Keywords
Machine Learning, Deep Learning, Neural Architecture Similarity, Graph-based Neural Network Representation, Model Representation Learning, Architectural Embeddings, Neural Architecture Search, Representation Similarity Metrics
This article is included in the Artificial Intelligence and Machine Learning gateway.
Machine Learning, Deep Learning, Neural Architecture Similarity, Graph-based Neural Network Representation, Model Representation Learning, Architectural Embeddings, Neural Architecture Search, Representation Similarity Metrics
The animal kingdom provides a huge variety of species; among others are vertebrates and invertebrates, mammals, birds and fish. They have one thing in common: a brain. And this brain always has the same task: turning sensory information into behaviour. However, how they do it can be totally different. Biologists introduced specific terms for this topic. On the one hand, there are functional analogues. Functional analogues have the same purpose or function, but their computational graphs are largely distinct, indicating a high functional similarity and a low structural similarity. They may have an independent evolutionary origin, for example, the fly’s mushroom body and our pallium, areas responsible for learning and memory, or the ctenophore neural system (Farris, 2008; Katz, 2011; Moroz, 2015). On the other hand, homologues share a common ancestral structure and show a high degree of structural similarity, such as the zebrafish’s optic tectum and the human superior colliculus. Studies provide evidence that in this case, the computational graph is highly similar, suggesting high structural similarity (Isa et al., 2021; Nevin et al., 2010). Based on these concepts grounded in biology, I distinguish in this article two independent yet interacting axes: (i) structural similarity, which is a property of the computational graph; and (ii) functional similarity, which is the degree to which two neural networks produce similar outputs or internal representations.
Let us move from the real biological neural networks to the computer science domain and use deep neural networks as a key architectural design in artificial intelligence. Many performance gains in contemporary literature are achieved through architectural choices that we understand only superficially. Consider the well-known equivalences in convolutional neural networks where, for example, a single 5×5 convolution can be replaced by two stacked 3×3 convolutions ( Figure 1), yielding a nearly identical receptive field and comparable or even better performance (Simonyan and Zisserman, 2015). Despite such substitutions being very common in architectural optimization, our understanding of how these design decisions affect the underlying architecture remains limited. That means while having a similar output (high functional similarity), the underlying computational graph has slightly changed, despite the fact that they are very related to each other. Using the terminology above, one would refer here to homologues.
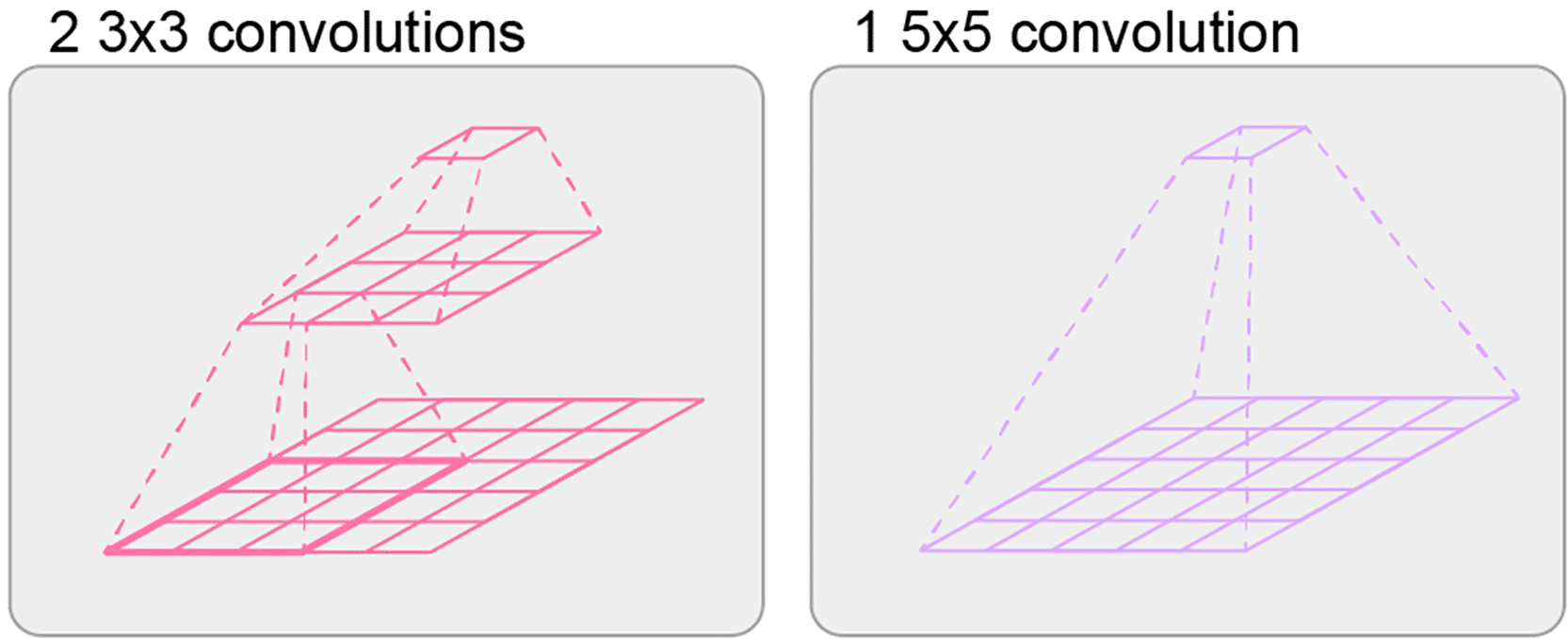
A pair of stacked 3×3 convolutions (left) produces an effective receptive field comparable to that of a single 5×5 convolution (right).
When we now think about the relationship between vision transformers and convolutional neural networks, a different picture emerges. The underlying neural architectures are based on fundamentally different concepts, but are able to handle the same computer vision task, such as image classification. In biological terms, the relationship between CNNs and Vision Transformers exemplifies homoplasy, where two independent evolutionary (or design) paths lead to the same functional capacity, here: image classification. Just as bird wings and insect wings represent distinct structural solutions to achieve the same function (flight), CNNs and Transformers are convergent solutions to vision tasks despite minimal structural similarity. Recent analyses show that CNNs and Vision Transformers develop notably different early-layer features but converge toward similar high-level representations (Raghu et al., 2021), illustrating representational convergence, i.e. high functional similarity, despite architectural divergence, i.e. low structural similarity. This highlights the need for formal criteria to distinguish “convergent” architectures from those that share a direct lineage and on which features any architecture converges.
The analogies given above and provided in Table 1 are conceptual rather than literal. DNNs do not evolve through phylogenetic inheritance like in biology, but the vocabulary provides a useful descriptive framework that I will keep using in the following.
As introduced above, we rely on two levels of similarity, one regarding the computational graph (structural similarity) and one regarding the output or internal representation (functional similarity). Two architectures are the same in terms of structure if their computational graphs are identical. In terms of functional similarity, one can think if the distance between outputs is minimal or the representations align. Then, any given similarity would be maximal. The higher the degree of deviation in any considered similarity, the higher the similarity measure drops.
Structural similarity. Suppose any two architectures achieve a similar score when measuring their endpoint performance. In that case, we can hardly derive anything about some underlying principles that make one architecture generalize better or be more robust to perturbations (Neyshabur et al., 2017). Even more critically, we actually do not have a thorough understanding of which computational graphs yield high endpoint performance without empirical testing. Changing a computational graph slightly can have tremendous implications for this endpoint performance. To identify those, we might try to compare two given architectures and their computational graph and compute their structural similarity.
A naive approach to structural similarity would be to count the layers and units per layer in a multilayer perceptron. Activation functions, as a major source of non-linearity, should also be considered. In a convolutional neural network, this expands to further parameters and layer kinds, such as kernel sizes, as well as normalization and pooling layers ( Figure 2a). We have recently suggested a structural similarity measure (Pava et al., 2024) that relies on the alignment of two neural network architectures’ high-level computational graphs. Our alignment strategy is based on the Needleman-Wunsch algorithm, originally designed for DNA and protein sequence alignment (Needleman and Wunsch, 1970). In our case, we consider different kinds of layers and their parameters and punish sequence mismatches and the introduction of gaps in the architecture (see Figure 2b). While effective for quantifying architectural lineage in tasks like Neural Architecture Search (NAS) by measuring the cost of layer insertions, deletions, or substitutions, sequence alignment is insufficient for comparing complex, non-linear topologies typical of deep learning, such as skip connections or parallel branches. The limitation arises because Needleman-Wunsch treats the network as a one-dimensional sequence, failing to account for skip connections, parallel processing streams, or the topological roles of nodes.
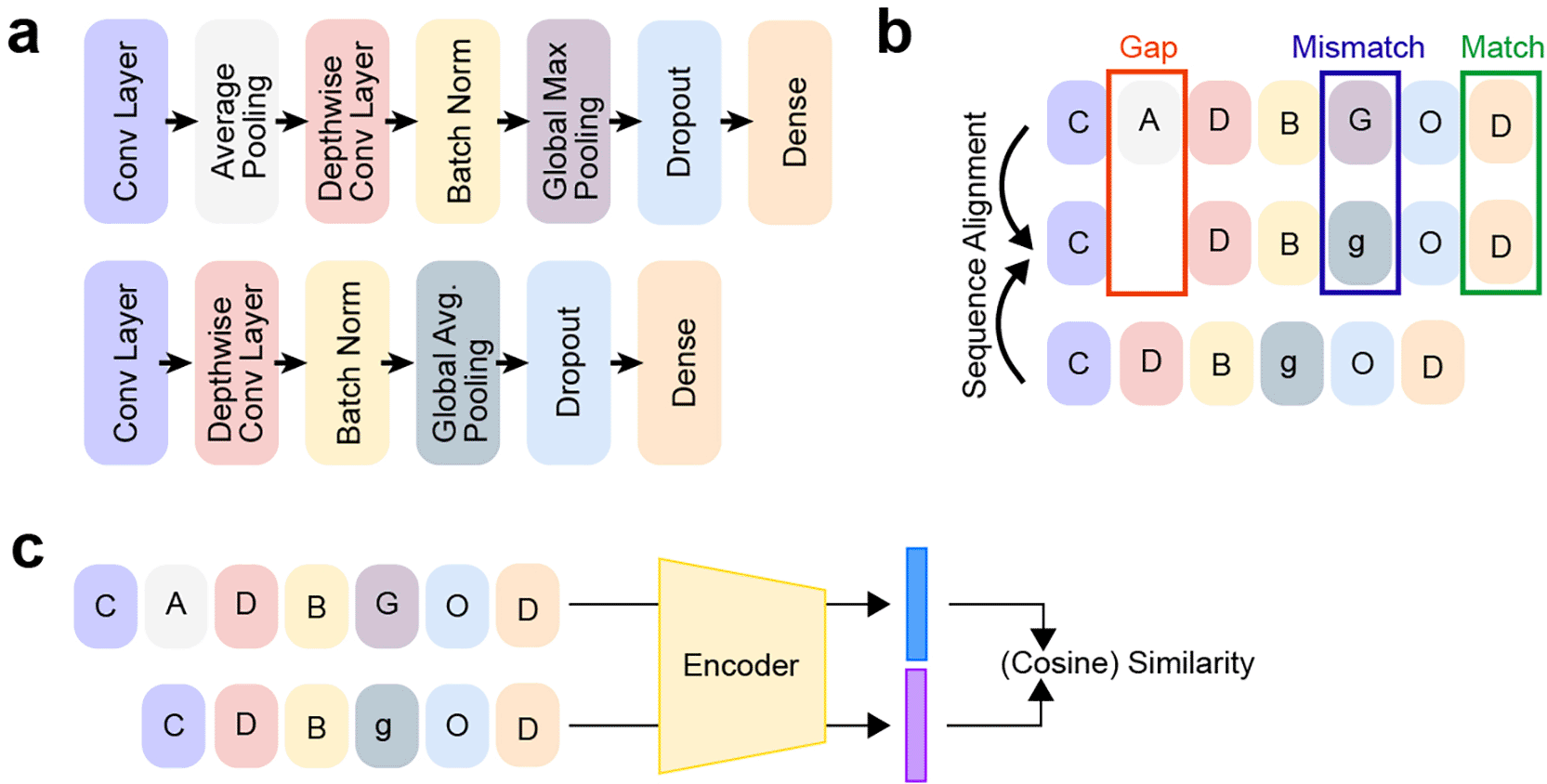
(a) Two example architectures are decomposed into ordered sequences of layer types, such as convolutional layers, pooling operations, normalization layers, and dense blocks. Each layer is represented as a symbolic token, enabling a compact, sequence-level description of the computational graph. (b) Structural alignment of the two architectures from (a) using a Needleman-Wunsch sequence alignment procedure. The alignment identifies gaps (insertions or deletions; red), mismatches between structurally different layers (purple), and matches where corresponding layers share the same type (green). This alignment yields a layer-wise correspondence and provides the basis for quantifying structural distance. (c) The two neural networks from (a) are passed through an encoder to produce some sort of embedding representation of each architecture, for example, by representing the computational graph or via a foundation model. The cosine similarity between these embeddings provides a differentiable structural similarity score.
Researchers are beginning to explore topological data analysis or graph-based metrics to compare architectures (Barannikov et al., 2021; Chen et al., 2025). However, differences between models are not necessarily captured by these approaches, and the lack of a universal ground truth limits the ability to validate these measures. The broader community would benefit from a concerted effort to develop and standardize approaches that measure structural similarity, ensuring that new methods can be consistently evaluated and compared.
An upcoming trend to represent any given modality is the use of foundation models (Awais et al., 2025). One can think of an embedding representation for any given neural network architecture, where we can compute cosine similarities across embeddings to compare any given neural network architectural designs ( Figure 2c). Representing an architecture as a vector or embedding has been used before (Cheng et al., 2021; Li et al., 2020; Xue et al., 2024; Yan et al., 2020), but expanding this via a self-supervised learning approach would be interesting, even thinking of what such a self-supervised learning paradigm would look like.
Representational similarity. Structural similarity here would mean not only the computational graph itself, but might also include intermediate representations. With the same multilayer perceptron architecture (two inputs, two hidden units and one output), I could compute the logical AND, OR, or XOR operation, depending on how I set the weights (see Figure 3). Representational similarity has been studied intensively, most notably using centred kernel alignment (CKA), which reliably identifies layer correspondences across different architectures and training initializations (Kornblith et al., 2019). Along similar lines, a very recent study focused on quantifying representational similarity and grounded their study on either prediction or design (Klabunde et al., 2024). For grounding similarity on predictions, the authors computed the Jensen-Shannon divergence of the class-wise probability scores. For grounding the similarity by design, the authors computed group representations across layers in an ordinal fashion and reported the conformity rate. They also introduced a new benchmark, ReSi, that should quantify this representational similarity.
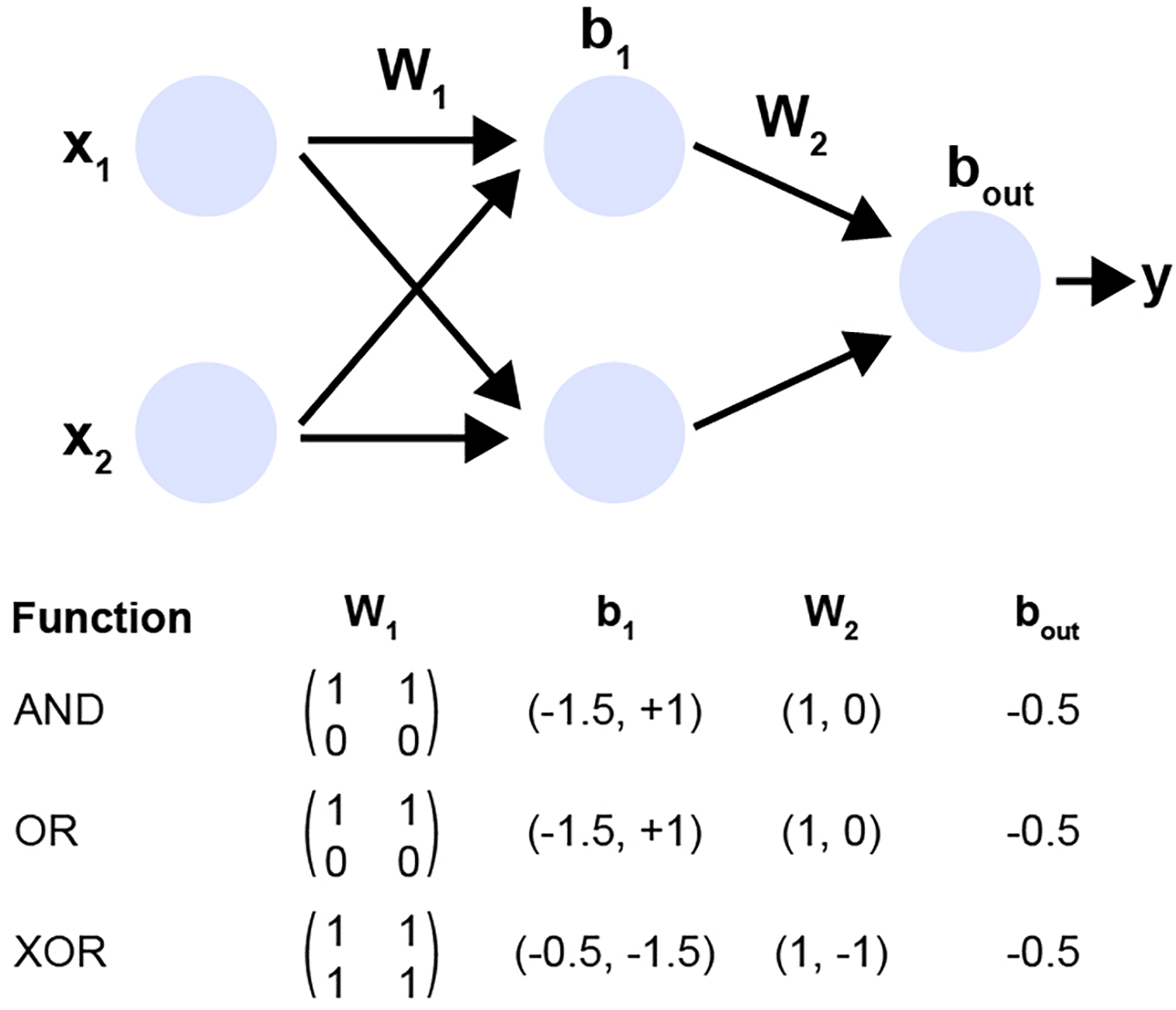
This example illustrates how a fixed two-layer perceptron architecture can implement qualitatively different Boolean functions, here AND, OR, and XOR, solely by modifying its weights and biases. The computational graph (top) consists of two input units (x1,x2), two hidden units, and a single output unit. The first layer is parameterized by weight matrix W1 and bias vector b1, followed by a nonlinear activation. The second layer maps the hidden representation to the output using W2 and output bias bout.
Although the architectural structure is identical across all three cases, the choice of parameters determines the function the network computes. The lower tabular panel summarizes specific parameter settings that allow the same architecture to implement each logic gate. The AND and OR functions can be realized with linearly separable decision boundaries, while the XOR function, classically non-linearly separable, requires the hidden layer to construct an intermediate representation that enables correct classification.
This demonstrates an important principle for structural similarity analysis: two networks may share an identical computational graph yet perform completely different computations due to differences in parameterization. Thus, architectural similarity alone is insufficient for characterizing functional similarity, motivating the need to consider both structural and representational components when assessing neural network similarity.
Functional similarity w.r.t. output. When measuring the functional similarity concerning output, we can use a variety of measures or metrics. Let’s use the term “measure” in the following being a mathematically vague description, to not imply certain specific constraints, such as the triangle inequality, needed for calling a measure a metric. In a typical scenario, a measure should be optimized for a specific goal. The Dice coefficient measures in a semantic segmentation task how well a given algorithm provides predictions with respect to a known ground-truth mask. Many measures have been described and lately comprehensively analyzed, pinpointing their strengths and limitations (Maier-Hein et al., 2024; Reinke et al., 2024). That means two identical neural network architectures should be able to produce very close results after training on the same data. As there is a stochastic component in initializing the networks, the trained weights might be dissimilar, i.e. not the same, as not the same local minimum will necessarily be reached after training. However, their measured performance, given the example of the Dice score above, should be similar. Still, we would be able to analyze their internal representations and compare the same structural networks in such a way.
Similarity in a nutshell. That means, a well-behaved overall similarity measure, or ideally metric, would incorporate both structural and functional similarity to determine the overall similarity. One can think of two independent terms and an interaction term to describe the structural similarity holistically (see conceptual equation in Equation 1). Crucially, neither structural nor functional similarity alone is sufficient. Structural similarity does not guarantee similar computations ( Figure 3), and functional similarity does not imply shared computational mechanisms (see CNN vs. ViT example). A meaningful similarity measure must therefore reflect both axes and their interaction.
One promising theoretical application of a structural similarity measure is the identification of architectural motifs – recurring sub-network patterns, also termed as canonical microcircuit – across different neural networks (Douglas et al., 1989; Harris et al., 2019). In biology, recurring patterns of interconnections (network “motifs”) have been identified in diverse systems as basic building blocks of information processing and specify the intrinsic circuitry that integrates top-down and bottom-up streams, serving as a highly parameter-efficient, repeatable computational unit (Milo et al., 2002), abundantly present in the mammalian cortex. Similar motifs were found in networks that perform information processing even when the elements differ, such as gene regulatory networks and neural circuits (Milo et al., 2002).
By analogy, deep neural networks may also contain frequently recurring motifs (such as convolutional block + activation + normalization sequences, or residual skip connections) that serve as functional building blocks. Basically, an architectural motif would be a subgraph of the total neural network that is statistically overrepresented relative to a graph null model and contributes meaningfully to the network’s representational structure. An effective structural similarity measure could automatically detect when two architectures share such a common motif – for instance, identifying that different U-Net-like neural networks contain repeating encoder-decoder subgraphs.
Open questions in this theoretical domain include: How should we rigorously define an “architectural motif” in an ANN? and How can we identify statistically significant motifs in a neural architecture, similar to how network motifs are defined by over-representation compared to random graphs? Developing algorithms to find partial alignments between architectures, similar to local sequence alignment in BLAST (Madden, 2013), could allow us to spot these motifs and avoid global sequence alignments. As introduced above, we found that this, in principle, works. It remains to be explored whether motifs correspond to particular functions and how to quantitatively link motif presence to network performance or robustness. Examples would be attention mechanisms in Transformers or bottleneck blocks from ResNets. We can also think one step further: we not only compare layer counts but also compare the distribution, integration and organization of these motifs, which we can think of as a motif spectrum. This motif spectrum could hint at necessary structural requirements for a task. This could potentially identify in the previous example (CNNs vs. Vision Transformers) the need for a given computational task, such as efficient feature extraction.
Going back to our initial hypothesis that there can be structural homologues, meaning having a high similarity and a similar endpoint performance, i.e. a low absolute difference in the performance, that can also be measured by the “grounded by prediction” measure introduced above (Klabunde et al., 2024). In addition, one could identify especially analogues when focusing on the structural aspect alone, which may also share similar intermediate representations. Defining homologues and analogues, one could start creating phylogenetic relationships between any architectures and show their relationships. This would create a new venue for meta-analyses of neural network architectures, providing a map of architectural evolution. This map would be thought of phylogenetic tree based on their structural similarity, a typical representation for the relationship of species and proteins.
In such a tree, “structural homologues”, i.e. networks that share a common blueprint or module set, would cluster together. For example, ResNet-50 and ResNet-101 would be neighbouring branches, as would Vision Transformer variants. Structural analogues, i.e. networks that achieve similar functional outcomes via different structures, might appear as separate branches that converge at the level of function. This approach draws inspiration from evolutionary biology: architectures that evolve by incremental modifications from a parent, such as adding a convolution here or a skip connection there, are comparable to divergent evolution (homology), whereas very different architectures that nonetheless converge to solve the same task (CNN vs. Transformer for image classification) are comparable to convergent evolution (analogy).
Practically, constructing an architecture phylogeny could yield insights into why certain designs perform well. If we find a cluster of high-performing architectures that are all structurally similar, that suggests a stable design motif exists. Conversely, if an architecture lies far from any cluster, basically a structural outlier, yet has high performance, it might represent a novel design paradigm, which would be analogous to discovering a new phylum in biology. Additionally, by analyzing architectural homologues that differ slightly, we could pinpoint which structural changes (“mutations”) significantly affect performance or robustness. We and others used such a meta-analytic view that is able to guide neural architecture search: rather than random search in a vast search space, one could use structural similarity to navigate the space, moving along the branches of the (thought) tree to find promising new variants (Pava et al., 2024; Xue et al., 2024; Yan et al., 2020).
To make this concrete, consider that many CNN architectures (VGG, ResNet, DenseNet) share a lot of common motifs (convolutions, ReLUs, skip connections) – they would form a homologous family. Transformers, on the other hand, form a different family. Both families achieve high accuracy on vision tasks (analogous function) but via divergent structures. A structural similarity framework might even allow us to quantify the “distance” between a given CNN and a given Transformer architecture, formalizing the intuitive notion that these are very different species of networks. Another intriguing possibility is identifying hybrid architectures that lie between families (like networks that combine convolutional and self-attention layers) – these could be seen as intermediate forms on the phylogenetic tree, potentially inheriting advantages of both parent families.
Here, “distance” is consciously in quotation marks, as we still would leave it vague if one is able to create a real metric, i.e. a real distance, satisfying, for example, triangle inequality and symmetry. Whether structural similarity can be formalized as a metric remains an open question and may depend on whether future strategies to create embeddings or graph representations satisfy the aforementioned metric properties.
In summary, establishing analogues and homologues among ANN architectures opens up a new analytical dimension. We can ask questions like: can we develop an algorithm to automatically cluster architectures by their structural similarity? What does the distribution of known architectures look like in such a potentially multidimensional space – are there clear “families” and isolated designs? And could we infer an “architectural lineage” for a given model? For instance, can we trace how ideas from LeNet led to AlexNet, then to ResNets, etc., in a quantitative way? The answers could not only satisfy a theoretical curiosity but also drive practical innovation by highlighting which structural routes have been well-explored and which remain underexplored.
When computing the structural similarity and the delta in functional similarity, here output related, one can draw plots as shown in Figure 4, illustrating architectural siblings with functional divergence. These could indicate prone-to-break architectural designs. In addition, one could find robust architectural designs that, regardless of subtle changes in the computational graph, the model will be relatively consistent in the output distribution. For example, removing a certain skip connection from an architecture might drastically degrade its accuracy under stress, marking it as a fragile design. This effect is well-documented in ResNets, where ablating their hallmark skip connections leads to catastrophic degradation in trainability and accuracy (He et al., 2015; Veit et al., 2016). Similarly, Vision Transformers exhibit high sensitivity to early-stage architectural perturbations. Removing or significantly altering the patch embedding layer severely disrupts both convergence and downstream accuracy (Dosovitskiy et al., 2021; Raghu et al., 2021). Conversely, if an architecture yields similar performance even after such a perturbation, it could be deemed structurally robust (Kist et al., 2022). Using a structural similarity measure, one could compare a network to a slightly perturbed version of itself to quantify how sensitive its function is to architectural tweaks.
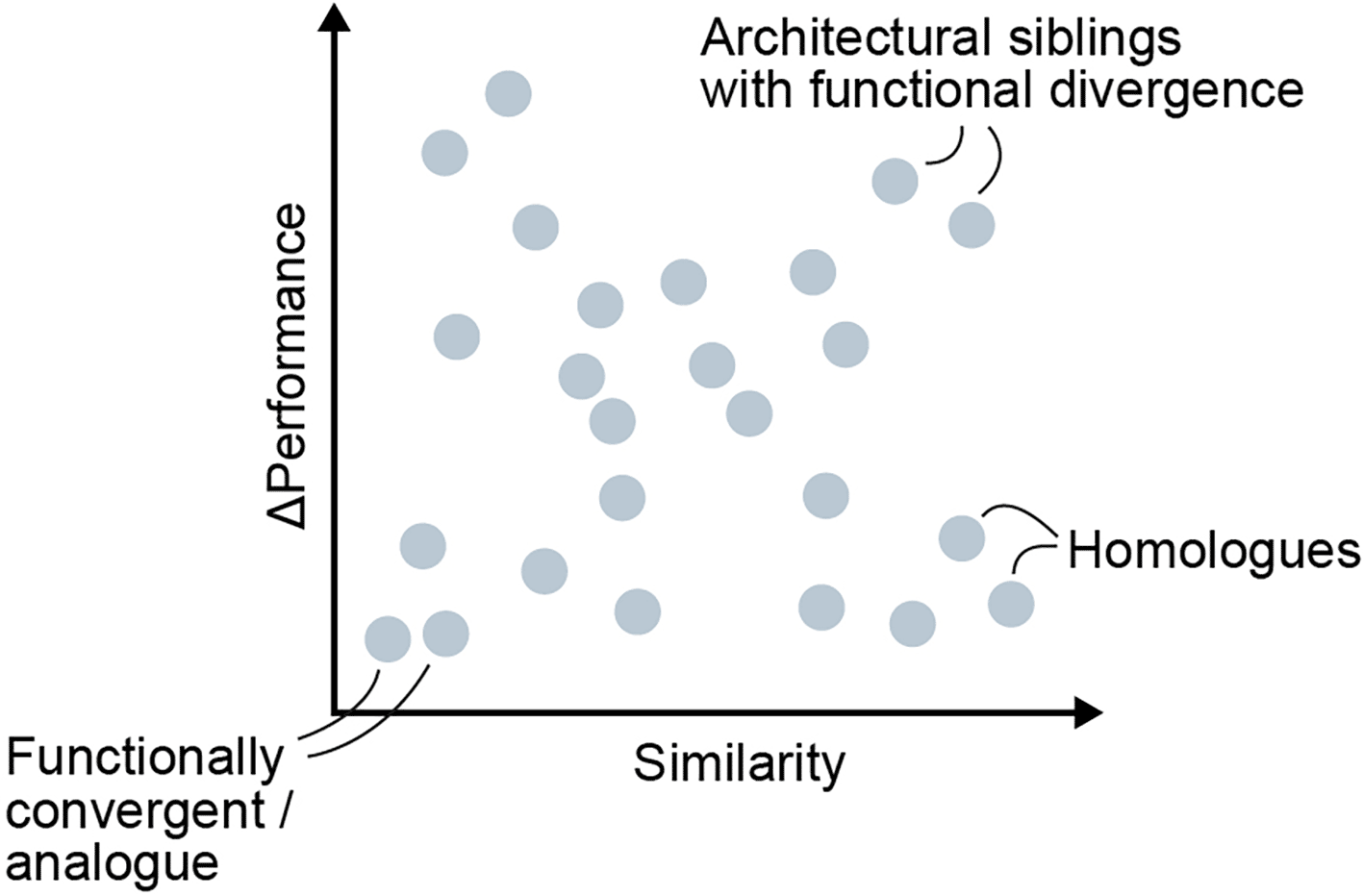
Each point represents a pairwise comparison between two architectures. The x-axis shows structural similarity, whereas the y-axis shows the difference in performance (Δ performance) between the two models. Pairs with high similarity and low Δ performance cluster on the lower right and correspond to homologues, i.e. architectures that share a common design lineage and behave similarly. Points in the upper right indicate architectural siblings with functional divergence, where small structural changes lead to large performance differences. Points near the lower left represent functionally convergent or analogous architectures, which achieve comparable performance despite minimal structural similarity.
In this application-driven domain, robustness becomes a key concern. A structural similarity measure could help predict a network’s robustness: if a network and a perturbed variant (e.g. with one layer removed or a module substituted) are still highly similar in function, that suggests the architecture has built-in redundancy or stability. On the other hand, a small structural change leading to a large functional divergence would indicate a fragile design. Open research questions here include which structural features (motifs or patterns) correlate with robustness to perturbations or adversarial attacks? Can we identify, using structural similarity, “prone-to-break” configurations systematically? For instance, are there specific layer arrangements that consistently cause networks to fail under domain shifts or noise? A structural similarity analysis across many models might reveal that certain architectures cluster together and all share an intolerance to, say, weight noise or input perturbations – indicating a vulnerable pattern.
Beyond robustness, transferability of learned knowledge is another application-driven concern. We could ask, if two architectures are structurally similar by our measure, does that imply we can transfer weights or features from one to the other with minimal fine-tuning? Currently, model transfer or fine-tuning often assumes a similar architecture, such as transferring knowledge between ResNet-50 and ResNet-101 in the first 50 layers. A very elegant application is, for example, weight transfer in knowledge distillation, if teacher and student have similar architectural designs (Yim et al., 2017). A formal similarity measure could generalize this. One could quantitatively predict when transfer learning will succeed based on structural closeness. This could enable a priori selection of a pre-trained source model that is structurally closest to a target architecture, maximizing transfer efficiency. Conversely, if two models are structurally very different, as indicated by low similarity, one might expect transferred features to be less useful.
Overall, identifying robust vs. fragile designs and understanding transferability via structural similarity could create best practices in model development. An architecture that is an “architectural sibling” of many others with consistent performance might be a safer choice for deployment, whereas an outlier architecture that shows dramatic performance swings with small changes might indicate cautious use.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)