Keywords
SQL Injection; Machine Learning; Robustness; Calibration; Adversarial Attacks; Intrusion Detection; Statistical Evaluation; Deployment Optimization
This article is included in the Fallujah Multidisciplinary Science and Innovation gateway.
SQL Injection; Machine Learning; Robustness; Calibration; Adversarial Attacks; Intrusion Detection; Statistical Evaluation; Deployment Optimization
Web applications are the key building blocks of modern-day digital ecosystems, which include financial apps, healthcare information systems, government portals, and cloud-based services.1,2 The level of vulnerability to cyber threats is directly proportional to the size and complexity of these systems.3 One of the most invasive and harmful web-based adversarial vectors is the SQL injection attack (SQLIA), which is an attack that takes advantage of the weaknesses in input checking and the dynamic creation of queries to compromise backend databases.4,5 Despite the availability of well-established defensive controls and secure code standards, SQL injection vulnerabilities remain very common in production systems, which is often due to the configuration of legacy systems, the lack of sanitization of the systems, or advanced obfuscation patterns by attackers.
SQL injection vulnerabilities allow attackers to insert written SQL code into user-controllable parameters and, in this way, gain unauthorized access to data, bypass authentication or control commanding privileges, or even maliciously exploit stored data.6,7 Security-wise, it is possible to state that such attacks directly impact the confidentiality, integrity, and availability (CIA) triad of information systems.8 Confidentiality breaches involve illegal exchange of sensitive information, integrity, the changing or destruction of records, and availability, subject to resource-intensive or disruptive requests. On this basis, highly efficient and dynamic detection controls are also a compulsory aspect of the modern intrusion detection software and web application firewalls.
The conventional methods of SQL injection detection have been mostly based on rule-based filtering, signature matching, and/or recognition of predetermined patterns. Although these approaches are computationally efficient and easy to analyze, they have poor resistance to obfuscated code and polymorphic instances of attacks. All of these techniques, including URL encoding, key fragmentation, comment injection, and operator substitution, can be used by the adversaries to avoid pattern-based, high-statistics defenses with little effort. Against this backdrop, machine learning (ML) methods have been receiving growing interest, due to their ability to acquire discriminative patterns directly through data and extrapolate beyond pre-determined signatures.9,10
There are a massive number of studies that have reported very high classification, when using classical ML models, such as Naïve Bayes,2 Support Vector Machines,11 Logistic Regression,12 and ensemble-based algorithms such as LightGBM13 and XGBoost.14 F1 -scores and ROC-AUC values are often reported to achieve unity on benchmark corpora. However, such assessments usually focus on nominal measures of discrimination; intensive statistical validation has rarely been done, and the ability to withstand adversarial changes is often restricted or not carried out. Further, the issue of calibration reliability and the aspect of operational deployment are relatively under scrutiny. This would mean that models look very efficient in the restrictive laboratory setting but may prove fragile or overconfident in the face of evasion maneuvers in the real world.
Nominal accuracy is not sufficient to ensure credible protection in the context of operations security.15 The detection systems should also be stable against syntactic perturbations, produce reliable probability estimates to make risk-conscious decisions, and act within severe latency and resource constraints. Minor differences in F1-score might not translate to significant deployment performance in case of poor robustness, calibration, or even computational infeasibility.16 Hence, the choice of ML models to detect SQL injection cannot be a single-dimensional ranking of models, but a multi-dimensional decision problem.
To overcome these drawbacks, the current paper proposes a deployment-focused evaluation system of SQL injection detection, which incorporates a statistical validation, adversarial robustness test, probability calibration test, threshold-sensitivity test, operational performance test, and structured error taxonomy test into a single experimental pipeline. The framework makes it easy to have an overall evaluation of candidate models, and therefore, the solutions chosen are not just discriminative but also resilient and dependable in the real-world setting.
In this paper, many machine-learning models are discussed, namely, Multinomial Naïve Bayes, Logistic Regression, LinearSVC, SGDClassifier, LightGBM, and XGBoost. All models are trained on TF-IDF character n -gram representations so as to provide the same feature modelling across the algorithmic spectrum. By going beyond the accuracy-focused comparison, the study provides a reliability-conscious approach to the selection of intrusion detection models that can be retained in operationally viable conditions in the adversarial and resource-constrained setting.
Many works in the area have grown significantly over the last ten years; this is in part due to the weakness of rule-based and signature-based systems in the presence of obfuscated or polymorphic payloads. Initial work was done on classical classifiers, including Naïve Bayes, Support Vector Machines,17 and Logistic Regression,18 which are generally trained on lexical or syntactic representations of SQL queries. These methods used token-frequency features, bag-of-words, or n-gram schemes and were frequently found to exhibit high discriminative performance. Their comparative ease and decipherability made them appropriate to lightweight intrusion-detection systems and real-time usage. With the development of the field, more and more researchers started to use ensemble and tree-based algorithms, such as Random Forest, Gradient Boosting,19 LightGBM,20 and XGBoost.21 These approaches have demonstrated close to ceiling F1 -scores and ROC -AUC rates in many benchmark studies, which can be explained by their ability to capture nonlinear feature interactions. However, the majority of assessments were still focused on nominal performance indices, and the progress was often provided in the form of a slight accuracy increase, and statistical validation and deployment-focused issues were rarely investigated in detail.
In more recent studies, convolutional neural networks (CNNs),22,23 recurrent neural networks (RNNs),24 and transformer-based models based on deep-learning are investigated as SQL injection detectors. The goal of these models is to acquire semantic representations directly out of crude query strings and thus lessen the burden of manually creating features. Even though encouraging performance has been achieved in controlled settings, deep-learning methods, in many cases, increase the cost of computation and training times.25 There are also a number of cases where the performance benefits per the reported performance are shown to be restricted by comparison with classical models when tested on structured SQL injection data sets. Although the range of algorithms explored is quite diverse, a major common weakness is present in much of the literature: practices of evaluation are largely accuracy-focused. Measurements of Accuracy, Precision, Recall, F1-score, and, in some cases, ROC -AUC are commonly used in most studies, whereas statistical significance testing, confidence -interval estimation, or paired model comparison are rarely used. Therefore, apparently incontrovertible minor performance discrepancies can be interpreted without strict verification.
Practical SQL injection attacks often use evasion techniques, such as URL encoding, splitting keywords, adding comments, using case variations, and operator replacements.26 Although obfuscation issues are recognized in some works, systematic transformation-based robustness analysis and worst-case degradation measurement are uncommon practices. Such a discrepancy restricts the trust in the practicality of most of the suggested solutions. Another dimension that has not been fully explored is probability calibration. Confidence scores can be used to prioritize alerts or be used in adaptive thresholding in operational security systems. Calibration reliability, that is, the reliability typically quantified by Brier score or reliability curves, is hardly ever assessed explicitly.27 Consequently, even high discrimination models can result in overconfident predictions, which destabilize deployment. Operational constraints also make the selection of models more complex because inference latency, throughput capacity, and memory consumption are the main points when it comes to the real-time intrusion-detection environment.28 A model with slightly better F1 -score at the expense of significantly more computational resources can be impractical in high-traffic settings.
Table 1 summarizes the summary of recent representative studies on SQL injection detection in the past three years, 2022–2025, to contextualize such limitations. Even though multiple works document F1-scores above 0.98 with a range of classical and deep-learning models, more extensive evaluation schemes, such as the combination of robustness evaluation, statistical validation, calibration evaluation, and operational profiling, are lacking. The current research fills this void as it employs a multi-dimensional assessment method that is systematic. Instead of concentrating on nominal discrimination only, it pays attention to reliability, stability, and deploy ability, showing that models with slightly better clean-set results are not always the best when dealing with adversarial or operational constraints.
As the analysis above shows, despite the number of studies that declare high nominal detection results, the still surviving literature has a curiously small number of deployment-oriented assessments. Precisely, statistical validation, systematic robustness interrogation, calibration test, and operational profiling are often not mentioned or moved to cursory mention. As a result, the so-called gains, as measured in terms of accuracy or F1 -score, might not reflect genuine reliability when applied to a real-world scenario. The proposed work attempts to cover this gap by suggesting a multi-dimensional analysis framework that integrates the overlooked elements into a logical experiment pipeline. The analysis is preoccupied not only with the marginal classification improvement but also with the reliability, robustness, stability, and pragmatic deployment constraints as the most important evaluation criteria of the models. It is on this higher plane that we attempt to provide a more loyal based upon the choice of SQL-injection detection paradigms in adversarial and operationally constrained milieus.
The proposed framework uses a deployment-based, multi-dimensional assessment system of the SQL injection attack. Instead of focusing on traditional techniques of model comparison based on standardized accuracy, the methodological design goes further by incorporating a rigorous statistical validation, strong assessment of adversarial resistance, careful calibration analysis, a systematic analysis of threshold sensitivity, detailed operational performance measures, and systematic interpretation of errors. Figure 1 demonstrates the general line of the experiment.
The corpus used in this investigation is SQL expressions that have been carefully labelled as benign and malicious. To achieve the goals of experimental rigor and to eliminate any possible data leakage, duplicate records were removed before the model started to be trained. The scheme of stratified partitioning used to maintain fidelity in the distribution of classes in training, validation, and test sets is such that performance metrics of the resultant performance will be independent and accurate indicators of true class distribution in the field. A TF n-gram character representation was used to transform the tokens in the text, where n was three to five. The rationale of a character-level implementation approach is its strong resistance to syntactic obfuscation and partial keyboard manipulation, which is a common attack pattern when using adversarial SQL injection attacks.
In contrast to traditional tokenizing word-based methods, character n-grams, being sensitive to fine-scale lexical structures, including encoded operators, comment delimiters, and fragmented SQL keywords, increase the sensitivity of detection to fine-scale structural distortions. The data used in this study was obtained by means of a publicly available SQL injection corpus that initially included 18,900 instances of queries. In order to avoid redundancy and prevent data leakage, duplicate entries have been removed before model training. After the de-duplication and consistency check, 11230 distinct queries were maintained as the subject of the experiment. The duplicate incidence was evident in the original corpus of about 40.6, expressed even though there is a need to learn to clean the data well to prevent inflated performance estimates.
The obtained final distilled data set consists of 6,972 malicious samples, with an average proportion of 0.621, and 4, 258 benign samples, with 0.379 as the average value. Such figures thus maintain the organically obtained class imbalances as part of the actual traffic distributions in the real world. In order to create class balance in each subset, a stratified split was done. As a result, the data, which were curated, were divided into 7,187 training samples, 1,797 validation samples, and 2,246 test samples, and the malicious sample ratio was maintained around 62% in all the partitions. The partitioning and the resultant findings of the experiments can be repeated by repairing the random seed. The recommended preprocessing pipeline consequently provides objective performance evaluation and no information leakage across stages, thereby strengthening the methodological soundness of the study. Different presentations of a spectrum of modeling paradigms were evaluated in a series of supervised machine-learning algorithms that included probabilistic baselines, linear discriminative models, and nonlinear ensemble methods. Multinomial Naive Bayes, Logistic Regression, LinearSVC, SGDClassifier, LightGBM, and XGBoost are all the chosen classifiers. The training of each model was done under the same feature-representation parameters to ensure fair comparison. In case of class-imbalance, mitigation was implemented through balanced weighting programs. In order to provide a systematic summary of the reviewed algorithms and their inherent modeling characteristics, Table 2 lists the classifiers involved in the comparative analysis.
Initial evaluation of the model performance was done by standard classification measures that were computed on a held-out test set. These measures included Accuracy, Precision, Recall, F1 -score, ROC -AUC, and PR -AUC. They provide a nominal discriminative evaluation, though not all the deployment reliability is captured. Therefore, statistical validation procedures were applied to ascertain that the performance differences that were observed could not be attributed to random variability. To support the performance claims, paired hypothesis tests were used across cross-validation folds, 95% confidence intervals were obtained with bootstrapping, and paired predictive comparison was done using the McNemar test. It was understood that verification of the adversary in the real world often employs the techniques of obfuscation to avoid being identified by the protective mechanism, and, therefore, the resistance testing was included in the analytical framework. The test queries were subjected to syntax-preserving adversarial transformations such as whitespace perturbation, comment injection, manipulation of cases, splitting of keywords, encoding of URLs, and replacing the operator.
The decline in performance of every transformation was measured, and the worst-case ΔF1 was calculated and used to test resilience to the adversarial conditions. The analysis makes it easier to determine the models that stand stable even on clean benchmark measurements. The issue of probability calibration was also studied to establish the accuracy of the predictive scores of confidences. Reliability diagrams were built where the predicted probability was compared to the frequency of empirical outcomes. Calibration quality was measured by the Brier and Expected Calibration Error (ECE), which, therefore, made it possible to measure over- or under-confidence tendencies. Since intrusion detection systems can be set up with probability thresholds as a way of using alert prioritisation, calibration reliability is a crucial factor when deploying. Threshold sensitivity was determined by sweeping threshold decision levels over the entire range of probability. Precision recall trade-offs were explored to determine the best operating points with specific deployment goals like high recall configurations, security-critical configuration and high accuracy, low false alarm conditions.
This method provides flexibility in adjusting model behaviour to the operational risk tolerance. It was tested on operational feasibility based on inference latency, throughput (queries per second), and memory consumption during prediction. Such metrics are critical in evaluating the viability of real-time deployment in the high-traffic web fronts. One that only had marginally higher levels of nominal accuracy but much higher computational levels may not be useful in actual production. Lastly, the analysis of the error taxonomy structure was used to explain the patterns of false positives and false negatives. False positives were divided by SQL injection feature, which included: Boolean manipulation, query by union, time attacks, comment obfuscation, encoding schemes, and stack query. This interpretation of predictive behaviour is based on knowledge of security and applied to attack semantics and CIA impact considerations. The model comparison, aided by this multi-methodological framework, is no longer restricted to a metric reporting method, but an evaluation paradigm that is reliability conscious, statistically based, and deployment relevant.
As the outcome of a strict experimental test that the given multidimensional deployment-oriented framework implies, a comparative evaluation of models is not just about their nominal predictive accuracy. The discriminative capacity of the six tested models on the held-out test set is almost perfect, as evidenced by their baseline performance. As shown in Table 3, all the classifiers achieved F1-scores over 0.99, with the ROC-AUC and PR-AUC nearly being equal to 1. The best nominal F1 -scores were assigned to the Drinks: LinearSVC and XGBoost, which are closely followed by Multinomial Naive Bayes and LightGBM, but lightly outperformed by Logistic Regression and SGDClassifier. In the best-performing models, there is a margin between the top models that is not greater than 0.3, which highlights the fact that the dataset is extremely separable when evaluating it in clean conditions.
Figure 2 visualises nominal discrimination in terms of Receiver Operating Characteristic (ROC) and Precision Recall (PR) curves for all the classifiers tested. Figure 2a illustrates the shockingly high true-positive rate (TPR) of every model at extremely low false-positive rate (FPR) boundaries. Such behaviour aligns with the near-unity ROC-AUC values given in Table 4 and demonstrates that the decision limits trained by the models are very useful in the discrimination between malicious and benign queries in clean conditions.
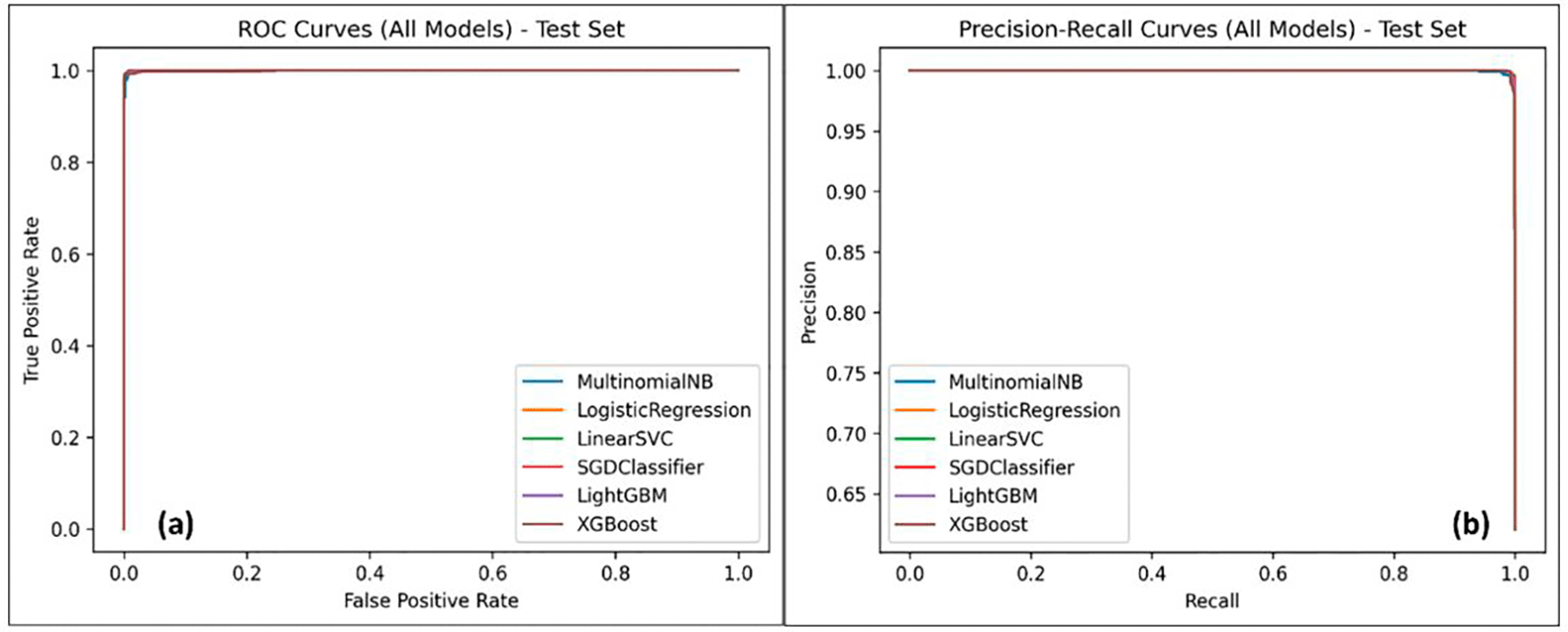
In applications with security requirements, a large detection sensitivity and reduced false alarms are a must, and the ROC profiles, hence, confirm that every model meets this criterion at nominal evaluation.29,30 This is further supported by the PR curves in Figure 2(b), which show maintained accuracy in the high-recall areas. Since the dataset presents a case of class imbalance, but more malicious samples are present, PR curves are a better informative view as compared to ROC.
The continuously high levels of precision in the recall values that are close to one imply that the classifiers make few error of classifying as a benign query, yet they intercept the large majority of malicious payloads. Notably, the curves almost overlap with each other in models, which proves graphically that differences in nominal rankings are insignificant. The intersection of this supports the statistical results to come later, in which bootstrap confidence intervals show significant metric intersection. It follows that, under clean conditions of evaluation, no conclusive decision can be made on model superiority on the basis of ROC or PR inspection, and this further substantiates the necessity of robustness, calibration, and operational analysis.
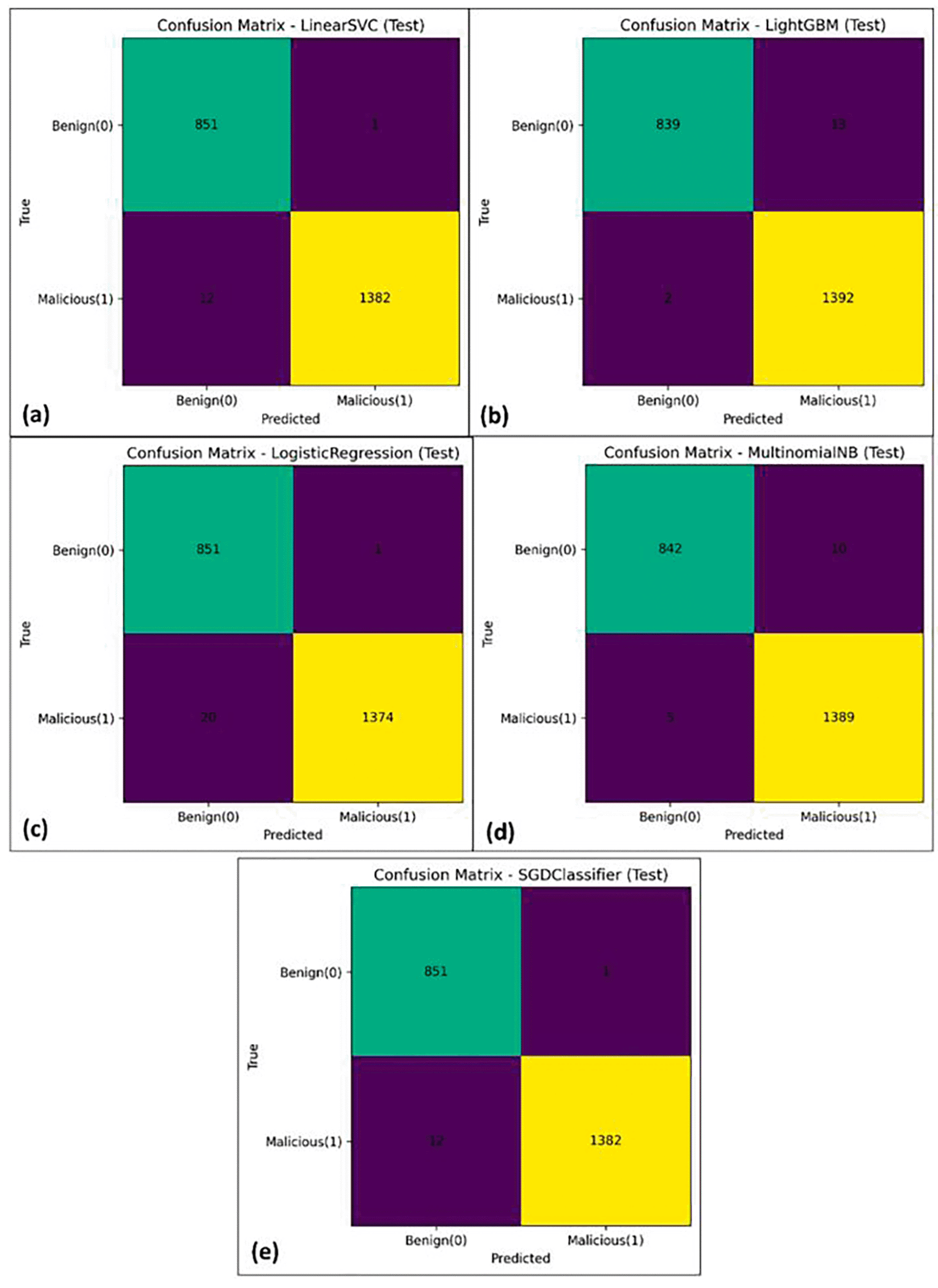
Confusion matrices were considered on each of the assessed classifiers in order to augment the aggregate performance measures with structural error understanding. Even though the dataset is very separable, and all the models have very low rates of false positives (FP) and false negatives (FN), confusion matrices are able to present in a more comprehensive way how the residual errors are spread out depending on classes. This difference is vital in terms of deployment: when this is a false negative, this can result in confidentiality and integrity breaches due to the undetected attack; conversely, when a false positive occurs, not only can alert fatigue be induced, but also can impact operational availability. Figure 3 shows representative confusion matrices to demonstrate the near-zero error regime, as well as to provide subtle variations in FP-FN balance across models. Based on,31 these structural observations are useful in reflecting on the later robustness and threshold sensitivity analysis because they relate to numerical and operational impact.
Nominal differences in performance are small, and hence we have made an extreme statistical verification to determine the survival of the metric gap we have identified under the pressure of sampling variance. Table 4 presents 95 95 per cent bootstrap confidence intervals (CIs) on F1, ROC-AUC, and PR-AUC. What stands out here is the fact that the saliency of the CIs on the most successful models strongly overlaps, and it indicates that the marginal outcome differences in the point estimates cannot be considered to be a decisive advantage for the models.
In order to further evaluate the fact that the higher-ranked models could vary in their error patterns on the same test instance, I used the paired test of McNemar. The contingency counts (b and c) are displayed in Table 5, which imply the cases when one model provides a correct prediction, and the other is not able to classify the given query. In contrast to aggregate measures of disagreement, this test measures the structure of the conflicts between classifiers. The p-value is not significant and indicates that both forms of models do not indicate a systematic advantage over the other on the same samples, so there is no statistical significance of performance differences. This finding is complementary to the bootstrap confidence-interval experiment and supports the fact that only slightly positive changes in the clean-set data cannot be regarded as sufficient evidence of a conclusive model choice.
| Model_A | Model_B | b(A correct, B wrong) | c(A wrong, B correct) | McNemar_stat | McNemar_p |
|---|---|---|---|---|---|
| LinearSVC | LightGBM | 13 | 11 | 0.042 | 0.838 |
Figure 4 is more of a refined illustration of the way degeneration takes place in all the types of perturbations. Although there are very slight differences in the way that the models are provided, none of the classifiers suffers a catastrophic breakdown in performance when the transformations are applied to them. Its may therefore conclude that the TF IDF character n -gram representation gives the system an intrinsic structural strength that repels the habitually utilized obfuscation strategies. Due to the features of character-level modeling, where sub-token motifs, encoded operators, fractured key-words, etc., are dealt with, the discriminative evidence survives even in the presence of partial lexical changes. In light of practical implementation, the strong stability suggests a pre-eminence of the feature representation of maintaining resilience, which could overshadow any architectural differences between linear and ensemble classifiers. In these regards, it is advised that calibration reliability and operational efficiency should be given precedence among other factors in determining which model to select when there are adversarial threats, instead of considering marginal differences in robustness.
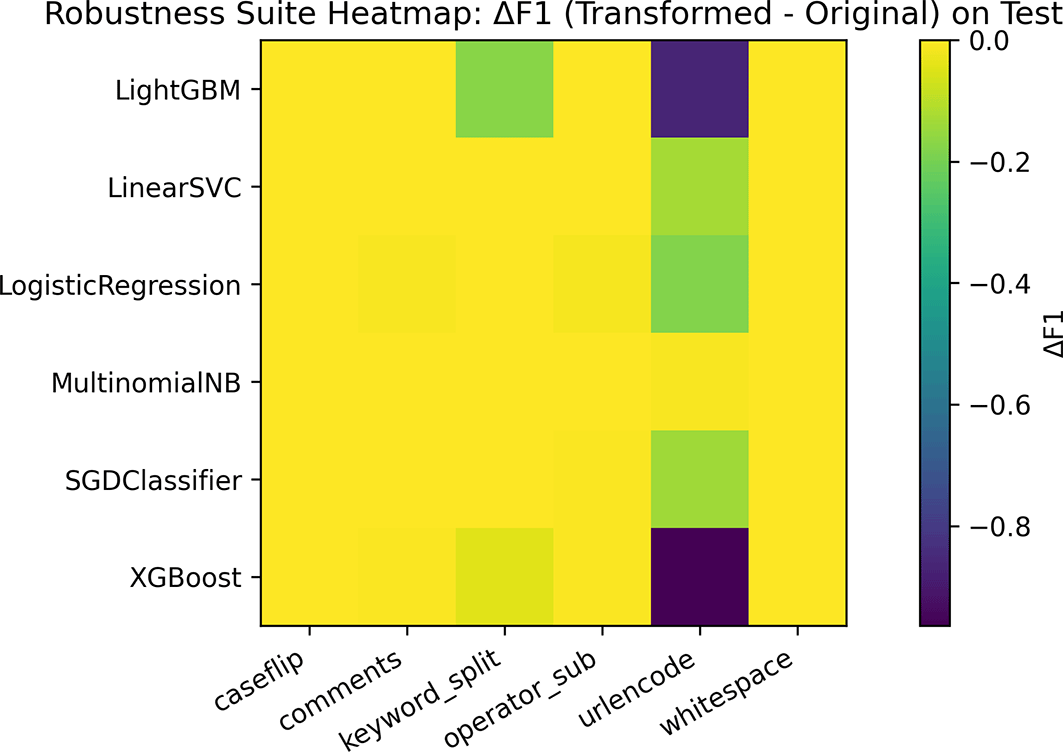
To provide a summary of conservative robustness adequate to be used in the deployment decision, the minimum value of ΔF1 in all the assessed transformations of any model has been calculated. These worst-case ΔF1 values are tabulated in Table 6, and should be visualised in Figure 5 to aid quick comparison between classifiers. Contrary to conventional degradation measures, worst -case analysis represents a threat-sensitive view: on adversarial examples, an adversary might choose to use the most efficient dissimilarity response strategy instead of using random perturbations. On this basis, robustness is supposed to be evaluated in the worst plausible transformation, to fix on levels of real-life attack. This conservative standard allows making a more security-relevant model comparison and enables relying on the deployment decisions based on reliability.
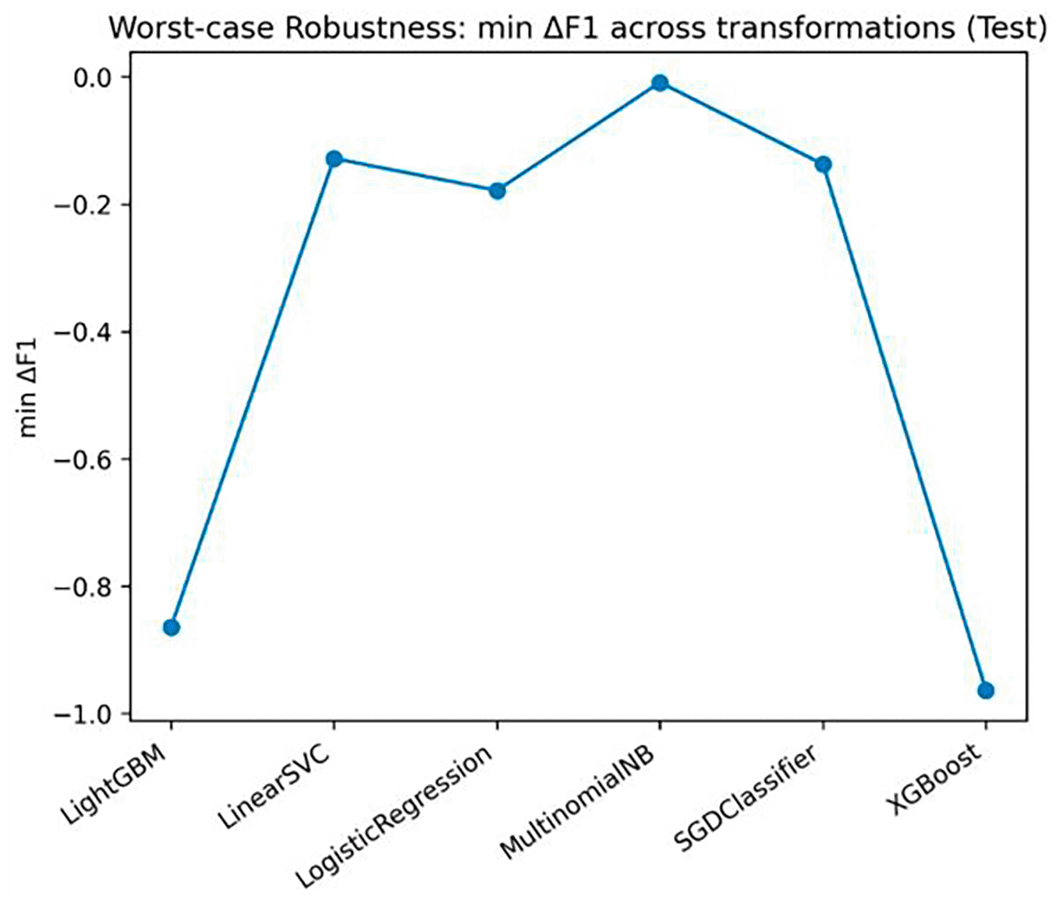
The findings on robustness provided in this paper provide a necessary perspective in which the security deployment strategies can be evaluated. Though sometimes having slightly better nominal performance, ensemble models are very susceptible to transformation-based perturbation; the vulnerability can lead to very rapid deterioration in attack-detection capacity when dealing with realistic evasion strategies. Linear models, on the contrary, are more likely to exhibit a constant performance profile in cases of obfuscation. This strength is due to the interactions between character n-gram representations and linear decision boundaries that can discover the fragmented substring evidence, although the token can be fragmented or encoded. This leads to the trade of between robustness and accuracy, taking a leading role in the wise choice of the models to be used in hostile operational environments.
The systematic analysis of probability calibration was made to understand the reliability of the estimated proofs of confidence, the sine condition of risk-wise deployment and alert prioritization based on threshold. The quantification of calibration efficacy was measured through the Brier score and Expected Calibration Error (ECE), whereby the fewer the number of metrics, equate to a better the identification of the genres of the model as it relates to the observed result frequencies. As described in Table 7, tree-based ensemble models, and especially LightGBM and XGBoost, exhibited the best Brier scores (= −0.004-0.005), which indicates high fidelity in estimating probability when the criteria are perfect. The current Naive Bayes and SGDClassifier models had similar calibration. On the contrary, Logistic Regression resulted in a somewhat high calibration error, whereas LinearSVC recorded the highest values of Brier and ECE. This differs, as LinearSVC implicitly does not generate probabilistic results, and deforms probability fidelity due to the scaling of its decision function.
| Model | Brier | ECE(10bins) |
|---|---|---|
| LightGBM | 0.004 | 0.373 |
| SGDClassifier | 0.005 | 0.379 |
| MultinomialNB | 0.005 | 0.376 |
| XGBoost | 0.005 | 0.376 |
| LogisticRegression | 0.011 | 0.387 |
| LinearSVC | 0.048 | 0.443 |
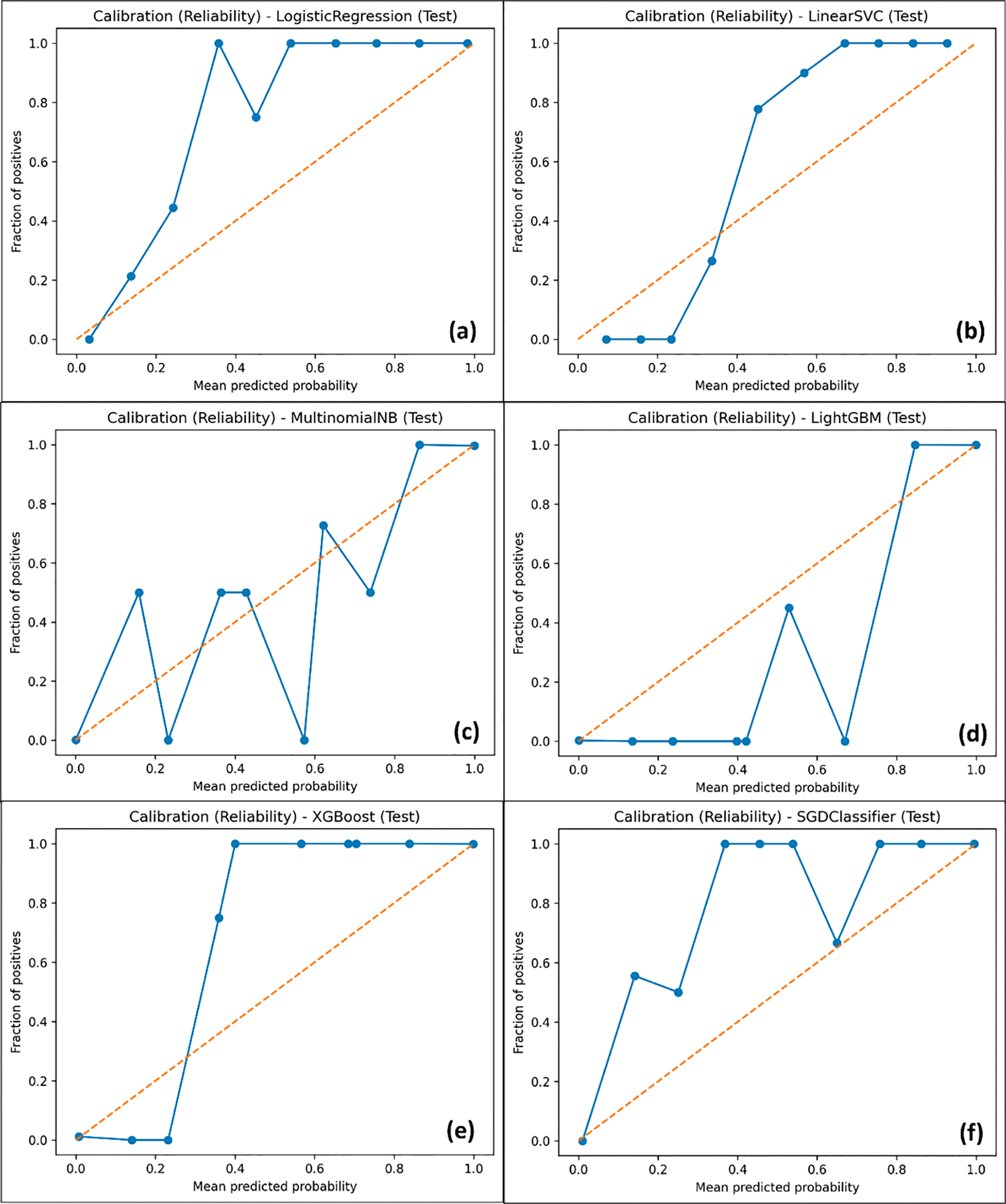
The diagrams of reliability are displayed in Figure 5. The ensemble classifiers have a smaller distance to the diagonal reference line, hence testifying to a better consistency of calibration. Linear models depict admirable discriminative performance yet frequently require additional early post-processing calibration schemes, like Platt scaling or isotonic regression, to provide empirically desirable results in probability-based decision systems. In the deployment sense, this observation highlights an essential difference between discrimination (Linear classifiers are known to be robust and computationally efficient) and probability reliability (Ensemble-based methods may be able to provide probabilistic confidence measures without any additional effort).
A threshold sensitivity analysis is beneficial. Since the security requirements vary between the realities of operation, two major operating perspectives are usually considered: a high recall regime (quantifying false negatives) and a high precision regime (quantifying false positives). Table 8 reflects the decision levels that will give the best performance of these operating points of each model. Its results indicate that the traditional default threshold of 0.5 is not necessarily optimal, and it is possible to substantially increase performance by choosing thresholds that reflect that of the organisation. Therefore, this flexibility will enable the administrators to strike a balance between integrity and confidentiality protection and the costs of alert fatigue and workload overload, thus adding to the flexibility of deployment.
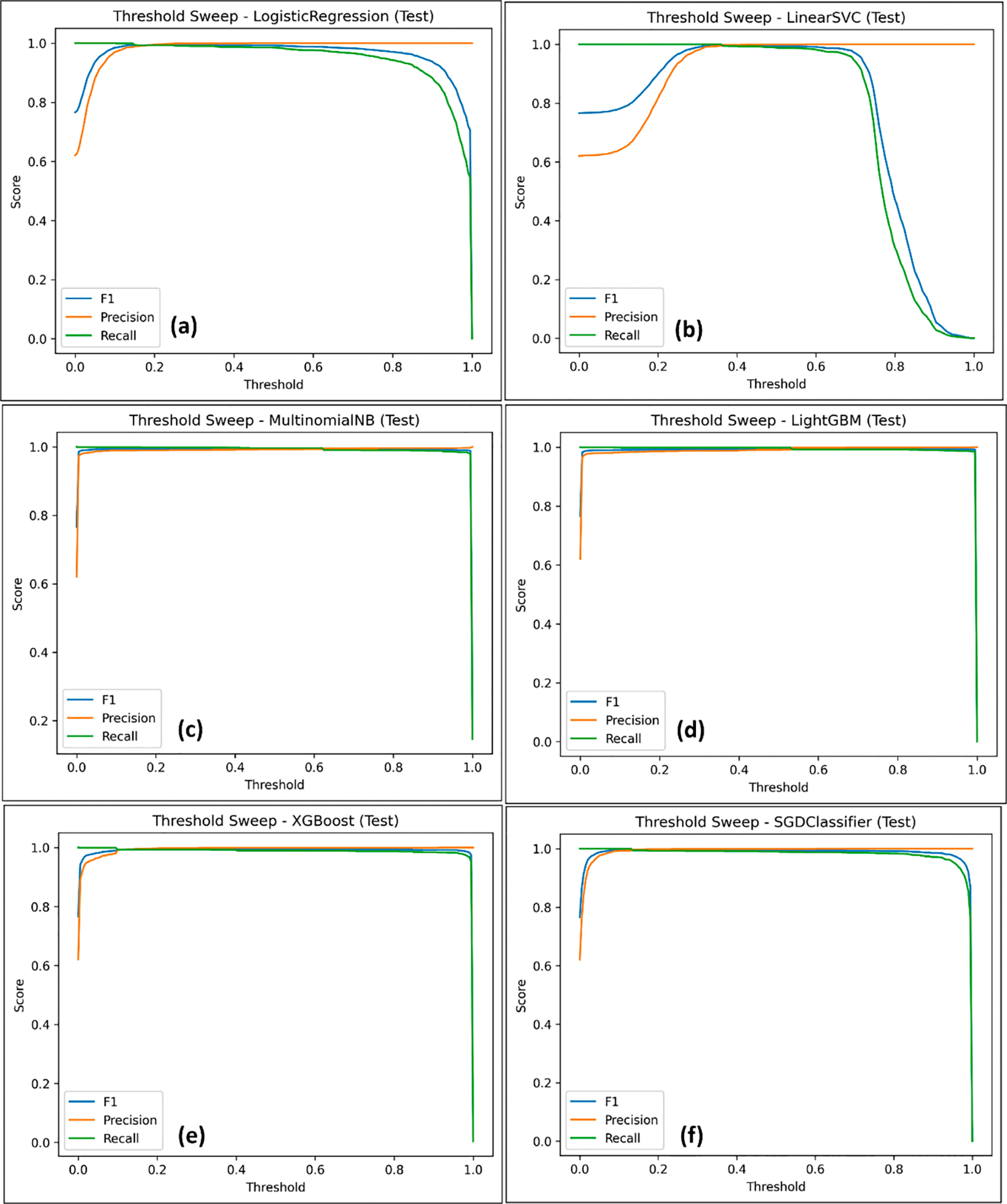
Figure 7 illustrates threshold sweeps of each model, which shows how F1-score, preciseness and recall change when the decision threshold varies over the entire probability spectrum. Such trajectories would give an understanding of model behaviour stability in the face of threshold readjustment, and continuous curves, smoothly varying, are preferable since they allow practitioners to tweak operating points, without causing sudden changes in performance. In the given results, a more gradual trade-off between precision and recall is more likely to be found in linear models, which has the result of a stable decision-boundary behaviour. On the other hand, some types of ensemble models exhibit significantly stiffer recalls with increased threshold, and this observation can arguably have some implication to a high-security scenario where false negatives are at the lowest priority. It is in the light of such differences that the interrogation of threshold dynamics must be accorded the significance it deserves, as opposed to relying entirely on fixed-threshold evaluation only.
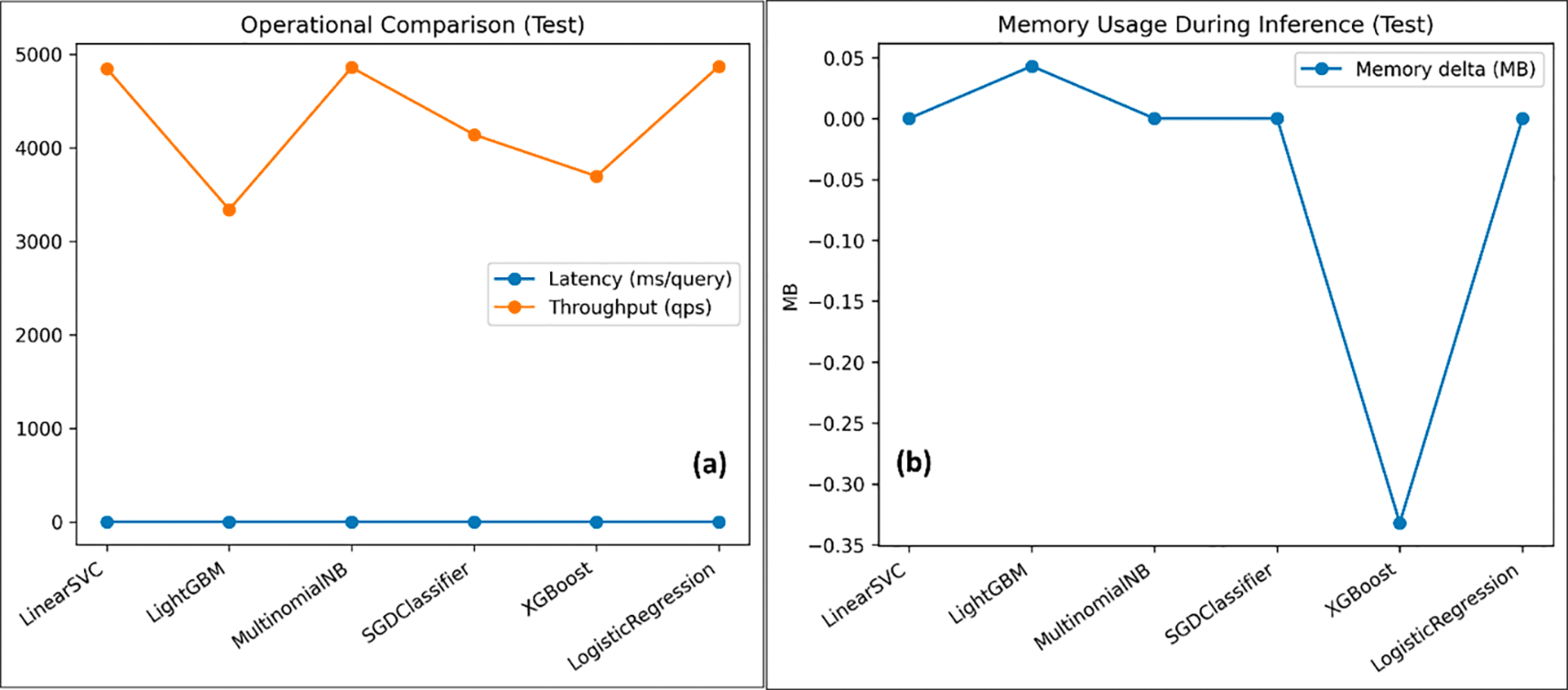
The feasibility of operations has been strictly tested by measuring inference latency, throughput, and memory usage in the prediction process, the three metrics that are critical to perpetuating real-time protection in a web environment characterized by heavy traffic. Whereas conventional measures of discrimination give us information regarding efficiency of detection, the viability of deployment is also subject to the same issue of being dependent on computational efficiency. The trade-off between inference speed and latency is depicted in Figure 8, which explains the interdependence between predictive performance and inference speed. Both results support the claim that the linear models generally provide a superior balance of precision and computational cost, making them especially appropriate in environments with latency limitations.
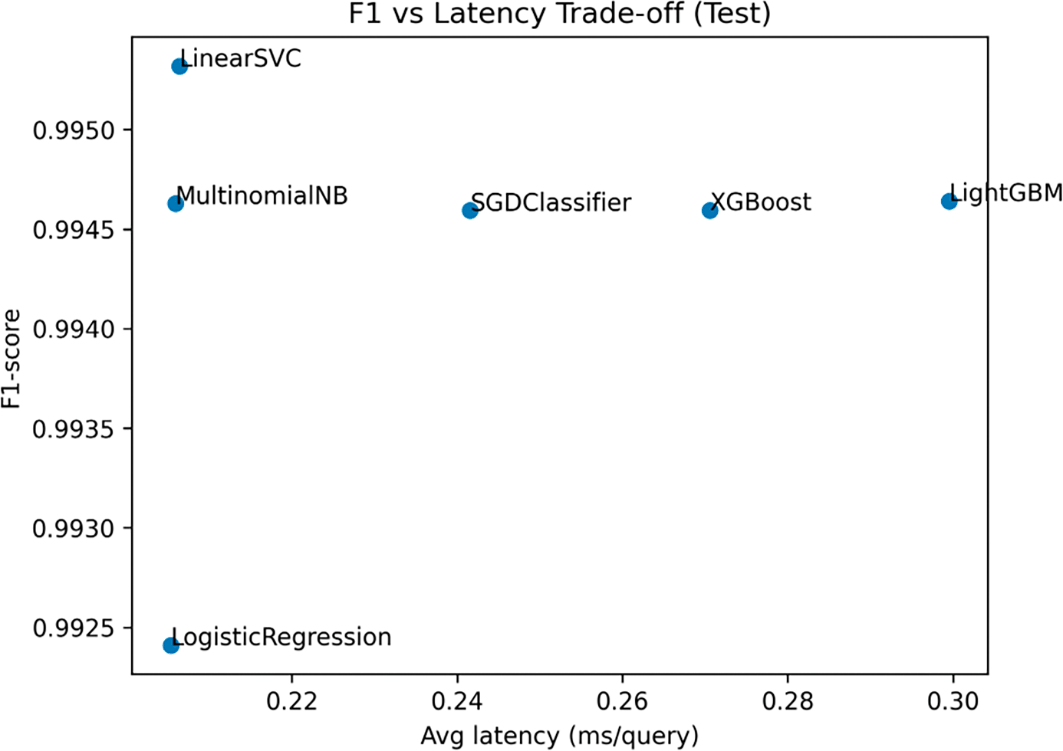
Figure 9(a) compares throughput based on the viewed models, and throughput is high since it is an indicator of the ability of the system to process larger quantities of incoming queries under tense real-time stringency. Figure 9 (b) tabulates the inferred memory consumption, which is essential when running on resource-limited infrastructures or edge-computing infrastructures. Together, these operational measures complement the predictive performance measures, thus enabling a deployment-oriented model selection procedure, which goes beyond the indicators of accuracy.
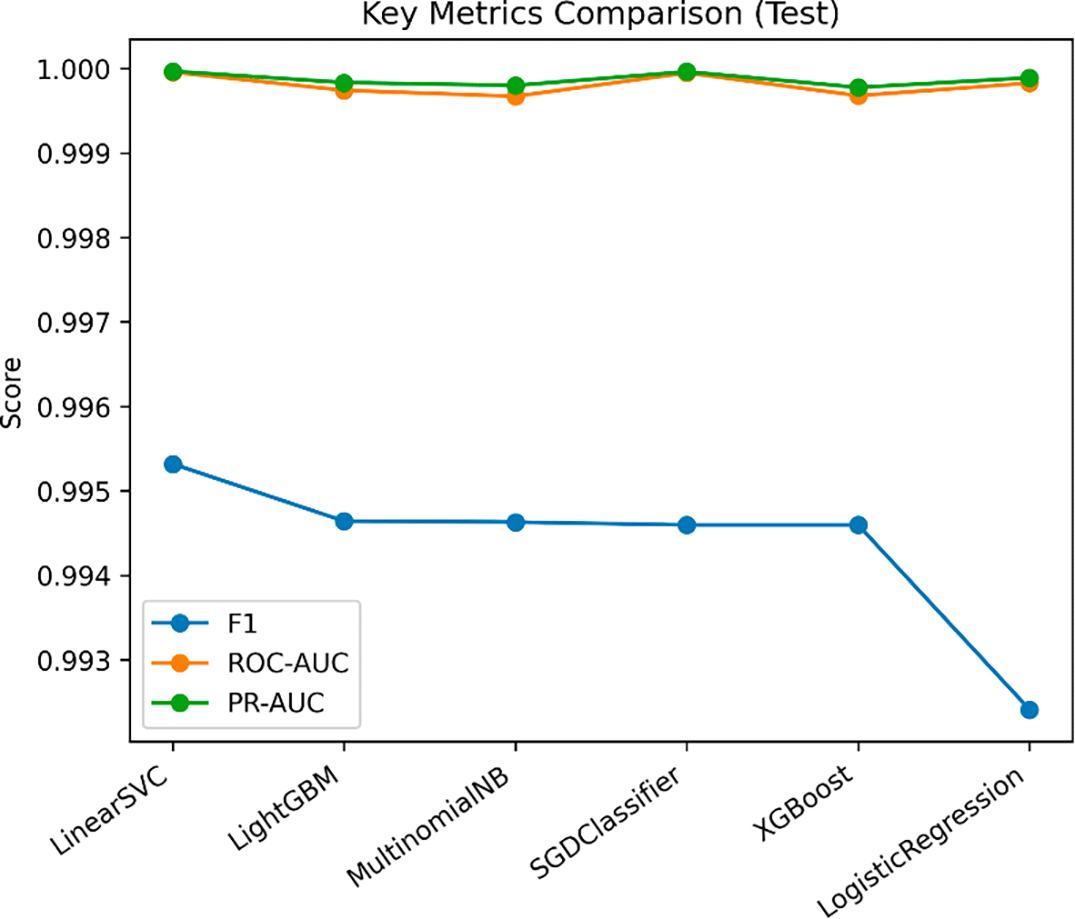
To have a big picture of the performance elements, Figure 10 graphically summarizes a sample of the discriminative measures, such as the F1 -score and other AUC -based measures, of all the models that were tested. The chart highlights that in essentially uncontaminated conditions of evaluation, the nominal performance of the classifiers is virtually similar; the only divergences that arise are small and define a small first-rate region. This close clustering supports the statistical inferences, which have been made above, and it at the same time brings out the fact that the metric of discrimination, on its own, is not adequate in providing a definitive model of pre-eminence.32 In this connection, the gap being low in Figure 10 therefore further emphasizes the urgent need to seek ancillary dimensions like robustness, calibration, and operational reasoning, to be able to make any meaningful discrimination when the models are exposed to a realistic context of deployment.
Lastly, an organized error taxonomy analysis was carried out with the purpose of explaining the residual failure pattern, and special attention was paid to a balanced linear model (LinearSVC). Figures 11(a) and 11(b) show the distribution of the false negatives and false positives in the given pre-defined categories of SQL injection. The number of aggregate errors is not very large, but a taxonomy-level examination can provide a useful view of the unique attack designs that form the core of the problem for the classifier. The problem of false negatives reflects the most dire failure mode, by CIA (confidentiality, integrity, availability) standards, since such malicious queries may go unnoticed and, therefore, compromise both confidentiality and integrity. The identification of the prevailing false negative categories in question can be used to come up with specific data-set augmentation and transformation-aware training ways in order to promote systematic robustness enhancement beyond the maximization of surface aggregate measures.
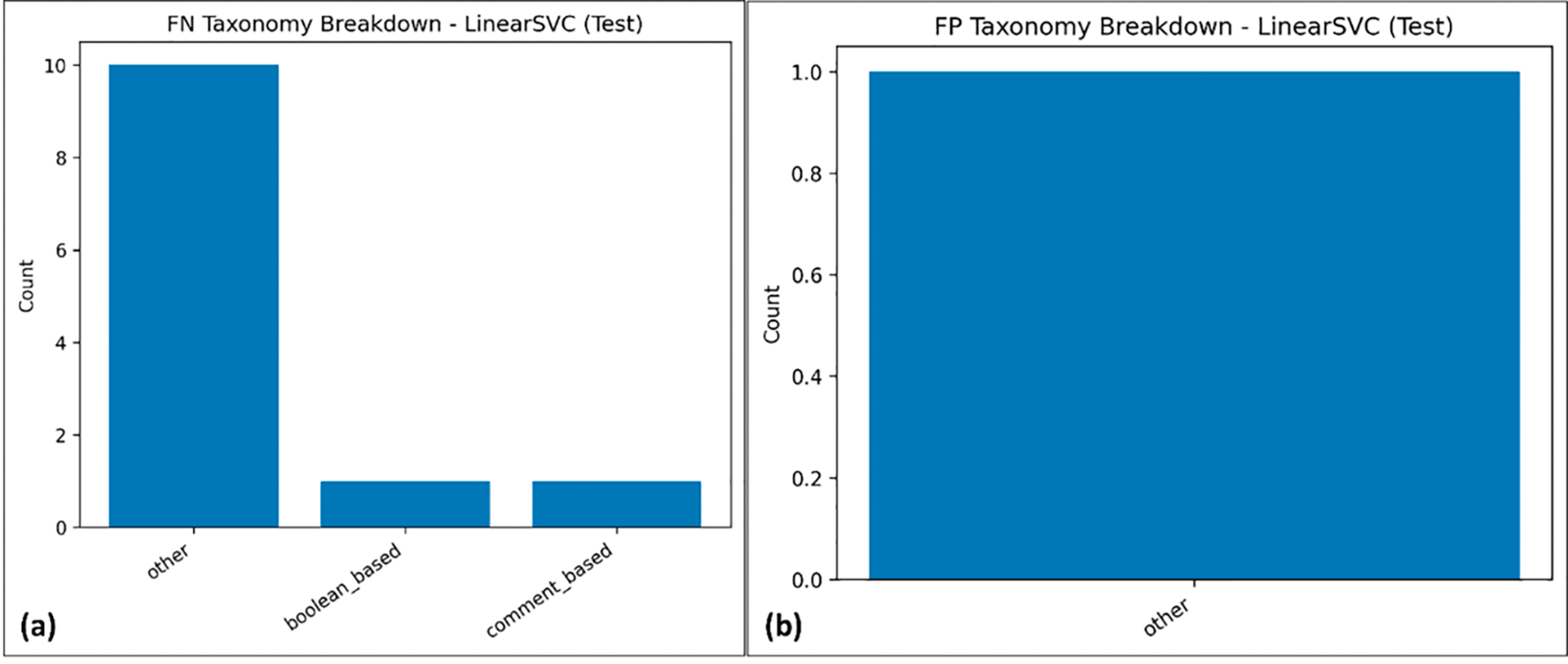
To supply a quantitative complement to the taxonomy plots, Table 9 lists the integer numbers of false-positive (FP) and false-negative (FN) events in taxonomies of LinearSVC. Even though the absolute error numbers are still not very huge, such a tabulated disaggregation allows identifying the dominant modes of failure much more easily. Specifically, those categories that play an oversized role in FN deserve increased attention in the area of security because they reflect the patterns of attacks that pass undetected. These insights can be used to develop specific hyper-adaptive mitigation policies such as adversarial augmentation, transformation-sensitive retraining, or focused encoding-based features or other structurally complex payloads. This measurable analysis thus solidifies the nexus between the assessment of models and actual security augmentation.
| error_type | taxonomy | count |
|---|---|---|
| FN | boolean_based | 1 |
| FN | comment_based | 1 |
| FN | other | 10 |
| FP | other | 1 |
Overall, the clean-set evaluation test shows that all the models have very high degrees of discriminatory power, and the statistical validation was to show that the observed nominal differences were not decisive. Conversely, robustness and calibration analyses provide more conclusive deployment advice: any model that has consistent behavior when obfuscated and produces stable probability estimates is better understood to be suitable for adversarial requirements. The threshold sweeps experiments demonstrate that operating points can be fine-tuned to observe operational risk-taking as it is in an organization, and operational profiling can affirm that linear models have striking trade-offs between performance and efficiency. Combined, these results support the hypothesis of a multi-dimensional assessment system as a more practical basis for the decision of how SQLIA detection models should be chosen in situations of security-related deployment.
The experimental results include the notion that there is no clear guarantee of deployment reliability in SQL injection detection in the case of extremely high nominal discrimination. Whereas the results of all the tested classifiers culminated in close to ceiling performance in clean testing situations, statistical validation shows that differences between best performing models are only of a marginal nature, which is not invariably decisive. The fact that the bootstrap confidence intervals and the non-significant test results of the McNemar test overlap significantly suggests that the differences in the F1-score values should be treated with a lot of care. In security-related tasks, incremental advances should not be counted on to provide the illusion of excellence, which would not convert into operational excellence. When the ability to survive adversarial transformations is taken into account, evaluation becomes more informative. All these models are highly resistant to syntax-preserving techniques of obfuscation, but still, notable variations in the degradation behavior may affect the deployment choices.
The findings point to the fact that the character-level TF-IDF representation is a viable contributor to this resilience. Such representations minimize the responsiveness to easy encoding strategies or manipulation of keywords by the method of capturing sub-token structures and fragmental patterns. This observation indicates that the feature design is a very important factor in adversarial robustness, which outweighs the architectural distinction between linear and ensemble classifiers in some situations. Another perspective is brought up under calibration analysis. In reality, the detection systems are commonly based on probabilistic scores to prioritize the alertness or dynamically change the decision boundaries. Models that give bad calibration of confidence estimates can seem to have high accuracy, but they act surprisingly when the thresholds change.
The findings demonstrate the variability of the quality of calibration between classifiers, pointing out that they are not similar in terms of discrimination and probability. In other instances, ensemble approaches have better calibration properties, whereas linear models have the benefits of stability and computational efficiency. This difference supports the notion that the suitability of deployment must be considered on a multi-dimensional level as opposed to being measured on the basis of a single performance indicator. This is also highlighted by threshold sensitivity analysis. The flexibility to make operating thresholds incremental is also important in circumstances where risk tolerance takes different shapes with varying institutions. A deployment with emphasis on security can take a recall-centered approach to relieve actions of missed attacks, whereas a deployment with operational constraints can take a precision-centered approach to relieve action of alert fatigue. It can be seen that the threshold curves of the observed models vary in their reaction to changes in threshold and provide more flexibility to the administrators when it comes to setting the detection policy without a sudden change in performance of the models.
Operational profiling follows these results by adding computational issues to the model selection. Even though the predictive performance of all models is equally high, the latency of inference, throughput, and memory consumption among classifiers are different. These variations may affect scalability and cost of deployment in the long term of large-scale web infrastructures. In particular, linear models exhibit desirable performance -efficiency trade-offs, thus are of interest to real-time environments, where responsiveness must be considered important. In a more general approach to methodology, this work makes a contribution to the SQL injection detection research by redefining the evaluation as a multi-criteria decision problem. Instead of introducing a new classification algorithm, the work is dedicated to the enhancement of the evaluation pipeline itself. Lesbians and gay men, as well as bisexuals and queers (gays and bisexuals), were incorporated into the study as part of one framework, which integrates statistical testing, robustness assessment, calibration analysis, threshold exploration, and operational measurement by these authors, thus handling several limitations that are typical in the literature. Such a method makes it possible to make a more realistic comparison of models under adversarial and deployment-constrained settings.
There are multiple limitations that ought to be mentioned. The analysis was performed on one curated dataset, and even though, upon eliminating duplicates, optimistic bias decreased, in reality, traffic can be even more variable. Furthermore, classical machine learning models were given an analysis in order to highlight the aspects of interpretability and efficiency; transformer-based models or hybrid systems can illuminate other trade-offs.33 Lastly, robustness testing was based on fixed strategies of transformation, and more adaptive or learning-based adversarial situations could be investigated in the future.
In general, the results highlight the fact that the choice of the SQL injection detection model must be balanced in favor of discrimination, robustness, stability, calibration reliability, and computational feasibility. Near-perfect clean-set accuracy on its own is not sufficient as a criterion of decision. The reliability-mindful evaluation framework is a more informative foundation for implementing machine learning models in adversarial security settings.
This paper presents our proposal offering an evaluation framework based on the framework of deployment-oriented SQL-injection detection, that out of the trope of comparing accuracy. Although all the models discussed showed almost maximum discriminative ability in the clean environment, statistical tests revealed that performance differences did not necessarily prove decisive. Based on a joint scrutiny of robustness, calibration behaviour, threshold dynamics, and operational efficiency are discerned. The findings indicate that model selection in an adversarial setting should consider stability, reliability, and inborn predictive performance. By combining statistical validation with adversarial stress-testing with system-level limitations into a single pipeline, this study further supports a more holistic, deployment-conscious approach to testing machine learning-backed-intrusion-detection systems. This multi-criteria view strengthens the principle of the selection of security models based on practice and riskiness.
Source code available from: GitHub Repository
Archived software available from: Zenodo Archive
License: MIT License.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)