Keywords
oral diadochokinesis; pediatric speech assessment; articulation; speech timing; preschool children; speech motor assessment; restricted data
This article is included in the Japan Institutional Gateway gateway.
oral diadochokinesis; pediatric speech assessment; articulation; speech timing; preschool children; speech motor assessment; restricted data
Oral diadochokinesis (DDK), elicited by rapid repetition of syllables such as /pa/, /ta/, and/ka/, is widely used in speech-language assessment.1–3 Rate is the most commonly reported metric, but timing variability may capture aspects of rhythmic speech-motor control that rate alone does not.2,3 Pediatric DDK studies have shown that task choice, age, and speech-sound status can affect interpretation.4–7 In pediatric work, values from the three monosyllabic tasks are sometimes averaged or interpreted as if they reflect one underlying ability. That practice is only defensible if the task measures show enough coherence to justify a composite.
The present study addressed a narrow interpretive question: when /pa/, /ta/, and /ka/ recordings are already available, should timing variability be interpreted by task or as a single mean across tasks? We examined whether coefficient-of-variation measures from typically developing Japanese preschool children were associated with articulation error count, and whether the cross-task mean captured or obscured task-level information.
This was a cross-sectional observational analysis of children recruited from two preschool settings in Japan. Data were collected between October 2022 and April 2023. Thirty-one children were initially enrolled, and three were excluded because usable DDK task data were unavailable for the present acoustic analyses. The final analyzed sample comprised 28 typically developing Japanese-speaking children aged 55 to 78 months. Children were included if they were judged to be typically developing and had no documented speech, language, hearing, neurologic, or structural oral-motor diagnosis at the time of assessment. Exact preschool names, site mapping, dates of birth, and exact assessment dates are withheld from public materials to reduce re-identification risk. No a priori sample-size calculation was performed; this secondary analysis used the available eligible preschool sample with usable DDK data. Sex information was incomplete in the source descriptive records and was not retained in the restricted analysis dataset used for modeling; sex/gender was not used as a model covariate, and the findings should not be interpreted as sex- or gender-specific estimates.
The Institutional Review Board of Kawasaki University of Medical Welfare approved the study (approval No. 21–077; approval date: 29 October 2021). The approved participant-protection materials included written informed consent from parents or guardians before data collection and a child-facing assent/explanation document for the preschool participants.
Speech-sound accuracy was assessed with the word version of the Japanese Articulation Test.8 Children named picture stimuli, and responses were scored by a certified speech-language pathologist for articulation errors. The total articulation error count served as the primary predictor.
Each child repeated /pa/, /ta/, and /ka/ as quickly and steadily as possible. Speech was recorded with an IC recorder and a video camera with an external microphone, and the right-channel audio track was extracted at 48 kHz. The acoustic pipeline applied a 200-Hz low-pass Butterworth filter to derive an amplitude envelope, used a locally run OpenAI Whisper-assisted screening step (exact local Whisper model/version not recorded in the processing log; run locally, not through a cloud/API service) to locate candidate task segments within longer assessment recordings,9 and then detected amplitude peaks using a median absolute deviation-based threshold applied to the envelope. Segment boundaries and retained peaks were visually reviewed in Praat before task-level values were accepted for analysis.10 Automated DDK extraction has been used in other clinical speech-motor contexts, but the present pipeline was treated as a measurement workflow requiring visual review rather than as a fully automated clinical tool.11,12
At least six peaks were required for a task to contribute to variability analyses. When the initial automated detection did not identify enough peaks, a rescue procedure based on root mean square envelope burst detection with relaxed thresholds was applied. The final derived dataset contained task-level rate and timing-variability measures for /pa/, /ta/, and/ka/.
For each task, coefficient of variation (CV) was calculated as the standard deviation of inter-peak/inter-response intervals divided by the mean inter-peak/inter-response interval. Derived CV values are ratios, not percentages. The primary cross-task measure was the participant-level arithmetic mean of /pa/, /ta/, and /ka/ CV values. Task-specific analyses examined /pa/, /ta/, and /ka/ CV values separately.
Participant-level ordinary least squares models were adjusted for age in months and anonymized site. Additional participant-level models examined rate adjustment, non-normalized variability metrics, and trimmed CV measures. Complete-case denominators for the non-normalized and trimmed-CV sensitivity models were n = 20 and n = 17, respectively. A task-level long-format ordinary least squares model examined the task-by-error-count interaction. The author-controlled analysis script fits participant-level models and task-level interaction/random-intercept models from the restricted derived numerical data using R, lme4, and lmerTest.13–15 The restricted-data repository record contains an analysis-workflow script and session information, but it does not contain participant-level data sufficient to rerun these models publicly. The random-intercept mixed model is retained for transparency, but it produced a singular-fit warning and should not be overinterpreted as evidence for stable between-participant random-intercept variance.
The analyzed sample included 28 children with complete derived values for the primary participant-level and task-level analyses. Age ranged from 55 to 78 months, and articulation error count ranged from 0 to 13. Sensitivity analyses using non-normalized inter-peak interval variability and trimmed CV used smaller complete-case denominators, as described in the Methods.
The cross-task mean CV was not detectably associated with articulation error count in the primary participant-level model (coefficient = −0.001, p = .778; Figure 1). The three task-specific CV measures also showed negligible correlations with one another: /pa/ versus /ta/, r = −0.155; /pa/ versus /ka/, r = −0.048; and /ta /versus /ka/, r = −0.041 ( Figure 3). These results did not support treating the three tasks as interchangeable indicators of a single timing-variability construct in this sample.
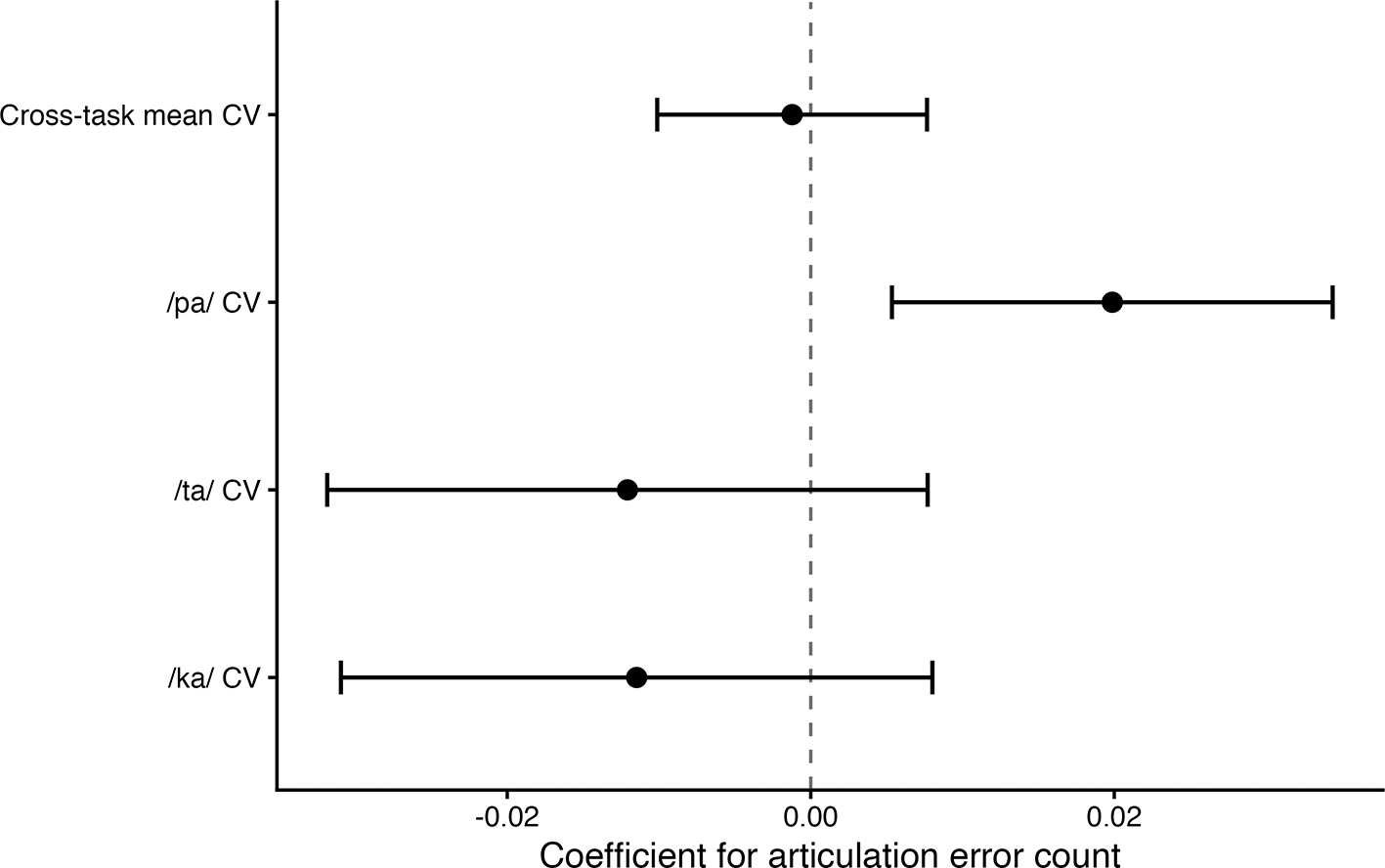
The plot compares the unstandardized articulation error count coefficients across the composite model and task-specific models. Horizontal lines indicate 95% confidence intervals.
Task-specific analyses suggested a pattern that was not apparent in the cross-task mean. Higher articulation error count was associated with higher /pa/ timing variability (coefficient = 0.020, p = .009), and this association remained similar after adjustment for/pa/rate (coefficient = 0.021, p = .008; Figure 2). In contrast, /ta/ and /ka/timing variability did not show comparable evidence of association with articulation error count. The task-level ordinary least squares interaction model was consistent with different error-count slopes across tasks. In the author-controlled mixed/random-intercept sensitivity model, the task-by-error-count term was statistically detectable (F = 4.75, p = .011), but the model was singular; the result is therefore presented as supportive sensitivity evidence rather than as a standalone primary mixed-effects result.
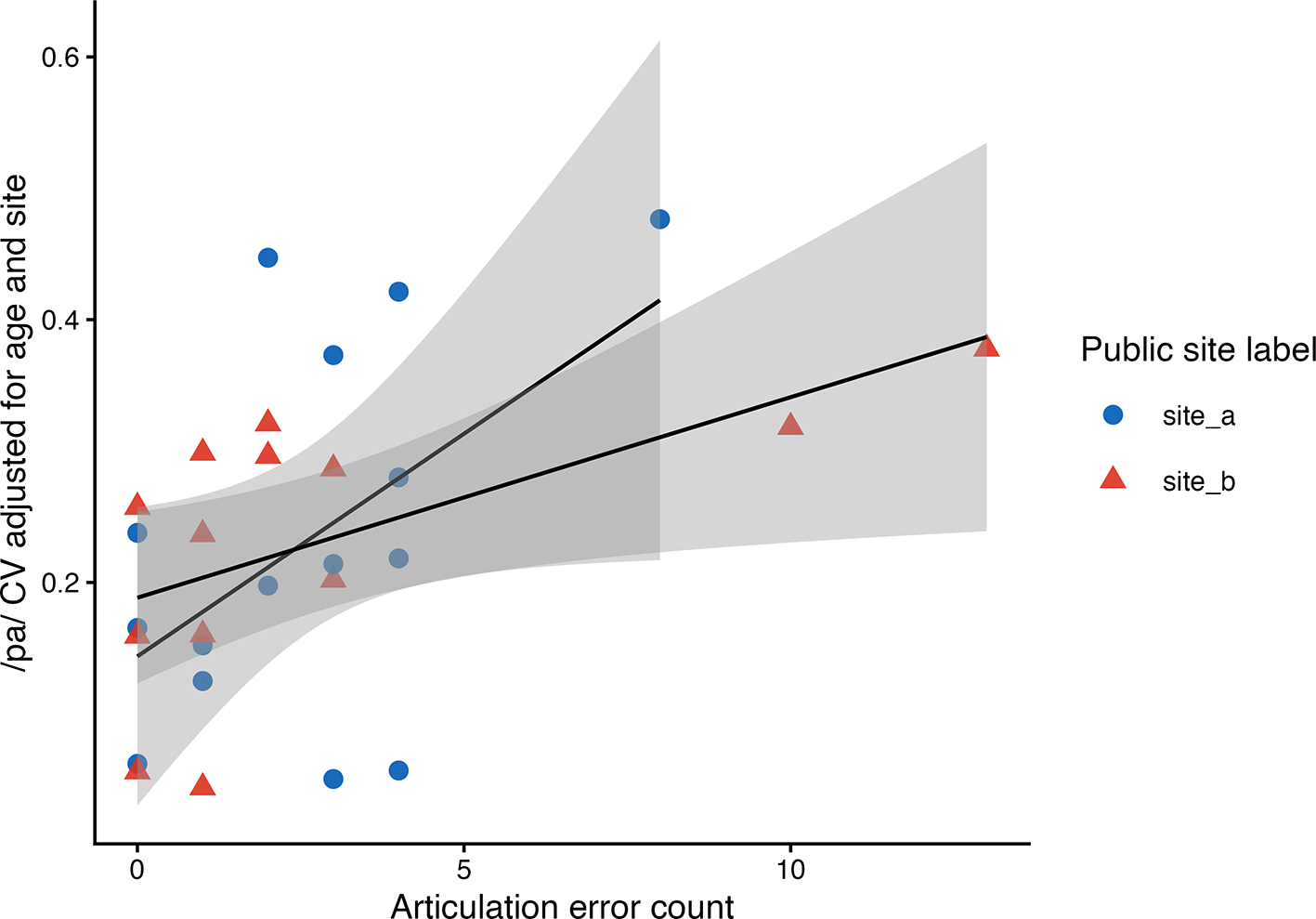
The plot illustrates the adjusted association between articulation error count and/pa/timing variability after adjustment for age in months and anonymized site. Public site labels are shown only as anonymized site_a and site_b categories to reduce disclosure of site-stratified participant-level information.
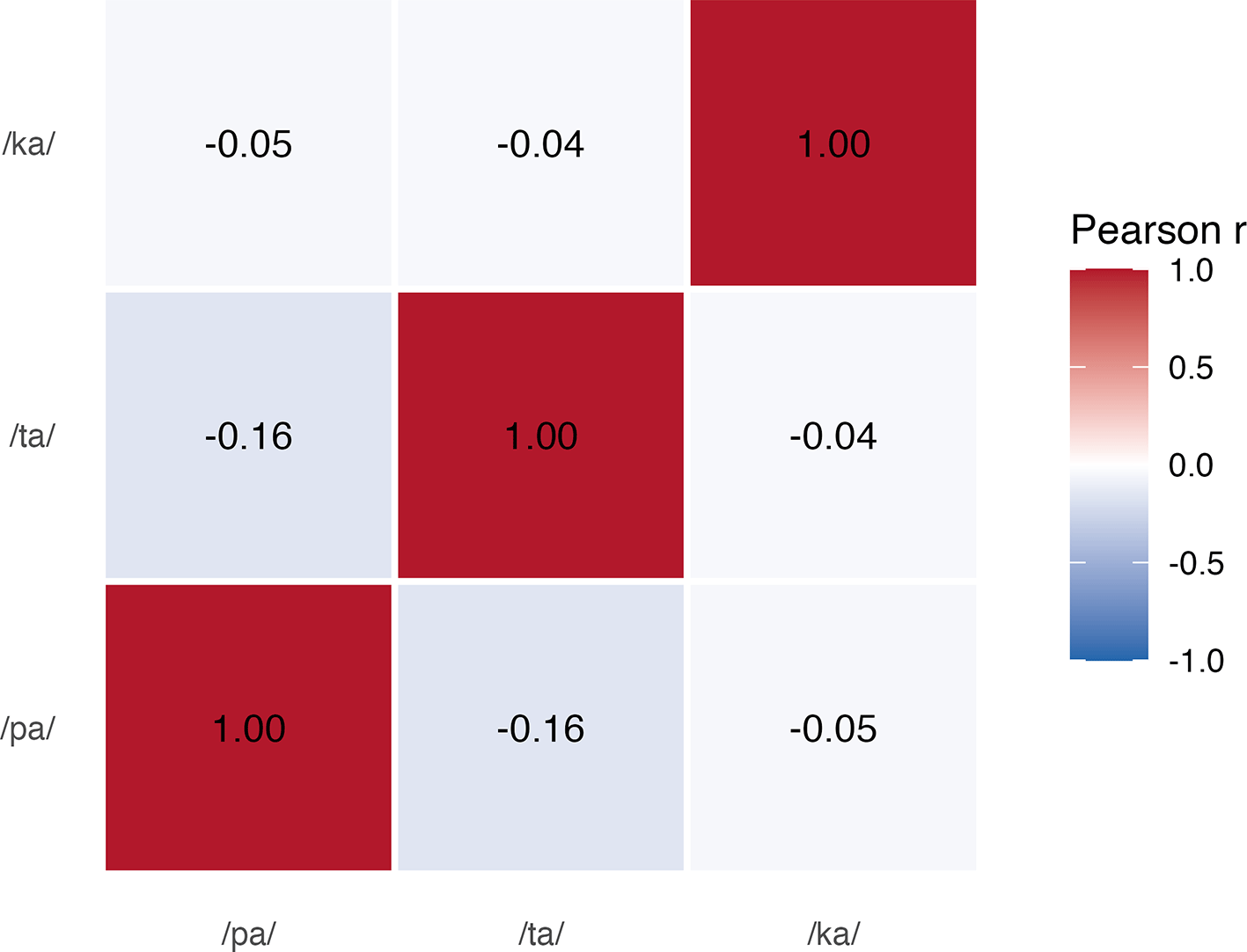
The heatmap shows Pearson correlations among /pa/, /ta/, and /ka/coefficient-of-variation measures.
The main finding is that /pa/, /ta/, and /ka/ timing variability did not behave as interchangeable measures in this small sample. The cross-task mean did not show a detectable association with articulation error count, whereas /pa/ CV showed evidence of a positive association. This pattern suggests that aggregating across tasks may hide a task-specific association, particularly when inter-task correlations are near zero.
The mechanism remains unresolved. The /pa/ pattern could reflect task-specific speech-motor timing, differences in acoustic detectability, measurement behavior of the envelope-based peak detection pipeline, developmental differences among consonant gestures, or a combination of these.16–18 One possible explanation is that bilabial burst timing in /pa/was more consistently captured by the envelope-based peak-detection workflow than the lingual gestures in /ta/ and /ka/; another is that anterior articulatory timing variability was more closely coupled to the articulation error counts used here. These explanations are speculative. The present data suggest an interpretable pattern, but they do not distinguish among physiological, developmental, and measurement explanations.
Several limitations constrain interpretation. The sample was small, cross-sectional, and restricted to typically developing children from two preschool sites. The findings do not establish diagnostic accuracy, clinical utility, developmental trajectories, or causal mechanisms. The mixed/random-intercept task-level model produced a singular-fit warning, so the task-level interaction should be read as supportive sensitivity evidence alongside the simpler task-specific models, not as a definitive hierarchical-model result. The analyses were reproduced locally from author-controlled de-identified derived numerical values, but the restricted-data repository record does not allow independent rerunning of participant-level or task-level models. Raw recordings are not publicly shared because they may identify preschool children and were not prepared for unrestricted public release. Replication in larger samples, including clinical samples and independent measurement pipelines, is needed.
In this small cross-sectional sample of typically developing Japanese preschoolers, the cross-task mean CV across /pa/, /ta/, and /ka/ was not detectably associated with articulation error count. In task-specific analyses, /pa/ CV showed evidence of a positive association with articulation error count, whereas /ta/ and /ka/ CV did not show comparable evidence. These findings suggest that aggregating DDK timing variability across tasks may obscure task-specific patterns, but the results are hypothesis-generating, exploratory, and require replication before clinical or developmental interpretation.
The study was approved by the Institutional Review Board of Kawasaki University of Medical Welfare (approval No. 21–077; approval date: 29 October 2021). The approved participant-protection materials included written informed consent from parents or guardians before data collection and a child-facing assent/explanation document for the preschool participants. No identifiable child recordings, images, videos, site names, dates of birth, assessment dates, or original identifiers are included in this article or repository record.
| Views | Downloads | |
|---|---|---|
| F1000Research | - | - |
|
PubMed Central
Data from PMC are received and updated monthly.
|
- | - |
Provide sufficient details of any financial or non-financial competing interests to enable users to assess whether your comments might lead a reasonable person to question your impartiality. Consider the following examples, but note that this is not an exhaustive list:
Sign up for content alerts and receive a weekly or monthly email with all newly published articles
Already registered? Sign in
The email address should be the one you originally registered with F1000.
You registered with F1000 via Google, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Google account password, please click here.
You registered with F1000 via Facebook, so we cannot reset your password.
To sign in, please click here.
If you still need help with your Facebook account password, please click here.
If your email address is registered with us, we will email you instructions to reset your password.
If you think you should have received this email but it has not arrived, please check your spam filters and/or contact for further assistance.
Comments on this article Comments (0)