Keywords
Sentence Embedding, Sentence Transformer, AraBERT, FastText for Arabic
This article is included in the Artificial Intelligence and Machine Learning gateway.
Sentence Embedding, Sentence Transformer, AraBERT, FastText for Arabic
The first attempt at real embedding was word embedding, representing a word as a numerical vector in a multi-dimensional space. It lies at the core of recent Natural Language Processing (NLP) tasks and applications. Proper embedding can impact all NLP pipelines that are used in many real applications; however, perfect embedding needs to capture the semantic and syntactic properties of words.1 Some research and experiments have extended the embedding of words into the embedding of a whole sentence and produced semantically meaningful sentence embeddings.2,3 These attempts have many challenges, such as capturing sentence semantics in a vector space and taking into account word orders, syntactic structure, and the context of the sentence. An interesting aspect of sentence embedding is that the similarity between two sentences is checked by comparing the two fixed-size vectors.
Traditional sentence representations have a long history, such as the One-hot Bag of Words (BoW) and Term Frequency-Inverse Document Frequency (tf-idf ) to represent a sentence, phrase, or whole document. But one of the first real attempts was in 2014, where Doc2Vec was introduced.3 However, the impactful revolution was introduced using the transformer architecture4 by Vaswani et al., where the model focuses on different parts of a sentence simultaneously, leading to better contextual understanding while preserving semantic and syntactic relevance. Based on the transformer mechanism, BERT was introduced by Devlin,5 where different representations can be used for the same word according to semantics and context. In 2019, Sentence-BERT2 was introduced as an extension to BERT, presenting the whole sentence in a single dense vector optimized for similarity comparisons that can be extended and used in multiple NLP tasks.
In the case of Arabic, a nonconcatenative-rich language that has complexity in morphology, syntax, and semantic levels, more preprocessing, different techniques, or specialized approaches are required.6 One of the early approaches used for Arabic was the AraVec Project.7 This was one of the first attempts to represent Arabic words in vector embedding. Following progress in the English language, Arabert was introduced for Arabic and became a major milestone in Arabic NLP. Following Arabert, the research community came up with Arabic-focused models such as CAMeL-BERT,8 which focused on dialectal Arabic, and MARBERT,9 which addressed the slang and dialects to be optimized for social media text. Each of these models addresses specific challenges in Arabic NLP.
Some attempts were made to create a universal language model, yet performance in the Arabic language was not promising, and it underperformed in dedicated language models because of the challenges mentioned before. Examples include XLM-R10 and Multilingual BERT (mBERT).11
Despite the progress that has taken place in this aspect of sentence embedding, finding a model that provides the best and closest meaning of words in the Arabic language requires many studies to solve the challenges. In this study, an approach was developed by concatenating two models: the sentence transformer-based model and a classical word-embedding model. Therefore, we represent each sentence as a combination of the two vectors.
Formally, Sentence embedding is not considered as a standalone task, but as part of other tasks such as IR, QA, summarization, and many others. Therefore, we start with word embedding, which can be used to produce sentence embedding, contextual embedding, and finally, a hybrid approach for producing sentence embedding.
For word embedding, many approaches have been used and tested for different languages, such as Word2Vec12 and GloVe,13 whereas Barhoumi14 presented an Arabic version of these models. FastText15 extended these models by incorporating sub-word information, addressing key limitations in morphologically rich languages, and handling out-of-vocabulary (OOV) terms, making it suitable for the Arabic language.16 All of the above word embeddings can be used for sentence embedding using pooling, such as max, average, or other techniques.
BERT5 introduced contextual embedding using transformer-based pre-trained language models. Sentence BERT (SBERT)2 is an extension of BERT that produces a sentence embedding of a fixed size.
Several BERT variants have been developed in the Arabic NLP domain, several BERT variants have achieved notable progress. AraBERT17 was trained on approximately 24GB of Arabic text from news sources and other sources. AraSBERT, a Siamese BERT architecture, enhances the performance on Arabic Semantic Textual Similarity (STS) tasks. Other models include multilingual BERT (mBERT), which supports multiple languages but often underperforms on Arabic because of a limited Arabic-specific vocabulary of around 2,000 tokens versus AraBERT’s 60,000,18 and CAMeLBERT-MSA, specialized for Modern Standard Arabic (MSA).8 These models capture the contextual nuances essential for disambiguating the inherent linguistic complexities of Arabic.
For multimodal text embeddings, the existing literature features common fusion strategies, including the simple concatenation of embedding vectors or the use of shallow neural networks. Hengle19 introduced a hybrid model for Arabic sarcasm detection and sentiment identification. Their approach concatenates the ‘[CLS]’ token vector from AraBERT with a feature vector from a CNN-BiLSTM ensemble. This combined vector is fed into the classification layer. Using ‘[CLS]’ token vector limited this embedding for a few applications, such as next sentence prediction but not for general- purpose Arabic sentence embeddings.
In addition, several studies have been performed using the AraBERT model, one of which is ArabBert-LSTM by AlOsaimi,20 who showed that hybrid architectures that use transformer-based AraBERT embeddings and LSTM networks can be very successful in Arabic sentiment analysis and are better than classical machine learning and deep learning methods. In addition, Jefry21 utilized AraBERT with BiLSTM to improve Arabic sentiment analysis. Similarly, Khachfeh22 designed a hybrid model to classify Arabic news based on the BERT-BiLSTM model. They showed that the performance of AraBERT on morphologically complex Arabic texts could be significantly improved by fine-tuning the final layer of the model and combining it with a downstream task that applies bidirectional processing.
Our proposed sentence-embedding approach combines pre-trained FastText and fine-tuned sentence AraBERT to bridge the Representational Chasm by leveraging their respective strengths.
Any model that uses embedding for the Arabic language suffers from many low-accuracy problems, especially when used in applications such as classification, summarization, and question answering. This is primarily due to the fact that the actual embedding values do not reflect the exact meaning of the sentence. Therefore, in this study, we assumed a combination of more than one model to enhance the extraction of sentence embedding.
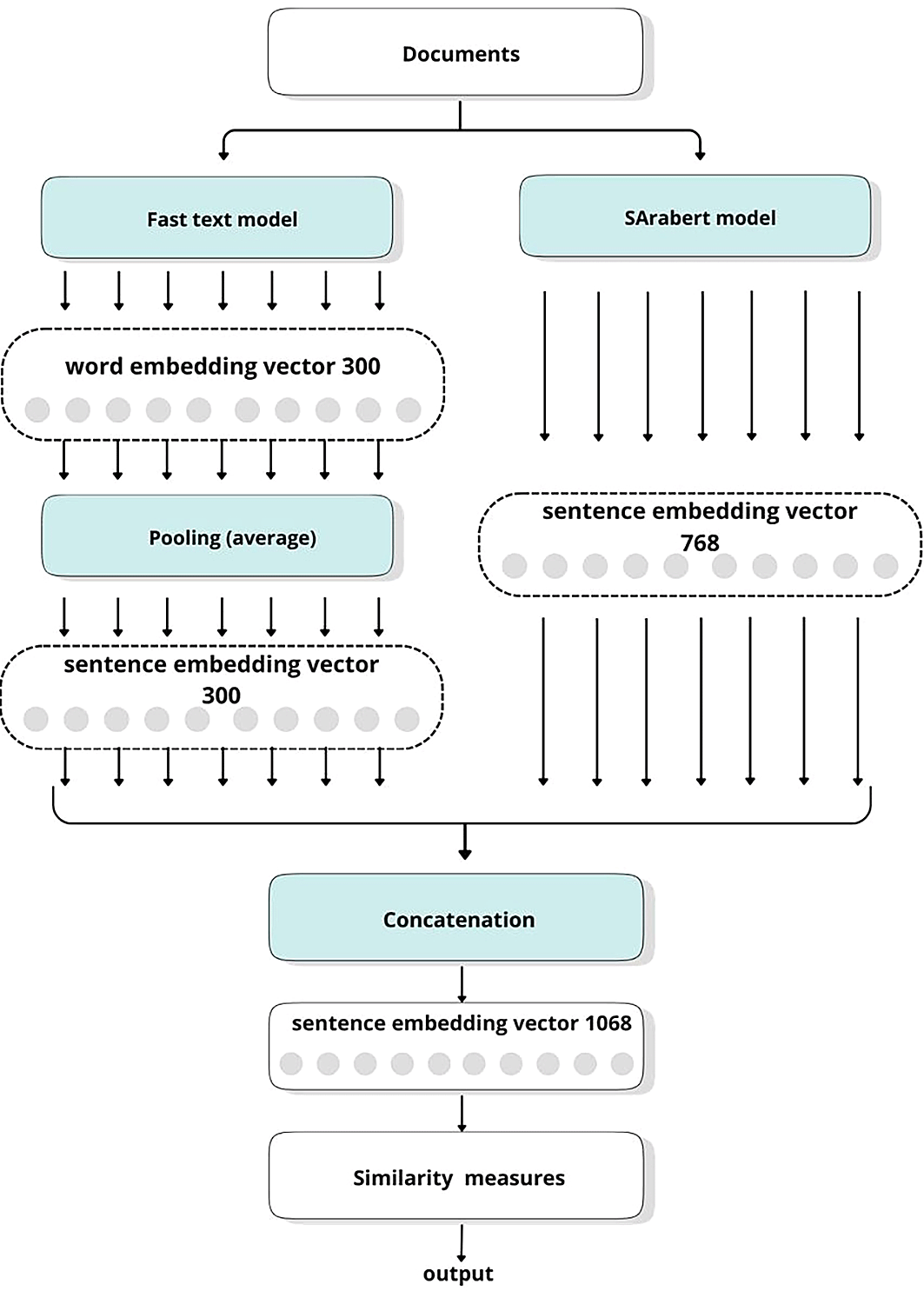
The proposed model combines FastText and Sentence AraBERT for Arabic sentence embedding to create a multimodal architecture. In the first step, the Arabert model is fine-tuned by utilizing a triple dataset of the Arabic language to produce the Sentence Arabic BERT (SAraBERT) model. Each row in the triple dataset consisted of three columns: anchor, positive, and negative. In the second step, the SAraBERT model and the pre-trained Arabic FastText model were used to produce the final sentence embedding in a concatenation manner. Figure 1 shows a block diagram of the proposed model, whose components are explained in more detail in the following sections.
Sentence-BERT (SBERT), by Reimers & Gurevych,2 works on the basis of a Siamese neural network that can be used to generate semantically meaningful sentences through the fine-tuning of BERT models on sentences suited to applications such as semantic textual similarity, sentence classification, question-answer systems, and many others. Nonetheless, the manner in which BERT produces its output at the token level requires the development of aggregation mechanisms to provide sentence-level representations. The key method for obtaining uniform sentence vectors is mean pooling, which involves adding all the token vectors before computing the mean. This method converts the problem of scaling repeated model evaluations into fast vector-space operations. The architecture is a combination of two identical BERT encoders processing the sentence independently with a pooling layer, usually mean pooling, which performs better than max pooling and pooling on the [CLS] token. In this study, we used the same methodology as that used by Reimers.2
We proposed Sentence AraBERT, which combines the SBERT2 methodology with AraBERT.17 The challenge of developing SAraBERT based on the AraBERT model would entail adopting this Siamese structure, where the AraBERT encoders would be replaced with SAraBERT models, which were modeled independently and specifically trained on Arabic corpora, thereby incorporating built-in knowledge of Arabic syntax, morphology, and semantics. Fine-tuning involves training the Siamese AraBERT model on Arabic sentence pair data, such as Arabic NLI triplet data or Arabic semantic textual similarity data, while retaining the same pooling and concatenation strategies used by SBERT. This adaptation would allow retention of the Arabic language using AraBERT and introduce the ability to encode semantics at the sentence level with high efficiency, resulting in a sentence transformer model best suited to Arabic text processing and semantic similarity applications. Figure 2 shows the SAraBert architecture, which follows the methodology of Reimers and Gurevych.2
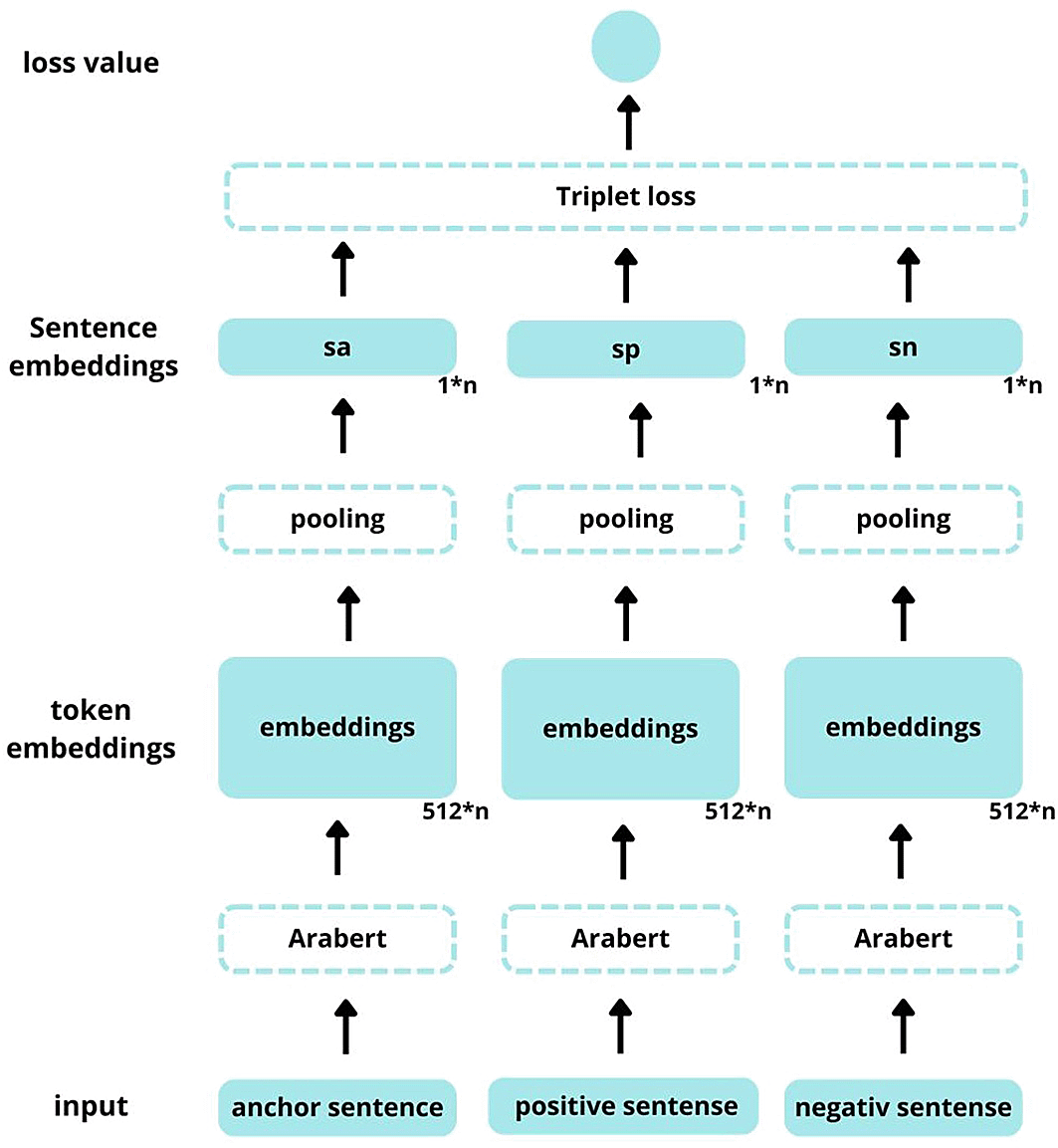
Parameter n refers to the dimensionality of embeddings (768 by default for ArBERT base).
FastText15 is a word-embedding model that trains sub-word information, making it robust to out-of-vocabulary (OOV) words. For the Arabic language, the pretrained Arabic FastText model of Grave23 was used. It was trained according to a Common Crawl dataset. This model is intended to create word embeddings that are as accurate as possible to represent the semantics of Arabic language words, and it can be broadly applied to most natural language processing (NLP) tasks. The output was a 300-dimensional vector representation of each word. For sentence embedding, the embedding for each word in the sentence using FastText was taken, and then the average of the word vectors was used to form the sentence vector in a pooling task. The sentence vector is a 300-dimensional vector of the same size as the word vector.
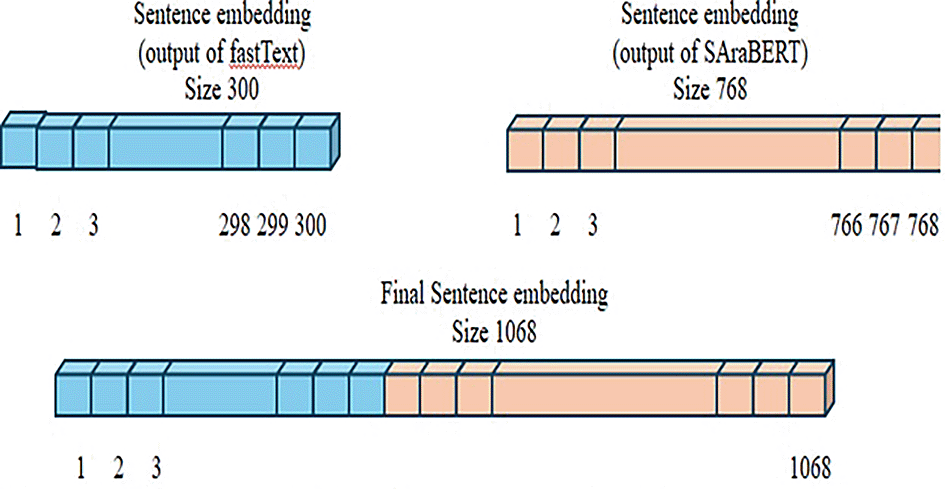
We have two vectors of different sizes: one of size 300 and the other of size 768. This difference makes the combination more difficult for traditional pooling methods, such as Max, Average, or [CLS] token embedding. Our suggestion was to concatenate the two embeddings to produce a new embedding size of 1068 dimensions, as shown in Figure 3.
All experiments were implemented using the latest version of Python with some libraries in a Kaggle environment. For fine-tuning, we used PyTorch 2.4.1+cu121 of the transformer model17 in Python 3.10.12, and the experiments were run in a multi-GPU setting with P100 GPUs. AraBERT, a 136-million-parameter BERT-base-Arabertv02, was used as a baseline to build the SAraBERT model.
For the evaluation process, the Mean Squared Error (MSE) and Pearson correlation coefficient were used for gold standard similarity annotation. MSE is the average of the squared difference between the predicted values ( ) and real values (yi). Eq. (1) shows the formula used for MSE for n examples.
The second measure of evaluation, the Pearson correlation coefficient (r), was employed to determine the intensity of the line correlation between perfect semantic similarity and cosine similarity. It runs between -1 (perfect negative linear correlation) and +1 (perfect positive linear correlation), where 0 corresponds to a lack of linear correlation. It is defined as in Eq. (2).
In the next subsections, a description of the datasets used, the results, and the analysis are presented.
Two types of datasets were used: one for training and fine-tuning the SAraBERT model, and one for evaluating the final sentence embedding output. FastText was used as a pre-trained model23; therefore, it did not require a training dataset.
The first dataset was the Arabic triplet dataset (ATrD)24 of one million triplets (342.53 MB). The split ratios used for training, validation, and testing were 70%, 20%, and 10%, respectively. A triplet contains an anchor, a positive example that is semantically similar to the anchor, and a negative example that is semantically different. This architecture enables the model to learn and recognize acceptable semantic variations. It was used for fine-tuning the learning of the proposed SAraBERT model.
The second dataset is the Arabic Version of the Semantic Textual Similarity Benchmark (STSB)24 based on the English version in,25 which is semantically similar to Arabic sentence pairs. It is a heterogeneous collection of sentence pairs with many different domains, such as news headlines, video and image captions, and natural-language inference data. Each sentence pair in the dataset was annotated manually with a similarity score rated on a scale of 1-5. In this particular Arabic variant, we normalized the similarity scores to a range of 0–1, allowing us to compare and analyze semantic similarity throughout the dataset. This dataset was used to evaluate the final sentence embedding.
We performed all-encompassing experiments to compare our contextualized embedding-based transformer encoder (CETE) to modern state-of-the-art methods. To evaluate the effectiveness of our methodology, we compare our model with some of our baseline configurations.
In our feature-based method, we used a hybrid embedding plan that combines SAraBERT contextualized embeddings and FastText word embedding. Such a combination takes advantage of AraBERT’s contextual capabilities and FastText sub-word information embedded in embeddings. This model is built upon AraBERT, a transformer-based language model specifically pre-trained on a vast corpus of Arabic text.
First, AraBERT was fine-tuned using the STSB dataset with Siamese BERT to produce SAraBERT. A pretrained fasttext was used; therefore, five types of testing were performed using the ATrD dataset. The MSE and correlation were estimated for these five types of tests as follows: FastText alone, AraBERT v2, SAraBERT, AraBERT+ FastText, and SAraBERT+ FastText. Table 1 shows the MSE and correlation for these tests, whereas Figure 4 shows the visualization for four of these models, excluding the combination of AraBERT v2+fasttext.
| Model | MSE | Correlation |
|---|---|---|
| FASTTEXT | 0.1109 | 0.5679 |
| Arabert v2 | 0.1774 | 0.3401 |
| SAraBERT | 0.0466 | 0.7869 |
| AraBERT v2+fasttext | 0.1292 | 0.5674 |
| SAraBERT v2+fasttext | 0.0355 | 0.8053 |
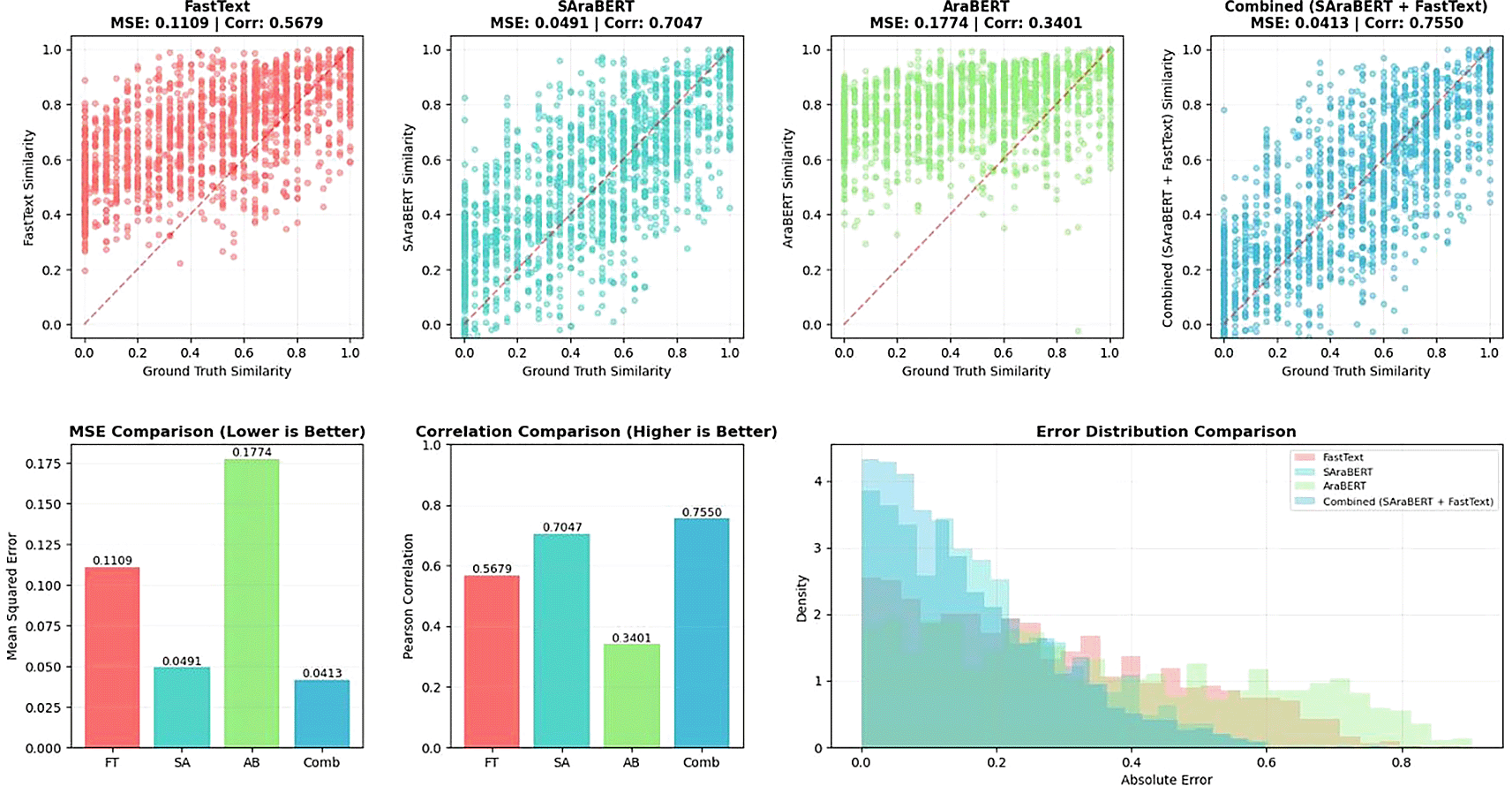
As shown in Table 1, Sarabert achieved a Mean Squared Error (MSE) of 0.0466, which is an improvement over AraBERT-V2. This means that fine-tuning with Siamese architecture is more powerful for Arabic sentence embedding. The best MSE and Correlation values were obtained from the proposed combination approach of SAraBERT v2 + fasttext, which were 0.0355 (minimum) and 0.8053 (maximum), respectively. Comparing this value of MSE with the nearest values (SAraBERT results), the value decreased by 0.1419. This signifies an enhanced precision and robustness, underscoring the benefits of integrating contextual and morphological information.
Despite AraBERT’s strength in the modeling context and disambiguating polysemous terms, it faces challenges with out-of-vocabulary words and dialectal expressions that are underrepresented in its training corpus. Informal social media slang, for example, may be fragmented by word-piece tokenization, reducing semantic clarity for such words.
The results also show that FastText complements AraBERT by modeling subword information, which enhances robustness in morphologically rich languages such as Arabic.
We used the baseline AraBERT model as our main point of comparison because it is the current standard for Arabic language processing tasks. The improved architecture also keeps the architectural size of the hidden layers and feed-forward networks unchanged at the baseline to allow a fair comparison. The only difference is the use of the sentence transform approach to capture deep contextual understanding and intricate semantic relationships within sentences.
For further comparison, we also fine-tuned the DistilBERT base multilingual based on the same dataset (STSB) and parameters that we used in AraBERT fine-tuning to produce S-DistilBERT. Table 2 presents the results obtained. We chose the DistilBERT model because, according to the given comparison in,26 this model is considered one of the best models for sentence embedding transformers for Arabic text classification. However, according to the results shown in Tables 1 and 2, the SAraBERT model gives better results in the embedding than DistilBERT, so we chose to combine it with the fasttext model.
The proposed work is an improvement in sentence embeddings using a combination of contextualized Sentence AraBERT representations with pooled FastText word vectors to perform better Arabic text processing tasks. Our experiments with several Arabic datasets indicate that the performance of our hybrid embedding method is significantly better than that of the AraBERT baselines. Moreover, we found that our hybrid approach successfully incorporates both contextual semantics via AraBERT and morphological features via FastText and pliant stronger sentence representations.
Sentence-AraBERT (SAraBERT) extends the original AraBERT architecture to include the Siamese network architecture (as in SBERT) in addition to triplet loss functions to generate sentence embeddings that preserve semantic meaning.
We found that our joint AraBERT-FastText model sets new standards for Arabic sentence embedding strategies. The hybrid approach is particularly useful in Arabic language processing because it has a rich morphological structure. In addition, the sub-word information provided by FastText was supplemented by contextual knowledge provided by AraBERT.
It has been shown that multi-paradigm embedding can bring significant benefits over single-paradigm methods, even when it is not fine-tuned or trained on additional large corpora. Finally, we provide our implementation and trained models to the public so that they can conduct further research and make our experiments reproducible.
At first glance, it may seem that the vector has a high dimension, but there are many practical models that have text embedding of more than 1068 dimensions. For example, in OpenAI Text-Embedding v3, vector embedding has a size of 1536/3072 while E5-Mistral-7B-Instruct has a vector embedding of 4096 dimensions. In addition to processing units, such as the GPT, the processing time is very small.
In future work, we will also explore how our hybrid embedding method performs on other Arabic NLP problems, including Arabic information retrieval applications, Arabic sentiment analysis, Arabic named-entity recognition, Arabic text classification on imbalanced datasets, and Arabic document summarization. Another area that we are planning to expand and test is how well we can incorporate other embedding techniques and how we can apply our approach to other morphologically rich languages.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)