Keywords
Uzbek language; legal named entity recognition; legal NLP; low-resource NLP; dataset; information extraction; synthetic augmentation; sequence labeling.
Uzbek language; legal named entity recognition; legal NLP; low-resource NLP; dataset; information extraction; synthetic augmentation; sequence labeling.
Named entity recognition (NER) is an important task in natural language processing and information extraction, especially in domains where entities carry legal, administrative, and operational value. In Uzbek legal and quasi-legal texts, entities such as persons, organizations, locations, dates, monetary amounts, document identifiers, legal references, courts, banks, tax identifiers, and cadastral identifiers are important for document understanding, indexing, retrieval, and downstream language technology applications.1 However, Uzbek remains a low-resource language in legal-domain NER, and publicly reusable resources for this setting are still limited in both label coverage and release design.2
The dataset described in this article was prepared as a reusable Uzbek legal-domain NER resource intended to support data curation, controlled reuse, and future resource development.3 The release covers 12 entity categories: PER, ORG, LOC, DATE, MONEY, POSITION, DOCNO, LAW, COURT, BANK, TIN, and CADASTRE. In addition to the data records themselves, the package includes supporting documentation, provenance-aware metadata, review-related status fields, and synchronized exports in XLSX, CSV, JSON, and JSONL formats. Character-level start and end offsets are included where recoverable.4
A central feature of the release is its layered structure. The package distinguishes between a core subset of manually reviewable source-grounded records and an extended augmented subset intended for training support in lower-frequency labels.5 This separation was introduced to improve transparency and to make it easier for future users to distinguish source-grounded material from synthetic support data.6 The release should therefore be interpreted as a human-reviewed, gold-ready resource rather than as a fully finalized gold-standard benchmark.7
The present article focuses on describing the dataset, its construction logic, package organization, and validation-oriented release structure. The resource is intended to support Uzbek legal NER research, dataset organization, and transparent reuse under provenance-aware conditions.
The dataset was designed as a reusable Uzbek legal-domain named entity recognition (NER) resource for low-resource information extraction research.8 The release covers 12 entity categories: PER, ORG, LOC, DATE, MONEY, POSITION, DOCNO, LAW, COURT, BANK, TIN, and CADASTRE. The main goal of the dataset construction process was to create a provenance-aware and human-reviewable resource that can support dataset curation, transparent reuse, and training support under provenance-aware conditions in Uzbek legal NLP.9
The release was organized as a multi-layer package rather than as a single flat table. In particular, the dataset distinguishes between:
1. A core benchmark-oriented subset containing the most reviewable and source-grounded records, and
2. An extended augmented subset containing additional examples reserved for training support, especially for lower-frequency labels.10
This layered design was adopted to preserve methodological transparency and to prevent benchmark-oriented records from being mixed with augmentation-oriented material without explicit provenance tracking.
The dataset was compiled from Uzbek legal and quasi-legal texts collected from publicly accessible and reusable sources. Source selection was guided by legal relevance, practical reusability, and the need to cover both standard entity classes (such as persons, organizations, and locations) and legal-administrative entity classes (such as document numbers, legal references, tax identifiers, and cadastral identifiers).11
Because the target schema includes specialized labels that are not uniformly represented in public texts, the collection process was label-aware. High-frequency entity classes such as PER, ORG, and LOC were gathered from broader institutional and formal texts, whereas lower-frequency and domain-specific classes such as BANK, COURT, TIN, and CADASTRE required more targeted retrieval.12 Source-level provenance was preserved wherever possible through metadata fields such as Source_Name, Source_URL, Data_Origin, and Source_Group.
After source collection, candidate records were assembled in a label-wise manner rather than through a single uniform pipeline. Intermediate label-specific tables were created first and then merged into a unified release structure.13 This approach made it possible to monitor class coverage, identify low-resource labels early, and perform targeted refinement where required.
During preprocessing, the dataset underwent several harmonization steps:
• Alignment of label-wise tables into a common schema;
• Sentence cleaning and normalization;
• Standardization of entity-bearing fields;
• Preservation of provenance metadata;
• Integration of review-related fields;
• Consolidation of repeated or redundant rows.
Each record in the final package was represented as a row containing a text context (Sentence), an associated entity mention (Extracted_Text), a label (Label), and supporting provenance, verification, and usage metadata. Whenever recoverable, character-level offsets (Start_Char and End_Char) were also included to facilitate later conversion into stricter span-based sequence-labeling formats. The principal record-level fields included in the released dataset are summarized in Table 1. These fields describe not only the text and entity content of each record, but also its provenance, review status, and intended use within the release structure.
The table summarizes the principal text, provenance, review, and release-management fields included in the dataset package.
The dataset uses a 12-class entity schema designed specifically for Uzbek legal and quasi-legal documents. The selected labels were intended to balance practical legal relevance with annotation interpretability. In addition to general-domain categories such as PER, ORG, LOC, and DATE, the schema includes legal-administrative categories such as DOCNO, LAW, COURT, BANK, TIN, and CADASTRE, which are important for legal document analysis, structured extraction, and retrieval-oriented NLP applications.
To reduce ambiguity, the release documentation distinguishes between labels that may be superficially similar but functionally different in legal texts, such as ORG vs BANK, ORG vs COURT, DOCNO vs TIN, and DOCNO vs CADASTRE.14 The full set of entity categories included in the release is summarized in Table 2. This overview clarifies the scope of the annotation schema and highlights the legal-domain relevance of the selected labels.
The table lists the 12 named entity categories included in the release together with their general interpretation and typical legal-domain use. Abbreviations: PER, person; ORG, organization; LOC, location; DOCNO, document number; LAW, legal reference; COURT, judicial institution; BANK, banking institution; TIN, tax identification number; CADASTRE, cadastral identifier.
The release was prepared through a review-oriented refinement workflow rather than as a fully finalized gold-standard benchmark. After merging and harmonization, the records were screened using a staged quality-control procedure. Priority was given to:
• Rows with missing extracted entity text;
• Lower-frequency and structurally sensitive labels;
• Rows with incomplete provenance;
• Rows reserved for augmentation-oriented use.
Review decisions were recorded explicitly using categories such as keep, edit, drop, and move_to_augmented_only. The release also preserves row-level review metadata through fields such as Is_Verified, Verification_Status, Gold_Status, Eligibility, and Quality_Flag. This design makes the current version more transparent and easier to refine collaboratively in future iterations.15
The present release should therefore be interpreted as a human-reviewed, gold-ready resource, rather than as a fully adjudicated final gold benchmark.
To support labels with limited naturally available coverage in public Uzbek legal texts, a controlled synthetic augmentation strategy was applied selectively. Synthetic rows were introduced only for lower-frequency classes where source-grounded examples were insufficient for practical experimental support. The augmentation process followed a template-based generation strategy, designed to preserve legal-domain plausibility and label clarity.16
Synthetic records were explicitly marked in the metadata and were kept separate from benchmark-oriented material. These rows are intended for training support only and should not be treated as equivalent to manually reviewable source-grounded examples in evaluation settings.
The final dataset was released in four synchronized formats: XLSX, CSV, JSON, and JSONL. These formats were chosen to support different user needs:
• XLSX for manual inspection and metadata review,
• CSV for tabular processing and descriptive analysis,
• JSON for structured record-based storage,
• JSONL for NLP pipelines and line-based machine processing.
In addition to the data files, the package includes supporting documentation such as a README, data dictionary, split description, known limitations, citation file, changelog, and license information. The main components of the released package and their practical roles are summarized in Table 3. This table makes the multi-format structure of the release explicit and shows how the package supports both manual inspection and machine-readable reuse.
The table summarizes the principal package components, their file formats, and their intended practical role in reuse. Abbreviations: XLSX, Microsoft Excel workbook; CSV, comma-separated values; JSON, JavaScript Object Notation; JSONL, line-delimited JSON; TXT, plain text; MD, Markdown.
The dataset preparation, harmonization, and export workflow was carried out using standard spreadsheet and scripting tools. Structured preprocessing and export operations were performed using Python, version 3.10 with standard data-processing libraries such as pandas, version 1.5.3 and json, openpyxl, and re (regular expressions). The scripts and supporting files used for preprocessing, entity extraction, and formatting for the Zenodo release are included in the associated Zenodo repository: https://doi.org/10.5281/zenodo.19682709.17
No task-specific model training was required for the generation of the released tabular package itself; however, semi-automatic processing steps such as field normalization, recoverable span localization, and export conversion were performed using the above software environment. Parameters that may affect reproducibility include text normalization rules, row filtering criteria, provenance-based subset separation, and the logic used to assign Recommended_Split, Gold_Status, and Verification_Status fields.18 The overall dataset construction and release workflow is illustrated in Figure 1.
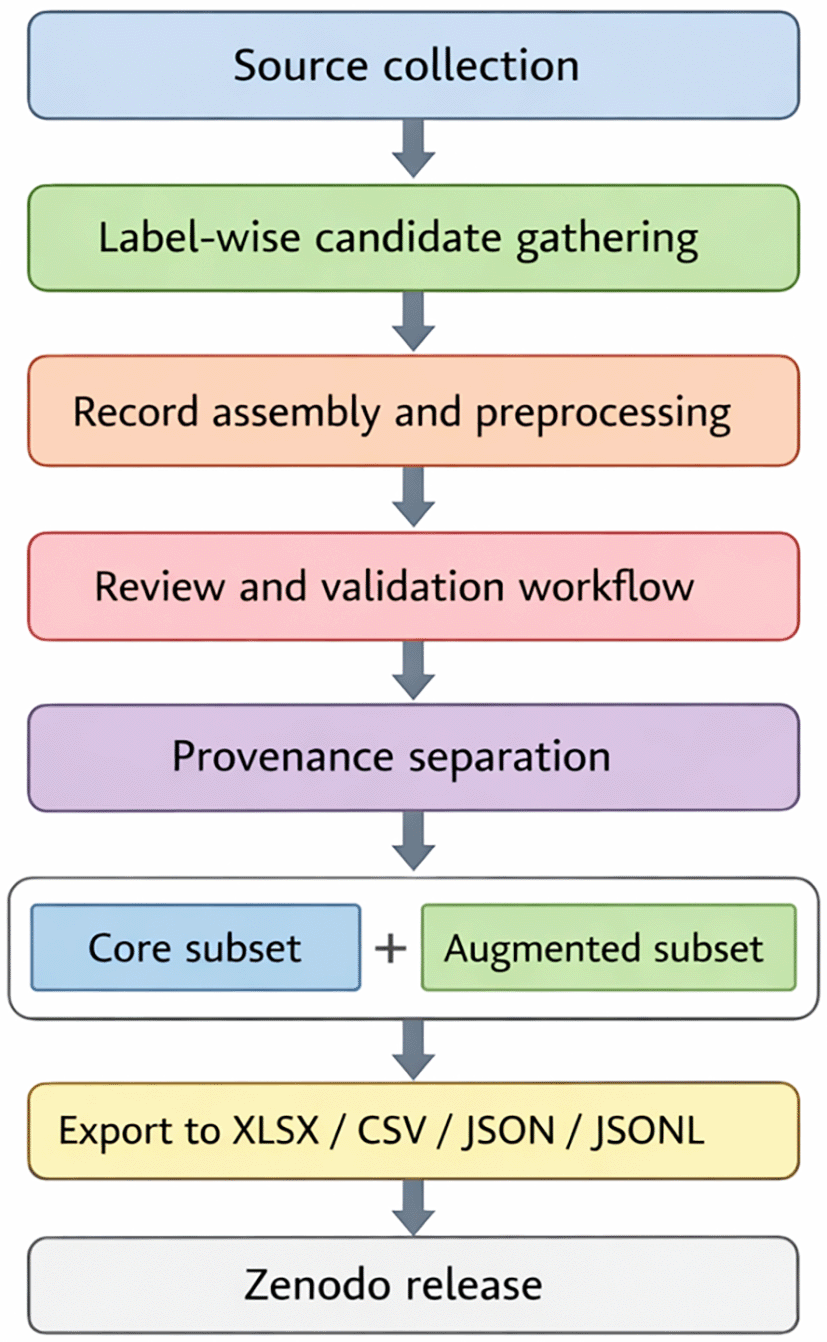
The workflow proceeds from source collection and label-wise candidate gathering to record assembly and preprocessing, review and validation, provenance separation, creation of the core and augmented subsets, export in XLSX, CSV, JSON, and JSONL formats, and final release via Zenodo. Abbreviations: XLSX, Microsoft Excel workbook; CSV, comma-separated values; JSON, JavaScript Object Notation; JSONL, line-delimited JSON.
The current release was validated through a staged quality-control and review workflow intended to improve structural consistency, provenance transparency, and practical reusability. Validation did not rely on a single binary accept/reject decision for the entire dataset; instead, it combined structural checks, review-oriented prioritization, and record-level status tracking.19
At the structural level, the dataset was checked for consistency across the released XLSX, CSV, JSON, and JSONL formats. These checks included field alignment, label consistency, preservation of provenance metadata, and consistency of release-specific fields such as Gold_Status, Verification_Status, Eligibility, Recommended_Split, and Quality_Flag. Where possible, recoverable character-level offsets (Start_Char and End_Char) were retained to support later conversion into stricter span-based NER formats.
At the record level, validation followed a review-oriented workflow. Priority was given to rows that were more likely to affect downstream benchmark quality, including records with missing extracted entity text, incomplete provenance, lower-frequency labels, and rows reserved for augmentation-oriented use. Review outcomes were tracked explicitly through categories such as keep, edit, drop, and move_to_augmented_only, together with supporting metadata fields such as Is_Verified, Verification_Status, Gold_Status, and Quality_Flag.
As shown in Table 4, the current release provides stronger coverage for high-frequency classes such as PER, ORG, and LOC, whereas lower-frequency classes such as BANK and COURT remain more limited and should therefore be interpreted with additional caution in benchmark-oriented settings.
| Label | Number of records |
|---|---|
| PER | 2000 |
| ORG | 2000 |
| LOC | 1700 |
| POSITION | 1300 |
| DATE | 1200 |
| MONEY | 1200 |
| DOCNO | 1200 |
| LAW | 1200 |
| TIN | 800 |
| CADASTRE | 700 |
| BANK | 411 |
| COURT | 325 |
| Total | 14,036 |
A further validation principle was explicit provenance separation. The release distinguishes between source-grounded open-source rows and synthetic augmentation rows, and this distinction was preserved through record-level metadata. Synthetic rows were not treated as equivalent to benchmark-oriented source-grounded examples and were retained only for augmentation-aware training use. This separation improves interpretability and reduces the risk of unintentionally mixing evaluation material with training support data.
The released package should therefore be interpreted as a human-reviewed, gold-ready dataset resource rather than as a fully finalized gold-standard benchmark. Its main strengths are its multi-format release design, explicit provenance metadata, and review-aware structure. These features make the dataset immediately usable for exploratory analysis, dataset refinement, and controlled training use under provenance-aware conditions.
At the same time, several limitations should be noted. First, not all records have undergone exhaustive final manual span adjudication. This is especially relevant for label pairs with higher ambiguity potential, such as ORG vs BANK, ORG vs COURT, DOCNO vs TIN, and DOCNO vs CADASTRE. Second, the current release is class-imbalanced, with stronger coverage for higher-frequency classes such as PER, ORG, and LOC, and more limited coverage for lower-frequency classes such as BANK and COURT. Third, the package contains both source-grounded and synthetic material with different evidential status, which requires provenance-aware filtering depending on the intended use case.
For conservative benchmark-oriented evaluation, users should prioritize the most reliable source-grounded rows and apply additional manual verification where necessary. For training-oriented experiments, the augmented subset may also be used, provided that the inclusion of synthetic support is reported explicitly.
This work did not involve animal experiments or direct human-subject research. The dataset was compiled from publicly accessible and reusable Uzbek legal and quasi-legal textual materials, together with controlled synthetic augmentation used for training support in lower-frequency labels. No direct participant recruitment, intervention, or experimental data collection was conducted. Therefore, ethical approval and informed consent were not required.
The release was prepared for research reuse with attention to provenance, documentation, and transparency. Users of the dataset are expected to follow applicable legal, ethical, and institutional requirements when handling identifier-like fields and other potentially sensitive legal-domain information.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)