Keywords
Robust quasi-Newton methods, Convergence analysis, Numerical experiments, ANNs. unconstrained optimization.
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
Robust quasi-Newton methods, Convergence analysis, Numerical experiments, ANNs. unconstrained optimization.
In recent years, some authors have used neural networks (ANNs) as an important technique to solve many real-world problems because of their specifications. Some authors have used ANNs to solve different types of differential equations, such that1,3 first proposed the concept of solving differential equations using ANNs by formulating a trial solution of the differential equation. The authors tested the applicability and accuracy of their developed method not only for differential equations but also for systems of coupled differential equations. Furthermore, the authors compared their results with those obtained using other numerical methods and reported that the developed ANN was superior in terms of memory requirements and accuracy.4–6 For this reason, the authors aimed to develop this technique to obtain the best results. One of these developments is the training rules, particularly the quasi-Newton method, because it is a second-order convergence. Many authors such7–12 have proposed modifications for the training algorithm. Others such13–20 suggest some rules for the speed of convergence. Several attempts have been made to solve different types of differential equations by using feed forward neural networks. In,21 reported a hybrid method was reported that combines optimization techniques with neural networks to solve high-order differential equations.
The quasi-Newton method is the most useful method for minimizing a smooth n variable function.
If H is not an invertible matrix, then the pseudoinverse of H.
Wolfe conditions are used to determine the step length ( ) and search direction ( ), as follows:
For each iteration, is the updated Hessian estimate. The Broyden Fletcher Goldfarb-Shanno (BFGS) approach, proposed by Broyden, Fletcher, Goldfarb, and Shanno, is now one of the most effective training methods. Using the following formula, matrix in the BFGS technique can be updated:
Let be the inverse of . Undoubtedly, the suggested update in (8) is publicly known as
See25,26 for further details. For the update process, we let:
A new additional update was derived using a quadratic model of the goal function. Consequently, the quadratic model of the objective function is given as
Thus, the curvature information in Eq. (10) can be approximated by
Because the updated is supposed to approximate the , it is reasonable to have
Using (11) in (13), we obtain:
The new quasi-Newton (QN-) equation is given by:
From the above equation, the different gradients can be written as
(i) For , Equation (16) becomes:
(ii) For , Equation (16) becomes:
(iii) For , Equation (16) becomes:
From the above explanation of the results, we can write the algorithm as follows:
Stage 1: Let , and
Stage 2: If , stop.
Stage 3: Evaluate .
Stage 4: Determine the optimal learning rate (step - size) by using Eqs. (4) & (5).
Stage 5: Let . Update by using Equations (9) and (16) if ; otherwise, leave .
Stage 6: Take , and then go to Stage 2.
The following theorem illustrates the theoretical benefits of the new quasi-Newton Equation (16). To ensure that the matrix is positive definite, we need only prove that holds.
Let matrix sequence be generated using Equation (6). Thus, the sequence is positive- definite.
From the different gradient definitions, we have:
By applying Wolfe's condition to the previous equation, we obtain:
Because and , Eq. (18), we obtain
Therefore, is positive -definite.
We provide a global convergence of innovative approaches under circumstances that are comparatively understated.
1. The level was set to be convex.
2. Because the gradient satisfies the Lipschitz continuity, there is a positive constant called :
The series generated by a new algorithm is evident in because is a decreasing series, and there is a constant that results in
for all , for more details see.12–14
By different gradient definitions and combining Equations (10) with (16), we obtain:
Utilizing the mean value theorem and Taylor series, we obtain:
Meeting Assumption 3, it is simple to surmise:
Then, we obtain different gradient definitions of by direct calculations:
The proof is finished.
If the constants and exist, then the following inequality holds:
The proof is straightforward, similar to the proof of Theorem 3 in.6
In this study, we prove a global convergence theorem for non-convex problems and suggest a cautious updating strategy that is comparable to that mentioned previously. We state a Powell-related lemma for motivational purposes.15
A smooth function f that is limited below can be treated using the BFGS technique if a constant exists, which makes the inequality:
If these Assumptions hold, is generated by the new algorithm. Then Eq. (32) holds.
If Eq.(33) fails to hold, then there exists a constant , such that:
Therefore, a constant exists, such that:
So, combining Eqs. (29) and (35) imply that:
The proof is finished.
In this section, we present a numerical comparison of QN -techniques and suggest modifications for solving 4th order nonlinear partial differential equations.
Consider the nonlinear 4th order has the form;
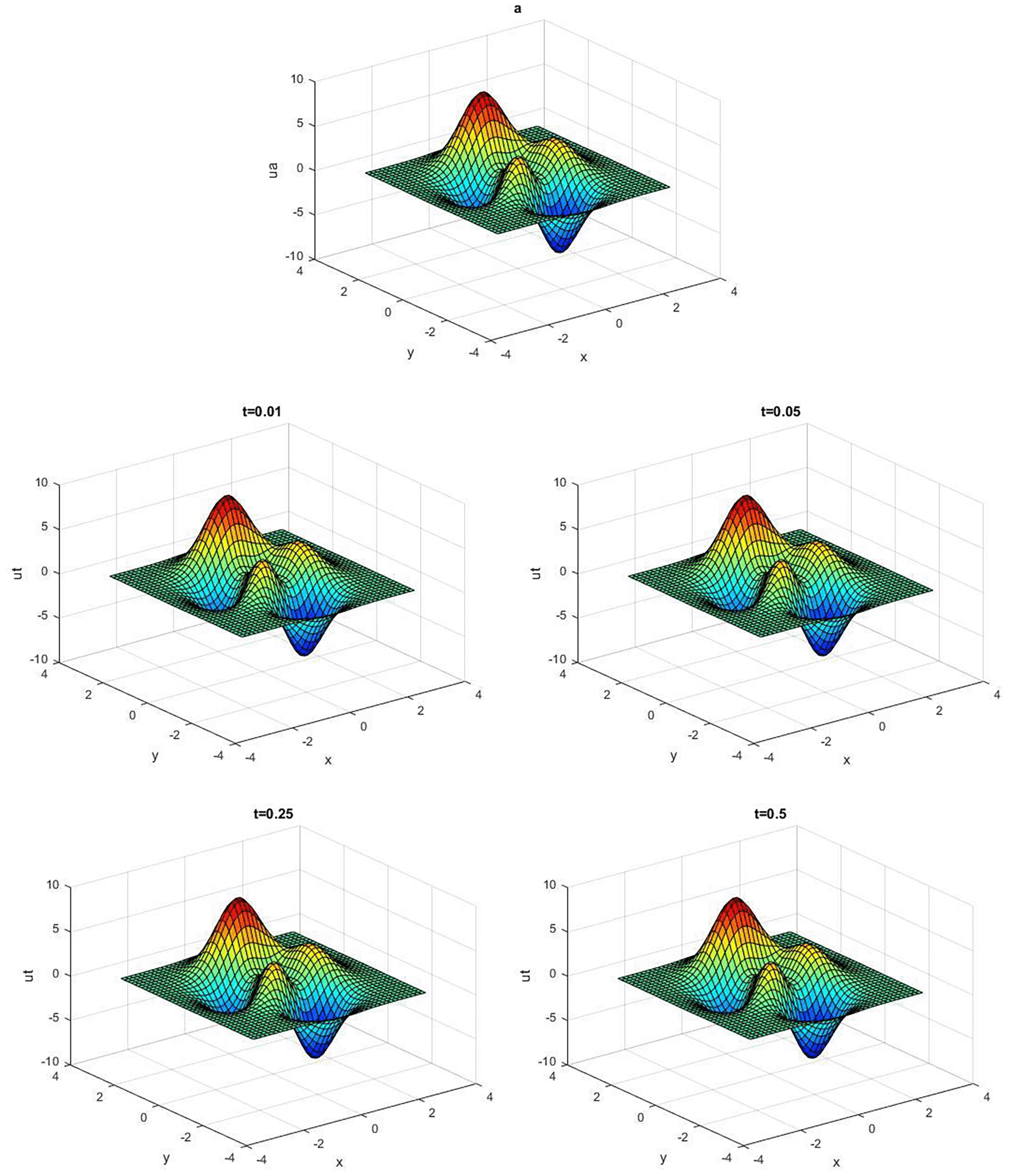
The results of solving the above equation at different times t are presented in Table 1. The neural solution for this equation is shown in Figure 1.
We stopped utilizing the algorithms by employing Himmeblau's law18:
If then . Otherwise, . For every problem, if is used, the program is terminated.
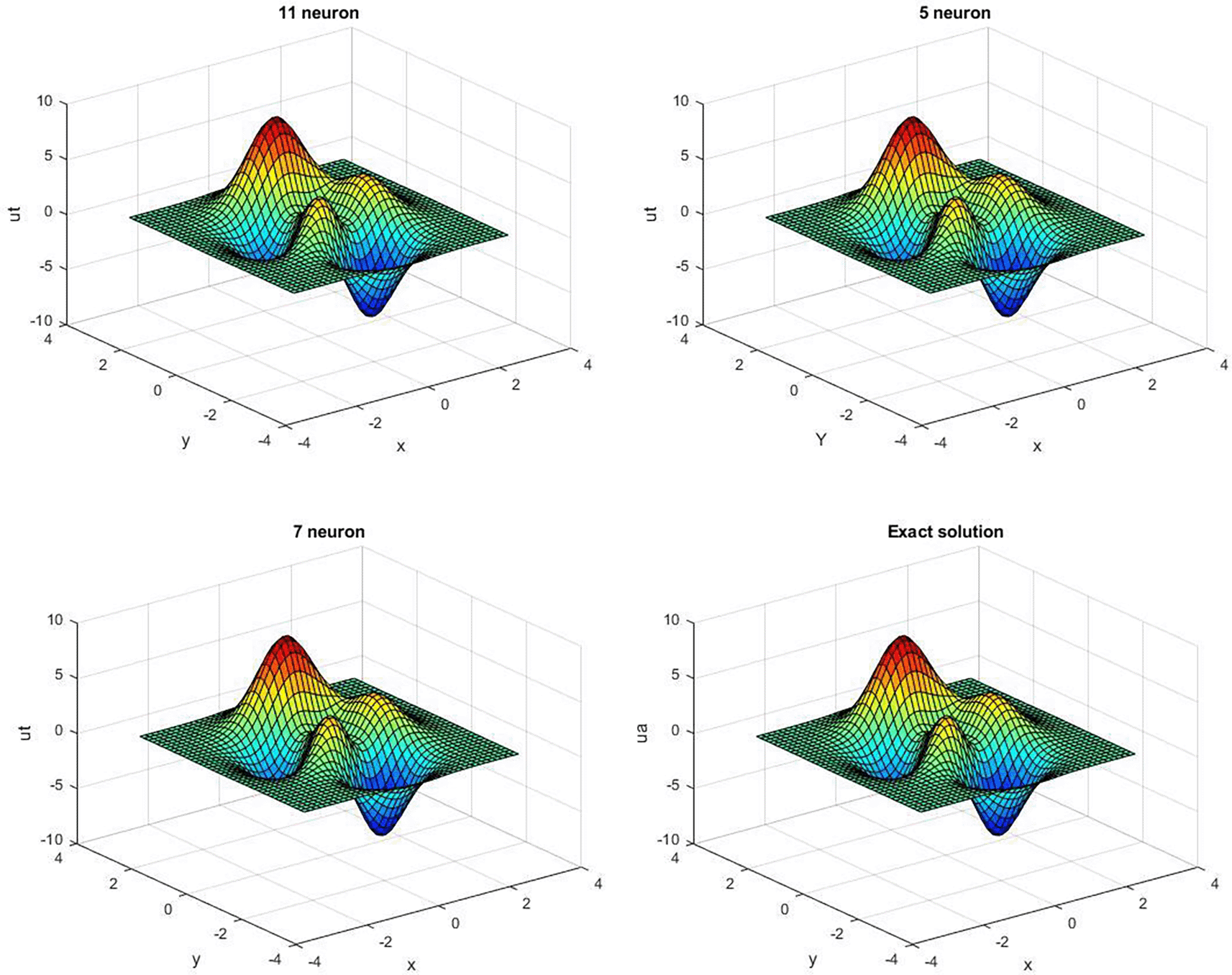
Quasi-Newton approaches perform better when an appropriate quasi-Newton equation is employed. The performance of the new update with was the best of the three methods, whereas the normal performance of the new update with and was somewhat better than that of the BFGS technique. As a result, among the QN -procedures for unconstrained problems, the new update with is the most well -organized.
Consider the nonlinear 4th order has the form:
The neural solution for this equation is shown in Figure 2 when z = -0.5. The accuracy for epochs and time is presented in Table 2, and Table 3, illustrates the results of the neural solution of the equation.
In this study, we constructed improved BFGS quasi-Newton updating formulae by using the proposed robust QN -equation. Second-order information from Hessian’s Hessian objective function Hessian’s is used in this study to develop a novel quasi-Newton equation. Two nonlinear 4th order example are provided to illustrate the accuracy of the suggested update, The results are consistent with the practical results and conform to the results that the suggested update, is globally convergent.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)