Keywords
Artificial Intelligence, Image Manipulation, Social Media, Deepfake Detection, Synthetic Media, Digital Forensics, Privacy Implications, Identity Misuse, TCCM Framework.
This article is included in the Uttaranchal University gateway.
This article is included in the Artificial Intelligence and Machine Learning gateway.
Artificial Intelligence, Image Manipulation, Social Media, Deepfake Detection, Synthetic Media, Digital Forensics, Privacy Implications, Identity Misuse, TCCM Framework.
Artificial Intelligence (AI) has transformed how visual information is created, edited, and distributed on digital platforms. Previously, image editing was dependent upon human ability and specialized software; however recent AI technology can rapidly edit, modify, replace, or change faces and images. As a result, interest in the scholarship of AI-generated images and other forms of visual editing is increasing (Gaikwad et al., 2025).
Social media is the primary platform in which visual content is created, disseminated, and viewed. Visual images and video on social media also can be transmitted quickly among various platforms (Banh & Strobel, 2023). This rapid dissemination makes identifying manipulated images difficult to validate. Manipulated images potentially will negatively impact individuals’ privacy, identity, reputation, public confidence and digital safety. For example, manipulating an individual’s facial likeness without their knowledge may lead to loss of privacy, damage to one’s identity, harm to an individual’s reputation, harassment, potential mis-information creation and difficulties validating the original un-manipulated image (Golda et al., 2024).
Based on the selected Scopus dataset, there has been significant increase in research regarding AI and image manipulation on social media since 2019 until 2026. There has been a faster rate of growth since 2022. The majority of current research into AI and social media is technically-based. Most research focuses on developing algorithms/methods for detecting Deep Fakes, classifying fake images, creating enhanced machine learning models, utilizing Convolutional Neural Networks (CNN), Generative Adversarial Network (GAN), and forensic validation techniques. While these approaches are valuable for reliably detecting manipulated media, they do not address the privacy dimension. Privacy is generally considered via related areas of investigation including face recognition authentication, face forgery detection, misinformation, cybersecurity or platform risks (Abdullah et al., 2024). Therefore, while there is considerable disparity between technical detection methodologies and privacy focused analyses in terms of overall literature coverage (Mifa et al., 2024).
There are several reasons why this disparity in literature coverage is relevant for social media investigations. Techniques for detecting manipulated images provide researchers with the means to determine if an image has been modified (Sajid et al., 2026). However, simply being able to detect modification does not capture all aspects of harm associated with the manipulation of an individual’s image. Privacy violations include the lack of informed consent for the use of one’s likeness, ownership issues surrounding one’s image, misuse of one’s identity, stigma from having one’s image used in negative contexts, damage to an individual’s reputation, emotional trauma from knowing one’s image has been manipulated for negative purposes and a lack of legal protections (Sajid et al., 2026). Therefore, the above referenced disparities highlight a need for a broader examination of the extant literature. Additionally, a bibliometric approach can help illustrate the scope of publications or research into AI and image manipulation on social media (Liu et al., 2022). Furthermore, a TCCM (Theory Context Characteristics Methodology) based review will enable classification of the extant literature within these parameters (Papasavva et al., 2025).
The purpose of this study is to investigate AI and image manipulation on social media using both a bibliometric analysis and a TCCM based review. Outputs from both Biblioshiny and VOSViewer were utilized to analyse annual productivity, importance of the source material, evolution of sources over time, contribution by country, globally cited articles, frequencies of keywords, evolving trends, relationships among three fields, co-occurrence of keywords and clustering of keywords (Papasavva et al., 2025). Following this analysis, the TCCM based review identified the underlying theories or frameworks employed within the extant literature. The social media context within which this research is conducted prominent characteristics exhibited by much of the literature reviewed, methodological practices employed throughout the literature reviewed, research gaps within the literature reviewed and areas of inquiry that should be pursued in future research (Prasoon et al., 2024).
In conclusion this study provides contributions to the literature in four distinct manners. First, this study establishes a bibliometric representation of the exponential growth of research into AI and image manipulation in social media from 2019–2026. Second, this study identifies the most prominent themes investigated in the extant literature, specifically Deep Fake Detection, Machine Learning, Digital Forensic Verification, Misinformation, Cyber Security, Synthetic Media (Wang et al., 2024). Thirdly, this study uses a TCCM (Theory Context Characteristic Method) as an extreme classification scheme for categorizing the literature that has been surveyed into categories of Theory, Context, Characteristic Methodologies (Agha, 2025). Finally, this study finds that privacy implications are relatively underdeveloped compared to technical detection.
The primary objective of this study is to assess both the bibliometric structure and TCCM based research direction for literature examining AI and Image manipulation on social media. Specifically,
1. To evaluate and characterize publication growth profiles examining research about AI and Image manipulation on social media from 2019–2026.
2. To establish leading sources, publication, affiliations, global citations for literature examined in selected Scopus datasets.
3. To analyse the main keywords, topic trends, keyword co-occurrence patterns, and thematic clusters related to Artificial intelligence, Image manipulation, Deepfake detection, Synthetic media and social media.
4. To apply the TCCM framework to classify the literature according to theory, context, characteristics, methodology, research gaps, and future research directions.
5. To evaluate the extent to which existing studies address privacy implications, including consent violation, identity misuse, image misuse, reputational harm, victim protection, and platform accountability.
This study used a bibliometric review design supported by the TCCM framework to examine research on artificial intelligence and image manipulation in social media. The method was selected because the paper aims to identify publication growth, source patterns, country contribution, citation structure, keyword relations, thematic clusters, and future research directions (Wang et al., 2024). The TCCM framework was used to classify the literature into theory, context, characteristics, and methodology. The TCCM framework has been used in review studies to organise theory, context, characteristics, and methodology for future research framing (Wikum & Wijayanayake, 2024).
The data were retrieved from the Scopus database. Scopus was selected because it provides structured bibliographic records, citation information, author details, source titles, affiliations, abstracts, keywords and document type details. These fields are suitable for bibliometric analysis and TCCM based review work. The following search string was used in Scopus:
TITLE-ABS-KEY((“artificial intelligence” OR AI OR “machine learning” OR “deep learning”) AND (“image manipulation” OR deepfake* OR “synthetic media” OR “AI-generated image*” OR “image alteration”) AND (“social media” OR “social networking site*” OR “digital media” OR “digital platform*”)).
The study did not include privacy as a mandatory search term because the purpose was to examine whether privacy appears within the wider literature on AI based image manipulation in social media. This approach allowed a systematic evaluation of the extent to which privacy has been considered as a key issue directly or indirectly. The search string was developed to find studies that have examined how people are using AI-based techniques with artificially manipulated or created visual content (i.e., “synthetic” visual content) within both social media and digital media environments. The first set of terms identified the technological foundation for this body of research, specifically focusing upon artificial intelligence, machine learning, and deep learning. The second set of terms focused upon the object of analysis, such as image manipulation, deep fakes, synthetic media, AI-generated images and image alteration. The third set of terms limited the search results to only those studies published within social media, social networking sites, digital media, and digital platforms.
Data coverage spanned from 2019 through 2026. A total of 195 documents were included in the study’s final data-set, published by an array of authors across 168 different sources (with 697 authors overall), having an average citation rate of 22.05 percent and 17.19 citations per document respectively.
Criteria for inclusion and exclusion were developed in order to ensure that the data set was consistent with the title, literature search strategy and objective of this investigation (Amerini et al., 2025). A record would be considered as part of this study if there was some reference in the title, abstract, authors’ keywords or indexer’s keywords of a record to either Artificial Intelligence, Image Manipulation, Deep Fake, Detection of Fake Images, Synthetic Media, Digital Media Forensics, Social Media Misinformation, Authentication, Cybersecurity or Privacy Concerns. Privacy was treated as an analytical concern rather than a mandatory search term because the study aimed to assess whether privacy implications were directly represented or indirectly embedded within the selected literature (Amerini et al., 2025).
Records were included when each study matched the search logic of artificial intelligence or related computational techniques, image manipulation or synthetic visual content, and social media or digital platform context. Studies published between 2019 and 2026 were retained. The literature survey includes articles, conference papers, reviews, book chapters, and books in order to include literature which has strong connections to computer science, engineering, conference proceedings, imaging science and other applied research literature outlets.
The records were removed if they did not relate to AI-based visual manipulation, social media, Deepfake detection, synthetic media, fake images identification, privacy risks, authentication, or digital media verification. Records that focused only on artificial intelligence without any clear relation to image manipulation, synthetic media, or digital platform context were excluded. Studies that discussed social media without a clear link to AI based visual manipulation or synthetic media were also excluded.
Duplicate records and incomplete bibliographic entries were removed during data cleaning. Records with no clear connection to social media-based image manipulation were not retained for the final analysis. This screening process helped ensure that the final dataset remained focused on the bibliometric and TCCM based review of artificial intelligence and image manipulation in social media (Shree et al., 2024).
The exported Scopus file was cleaned before analysis. Duplicate entries were removed. Titles, source names, author keywords, indexed keywords, publication year, citation count, country information, and affiliation data were checked for consistency. Although related terms were reviewed for consistency, terms such as deepfake, deepfakes and deepfake detection were retained when they represented different uses in the dataset.
This clean dataset was also utilized for descriptive bibliometric analysis, source analysis, citation analysis, country analysis, keyword analysis, co-occurrence mapping, cluster analysis and TCCM Classification (Shree et al., 2024). This clean dataset provided all the main tables and figures depicted in the Results Section.
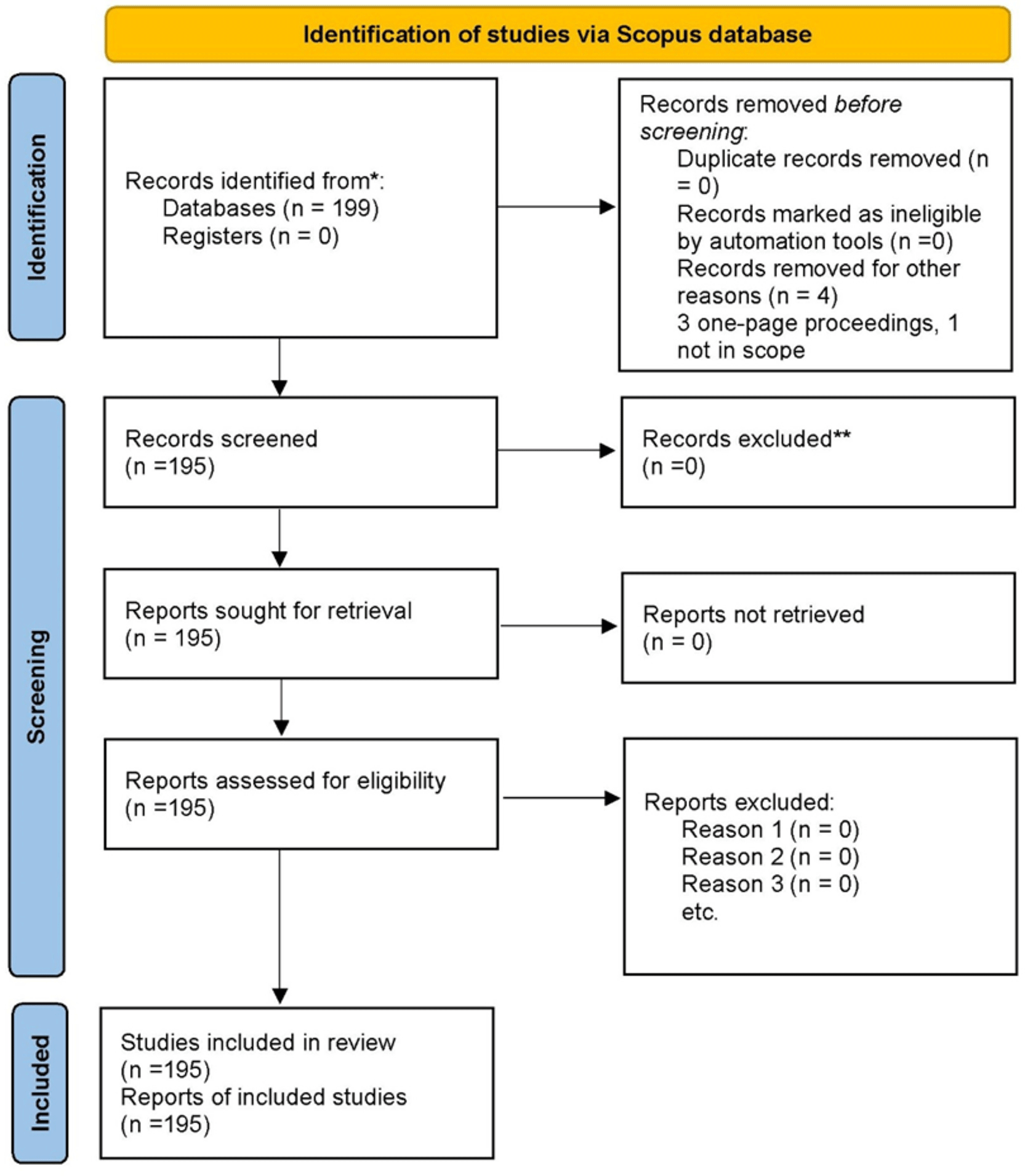
A flow chart is provided as Figure 1 to illustrate how data preparation occurred for the final dataset. The initial Scopus search yielded a total of 199 references. Before screening began four references were removed from consideration (three one-page conference proceeding references; and one reference that fell outside the focus of this research). Thus, all other references (195) were considered for inclusion in the final TCCM bibliometric review. As such, it can be confirmed that the final analyses were performed using 195 indexed references in Scopus.
In order to assess how much this body of research has grown since it began, bibliometric analysis was performed. Publication quantity (scientific) for each year from 2019 through 2026 was used to determine if there was an upward trend of productivity within those years. The results are: 4 in 2019; 10 in 2020; 12 in 2021; 8 in 2022; 29 in 2023; 50 in 2024; 63 in 2025; and, as of 25 Mar. 2026, 19. The 2026 total is considered a partial because data extraction stopped on that date.
In order to determine where the majority of publications came from, a source analysis was completed (Schmitt & Fléchais, 2024). That source analysis indicated that the publications appeared throughout various disciplines including Computer Science, Engineering, Network Systems, Conference Proceedings, Imaging Science and Applied Scientific journals. There was no single source that generated most of the documents found in the dataset. Therefore, the distribution of sources indicates that the development of the body of knowledge is occurring across multiple publication channels and not confined to a particular journal or discipline.
A citation analysis was also performed to determine which authors (Sharma et al., 2024) and organizations received the greatest amount of academic attention. At the country-level, India published the largest number of articles at 66 and the U.S. received the most citations with 1750. This comparison allowed researchers to differentiate between article quantity (or “volume”) versus article quality or citation influence (Vhatkar et al., 2025).
Keyword evaluation was performed to establish the primary research topics represented in the data set (Uddin et al., 2025). Tree map and co-occurrence evaluations identified social media, Deep learning, Deepfake, Artificial intelligence, Deepfake detection, Fake detection, Machine learning, Digital forensic science, Cybersecurity, Misinformation, Facial recognition, authentication and synthetic media as the primary terms found in the literature. The term “social media” was evaluated as the most dominant term, appearing 125 times or 11% of all terms analysed.
Cluster analysis divided the literature into five categories: Artificial Intelligence & Social Media; Synthetic Media & Deep Fake; Detection Methods and Machine Learning; Digital Forensic Science & Media Verification; Platform Security (Content Integrity). These categories supported both the TCCM analysis and subsequent research directions (Shoaib et al., 2023).
Biblioshiny was utilized to provide descriptive bibliometric data, an analysis of annual scientific productivity by year (Zhao & Lye, 2024), a source analysis, the most important references related to the research topic, a keyword tree map, a word frequency trend, thematic output and global citation analysis. VOSviewer was utilized for visualizing networks in bibliographic citations, specifically an analysis of publication and citation trends by country and a co-occurrence mapping of keywords (Yang & Menczer, 2024). Both Biblioshiny and VOSviewer were chosen due to their suitability for analysing bibliometric maps and the structures of research (Solanki, 2026). Outputs generated using these two software applications were also compared against the cleaned Scopus database prior to interpreting the information (Yazdani et al., 2025). This process allowed for maintaining consistency between the database values and the tables and figures in the manuscript (Ferrara, 2024).
Following the application of the TCCM (Theory Context Characteristics Methodology) framework for structuring a future research agenda based on bibliometric and keyword analysis (Gupta & Fatunmbi, 2024). The TCCM Framework identified four categories in which to group the findings: theory, context, characteristics and methodology. The use of this framework is consistent with the organisational structure found in all reviews based on the TCCM framework (Liu et al., 2024). In these reviews’ theory, context, characteristics and methodology are employed as an organising principle for prior literature to identify new areas of investigation.
The ‘theory’ component of the framework included Artificial Intelligence (AI), Deepfake Detection, Machine Learning (ML), Digital Media Forensic Science, Misinformation, Cybersecurity. The ‘context’ component included social media platforms, online platforms, AI generated images, Circulation of Deepfakes and Synthetic media sharing. The ‘characteristics’ component included Deepfakes, Fake Images, Face Swap, Authentication, Digital Media Authenticity, Misinformation. The ‘methodology’ component included Deep Learning (DL), ML, Convolutional Neural Network (CNN), Generative Adversarial Network (GAN), Feature Engineering, Face Recognition/Detection, Digital Watermarking and Forensic Verification.
This structured method of TCCM Analysis identified the primary research gap from the current literature (Loth et al., 2024). Results showed that existing literature has given greater priority to detection/verification aspects rather than privacy-centred concerns. As such the TCCM framework was utilised to develop proposals for future research in relation to consent, identity misuse, reputational harm, victim protection, legal safeguards and platform accountability.
The study is confined to data that were retrievable from Scopus at the time of the retrieval. The citation counts may be modified when additional articles are added to the index and authors’ subsequent articles are cited. Only partial year (i.e., through 31 Dec) 2026 article counts can be represented since the database was downloaded on 25 Mar 2026. In addition to these limitations, the results reported herein have been shaped by the search terms selected for this project and how Scopus has indexed related material. However, the dataset will provide an adequate basis for analysing both the bibliometric structure of artificial intelligence and image manipulation in social media and the future research directions of artificial intelligence and image manipulation in social media based upon TCCM.
This section provides an overview of both the thematic pattern and also the quantitative data of all Scopus literature from 2019–2026 that contains Artificial Intelligence and Image manipulation in social media.
Table 1 provides a general overview of the main bibliometric characteristics of the selected literature related to artificial intelligence and the use of image manipulation within social media. The bibliography includes 195 documents from 168 different publication sources that were released between 2019 through 2026. The annual growth rate of 24.93 percent shows a steady rise in publication activity, which indicates increasing academic attention toward AI generated visual content, Deepfake detection, synthetic media, fake image identification, and social media based digital risk. The involvement of 697 authors shows that the topic has attracted a wide research community across computer science, engineering, media studies, information security, digital communication, and privacy research. The international co authorship rate of 22.05 percent indicates moderate cross-country collaboration. The average citation rate of 17.19 citations per document shows that the selected literature has received measurable citation attention, especially in studies related to deepfake detection, media forensics, fake image identification, and privacy related risks.
| Time period | 2019–2026 |
|---|---|
| Number of documents | 195 |
| Number of sources | 168 |
| Annual growth rate | 24.93% |
| Authors | 697 |
| International co-authorship | 22.05% |
| Average citations per document | 17.19 |
Figure 2 presents the annual publication output and average citation pattern of research on artificial intelligence and image manipulation in social media from 2019 to 2026. The first graph shows annual scientific production, while the second graph presents average citations per year. Both graphs provide a clear view of the growth and citation pattern of the selected Scopus literature.
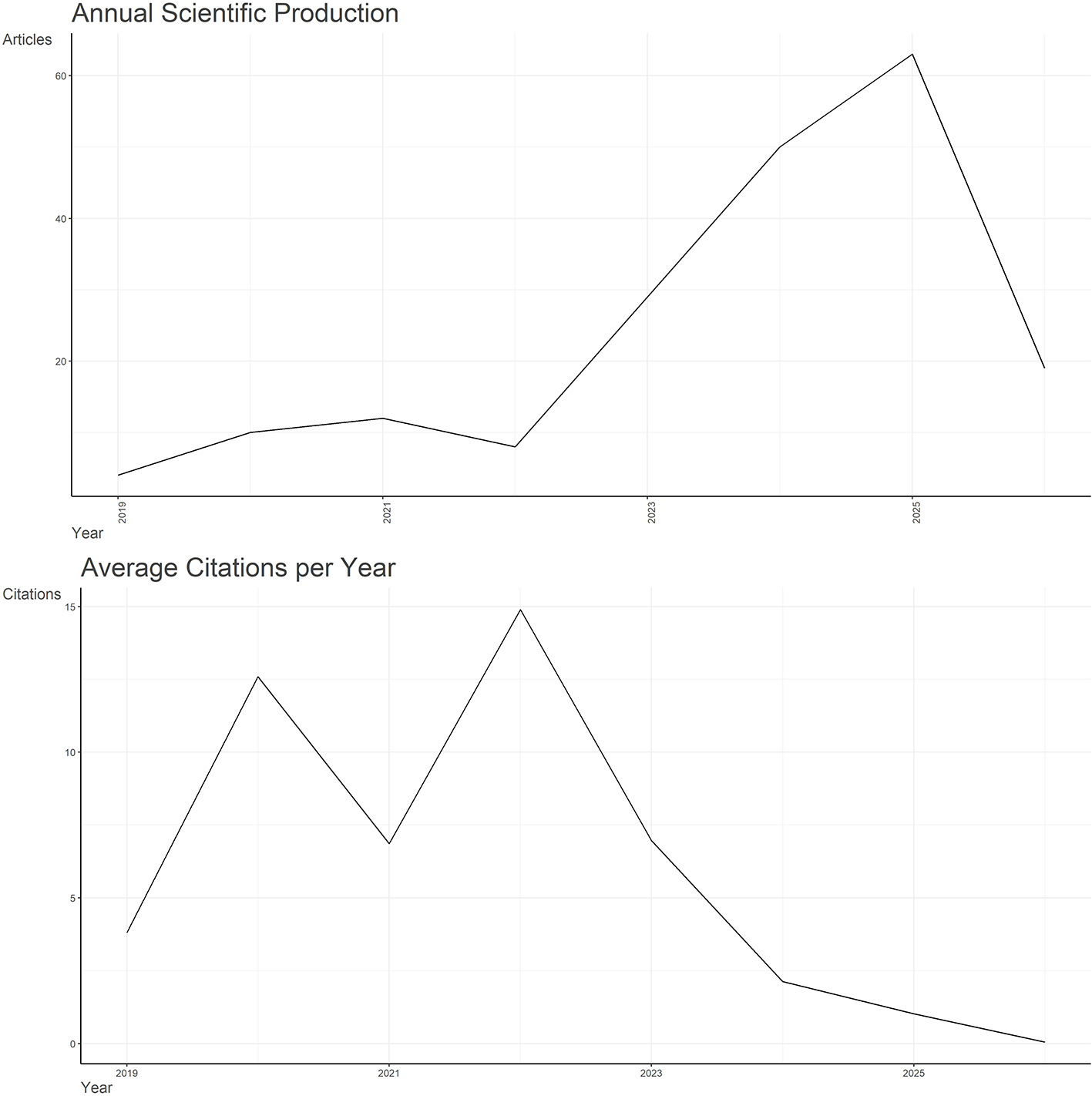
The annual production graph shows that publication activity was limited in the early years. The dataset records 4 publications in 2019, 10 in 2020, 12 in 2021, and 8 in 2022. After 2022, the field shows clear growth. The number of publications increased to 29 in 2023, 50 in 2024, and 63 in 2025. This rising trend is indicative of increasing academic interest in AI based image editing, Deep fakes (synthetic visual content), detection of fake media, privacy risks associated with social media platforms etc.
The downward trend seen for 2026 does not represent an absolute decline in research interest. There were 19 publications in 2026 recorded in this dataset; however the date these records were retrieved from Scopus was 25th March 2026. Thus the 2026 record reflects only partial year data and could potentially have been higher if additional publications which will be added to the index over the course of the remainder of 2026 are included.
Figure 2 illustrates that research output has increased post-2022 whilst citation averages show greater levels of citations in previous years due to having a longer citation period. The Lower Citations per Publication seen in both 2025 & 2026 can therefore be viewed solely as being related to the time window and not as evidence of declining Academic Interest.
Table 2 shows the cumulative publication output of the top publishing sources for this Scopus dataset (from 2019–2026). In addition to showing which publishing sources contributed to the literature at various times during the study period, Table 2 also helps to visualize a source’s contribution to the overall body of work. As can be seen from the data in Table 2, Lecture Notes in Computer Science had been producing literature since the start of the study period. During the 8 years included in the study period, it produced one article in 2019, one article in 2020, two articles in both 2021 and 2022, four articles in both 2023 and 2024, and four articles in both 2025 and 2026. These numbers are consistent with a source that is providing an ongoing venue for publishing studies on Artificial intelligence, Image manipulation, detecting deepfakes and privacy issues as they relate to social media.
At the beginning of the study period Communications in Computer and Information Science did not have a single article published during either of its first two years. However, the next year it began to produce literature. Between 2021 and 2026, it produced one article each in those three years, then two articles in 2024, three articles in 2025, and four articles in 2026. Thus, these numbers suggest that this source has become more prominent in the second half of the study period.
Engineering and Network based sources showed an increase in their production of literature over time. Specifically, Lecture Notes in Electrical Engineering had no articles prior to 2022. Then in 2022 it had one article and by 2026 it had four articles. Lecture Notes in Networks and Systems had no articles until 2023. Its first year of production included one article. Then it continued to publish one article per year until 2025 when it published two articles. Finally, in 2026 it published four articles. Overall, these patterns indicate that academic studies using AI for manipulating images, etc., were appearing more frequently in engineering and system-oriented journals and conferences toward the end of the study period.
ACM International Conference Proceedings Series had only one article published prior to 2022. From thereon out it published three articles annually from 2023 to 2026. This pattern aligns well with the type of technical subject matter discussed above because most studies on identifying fake videos/images or video/image forensic techniques are typically presented through conference proceeding formats.
Proceedings of SPIE demonstrated production activity only from 2024 forward. In 2024, it published three articles. In both 2025 and 2026, it also published three articles. Therefore, these numbers demonstrate the application of image processing/optical engineering/visual analysis concepts to AI-based image manipulation studies.
Scientific Reports demonstrates a late entry into this research area. The first year it appeared in this dataset was 2025. It published three articles that year. In 2026, it again published three articles. These numbers suggest that there may be increasing academic interest in studying AI and image manipulation studies as reflected by an increase in scholarly journal level publications regarding this research area (Loth et al., 2024).
Figure 3 illustrates the topmost publication sources identified from the Scopus database on artificial intelligence and image manipulation within social media. The number of documents per publication source was used to determine which sources were the most influential in terms of quantity (Ilavendhan & Vignesh, 2023).
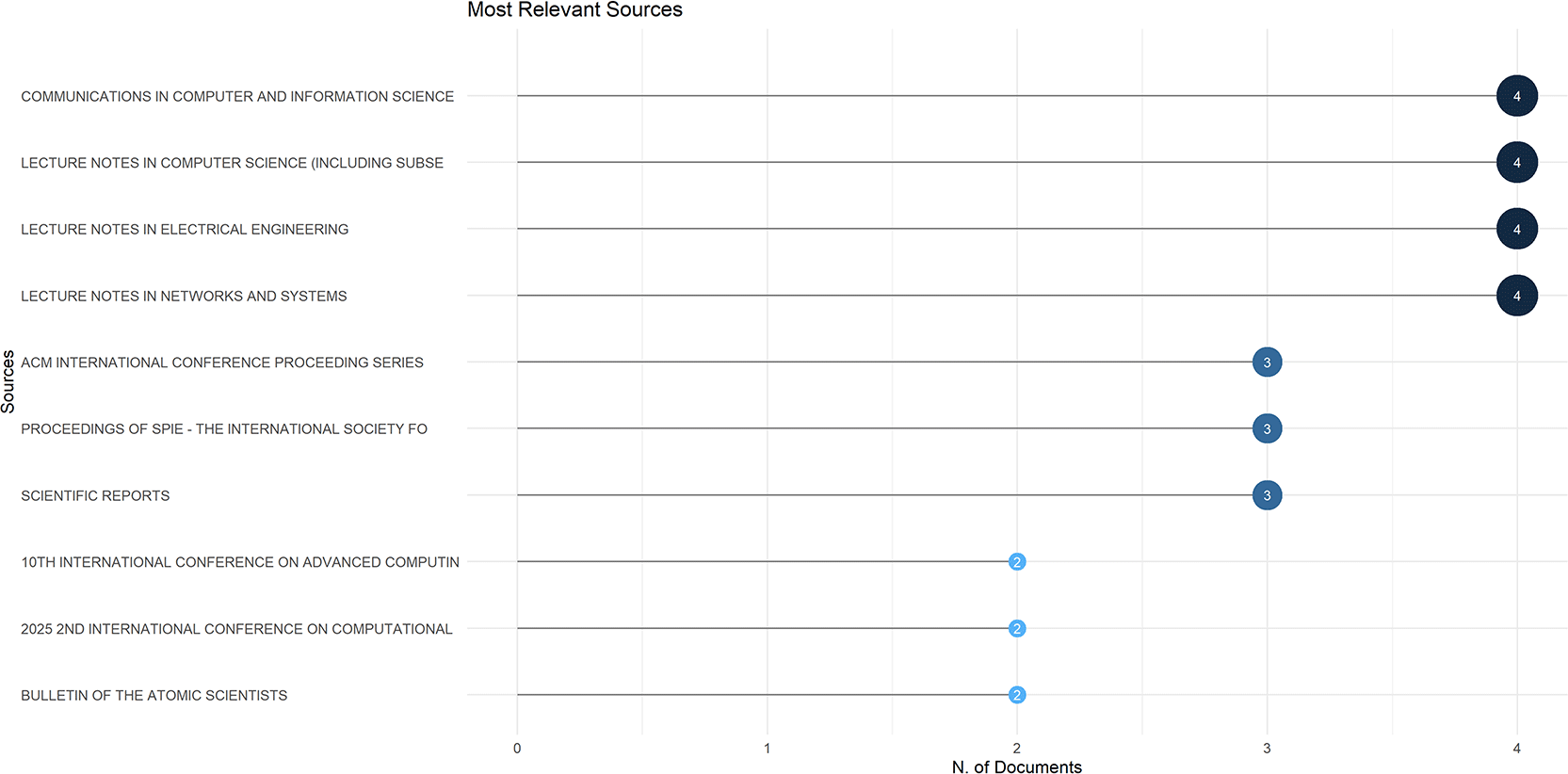
The figure identifies that there are four publication sources that had the largest quantity of documents (each with 4). The four sources include Communications in Computer and Information Science, Lecture Notes in Computer Science, Lecture Notes in Electrical Engineering and Lecture Notes in Networks and Systems.
This presence of these four sources indicates that research on Artificial Intelligence based Image Manipulation, Deepfake detection, Synthetic media analysis and Fake image identification rely heavily on Technical and Computational Approaches.
The next grouping includes the ACM International Conference Proceeding Series, Proceedings of SPIE, and Scientific Reports each having three documents. These sources represent how research based at conferences (ACM), Imaging Sciences (Proceedings of SPIE) and Applied Scientific Research (Scientific Reports) contribute to the field. The inclusion of Proceedings of SPIE, further supports how researchers applying image processing, visual analysis and Optical Engineering approaches utilize techniques in their study of manipulated images and synthetic visual content.
Figure 3 demonstrates that while one publication source did dominate the number of publications in this dataset, it was by an extremely small margin; i.e., the maximum number of documents found in any single journal was 4. Therefore, the literature in artificial intelligence and image manipulation is dispersed over a variety of journals. The distribution of literature over multiple journals suggests that artificial intelligence and image manipulation is developing as an integrated body of knowledge. Additionally, the dispersion of literature across multiple publication types (technical, media, security and platform) where technical detection studies, privacy concerns, social media risks and digital security concerns are being researched across various publication types demonstrate that this body of knowledge is still evolving (Ilavendhan & Vignesh, 2023).
Figure 4 highlights those institutions (affiliations) identified within the selected Scopus dataset as having produced research into artificial intelligence and image manipulation in social media. The number of articles associated with each affiliated institution allows for ranking and comparison. The purpose of this was to determine which institutions were the major contributors in terms of producing peer-reviewed literature on artificial intelligence, image manipulation, deepfakes and visual media processing (Willie, 2025).
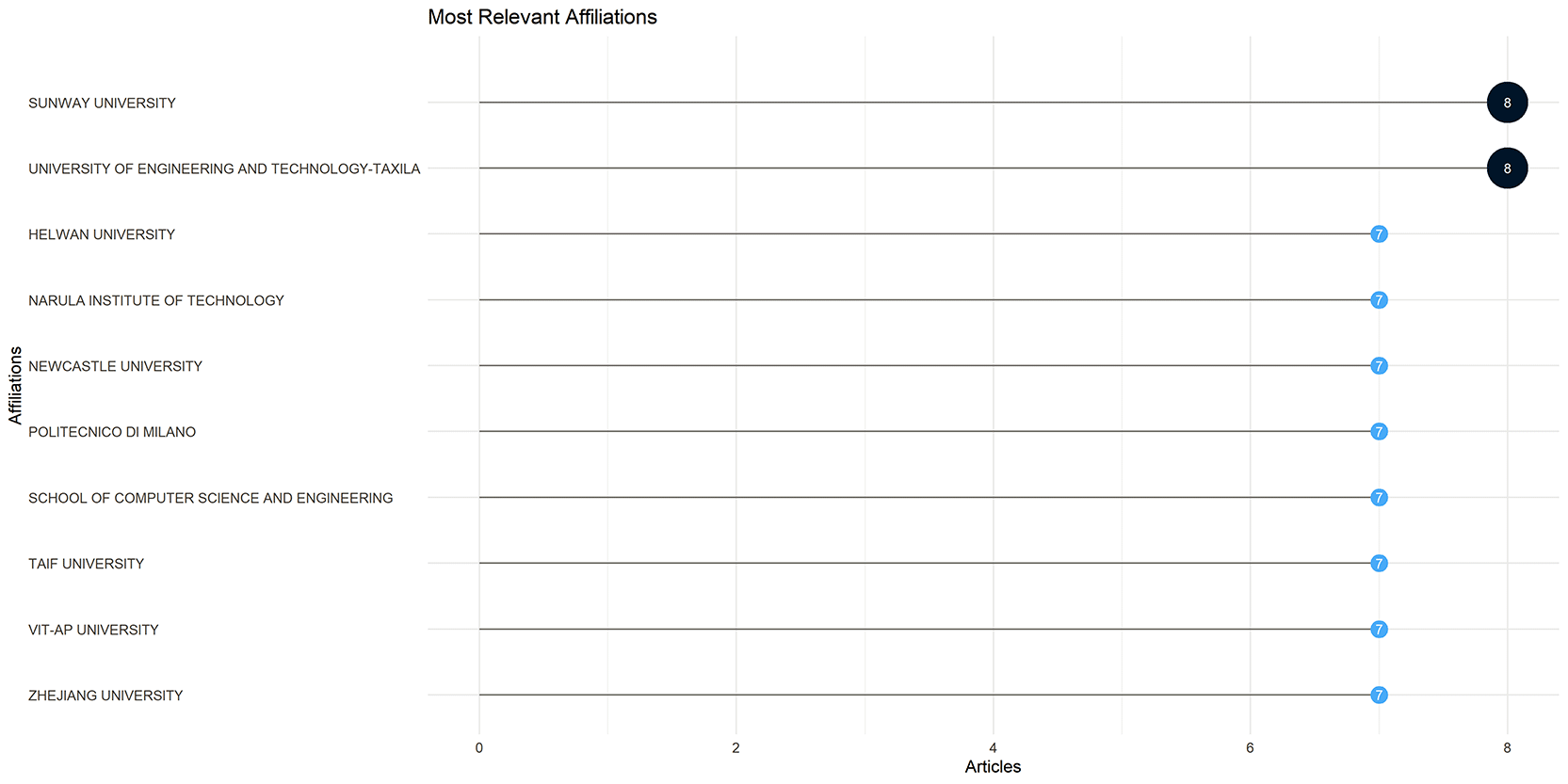
Sunway University and the University of Engineering and Technology, Taxila appear to have the greatest association within the data set, at 8 articles per affiliation. As such it would appear they have an active research community studying topics related to artificial intelligence, image manipulation, deepfake detection, visual media processing and related digital privacy concerns. It is important to note that due to authors being indexed in institutional databases by Scopus and how Scopus parses author affiliation data, it views this as a general trend in affiliation levels rather than an indicator of the level of quality or quantity of the research conducted by each institution (Willie, 2025).
Following the two institutions with 8 articles each are the institutions from the second tier. Institutions that appear in this tier include; Helwan University, National Institute of Technology, Newcastle University, Politecnico di Milano, School of Computer Science and Engineering, Taiyuan University, VIT AP University, and Zhejiang University. Each of these institutions contributes to our understanding that the literature on this subject is being developed globally. This global distribution lends itself well to the topic since AI-based image manipulation and social media privacy risks do not exist geographically.
Additionally, the affiliation pattern also supports the technical orientation of the research field. As previously mentioned, many of the listed universities are affiliated with departments in fields including computer science, engineering, information technologies, and applied computing. This is consistent with the characteristics of the dataset where numerous studies focused on developing machine learning based approaches for identifying fake images, detecting deepfakes, media forensic analysis, and other areas of study related to analysing synthetic visual content.
India had the largest number of publications (66) in the selected Scopus dataset relating to artificial intelligence and image manipulation in social media. Therefore, there is substantial research being carried out at Indian universities or colleges relating to artificial intelligence, image manipulation and related fields (Han et al., 2024). However, India’s citation count was only 445. While the U.S. produces less documents (only 38), it receives a significantly higher citation rate (1,750). In other words, publications by authors based in the U.S. are generally better recognized academically within the selected dataset than those published by authors who are based elsewhere.
Therefore, a nation can publish fewer documents but still be able to achieve a larger citation ratio depending on how often its authored papers are referenced.
Additionally, China produced 16 documents and received 230 citations. This represents stable research contribution in AI-related applications for visual content processing.
In addition, the UK produced 14 documents and obtained 107 citations. Similarly, Saudi Arabia produced 13 documents and received 109 citations. The above statistics suggest that research into these subjects is taking place in many different research systems around the world.
From Figure 5 it is seen that there are two key trends. Firstly, India has the largest numbers of publications and therefore there is significant research productivity occurring in India. Second, the United States leads in citation impact, which reflects stronger citation influence within the dataset. The figure also confirms that research on artificial intelligence and image manipulation in social media is not limited to one region.
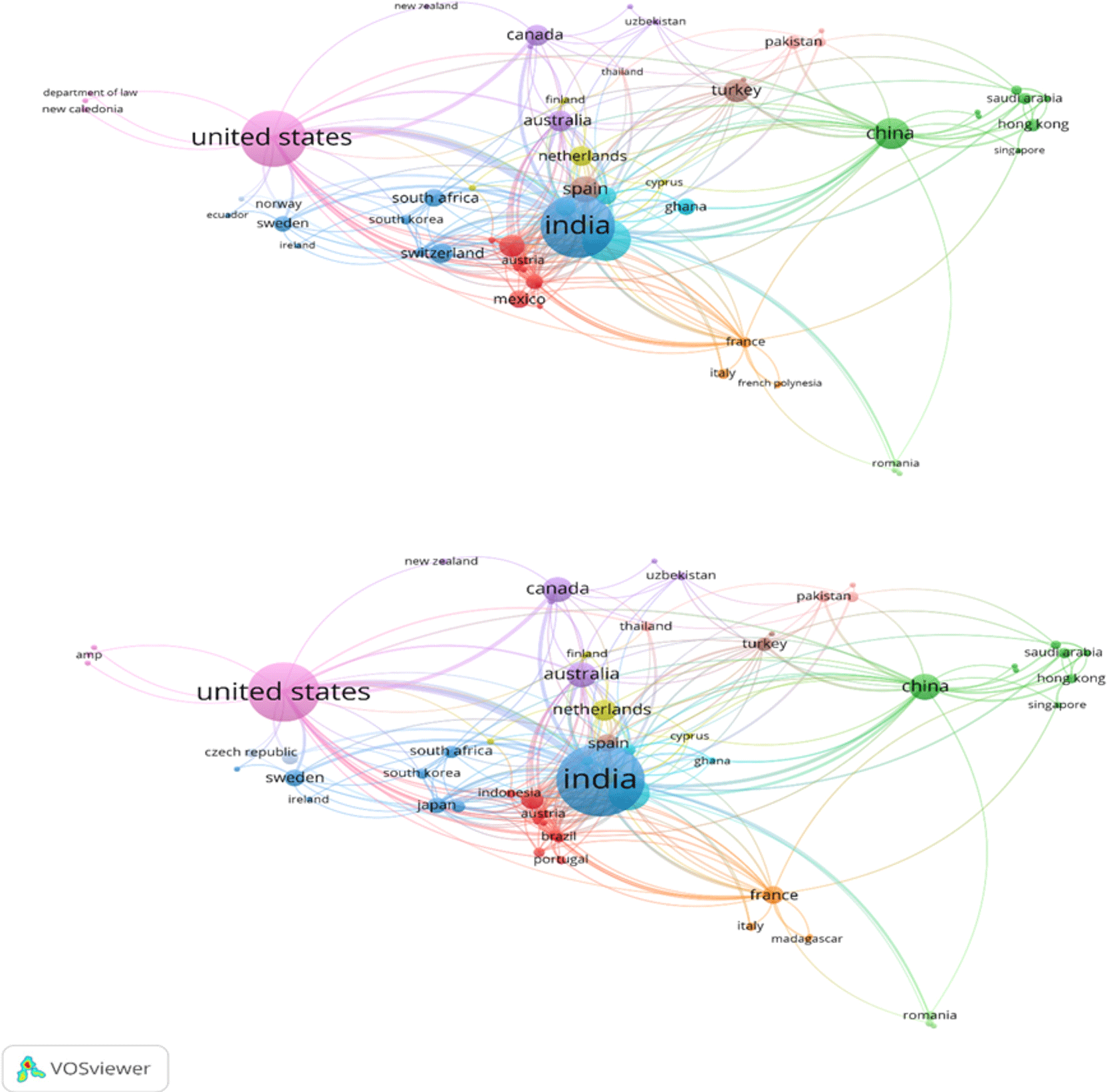
Figure 6 presents the top 10 globally cited documents in the selected Scopus dataset. The figure helps identify the studies that have received the highest citation attention in research on artificial intelligence and image manipulation in social media. The citation pattern shows that the most cited works are mainly related to deepfake detection, synthetic media, spoofing, digital media manipulation, and social media-based fake content detection.
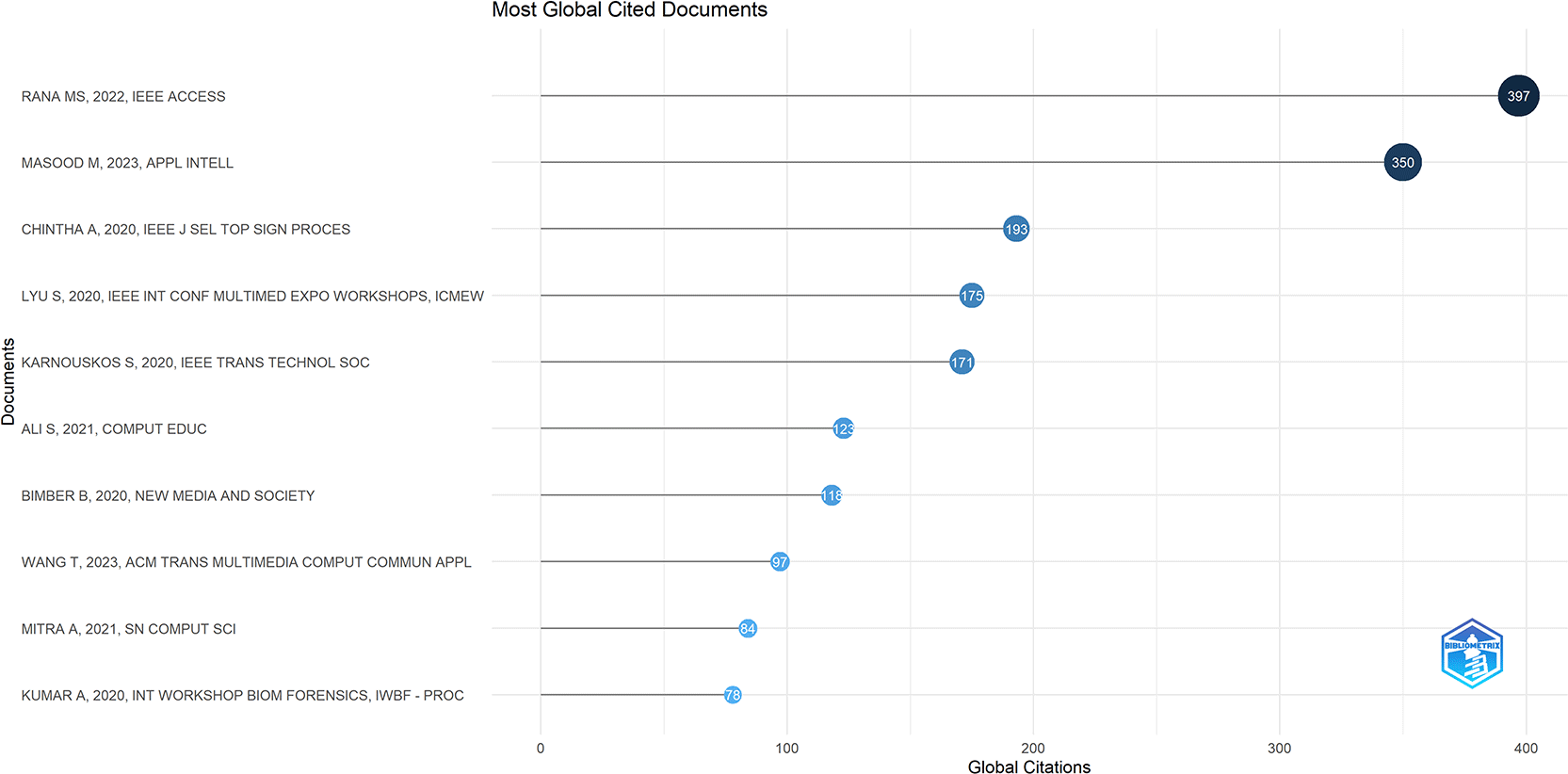
The most cited document is “Deepfake Detection: A Systematic Literature Review” by Rana et al. published in 2022, with 397 citations. This ranking demonstrates the increasing importance of summary-based reviews as a primary source of knowledge in the field. A further indication that researchers rely upon organized summaries of detection methodologies, datasets, challenges and future directions for their research.
The second-highest number of citations (second after the most frequently cited document) belongs to “Deepfakes Generation and Detection: State-of-the-Art, Open Challenges, Countermeasures, and Way Forward,” a manuscript authored by Masood et al. and published in 2023. With 350 citations, the frequency of citations illustrates significant academic interest in both the creation of deepfakes and detecting them. Additionally, the high volume of citations shows that the area of study goes beyond identifying manipulated video/photographic content; it includes how such content is created, disseminated, and regulated.
The two documents ranked fourth and fifth according to citation counts are technical-based articles discussing detection methodology. In 2020 Chintha et al. published “Recurrent Convolutional Structures for Audio Spoof and Video Deepfake Detection” with 193 citations. Lyu’s work titled “DeepFake Detection: Current Challenges and Next Steps” was also cited 175 times in 2020. Both of these works demonstrate that many of the first technical studies laid the groundwork for subsequent research into models, detection complexity and limitations of detection methodology for identifying manipulations of media. Overall, Figure 6 illustrates that the highly-cited literature in this sample is heavily concentrated on deepfake detection and synthetic media analysis.
Figure 7 demonstrates the distribution of keywords from Scopus articles examining artificial intelligence and image manipulation in social media. The tree map illustrates how often each group of key words (and their relative proportion) occurred within the data set. The larger box size indicates the number of times a word was found, and the smaller box sizes illustrate that even though some words were not as frequently identified they are still significant.
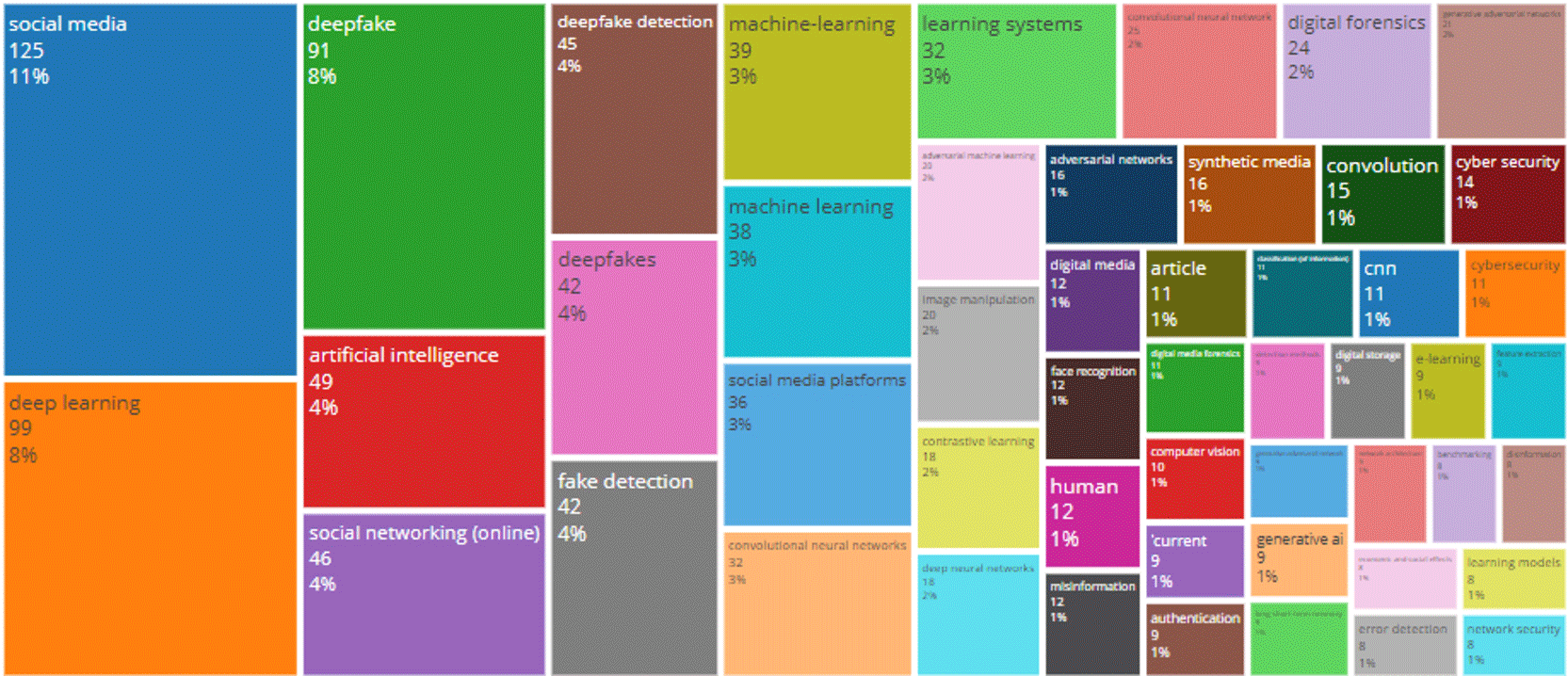
Since the most prominent keywords reflect the article’s focus on social media; the use of deep fakes; artificial intelligence; machine learning; image modification; digital forensic analysis; cyber security; and disinformation, the tree map is directly linked to the research being presented.
Social media has the highest number of keyword instances at 125, and accounts for 11% of all the keyword instances in the dataset. The large amount of keyword instances of social media demonstrates that it is the primary location where researchers have focused their investigations. Since the study examines how images are modified in social media-based environments, the large number of keyword instance occurrences of social media supports the scope of this paper. Additionally, since social media is an area where manipulated visual material may rapidly disseminate through online platforms, researchers have examined Privacy Risks associated with these online platforms.
Deep Learning follows closely behind social media, having 99 instances of the keyword (which equates to approximately 8% of all keyword shares). Deep Fake comes in third, with 91 keyword occurrences (also equating to about 8% of the total keyword shares). The fact that both terms are present in the keyword data, demonstrates that the body of literature analysed is heavily influenced by the techniques utilized to generate and identify manipulated visual content. Also, since both terms demonstrate that deep fake is a major component of the dataset analysed, it should also be considered one of the primary components of the manuscript.
Additional supporting evidence for this trend is provided by keywords including Artificial Intelligence with 49 instances of the keyword, Deepfake Detection with 45 instances of the keyword, Deepfakes with 42 instances of the keyword, and Fake Detection with 42 instances of the keyword. These additional terms clearly demonstrate that a substantial portion of the literature focuses on detection systems using AI for classification, and identifying manipulated media. This finding is consistent with previous findings demonstrating that computer science/engineering publications are among the primary places where researchers publish their research.
In addition to methodology related terms such as Machine Learning, Method-related terms like Convolutional Neural Networks, Learning Systems, Adversarial Networks, Generative Adversarial Networks, Deep Neural Networks, Contrastive Learning in the tree map demonstrate that most researchers use computational methodologies.
Figure 8 presents the changing trend of major topics in the selected Scopus literature on artificial intelligence and image manipulation in social media. The figure shows topic movement across the study period and indicates the relative frequency of each term through bubble size. Larger bubbles represent terms with higher frequency in the dataset.
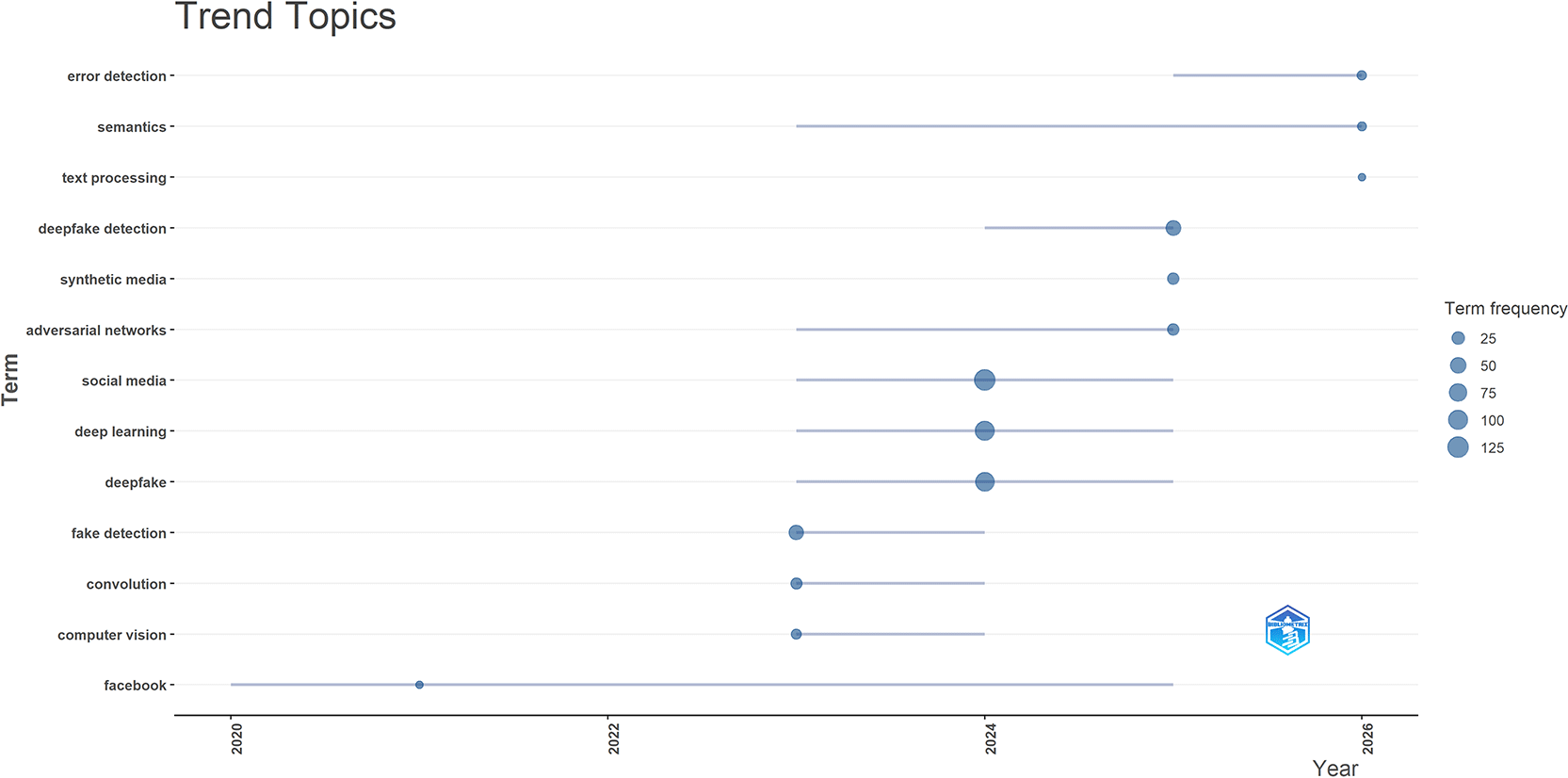
The appearance of Facebook around 2021 suggests that some early studies referred to specific platform settings before the literature moved toward broader AI based detection topics. Over time, the focus shifted from platform-specific discussion toward broader technical and risk-based topics.
Terms like “Social Media”, “Deep Learning” and “Deep Fake” were far more apparent when it comes to frequency (larger bubbles) within the dataset in both 2023 and 2024. It is no surprise then that the field’s focus became much more centered around AI-driven Visual Manipulation, DeepFake Content Generation and Automated Detection Methods. The abundance of social media clearly establishes that these same online platforms are where the majority of the selected literature was conducted.
The bubble chart depicts the emergence of fake detection, convolution, and computer vision around 2023. These themes represent the technical foundation of the field. Most of the studies that emerged during this time seem to be focused on image classification, visual analysis, detecting manipulation through various models and computation methods.
By 2024–25, terms such as deepfake detection, synthetic media, and adversarial networks began to emerge. This shift towards more specific research related to detection and generation implies that there is an evolution from discussing deep fakes in a general sense to more research specifically studying how to detect or create them. The emergence of Adversarial Networks is particularly significant because they relate directly to creating Generative Models and subsequently creating Synthetic/Manipulated Media.
Finally, by late 2025–26, terms such as Error Detection, Semantics, and Text Processing emerged. These terms imply that the current body of literature is moving beyond just Image and Video based Detection and into Broader Detection and Interpretation Methods (such as Content Level Analysis and Meaning Based Processing). This could possibly indicate that some of the more recent studies have begun to link Visual Manipulation to broader Content Verification methodologies; however, at present, Image and Video based Detection continues to dominate most of the literature.
Figure 9 displays a Three-Field Plot showing relationships between sources (left), key words (middle) and countries (right) for the selected Scopus data set. Each element is shown to be related via lines. Lines connect sources, countries to key word(s) (Verde et al., 2023), (Navigating the dual nature of deepfakes, 2024).
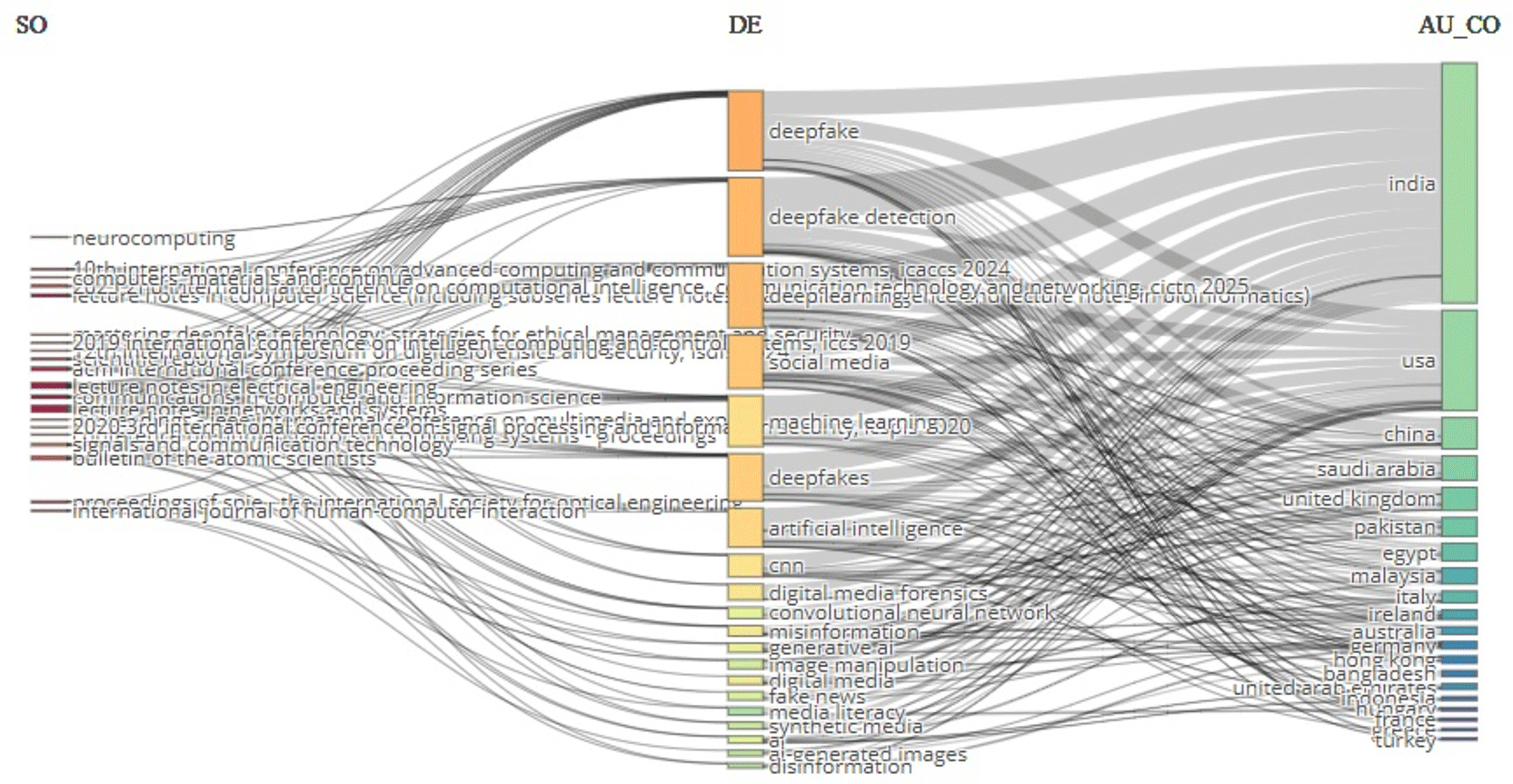
As can be seen from the three field plots, most of the literature is centered around the key words: Deep Fake Detection, Social Media, Machine Learning, Digital Forensic, Convolution Neural Network, Misinformation, Artificial Intelligence, Synthetic Media, Image Manipulation, Disinformation etc. These keywords suggest that the selected literature is primarily organized around: Detection; AI based media creation; Online Content Risks.
Deep Fake and Deep Fake Detection have the highest number of keyword links. As such it is reasonable to conclude that the selected dataset’s center or core relates to deep-fake related research. The strong presence of Machine Learning, CNN, Convolutional Neural Network, also suggests that the area is heavily influenced by Methodological approaches using Automated Systems.
On the Country side of the plot, India appears to be most closely tied to the Keywords above and below, USA, China, Saudi Arabia, UK, Pakistan & many others. Clearly, this demonstrates that Research Activity exists at a National Level. India clearly has the greatest proportion of publications visible in this plot and this aligns well with the overall publication trends at a Country level displayed in Figure 5.
Figure 9 shows a clear relationship between Publication Sources, research terms and contributing countries. Strongest connections exist surrounding Deepfake Detection, Artificial Intelligence, Machine Learning and social media.
Figure 10 displays the co-occurrence network of selected Scopus data keywords. It illustrates the relationships between primary concepts associated with the use of artificial intelligence to manipulate images circulated via social media. Nodes representing keywords are larger for those that have occurred more frequently and, therefore, linkages between these nodes indicate greater relationships between them.
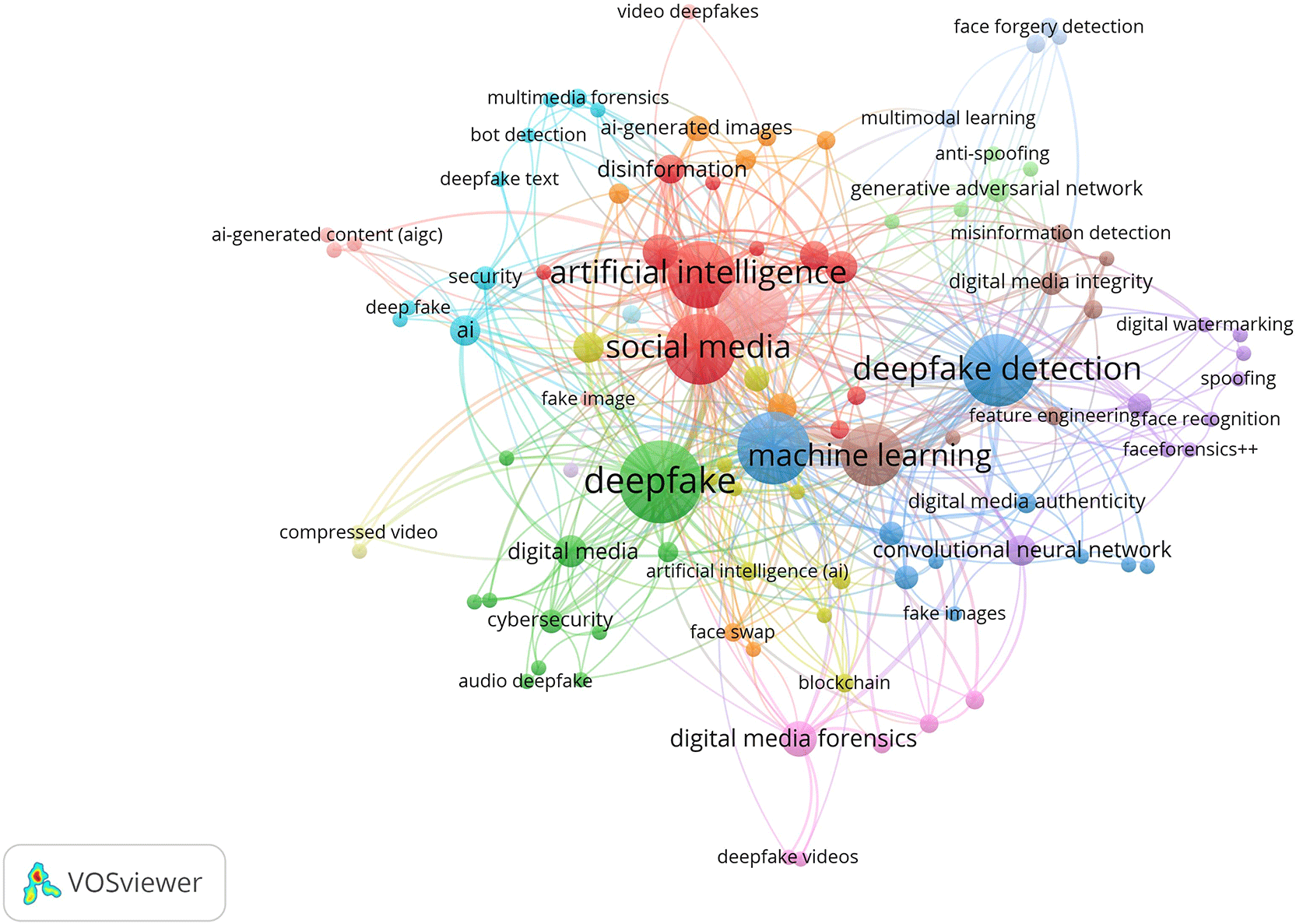
Artificial intelligence, machine learning, social media, deepfakes and deepfake detection are the most prominent terms in this network. The size and connectivity of each node illustrate that much of the current body of knowledge is organized around AI based social media manipulation (deepfakes), social media image circulation (social media) and AI-based detection techniques (machine learning).
As a result of its location at the centre of the network, it appears that social media represents the primary medium through which manipulated images (synthetic content/visual misrepresentations) are exchanged.
Terms Deep Fake and Deep Fake Detection also have an extensive connection to other terms in the network. The connections of Deep Fake and Deep Fake Detection with Machine Learning, Convolutional Neural Network (CNN), Generative Adversarial Networks (GAN), Face Recognition, Anti-Spoofing, Feature Engineering and Forensic Analysis illustrate that much of the field’s focus has been on developing technologies for detecting AI generated synthetic content. This is consistent with previous Figures which demonstrated that Computer Science and Engineering disciplines had made significant contributions to the development of these detection technologies.
Additionally, Digital Media Forensics, Digital Media Integrity, Digital Watermarking, Multimedia Forensics, and Face Forgery Detection illustrate that establishing authenticity and providing verifiable evidence for image detection remains an essential area of study. These terms connect the technical literature with questions of authenticity, trust, and digital evidence.
Several terms such as misinformation detection, disinformation, fake text, fake images, AI-generated content, and AI-generated images show that the field is not limited to deepfake detection alone. It also includes wider concerns about false content, manipulated communication, and platform-based harm.
Privacy implications are visible indirectly through terms such as face recognition, anti-spoofing, face forgery detection, digital media authenticity, security, and cybersecurity. These terms indicate concerns related to identity misuse, unauthorised facial manipulation, verification failure, and trust in visual content. However, the network does not show privacy as a dominant central term. This suggests that privacy is present as an associated concern rather than as the main organising theme of the literature. This finding supports the fifth objective because privacy appears as an associated concern rather than as the main organising theme of the keyword network. Cluster names were assigned after examining the dominant keywords within each cluster and identifying their common research focus (Singh et al., 2025).
Table 3 presents the cluster analysis derived from the keyword co-occurrence network shown in Figure 10. The clusters classify the selected literature into five main research areas: artificial intelligence and social media, deepfake and synthetic media, detection and machine learning methods, digital forensics and media verification, and platform security with content integrity.
Cluster 1- links artificial intelligence with social media, AI-generated images, AI-generated content, misinformation, disinformation, and fake text. This cluster shows that social media is a central setting for the circulation of AI-generated and manipulated content. It also indicates that false content and platform-based communication risks are closely connected with the research field. The presence of fake text indicates that image manipulation is often studied within wider multimodal misinformation research.
Cluster 2 - Keywords including “deepfakes,” “fake images,” “face swaps,” “audio deepfakes,” “video deepfakes,” and “deepfake videos” reflect that there is a significant amount of literature concerning manipulations to both the visual and auditory aspects of digital media. Cluster 2 is closely associated to the research paper’s primary area of interest – image manipulation and privacy implications; due to the fact that Deepfake media has potential for creating issues regarding consent, misusing identities, and reputations.
Cluster 3- Keywords including “deepfake detection”, “machine learning”, “convolutional neural networks”, “generative adversarial networks”, “feature engineering”, “face recognition”, and “anti-spoofing” confirm that most studies are focused on developing models and automating the process of identifying manipulated media. This affirms that the literature is being heavily influenced by computer science methods.
Cluster 4- Terms like “digital media forensics”, “multimedia forensics”, “digital media authenticity,” “digital watermarking,” “face forgery detection” and “spoofing” demonstrate that researchers are interested in authenticating and verifying digital media, particularly when it comes to detecting if the content was tampered with or created artificially. The connection between this cluster and the technical literature demonstrates the need to detect tampering of digital media and maintain public confidence in digital media.
Cluster 5- Keywords including “bot detection”, “multimodal learning”, “compressed video”, “security”, “cybersecurity”, “blockchain”, and “digital media integrity” illustrate that researchers have a broad scope of concern with regard to platform level risks and verification processes. Overall, Cluster 5 illustrates that the problem of manipulating content goes beyond just individual image manipulation, but involves broader platform governance and security issues.
The cluster analysis shows that privacy implications are present across the selected literature, but remain less central than technical detection. The major privacy issues are reflected through the use of deepfake media, fake images, face swap, artificial intelligence (AI) created images, face recognition, authentication, digital media’s authenticity, misinformation, disinformation and cyber security-related terms. Each of these words reflects how manipulated image-based content may be used to negatively impact an individual’s ability to provide informed consent regarding their own identity; protect their identity; their reputation and/or have faith in digitally-created media.
However, based on the keyword network there is no indication that privacy was positioned as a primary or central issue. This suggests that existing studies address privacy mainly through related concerns such as identity misuse, face forgery, digital authenticity, authentication, misinformation, and platform risk rather than through direct privacy centred analysis. Therefore, future research should connect detection-based studies with consent violation, image misuse, reputational harm, victim protection, legal safeguards, and platform accountability.
Table 4 presents the main privacy implications identified from the keyword and cluster findings. It links each privacy concern with related keywords, cluster position, research gap, and future research direction.
Table 4 indicates that privacy issues exist within each of the five categories listed in Table 2. In addition to being connected to the literature (consent violations, misuse of identities, misuse of images, reputational damage, victim protection, legal protections, and platform responsibility), however, these privacy related issues are significantly less relevant than detection/verification. These findings support the need for further research into connecting technical means for detecting social media content with protecting users’ privacy and reducing user-based harms.
The TCCM Framework has been used as a means of structuring the chosen studies that deal with Artificial Intelligence and Image Manipulation within social media. In doing so, the TCCM Framework divides the identified literature along four dimensions: Theory, Context, Characteristics and Methodology. In this study, the framework helps connect bibliometric findings with the research gap on privacy implications. Figure 11 presents the overall TCCM framework used in the study.
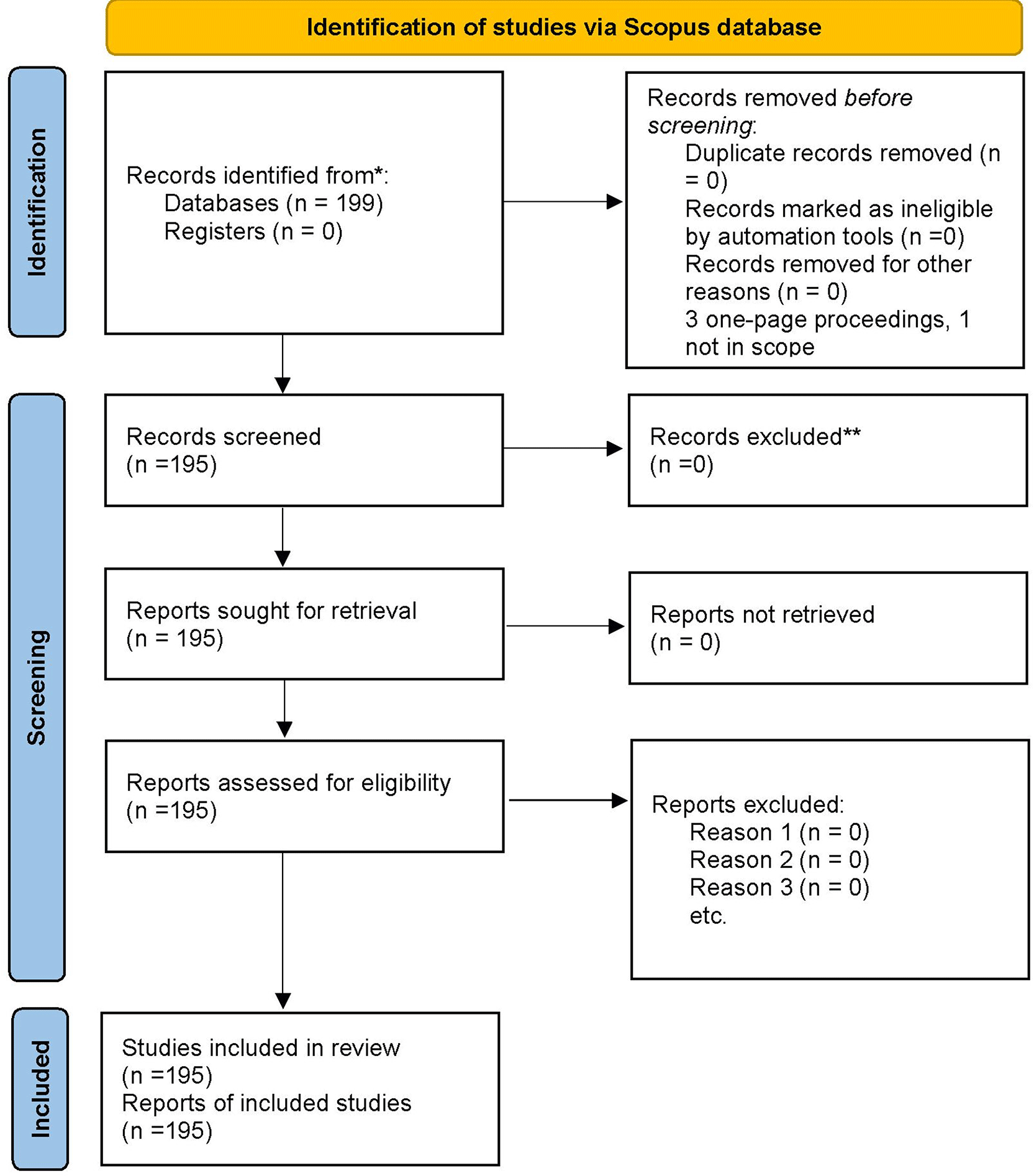
Figure 11 presents the TCCM framework for the selected literature. The theory dimension includes the main technical and conceptual bases of the field, such as artificial intelligence, deepfake detection, machine learning, digital media forensics, misinformation, disinformation, and cybersecurity. The context dimension covers social media and digital platform settings where AI generated images, deepfakes, fake images, and synthetic media circulate. The characteristics dimension includes deepfake content, fake images, face swap, authentication, digital media authenticity, misinformation, platform risk, and privacy related harm. The methodology dimension includes deep learning, machine learning, convolutional neural networks, generative adversarial networks, face recognition, digital watermarking, and forensic verification.
Overall, Figure 11 shows that the literature is mainly organised around detection, verification, forensic analysis, and platform-based risk. As such privacy is represented throughout all dimensions. However, remains far from being the focus of detection, this supports the requirement for further study on consent, Identity misuse, Reputational harm, Victim protection, Legal safeguards and Platform accountability.
The Theory Dimension indicates that the majority of the literature reviewed was driven primarily by technical (i.e., detection-based), verification-based approaches with a lesser emphasis on established privacy theories (Lyu, 2024). This pattern can be seen when examining the “most cited” publications as these were largely focused on developing algorithms to detect deepfakes, generating synthetic media, spoofing media, and the challenges associated with detecting or manipulated media. As shown in Figure 6, the authors’ citation base is highly concentrated around deepfake-related research.
The development of the field appears to have been derived from Artificial Intelligence or Machine Learning, Digital Media Forensics, Misinformation, Cybersecurity etc. While these areas may help identify manipulated content, they provide little insight into privacy harms (Dabbir, 2025). Very little attention has been paid to developing Privacy Theory, Consent Theory, Protection of Digital Identity, Victim Protection or Platform Accountability. Future research needs to develop more formalized privacy-focused theoretical frameworks for how privacy harms occur through AI-generated Image Manipulation in social media.
The social media setting dimension indicates that most of the literature reviewed was produced about social media. This matches the keyword dimension which found that social media is the most commonly used keyword. It is additionally apparent from the reviewed literature that researchers often refer to other aspects of the internet such as, AI generated images, Deep fakes, Synthetic media, Misinformation and Digital media (Ansari & Sharma, 2025), (Babaei et al., 2025). Many of the studies looked at how privacy can be harmed through the use of social media but they did so by treating all social media sites as being similar (Ghosh, 2025). However, the type of platform people is using for privacy harm could have an effect on whether or how much privacy harm occurs.
Therefore, future studies need to look into the differences in privacy harms based upon the type of social media site being used. There are several ways to do this: for instance, studies could compare privacy harms from public social networking sites (i.e., Facebook), short video sharing apps (e.g. TikTok) and image sharing sites (e.g., Instagram) (Ghariwala, 2025). Studies could also compare privacy harms resulting from private direct messages sent to individuals versus those sent out to groups (Ferrara, 2023). Additionally, studies comparing privacy harms from social networks focused primarily on news sharing (e.g. Twitter) would be valuable (Amini et al., 2024).
The Characteristics Dimension indicates that the Literature is primarily organized around six categories: (1) Artificial Intelligence-generated content (2) Deep fake Media (3) Fake Image Identification (4) Machine Learning-based Detection Methods (5) Forensic Verification and (6) Platform Security. These Characteristic Dimensions can be identified through Keyword Clusters and Co-Occurrence Analysis (Chapagain et al., 2025).
The most significant gap in the current state of the Literature is that while it focuses on the detection or verification aspects of AI-manipulated media, it does so to a much lesser extent than the privacy implications of AI-manipulated media for victims. In addition to Consent Status, Facial Likeness, Victim Visibility, Circulation Speed, Anonymity of the Uploader and Platform Response, the Characteristics Dimension should take into account other dimensions as well. Such as consent violations, identity theft, reputational injuries, stigmatization, psychological trauma or harm to victims’ emotions and lack of access to legal remedies (Çiftçi et al., 2020).
Therefore, future Research should investigate how manipulated images are misused as a method of exploitation and what types of harms individuals suffer when their consents are violated.
The methodology aspect of this study demonstrates that the majority of the literature reviewed in this study is technical. In addition to being technical, a large portion of the literature included in the database consists of conference paper abstracts. This suggests a strong connection to journal publication areas in engineering, computer science, imaging and applied research. Keyword searches on these topics indicate that many authors have used machine learning, deep learning, convolutional neural networks, generative adversarial networks, face recognition, digital watermarking and digital media forensics in their work.
While all of these approaches may provide some ability to detect AI-manipulated image(s) they do not address or quantify consent violations, identity misuse, psychological harm, social harm, legal protections for users or platform responsibilities.
Therefore, future research should include expanding the methodologies used to evaluate privacy effects in manipulated images. This could include using technical detection as well as survey research, interview data, case studies, legal analysis of current laws governing platforms, platform policies related to privacy and responsible practices and privacy impact assessments (Chiang et al., 2025). These types of expanded methodological approaches will assist in evaluating the relationship between how models perform with respect to privacy effects and reducing user harm (Falade, 2023).
The TCCM results show that the majority of articles analysed use keywords related to technological aspects of detection, deepfakes, digital forensic investigation, platform security and how images are spread via social media. Although privacy concerns exist within the body of literature, these have been secondary to other concerns as shown by the organisation of the literature through keyword usage, citation patterns and methodology for study.
Therefore, a stronger research agenda on artificial intelligence and its effects on image manipulation with respect to social media would be to place greater emphasis upon the privacy aspects of AI or image manipulation than currently exists in the existing research base.
This study made contributions to the body of knowledge for artificial intelligence and image manipulation in social media in four major respects.
Firstly, the study provided a bibliometric profile of the research published between 2019 and 2026. It mapped the production of research in terms of publication growth; source distribution (e.g., journals); journal contributions; author affiliations; country level outputs; and globally cited papers. These help provide a structured view of the chosen Scopus literature.
Secondly, the study identified key research topics within the field using keyword analysis, trending keywords over time, keyword co-occurrences, and clustering techniques. Research activity was primarily focused upon artificial intelligence and its application in social media contexts including deep learning, deepfakes, machine learning, digital forensics, cyber security, misinformation, digital authentication, synthetic media, and facial forgery detection.
Thirdly, the study used the TCCM (Theory Context Characteristics Methodology) framework to categorise the literature into theory, context, characteristics and methodology categories. The categorisation enabled an understanding of how the field had evolved, where research effort was concentrated and where gaps existed in terms of required research focus.
Finally, the study demonstrated that privacy implications were relatively under-represented as a primary area of concern in the current body of knowledge. Privacy was identified via secondary concerns such as face recognition, detecting forged faces with face forgery detectors, identity theft or misuse, authentication of images/social media posts, digital authenticity of social media posts or cybersecurity issues.
This study investigated the research regarding artificial intelligence (AI) and the manipulation of images within social media using both a bibliometric approach and the Technical, Contextual, Characteristics, Methodological (TCCM) model. The bibliometric investigation used 195 Scopus-indexed articles published between 2019–2026. The articles were mapped for their production rate, publication venues, countries contributing to publications, citation structure, keywords, thematic clusters and areas requiring additional research. In terms of the bibliometric data, there is an upward trend in publications starting in 2022 with the most produced articles being published in 2025. Based on source patterns, it appears that much of this research is coming from Computer Science, Engineering Conference Proceedings and Applied Research Outlets. At the country level, India is producing the most articles while the U.S. holds the greatest number of citations. These results indicate that there is no direct correlation between article production and citation influence. Keyword clustering identified three main themes: social media; Deep fake Content; Machine Learning Methods; Digital Forensics; Media Verification; Misinformation; Cybersecurity and Platform Security. Clustering confirmed that the majority of the literature focuses on detection. While detecting manipulated content is important, so too are improving detection models, verifying media authenticity and maintaining content integrity. The TCCM analysis indicated that much of the development in the area has come from technical/verification focused research. Theory dimension is primarily influenced by forensic/detection approaches. Contextually, the focus is social media platforms. Future research needs to consider privacy issues surrounding AI-based image manipulation in social media. Detection is still important but will not be sufficient to explain all the harm associated with visual manipulations.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)