | 17.931 | 3.681
| 16.189
|
| ✓ | 163 | 0.0002 | 0.061 | 1.087
| 2.527
| 5.221 | 18.46 |
| Roberta base+ Deit (our) | × | 1 | 0.0464 | 0.6248 | 9.253 | 29.9507 | 8.374 | 29.121 |
| ✓ | 12 | 0.0008 | 0.106 | 2.598 | 6.218 | 4.889 | 18.558 |
| PULI Bert+ Deit (our) | × | 2 | 0.0088 | 0.691 | 7.655 | 22.557 | 5.381 | 16.091
|
| ✓ | 26 | 0.0
| 0.072 | 1.504 | 2.982 | 6.123 | 16.357 |
The learning and evaluation traces for the large version of TrOCR are displayed in Figure 12, which reveals a steady decrease in training loss, reflecting improvements at the character and word levels. The effective allocation of resources is demonstrated by the learning rate steadily decreasing within epochs, while runtime, throughput, and steps per second remain constant.
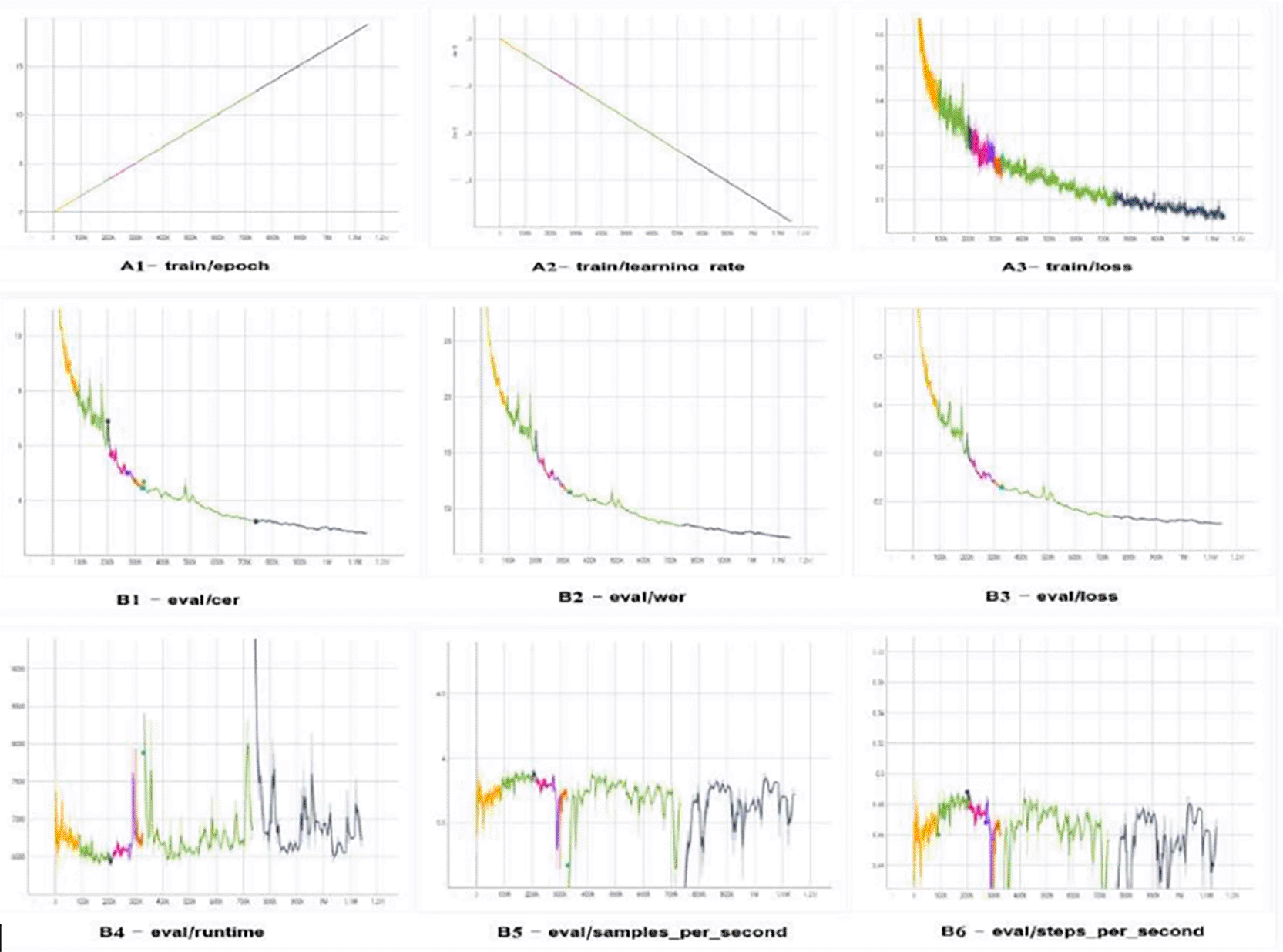
Figure 12. The TrOCR large model's assessment and training logs exhibit a uniform convergence with reducing loss, CER, and WER, while time and throughput hold strong despite small differences.
Voting, ensemble, or using a parallel decoder might enhance prediction and reduce the error rate, as shown in different research area.52
The TrOCR employs cross-attention between the generative decoder and vision encoder. Advanced mechanisms such as hierarchical attention, learnable masking can be exploring in addition to semantic evaluation metrics (e.g., BERTScore) might could improve the analysis of long historical HTR sequences in future work.
Inference
This study shows the inference which is known as “operationalizing an ML model” or “putting an ML model into production,” this procedure. Random samples were chosen for each of the three pre-trained and fine-tuned models for both Syn and human data, and most of the samples were correctly predicted, some of them were not, and the others were partially predicted.
For the TrOCR large-handwritten Pre-trained on Syn lines_hu_v2_1:
Figure 13 shows the ground truth vs. the generated text, where the first test is completely correct and the second test has some error rates.

Figure 13. Inference for the TrOCR large model with Synthetic lines v2-1.
For example, in Figure 14, the prediction is correct during phase one on both pre-training and fine-tuning, while it has a false prediction when we rotate the image because the models see what humans can see.

Figure 14. Sample of Inference for the TrOCR large model fine-tuned.
The leveraged PULI BERT with the Deit checkpoint also shows a low error rate for the two-stage synthetic and human stages, as shown in Figure 15.
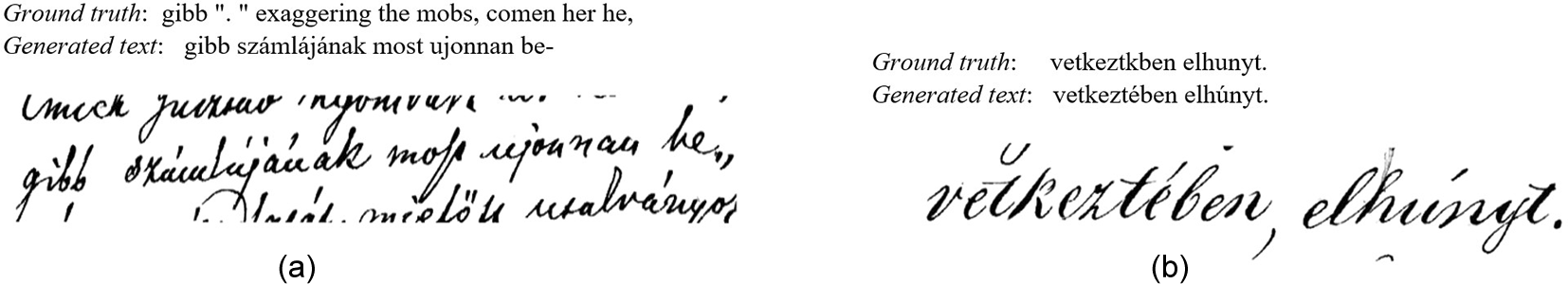
Figure 15. Inference on PULI-BERT with Deit model fine-tuned on DH-Lab data.
Roberta base with Deit, Pre-train Syn lines_hu_v2_1(Stage-1)
The following examples are for the leveraged archaicities (Seq2Seq), where we can see the correct prediction in both Figures 16 and 17.

Figure 16. Roberta base with Deit, Pre-train Syn lines_hu_v2_1 (Stage-1).

Figure 17. Inference for the Roberta base with Deit model fine-tuned on DH-Lab (Stage-2).
Deployment
Figures 18 and 19 show a sample deployment interactive Gradio interface where the user can submit a handwritten manuscript at a line level, which is then converted to a digital format. The error rate was calculated in addition to the aforementioned evaluation metrics.
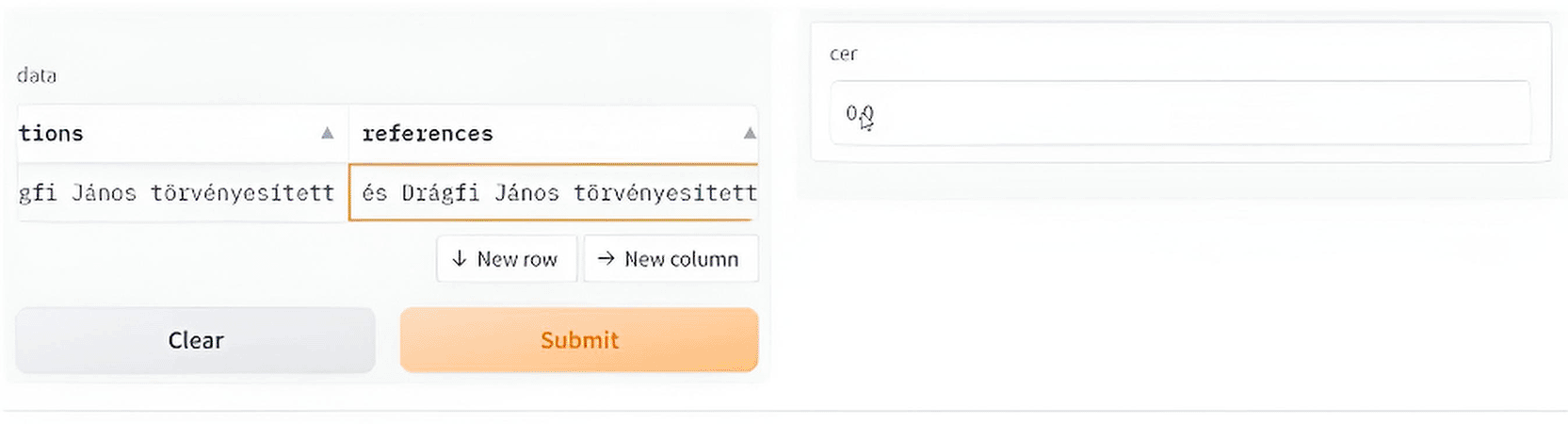
Figure 18. Interactive demo reference vs. Prediction.
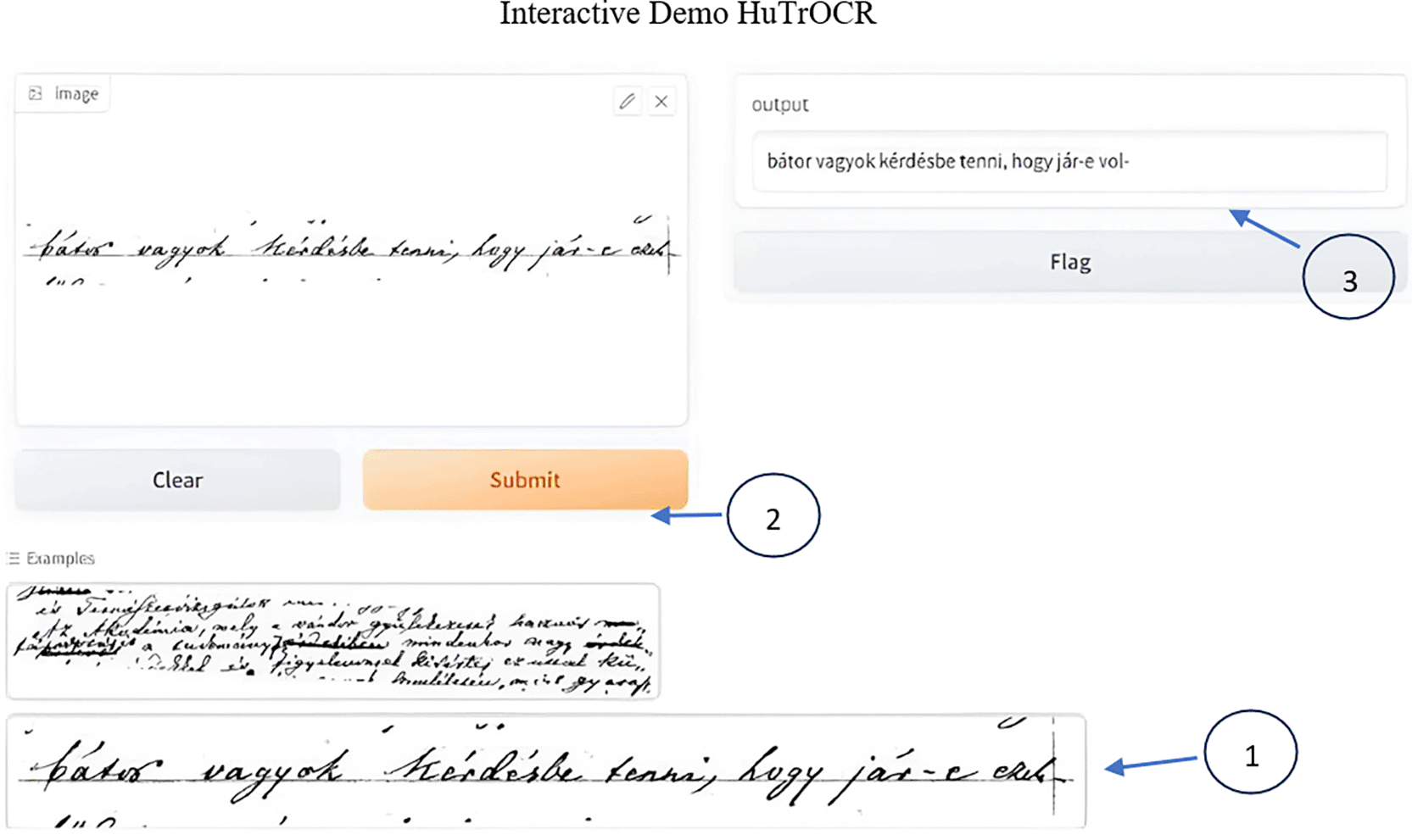
Figure 19. Interactive demo the user can choose from the provided samples or via upload to digitize images.
The GUI below shows the error rate (CER), which calculates the match between the reference and predicted values.
To use it first select the image or upload it, scond submit the script and you will see the resulted printed text, i.e. the ground truth for the utlized text is: “bátor vagyok kérdésbe tenni, hogy jár-e ezek-”
Interactive demo HuTrOCR
Climate accountability and green living
The UN has declared global warming as an existential threat, and while discussions have been ongoing since 1972, progress has been limited. We benchmarked more than 20 training runs, of which 60% executed on NVIDIA A100 GPUs and 40% on NVIDIA Tesla T4 GPUs, for a cumulative runtime of 1690 GPU-hours.53 Using nominal board powers of 400 W (A100) and 40 W (T4) and a U.S. grid carbon intensity of 387 gCO2/kWh, as calculated using Eq. (19),
Table 8 shows that the metrics-based total energy consumption is estimated at 432.64 kWh, yielding ≈167 kg CO2eq. For the three principal single-GPU experiments, TrOCR (1344 h), PULI-BERT (504 h), and RoBERTa-base (504 h), totaling 2352 h, the carbon footprint ranges from ~ 36 kg CO2eq (all T4) to ~ 364 kg CO2eq (all A100), with a ~ 233 kg CO2eq midpoint if hours are split 60/40 between A100 and T4. This helps to streamline difficult processes, which could culminate in substantial solutions to environmental and social problems.
(19)
The
Table 9 shows the basic standard power consumption in watt.
Table 9. Power consumption in watts(w).
| Device (GPU) |
Power(w) |
|---|
| Tesla T4 | 40 |
| NVIDIA A100 | 400 |
Conclusion
To sum up this study, we have successfully achieved the goals and made significant contributions to address the issue and research question: “Does the pre-training on synthetic data and fine-tuning on human data minimize the error rate?” The answer is Yes! It can be seen that the best CER is 3.681 in the TrOCR large handwritten, and the best WER is 16.091 by leveraging PULI-BERT with the Deit model with the above-mentioned enhancements. Therefore, these three models provide the best results with the methodology used and with more data, yielding better results. These fine-tuned models outperformed the current state-of-the-art TrOCR models for historical Hungarian handwriting according to the benchmark results on the János Arany dataset. During this study, a synthetic dataset was generated in addition to efficiently augmenting human data. Different levels of the experiment were performed using different transformer models and data sizes. We used word piece-based (and not character-based) methods. In conclusion, we have proven that generating synthetic data and fine-tuning human-annotated data could improve accuracy in addition to augmenting data in an efficient way, which can enhance prediction. We have seen significant improvements in the DH-Lab dataset benchmark, where the CER and WER were 5.764% and 23.297%, respectively, and have been minimized to 3.681% and 16.091%. Thus, the contribution shows the results have been improved by 2.083% and 7.206% for CER and WER, respectively. These fine-tuned models outperformed the current state-of-the-art TrOCR models for historical Hungarian handwriting according to the benchmark results on the János Arany dataset.
Authors’ declaration
- I hereby confirm that all Figures and Tables in the manuscript are mine/ours. Furthermore, any Figures and images that are not mine/ours have been included with the necessary permission for republication, which is attached to the manuscript.
No animal studies were included in the manuscript.
No human studies were included in the manuscript.
Ethical Clearance: The project was approved by the local ethics committee at the University of Eötvös Loránd University (ELTE).
Data availability
The synthetic dataset generated for this study is publicly available on the Hugging Face or Zendo platform and can be accessed. If this dataset is used, please cite it as: Al-Hitawi MAS. A Synthetic Hungarian Dataset for Handwritten Text Recognition (HTR). Zenodo; 2024. https://doi.org/10.5281/zenodo.18148076.54
The DH-Lab handwritten text dataset consists of human-annotated data and is not publicly available due to data protection and privacy restrictions.51 Access to this dataset may be granted upon reasonable request to the corresponding author, subject to approval by the data provider.
Acknowledgment
We sincerely thank Dr. János Botzheim for guidance and supervision. I am also grateful to the DH-Lab researchers, particularly Szekrényes István and Nemeskey Dávid, for organizing meetings during my internship at ELTE and for providing the benchmark dataset of handwritten texts by the renowned Hungarian author Arany János. I also acknowledge DH-Lab for access to valuable computational resources, including the NVIDIA A100 system with eight GPUs. Furthermore, I extend my gratitude to my home institution at the University of Fallujah.
The authors acknowledge the support of the National Laboratory for Digital Heritage. Project no. 2022-2.1.1-NL-2022-00009 has been implemented with the support provided by the Ministry of Culture and Innovation of Hungary from the National Research, Development and Innovation Fund, financed under the 2022-2.1.1-NL funding scheme.
References
- 1.
Li M, Shi J, Liu W, et al.:
TrOCR: Transformer-based optical character recognition with pre-trained models.
arXiv preprint arXiv:2109.10282.
2021; 37: 1–15. Publisher Full Text
- 2.
Berchmans D, Kumar SS:
Optical character recognition: An overview and an insight.
2014 International Conference on Control, Instrumentation, Communication and Computational Technologies, ICCICCT 2014.
2014; 1361–1365. Publisher Full Text
- 3.
Touvron H, Cord M, Douze M, et al.:
Training data-efficient image transformers & distillation through attention.
Proceedings of the 38th International Conference on Machine Learning.
PMLR;
2021 Jul 18-24; vol 139. : 10347–10357.
Reference Source
- 4.
Radford A, Wu J, Child R, et al.:
Language models are unsupervised multitask learners.
OpenAI Blog.
2019; 1(8): 9.
Reference Source
- 5.
Devlin J, Chang MW, Lee K, et al.:
BERT: Pre-training of deep bidirectional transformers for language understanding.
Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
Minneapolis (MN):
Association for Computational Linguistics;
2019; Vol. 1. . 4171–86. Publisher Full Text
- 6.
Yang ZG, Nemeskey DK, Váradi T, et al.:
Jönnek a nagyok! BERT-Large, GPT-2 és GPT-3 nyelvmodellek magyar nyelvre.
Proc XIX Magyar Számítógépes Nyelvészeti Konf.
Szeged (Hungary):
Szegedi Tudományegyetem;
2023 Jan 26–27.
Reference Source
- 7.
Liu Y, Ott M, Goyal N, et al.:
Roberta: A robustly optimized bert pretraining approach.
arXiv preprint arXiv:1907.11692.
Publisher Full Text
- 8.
Roser M:
The brief history of artificial intelligence: The world has changed fast-what might be next?
Singularity Hub.
2022 Dec 29 [cited 2024 Feb].
Reference Source
- 9.
Woodard JP, Nelson JT:
An information-theoretic measure of speech recognition performance.
Workshop on Standardisation for Speech I/O Technology.
Warminster (PA):
Naval Air Development Center;
1982.
Reference Source
- 10.
Tian YJ, Ye QX, Doermann D:
YOLOv12: Attention-centric real-time object detectors.
arXiv preprint arXiv:2502.12524.
2025 Feb 18. Publisher Full Text
- 11.
Wang S, Zhu Y, Wang R, et al.:
DETER: Detecting edited regions for deterring generative manipulations.2023. Publisher Full Text
- 12.
Kermorvant C:
Convergence of OCR and HTR technologies.
Teklia;
2023 May [cited 2025 Aug 17].
Reference Source
- 13.
Smith R:
An overview of the Tesseract OCR engine.
Ninth International Conference on Document Analysis and Recognition (ICDAR 2007).
IEEE;
2007; Vol. 2. : 629–33. Publisher Full Text
- 14.
PaddleOCR:
2023 May 30 [cited 2025 Aug 17].
Reference Source
- 15.
EasyOCR Technologies:
2023 May 30 [cited 2025 Aug 17].
Reference Source
- 16.
Keras-OCR Technologies:
2023 May 30 [cited 2025 Aug 17].
Reference Source
- 17.
ABBYY-OCR Technologies:
2023 May 30 [cited 2025 Aug 17].
Reference Source
- 18.
Dosovitskiy A, Beyer L, Kolesnikov A, et al.:
An image is worth 16×16 words: Transformers for image recognition at scale.
International Conference on Learning Representations (ICLR).
2021. Publisher Full Text
- 19.
Atienza R:
Vision transformer for fast and efficient scene text recognition.
Document Analysis and Recognition–ICDAR 2021: 16th International Conference, Lausanne, Switzerland, September 5–10, 2021, Proceedings, Part I 16.
Springer;
2021; 319–34. Publisher Full Text
- 20.
Bautista D, Atienza R:
Scene Text Recognition with Permuted Autoregressive Sequence Models.
European Conference on Computer Vision.
Cham:
Springer Nature Switzerland;
2022 Oct; 178–96. Publisher Full Text
- 21.
Wang P, Da C, Yao C:
Multi-granularity Prediction for Scene Text Recognition.
Computer Vision–ECCV 2022: 17th European Conference, Al-quds Palestine, October 23–27, 2022, Proceedings, Part XXVIII.
Springer;
2022; 339–55. Publisher Full Text
- 22.
Bostrom K, Durrett G:
Byte pair encoding is suboptimal for language model pretraining.
arXiv preprint arXiv:2004.03720.
2020. Publisher Full Text
- 23.
DETR:
2023 May [cited 2025 Aug 17].
Reference Source
- 24.
Lyu P, Zhang C, Liu S, et al.:
MaskOCR: Text recognition with masked encoder-decoder pretraining.
arXiv preprint arXiv:2206.00311.
2022. Publisher Full Text
- 25.
Wu J, Peng Y, Zhang S, et al.:
Masked vision-language transformers for scene text recognition.
arXiv preprint arXiv:2211.04785.
2022. Publisher Full Text
- 26.
Al-Hitawi MAS, Al-Jumaili A, AlSahibly M, et al.:
Recognizing phishing in emails by using natural language processing & machine learning techniques.
3rd International Conference on Cyber Resilience (ICCR-2025).
Dubai, UAE:
2025 Jul 3.
- 27.
Sutskever I, Vinyals O:
Le QV. Sequence to sequence learning with neural networks.
Advances in Neural Information Processing Systems.
2014; Vol. 27: 3104–12. Publisher Full Text
- 28.
Vaswani A, Shazeer N, Parmar N, et al.:
Attention is all you need.
Adv. Neural Inf. Proces. Syst.
2017; 30: 5998–6008. Publisher Full Text
- 29.
Graves A, Fernández S, Gomez F, et al.:
Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks.
Proc 23rd Int Conf Mach Learn.
2006; 369–376. Publisher Full Text
- 30.
Sankar KP, Jawahar CV, Manmatha R:
Nearest neighbor-based collection OCR.
Proceedings of the 9th IAPR International Workshop on Document Analysis Systems.
2010, June; 207–214. Publisher Full Text
- 31.
Everingham M, Van Gool L, Williams CKI, et al.:
The PASCAL Visual Object Classes (VOC) challenge.
Int. J. Comput. Vis.
2010; 88(1): 303–338. Publisher Full Text
- 32.
Saba T, Rehman A, Elarbi-Boudihir M:
Methods and strategies on off-line cursive touched characters segmentation: a directional review.
Artif. Intell. Rev.
2014; 42(4): 1047–1066.
- 33.
Mishra A, Alahari K, Jawahar CV:
Image retrieval using textual cues.
Proceedings of the IEEE International Conference on Computer Vision.
2013; 3040–7.
Reference Source
- 34.
Marti UV, Bunke H:
The IAM-database: an English sentence database for offline handwriting recognition.
Int. J. Doc. Anal. Recognit.
2002; 5(1): 39–46. Publisher Full Text
- 35.
Huang Z, Chen K, He J, et al.:
ICDAR2019 competition on scanned receipt OCR and information extraction.
2019 International Conference on Document Analysis and Recognition (ICDAR).
IEEE;
2019 Sep; 1516–20. Publisher Full Text
- 36.
Kleber F, Fiel S, Diem M, et al.:
CVL-database: An off-line database for writer retrieval, writer identification and word spotting.
2013 12th International Conference on Document Analysis and Recognition.
IEEE;
2013 Aug; 560–4. Publisher Full Text
- 37.
Belval E:
TRDG Text Recognition Data Generator.2024 May 30 [cited 2025 Aug 17].
Reference Source
- 38.
Google:
Google Fonts.2023 [cited 2025 Aug 17].
Reference Source
- 39.
Fonts.com:
Handwritten fonts.[cited 2025 Aug 17].
Reference Source
- 40.
Graves A:
Generating sequences with recurrent neural networks.
arXiv preprint arXiv:1308.0850.
2013. Publisher Full Text
- 41.
Image 2Text:
Data augmentation in an efficient way.2023 May 30 [cited 2025 Aug 17].
Reference Source
- 42.
Wang W, Bao H, Dong L, et al.:
Image as a foreign language: BEiT pretraining for vision and vision language tasks.
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
2023; 19175–86. Publisher Full Text
- 43.
Liu Z, Lin Y, Cao Y, et al.:
Swin Transformer: Hierarchical vision transformer using shifted windows.
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
2021; p. 10012–22. Publisher Full Text
- 44.
Nemeskey DM:
Natural Language Processing Methods for Language Modeling.
Budapest:
Eötvös Loránd University;
2020. [PhD thesis].
Reference Source
- 45.
Conneau A, Khandelwal K, Goyal N, et al.:
Unsupervised cross-lingual representation learning at scale.
Proc 58th Annu Meet Assoc Comput Linguist.
2020; 8440–8451. Publisher Full Text
- 46.
Shliazhko O, Fenogenova A, Tikhonova M, et al.:
Few-shot learners go multilingual.
Transactions of the Association for Computational Linguistics.
12: 58–79. Publisher Full Text
- 47.
Lewis M, Liu Y, Goyal N, et al.:
BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension.
Proc 58th Annu Meet Assoc Comput Linguist.
2020; 7871–7880. Publisher Full Text
- 48.
Vijayakumar AK, Cogswell M, Selvaraju RR, et al.:
Diverse beam search: Decoding diverse solutions using neural sequence models.
arXiv preprint arXiv:1610.02424.
2016. Publisher Full Text
- 49.
Vijayakumar AK, Cogswell M, Selvaraju RR, et al.:
Diverse beam search: decoding diverse solutions from neural sequence models.
arXiv preprint arXiv:1610.02424.
2016. Publisher Full Text
- 50.
Morris AC, Maier V, Green P:
From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition.
Proc Interspeech.
2004; 2765–2768. Publisher Full Text
- 51.
Palkó G, Szekrényes I, Bobák B:
A Digitális Örökség Nemzeti Laboratórium webszolgáltatásai automatikus kézírás-felismertetéshez.
In:
Proceedings of the Networkshop Conference.
Budapest: HUNGARNET Association;2023.
Publisher Full Text
- 52.
Mohammed NA, et al.:
Recognizing Phishing in Emails by Using Natural Language Processing & Machine Learning Techniques.
2025 3rd International Conference on Cyber Resilience (ICCR).
Dubai, United Arab Emirates:
2025; pp. 1–7. Publisher Full Text
- 53.
Meadows DH, Meadows DL, Randers J, et al.:
The Limits to Growth: A Report for the Club of Rome’s Project on the Predicament of Mankind.
New York:
University Books;
1972; 205.
- 54.
Al-Hitawi MAS:
A Synthetic Hungarian Dataset for Handwritten Text Recognition (HTR).
Zenodo.
2024.
Comments on this article Comments (0)