Keywords
Bayesian inference, Expectile regression, Single-index model, Asymetric Normal Distribution
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
Bayesian inference, Expectile regression, Single-index model, Asymetric Normal Distribution
Expectiles of a probability distribution F, like the quantiles of a probability distribution F, represent different points of a distribution, but they are determined by tail expectations rather than tail probabilities. Expectiles depend on both the tail realizations and their probability, while quantiles only depend on the frequency of tail observations. There exists an one-to-one mapping from expectiles to quantiles,27 i.e. for each τth expectile, there is a corresponding th quantile, where and . Hence, expectiles can be utilized to estimate quantiles.
The th expectile of is the quantity that satisfies
Expectiles are a generalization of the mean and the expectile loss is a generalization of the mean squared error in the same way as quantiles are a generalization of the median and the quantile loss is a generalization of the mean absolute error. Standard regression model aims to estimate the conditional expectation of the outcome variable given the vector of covariates . In many applications, however, it is required to study conditional distributions beyond the mean (conditional expectation). A nice tool for this purpose was offered by17 in the form of expectile regression. Expectile regression17 models the relationship between the covariates and the conditional expectiles of the outcome variable. The methodology is a generalization of the mean regression and closely related to quantile regression. It uses expectiles-points that minimize an asymmetric quadratic loss function rather than the absolute loss function used in quantile regression. Both the expectile level and the quantile level determine the degree of asymmetry of the loss function. Examining the asymmetric quadratic loss function reveals many of the properties that make expectile regression an attractive measure of risk.
Compared to the mean value, expectiles are more sensitive to extreme values, and to the shape of the distribution in general. Furthermore, standard regression implicitly assumes normally distributed residuals, while such an assumption is not necessary in expectile regression. Expectile regression often leads to more efficient estimators compared to quantile regression, especially when the underlying error distribution is close to normal or when you’re interested in extreme values of the conditional distribution. Estimation of expectile regression models can be done using iterative algorithms, such as weighted least squares or stochastic gradient descent, and reliable estimation approaches have been developed in both the classical and Bayesian literatures.
Since its inception, expectile regression has attracted considerable interest in the literature. It has been applied in many different areas: finance and risk management,3,6,14 actuarial science,4,7,16 ecology and environmental studies,10,21,24 social sciences,19,28 and so on. In the recent decades, there exists considerable interest in the study of nonparametric and semiparametric models. Single-index model provides an efficient way of coping with high-dimensional nonparametric estimation problems and gives more flexibility and capture parameter heterogeneity and nonlinearity. Expectile regression with single-index models is an efficient method to model asymmetric relationships in data while achieving dimension reduction. There exists a large literature on classical methods for expectile regression with single-index models, and we refer to12,13 for an overview. In contrast, a Bayesian method for estimating expectile regression with single index model has not been proposed, yet.
In this paper, we consider a single-index expectile regression model. For a given expectile level and training data , it is given by
Here, ) is the th expectile function of given , is the covariate vector for the -th observation, is the response corresponding to the covariate vector , is the unknown univariate link function, and is the parametric index vector which implicitly depends on the desired expectile level . Following15 and12 for the sake of identifiability, we assume that and that the first component of is positive, refers to the Euclidean norm.
The single index regression model is a form of dimension reduction in regression where the covariate vector is reduced to a one-dimensional index, so that is a univariate function instead of k-variate one, allowing for more interpretable and efficient modeling of the outcome of interest. In this paper, we establish a hierarchical Bayesian model by using asymmetric normal distribution (AND). As shown in Figure 1, the asymmetric normal distribution exhibits different shapes depending on the expectile level τ. For detailed information on Bayesian expectile regression methods, see,25,23,26 and.20 Following11 and,29 we assign a Gaussian process prior distribution on , to get a flexible nonparametric expectile regression model.
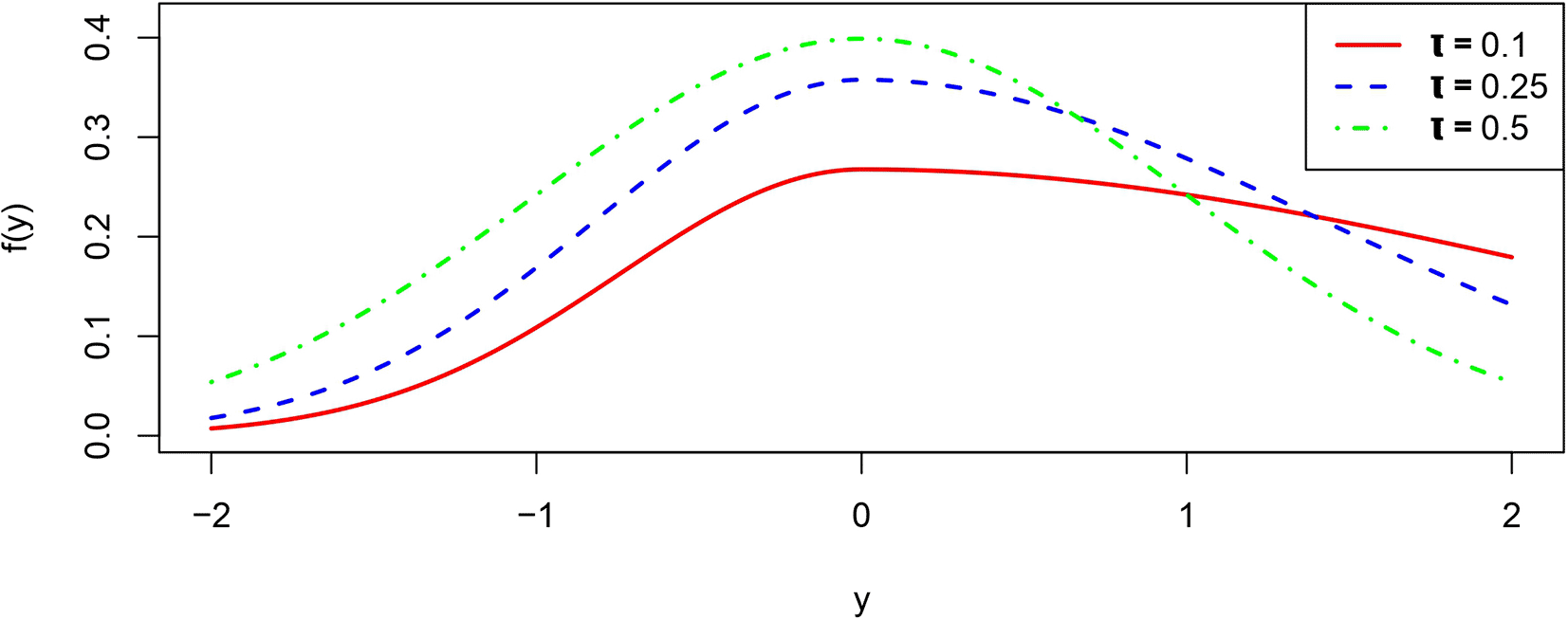
This paper proceeds as follows. In Section 2, we introduce single-index expectile regression, the proposed Bayesian hierarchical model, and derive the corresponding MCMC samplers. Simulation studies are then presented in Section 3 followed by a real data example in Section 4. Conclusions is put in Section 5.
In the single-index expectile regression, the regression coefficients can be estimated through optimizing the following empirical loss function
Equivalently, we may write (3) as
Rather than minimizing the usual expectile loss function (2), we solve the minimization problem by constructing a Markov chain having the joint posterior for the expectile regression coefficients as its stationary distribution with the minimizer of (2) as its global mode. The quadratic asymmetric loss function (2) is exactly equivalent to the AND; see23,25 and.20 The density function of an AND is
Following11,29,5 and,8 we model the nonparametric link function by a Gaussian process (GP) prior with mean zero and covariance function , i.e. , where
Here, and are two hyperparameters. Following11 and,29 we replace with a new index vector, still denoted by , to simplify the estimation procedure. Thus, the Gaussian process (GP) prior in (5) can be written as
To proceed a Bayesian analysis, we assign a Laplace prior for of the form2,22
The posterior distribution of all parameters of interest is found via MCMC sampling algorithm and the details of full conditional distributions are given below.
1. Sample the regression coefficients from their posteriors using a random walk Metropolis-Hastings steps,
In this section, we investigate the prediction accuracy of the proposed approach (BESIM) and compare its performance with a non-Bayesian single-index expectile regression12 referred as “ESIM”. We simulate data from the model
The covariates are simulatted independently from the uniform distribution on and is i.i.d. N . We experiment with four different scenarios by varying the sample size and simulations are repeated times for each of given and .
The simulation setup is similar to Example 1 in11,29 with different parameter values for the regression coefficients and error distribution. We generate data sets from model (16), where , .
For a Bayesian point estimator we consider the posterior mean using iterations of the MCMC after iterations as burn-in. The resulting estimates are summarized in boxplot Figures 2 and 3 based on 100 replications. These boxplots display the estimated coefficients, comparing BESIM and ESIM, with . In general, the boxplots give the impression that the Bayesian estimates (BESIM) produces more precise and stable estimates than classical estimates (ESIM). Mean squared errors (MSE) of the estimates based on the replications in each case are shown in Tables 1 and 2 for four sample sizes and 500 and all nine expectiles. MSE results show that the proposed method generally behaves better than the ESIM method in terms of the MMAD.
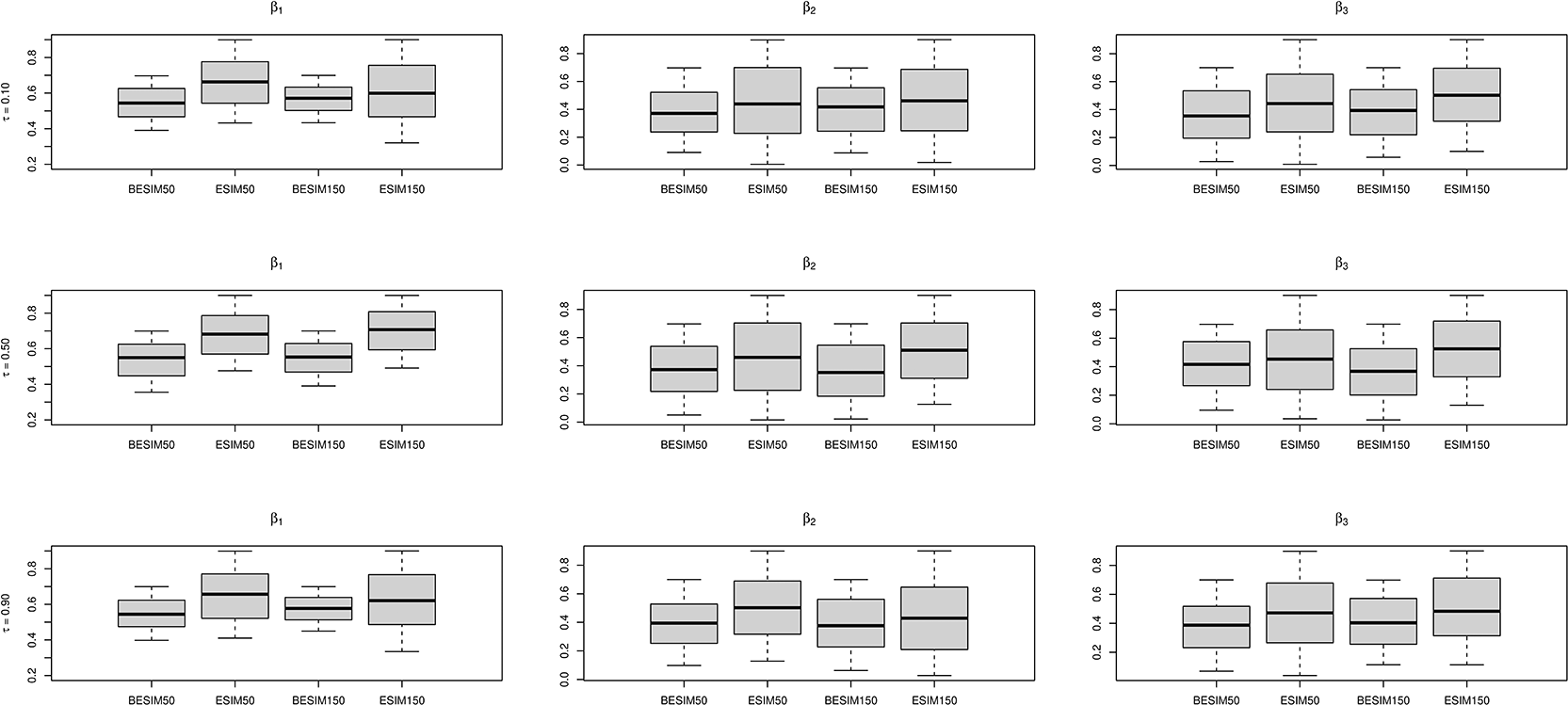
500 and all nine expectiles. MSE results show that the proposed method generally behaves better than the ESIM method in terms of the MMAD.
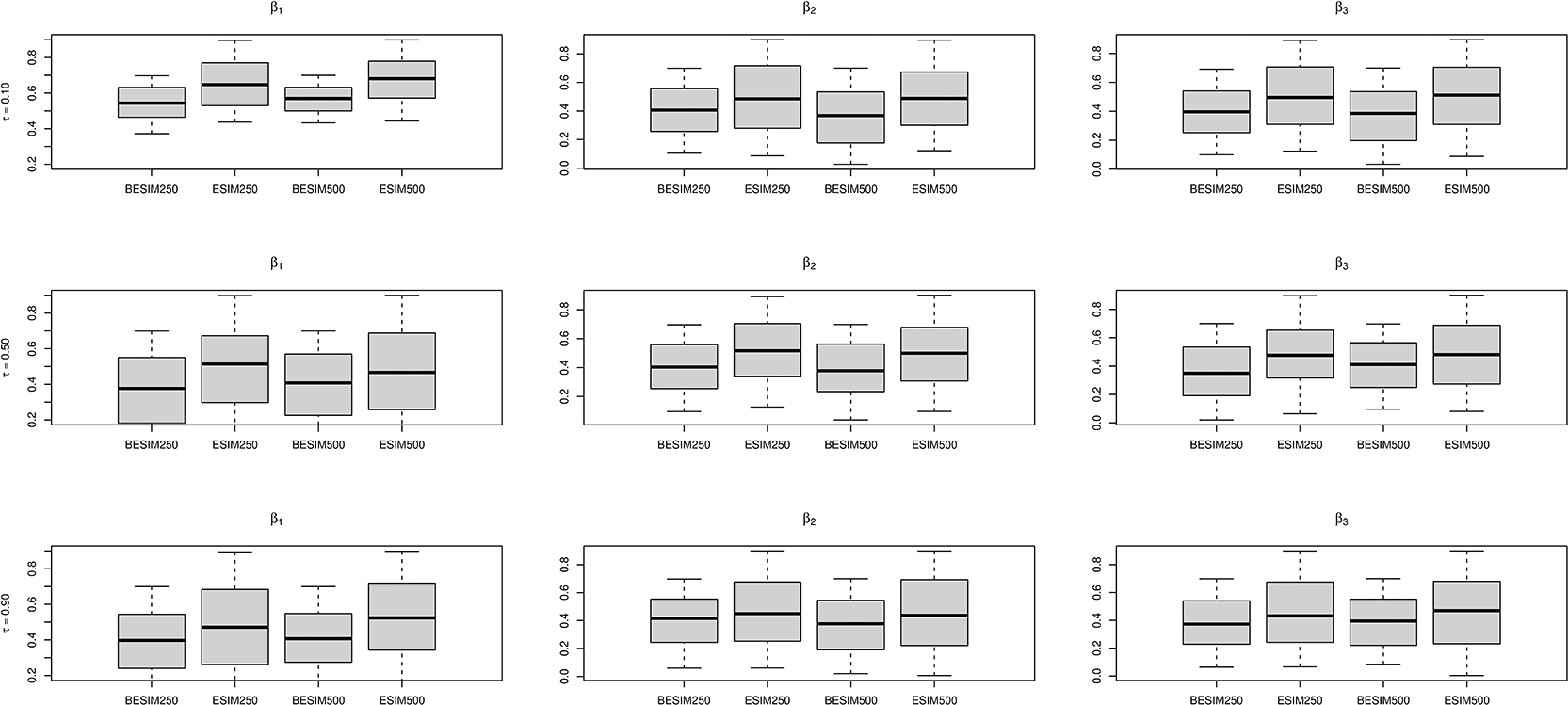
In this simulation study, we simulate data from model (16), where and . Mean squared errors (MSE) of the estimates based on the 100 replications in each case are shown in Tables 3 and 4 for four sample sizes and and all nine expectiles. Again, MSE results show that the proposed method generally behaves better than the ESIM method in terms of the MSE.
We examine the proposed method using the Boston Housing data (BHD). BHD was collected by9 in a study regarding the impact of clean air on housing prices, which is available in the R package spdep. BHD contains information collected from a random sample of size population census areas in the Boston city. The description of the variables is summarized in Table 5.
| Method | Test error | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| τ = 0.1 | τ = 0.2 | τ = 0.3 | τ = 0.4 | τ = 0.5 | τ = 0.6 | τ = 0.7 | τ = 0.8 | τ = 0.9 | |
| ESIM | 0.053 | 0.053 | 0.052 | 0.051 | 0.050 | 0.052 | 0.052 | 0.053 | 0.053 |
| BESIM | 0.046 | 0.046 | 0.044 | 0.042 | 0.040 | 0.045 | 0.046 | 0.045 | 0.046 |
Similar as in Tables 1, 2, 3, and 4, we consider nine choices of and 0.9. we consider 5-fold cross-validation to evaluate the performance of the both approaches (ESIM and BESIM). It can be seen that the BESIM performs better than its non-Bayesian counterpart, ESIM, uniformly for all expectiles considered.
Single-index expectile regression models provide a flexible semiparametric regression frame-work for high-dimensional covariates, and capture parameter heterogeneity and nonlinearity especially when focusing on different parts of the conditional distribution of the outcome of interest. In this paper, we introduce the Bayesian expectile regression with single-index model. A Bayesian hierarchical formulation is developed for expectile regression with single-index model (BESIM). Simulations and real data studies show that BESIM generally perform better compared with ESIM.
This study does not involve human participants or animals, therefore ethical approval was not required.
The underlying data is available in Zenodo. https://doi.org/10.5281/zenodo.184795341
Data are available under the terms of the Creative Commons Attribution 4.0 International license (CC-BY 4.0).
The R code supporting the findings of this study is openly available in the Zenodo repository at: https://doi.org/10.5281/zenodo.18681405.30
This code is also accessible via GitHub at: https://github.com/zena158/Bayesian-Single-Index-Expectile-Regression/tree/v1.0.1.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)