Keywords
data management, data exchange, knowledge graph, open science, structured data
This article is included in the Data: Use and Reuse collection.
data management, data exchange, knowledge graph, open science, structured data
Establishing large-scale research collaborations, projects or research groups united by a common research question, requires the development of well-planned research strategies, as well as secure management, transfer, and long-term sustainability of generated knowledge and collected data Mittal (2023). To foster and facilitate inter-project collaborations within such collaborations, it is essential to collect and systematically organize relevant metadata (e.g., data types, participant groups, methods of analysis) of the planned studies and systematically organize them to (1) provide a comprehensive overview of individual projects, (2) highlight their interconnections and thereby, (3) facilitate possibilities for data sharing and reuse across projects.
It is crucial to highlight the importance of these topics early, especially when working with data collected from humans, as compliance with European law regulations (GDPR, 2016) is mandatory when handling personal data. Transferring such knowledge to projects ensures adherence with ethical guidelines, including understanding the principles of informed consent, developing consent forms, submitting ethics applications, and promoting Open Science principles such as the FAIR principles Wilkinson et al. (2016). Moreover, raising awareness of legal obligations within projects is essential. This includes informing researchers about Record of Processing Activities, a key requirement of the General Data Protection Regulation (Art. 30, GDPR, 2016), as well as the Technical and Organizational Measures, which must be implemented to protect personal data (Art. 32, GDPR, 2016). An early assessment of relevant information serves to (1) raise researchers’ awareness of legal and data sharing considerations, (2) identify knowledge resources and gaps, and (3) uncover potential connections between projects and resource-sharing opportunities.
The structured collection and integration of project-level metadata can serve as a strategic tool to strengthen collaboration and inform the future development of the research consortium. Constructing knowledge graphs of these metadata help to make methodological, linguistic, and participant-related commonalities and differences across projects visible, thus supporting evidence-based decisions about coordination, shared resources, and infrastructure planning. Especially within large research consortia, this enables researchers and coordinators to identify meaningful connections between projects, foster interdisciplinary exchange, and reduce redundant efforts, thereby increasing both scientific impact and operational efficiency.
This paper outlines an approach to addressing these challenges and introduces a methodology for systematically collecting, restructuring, and visualizing relevant information and metadata. We developed and conducted a semi-structured interview protocol used across all research projects within a large Collaborative Research Centre (CRC) in linguistics in Germany. They were conducted as part of the infrastructure project (INF), which is meant to ensure the “systematic management of data relevant in the context of the Collaborative Research Centre […] intended to facilitate scientific synergies […] through shared data platforms and/or communication forums as well as through efficient use of data.” (form 50.06, Forschungsgemeinschaft, 2022, p. 10–11). Based on the knowledge gained from the interviews, INF is developing a metadata infrastructure platform designed to handle the management, storage, (re-)use, and sharing of the diverse empirical linguistic data collected within the CRC (Jorschick et al., 2024). Many data types contain personal information or sensitive health data, which imposes legal and ethical constraints on this project (Berez-Kroeker et al., 2022). However, the careful collection, processing, and visualization of this information and its interconnections, as described here, constitute the first steps toward the construction of this platform. The interviews outlined in the following sections lay the groundwork for these objectives.
The interviews covered key aspects of data collection, management, storage, protection, reuse, and sharing. Additionally, they served to raise awareness among project researchers regarding legal and technical aspects, evaluated existing knowledge, and helped define training priorities. Subsequently, the collected information was transcribed, filtered for relevance, and systematically structured before being used to build a knowledge base and to visualize interconnections through knowledge graphs.
In what follows, we first describe the development and implementation of the semi-structured interviews, with the full list of questions provided in Appendix A. The subsequent outlines the processing and (re-)coding of the data to construct a knowledge base and visualization of relevant information.
The development of the interview questions and methodology was based on the goals of the INF project outlined in the previous section. In this section, we first describe the development and piloting of the interview questions, followed by a description of how the interviews were conducted.
In the preparation phase, the interview questions were designed by first reviewing the project proposals to identify possible groupings of projects in regards to e.g., the kind of data they work with or the type of analysis they plan to run. Additionally, the goals of the interview were defined clearly in order to develop an effective interview schedule that ensured we could collect rich data on the topics the INF project was interested in (Bearman, 2019). Questions were grouped by their general topic to make the conversation flow more naturally during the interviews. The questions were designed for a semi-structured interview (SSI), c.f. e.g., Karatsareas (2022), which contains both closed (e.g., Are there any PIs in your project that are not from Own University Name?) and open questions (e.g., How do you plan to analyse your data? Are special analysis methods required?) or a combination of both (e.g., If you are running experiments: Do you plan to compensate your participants? If so, how?).
This led to the development of the following sets of questions:
1. general requirements for data management and data protection,
2. data collection and documentation,
3. data storage, processing, and analysis,
4. archiving and reuse according to FAIR principles1
5. required support from the INF project, and
6. space for additional comments or questions.
Each set consisted of several questions, which can be found in full in the appendix of this paper. The following example consists of the questions regarding (1) general requirements for data management and data protection.
(a) Are there any PIs in your project that are not from Own University Name? If not, are there any collaborators from other universities that you are planning to share personal data with?
(b) Who is responsible for the data management in the project?
(c) What type of data does the project work with (audio, video, text generation, perception, ratings, etc.)?
(d) If you are running experiments: How many experiments do you plan to run?
(e) If you are running experiments: Who are your target participants (children, elderly, clinically-oriented, etc.)?
(f ) If you are running experiments: Do you plan to compensate your participants? If so, how (cash, voucher, course credit; on site, via third party)?
(g) Do you have personal, pseudonymized, or anonymous data? (Note that this can change depending on the stage of the project)
(h) What language are you working on? Have you considered offering a consent form in that language (other than English and German), too?
These questions can be used as an example how the SSI was meant to guide researchers through the whole project development and setup phase. In the beginning, the projects are supposed to write data management plans and to think about what data they need, whether they plan on collecting personal data or data from vulnerable groups, and how often they want to collect data. Table 1 gives an overview of the alignment of the interview goals with the questions asked, i.e., the association between questions, schedule, and rationale suggested by Bearman (2019).
The table presents the correspondences between an example set of SSI questions and the rationale behind asking the questions. Sending the list of questions to the projects beforehand ensured that they had talked about their plans and responsibilities and were able to ask clarifying questions during the interview itself.
Although the later analysis does not directly process any personal data, project details can be easily inferred due to the known identities of individuals involved in the projects. Therefore, ethics approval from the university ethics committee was obtained before starting the interviews. All projects signed a written consent form prior to their interview session, which detailed the data handling procedures (see Ethics statement).2
After reviewing the initial project proposals, we conducted a pilot phase involving three projects: one that required special data protection measures for sensitive health data from participants with aphasia, one working with written corpus data free of copyright constraints, and one handling pseudonymized or anonymized experimental data from psycholinguistic studies.
Following the pilot phase, we revised the list of questions based on feedback from the pilot projects and the interviewers’ experience. Although individual questions remained unchanged, we reordered some to improve conversational flow (see Appendix A for a full list of questions). Subsequently, we contacted all remaining projects except one, which has no research objectives but a coordinating function, via email. The email outlined the interviews’ objectives and included the questionnaire as well as the consent form for prior within-team review. Projects were given the opportunity to ask clarifying questions prior to choosing a time slot. Each project selected a two-hour slot from a predefined list via the non-tracking planning tool, Nuudel. We, very generously, allotted two hours per interview to accommodate any additional questions arising during the discussion. SSIs typically last no longer than one hour, and later we will see that this was almost always the case indeed. The two-hour window also accounted for potential technical issues in hybrid setups or delays caused by traffic.
Interviews were conducted on-site or in a hybrid format, depending on project members’ availability, with one interview held entirely online. In total, sixteen projects were interviewed. Project teams were encouraged to participate fully, and at least one principal investigator (PI) was required to attend to ensure representation by a member responsible for the project. When scheduling conflicts prevented individual project members from attending, teams discussed the questions beforehand to ensure all attendees were informed of their colleagues’ perspectives.
At least two INF project members conducted each interview, except in three cases where illness reduced participation to one. In sessions with two INF members present, one led the interview and took notes, while the other provided support and posed follow-up questions. We held sessions in a dedicated meeting room using a 360° video conferencing device (Meeting Owl 3) with Zoom for hybrid formats, to ensure high audio quality and seamless on-site and remote participation.
At the start of each interview, participants were reminded of the interview’s purpose, and it was confirmed that the consent form was understood and signed by a project leader. The interview procedure and note-taking process were explained, and participants could ask clarifying questions in advance. The interview questions were then discussed in chronological order as listed in Appendix A. If necessary, discussions shifted to other relevant questions, which each of these shifts to another question mentioned explicitly by the interviewer. Although written responses were not mandatory, teams were strongly encouraged to review questions in advance and ensure the members familiar with data management and analysis.
One interviewer took real-time notes directly in a GitLab markdown file, which were later reviewed for typographical errors and then forwarded to each project for validation of contents. All subsequent corrections and comments were incorporated into GitLab directly to ensure version control. Most interviews lasted between 60 and 75 minutes; the shortest was 45 minutes and the longest two hours. Sessions with projects with sensible data and a large number of international collaborations took longer than e.g., interviews with projects who do not elicit data from participants but work with data from existing corpora without any copyright restrictions.
The qualitative insights from the interview notes were particularly valuable in informing research teams about essential (data management) rules and strategies to consider during their studies. Furthermore, the interviews produced rich datasets and metadata from the individual projects, offering resources for identifying potential collaborative opportunities and enhancing data reusability across teams.
These opportunities are not typically apparent at the surface level, as projects often appear independent and disconnected from one another, making their potential interrelations unclear. However, through deeper investigation into various dimensions of each project, such (indirect) connections can be uncovered, revealing avenues for future collaboration and integrated research efforts.
To systematically represent and explore this information, we employed knowledge graphs, structured frameworks that model entities (in this case, individual projects) as nodes and their relationships as edges. This approach enables the organization and integration of data sources, revealing indirect or hidden connections. Knowledge graphs facilitate semantic search, enrich data exploration, and simplify decision-makings by surfacing relationships that may not be immediately apparent.
The next section outlines the development of the coding schema and the process of transforming descriptive interview notes into a structured dataset. We then present illustrative examples of the resulting knowledge graphs.
The coding schema was developed after completing all interviews, ensuring consistency across the dataset. In the first step, we filtered the data by excluding entries that did not offer generalizable insights applicable to other projects, including: (i) personal data that may change, e.g., the designated data steward of the projects, (ii) information that has not yet been finalized, such as archiving processes, and (iii) items primarily intended to inform teams about essential (data management) rules and strategies, such as completing specific data protection forms or procedures.
In the second step, we constructed a structured dataset from the remaining information, assigning one column to each data point. The coding scheme was developed based on questions concerning both the data and metadata that the projects intended to engage with. For instance, it included questions about the type of data being used (e.g., audio, video, text generation), participant type (e.g., children, adults, elderly, autistic individuals), and the languages used in experiments (e.g., English, German, Farsi). Table 2 presents a toy example of the dataset (for details, in Appendix B).
In the third step, we established a set of rules to ensure consistent and dynamic data conversion, trying to create a machine- and human-readable dataset, as well as allowing new data to be added without requiring modifications to the analysis code. The coding schema followed the standardized.csv format, in which columns are separated by commas (,). For columns containing multiple values (e.g., Language) individual values were separated by semicolons (e.g., English;German). During the visualization stage (see the next section), semicolon-separated values were dynamically converted into lists to support analytical tasks. Since the analysis scripts handled these conversions automatically, the order of values was inconsequential. For instance, entries such as “English;German” and “German;English” in the Language column were treated as equivalent.
We avoided abbreviations and ensured that column names and values were meaningful and easy to interpret in the generated graphs and analysis. Furthermore, we introduced meaningful placeholder values such as None and NotApplicable to prevent empty entries in the dataset. These placeholders helped maintain data consistency and avoid potential issues of white-spaces in data analysis (see also the description of the data cleaning in next section).
The dataset was designed with three types of columns: (i) Open Values, where no predefined list of values was specified, allowing annotators to add entries dynamically during data conversion. For example, the Language column included a list of languages extracted from interview notes. (ii) Exhaustive Values, which had a fixed set of predefined values. For instance, the Identification column was limited to the values {anonymized, unanonymized, pseudonymized}. (iii) Non-Exhaustive Values, where an initial set of predefined values was provided, but the list could be expanded as needed. For example, the DataType initially included {audio, video, text, rating}, but new values could be added during the conversion. An overview of these types of columns is provided in Table 2.
This approach ensured that the dataset remained adaptable, enabling projects to incorporate new data without requiring changes to the dataset structure or the accompanying (R) coding scripts. The scripts were designed to dynamically integrate newly added values into the visualizations (see the next section). Finally, the interviewer who initially took the notes during the meetings converted them into a structured dataset, following the schema and rules outlined above. This approach ensured both consistency and accuracy in the resulting dataset.
The interviews conducted contributed not only to the conceptual development of the data management software but also served as the foundation for building knowledge bases for the projects. These knowledge bases enable researchers to identify potential connections between projects and uncover opportunities for resource sharing opportunities, within their current studies or in future collaborations. This approach helps minimize redundant efforts by reducing the need to conduct new experiments when relevant data has already been collected by other teams, ultimately conserving both time and financial resources.
Data analysis was conducted using R Studio (Version 2024.12.0+467) (R studio team, 2025). First, we developed a script to dynamically convert multi-value columns into individual rows, restructuring it into long format. Next, a data-cleaning step was performed to eliminate empty columns and rows. Although placeholders like None were used to fill empty fields, empty values could still result from inadvertent whitespaces in semicolon-separated columns, despite the annotators’ efforts to avoid spaces within or at the end of lists. Finally, we generated several knowledge graphs from the processed dataset, using the visNetwork package (Version 2.1.2) (Almende B.V. and Contributors and Thieurmel, 2025).
The following sample graphs were generated using visNetwork function, with ProjectID as the list for nodes in relation to other entities, such as Collaborators, Language or ParticipantType, represented as edges. The default “barnesHut”’ solver in the visPhysics setting was employed, which positions nodes by approximating the forces between distant nodes, rather than computing pairwise interactions, thereby optimizing computational efficiency. This means that for the visualizations in the following figures, spatial proximity does not imply closer relationships between projects. For a zoomable and interactive version of the graphs, please see OSF.
Figure 1 represents a knowledge graph illustrating the interconnections among projects. In this visualization, nodes (circles labelled with project numbers) represent individual projects, while edges denote research collaborations. Projects are color-coded according to their respective research areas (A, B, C) to enhance visual distinction. Edges are represented by arrows, indicating either unidirectional or bidirectional collaborative relationships. The number of arrows connected to a node reflects the extent of that project’s involvement within the network; the more arrows, the more collaborative links it maintains. For example, project Ö, as the central project, is directly connected to nearly all other projects. While some projects primarily benefit from collaborating with Ö, others engage in reciprocal partnerships. Thus, the bidirectional edge between Ö and B04 indicates mutual collaboration, whereas the unidirectional edge from Ö to A02 suggests that the collaboration benefits A02 without a reciprocal contribution.
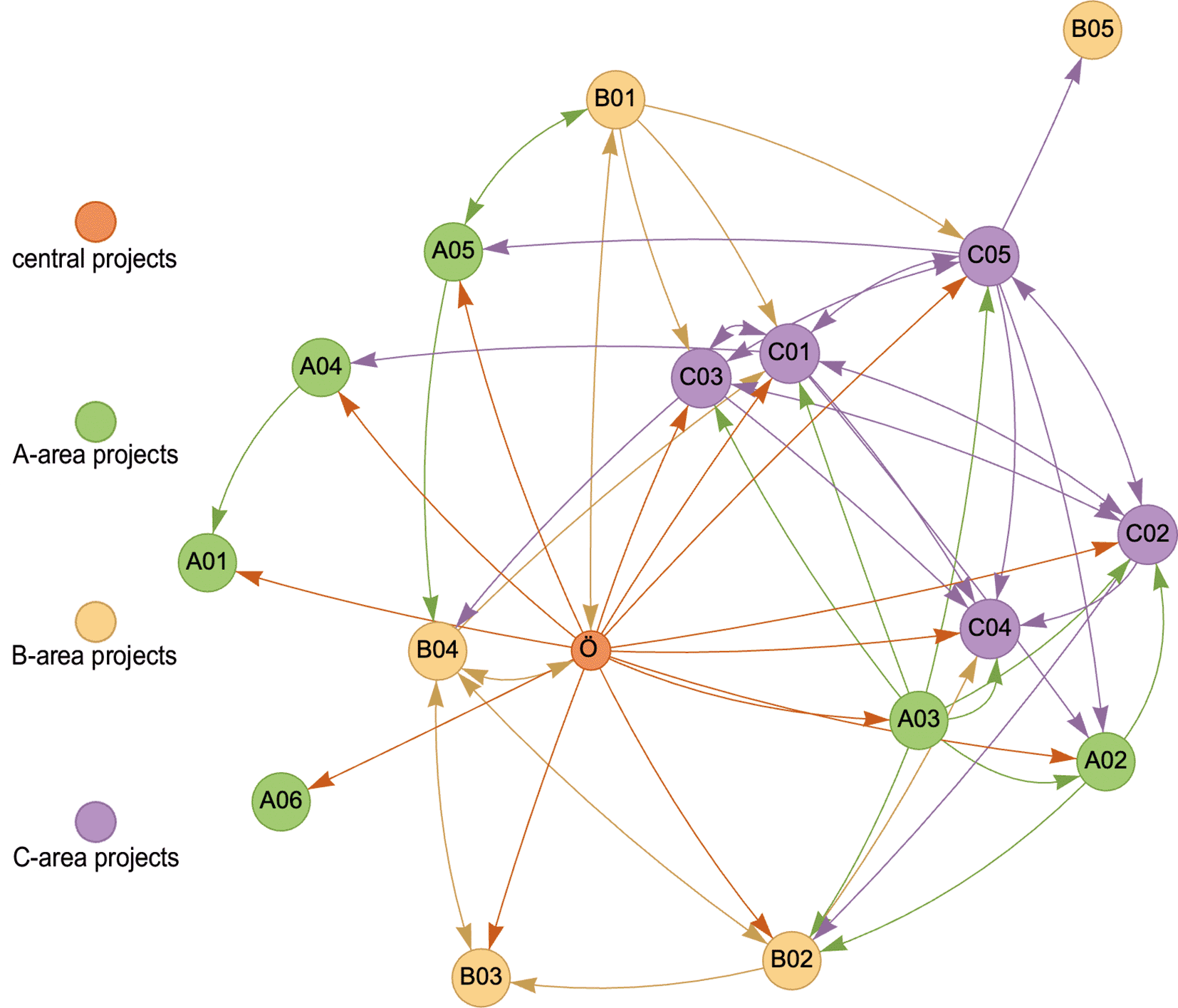
One advantage of this kind of visualization is that it can reveal ‘intermediate projects’, which might benefit from a collaboration with projects that already share an edge. One example for this is the connection between Ö and B05 (cf. Figure 1). These two projects do not share an edge, meaning that they do not collaborate directly. However, they both share edges with C05, which is the intermediate project between them. Identifying such interconnections highlights potential for future collaborative opportunities.
Figures 2 and 3 illustrate the distribution of languages and participant types across the experimental projects. In large-scale collaborative researches, such metadata serve as valuable resources for other projects seeking data involving specific languages or particular participant groups. This facilitates the finding of relevant datasets and supports the identification of potential opportunities for data sharing and re-usability cross-project.
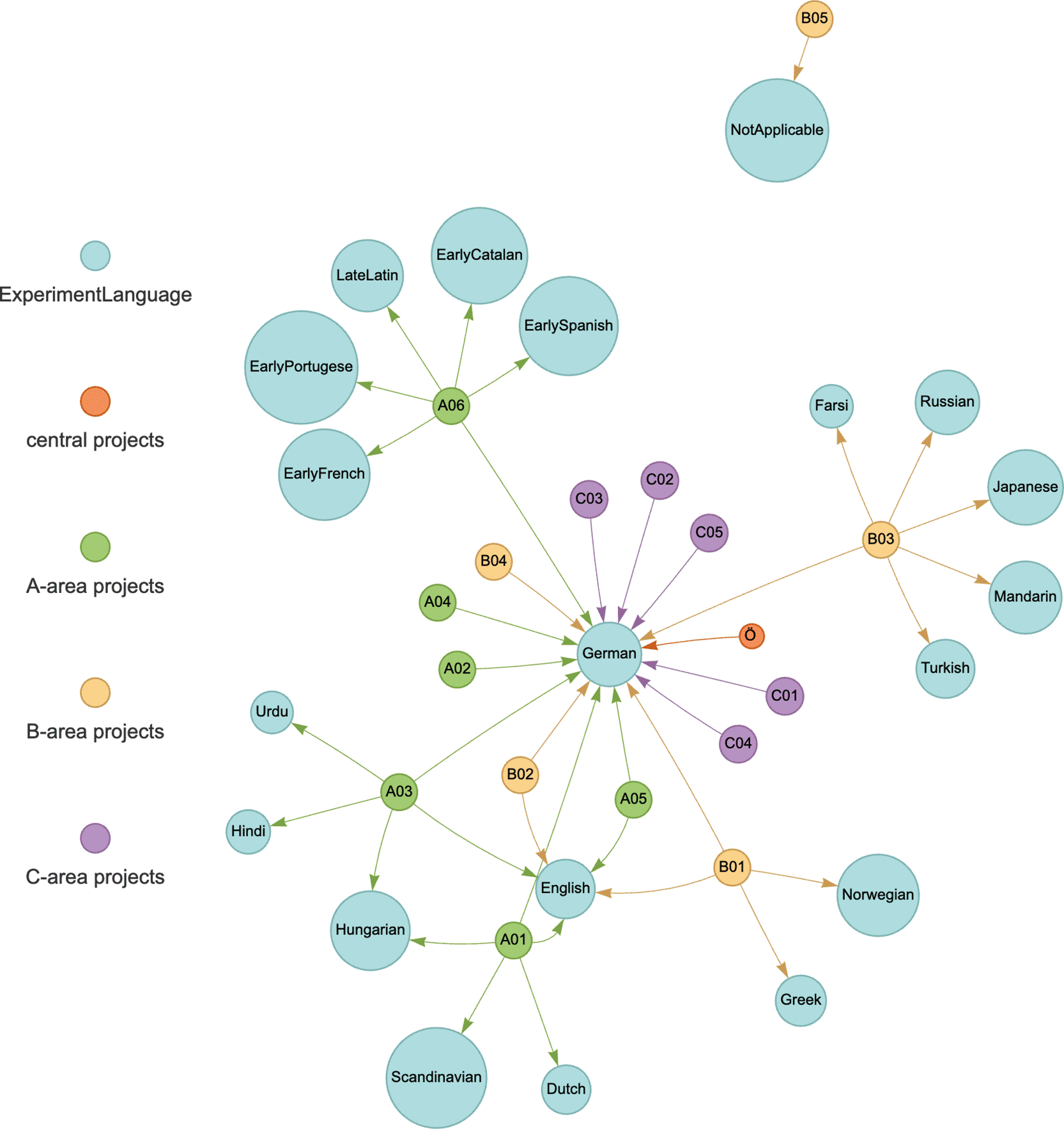
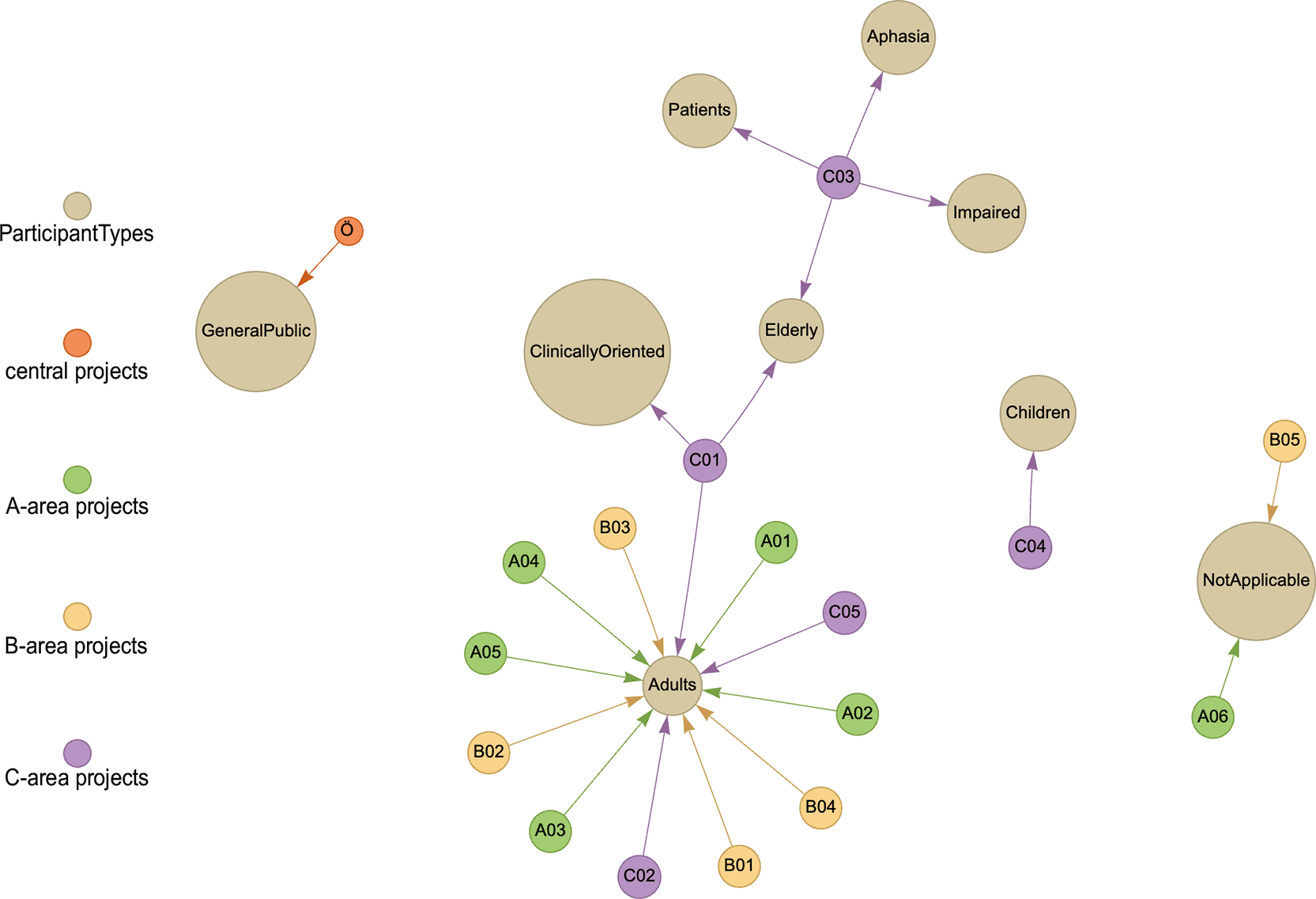
A visualization like this can highlight both similarities and differences between projects. For example, two projects focusing on different languages may still have potential for collaboration if they both involve adult participants. Conversely, multiple projects working with the same language, e.g., Hungarian, share a common language, even if they involve different participant groups or study distinct phenomena. Thus, identifying these connections is crucial not only for tailoring support in areas such as ethical compliance or data management processes, but also for the development of an effective metadata schema for the data management platform (see Section 1).
This paper presented a systematic approach to collecting, restructuring, and visualizing (meta) data of project methodology, data types, and requirements in a large CRC in linguistics. For this, the construction and implementation of a semi-structured interview was described. The goal of the interviews was twofold: First, they helped raise awareness among projects regarding legal, ethical, and technical aspects. The projects of the CRC process e.g., personal information or sensitive health data, imposing legal and ethical constraints on data management and processing. Second, the information in the interviews was transcribed and re-coded comprehensively via a coding scheme in order to develop a structured knowledge base of intra-CRC connections between projects. The dataset was converted into knowledge graphs, a structured visualization of information where entities (nodes) and their relationships (edges) were modelled to capture and organize knowledge. One of the key advantages of this visualization is its ability to reveal potential interconnections via intermediate projects, a benefit often overlooked in large-scale projects. In the future, we aim to refine the model into a conceptual framework by developing a relevant ontology based on specific knowledge bases. The ontology models will enhance the consistency and establish higher standards across a broader domain.
The method described here can be improved on by extending it to other research collaborations and thereby being able to highlight potential for additional collaborations. A further limitation is that we could not share the full dataset underlying the described method due to confidentiality constraints.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)