Keywords
Anderson Darling estimation, Nadarajah Haghighi distributions, T-X family, Cramer Von Mises, quantile function, Order Statistics, Entropy, Simulation
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
Anderson Darling estimation, Nadarajah Haghighi distributions, T-X family, Cramer Von Mises, quantile function, Order Statistics, Entropy, Simulation
Statistical distributions are essential for understanding complex data. Although the T-X family has grown, many traditional distributions are still too rigid to handle different types of data, which makes it difficlt to reflect real-world complexity. In this study, we present an extended generalized Rayleigh-Nadarajah-Haghighi (EGRNH) distribution as a solution. This model uses the single-generalized distribution method within the Rayleigh-Nadarajah-Haghighi framework, giving researchers more flexibility to model varied data and better control over the distribution’s shape and risk. As a result, it is well-suited for a range of practical applications. As a result, various research have investigated the properties and uses of these novel models, including odd Nadarajah Haghighi distribution,1 A novel two-parameter Nadarajah-Haghighi Extension,2 Generalized Exponential Rayleigh Model,3 Exponentiated (Lehmann Type-II) Nadarajah-Haghighi Distribution,4 Nadarajah–Haghighi Lomax,5 New Generalized Nadarajah Haghighi,6 Wavelet-Based Nonparametric Estimation of the Hazard Rate and density Functions: A Simulation Study,7,8 Simulation-Based Estimation of Two Weibull Distribution Parameters.9 The Gompertz Nadarajah-Haghighi (GoNH) Distribution Properties The Gompertz Nadarajah-Haghigh,10 Our approach extends the method proposed by Alzaatreh, which introduced generating families of continuous probability distributions,11 odd generalized Rayleigh a broad generalization. This makes it a suitable families,12 A Novel Three-Parameter Nadarajah Haghighi.13 The proposed model is used an extension of T-X distributions, especially the EORNH distribution. This model addresses the gaps in previous traditional statistical distributions by offering a greater adaptive potential for modeling data with heavy tails and pronounced skewness. It is significantly superior to the existing distributions in managing complex and long-term data. By offering a powerful and versatile distribution, it accurately and easily maps complex data, especially when standard methods are falter. However previous researches have not found an understandable solution for complex data. Therefore, we propose an extension to the distribution that fills this gap in previous distributions, where we write a new extension to the generalized Rayleigh- Nadarajah-Haghigh distribution. This model is more flexible and is useful for data that do not fit the classical probability models. We used probabilistic methods such as MLE and OLS. We then compared these results with those of the Anderson Darling and Cramervon Mises methods. The results show that the proposed extension provides a more efficient and flexible framework for analyzing non-traditional data in which statistical applications are advanced. In addition, some unconventional data that do not fit the standard statistical assumptions appear here.
This paper proposes a new family, called the extended odd generalized Rayleigh family (EOGR-G). The basis of this family is the generalized Rayleigh distribution. To begin, we define the random variable x > 0 in its odd-generalized form as follows:
The Nadarajah–Haghighi (NH) distribution is described as a probability distribution with a scale parameter and shape parameter. cdf and pdf are given by
A new EOGRNHD pdf and cdf are introduced by substituting Equation (3) into Equation (1) and Equation (2) into Equation (4). The results are as follows:
For the EOGRNHD, we derive the hazard & survival functions by:
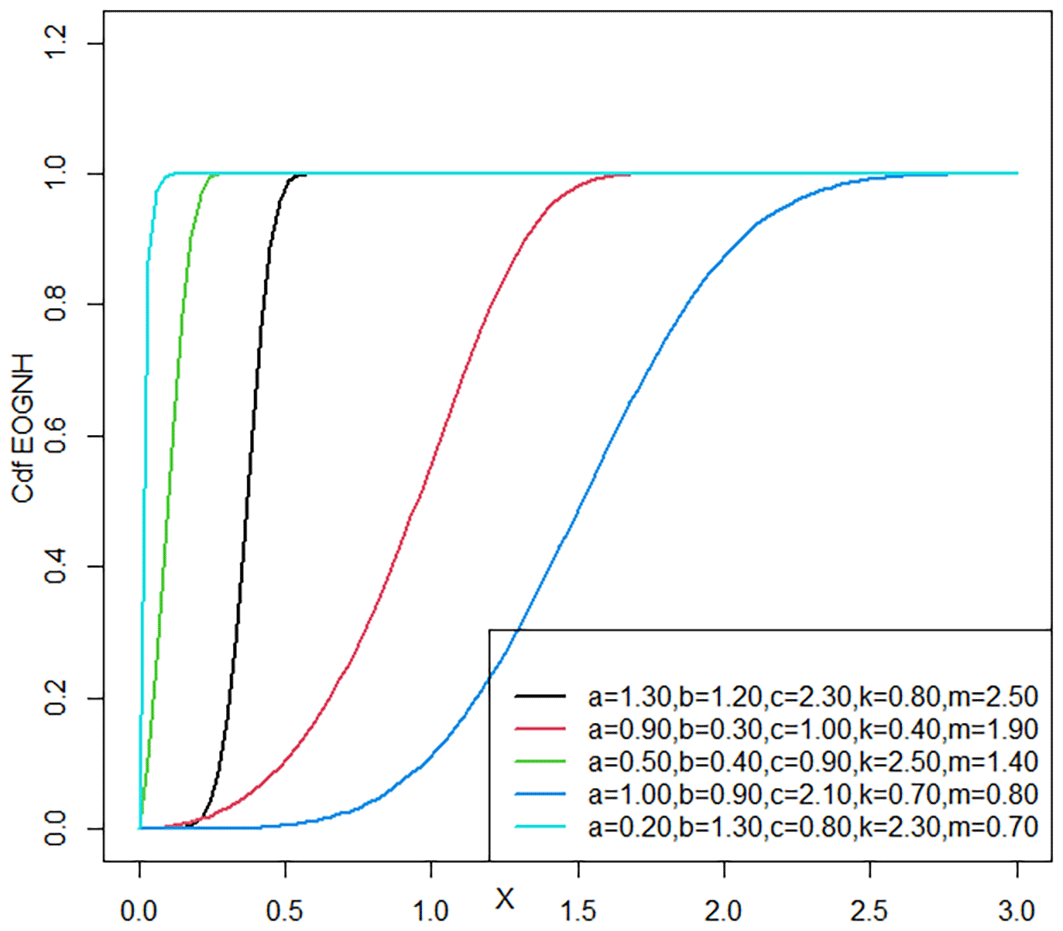
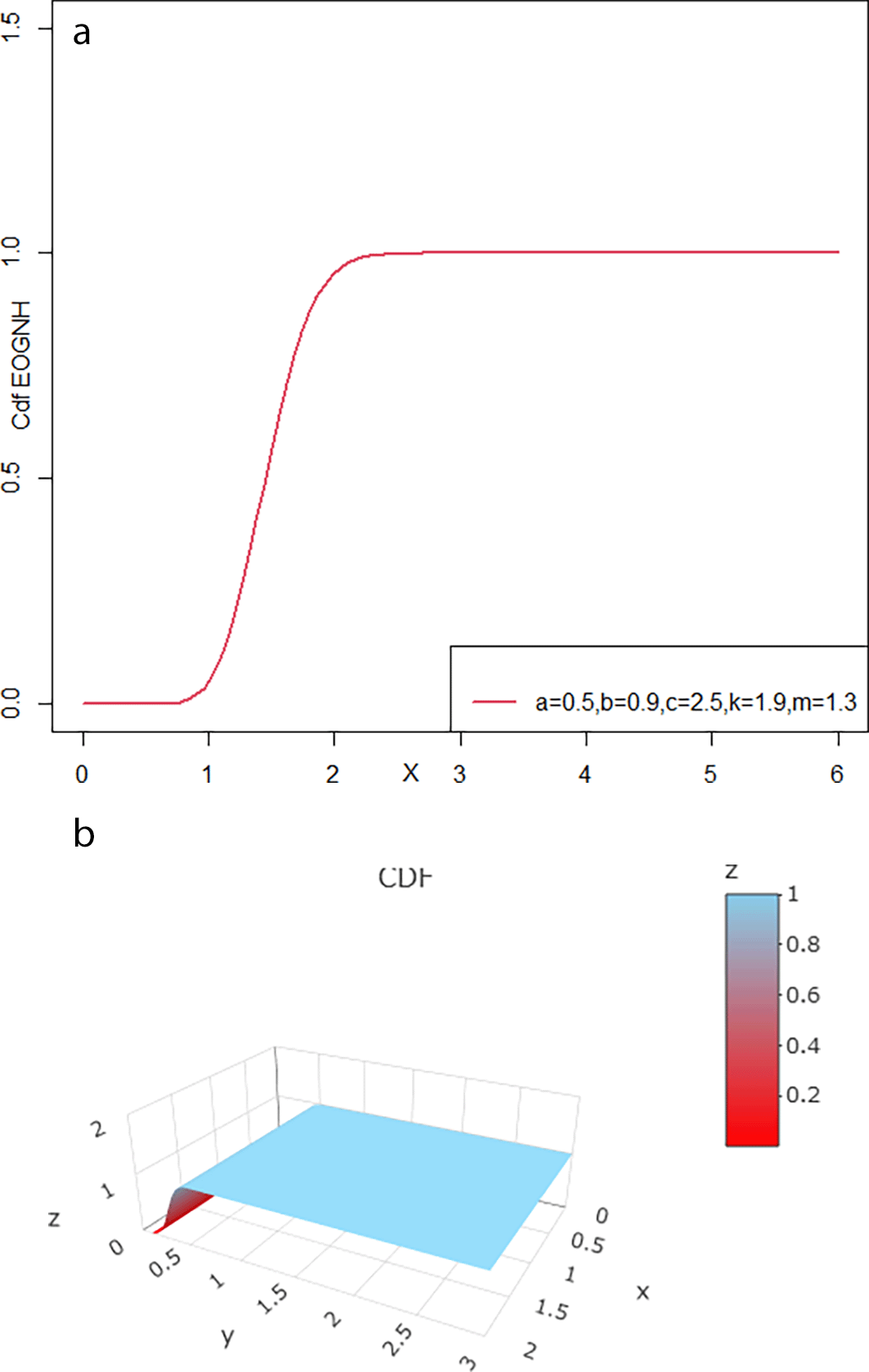
Figures 1 and 3 shows the variance of curves representing different distributions and how parameter values affect the shape of the (cdf ). The curves associated with small parameter values show a sharp rise in probabilities at low levels, indicating the density of data around those values. The curves appear at intermediate values to a critical balance point between the rate of increase of the probability and the rate of approach to the threshold value, producing a more stable and balanced distribution. When the parameters are larger, the curves exhibit a more stable behavior, with the rate of increase of probabilities slowing. As the range of possible values increased, the distribution widened. Larger parameter values make the probability curves more balanced because the probability increase more slowly. This means that the distribution covers more values, including higher values, so large outcomes occur more often.
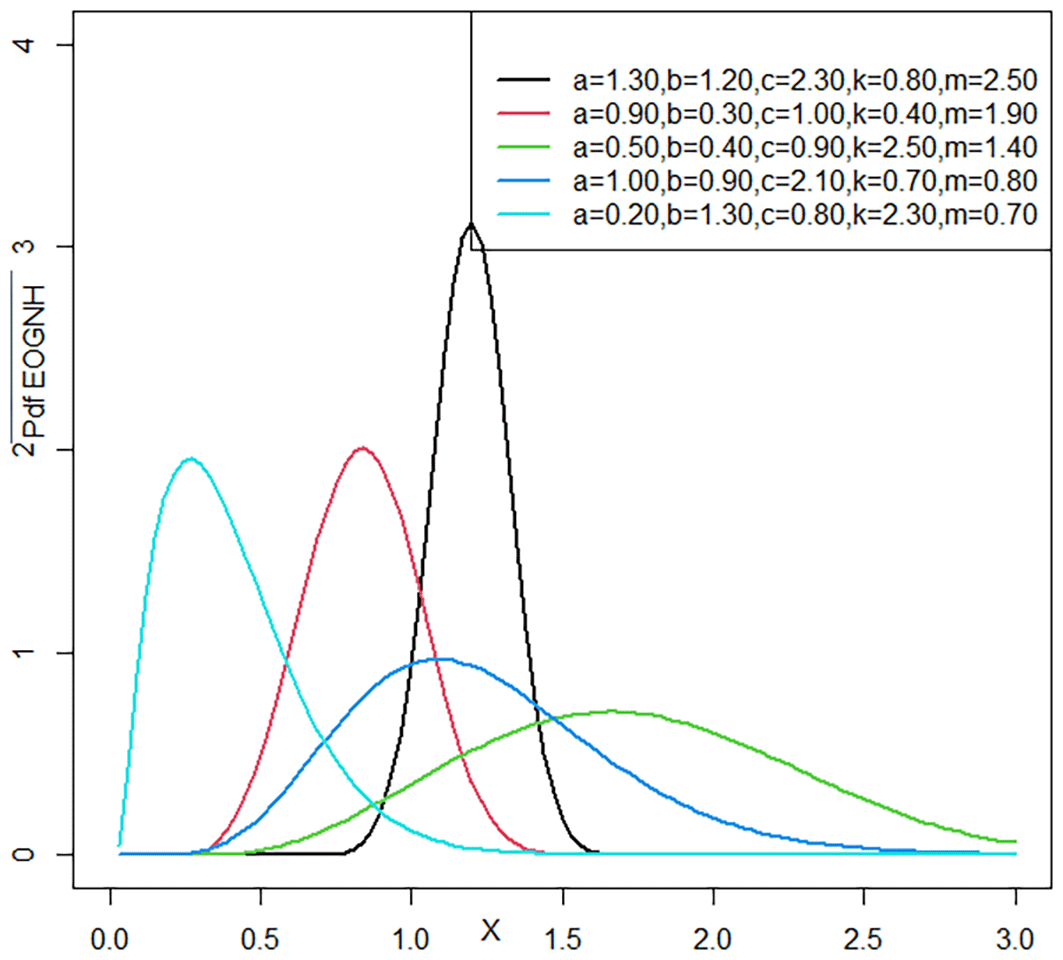
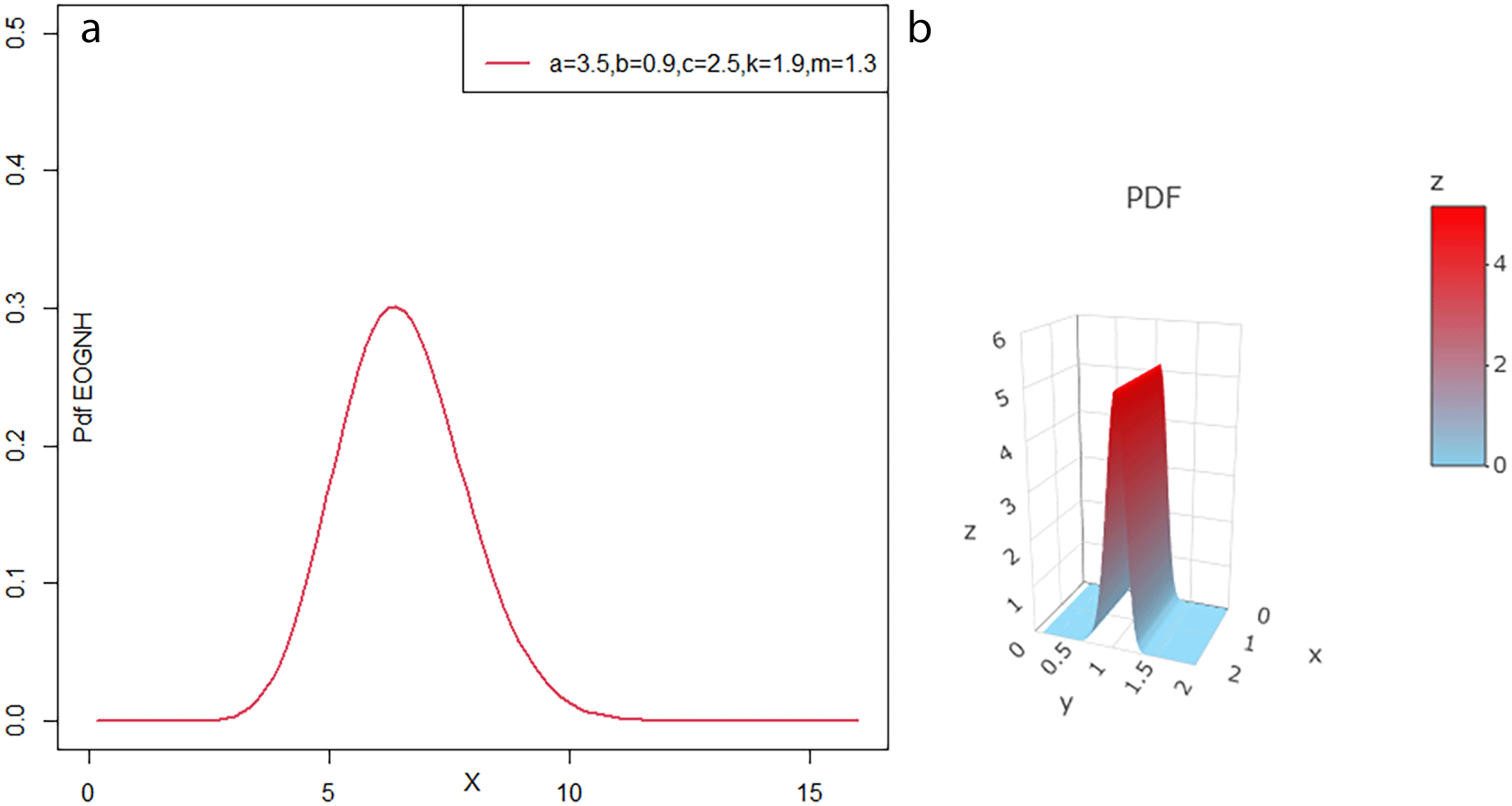
The shapes of the probability density function curves in Figures 2 and 4 depend significantly on the parameter values. When the parameters are small, the curves are sharp and peak, indicating that most data points are closely grouped together. When the parameters are averaged, the curves become flatter and less curved, which means that the data are spread out more evenly, and there is more variation. Therefore, some parameter values may exhibit multi- peak distributions, reflecting the presence of distinct subgroups in the data. Accordingly, the significant impact of changing parameter values on the shape of the PDF curve gives researchers flexibility in choosing the most appropriate models to better analyze and explain the data.
This section focuses on examining the mathematical properties of the EOGRNH, including the expanded form of the pdf, moments, order statistics, incomplete moments, quantile function, moment-generating function, and Rényi entropy.
This section presents a formal simplification of Equation (3) by applying the following: , , and 14–16
By simplifying the equation pdf we get the following equation:
By applying PDF and CDF Equations (4 & 5) where
It is considered one of the basic properties because, through it, the first and second expectations find variance, skewness and kurtosis17:
When we use Equation (11) we get:
It is one of the important properties that we obtain and is given by the following formula:
We’ve substituted Equation (9)
Let be the order statistics of size from EOGRNH. pdf is defined as follows.19
From Equations (5 & 6) into , and the result is as follows:
One of the important characteristics that play a fundamental role in extracting information is the measure of randomness defined as follows:
By using Equation (6), we get:
Let be a randomsample of EOGRNH. The likelihood is:
To estimate each parameter, we calculated the derivatives of the logarithm from parameters , as follows:
The above equations are set equal to zero and subsequently solved using R to obtain the estimated values of the parameters.
OLS is the most popular technique for estimating the linear or nonlinear variables that constitute the model parameters. The primary goal of this method is to minimize the sum of squared differences between the predicted values and the observed sample values regressed by the OLS.20,21
Maximum-likelihood and ordinary-least-squares methods were used to estimate the EOGRNH distribution parameters. The simulation study is compared by evaluating the average values of the three measured quantities.: absolute Bais , mean square error (MSE), To perform the simulation, observations from the EOGRNH distribution were generated using U as a uniform r.v. defined in [0,1]. We generate N = 5,000 random samples, and sample sizes n = 5, 100 and 200 from the EOGRNH with two different sets of initial parameter values. For each parameter combination and sample, we estimated the EOGRNH parameters, and using two different estimators which are OLS and MLE. Subsequently, and MSEs of the parameter estimates were computed. Simulated outcomes are shown in Tables 1 & 2.
Tables 1 & 2 show the estimates for a range of parameters using (MLE) and (OLS) estimation methods across different sample sizes (50, 100, and 200). The accuracy of the estimates became more evident as the sample size increased. The estimates converge to the true values of the parameters as the sample size increases, reducing the variance of the estimates and enhancing their consistency, as demonstrated by the decreasing mean square error (MSE) values. For the smaller sample (50), the values were less accurate, whereas for the larger samples (100 and 200), the estimates were more reliable, indicating that the MLE and OLSE methods become more accurate and consistent with increasing sample size. This reflects the importance of using larger samples to obtain reliable estimates in statistical analyses.
In this section we compare our distribution with the Gompertz Nadarajah-Haghighi (GoNH) and Nadarajah-Haghighi (NH) distributions based on a real dataset that records the failure times of 50 components, measured per 1000 hours.22
1.600, 0.058, 2.006, 3.704, 0.078, 0.086, 6.816, 11.020, 0.103, 0.114, 0.148, 7.896, 0.254, 0.381, 0.538, 3.058, 0.590, 3.931, 0.618, 0.645, 0.961, 14.730, 1.228, 2.054, 0.262, 3.076, 0.183,3.147, 3.625, 0.379, 4.073, 0.074, 4.393, 4.893, 0.061, 6.274, 0.102, 0.116, 7.904, 2.804, 10.940, 13.880, 0.570, 15.080, 0.036, 0.574, 9.337, 8.022, 4.534, 0.192.
Goodness-of-fit measures, including the Bayesian information criterion (BIC), Akaike information criterion (CAIC), Cramer Von-Mises (Ⱳ), Anderson Darling (Ą), and Kolmogorov-Smirnov ( Ҝ-ᵴ) statistics, are calculated to assess the fit of each model to the data.
Table 3 shows descriptive arithmetic for dataset, while the data in the Tables 4, 5, and 6 demonstrate that the proposed EOGRNH distribution outperforms both the GoNH and NH distributions for the following reasons. The EOGRNH distribution yielded the lowest AIC, BIC, CAIC, and HQIC values, indicating a superior balance between the model complexity and data fit. Additionally, the W value for this distribution is 0.0628, which is lower than the other values, indicating a better fit with the data and stronger support for the hypothesis that the data follows this distribution. The p-values also show that there is no substantial statistical significance, which makes the model better at understanding data. Thus, it is evident that EOGRNH is the most popular of the three distributions examined.
| Variance | n | Median | Max. | Min. | Mean | Skew. | Kurtosis |
|---|---|---|---|---|---|---|---|
| x | 50 | 1.41 | 15.08 | 0.04 | 3.34 | 1.37 | 0.92 |
| Distribution | Ⱳ | Ą | Ҝ-ᵴ | -value |
|---|---|---|---|---|
| EOGRNH | 0.0628 | 0.4653 | 0.1010 | 0.6493 |
| GoNH | 0.1603 | 0.9959 | 0.1438 | 0.2292 |
| NH | 0.1764 | 1.0951 | 0.1472 | 0.2068 |
| Distribution | -2L | AIC | CAIC | BIC | HQIC |
|---|---|---|---|---|---|
| EOGRNH | 97.44 | 204.88 | 206.24 | 214.44 | 208.52 |
| GoNH | 103.04 | 214.12 | 215.01 | 221.77 | 217.03 |
| NH | 103.12 | 210.24 | 210.49 | 214.06 | 211.69 |
| Distribution | |||||
|---|---|---|---|---|---|
| EOGRNH | 4.9552 | 0.0099 | 0.0940 | 5.1173 | 0.3822 |
| GoNH | 1.3983 | 0.3844 | 1.9205 | 0.2853 | ------------- |
| NH | 3.2474 | 0.3464 | ----------- | ----------- | ------------- |
You can look at the attached graphs Figures 5 & 6 to get a better idea of how the data are spread. The EOGRNH curve in Figure 4, which is the distribution density function (PDF), indicates that most values are near zero because there is a lot of data at the bottom and it quickly drops off. The apex of the GoNH curve is less sharp, indicating that the data are more variable. The NH curve looks similar to the GoNH curve, but is not as steep, which means that the values are spread across a wider range. cumulative distribution function (CDF) is presented. The probability increased as the values increased. The EOGRNH, GoNH, and NH curves cluster together slowly, but are formed differently. The EOGRNH curve is convex, therefore, its values cluster quickly at the low end. In contrast, the GoNH and NH curves had gentler slopes, causing their values to spread out more. In general, these graphs show that the EOGRNH, GoNH, and NH models provide information on the nature and spread of the data. This helps you make better choices when performing statistical analysis.
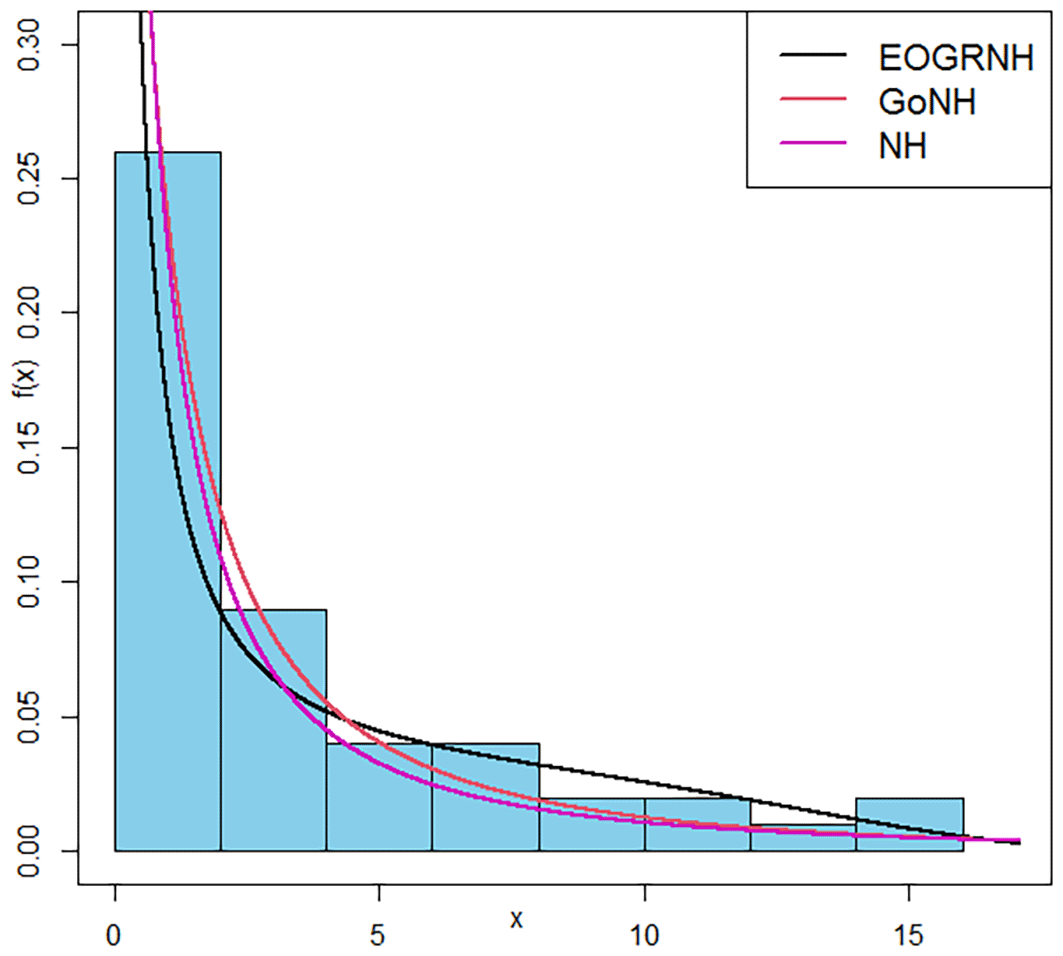
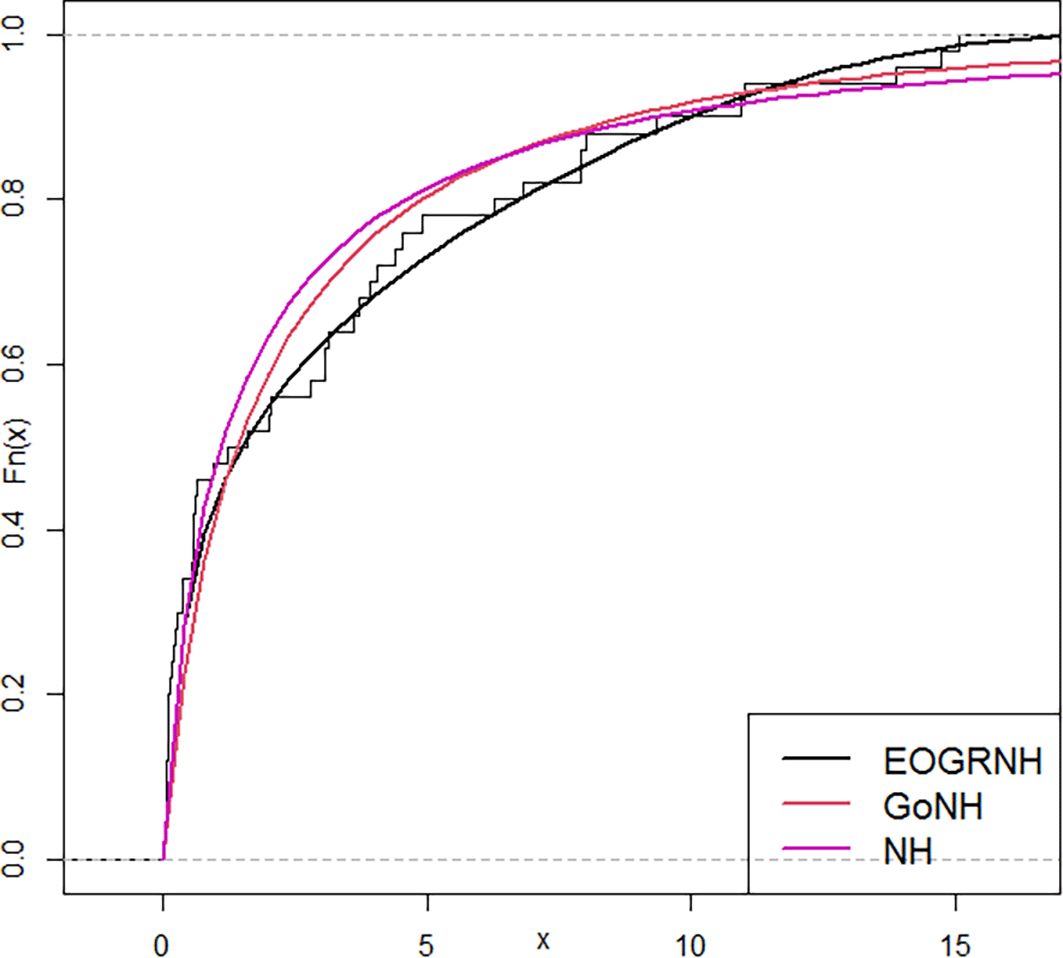
The EOGRNH distribution outperformed the GoNH and NH distributions in modeling the failure time data, achieving the best fit to thereal data. The maximum likelihood estimator (MLE) is more accurate than ordinary least squares estimation (OLS), particularly when the parameter is large. Because of the superior efficiency and accuracy of the EOGNH distribution, it can be used to analyze reliable data when applying the maximum likelihood estimation (MLE) methodology. In future studies, this work can be built upon by using it to improve statistical inference, or by applying the model to real data.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)